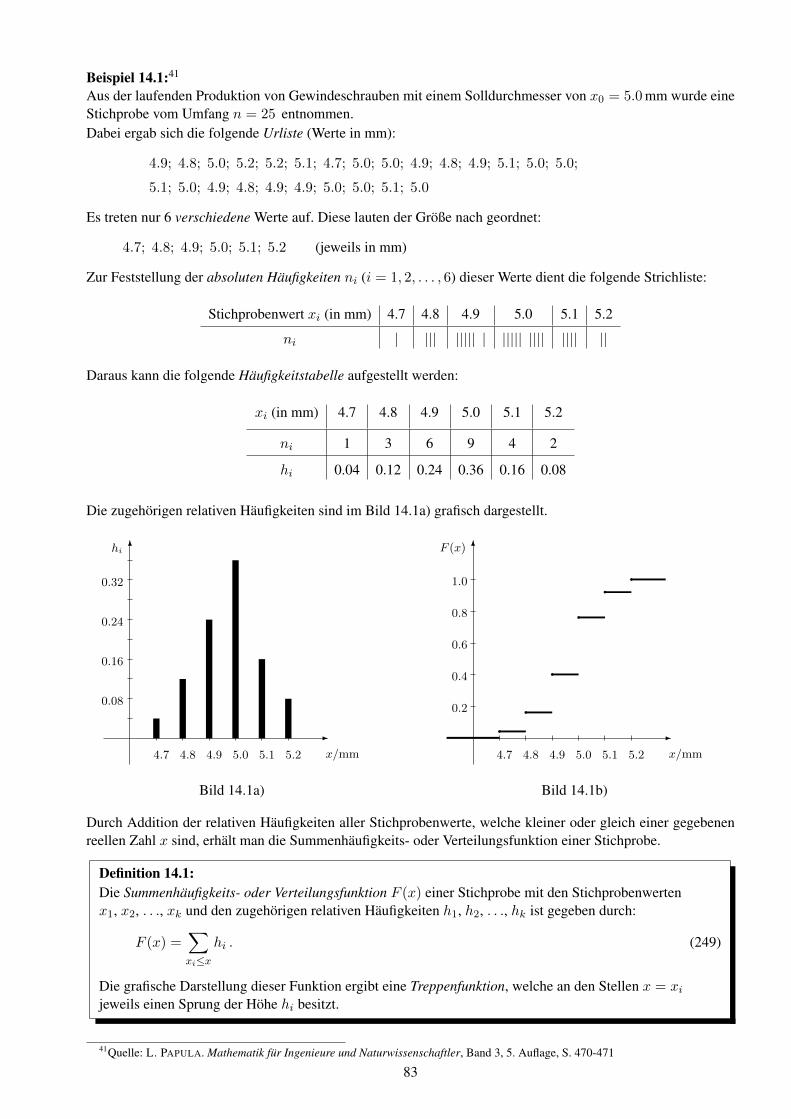
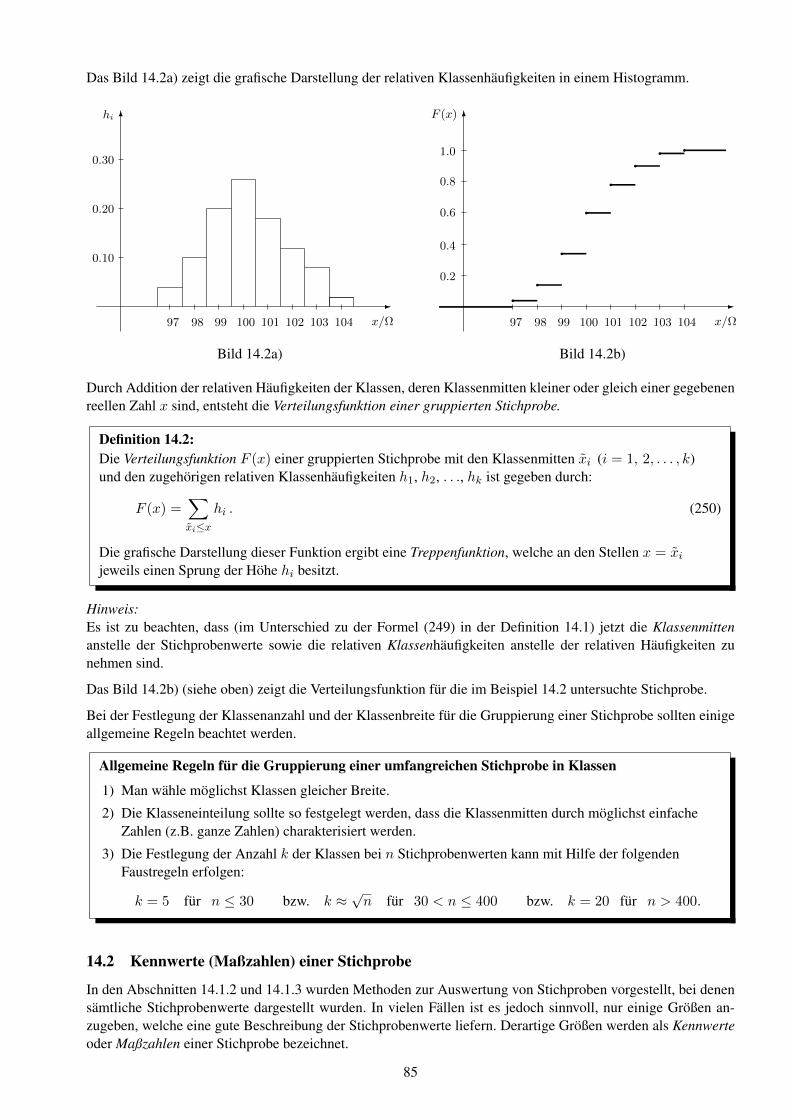
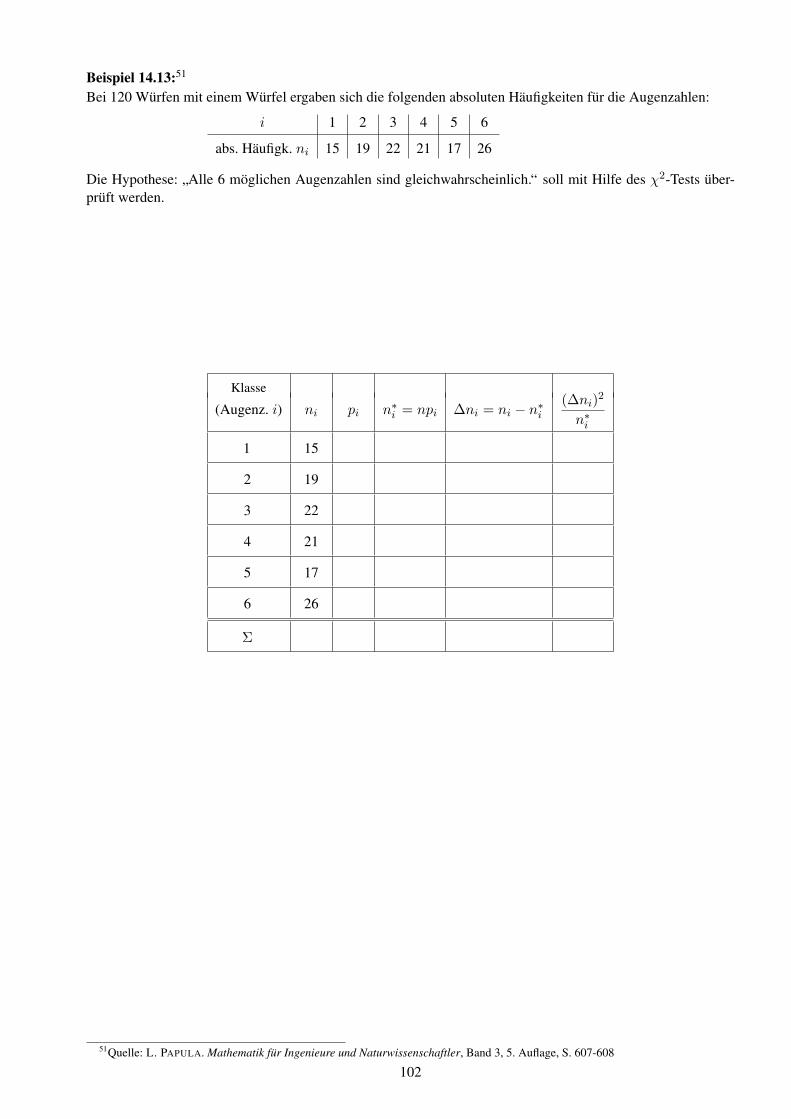
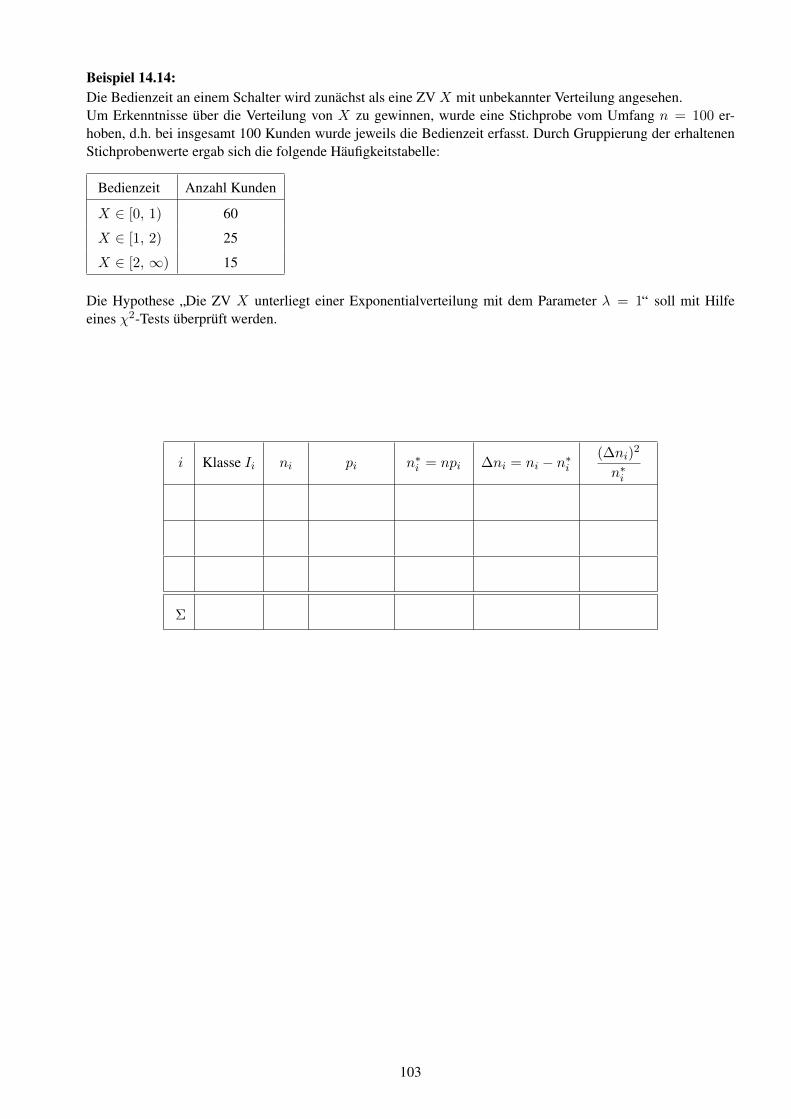
Hochschule f ¨ ur Technik und Wirtschaft Dresden Fakult ¨ at Informatik/Mathematik Prof. Dr. B. Jung Skript zur Vorlesung Mathematik 3 f¨ ur den Studiengang Elektrotechnik/Informationstechnik Stoffgebiete: 9. Gew¨ ohnliche Differentialgleichungen 10. Fourier-Transformation und Anwendungen 11. Partielle Differentialgleichungen (Einblick) 12. Grundlagen der Wahrscheinlichkeitsrechnung 13. Wahrscheinlichkeitsverteilungen 14. Mathematische Statistik
Transcript
Hochschule fur Technik und Wirtschaft DresdenFakultat Informatik/MathematikProf. Dr. B. Jung
Definition 9.1: Eine Gleichung, in der Ableitungen einer unbekannten Funktion y = y(x) bis zur n-tenOrdnung auftreten, heißt gewohnliche Differentialgleichung n-ter Ordnung. Man unterscheidet dabei noch:implizite Form: F (x, y, y′, . . . , y(n)) = 0
Definition 9.2: Eine Funktion y = y(x) heißt Losung der Differentialgleichung, wenn sie mit ihrenAbleitungen die Differentialgleichung identisch erfullt.
Bezuglich der Losungen einer Differentialgleichung wird noch die folgende Unterscheidung getroffen:
(1) allgemeine Losung einer Differentialgleichung n-ter Ordnung:Diese enthalt noch n voneinander unabhangige, frei wahlbare Parameter (Konstante).Es handelt sich hier nicht um eine einzelne Funktion, welche die Differentialgleichung lost, sondern um eineSchar von Losungen (bei der grafischen Darstellung der Losungsmenge: eine Schar von Losungskurven).
(2) partikulare (spezielle) Losung einer Differentialgleichung n-ter Ordnung:Eine solche Losung wird durch eine spezielle Wahl der Parameter aus der allgemeinen Losung gewonnen.Die Werte dieser Parameter ergeben sich dadurch, dass die Losungsfunktion zusatzliche Bedingungen erful-len soll, siehe dazu Abschnitt 9.1.3.
(3) singulare Losung einer Differentialgleichung n-ter Ordnung:Das ist eine Losung der Differentialgleichung , die nicht aus der allgemeinen Losung gewonnen werdenkann.
Beispiel 9.2:
Bemerkung:
Neben gewohnlichen Differentialgleichungen gibt es noch partielle Differentialgleichungen. Diese enthaltenpartielle Ableitungen (siehe Kapitel 7) einer unbekannten Funktion von mehreren Variablen.
Zahlreiche Problemstellungen in Physik und Technik lassen sich mit Hilfe gewohnlicher Differentialgleichungenmodellieren und losen. Im weiteren werden einige Beispiele dazu betrachtet.
5
Beispiel 9.3: Harmonische Schwingung eines Feder-Masse-Schwingers (Federpendels)1
Dieses einfache Modell eines schwingungsfahigenSystems laßt sich durch eine Differentialgleichungbeschreiben.
m
elast. Feder
Bei der Modellierung werden die folgenden Krafte berucksichtigt:- Ruckstellkraft der Feder: F1 = −cx (c: Federkonstante, x: Auslenkung der Feder zur Zeit t)- Reibungskraft: F2 = −kv (k: Reibungskoeffizient, v: Geschwindigkeit)Nach dem zweiten Newtonschen Gesetz gilt:
ma = F = F1 + F2 = −cx− kv ,wobei a die Beschleunigung bezeichnet. Auf Grund der Beziehungen v = x und a = x (vgl. dazu auch: Ab-schnitt 5.4.1 im Skript zur Vorlesung Mathematik 1) entsteht daraus die folgende Differentialgleichung 2. Ord-nung (Schwingungsgleichung):
mx = −cx− kx bzw. mx+ kx+ cx = 0 .
Wichtiger Spezialfall: k = 0 (d.h. es treten keine Reibungskrafte auf)
mx+ cx = 0 oder x+ ω20 x = 0 (mit ω2
0 =c
m)
Beispiel 9.4: Beschreibung des Zeitverhaltens eines Stromes2
Ein Stromkreis mit einer Gleichurspannung U ,einer Induktivitat L und einem Gesamtwiderstand Rwird zur Zeit t = 0 geschlossen.
U
L
R
Die Summe der Spannungsabfalle ist gleich der vorhandenen Urspannung:uR + uL = U .
Mit Hilfe der Beziehungen uR = I ·R und uL = L · dIdt
erhalt man eine Differentialgleichung 1. Ordnung zurBeschreibung des Zeitverhaltens des Stromes:
IR+ LdI
dt= U bzw.
dI
dt+R
LI =
U
L.
Die allgemeine Losung dieser Differentialgleichung lautet:
I =U
R+ Ce−
RLt mit C ∈ R (Konstante) ,
denn es gilt:dI
dt= −C R
Le−
RLt, und dies eingesetzt in die linke Seite der obigen Differentialgleichung ergibt:
dI
dt+R
LI = −CR
Le−
RLt +
R
L·(U
R+ Ce−
RLt)
=U
L.
Beispiel 9.5:Die Differentialgleichung der Bewegung eines Fadenpendels lautet:
ml2 α+mg l sinα = 0 bzw. α+g
lsinα = 0 ,
wobei die folgenden Bezeichnungen gelten: m: Masse, l: Lange des Fadens, α = α(t): Auslenkwinkel.
Beispiel 9.6:Die Differentialgleichung des elektrischen Reihenschwingkreises (unter der Voraussetzung, dass die von außenangelegte Spannung konstant ist) lautet:
d2i
dt2+R
L· didt
+1
LC· i = 0 ,
wobei i = i(t) die Stromstarke,R den ohmschen Widerstand, L die Induktivitat und C die Kapazitat bezeichnet.1Quelle: L. PAPULA. Mathematik fur Ingenieure und Naturwissenschaftler, Band 2, 12. Auflage (2009), S. 348-3492Quelle: W. LEUPOLD (Hrsg.). Mathematik - ein Studienbuch fur Ingenieure (Band 2: Reihen - Differentialgleichungen - Analysis
fur mehrere Variable - Stochastik), 2. Auflage (2006), S. 84
6
9.1.3 Anfangswertprobleme (AWP) und Randwertprobleme (RWP)
Bei einem Anfangswertproblem (AWP) werden der Losungsfunktion y = y(x) insgesamt n Wertevorgeschrieben, und zwar der Funktionswert und die Werte der ersten (n− 1) Ableitungen an einerbestimmten Stelle x0. Diese Werte
y(x0), y′(x0), . . . , y
(n−1)(x0)
werden als Anfangswerte (AW) oder Anfangsbedingungen (AB) bezeichnet.Sie liefern n Bestimmungsgleichungen fur die noch unbekannten Parameter in der allgemeinen Losungder Differentialgleichung (siehe dazu Abschnitt 9.1.1). Die partikulare Losung ist durch die AB stetseindeutig bestimmt.
Beispiel 9.7:
Beispiel 9.8:Das AWP3
x+ ω20 x = 0, x(0) = x0, x(0) = 0 (x0 > 0)
beschreibt die harmonische Schwingung eines elastischen Federpendels (vgl. auch Beispiel 9.3) unter den fol-genden Versuchsbedingungen (Anfangsbedingungen):
- Das Federpendel besitzt zu Beginn der Bewegung, d.h. zum Zeitpunkt t = 0, eine Auslenkung x0 in derpositiven Richtung.
- Die Bewegung erfolgt aus der Ruhe heraus (Anfangsgeschwindigkeit v0 = x(0) = 0).
Die allgemeine Losung dieser Schwingungsgleichung lautet:
x(t) = A · sin(ω0t+ ϕ) mit den Parametern A > 0 und 0 ≤ ϕ < 2π .
Diese beiden Parameter konnen aus den Anfangswerten bestimmt werden:1) x(0) = x0⇒ A · sinϕ = x0
Wegen A > 0 und x0 > 0 muss sinϕ > 0 gelten (siehe 1)), so dass nur die Losung ϕ = π2 moglich ist.
Aus 1) folgt dann: A = x0.
Die Schwingung des Federpendels unter den genannten Anfangsbedingungen wird daher durch die folgendeFunktion beschrieben:
x(t) = x0 · sin(ω0t+
π
2
)= x0 · cos(ω0t) .
Bei einem Randwertproblem (RWP) werden der Losungsfunktion y = y(x) an mindestens zwei verschie-denen Stellen x1 und x2 zusatzliche Bedingungen (in Form von Funktions- oder Ableitungswerten) vorge-schrieben. Diese werden als Randwerte (RW) oder Randbedingungen (RB) bezeichnet.Haufig sucht man die Losung einer Differentialgleichung in einem Intervall [x1, x2] und stellt die zusatzli-chen Bedingungen in den Randpunkten dieses Intervalls.Aus den Randbedingungen ergeben sich n Bestimmungsgleichungen fur die noch unbekannten Parameterin der allgemeinen Losung der Differentialgleichung. Im Gegensatz zum AWP muss die Losung eines RWPnicht eindeutig sein. Auch der Fall, dass keine Losung existiert, kann bei RWP eintreten.
3Quelle: L. PAPULA. Mathematik fur Ingenieure und Naturwissenschaftler, Band 2, 12. Auflage (2009), S. 352
7
Beispiel 9.9: RWP zur Berechnung der Biegelinie eines Balkens4
Es wird ein Balken der Lange l betrachtet, der auf zwei Stutzen ruht und durch eine konstante Streckenlast qgleichmaßig belastet ist.
-x
l
AAA
Biegelinie y = y(x)
? ? ? ? ? ? ? ?
?y
x
q = const.
Die Biegelinie y = y(x) genugt fur kleine Durchbiegungen naherungsweise der Differentialgleichung 2. Ord-
nung (Biegegleichung): y′′ = − Mb
EI, wobei die folgenden Bezeichnungen gelten:
E - Elastizitatsmodul (Materialkonstante), I - Flachenmoment des Balkenquerschnitts, Mb - Biegemoment.
Das ortsabhangige Biegemoment Mb betragt in diesem Fall: Mb =q
2(lx − x2) , so dass die Biegegleichung die
folgende Gestalt annimmt:
y′′ = − q
2EI(lx− x2) fur 0 ≤ x ≤ l.
In den beiden Randpunkten x = 0 und x = l ist keine Durchbiegung moglich.Somit ist das folgende Randwertproblem zu losen:
Eine explizite Differentialgleichung 1. Ordnung hat allgemein die Form (siehe dazu auch Abschnitt 9.1.1):
y′ = f(x, y). (161)
Auf Grund der geometrischen Deutung der ersten Ableitung einer Funktion (Anstieg der Kurventangente; siehedazu auch: Abschnitt 5.3.1 im Skript zur Vorlesung Mathematik 1) kann eine geometrische Interpretation derGleichung (161) angegeben und daraus eine Methode zur grafischen Losung hergeleitet werden. Diese wird imfolgenden erlautert.Es wird vorausgesetzt, dass die Funktion f(x, y) auf einer TeilmengeD der (x, y)-Ebene definiert sei. Dann wirdjedem Punkt (x0, y0) ∈ D durch die Gleichung (161) eine eindeutig bestimmte Richtung y′(x0) = f(x0, y0)zugeordnet. In dem Punkt (x0, y0) wird ein Geradenstuck mit dem Anstieg f(x0, y0) eingezeichnet. Der Punktmit dem zugehorigen Geradenstuck wird Richtungselement (oder Linienelement) genannt.
Richtungsfeld und IsoklinenDas Richtungsfeld der Differentialgleichung (161) wird aus samtlichen Richtungselementen gebildet(siehe Bild 9.1a)).Verbindet man jeweils alle Punkte, deren zugehorige Richtungselemente die gleiche Richtung besitzen,so erhalt man die Isoklinen. Die Isoklinen werden durch die Gleichung f(x, y) = const. charakterisiert.
Eine Kurve y(x) ist genau dann Losungskurve der gegebenen Differentialgleichung, wenn sie in das Richtungs-feld ”passt“, d.h. wenn in jedem Punkt der Kurve die Tangente mit dem eingezeichneten Geradenstuck (Rich-tungselement) zusammenfallt. Die Methode zur (naherungsweisen) grafischen Losung der Differentialgleichung(161) lasst sich nun folgendermaßen beschreiben. Mit Hilfe der Gleichung f(x, y) = const. konnen (jeweilsdurch spezielle Wahl der Konstanten) Isoklinen der Differentialgleichung gezeichnet werden. Auf den Isoklinenwerden dann die Richtungselemente eingetragen. Dabei genugt es, auf jeder Isokline nur ein Richtungselementeinzuzeichnen, da die anderen durch Parallelverschiebung entstehen. Die Naherungen fur die Losungskurvensind so zu konstruieren, dass sie in den Schnittpunkten mit den Isoklinen parallel zu den zugehorigen Richtungs-elementen verlaufen.
4Quelle: L. PAPULA. Mathematik fur Ingenieure und Naturwissenschaftler, Band 2, 12. Auflage (2009), S. 353-354
8
Ist zusatzlich zu der Differentialgleichung (161) eine Anfangsbedingung y(xa) = ya vorgegeben, so ist die(Naherungs-)Losung dieses AWP durch diejenige Kurve aus der Kurvenschar gegeben, die durch den Punkt mitden Koordinaten (x, y) = (xa, ya) verlauft (vgl. Bild 9.1b)).
Bild 9.1a) Bild 9.1b)
Beispiel 9.10:Es wird die Differentialgleichung y′ =
y
x(mit x 6= 0) betrachtet.
Gemaß (161) gilt: f(x, y) =y
x, d.h. die Isoklinen werden durch
die Gleichung y
x= const. = m charakterisiert. Es handelt sich
um eine Schar von Halbgeraden, welche durch Gleichungen derForm y = mx mit x, y 6= 0 beschrieben werdena. Das Rich-tungsfeld der Differentialgleichung ist in der nebenstehenden Ab-bildung dargestellt. Fur die betrachtete Differentialgleichung fal-len die Losungskurven mit den Isoklinen zusammen.
aDie Gleichungen y = mx sind zwar Gleichungen von Geraden. Aber aufGrund der Bedingung x, y 6= 0 ”zerfallen“ diese Geraden jeweils in zwei Halb-geraden.
−5
5
5−5
9.2.2 Differentialgleichungen mit trennbaren Variablen (separable Differentialgleichungen)
Unter einer separablen Differentialgleichung 1. Ordnung versteht man eine Differentialgl. vom folgenden Typ:
y′ = f(x) · g(y) oderdy
dx= f(x) · g(y) , (162)
d.h. auf einer Seite der Gleichung steht die erste Ableitung der gesuchten Funktion y = y(x), der Ausdruck aufder anderen Seite der Gleichung lasst sich als Produkt einer nur von x abhangigen Funktion f(x) und einer nurvon y abhangigen Funktion g(y) darstellen.Derartige Differentialgleichungen konnen mit der Methode der Trennung der Variablen gelost werden.
Losung einer separablen Differentialgleichung mittels Trennung der Variablen
1) Die vorliegende Differentialgleichungdy
dx= f(x) · g(y) wird wie folgt umgestellt:
dy
g(y)= f(x) dx ,
d.h. es entsteht eine Gleichung, bei der eine Seite nur noch von der Variablen x,die andere Seite nur noch von der Variablen y abhangt. Dabei wird vorausgesetzt, dass g(y) 6= 0 gilt.
2) Auf beiden Seiten der Gleichung aus Schritt 1) wird eine unbestimmte Integration durchgefuhrt:∫dy
g(y)=∫f(x) dx .
3) Die allgemeine Losung der Differentialgleichung liegt nun in der impliziten Form: F1(y) = F2(x) vor.Die Auflosung nach y - falls uberhaupt moglich - ergibt die allgemeine Losung der Differentialgleichungin der expliziten Form y = y(x).
Hinweis: Bei dem soeben beschriebenen Losungsweg wurde zunachst g(y) 6= 0 vorausgesetzt. In dem Fallg(y) = 0 hat die betrachtete Differentialgleichung die Form y′ = f(x) · 0 = 0, d.h. ihre Losungen sind vomTyp y = const. = a (a ∈ R).
Beispiel 9.11:9
Beispiel 9.12: Das AWP5 fur die Differentialgleichung des freien Falles mit Luftwiderstand:
m
c
dv
dt+ v2 =
mg
c, v(0) = 0
ist zu losen (c: Proportionalitatsfaktor).Zunachst wird die Differentialgleichung ohne Berucksichtigung der AB mittels Trennung der Variablen gelost:
dv
dt= g − c
mv2 ⇒ dv
g − cm v2
= dt ⇒ dv
g(
1− cmg v
2) = dt
(falls v 6=
√mg
c
). (163)
Die Integration der linken Seite der Gleichung (163) erfolgt durch die Substitution u =√
c
mgv und mit Hilfe
des Grundintegrals∫
du
1− u2= artanhu+ C.
Insgesamt ergibt die Integration der Gleichung (163):√m
cgartanh
(√c
mgv
)= t+ C.
Nach Berucksichtigung der AB erhalt man: C = 0, d.h. die Losung des AWP (partikulare Losung der Dgl.)lautet:
v =
√mg
ctanh
(√cg
mt
)bzw. v =
√mg
c
ekt − e−kt
ekt + e−ktmit k :=
√cg
m.
9.2.3 Losung von Ahnlichkeits-Differentialgleichungen
Eine Differentialgleichung der Form
y′ = f(y
x
)wird als Ahnlichkeits-Differentialgleichung bezeichnet. Auf der einen Seite der Differentialgleichung befindetsich die erste Ableitung der gesuchten Funktion, auf der anderen Seite ein Ausdruck, der als Funktion desQuotienten y
xgeschrieben werden kann. Die Losung derartiger Differentialgleichungen wird mit Hilfe der
Substitution u =y
xauf die Losung von Differentialgleichungen mit trennbaren Variablen zuruckgefuhrt.
Vorgehensweise bei der Losung von Dgln. der Form y′ = f( yx
)(Ahnlichkeits-Dgln.)
1) Aufstellen und Losen der folgenden Differentialgleichung mit getrennten Variablen:
du
f(u)− u=dx
x(164)
Der Ausdruck fur f(u) entsteht aus f(y
x
), indem y
xdurch u ersetzt wird.
Das Losen der Gleichg. (164) erfolgt wie im Abschn. 9.2.2 beschrieben, die allgemeine Losung lautet u.Hinweis: Wenn der Fall f(u)− u = 0 eintreten kann, ist dieser gesondert zu behandeln.
2) Die allgemeine Losung der gegebenen Ahnlichkeits-Differentialgleichung erhalt man als: y = u · x,mit u aus 1).
Begrundung dieser Vorgehensweise:Zunachst wird die Funktion u =
y
xeingefuhrt. Dann gilt: y = u · x. Diese Gleichung wird nun nach x
differenziert, wobei die Produktregel anzuwenden ist (denn u ist eine von der Variablen x abhangige Funktion).Das fuhrt zunachst auf die Gleichung
y′ = u′ · x+ u · 1 . (165)5Quelle: W. LEUPOLD (Hrsg.). Mathematik - ein Studienbuch fur Ingenieure (Band 2: Reihen - Differentialgleichungen - Analysis
fur mehrere Variable - Stochastik), 2. Auflage (2006), S. 98-99
10
Wenn in der zu losenden Differentialgleichung der Quotient y
xdurch u ersetzt wird, dann entsteht die Gleichung:
y′ = f(u). Dies ergibt zusammen mit (165):
f(u) = u′ · x+ u = x · dudx
+ u ⇒ f(u)− u = x · dudx⇒ f(u)− u
du=
x
dx
Diese Gleichung ist aquivalent zu der folgenden Differentialgleichung mit getrennten Variablen:
du
f(u)− u=dx
x.
Nachdem diese Differentialgleichung gemaß der im Abschnitt 9.2.2 beschriebenen Vorgehensweise gelost wur-de, entsteht die Losung y der Ausgangsgleichung als: y = u · x.
Beispiel 9.13:
9.2.4 Lineare Differentialgleichungen 1. Ordnung
Definition 9.3:Eine Differentialgleichung 1. Ordnung heißt linear, wenn sie in der folgenden Form darstellbar ist:
y′ + f(x) · y = g(x) . (166)
Die Funktion g(x) wird Storfunktion oder Storglied genannt.Falls g(x) ≡ 0 gilt, wird die Differentialgleichung als homogene lineare Differentialgleichung bezeichnet.Anderenfalls handelt es sich um eine inhomogene lineare Differentialgleichung.
Beispiel 9.14:
Bei der Erlauterung der Methoden zur Losung linearer Differentialgleichungen wird zunachst der Fall einerhomogenen Gleichung betrachtet (d.h. Gleichung (166) mit g(x) ≡ 0).
Losung einer homogenen linearen Differentialgleichung 1. OrdnungDie Differentialgleichung y′ + f(x) · y = 0 hat die allgemeine Losung:
y = C · e−∫f(x) dx (C ∈ R) . (167)
Begrundung fur Formel (167):Bei der Differentialgleichung y′ + f(x) · y = 0 kann eine Trennung der Variablen vorgenommen werden:
dy
dx+ f(x) · y = 0 ⇒ dy
dx= −f(x) · y ⇒ dy
y= −f(x) dx (falls y 6= 0). (168)
Die Integration beider Seiten dieser Gleichung ergibt:∫dy
y= −
∫f(x)dx ⇒ ln |y| = −
∫f(x)dx+ C (C ∈ R) .
Die letztgenannte Gleichung wird nach |y| aufgelost:
|y| = e−∫f(x)dx+C = eC · e−
∫f(x)dx .
Somit lautet die allgemeine Losung6 der gegebenen Differentialgleichung
y = C · e−∫f(x)dx mit C ∈ R (siehe Formel (167)).
6Bei der Auflosung nach y entsteht zunachst eine Konstante ungleich 0. Da die Funktion y = 0 ebenfalls Losung der Differential-gleichung ist, lasst sich die Losungsmenge in der genannten Form darstellen.
11
Nun wird eine Formel zur Berechnung der allgemeinen Losung einer inhomogenen Gleichung (d.h. Gleichung (166)mit g(x) 6≡ 0) angegeben.
Losung einer inhomogenen linearen Differentialgleichung 1. Ordnung mit der Methodeder Variation der KonstantenDie Differentialgleichung y′ + f(x) · y = g(x) (mit g(x) 6≡ 0 ) hat die allgemeine Losung:
y =[ ∫
g(x) · e∫f(x)dxdx+ C
]· e−
∫f(x)dx, C ∈ R. (169)
Begrundung fur Formel (169):Die zu der Ausgangsgleichung
y′ + f(x) · y = g(x) (170)
gehorige homogene lineare Differentialgleichung 1. Ordnung y′ + f(x) · y = 0 hat die allgemeine Losungyh = C · e−
∫f(x)dx (siehe (167)).
Der Ansatz fur die Losung y der inhomogenen Differentialgleichung (170) nach der Methode der Variation derKonstanten wird wie folgt aufgestellt:
y = K(x) · yh = K(x) · e−∫f(x)dx , (171)
d.h. y wird dargestellt als Produkt einer (bisher unbekannten, von x abhangigen) Konstanten K(x) und der be-reits berechneten allgemeinen Losung der homogenen Differentialgleichung. Die erste Ableitung des Losungs-ansatzes lautet (nach Produkt- und Kettenregel):
y′ = K ′(x) · e−∫f(x)dx −K(x) · f(x) · e−
∫f(x)dx , (172)
da die Ableitung des Integrals∫f(x) dx den Integranden f(x) ergibt. Einsetzen von (171) und (172) in (170)
liefert:
K ′(x) · e−∫f(x)dx −K(x) · f(x) · e−
∫f(x)dx + f(x) ·K(x) · e−
∫f(x)dx = g(x)
⇒ K ′(x) · e−∫f(x)dx = g(x) bzw. K ′(x) = g(x) · e
∫f(x)dx
Durch Integration der letztgenannten Gleichung erhalt man: K(x) =∫g(x) · e
∫f(x)dxdx+ C (C ∈ R)
und nach Einsetzen in (171) ergibt sich die Formel (169) fur die allgemeine Losung der Differentialgleichung(170).
Beispiel 9.15:
12
Beispiel 9.16:Der zeitliche Verlauf der Stromstarke i = i(t) in einem Stromkreis mit zeitabhangigem ohmschen Widerstandwerde durch die lineare inhomogene Differentialgleichung 1. Ordnung
di
dt+ cos t · i = 2 · cos t (t ≥ 0)
beschrieben. Man berechne die allgemeine Losung dieser Differentialgleichung .Wie lautet die Losung der Differentialgleichung, wenn die Anfangsbedingung i(0) = 0 gestellt wird?
Bezuglich der Losungsmenge von linearen inhomogenen Differentialgleichungen 1. Ordnung gilt allgemein diefolgende Aussage.
Darstellung der Losung einer inhomogenen linearen Differentialgleichung 1. OrdnungDie allgemeine Losung y = y(x) der Differentialgleichung y′ + f(x) · y = g(x) (mit g(x) 6≡ 0 )ist stets in der Form
y(x) = yh(x) + yp(x) (173)
darstellbar, wobei die folgenden Bezeichnungen geltenyh(x): allgemeine Losung der zugehorigen homogenen Differentialgleichung y′ + f(x) · y = 0,yp(x): (beliebige) partikulare Losung der inhomogenen Differentialgleichung.
Begrundung fur Formel (173):Sei yh die allgemeine Losung der zugehorigen homogenen Differentialgleichung, dann gilt:
y′h + f(x) · yh = 0 .
Jede partikulare Losung yp der inhomogenen Differentialgleichung besitzt die Eigenschaft:
d.h. die Funktion y(x) = yh(x) + yp(x) erfullt die Ausgangsgleichung y′ + f(x) · y = g(x) und ist zugleichallgemeine Losung dieser Differentialgleichung (da ein freier Parameter in y enthalten ist).
Schlussfolgerung aus (173):Zur Ermittlung der allgemeinen Losung einer inhomogenen Differentialgleichung y′ + f(x) · y = g(x)genugt es, eine partikulare Losung yp dieser Gleichung zu bestimmen. Dies ist oft durch einen speziellenAnsatz moglich (siehe dazu den nachfolgenden Abschnitt 9.2.5).
Bemerkung:Auch bei linearen Differentialgleichungen 2. und hoherer Ordnung besitzt die allgemeine Losung die Darstel-lung (173).
13
9.2.5 Lineare Differentialgleichungen 1. Ordnung mit konstanten Koeffizienten
Eine lineare Differentialgleichung 1. Ordnung mit konstanten Koeffizienten hat die Gestalt:
y′ + a · y = g(x) mit a ∈ R. (174)
Es handelt sich um einen Spezialfall der bisher betrachteten Differentialgleichungen vom Typ (166), und zwargilt hier: f(x) = a, a ∈ R.Gemaß den Ausfuhrungen im vorangegangenen Abschnitt ist die Methode der Variation der Konstanten zurLosung derartiger Differentialgleichungen geeignet. Wenn jedoch die Storfunktion von einem speziellen Funk-tionstyp (z.B. Exponentialfunktion, Polynom oder trigonometrische Funktion) ist, bietet sich als Alternative dieLosung mit Hilfe eines speziellen Ansatzes an7. Letztere ist meistens einfacher. Zunachst wird die Vorgehens-weise bei einem solchen Losungsweg beschrieben und anschließend werden mogliche Ansatze vorgestellt.
Losung linearer Differentialgleichungen 1. Ordnung mit konstanten Koeffizienten bei Vorliegenspezieller Storfunktionen
1) Die allgemeine Losung der zugehorigen homogenen Differentialgleichung y′+a ·y = 0 wird berechnet.
Diese Losung lautet gemaß (167): yh = C · e−∫a dx = C · e−ax (C ∈ R).
2) Um eine partikulare Losung yp der inhomogenen Differentialgleichung (174) zu finden, wird ein Ansatzin Form einer Funktion, die im Wesentlichen dem Typ der Storfunktion entspricht, verwendet(haufig verwendete Ansatze: siehe unten).
3) Die allgemeine Losung y von (174) ergibt sich gemaß (173) als: y = yh + yp .
Ubersicht uber Ansatze fur die partikulare Losung yp der inhomogenen Differentialgleichungy′ + a · y = g(x) (a 6= 0)
g(x) = c · sin(ωx) yp = A · sin(ωx) +B · cos(ωx) oderg(x) = c · cos(ωx) yp = C · sin(ωx+ ϕ)
g(x) = c1 · sin(ωx) + c2 · cos(ωx) Parameter: A, B bzw. C, ϕ
g(x) = b · ecx yp = A · ecx fur c 6= −ayp = A · x · ecx fur c = −aParameter: A
Hinweise zur Tabelle:- Die in der Tabelle (rechte Spalte) genannten Parameter sind zunachst unbekannt. Nach Einsetzen des gewahl-
ten Ansatzes fur yp sowie dessen Ableitung y′p in die zu losende Differentialgleichung kann ein Koeffizienten-vergleich durchgefuhrt werden. Dieser liefert Bedingungen (in Form linearer Gleichungen) fur die gesuchtenParameter, aus denen diese Parameter berechnet werden konnen. Die Beispiele 9.17 und 9.18 verdeutlichendiese Vorgehensweise.
- Besteht die Storfunktion g(x) aus mehreren additiven Storgliedern, so erhalt man den Losungsansatz fur ypals Summe der Losungsansatze fur die Einzelglieder.7Dafur wird haufig auch die Bezeichnung ”Storgliedansatz“ verwendet.
14
Beispiel 9.17:
Beispiel 9.18:
Beispiel 9.19:8
Ein Stromkreis mit einem Ohmschen Widerstand R, der Induktivitat L und der Wechselspannungsquelleu(t) = u0 sin(ωt) wird zur Zeit t = 0 geschlossen. Das Zeitverhalten des Stromes i = i(t) wird durchdie lineare inhomogene Differentialgleichung 1. Ordnung
di
dt+R
Li =
u0L
sin(ωt) (175)
beschrieben.Offensichtlich handelt es sich um eine Differentialgleichung mit konstanten Koeffizienten.
Die zu (175) gehorige homogene Differentialgleichungdi
dt+R
Li = 0 hat die allgemeine Losung ih = C · e−
RLt
mit C ∈ R (vgl. dazu Relation (167)). Die Storfunktion in der inhomogenen Gleichung (175) hat die Form
g(t) =u0L
sin(ωt) , d.h. sie ist vom Typ c · sin(ωt). Daher eignet sich der Ansatz ip = A · sin(ωt) +B · cos(ωt)
zur Berechnung einer partikularen Losung von (175).
Es gilt dann:dipdt
= A · ω · cos(ωt)−B · ω · sin(ωt) . Einsetzen in die Differentialgleichung (175) ergibt:
dipdt
+R
Lip = A · ω · cos(ωt)−B · ω · sin(ωt) +
R
L[A · sin(ωt) +B · cos(ωt)] =
u0L· sin(ωt)
⇒(A · ω +
R
L·B)
cos(ωt) +
(−B · ω +
R
L·A)· sin(ωt) =
u0L· sin(ωt) .
Durch Vergleich der Koeffizienten bei sin(ωt) sowie bei cos(ωt) erhalt man:R
L·A−B · ω =
u0L
A · ω +R
L·B = 0.
Die Losung dieses linearen Gleichungssystems ist: A =u0 ·R
R2 + ω2L2, B =
−u0 · ω · LR2 + ω2L2
.
Damit erhalt man als partikulare Losung der Gleichung (175):
ip =u0
R2 + ω2L2[R sin(ωt)− ωL cos(ωt)] .
Folglich lautet die allgemeine Losung der Differentialgleichung (175):
i = ih + ip = C · e−RLt +
u0R2 + ω2L2
[R sin(ωt)− ωL cos(ωt)] (C ∈ R).
9.2.6 Exakte Differentialgleichungen
Definition 9.4: Eine Differentialgleichung der Gestalt
y′ =dy
dx= −g(x, y)
h(x, y)oder g(x, y) dx+ h(x, y) dy = 0 (176)
heißt exakte Differentialgleichung, wenn der Ausdruck auf der linken Seite der letztgenannten Gleichungdas totale Differential einer Funktion f(x, y) (vgl. dazu Abschnitt 7.3 im Skript zur Vorlesung Mathe-matik 2) ist. Dies bedeutet, dass eine Funktion f(x, y) mit dem totalen Differential
df(x, y) = fx(x, y) dx+ fy(x, y) dy = g(x, y) dx+ h(x, y) dy (177)
existieren muss.
Die Funktion f(x, y) ist zunachst nicht bekannt, aber mit Hilfe der folgenden
fur mehrere Variable - Stochastik), 2. Auflage (2006), S. 109-110
15
kann gepruft werden, ob es sich bei der Gleichung (176) tatsachlich um eine exakte Differentialgleichung han-delt. Wenn die Integrabilitatsbedingung erfullt ist, hat die Differentialgleichung (176) die (in impliziter Formvorliegende) Losung f(x, y) = C mit C ∈ R, wobei fx(x, y) = g(x, y) und fy(x, y) = h(x, y) gilt, sie-he (177). Diese beiden Beziehungen werden zur Berechnung der Losung f(x, y) verwendet. Zunachst wird dieerste dieser Gleichungen unbestimmt nach x integriert (wobei zu beachten ist, dass dabei eine von y abhangigeIntegrationskonstante entsteht). Dann ist f(x, y) bis auf diese additive Konstante bereits bestimmt. Die Berech-nung dieser Konstanten erfolgt, indem noch die Bedingung fy(x, y) = h(x, y) berucksichtigt wird. Somit lasstsich die Vorgehensweise bei der Losung exakter Differentialgleichungen folgendermaßen beschreiben.9
Losung der exakten Differentialgleichung g(x, y) dx+ h(x, y) dy = 0
⇒ Die Losung der gegebenen Differentialgleichung hat die Form f(x, y) = G(x, y) + C0(y).
2) Berechnung von: fy(x, y) =∂
∂y(G(x, y) + C0(y)) =
∂G(x, y)
∂y+ C ′0(y)
3) Gleichsetzung von fy(x, y) mit h(x, y) ergibt eine Gleichung fur C ′0(y)
4) Berechnung von C0(y) durch unbestimmte Integration (nach y) des Ausdrucks fur C ′0(y)
5) Die allgemeine Losung der gegebenen Differentialgleichung ergibt sich (in impliziter Form) als:f(x, y) = G(x, y) + C0(y) = C, mit G(x, y) aus 1), C0(y) aus 4) und C ∈ R.
Beispiel 9.20:
Bemerkungen:
- Wenn zusatzlich zu der exakten Differentialgleichung eine Anfangsbedingung gegeben ist, kann die Losungdieses AWP als Summe zweier bestimmter Integrale dargestellt werden, siehe dazu z.B.:G. MERZIGER, G. MUHLBACH, D. WILLE, TH. WIRTH. Formeln + Hilfen zur hoheren Mathematik,7. Auflage (2014), S. 165.
- Wenn bei einer Differentialgleichung der Form (176) die Integrabilitatsbedingung nicht erfullt ist, kann dasaufgefuhrte Losungsverfahren nicht unmittelbar angewendet werden. Gegebenenfalls ist es jedoch moglich,die Gleichung durch Erweitern mit einer speziellen Funktion (integrierender Faktor) in eine exakte Differenti-algleichung zu verwandeln. Weitere Ausfuhrungen und Beispiele dazu findet man z.B. in:H.-J. BARTSCH. Taschenbuch mathematischer Formeln fur Ingenieure und Naturwissenschaftler,23. Auflage (2014), S. 549f. oder:W. PREUSS, G. WENISCH (Hrsg.). Lehr- und Ubungsbuch Mathematik, Band 2, 3. Auflage (2003), S. 283f.
9.3 Lineare Differentialgleichungen 2. und hoherer Ordnung mit konstanten Koeffizienten
Derartige Differentialgleichungen sind in der Praxis haufig anzutreffen. Beispielsweise konnen mechanische undelektromagnetische Schwingungen durch lineare Differentialgleichungen mit konstanten Koeffizienten beschrie-ben werden (siehe auch Abschnitt 9.1.2).
9.3.1 Lineare Differentialgleichungen 2. Ordnung mit konstanten Koeffizienten
Definition 9.5:Eine Differentialgleichung der Form
y′′ + ay′ + by = g(x) (a, b ∈ R) (179)
heißt lineare Differentialgleichung 2. Ordnung mit konstanten Koeffizienten.
Beispiel 9.21:
9Vor Ausfuhrung dieser Losungschritte ist mittels (178) zu uberprufen, ob tatsachlich eine exakte Differentialgleichung vorliegt.
16
9.3.1.1 Losung der homogenen Differentialgleichung
Ahnlich wie im Abschnitt 9.2.5 wird zunachst die zu der inhomogenen Differentialgleichung (179) gehorigehomogene Differentialgleichung gelost. Fur die allgemeine Losung dieser homogenen Differentialgleichung giltdie folgende Aussage.
Die allgemeine Losung einer homogenen linearen Differentialgleichung 2. Ordnung mit konstanten Koeffi-zienten (siehe (179), speziell mit g(x) ≡ 0) ist als Linearkombination zweier linear unabhangiger Losungen(Basislosungen) y1(x) und y2(x) darstellbar:
y(x) = C1 y1(x) + C2 y2(x) (C1, C2 ∈ R). (180)
Die Losungen y1(x) und y2(x) sind linear unabhangig, wenn gilt:
W (y1, y2) =
∣∣∣∣ y1(x) y2(x)y′1(x) y′2(x)
∣∣∣∣ 6= 0 (W (y1, y2) heißt Wronski-Determinante).
Diese Losungen bilden dann ein Fundamentalsystem der Differentialgleichung (179).
Zum Auffinden eines solchen Fundamentalsystems wird ein Losungsansatz der Form y = Ceλx mit demzunachst unbekannten Parameter λ verwendet (C sei konstant). Nach Einsetzen dieser Funktion y und ihrerAbleitungen y′ = Cλeλx , y′′ = Cλ2eλx in die zu losende Differentialgleichung y′′ + ay′ + by = 0 entstehtdie Gleichung
Cλ2eλx + aCλeλx + bCeλx = 0 .
Nach Division durchCeλx (unter der VoraussetzungC 6= 0 ist dieser Ausdruck von Null verschieden) ergibt sicheine bezuglich λ quadratische Gleichung, mit deren Hilfe linear unabhangige Losungen der Differentialgleichungermittelt werden konnen.
Die Gleichung
λ2 + aλ+ b = 0 (181)
heißt charakteristische Gleichung der Differentialgleichung y′′ + ay′ + by = 0.
Bezuglich der Losungsmenge der Gleichung (181) sind die folgenden Falle zu unterscheiden:
1. Fall: zwei verschiedene reelle Losungen λ1, λ2 der charakteristischen Gleichung⇒ y1 = eλ1x und y2 = eλ2x bilden ein Fundamentalsystem der Differentialgleichung.
⇒ y1 = eλ1x und y2 = x · eλ1x erfullen die Differentialgleichung und bilden ein Fundamental-system der Differentialgleichung.
3. Fall: zwei konjugiert-komplexe Losungen λ1 = α+ jβ , λ2 = α− jβ der charakteristischen Gleichung(α, β ∈ R, β 6= 0):Zunachst konnen die (komplexwertigen) Losungen: e(α+jβ)x und e(α−jβ)x gebildet werden.Mit e(α+jβ)x = eαx · e jβx = eαx · [cos(βx) + j sin(βx)] (und analog fur e(α−jβ)x) erhalt man diereellen Losungen y1 = eαx sin(βx) und y2 = eαx cos(βx). Diese bilden ein Fundamentalsystem derDifferentialgleichung.
Die Aussage, dass die Losungen y1 und y2 in den genannten Fallen jeweils linear unabhangig sind (d.h. einFundamentalsystem bilden), lasst sich mit Hilfe der Wronski-Determinante rechnerisch leicht begrunden.Beispielsweise gilt im 1. Fall:
W (y1, y2) =
∣∣∣∣ y1 y2y′1 y′2
∣∣∣∣ =
∣∣∣∣ eλ1x eλ2x
λ1eλ1x λ2e
λ2x
∣∣∣∣ = (λ2 − λ1)eλ1xeλ2x 6= 0 , da λ1 6= λ2 .
Zur Ermittlung der allgemeinen Losung einer homogenen linearen Differentialgleichung mit konstanten Koeffi-zienten sind somit die folgenden Arbeitsschritte erforderlich.
17
Berechnung der allgemeinen Losung der Differentialgleichung y′′ + ay′ + by = 0
1) Aufstellen der charakteristischen Gleichung λ2 + aλ+ b = 0
2) Losen der charakteristischen Gleichung und Aufstellen des Fundamentalsystems y1(x), y2(x)der Differentialgleichung entsprechend der Fallunterscheidung (siehe vorige Seite)
3) Bilden einer Linearkombination der Losungen y1(x) und y2(x) gemaß (180)
Beispiel 9.22:
9.3.1.2 Losung der inhomogenen Differentialgleichung
Die allgemeine Losung der Differentialgleichung (179) ist darstellbar in der Form
y(x) = yh(x) + yp(x)
(vgl. auch (173) im Fall einer linearen Differentialgleichung 1. Ordnung).Ahnlich wie bei linearen Differentialgleichungen 1. Ordnung mit konstanten Koeffizienten kann zur Ermittlungeiner partikularen Losung der inhomogenen Differentialgleichung auf spezielle Ansatze zuruckgegriffen werden,wenn die Storfunktion z.B. eine Exponentialfunktion, ein Polynom oder eine trigonometrische Funktion ist.Zuerst wird die Vorgehensweise bei einem solchen Losungsweg beschrieben und anschließend werden moglicheAnsatze aufgezahlt.
Losung linearer Differentialgleichungen 2. Ordnung mit konstanten Koeffizienten bei Vorliegenspezieller Storfunktionen
1) Die allgemeine Losung yh der zugehorigen homogenen Differentialgleichung y′′ + ay′ + by = 0wird berechnet (gemaß der im Abschnitt 9.3.1.1 beschriebenen Vorgehensweise, siehe oben).
2) Um eine partikulare Losung yp der inhomogenen Differentialgleichung (179) zu finden, wird ein Ansatzin Form einer Funktion, die im Wesentlichen dem Typ der Storfunktion entspricht, verwendet(haufig verwendete Ansatze: siehe nachste Seite).
3) Die allgemeine Losung y der Gleichung (179) ergibt sich als: y = yh + yp .
18
Ubersicht uber Ansatze fur die partikulare Losung yp der inhomogenen Differentialgleichungy′′ + ay′ + by = g(x)
Storfunktion g(x) Losungsansatz fur yp(x)
Polynom vom Grad n yp = Qn(x) falls b 6= 0, d.h.: 0 ist keine Losung der charakteristischeng(x) = Pn(x) Gleichung
yp = x ·Qn(x) falls a 6= 0, b = 0, d.h.: 0 ist eine einfache Losungder charakteristischen Gleichung
yp = x2 ·Qn(x) falls a = b = 0, d.h.: 0 ist eine doppelte Losungder charakteristischen Gleichung
Qn(x): Polynom vom Grad nParameter: Koeffizienten des Polynoms Qn(x)
Exponentialfunktion yp = A · ecx falls c keine Losung der charakteristischen Gleichungg(x) = decx (c, d ∈ R) yp = Ax · ecx falls c eine einfache Losung der charakteristischen Gleichung
yp = Ax2 · ecx falls c eine doppelte Losung der charakteristischen GleichungParameter: jeweils A
Sinusfunktion Falls jβ keine Losung der charakteristischen Gleichung:g(x) = d1 sin(βx) (d1, β ∈ R) yp = A · sin(βx) +B · cos(βx)
oder oder yp = C · sin(βx+ ϕ)
Kosinusfunktion Falls jβ eine Losung der charakteristischen Gleichung:g(x) = d2 cos(βx) (d2, β ∈ R) yp = x [A · sin(βx) +B · cos(βx)]
oder Linearkombination oder yp = Cx · sin(βx+ ϕ)
aus beiden Funktionen Parameter: jeweils A,B bzw. C,ϕ
g(x) = ecx · Pn(x) yp = ecx ·Qn(x) falls c keine Losung der charakteristischen Gleichung(Pn(x): Polyn. vom Grad n, yp = x · ecx ·Qn(x) falls c eine einfache Losung der charakterist. Gleichungc ∈ R) yp = x2 · ecx ·Qn(x) falls c eine doppelte Losung der charakterist. Gleichung
Qn(x): Polynom vom Grad nParameter: Koeffizienten dieses Polynoms
g(x) = ecx · cos(βx) Falls c+ jβ eine Losung der charakteristischen Gleichung:(c, β ∈ R) yp = x · ecx · [A sin(βx) +B cos(βx)]
oder Linearkombination Parameter: jeweils A,B
g(x) = Pn(x) · sin(βx) Falls jβ keine Losung der charakteristischen Gleichung:oder yp = Qn(x) · sin(βx) +Rn(x) · cos(βx)
g(x) = Pn(x) · cos(βx) Falls jβ eine Losung der charakteristischen Gleichung:(Pn(x): Polyn. vom Grad n, yp = x · [Qn(x) · sin(βx) +Rn(x) · cos(βx)]
β ∈ R) Qn(x), Rn(x): Polynome vom Grad nParameter: Koeffizienten dieser Polynome
Hinweise zur obigen Tabelle:
- Besteht die Storfunktion g(x) aus mehreren additiven Storgliedern, so erhalt man den Losungsansatz fur ypals Summe der Losungsansatze fur die Einzelglieder.
- Die Falle, in denen c (bzw. jβ oder c+ jβ) eine Losung der charakteristischen Gleichung ist, entsprechen derSituation, dass die Storfunktion in der allgemeinen Losung der homogenen Differentialgleichung vorkommt.Man spricht in derartigen Fallen auch von Resonanz.
Beispiel 9.23:19
Bemerkungen:
- Sind zu der Differentialgleichung (179) zusatzlich Anfangsbedingungen (AB) vorgegeben, so bleiben diesezunachst unberucksichtigt. Erst nach Berechnung der allgemeinen Losung der Differentialgleichung werdendiese eingearbeitet, d.h. aus diesen AB werden Bedingungsgleichungen fur die Konstanten C1 und C2 (siehe(180)) in der allgemeinen Losung aufgestellt und anschließend gelost.
- Wenn eine inhomogene lineare Differentialgleichung 2. Ordnung mit konstanten Koeffizienten zu losen ist,bei der die Storfunktion nicht die in der obigen Tabelle aufgefuhrte Form hat, kann zum Auffinden einer parti-kularen Losung yp die Methode der Variation der Konstanten angewendet werden. Dabei wird nach Ermittlungdes Fundamentalsystems y1(x), y2(x) fur die zugehorige homogene Differentialgleichung ein Ansatz in derForm yp = c1(x)y1 + c2(x)y2 aufgestellt (fur weitere Details siehe z.B.: G. MERZIGER, G. MUHLBACH,D. WILLE, TH. WIRTH. Formeln + Hilfen zur hoheren Mathematik, 7. Auflage, S. 169).
9.3.1.3 Anwendungsbeispiele fur lineare Differentialgleichungen 2. Ordng. mit konstanten Koeffizienten
Beispiel 9.24: Differentialgleichung einer mechanischen Schwingung (Schwingungsgleichung)10
Das betrachtete System besteht aus einer Masse m, einer demHookeschen Gesetz genugenden elastischen Feder und einerDampfungsvorrichtung (wesentlicher Unterschied zu der imBeispiel 9.3 betrachteten Situation).Annahme:Feder und Dampfungskolben seien masselos.Mit x = x(t) wird die Auslenkung der Feder aus der Gleichge-wichtslage (Ruhelage) zur Zeit t (t ≥ 0) bezeichnet.
XXXm
elast. Feder
Dampfungsvorrichtg.
Auf die Masse m wirken die folgenden Krafte ein:
- Ruckstellkraft der Feder: F1 = −cx (c: Federkonstante; c > 0)
- Dampfungskraft, proportional zur Geschwindigkeit v = x: F2 = −bv = −bx (b: Dampferkonstante)
- eine von außen einwirkende, meist zeitabhangige Kraft: F3 = F (t)
Nach dem Newtonschen Grundgesetz der Mechanik gilt:
ma = F1 + F2 + F3 ⇒ mx = −cx− bx+ F (t)
Das schwingungsfahige System wird somit durch die folgende lineare Differentialgleichung 2. Ordnung mitkonstanten Koeffizienten beschrieben:
mx+ bx+ cx = F (t) .
Diese Gleichung wird auch als Schwingungsgleichung der Mechanik bezeichnet.
Bei mechanischen Schwingungen werden die folgenden speziellen Schwingungstypen unterschieden:
1. freie SchwingungenDas System unterliegt keiner außeren Kraft, d.h. es gilt: F (t) = 0. Dabei wird noch die folgende Unterschei-dung getroffen:
a) freie ungedampfte SchwingungIn der Schwingungsgleichung ist b = 0 zu setzen, d.h. man erhalt die Gleichung
mx+ cx = 0
zur Beschreibung dieses Schwingungstyps.Die allgemeine Losung dieser Differentialgleichung lautet (siehe dazu Abschnitt 9.3.1.1):
x(t) = C1 sin(ω0t) + C2 cos(ω0t) mit ω20 =
c
mund C1, C2 ∈ R.
10Quelle: L. PAPULA. Mathematik fur Ingenieure und Naturwissenschaftler, Band 2, 12. Auflage (2009), S. 417-418
20
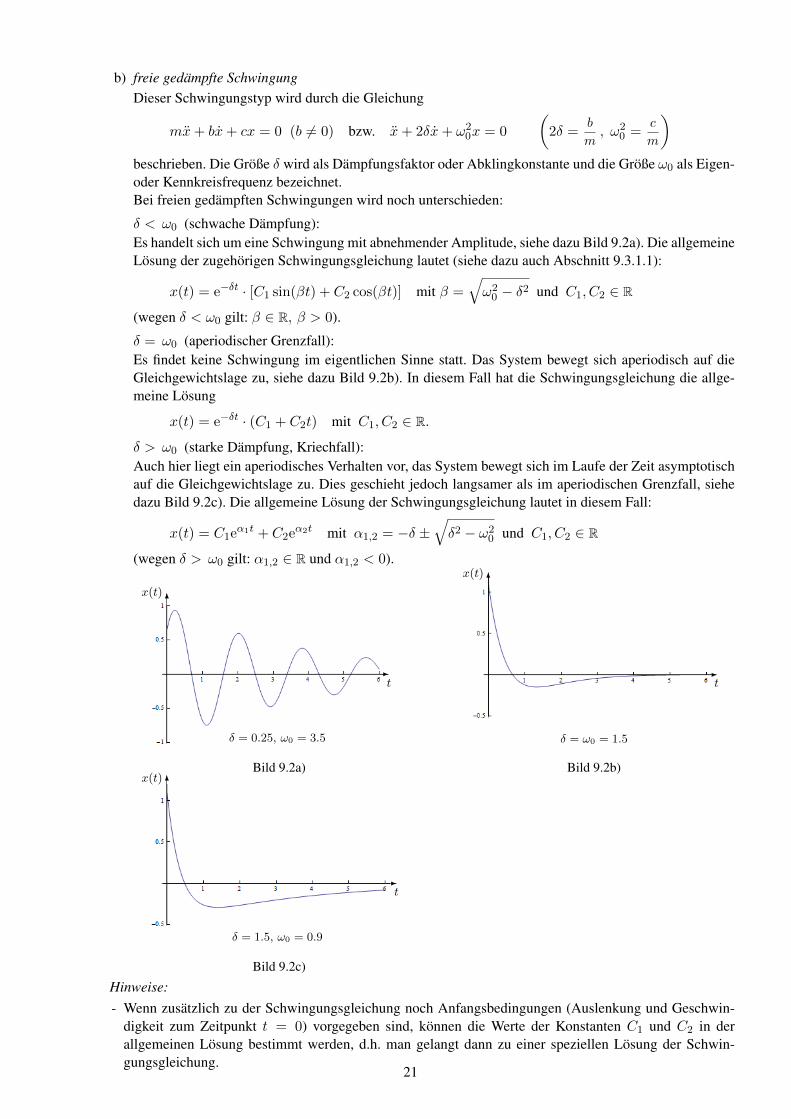
b) freie gedampfte SchwingungDieser Schwingungstyp wird durch die Gleichung
mx+ bx+ cx = 0 (b 6= 0) bzw. x+ 2δx+ ω20x = 0
(2δ =
b
m, ω2
0 =c
m
)beschrieben. Die Große δ wird als Dampfungsfaktor oder Abklingkonstante und die Große ω0 als Eigen-oder Kennkreisfrequenz bezeichnet.Bei freien gedampften Schwingungen wird noch unterschieden:
δ < ω0 (schwache Dampfung):Es handelt sich um eine Schwingung mit abnehmender Amplitude, siehe dazu Bild 9.2a). Die allgemeineLosung der zugehorigen Schwingungsgleichung lautet (siehe dazu auch Abschnitt 9.3.1.1):
x(t) = e−δt · [C1 sin(βt) + C2 cos(βt)] mit β =√ω20 − δ2 und C1, C2 ∈ R
(wegen δ < ω0 gilt: β ∈ R, β > 0).
δ = ω0 (aperiodischer Grenzfall):Es findet keine Schwingung im eigentlichen Sinne statt. Das System bewegt sich aperiodisch auf dieGleichgewichtslage zu, siehe dazu Bild 9.2b). In diesem Fall hat die Schwingungsgleichung die allge-meine Losung
x(t) = e−δt · (C1 + C2t) mit C1, C2 ∈ R.
δ > ω0 (starke Dampfung, Kriechfall):Auch hier liegt ein aperiodisches Verhalten vor, das System bewegt sich im Laufe der Zeit asymptotischauf die Gleichgewichtslage zu. Dies geschieht jedoch langsamer als im aperiodischen Grenzfall, siehedazu Bild 9.2c). Die allgemeine Losung der Schwingungsgleichung lautet in diesem Fall:
x(t) = C1eα1t + C2e
α2t mit α1,2 = −δ ±√δ2 − ω2
0 und C1, C2 ∈ R
(wegen δ > ω0 gilt: α1,2 ∈ R und α1,2 < 0).
-
6
t
x(t)
-
6
t
x(t)
Bild 9.2a) Bild 9.2b)
δ = 0.25, ω0 = 3.5 δ = ω0 = 1.5
-
6
t
x(t)
δ = 1.5, ω0 = 0.9
Bild 9.2c)
Hinweise:- Wenn zusatzlich zu der Schwingungsgleichung noch Anfangsbedingungen (Auslenkung und Geschwin-
digkeit zum Zeitpunkt t = 0) vorgegeben sind, konnen die Werte der Konstanten C1 und C2 in derallgemeinen Losung bestimmt werden, d.h. man gelangt dann zu einer speziellen Losung der Schwin-gungsgleichung.
21
- In den Bildern 9.2b) und 9.2c) ist jeweils die Situation dargestellt, dass die Funktion x(t) genau eineNullstelle besitzt. In Abhangigkeit von den Anfangsbedingungen kann auch der Fall eintreten, dass x(t)keine Nullstelle hat. Fur eine ausfuhrliche Diskussion dieser Problematik sei auf die folgende Litera-turstelle verwiesen: A. FETZER, H. FRANKEL. Mathematik 2: Lehrbuch fur ingenieurwissenschaftlicheStudiengange. Springer, 6. Auflage, 2009, S. 436-439.
2. erzwungene SchwingungenDas System unterliegt einer von außen einwirkenden zeitabhangigen periodischen Kraft F (t) = F0 · sin(ωt)mit der Erregerkreisfrequenz ω:
mx+ bx+ cx = F0 · sin(ωt).
In diesem Fall liegt also eine inhomogene Differentialgleichung vor. Auch bei erzwungenen Schwingungenwird zusatzlich unterschieden, ob es sich um eine ungedampfte Schwingung handelt oder ob eine Dampfungvorliegt.
a) erzwungene ungedampfte SchwingungIn der o.g. Schwingungsgleichung ist b = 0 zu setzen. Wenn die Erregerkreisfequenz ω mit der Eigen-
kreisfrequenz ω0 =√
c
mdes Systems ubereinstimmt, dann tritt Resonanz ein.
b) erzwungene gedampfte SchwingungIn diesem Fall gilt b 6= 0. Detaillierte Informationen bezuglich erzwungener Schwingungen bei schwa-cher Dampfung (d.h. δ < ω0) findet man z.B. in: L. PAPULA. Mathematik fur Ingenieure und Naturwis-senschaftler, Band 2, 12. Auflage, 2009, S. 435-443.
Beispiel 9.25: siehe Ubung
Beispiel 9.26: Schwingungsgleichung eines elektrischen ReihenschwingkreisesDie Differentialgleichung des elektrischen Reihenschwingkreises lautet:
Ld2i
dt2+R
di
dt+
1
Ci =
duadt
,
oder
d2i
dt2+ 2δ
di
dt+ ω2
0 i =1
L
duadt
mit δ =R
2L, ω0 =
1√LC
,
wobei i = i(t) die Stromstarke,R den ohmschen Widerstand,L die Induktivitat,C die Kapazitat und ua = ua(t)die von außen angelegte Spannung bezeichnet.Der elektrische Reihenschwingkreis ist das ”elektrische Analogon“ zum Feder-Masse-Schwinger.
Definition 9.6:Eine Differentialgleichung n-ter Ordnung vom Typ
y(n) + an−1y(n−1) + . . .+ a1y
′ + a0y = g(x) (a0, a1, . . . , an−1 ∈ R) (182)
heißt lineare Differentialgleichung n-ter Ordnung mit konstanten Koeffizienten.
Beispiel 9.27:
22
Die Vorgehensweise beim Losen solcher Differentialgleichungen ist weitestgehend analog zu den bereits be-trachteten linearen Differentialgleichungen 2. Ordnung mit konstanten Koeffizienten (siehe Abschnitte 9.3.1.1-9.3.1.3). Auch jetzt wird zunachst wieder die zu (182) gehorige homogene Differentialgleichung betrachtet.
Die allgemeine Losung der homogenen Differentialgleichung y(n) + an−1y(n−1) + . . . + a1y
darstellbar, wobei die Funktionen y1(x), y2(x), . . . , yn(x) ein Fundamentalsystem (d.h. ein System linearunabhangiger Losungen) bilden.Das Auffinden eines Fundamentalsystems erfolgt wiederum durch Losung der charakteristischen Gleichung.Diese lautet:
λn + an−1λn−1 + . . .+ a1λ+ a0 = 0 . (184)
Da es sich bei (184) um eine Gleichung n-ter Ordnung (n ≥ 3) in λ handelt, ist die Ermittlung der Losungendieser Gleichung meist schwieriger als bei der charakteristischen Gleichung fur Differentialgleichungen 2. Ord-nung (dort liegt stets eine quadratische Gleichung in λ vor).Bezuglich der Losungsmenge der Gleichung (184) sind die folgenden Falle zu unterscheiden:
1. Fall: Alle Losungen sind reell und paarweise verschieden.Fundamentalsystem der Differentialgleichung : y1 = eλ1x, y2 = eλ2x, . . . , yn = eλnx
allgemeine Losung der Differentialgleichung : y = C1eλ1x + C2e
λ2x + . . .+ Cneλnx
2. Fall: Es treten mehrfache reelle Losungen auf.Sei λ = α eine m-fache reelle Losung der charakteristischen Gleichung,d.h. λ1 = λ2 = . . . = λm = α, so gehoren zu hierzu die m linear unabhangigen Losungen:y1 = eαx, y2 = x · eαx, y3 = x2 · eαx, . . . , ym = xm−1 · eαx .Die allgemeine Losung der Differentialgleichung enthalt daher die folgenden Summanden:C1e
αx + C2x · eαx + C3x2 · eαx + . . .+ Cmx
m−1 · eαx .3. Fall Es treten konjugiert-komplexe Losungen auf.
Sei λ1,2 = α± jβ eine (einfache) konjugiert-komplexe Losung der charakteristischen Gleichung, dannsind die (reellwertigen) Funktionen y1 = eαx · sin(βx) und y2 = eαx · cos(βx) linear unabhangigeLosungen der Differentialgleichung. In der allgemeinen Losung der Differentialgleichung liefern sieden Beitrag: C1 · eαx · sin(βx) + C2 · eαx · cos(βx) = eαx [C1 sin(βx) + C2 cos(βx)] .
Die Losung der inhomogenen Differentialgleichung (182) besitzt die Darstellung y = yh + yp . Eine partikulareLosung yp der Differentialgleichung kann wiederum mittels eines geeigneten Ansatzes gefunden werden, wenndie Storfunktion g(x) z.B. eine Exponentialfunktion, ein Polynom oder eine trigonometrische Funktion ist11.Mogliche Losungsansatze ist auf der nachsten Seite dargestellt.
11Wenn dies nicht zutrifft, kommt die Methode der Variation der Konstanten zur Anwendung, vgl. dazu die Bemerkung am Ende desAbschnitts 9.3.1.2.
23
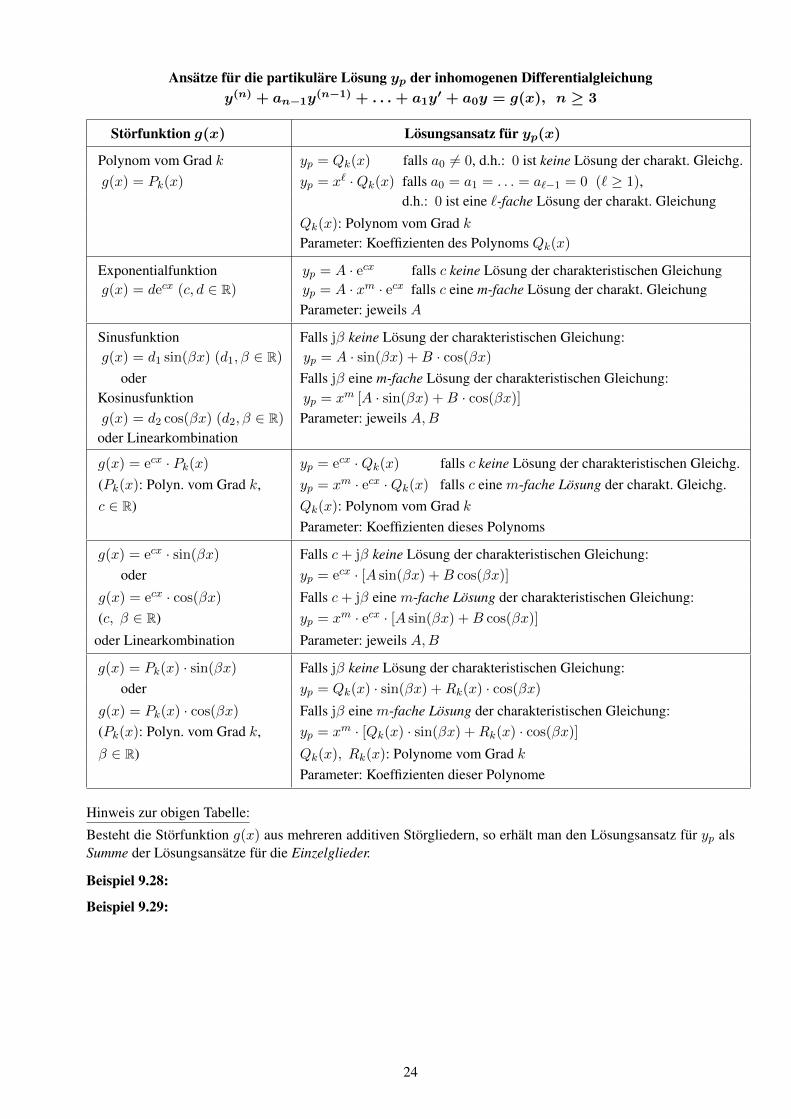
Ansatze fur die partikulare Losung yp der inhomogenen Differentialgleichungy(n) + an−1y
(n−1) + . . .+ a1y′ + a0y = g(x), n ≥ 3
Storfunktion g(x) Losungsansatz fur yp(x)
Polynom vom Grad k yp = Qk(x) falls a0 6= 0, d.h.: 0 ist keine Losung der charakt. Gleichg.g(x) = Pk(x) yp = x` ·Qk(x) falls a0 = a1 = . . . = a`−1 = 0 (` ≥ 1),
d.h.: 0 ist eine `-fache Losung der charakt. Gleichung
Qk(x): Polynom vom Grad kParameter: Koeffizienten des Polynoms Qk(x)
Exponentialfunktion yp = A · ecx falls c keine Losung der charakteristischen Gleichungg(x) = decx (c, d ∈ R) yp = A · xm · ecx falls c eine m-fache Losung der charakt. Gleichung
Parameter: jeweils A
Sinusfunktion Falls jβ keine Losung der charakteristischen Gleichung:g(x) = d1 sin(βx) (d1, β ∈ R) yp = A · sin(βx) +B · cos(βx)
oder Falls jβ eine m-fache Losung der charakteristischen Gleichung:Kosinusfunktion yp = xm [A · sin(βx) +B · cos(βx)]
g(x) = ecx · Pk(x) yp = ecx ·Qk(x) falls c keine Losung der charakteristischen Gleichg.(Pk(x): Polyn. vom Grad k, yp = xm · ecx ·Qk(x) falls c eine m-fache Losung der charakt. Gleichg.c ∈ R) Qk(x): Polynom vom Grad k
g(x) = Pk(x) · sin(βx) Falls jβ keine Losung der charakteristischen Gleichung:oder yp = Qk(x) · sin(βx) +Rk(x) · cos(βx)
g(x) = Pk(x) · cos(βx) Falls jβ eine m-fache Losung der charakteristischen Gleichung:(Pk(x): Polyn. vom Grad k, yp = xm · [Qk(x) · sin(βx) +Rk(x) · cos(βx)]
β ∈ R) Qk(x), Rk(x): Polynome vom Grad kParameter: Koeffizienten dieser Polynome
Hinweis zur obigen Tabelle:
Besteht die Storfunktion g(x) aus mehreren additiven Storgliedern, so erhalt man den Losungsansatz fur yp alsSumme der Losungsansatze fur die Einzelglieder.
Beispiel 9.28:
Beispiel 9.29:
24
Abschließend wird eine Anwendungssituation fur lineare Differentialgleichungen 4. Ordnung mit konstantenKoeffizienten vorgestellt.
Beispiel 9.30: Eulersche Knicklast fur einen Stab12
Ein elastischer Stab der Lange l verlaufe in Richtung der x-Achse und sei an einem Ende eingespannt, an demanderen Ende gelenkig gelagert. Die konstante Biegesteifigkeit des Stabes sei α. In Richtung der Stabachse wirkteine Einzelkraft F . Dann genugt die Durchbiegung y(x) des Stabes fur 0 < x < l der Differentialgleichung
y(4) + µ2y′′ = 0 mit µ =
√F
α.
Die Losung dieser Differentialgleichung muss zudem die folgenden Randbedingungen erfullen:
y(0) = 0 , y(l) = 0 (da an den Stabenden keine Durchbiegung vorliegt)
y′(0) = 0 (da an dem eingespannten Ende die Tangente an die Biegelinie horizontal verlauft)
y′′(l) = 0 (da das Biegemoment Mb(x) = −αy′′(x) an dem gelenkig gelagerten Stab-ende verschwindet).
Zur Berechnung der Durchbiegung des Stabes ist somit ein Randwertproblem (vgl. dazu auch Abschnitt 9.1.3)zu losen. Dazu sei bemerkt, dass dieses Randwertproblem stets (d.h. fur jeden beliebigen Wert von µ) die trivialeLosung y ≡ 0 hat, die jedoch aus praktischer Sicht nicht von Interesse ist. Dagegen existieren nichttrivialeLosungen des Randwertproblems nur fur bestimmte Werte von µ. Die zu dem kleinsten µ-Wert gehorige Kraftwird als Eulersche Knicklast bezeichnet.
9.3.3 Losung der Eulerschen Differentialgleichung durch Ruckfuhrung auf eine lineare Differentialglei-chung mit konstanten Koeffizienten
Definition 9.7:Eine Differentialgleichung der Form
anxny(n) +an−1x
n−1y(n−1) + . . .+a1xy′+a0y = g(x) (a0, a1, . . . , an ∈ R, an 6= 0) (185)
wird als Eulersche Differentialgleichung bezeichnet.
Beispiel 9.31:
Offensichtlich handelt es sich bei der Eulerschen Differentialgleichung nicht um eine Differentialgleichung mitkonstanten Koeffizienten, da vor der i-ten Ableitung (0 ≤ i ≤ n) der gesuchten Funktion y(x) jeweils dervon x abhangige Koeffizient aixi steht. Auf Grund der speziellen Struktur dieser Koeffizienten ist jedoch eineRuckfuhrung auf eine lineare Differentialgleichung mit konstanten Koeffizienten moglich.Bei den weiteren Betrachtungen wird die Einschrankung x > 0 vorgenommen.
Vorgehensweise bei der Losung Eulerscher DifferentialgleichungenEine Eulersche Differentialgleichung kann fur x > 0 durch die Substitution
y(x) = u(t) mit x = et (186)
auf eine lineare Differentialgleichung n-ter Ordnung mit konstanten Koeffizienten zuruckgefuhrt werden.Dazu mussen noch die Terme x · y′, x2 · y′′, . . . aus der Differentialgleichung (185) mit Hilfe der Funktionu und ihrer Ableitungen (nach t) ausgedruckt werden. Es gilt:
x · y′ = du
dt, x2 · y′′ = d2u
dt2− du
dt, x3 · y′′′ = d3u
dt3− 3
d2u
dt2+ 2
du
dt(187)
(Erlauterung zu diesen Beziehungen: siehe unten). Bei Bedarf sind weitere Produkte der Form xi · y(i),4 ≤ i ≤ n, zu berechnen. Mit Hilfe der Beziehungen (187) werden die Terme x · y′, x2 · y′′, . . . in derDifferentialgleichung (185) durch Ableitungen der Funktion u(t) ersetzt und die rechte Seite g(x) wird inder Form g(et) geschrieben. Dann entsteht eine lineare Differentialgleichung n-ter Ordnung mit konstantenKoeffizienten a0, a1, . . . , an, deren Losung die Funktion u(t) ist. Zur Losung dieser Gleichung konnen(bei passender Struktur der Storfunktion) die in den Abschnitten 9.3.1 bzw. 9.3.2 vorgestellten Methoden an-gewendet werden. Nach Berechnung von u(t) ist eine Rucksubstitution durchzufuhren, um die Losung y(x)der Ausgangsgleichung zu erhalten (siehe dazu (186)).
Erlauterung zu (187):Die Differentiation der Funktion u(t) = y(x(t)) nach der Kettenregel (siehe Abschnitt 5.3.1 im Skript zurVorlesung Mathematik 1) ergibt unter Beachtung von (186):
du
dt=dy(x(t))
dt=dy
dx· dxdt
= y′ · et = y′ · x .
Nochmaliges Differenzieren bei zusatzlicher Anwendung der Produktregel liefert:
d2u
dt2=
d
dt(y′ · et) = y′′ · (et)2 + y′ · et = y′′ · x2 +
du
dt⇒ x2 · y′′ = d2u
dt2− du
dt.
Beispiel 9.32:
Bemerkung:
Als Spezialfall wird nun die Eulersche Differentialgleichung (185) mit n = 1 betrachtet: a1xy′ + a0y = g(x).
Unter der Voraussetzung x > 0 geht diese Gleichung nach Division durch (a1x) uber in: y′ + a0a1x
y =g(x)
a1x.
Dabei handelt es sich um eine lineare Differentialgleichung 1. Ordnung (vgl. Formel (166)) fur die gesuchteFunktion y(x). Zur Losung dieser Differentialgleichung kann die Methode der Variation der Konstanten (For-mel (169)) angewendet werden, d.h. in dem vorliegenden Spezialfall ist es nicht erforderlich, die Substituti-on (186) durchzufuhren.
26
9.4 Die Laplace-Transformation und ihre Anwendungen
9.4.1 Spezielle Funktionen
(I) Die Einheitssprungfunktion (Heaviside-Funktion)Diese ist wie folgt definiert:
ε(t) =
0 fur t < 0
1 fur t ≥ 0 ,(188)
d.h. es handelt sich um eine stuckweise konstanteFunktion, siehe Bild 9.3.
-
6ε
t
r1
0
Bild 9.3
Diese Funktion findet Anwendung bei der Beschreibung von Einschaltvorgangen in technischen Sachver-halten (siehe nachfolgendes Beispiel).
Beispiel 9.33:
Die Funktion ε(t) besitzt die sog. Ausblendeigenschaft, d.h. mit Hilfe von ε(t) kann eine Funktion f(t) furalle t aus einem gewissen Teilbereich des Definitionsbereiches gleich 0 gesetzt (”ausgeblendet“) werden.Diese Eigenschaft wird im folgenden genauer erlautert.
Sei ε(t) die durch (188) gegebene Funktion und f(t) eine (beliebige) Funktion der Variablen t ∈ R.Dann gilt:
[ε(t− a)− ε(t− b)] · f(t) = 0 fur t < a und t ≥ b (a, b ∈ R und a < b) ,(189)
[ε(t− a)− ε(t− b)] · f(t) = f(t) fur a ≤ t < b ,
d.h. es entsteht eine Funktion, die im Intervall [a, b) gleich der ursprunglichen Funktion f(t) ist und sonstverschwindet. Die unter (189) genannten Eigenschaften konnen folgendermaßen begrundet werden. Es gilt:
ε(t− a) =
0 fur t− a < 0 , d.h. fur t < a
1 fur t− a ≥ 0 , d.h. fur t ≥ a(siehe Bild 9.4a)) sowie
ε(t− b) =
0 fur t− b < 0 , d.h. fur t < b
1 fur t− b ≥ 0 , d.h. fur t ≥ b(siehe Bild 9.4b)).
Damit ist ε(t− a)− ε(t− b) = 0− 0 = 0 fur t < a sowie ε(t− a)− ε(t− b) = 1− 1 = 0 fur t ≥ b ,woraus sofort (189) (die erste Eigenschaft) folgt.Weiterhin ist ε(t− a)− ε(t− b) = 1− 0 = 1 fur a ≤ t < b (siehe Bild 9.4c)), d.h. dort gilt:[ε(t− a)− ε(t− b)] · f(t) = 1 · f(t) = f(t) , womit auch die zweite Eigenschaft aus (189) bestatigt ist.
-
6
0 ta
1
ε(t− a)
-
6
0 t-
6
0 t
1
ε(t− b)
1
b
ε(t− a)− ε(t− b)
a b
r r rr
Bild 9.4a) Bild 9.4b) Bild 9.4c)
27
(II) Die Diracsche δ-Funktion (Dirac-Stoß, Impulsfunktion)Ein sehr kurzzeitig wirkender Impuls (z.B. Hammerschlag oder Stromstoß) kann durch einen Rechteck-impuls (vgl. dazu Bild 9.4c)), welcher zeitlich stark begrenzt ist und eine sehr große Amplitude besitzt,beschrieben werden. Dies fuhrt zu der folgenden Definition der δ-Funktion:
δ(t− t0) =
0 fur t 6= t0∞ fur t = t0 ,
(190)
d.h. hier wird der Gesamtimpuls auf einen Zeitpunkt t = t0 ”konzentriert“.Es sei bemerkt, dass es sich bei der δ-Funktion um eine verallgemeinerte Funktion handelt, denn fur eineFunktion im eigentlichen Sinne ist ja der Funktionswert ”∞“ nicht moglich.Es gelten die folgenden symbolischen Beziehungen:
∞∫−∞
δ(t− t0) dt = 1 ,
b∫a
δ(t− t0)f(t) dt =
f(t0) fur a ≤ t0 ≤ b
0 sonstfur eine auf (−∞,∞) stetige Funktion f(t),
d.h. δ(t− t0) ordnet dieser Funktion ihren Wert bei t = t0 zu.
Fur weitere Informationen uber die δ-Funktion (z.B. die Darstellung dieser Funktion als eine Folge stetigerFunktionen) sei auf die folgende Literaturstelle verwiesen:W. PREUSS, G. WENISCH (Hrsg.): Lehr- und Ubungsbuch Mathematik fur Elektro- und Automatisierungs-techniker, 1998, S. 79-80.
9.4.2 Die Laplace-Transformation: Definition und Rechenregeln
Definition 9.8:Sei f(t) eine reellwertige Funktion der reellen Variablen t, wobei f(t) = 0 fur t < 0 gelte.Die Laplace-Transformation von f(t) ist definiert durch:
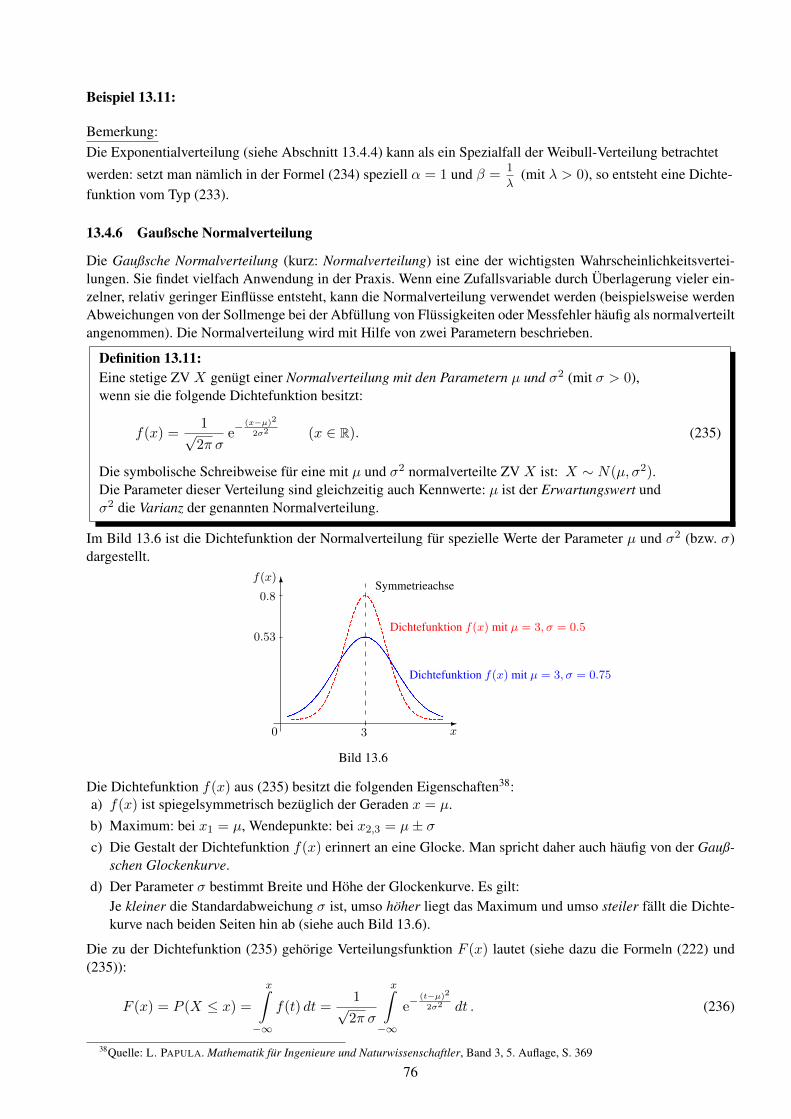
F (s) = Lf(t) =
∞∫0
e−st · f(t) dt mit s ∈ C . (191)
Bezeichnungen: f(t) - Originalfunktion, F (s) - Bildfunktion (Laplace-Transformierte)
Die Menge der Originalfunktionen wird als Originalbereich, die Menge der Bildfunktionen als Bildbereich be-zeichnet. Die Laplace-Transformation ist eine Funktionaltransformation, die einer Funktion der reellen Varia-blen t eine Funktion der komplexen Variablen s zuordnet13. Der Zusammenhang zwischen der Originalfunkti-on f(t) und der Bildfunktion F (s) wird auch als Korrespondenz bezeichnet und durch f(t) −−•F (s) symbo-lisiert.Da es sich bei dem Integral in (191) um ein uneigentliches Integral (siehe Abschnitt 6.5 im Skript zur VorlesungMathematik 2) handelt, muss noch geklart werden, unter welchen Bedingungen dieses Integral konvergiert (unddamit die Laplace-Transformierte von f(t) uberhaupt existiert).Hinreichende Bedingungen fur die Existenz der Laplace-Transformierten:
(I) Die Funktion f(t) ist stuckweise stetig (d.h. sie kann aus endlich vielen stetigen ”Teilfunktionen“ zusam-mengesetzt werden).
(II) Es existieren reelle Konstante α und M > 0 so, dass |f(t)| ≤M · eαt gilt.
Die Laplace-Transformierte existiert dann fur alle s mit Re(s) > α.
13Manchmal wird bei der Definition der Laplace-Transformation auch die Variablenbezeichnung p anstelle von s verwendet.
28
Beispiel 9.34:Die Laplace-Transformierte der Einheitssprungfunktion ε(t) (siehe (188)) ist zu berechnen.Sei s ∈ C mit s = s1 + js2. Mit f(t) = ε(t) erhalt man nach Formel (191) und unter Berucksichtigungder Gesetzmaßigkeiten fur die Berechnung uneigentlicher Integrale (siehe dazu Abschnitt 6.5 im LehrmaterialMathematik 2):
F (s) = Lf(t) = Lε(t) =
∞∫0
e−st · 1 dt = limc→∞
c∫0
e−st dt = limc→∞
[−1
s· e−st
]c0
= limc→∞
[−1
s· e−(s1+js2)t
]c0
= limc→∞
[−1
s· e−s1t · e−js2t
]c0
= −1
s· limc→∞
(e−s1c · e−js2c) +1
s· 1 · 1
= −1
s· limc→∞
e−s1c · limc→∞
e−js2c +1
s=
1
s, falls s1 = Re(s) > 0,
denn dann gilt: limc→∞ e−s1c = 0 (der Faktor limc→∞ e−js2c ist stets beschrankt).
Beispiel 9.35:
Sei f(t) =
0 fur t < 0
eat fur t ≥ 0 ,wobei a ∈ C mit a = α+ jβ.
Dann wird die Laplace-Transformierte von f(t) wie folgt berechnet (es sei wiederum s = s1 + js2):
F (s) =
∞∫0
e−st · f(t) dt =
∞∫0
e−st · eat dt =
∞∫0
e−(s−a)t dt = limc→∞
c∫0
e−(s−a)t dt
= limc→∞
[−1
s− ae−(s−a)t
]c0
= limc→∞
[−1
s− ae−(s1−α)t · e−j(s2−β)t
]c0
=−1
s− a· limc→∞
(e−(s1−α)c · e−j(s2−β)c) +1
s− a=
1
s− a, falls s1 = Re (s) > α,
denn dann gilt: limc→∞ e−(s1−α)c = 0 (der Faktor limc→∞ e−j(s2−β)c ist stets beschrankt).
Unter der inversen Laplace-Transformation (Rucktransformation) versteht man die Berechnung der Original-funktion f(t) aus einer gegebenen Bildfunktion F (s).
Formel fur die inverse Laplace-Transformation (Rucktransformation)
f(t) = L−1F (s) =1
2πj
c+j∞∫c−j∞
est · F (s) dt
Da die Berechnung der Laplace-Transformierten bzw. ihrer Inversen mit Hilfe der genannten Formeln nicht un-bedingt einfach ist, greift man haufig auf die Korrespondenztabellen fur die Laplace-Transformation zuruck.Dort kann fur bestimmte Funktionstypen f(t) sofort die Bildfunktion F (s) abgelesen werden und umgekehrtkann fur bestimmte Bildfunktionen F (s) sofort die Originalfunktion f(t) gefunden werden. Derartige Tabellensind in Formelsammlungen zu finden, siehe z.B.:
G. MERZIGER, G. MUHLBACH, D. WILLE, TH. WIRTH. Formeln + Hilfen zur hoheren Mathematik,7. Auflage, S. 125
oder: H.-J. BARTSCH. Taschenbuch mathematischer Formeln fur Ingenieure und Naturwissenschaftler,23. Auflage (2014), S. 639ff.
Die nachfolgende Tabelle (siehe nachste Seite) enthalt spezielle Korrespondenzen der Laplace-Transformation.Einige dieser Korrespondenzen resultieren unmittelbar aus den zuvor genannten Rechenregeln (z.B. dem Ver-schiebungssatz) bzw. den zugehorigen Umkehrtransformationen.
29
Einige spezielle Korrespondenzen der Laplace-TransformationMit ε(t) ist die Einheitssprungfunktion bezeichnet, mit δ(t) der Dirac-Stoß (Impulsfunktion).
Es gilt a, b ∈ R und a > 0 , Re(s) sei hinreichend groß.
f(t) F (s) = Lf(t) f(t) F (s) = Lf(t)
ε(t)1
sε(t− a) · e b(a−t) e−as
s+ b
ε(t− a)e−as
s
1
b· ε(t− a) · (1− e b(a−t)) (b 6= 0)
e−as
s(s+ b)
δ(t) 1 ε(t− a) · (t− a) · e b(a−t) e−as
(s+ b)2
δ(t− a) e−as1
b· ε(t− a) · sin[b(a− t)] (b 6= 0)
e−as
s2 + b2
Hinweis: In einigen Formelsammlungen ist die Korrespondenz 1 −−• 1
szu finden. Da bei der Originalfunkti-
on f(t) stets f(t) = 0 fur t < 0 vorausgesetzt wird, entspricht dies genau der Korrespondenz ε(t) −−• 1
sin der
obigen Tabelle (vgl. auch Formel (188)).
Wenn eine gegebene, echt gebrochenrationale Bildfunktion jedoch nicht in der Korrespondenztabelle zu findenist, sollte diese Funktion in reelle Partialbruche (siehe dazu : Skript Mathematik 2, Abschnitt 6.2.3) zerlegt wer-den. Anschließend kann fur jeden Summanden der Partialbruchzerlegung die Rucktransformation vorgenommenwerden und die gesuchte Originalfunktion entsteht als Summe dieser Teilresultate.Eine Alternative zu dieser Vorgehensweise bietet (unter gewissen Voraussetzungen) die Anwendung der Heavi-side’schen Formel.
Heaviside’sche (Umkehr-)Formel (oder: Heaviside’scher Entwicklungssatz)Gegeben sei eine echt gebrochenrationale Bildfunktion:
F (s) =P (s)
Q(s)(P (s) : Zahlerpolynom, Q(s) : Nennerpolynom).
Unter der Voraussetzung, dass das Nennerpolynom Q(s) nur einfache Nullstellen besitzt, kann die zu F (s)gehorige Originalfunktion f(t) fur t ≥ 0 nach der folgenden folgenden Formel berechnet werden:
f(t) =
n∑k=1
P (sk)
Q′(sk)· eskt (sk : Nullstellen des Polynoms Q(s); k = 1, 2, . . . , n).
Die Anwendung dieser Formel erfordert also nur die Ermittlung der Nullstellen sk des Nennerpolynoms Q(s)sowie die Berechnung der Werte der Polynome P (s) und Q′(s) an den Stellen sk, k = 1, 2, . . . , n.
Im weiteren werden Rechenregeln fur die Laplace-Transformation angegeben. Einige dieser Regeln finden un-mittelbar Anwendung bei der Losung von AWP fur Differentialgleichungen (siehe Abschnitt 9.4.3).
30
Rechenregeln fur die Laplace-Transformation
1) Linearitat der Laplace-Transformation
Laf1(t) + bf2(t) = aLf1(t)+ bLf2(t) = aF1(s) + bF2(s) (a, b ∈ C)
2) Verschiebungssatz
Lf(t− t0) = e−st0F (s) (t0 ≥ 0)
3) Dampfungssatz
Le−atf(t) = F (s+ a) (a ∈ C)
4) Faltungssatz
Sei f(t) das Faltungsprodukt zweier Originalfunktionen, d.h.
f(t) = (f1 ∗ f2)(t) =
t∫0
f1(t− τ) · f2(τ) dτ .
Dann gilt : Lf(t) = Lf1(t) · Lf2(t) = F1(s) · F2(s)
bzw. L−1F1(s) · F2(s) = (f1 ∗ f2)(t)
5) Integrationssatz fur die Originalfunktion
L∫ t
0f(τ) dτ
=
1
sF (s)
6) Differentiationssatz fur die Originalfunktion
Lf ′(t) = s · F (s)− f(+0) mit f(+0) = limt→0+0
f(t) (Anfangswert der Originalfunktion)
Lf ′′(t) = s2 · F (s)− s · f(+0)− f ′(+0)
Lf (n)(t) = sn · F (s)− sn−1 · f(+0)− sn−2 · f ′(+0)− . . .− s · f (n−2)(+0)− f (n−1)(+0)
Beispiel 9.36:
31
9.4.3 Anwendung der Laplace-Transformation zur Losung von AWP fur gewohnliche Differentialglei-chungen
Es wird vorausgesetzt, dass eine lineare Differentialgleichung mit konstanten Koeffizienten (vgl. Abschnitt 9.3)gelost werden soll. Dazu seien entsprechende Anfangsbedingungen (AB) vorgegeben. Die gesuchte Losung ydes AWP sei eine Funktion der Variablen t (”Zeitfunktion“).
Vorgehensweise bei der Losung von AWP fur gewohnliche Differentialgleichungenmittels Laplace-Transformation
1) Anwendung der Laplace-Transformation auf die Differentialgleichung(Linearitat und Differentiationssatz nutzen)
2) Auflosung der entstandenen Gleichung nach Y (s) (Laplace-Transformierte der gesuchten Losung y(t))
3) Rucktransformation (inverse Laplace-Transformation): y(t) = L−1Y (s),ggf. nach Partialbruchzerlegung des Ausdrucks fur Y (s)
Die soeben beschriebene Vorgehensweise lasst sich wie folgt schematisch darstellen:
Bei der Losung eines AWP mittels Laplace-Transformation werden die Anfangswerte sofort berucksichtigt, wo-hingegen sie bei den im Abschnitt 9.3 beschriebenen Losungsverfahren zunachst unberucksichtigt bleiben underst nach Ermittlung der allgemeinen Losung eingearbeitet werden.
Beispiel 9.37:
32
Beispiel 9.38: Ausschaltvorgang in einem RL-SchaltkreisAn eine Spule mit dem Ohmschen WiderstandR und der InduktivitatLwird eine konstante SpannungU angelegt(d.h. ein Gleichstrom der Starke I = U/R fließt). Zum Zeitpunkt t = 0 wird die Spule durch Umlegen einesSchalters von der Spannungsquelle getrennt und mit dem Ohmschen Widerstand R0 verbunden.Gesucht ist der zeitliche Verlauf der Stromstarke im Zeitintervall t ≥ 0.Das zugehorige AWP lautet:
di
dt+
(R+R0)
Li = 0 , i(0) =
U
R
bzw. mit τ := L/(R+R0) :di
dt+
1
τi = 0 , i(0) =
U
R
Mit Ldi
dt
= s ·I(s)−i(0) = s ·I(s)− U
Rund L0 = 0 ergibt die Anwendung der Laplace-Transformation
auf die Differentialgleichung :
s · I(s)− U
R+
1
τI(s) = 0 .
Die Auflosung dieser Gleichung nach I(s) ergibt:
I(s) ·(s+
1
τ
)− U
R= 0 ⇒ I(s) =
U
R· 1
s+ 1τ
.
Laut Korrespondenztabelle gilt: L−1
1
s− a
= eat, und mit a := −1
τist dann die Losung des AWP:
i(t) =
(U
R
)· e−t
τ (t ≥ 0) .
Beispiel 9.39:
Bemerkung:
Bisher wurden nur AWP fur Differentialgleichungen 1. oder 2. Ordnung mit Hilfe der Laplace-Transformationgelost. Allgemein erfolgt die Losung von AWP fur lineare Differentialgleichungen n-ter Ordnung mit konstantenKoeffizienten unter Anwendung des Differentiationssatzes fur samtliche Ableitungen y(n), y(n−1), . . . , y′.
33
9.4.4 Anwendung der Laplace-Transformation in der Regelungstechnik (lineare Ubertragungssysteme)
Da sich Ubertragungssysteme in der Regelungstechnik durch Differentialgleichungen beschreiben lassen, wirddie Laplace-Transformation fur derartige Problemstellungen haufig angewendet. Zunachst werden einige Grund-begriffe14 zusammengestellt.
Lineare Ubertragungssysteme: einige Grundbegriffe
- zeitkontinuierliches Ubertragungssystem:wandelt ein zeitlich kontinuierliches Eingangssignal x(t), t ∈ R, in ein Ausgangssignal y(t) um;symbolisch: y(t) = Sx(t)(z.B.: Verstarkerschaltung zur Vergroßerung der Signalamplitude)
- lineares Ubertragungssystem:Fur alle Eingangssignale x1(t), x2(t) und alle a1, a2 ∈ C gilt:
Fur alle Eingangssignale x(t) und beliebiges t0 ∈ R folgt aus y(t) = Sx(t): y(t− t0) = Sx(t− t0)(d.h. bei einer Verschiebung des Eingangssignals um eine Zeitspanne t0 verschiebt sich das Ausgangs-signal entsprechend)
- LTI-System:lineares und zeitinvariantes Ubertragungssystem (linear time invariant)
- Impulsantwort eines Systems:das Ausgangssignal, welches durch das Eingangssignal x(t) = δ(t) (δ-Impuls) erzeugt wurde;symbolisch: g(t) = Sδ(t)
- Sprungantwort eines Systems:das Ausgangssignal, welches durch das Eingangssignal x(t) = ε(t) (Einheitssprungfunktion)erzeugt wurde; symbolisch: h(t) = Sε(t)
Zeitkontinuierliche LTI-Systeme konnen durch lineare Differentialgleichungen mit konstanten Koeffizienten be-schrieben werden:
any(n)(t)+an−1y
(n−1)(t)+ . . .+a1y′(t)+a0y(t) = bmx
(m)(t)+bm−1x(m−1)(t)+ . . .+b1x
′(t)+b0x(t)(192)
(mit a0, . . . , an, b0, . . . , bm ∈ R), d.h. es wird das Ausgangssignal y(t) gesucht, wobei das Eingangssignal x(t)und dessen Ableitungen bis zur Ordnung m gegeben sind.Falls y(0) = y′(0) = . . . = y(n−1)(0) = x(0) = x′(0) = . . . = x(m−1)(0) = 0 gilt, dann entsteht nachLaplace-Transformation der Gleichung (192) (bei Anwendung der Linearitat und des Differentiationssatzes):
(ansn + an−1s
n−1 + . . .+ a1s+ a0)Y (s) = (bmsm + bm−1s
m−1 + . . .+ b1s+ b0)X(s) .
Dies wird nun nach Y (s) (Bildfunktion des gesuchten Ausgangssignals) umgestellt:
Y (s) = G(s)X(s) , mit G(s) =bms
m + bm−1sm−1 + . . .+ b1s+ b0
ansn + an−1sn−1 + . . .+ a1s+ a0. (193)
Die gebrochenrationale Funktion G(s) wird als Ubertragungsfunktion des LTI-Systems bezeichnet. Sie lasstsich aus den Koeffizienten der Differentialgleichung (192) berechnen. Andererseits lassen sich die Eigenschafteneines LTI-Systems aus seiner Ubertragungsfunktion vollstandig ablesen.
14Quelle: W. PREUSS, G. WENISCH (Hrsg.). Lehr- und Ubungsbuch Mathematik fur Elektro- und Automatisierungstechniker, 1998,S. 85f.
34
Beispiel 9.40: Ubertragungsfunktion eines speziellen LTI-Systems15
bbi(t)
L
C
x(t) = ue(t)y(t) = ua(t)
R
Eingangssignal: x(t) = ue(t)
(Eingangsspannung)
Ausgangssignal: y(t) = ua(t)
(Ausgangsspannung)
Dieses System wird beschrieben durch die Differentialgleichung
CL · y′′ + CR · y′ + y = x . (194)
Somit gilt: m = 0, n = 2 und die Koeffizienten in der beschreibenden Differentialgleichung (vgl. (192)) lauten:b0 = 1, a2 = CL, a1 = CR, a0 = 1.Wenn das System zur Zeit t = 0 energielos ist, dann gilt: y(0) = ua(0) = 0, y′(0) = u′a(0) = 0 , d.h. dieVoraussetzungen fur die Anwendung der Formel (193) sind erfullt und man erhalt fur die Ubertragungsfunktion:
G(s) =b0
a2s2 + a1s+ a0=
1
CLs2 + CRs+ 1.
Wird nun als Eingangssignal fur ein zeitkontinuierliches LTI-System speziell die Diracsche δ-Funktion (sieheAbschnitt 9.4.1) gewahlt, d.h. x(t) = δ(t), so ist das Ausgangssignal y(t) die Impulsantwort g(t). Somit ist:Y (s) = Ly(t) = Lg(t). Außerdem gilt (wegen X(s) = Lx(t) = Lδ(t) = 1 und nach (193)):Y (s) = G(s) · 1 = G(s). Dies fuhrt zu der folgenden wichtigen Aussage:
Die Laplace-Transformierte der Impulsantwort ist die Ubertragungsfunktion:
G(s) = Lg(t) .
Beispiel 9.41:
Aus der Beziehung (193) und dem Faltungssatz (siehe Abschnitt 9.4.2) ergibt sich weiterhin:
y(t) = L−1Y (s) = L−1G(s) ·X(s) = (g ∗ x)(t) =
t∫0
g(t− τ) · x(τ) dτ .
Daraus kann die folgende Schlussfolgerung gezogen werden:
Wenn die Impulsantwort eines zeitkontinuierlichen LTI-Systems bekannt ist, kann das zu demEingangssignal x(t) gehorige Ausgangssignal y(t) mit Hilfe der Formel
y(t) =
t∫0
g(t− τ) · x(τ) dτ
berechnet werden.
15Quelle: P. STINGL. Mathematik fur Fachhochschulen, 8. Auflage (2009), S. 571
35
9.5 Systeme linearer Differentialgleichungen
9.5.1 Definition und Anwendungsbeispiele
Definition 9.9:Ein System von m Gleichungen, das die unbekannten Funktionen y1(x), y2(x), . . . , ym(x)
sowie deren Ableitungen y′1(x), y′′1(x), . . . , y(n1)1 (x), . . . , y′m(x), y′′m(x), . . . , y
(nm)m (x) enthalt, heißt
Differentialgleichungssystem (DGLS).Die Ordnung des DGLS ergibt sich als Summe der Ordnungen der einzelnen Differentialgleichungendes Systems.
Das DGLS heißt homogen, wenn die Storfunktionen in allen zum System gehorigen Differentialgleichungengleich 0 sind, anderenfalls heißt es inhomogen. Solche Begriffe wie: allgemeine Losung, partikulare Losung,AWP, RWP (siehe Abschnitt 9.1) lassen sich auf DGLS ubertragen.
Im folgenden werden zwei Anwendungsbeispiele fur DGLS angegeben.
Beispiel 9.42:Berechnung der Maschenstrome in einem Kettenleiter16
Der dargestellte Stromkreis (Kettenleiter) wird durch die(zeitabhangige) Spannung u = u(t) gespeist. In den Maschen Iund II fließen die (ebenfalls zeitabhangigen) Strome i1 = i1(t)und i2 = i2(t).
u = u(t) R R
L L
?
i1 i2
i1 − i2
IIII
I
Durch Anwendung der Maschenregel erhalt man die beiden Beziehungen
Ldi1dt
+R(i1 − i2)− u = 0
Ldi2dt−R(i1 − i2) +Ri2 = 0 .
Diese beiden Gleichungen konnen auch in der Form
di1dt
= −RLi1 +
R
Li2 +
u
L
di2dt
=R
Li1 −
2R
Li2
geschrieben werden. Sie bilden ein System linearer Differentialgleichungen 1. Ordnung mit konstanten Koeffi-zienten zur Berechnung der Maschenstrome i1(t) und i2(t) (d.h. die Ordnung des DGLS betragt 2).
Beispiel 9.43:Bewegungsgleichungen fur gekoppelte mechanische Systeme17
Die dargestellten schwingungsfahigen Systeme seienuber eine Kopplungsfeder (Federkonstante: c12) mitein-ander verbunden.
@@@@@@@@@@@@@@
@@@@@@@@@@@@@@
BBBBBB
BB
c1 m1
-x1
BBBBBB
BB
c12
BBBBBB
BB
c2m2
-x2
Mit Hilfe des Hookeschen Gesetzes und des Newtonschen Grundgesetzes der Mechanik erhalt man fur dieAuslenkungen x1 = x1(t) und x2 = x2(t) der beiden Massen (bei Vernachlassigung der Reibungskrafte):
16Quelle: L. PAPULA. Mathematik fur Ingenieure und Naturwissenschaftler, Band 2, 12. Auflage (2009), S. 48717Quelle: L. PAPULA. Mathematik fur Ingenieure und Naturwissenschaftler, Band 2, 12. Auflage (2009), S. 513-514
36
Die Bewegungsgleichungen fur die beiden gekoppelten mechanischen Systeme konnen auch in der Form
m1x1 + c1x1 + c12(x1 − x2) = 0
m2x2 + c2x2 + c12(x2 − x1) = 0
geschrieben werden.Sie bilden ein System homogener linearer Differentialgleichungen 2. Ordnung mit konstanten Koeffizienten zurBerechnung der Auslenkungen x1 und x2 (d.h. die Ordnung des DGLS betragt 4).
9.5.2 Methoden zur Losung von linearen DGLS (Fallbeispiele)
In diesem Abschnitt werden verschiedene Losungsmethoden jeweils anhand eines Beispiels vorgestellt. Dabeiwerden ausschließlich solche DGLS betrachtet, in denen nur Differentialgleichungen mit konstanten Koeffizien-ten vorkommen.
9.5.2.1 EliminationsmethodeDie Eliminationsmethode zielt darauf, aus den gegebenen m Gleichungen des DGLS eine einzelne Differential-gleichung herzuleiten, in der nur noch eine derm gesuchten Funktionen vorkommt. Diese Differentialgleichungbesitzt hochstens die Ordnung m.
Beispiel 9.44:Zu losen sei das DGLS:
y′1 = −y1 + 3y2 + x (I)
y′2 = 2y1 − 2y2 + e−x (II)
(lineares inhomogenes DGLS 2. Ordnung mit konstanten Koeffizienten).Bei der Losung dieses DGLS mittels Eliminationsmethode wird zunachst die Gleichung (I) nach y2 aufgelostund anschließend nach x differenziert:
y2 =1
3(y′1 + y1 − x) (I′) ⇒ y′2 =
1
3(y′′1 + y′1 − 1).
Durch Einsetzen dieses Ausdrucks fur y′2 sowie der Beziehung (I′) in die Gleichung (II) wird y2 aus der Glei-chung (II) eliminiert:
1
3(y′′1 + y′1 − 1) = 2y1 −
2
3(y′1 + y1 − x) + e−x
⇒ y′′1 + 3y′1 − 4y1 = 2x+ 1 + 3e−x ,
d.h. es ist eine lineare Differentialgleichung 2. Ordnung mit konstanten Koeffizienten entstanden. Diese Glei-chung kann mit den Methoden aus Abschnitt 9.3 gelost werden (wobei beachtet werden muss, dass der Ansatzfur die partikulare Losung y1,p in der Form y1,p = a1x+ a0 + be−x aufzustellen ist). Man erhalt die allgemeineLosung:
y1 = C1 e−4x + C2 ex − 1
2x− 5
8− 1
2e−x (C1, C2 ∈ R).
Somit gilt:
y′1 = −4C1 e−4x + C2 ex − 1
2+
1
2e−x .
Wird dies zusammen mit dem soeben erhaltenen Ausdruck fur y1 in die Gleichung (I′) eingesetzt, dann ergibtsich:
y2 =1
3
(−4C1 e−4x + C2 ex − 1
2+
1
2e−x + C1 e−4x + C2 ex − 1
2x− 5
8− 1
2e−x − x
)= −C1 e−4x +
2
3C2 ex − 1
2x− 3
8(C1, C2 ∈ R) .
Die Funktionen y1 und y2 bilden zusammen die allgemeine Losung des DGLS (I), (II).
Fortsetzung zu Beispiel 9.42:37
Bemerkung:
Die Eliminationsmethode ist nur dann effektiv anwendbar, wenn das DGLS wenige Gleichungen enthat undseine Ordnung sehr klein ist.
9.5.2.2 Losung mittels ExponentialansatzBeispiel 9.45:Zu losen sei das DGLS:
y′1 = −y1 + 3y2 (I)
y′2 = 2y1 − 2y2 (II)
(lineares homogenes DGLS 2. Ordnung mit konstanten Koeffizienten).Fur die weiteren Uberlegungen ist es von Vorteil, das DGLS in Matrixschreibweise zu notieren, d.h.:
y′ =
(y′1y′2
)=
(−1 3
2 −2
)(y1y2
)= Ay (III) .
Fur den Losungsvektor y wird nun ein Exponentialansatz aufgestellt:
Die Ableitungen dieser Funktionen lauten: y′1 = k1 λ eλx, y′2 = k2 λ eλx. Diese werden zusammen mit demAnsatz fur y1 und y2 in die Gleichungen (I) und (II) eingesetzt:
λ k1 eλx = −k1 eλx + 3 k2 eλx
λk2 eλx = 2 k1 eλx − 2 k2 eλx .
Nach Division beider Gleichungen durch eλx und Umstellen ergibt sich das folgende homogene lineare Glei-chungssystem mit den Unbekannten k1 und k2:
(−1− λ)k1 + 3k2 = 0
2k1 + (−2− λ)k2 = 0 ,
welches in Matrixschreibweise folgendermaßen lautet:(−1− λ 3
2 −2− λ
)(k1k2
)=
(00
).
Bei diesem linearen Gleichungssystem interessieren nur die nichttrivialen Losungen, da anderenfalls (d.h. furk1 = k2 = 0) nach dem obigen Ansatz nur die triviale Losung y1 = y2 = 0 des DGLS entstehen wurde. Gemaßder Theorie der Eigenwerte und Eigenvektoren von Matrizen (siehe dazu Abschnitt 4.8 im Skript zur VorlesungMathematik 1) sind die zu berechnenden Werte fur λ genau die Eigenwerte der MatrixA aus der Gleichung (III).Man erhalt fur die Matrix A die beiden (reellen) Eigenwerte: λ1 = −4, λ2 = 1, so dass die Komponente y1des Losungsvektors des DGLS folgendermaßen lautet:
Aus der Gleichung (I) (umgestellt nach y2) des DGLS folgt schließlich:
y2 =1
3(y′1 + y1) =
1
3
(−4C1 e−4x + C2 ex + C1 e−4x + C2 ex
)= −C1e
−4x +2
3C2e
x .
Die Funktionen y1 und y2 bilden zusammen die allgemeine Losung des DGLS (I), (II).Bemerkungen:
- Falls fur die Eigenwerte der Matrix A gilt: λ1 = λ2 = α (d.h. es liegt ein doppelter reeller Eigenwert vor),lautet die Darstellung fur y1: y1 = C1 eαx + C2 x eαx (C1, C2 ∈ R).Im Fall eines Paares konjugiert-komplexer Eigenwerte: λ1 = α + jβ, λ2 = α − jβ erhalt man fur y1:y1 = eαx(C1 sin(βx) + C2 cos(βx)) (C1, C2 ∈ R).
- Falls die beschriebene Methode zur Losung eines inhomogenen linearen DGLS angewendet werden soll,ist zunachst das zugehorige homogene System zu losen (analog zu Beispiel 9.44). Zum Auffinden einerpartikularen Losung y1,p, y2,p des inhomogenen Systems kann ein Ansatz je nach Typ der Storfunktionen(vgl. auch Abschnitte 9.2.5 und 9.3) verwendet werden.
38
- Bei einer großeren Anzahl von Gleichungen im DGLS vergroßert sich die Dimension der Matrix A entspre-chend, wodurch die Berechnung der Eigenwerte schwieriger wird.
9.5.2.3 Laplace-TransformationNachdem im Abschnitt 9.4 die Laplace-Transformation als eine Methode zur Losung von AWP fur Differential-gleichungen vorgestellt wurde, soll die Anwendung dieser Methode jetzt auf Systeme linearer Differentialglei-chungen erweitert werden.
Beispiel 9.46:Es wird das folgende AWP fur ein DGLS betrachtet:
y′1(t) = −3y1(t)− y2(t) (I)
y′2(t) = y1(t)− y2(t) (II) mit y1(0) = 2, y2(0) = 3.
Die Anwendung der Laplace-Transformation auf die beiden Differentialgleichungen ergibt unter Berucksichti-gung der AB:
s Y1(s)− y1(+0) = s Y1(s)− 2 = −3Y1(s)− Y2(s) (s+ 3)Y1(s) + Y2(s) = 2 (I′)⇒
s Y2(s)− y2(+0) = s Y2(s)− 3 = Y1(s)− Y2(s) − Y1(s) + (s+ 1)Y2(s) = 3 . (II′)
Nun wird die Gleichung (I′) nach Y2(s) umgestellt und der erhaltene Ausdruck in die Gleichung (II′) eingesetzt:
Nach geeigneter Zusammenfassung der Ausdrucke auf der linken Seite dieser Gleichung ergibt sich:
Y1(s)(−s2 − 4s− 4) + 2s+ 2 = 3 ⇒ Y1(s) =−1 + 2s
s2 + 4s+ 4=
−1
(s+ 2)2+
2s
(s+ 2)2 .
Jeder der beiden Summanden auf der rechten Seite dieser Gleichung kann auf einfache Weise (z.B. mittelsKorrespondenztabelle) rucktransformiert werden:
y1(t) = L−1Y1(s) = L−1−1
(s+ 2)2+
2s
(s+ 2)2
= −te−2t + 2e−2t(1− 2t) = e−2t(2− 5t) .
Zur Berechnung von y2(t) kann die aus der Gleichung (I) abgeleitete Beziehung y2(t) = −3y1(t) − y′1(t)genutzt werden; dazu wird noch die erste Ableitung der soeben berechneten Funktion y1(t) benotigt. Man erhaltschließlich:
y2(t) = 3e−2t + 5te−2t = e−2t(3 + 5t) .
Die Funktionen y1(t) und y2(t) bilden zusammen die Losung des gegebenen AWP.
Bemerkung:
Zu der Thematik ”Gewohnliche Differentialgleichungen“ sei abschließend bemerkt, dass bei weitem nicht allein der Praxis vorkommenden Differentialgleichungen bzw. AWP mit den besprochenen Methoden gelost wer-den konnen. Zum Teil sind die gestellten Voraussetzungen nicht erfullt (d.h. die Differentialgleichungen sindkomplizierter als in den von uns betrachteten Fallen) oder es existiert keine geschlossene Losungsdarstellung.In solchen Fallen muss dann auf numerische Losungsverfahren zuruckgegriffen werden, d.h. es werden Nahe-rungslosungen fur die gestellten Probleme ermittelt. Einige numerische Losungsverfahren fur AWP bei gewohn-lichen Differentialgleichungen werden beschrieben in: A. FETZER, H. FRANKEL. Mathematik 2: Lehrbuch furingenieurwissenschaftliche Studiengange, Springer, 6. Auflage (2009), S. 480-498.
39
10 Fourier-Transformation und Anwendungen
10.1 Einfuhrung
Im Abschnitt 6.3 (siehe Skript zur Vorlesung Mathematik 2) wurden Fourier-Reihen betrachtet. Dabei wurdeeine periodische Funktion f(t) (mit Periode T ) als Uberlagerung harmonischer Schwingungen mit den diskretenFrequenzen kω = k 2π
T dargestellt.Jetzt soll eine nichtperiodische Funktion f(t) als Uberlagerung harmonischer Schwingungen dargestellt werden,wobei samtliche Frequenzen ω ∈ (−∞,∞) beteiligt sind, d.h. das Frequenzspektrum ist kontinuierlich.
Definition 10.1:Sei f(t) eine Funktion der reellen Variablen t. Die Fourier-Transformation von f(t) ist definiert durch:
F (ω) = Ff(t) =
∞∫−∞
e−jωt · f(t) dt fur ω ∈ R . (195)
Bezeichnungen: f(t) - Originalfunktion,F (ω) - Bildfunktion (Fourier-Transformierte oder Spektralfunktion)
Die Menge der Originalfunktionen wird Original- oder Zeitbereich genannt, die Menge der Bildfunktionen heißtBild- oder Frequenzbereich. Der Zusammenhang zwischen der Originalfunktion f(t) und der Bildfunktion F (ω)wird wie folgt symbolisch dargestellt: f(t) −−•F (ω) .Da es sich bei dem Integral in (195) um ein uneigentliches Integral handelt, ist noch zu klaren, unter welchenBedingungen dieses Integral konvergiert (und damit die Fourier-Transformierte von f(t) uberhaupt existiert).Hinreichende Bedingungen fur die Existenz der Fourier-Transformierten:
(I) Die Funktion f(t) ist stuckweise stetig (d.h. sie kann aus endlich vielen stetigen ”Teilfunktionen“ zusam-mengesetzt werden).
(II) Es gilt:∞∫−∞
|f(t)| dt <∞.
Definition 10.2:Das Amplitudenspektrum A(ω) und das Phasenspektrum ϕ(ω) der nichtperiodischen Funktion f(t)sind gegeben durch:
A(ω) = |F (ω)| , ϕ(ω) = argF (ω) . (196)
Beispiel 10.1:
Beispiel 10.2:
Gesucht ist die Fourier-Transformierte des Rechteckimpulses
f(t) =
1 fur |t| ≤ 1
0 fur |t| > 1.
-
6
0 t−1 1
f(t)
1
Fur ω 6= 0 gilt gemaß Formel (195):
F (ω) =
∞∫−∞
e−jωtf(t)dt =
1∫−1
e−jωtdt =
[−1
ωje−jωt
]1−1
= − 1
ωj(e−jω − e jω)
= − 1
ωj[ cos(−ω) + j sin(−ω)− (cosω + j sinω)] = − 1
ωj· (−2j sinω) = 2
sinω
ω.
(Hinweis: Fur die Berechnung wurden die Eulersche Formel, siehe Abschnitt 1.4.1 im Skript zur Vorlesung Ma-thematik 1, sowie die trigonometrischen Beziehungen cos(−ω) = cosω und sin(−ω) = − sinω genutzt.)
40
Fur ω = 0 erhalt man:
F (ω) =
∞∫−∞
e−jωtf(t)dt =
1∫−1
1dt =[t]1−1
= 2.
Somit gilt:
Ff(t) = F (ω) = 2 sinc(ω), mit sinc(ω) :=
sinω
ωfur ω 6= 0
1 fur ω = 0.
Die Funktion sinc (”Sinus cardinalis“ oder ”Kardinalsinus“) wird auch haufig Spaltfunktion genannt. Sie spielteine wichtige Rolle in der digitalen Signalverarbeitung (z.B. bei der Rekonstruktion zeitkontinuierlicher Signaleaus Abtastwerten) und bei der Beugung von Lichtwellen.
Unter der inversen Fourier-Transformation (Rucktransformation) versteht man die Berechnung der Original-funktion f(t) aus einer gegebenen Bildfunktion F (ω).
Formel fur die inverse Fourier-Transformation (Rucktransformation)
f(t) = F −1F (ω) =1
2π
∞∫−∞
e jωt · F (ω) dω (197)
Beispiel 10.3:
Die Ermittlung der Fourier-Transformierten bzw. ihrer inversen erfolgt haufig mit Hilfe von Korrespondenztabel-len (nicht uber die Berechnung der Integrale). Im folgenden sind die Fourier-Transformierten einiger Funktionenaufgelistet.
Fourier-Transformierte ausgewahlter Funktionen18
Mit ε(t) ist die Einheitssprungfunktion bezeichnet, mit δ(t) der Dirac-Stoß (Impulsfunktion).Es gilt a, b ∈ R und a > 0 , b > 0.
18Quelle: W. PREUSS. Funktionaltransformationen, 2. Auflage (2009), S. 50
41
Bemerkungen:
- Die Fourier-Transformierte und ihre Inverse wurden so eingefuhrt, dass das Integral in (195) keinen Vorfaktorund das Integral in (197) den Vorfaktor 1
2π besitzt. Es besteht aber auch die Moglichkeit, diesen Faktor vordas Integral in (195) zu schreiben oder vor beide Integrale den Faktor 1√
2πzu schreiben.
- Mittels Grenzwertbetrachtungen kann gezeigt werden, dass die Fourier-Transformation eine Art Fourier-Reihe fur nichtperiodische Funktionen darstellt (siehe dazu: J. KOCH, M. STAMPFLE. Mathematik fur dasIngenieurstudium, S. 590-593) .
- Die Begriffe Amplitudenspektrum und Phasenspektrum wurden fur periodische Funktionen bereits im Ab-schnitt 6.3.3 (siehe Skript zur Vorlesung Mathematik 2) erlautert.
- Fur Funktionen f(t) mit f(t) = 0 fur t < 0 ist die Fourier-Transformation ein Spezialfall der Laplace-Transformation. Die Fourier-Transformierte einer solchen Funktion entsteht, indem in der Laplace-Transfor-mierten dieser Funktion die Variable s durch jω ersetzt wird. (Voraussetzung ist dabei die Existenz derLaplace-Transformierten fur s ∈ C mit Re(s) = 0.)
10.2 Rechenregeln
Rechenregeln fur die Fourier-Transformation1) Linearitat der Fourier-Transformation
Faf1(t) + bf2(t) = aFf1(t)+ bFf2(t) = aF1(ω) + bF2(ω) (a, b ∈ C)
2) Verschiebungssatz (Zeitverschiebungssatz)
Ff(t− t0) = e−jωt0 · F (ω) (t0 ∈ R)
3) Dampfungssatz (Frequenzverschiebungssatz)
Fe jω0t · f(t) = F (ω − ω0)
4) Faltungssatz
Sei f(t) = (f1 ∗ f2)(t) , dann gilt : Ff(t) = Ff1(t) · Ff2(t) = F1(ω) · F2(ω)
10.3 Fourier-Kosinus-Transformation und Fourier-Sinus-Transformation
Definition 10.3:Die Fourier-Kosinus-Transformation der Funktion f(t) ist definiert durch:
FC(ω) = FCf(t) =
∞∫0
cos(ωt) · f(t) dt (198)
und die zugehorige inverse Transformation ist gegeben durch:
f(t) = F −1C FC(ω) =2
π
∞∫0
cos(ωt) · FC(ω) dω . (199)
Analog werden die Fourier-Sinus-Transformation und die dazu inverse Transformation berechnet:
FS(ω) = FSf(t) =
∞∫0
sin(ωt) · f(t) dt (200)
f(t) = F −1S FS(ω) =2
π
∞∫0
sin(ωt) · FS(ω) dω . (201)
Zu der durch (195) definierten Fourier-Transformation F (ω) besteht der folgende Zusammenhang.
Fur eine gerade Originalfunktion (d.h. f(−t) = f(t) fur alle t ∈ D(f)) gilt: F (ω) = 2FC(ω)
und fur eine ungerade Originalfunktion (d.h. f(−t) = −f(t) fur alle t ∈ D(f)): F (ω) = −2jFS(ω).
Somit kann die Berechnung der Fourier-Transformierten einer geraden (bzw. ungeraden) Funktion mit Hilfe vonFormel (198) (bzw. (200)) erfolgen, wodurch die Rechnung meist einfacher wird im Vergleich zur Anwendungder Formel (195). In diesem Zusammenhang sei daran erinnert, dass die Fourier-Reihe einer geraden Funktionnur den Summanden a0
2und Kosinusglieder enthalt, wohingegen die Fourier-Reihe einer ungeraden Funktion
nur aus Sinusgliedern besteht (siehe dazu Abschnitt 6.3.2 im Skript zur Vorlesung Mathematik 2) .
Beispiel 10.6:
10.4 Anwendungen in der Regelungstechnik
In diesem Abschnitt werden wieder lineare und zeitinvariante Ubertragungssysteme (LTI-Systeme) betrachtet(siehe dazu Abschnitt 9.4.4). Derartige Systeme reagieren auf harmonische Eingangssignale beliebiger Frequenzmit harmonischen Ausgangssignalen der gleichen Frequenz. Die Amplituden und Phasen der Ausgangssignalesind i.allg. nicht gleich den Amplituden und Phasen der Eingangssignale. Die Beschreibung der Amplituden-bzw. Phasenanderungen kann mit Hilfe des Amplituden- bzw. Phasengangs erfolgen.
Frequenzgang, Amplitudengang und Phasengang eines UbertragungssystemsFrequenzgang: G(ω) = Fg(t) (Fourier-Transformierte der Impulsantwort)Amplitudengang: A(ω) = |G(ω)| (Betrag des Frequenzgangs)Phasengang: Φ(ω) = argG(ω) (Argument des Frequenzgangs)
Die Amplitude des Ausgangssignals entsteht durch Multiplikation der Amplitude des Eingangssignals mit demBetrag des Frequenzgangs (Amplitudengang). Die Phase des Ausgangssignals entsteht durch Addition der Phasedes Eingangssignals und dem Argument des Frequenzgangs (Phasengang).
Beispiel 10.7:43
Beispiel 10.8: Gegeben ist das folgende LTI-System (RC-Glied):
bbC
x(t) = ue(t)y(t) = ua(t)
R
Eingangssignal: x(t) = ue(t)
(Eingangsspannung)
Ausgangssignal: y(t) = ua(t)
(Ausgangsspannung)
Dieses System wird beschrieben durch die Differentialgleichung
RC · y + y = x .
Die Impulsantwort dieses Systems lautet (siehe Ubung): g(t) =1
RCe−t/RC fur t > 0
(bzw. g(t) =1
RCε(t)e−t/RC fur t ∈ R).
Somit betragt der Frequenzgang dieses Systems:
G(ω) = Fg(t) =1
RCFε(t) e−t/RC
=
1
RC· 1(
1RC + jω
) =1
1 + jωRC.
Unter Verwendung von Rechenregeln fur komplexe Zahlen erhalt man weiterhin:
Amplitudengang: A(ω) = |G(ω)| = 1√1 + ω2R2C2
Phasengang: Φ(ω) = argG(ω) = − arccos
(1√
1 + ω2R2C2
)= − arctan(ωRC) .
Bemerkung:
Da die Fourier-Transformation ein Spezialfall der Laplace-Transformation ist (siehe dazu: letzte Bemerkung amEnde von Abschnitt 10.1), kann der Frequenzgang eines LTI-Systems aus dessen Ubertragungsfunktion (sieheAbschnitt 9.4.4) ermittelt werden, indem dort s = jω gesetzt wird.
10.5 Diskrete und schnelle Fourier-Transformation (Einblick)
Bisher wurde vorausgesetzt, dass die Werte der zu transformierenden Funktion f(t) fur alle Zeitpunkte t be-kannt sind. In der Praxis trifft man jedoch haufig die Situation an, dass nur endlich viele einzelne (d.h. diskrete)Funktionswerte vorliegen, z.B. Messwerte einer physikalischen Große zu aquidistanten Zeitpunkten. In solchenFallen erfolgt der Ubergang zu einer zeitlich diskreten Folge von Funktionswerten fd(n), z.B. in der Form:fd(n) = f(nτ), n = 0, 1, . . . , N − 1, wobei τ den (aquidistanten) Abstand zwischen zwei Messzeitpunktenbezeichnet.In solchen Fallen wird anstelle der bisher betrachteten Fourier-Transformation die diskrete Fourier-Transfor-mation (kurz: DFT) angewendet.
Definition 10.4:Die DFT einer Folge f(n), n = 0, 1, . . . , N , von Funktionswerten wird berechnet nach der Formel:
F (m) =
N−1∑n=0
f(n) e−j2πmn/N , m = 0, 1, . . . , N − 1 . (202)
Die inverse diskrete Fourier-Transformation (IDFT) ist gegeben durch:
f(n) =1
N
N−1∑m=0
F (m) e j2πmn/N , n = 0, 1, . . . , N − 1 . (203)
44
Beispiel 10.9: Diskrete Fourier-Transformation (DFT) fur eine spezielle Folge
Gegeben ist die Folge von Funktionswerten f(n): 1, 1, 1, 1, 0, 0, 0, 0. Die DFT dieser Folge wird mit Hilfe derFormel (202) berechnet, wobei N = 8 gilt. Wegen f(4) = f(5) = f(6) = f(7) = 0 konnen die Summations-grenzen jedoch auf n = 0 bis n = 3 gesetzt werden. Man erhalt:
fur m = 0: F (0) =3∑
n=0
f(n) e−j2π·0·n/8 =3∑
n=0
1 · e0 = 4 · 1 = 4
fur m = 1: F (1) =
3∑n=0
f(n) e−j2π·1·n/8 =
3∑n=0
1 · e−jπn/4 = e0 + e−jπ/4 + e−jπ/2 + e−jπ3/4
= 1− (√
2 + 1)j ≈ 1− 2.4142j,
die Komponenten F (m) fur m = 2, . . . , 7 werden analog berechnet. Die Ergebnisse lauten:
F (2) = 0, F (3) = 1− (√
2− 1)j ≈ 1− 0.4142j,
F (4) = 0, F (5) = 1 + (√
2− 1)j ≈ 1 + 0.4142j,
F (6) = 0, F (7) = 1 + (√
2 + 1)j ≈ 1 + 2.4142j .
Wichtige Anwendungsgebiete fur die DFT/IDFT sind z.B. die Rekonstruktion abgetasteter Signale und die Im-plementierung digitaler Filter. Die numerisch effiziente Umsetzung der DFT ist durch den Algorithmus derschnellen Fourier-Transformation FFT (fast Fourier transform) gegeben. Dieser Algorithmus wurde erstmalsim Jahre 1965 von J. COOLEY und J.W. TUKEY veroffentlicht. Die Grundidee des Algorithmus besteht in derAusnutzung von Symmetrien in den zu berechnenden Summen, falls die Zahl N eine Zweierpotenz ist.DFT-Algorithmen stehen in modernen Software-Paketen zur Verfugung.
45
11 Partielle Differentialgleichungen (Einblick)
11.1 Grundbegriffe
Zahlreiche physikalische oder technische Prozesse konnen durch partielle Differentialgleichungen beschriebenwerden. Das Anliegen dieses Kapitels besteht darin, einige Grundlagen zu dieser an sich sehr umfangreichenProblematik zu vermitteln und einige Anwendungsgebiete derartiger Gleichungen vorzustellen.Zunachst sei die grundlegende Eigenschaft partieller Differentialgleichungen genannt (dadurch wird auch derUnterschied zu den gewohnlichen Differentialgleichungen, die im Kapitel 9 behandelt wurden, deutlich).
Bei einer partiellen Differentialgleichung hangt die gesuchte Funktion von mehreren Variablen abund in der Gleichung treten partielle Ableitungen dieser Funktion auf.
Beispiel 11.1:Bei den folgenden Differentialgleichungen handelt es sich um partielle Differentialgleichungen:
a) Laplace-Gleichung (siehe auch (144)): ∆U =∂2U
∂x2+∂2U
∂y2+∂2U
∂z2= 0 fur U = U(x, y, z)
b)∂U
∂t+ 2
∂U
∂x− U = sinx fur U = U(x, t)
c)∂2u
∂x2= α
∂2u
∂t2+ β
∂u
∂t+ γu fur u = u(x, t) (α, β, γ seien Konstante)
Die Ordnung einer partiellen Differentialgleichung ist gleich der Ordnung der hochsten vorkommendenpartiellen Ableitung der gesuchten Funktion.
Fortsetzung zu Beispiel 11.1:Die unter a) und c) genannten Differentialgleichungen sind partielle Differentialgleichungen 2. Ordnung, denndie hochste vorkommende Ableitung hat jeweils die Ordnung 2.Dagegen ist die Differentialgleichung aus b) eine partielle Differentialgleichung 1. Ordnung, denn sie enthalt nurpartielle Ableitungen 1. Ordnung.
Insbesondere fur die Auswahl geeigneter Losungsmethoden ist es wichtig, eine Unterscheidung zwischen linea-ren und nichtlinearen partiellen Differentialgleichungen zu treffen.
Bei einer linearen partiellen Differentialgleichung treten die gesuchte Funktion und deren partielleAbleitungen nur in einem linearen Zusammenhang auf.Anderenfalls heißt die partielle Differentialgleichung nichtlinear.
Beispiel 11.2:Alle im Beispiel 11.1 betrachteten partiellen Differentialgleichungen sind linear.
Die partielle Differentialgleichung(∂2u
∂x2
)2
+∂u
∂y= sin(x+ y) ist nichtlinear, denn die Ableitung
∂2u
∂x2tritt in
einem nichtlinearen Zusammenhang auf (die Differentialgleichung enthalt das Quadrat dieser Ableitung).
Ein System partieller Differentialgleichungen besteht aus m Gleichungen (m ≥ 2), die m unbekannteFunktionen mehrerer reeller Variabler und partielle Ableitungen dieser Funktionen enthalten.
Ein Beispiel fur ein System partieller Differentialgleichungen wird im Abschnitt 11.2 angegeben.
46
Schließlich ist noch zu klaren, was man unter einer Losung einer partiellen Differentialgleichung versteht.
Jede Funktion, die eine partielle Differentialgleichung identisch erfullt, ist eine Losung dieser Gleichung.
Beispiel 11.3:Das skalare Feldfunktion19 U(~r) = ln |~r | = ln r im R3 (mit r > 0) ist eine Losung der partiellen Differential-
gleichung ∆U =1
r2.
Begrundung:Es sind die partiellen Ableitungen (bis zur 2. Ordnung) der Funktion U = ln |~r | = ln r = ln
√x2 + y2 + z2 zu
berechnen und in die linke Seite der Differentialgleichung
∆U =∂2U
∂x2+∂2U
∂y2+∂2U
∂z2=
1
r2=
1
x2 + y2 + z2(204)
einzusetzen. Wenn dadurch eine wahre Aussage entsteht, ist die Differentialgleichung erfullt. Vor der Berech-nung der Berechnung der Ableitungen kann der Ausdruck fur U noch etwas vereinfacht werden. Mittels einesLogarithmengesetzes erhalt man: ln
√x2 + y2 + z2 = ln
[(x2 + y2 + z2)1/2
]= 1
2 ln(x2 + y2 + z2).Bei der Berechnung der Ableitungen sind die Kettenregel und die Quotientenregel zu berucksichtigen:
∂U
∂x=
∂
∂x
[1
2ln(x2 + y2 + z2)
]=
1
2· 1
x2 + y2 + z2· 2x =
x
x2 + y2 + z2
∂2U
∂x2=
∂
∂x
(x
x2 + y2 + z2
)=
1 · (x2 + y2 + z2)− 2x · x(x2 + y2 + z2)2
=−x2 + y2 + z2
(x2 + y2 + z2)2.
Vollig analog dazu erhalt man:
∂2U
∂y2=
x2 − y2 + z2
(x2 + y2 + z2)2sowie
∂2U
∂z2=
x2 + y2 − z2
(x2 + y2 + z2)2.
Einsetzen dieser Ableitungen in die linke Seite der Differentialgleichung (204) und Vereinfachen liefert:
∆U =∂2U
∂x2+∂2U
∂y2+∂2U
∂z2=
x2 + y2 + z2
(x2 + y2 + z2)2=
1
(x2 + y2 + z2),
d.h. es ist die rechte Seite der Differentialgleichung (204) entstanden.
Die Funktion U(~r) = ln |~r | = ln r erfullt somit die partielle Differentialgleichung ∆U =1
r2.
11.2 Partielle Differentialgleichungen in der Praxis
Bei den Beispielen 11.4 bis 11.7 bezeichnet u eine gesuchte Funktion (d.h. die Losung der entsprechendenDifferentialgleichung), f ist eine gegebene Funktion. Außerdem sind a und b vorgegebene Konstante.
Beispiel 11.4:Laplace-Gleichung: ∆u = 0 (siehe auch Formel (144) aus Abschnitt 8.3)Poisson-Gleichung: ∆u = f oder −∆u = f
Die Funktionen u und f sind ortsabhangig, aber zeitunabhangig.
Physikalische Bedeutung dieser Gleichungen:20
- Wenn f = f(x, y, z) eine Massendichte im Raum ist, so stellt die Losung u = u(x, y, z) das Gravitations-potential des zugehorigen Gravitationsfeldes dar.
- Analog dazu ist u das elektrische Potential, falls f = f(x, y, z) eine Ladungsdichte im Raum bezeichnet.
- In der Theorie der Warmeleitung ist u die stationare, d.h. zeitunabhangige Temperatur, die sich nach einerlangeren Zeit einstellt, wenn innere Warmequellen der Intensitat f vorhanden sind. Der Fall f = 0 (Laplace-Gleichung) entspricht der Situation, dass keine inneren Warmequellen existieren.19Bei der Darstellung von U beachte man den Unterschied zwischen ~r und r: mit ~r ist der Ortsvektor eines Raumpunktes mit den
Koordinaten (x, y, z) bezeichnet, dagegen ist r der Abstand dieses Punktes zum Koordinatenursprung (siehe dazu auch die Gleichun-gen (132) zur Transformation in Kugelkoordinaten).
20Quelle: W. PREUSS, H. KIRCHNER. Mathematik in Beispielen (Band 8: Partielle Differentialgleichungen), 1. Auflage, S. 127
47
Beispiel 11.5:
Warmeleitungsgleichung:∂u
∂t− a2∆u = f (siehe auch Beispiel 8.21 aus Abschnitt 8.7.2)
Diffusionsgleichung:∂u
∂t− a2∆u+ bu = f
(u und f sind Funktionen der Zeit t und des Ortes)
Physikalische Bedeutung dieser Gleichungen:21
- Warmeleitungsgleichung:Wenn f = f(x, y, z, t) die Intensitat der in einem (homogenen, isotropen) Medium befindlichen Warmequellezur Zeit t an der Stelle (x, y, z) bezeichnet, so ist u = u(x, y, z, t) die Temperatur zur Zeit t an dieser Stelle.
- Diffusionsgleichung:f bezeichnet die Intensitat der inneren Stoffquellen und u ist die Teilchendichte zum Zeitpunkt t an der Stel-le (x, y, z) .
Beispiel 11.6:22
Saitenschwingungsgleichung:∂2u
∂t2− a2 ∂
2u
∂x2= f
(u und f sind Funktionen der Zeit t und des Ortes)Physikalische Bedeutung dieser Gleichung:Die Gleichung beschreibt kleine Querschwingungen einer ein-gespannten, biegsamen Saite. Dabei bezeichnet f = f(x, t) dieaußere Anregung (außere Krafteinwirkung) an der Stelle x zurZeit t und u(x, t) ist die Auslenkung eines beliebigen Punktes xder Saite zur Zeit t (siehe auch Bild 11.1).
Bild 11.1: Auslenkungen der Punkte der Saitezu einem festen Zeitpunkt tBeispiel 11.7:
Wellengleichung:∂2u
∂t2− a2∆u = f
(u und f sind Funktionen der Zeit t und des Ortes; Betrachtung im R2 oder im R3)
Physikalische Bedeutung dieser Gleichung:Durch diese Gleichung werden Schwingungen von raumlichen oder flachenhaften Korpern (Membranen) bzw.die Ausbreitung von Wellen in flussigen oder gasformigen Medien beschrieben. Die Bedeutung der Funktio-nen f und u ist analog zu Beispiel 11.6. (Man beachte, dass der Unterschied zwischen den in Beispiel 11.6 undBeispiel 11.7 betrachteten Differentialgleichungen darin besteht, dass in 11.6 nur die Ortsvariable x, in 11.7dagegen die Ortsvariablen x und y bzw. x, y und z vorhanden sind. Die Saitenschwingungsgleichung wird daherauch als eindimensionale Wellengleichung bezeichnet.)
Nachfolgend werden zwei Beispiele23 fur Systeme partieller Differentialgleichungen angegeben.
Beispiel 11.8:Leitungsgleichungen (oder Telegrafengleichungen):
∂u
∂x+ LL
∂i
∂t+RLi = 0
∂i
∂x+ CL
∂u
∂t+GLu = 0
Gesucht sind die Spannung u = u(x, t) sowie die Stromstarke i = i(x, t).Gegeben sind die (konstanten) Koeffizienten der Differentialgleichungen: CL - Leitungskapazitat, GL - Ohm-sche Ableitung, LL - Leitungsinduktivitat, RL - Ohmscher Widerstand der Leitung.Diese Differentialgleichungen sind gekoppelt, d.h. die gesuchten Funktionen (bzw. ihre Ableitungen) treten inbeiden Gleichungen auf, so dass es nicht moglich ist, diese Gleichungen einzeln zu losen.
21Quelle: W. PREUSS, H. KIRCHNER. Mathematik in Beispielen (Band 8: Partielle Differentialgleichungen), 1. Auflage, S. 12822Quelle: M. R. SPIEGEL. Hohere Mathematik f. Ingenieure u. Naturwissenschaftler - Theorie u. Anwendung, Nachdruck 1991, S. 25923Quelle: W. PREUSS, H. KIRCHNER. Mathematik in Beispielen (Band 8: Partielle Differentialgleichungen), 1. Auflage, S. 52-53
48
Beispiel 11.9:Modell einer chemischen Reaktion in einem Rohrenreaktor:
∂u
∂t−D1
∂2u
∂x2− u2v + (b+ 1)u− a = 0
∂v
∂t−D2
∂2v
∂x2+ u2v − bu = 0
Gesucht sind die Konzentrationen u = u(x, t) und v = v(x, t) der Stoffe U und V , die im Reaktor diffundieren.Gegeben sind die Diffusionskoeffizienten D1 und D2 sowie die (naherungsweise konstanten) Konzentrationen aund b von Ausgangsstoffen A und B.
11.3 Partielle Differentialgleichungen mit Nebenbedingungen
Bei der Modellierung technisch-physikalischer Systeme oder Prozesse mit Hilfe von (gewohnlichen oder par-tiellen) Differentialgleichungen sind meistens zusatzliche Bedingungen wie z.B. der gegebene Anfangszustandeines Systems zu berucksichtigen. Wahrend im vorangegangenen Abschnitt nur die Gleichungen selbst im Mit-telpunkt standen, ist dieser Abschnitt den partiellen Differentialgleichungen mit Rand- oder Anfangsbedingun-gen (zusammengefasst unter dem Begriff ”Nebenbedingungen“) gewidmet. Bei den Beispielen wird jeweils aucheine physikalische Interpretation dieser Nebenbedingungen angegeben.Im weiteren wird davon ausgegangen, dass die Losung u einer partiellen Differentialgleichung in einem Be-reich B ⊂ Rn (n = 1, 2 oder 3) gesucht ist. Der Rand dieses Bereiches wird mit ∂B bezeichnet.
Arten von Nebenbedingungen bei partiellen DifferentialgleichungenRandbedingung: Auf ∂B soll die Fkt. u oder eine Ableitung von u vorgegebene Werte annehmen.Anfangsbedingung: Zum Zeitpunkt t = 0 werden der Funktion u oder einer Ableitung von u (nach t)
Werte vorgeschrieben.
Beispiel 11.10:24
Gesucht ist eine Funktion u = u(x, y, z), die fur (x, y, z) ∈ B (d.h. im Bereich B) die Differentialgleichung
−∆u = f
mit einer vorgegebenen Funktion f = f(x, y, z) sowie fur (x, y, z) ∈ ∂B die Randbedingung
u|∂B = ϕ (Randbedingung 1. Art)
oder∂u
∂~n
∣∣∣∂B
=∂u
∂xn1 +
∂u
∂yn2 +
∂u
∂zn3
∣∣∣∂B
= ϕ (Randbedingung 2. Art)
oder∂u
∂~n+ αu
∣∣∣∂B
= ϕ (Randbedingung 3. Art)
erfullt. Dabei sind ϕ = ϕ(x, y, z) und α = α(x, y, z) gegebene Funktionen, ~n = (n1, n2, n3)T ist der außere
Einheitsnormalenvektor an B und ∂u
∂~ndie Richtungsableitung in Richtung des Einheitsnormalenvektors (Nor-
malenableitung).In diesem Beispiel wird die Losung einer partiellen Differentialgleichung gesucht, wobei zusatzlich eine Rand-bedingung gestellt wird. Es handelt sich hier um ein reines Randwertproblem.
Physikalische Interpretation:Es liegt ein stationares Warmeleitproblem vor (siehe dazu Beispiel 11.4 aus dem Abschnitt 11.2). Die Funktionf bezeichnet die (gegebene) Intensitat der Warmequelle, u die (gesuchte) Temperatur im Inneren eines Korpers.Die Randbedingungen besitzen die folgende Bedeutung:Randbedingung 1. Art: entspricht einer vorgegebenen Temperatur am RandRandbedingung 2. Art: vorgegebener Warmefluss am RandRandbedingung 3. Art: freier Warmeaustausch mit der Umgebung
24Quelle: W. PREUSS, H. KIRCHNER. Mathematik in Beispielen (Band 8: Partielle Differentialgleichungen), 1. Auflage, S. 127-128
49
Beispiel 11.11:25
Gesucht ist eine Funktion u = u(x, t), die fur x ∈ B := (0, l) und t > 0 die Differentialgleichung
∂u
∂t= a2
∂2u
∂x2+ f
mit einer vorgegebenen Funktion f = f(x, t) und einer Konstanten a > 0 lost.Außerdem soll die Funktion u folgende Bedingungen erfullen (ϕ(x), ψ1(t) und ψ2(t) sind vorgegeben):Anfangsbedingung: u(x, 0) = ϕ(x) fur 0 ≤ x ≤ l sowieRandbedingung 1. Art: u(0, t) = ψ1(t) und u(l, t) = ψ2(t) fur t > 0
Hier liegt ein Anfangs-Randwertproblem vor.
Physikalische Interpretation:Die vorliegende Differentialgleichung beschreibt die instationare Warmeleitung26 in einem Stab der Lange l.Die Anfangsbedingung sagt aus, dass die Anfangstemperatur des Stabes zur Zeit t = 0 festgelegt ist (namlichdurch die gegebene Funktion ϕ(x)). Durch die Randbedingung 1. Art ist der Temperaturverlauf an den Endendes Stabes (d.h. fur x = 0 und x = l) zu jedem beliebigen Zeitpunkt t > 0 vorgegeben.
Bemerkung:
Wird bei der instationaren Warmeleitung anstelle eines Stabes der Lange l ein ”unendlich langer“ Stab betrachtet,so entfallt die im Beispiel 11.11 gestellte Randbedingung. Es wird nur dieAnfangsbedingung: u(x, 0) = ϕ(x) fur alle x ∈ Rgestellt. Dann handelt es sich um ein reines Anfangswertproblem. Jedoch muss aus physikalischer Sicht die zuberechnende Temperatur u(x, t) beschrankt sein (insbesondere fur x → ±∞). Auf diese Weise unterliegt dieLosung des Problems einer weiteren Nebenbedingung.
11.4 Methoden zur Losung partieller Differentialgleichungen (Einblick)
So vielfaltig wie sich die partiellen Differentialgleichungen gestalten (Abschnitt 11.2 vermittelt nur einen kleinenEinblick!), so verschieden sind auch die Losungsmethoden fur diese Gleichungen. Im Abschnitt 11.4.1 soll einrecht haufig verwendetes Losungsverfahren vorgestellt werden. Es handelt sich dabei um den Separationsansatz(oder: Produktansatz bzw. Trennung der Variablen). Der Abschnitt 11.4.2 ist der Losung der Saitenschwingungs-gleichung nach der Methode von d’Alembert gewidmet.
11.4.1 Losung durch Separationsansatz
Der Separationsansatz ist anwendbar beispielsweise fur lineare homogene partielle Differentialgleichungen,wenn die Koeffizienten konstant sind und keine gemischten Ableitungen auftreten. Wie der Name schon ver-muten lasst, wird angenommen, dass die Losung ein Produkt unbekannter Funktionen ist, die jeweils nur voneiner Variablen abhangen. Dadurch kann die Losung der partiellen Differentialgleichung auf die Losung vongewohnlichen Differentialgleichungen zuruckgefuhrt werden. Die Vorgehensweise bei Anwendung des Separa-tionsansatzes wird anhand des nachfolgenden Beispiels erlautert.
Beispiel 11.12:Zu losen ist die (eindimensionale) Warmeleitungsgleichung:
∂u
∂t− a2 ∂
2u
∂x2= 0 mit u = u(x, t), a = const., a > 0 (205)
(vgl. auch Beispiel 11.5 aus dem Abschnitt 11.2; jetzt wurde speziell die Storfunktion f = 0 gewahlt, wodurcheine homogene Differentialgleichung entsteht).
Fur die Losung der Differentialgleichung wird der Ansatz u(x, t) = v(t) · w(x) gewahlt, d.h. die gesuchteFunktion wird dargestellt als Produkt einer nur von der Variablen t und einer nur von der Variablen x abhangigen
25Quelle: K. MEYBERG, P. VACHENAUER. Hohere Mathematik 2 (Differentialgleichungen, Funktionentheorie, Fourier-Analysis,Variationsrechnung), 2. Auflage, S. 383
26Es wird eine zu Beispiel 11.5 analoge Gleichung betrachtet, jetzt jedoch nur mit einer Ortsvariablen.
50
Funktion. Zielstellung ist nun die Berechnung der Funktionen v(t) und w(x). Da u eine Losung der Differenti-algleichung (205) ist, werden die in dieser Gleichung vorkommenden Ableitungen der Funktion u jetzt mit Hilfevon v und w ausgedruckt:
∂u
∂t=
∂
∂t(v(t) · w(x)) = v′(t) · w(x) ,
∂2u
∂x2=
∂2
∂x2(v(t) · w(x)) = v(t) · w′′(x)
(man beachte, dass die Ableitungen von v und w keine partiellen, sondern gewohnliche Ableitungen sind, dadiese Funktionen jeweils nur von einer Variablen abhangen). Einsetzen dieser Ableitungen in die Gleichung (205)liefert:
und nach Division beider Seiten dieser Gleichung durch den Term a2 · v(t) · w(x) entsteht:
v′(t)
a2 · v(t)=w′′(x)
w(x),
d.h. eine Gleichung mit getrennten Variablen. Da die linke Seite dieser Gleichung nur von t, die rechte Seitenur von x abhangt, ist die Gleichheit sicher dann gewahrleistet, wenn beide Seiten der Gleichung gleich einerKonstanten sind. Um dies zum Ausdruck zu bringen, fuhrt man einen Separationsparameter, hier −β genannt,ein, d.h. es soll gelten:
v′(t)
a2 · v(t)=w′′(x)
w(x)= −β mit dem Separationsparameter β ∈ R.
Wird in dieser Gleichung der von t abhangige Ausdruck zeitweilig weggelassen, so erhalt man:
w′′(x)
w(x)= −β ⇒ w′′(x) + β · w(x) = 0. (206)
Analog ergibt sich, wenn der von x abhangige Ausdruck zeitweilig weggelassen wird:
v′(t)
a2 · v(t)= −β ⇒ v′(t) + β · a2 · v(t) = 0. (207)
Damit wurde ein sehr wichtiger Schritt zur Losung des gestellten Problems vollzogen: die Losung der partiellenDifferentialgleichung (205) kann auf die Losung der beiden gewohnlichen Differentialgleichungen (206) und(207) zuruckgefuhrt werden. Dadurch konnen die Losungsmethoden aus Kapitel 9 angewendet werden.Die Gleichung (207) ist eine lineare homogene Differentialgleichung 1. Ordnung.Gemaß der Formel (167) aus Abschnitt 9.2.4 hat diese die allgemeine Losung:
v(t) = C · e−βa2t, C ∈ R.
Die Gleichung (206) ist eine lineare homogene Differentialgleichung 2. Ordnung mit konstanten Koeffizienten.Gemaß den Ausfuhrungen im Abschnitt 9.3.1 erfolgt die Losung derartiger Gleichungen mit Hilfe der charak-teristischen Gleichung (siehe Formel (181)) und die Struktur der allgemeinen Losung hangt davon ab, ob diecharakteristische Gleichung zwei verschiedene reelle Losungen, eine reelle Doppellosung oder zwei konjugiert-komplexe Losungen besitzt. Im Fall der Differentialgleichung (206) lautet die charakteristische Gleichung:λ2+β = 0 . Da der Separationsparameter β beliebig reell sein kann, treten bei der Losung der charakteristischenGleichung (und somit bei der Losung von (206)) insgesamt drei verschiedene Falle auf.Die allgemeine Losung der Differentialgleichung (206) lautet (K1 und K2 sind reelle Konstante):
w(x) = K1 cos(√β x)
+K2 sin(√β x), falls β > 0,
w(x) = K1x+K2 falls β = 0,
w(x) = K1e√|β|x +K2e
−√|β|x falls β < 0.
Auf Grund des Ansatzes u(x, t) = v(t) · w(x) konnen jetzt die Losungen der partiellen Differentialglei-chung (205) (Warmeleitungsgleichung) durch Multiplikation der Losungen der Gleichungen (206) und (207)gebildet werden. Die entstehenden Resultate sind auf der nachsten Seite zusammengefasst.
51
Zusammenfassung: Losungen der Warmeleitungsgleichung (205)Fur die Gleichung (205) wurden mittels Separationsansatz die folgenden Losungen berechnet(Fallunterscheidung nach dem Separationsparameter β):
β > 0 : u(x, t) = e−a2βt[C1 cos
(√β x)
+ C2 sin(√β x)]
β = 0 : u(x, t) = u(x) = C1x+ C2
β < 0 : u(x, t) = ea2|β|t
(C1e√|β|x + C2e
−√|β|x)
Dabei sind C1 und C2 reelle Konstante (es gilt: C1 = C ·K1, C2 = C ·K2).
Hinweis:In dem Fall β = 0 vereinfacht sich die Losung der Differentialgleichung (207):v(t) = C · e−βa2t = C · e−0·a2·t = C · 1 = C (C ∈ R), dadurch ist die Losung der Warmeleitungsgleichung indiesem Fall nur von x abhangig.
Bemerkung:
Bisher wurde nur die partielle Differentialgleichung ohne Berucksichtigung von Nebenbedingungen gelost. Wennzusatzlich zur Differentialgleichung noch Anfangs- und Randbedingungen (vgl. dazu auch Abschnitt 11.3) erfulltsein sollen, muss die berechnete Losung im Nachhinein noch an diese Bedingungen angepasst werden. DieAnpassung der Losung an die Anfangsbedingung kann unter Verwendung einer Fourier-Reihenentwicklung derFunktion aus der Anfangsbedingung erfolgen.
11.4.2 Losung nach der Methode von d’Alembert
Zunachst wird der Fall einer ”unendlich langen“ schwingenden Saite betrachtet.Zu losen ist dann die Differentialgleichung
∂2u
∂t2− a2 ∂
2u
∂x2= 0 mit u = u(x, t), a = const., a > 0 (208)
(siehe Beispiel 11.6, jetzt speziell mit f = 0)unter den Anfangsbedingungen27
u(x, 0) = ϕ1(x),∂
∂tu(x, 0) = ϕ2(x) mit x ∈ R und gegebenen Funktionen ϕ1(x), ϕ2(x). (209)
Die Funktionen ϕ1(x) und ϕ2(x) beschreiben die Anfangsauslenkung und die Anfangsgeschwindigkeit, bezogenauf die Punkte der Saite.Die d’Alembertsche Losung28 des Anfangswertproblems (208), (209) lautet dann:
u(x, t) =1
2[ϕ1(x+ at) + ϕ1(x− at)] +
1
2c
x+at∫x−at
ϕ2(ξ) dξ . (210)
Diese Formel sagt aus, dass die Losungsfunktion des Anfangswertproblems (208), (209) durch Superpositioneiner in positiver und einer in negativer x-Richtung (jeweils mit Geschwindigkeit a) fortschreitenden Teilwelleentsteht.In dem speziellen Fall, dass ϕ2(x) = 0 gilt, vereinfacht sich die Gleichung (210) zu:
u(x, t) =1
2[ϕ1(x+ at) + ϕ1(x− at)] .
Als nachstes wird eine Saite der Lange l betrachtet, welche an beiden Enden fest eingespannt ist. Anstelle desbisher betrachteten Anfangswertproblems ist jetzt ein Anfangs-Randwertproblem zu losen.
27Es wird vorausgesetzt, dass die Funktion ϕ1(x) zweimal und die Funktion ϕ2(x) einmal stetig differenzierbar ist.28Eine Herleitung dieser Formel ist z.B. zu finden in: H. DALLMANN, K.-H. ELSTER. Einfuhrung in die hohere Mathematik fur
Naturwissenschaftler und Ingenieure (Band III), 1. Auflage, S. 284-285.
52
Im Vergleich zu der Problemstellung (208), (209) ergeben sich dann die folgenden Anderungen:
- Die Funktionen ϕ1(x) und ϕ2(x) sind nur fur x ∈ [0, l] vorgegeben.
- Es sind zusatzlich die Randbedingungen u(0, t) = 0, u(l, t) = 0 zu berucksichtigen. Dabei muss aus Stetig-keitsgrunden gelten: ϕ1(0) = ϕ1(l) = 0 sowie ϕ2(0) = ϕ2(l) = 0.
Die Losung des Anfangs-Randwertproblems ist ebenfalls durch die Formel (210) gegeben, wenn die Funktio-nen ϕ1(x) und ϕ2(x) von dem Intervall [0, l] als ungerade Funktionen in das Intervall [−l, 0] und anschließenduber das Intervall [−l, l] hinaus nach beiden Seiten 2l-periodisch fortgesetzt werden.
Bemerkung:
Der Vorteil der Losungsdarstellung (210) besteht darin, dass die Nebenbedingungen bereits eingearbeitet sind.Alternativ zur Methode von d’Alembert ist auch die folgende Vorgehensweise zur Losung des Anfangswertpro-blems (208), (209) (bzw. des entsprechenden Anfangs-Randwertproblems) moglich:Zunachst wird die Differentialgleichung (208) ohne Berucksichtigung von Nebenbedingungen mittels Separa-tionsansatz (vgl. Abschnitt 11.4.1) gelost. Anschließend wird die erhaltene Losung an die Randbedingungen(falls vorhanden) sowie an die Anfangsbedingungen angepasst, wobei wiederum die Fourier-Reihenentwicklungder Funktionen aus den Anfangsbedingungen verwendet werden kann.
Bemerkung (abschließend zu Abschnitt 11.4):
Da nur ein kleiner Einblick in die Methoden zur Losung partieller Differentialgleichungen gegeben werdenkonnte, seien hier einige weitere Losungsverfahren zumindest genannt:
- Integration nach einer Variablen (wenn nur partielle Ableitungen nach einer Variablen in der Gleichung auf-treten)
- Erzeugung von Losungen durch Superposition (anwendbar bei linearen Differentialgleichungen)
- Fourier- oder Laplace-Transformation (nach einer Variablen)
- numerische Losung (d.h. Berechnung von Naherungslosungen), z.B. durch: Finite-Elemente-Methode, Diffe-renzenverfahren oder Randelementmethode.
53
12 Grundlagen der Wahrscheinlichkeitsrechnung
12.1 Hilfsmittel aus der Kombinatorik
Definition 12.1:Als Permutationen von n Elementen ohne Wiederholung bezeichnet man Anordnungen dieser n verschie-denen Elemente, die sich nur durch die Reihenfolge dieser Elemente unterscheiden.Eine Permutation von n Elementen mit Wiederholung liegt vor, wenn nicht alle n Elemente voneinanderverschieden sind.
Fur die Berechnung der Permutationen (d.h. die Anzahl der moglichen Anordnungen) gelten die folgendenFormeln.
Permutationen von n Elementen ohne Wiederholung: P (n) = n · (n− 1) · (n− 2) · . . . · 1 = n!
Permutationen von n Elementen, unter denensich jeweils n1, n2, . . . , nk einander gleiche befinden: P (n; n1, n2, . . . , nk) =
n!
n1! · n2! · . . . · nk!
mit n1 + n2 + . . .+ nk = n
Beispiel 12.1:
Definition 12.2:Unter Variationen von n Elementen zur k-ten Klasse ohne Wiederholung versteht man Teilmengen vonje k Elementen, die unter Berucksichtigung der Anordnung aus n gegebenen Elementen ausgewahlt werden(1 ≤ k ≤ n).Eine Variation von n Elementen zur k-ten Klasse mit Wiederholung liegt vor, wenn die ausgewahltenElemente mehrfach auftreten durfen.
Variationen von n Elementen zur k-ten Klasse
ohne Wiederholung: V (n; k) = n · (n− 1) · . . . · (n− (k − 1)) =n!
(n− k)!(mit 1 ≤ k ≤ n)
mit Wiederholung: VW (n; k) = nk
Beispiel 12.2:
54
Definition 12.3:Als Kombinationen von n Elementen zur k-ten Klasse ohne Wiederholung bezeichnet man Teilmengen vonje k Elementen, die ohne Berucksichtigung der Anordnung aus n gegebenen Elementen ausgewahlt werden(1 ≤ k ≤ n).Eine Kombination von n Elementen zur k-ten Klasse mit Wiederholung liegt vor, wenn die ausgewahltenElemente mehrfach auftreten durfen.
Kombinationen von n Elementen zur k-ten Klasse
ohne Wiederholung: C(n; k) =n!
k! · (n− k)!=
(nk
)(Binomialkoeffizient)
mit Wiederholung: CW (n; k) =
(n+ k − 1
k
)Bei den Kombinationen ohne Wiederholung muss gelten: 1 ≤ k ≤ n.
Beispiel 12.3:
12.2 Grundbegriffe der Wahrscheinlichkeitsrechnung
12.2.1 Das Zufallsexperiment und weitere Grundbegriffe
Definition 12.4:Das Zufallsexperiment ist ein Versuch, bei dem die folgenden Bedingungen (Voraussetzungen) erfullt sind:1) Der Versuch lasst sich unter den gleichen außeren Bedingungen beliebig oft wiederholen.
2) Bei der Durchfuhrung des Versuchs sind mehrere sich gegenseitig ausschließende Ergebnisse moglich.
3) Das Ergebnis einer konkreten Durchfuhrung des Versuchs lasst sich dabei nicht mit Sicherheit voraus-sagen, sondern ist zufallsbedingt.
Beispiel 12.4:
Definition 12.5:Die moglichen, sich gegenseitig ausschließenden Ergebnisse eines Zufallsexperiments heißenElementarereignisse.Schreibweise: ω1, ω2, ω3, . . . .
Die Menge aller Elementarereignisse heißt Ergebnismenge Ω.
55
Beispiel 12.5:
Die Teilmengen der Ergebnismenge Ω beschreiben Versuchsausgange, die bei der Durchfuhrung des Versuchseintreten konnen, aber nicht unbedingt eintreten mussen. Dies gibt Anlass zur Definition des Begriffes Ereignis.
Definition 12.6:Eine Teilmenge A der Ergebnismenge Ω eines Zufallsexperiments wird Ereignis genannt.Die Menge aller Ereignisse, die aus der Ergebnismenge eines Zufallsexperiments gebildet werden konnen,heißt Ereignisraum oder Ereignisfeld.
Nach den Gesetzmaßigkeiten der Mengenlehre sind sowohl die leere Menge ∅ als auch die Ergebnismenge Ωselbst Teilmengen von Ω. Sie stellen Ereignisse mit folgender Bedeutung dar:
∅ : unmogliches Ereignis (ein Ereignis, das nie eintreten kann)
Ω : sicheres Ereignis (ein Ereignis, das immer eintritt).
Ein Ereignis A ist somit entweder
- das unmogliche Ereignis ∅ (siehe oben; A enthalt dann kein Element von Ω) oder
- ein Elementarereignis (siehe Definition 12.5; A enthalt genau ein Element von Ω) oder
- eine Menge mehrerer Elementarereignisse (A enthalt mehrere Elemente von Ω) oder
- das sichere Ereignis Ω (siehe oben; A enthalt alle Elemente von Ω, d.h. A = Ω).
Beispiel 12.6:
12.2.2 Verknupfungen von Ereignissen
Gemaß Definition 12.6 sind Ereignisse als Teilmengen der Ergebnismenge Ω anzusehen, d.h. es handelt sichum Mengen. Somit kann man bei Ereignissen - ebenso wie bei Mengen - Verknupfungen betrachten. Auf dernachfolgenden Seite wird eine Ubersicht uber Verknupfungen von Ereignissen gegeben. Die Veranschaulichungerfolgt jeweils mit Hilfe von Mengendiagrammen.
56
Mit A und B sind Ereignisse im Sinne der Definition 12.6 bezeichnet.
Verknupfung Bedeutung Darstellung im Diagramm
Teilereignis: A ⊆ B A zieht B nach sichA B
Vereinigung (Summe): A ∪B mindestens eines der Ereignisse A, Btritt ein (d.h.: A oder B) A B
Durchschnitt (Produkt): A ∩B sowohl A als auch B tritt ein(d.h.: A und B) A B
Differenz: A \B A tritt ein, jedoch nicht gleichzeitig B A B
Fur die Verknupfungen von Ereignissen gelten - wie auch fur die Verknupfungen von Mengen - Gesetzmaßig-keiten wie Kommutativgesetze, Assoziativgesetze, Distributivgesetze sowie die DE MORGANschen Gesetze:
A ∪B = A ∩B, A ∩B = A ∪B(A und B sind wiederum Ereignisse im Sinne der Definition 12.6).
Das zu A komplementare Ereignis tritt genau dann ein, wenn A nicht eintritt.Bezeichnung: A; es gilt: Ω \A = A
Die Ereignisse A und B heißen disjunkt (oder unvereinbar), wenn gilt: A ∩B = ∅.
Beispiel 12.7:
Definition 12.7:Die Ereignisse Ai (i = 1, 2, . . . , n) heißen Zerlegung des Ereignisses A, wenn gilt:
n⋃i=1
Ai = A und Ai ∩Aj = ∅ fur alle i, j mit i 6= j .
Sie bilden ein vollstandiges System zufalliger Ereignisse, wenn gilt:n⋃i=1
Ai = Ω und Ai ∩Aj = ∅ fur alle i, j mit i 6= j (Zerlegung des sicheren Ereignisses).
Ein vollstandiges System zufalliger Ereignisse A1, A2, . . . , An besitzt die folgende Eigenschaft: als Ergebniseines zufalligen Versuches muss genau eines von ihnen eintreten.
Beispiel 12.8:
57
12.3 Der Begriff der Wahrscheinlichkeit
12.3.1 Laplace-Experimente, absolute und relative Haufigkeit
Definition 12.8:Ein Zufallsexperiment mit der endlichen Ergebnismenge Ω = ω1, ω2, . . . , ωm heißtLaplace-Experiment, wenn alle Elementarereignisse ωi die gleiche Wahrscheinlichkeit besitzen:
P (ωi) = p(ωi) =1
m(i = 1, 2, . . . ,m).
Die Wahrscheinlichkeit eines Ereignisses A ist dann gegeben durch:
P (A) =g(A)
m,
wobei g(A) : Anzahl der fur das Ereignis A gunstigen Falle (d.h. der Falle, in denen das Ereignis A eintritt)
m : Anzahl der insges. moglichen Falle (Anzahl der gleichwahrscheinlichen Elementarereignisse)
Hinweis: Dies wird auch als klassische Definition der Wahrscheinlichkeit bezeichnet (nur anwendbar fur Laplace-Experimente !).
Beispiel 12.9:Bei dem Zufallsexperiment ”Wurf eines homogenen Wurfels“ treten alle 6 moglichen Augenzahlen (Elementar-ereignisse) mit der gleichen Wahrscheinlichkeit auf:
p(i) =g(i)
m=
1
6fur i = 1, 2, . . . , 6.
Beispiel 12.10:
Fur die Festlegung unbekannter Wahrscheinlichkeiten in der Praxis (siehe Abschnitt 12.3.2) werden noch dieBegriffe der absoluten und relativen Haufigkeit benotigt.
Definition 12.9:Wird ein Zufallsexperiment n-mal durchgefuhrt und tritt dabei das Ereignis A genau n(A)-mal ein, so wird
n(A) als absolute Haufigkeit des Ereignisses A und
hn(A) =n(A)
nals relative Haufigkeit des Ereignisses A
bezeichnet.
Die absolute Haufigkeit eines Ereignisses kann somit durch einfaches ”Abzahlen“ ermittelt werden.
12.3.2 Wahrscheinlichkeitsaxiome und Schlussfolgerungen
Wie im vorigen Abschnitt bereits ausgefuhrt wurde, ist der klassische Wahrscheinlichkeitsbegriff ausschließ-lich auf Laplace-Experimente anwendbar. In der modernen Wahrscheinlichkeitsrechnung wird der Begriff der
”Wahrscheinlichkeit eines zufalligen Ereignisses“ mit Hilfe gewisser Axiome29 eingefuhrt. Diese heißen (nachihrem Begrunder) Wahrscheinlichkeitsaxiome von Kolmogoroff und werden im folgenden aufgefuhrt.30
29Ein Axiom ist ein nicht aus anderen Aussagen abgeleiteter Grundsatz, welcher nicht bewiesen wird. Aus Axiomen werden weitereSatze eines Wissensgebietes hergeleitet.
30Quelle: L. PAPULA. Mathematik fur Ingenieure und Naturwissenschaftler, Band 3, 5. Auflage, S. 282-283
58
Wahrscheinlichkeitsaxiome von KolmogoroffJedem Ereignis A eines Zufallsexperiments mit der Ergebnismenge Ω wird eine reelle Zahl P (A),genannt: Wahrscheinlichkeit des Ereignisses A, so zugeordnet, dass die folgenden Axiome erfullt sind:
Axiom 1:P (A) ist eine nichtnegative Zahl, die hochstens gleich 1 ist: 0 ≤ P (A) ≤ 1 .
Axiom 2:Fur das sichere Ereignis (Ergebnismenge) Ω gilt: P (Ω) = 1.
P (A1 ∪A2 ∪A3 ∪ . . .) = P (A1) + P (A2) + P (A3) + . . . .
Man beachte: Die Wahrscheinlichkeitsaxiome beinhalten keinerlei Aussagen daruber, wie man bei einem kon-kreten Zufallsexperiment die Wahrscheinlichkeiten der auftretenden Ereignisse ermitteln kann. Sie stellen aberin gewisser Hinsicht Rechenregeln fur Wahrscheinlichkeiten dar.
Folgerungen aus den Wahrscheinlichkeitsaxiomen von Kolmogoroff1) Fur das unmogliche Ereignis gilt: P (∅) = 0 .
2) Fur das zum Ereignis A komplementare Ereignis gilt: P (A) = 1− P (A) .
3) Fur zwei sich gegenseitig ausschließende Ereignisse A und B folgt aus Axiom 3:P (A ∪B) = P (A) + P (B) .
In gewissen Fallen ist es moglich, Versuchsergebnisse als Punkte eines Intervalls bzw. einer ebenen oder raumli-chen Punktmenge zu interpretieren. Dies fuhrt zur geometrischen Wahrscheinlichkeitsformel, welche im folgen-den angegeben wird31.
Geometrische WahrscheinlichkeitsformelWenn dem zufalligen Ereignis A ein Teilbereich des Grundbereiches G zugeordnet wird, dann kanndie Wahrscheinlichkeit P (A) des Ereignisses A mit Hilfe der Formel
P (A) =I(A)
I(G)(211)
berechnet werden. Dabei gelten die Bezeichungen:I(A)− geometrischer Inhalt des fur A gunstigen TeilbereichesI(G)− geometrischer Inhalt des Grundbereiches.Voraussetzung fur die Anwendbarkeit dieser Formel ist, dass alle Punkte des Grundbereiches Ggleichberechtigt sind.
Der geometrische Inhalt ist - in Abhangigkeit von der Dimension der betrachteten Punktmenge - entweder eineLange, ein Flacheninhalt oder ein Volumen.
Beispiel 12.11:
31Quelle: W. LEUPOLD (Hrsg.). Mathematik - ein Studienbuch fur Ingenieure (Band 2: Reihen - Differentialgleichungen - Analysisfur mehrere Variable - Stochastik), 2. Auflage, S. 351
59
Bei praktischen Sachverhalten ist es haufig so, dass die Zufallsexperimente nicht als Laplace-Experimente ange-sehen werden konnen und die Wahrscheinlichkeiten von Elementarereignissen nicht von vornherein bekannt oderberechenbar sind. In solchen Fallen bedient man sich statistischer (oder empirischer) Wahrscheinlichkeitswerte.Dazu sei n die (hinreichend große!) Anzahl der Einzelversuche einer Versuchsreihe und A ein zufalliges Ereig-nis, welches als Versuchsergebnis auftreten kann. Dann wird die relative Haufigkeit hn(A) (vgl. Definition 12.9)des Ereignisses A festgestellt und
P (A) ≈ hn(A)
fur die unbekannte Wahrscheinlichkeit P (A) angenommen (d.h. die ermittelte relative Haufigkeit von A dientals Schatzwert fur die unbekannte Wahrscheinlichkeit P (A)).
Beispiel 12.12:Statistische Wahrscheinlichkeitswerte konnen z.B. angewendet werden fur- die Wahrscheinlichkeit fur eine Jungen- oder Madchengeburt- die Wahrscheinlichkeit des Ausfalls eines Maschinenelementes wahrend einer vorgegebenen Laufzeit.
12.3.3 Additionssatz, bedingte Wahrscheinlichkeit und Multiplikationssatz
Wenn A und B disjunkte Ereignisse sind (d.h.: A ∩ B = ∅), dann gilt nach dem Wahrscheinlichkeitsaxiom 3(siehe Abschnitt 12.3.2): P (A∪B) = P (A)+P (B). Falls die Voraussetzung, dass die Ereignisse disjunkt sind,nicht erfullt ist, ist der folgende Satz anzuwenden:
Additionssatz fur zwei beliebige EreignisseSeien A und B zwei beliebige Ereignisse eines Ereignisraumes, dann gilt:
P (A ∪B) = P (A) + P (B)− P (A ∩B) . (212)
Beispiel 12.13:
Wenn A und B Ereignisse ein und desselben Ereignisraumes sind, kann man bedingte Wahrscheinlichkeitenbetrachten, und zwar:
- die bedingte Wahrscheinlichkeit von A unter der Bedingung B(d.h. es wird vorausgesetzt, dass das Ereignis B bereits eingetreten ist) oder
- die bedingte Wahrscheinlichkeit von B unter der Bedingung A(es wird vorausgesetzt, dass A bereits eingetreten ist).
Die Schreibweise fur die genannten Wahrscheinlichkeiten ist: P (A |B) bzw. P (B |A) .Die Berechnung bedingter Wahrscheinlichkeiten wird mit Hilfe der nachfolgenden Formeln durchgefuhrt.
Berechnung bedingter WahrscheinlichkeitenBedingte Wahrscheinlichkeit von A unter der Bedingung B:
P (A |B) =P (A ∩B)
P (B)(wobei P (B) 6= 0 gelten muss) (213)
Bedingte Wahrscheinlichkeit von B unter der Bedingung A:
P (B |A) =P (A ∩B)
P (A)(wobei P (A) 6= 0 gelten muss) (214)
Beispiel 12.14:
60
Als unmittelbare Schlussfolgerung aus den Formeln fur die bedingte Wahrscheinlichkeit erhalt man die folgendeAussage.
Multiplikationssatz (fur beliebige Ereignisse)Die Wahrscheinlichkeit fur das gleichzeitige Eintreten der beiden Ereignisse A und B wird berechnetnach der Formel:
P (A ∩B) = P (A) · P (B |A). (215)
Hinweis: In (215) bedeutet P (A) die Wahrscheinlichkeit fur das Eintreten von A (ohne jede Bedingung!) undP (B |A) die Wahrscheinlichkeit fur das Eintreten von B unter der Bedingung, dass A bereits eingetreten ist.
Beispiel 12.15:
Ausgehend von den bedingten Wahrscheinlichkeiten konnen aber auch die Falle:
P (A |B) = P (A) bzw. P (B |A) = P (B)
in Betracht gezogen werden.In dem ersten Fall gilt: Die Wahrscheinlichkeit des Eintretens von A unter der Bedingung B ist gleich der Wahr-scheinlichkeit des Eintretens von A (ohne Bedingung). Dies kann so interpretiert werden, dass das Eintreten desEreignissesB keinen Einfluss auf das Eintreten des EreignissesA hat. Oder, anders ausgedruckt: Das EreignisAist (stochastisch) unabhangig von dem Ereignis B.Analog dazu bedeutet der zweite der o.g. Falle, dass das Ereignis B (stochastisch) unabhangig von dem Ereig-nis A ist.In dem speziellen Fall stochastisch unabhangiger Ereignisse kann der o.g. Multiplikationssatz wie folgt formu-liert werden.
Multiplikationssatz fur stochastisch unabhangige EreignisseWenn die Ereignisse A und B stochastisch unabhangig sind, dann gilt:
P (A ∩B) = P (A) · P (B). (216)
Die Formel (216) entsteht aus (215), indem dort P (B |A) = P (B) gesetzt wird. Diese Beziehung ist auf Grundder vorausgesetzten Unabhangigkeit der Ereignisse A und B stets gultig.
61
Die Formel (216) kann auch auf den Fall von n Ereignissen verallgemeinert werden. Wenn die EreignisseA1, A2, . . . , An ein vollstandiges System stochastisch unabhangiger Ereignisse bilden, dann gilt:
P
(n⋂i=1
Ai
)= P (A1) · P (A2) · . . . · P (An) =
n∏i=1
P (Ai). (217)
Mit dieser Formel lasst sich die Wahrscheinlichkeit fur das gleichzeitige Eintreten von n stochastisch unabhangi-gen Ereignissen berechnen, falls die Wahrscheinl. fur das Eintreten jedes einzelnen Ereignisses bekannt sind.
Beispiel 12.16:
Bemerkungen:
- Wenn die Ereignisse A und B stochastisch unabhangig sind, dann sind auch die Ereignisse A und B stocha-stisch unabhangig, ebenso die Ereignisse A und B sowie die Ereignisse A und B.
- Fur drei beliebige Ereignisse A,B,C lautet der Additionssatz:
P (A ∪B ∪ C) = P (A) + P (B) + P (C)− P (A ∩B)− P (A ∩ C)− P (B ∩ C) + P (A ∩B ∩ C).
Fur eine Verallgemeinerung des Additionssatzes auf n beliebige Ereignisse sei auf die folgende Literaturstelleverwiesen: W. VOSS (Hrsg.): Taschenbuch der Statistik, 1. Auflage (2000), S. 305.
12.3.4 Baumdiagramme, totale Wahrscheinlichkeit von Ereignissen
Wenn mehrere gleichartige Zufallsexperimente nacheinander durchgefuhrt werden, spricht man auch von einemmehrstufigen Zufallsexperiment.
Erganzung zu Beispiel 12.15:Die Ziehung zweier Kugeln aus einer Urne ohne Zurucklegen kann als 2-stufiges Zufallsexperiment aufgefasstwerden, wenn man die Ziehung einer Kugel als ”einfaches“ Zufallsexperiment ansieht.
Zur Veranschaulichung mehrstufiger Zufallsexperimente werden haufig Baumdiagramme (Ereignisbaume) ver-wendet. Zunachst wird ein Beispiel angegeben und anschließend werden einige allgemeine Aussagen32 zuBaumdiagrammen getroffen.
Beispiel 12.17:Aus einer Urne mit 4 roten und 2 gelben Kugeln werden 2 Kugeln nacheinander ohne Zurucklegen entnommen(siehe auch Beispiel 12.15). Das vorliegende Baumdiagramm (siehe Bild 12.1) veranschaulicht die moglichenErgebnisse dieses Experiments zusammen mit den Wahrscheinlichkeiten der ”Zwischenergebnisse“.
x0
23
13
35
25
45
15
Bild 12.1
Erlauterung:
32Quelle: L. PAPULA. Mathematik fur Ingenieure und Naturwissenschaftler, Band 3, 5. Auflage, S. 301-302
62
Aufbau eines BaumdiagrammsDas Baumdiagramm setzt sich zusammen aus einer Wurzel (Ausgangspunkt) sowie Verzweigungspunktenund Zweigen.Die Verzweigungspunkte charakterisieren die moglichen Zwischenergebnisse nach einer bestimmten Stufedes Zufallsexperiments.Die Zweige fuhren zu den jeweils moglichen Ergebnissen der nachfolgenden Stufe.Ein mogliches Endergebnis des Zufallsexperiments erreicht man (ausgehend von der Wurzel)langs eines bestimmten Pfades.
Wenn die Berechnung der Wahrscheinlichkeit eines Ereignisses (das als Ergebnis eines mehrstufigen Zufalls-experiments auftreten kann) mit Hilfe eines Baumdiagramms erfolgen soll, konnen die folgenden Pfadregelnangewendet werden.
Regeln bei der Berechnung von Wahrscheinlichkeiten mit Hilfe eines BaumdiagrammsEs gelten die folgenden Pfadregeln:
1) Die Wahrscheinlichkeiten langs eines Pfades werden miteinander multipliziert.
2) Wenn mehrere Pfade zum gleichen Endergebnis fuhren, dann addieren sich ihre Wahrscheinlichkeiten.
Fortsetzung zu Beispiel 12.17:
Um den Begriff der totalen Wahrscheinlichkeit einfuhren zu konnen, werden folgende Ereignisse betrachtet:
Ai (i = 1, 2, . . . , n): disjunkte Ereignisse mit P (Ai) 6= 0 fur alle i,B : ein Ereignis, das stets zusammen mit einem der Ereignisse Ai eintritt.Das Diagramm in Bild 12.2 veranschaulicht eine solche Situationfur den Fall n = 4.
A1
A2
A3
A4
B
Bild 12.2
Formel fur die totale Wahrscheinlichkeit eines EreignissesUnter den o.g. Voraussetzungen gilt fur die Wahrscheinlichkeit des Ereignisses B:
P (B) =
n∑i=1
P (B ∩Ai) =
n∑i=1
P (Ai) · P (B |Ai) . (218)
Hinweis: Der Summand P (Ai) · P (B |Ai) in (218) ist die Wahrscheinlichkeit dafur, dass das Ereignis B uberdie ”Zwischenstation“ Ai (fur das jeweilige i) erreicht wurde.
Begrundung fur die Formel (218):Es gilt (siehe dazu auch Bild 12.2): B = (B ∩A1) ∪ (B ∩A2) ∪ . . . ∪ (B ∩An).Da die Ereignisse Ai (i = 1, 2, . . . , n) als disjunkt vorausgesetzt wurden, sind auch die Ereignisse (B ∩ Ai) furi = 1, 2, . . . , n disjunkt. Durch Anwendung des Wahrscheinlichkeitsaxioms 3 (siehe Abschnitt 12.3.2) und derFormel (215) ergibt sich dann:
P (B) =
n∑i=1
P (B ∩Ai) =
n∑i=1
P (Ai ∩B) =
n∑i=1
P (Ai) · P (B |Ai) .
Beispiel 12.18:
63
Bayessche Formel:
P (Aj |B) =P (Aj) · P (B |Aj)n∑i=1
P (Ai) · P (B |Ai). (219)
Bedeutung dieser Formel:Jetzt wird vorausgesetzt, dass das Ereignis B bereits eingetreten ist. Dann ermoglicht die Bayessche Formel dieBerechnung der Wahrscheinlichkeit dafur, dass das Ereignis B uber die ”Zwischenstation“ Aj erreicht wurde.
Fortsetzung zu Beispiel 12.18:
64
13 Wahrscheinlichkeitsverteilungen
13.1 Stetige und diskrete Zufallsvariable (ZV)
Dem Begriff der Zufallsvariablen kommt in diesem Kapitel eine zentrale Rolle zu. Im folgenden wird fur denBegriff ”Zufallsvariable“ meistens die Abkurzung ZV verwendet. Man unterscheidet zwischen stetigen und dis-kreten Zufallsvariablen.
Definition 13.1:Unter einer Zufallsvariablen (oder Zufallsgroße) X versteht man eine Abbildung, die jedem Elementar-ereignis ω aus der Ergebnismenge Ω eines Zufallsexperiments genau eine reelle Zahl X(ω) zuordnet.Eine ZV heißt dabei diskret, wenn sie nur endlich viele oder abzahlbar unendlich viele reelle Werte anneh-men kann.Eine ZV heißt stetig, wenn sie jeden beliebigen Wert aus einem (reellen) endlichen oder unendlichenIntervall annehmen kann.
Die Werte, die eine Zufallsvariable annehmen kann, heißen Realisierungen. Sie werden ublicherweise mit klei-nen Buchstaben bezeichnet.
Beispiel 13.1:
13.2 Verteilungsfunktion einer ZV
Bei praktischen Anwendungen der Wahrscheinlichkeitsrechnung wird haufig die Frage gestellt, mit welcherWahrscheinlichkeit eine ZV einen bestimmten Wert annimmt bzw. der Wert der ZV kleiner (oder großer) als einebestimmte Zahl ist. Dies fuhrt auf den Begriff der Verteilungsfunktion.
Definition 13.2:Die Verteilungsfunktion einer ZV X ist gegeben durch:
F (x) = P (X ≤ x) , (220)
d.h. sie gibt an, mit welcher Wahrscheinlichkeit die ZV X einen Wert annimmt, der kleiner oder gleicheiner vorgegebenen reellen Zahl x ist.
Eine ZV X wird durch ihre zugehorige Verteilungsfunktion vollstandig beschrieben.Nachfolgend sind wichtige Eigenschaften von Verteilungsfunktionen zusammengestellt. Diese gelten allgemein,d.h. unabhangig von der konkreten ZV.
65
Eigenschaften von VerteilungsfunktionenSei X eine beliebige (diskrete oder stetige) Zufallsvariable und F (x) die zugehorige Verteilungsfunktion.Diese Funktion besitzt die folgenden Eigenschaften:
1) F (x) ist eine monoton wachsende Funktion und es gilt: 0 ≤ F (x) ≤ 1 fur alle x ∈ R.
2) limx→−∞ F (x) = 0
3) limx→∞ F (x) = 1
4) Die Wahrscheinlichkeit, dass a < X ≤ b gilt, lasst sich mit Hilfe der Verteilungsfunktionwie folgt berechnen: P (a < X ≤ b) = F (b)− F (a).
Die Eigenschaften 2) und 3) sind unmittelbare Schlussfolgerungen aus der Definition 13.2 und der Tatsache,dass die Wahrscheinlichkeit des unmoglichen Ereignisses gleich 0, die des sicheren Ereignisses gleich 1 ist(siehe dazu auch Abschnitt 12.3.2).Die Fragestellung, zu einem gegebenen Wert der Verteilungsfunktion das zugehorige Argument zu finden, fuhrtauf den Begriff des Quantils.
Definition 13.3:Sei X eine ZV mit der zugehorigen Verteilungsfunktion F (x) und p0 (mit p0 ∈ [0, 1]) eine vorgegebenereelle Zahl.Dann wird jede Zahl x0 mit der Eigenschaft: F (x0) = P (X ≤ x0) = p0 als p0-Quantil der Zufalls-variablen X bezeichnet.
Ein Quantil kann genau dann eindeutig bestimmt werden, wenn die entsprechende Verteilungsfunktion strengmonoton wachsend ist.
13.2.1 Verteilungsfunktion einer diskreten ZV (diskrete Verteilung)
Bei einer diskreten ZV X (vgl. Definition 13.1) gehort zu jeder Realisierung xi eine bestimmte Wahrschein-lichkeit: P (X = xi) = pi (Einzelwahrscheinlichkeit). Die Realisierungen der ZV konnen zusammen mit denzugehorigen Einzelwahrscheinlichkeiten in einer Verteilungstabelle dargestellt werden:
xi x1 x2 x3 . . . xm . . .
P (X = xi) p1 p2 p3 . . . pm . . .
Mit Hilfe dieser Tabelle kann die Verteilungsfunktion der diskreten ZV ermittelt werden.
Verteilungsfunktion F (x) einer diskreten ZVX:
F (x) = P (X ≤ x) =∑xi≤x
pi fur x ∈ R und mit pi = P (X = xi) (221)
Es wurden bereits einige Eigenschaften von Verteilungs-funktionen genannt (siehe oben). In dem hier vorliegendenFall einer diskreten ZV kommt noch die folgende Eigen-schaft hinzu:Die grafische Darstellung der Verteilungsfunktion einerdiskreten ZV ergibt eine stuckweise konstante Funktion(auch Treppenfunktion genannt), siehe dazu Bild 13.1. -
6
0 x
F (x)
x1 x2 x3 . . . xn
...
1
p1
p1 + p2
p1 + p2 + p3
s s ss
Bild 13.1
66
Beispiel 13.2:
13.2.2 Verteilungsfunktion einer stetigen ZV (stetige Verteilung)
Verteilungsfunktion F (x) einer stetigen ZVX:
F (x) = P (X ≤ x) =
x∫−∞
f(t) dt (222)
fur x ∈ R, wobei die Funktion f als Wahrscheinlichkeitsdichte oder Dichtefunktion bezeichnet wird
Die Dichtefunktion f(x) besitzt die folgenden Eigenschaften33
1) f(x) ≥ 0 fur alle x ∈ R
2) f(x) = F ′(x), d.h. die Dichtefunktion ist gleich der ersten Ableitung der Verteilungsfunktion
3)∞∫−∞
f(x) dx = 1
Diese Eigenschaft wird auch als Normiertheit der Dichtefunktion bezeichnet.
4) Die Wahrscheinlichkeit, dass X einen Wert zwischen a und b annimmt, kann mit Hilfe der Dichtefunktionwie folgt berechnet werden:
P (a ≤ X ≤ b) = F (b)− F (a) =
b∫−∞
f(x) dx−a∫
−∞
f(x) dx =
b∫a
f(x) dx
(vgl. dazu auch Formel (222)).
Die Eigenschaft 3) folgt aus:∞∫−∞
f(x) dx = P (−∞ < X <∞) = 1 (Wahrscheinl. des sicheren Ereignisses).
Die Eigenschaft 4) kann wie folgt veranschaulicht werden: die im Bild 13.2 grau unterlegte Flache entsprichtder Wahrscheinlichkeit, dass die ZV X einen Wert zwischen a und b annimmt.
-
6
x
f(x)
a b
Bild 13.2
33An dieser Stelle wird f als eine von der Variablen x abhangige Funktion betrachtet, wahrend in der Formel (222) auf Grund derBezeichnung der oberen Integrationsgrenze die Schreibweise f(t) verwendet wurde.
67
Beispiel 13.3:
13.3 Kennwerte einer Wahrscheinlichkeitsverteilung
Bei der Beschreibung von ZV ist (außer den bereits eingefuhrten Funktionen) auch die Angabe von Kennwer-ten hilfreich. In diesem Abschnitt werden die folgenden Kennwerte34 eingefuhrt: Erwartungswert, Varianz undStandardabweichung einer ZV. Bei der Berechnung dieser Kennwerte wird nach diskreten und stetigen ZV un-terschieden.
Definition 13.4:Sei X eine diskrete ZV mit den Realisierungen x1, x2, . . . , xn und den Einzelwahrscheinlichkeitenp1, p2, . . . , pn (mit pi = P (X = xi), siehe Abschnitt 13.2.1).Dann werden die Kennwerte von X wie folgt berechnet:
Erwartungswert: µ = E(X) =n∑i=1
xi · pi (223)
Varianz (Streuung): σ2 = D2(X) = Var(X) =
n∑i=1
(xi − µ)2 · pi (224)
Standardabweichung: σ = D(X) =√
Var(X) (225)
Wenn die ZV X abzahlbar unendlich viele Realisierungen besitzt, ist in (223) und (224) die obere Summa-tionsgrenze gleich ”∞“ zu setzen.
Die Varianz ist ein Maß fur die Variabilitat der Verteilung. Gemaß (223) ist die Varianz gleich dem Erwartungs-wert der Zufallsvariablen Z = (X − µ)2.Die Standardabweichung wird auch mittlere quadratische Abweichung genannt. Der Vorteil der Standardabwei-chung (im Vergleich zur Varianz) besteht darin, dass sie die gleiche Dimension und Maßeinheit wie die ZV Xbesitzt. Fur praktische Berechnungen ist die folgende Formel fur die Varianz:
σ2 = E(X2)− µ2 (226)
meistens leichter zu handhaben als die Formel (224). Der in (226) vorkommende Erwartungswert der Zufalls-variablen X2 kann ermittelt werden, indem in (223) anstelle von xi jeweils x2i eingesetzt wird.
Beispiel 13.4:
34Weitere Kennwerte sind Variationskoeffizient, Schiefe und Exzess. Darauf wird hier nicht naher eingegangen, es sei auf die folgendeLiteraturstelle verwiesen: W. LEUPOLD (Hrsg.). Mathematik - ein Studienbuch fur Ingenieure (Band 2: Reihen - Differentialgleichungen- Analysis fur mehrere Variable - Stochastik), 2. Auflage, S. 368-369.
68
Definition 13.5:Sei X eine stetige ZV mit der Dichtefunktion f(x) (siehe (222)). Dann werden die Kennwerte von Xwie folgt berechnet:
Erwartungswert: µ = E(X) =
∞∫−∞
x · f(x) dx (227)
Varianz (Streuung): σ2 = D2(X) = Var(X) =
∞∫−∞
(x− µ)2 · f(x) dx (228)
Standardabweichung: σ = D(X) =√
Var(X) (229)
Die Berechnung der Varianz kann wiederum mittels der Formel (226) (anstatt von (228)) erfolgen. Um denbenotigten Erwartungswert E(X2) zu berechnen, ist in dem Integranden auf der rechten Seite von (227) derFaktor x2 anstelle des Faktors x zu nehmen.
Beispiel 13.5:
Bemerkungen:
- Nicht jede ZV besitzt einen Erwartungswert. Der Erwartungswert existiert fur eine stetige ZV nur dann,wenn das uneigentliche Integral in (227) konvergiert. Im Fall einer diskreten ZV mit abzahlbar unendlich
vielen Realisierungen muss die Summe∞∑i=1
xi · pi (vgl. Formel (223)) einen endlichen Wert besitzen, damit
der Erwartungswert existiert.
- Eine ZV X heißt
zentriert, wenn gilt: E(X) = 0.
normiert, wenn gilt: Var(X) = 1.
standardisiert, wenn sie zentriert und normiert ist.
69
13.4 Spezielle Wahrscheinlichkeitsverteilungen
In praktischen Anwendungssituationen der Wahrscheinlichkeitsrechnung werden spezielle Verteilungsfunktio-nen benotigt, welche den vorliegenden Sachverhalt moglichst gut beschreiben. Das Anliegen dieses Abschnittsbesteht darin, einige in der Praxis haufig vorkommende Wahrscheinlichkeitsverteilungen vorzustellen.
13.4.1 Binomialverteilung
Ausgangspunkt der Uberlegungen bei der Einfuhrung der Binomialverteilung ist das Bernoulli-Experiment35 .
Bernoulli-Experiment- Zufallsexperiment, bei dem ein Ereignis A mit der Wahrscheinlichkeit p und das zu A komplementare
Ereignis A mit der Wahrscheinlichkeit q = 1− p eintritt (d.h. es gibt nur zwei mogliche Ergebnisse)
- Dies gilt auch fur jede Wiederholung des Experiments.
- Beispiel: Beim Wurf einer homogenen Munze gibt es nur die Ereignisse:A: ”Zahl“ und A: ”Wappen“.Sie treten mit den Wahrscheinlichkeiten: p = P (A) = 1
2 und q = P (A) = 1− 12 = 1
2 auf.
Bernoulli-Experiment vom Umfang n- mehrstufiges Experiment: n-fache Ausfuhrung eines Bernoulli-Experiments mit den beiden
moglichen Ereignissen A und A
- Das Ereignis A tritt in jedem der n Teilexperimente mit der gleichen Wahrscheinlichkeit p auf.
- Die Ergebnisse der einzelnen Stufen sind voneinander unabhangig.
- Ein derartiges Experiment wird als Bernoulli-Experiment vom Umfang n bezeichnet.
- Zufallsvariable X: Anzahl der Versuche, in denen das Ereignis A bei einem Bernoulli-Experimentvom Umfang n auftritt⇒ X kann jeden der Werte 0, 1, 2, . . . n annehmen
- Die Fragestellung: Mit welcher Wahrscheinlichkeit nimmt die ZV X den Wert k an?(d.h.: Wie groß ist die Wahrscheinlichkeit, dass das Ereignis A genau k-mal eintritt?)fuhrt auf die Binomialverteilung.
Definition 13.6:Eine diskrete ZV X heißt binomialverteilt mit den Parametern n und p, falls sie die Werte 0, 1, . . . , nannehmen kann und diese mit den Einzelwahrscheinlichkeiten
pk = P (X = k) =
(nk
)pk(1− p)n−k (k = 0, 1, . . . , n) (230)
auftreten. Dabei gelten die folgenden Bezeichnungen:p: konstante Wahrscheinlichkeit fur das Ereignis A beim Einzelversuchn: Anzahl der Ausfuhrungen des Bernoulli-Experiments.
Um zum Ausdruck zu bringen, dass eine ZV X einer derartigen Verteilung unterliegt, kann auch die Schreib-weise: X ∼ B(n, p) verwendet werden.Zur weiteren Beschreibung der Binomialverteilung werden nachfolgend die Verteilungsfunktion sowie die Kenn-werte dieser Verteilung angegeben (siehe nachste Seite).
35Quelle: L. PAPULA. Mathematik fur Ingenieure und Naturwissenschaftler, Band 3, 5. Auflage, S. 346-347
70
Verteilungsfunktion der BinomialverteilungB(n, p)
F (x) =
0 fur x < 0∑k≤x
(nk
)pk(1− p)n−k fur x ≥ 0
Insbesondere gilt: F (x) = 1 fur x ≥ n.
Kennwerte der BinomialverteilungB(n, p)
Erwartungswert: µ = np
Varianz: σ2 = np(1− p)
Beispiel 13.6:
13.4.2 Poisson-Verteilung
Bei Ereignissen, die mit einer geringen Wahrscheinlichkeit (d.h. sehr selten36) auftreten, wird haufig von einerPoisson-Verteilung ausgegangen.
Definition 13.7:Eine diskrete ZV X heißt Poisson-verteilt mit dem Parameter λ, falls sie die Werte 0, 1, 2, . . .annehmen kann und diese mit den Einzelwahrscheinlichkeiten
pk = P (X = k) =λk
k!e−λ (k ∈ N) (231)
auftreten.
Die symbolische Schreibweise X ∼ Π(λ) bedeutet, dass die ZV X Poisson-verteilt mit dem Parameter λ ist.Die Poisson-Verteilung wird vollstandig durch den Parameter λ charakterisiert.
Verteilungsfunktion der Poisson-Verteilung Π(λ)
F (x) =
0 fur x < 0∑k≤x
λk
k!e−λ fur x ≥ 0
Kennwerte der Poisson-Verteilung Π(λ)
Erwartungswert: µ = λ
Varianz: σ2 = λ
Beispiel 13.7:
36Die Poisson-Verteilung wird deshalb auch ”Verteilung der seltenen Ereignisse“ genannt.
71
Zwischen der Poisson-Verteilung und der Binomialverteilung (siehe Abschnitt 13.4.1) besteht ein wichtiger Zu-sammenhang. Die Poisson-Verteilung lasst sich namlich aus der Binomialverteilung fur den Grenzubergangn → ∞, p → 0 herleiten, und zwar unter der Voraussetzung, dass dabei der Erwartungswert µ = np konstantbleibt. Daraus ergibt sich die folgende Schlussfolgerung.
Zusammenhang zwischen Poisson-Verteilung und BinomialverteilungDie Binomialverteilung mit den Parametern n und p darf fur großes n und kleines p in guter Naherungdurch die rechnerisch bequemere Poisson-Verteilung mit dem Parameter (Erwartungswert) λ = npersetzt werden.Dabei gilt die folgende Faustregel:Falls die Bedingungen np < 10 und n > 1500 p erfullt sind, darf die o.g. Ersetzung vorgenommenwerden.
Beispiel 13.8:
Die Poisson-Verteilung und die Binomialverteilung sind Verteilungen diskreter Zufallsvariablen. Die restlichenBetrachtungen im Abschnitt 13.4 werden sich auf Verteilungen stetiger Zufallsvariablen beziehen. Es sei daranerinnert, dass in diesen Fallen die Charakterisierung der ZV mittels der zugehorigen Dichtefunktion (siehe Ab-schnitt 13.2.2) erfolgt - im Gegensatz zu den betrachteten diskreten ZV, bei denen Einzelwahrscheinlichkeitenangegeben werden konnten.
Das stetige Analogon zur diskreten Gleichverteilung (siehe Beispiel 13.2) ist die stetige Gleichverteilung.
Definition 13.8:Eine stetige ZVX heißt gleichverteilt uber dem Intervall [a, b], wenn ihre Dichtefunktion gegeben ist durch:
f(x) =
0 fur −∞ < x < a
1
b− afur a ≤ x ≤ b
0 fur b < x <∞ .
(232)
Auf Grund des Aussehens der Dichtefunktion (232) (siehe dazu auch Bild 13.3a) auf der nachsten Seite) wirddie stetige Gleichverteilung uber [a, b] auch als Rechteckverteilung R(a, b) bezeichnet.
Verteilungsfunktion der stetigen Gleichverteilung (Rechteckverteilung)R(a, b)
F (x) =
0 fur −∞ < x < a
x− ab− a
fur a ≤ x ≤ b
1 fur b < x <∞ .
Kennwerte der stetigen Gleichverteilung (Rechteckverteilung)R(a, b)
Erwartungswert: µ =a+ b
2
Varianz: σ2 =(b− a)2
12
72
Zur Berechnung des Erwartungswertes und der Varianz:
Die Verteilungsfunktion F (x) der stetigen Gleichverteilung steigt in dem Intervall [a, b] von dem Wert 0 linearauf den Wert 1 an, siehe dazu auch Bild 13.3b).
-
6
x
f(x)
0 a b
1b−a
-
6
x
F (x)
0 a b
1
Bild 13.3a) Bild 13.3b)
Die stetige Gleichverteilung uber dem Intervall [0, 1] spielt bei der Simulation von Zufallszahlen eine Rolle.
Beispiel 13.9:
13.4.4 Exponentialverteilung
Wichtige Anwendungsgebiete der Exponentialverteilung sind Lebensdauerverteilungen oder Bedienzeitvertei-lungen.
Definition 13.9:Eine stetige ZV X heißt exponentialverteilt mit dem Parameter λ (λ > 0), wenn ihre Dichtefunktiongegeben ist durch
f(x) =
0 fur x < 0
λe−λx fur x ≥ 0 .(233)
Durch die symbolische Schreibweise X ∼ exp(λ) wird zum Ausdruck gebracht, dass die ZV X exponential-verteilt mit dem Parameter λ ist.
Verteilungsfunktion der Exponentialverteilung mit dem Parameter λ
F (x) =
0 fur x < 0
1− e−λx fur x ≥ 0 .
Zur Berechnung der Verteilungsfunktion der Exponentialverteilung:
73
In den Bildern 13.4a) und 13.4b) sind die Dichtefunktion und die Verteilungsfunktion einer Exponentialvertei-lung fur verschiedene Werte des Parameters λ dargestellt.
-
6
x
f(x)
0 2 4 6 8
0.1
0.2
0.3
0.4
0.5 λ = 2
λ = 0.5
-
6
x
F (x)
0 2 4 6 8
0.2
0.4
0.6
0.8
1λ = 2
λ = 0.5
Bild 13.4a) Bild 13.4b)
Kennwerte der Exponentialverteilung exp(λ)
Erwartungswert: µ =1
λ
Varianz: σ2 =1
λ2
Ein besonderes Merkmal der Exponentialverteilung besteht also darin, dass ihr Erwartungswert und ihre Stan-dardabweichung ubereinstimmen (d.h. die Abweichungen der Realisierungen der ZV vom Erwartungswert sindim Mittel genau so groß wie der Erwartungswert selbst).
Zur Berechnung des Erwartungswertes der Exponentialverteilung:
Beispiel 13.10:
13.4.5 Weibull-Verteilung
Die Weibull-Verteilung wird haufig zur Beschreibung von Ermudungserscheinungen bei Werkstoffen sowie inder Zuverlassigkeitstheorie verwendet.Diese Wahrscheinlichkeitsverteilung wird (im Gegensatz zur Exponentialverteilung, welche vollstandig durchden Parameter λ bestimmt ist) durch zwei Parameter charakterisiert.37
Definition 13.10:Eine stetige ZV X unterliegt einer Weibull-Verteilung mit den Parametern α und β, wenn ihre Dichte-funktion folgendermaßen lautet:
f(x) =
0 fur x < 0
α
β
(x
β
)α−1e−( x
β)α fur x ≥ 0 .
(234)
Die symbolische Schreibweise X ∼ W (α, β) sagt aus, dass die ZV X Weibull-verteilt mit den Parametern αund β ist.
37Im vorliegenden Skript werden die Parameter mit α und β bezeichnet; in der Literatur findet man aber auch Darstellungen derWeibull-Verteilung mit den Parametern γ und r, siehe z.B.: W. PREUSS, G. WENISCH (Hrsg.): Lehr- und Ubungsbuch Mathematik(Band 3: Lineare Algebra - Stochastik), Fachbuchverlag Leipzig im Carl Hanser Verlag, 2. Auflage, S. 172.
74
Verteilungsfunktion der Weibull-Verteilung mit den Parametern α und β
F (x) =
0 fur x < 0
1− e−( x
β)α fur x ≥ 0
In den Bildern 13.5a) und 13.5b) sind die Dichtefunktionen und die Verteilungsfunktionen von Weibull-Verteilungenfur verschiedene Werte der Parameter α und β dargestellt.
-
6
x
f(x)
0
1
1
α = 1/2, β = 1/3
α = 2, β = 1
-
6
x
F (x)
0
0.5
1
α = 1/2, β = 1/3
α = 2, β = 1
Bild 13.5a) Bild 13.5b)
Bei der Berechnung des Erwartungswertes der Weibull-Verteilung nach der Formel (227) tritt ein Integral auf, dasmit elementaren Mitteln nicht berechenbar ist, jedoch mit Hilfe einer speziellen Funktion ausgedruckt werdenkann. Diese Funktion wird Gamma-Funktion genannt und mit dem Symbol Γ(x) bezeichnet. Fur die Definitiondieser Funktion und einige Eigenschaften sei auf die folgende Literaturstelle verwiesen:H.-J. BARTSCH. Taschenbuch mathematischer Formeln fur Ingenieure und Naturwissenschaftler,23. Auflage (2014), S. 563.Nachfolgend werden der Erwartungswert und die Varianz der Weibull-Verteilung angegeben, ohne auf die Her-leitung naher einzugehen.
Erwartungswert und Varianz der Weibull-VerteilungW (α, β)
Erwartungswert: µ = β · Γ(
1 +1
α
)Varianz: σ2 = β2
[Γ(
1 +2
α
)−(
Γ(
1 +1
α
))2]Um diese Formeln anwenden zu konnen, mussen die entsprechenden Werte der Gamma-Funktion bekanntsein. Diese Funktionswerte sind jedoch nur in speziellen Fallen einfach zu bestimmen; im allgemeinen Fallist die Verwendung von Rekursionsformeln, Naherungsformeln, tabellierten Werten oder der entsprechendenTaschenrechner-Funktion erforderlich.Der nachfolgende Tabelle konnen die Funktionswerte Γ
(1 +
1
α
)sowie Γ
(1 +
2
α
)fur spezielle Werte des
Parameters α entnommen werden (jeweils auf vier Nachkommastellen gerundet).
α Γ(
1 +1
α
)Γ(
1 +2
α
)1.0 1.0000 2.0000
1.5 0.9027 1.1906
2.0 0.8862 1.0000
2.5 0.8873 0.9314
3.0 0.8930 0.9027
3.5 0.8997 0.8906
4.0 0.9064 0.8862
75
Beispiel 13.11:
Bemerkung:Die Exponentialverteilung (siehe Abschnitt 13.4.4) kann als ein Spezialfall der Weibull-Verteilung betrachtet
werden: setzt man namlich in der Formel (234) speziell α = 1 und β =1
λ(mit λ > 0), so entsteht eine Dichte-
funktion vom Typ (233).
13.4.6 Gaußsche Normalverteilung
Die Gaußsche Normalverteilung (kurz: Normalverteilung) ist eine der wichtigsten Wahrscheinlichkeitsvertei-lungen. Sie findet vielfach Anwendung in der Praxis. Wenn eine Zufallsvariable durch Uberlagerung vieler ein-zelner, relativ geringer Einflusse entsteht, kann die Normalverteilung verwendet werden (beispielsweise werdenAbweichungen von der Sollmenge bei der Abfullung von Flussigkeiten oder Messfehler haufig als normalverteiltangenommen). Die Normalverteilung wird mit Hilfe von zwei Parametern beschrieben.
Definition 13.11:Eine stetige ZV X genugt einer Normalverteilung mit den Parametern µ und σ2 (mit σ > 0),wenn sie die folgende Dichtefunktion besitzt:
f(x) =1√2π σ
e−(x−µ)2
2σ2 (x ∈ R). (235)
Die symbolische Schreibweise fur eine mit µ und σ2 normalverteilte ZV X ist: X ∼ N(µ, σ2).Die Parameter dieser Verteilung sind gleichzeitig auch Kennwerte: µ ist der Erwartungswert undσ2 die Varianz der genannten Normalverteilung.
Im Bild 13.6 ist die Dichtefunktion der Normalverteilung fur spezielle Werte der Parameter µ und σ2 (bzw. σ)dargestellt.
-
6
x
f(x)
0
0.8
0.53
3
Symmetrieachse
Dichtefunktion f(x) mit µ = 3, σ = 0.5
Dichtefunktion f(x) mit µ = 3, σ = 0.75
Bild 13.6
Die Dichtefunktion f(x) aus (235) besitzt die folgenden Eigenschaften38:a) f(x) ist spiegelsymmetrisch bezuglich der Geraden x = µ.b) Maximum: bei x1 = µ, Wendepunkte: bei x2,3 = µ± σc) Die Gestalt der Dichtefunktion f(x) erinnert an eine Glocke. Man spricht daher auch haufig von der Gauß-
schen Glockenkurve.d) Der Parameter σ bestimmt Breite und Hohe der Glockenkurve. Es gilt:
Je kleiner die Standardabweichung σ ist, umso hoher liegt das Maximum und umso steiler fallt die Dichte-kurve nach beiden Seiten hin ab (siehe auch Bild 13.6).
Die zu der Dichtefunktion (235) gehorige Verteilungsfunktion F (x) lautet (siehe dazu die Formeln (222) und(235)):
F (x) = P (X ≤ x) =
x∫−∞
f(t) dt =1√2π σ
x∫−∞
e−(t−µ)2
2σ2 dt . (236)
38Quelle: L. PAPULA. Mathematik fur Ingenieure und Naturwissenschaftler, Band 3, 5. Auflage, S. 369
76
Das Integral auf der rechten Seite dieser Gleichung ist nicht in geschlossener Form losbar. Dieses Problem kannjedoch umgangen werden, indem eine Ruckfuhrung auf die standardisierte Normalverteilung mit den Parame-tern µ = 0 und σ2 = 1 vorgenommen wird. Die Dichtefunktion der standardisierten Normalverteilung wirdmit ϕ(x) bezeichnet. Durch Einsetzen der Parameter µ = 0 und σ2 = 1 in die Formel (235) erhalt man:
ϕ(x) =1√
2π · 1e−
(x−0)2
2·1 =1√2π· e−
x2
2 . (237)
Im Bild 13.7 ist die Dichtefunktion ϕ(x) der standardisierten Normalverteilung dargestellt.
-
6
x
ϕ(x)
0−1 1
q0.4
Bild 13.7
Die Dichtefunktion ϕ(x) hat folgende Eigenschaften:
a) ϕ(x) ist eine gerade Funktion, d.h. ϕ(x) = ϕ(−x) (da die Symmetrieachse mit der Geraden x = 0, d.h. mitder y-Achse zusammenfallt).
b) Maximum: bei x1 = 0, Wendepunkte: bei x2,3 = ±1
Die zu der Funktion ϕ(x) gehorige Verteilungsfunktion wird mit dem Symbol Φ(x) bezeichnet. Aus (236), jetztspeziell mit f(t) = ϕ(t), sowie (237) ergibt sich:
Φ(x) = P (X ≤ x) =
x∫−∞
ϕ(t) dt =1√2π
x∫−∞
e−t2
2 dt . (238)
Diese Funktion wird auch haufig Gaußsches Fehlerintegral genannt.
Zusammenhang zwischen den Verteilungsfunktionen F (x) und Φ(x)
Zwischen der Verteilungsfunktion F (x) einer Normalverteilung mit den Parametern µ und σ2 (sieheFormel (236)) und der Verteilungsfunktion Φ(x) der standardisierten Normalverteilung mit den Parameternµ = 0 und σ2 = 1 (siehe Formel (238)) besteht der folgende Zusammenhang:
F (x) = Φ
(x− µσ
). (239)
Die Verteilungsfunktion Φ(x) ist tabelliert (siehe z.B.: H.-J. BARTSCH. Taschenbuch mathemat. Formeln furIngenieure u. Naturwissenschaftler, 23. Auflage, S. 780). Daher muss, wenn der Funktionswert F (x) bei vorge-
gebenen Parametern µ und σ2 zu ermitteln ist, lediglich der Wert x− µσ
ausgerechnet und dann Φ(x− µσ
)aus
der Tabelle entnommen werden. Bei der Berechnung von x− µσ
konnen auch negative Zahlen entstehen. Solche
sind in der Tabelle nicht aufgefuhrt, aber es kann die folgende wichtige Beziehung zu Hilfe genommen werden:
Fur die Werte der Verteilungsfunktion Φ(x) der standardisierten Normalverteilung gilt allgemein:
Φ(−x) = 1− Φ(x) fur x > 0. (240)
Beispiel 13.12:
Bei Betrachtung der Funktionsbilder der Dichtefunktionen f(x) und ϕ(x) (siehe Bild 13.6 und Bild 13.7) be-merkt man, dass fur solche x-Werte, die nahe bei µ liegen, die Werte dieser Dichtefunktionen relativ groß sind(im Vergleich zu Werten von f(x) und ϕ(x), wenn x ”weit entfernt“ von µ ist). Mit anderen Worten: die Wahr-scheinlichkeit, dass eine normalverteilte ZV X Werte annimmt, die nahe bei dem Erwartungswert µ liegen, istrelativ hoch.
77
Dies gibt Anlass zu der folgenden Fragestellung:Mit welcher Wahrscheinlichkeit hat ein Wert einer normalverteilten ZV X vom Erwartungswert µeinen Abstand, der kleiner als ein vorgegebenes ε > 0 ist ?
Diese Frage kann wie folgt beantwortet werden39, wenn man fur ε bestimmte Vielfache der Standardabwei-chung σ nimmt.
Fur jede ZV X , die einer Normalverteilung mit den Parametern µ und σ2 genugt, gilt:
P (|X − µ| < σ) = 2Φ(1)− 1 = 0.6827
P (|X − µ| < 2σ) = 2Φ(2)− 1 = 0.9545 (241)
P (|X − µ| < 3σ) = 2Φ(3)− 1 = 0.9973 .
Daraus kann die folgende Schlussfolgerung gezogen werden: Bei einer normalverteilten Zufallsvariablenliegen 99.73 % aller Werte (d.h. fast alle Werte) innerhalb der 3σ-Grenzen.
Die letzte Gleichung in (241) wird auch ”3σ-Regel“ genannt. Sie spielt eine wichtige Rolle in der statistischenQualitatssicherung.
Begrundung zu (241):Es gelte: X ∼ N(µ, σ2). Um die Wahrscheinlichkeit P (|X −µ| < ε) zu berechnen, wird ε = kσ gesetzt, eineneue ZV Y eingefuhrt und der Zusammenhang mit der standardisierten Normalverteilung (vgl. (239)) genutzt:
P (|X − µ| < kσ) = P(|X − µ|
σ< k
)= P (|Y | < k) = P (−k < Y < k)
= P (Y < k)− P (Y < −k) = Φ(k)− Φ(−k) = Φ(k)− (1− Φ(k))
= 2Φ(k)− 1 .
Die obigen Aussagen ergeben sich nun, indem man in dieser Gleichung nacheinander k = 1, k = 2 und k = 3setzt und den entsprechenden Wert von Φ(k) ermittelt.
39Quelle: W. LEUPOLD (Hrsg.). Mathematik - ein Studienbuch fur Ingenieure (Band 2: Reihen - Differentialgleichungen - Analysisfur mehrere Variable - Stochastik), 2. Auflage, S. 382
78
Im Abschnitt 13.4.2 wurde ausgefuhrt, dass die Binomialverteilung durch die rechnerisch bequemere Poisson-Verteilung angenahert werden kann. Zwischen der Binomialverteilung und der Normalverteilung besteht eben-falls ein Zusammenhang, der eine Approximation erlaubt.
Zusammenhang zwischen Binomialverteilung und NormalverteilungDie Binomialverteilung mit den Parametern n und p kann, falls die Bedingung
n · p · (1− p) > 9 (242)erfullt ist, durch die Normalverteilung mit den Parametern µ = np und σ2 = np(1− p)approximiert werden.
Die Besonderheit besteht darin, dass jetzt eine stetige Wahrscheinlichkeitsverteilung zur Approximation derBinomialverteilung (die ja bekanntlich eine diskrete Wahrscheinlichkeitsverteilung ist) verwendet wird. Dies istauch der Grund dafur, dass bei der Berechnung von Wahrscheinlichkeiten mit Hilfe dieser Approximation eineStetigkeitskorrektur vorgenommen werden muss. Es gilt die nachfolgend genannte Naherungsformel.
Naherungsformel zur Berechnung von Wahrscheinlichkeiten bei der BinomialverteilungDie ZV X sei binomialverteilt mit den Parametern n und p, wobei die Ungleichung (242) erfullt sein soll.Dann kann zur Berechnung der Wahrscheinlichkeit P (a ≤ X ≤ b) die Formel
P (a ≤ X ≤ b) ≈ Φ
(b+ 0.5− µ
σ
)− Φ
(a− 0.5− µ
σ
)(243)
mit µ = np und σ =√np(1− p) verwendet werden (Φ: Verteilungsfunktion der standardisierten
Normalverteilung, siehe (238)).
Die Stetigkeitskorrektur wird durch die Summanden +0.5 bzw. −0.5 in der Formel (243) realisiert.
Beispiel 13.13:
13.5 Aussagen uber Summen und Produkte von Zufallsvariablen
In den bisherigen Ausfuhrungen wurde stets von genau einer ZV ausgegangen. Bei praktischen Anwendungenliegt jedoch haufig die Situation vor, dass mehrere ZV auftreten, welche dann z.B. addiert oder multipliziertwerden. Zielstellung dieses Abschnittes ist es, die Kennzahlen von Summen oder Produkten von ZV anzugeben.Eine große Bedeutung kommt dabei auch dem Zentralen Grenzwertsatz (siehe Abschnitt 13.5.2) zu.
13.5.1 Kennwerte von Summen und Produkten von Zufallsvariablen
Zunachst sei bemerkt, dass die Summe bzw. das Produkt von Zufallsvariablen wiederum eine Zufallsvariable ist.Bevor Aussagen uber den Erwartungswert und die Varianz dieser ”neuen“ ZV getroffen werden, wird der Begriffder Unabhangigkeit zweier ZV eingefuhrt. Dazu ist es erforderlich, mehrdimensionale Verteilungsfunktionen(d.h. Verteilungsfunktionen, die von mehr als einer Variablen abhangen) zu betrachten.SeienX und Y zwei ZV, so kann aus diesen ein zweidimensionaler Zufallsvektor (X,Y ) gebildet werden. Dieserkann vollstandig durch die Verteilungsfunktion
F (x, y) = P (X ≤ x, Y ≤ y) (244)
beschrieben werden40.
Definition 13.12:Seien X und Y Zufallsvariable mit den zugehorigen Verteilungsfunktionen FX(x) und FY (y).Weiterhin sei F (x, y) die Verteilungsfunktion des aus X und Y gebildeten zweidimensionalen Zufalls-vektors (X,Y ) (siehe (244)). Die Zufallsvariablen X und Y heißen (stochastisch) unabhangig, wenn furalle x und y die folgende Bedingung erfullt ist:
F (x, y) = FX(x) · FY (y) . (245)
40Auf die allgemeinen Eigenschaften einer solchen Verteilungsfunktion sowie auf die zugehorige Dichtefunktion wird an dieser Stellenicht eingegangen. Es sei auf die folgende Literaturstelle verwiesen: L. PAPULA. Mathematik fur Ingenieure und Naturwissenschaftler,Band 3, 5. Auflage, Kapitel II, Abschnitt 7.2.
79
Die Beziehung (245) ist das Analogen zur (stochastischen) Unabhangigkeit von Ereignissen (siehe dazu Ab-schnitt 12.3.3), denn sie sagt aus, dass die Ereignisse A : ”X ≤ x“ und B : ”Y ≤ y“ unabhangig sind.Die Aussage von Definition 13.12 lasst sich auf eine endliche Anzahl n von Zufallsvariablen ubertragen.
Fur die Summe von n Zufallsvariablen gelten die folgenden Aussagen.
Additionssatz fur ErwartungswerteSeien X1, X2, . . ., Xn (diskrete oder stetige) Zufallsvariable mit den Erwartungswerten µ1 = E(X1),µ2 = E(X2), . . . , µn = E(Xn). Dann besitzt die Summe Z = X1+X2+ . . .+Xn dieser Zufallsvariablenden Erwartungswert
Additionssatz fur VarianzenSeien X1, X2, . . ., Xn (diskrete oder stetige) Zufallsvariable mit den Varianzen σ21 = Var(X1),σ22 = Var(X2), . . . , σ2n = Var(Xn). Weiterhin wird vorausgesetzt, dass diese Zufallsvariablen stochastischunabhangig sind. Dann besitzt die Summe Z = X1 +X2 + . . .+Xn dieser Zufallsvariablen die Varianz
Man beachte, dass der Additionssatz fur Varianzen nur im Fall der Unabhangigkeit der ZV X1, X2, . . ., Xn gilt.
Beispiel 13.14:
Multiplikationssatz fur ErwartungswerteSeien X1, X2, . . ., Xn (diskrete oder stetige) Zufallsvariable mit den Erwartungswerten µ1 = E(X1),µ2 = E(X2), . . . , µn = E(Xn). Außerdem wird vorausgesetzt, dass diese Zufallsvariablen stochastischunabhangig sind. Dann besitzt das ProduktZ = X1·X2·. . .·Xn dieser Zufallsvariablen den Erwartungswert
Bisher wurden zwar Aussagen uber den Erwartungswert bzw. die Varianz einer Summe von ZV getroffen, aberdie genannten Satze gaben keine Auskunft uber die Wahrscheinlichkeitsverteilung (d.h. den Typ der Verteilungs-funktion) dieser Summe. Wenn weitere Voraussetzungen getroffen werden, kann ggf. auch die Wahrscheinlich-keitsverteilung einer Summe von ZV benannt werden. Der folgende Fall ist fur praktische Anwendungen vongroßer Bedeutung.
80
Aussagen uber die Summe von unabhangigen und normalverteilten ZVDie Zufallsvariablen X1, X2, . . ., Xn seien unabhangig und normalverteilt mit den Erwartungswertenµ1, µ2, . . . , µn und den Varianzen σ21 , σ22 , . . . , σ2n. Die Summe Z = X1 +X2 + . . .+Xn dieser Zufalls-variablen unterliegt dann ebenfalls einer Normalverteilung. Die Parameter dieser Normalverteilung sind:µZ = µ1 + µ2 + . . .+ µn sowie σ2Z = σ21 + σ22 + . . .+ σ2n .
Beispiel: siehe Ubung
13.5.2 Zentraler Grenzwertsatz
Im folgenden wird die Voraussetzung, dass die ZV einer Normalverteilung unterliegen mussen, fallengelassen.Es wird nur verlangt, dass alle betrachteten ZV unabhangig sind und die gleiche (ggf. aber unbekannte!) Vertei-lungsfunktion besitzen.
Zentraler Grenzwertsatz der WahrscheinlichkeitsrechnungSeien X1, X2, . . ., Xn unabhangige Zufallsvariable, die alle der gleichen Verteilungsfunktion mit demErwartungswert µ und der Varianz σ2 genugen. Dann konvergiert die Verteilungsfunktion der standardisier-
ten Zufallsvariablen Zn =X1 +X2 + . . .+Xn − nµ√
nσfur n→∞ gegen die Verteilungsfunktion Φ
der standardisierten Normalverteilung.
Bei praktischen Anwendungen wird anstelle der Grenzwertbetrachtung n→∞ haufig die Faustregel angewen-det, dass fur die Anzahl n der ZV gelten soll: n ≥ 30. Dann kann davon ausgegangen werden, dass die SummeX1 +X2 + . . .+Xn der ZV annahernd einer Normalverteilung mit den Parametern nµ und nσ2 genugt.
Beispiel 13.15:
Bemerkung:Die im Zentralen Grenzwertsatz angegebenen Voraussetzungen konnen auch noch abgeschwacht werden;dazu sei auf die folgende Literaturstelle verwiesen: K. BOSCH. Statistik-Taschenbuch, 3. Auflage, S. 334-335.
81
14 Mathematische Statistik
14.1 Einfuhrung
Eine grundlegende Aufgabe der Statistik besteht in der Gewinnung von Kenntnissen und Informationen uberdie Eigenschaften oder Merkmale einer bestimmten Menge von Objekten, ohne dass dabei alle Objekte in dieUntersuchung einbezogen werden mussen. Statt dessen werden Stichproben aus einer Grundgesamtheit entnom-men (zur Erlauterung der Begriffe ”Stichprobe“ und ”Grundgesamtheit“: siehe Abschnitt 14.1.1) und es wirdversucht, mit Hilfe der Wahrscheinlichkeitsrechnung die gewunschten Informationen zu bekommen.
14.1.1 Einige Grundbegriffe
Einige Grundbegriffe der mathematischen StatistikGrundgesamtheit:Gesamtheit gleichartiger Objekte oder Elemente, die hinsichtlich eines bestimmten Merkmals zu unter-suchen sind; dieses Merkmal wird durch Zufallsvariable X beschrieben
Zufallsstichprobe vom Umfang n:eine aus der Grundgesamtheit zufallig herausgegriffene Teilmenge mit n Elementen (dabei: Auswahl derElemente wahllos und unabhangig voneinander; alle Elemente mussen die gleiche Chance haben,ausgewahlt zu zu werden)Im weiteren wird die Bezeichnung ”Stichprobe von Umfang n“ verwendet.
Stichprobenwerte:beobachtete Merkmalswerte x1, x2, . . ., xn der n Elemente (Realisierungen der Zufallsvariablen X)
14.1.2 Verteilungsfunktion einer Stichprobe
Es wird von der folgenden Situation ausgegangen:Aus einer (endlichen oder unendlichen) Grundgesamtheit wurde eine Stichprobe vom Umfang n entnommen undes wurden die Merkmalswerte x1, x2, . . ., xn (Stichprobenwerte) beobachtet. Diese liegen in Form einer Urlistevor, d.h. sie wurden in der Reihenfolge ihres Auftretens erfasst.
Die weitere Auswertung der vorliegenden Stichprobe kann wie folgt vorgenommen werden:
- Feststellung der verschiedenen, in der Stichprobe vorkommenden Werte; ihre Anzahl sei k (k ≤ n),dann werden im folgenden die (der Große nach geordneten) Stichprobenwerte x1, x2, . . ., xk betrachtet
- Feststellung, wie oft jedes xi in der Stichprobe enthalten istDies fuhrt auf den Begriff: absolute Haufigkeit ni des Stichprobenwertes xi (i = 1, 2, . . . , k),
es gilt:k∑i=1
ni = n
- Ermittlung der relativen Haufigkeit hi des Stichprobenwertes xi (i = 1, 2, . . . , k):
hi =nin
, wobei 0 < hi ≤ 1 undk∑i=1
hi = 1
- Darstellung von xi, ni und hi in einer Haufigkeitstabelle (siehe Beispiel 14.1)
Die grafische Darstellung der relativen Haufigkeiten erfolgt im Stabdiagramm (siehe Beispiel 14.1).
82
Beispiel 14.1:41
Aus der laufenden Produktion von Gewindeschrauben mit einem Solldurchmesser von x0 = 5.0 mm wurde eineStichprobe vom Umfang n = 25 entnommen.Dabei ergab sich die folgende Urliste (Werte in mm):
Es treten nur 6 verschiedene Werte auf. Diese lauten der Große nach geordnet:
4.7; 4.8; 4.9; 5.0; 5.1; 5.2 (jeweils in mm)
Zur Feststellung der absoluten Haufigkeiten ni (i = 1, 2, . . . , 6) dieser Werte dient die folgende Strichliste:
Stichprobenwert xi (in mm) 4.7 4.8 4.9 5.0 5.1 5.2
ni | ||| ||||| | ||||| |||| |||| ||
Daraus kann die folgende Haufigkeitstabelle aufgestellt werden:
xi (in mm) 4.7 4.8 4.9 5.0 5.1 5.2
ni 1 3 6 9 4 2
hi 0.04 0.12 0.24 0.36 0.16 0.08
Die zugehorigen relativen Haufigkeiten sind im Bild 14.1a) grafisch dargestellt.
-
6
x/mm
hi
4.7 4.8 4.9 5.0 5.1 5.2
0.08
0.16
0.24
0.32
-
6
x/mm
F (x)
4.7 4.8 4.9 5.0 5.1 5.2
1.0
0.8
0.6
0.4
0.2 qqq
q q q
Bild 14.1a) Bild 14.1b)
Durch Addition der relativen Haufigkeiten aller Stichprobenwerte, welche kleiner oder gleich einer gegebenenreellen Zahl x sind, erhalt man die Summenhaufigkeits- oder Verteilungsfunktion einer Stichprobe.
Definition 14.1:Die Summenhaufigkeits- oder Verteilungsfunktion F (x) einer Stichprobe mit den Stichprobenwertenx1, x2, . . ., xk und den zugehorigen relativen Haufigkeiten h1, h2, . . ., hk ist gegeben durch:
F (x) =∑xi≤x
hi . (249)
Die grafische Darstellung dieser Funktion ergibt eine Treppenfunktion, welche an den Stellen x = xijeweils einen Sprung der Hohe hi besitzt.
41Quelle: L. PAPULA. Mathematik fur Ingenieure und Naturwissenschaftler, Band 3, 5. Auflage, S. 470-471
83
Fortsetzung zu Beispiel 14.1:Mit Hilfe der Formel fur die Summenhaufigkeits- oder Verteilungsfunktion erhalt man die folgende Tabelle:
xi (in mm) 4.7 4.8 4.9 5.0 5.1 5.2
F (xi) 0.04 0.16 0.4 0.76 0.92 1
Das Bild 14.1b) (siehe vorige Seite) zeigt die grafische Darstellung der Funktion F (x).
14.1.3 Gruppierung der Stichprobenwerte bei umfangreichen Stichproben
Wenn die entnommene Stichprobe sehr umfangreich ist, kann die im vorangegangenen Abschnitt eingefuhrteHaufigkeitstabelle sehr umfangreich oder sogar unubersichtlich werden. Daher erweist sich in derartigen Falleneine Gruppierung der Stichprobenwerte als vorteilhaft.Dabei geht man wie folgt vor:- Die Stichprobenwerte werden der Große nach geordnet und der kleinste sowie der großte Stichprobenwert
(xmin und xmax) werden bestimmt.
- Das Intervall I , das alle Stichprobenwerte enthalt, wird in k Teilintervalle ∆Ii eingeteilt, welche rechtsseitighalboffen sind und alle die gleiche Breite ∆x besitzen. Diese Teilintervalle werden Klassen genannt. Mit xibezeichnet man jeweils die Klassenmitte eines jeden Teilintervalls Ii.
- Es wird ausgezahlt, wieviele Stichprobenwerte in welche Klasse fallen. Dann konnen die absoluten und re-lativen Klassenhaufigkeiten ni und hi (vgl. Abschnitt 14.1.2 fur ”nicht gruppierte“ Stichproben) bestimmtwerden.
- Bei der Aufstellung der Haufigkeitstabelle (vgl. Abschnitt 14.1.2) wird allen Elementen einer Klasse dieentsprechende Klassenmitte als Wert zugeordnet.
Die relativen Klassenhaufigkeiten konnen in einem Stabdiagramm (vgl. Abschnitt 14.1.2) oder in einem Histo-gramm (siehe Bild 14.2a)) veranschaulicht werden. In einem Histogramm sind die Flacheninhalte der Rechteckeproportional zu den jeweiligen Klassenhaufigkeiten.
Beispiel 14.2:42
Aus der laufenden Produktion von Ohmschen Widerstanden mit einem Sollwiderstand von 100 Ω wurde eineStichprobe vom Umfang n = 50 entnommen. Die Widerstandswerte lagen dabei zwischen xmin = 96.7 Ωund xmax = 104.2 Ω. Um moglichst einfache Zahlen fur die Klassenbreiten und -mitten zu erhalten, wird dasIntervall I := [ 96.5 Ω, 104.5 Ω ) gewahlt. Es erfolgt eine Einteilung in 8 Klassen der gleichen Breite 1 Ω. Somitsind die Klassenmitten: 97, 98 ,. . . , 104 (jeweils in Ω).
Es wurde die folgende Haufigkeitstabelle ermittelt (die Urliste ist hier nicht mit aufgefuhrt):
Klassen-Nr. i Klassengrenzen Klassenmitte xi abs. Klassenhauf. ni rel. Klassenhauf. hi(in Ω) (in Ω)
1 [96.5, 97.5) 97 2 0.04
2 [97.5, 98.5) 98 5 0.10
3 [98.5, 99.5) 99 10 0.20
4 [99.5, 100.5) 100 13 0.26
5 [100.5, 101.5) 101 9 0.18
6 [101.5, 102.5) 102 6 0.12
7 [102.5, 103.5) 103 4 0.08
8 [103.5, 104.5) 104 1 0.02
Σ 50 1
42Quelle: L. PAPULA. Mathematik fur Ingenieure und Naturwissenschaftler, Band 3, 5. Auflage, S. 477-479
84
Das Bild 14.2a) zeigt die grafische Darstellung der relativen Klassenhaufigkeiten in einem Histogramm.
-
6
x/Ω
hi
97 98 99 100 101 102 103 104
0.10
0.20
0.30
Bild 14.2a)
-
6
x/Ω
F (x)
97 98 99 100 101 102 103 104
1.0
0.2
0.4
0.6
0.8
q qq
qq q q q
Bild 14.2b)
Durch Addition der relativen Haufigkeiten der Klassen, deren Klassenmitten kleiner oder gleich einer gegebenenreellen Zahl x sind, entsteht die Verteilungsfunktion einer gruppierten Stichprobe.
Definition 14.2:Die Verteilungsfunktion F (x) einer gruppierten Stichprobe mit den Klassenmitten xi (i = 1, 2, . . . , k)und den zugehorigen relativen Klassenhaufigkeiten h1, h2, . . ., hk ist gegeben durch:
F (x) =∑xi≤x
hi . (250)
Die grafische Darstellung dieser Funktion ergibt eine Treppenfunktion, welche an den Stellen x = xijeweils einen Sprung der Hohe hi besitzt.
Hinweis:Es ist zu beachten, dass (im Unterschied zu der Formel (249) in der Definition 14.1) jetzt die Klassenmittenanstelle der Stichprobenwerte sowie die relativen Klassenhaufigkeiten anstelle der relativen Haufigkeiten zunehmen sind.
Das Bild 14.2b) (siehe oben) zeigt die Verteilungsfunktion fur die im Beispiel 14.2 untersuchte Stichprobe.
Bei der Festlegung der Klassenanzahl und der Klassenbreite fur die Gruppierung einer Stichprobe sollten einigeallgemeine Regeln beachtet werden.
Allgemeine Regeln fur die Gruppierung einer umfangreichen Stichprobe in Klassen
1) Man wahle moglichst Klassen gleicher Breite.
2) Die Klasseneinteilung sollte so festgelegt werden, dass die Klassenmitten durch moglichst einfacheZahlen (z.B. ganze Zahlen) charakterisiert werden.
3) Die Festlegung der Anzahl k der Klassen bei n Stichprobenwerten kann mit Hilfe der folgendenFaustregeln erfolgen:
k = 5 fur n ≤ 30 bzw. k ≈√n fur 30 < n ≤ 400 bzw. k = 20 fur n > 400.
14.2 Kennwerte (Maßzahlen) einer Stichprobe
In den Abschnitten 14.1.2 und 14.1.3 wurden Methoden zur Auswertung von Stichproben vorgestellt, bei denensamtliche Stichprobenwerte dargestellt wurden. In vielen Fallen ist es jedoch sinnvoll, nur einige Großen an-zugeben, welche eine gute Beschreibung der Stichprobenwerte liefern. Derartige Großen werden als Kennwerteoder Maßzahlen einer Stichprobe bezeichnet.
85
Definition 14.3:Es liege eine Stichprobe vom Umfang n mit den Stichprobenwerten x1, x2, . . ., xn (Urliste) vor.Der Mittelwert dieser Stichprobe (oder Stichprobenmittelwert bzw. empirische Mittelwert ) wirdwie folgt berechnet:
x =1
n
n∑i=1
xi . (251)
Fur die Varianz dieser Stichprobe (oder Stichprobenvarianz bzw. empirische Varianz ) gilt die Formel:
s2 =1
n− 1
n∑i=1
(xi − x)2 . (252)
Die Standardabweichung wird berechnet nach:
s =√s2 . (253)
Bei der Berechnung der Varianz ist die (zu (252) aquivalente) Formel
s2 =1
n− 1
(n∑i=1
x2i − nx 2
)(254)
meist bequemer zu handhaben.
Weitere Kennwerte zur Beschreibung von Stichproben sind: Modalwert (oder Dichtemittel), Median (oder Zen-tralwert), Spannweite (oder Variationsbreite) sowie Variationskoeffizient (oder Variabilitatskoeffizient).
Modalwert xD einer Stichprobe: Stichprobenwert mit der großten absoluten Haufigkeit
Median x einer Stichprobe: bei der Große nach geordneten Daten x∗1 ≤ x∗2 ≤ . . . ≤ x∗n:
x =
x∗(n+1)/2 falls n ungerade
(x∗n/2 + x∗n/2+1)/2 falls n gerade
Spannweite R einer Stichprobe: R = xmax − xmin
Variationskoeffizient v einer Stichprobe: v =s
x(relatives Streuungsmaß)
Hinweise:
- Der Modalwert ist nicht immer eindeutig bestimmt. Es kann vorkommen, dass die großte absolute Haufigkeitgleichzeitig von mehreren Stichprobenwerten angenommen wird.
- Falls jeder Stichprobenwert nur einmal auftritt, gibt es keinen Modalwert.
- Bei gruppierten Stichproben ergibt sich der Modalwert als Klassenmitte der am starksten besetzten Klasse.
- Der Median hangt lediglich von dem mittelsten Wert bzw. den beiden mittleren Werten der Stichprobe ab,wenn die Daten der Große nach geordnet sind (vgl. obige Formel). Daher konnten die ubrigen Stichproben-werte beliebig variiert werden, ohne dass sich der Median verandert (wohingegen sich der Mittelwert derStichprobe in diesen Fallen stark verandern kann). Somit ist der Median - im Gegensatz zum Mittelwert derStichprobe - robust gegenuber ”Ausreißern“, d.h. gegenuber extrem kleinen oder extrem großen Stichproben-werten.Ebenso ist der Modalwert robust gegenuber ”Ausreißern“.
Beispiel 14.3:
86
Bei Anwendung der Formeln (251) bis (254) zur Berechnung der Kennwerte einer Stichprobe geht jeder einzelneStichprobenwert ohne Berucksichtigung seiner Haufigkeit in die Berechnung ein. Bei Stichproben, wo ein mehr-faches Auftreten von Stichprobenwerten beobachtet wurde, erweist sich die Berechnung der Kennwerte unterVerwendung der absoluten Haufigkeiten als effektiver.
Berechnung der Kennwerte einer Stichprobe unter Berucksichtigung der absoluten HaufigkeitenEs liege eine Stichprobe mit den verschiedenen Stichprobenwerten x1, x2, . . ., xk vor.Weiterhin seien n1, n2, . . ., nk die zugehorigen absoluten Haufigkeiten. Fur die Berechnung des Mittel-wertes x und der Varianz s2 der Stichprobe gelten dann die folgenden Formeln:
x =1
n
k∑i=1
xini (255)
s2 =1
n− 1
k∑i=1
(xi − x)2 · ni oder s2 =1
n− 1
(k∑i=1
x2i · ni − nx 2
)(256)
Fortsetzung zu Beispiel 14.1:
Zur Berechnung des Mittelwertes und der Varianz von gruppierten Stichproben (siehe Abschnitt 14.1.3) wird diejeweilige Klassenmitte herangezogen.
Berechnung der Kennwerte einer gruppierten StichprobeGegeben sei eine gruppierte Stichprobe mit k Klassen und den Klassenmitten xi (i = 1, 2, . . . , k).Weiterhin seien n1, n2, . . ., nk die absoluten Klassenhaufigkeiten (siehe Abschnitt 14.1.3). Der Mittelwertx und die Varianz s2 dieser Stichprobe konnen dann nach den folgenden Formeln berechnet werden:
x =1
n
k∑i=1
xini (257)
s2 =1
n− 1
k∑i=1
(xi − x)2 · ni oder s2 =1
n− 1
(k∑i=1
x2i · ni − nx 2
)(258)
Fortsetzung zu Beispiel 14.2:
14.3 Korrelationsrechnung
Bei den bisherigen Betrachtungen wurde eine Stichprobe stets nur hinsichtlich eines Merkmals untersucht. Furdie Praxis ist es jedoch haufig von Interesse, zwei Merkmale einer Stichprobe zu beobachten und zu entscheiden,ob zwischen diesen Merkmalen ein Zusammenhang (eine Abhangigkeit) besteht.Im weiteren wird davon ausgegangen, dass bei einer vorliegenden Stichprobe zwei Merkmale zu untersuchensind. Diese werden durch die beiden Zufallsvariablen X und Y beschrieben. Die beobachteten Merkmalswerte(Realisierungen der ZV X und Y ) seien x1, x2, . . ., xn sowie y1, y2, . . ., yn. Daraus werden n geordneteWertepaare
(x1; y1), (x2; y2), . . . , (xn; yn)
gebildet (zweidimensionale Stichprobe vom Umfang n).
87
Der Zusammenhang zwischen den beiden Zufallsvariablen X und Y kann mit Hilfe zweier Kennwerte der zwei-dimensionalen Stichprobe: empirische Kovarianz und empirischer Korrelationskoeffizient charakterisiert werden.
Empirische Kovarianz und empirischer KorrelationskoeffizientGegeben sei eine zweidimensionale Stichprobe vom Umfang n: (x1; y1), (x2; y2), . . . , (xn; yn).Dann gilt (unter der Voraussetzung, dass sX 6= 0, sY 6= 0):
empirische Kovarianz: sXY =1
n− 1·n∑i=1
(xi − x)(yi − y)
(259)
=1
n− 1·(
n∑i=1
xiyi − nx y)
empirischer Korrelationskoeffizient: r = rXY =sXYsX · sY
(260)
mit: x =1
n·n∑i=1
xi , y =1
n·n∑i=1
yi , s2X =1
n− 1·n∑i=1
(xi − x)2 =1
n− 1
(n∑i=1
x2i − nx 2
),
s2Y =1
n− 1·n∑i=1
(yi − y)2 =1
n− 1
(n∑i=1
y2i − ny 2
)(vgl. dazu auch: Formeln (251), (252), (254)).
Die folgenden Formel ist zu (260) aquivalent:
r =
n∑i=1
xiyi − nx y√(n∑i=1
x2i − nx2)(
n∑i=1
y2i − n y2) .
Fur den empirischen Korrelationskoeffizienten r gilt stets: −1 ≤ r ≤ 1.Wenn zudem eine Darstellung der Wertepaare (x1; y1), (x2; y2), . . . , (xn; yn) in einem rechtwinkligen kar-tesischen Koordinatensystem erfolgt (”Punktwolke“ im Streuungsdiagramm), konnen aus der Große von r fol-gende Schlussfolgerungen gezogen werden:
- Wenn sich r nur geringfugig von 1 oder -1 unterscheidet, liegen die Stichprobenpunkte (xi, yi) nahezu aufeiner Geraden (siehe Bild 14.3a)).
- Falls |r| = 1 gilt, liegen die Stichprobenpunkte exakt auf einer Geraden. Es besteht eine exakte linea-re Abhangigkeit zwischen den ZV X und Y . Fur r = 1 hat die Gerade einen positiven Anstieg (sieheBild 14.3b)), fur r = −1 einen negativen Anstieg (siehe Bild 14.3c)).
- Falls r = 0 gilt, besteht zwischen den Zufallsvariablen X und Y kein linearer Zusammenhang. Es handeltsich dann um unkorrelierte ZV. Das bedeutet aber nicht unbedingt, dass diese ZV stochastisch unabhangig(vgl. Definition 13.12) sind. Andererseits sind stochastisch unabhangige ZV stets unkorreliert.
Der empirische Korrelationskoeffizient r ist somit ein Maß fur den linearen Zusammenhang der Auspragungenzweier Merkmale. Dabei ist zu beachten, dass die Berechnung des Korrelationskoeffizienten r nur dann sinnvollist, wenn zwischen den Merkmalen ein sachlich begrundeter innerer Zusammenhang besteht.
-
6
x
y
r r rr r r
Bild 14.3a)
-
6
x
y
r r r r r r
Bild 14.3b)
-
6
x
ySSSSSSSS
r r rr r r
Bild 14.3c)
88
Beispiel 14.4:Die Jahresproduktion einer Firma wird als Zufallsvariable X und die Jahresgesamtkosten dieser Firma als Zu-fallsvariable Y angesehen. Die Wahrscheinlichkeitsverteilung dieser ZV ist nicht bekannt. In insgesamt n = 10Zweigstellen dieser Firma wurden die folgenden Daten erfasst:
Im weiteren wird der Zusammenhang zwischen Korrelationsrechnung und Ausgleichsrechnung erlautert.Die folgende Problemstellung wurde im Abschnitt 7.5 (siehe Skript zur Vorlesung Mathematik 2) betrachtet:Gegeben seien n Punkte mit den kartesischen Koordinaten (xi; yi), i = 1, 2, . . . , n, mit n ≥ 3 sowie xi 6= xjfur i 6= j. Nun soll eine Gerade y = f(x) = a1x + a0 so in diese Punktmenge eingepasst werden, dass der
”Trend“ in der Anordnung der Punkte moglichst gut wiedergegeben wird (vgl. Bild 14.4). Diese Gerade wird alsAusgleichs- oder Regressionsgerade bezeichnet. Als Kriterium fur die Gute dieser Ausgleichsgeraden dient dieSumme aller Fehlerquadrate d2i (i = 1, 2, . . . , n) mit d2i = [f(xi)− yi]2, welche minimal werden soll43.
-
6
x
y
0
r r r r r r r r r r rf(x) = a1x+ a0
Bild 14.4
Im Abschnitt 7.5 wurden geeignete Großen a1 und a0 fur die Ausgleichsgerade als Losungen einer Extremwert-aufgabe fur eine Funktion zweier reeller Variabler berechnet.Mit Hilfe der Losung des linearen Gleichungssystems (122) im Abschnitt 7.5 und den Formeln (259) sowie(260) kann der folgende Zusammenhang zwischen a1 (Anstieg der Ausgleichsgeraden) und dem empirischenKorrelationskoeffizient r hergestellt werden:
a1 =(n− 1)sXY(n− 1)s2X
=sXYs2X
=rsXsYs2X
= rsYsX
.
Weiterhin gilt:
a0 = y − a1x .
Fortsetzung zu Beispiel 14.4:
43Dieses Verfahren zur Berechnung der Ausgleichsgeraden wurde als Methode des Gaußschen Fehlerquadratminimums bezeichnet.
89
14.4 Statistische Schatzmethoden fur die unbekannten Parameter einer Wahrscheinlichkeits-verteilung (”Parameterschatzungen“)
14.4.1 Einfuhrung
Es wird von der Situation ausgegangen, dass die Wahrscheinlichkeitsverteilung einer ZufallsvariablenX (die einbestimmtes Merkmal der Elemente einer Grundgesamtheit beschreibt) zwar vom Typ her bekannt ist, aber nochunbekannte Parameter (z.B. µ, σ2 bei einer Normalverteilung) enthalt. In solchen Fallen ist es wunschenswert,zumindest Schatzungen fur diese Parameter ermitteln zu konnen. Daraus ergeben sich die folgenden Aufgabender Parameterschatzung:44
1) Bestimmung von Schatz- oder Naherungswerten fur die unbekannten Parameter der VerteilungDazu soll eine konkrete Stichprobe, die der betreffenden Grundgesamtheit entnommen wird, verwendet wer-den. Der Schatzwert eines Parameters kann als Punkt auf der Zahlengeraden gedeutet werden. Daher wirddiese Art der Parameterschatzung auch als Punktschatzung bezeichnet.
2) Konstruktion von sog. Konfidenz- oder VertrauensintervallenEs handelt sich hier um Intervalle, in denen die Werte der unbekannten Parameter mit einer vorgegebenenWahrscheinlichkeit vermutet werden. Diese Art von Schatzung wird auch als Intervall- oder Bereichsschat-zung bezeichnet. Sie wird ebenfalls anhand einer konkreten Stichprobe durchgefuhrt.
14.4.2 Punktschatzungen
Um einen Schatzwert fur einen unbekannten statistischen Parameter (hier allgemein mit ϑ bezeichnet) zu gewin-nen, werden Schatzfunktionen verwendet. Dies sind spezielle Stichprobenfunktionen vom Typ
Θ = g(X1, X2, . . . , Xn)
die fur jede konkrete Stichprobe x1, x2, . . . , xn einen Schatzwert
ϑ = g(x1, x2, . . . , xn)
fur den Parameter ϑ liefern. Dabei sind X1, X2, . . . , Xn unabhangige Zufallsvariable, die alle die gleiche Ver-teilungsfunktion F (x) besitzen.Eine Schatzfunktion Θ wird dabei als optimal angesehen, wenn sie die folgenden Eigenschaften45 hat:
1) Die Schatzfunktion Θ ist erwartungstreu, d.h. ihr Erwartungswert ist gleich dem zu schatzenden Parameter:E(Θ) = ϑ.
2) Die Schatzfunktion Θ ist konsistent (passend), d.h. Θ konvergiert mit zunehmendem Stichprobenumfang ngegen den Parameter ϑ.
3) Die Schatzfunktion Θ ist effizient (wirksam), d.h. es gibt bei gleichem Stichprobenumfang n keine andereerwartungstreue Schatzfunktion mit einer kleineren Varianz.
44Quelle: L. PAPULA. Mathematik fur Ingenieure und Naturwissenschaftler, Band 3, 5. Auflage, S. 48845Quelle: L. PAPULA. Mathematik fur Ingenieure und Naturwissenschaftler, Band 3, 5. Auflage, S. 492
90
Schatzung fur den Erwartungswert µSei µ der unbekannte Erwartungswert der Wahrscheinlichkeitsverteilung der Zufallsvariablen X,welche das zu untersuchende Merkmal beschreibt. Es liege eine konkrete Stichprobe x1, x2, . . . , xnaus der zu betrachtenden Grundgesamtheit vor. Dann ist durch
µ = x =1
n
n∑i=1
xi (261)
(vgl. auch Formel (251)) ein Schatzwert fur den Erwartungswert µ gegeben.Der Wert x ist eine konkrete Realisierung der Stichprobenfunktion
X =1
n
n∑i=1
Xi (262)
(Stichprobenmittel). Sie liefert eine erwartungstreue Schatzung fur µ.
Schatzung fur die Varianz σ2
Sei σ2 die unbekannte Varianz der Wahrscheinlichkeitsverteilung der Zufallsvariablen X . Dann liefert
σ2 = s2 =1
n− 1
n∑i=1
(xi − x)2 mit x aus (261) (263)
(vgl. auch Formel (252)) eine erwartungstreue Schatzung fur die Varianz σ2.Der Wert s2 ist eine konkrete Realisierung der Stichprobenfunktion
S2 =1
n− 1
n∑i=1
(Xi −X)2 (264)
(Stichprobenvarianz).
Hinweise:
- Die Stichprobenfunktion S =√S2 ist eine Schatzfunktion fur die Standardabweichung σ, jedoch ist diese
nicht erwartungstreu (d.h. es gilt: E(S) 6= σ).
- Wenn alle ZV Xi normalverteilt sind, so ist auch die Schatzfunktion X normalverteilt mit E(X) = µ und
Var(X) =σ2
n.
- Im Fall einer gruppierten Stichprobe mit k Klassen (siehe Abschnitt 14.1.3) konnen die Schatzungen µ = xmit x aus (257) fur den Erwartungswert µ und σ2 = s2 mit s2 aus (258) fur die Varianz σ2 verwendetwerden.
Nachfolgend wird eine Schatzung fur den unbekannten Parameter p einer Binomialverteilung (siehe Abschnitt13.4.1) angegeben.
Schatzung fur den Parameter p einer BinomialverteilungEin Bernoulli-Experiment (siehe Abschnitt 13.4.1) werde n-mal durchgefuhrt, wobei p die unbekannteWahrscheinlichkeit des Eintretens des Ereignisses A sei. Dann ist durch
p = h(A) =k
n(k : absolute Haufigkeit des Eintretens des Ereignisses A) (265)
ein Schatzwert fur p gegeben.Der Wert p ist eine konkrete Realisierung der Schatzfunktion: P =
X
n(der Wert der ZV X ergibt sich
als Anzahl des Auftretens des Ereignisses A bei n-maliger Durchfuhrung des Bernoulli-Experiments).Die Schatzfunktion P liefert eine erwartungstreue Schatzung fur p.
91
14.4.3 Bestimmung von Konfidenzintervallen (Vertrauensintervallen)
Durch die im vorangegangenen Abschnitt beschriebene Methode konnten Schatzwerte fur unbekannte Parameterberechnet werden. Jedoch sind - insbesondere wenn der Stichprobenumfang klein ist - noch großere Abweichun-gen von dem tatsachlichen Wert moglich. Um das Problem der Genauigkeit und Sicherheit des Schatzwertes zulosen, soll ein Intervall bestimmt werden, das den unbekannten Parameterwert mit hoher Wahrscheinlichkeiteinschließt. Ein solches Intervall nennt man Konfidenzintervall (oder Vertrauensintervall).
Konfidenzintervall fur den unbekannten Parameter ϑ einer vom Typ her bekannten Wahrscheinlich-keitsverteilunga
Sei X eine Zufallsvariable, deren Wahrscheinlichkeitsverteilung einen unbekannten Parameter ϑ enthalte.Fur diesen Parameter lasst sich unter Verwendung einer konkreten Stichprobe x1, x2, . . . , xn auf folgendeWeise ein Konfidenzintervall bestimmen:
1) Es wird ein bestimmtes Konfidenzniveau (Vertrauensniveau) γ = 1− α gewahlt(0 < γ < 1; α: Irrtumswahrscheinlichkeit).
2) Dann werden fur den Parameter ϑ zwei Stichproben- oder Schatzfunktionen
bestimmt, die mit der gewahlten Wahrscheinlichkeit γ = 1 − α den wahren Wert des Parameters ϑeinschließen:
P (Θu ≤ ϑ ≤ Θo) = γ = 1− α .3) Aus der vorgegebenen konkreten Stichprobe x1, x2, . . . , xn werden die Werte der beiden Stichproben-
funktionen Θu und Θo berechnet:
cu = gu(x1, x2, . . . , xn) , co = go(x1, x2, . . . , xn) .
Diese liefern die Grenzen des gesuchten Konfidenzintervalls.
4) Das Konfidenzintervall fur den unbekannten Parameter ϑ lautet:
cu ≤ ϑ ≤ co .
aQuelle: L. PAPULA. Mathematik fur Ingenieure und Naturwissenschaftler, Band 3, 5. Auflage, S. 511
Die soeben beschriebene allgemeine Vorgehensweise wird nun in einem konkreten Fall angewendet: fur denunbekannten Erwartungswert µ einer Normalverteilung soll bei bekannter Varianz σ2 ein Konfidenzintervallermittelt werden. Grundlage der Berechnung ist die Tatsache, dass die Stichprobenfunktion
X =1
n(X1 +X2 + . . .+Xn) (Stichprobenmittel) normalverteilt ist mit E(X) = µ und Var(X) =
σ2
n,
siehe dazu auch die Hinweise im Abschnitt 14.4.2.Zudem wird der Begriff des Quantils (siehe Definition 13.3) benotigt.
Bestimmung eines Konfidenzintervalls fur den unbekannten Erwartungswert einer Normalverteilungbei bekannter Varianz σ2
1) Festlegung eines Konfidenzniveaus γ (ublicherweise: γ = 0.95 od. γ = 0.99),α = 1− γ ist dann die Irrtumswahrscheinlichkeit
2) Ermittlung des (1− α/2)-Quantils der Standard-Normalverteilung: z1−α/2 (aus der Tabelle)
3) Berechnung des Mittelwertes x der konkreten Stichprobe x1, x2, . . . , xn (gemaß Formel (251))
4) Berechnung der Grenzen des gesuchten Konfidenzintervalls [gu, go]:
gu = x− σ√nz1−α/2 , go = x+
σ√nz1−α/2 .
Hinweis:In dem Fall, dass ein Konfidenzintervall in der Form [ gu,∞) oder (−∞, go] zu berechnen ist, muss im Schritt 2)das (1− α)-Quantil (anstelle des (1− α/2)-Quantils) genommen werden.
92
Beispiel 14.5:46
Die Langenmessung (in mm) von 10 Schrauben, welche zufallig aus einem bestimmten Sortiment ausgewahltwurden, ergab die folgenden Werte:
Unter der Voraussetzung, dass diese Stichprobe aus einer normalverteilten Grundgesamtheit stammt, ist ein Kon-fidenzintervall fur den unbekannten Erwartungswert µ (d.h. den Erwartungswert fur die Lange der Schrauben)zu berechnen. Es wird davon ausgegangen, dass die Varianz bekannt ist, und zwar: σ2 = 4 mm2.
Wenn ein Konfidenzintervall fur den unbekannten Erwartungswert µ einer Normalverteilung bei unbekannter
Varianz σ2 ermittelt werden soll, dann wird ausgenutzt, dass die ZV X − µS/√n
(wobei X aus (262) und S =√S2
mit S2 aus (264)) einer t-Verteilung mit n− 1 Freiheitsgraden unterliegt.Die t-Verteilung47 ist eine Prufverteilung, die bei statistischen Pruf- und Testverfahren angewendet wird.Die wichtigsten Quantile der t-Verteilung sind tabelliert, siehe z.B.:H.-J. BARTSCH. Taschenbuch mathematischer Formeln fur Ingenieure und Naturwissenschaftler,23. Auflage (2014), S. 781.
Bestimmung eines Konfidenzintervalls fur den unbekannten Erwartungswert einer Normalverteilungbei unbekannter Varianz σ2
1) Festlegung eines Konfidenzniveaus γ (ublicherweise: γ = 0.95 od. γ = 0.99),α = 1− γ ist dann die Irrtumswahrscheinlichkeit
2) Bestimmung des (1− α/2) -Quantils der t-Verteilung mit n− 1 Freiheitsgraden: tn−1;1−α/2(aus der Tabelle)
3) Berechnung des Mittelwertes x und der Varianz s2 bzw. der Standardabweichung sder konkreten Stichprobe x1, x2, . . . , xn (gemaß (251), (252))
4) Berechnung der Grenzen des gesuchten Konfidenzintervalls [gu, go]:
gu = x− s√ntn−1;1−α/2 , go = x+
s√ntn−1;1−α/2 .
Hinweis:Bei umfangreichen Stichproben (n > 30) wird davon ausgegangen, dass σ ≈ s gilt. Dann kann bei der Bestim-mung des Konfidenzintervalls auf den Fall ”bekannte Varianz“ (siehe vorige Seite) zuruckgegriffen werden.
46Quelle: L. PAPULA. Mathematik fur Ingenieure und Naturwissenschaftler, Band 3, 5. Auflage, S. 517-51847Auf die Dichte- und die Verteilungsfunktion der t-Verteilung soll an dieser Stelle nicht naher eingegangen werden. Es sei auf die
folgende Literaturstelle verwiesen: L. PAPULA. Mathematik fur Ingenieure und Naturwissenschaftler, Band 3, 5. Auflage, S. 440-443.
93
Beispiel 14.6:Aus einer Serienproduktion von Widerstanden wurden 12 Stuck zufallig entnommen. Die Messung dieser Wider-stande (in Ω) ergab:
i 1 2 3 4 5 6 7 8 9 10 11 12
xi 100 98 101 97 96 103 99 100 98 101 99 102
Unter der Voraussetzung, dass diese Stichprobe aus einer normalverteilten Grundgesamtheit stammt, ist ein Kon-fidenzintervall fur den unbekannten Erwartungswert µ zu ermitteln, wobei die Varianz σ2 ebenfalls unbekanntist.
Im Zusammenhang mit der Normalverteilung wird schließlich noch der Fall betrachtet, dass ein Konfidenzinter-vall fur die unbekannte Varianz σ2 bei ebenfalls unbekanntem Erwartungswert µ zu bestimmen ist. Bei dieser
Berechnung wird genutzt, dass die ZV (n− 1)S2
σ2(wobei S =
√S2 mit S2 aus (264)) einer Chi-Quadrat-
Verteilung mit n− 1 Freiheitsgraden genugt.Die Chi-Quadrat-Verteilung48 (kurz: χ2-Verteilung) ist ebenfalls eine Prufverteilung.Die wichtigsten Quantile der χ2-Verteilung sind tabelliert, siehe z.B.:H.-J. BARTSCH. Taschenbuch mathematischer Formeln fur Ingenieure und Naturwissenschaftler,23. Auflage (2014), S. 782.
Bestimmung eines Konfidenzintervalls fur die unbekannte Varianz σ2 einer Normalverteilung
1) Festlegung eines Konfidenzniveaus γ (ublicherweise: γ = 0.95 od. γ = 0.99),α = 1− γ ist dann die Irrtumswahrscheinlichkeit
2) Bestimmung des α/2-Quantils und des (1−α/2)-Quantils der χ2-Verteilung mit n−1 Freiheitsgraden:χ2n−1;α/2 und χ2
n−1; 1−α/2 (aus der Tabelle)
3) Berechnung der Varianz s2 der konkreten Stichprobe x1, x2, . . . , xn (gemaß (252))
4) Berechnung der Grenzen des gesuchten Konfidenzintervalls [gu, go]:
gu =(n− 1)s2
χ2n−1; 1−α/2
, go =(n− 1)s2
χ2n−1;α/2
.
Fortsetzung zu Beispiel 14.6:
48fur die Dichte- und die Verteilungsfunktion der χ2-Verteilung: siehe L. PAPULA. Mathematik fur Ingenieure und Naturwissenschaft-ler, Band 3, 5. Auflage, S. 435-439.
94
Um ein Konfidenzintervall fur den unbekannten Parameter p einer Binomialverteilung zu erhalten, kann aus-genutzt werden, dass die Binomialverteilung mit den Parametern n und p durch eine Normalverteilung mit denParametern µ = np und σ2 = np(1−p) approximiert werden kann (siehe dazu Abschnitt 13.4.6). Voraussetzungdafur ist, dass eine umfangreiche Stichprobe (gemaß der Bedingung (242)) vorliegt.
Bestimmung eines Konfidenzintervalls fur den unbekannten Parameter p einer Binomialverteilung
1) Festlegung eines Konfidenzniveaus γ (ublicherweise: γ = 0.95 od. γ = 0.99),α = 1− γ ist dann die Irrtumswahrscheinlichkeit
2) Ermittlung des (1− α/2)-Quantils der standardisierten Normalverteilung: z1−α/2 (aus der Tabelle)
3) Berechnung des Schatzwertes p =k
naus der konkreten Stichprobe
(”k Erfolge bei insgesamt n Ausfuhrungen des Bernoulli-Experiments“, siehe auch (265))
4) Wenn die Bedingung ∆ = n · p · (1− p) > 9 fur eine umfangreiche Stichprobe erfullt ist,lauten die Grenzen des gesuchten Konfidenzintervalls [ gu, go]:
gu = p−z1−α/2
n
√∆ , go = p+
z1−α/2
n
√∆ .
Beispiel 14.7:
Bemerkung:Bei den bisherigen Ausfuhrungen zur Bestimmung von Konfidenzintervallen wurde stets davon ausgegangen,dass der Typ der Wahrscheinlichkeitsverteilung bekannt ist (Normalverteilung oder Binomialverteilung). Beieiner beliebig verteilten ZV konnen zur Berechnung von Konfidenzintervallen fur den Erwartungswert E(X)die genannten Methoden angewendet werden, falls der Stichprobenumfang hinreichend groß ist (Faustregel:n > 30).
14.5 Statistische Prufverfahren fur die unbekannten Parameter einer Wahrscheinlichkeitsver-teilung (”Parametertests“)
14.5.1 Statistische Hypothesen und Parametertests
statistische Hypothese: Annahme (Vermutung, Behauptung) uber die Wahrscheinlichkeitsverteilungeiner ZV und deren Parameter
Parametertest: statistisches Prufverfahren fur unbekannte Parameter einer Wahrscheinlich-keitsverteilung, wobei der Verteilungstyp bekannt ist
Ziel des Parametertests: Hypothese (Nullhypothese) uberprufen, um zu entscheiden,ob diese Hypothese beibehalten (d.h. nicht abgelehnt) werden kann
Beispiel 14.8:a) Bei dem Zufallsexperiment ”Wurf einer Munze“ wird das Ereignis A: ”Zahl wurde geworfen“ mit der Wahr-
scheinlichkeit p = 0.5 eintreten, wenn es sich um eine unverfalschte Munze handelt. Um dies zu uber-prufen, fuhrt man das Zufallsexperiment mehrfach aus und stellt die Haufigkeit des Ereignisses A fest. Beider anschließenden Auswertung wird die Nullhypothese H0 : p(A) = 0.5 gegen die Alternativhypothe-se H1 : p(A) 6= 0.5 getestet.Es handelt sich hier um einen zweiseitigen Test, da die Alternativhypothese sowohl die Werte p < 0.5 alsauch p > 0.5 zulasst.
b) Fur die Bruchfestigkeit von Werkstucken sei ein gewisser Mindestwert, hier mit µ0 bezeichnet, vorgegeben.Bei einer gewissen Anzahl von Werkstucken wird die Bruchfestigkeit gemessen und aus dieser Stichprobeein Mittelwert µ = x berechnet. Dann wird die Nullhypothese H0 : µ ≥ µ0 (”Mindestwert fur die Bruch-festigkeit wird erreicht oder uberschritten“) gegen die Alternativhypothese H1 : µ < µ0 (”Mindestwert furdie Bruchfestigkeit wird unterschritten“, d.h. das Werkstuck ist unbrauchbar) getestet.Hier handelt es sich um einen einseitigen Test, da die Alternativhypothese nur die Werte µ < µ0 zulasst.
95
Um einen Parametertest durchzufuhren, wird eine Stichprobe (vom Umfang n) aus der betreffenden Grund-gesamtheit entnommen und untersucht. Zur Untersuchung werden wiederum geeignete Stichprobenfunktionen,d.h. Funktionen der unabhangigen ZV X1, X2, . . . , Xn (siehe auch Abschnitt 14.4.2), verwendet.
Planung und Durchfuhrung eines Parametertestsa
Voraussetzungen:Die Wahrscheinlichkeitsverteilung der ZV X sei vom Typ her bekannt, der Parameter ϑ der Verteilung seiunbekannt. Es liege eine konkrete Stichprobe x1, x2, . . . , xn aus der zu betrachtenden Grundgesamtheit vor.
Vorgehensweise:1) Formulierung der Nullhypothese H0: ϑ = ϑ0 sowie der Alternativhypothese H1: ϑ 6= ϑ0
(zweiseitiger Parametertest)
2) Festlegung der Signifikanzzahl (Signifikanzniveau, Irrtumswahrscheinlichkeit) α (0 < α < 1)Diese entspricht der Wahrscheinlichkeit dafur, dass die Nullhypothese H0 abgelehnt wird,obwohl sie richtig ist.
3) Bestimmung einer geeigneten Test- oder Prufvariablen (Stichprobenfunktion) T , die noch vonden n unabhangigen Zufallsvariablen X1, X2, . . . , Xn abhangt: T = g(X1, X2, . . . , Xn)
4) Bestimmung des nicht-kritischen Bereichs cu ≤ T ≤ co derart, dass die Testvariable Tmit der Wahrscheinlichkeit γ = 1− α Werte aus dem Intervall [cu, co] annimmt
5) Berechnung des Wertes der Testvariablen T aus der konkreten Stichprobe x1, x2, . . . , xn(Einsetzen dieser Werte fur die ZV X1, X2, . . . , Xn)Der erhaltene Funktionswert t = g(x1, x2, . . . , xn) heißt Test- oder Prufwert von T .
6) Testentscheidung: Ablehnung oder Nichtablehnung der Nullhypothese?1. Fall: Testwert t fallt in den nicht-kritischen Bereich der Testvariablen T,
d.h. cu ≤ t ≤ co ⇒ Nullhypothese wird nicht abgelehnt2. Fall: Testwert t fallt in den kritischen Bereich⇒ Nullhypothese H0 wird abgelehnt
(d.h. zugunsten der Alternativhypothese H1 verworfen)
aQuelle: L. PAPULA. Mathematik fur Ingenieure und Naturwissenschaftler, Band 3, 5. Auflage, S. 435-439.
In den nachsten Abschnitten wird die soeben beschriebene allgemeine Vorgehensweise in konkreten Fallen an-gewendet.
Bemerkungen:
- Die Ausdrucksweise ”Nullhypothese wird nicht abgelehnt“ (vgl. oben) bedeutet nicht, dass die Richtigkeitdieser Hypothese bewiesen ist. Sie besagt lediglich, dass die Auswertung der Stichprobe keinen Widerspruchzur Nullhypothese ergeben hat.
- Die Ausdrucksweise ”Nullhypothese wird abgelehnt“ besagt, dass die Auswertung der Stichprobe signifi-kante (statistisch gesicherte) Abweichungen zur Nullhypothese ergeben hat. Damit ist jedoch nicht bewiesen,dass die Nullhypothese falsch ist.
- Bei der Testentscheidung konnen Fehler 1. Art (Ablehnung einer an sich richtigen Nullhypothese) oderFehler 2. Art (Nichtablehnung einer Nullhypothese, die an sich falsch ist) auftreten. Fur eine detaillierteDarstellung dieser Problematik sei auf die folgende Literaturstelle verwiesen:W. DURR, H. MAYER. Wahrscheinlichkeitsrechnung und Schließende Statistik, 8. Auflage, S. 160-163.
14.5.2 Tests fur den unbekannten Erwartungswert µ einer Normalverteilung
Zunachst wird der Fall betrachtet, dass die Varianz σ2 der normalverteilten ZV X bekannt ist und ein Test furden unbekannten Erwartungswert µ durchzufuhren ist. Dabei soll die Nullhypothese H0: µ = µ0 gegen dieAlternativhypothese H1: µ 6= µ0 getestet werden. Grundlage fur diesen Test ist die Tatsache, dass die ZVX − µ0
σ/√n
der standardisierten Normalverteilung genugt (X: Stichprobenmittel, siehe Formel (262)).
96
Zweiseitiger Test fur den unbekannten Erwartungswert µ einer Normalverteilung bei bekannterVarianz σ2
2) Festlegung einer Signifikanzzahl α (meist α = 0.05 oder α = 0.01)
3) Testvariable: T =X − µ0
σ/√n
4) Bestimmung des (1− α/2)-Quantils der standardisierten Normalverteilung: z1−α/2 (aus der Tabelle)und Festlegung des nicht-kritischen Bereiches: −z1−α/2 ≤ T ≤ z1−α/2 (oder: |T | ≤ z1−α/2)
5) Berechnung des Mittelwertes x der vorliegenden Stichprobe sowie des Test- oder Prufwertes:
t =x− µ0σ/√n
6) Testentscheidung: Falls−z1−α/2 ≤ t ≤ z1−α/2 ⇒ Nullhypothese H0 : µ = µ0 wird nicht abgelehnt.Anderenfalls wird sie zugunsten der Alternativhypothese H1 abgelehnt.
Beispiel 14.9:
Bei einem einseitigen Test lautet die Nullhypothese: H0: µ ≤ µ0 (oder: H0: µ ≥ µ0). Die Alternativhypotheseist dann: H1: µ > µ0 (bzw. H1: µ < µ0 ).Im Schritt 4) der oben beschriebenen Vorgehensweise ist dann das (1− α)-Quantil z1−α der standardisiertenNormalverteilung zu bestimmen (anstelle von z1−α/2). Der nicht-kritische Bereich lautet:T ≤ z1−α, wenn die Hypothese H0: µ ≤ µ0 getestet wird bzw.T ≥ −z1−α , wenn die Hypothese H0: µ ≥ µ0 getestet wird.Die Testentscheidung (siehe Schritt 6)) ist dementsprechend zu modifizieren.
In dem Fall, dass ein Test fur den unbekannten Erwartungswert µ einer Normalverteilung bei unbekannter Va-rianz durchzufuhren ist, kann bei der Aufstellung der Testvariablen T nicht auf den Wert σ zuruckgegriffenwerden.
Statt dessen wird verwendet, dass die ZV X − µ0
S/√n
einer t-Verteilung mit n−1 Freiheitsgraden genugt (S =√S2,
wobei S2 die gemaß (264) berechnete Stichprobenvarianz bezeichnet).
Zweiseitiger Test fur den unbekannten Erwartungswert µ einer Normalverteilung bei unbekannterVarianz σ2
2) Festlegung einer Signifikanzzahl α (meist α = 0.05 oder α = 0.01)
3) Testvariable: T =X − µ0
S/√n
4) Bestimmung des (1− α/2)-Quantils der t-Verteilung mit n− 1 Freiheitsgraden: tn−1;1−α/2(aus der Tabelle) und Festlegung des nicht-kritischen Bereiches: −tn−1;1−α/2 ≤ T ≤ tn−1;1−α/2(oder: |T | ≤ tn−1;1−α/2)
5) Berechnung des Mittelwertes x und der Standardabweichung s der vorliegenden Stichprobe sowie desTest- oder Prufwertes:
t =x− µ0s/√n
6) Testentscheidung: Falls −tn−1;1−α/2 ≤ t ≤ tn−1;1−α/2 ⇒ Nullhypothese H0 : µ = µ0 wird nichtabgelehnt. Anderenfalls wird sie abgelehnt.
Beispiel 14.10:
97
Bemerkungen:
- Im Fall eines einseitigen Tests ist entsprechend das (1 − α)-Quantil (anstelle des (1− α/2)-Quantils) dert-Verteilung mit n− 1 Freiheitsgraden zu verwenden.
- Falls der Stichprobenumfang hinreichend groß ist (Faustregel: n > 30), kann davon ausgegangen werden,dass die Testvariable T annahernd der Standard-Normalverteilung unterliegt. Dann kann die Testmethode furden Fall ”bekannte Varianz“ angewendet werden.
14.5.3 Tests fur die unbekannte Varianz σ2 einer Normalverteilung
Methoden zum Test der Varianz werden z.B. bei der Untersuchung der Genauigkeit der Arbeitsweise von Geratenoder Maschinen benotigt. Zunachst wird ein Parametertest vorgestellt, bei dem die Nullhypothese σ2 = σ20 ge-gen die Alternativhypothese H1: σ2 6= σ20 getestet wird (zweiseitiger Test). Die Grundlage dieses Tests ist die
Tatsache, dass die Zufallsvariable (n− 1)S2
σ20
der χ2-Verteilung mit n− 1 Freiheitsgraden genugt (S2: Stichpro-
benvarianz, siehe Formel (264)).
Zweiseitiger Test fur die unbekannte Varianz σ2 einer Normalverteilung
2) Festlegung einer Signifikanzzahl α (meist α = 0.05 oder α = 0.01)
3) Testvariable: T = (n− 1)S2
σ20
4) Bestimmung des (α/2)-Quantils und des (1− α/2)-Quantils der χ2-Verteilung mit (n− 1) Freiheits-
graden: χ2n−1;α/2 und χ2
n−1;1−α/2 (aus der Tabelle) und Festlegung des nicht-kritischen Bereiches:
χ2n−1;α/2 ≤ T ≤ χ
2n−1;1−α/2
5) Berechnung der Varianz s2 der vorliegenden Stichprobe sowie des Test- oder Prufwertes:
t = (n− 1)s2
σ20
6) Testentscheidung: Falls χ2n−1;α/2 ≤ t ≤ χ
2n−1;1−α/2 ⇒ Nullhypothese H0 : σ2 = σ20 wird nicht
abgelehnt. Anderenfalls wird sie zugunsten der Alternativhypothese H1 abgelehnt.
Bei einem einseitigen Test lautet die Nullhypothese: H0: σ2 ≤ σ20 (oder: H0: σ2 ≥ σ20). Die Alternativhypotheseist dann: H1: σ2 > σ20 (bzw. H1: σ2 < σ20 ). Im Schritt 4) sind die Quantile χ2
n−1;1−α bzw. χ2n−1;α der χ2-
Verteilung mit (n− 1) Freiheitsgraden zu bestimmen. Der nicht-kritische Bereich lautet:T ≤ χ2
n−1;1−α, wenn die Hypothese H0: σ2 ≤ σ20 getestet wird bzw.T ≥ χ2
n−1;α , wenn die Hypothese H0: σ2 ≥ σ20 getestet wird.Die Testentscheidung (siehe Schritt 6)) ist dementsprechend zu modifizieren.
Beispiel 14.11:
14.5.4 Tests fur die unbek. Erwartungswerte µ1 und µ2 zweier Normalverteilungen (Differenzentests)
Die Zielstellung solcher Tests besteht darin, dass festgestellt werden soll, ob die Erwartungswerte µ1 und µ2zweier normalverteilter Grundgesamtheiten ubereinstimmen oder sich signifikant voneinander unterscheiden.Die Vorgehensweise beim Test wird dadurch bestimmt, ob die beiden Stichproben voneinander abhangig sind.
Definition 14.4:Zwei Stichproben heißen voneinander abhangig, wenn1) sie den gleichen Umfang haben und2) jedem Wert der einen Stichprobe genau ein Wert der anderen Stichprobe zugeordnet wird.
Anderenfalls werden die Stichproben als voneinander unabhangige Stichproben bezeichnet.
98
Wenn zwei Messverfahren oder Messgerate miteinander verglichen werden, entstehen haufig voneinander abhangi-ge Stichproben, siehe dazu auch Beispiel 14.12.Der Fall, dass ein Differenzentest unter Verwendung abhangiger Stichproben durchgefuhrt werden soll, lasstsich auf die im Abschnitt 14.5.2 eingefuhrten Testverfahren zuruckfuhren.
Zweiseitiger Test fur die Gleichheit der unbekannten Erwartungswerte µ1 und µ2 zweier Normal-verteilungen bei abhangigen Stichprobena
Voraussetzungen:Die ZV X und Y seien normalverteilt mit den Erwartungswerten µ1 und µ2. Es liegen zwei abhangigeStichproben x1, x2, . . . , xn und y1, y2, . . . , yn aus den entsprechenden Grundgesamtheiten vor.Zielstellung:Auf der Basis dieser Stichproben soll die Nullhypothese H0: µ1 = µ2 gegen die AlternativhypotheseH1: µ1 6= µ2 getestet werden (zweiseitiger Parametertest).Vorgehensweise:Dieser Parametertest wird auf einen Test des Hilfsparameters µ = µ1 − µ2 zuruckgefuhrt. Dann wird dieNullhypothese H0: µ = 0 gegen die Alternativhypothese H1: µ 6= 0 getestet.Dazu werden aus den beiden abhangigen Stichproben die Differenzen zi = xi − yi (i = 1, 2, . . . , n) gebil-det. Diese werden als Stichprobenwerte einer neuen Stichprobe vom Umfang n betrachtet: z1, z2, . . . , zn.Mittels der im Abschnitt 14.5.2 erlauterten Testverfahren (bezogen auf die Stichprobe z1, z2, . . . , zn) kannuber die Nichtablehnung oder Ablehnung der Hypothese H0: µ = 0 entschieden werden. Dabei ist zubeachten: Wenn die Varianzen der Zufallsvariablen X und Y bekannt sind oder umfangreiche Stichprobenvorliegen (Faustregel: n > 30), ist die im Abschnitt 14.5.2 zuerst genannte Vorgehensweise (d.h. der Fall
”bekannte Varianz“) anzuwenden. Anderenfalls ist so vorzugehen wie im Fall ”unbekannte Varianz“.aQuelle: L. PAPULA. Mathematik fur Ingenieure und Naturwissenschaftler, Band 3, 5. Auflage, S. 566
Beispiel 14.12:49
Zwei verschiedene Messmethoden fur elektrische Widerstande sollen miteinander verglichen werden. Dazu wur-den an 6 Widerstanden Parallelmessungen durchgefuhrt, deren Ergebnisse in dem folgenden Messprotokoll dar-gestellt sind (xi: Messwerte nach der Methode A, yi: Messwerte nach der Methode B).
i 1 2 3 4 5 6
xi in Ω 100.5 102.0 104.3 101.5 98.4 102.9
yi in Ω 98.2 99.1 102.4 101.1 96.2 101.8
Zu jedem der 6 Widerstande gehort genau ein Wertepaar (xi, yi). Daher handelt es sich um abhangige Stichpro-ben. Durch Differenzbildung zi = xi − yi ergibt sich als neue Stichprobe:
i 1 2 3 4 5 6
zi in Ω 2.3 2.9 1.9 0.4 2.2 1.1
Die beiden Messmethoden A und B werden als gleichwertig angesehen, wenn diese Stichprobe aus einer (nor-malverteilten) Grundgesamtheit mit dem Erwartungswert µ = 0 stammt.Da es sich um eine Stichprobe vom Umfang n < 30 handelt und die Varianz der Normalverteilung nicht vor-gegeben ist, muss hier der zweiseitige Test fur den unbekannten Erwartungswert µ einer Normalverteilung beiunbekannter Varianz (siehe Abschnitt 14.5.2) angewendet werden. Anstelle der Bezeichnungen xi, x und Xwerden jetzt die Bezeichnungen zi, z und Z verwendet.
49L. PAPULA. Mathematik fur Ingenieure und Naturwissenschaftler, Band 3, 5. Auflage, S. 567-570
99
Im weiteren wird die Vorgehensweise beim Test fur die Gleichheit der Erwartungswerte µ1 und µ2 zweier Nor-malverteilungen unter Verwendung unabhangiger Stichproben beschrieben. Die entsprechenden Varianzen σ21und σ22 seien gleich, mussen aber nicht unbedingt bekannt sein. Es wird vorausgesetzt, dass die erste Stichprobeden Umfang n1 und die zweite den Umfang n2 hat (wobei n1 6= n2 moglich ist). Die Stichprobenwerte der erstenStichprobe seien: x1, x2, . . . , xn und die Stichprobenwerte der zweiten Stichprobe seien: y1, y2, . . . , yn .
Zweiseitiger Test fur die Gleichheit der unbekannten Erwartungswerte µ1 und µ2 zweier Normal-verteilungen bei unabhangigen Stichproben1) Nullhypothese H0: µ1 = µ2, Alternativhypothese H1: µ1 6= µ2
2) Festlegung einer Signifikanzzahl α (meist α = 0.05 oder α = 0.01)
3) Testvariable: T =
√n1n2(n1 + n2 − 2)
n1 + n2· X − Y√
(n1 − 1)S21 + (n2 − 1)S2
2
(X , Y : Stichprobenmittel der ersten bzw. zweiten Stichprobe; S1, S2: Stichprobenvarianz der erstenbzw. zweiten Stichprobe)
4) Bestimmung des (1− α/2)-Quantils der t-Verteilung mit n1+n2−2 Freiheitsgraden: tn1+n2−2;1−α/2(aus der Tabelle) und Festlegung des nicht-kritischen Bereiches:−tn1+n2−2;1−α/2 ≤ T ≤ tn1+n2−2;1−α/2 (oder: |T | ≤ tn1+n2−2;1−α/2)
5) Berechnung der Mittelwerte x, y und der Varianzen s21, s22 der vorliegenden Stichproben sowiedes Test- oder Prufwertes:
t =
√n1n2(n1 + n2 − 2)
n1 + n2· x− y√
(n1 − 1)s21 + (n2 − 1)s22
6) Testentscheidung: Falls −tn1+n2−2;1−α/2 ≤ t ≤ tn1+n2−2;1−α/2 ⇒ Nullhypothese H0 : µ1 = µ2wird nicht abgelehnt. Anderenfalls wird sie abgelehnt.
100
14.6 Statistische Prufverfahren fur die unbekannte Verteilungsfunktion einer Wahrscheinlich-keitsverteilung (”Anpassungs- oder Verteilungstests“)
Bei den im Abschnitt 14.5 beschriebenen Prufverfahren wurde stets davon ausgegangen, dass der Verteilungstyp(d.h. die Art der Verteilungsfunktion) bekannt war. Die Hypothesen bezogen sich auf die Parameterwerte derjeweiligen Wahrscheinlichkeitsverteilung. Es ist jedoch auch die Situation moglich, dass der Verteilungstyp nichtals bekannt vorausgesetzt werden kann, sondern eine Hypothese bzgl. der Art der Verteilungsfunktion uberpruftwerden soll. Derartige Tests werden als Anpassungstests50 (oder Verteilungstests) bezeichnet.Das Ziel solcher Tests besteht in folgendem: einer ZVX mit der unbekannten Verteilungsfunktion F (x) soll einebekannte Verteilungsfunktion F0(x) ”angepasst“ werden, d.h. es wird uber die Ablehnung oder Nichtablehnungder Nullhypothese H0 : F (x) = F0(x) entschieden. Ein sehr haufig angewendeter Anpassungstest ist derChi-Quadrat-Anpassungstest (kurz: χ2-Test). Dieser Test beruht auf einem Vergleich der aus der Stichprobegewonnenen empirischen Haufigkeitsverteilung mit der theoretisch erwarteten Verteilung.
χ2-Test zur Uberprufung einer Hypothese uber die unbekannte Verteilungsfunktioneiner GrundgesamtheitVoraussetzung: Es liege eine konkrete Stichprobe x1, x2, . . . , xn aus der zu betrachtenden Grundgesamtheitvor.
Vorgehensweise bei der Durchfuhrung des Tests:
1) Nullhypothese H0 : F (x) = F0(x) , Alternativhypothese H1 : F (x) 6= F0(x)
2) Festlegung eines Signifikanzniveaus α (meist α = 0.05 oder α = 0.01)
3) Unterteilung der n Stichprobenwerte in k Klassen I1, I2, . . . , Ik und Feststellung der absolutenKlassenhaufigkeiten n1, n2, . . . , nk
4) Fur jede Klasse Ii (1 ≤ i ≤ k): mit Hilfe von F0(x) die hypothetische Wahrscheinlichkeitpi = P (X ∈ Ii) und die Anzahl n∗i = npi der theoretisch erwarteten Stichprobenwerte berechnenDabei sollte fur alle i gelten: npi ≥ 5 (Faustregel); anderenfalls mussen nachtraglich Klassenzusammengelegt werden.
5) Testvariable: T =k∑i=1
(Ni − n∗i )2
n∗i=
k∑i=1
(Ni − npi)2
npi
(Ni: beobachtete Anzahl der Stichprobenwerte in der i-ten Klasse)
6) Bestimmung des (1− α) -Quantils der χ2-Verteilung mit (k − r − 1) Freiheitsgraden: χ2k−r−1; 1−α
(r: Anzahl der geschatzten Parameter von F0(x)) und Festlegungdes nicht-kritischen Bereiches: T ≤ χ2
k−r−1; 1−α7) Berechnung des Testwertes
t =k∑i=1
(ni − n∗i )2
n∗i=
k∑i=1
(ni − npi)2
npi
8) Testentscheidung: Falls t ≤ χ2k−r−1; 1−α gilt⇒ Nullhypothese H0 wird nicht abgelehnt.
Anderenfalls wird sie zugunsten der Alternativhypothese H1 abgelehnt.
Hinweis:Im Fall einer diskreten ZV sind die Klassen die Werte (Realisierungen) der ZV selbst (vgl. Beispiel 14.13), furstetige ZV sind die Klassen Intervalle.
50Anpassungstests gehoren zu den nichtparametrischen Tests. Weitere nichtparametrische Tests - außer dem hier vorgestellten Chi-Quadrat-Anpassungstest - findet man z.B in: W. PREUSS, G. WENISCH (Hrsg.): Lehr- und Ubungsbuch Mathematik (Band 3: LineareAlgebra - Stochastik), 2. Auflage, Kapitel 19.5 und 21.5 oder K. BOSCH: Großes Lehrbuch der Statistik, Kapitel 10.
101
Beispiel 14.13:51
Bei 120 Wurfen mit einem Wurfel ergaben sich die folgenden absoluten Haufigkeiten fur die Augenzahlen:
i 1 2 3 4 5 6
abs. Haufigk. ni 15 19 22 21 17 26
Die Hypothese: ”Alle 6 moglichen Augenzahlen sind gleichwahrscheinlich.“ soll mit Hilfe des χ2-Tests uber-pruft werden.
Klasse
(Augenz. i) ni pi n∗i = npi ∆ni = ni − n∗i(∆ni)
2
n∗i
1 15
2 19
3 22
4 21
5 17
6 26
Σ
51Quelle: L. PAPULA. Mathematik fur Ingenieure und Naturwissenschaftler, Band 3, 5. Auflage, S. 607-608
102
Beispiel 14.14:Die Bedienzeit an einem Schalter wird zunachst als eine ZV X mit unbekannter Verteilung angesehen.Um Erkenntnisse uber die Verteilung von X zu gewinnen, wurde eine Stichprobe vom Umfang n = 100 er-hoben, d.h. bei insgesamt 100 Kunden wurde jeweils die Bedienzeit erfasst. Durch Gruppierung der erhaltenenStichprobenwerte ergab sich die folgende Haufigkeitstabelle:
Bedienzeit Anzahl Kunden
X ∈ [0, 1) 60
X ∈ [1, 2) 25
X ∈ [2, ∞) 15
Die Hypothese ”Die ZV X unterliegt einer Exponentialverteilung mit dem Parameter λ = 1“ soll mit Hilfeeines χ2-Tests uberpruft werden.
i Klasse Ii ni pi n∗i = npi ∆ni = ni − n∗i(∆ni)
2
n∗i
Σ
103
QuellenangabenDas Vorlesungsskript wurde unter Verwendung der nachfolgend aufgefuhrten Literatur erstellt:
H.-J. BARTSCH: Taschenbuch mathematischer Formeln fur Ingenieure und Naturwissenschaftler. Fachbuchverlag Leipzigim Carl Hanser Verlag, 23. Auflage, 2014.
K. BOSCH: Großes Lehrbuch der Statistik. R. Oldenbourg Verlag, 1996.
K. BOSCH: Statistik-Taschenbuch. R. Oldenbourg Verlag, 3. Auflage, 1998.
H. DALLMANN, K.-H. ELSTER: Einfuhrung in die hohere Mathematik fur Naturwissenschaftler und Ingenieure (BandIII). Gustav Fischer Verlag Jena, 1. Auflage, 1983.
W. DURR, H. MAYER: Wahrscheinlichkeitsrechnung und Schließende Statistik, Carl Hanser Verlag Munchen,8. Auflage, 2017.
G. ENGELN-MULLGES, W. SCHAFER, G. TRIPPLER: Kompaktkurs Ingenieurmathematik mit Wahrscheinlichkeitsrech-nung und Statistik. Fachbuchverlag Leipzig im Carl Hanser Verlag, 3. Auflage, 2004.
A. FETZER, H. FRANKEL: Mathematik 2: Lehrbuch fur ingenieurwissenschaftliche Studiengange. Springer, 6. Auflage,2009.
S. HANDROCK-MEYER: Differenzialgleichungen fur Einsteiger. Fachbuchverlag Leipzig im Carl Hanser Verlag, 2. Auf-lage, 2007.
J. KOCH, M. STAMPFLE: Mathematik fur das Ingenieurstudium. Carl Hanser Verlag Munchen, 2010.
W. LEUPOLD (Hrsg.): Mathematik - ein Studienbuch fur Ingenieure (Band 2: Reihen - Differentialgleichungen - Analysisfur mehrere Variable - Stochastik). Fachbuchverlag Leipzig im Carl Hanser Verlag, 2. Auflage, 2006.
G. MERZIGER, G. MUHLBACH, D. WILLE, TH. WIRTH. Formeln + Hilfen zur hoheren Mathematik, Binomi Verlag,7. Auflage, 2014.
K. MEYBERG, P. VACHENAUER: Hohere Mathematik 1 (Differential- und Integralrechnung, Vektor- undMatrizenrechnung), Springer, 5. Auflage, 1999.
K. MEYBERG, P. VACHENAUER: Hohere Mathematik 2 (Differentialgleichungen, Funktionentheorie, Fourier-Analysis,Variationsrechnung), Springer, 2. Auflage, 1997.
L. PAPULA: Mathematik fur Ingenieure und Naturwissenschaftler: Ein Lehr- und Arbeitsbuch fur das Grundstudium(Band 2). Vieweg+Teubner, 12. Auflage, 2009.
L. PAPULA: Mathematik fur Ingenieure und Naturwissenschaftler: Ein Lehr- und Arbeitsbuch fur das Grundstudium(Band 3). Vieweg+Teubner, 5. Auflage, 2008.
W. PREUSS, H. KIRCHNER: Mathematik in Beispielen (Band 8: Partielle Differentialgleichungen), Fachbuchverlag Leip-zig, 1. Auflage, 1990.
W. PREUSS, G. WENISCH (Hrsg.): Lehr- und Ubungsbuch Mathematik (Band 2: Analysis). Fachbuchverlag Leipzig imCarl Hanser Verlag, 3. Auflage, 2003.
W. PREUSS, G. WENISCH (Hrsg.): Lehr- und Ubungsbuch Mathematik (Band 3: Lineare Algebra - Stochastik). Fachbuch-verlag Leipzig im Carl Hanser Verlag, 2. Auflage, 2001.
W. PREUSS, G. WENISCH (Hrsg.): Lehr- und Ubungsbuch Mathematik fur Elektro- und Automatisierungstechniker, Fach-buchverlag Leipzig im Carl Hanser Verlag, 1998.
W. PREUSS: Funktionaltransformationen. Fachbuchverlag Leipzig im Carl Hanser Verlag, 2. Auflage, 2009.
I. RENNERT, B. BUNDSCHUH: Signale und Systeme - Einfuhrung in die Systemtheorie, Fachbuchverlag Leipzig im CarlHanser Verlag, 2013.
M. RICHTER. Grundwissen Mathematik fur Ingenieure, Vieweg+Teubner, 2. Auflage, 2009.
M. R. SPIEGEL: Hohere Mathematik f. Ingenieure u. Naturwissenschaftler - Theorie u. Anwendung,McGraw-Hill, Nachdruck 1991.
P. STINGL: Mathematik fur Fachhochschulen, Carl Hanser Verlag Munchen, 8. Auflage, 2009.
R. STORM: Wahrscheinlichkeitsrechnung, mathematische Statistik und statistische Qualitatskontrolle.Fachbuchverlag Leipzig im Carl Hanser Verlag, 12. Auflage, 2007.