215
Mathematik f ¨ ur Anwender I Julio Jos´ e Moyano Fern´ andez Skript zur Vorlesung SS 2013

Mathematik fur Anwender I
Julio Jose Moyano Fernandez
Skript zur Vorlesung SS 2013


Inhaltsverzeichnis
Vorwort 1
Motivation 3
1. Aussagenlogik (fur Anwender) 5
2. Beweismethoden. Das Induktionsprinzip 13
3. Mengen und Abbildungen 21
4. Angeordnete Korper. Die reellen Zahlen 29
5. Folgen reeller Zahlen (I): Konvergenz 37
6. Folgen reeller Zahlen (II): Monotonie. Konvergenzkriterien 45
7. Folgen reeller Zahlen (III): Reihen 51
8. Stetigkeit und Grenzwerte reeller Funktionen 61
9. Der Zwischenwertsatz von Bolzano 69
10. Elementare Funktionen der Analysis 77
11. Differenzierbarkeit reeller Funktionen 87
12. Mittelwertsatze der Differenzialrechnung 97
13. Integrierbarkeit reeller Funktionen a la Riemann 105
14. Der Hauptsatz der Infinitesimalrechnung 117
15. Ein Ruckblick auf die Infinitesimalrechnung 125
16. Lineare Gleichungssysteme 133
17. Vektorraume 145
18. Basen und Dimension 155
19. Lineare Abbildungen 165
20. Matrizenrechnung (I): Der Rang einer linearen Abbildung 173

iv Abschnitt 0
21. Matrizenrechnung (II): Basiswechsel 181
22. Determinanten 189
23. Eigenwerte und Eigenvektoren 201
Nachwort 209
Literaturverzeichnis 211

Vorwort
Der vorliegende Text ist die Niederschrift der Vorlesung”Mathematik fur An-
wender I”, die ich im Sommersemester 2013 gehalten habe. Ziel des Kurses ist, die
wichtigsten Begriffe der Infinitesimalrechnung und linearen Algebra – auf einem
universitaren Niveau– zu vermitteln.
Das Skript basiert auf vorangegangenen Vorlesungen, insbesondere der”Ma-
thematik fur Anwender I”, die im Wintersemester 2012/13 bei Herrn Prof. Dr. Tim
Romer gehalten wurde. Inspirationsquellen sind die Skripte von meinen Kollegen
Herrn Prof. Dr. Winfried Bruns (vor allem der Abschnitt 23) und Herrn Prof. Dr.
Holger Brenner, sowie das Buch von Alexander Markowitsch Ostrowski”Vorle-
sungen uber Differential- und Integralrechnung”. Auch das Buch”Analysis by Its
History” von Ernst Hairer und Gerhard Wanner, vor allem was den Abschnitt uber
Integration angeht, soll in diesem Zusammenhang genannt werden.
Ich danke den Tutoren, die bei der muhsamen Tatigkeit des wochentlichen Kor-
rigierens mitgeholfen haben; auch Frau Marianne Gausmann, die meine Lucken in
LATEX immer gerne gefullt hat, und Herr Franceso Pascariello, fur seine sorgfaltige
Lekture des Textes. Mein Dank gilt insbesondere Dr. Jan Ulickza fur seine sorgfalti-
ge Betreuung der Ubung, sein konstantes Interesse an den Fortschritten der Studen-
ten und seine didaktischen und wissenschaftlichen Kommentare und Vorschlage,
welche die Veranstaltung zweifellos bereichert haben.
Osnabruck, Juli 2013 Julio Jose Moyano Fernandez


Motivation
Ex nihilo nihil fit: Von nichts kommt nichts. Mit diesem beruhmten Prinzip,
das von Parmenides kommen soll, wollen wir unseren Weg durch die Grundla-
gen der Mathematik beginnen. Deswegen mussen wir zunachst prasentieren, was
uberhaupt notig ist, damit wir uns moglichst bald mit der Erarbeitung der Grund-
lagen der reellen Analysis und der linearen Algebra als Basis fur Anwendungen
beschaftigen konnen. Es ist also unvermeidlich, uber Aussagenlogik, Mengen und
Zahlenbereiche ein paar Abschnitte aufzugreifen. Auch scheint es sinnvoll, eine
Beschreibung der typischen Beweismethoden, die im Laufe der Vorlesung auftau-
chen werden, zu thematisieren. Nebenbei gemerkt, der Name der Veranstaltung ist
”Mathematik fur Anwender”, und nicht
”Anwendungen der Mathematik”. Damit
ist gemeint, dass in erster Linie mathematische Begriffe betrachtet werden.
Nach den Grundlagen der Mathematik knupfen wir unmittelbar an die Infini-
tesimalrechnung an. In diesem Teil fangen wir mit den wichtigsten Eigenschaften
der reellen Zahlen an, und analysieren ihr Verhalten der Unendlichkeit gegenuber:
So untersuchen wir Folgen reeller Zahlen, und als Spezialfalle davon, Reihen reel-
ler Zahlen. Ein zweiter Teil der Analysis ist dem Begriff von Funktion gewidmet:
Definition, bedeutungsvolle Beispiele und Untersuchung der Stetigkeit, Differen-
zierbarkeit und Integierbarkeit von Funktionen. Hierzu werden Ableitungs- und
Stammfunktionsrechnung in Erinnerung gerufen.
Alle diese Kenntnisse fuhren in naturlicher Weise zum Begriff Gleichung,
oder allgemeiner, Gleichungssystem. Die Losung einer Gleichung bzw. eines Glei-
chungssystems ist in der Regel alles anderes als einfach. Es hangt von Art der
involvierten Funktionen und vom Zahlbereich der gesuchten Losung ab 1. Es
gibt aber Spezialfalle, in denen dies einfach ist; als einfachste, die linearen Glei-
chungssysteme. Die Losungsmenge eines linearen Gleichungssystems besitzt eine
besondere Struktur, namlich die Struktur eines affinen Raumes, welche aus der
Struktur von Vektorraum verallgemeinert wird. Dies ist unsere Motivation um die
lineare Algebra zu entwickeln. Die lineare Algebra ist dann fur uns die Untersu-
chung von Vektorraumen und ihren Relationen (lineare Abbildungen gennant).
1Dies ist schon klar: Betrachten wir z.B. die Gleichung x2 +√
2 = 0. Wie viele Losungen konnen wir
innerhalb der naturlichen Zahlen finden?

4 Abschnitt 0
Dies ist allerdings nicht trivial. Vektoren werden nicht mehr nur Pfeilchen auf
der Ebene sein: Wir abstrahieren den Begriff; Vektoren konnen nun Funktionen, In-
tegrale, Matrizen sein, d.h. alles, worauf eine Vektorraumsstruktur definiert werden
kann. Dieser Gedankenstil ist das A und O der hoheren Mathematik, und macht den
großten Unterschied zum Mathematikunterricht. Aber keine Panik! Wir werden in
dieser Vorlesung nur einen eingeschrankten Abstraktionsgrad erreichen, weil wir
uns einfach eine Einfuhrung vornehmen.
Schließlich mochte ich noch ein paar Ratschlager geben: Falls Sie eines nicht
verstehen, oder anderes vertiefen mochten... einfach fragen! Tutoren, Ubungsleiter
und ich selber werden uns gerne immer wieder zur Verfugung stellen.
Auch rufen wir uns noch den Spruch in Erinnerung, den H. Hauser in seinem
”Lehrbuch der Analysis” erwahnt: Bruder Beispiel ist der beste Prediger. Wenn
Sie also eine neue Definition wirklich verstehen wollen, sollten Sie sich immer die
folgenden drei Objekte vorstellen konnen:
(i) Ein triviales Beispiel davon (etwa: Entspricht die leere Menge, oder der
ganze Raum, der Definition?)
(ii) Ein nicht triviales Beispiel: (d.h. eines, bei dem Sie ein paar Rechnungen
machen mussen, um sich selber zu uberzeugen.)
(iii) Ein Gegenbeispiel (d.h., ein Objekt, das der Definition nicht entspricht.)
Ich hoffe, lieber Besucher dieser Vorlesung, es wird Ende des Sommerse-
mesters gesagt: Wir haben etwas gelernt! Und vielleicht noch dazu: Wir hatten
(manchmal) Spaß dabei!
Valladolid/Osnabruck, Karwoche 2013
Julio Jose Moyano Fernandez

ABSCHNITT 1
Aussagenlogik (fur Anwender)
Sehen wir den Mathematiker als einen Rechner, der Behauptungen in Theoreme
verwandelt1, dann sollten wir uns fragen, was fur eine Methasprache er versteht. Sie
ist nichts anderes als die Lehre des vernunftigen Schlussfolgerns, d.h., die Logik.
Mit Hilfe von definierten Regeln der Schlussfolgerung wollen die Mathematiker
standig Aussagen auf ihrer Gultigkeit prufen. Das Verstandnis des grundlegenden
Prozesses dabei ist die Aufgabe der Logik. Aus terminlichen Grunden werden wir
nur die wichtigsten Aspekten der fur uns interessantesten Situation, namlich die so
genannte Aussagenlogik, thematisieren.
Die Aussagenlogik ist jenes Teilgebiet der Logik, das sich mit Aussagen und
deren Verknupfungen durch Junktoren befasst. Im Folgenden erklaren wir, was
unter Aussagen und Junktoren zu verstehen ist.
Aussagen sind deskriptive, also beschreibende Satze:”Das Gebaude ist schon”,
”die Schnee ist weiß”. Fragen, normative Satze und andere sprachliche Außerun-
gen gehoren nicht dazu. Bei den folgenden Beispielen handelt es sich nicht um
Aussagen:
* /0;
* 67+78;
* Eine Multiplikation von sechs Quadraten;
* Die Menge aller ganzen Zahlen.
Ausgangspunkte sind die Elementaraussagen, d.h., einfache Aussagen (wie z.B.
”Das Madchen ist klein”), im Gegensatz zu zusammengesetzten Aussagen (wie
”Das Madchen ist klein und ihr Bruder auch”). Diesen Elementaraussagen wird
ein Wahrheitswert zugeordnet. Grundlegend bleiben Satze, die innerhalb eines Sy-
stems nicht begrundet oder abgeleitet werden (konnen): Diese nennen wir Axiome.
Der Ausdruck Axiom bezeichnet
(i) einen unmittelbar einleuchtenden Grundsatz (klassischer Axiombegriff);
(ii) ein vielfach bestatigtes allgemeines Naturgesetz (naturwissenschaftlicher
Axiombegriff);
(iii) einen zu Grunde gelegten, nicht ableitbaren Ausgangssatz (moderner
Axiombegriff).
1Paraphrase des beruhmten Zitats von P. Erdos:”Ein Mathematiker ist eine Maschine, die Kaffee in
Theoreme verwandelt.”

6 Abschnitt 1
In der Aussagenlogik von Aristoteles befinden sich die folgenden klassischen
Beispiele von Axiomen:
(a) Das Indentitatsprinzip, das besagt, dass ein Gegenstand A genau dann mit
einem Gegenstand B identisch ist, wenn sich zwischen A und B kein Un-
terschied finden lasst.
(b) Das Prinzip vom ausgeschlossenen Widerspruch, das besagt, dass zwei ein-
ander widersprechende Gegensatze nicht zugleich zutreffen konnen.
(c) Das Prinzip vom ausgeschlossenen Drittel, das beruhmte Principium exclu-
si tertii2, oder Tertium non datum (d.h., ein Drittes ist nicht gegeben): Es
besagt, dass von zwei einander widersprechenden Gegensatzen mindestens
einer zutreffen muss.
Es gibt viele andere Beispiele. In der Mathematik konnen wir hierzu zwei
erwahnen:
(d) Das Parallelenaxiom: Zu jeder Geraden und jedem Punkt, der nicht auf
dieser Geraden liegt, gibt es genau eine zu der Geraden parallele Gerade
durch diesen Punkt3.
(e) Jede naturliche Zahl n hat genau einen Nachfolger n+1.
Tatsachlich kann man aus mehreren verschiedenen Aussagen neue Aussagen
bilden. Aus der Aussage”Peter ist hier” kann man die negierte Aussage
”Peter ist
nicht hier” machen. Aus den Aussagen
”Julia ist krank” und
”Julia ist im Krankenhaus”
kann man beispielsweise die folgenden neuen Aussagen basteln:
Julia ist krank, deswegen ist sie im Krankenhaus.
Julia ist nicht krank, aber sie ist im Krankenhaus.
Julia ist nicht im Krankenhaus, obwohl sie krank ist.
Zwei verschiedene Aussagen sind in dieser Art und Weise in einen logischen
Zusammenhang zueinander gebracht worden. Dieser Prozess erfolgt nach Ge-
brauch logischer Verknupfungen, die man Junktoren nennt. Der Wahrheitsgehalt
der zusammengesetzten Aussagen ergibt sich allein aus den Wahrheitsgehalten der
beteiligten Aussagen.
Bemerkungen:
(i) Die Untersuchung, ob eine einfache Aussage wahr ist oder nicht, fallt nicht in
den Bereich der formalen Logik. Wir werden nur die wahrheitsdefinierte, klassi-
sche, zweiwertige Aussagenlogik betrachten (d.h., es wird vorausgesetzt, dass jede
2Principium exclusii tertii sive medii inter duo contradictoria.3Das Parallelenaxiom ist ein umstrittenes Axiom der Euklidischen Geometrie, mit einer langen Ge-
schichte hinter sich. Es lohnt sich, etwas daruber zu lesen.

Aussagenlogik (fur Anwender) 7
Aussage entweder wahr oder falsch ist).
(ii) Es gibt naturlich Satze, die in einer bestimmten Situation wahr, in einer anderen
falsch sein konnen, wie z. B.”Es zieht jetzt hier”. Mogliche Mehrdeutigkeiten las-
sen sich aber durch geeignete Zusatzangaben (wann und wo genau) ausschliessen.
Es steht weiterhin eine starke Mehrdeutigkeit zwischen konkreten Aussagen
und ihren Bedeutungen, wie es beispielsweise hier der Fall ist:
Ich bin verletzt, deswegen kann ich nicht mitspielen.
Weil ich verletzt bin, kann ich nicht mitspielen.
Dies wollen wir vermeiden, indem wir Aussagenvariablen fur die Aussagen
und bestimmte Symbole fur die Junktoren nutzen. Fur die Aussagen schreiben wir
p,q,r,s, . . .
An dem Gehalt von p sind wir nicht interessiert, sondern an den moglichen Wahr-
heitswerte von p, welche wir mit w (wahr) oder f (falsch) bezeichen. Fur die Ne-
gation (oder Verneinung) einer Aussage p, die wir ¬p bezeichnen, bekommen wir
die folgenden Wahrheitswerte:
p ¬p
w f
f w
Die Tabelle, die vorliegt, nennt man die Wahrheitstabelle der Verneinung. Genauso
konnen wir fur weitere Junktoren zwischen zwei Aussagen p und q die entspre-
chende Wahrheitstabelle einsetzen. Erstens betrachten wir die Konjunktion (oder
Und-Verknupfung) p∧q; Sie ist genau dann wahr, wenn beide Teilaussagen wahr
sind, also sonst falsch:
p q p∧q
w w w
w f f
f w f
f f f
Die Disjunktion p∨q ist die einschließende Oder-Verknupfung: Sie ist wahr sobald
mindestens eine der Teilaussagen wahr ist, also falsch, wenn beide Teilaussagen
falsch sind:

8 Abschnitt 1
p q p∨q
w w w
w f w
f w w
f f f
Eine Variante davon ist die ausschließende Oder-Verknupfung (p ⊻ q), inder
eine und nur eine4 der Teilaussagen wahr ist (auch (p∧¬q)∨ (¬p∧q)):
p q p⊻q
w w f
w f w
f w w
f f f
Die Implikation zweier Aussagen p⇒ q ist der wichtigste Junktor der Mathematik.
Sie kann in vielfacher Form ausgedruckt werden: Wenn p wahr ist, dann ist auch
q wahr; q, falls p; unter der Bedingung p gilt q; p ist eine hinreichende Bedingung
fur q; q ist eine notwendige Bedingung fur p:
p q p ⇒ q
w w w
w f f
f w w
f f w
Die Ausage p heißt Voraussetzung, die Aussage q heißt Konklusion. Der wichtige
Fall, in dem die zwei Implikationen p ⇒ q und q ⇒ p zugleich gelten, ist bemer-
kenswert: Man spricht dann uber Aquivalenz von p und q, und schreibt p ⇔ q:
p q p ⇔ q
w w w
w f f
f w f
f f w
Es gibt Aussagen, deren Wahrheitswerte immer wahr sind. Sie heißen tautologi-
sche oder allgemeingultige Aussagen, oder auch Tautologien (tautos = aus sich
4Solche Unterscheidungen sind manchmal besonders nutzlich. Hierzu konnte man den alten Witz
erwahnen: Ein Mathematiker kommt nach Hause, schenkt seiner Frau einen großen Strauß Rosen und sagt:
”Ich liebe Dich!”. Sie nimmt die Rosen, haut sie ihm um die Ohren, gibt ihm einen Tritt und wirft ihn aus
der Wohnung. Was hat er falsch gemacht? Er hatte sagen mussen:”Ich liebe Dich und nur Dich”.

Aussagenlogik (fur Anwender) 9
heraus). Axiome sind immer Tautologien. Als Beispiele betrachten wir die drei
Axiome von Aristoteles. Die Wahrheitstabelle des Indentitatsprinzips lautet
p p ⇒ p
w w
f w
Das Prinzip vom ausgeschlossenen Widerspruch besitzt die Wahrheitstabelle
p ¬p p∧¬p ¬(p∧¬p)w f f w
f w f w
Und die Wahrheitstabelle des Prinzips vom ausgeschlossenen Drittel ist
p ¬p p∨¬p
w f w
f w w
Zum Schluss fuhren wir das Gegenstuck von Tautologien ein: Wenn der Gesamt-
wahrheitswert fur jede mogliche Bewertung immer falsch ist, heißen solche Aus-
sagen kontradiktorisch (oder unerfullbar). Speziell ist jede Negation einer Tautolo-
gie kontradiktorisch. Aussagen, die nicht kontradiktorisch sind, mussen bei minde-
stens einer Bewertung den Wahrheitswert wahr (”w”) haben; wir nennen sie daher
erfullbare Aussagen.
Folgendes ist ein Beispiel einer kontradiktorischen Aussage:
p q ¬p p ⇒ q (p ⇒ q)⇒ p ((p ⇒ q)⇒ p)⇔¬p
w w f w w f
w f f f w f
f w w w f f
f f w w f f
Zum Schluss wird von Quantoren die Rede sein. Betrachten wir die Aussagen
”Lichtalben sind schoner als die Sonne5”
und (nach dem Vorkurs Mathematik WS 2009/10 von Herr Prof. Dr. Brenner)
”Ich fresse einen Besen”,
und gucken uns die innere Struktur genauer an.
Mit der ersten Aussage kann man meinen, dass Lichtalben”im Normalfall”
oder”fast immer” schoner als die Sonne sind, oder aber im strengeren Sinn, dass
wirklich alle Lichtalben schoner als die Sonne sind.
5Die von Arnulf Krause angepasste Ubersetzung der klassischen Beschreibung von Lichtalben heißt
Lichtalben sind schoner als die Sonne von Angesicht. Vgl. Gylfaginning, XVII. In”Die Edda des Snorri
Sturluson”, Ausw., Ubers. u. Komm. Arnulf Krause. Reclam Verlag, 1997.

10 Abschnitt 1
In der Mathematik interessiert man sich fur Aussagen, die ohne Ausnahmen
gelten (wobei man allerdings in einer mathematischen Aussage die Ausnahmen
auch explizit machen kann), so dass wir die Aussage im strengen Sinn verstehen
wollen. Es handelt sich um eine sogenannte Allaussage. In ihr kommen zwei At-
tribute vor, die man Pradikate nennt:
- ein Lichtalb zu sein, und
- schoner als die Sonne zu sein.
Ein Pradikat P ist eine Eigenschaft, was einem Subjekt zukommen oder nicht zu-
kommen kann; Es ist fur sich genommen keine Aussage, aber daraus kann man
grundsatzlich auf zwei verschiedene Arten eine Aussage machen:
(a) durch Einsetzen: Man bildet fur ein konkretes Objekt x die Aussage
P(x)
die bedeutet, dass das Objekt x die Eigenschaft P besitzt, was wahr sein
kann (oder nicht),
(b) durch Quantifizierung: Man bildet die Aussage, dass alle Objekte (typi-
scherweise aus einer bestimmten Grundmenge) die Eigenschaft P haben,
was wiederum wahr oder falsch sein kann. Das druckt man durch
∀xP(x)
aus. Das Symbol ∀ ist eine abkurzende Schreibweise fur”fur alle”. Es wird
Allquantor genannt.
Die obige Aussage uber Lichtalben kann man als
∀x(L(x)⇒ S(x))
schreiben. Das bedeutet, dass fur alle Objekte ohne weitere Einschrankung gilt:
wenn es sich um einen Lichtalb handelt (wenn also L zutrifft), dann ist er auch
schoner als die Sonne (trifft dann S zu). Fur jedes x steht in der großen Klam-
mer eine Aussage in der Form einer Implikation, die eben besagt, dass wenn der
Vordersatz wahr ist, dann auch der Nachsatz wahr sein muss.
Die zweite Beispielaussage,”Ich fresse einen Besen”, kann bedeuten, dass ich
genau einen Besen fresse oder aber mindestens einen Besen. Die Wortbedeutung
des unbestimmten Artikels”ein” ist nicht eindeutig (in einer Aussage wie
”ein
Land braucht Friede” bedeutet”eins” sogar
”alle”!) In der Mathematik bedeutet es
fast immer”mindestens einen”. Die Besenaussage kann man also durch Quantifi-
zierung paraphrasieren als
Es gibt einen Besen, den ich fresse.
Mit Hilfe von Aussagenvariablen und Quantoren ist diese als
∃x(B(x)∧F(x)), genauso als ∃x(F(x)∧B(x))

Aussagenlogik (fur Anwender) 11
verdolmetscht, wobei B(x) bedeutet, dass das Objekt x ein Besen ist und wobei
F(x) bedeutet, dass ich dieses x fresse. Das Zeichen ∃ wird”es gibt” oder
”es
existiert” gesprochen und der Existenzquantor (oder Existenzoperator) genannt.
Damit ist naturlich”es existiert mindestens einen” gemeint6.
Der Allquantor und der Existenzquantor sind uber die Negation eng miteinan-
der verknupft und lassen sich gegenseitig ersetzen:
¬(∀xP(x)) ist gleichbedeutend mit ∃x(¬P(x))
und
¬(∃xP(x)) ist gleichbedeutend mit ∀x(¬P(x))
und
∀xP(x) ist gleichbedeutend mit ¬(∃x(¬P(x)))
und
∃xP(x) ist gleichbedeutend mit ¬(∀x(¬P(x))).
Neben einstelligen Pradikaten wie P(x) gibt es auch mehrstellige Pradikate der
Form
P(x,y), oder Q(x,y,z), etc.,
die eine Beziehung zwischen mehreren Objekten ausdrucken, wie z.B.”ist ver-
wandt mit”,”ist großer als”,
”sind Eltern von” usw. Entsprechend kann dann uber
die verschiedenen Variablen quantifiziert werden, d.h. man hat Ausdrucke der
Form
∀x(∃yP(x,y)),∃x(∀yP(x,y)),∀x(∃y(∀zQ(x,y,z))) usw.
Dabei darf man aber nur Variablennamen (also Buchstaben x,y,z, . . .) verwenden,
die im gegenwartigen Kontext nicht schon anderweitig verwendet sind. Eine Aus-
sage wie ∀x(∀xP(x,x)) ergibt keinen Sinn. Auf jede Variable darf sich maximal
nur ein Quantor beziehen. Zu beachten sind auch folgende Regeln:
- Statt ∀x∀y∀zQ(x,y,z) schreibt man manchmal auch ∀xyzQ(x,y,z).- Die Variablenbezeichnung in einer quantifizierten Aussage ist grundsatz-
lich unwichtig, d.h. es ist egal, ob man ∀αP(α) oder ∀βP(β ) schreibt.
Die Logik, die sich mit quantifizierten Aussagen auseinandersetzt, heißt Pradika-
tenlogik oder Quantorenlogik. Wir werden sie nicht systematisch entwickeln, da
sie in der Mathematik als Mengentheorie auftritt. Statt P(x), dass also ein Pradikat
einem Objekt zukommt, schreiben wir x ∈ P, wobei dann P die Menge aller Ob-
jekte bezeichnet, die diese Eigenschaft haben. Mehrstellige Pradikate treten in der
Mathematik als Relationen auf. Die Sprache der Mathematik wird in der Sprache
der Mengen formuliert. In Abschnitt 3 werden wir diese ganz elementar vorstellen.
6Nebenbei bemerkt: Wird”es existiert genau einen” gemeint, so schreibt man aus praktischen Grunden
in der Mathematik oft”∃!”


ABSCHNITT 2
Beweismethoden. Das Induktionsprinzip
Wir bezeichnen mit
N die Menge der naturlichen Zahlen (einschließlich 0),
Z die Menge der ganzen Zahlen,
Q die Menge der rationalen Zahlen,
R die Menge der reellen Zahlen.
Wir gehen davon aus, dass der Leser auf der Schule gelernt hat, in diesen Zahlberei-
chen zu rechnen, und dass er die Zeichen < (”kleiner“), ≤ (
”kleiner oder gleich“),
> (”großer“), ≥ (
”großer oder gleich“) kennt.
Ein kluger Kopf hat festgestellt:
- Wenn man die Zahl 1 quadriert, bekommt man wieder 1.
- Wenn man die Zahl 3 quadriert, bekommt man die 9.
- Wenn man die Zahl 5 quadriert, bekommt man die 25.
- Wenn man die Zahl 7 quadriert, bekommt man die 49.
So viel kann man stets sagen: Wenn man die ersten vier ungeraden Zahlen
quadriert, bekommt man wieder eine ungerade Zahl. Dieser Feststellung liegt die
Frage nahe: Ist dies immer so? D.h., gilt immer, dass wenn man eine ungerade
Zahl quadriert, bekommt man wieder eine ungerade? Leicht umformuliert: Ist das
Quadrat einer (beliebigen) ungeraden Zahl, sagen wir n, wieder ungerade?
Wenn die Menge N der naturlichen Zahlen endlich ware, und damit die Men-
ge aller ungeraden naturlichen Zahlen, konnte man die Liste ausschopfen und fur
jeden einzelnen Fall uberprufen, ob es tatsachlich stimmte. Es ist aber nicht der
Fall. Wie kann man dann nachprufen, dass die obige Aussage richtig, also allge-
meingultig, ist? Man muss nach einem Beweis dafur suchen.
Ein Beweis ist in der Mathematik, die als fehlerfrei anerkannte Herleitung der
Richtigkeit oder auch Unrichtichkeit einer Aussage aus einer Menge von Axiomen,
die als wahr vorausgesetzt werden, und anderen Aussagen, die bereits bewiesen
wurden.
Ein Beweis kann entweder direkt oder indirekt gefuhrt werden. Bei einem di-
rekten Beweis wird die Behauptung durch Anwendung von bereits bewiesenen
Aussagen und durch logische Folgerungen nachgepruft, also, bewiesen.

14 Abschnitt 2
Bei einem indirekten Beweis (auch Widerspruchsbeweis genannt) zeigt man,
dass ein Widerspruch entstande, wenn die zu beweisende Behauptung falsch ware.
Dazu nimmt man an, dass die Behauptung falsch ist, und wendet die gleiche Me-
thoden wie beim direkten Beweis an. Wenn daraus einen Widerspruch entsteht,
dann kann die Behauptung nicht falsch sein, muss die also richtig sein.
Beispiel. Die Behauptung lautet: Das Quadrat einer ungeraden naturlichen Zahl
n ist ungerade.
Direkter Beweis. Es sei n eine ungerade naturliche Zahl. Dann lasst sich n darstel-
len als n = 2k+1, wobei k eine weitere naturliche Zahl ist. Daraus folgt:
n2 = n ·n = (2k+1) · (2k+1) = 4k2 +4k+1 = 2 · (2k2+2k)+1.
Aus dieser Darstellung folgt unmittelbar, dass n2 der Gestalt 2k+1, mit k := 2k2+2k ∈ N, ist; also, dass n2 eine ungerade naturliche Zahl ist. �
Indirekter Beweis. Angenommen, es existierte eine ungerade Zahl m, sagen wir
m = 2m′+1 mit m′ ∈N so dass m2 gerade ware. Wir haben
m2 = (2m′+1)2 = 4(m′)2 +4m′+1 = 4((m′)2 +m′)+1
Einerseits setzen wir voraus, dass m2 gerade ist. Andererseits besagen die obigen
Gleichungen, dass m2 die Form 2(2(m′)2 + 2m′)+ 1 hat, d.h., dass m2 eine unge-
rade Zahl ist. Hier entsteht der Widerspruch: Eine naturliche Zahl kann entweder
gerade oder ungerade sein, aber nicht beides zugleich. �
Wir geben ein weiteres Beispiel eines Widerspruchsbeweises an. Es handelt
sich um den beruhmten Beweis uber die Existenz unendlich vieler Primzahlen1
von Euklid:
Beispiel (Indirekter Beweis). Die Behauptung lautet: Es gibt unendlich viele Prim-
zahlen.
Beweis. Angenommen, es gabe nur endlich viele Primzahlen p1, . . . , pn.
Es sei m := p1 · . . . · pn. Wir machen hierzu eine einfache Fallunterscheidung:
(1) Ist m+1 eine Primzahl, dann ist sie nach Konstruktion großer als p1, . . . , pn
und somit eine weitere Primzahl, die keine von den vorgegebenen ist, im Wider-
spruch zur Annahme.
(2) Anderenfalls, sei q ein Primteiler von m+ 1. Ware q eine der Primzahlen
p1, . . . , pn, so wurde q sowohl m als auch m+ 1 teilen, d.h., q wurde die Diffe-
renz (m+1)−m = 1 teilen, was absurd ist. Also ist q eine weitere Primzahl, was
wiederum der Annahme widerspricht.
Mehr Falle als (1) und (2) gibt es nicht. Die Annahme, es gabe nur endlich viele
Primzahlen, ist also falsch. �
1Eine Primzahl ist eine von 0 und 1 verschiedene naturliche Zahl, die nur durch 1 und sich selbst teilbar
ist.

Beweismethoden. Das Induktionsprinzip 15
Dieser Beweis von Euklid ist reizvoll: Es ist ein Beispiel von einem nicht-
konstruktiven Beweis, da er keine Formel fur eine beliebig große Primzahl angibt,
sondern nur zeigt, dass es sie geben muss. Aber dort wurde auch ein Beweis durch
Fallunterscheidung durchgefuhrt. Das ist ein weiteres Beweisprinzip.
Bei der Fallunterscheidung mochte man eine Aussage q beweisen, und man
beweist sie dann einerseits (Fall 1) unter der zusatzlichen Annahme p und anderer-
seits (Fall 2) unter der zusatzlichen Annahme ¬p. Dabei muss man zweimal etwas
machen, der Vorteil ist aber, dass die zusatzlichen Annahmen zusatzliche Metho-
den und Techniken erlauben, sodass sich das ursprungliche Problem moglicherwei-
se vereinfachern lasst. Die entsprechende Wahrheitstabelle der Fallunterscheidung
konnen wir noch erwahnen:
p q ¬p p ⇒ q ¬p ⇒ q (p ⇒ q)∧ (¬p ⇒ q) ((p ⇒ q)∧ (¬p ⇒ q))⇒ q
w w f w w w w
w f f f w f w
f w w w w w w
f f w w f f w
Es handelt sich selbstverstandlich um eine Tautologie.
Ein weiteres Prinzip, das oft verwendet wird, ist die Kontraposition: In einem
Beweis nimmt man einen pragmatischen Standpunkt ein, und manchmal ist es
einfacher, von ¬q nach ¬p zu gelangen als von p nach q. Beide Methoden sind
tatsachlich aquivalent:
p q ¬q ¬p p ⇒ q ¬q ⇒¬p (p ⇒ q)⇔ (¬q ⇒¬p)w w f f w w w
w f w f f f w
f w f w w w w
f f w w w w w
Man unterscheidet auch zwischen konstruktiven und nicht konstruktiven Be-
weisen: Manchmal kann man nur die Existenz eines mathematischen Objekts zei-
gen, ohne das Objekt selbst anzudeuten. In diesem Fall liegt ein nicht-konstruktiver
(oder rein-existenzieller) Beweis vor. Manchmal kann man aber das Objekt, dessen
Existenz bewiesen wurde, prazise beschreiben, oft sogar mittels eines Algorithmus,
der das Objekt berechnet: Hier liegt ein konstruktiver Beweis vor.
Beispiel. Die Behauptung lautet: Die reelle Funktion f (x) = 2x− 1 besitzt eine
Nullstelle x0 ∈ R mit 0 ≤ x0 ≤ 1.
Konstruktiver Beweis. Sei x0 =12. Dann gilt
f (x0) = 2 · x0 −1 = 2 · 1
2−1 = 1−1 = 0.

16 Abschnitt 2
Das heißt, x0 = 12
ist eine Nullstelle von f . Offenbar ist 0 ≤ 12≤ 1. Dann ist die
Behauptung bewiesen. �
Die Nullstelle ist sogar mit x0 =12
angegeben. Hier sieht man, dass wir irgend-
wie geahnt haben, was die Losung war. Mogliche Losungen zu erraten ist eine
Eigenschaft, die man trainieren kann, aber die, die Mathematik—vor allem am
Anfang—schwierig macht.
Nicht-konstruktiver Beweis. Die Funktion f ist stetig2. Ferner ist f (0) = −1 <0 und f (1) = 1 > 0, und deswegen sind wir in der Lage, den Zwischenwertsatz
anzuwenden, nachdem die Behauptung folgt. �
Uber den Wert der Nullstelle ist jedoch nichts bekannt!
Eine weitere wichtige, etwas komplizierte Methode Beweise zu fuhren ist die
vollstandige Induktion. Sei dazu A eine Aussage uber naturliche Zahlen.
(IA) Induktionsanfang: (Man zeigt:) A gilt fur die naturliche Zahl n0.
(IV) Induktionsvoraussetzung (Man nimmt an:) A gilt fur eine naturliche Zahl
n ≥ n0.
(IS) Induktionsschritt: (Man zeigt:) Aus der I.V. folgt, dass A auch fur n+1 gilt.
(IS’) Induktionsschluss: (Es folgt:) Daher gilt A fur alle naturlichen Zahlen ≥ n0.
Beispiel. Fur alle n ∈N gilt
0+1+2+3+4+ . . .+n =n(n+1)
2.
Wir beweisen dies durch vollstandige Induktion:
(IA) Die Aussage gilt fur die naturliche Zahl n0 = 0; denn es ist offensichtlich
0 =0(0+1)
2.
(IV) Die Aussage gelte fur die naturliche Zahl n ≥ n0 = 0.
(IS) Es ist
0+1+ . . .+n+(n+1) = (0+1+ . . .+n)+(n+1) =n(n+1)
2+n+1
=n(n+1)+2(n+1)
2=
(n+1)(n+2)
2.
Hier haben wir in der zweiten Gleichung die I.V. benutzt.
(IS’) Die Aussage gilt fur alle naturlichen Zahlen n.
Das Induktionsschema beschreibt eine fundamentale Eigenschaft der naturli-
chen Zahlen, die man letztlich nicht aus einfacheren Eigenschaften der naturlichen
2Das Konzept stetige Funktion werden wir in Abschnitt 6 betrachten. Ein wichtiger Satz in dieser
Theorie ist der Zwischenwertsatz: Sei I ein Intervall, sei f : R→ I eine stetige Funktion auf I mit a,b ∈ I
und a ≤ b. Fur ein c ∈R gelte f (a)≤ c ≤ f (b) (oder f (b)≤ c ≤ f (a)). Dann existiert ein ξ mit a ≤ ξ ≤ b
mit f (ξ ) = c.

Beweismethoden. Das Induktionsprinzip 17
Zahlen herleiten kann. Es prazisiert das”und so weiter“-Argument. Das Schema
kann hinsichtlich der Bezeichnungen variiert werden.
Verwandt mit dem Prinzip der vollstandigen Induktion sind rekursive Defini-
tionen. Hier werden wir nur einige (sehr nutzliche) Beispiele dazu betrachten. Wir
haben bereits Summen
1+ . . .+n
unbefriediegend verwendet, weil die Bezeichnung”· · ·“ a priori keine prazise No-
tation ist. Als erstes Beispiel von rekursiver Definition fuhren wir das Summenzei-
chen ∑ ein:
0
∑i=0
ai := a0,
n
∑i=0
ai :=n−1
∑i=0
ai +an bei n ≥ 1.
Etwas ungenau schreiben wir dann gelegentlich auch wieder, fur m ≤ nn
∑i=m
ai = am + . . .+an.
Aus praktischen Grunden definieren wir ∑ni=m ai := 0 fur n < m, und wir sprechen
dann uber die leere Summe.
Wir geben eine naheliegende Verallgemeinerung des Summenzeichens an: Fur
m, n ∈ Z, m ≤ n, sein
∑k=m
ak :=n−m
∑k=0
ak+m.
(Mit dieser Definition lasst sich die Summation beliebig verschieben.) Die folgen-
den, leicht beweisbaren, Rechenregeln werden wir standig verwenden:n
∑k=m
ak +n
∑k=m
bk =n
∑k=m
(ak +bk), cn
∑k=m
ak =n
∑k=m
cak.
Analog fuhrt man das Produktzeichen ∏ ein:
0
∏i=0
ai := a0,
n
∏i=0
ai :=n−1
∏i=0
ai ·an bei n ≥ 1.
Ein weiteres Beispiel einer rekursiven Definition sind die Potenzen einer reellen
Zahl a mit Exponenten n ∈ N:
a0 := 1, an := an−1 ·a.

18 Abschnitt 2
Um das Induktionsprinzip zu uben, beweisen wir die folgende nutzliche Aussage:
Satz 2.1 (Geometriche Summenformel). Es istn
∑k=0
ak =1−an+1
1−a
fur alle a ∈ R, a 6= 1, und alle n ∈ N.
Beweis. Die Aussage ist in der Tat fur n0 = 0 richtig. Sie gelte fur ein n ≥ 0. Dann
ist sie auch fur n+1 richtig:
n+1
∑k=0
ak =n
∑k=0
ak +an+1 =1−an+1
1−a+an+1
=1−an+1 +an+1(1−a)
1−a=
1−an+2
1−a.
Die Aussage gilt somit fur alle naturlichen Zahlen. �
Sei n ≥ 1 eine naturliche Zahl. Dann definiert man die n-Fakultat
n! :=n
∏i=1
i (= 1 ·2 ·3 · · ·n).
Wir erganzen die Definition von n! noch durch
0! := 1.
Eng mit n! verwandt sind die Binomialkoeffizienten: Fur alle n,k ∈N definieren
wir (n
k
):=
n!
k!(n− k)!.
Das Symbol(
nk
)wird
”n uber k“ gesprochen. Fur das Rechnen mit Binomialkoef-
fizienten wird haufig die folgende Aussage herangezogen.
Satz 2.2. Fur alle k,n ∈ N ist(n+1
k
)=
(n
k
)+
(n
k−1
).
Beweis. Fur k ≥ n und k = 0 folgt die Formel direkt. Fur 0 < k < n gilt:(
n
k
)+
(n
k−1
)=
n!
k!(n− k)!+
n!
(k−1)!(n− k+1)!
=n!(n− k+1)+n!(k)
k!(n+1− k)!=
n!((n− k+1)+ k)
k!(n+1− k)!
=(n+1)!
k!(n+1− k)!=
(n+1
k
). �
Die Binomialkoeffizienten haben ihren Namen wegen

Beweismethoden. Das Induktionsprinzip 19
Satz 2.3. Fur alle a, b ∈ R und alle n ∈ N gilt die”
binomische Formel“:
(a+b)n =n
∑k=0
(n
k
)an−kbk.
Beweis. Wir verwenden das Induktionsprinzip. Offenbar ist nur beim Induktions-
schritt etwas zu beweisen. Es ist
(a+b)n+1 = (a+b)(a+b)n = (a+b)n
∑k=0
(n
k
)an−kbk
=n
∑k=0
(n
k
)an+1−kbk +
n
∑k=0
(n
k
)an−kbk+1
= an+1 +n
∑k=1
(n
k
)an+1−kbk +
n−1
∑k=0
(n
k
)an−kbk+1 +bn+1
= an+1 +n
∑k=1
(n
k
)an+1−kbk +
n
∑k=1
(n
k−1
)an+1−kbk +bn+1
= an+1 +n
∑k=1
((n
k
)+
(n
k−1
))an+1−kbk +bn+1
= an+1 +n
∑k=1
(n+1
k
)an+1−kbk +bn+1
=n+1
∑k=0
(n+1
k
)an+1−kbk.
Dabei haben wir den Summationsindex verschoben und 2.2 benutzt. �
Die Binomialkoeffizienten lassen sich dank 2.2 besonders einfach mit Hilfe des
Pascalschen Dreiecks ermitteln:
1
1 1
1 2 1
1 3 3 1
1 4 6 4 1
1 5 10 10 5 1
. . .
Die n-te Zeile des Schemas (n = 0,1,2, . . . ) enthalt der Reihe nach die Binomial-
koeffizienten(
nk
)(k = 0, . . . ,n). Bei 1 ≤ k ≤ n−1 erhalt man sie gemaß 2.2 durch
Addition der beiden unmittelbar schrag daruber stehenden.


ABSCHNITT 3
Mengen und Abbildungen
Ein wichtiger Bestandteil der modernen mathematischen Sprache sind Men-
gen, Abbildungen und die mit ihnen verbundenen Operationen. Die bereits in Ab-
schnitt 2 benutzten Symbole N, Z, Q, R bezeichnen nicht einzelne Zahlen, sondern
gewisse Mengen von Zahlen.
Wir setzen voraus, dass der Leser mit dem Begriff”Menge“ vertraut ist. Eine
prazise Definition des Begriffs”Menge“ konnen wir nicht geben. Dies wird aber
fur unsere Zwecke zu keinerlei Schwierigkeiten fuhren. Der Schopfer der Mengen-
lehre, Georg Cantor, hat folgendermaßen beschrieben, was er unter einer Menge
versteht: Eine Menge M ist die Zusammenfassung von bestimmten wohlunterschie-
denen Objekten unserer Anschauung oder unseres Denkens (welche die Elemente
von M genannt werden) zu einem Ganzen.
Mengentheoretische Symbole, die uns vielleicht schon vertraut sind, werden
zunachst erklart: In
N⊂ Z⊂Q⊂R bedeutet ⊂”Teilmenge von“, in
N$ Z $Q$ R bedeutet $”echte Teilmenge von“, in
Z 6⊂N bedeutet 6⊂”nicht Teilmenge von“, in
3 ∈ Z bedeutet ∈”Element von“ und in
−5 /∈N bedeutet /∈”nicht Element von“.
Es gibt eine Menge, die keine Elemente enthalt: Sie heißt die leere Menge, und
wird mit /0 bezeichnet. Haufig werden wir Mengen M dadurch definieren, dass wir
alle Elemente einer gegebenen Menge, die eine gewisse Eigenschaft besitzen, in
M zusammenfassen. Dabei ist der Definitionsdoppelpunkt nutzlich: Etwa
M:={n ∈ N : n ungerade}.
{. . .} ist das Mengenklammernpaar, und wir definieren (durch das Symbol :=),
dass M die Menge aller ungeraden naturlichen Zahlen bezeichnet. Unprazise wird
manchmal M := {1,3,5,7, . . .} geschrieben.
Wir konnen Mengen in aufzahlender Form beschreiben, etwa
M = {1,2,3,4,5},

22 Abschnitt 3
oder durch Angabe der Eigenschaften, die die Elemente der Menge charakterisie-
ren:
M = {n ∈ N : 1 ≤ n ≤ 5}.Eine Menge N heißt Teilmenge der Menge M, symbolisch N ⊂ M, wenn jedes
Element von N auch Element von M ist. Die leere Menge /0 ist Teilmenge jeder
Menge. Statt N ⊂ M schreiben wir auch M ⊃ N und nennen M eine Obermenge
von N, oder N umfassende Menge.
Mengen A, B stimmen uberein, wenn sie die gleichen Elemente enthalten —die
Beschreibung von A und B spielt dabei keine Rolle. Es gilt offensichtlich
A = B ⇐⇒ A ⊂ B und B ⊂ A.
Der Durchschnitt M1 ∩M2 von Mengen M1, M2 ist gegeben durch
M1 ∩M2 = {x : x ∈ M1 und x ∈ M2}.Ihre Vereinigung M1 ∪M2 ist
M1 ∪M2 = {x : x ∈ M1 oder x ∈ M2}.(Man beachte, dass dabei
”oder“ im nicht ausschließenden Sinn gebraucht wird;
”oder“ bedeutet nicht
”entweder – oder“.)
Beispiele.
{1,2,3}∪{2,3,4,5}= {1,2,3,4,5},{1,2,3}∩{2,3,4,5}= {2,3}.
Ferner konnen wir das Komplement von M1 in M2 bilden:
M2 \M1 = {x ∈ M2 : x 6∈ M1}.Rechenregeln fur die genannten Operationen mit Mengen werden in den Ubungsaufgaben
formuliert. Eine wichtige Kennzahl von Mengen M ist die Anzahl |M| ihrer Ele-
mente. Wenn M endlich ist und n Elemente hat, setzen wir
|M|= n.
Bei unendlichen Mengen schreiben wir
|M|= ∞.
Eine weitere wichtige Konstruktion ist das kartesische Produkt zweier Mengen:
M1 ×M2 = {(x1,x2) : x1 ∈ M1,x2 ∈ M2}.Dabei bezeichnet (x1,x2) das Paar mit erster Komponente x1 und zweiter Kompo-
nente x2. Wenn x1 6= x2, so ist
(x1,x2) 6= (x2,x1)

Mengen und Abbildungen 23
(hingegen {x1,x2} = {x2,x1}). Statt M × M schreibt man auch M2. So ist uns
gelaufig, dass jedem Punkt der Ebene genau ein Element von R2 entspricht.
Durchschnitt, Vereinigung und kartesisches Produkt lassen sich allgemein fur
endlich viele Mengen so definieren:
M1 ∩ . . .∩Mn =n⋂
i=1
Mi =⋂
i∈{1,...,n}Mi := {x : x ∈ Mi fur alle i ∈ {1, . . . ,n}}
M1 ∪ . . .∪Mn =n⋃
i=1
Mi =⋃
i∈{1,...,n}Mi := {x : x ∈ Mi fur ein i ∈ {1, . . . ,n}}
M1 × . . .×Mn := {(x1, . . . ,xn) : xi ∈ Mi fur 1 ≤ i ≤ n},wobei die Menge der Indizes {1, . . . ,n} Indexmenge genannt wird. Die ersten zwei
Mengen lassen sich fur eine beliebige Indexmenge I (nicht notwendigerweise end-
lich) leicht definieren. Wir werden dann⋂
i∈I
Mi und⋃
i∈I
Mi.
schreiben. Wenn man das kartesische Produkt von M n-mal mit sich selber nimmt,
dann schreibt man Mn.
Beim Begriff”Abbildung“ geht es uns ebenso wie beim Begriff
”Menge“. Wir
konnen nur eine vage, fur unsere Zwecke aber hinreichend prazise Beschreibung
angeben. Eine Abbildung f einer Menge A in eine Menge B ist eine Vorschrift, die
jedem Element von A genau ein Element von B zuordnet. Wir bezeichnen dies kurz
durch
f : A → B.
Man nennt A den Definitionsbereich, B den Wertebereich von f . Das x ∈ A zuge-
ordnete Element aus B wird mit f (x) bezeichnet und heißt Bild von x unter f oder
auch Wert von f an der Stelle x. Zwei Abbildungen f : A → B, g : C → D sind
gleich, wenn A =C, B = D und f (x) = g(x) fur alle x ∈ A gilt.
Abbildungen sind aus dem Schulunterricht vor allem als Funktionen bekannt,
z.B.
f : R→R, f (x) = x2 fur alle x ∈ R.
Es ist wichtig festzuhalten, dass Abbildungen (laut Definition) eindeutig sind. Bei-
spielsweise wird durch
f : {x ∈ R : x ≥ 0}→ R, f (x) =±√
x
keine Abbildung definiert. Auf jeder Menge ist die identische Abbildung definiert:
idM : M → M, idM(x) = x fur alle x ∈ M.

24 Abschnitt 3
Sei f : A → B eine Abbildung. Fur eine Teilmenge A′ ⊂ A setzen wir
f (A′) := { f (x) : x ∈ A′};
f (A′) heißt das Bild von A′ unter f . Fur f (A) schreiben wir auch Bild f . Fur B′ ⊂ B
sei
f−1(B′) := {x ∈ A : f (x) ∈ B′}das Urbild von B′ unter f . Fur y ∈ B setzen wir
f−1({y}) := {x ∈ A : f (x) = y}.
Fur das Beispiel f : R→ R, f (x) = x2, ist
f ({1,2,3}) = {1,4,9},f−1({4}) = {2,−2},
f−1({1,4,9}) = {1,−1,2,−2,3,−3}.
Es wird oft wichtig sein, dass wir den Definitionsbereich einer Abbildung ein-
schranken. Sei f : A → B eine Abbildung und A′ ⊂ A; dann ist die Abbildung
f | A′ : A′ → B
gegeben durch ( f | A′)(x) = f (x) fur alle x ∈ A′. Diese Abbildung heißt Be-
schrankung von f auf A′. Wenn wir f auf A′ beschranken, tun wir wirklich nichts
anderes, als die f definierende Zuordnung nur auf Elemente von A′ anzuwenden.
Definition. Sei f : A → B eine Abbildung.
(a) f ist injektiv, wenn fur x1, x2 ∈ A mit x1 6= x2 auch f (x1) 6= f (x2) ist.
(b) f ist surjektiv, wenn f (A) = B gilt.
(c) f ist bijektiv, wenn f injektiv und surjektiv ist.
Wir konnen dies auch so beschreiben:
f ist injektiv ⇐⇒ Zu jedem y ∈ B gibt es hochstens
eine Losung der Gleichung f (x) = y.
f ist surjektiv ⇐⇒ Zu jedem y ∈ B gibt es mindestens
eine Losung der Gleichung f (x) = y.
f ist bijektiv ⇐⇒ Zu jedem y ∈ B gibt es genau
eine Losung der Gleichung f (x) = y.
Wir setzen R+ = {x ∈ R : x ≥ 0} und definieren
f1 : R→ R, f2 : R+ → R, f3 : R→ R+, f4 : R+ → R+

Mengen und Abbildungen 25
samtlich durch die Vorschrift fi(x) = x2, i = 1, . . . ,4. Dann ist
f1 weder injektiv, noch surjektiv,
f2 injektiv, aber nicht surjektiv,
f3 nicht injektiv, aber surjektiv,
f4 bijektiv.
Definition. Seien f : A → B und g : B →C Abbildungen. Die Abbildung
g◦ f : A →C, (g◦ f )(x) = g( f (x))
heißt Komposition (auch: Hintereinanderschaltung) von f und g.
Wenn f , g : R→ R durch f (x) = x2 und g(y) = 3+ y gegeben sind, so ist
(g◦ f )(x) = g(x2) = 3+ x2,
( f ◦g)(x) = f (3+ x) = (3+ x)2.
Wichtige Beispiele von Mengen sind die Zahlenbereiche. Die naturliche Zahlen
N := {0,1,2,3 . . .} stehen hierbei am Anfang. Darauf kann man eine Verknupfung
namens Addition definieren, d.h., eine Abbildung von N×N → N definieren, in-
dem jedes Paar naturlicher Zahlen (a,b) in ihre Sume a+ b abgebildet wird. Das
zeigt zunachst, dass die naturlichen Zahlen abgeschlossen der Addition gegenuber
sind, weil a+ b wiederum eine naturliche Zahl ist. Diese Addition erfult weitere
Eigenschaften, und zwar:
(i) Es existiert ein Element e so dass e+ a = a+ e = a fur alle a ∈ N. Wir
wissen sogar, wer e in diesem Fall ist: e ist die Null. Wir sagen, dass die
Null das (!) neutrale Element der Addition von naturlichen Zahlen ist.
(ii) Seien a,b,c drei naturliche Zahlen. Es gilt (a+b)+c= a+(b+c). D.h.,
wenn man drei (oder mehr) naturliche Zahlen zu addieren hat, ist es egal,
wie man diese gruppiert. Die Addition ist also assoziativ.
Das heißt, wir haben eine Menge (namlich N), worauf wir eine Verknupfung
definiert haben (die ubliche Addition +), welche bestimmte Regeln erfullt (die
Existenz eines neutralen Elements und die Assoziativitat). Wir betrachten dann das
Paarchen (N,+), das diese Eigenschaften hat, und wir sagen, dassN zusammen mit
der soeben eingefuhrten Verknupfung + ein Monoid bildet.
Neben (i) und (ii) konnen wir andere Gesetze an (N,+) erkennen, zum Beispiel
die wohlbekannte Kommutativitat:
(iii) Fur alle a,b ∈ N gilt: a+b = b+a.
Diese durch (i) und (ii) gegebene Monoid-Struktur lasst sich abstrahieren: Ein
Paar (M,∗) wird Monoid genannt, wenn ∗ eine Verknupfung1 auf die Menge M ist,
1D.h. eine Abbildung ∗ : M×M → M.

26 Abschnitt 3
welche ein neutrales Element besitzt und assoziativ ist. Die Abgeschlossenheit von
∗ muss naturlich auch gelten. Gilt fur ∗ das kommutative Gesetz (iii), dann heißt
das Monoid kommutativ.
Andere Strukturen lassen sich auch auf eine Menge M erklaren. Zum Beispiel
konnen wir zu (i) und (ii) noch eine dritte Eigenschaft verlangen:
(iv) Zu jedem Element a ∈ M existiert ein Element b ∈ M so dass a+b = e.
Das zu a so definierte Element b :=−a heißt das Inverse von a (bezuglich +).
Diese Eigenschaft ist nicht mehr an den naturlichen Zahlen mit der ublichen
Addition zu erkennen: Zu 5 existiert keine naturliche Zahl x so dass 5+ x = 0.
Das ist bloß der Fall fur die ganze Zahlen zusammen mit der Addition, d.h. (Z,+),wobei
Z= {. . .−4,−3,−2,−1,0,1,2,3,4, . . .}bezeichnet. Da die Eigenschaften (i), (ii) und (iv) erfullt sind, sagt man, dass (Z,+)eine Gruppe ist. Da (iii) auch gilt, ist die Gruppe (Z,+) kommutativ oder abelsch2
gennant.
Hier muss man schon vorsichtig vorgehen: Wenn man die abelsche Gruppe
(Z,+) betrachtet, ist im Prinzip die Rechnung 67− 9 nicht definiert, denn wir
durfen nur”+” nehmen. Die Bedeutung von 67−9 ist eigentlich
67+(−9),
wobei −9 das Inverse von 9 bezeichnet; D.h., wir addieren 67 und −9 auf, und
nach der Definition von + bekommen wir 58 als Ergebnis.
Wir konnen auch die Multiplikation betrachten: Genauso sind (N, ·) und (Z, ·)kommutative Monoide, wobei diesmal die 1 das neutrale Element ist. Betrachtet
man die Menge der rationalen Zahlen
Q :={m
n: m ∈ Z,n ∈ N\{0}
},
kann man sich sofort uberlegen, dass z.B. (Q \ {0}, ·) eine abelsche Gruppe ist.
Insbesondere hat jedes von 0 verschiedenen Element a in Q ein (multiplikatives)
Inverses, das mit a−1 oder 1a
bezeichnet wird. Dass die Null ausgeschlossen werden
muss sollte uns nicht uberraschen: Immer wieder haben wir gehort”durch 0 darf
man nicht teilen”.
Soweit haben wir die Addition und die Multiplikation als Verknupfungen auf
verschiedene Mengen gesehen, allerdings immer im Einzelnen betrachtet. Wurde
dann nicht so eine Struktur wie (Z,+, ·) existieren? In der Tat! Wir sehen sofort:
Bezuglich der Addition erfullt Z die Axiome (i)–(iv) von abelscher Gruppe; und
bezuglich der Multiplikation sind (i) bis (iii) erfullt; mit anderen Worten, (Z,+) ist
2Nach dem norwegischen Mathematiker N.H. Abel (1802–1829).

Mengen und Abbildungen 27
eine abelsche Gruppe und (Z, ·) ein kommutatives Monoid. Das Einzige, das uns
fehlt, ist”+” mit
”·” zusammenzubringen (d.h. es fehlt uns noch eine Regel, die
besagt, wie die beiden Verknupfungen miteinander vertraglich sind): Das tut das
sogenannte Distributivgesetz:
(v) Fur alle x,y,z ∈ Z gilt: x · (y+ z) = x · y+ x · z.
Man sagt, dass (Z,+, ·) mit den entsprechenden Axiomen (i)–(v) ein kommutati-
ver3 Ring, oder fur uns einfach nur ein Ring, ist.
Es ist zu beachten, dass in Z nicht jedes Element ein Inverses bezuglich der
Multiplikation hat. Zum Beispiel: Die 5 hat kein Inverses bezuglich”·”: Was ist
die ganze Zahl x so dass 5 · x = 1 gilt? Unsere naturliche Antwort ist x = 15, aber
15
ist keine ganze Zahl! Die einzigen ganzen Zahlen, die so ein inverses Element
bezuglich der Multiplikation4 besitzen, sind 1 und −1. Es gibt deshalb so wenig,
weil (Z, ·) nur ein Monoid ist, aber keine Gruppe. Deswegen hat nicht jedes Ele-
ment ein Inverses (einige schon, namlich 1 und −1, wie soeben gesagt, aber nicht
alle!)
Dieses Phanomen tritt nicht mehr fur Q oder fur R auf: In diesen Zahlenberei-
chen hat jedes Element, das von der 0 verschieden ist, ein multiplikatives Inverses,
weil doch sowohl (Q\{0}, ·) als auch (R\{0}, ·) abelsche Gruppen sind. Sie sind
Beispiele von Korpern:
Definition. Eine Menge K 6= /0 zusammen mit zwei Verknupfungen + : K ×K →K, die Addition genannt wird, und · : K×K → K, die Multiplikation genannt wird,
heißt Korper, wenn:
(a) (K,+) eine abelsche Gruppe ist (d.h. erfullt die Eigenschaften (i) bis (iv)
von oben, wobei mit 0K , oder einfach 0, das neutrale Element bezuglich
der Addition bezeichnet wird)
(b) (K \ {0}, ·) eine abelsche Gruppe ist (d.h. erfullt die Eigenschaften (i) bis
(iv) von oben, wobei mit 1K , oder einfach 1, das neutrale Element bezuglich
der Multiplikation bezeichnet wird)
(c) das Distributivgesetz (v) gilt.
Grob gesprochen, ein Korper K ist ein Ring bei dem zusatzlich alle von 0K
verschiedenen Elementen ein multiplikatives Inverses besitzen.
Der nachste Abschnitt ist dem Korper der reellen Zahlen (R,+, ·) gewidmet.
Wir werden in diesem noch ein weiteres wichtiges Beispiel vom Korper kurz vor-
stellen, namlich den Korper C der komplexen Zahlen. Eine komplexe Zahl ist ein
Ausdruck der Form
z = a+bi mit a,b ∈ R und i :=√−1.
3weil die Multiplikation kommutativ ist.4Oft auch multiplikatives Inverses genannt, um es zu dem additiven Inversen zu unterscheiden.

28 Abschnitt 3
Dabei heißt a :=Re(z) der Realteil von z und b := Im(z) der Imaginarteil von z. Be-
achten Sie, dass sowohl Re(z) als Im(z) definitionsgemaß reelle Zahlen sind. Die
imaginare Einheit i hat die Eigenschaft, dass i2 =−1 ist. Daruber hinaus stimmen
zwei komplexe Zahlen a+bi und c+di genau dann uberein, wenn Real- und Ima-
ginarteil ubereinstimmen, d.h., wenn a= c und b= d gilt. Die Rechnenoperationen
von R lassen sich sofort auf C verallgemeinern:
(a+bi)+(c+di) := (a+ c)+(b+d)i
(a+bi) · (c+di) := ac+(ad+bc)i+bdi2 = (ac−bd)+(ad+bc)i.
Eine komplexe Zahl z = a+ bi lasst sich einem Punkt (a,b) auf der Ebene R2
zuordnen. Deswegen ist es manchmal von der komplexen Zahlenebene die Re-
de. Man uberpruft leicht, dass C mit den soeben definierten Verknupfungen einen
Korper bildet: Das neutrale Element bezuglich der Addition ist
0C = 0 = 0+0i,
denn z+0 = z fur alle z ∈ C, und bezuglich der Multiplikation ist
1C = 1 = 1+0i,
denn z ·1 = z fur alle z ∈ C. Das additive Inverse einer komplexen Zahl z = a+bi
ist −z =−a+(−b)i=−a−bi, und das multiplikative Inverse einer von 0 = 0+0i
verschiedenen komplexen Zahl z = a+bi ist aa2+b2 +
−ba2+b2 i, denn
(a+bi) ·( a
a2 +b2+
−b
a2 +b2i)=
a2 +b2
a2 +b2+
−ab+ab
a2 +b2i = 1+0i = 1.
Eine wichtige Operation auf C ist die komplexe Konjugation: Die Zahl
a+bi := a−bi
wird die zu a+bi komplex konjugierte Zahl genannt. Die reelle Zahl
|a+bi| :=√
a2 +b2
nennt man den Betrag von a+bi.
Die wichtigste Eigenschaft bei C ist, dass komplexe Zahlen das Paradebeispiel
eines algebraisch abgeschlossenen Korpers sind; das heißt, der folgende Satz gilt:
Satz 3.1 (Fundamentalsatz der Algebra). Seien n ∈ N mit n ≥ 1 und komplexe
Zahlen ξ0,ξ1, . . . ,ξn. Jede Gleichung der Form
xn +ξn−1xn−1 +ξn−2xn−2 + . . .+ξ2x2 +ξ1x+ξ0 = 0
besitzt mindestens eine Losung in C.
Denken wir zum Beispiel an die Gleichung x2 + 1 = 0. Sie hat keine reellen
Losungen, doch aber zwei komplexe, namlich sowohl i als auch −i. Auf einen
Beweis des Satzes 3.1 mussen wir (leider) verzichten.

ABSCHNITT 4
Angeordnete Korper. Die reellen Zahlen
Man betrachtet ein �, dessen Seiten der Lange 1 sind. Nach dem Satz von
Pythagoras ist es klar, dass die Lange der Diagonalen√
2 ist. In jener Zeit war eine
große Kontroverse, ob diese Zahl rational war. Die Pythagoreer fanden die Losung,
die wir jetzt als Satz formulieren.
Satz 4.1. Es gilt:√
2 /∈Q.
Beweis. Durch Widerspruch. Angenommen doch, also, angenommen es existier-
ten m ∈ Z und n ∈N\{0} so dass√
2 =m
n.
OBdA1 konnen wir annehmen, dass der Bruch mn
in gekurzter Form ist (d.h. dass
m und n keine gemeinsame Teiler in Z außer der Eins haben, oder anders gesagt,
dass m und n teilerfremd sind). In der obigen Gleichung kann man quadrieren, und
nach einer leichten Umformung folgt
m2 = 2n2.
Damit ist m2 gerade, und dann muss m auch gerade sein, d.h., wir durfen schreiben
m = 2m fur ein m ∈ Z.
Einsetzen ergibt
4m2 = 2n2, oder anders geschrieben, n2 = 2m2.
Damit ist n2 gerade, also n muss gerade sein. Wir haben gezeigt: Sowohl m als
auch n sind gerade Zahlen, sie haben also 2 als gemeinsamen Teiler. Das ist ein
Widerspruch zur Tatsache, dass m und n teilerfremd sind. D.h., die Zahl√
2 kann
nicht rational sein. �
Ahnliches kann man bei√
3,√
5,√
7 . . . machen. Auch Zahlen wie π fallen
nicht innerhalb von Q. Die rationalen Zahlen reichen also nicht, um die Natur zu
erklaren. Ein neuer Zahlenbereich muss eingefurt werden: Die reellen Zahlen.
Wir haben schon gesehen, dass auf R, so wie auf Q und auf C, die Struktur
vom Korper definiert werden kann. Nun werden wir eine weitere gemeinsame Ei-
genschaft zwischen Q und R untersuchen: In beiden Fallen konnen wir vernunftig
1Ohne Beschrankung der Allgemeinheit.

30 Abschnitt 4
eine Ordnungsrelation definieren, im Gegensatz zu beispielsweise der komplexen
Zahlen. Der Abschnitt wird verabschiedet mit der Eigenschaft, die R wesentlich
anders von Q macht: Die archimedische Eigenschaft.
Seien M, M′ Mengen. Eine Teilmenge R von M ×M′ nennt man auch eine
Relation zwischen M und M′; im Fall M′ = M nennen wir R eine Relation auf M.
Wir kennen viele solcher Relationen, z.B. fur M = M′ = R die”Kleiner-gleich-
Beziehung“
R = {(x,y) ∈ R×R : x ≤ y}.Die
”Kleiner-gleich-Beziehung“ ein ein typisches Beispiel fur eine Ordnungs-
relation:
Definition. Man nennt eine Relation R auf einer Menge M eine Ordnungsrelation,
wenn folgende Bedingungen fur alle x,y,z ∈ M erfullt sind:
(a) (x,x) ∈ R fur alle x ∈ M, d.h., R ist symmetrisch,
(b) (x,y) ∈ R und (y,x) ∈ R =⇒ x = y, d.h., R ist antisymmetrisch,
(c) (x,y) ∈ R, (y,z) ∈ R =⇒ (x,z) ∈ R, d.h., R ist transitiv.
Suggestiv werden wir x � y statt (x,y) ∈ R schreiben. Eine Ordnungsrelation R
heißt total wenn fur jede x,y ∈ M gilt (x,y) ∈ R oder (y,x) ∈ R, also x � y oder
y � x. (Mit anderen Worten, alle Elementen aus M sind vergleichbar.)
Eine total angeordnete Menge ist ein Paar (M,�), wobei M eine nicht-leere
Menge und � eine totale Ordnungsrelation sind.
Sei K ein Korper und � eine totale Ordnungsrelation, so dass fur alle x,y,z gilt
(a) Monotonie der Addition: Aus x � y folgt x+ z � y+ z;
(b) Monotonie der Multiplikation: Aus x � y und 0 � z folgt xz � yz.
So heißt K ein angeordneter Korper bezuglich �. Wir schreiben (K,�). Diese
Monotonieaxiomen gewahrleisten die Kompatibilitat der Ordnung mit der Korper-
struktur. Aus denen folgen die ublichen Regeln des Umgehens mit Ungleichungen,
die uns seit langem schon vertraut sind, im folgenden Satz zusammengefasst. Wir
merken, dass wir x ≺ y schreiben, wenn x � y und x 6= y gilt. Oft verwenden wir
y � x bzw. y ≻ x statt x � y bzw. x ≺ y. Die obige Monotonieaxiome gelten trivia-
lerweise noch, wenn man � durch ≺ ersetzt. Weitere Eigenschaften sind:
Satz 4.2. Sei (K,�) ein angeordneter Korper. Fur alle x,y,z,v,w ∈ K gilt:
(a) Aus x � y und v ≺ w folgt x+ v ≺ y+w.
(b) Aus x � y folgt −x �−y.
(c) Aus x � y und z � 0 folgt xz � yz.
(d) Es ist x2 � 0, also x2 ≻ 0 wenn x 6= 0. Insbesondere ist 1 = 12 ≻ 0.
(e) Aus x ≻ 0 folgt 1/x ≻ 0.
(f) Aus 0 ≺ x � y folgt 1/x � 1/y.

Angeordnete Korper. Die reellen Zahlen 31
Die Beweise dieser Rechenregeln sind dem Leser als Ubungsaufgabe uberlas-
sen.
Ein Element x eines angeordneten Korpers (K,�) heißt positiv, falls x ≻ 0 ist,
und negativ, falls x ≺ 0 ist. Ferner, fur x ∈ K heißt
|x| :={
x, falls x � 0
−x, falls x ≺ 0.
der (Absolut-)Betrag von x.
Satz 4.3. Der Betrag eines elements x ∈ K besitz folgende Eigenschaften:
(a) |x|= max(x,−x), d.h., |x| ist von x und −x die großte Zahl.
(b) |x|= |− x|;(c) Es ist |x| � 0, und es gilt genau dann |x|= 0, wenn x = 0 ist.
(d) Es gilt |xy|= |x||y|.(e) Es gilt |xy−1|= |x||y|−1, falls y 6= 0.
Beweis. (a), (b) und (c) folgen direkt aus der Definition.
(d) Falls x,y � 0 gilt, dann ist die Aussage trivial. Sei nun x = −x′ mit x′ � 0 und
y � 0. Dann folgt
|xy|= |(−x′)y|= |− (x′y)|= |x′y|= |x′||y|= |− x′||y|= |x||y|.Die anderen Falle folgen analog.
(e) Die Behauptung folgt aus
|x|= |xy−1y|= |xy−1||y|.�
Außerdem sind folgende Ungleichungen von erheblicher Bedeutung:
Satz 4.4. Sei (K,�) ein angeordneter Korper, seien x,y ∈ K. Dann gilt
|x+ y| � |x|+ |y| und |x− y| �∣∣∣|x|− |y|
∣∣∣.
Beweis. Wegen x � |x| und y � |y| ist x+ y � |x|+ |y|. Analog folgt aus −x � |x|und −y � |y|, dass −(x+ y)� |x|+ |y|. Insgesamt erhalten wir
|x+ y|= max{x+ y,−(x+ y)} � |x|+ |y|und damit ist die erste Ungleichung bewiesen. Aus dieser ergibt sich
|x|= |(x− y)+ y| � |x− y|+ |y| =⇒ |x|− |y| � |x− y|und nach Vertausch von x und y erhalt man auch
|y|= |− y|= |(x− y)− x| � |x− y|+ |x| =⇒ −(|x|− |y|)� |x− y|,
woraus sich die Ungleichung |x− y| �∣∣∣|x|− |y|
∣∣∣ ergibt. �

32 Abschnitt 4
Es ist zweckmaßig, den Korper K durch Hinzufugen von einem kleinsten −∞und einem großten Element ∞ mit −∞ 6= ∞ zu einer Menge K := K ∪{−∞,∞} zu
vergroßern so dass
−∞ � x � ∞
fur alle x ∈ K gilt. Fur das Rechnen mit den neuen Elementen erweitern wir die
Korperverknupfungen wie folgt:
(a) x+∞ := ∞+ x := ∞ fur alle x ∈ K, x 6=−∞.
(b) x+(−∞) := (−∞)+ x :=−∞ fur alle x ∈ K, x 6= ∞.
(c) x ·∞ := ∞ · x := ∞, x · (−∞) := (−∞) · x :=−∞ fur alle x ∈ K, x ≻ 0.
(d) x ·∞ := ∞ · x :=−∞, x · (−∞) := (−∞) · x := ∞ fur alle x ∈ K, x ≺ 0.
(e) x∞ := x
−∞ := 0 fur alle x ∈ K.
Die Summen ∞+(−∞) und (−∞)+∞ und die Produkte 0 · (±∞), (±∞) · 0 und±∞∞ , ±∞
−∞ sind hierzu nicht definiert!
Seien a,b Elemente des angeordneten Korpers K mit a � b. Dann heißen
(a) [a,b] := {x ∈ K | a � x � b} das abgeschlossene Intervall,
(b) ]a,b[ := {x ∈ K | a ≺ x ≺ b} das offene Intervall,
(c) [a,b[ := {x ∈ K | a � x ≺ b} und
(d) ]a,b] := {x ∈ K | a ≺ x � b} die halboffenen Intervalle,
die durch die Intervallgrenzen a und b bestimmt sind. Die Differenz b− a heißt
die Lange des Intervalls. Alle diese heißen beschranke Intervalle. Falls wir in K
die Elemente −∞ oder ∞ als Intervallgrenzen betrachten, so sprechen wir von un-
beschrankten Intervallen. Beschrankte Intervalle sind beschrankte Mengen im fol-
genden Sinne:
Definition. Sei K ein angeordneter Korper. Sei A eine nicht-leere Teilmenge von
K.
(a) A heißt nach oben beschrankt, wenn es ein S ∈ K gibt mit x � S fur alle
x ∈ A. Die Zahl S heißt eine obere Schranke von A in K.
(b) A heißt nach unten beschrankt, wenn es ein s ∈ K mit x � s fur alle x ∈ A
gibt. Die Zahl S heißt dann eine untere Schranke von A in K.
(c) Wenn A nach oben und nach unten beschrankt ist, nennen wir sie be-
schrankt.
(d) Ist A nach oben beschrankt und existiert eine kleinste obere Schranke x∈K
von A, dann heißt x das Supremum von A. Wir schreiben x = sup(A). Mit
anderen Worten
sup(A) := min{S ∈ K | S ist obere Schranke von A}.
Gilt x ∈ A, dann heißt x das Maximum von A; Wir schreiben max(A) = x.

Angeordnete Korper. Die reellen Zahlen 33
(e) Ist A nach unten beschrankt und existiert eine großte untere Schranke x∈K
von A, dann heißt x das Infimum von A. Wir schreiben x = inf(A). Mit
anderen Worten
inf(A) := max{s ∈ K | s ist untere Schranke von A},Gilt x∈ A, dann heißt x das Minimum von A, und wir schreiben min(A) = x.
Beispiel. (R,≤) ist ein angeordneter Korper. Sei A:=[0,1[⊂ R. Das Intervall ist
nach oben beschrankt: Die Elemente in
{x ∈ R : x ≥ 1}sind die oberen Schranken von A. Die kleinste obere Schranke ist daher 1, aber
1 /∈ A. Deswegen ist 1 das Supremum von A, aber kein Maximum.
Das Intervall A ist auch nach unten beschrankt: In der Tat ist
{x ∈ R : x ≤ 0}die Menge der unteren Schranken von A. Die großte dabei ist 0, und 0 ∈ A. Dann
ist 0 sowohl das Infimum von A als auch das Minimum. Da A sowohl nach unten
als auch nach oben beschrankt ist, ist A beschrankt.
Ein weiteres Paradebeispiel eines angeordneten Korpers ist Q zusammen mit
der durch ≤ gegebene Ordnungsrelation. Es ist doch ein erhebliches Beispiel,
das allerdings einen kleinen”Schonheitsfehler” enthalt; Es ist nicht ordnungs-
vollstandig im folgenden Sinne:
Satz 4.5. Nicht jede Teilmenge aus Q, die nach oben beschrankt ist, besitzt ein
Supremum.
Beweis. Wir wissen, dass kein x ∈ Q existiert mit x2 = 2. Nun betrachten wir die
Menge
M := {x ∈Q : x2 ≤ 2}= {x ∈Q : x2 < 2}.Offensichtlich ist M eine nicht-leere Teilmenge von Q, die nach oben beschrankt
ist: Die Menge aller oberen Schranken ist
N = {y ∈Q : y > 0 und y2 > 2}.Zu zeigen ist nun, dass N kein kleinstes Element enthalt. Mit anderen Worten, zu
zeigen ist, dass fur jedes y∈N eine rationale Zahl z in N mit z< y gefunden werden
kann. Zu jedem y ∈Q, y > 0 setzen wir
z := y− y2 −2
y+2
∗=
2y+2
y+2
Quadrieren liefert
z2 −2∗∗=
2(y2 −2)
(y+2)2.

34 Abschnitt 4
Falls y ∈ N, so gilt y2 −2 > 0 nach der Definition von N. Dann folgt 0 < z < y aus
der Gleichung ∗, und z2 > 2 aus ∗∗. Daher ist z in N fur jedes y ∈ N und damit
kann M kein Supremum haben. �
Diese Eigenschaft, die gerade bei Q fehlt, charakterisiert den Korper der reellen
Zahlen:
Definition. Sei (K,+, ·) ein angeordneter Korper, der das Vollstandigkeitsaxiom
erfullt, namlich
jede nach oben beschrankte Teilmenge A 6= /0 von K besitzt ein Supremum.
Dann heißt K der Korper der reellen Zahlen (oder auch die Zahlengerade). Wir
bezeichnen es mit R.
Die Existenz von R kann man konstruktiv beweisen. Ferner stimmen alle
moglichen Mengen von reellen Zahlen im Wesentlichen, d.h, bis auf Identifikati-
on, uberein (vgl. zahlreiche Literatur).
Der Korper C der komplexen Zahlen ist im Gegensatz zu R nicht angeordnet:
Satz 4.6. Fur den Korper C lasst sich keine totale Anordnung angeben.
Beweis. Durch Widerspruch. Angenommen doch, d.h., angenommen es existierte
eine totale Anordnung � von C. Aus Satz 4.2(d) gilt 1 ≻ 0. Auf der anderen Seite
ist −1 = i2 und nach 4.2(d) ist dann −1 ≻ 0, was nach 4.2(b) gleichbedeutend mit
1 ≺ 0 ist. Widerspruch! �
Wir schliessen den Abschnitt mit zwei wichtigen Eigenschaften der reellen
Zahlen, namlich die Archimedische Eigenschaft und die Tatsache, dass Q dicht
in R ist. (Weitere Eigenschaften von R, wie z.B. die Existenz der Wurzel, werden
dem interessierten Leser anvertraut bzw. vorausgesetzt.)
Satz 4.7 (Archimedische Eigenschaft). Fur je zwei Zahlen x,y ∈ R mit x,y > 0
existiert eine naturliche Zahl m mit
mx > y.
Insbesondere ist N in R nicht nach oben beschrankt.
Beweis. Durch Widerspruch. Angenommen, dass es mx ≤ y fur alle m ∈ N gelte.
Dann ware y eine obere Schranke fur die Menge
M := {mx : m ∈ N}.Nach dem Vollstandigkeitsaxiom von R existiert z := supM . Es ist dann z−x < z,
also z− x ist keine obere Schranke mehr fur M und es existiert ein m ∈ N mit
z− x < mx, d.h., mit z < (m+1)x, was die Definition von z widerspricht. �

Angeordnete Korper. Die reellen Zahlen 35
Aus dem Satz 4.7 folgt: Ist x ∈ R, x ≥ 0, so existiert eine Zahl m ∈ N mit
m ≤ x < m+ 1. Ist x < 0, so gibt es eine Zahl m ∈ N mit m < −x ≤ m+ 1, oder,
anders geschrieben, −(m+1) ≤ x < −m. D.h., zu einer beliebigen reellen Zahl x
gibt es eine eindeutig bestimmte ganze Zahl [x] so dass [x]≤ x < [x]+1. Sie heißt
der ganze Teil von x. Zum Beispiel ist [π] = 3 und [−π] =−4.
Der ganze Teil induziert eine Abbildung R→R, x 7→ [x], die den Name Gauß-
Klammer, oder auch Gauß-Symbol bekommt.
Zum Schluss erwahnen wir noch die wichtige Feststellung, dass zwischen zwei
reellen Zahlen immer eine rationale Zahl zu finden ist.
Satz 4.8. Fur alle x,y∈R mit x< y existiert ein q∈Q mit x < q < y. Insbesondere
ist Q dicht in R, d.h.
fur alle x ∈ R und alle ε ∈R,ε > 0 existiert ein q ∈Q mit q ∈ ]x− ε,x+ ε[.
Beweis. Wir suchen eine rationale Zahl mn
mit x < mn< y und mussen hierfur m,n
geeignet wahlen. Wir unterscheiden drei Falle:
(a) 0 ≤ x < y: Wegen Satz 4.7 existiert ein n ∈ N mit
n(y− x)> 1.
Sei m := min{p ∈N : nx < p}. Dann ist nx < m und m−1 ≤ nx. Also folgt
m = (m−1)+1 ≤ nx+1 < nx+n(y− x) = ny.
Es ergibt sich nx < m < ny und daher gelten die gewunschten Ungleichun-
gen x < mn< y.
(b) x < y ≤ 0: Wir betrachten 0 ≤ −y < −x. Nach dem bisher Bewiesenen
existiert ein w ∈Q mit −y < w <−x. Nun wahlen wir q =−w. Dann gilt
x < q < y.
(c) x < 0 < y: der Fall ist trivial, da fur q = 0 ∈Q gilt x < q < y.
�


ABSCHNITT 5
Folgen reeller Zahlen (I): Konvergenz
Nach dem Induktionsprinzip machen wir jetzt unsere nachste mathematische
Erfahrung mit der Unendlichkeit. Folgen reeller Zahlen stehen am Anfang der In-
finitesimalrechnung. Ihre genauere Betrachtung fing mit D’Alembert und Cauchy
an. Unsere Sicht von Folge als Sequenz, wie z.B. die Folge ungerader naturlichen
Zahlen 1,3,5, . . . lasst sich als Abbildung prazisieren:
Eine Folge reeller Zahlen mit Startwert s0 ∈N ist eine Abbildung
f : {n ∈ N : n ≥ s0} −→R.
Das Bild f (n) von n heißt das n-te Glied der Folge, und wird mit an bezeich-
net. So wird die Folge mit (an)n≥s0bezeichnet. Oft ist s0 = 0, und dann schreibt
man (an)n∈N. Ist der Startwert anzunehmen oder unerheblich, wird eine Folge ein-
fach (an) bezeichnet. Die Menge {an : n ≥ s0} nennt man oft das Folgenbild von
(an)n≥s0
Beispiele. (a) Sei die Folge f : N → R, n 7→ 2. Alle Glieder sind 2, d.h., das
Folgenbild ist {2}. Solche Art von Folgen nennen wir konstant.
(b) Sei die Folge g : N→ R mit
g(n) ={
1, falls n ungerade;
−1, falls n gerade.
Das n-te Glied lasst sich als an = (−1)n+1 schreiben. Das Folgenbild ist
dann {−1,1}.
(c) Folgen konnen rekursiv definiert werden. Sei
a1 := 0, a2 := 1, und an := an−1 +an−2 fur n ≥ 3.
Dann heißt (an)n≥1 = (0,1,1,2,3,5,8, . . .) die Fibonacci-Folge, die bei-
spielsweise eine erhebliche Bedeutung bei Wachstumsprozessen in der Na-
tur beschreibt.
Der entscheidende Begriff ist die Konvergenz einer Folge:
Definition. Eine Folge (an) heißt konvergent, wenn es ein a∈R gibt mit folgender
Eigenschaft:
Zu jedem (noch so kleinen reellen) ε > 0 existiert ein n0 ∈ Nmit |an −a|< ε fur alle naturlichen Zahlen n ≥ n0.

38 Abschnitt 5
Dieses Element a ist durch die Folge (an) eindeutig bestimmt:
Ware namtlich a′ ∈ R ein weiteres davon verschiedenes Element mit der ent-
sprechenden Eigenschaft, so ware
ε :=1
2|a−a′|> 0
und es gabe naturliche Zahlen n0 und n′0 mit
|an −a|< ε fur alle n ≥ n0
|an −a′|< ε fur alle n ≥ n′0.
Dann erhalt man mit einem n ≥ max(n0,n′0) den Widerspruch
|a−a′| = |a−an +an −a′| ≤ |an −a|+ |an−a′|< ε + ε = |a−a′|.
Das somit durch die konvergente Folge (an) gemaß obiger Definition eindeu-
tig bestimmte Element a heißt der Grenzwert oder der Limes der Folge (an). Wir
schreiben
a = limn→∞
an, auch kurz an → a,
und sagen, dass (an) gegen a konvergiert. Eine Folge (an) konvergiert gegen a
genau dann wenn die Folge (an−a) gegen 0 konvergiert. Eine konvergente Folge,
die gegen 0 konvergiert, heißt eine Nullfolge. Eine Folge, die nicht konvergiert,
heißt divergent.
Anmerkung. Die Zahl n0 ∈N in der Definition hangt selbstverstandlich von ε ab:
Je kleiner ε ist, desto großer hat man im Allgemeinen n0 zu wahlen. In diesem
Zusammenhang ist die folgende aquivalente Formulierung nutzlich:
|an −a|< ε ist gleichbedeutend mit an ∈ ]a− ε,a+ ε[.
Deswegen formuliert man anschaulicher die Bedingung der Definition so:
an liegt fur alle n ≥ n0 in der ε-Umgebung Uε(a) := ]a− ε,a+ ε[ von a.
Damit wird auch unmittelbar klar, dass man eine konvergente Folge in endlich
vielen Gliedern abandern darf, ohne an Konvergenz und Limes etwas zu andern.
Damit ist auch klar, dass der obige Beweis fur die Eindeutigkeit des Limes darauf
beruht, dass in den disjunten ε-Umgebungen von a und a′ nicht zugleich fast alle
Glieder der folge (an) liegen konnen.
Oft benutzt man in der Mathematik den Ausdruck fur fast alle. Damit ist ge-
meint, fur alle bis auf endlich viele. So konnen wir die Definition von Konvergenz
etwas umgangssprachlich umformulieren und sagen, dass die Folge (an) gegen a
konvergiert, wenn jede Umgebung von a fast alle an enthalt.

Folgen reeller Zahlen (I): Konvergenz 39
Wir illustrieren die Definition mit folgendem Beispiel. Sei (an) die Folge ge-
geben durch an =2n
2n+5. Wir beobachten, dass ihr Limes 1 sein konnte. Sei ε > 0
vorgegeben. Man muss eine naturliche Zahl n0 bestimmen, so dass fur alle n ≥ n0
die Ungleichung | 2n2n+5
−1| < ε gilt. Diese Ungleichung ist offensichtlich aquiva-
lent zu den Folgenden:∣∣∣∣2n−2n−5
2n+5
∣∣∣∣< ε ⇐⇒∣∣∣∣
−5
2n+5
∣∣∣∣< ε ⇐⇒ 5
2n+5< ε
Mit anderen Worten, es muss 5 < 2nε +5ε gelten, also n > 5−5ε2ε . Damit ist n0 zu
wahlen als
n0 =
[5−5ε
2ε
]+1
Zum Beispiel ist n0 = 23 fur ε = 0.1; fur ε = 0.01 ist n0 = 248.
Es ist hier anzumerken: Wir mussten den Grenzwert irgendwie erraten. Wir
werden sehen, dass dies manchmal schwierig ist. Cauchy schlug eine andere De-
finition fur konvergente Folgen vor, die wir heute Cauchy-Folgen nennen. Wir be-
trachten sie kurz im nachsten Abschnitt.
Beispiele. (a) Eine konstante Folge (an) mit Folgenbild {a} konvergiert of-
fenbar gegen a.
(b) Sei xn := 1n
fur alle n ≥ 1. Die Folge (xn) ist eine Nullfolge: Sei dazu ε >0 vorgegeben. Nach der Archimedischen Eigenschaft von R existiert ein
n0 ∈ N so dass εn0 > 1, d.h., n0 >1ε . Dann folgt fur jedes n ≥ n0, dass
|xn −0|= 1
n≤ 1
n0< ε.
(c) Sei yn := (−1)n fur n ∈ N. Dann ist (yn) divergent. Wir zeigen dies durch
Widerspruch. Angenommen, es existierte ein y ∈ R mit y = limn→∞ yn.
Ware y ≤ 0, dann gelte jedoch yn /∈ ]y−1,y+1[ fur alle geraden Zahlen
n, denn
|yn − y|= |1− y|= 1− y ≥ 1, fur n gerade.
Ware andererseits y > 0, dann sehen wir analog, dass yn /∈ ]y−1,y+1[ fur
alle ungeraden Zahlen n. Daher kann y nicht der Grenzwert von (yn) sein
und somit ist die Folge divergent.
Eine Folge (an) heißt nach oben (bzw. unten) beschrankt, wenn das Folgenbild
nach oben (bzw. unten) beschrankt ist. Eine Folge heißt beschrankt, wenn sie so-
wohl nach oben als auch nach unten beschrankt ist, d.h., wenn es ein M ∈ R gibt
so dass |an| ≤ M fur alle n ∈ N, d.h. fur alle Glieder, gilt.
Satz 5.1. Jede konvergente Folge (an)n≥s0ist beschrankt.

40 Abschnitt 5
Beweis. Sei ε = 1 vorgegeben. Dann existiert n0 ∈ N so dass an ∈ ]l −1, l+1[fur n ≥ n0. Außerhalb des Intervalls ]l −1, l+1[ befinden sich hochstens n0 − 1
Terme der Folge, d.h., eine endliche Menge, also eine beschrankte Menge. Da das
Intervall ]l−1, l +1[ auch beschrankt ist, sind wir fertig. �
Beispiel. Die Folge (zn) = (n)n∈N ist divergent: Das lasst sich durch Kontrapositi-
on trivial beweisen: Nach dem Satz 5.1 reicht es zu zeigen, dass die Menge N nicht
beschrankt ist; also, dass N nicht nach oben beschrankt ist, was schon in Satz 4.7
bewiesen wurde.
Grenzwerte lassen sich laut folgenden Satzen leicht betrachten:
Satz 5.2. Es gelten die folgenden Eigenschaften uber konvergente Folgen:
(i) Sei (an) eine beschrankte Folge und (bn) eine Nullfolge. Dann ist (an ·bn)eine Nullfolge.
(ii) Sei (an) eine konvergente Folge mit Grenzwert a 6= 0. Ist a > 0 (bzw. a < 0)
und nehmen wir ein α ∈ R mit 0 < α < a (bzw. a < α < 0), dann existiert
n0 ∈ N so dass an > α (bzw. an < α) fur alle n ≥ n0.
(iii) Ist (bn) eine konvergente Folge mit Grenzwert b 6= 0 und bn 6= 0 fur alle
n ∈ N, dann ist die Folge ( 1bn) beschrankt.
(iv) Ist (an) bzw. (bn) konvergent gegen a bzw. b mit an ≤ bn fur fast alle n,
dann gilt auch a ≤ b
Beweis.
Zu (i): Es existiert M > 0 mit |an| ≤ M fur alle n ∈N. Sei ε > 0 vorgegeben. Dann
gibt es ein n0 ∈ N so dass |bn − 0| = |bn| < εM
fur n ≥ n0 gilt. Dann ist
|anbn −0|= |anbn|= |an||bn|< M εM= ε fur alle n ≥ n0.
Zu (ii): Wir betrachten den Fall a > 0 (der andere folgt analog). Sei ε = a−α > 0.
Dann gibt es ein n0 ∈ N mit
an ∈ ]a− (a−α),a+(a+α)[ = ]α,2a−α[ fur n ≥ n0,
d.h., an > α fur n ≥ n0.
Zu (iii): Es folgt unmittelbar wenn man an durch 1bn
im Beweis von (ii) ersetzt.
Zu (iv): Zu jedem ε > 0 gibt es ein n0 ∈ N so dass fur n ≥ n0 gleichzeitig gilt
a− ε < an ≤ bn < b+ ε.
Daraus folgt a− b < 2ε und zwar fur beliebiges ε , was nur fur a− b ≤ 0
moglich ist.
�
Ahnlich wie (iv) in Satz 5.2 zeigt man folgendes Einschließungskriterium:

Folgen reeller Zahlen (I): Konvergenz 41
Satz 5.3 (Sandwich-Kriterium). Sei (an) eine Folge. Seien (xn) und (yn) konver-
gente Folgen mit gleichem Grenzwert, so dass xn ≤ an ≤ yn fur fast alle n. Dann ist
auch (an) konvergent mit limn→∞ an = limn→∞ xn = limn→∞ yn.
Beispiel. Die Folge ( 12n ) ist eine Nullfolge nach Satz 5.3, denn 0 ≤ 1
2n ≤ 1n. Ge-
nauso ist ((−1)n 1n) eine Nullfolge, denn −1
n≤ (−1)n 1
n≤ 1
n.
Satz 5.4. Seien (an)n≥s0und (bn)n≥s0
konvergente Folgen und c ∈R.
(i) Die folge (an±bn)n≥s0ist konvergent und es gilt
limn→∞
(an ±bn) = limn→∞
an ± limn→∞
bn.
(ii) Die folge (xn · yn)n≥s0ist konvergent und es gilt
limn→∞
(an ·bn) = limn→∞
an · limn→∞
bn.
(iii) Die folge (c ·an)n≥s0ist konvergent und es gilt
limn→∞
(c ·an) = c · limn→∞
an.
(iv) Falls (bn)n≥s0eine konvergente Folge mit Limes 6= 0 ist, dann gibt es ein
t0 ≥ s0 mit yn 6= 0 fur n ≥ t0. Die Folge (anbn)n≥t0 ist konvergent und es gilt
limn→∞
(an
bn
)=
limn→∞ an
limn→∞ bn
.
Beweis. Seien a := limn→∞ an und b := limn→∞ bn.
Zu (i): Wir betrachten die Folge (an + bn). Sei ε > 0 vorgegeben. Es existieren
n0,n′0 ∈ N mit
|an−a|< ε
2fur n ≥ n0 und |bn −b|< ε
2fur n ≥ n′0.
Sei nun N := max{n0,n′0}. Dann folgt fur n ≥ N, dass
|(an +bn)− (a+b)|= |an −a+bn−b| ≤ |an −a|+ |bn−b|< ε
2+
ε
2= ε.
So ist die Konvergenz der Summenfolge mit dem Limes a+ b erledigt.
Analog beweist man, dass (an −bn) gegen a−b konvergiert.
Zu (ii): Eine leichte Rechnung ergibt:
anbn −ab = anbn −anb+anb−ab = (an) · (bn −b)+b(an−a).
Die Folge (an) ist nach Satz 5.1 beschrankt, und b ist eine Konstante. Nach
dem Satz 5.2 (i) ist diese eine Nullfolge, und daraus folgt die Konvergenz
der Produktfolge mit dem Limes ab.
Zu (iii): Es folgt unmittelbar aus (ii), wenn man die konstante Folge (bn) mit bn = c
betrachtet.

42 Abschnitt 5
Zu (iv): Man pruft leicht nach:
an
bn
− a
b=
ban −abn
bbn
=
(1
bbn
)· (ban −abn).
Da (ban − abn) eine Nullfolge ist, und die Folge(
1bbn
)nach dem Satz
5.2(iii) beschrankt ist, folgt die Behauptung aus dem Satz 5.2 (i).
�
Beispiel. Sei (an)n∈N mit an =2n2+1
5n2+3n+1=
2+ 1
n2
5+ 3n+
1
n2
. Es gilt:
limn→∞
(2+
1
n2
)= lim
n→∞2+
(limn→∞
1
n
)2
= 2+0 = 2, und limn→∞
(5+
3
n+
1
n2
)= 5.
Schließlich erhalten wir mit Satz 5.4, dass
limn→∞
(2n2 +1
5n2 +3n+1
)= lim
n→∞
(2+ 1
n2
5+ 3n+ 1
n2
)=
limn→∞
(2+ 1
n2
)
limn→∞
(5+ 3
n+ 1
n2
) =2
5.
Wenn man sich die Folgen (yn) = ((−1)n)n∈N und (zn) = (n)n∈N genauer an-
schaut, stellt man zumindest heuristisch fest, dass diese auf verschiedene Arten
divergieren: Die Folge (zn) lauft gegen ∞, wahrend (yn) zwei bestimmten Wer-
te annimmt, namlich −1 und 1. Eine Formalisierung dieser Tatsachen liefert die
folgende Definition.
Definition. Sei (an) eine Folge. Sie heißt
(a) bestimmt divergent gegen ∞, wenn:
Zu jedem c ∈ R existiert ein n0 ∈ N so dass an > c fur alle n ≥ n0.
Wir schreiben dann limn→∞ an = ∞.
(b) bestimmt divergent gegen −∞, wenn:
Zu jedem c ∈ R existiert ein n0 ∈ N so dass an < c fur alle n ≥ n0.
Wir schreiben dann limn→∞ an =−∞.
Den Gebrauch von den Symbolen −∞ und ∞ haben wir in Abschnitt 4 gerechtfer-
tigt, indem wir die total angeordnete Menge R := R∪{−∞,∞} eingefuhrt haben.
Beispiele. (a) Die Folge (n)n∈N ist bestimmt divergent gegen ∞.
(b) Die Folge (−n)n∈N ist bestimmt divergent gegen −∞.
(c) Die Folge (−1)n ist divergent, aber nicht bestimmt divergent.
Die Folge (−1)n hat keinen Grenzwert; Es ist trotzdem unmittelbar klar: Wenn
wir gerade Zahlen n angeben, bekommen wir immer 1, anderenfalls −1; jeder Wert
hat ein ahnliches Verhalten als wenn er eine Art von Grenzwert ware. Definitions-
gemaß darf dies aber nicht sein.

Folgen reeller Zahlen (I): Konvergenz 43
Mit anderen Worten: Wenn wir die Teilfolge (−1)2n der Folge (−1)n nehmen,
konvergiert sie gegen 1, dementsprechend konvergiert die Teilfolge (−1)2n+1 ge-
gen −1. Die Folge (−1)n besitz naturlich keinen Grenzwert, allerdings spielen −1
und 1 dabei eine besondere Rolle: sie sind die Grenzwerte der erwahnten Teilfol-
gen, und werden Haufungspunkte der Folge (−1n)n∈N genannt. Wir prazisieren
nun diese Begriffe.
Sei (an)n≥s0eine Folge. Sei dazu (nk)k∈N eine Folge naturlicher Zahlen mit
s0 ≤ nk < nk+1 fur alle k ∈N. Dann heißt (ank)k∈N eine Teilfolge der Folge (an)n≥s0
.
Man sagt, dass α ∈ R ein Haufungspunkt der Folge (an) ist, wenn zu jedem ε > 0
unendlich viele n ∈ N existieren mit |an −α|< ε .
Dieses Verhalten kann auch bei ±∞ vorkommen. Dann heißt ∞ (bwz. −∞) ein
uneigentlicher Haufungspunkt der Folge (an), wenn zu jedem c ∈ R unendlich
viele n ∈ N existieren mit an > c (bzw. an < c.)
Jede Teilfolge einer konvergenten Folge konvergiert, und zwar gegen denselben
Grenzwert (!). Außerdem:
Satz 5.5. (i) Sei (an) eine Folge. Ist genau dann α ∈R ein Haufungspunkt der
Folge, wenn eine Teilfolge (ank) von (an) existiert, die gegen α konvergiert.
(ii) Sei (an) eine Folge. Ist ∞ (bwz. −∞) genau dann ein uneigentlicher
Haufungspunkt der Folge, wenn es eine Teilfolge (ank) von (an) gibt, die
bestimmt divergent gegen ∞ (bzw. gegen −∞) ist.
Beweis. Zu (i): Falls eine Teilfolge (ank) von (an) gegen α ∈ R konvergiert,
dann ist α trivialerweise ein Haufungspunkt der Folge (an). Sei umgekehrt α ein
Haufungspunkt der Folge (an). Wir konstruieren nun eine Folge naturlicher Zahlen
(nk) derart, dass
nk+1 > nk und |ank−α|< 1
kfur alle k ≥ 1.
Die Folge (ank) konvergiert dann gegen α , denn 1/k −→ 0. Da α ein Haufungs-
punkt von (an) ist, existiert ein n1 ∈ Z mit |an1−α|< 1. Angenommen wir haben
naturliche Zahlen n1, . . . ,nk, k ≥ 1 mit den gewunschten Bedingungen gefunden.
Da α auch ein Haufungspunkt von (an)n>nkist, existiert ein nk+1 ∈ Z mit
|ank+1−α|< 1
k+1und nk+1 > nk.
Der Beweis von (ii) verlauft analog und ist dem Leser als Ubungsaufgabe uberlas-
sen. �
Es stellt sich die Frage, wann Haufungspunkte immer existieren. Die Antwort
wird durch einen bekannten Satz der Analysis gegeben (der Satz von Bolzano-
Weierstraß). Dafur mussen wir zuerst den Begriff von Monotonie einer Folge
einfuhren. Das wird im nachsten Abschnitt geschehen.


ABSCHNITT 6
Folgen reeller Zahlen (II): Monotonie. Konvergenzkriterien
In diesem Abschnitt mochten wir Kriterien angeben, die uns erlauben sowohl
die Existenz von Haufungspunkten als auch die Konvergenz einer Folge reeller
Zahlen festzustellen. Das Wachstum einer Folge spielt dabei eine entscheidende
Rolle. Ein fur unsere Zwecke gutes Wachstumsverhalten wird durch die Monotonie
gekennzeichnet:
Definition. Sei (an)n≥s0eine Folge.
(i) (an)n≥s0heißt monoton fallend (bzw. monoton wachsend), wenn
an+1 ≤ an (bzw. an+1 ≥ an) fur alle n.
(ii) (an)n≥s0heißt streng monoton fallend (bzw. streng monoton wachsend),
wenn
an+1 < an (bzw. an+1 > an) fur alle n.
(iii) (an)n≥s0heißt monoton, wenn sie entweder monoton wachsend oder mo-
noton fallend ist.
Beispiel. Die Folge (1n)n≥1 ist streng monoton fallend. Die Folge (n2)n∈N ist streng
monoton wachsend. Die Folge ((−1)n)n∈N ist nicht monoton.
Der Satz 5.1 zeigt, dass jede konvergente Folge beschrankt ist. Die Umkehrung
gilt naturlich nicht, wie bereits die Folge ((−1)n)n∈N zeigt. Diese ist aber nicht
monoton; Fur monotone Folgen gilt doch die Umkehrung des Satzes 5.1:
Satz 6.1. Jede beschrankte, monotone Folge (an)n≥s0konvergiert, und zwar:
(i) eine wachsende gegen sup(A), wobei A := {an : n ∈N} das Folgenbild ist;
(ii) eine fallende gegen inf(A).
Beweis.
Zu (i): Sei s := sup(A). Da s die kleinste obere Schranke fur A ist, gibt es zu jedem
ε > 0 ein aN mit s− ε < aN . Damit folgt
s− ε < aN ≤ an ≤ s fur n > N.
Zu (ii): Dies kann analog gezeigt oder mittels der Folge (−an) auf (i) zuruck-
gefuhrt werden.
�

46 Abschnitt 6
Beispiel. Sei a> 1. Die Folge ( n√
a)n≥1 ist offenbar streng monoton fallend. Ferner
ist a1n > 1
1n = 1, also die Folge ist nach unten beschrankt und damit beschrankt.
Dann konvergiert sie nach dem Satz 6.1, und zwar gegen inf({an : n ≥ 1}) = 1.
Beispiel. Wir mochten zeigen: Fur 0 ≤ a ≤ b gilt n√
an +bn → b. Es gilt
b ≤ n√
an +bn ≤ bn√
2.
Nach dem letzten Beispiel istn√
2 → 1, somit ist die Aussage klar nach dem
Sandwich-Kriterium 5.3.
Beispiel. Sei (an)n≥1 die Folge gegeben durch an = (1+ 1n)n. Wir zeigen, dass
diese Folge konvergent ist, und geben eine obere Schranke fur ihren Grenzwert.
Zunachst uberlegt man durch direkte Rechnung, dass fur m,n ∈ N mit m < n gilt
1
mk
(m
k
)<
1
nk
(n
k
)≤ 1
k!≤ 1
2k−1fur k = 2,3, . . . ,n.
Dass die Folge beschrankt ist und 3 als obere Schranke hat, sieht man nach Ver-
wendung des binomischen Lehrsatzes und der obigen Ungleichungen:
an =n
∑k=0
(n
k
)1
nk
<n
∑k=0
1
k!
≤n
∑k=0
1
2k−1= 1+
1− 12n
1− 12
= 3− 1
2n−1
< 3.
Dass die Folge streng monoton wachsend ist, ist im Wesentlichen analog:
an =n
∑k=0
(n
k
)1
nk
<n
∑k=0
(n+1
k
)1
(n+1)k+
(n+1
n+1
)1
(n+1)n+1
=n+1
∑k=0
(n+1
k
)1
(n+1)k= an+1.
Aus dem Satz 6.1 folgt, dass die Folge konvergent ist.
Die Beziehung zwischen unbeschrankten und divergenten Folgen ist zu erwar-
ten:
Satz 6.2. (i) Nicht jede divergente Folge (an)n≥s0ist unbeschrankt.

Folgen reeller Zahlen (II): Monotonie. Konvergenzkriterien 47
(ii) Jede bestimmt divergente Folge (an)n≥s0ist unbeschrankt. Falls an → ∞,
dann ist sie nach unten beschrankt. Falls an →−∞, dann ist sie nach oben
beschrankt
(iii) Jede nicht beschrankte monoton wachsende (bzw. fallende) Folge ist be-
stimmt divergent gegen ∞ (bzw. −∞).
Beweis.
Zu (i): Wie oben gezeigt ist die divergente Folge ((−1)n)n∈N beschrankt.
Zu (ii): Die Aussagen folgen unmittelbar aus der Definition.
Zu (iii): Wir betrachten den Fall monoton wachsend (der andere ist analog). Sei
M > 0. Da M keine obere Schranke der Folge nach (ii) sein kann, muss ein
n0 ∈ N existieren so dass an0> M. Da (an) monoton wachsend ist, gilt fur
n ≥ n0:
an ≥ an0> M,
und daher muss (an) bestimmt divergent gegen ∞ sein.
�
Als Anwendung beweisen wir die folgende Aussage:
Satz 6.3. Seien (an) eine monoton wachsende und (bn) eine monoton fallende Fol-
ge mit folgenden Eigenschaften:
(a) Es ist an ≤ bn fur alle n ∈ N.
(b) Es ist limn→∞(bn −an) = 0.
Dann gibt es genau eine reelle Zahl α mit an ≤ α ≤ bn fur alle n ∈ N.
Beweis. Die Folgen (an) und (bn) sind auch bescherankt, also auch konvergent.
Wegen 0 = lim(bn −an) = lim(bn)− lim(an) haben die Folgen (an) und (bn) den-
selben Grenzwert α . Aus der Monotonie dieser Folgen ergibt sich an ≤ α ≤ bn
fur alle n ∈ N. Dieses α ist auch eindeutig bestimmt: Angenommen, es existier-
te eine weitere solche Zahl α ′, so gelte |α −α ′| ≤ bn − an fur alle n und daher
notwendigerweise |α −α ′|= 0, d.h., α = α ′. �
Zwei Folgen (an) und (bn) wie in Satz 6 definieren eine Folge von abgeschlos-
senen Intervallen In := [an,bn], n ∈N, fur die
I0 ⊂ I1 ⊂ I2 ⊂ . . .⊂ In ⊂ In+1 ⊂ . . .
gilt und deren Langen eine Nullfolge bilden. Man nennt eine solche Folge von ab-
geschlossenen Intervallen eine Intervallschachtelung. Nach dem Satz gibt es genau
eine Zahl α , die in jedem der Intervalle In liegt. Diese Zahl α heißt die durch die
Intervallschachtelung definierte Zahl. Es ist
a0 ≤ a1 ≤ a2 ≤ . . .≤ α ≤ . . .≤ b2 ≤ b1 ≤ b0.

48 Abschnitt 6
Diese Uberlegungen fuhren zu der am Ende des Abschnittes 5 angekundigten
Frage, wann ist die Existenz von Haufungspunkten immer sichergestellt. Die ge-
naue Antwort ist folgendes Ergebnis.
Satz 6.4 (Bolzano-Weierstraß). Eine beschrankte Folge hat mindestens einen
Haufungspunkt, und daher hat eine konvergente Teilfolge.
Beweis. Sei (an) eine beschrankte Folge. Dann liegen alle Glieder in einem be-
schrankten Intervall [a,b]⊂ R. Zur Bestimmung eines Haufungspunktes von (an)konstruieren wir eine Intervallschachtelung [xn,yn], n ∈ N, derart, dass in jedem
Intervall dieser Folge unendlich viele Glieder der Folge (an) liegen. Dann ist die
durch diese Intervallschachtelung definierte Zahl α offenbar ein Haufungspunkt
von (an).Eine solche Intervallschachtelung geben wir mit dem sogenannten Intervallhal-
bierungsverfahren an. Dazu setzen wir x0 = x, y0 = y. Sind xn und yn gewahlt, so lie-
gen im Intervall [xn,yn] nach Konstruktion unendlich viele Glieder der Folge (an).Das gilt dann auch fur mindestens eines der beiden Teilintervalle [xn,(xn + yn)/2]und [(xn + yn)/2,yn], dessen Endpunkte wir dann fur xn+1 und yn+1 nehmen. Gilt
dies fur beide Teilintervalle, so nehmen wir der Eindeutigkeit halber die linke Half-
te. Wegen yn − xn = (y− x)/2n handelt es sich um eine Intervallschachtelung. �
Den Satz von Bolzano-Weierstraß haben wir betrachtet, um ein letztes Konver-
genzkriterium reeller Folgen beweisen zu konnen: das Cauchysche Konvergenz-
kriterium.
Die Definition von der Konvergenz einer Folge nutzt die Kenntnis ihres Grenz-
wertes aus: Wir sind gezwungen, die Ungleichung |an − a| < ε einzuschatzen,
wobei a der Grenzwert ist. Es gibt aber Folgen bei denen es schwierig oder sehr
schwierig ist, ihre Grenzwerte zu bestimmen:
Beispiel. Wir betrachten die Folge (an)n≥1 mit
an :=n
∑i=1
(−1)[(i−1)
2 ]1
i,
wobei [i/2] die Gauß-Klammer bezeichnet. Die ersten Glieder dieser Folge sind
a1 = 1, a2 = 1+1
2, a3 = 1+
1
2− 1
3, a4 = 1+
1
2− 1
3− 1
4, . . .
Es ist zunachst nicht mehr so direkt zu ersehen, ob diese Folge konvergiert. Wol-
len wir die Definition von Konvergenz anwenden, mussen wir den Limes—falls
er existiert—bestimmen. Ein erstes numerisches Experiment mit einem Rechner
zeigt, dass die Folge gegen 1.13 zu konvergieren scheint. In der Tat kann man mit
etwas fortgeschrittenen Techniken beweisen, dass die Folge gegen (π +2log2)/4
konvergiert.

Folgen reeller Zahlen (II): Monotonie. Konvergenzkriterien 49
Nach der Definition von Konvergenz und mit Hilfe eines Rechners und Geduld
beobachtet man, dass es fur ein vorgegebenes ε (hier ε = 0.058) ein letztes an (hier
a16) gibt, bei dem die Ungleichung |an −a|< ε verletzt ist. Das heißt, die n0 ∈ N,
die nach der Definition von Konvergenz existieren muss, so dass fur alle ε > 0
und alle n ≥ n0 die Ungleichung |an − a| < ε gilt, ist n0 = 17. Die Folge ist also
konvergent. Wer hatte es gedacht!
Ohne die Bestimmung des Grenzwertes im obigen Beispiel ware eine prazise
Einschatzung von |an−a|< ε fur jedes ε > 0 unmoglich gewesen! Cauchy kam auf
die folgende Idee: Man ersetze die Ungleichung |an−a|< ε durch |an−an+k|< εfur alle Nachfolgern an+k, mit k ≥ 1, von an:
Definition. Eine Folge (an)n≥s0heißt Cauchy-Folge, wenn:
Zu jedem ε > 0 existiert ein n0 ∈ N so dass
fur alle k ∈ N ist |an −an+k|< ε fur alle n ≥ n0.
Mit anderen Worten (um die Betrachtung zu vereinfachen):
Zu jedem ε > 0 existiert ein n0 ∈ N so dass |am −an|< ε fur m,n ≥ n0.
Beispiel. Sei (an)n≥1 die Folge aus dem letzten Beispiel. Fur ε = 0.11 ist die De-
finition von Cauchy-Folge fur alle n ≥ 17 erfullt. Genauso kann man zeigen, dass
die Definition fur jedes ε > 0 gilt, denn
|an −an+k|=∣∣∣
n+k
∑i=n+1
(−1)[(i−1)
2 ]1
i
∣∣∣≤ 1
n+1+
1
n+2+ . . .+
1
n+ k−→ 0.
Cauchy-Folgen sind schon (unbewusst!) bekannt:
Satz 6.5. Jede konvergente Folge (an) ist eine Cauchy-Folge.
Beweis. Ist l = limn→∞ an, dann existiert fur ε > 0 vorgegeben ein n0 ∈ N mit
|an − l|< ε
2fur n ≥ n0,
nach der Definition vom Limes. Seien nun m,n ∈ N mit m,n ≥ n0. Dann gilt
|am −an|= |am − l+ l −an| ≤ |am − l|+ |an− l|< ε
2+
ε
2= ε
und damit ist (an) eine Cauchy-Folge. �
In unserer Situation, namlich Folgen reeller Zahlen, gilt auch die Umkehrung
dank dem Vollstandigkeitsaxiom (das heißt, in R ist der Begriff”Cauchy-Folge”
gleichbedeutend zum Begriff”konvergente Folge”):
Satz 6.6.
(i) Jede Cauchy-Folge ist beschrankt.
(ii) Jede Cauchy-Folge ist konvergent.

50 Abschnitt 6
Beweis.
Zu (i): Fur vorgegebenes ε = 1 existiert n0 ∈N so dass |am−an|< 1 fur m,n≥ n0.
Insbesondere ist |am −an0|< 1. Dann gilt fur m ≥ n0:
am ∈ ]an0−1,an0
+1[.
Da der Rest der Terme endlich viele sind, sind wir fertig.
Zu (ii): Sei (an) eine Cauchy-Folge. Nach Satz 6.6 ist sie beschrankt. Nach dem
Satz von Bolzano-Weierstraß hat sie eine konvergente Teilfolge, sagen wir
(ank)k∈N. Sei l = limk→∞ ank
. Es ist zu zeigen, dass l = limn→∞ an ist: Sei
dafur ε > 0 vorgegeben. Da (an) eine Cauchy-Folge ist, existiert ein n0 ∈Nso dass
|am −an|(∗)<
ε
2fur m,n ≥ n0
Da die Teilfolge (ank) konvergent ist, muss auch ein k0 ∈ N existieren so
dass nk0≥ n0 und
|ank− l|
(∗∗)<
ε
2fur k ≥ k0
Dann gilt fur alle n ≥ n0
|an− l|= |an−ank0+ank0
− l| ≤ |an −ank0|+ |ank0
− l|(∗)+(∗∗)
<ε
2+
ε
2= ε.
�
Tatsachlich gilt die zweite Aussage in Q nicht: Die Folge
1,1.4,1.41,1.414,1.4142,1.41421, . . .
ist eine Cauchy-Folge (wegen |an −an+k|< 10−n), deren Glieder rationale Zahlen
sind, aber ihr Limes ist√
2 /∈Q.
Cauchy-Folgen werden wieder eine Rolle im nachsten Abschnitt bei der Be-
trachtung ein sehr spezielles Typus von Folgen spielen: Die Reihen.

ABSCHNITT 7
Folgen reeller Zahlen (III): Reihen
Sei (ak)k≥s0eine Folge reeller Zahlen. Eine Reihe reeller Zahlen ist eine Folge
reeller Zahlen (Sn)n≥s0mit
Sn := as0+as0+1 + . . .+as0+n.
Die Zahl ak heißt der k-te Term der Reihe. Die Zahl Sn heißt die n-te Partialsumme
der Reihe. Die Folge (Sn)n≥s0wird die Folge der Partialsummen gennant. Um die
Bezeichnung zu entlasten werden wir im Allgemeinen s0 = 0 annehmen.
Eine Reihe heißt konvergent wenn die Folge der Partialsummen konvergiert.
Den Grenzwert bezeichnen wir mit∞
∑k=0
ak := limn→∞
Sn.
und nennen wir die Summe der Reihe. Eine nicht-konvergente Reihe heißt diver-
gent.
Achtung!
Die Schreibweise ∑∞k=0 ak ist nur eine Bezeichnung. Eine Reihe sollte man sich
nicht als unendliche Summe vorstellen, weil dies der Anfang allerlei Missverstand-
nisse sein kann.
Es ist noch zu beachten: Die Schreibweise ∑∞k=0 ak ist zweideutig (und daher
gefahrlich!): Sie bezeichnet sowohl die Reihe als auch ihre Summe, falls sie kon-
vergiert. Dieser Gebrauch ist so verbreitet, dass wir nichts anderes machen konnen.
Die Frage nach der Konvergenz von Reihen spielt wieder eine zentrale Rolle.
Ein erstes Kriterium verdanken wir Cauchy:
Satz 7.1 (Cauchy-Kriterium fur Reihen). Die Reihe ∑∞k=0 ak konvergiert genau
dann, wenn:
Zu jedem ε > 0 existiert ein n0 ∈ N mit |∑nk=m ak|< ε fur alle m,n ≥ n0.
Beweis. Sei Sn = ∑nk=0 ak. OBdA nehmen wir n ≥ m an. Dann ist
n
∑k=m
ak = Sn −Sm−1.

52 Abschnitt 7
Daher folgt die Aussage nun aus den Satzen 6.5 und 6.6(ii), die besagen, dass die
Folge (Sn) genau dann konvergiert, wenn diese Folge eine Cauchy-Folge ist. �
Das Cauchy-Kriterium ergibt eine notwendige Bedingung fur die Konvergenz:
Satz 7.2. Ist die Reihe ∑∞k=0 ak konvergent, so ist (ak)k∈N eine Nullfolge.
Beweis. Sei ε > 0 vorgegeben. Nach dem Satz 7.1 existiert ein n0 ∈ N so dass
|∑nk=m ak|< ε fur m,n ≥ n0 gilt. Wahlt man m ≥ n0 und n = m, so erhalt man
∣∣∣n
∑k=m
ak
∣∣∣=∣∣∣
m
∑k=m
ak
∣∣∣= |am|< ε.
�
Die Bedingung ist nicht hinreichend, d.h., es kann passieren, dass (ak)k∈N eine
Nullfolge ist, aber die Reihe ∑∞k=0 ak divergiert, wie folgendes Beispiel zeigt:
Beispiel (Die harmonische Reihe). Sei die Reihe∞
∑k=1
1
k.
Obwohl die Folge (1k)k≥1 eine Nullfolge ist, divergiert die Reihe deshalb, weil die
Folge der Partialsummen (Sn)n≥1 mit
Sn = 1+1
2+
1
3+ . . .+
1
n−1+
1
n
nicht beschrankt ist, und damit ist die Reihe divergent. Und sie ist nicht beschrankt
aufgrund der folgenden Abschatzung:
2n
∑k=1
1
k= 1+
1
2+(1
3+
1
4
)+(1
5+
1
6+
1
7+
1
8
)+ . . .+
( 1
2n−1 −1+ . . .+
1
2n
)
> 1+1
2+2 · 1
4+4 · 1
8+ . . .+2n−1 · 1
2n
= 1+n
2.
Satz 7.3 (Die geometrische Reihe). Sei x∈R. Die Reihe ∑∞k=0 xk konvergiert genau
dann, wenn |x|< 1. In diesem Fall gilt
∞
∑k=0
xk =1
1− x
Beweis. Dass die Reihe fur |x| ≥ 1 divergiert, ist eine Folgerung des Satzes 7.2.
Sei |x|< 1. Es gilt:
n
∑k=0
xk =1− xn+1
1− x=
1
1− x− 1
1− xxn+1.

Folgen reeller Zahlen (III): Reihen 53
Daher konvergiert die Reihe genau dann, wenn die Folge (xn) konvergiert, und das
ist in der Tat so fur |x|< 1, und zwar gegen 0. Daraus folgt unmittelbar
∞
∑k=0
xk = limn→∞
n
∑k=0
xk = limn→∞
1− xn+1
1− x= lim
n→∞
1
1− x− 1
1− xxn+1
=1
1− x− 1
1− xlimn→∞
xn+1 =1
1− x−0 =
1
1− x.
�
Beispiele.
(a) Arithmetisch-Geometrische Reihen: Sie sind Reihen der Form (c,d ∈ R)∞
∑k=0
(ck+d)xk.
Ahnlich wie bei der geometrischen Reihe zeigt man, dass die Reihe genau
dann konvergiert, wenn |x|< 1 ist. Konkret betrachten wir die Reihe
∞
∑k=0
k
3k.
Da 13< 1 ist, konvergiert die Reihe. Um die Summe zu bestimmen, schauen
wir uns zunachst die Partialsummen Sn und 3Sn:
Sn =1
3+
2
32+
3
33+ . . .+
n−1
3n−1+
n
3n
3Sn = 1+2
3+
3
32+ . . .+
n−1
3n−2+
n
3n−1.
Wir rechnen 3Sn −Sn = 2Sn durch:
2Sn = 1+1
3+
1
32+ . . .+
1
3n−1− n
3n=
n−1
∑i=0
1
3i− n
3n=
3
2
(1− 1
3n
)− n
3n
Dann ist Sn =34
(1− 1
3n
)− n
2·3n und somit ist die Summe S= limn→∞ Sn =34.
(b) Teleskope Reihen: Sie sind die Reihen, deren k-tes Glied ak in der Form
bk −bk−1 gebracht werden kann. Genau dann ist die Reihe ∑∞k=0 ak konver-
gent, wenn die Folge (bk) konvergiert. In solchen Fall ist die Summe der
Reihe gleich limk→∞ bk −b0. Als direkte Anwendung sei die Reihe∞
∑k=1
k+1
(k+2)!.
Der Term ak =k+1
(k+2)! gleicht
k+2−1
(k+2)!=
k+2
(k+2)!− 1
(k+2)!=
1
(k+1)!− 1
(k+2)!= bk+1 −bk+2,

54 Abschnitt 7
wobei bk =1k!
ist. Dann sind die Partialsummen
Sn = a1 + . . .+an = (b2 −b3)+(b3 −b4)+ . . .+(bn+1 −bn+2),
und damit ist die Summe S der Reihe
S = limn→∞
Sn = limn→∞
(b2 −bn+2) = b2 − limn→∞
bn+2 =1
2!−0 =
1
2.
Da Reihen ein Spezialfall von Folgen sind, haben sie grundsatzlich identische
Eigenschaften, die sich letztlich aus denen von den Folgen beweisen lassen:
Satz 7.4. (a) Sei ∑∞k=0 ak eine Reihe. Sei ∑∞
k=0 bk eine weitere Reihe, die aus
der ersten entsteht nach Modifizierung oder Streichung endlich vieler Ter-
me. Genau dann ist ∑∞k=0 bk konvergent, wenn ∑∞
k=0 ak konvergiert. Im kon-
vergenten Fall kann den Grenzwert gewechselt haben!)
(b) Sei c 6= 0. Dann ist ∑∞k=0 ak genau dann konvergent, wenn ∑∞
k=0 c · ak kon-
vergent ist.
(c) Seien ∑∞k=0 ak und ∑∞
k=0 bk konvergente Reihen. Dann ist ∑∞k=0 αak + βbk
auch konvergent. Ferner gilt fur den Grenzwert
∞
∑k=0
αak +βbk = α∞
∑k=0
ak +β∞
∑k=0
bk.
Eine hinreichende Bedingung hat Leibniz in 1682 schon bemerkt, und zwar fur
die Konvergenz alternierender Reihen: Eine Reihe heißt alternierend, wenn ihre
Glieder abwechselnd ≥ 0 und ≤ 0 sind, also eine Reihe der Gestalt∞
∑k=0
ak
fur ai ∈R. Das Leibniz-Kriterium ergibt eine hinreichende Bedingung fur die Kon-
vergenz dieser Reihen:
Satz 7.5 (Leibniz-Kriterium). Sei (ak)k∈N eine monoton fallende Nullfolge von
nicht-negativen reellen Zahlen, d.h., eine Folge so dass fur alle k gilt:
ak ≥ 0, ak ≥ ak+1 und limk→∞
ak = 0.
Dann konvergiert die Reihe∞
∑k=0
(−1)kak.
Beweis. Ist die Reihe konvergent, dann ist ((−1)kak) nach Satz 7.2 eine Nullfolge.
Mithin ist (ak) eine Nullfolge. Sei nun umgekehrt (ak) eine Nullfolge. Wir setzen
Sn = ∑nk=0(−1)kak. Es folgt aus der Voraussetzung
S2(n+1) = S2n − (a2n+1 −a2n+2)≤ S2n.

Folgen reeller Zahlen (III): Reihen 55
Daher ist (S2n) monoton fallend. Analog sieht man, dass (S2n−1) monoton wach-
send ist. Es ist
S0 ≥ S2n ≥ S2n−1 ≥ S1.
Daher sind (S2n) und (S2n−1) beschrankt und monoton, also konvergent. Wegen
limn→∞
(S2n −S2n−1) = limn→∞
a2n = 0
haben beide Folgen den gleichen Grenzwert a ∈R. Hieraus ergibt sich direkt, dass
auch (Sn) gegen a konvergiert und daher ist ∑∞k=0(−1)kak konvergent. �
Die alternierende harmonische Reihe
∞
∑k=1
(−1)k−1 1
k
ist nach dem Leibniz-Kriterium konvergent. Man konnte auf folgende Idee kom-
men: Gilt das noch fur jede Umordnung der Reihe? Die Frage ist nicht trivial.
Wenn wir die Reihe
1− 1
2+
1
3− 1
4+
1
5− 1
6+
1
7− 1
8+
1
9− 1
10+
1
11− 1
12+
1
13− 1
14+
1
15− 1
16+ . . .
wie folgt umordnen
1− 1
2︸ ︷︷ ︸1/2
−1
4+
1
3− 1
6︸ ︷︷ ︸1/6
−1
8+
1
5− 1
10︸ ︷︷ ︸1/10
− 1
12+
1
7− 1
14︸ ︷︷ ︸1/14
− 1
16+
1
9− 1
18︸ ︷︷ ︸1/18
− 1
20+ . . . ,
dann ergibt sich
1
2− 1
4+
1
6− 1
8+
1
10− 1
12+ . . .=
1
2
(1− 1
2+
1
3− 1
4+
1
5− 1
6+ . . .
),
was so viel wie die Halfte der ursprunglichen Reihe ist! Das zeigt schon, dass
die Summe einer Reihe von der Summationsordnung abhangig ist. Es ist sogar
schlimmer: Man kann eine Umordnung finden, so dass die Reihe nicht mehr kon-
vergent ist! Seien dazu die Folgenglieder (−1)k−1 1k
ungerader Ordnung fur k =
2k +1,2k +3,2k +5 . . . ,2k+1 −1. Es gilt
1
2k +1+
1
2k +3+ . . .+
1
2k+1 −1> 2k−1 1
2k+1=
1
4.

56 Abschnitt 7
Betrachte die Umordnung
1− 12+ 1
3− 1
4= 7
12
+(
15+ 1
7
)− 1
6> 1
4− 1
6
+(
19+ 1
11+ 1
13+ 1
15
)− 1
8> 1
4− 1
8
+ . . ....
+(
12k+1
+ 12k+3
+ 12k+5
+ . . .+ 12k+1−1
)− 1
2k+2> 1
4− 1
2k+2
+ . . ....
Die Folge der Partialsummen (Sk)k≥1 mit
S1 =7
12, S2 =
(1
5+
1
7
)− 1
6, S3 =
(1
9+
1
11+
1
13+
1
15
)− 1
8, . . .
ist keine Nullfolge, also sie ist divergent nach dem Satz 7.2 und damit ist die Reihe
∑∞k=0 Sk, die als Umordnung der alternierenden harmonischen Reihe gebastelt wird,
divergent. Das sei”... ein Umstand, welcher von den Mathematikern des vorigen
Jahrhunderts ubersehen wurde...”1. Riemann hat das Phanomen verstanden: Letzt-
lich ist das so, weil sowohl die Summe aller positiven Terme als auch die Summe
aller negativen Terme der alternierenden harmonischen Reihe, d.h.
1+1
3+
1
5+
1
7+
1
9+ . . . und − 1
2− 1
4− 1
6− 1
8− 1
10− . . .
beide divergent sind; oder anders gesagt, die alternierende harmonische Reihe, mit
jedem Glied durch seinen Absolut-Betrag ersetzt, divergent ist. Das ist uns be-
kannt, denn diese Reihe ist doch die harmonische Reihe
∞
∑k=1
∣∣∣(−1)k−1 1
k
∣∣∣=∞
∑k=1
1
k,
und sie divergiert. Das hatte nicht passieren konnen, wenn die Reihe ∑∞k=1
∣∣∣(−1)k−1 1k
∣∣∣,d.h., die Reihe, die sich durch Absolut-Betrage bilden lasst, konvergiert hatte. Kon-
vergente Reihen, bei denen jede ihrer Umordnungen wieder konvergiert, heißen
unbedingt konvergent. Dieser Begriff hort sich fremd an, er kommt oft vor:
Definition. Eine Reihe ∑∞k=0 ak heißt absolut konvergent, wenn die Reihe
∞
∑k=0
|ak|
konvergent ist.
1Zitat aus Riemann, 1854: Werke, p. 235.

Folgen reeller Zahlen (III): Reihen 57
Bedingt konvergente Reihen sind die, welche konvergent aber nicht absolut
konvergent sind, wie die alternierende harmonische Reihe. Dirichlet bewies, dass
absolut konvergente und unbedingt konvergente Reihen das Gleiche sind (vgl.
[Heu, Satz 32.3]). Wir beweisen nur eine Richtung:
Satz 7.6. Ist eine Reihe ∑∞k=0 ak absolut konvergent, dann konvergieren auch al-
le ihre Umordnungen, und zwar gegen denselben Grenzwert, also gegen dieselbe
Summe.
Beweis. Nach dem Cauchy-Kriterium 7.1 ist die Reihe absolut konvergent wenn
zu jedem ε > 0 existiert ein n0 ∈ N so dass
|ak+1|+ |ak+2|+ . . .+ |ak+n|< ε fur alle n ≥ 1 und k ≥ n0.
Dann wahlen wir zu jedem ε > 0 und entsprechenden n0 ≥ 0 eine naturliche Zahl
M so dass alle Terme a0,a1, . . . ,an0in der M-ten Partialsumme
S′M =M
∑k=0
a′k
der umgeordneten Reihe vorkommen. Das heißt, alle Terme a0,a1, . . . ,an0in der
Differenz Sm −S′m (fur m ≥ M) verschwinden, und somit ist
|Sm −S′m| ≤ |an0+1|+ |an0+2|+ . . .+ |an0+n|< ε
�
Was ist die exakte Beziehung zwischen der Konvergenz und der absoluten Kon-
vergenz? Die obige Diskussion mit der alternierenden harmonischen Reihe zeigt:
Nicht jede konvergente Reihe ist absolut konvergent. Die Umkehrung gilt dank
dem Cauchy-Kriterium:
Satz 7.7. Eine absolut konvergente Reihe ist konvergent.
Beweis. Sei ∑∞k=0 ak absolut konvergent. Wir wenden Satz 7.1 an. Sei ε > 0 vorge-
geben. Dann gibt es ein n0 ∈ N mit
∣∣∣n
∑k=m
|ak|∣∣∣=
n
∑k=m
|ak|< ε fur alle m,n ≥ n0.
Dann ergibt sich
∣∣∣n
∑k=m
ak
∣∣∣≤∑ |ak|< ε fur alle m,n ≥ n0.
Daher ist wiederum nach Satz 7.1 die Reihe ∑∞k=0 ak konvergent. �
Nun fuhren wir drei Kriterien fur die absolute Konvergenz ein.

58 Abschnitt 7
Satz 7.8 (Majoranten-Kriterium). Sei ∑∞k=0 bk eine konvergente Reihe und (ak)k∈N
eine Folge mit |ak| ≤ bk fur alle k ∈ N. Dann ist die Reihe
∞
∑k=0
ak
absolut konvergent.
Beweis. Sei ε > 0 vorgegeben. Dann gibt es ein n0 ∈ N mit∣∣∣
n
∑k=m
bk
∣∣∣< ε fur alle n,m ≥ n0.
Dann folgt die Behauptung aus
n
∑k=m
|ak| ≤n
∑k=m
bk < ε fur alle n,m ≥ n0.
�
Beispiel. Zunachst bestimmen wir die Summe folgender Teleskopen Reihe:
∞
∑k=1
1
k(k+1)= lim
n→∞
n
∑k=1
1
k(k+1)= lim
n→∞
n
∑k=1
(1
k− 1
k+1
)= lim
n→∞
n
n+1= 1.
Fur s ≥ 2 und k ≥ 1 gilt1
ks≤ 1
k2≤ 2
k(k+1).
Aus dem Majoranten-Kriterium 7.8 folgt nun fur s ≥ 2 die Konvergenz der Reihe
∞
∑k=1
1
ks.
Satz 7.9 (Quotientenkriterium). Sei ∑∞k=0 ak eine Reihe mit ak 6= 0 fur alle k ≥ k0
mit k0 ∈ N. Falls eine Zahl q ∈ R, 0 ≤ q < 1 existiert mit∣∣∣∣ak+1
ak
∣∣∣∣≤ q fur k ≥ k0,
dann ist ∑∞k=0 ak absolut konvergent.
Beweis. Wir konnen endlich viele Glieder einer Reihe abandern, ohne an der (ab-
soluten) Konvergenz etwas zu andern (vgl. Satz 7.4(a)). Daher konnen wir oBdA
k0 = 0 annehmen. Eine vollstandige Induktion nach k liefert
|ak| ≤ qk|a0| fur alle k ≥ 0.
Wir wissen, dass ∑∞k=0 qk|a0| konvergiert und daher ist ∑∞
k=0 ak absolut konvergent
wegen Satz 7.8.
�

Folgen reeller Zahlen (III): Reihen 59
Beispiel. Sei ∑∞k=0 ak mit ak =
(2kk
)2−3k. Wir verwenden das Quotientenkriterium.
Es ist
limk→∞
∣∣∣∣ak+1
ak
∣∣∣∣ = limk→∞
(2(k+1))!
((k+1)!)2 ·23(k+1)· (k!)2 ·23k
(2k)!
= limk→∞
(2k+2)(2k+1)
(k+1)2· 1
23
=1
8limk→∞
4k2+6k+2
k2+2k+1
=1
8·4 =
4
8=
1
2
Da limk→∞
∣∣∣ak+1
ak
∣∣∣ = 12< 1, ist die Reihe nach dem Quotientenkriterium absolut
konvergent, und nach dem Satz 7.7 konvergent.
Das Quotientenkriterium ist zwar nutzlich aber von eingeschrankten Anwen-
dungsmoglichkeiten.
Beispiel. Auf Konvergenz mochten wir die Reihe∞
∑k=1
1
2k+(−1)k
2
untersuchen. Wir versuchen, das Quotientenkriterium anzuwenden. Wir realisieren
aber, dass
limk→∞
∣∣∣ak+1
ak
∣∣∣= limk→∞
ak+1
ak
= limk→∞
22·(−1)k−2
2 =
{14, falls k ungerade
1, falls k gerade
gilt. Das heißt, das Quotientenkriterium kann nicht verwendet werden.
In solchen Fallen konnte uns noch folgendes Kriterium weiter helfen:
Satz 7.10 (Wurzelkriterium). Sei ∑∞k=0 ak eine Reihe. Wenn ein q∈R mit 0≤ q< 1
und ein k0 ∈N existieren mit k√
|ak| ≤ q fur alle k ≥ k0, dann konvergiert die Reihe
∑∞k=0 ak absolut.
Beweis. Es gilt genau dann k√
|ak| ≤ q, wenn |ak| ≤ qk. Da 0 ≤ q < 1 ist, konver-
giert die Reihe ∑∞k=0 qk, also konvergiert ∑∞
k=0 ak absolut nach dem Majoranten-
Kriterium 7.8. �
Beispiel. Fur das obige Beispiel ∑∞k=1 ak mit ak =
1
2k+
(−1)k
2
> 0 kann man das Wur-
zelkriterium 7.10 anwenden, denn es gilt
limk→∞
k√
ak = limk→∞
k
√1
2k+(−1)k
2
= limk→∞
1
2k
√1
2(−1)k
2
=1
2< 1.

60 Abschnitt 7
Beispiel. Fur jedes x ∈ R ist die Exponentialreihe
exp(x) :=∞
∑k=0
xk
k!
absolut konvergent: Fur x = 0 ist nichts zu zeigen. Sei nun x 6= 0. Mit ak =xk
k!gilt
fur k ≥ 2|x|∣∣∣ak+1
ak
∣∣∣=∣∣∣
xk+1
(k+1)!
k!
xk
∣∣∣=|x|
k+1≤ 1
2.
Nun folgt aus dem Quotientenkriterium die Behauptung. Die Eulersche Zahl e de-
finieren wir durch
e := exp(1) =∞
∑k=0
1
k!(= 2,71828 . . .)
Als nachstes uberlegen wir uns, dass exp(x+ y) = exp(x) · exp(y) gilt. Dafur
brauchen wir:
Satz 7.11 (Cauchy-Produkt von Reihen). Seien ∑∞k=0 ak und ∑∞
k=0 bk absolut kon-
vergente Reihen. Sei ck := ∑km=0 ambk−m fur k ∈ N. Dann ist die Reihe ∑∞
k=0 ck
absolut konvergent und es gilt∞
∑k=0
ck =( ∞
∑k=0
ak
)·( ∞
∑k=0
bk
).
Als eine erste Anwendung erhalten wir das Gewunschte:
Satz 7.12 (Funktionalgleichung der Exponentialfunktion). Fur alle x,y ∈ R gilt
exp(x+ y) = exp(x) · exp(y).
Beweis. Die Behauptung folgt aus Satz 7.11, da
(x+ y)k
k!=
1
k!
k
∑m=0
(k
m
)xk−mym =
k
∑m=0
1
k!
k!
m!(k−m)!xk−mym =
k
∑m=0
xk−m
(k−m)!· ym
(m)!.
�
Die Exponentialreihe definiert in der Tat eine Funktion (d.h. eine Abbildung,
deren Wertebereich eine Teilmenge von R ist) exp : R→ R, x 7→ exp(x). Sie heißt
die Exponentialfunktion. Ab dem nachsten Abschnitt werden die Funktionen die
Hauptobjekte unserer analytischen Untersuchungen sein.

ABSCHNITT 8
Stetigkeit und Grenzwerte reeller Funktionen
Den Abstand zwischen zwei reellen Zahlen x und x′ bezeichnen wir mit
d(x,x′) := |x− x′|. Bei einer Funktion f : R → R kann man sich fragen, inwie-
fern der Abstand in der Wertemenge durch den Abstand in der Definitionsmenge
kontrollierbar ist. Sei x ∈ R und y = f (x) der Bildpunkt. Man mochte, dass fur
Punkte x′, die”nahe” an x sind, auch die Bildpunkte f (x′)
”nahe” an f (x) sind. Die
Zielsetzung ist, dass zu einer gewunschten Genauigkeit im Bildbereich uberhaupt
eine Ausgangsgenauigkeit gefunden werden kann, die sichert, dass die Funktions-
werte innerhalb der gewunschten Genauigkeit beieinander liegen.
Um diese intuitive Vorstellung zu prazisieren, sei ein ε > 0 vorgegeben. Dieses
ε reprasentiert eine”gewunschte Zielgenauigkeit”. Die Frage ist dann, ob man ein
δ > 0 finden kann (eine”Startgenauigkeit”) mit der Eigenschaft, dass fur alle x′
mit d(x,x′)< δ die Beziehung d( f (x), f (x′))< ε gilt. Dies fuhrt zum Begriff der
stetigen Abbildung:
Definition. Sei D ⊂ R eine Teilmenge, f : D → R eine Funktion und x ∈ D. Man
sagt, dass f stetig im Punkt x ist, wenn es zu jedem ε > 0 ein δ > 0 gibt derart,
dass fur alle x′ mit d(x,x′)< δ die Abschatzung d( f (x), f (x′))< ε gilt. Man sagt,
dass die Funktion f stetig ist, wenn sie in jedem Punkt x ∈ D stetig ist.
Beispiele.
(a) Eine konstante Funktion f : R→R, x 7→ c, ist stetig: Zu jedem vorgegeben
ε > 0 kann man hier ein beliebiges δ > 0 wahlen, da ja ohnehin
d( f (x), f (x′)) = d(c,c) = 0 < ε
fur alle x′ gilt.
(b) Die Identitat id : R→R, x 7→ x ist ebenfalls stetig: Zu jedem vorgegebenen
ε > 0 kann man hierzu δ = ε wahlen, was zu der Tautologie fuhrt: wenn
d(x,x′)< δ = ε , so ist
d( f (x), f (x′)) = d(x,x′)< ε.
(c) Wir betrachten die Funktion f : R→ R mit
f (x) ={
0 falls x < 0,1 falls x ≥ 0.

62 Abschnitt 8
Diese Funktion ist im Nullpunkt 0 nicht stetig. Fur ε = 12
und jedes belie-
bige positive δ gibt es namlich negative Zahlen x′ mit d(0,x′) = |x′| < δ .
Fur diese ist aber
d( f (0), f (x′)) = d(1,0) = 1 6< 1
2.
Das folgende Resultat bringt die Stetigkeit von Funktionen mit konvergenten
Folgen in Verbindung.
Satz 8.1. Sei D ⊂ R eine Teilmenge, f : D → R eine Funktion und x ∈ D. Dann
sind folgende Aussagen aquivalent:
(i) f ist stetig im Punkt x.
(ii) Fur jede konvergente Folge (xn)n∈N in D mit limn→∞ xn = x ist auch die
Bildfolge ( f (xn))n∈N konvergent mit dem Grenzwert f (x).
Beweis. Wir zeigen die zwei Implikationen der Aquivalenz:
(i) ⇒ (ii) Sei (xn)n∈N eine Folge in D, die gegen x konvergiert. Wir mussen zeigen,
dass limn→∞ f (xn) = f (x) ist. Dazu sei ε > 0 gegeben. Wegen (i) gibt es
ein δ mit der angegebenen Eigenschaft, und wegen der Konvergenz von
(xn)n∈N gegen x gibt es eine naturliche Zahl n0 derart, dass fur alle n ≥ n0
gilt
d(xn,x)< δ .
Nach der Wahl von δ ist dann
d( f (xn), f (x))< ε fur alle n ≥ n0,
so dass die Folge ( f (xn))n∈N gegen f (x) konvergiert.
(ii) ⇒ (i) Durch Widerspruch: Angenommen, dass f nicht stetig ware. Dann gibt es
ein ε > 0 derart, dass es fur alle δ > 0 Elemente z ∈ D gibt, deren Abstand
zu x maximal gleich δ ist, deren Wert f (z) unter der Abbildung aber zu
f (x) einen Abstand besitzt, der großer als ε ist. Dies gilt dann insbesondere
fur die Stammbruche δ = 1/n, n ∈ N. D.h. fur jede naturliche Zahl gibt es
ein xn ∈ D mit
d(xn,x)<1
nund mit d( f (xn), f (x))≥ ε
Diese so konstruierte Folge (xn)n∈N konvergiert gegen x, aber die Bildfolge
( f (xn))n∈N konvergiert nicht gegen f (x), da der Abstand der Bildfolgen-
glieder zu f (x) zumindest ε ist. Dies ist ein Widerspruch zu (ii). gibt,
�
Direkt aus der Folgencharakterisierung der Stetigkeit 8.1 ergeben sich die fol-
genden Rechenregeln fur stetige Funktionen:

Stetigkeit und Grenzwerte reeller Funktionen 63
Satz 8.2. Seien D,E ⊂ R Teilmengen und f : D → R und g : E → R Funktionen
mit f (D)⊂ E. Dann gelten folgende Aussagen:
(i) Wenn f in x ∈ D und g in f (x) stetig sind, so ist auch die Hintereinander-
schaltung g◦ f in x stetig.
(ii) Wenn f und g stetig sind, so ist auch g◦ f stetig.
Aus den Satzen 8.1 und 5.4 folgt auch:
Satz 8.3. Sei D ⊂ R und f ,g : D → R stetige Funktionen. Dann sind auch die
folgenden Funktionen stetig:
(i) Die Funktion f +g : D → R, x 7→ f (x)+g(x)(ii) Die Funktion f −g : D → R, x 7→ f (x)−g(x)
(iii) Die Funktion f ·g : D → R, x 7→ f (x) ·g(x)(iv) Fur eine Teilmenge U ⊂ D, auf der g keine Nullstelle besitzt, die Funktion
f
g: U → R, x 7→ f (x)
g(x).
Beispiele. Wir sehen jetzt die ersten nicht-trivialen Beispiele von stetigen Funk-
tionen:
(i) Sei K ein Korper und seien a0,a1, . . .an ∈ K. Eine Funktion
K → K, x 7→ P(x),
mit
P(x) =n
∑i=0
aixi = a0 +a1x+ . . .+anxn
heißt Polynomfunktion. Polynomfunktionen
P : R→ R, x 7→ P(x)
sind stetig: Aufgrund der Stetigkeit der Identitat und Satz 8.3 sind fur jedes
n ∈ N die Potenzen R→R, x 7→ xn stetig. Daher sind auch fur jedes a ∈Rdie Funktionen R → R, x 7→ axn stetig und wiederum aufgrund von Satz
8.3 sind auch alle Funktionen
R→ R, x 7→ anxn +an−1xn−1 + . . .+a1x+a0.
stetig.
(ii) Seien P und Q zwei Polynomfunktionen, und sei U := {x ∈R : Q(x) 6= 0}.
Dann ist die rationale Funktion
U → R, x 7→ P(x)
Q(x)
stetig: Dies folgt aus dem Satz 8.3 zusammen mit (i).

64 Abschnitt 8
Definition. Es sei D⊂R eine Teilmenge und sei a∈R ein Punkt. Es sei f : D→Reine Funktion. Dann heißt b ∈R Grenzwert (oder Limes) von f in a, wenn fur jede
Folge (xn)n∈N in D, die gegen a konvergiert, auch die Bildfolge ( f (xn))n∈N gegen
b konvergiert. In diesem Fall schreibt man
limx→a
f (x) = b.
Anmerkung. Diese Definition ist aquivalent zur Folgenden: Zu jedem ε > 0 exi-
stiert eine reelle Zahl δ > 0 derart, dass fur jedes x ∈ D mit 0 < |x− a| < δ die
Abschatzung
| f (x)−b|< ε
gilt.
Beispiel. Die Gauß-Klammer Funktion besitzt keinen Grenzwert im Nullpunkt,
denn
limn→∞
[1
n
]= 0 aber lim
n→∞
[− 1
n
]=−1.
Dieser Begriff ist eigentlich nur dann sinnvoll, wenn es uberhaupt Folgen in
D gibt, die gegen a konvergieren. Aus der Tatsache, dass Grenzwerte von Folgen
eindeutig bestimmt sind, folgt unmittelbar, dass Grenzwerte von Funktionen auch
eindeutig bestimmt sind.
Wie bei Folgen sind auch bei der Bestimmung von Grenzwerten von Funktio-
nen die folgenden Rechenregeln sehr nutzlich. Direkt aus dem Satz 5.4 ergibt sich
dann:
Satz 8.4. Seien D ⊂ R eine Teilmenge und a ∈ R ein Punkt. Es seien f : D → Rund g : D → R Funktionen derart, dass die Grenzwerte
limx→a
f (x) und limx→a
g(x)
existieren. Dann gelten folgende Beziehungen:
(i) Die Summe f +g besitzt einen Grenzwert in a, und zwar ist
limx→a
( f (x)+g(x)) = limx→a
f (x)+ limx→a
g(x).
(ii) Das Produkt f ·g besitzt einen Grenzwert in a, und zwar ist
limx→a
( f (x) ·g(x)) = limx→a
f (x) · limx→a
g(x).
(iii) Es sei g(x) 6= 0 fur alle x ∈ D und limx→a g(x) 6= 0. Dann besitzt der Quo-
tient f/g einen Grenzwert in a, und zwar ist
limx→a
f (x)
g(x)=
limx→a f (x)
limx→a g(x).

Stetigkeit und Grenzwerte reeller Funktionen 65
Bei Betrachtung von R lassen sich sofort unendliche Grenzwerte definieren
(dies entspricht der Situation b = ±∞ in der obigen Definition). Auch kann man
Limiten einfuhren, bei denen x gegen ±∞ strebt (dies entspricht a = ±∞ in der
obigen Definition):
Definition. Es sei D = [a,∞[ (oder D =]−∞,a]) ein rechtsseitig (bzw. linksseitig)
unbeschranktes Intervall und f : D → R eine Funktion. Dann heißt b ∈ R Grenz-
wert (oder Limes) von f fur x → ∞ (bzw. x → −∞), wenn es fur jedes ε > 0 ein
x0 ≥ a (bzw. x0 ≤ a) gibt mit | f (x)−b|< ε fur alle x ≥ x0 (bzw. x ≤ x0). In diesem
Fall schreibt man
limx→∞
f (x) = b bzw. limx→−∞
f (x) = b.
Die Rechenregeln fur diesen Grenzwertbegriff sind weitgehend analog zu den
Rechenregeln in Satz 8.4. Sie sind auch analog zu den Rechenregeln fur Limiten
von Folgen (vgl. Satz 5.4).
Es gilt auch eine Folgencharakterisierung zur Existenz von Limiten, die analog
zu Satz 8.1 beweisen lasst. Dafur brauchen wir wieder den Begriff”Haufungs-
punkt” in diesem Kontext. Zur Erinnerung, fur eine Menge D ⊂ R und a ∈ R
ist a ein Haufungspunkt von D, wenn eine Folge (xn) in D \ {a} existiert mit
limn→∞ xn = a.
Satz 8.5. Sei D ⊂ R eine Teilmenge, sei f : D → R eine Funktion und sei a ∈ D
ein Haufungspunkt. Folgende Aussagen sind aquivalent:
(i) Es existiert limx→a f (x) = α ∈ R.
(ii) Fur jede konvergente Folge (xn)n∈N in D mit xn 6= a fur alle n ∈ N und mit
Grenzwert a ist limn→∞ f (xn) = α.
Insbesondere ist dieses Kriterium nutzlich um der Existenz von Limiten zu
widersprechen, indem man zwei konvergente Folgen (xn)n∈N,(yn)n∈N in D mit
xn,yn 6= a und Grenzwert a konstruiert, bei denen aber
limn→∞
f (xn) 6= limn→∞
f (yn)
ist.
Beispiel. Wir betrachten die Funktion R \ {0} → R, x 7→ 1x. Es ist limx→∞
1x= 0,
denn: Ist (xn)n∈N eine Folge mit xn 6= 0 und limn→∞ xn =∞, dann ist limn→∞ 1/xn =0. Genauso ergibt sich limx→−∞ 1/x = 0. Dagegen hat 1/x im Nullpunkt 0 keinen
Grenzwert: Es ist
limn→∞
1
1/n= ∞, aber lim
n→∞
1
−1/n=−∞.
Fur die Stetigkeit einer Funktion f : D → R, x 7→ f (x) in einem Punkt a ist
also erstens zu verlangen, dass der Grenzwert limx→a f (x) existiert, und zweitens,

66 Abschnitt 8
dass er gerade gleich dem Wert von f an der Stelle a ist. Manchmal ist die Funk-
tion f nur links bzw. nur rechts von a definiert. Dafur ist es nutzlich, die Begriffe
linksseitig bzw. rechtsseitig stetig einzufuhren.
Zunachst definieren wir was unter rechtsseitige bzw. linksseitige Grenzwerte
zu verstehen ist. Eine Funktion
f : D → R, x 7→ f (x)
konvergiert fur x ↓ a gegen den Wert b (man sagt auch: konvergiert fur x → a+
gegen b, oder auch sie hat in a den rechtsseitigen Grenzwert b), wenn es zu jedem
ε > 0 ein δ > 0 existiert derart, dass | f (x)− b| < ε ist, sobald 0 < x− a < δ ist.
Wir schreiben dafur
limx↓a
f (x) = b oder auch limx→a+
f (x) = b.
Geometrisch bedeutet dies: Man betrachte das Intervall um b
]b− ε,b+ ε[.
Dann gehort dazu ein von rechts an a anstoßendes Intervall ]a,a+δ [ von der Lange
δ so dass fur alle x aus diesem Intervall die zugehorigen Funktionswerte in das
obige Intervall ]b− ε,b+ ε[ hineinfallen. In durchaus symmetrischer Weise wird
auch der Begriff des linksseitigen Grenzwertes definiert. Es wird mit
limx↑a
f (x) = b oder auch limx→a−
f (x) = b.
bezeichnet. Gilt nun in einem Punkt a
limx↑a
f (x) = f (a) bzw. limx↓a
f (x) = f (a),
so heißt die Funktion f linksseitig bzw. rechtsseitig stetig im Punkt a.
Anmerkung. Man pruft leicht nach: Genau dann besitzt die Funktion f einen
Grenzwert im Punkt a, wenn sowohl der rechtsseitige als auch der linksseitige
Grenzwert existieren und ubereinstimmen. Daraus folgt auch: Genau dann ist eine
Funktion stetig in einem Punkt, wenn sie sowohl linksseitig als auch rechtsseitig
stetig in diesem Punkt ist.
Beispiel. Sei die Funktion f : R→ R gegeben durch
f (x) =1
1− exp(
x1−x
) .
Erstens beobachten wir, dass limx→0
(1−exp
(x
1−x
))= 0, da limx→0
x1−x
= 0. An-
dererseits ist1− exp( x
1−x)< 0 falls 0 < x < 1,
1− exp( x1−x
)> 0 falls x < 0.

Stetigkeit und Grenzwerte reeller Funktionen 67
Dann existieren der linksseitige und der rechtsseitige Grenzwerte, namlich
limx↑0
1
1− exp(
x1−x
) = ∞, limx↓0
1
1− exp(
x1−x
) =−∞.
Daraus folgt, dass die Funktion f kein Limes im Nullpunkt besitzt, denn die rechts-
und linksseitigen Grenzwerte nicht ubereinstimmen (obwohl sie existieren). Daher
ist f auch nicht stetig im Nullpunkt.
Zum Schluss rufen wir uns die Definition der Exponentialfunktion in Erinne-
rung. Sie wurde durch eine konvergente Reihe definiert. Der folgende Satz stellt
sicher, dass die auf dieser Art und Weise definierten Funktionen stetig sind:
Satz 8.6. Seien a ∈ R und ∑∞k=0 ckak eine konvergente Reihe. Sei f : R → R die
Funktion, die durch
x 7→∞
∑k=0
ckxk
gegeben ist. Dann gibt es ein positives ρ (wobei ρ = ∞ erlaubt ist) derart, dass fur
alle x ∈ R mit |x| < ρ die Reihe konvergiert. Auf einem solchen Intervall {x ∈ R :
|x|< ρ} ist die Funktion f stetig.
Beweis. Der Beweis beruht auf einer systematischen Untersuchung von Reihen
dieser Art (”Potenzreihen” genannt) und dem Grenzwert von Funktionenfolgen,
was wir in unserer Vorlesung nicht durchfuhren werden. �
Beispiele.
(a) Die in Abschnitt 7 definierte Exponentialfunktion ist nach dem Satz 8.6 auf
den ganzen R stetig.
(b) Die Sinusfunktion sin : R→ R definiert durch
x 7→ sinx :=∞
∑k=0
(−1)k x2k+1
(2k+1)!
ist nach dem Satz 8.6 stetig auf den ganzen R.
(c) Die Kosinusfunktion cos : R→ R definiert durch
x 7→ cosx :=∞
∑k=0
(−1)k x2k
2k!
ist nach dem Satz 8.6 auch auf R stetig.
Weitere Eigenschaften von elementaren Funktionen wie die Exponentialfunk-
tion oder die trigonometrischen Funktionen werden wir in Abschnit 10 betrachten.
Im nachsten Abschnitt 9 wollen wir noch einen wichtigen Satz von stetigen Funk-
tionen prasentieren: der beruhmte Satz von Bolzano oder Zwischenwertsatz.


ABSCHNITT 9
Der Zwischenwertsatz von Bolzano
Wir interessieren uns dafur, was unter einer stetigen Abbildung mit einem In-
tervall passiert. Der Zwischenwertsatz oder Satz von Bolzano besagt, dass das Bild
eines Intervalls durch eine stetige Funktion wieder ein Intervall ist:
Satz 9.1 (Zwischenwertsatz). Seien a ≤ b reelle Zahlen und sei f : [a,b]→R eine
stetige Funktion. Es sei c eine reelle Zahl zwischen f (a) und f (b). Dann gibt es
ein ξ ∈ [a,b] mit
f (ξ ) = c.
Beweis. Wir beschranken uns auf die Situation f (a) ≤ c ≤ f (b) und zeigen die
Existenz von einem solchen ξ mit Hilfe einer Intervallhalbierung. Dazu setzt man
a0 := a und b0 := b, betrachtet die Intervallmitte
ξ0 :=a0 +b0
2
und berechnet f (ξ0). Bei f (ξ0)≤ c setzt man
a1 := ξ0 und b1 := b0
und bei f (ξ0)> c setzt man
a1 := a0 und b1 := ξ0.
In jedem Fall hat das neue Intervall [a1,b1] die halbe Lange des Ausgangsintervalls
und liegt in diesem. Da es wieder die Voraussetzung
f (a1)≤ c ≤ f (b1)
erfullt, konnen wir darauf das gleiche Verfahren anwenden und gelangen so re-
kursiv zu einer Intervallschachtelung. Sei ξ die durch diese Intervallschachtelung
definierte reelle Zahl (vgl. Abschnitt 6):
(a) Fur die unteren Intervallgrenzen gilt f (an) ≤ c und das ubertragt sich we-
gen der Stetigkeit nach dem Folgenkriterium auf den Grenzwert ξ , also
f (ξ )≤ c.
(b) Fur die oberen Intervallgrenzen gilt f (bn)≥ c und das ubertragt sich eben-
falls auf ξ , also f (ξ )≥ c.
Daraus folgt f (ξ ) = c. �
Unmittelbar aus dem Zwischenwertsatz folgt die Darbouxsche Eigenschaft:

70 Abschnitt 9
Satz 9.2. Seien a ≤ b reelle Zahlen und sei f : [a,b]→R eine stetige Funktion mit
f (a)≤ 0 und f (b)≥ 0.
Dann gibt es ein x ∈ [a,b] mit f (x) = 0, d.h. f besitzt eine Nullstelle zwischen a
und b.
Satz 9.3. Sei I ⊂R ein Intervall, sei f : I →R eine stetige Funktion. Dann ist f (I)ein Intervall.
Beweis. Intervalle J ⊂ R sind gekennzeichnet durch folgende Eigenschaft:
x,y ∈ J =⇒ z ∈ J fur alle z ∈ R mit x ≤ z ≤ y.
Seien nun u,v ∈ f (I), also u = f (a) und v = f (b) mit a,b ∈ I. Nach eventuellem
Wechsel der Bezeichnungen konnen wir a ≤ b annehmen. Nach Satz 9.1 existiert
zu jedem w mit u ≤ w ≤ v ein x ∈ I mit f (x) = w. �
Beispiel. Der Zwischenwertsatz lasst sich nicht auf jeden Korper verwenden. Wir
betrachten dazu die Abbildung
f : Q→Q, x 7→ x2 −2.
Sie ist stetig, aber genugt nicht dem Zwischenwertsatz: Fur x= 0 ist f (0)=−2< 0
und fur x= 2 ist f (2)= 2> 0, aber es gibt kein x∈Q mit f (x) = 0, da hierzu x2 = 2
sein muss, wofur es in Q keine Losung gibt.
Beispiel. Mit Hilfe des Zwischenwertsatzes lasst sich in manchen Fallen sehr
leicht die Existenz von reellen Nullstellen von Gleichungen beweisen. Sei zum
Beispiel
f (x) = x2n+1 +a1x2x + . . .+a2n+1
eine Polynomfunktion des ungeraden Grades 2n+1 mit reellen Koeffizienten. Wir
behaupten, dass die Gleichung f (x) = 0 wenigstens eine reelle Nullstelle besitzt.
In der Tat lasst sich zeigen, dass es eine Konstante C > 0 existiert so, dass
f (x)
x2n+1>
1
2mit |x| ≥C
ist. Wenden wir dies nun auf x =C und x =−C an, so ergibt sich fur x =C
f (C)
C2n+1>
1
2, f (C)> 0
und fur x =−Cf (−C)
(−C)2n+1>
1
2, f (−C)< 0.
Da also die Funktion f (x) in den Endpunkten des Intervalls [−C,C] Werte ver-
schiedenen Vorzeichens annimmt, muss sie irgendwo in diesem Intervall den da-
zwischen liegenden Wert 0 annehmen.

Der Zwischenwertsatz von Bolzano 71
Beispiel. Sei f : [a,b] → R eine stetige Funktion. Wir mochten zeigen, dass es
ein ξ ∈ [a,b] existiert so dass f (ξ ) = 12( f (a)+ f (b)). Man kann zwei Falle un-
terscheiden: Ist f (a) = f (b), dann ist die Ausage mit ξ = a oder ξ = b trivial,
denn
f (a) =1
2( f (a)+ f (b)) = f (b).
Ist f (a) 6= f (b), dann folgt die Behauptung unmittelbar aus dem Zwischenwertsatz,
denn es ist entweder
f (a)<1
2( f (a)+ f (b))< f (b) oder f (a)>
1
2( f (a)+ f (b))> f (b),
je nachdem es entweder f (a)< f (b) oder f (a)> f (b) gilt.
Eine weitere Anwendung des Zwischenwertsatzes hat mit dem Wachstum ste-
tigen Funktionen zu tun. Dafur mussen wir die Begriffe von Maximum und Mini-
mum (sowohl im lokalen als auch in globalen Sinne) einfuhren:
Definition. Sei D ⊂ R eine Menge und f : D → R eine Funktion. Man sagt, dass
f in einem Punkt x ∈ D das globale Maximum annimmt, wenn
f (x)≥ f (x′) fur alle x′ ∈ D gilt,
und dass f das globale Minimum annimmt, wenn
f (x)≤ f (x′) fur alle x′ ∈ D gilt.
Die gemeinsame Bezeichnung fur ein Maximum oder ein Minimum ist Extre-
mum. Ist die Untersuchung dieses Verhaltens auf eine Umgebung eines Punktes
eingeschrankt, so spricht man von lokalen Extrema:
Definition. Sei D ⊂ R eine Teilmenge und f : D → R eine Funktion. Man sagt,
dass f in einem Punkt x ∈ D ein lokales Maximum bzw. lokales Minimum besitzt,
wenn es ein ε > 0 derart gibt, dass fur alle x′ ∈ D mit d(x,x′)< ε die Abschatzung
f (x)≥ f (x′) bzw. f (x)≤ f (x′)
gilt.
Ist f (x) > f (x′) (bzw. f (x) < f (x′)) fur alle x′ 6= x, so spricht man von einem
isolierten Maximum (bzw. isolierten Minimum).
Satz 9.4 (Weierstraß). Sei [a,b] ⊂ R ein abgeschlossenes beschranktes Intervall,
und sei f : [a,b]→ R eine stetige Funktion. Dann gibt es ein x ∈ [a,b] mit
f (x)≥ f (x′) fur alle x′ ∈ [a,b].
D.h. die Funktion f ihr Maximum (und ihr Minimum) annimmt.

72 Abschnitt 9
Beweis. Nach dem Zwischenwertsatz wissen wir, dass das Bild
J := f ([a,b])
ein Intervall ist (vgl. Satz 9.3). Zunachst zeigen wir, dass J sowohl nach oben als
auch nach unten beschrankt, also beschrankt, ist: Angenommen, dass J nicht nach
oben beschrankt ware, dann gabe es eine Folge
(xn)n∈N
in [a,b] mit f (xn)≥ n. Nach dem Satz von Bolzano-Weierstraß besitzt (xn)n∈N eine
konvergente Teilfolge (xnk)k∈N. Da [a,b] abgeschlossen ist, gehort der Grenzwert
der Teilfolge zu [a,b]. Wegen der Stetigkeit von f muss dann auch die Bildfolge
( f (xnk))k∈N
konvergieren. Diese ist aber unbeschrankt, so dass sie nach Satz 5.1 nicht konver-
gieren kann, also Widerspruch!
Nach dieser Uberlegungen und dem Vollstandigkeitsaxiom von R besitzt J ein
(eindeutig bestimmtes) Supremum: Sei nun y das Supremum von J. Es ist zu zei-
gen, dass y ∈ J ist. Es gibt eine Folge (yn)n∈N in J, die gegen y konvergiert. Nach
der Definition von J gibt es eine Folge (xn)n∈N so dass
f (xn) = yn
fur jedes n ist. Diese Folge hat wieder nach dem Satz von Bolzano-Weierstraß eine
konvergente Teilfolge. Bezeichnen wir ihren Grenzwert mit x, so ist aufgrund der
Stetigkeit f (x) = y und daher ist y ∈ J.
Das die Funktion auch ein Minimum in [a,b] annimmt ergibt sich aus der Be-
trachtung der Funktion − f . �
Aus dem Satz 9.4 folgt sofort, dass die stetige Funktion f : [a,b]→R auf einem
beschrankten und abgeschlossenen Intervall beschrankt sein muss, d.h., es existiert
ein c ∈ R mit
| f (x)| ≤ c fur alle x ∈ [a,b].
Die abgeschlossenheit des Intervalls ist dabei entscheidend: Zum Beispiel ist
die Funktion f :]0,2] → R, x 7→ 1/x stetig, aber nicht beschrankt: Die Funktion
nimmt im Intervall ]1,2[ offenbar Werte an, die zwischen 1 und 12
liegen und belie-
big nah sowohl an 1 als auch an 12
herauskommen. Die Werte 1 und 12
selbst werden
von f aber erst in den Punkten x = 1 und x = 2 angenommen, die hier nicht zum
Intervall gehoren. Die Funktion f besitzt also auf ]1,2[ weder ein Maximum noch
ein Minimum.
Unser Repertoire an Funktionen ist bisher klein. Als Verfahren zur Konstrukti-
on neuer Funktionen haben wir nur die arithmetischen Operationen und die Hinter-
einanderschaltung kennengelernt. Man kann noch ein weiteres Verfahren betrach-
ten: Zu einer gegebenen Funktion ihre Umkehrfunktion zu bilden. Daher wollen

Der Zwischenwertsatz von Bolzano 73
wir erstens die Definition von Umkehrfunktion angeben und zweitens das Problem
der Stetigkeit von Umkehrfunktionen diskutieren.
Es ist nicht schwierig zu beweisen:
Satz 9.5. Seien M,N nicht leere Mengen und f : M → N eine Abbildung. Sie ist
genau dann bijektiv, wenn eine Abbildung g : N → M existiert so dass
f ◦g = idN und g◦ f = idM,
wobei idN bzw. idM die Identitat auf N bzw. die Identitat auf M sind. In diesem Fall
ist die Abbildung g eindeutig bestimmt und wird mit f−1 bezeichnet. Die Abbil-
dung f−1 heißt die Umkehrabbildung von f . Ist f eine Funktion, so heißt f−1 die
Umkehrfunktion von f .
Beweis. Zunachst nehmen wir an, dass f eine Bijektion ist. Dann existiert zu je-
dem y ∈ N ein eindeutig bestimmtes xy ∈ M mit f (xy) = y. Man definiert dann die
Abbildung g : N → M durch g(y) = xy. Einerseits gilt dann
( f ◦g)(y) = f (g(y)) = f (xy) = y = idN(y)
und daher ist f ◦g = idN . Andererseits sei zu y = f (x) zu x ∈ M. Dann ist g(y) = x
und daher (g( f (x))) = f (x). Aus der Injektivitat von f ergibt sich nun
(g◦ f )(x) = g( f (x)) = x = idM(x),
also g◦ f = idM. Sei umgekehrt eine Abbildung g : N → M gegeben mit f ◦g = idN
und g◦ f = idM. Sei dazu y ∈ N. Dann ist
y = idN(y) = ( f ◦g)(y) = f (g(y)),
woeaus sich die Surjektivitat von f ergibt. Seien ferner x,y ∈ M mit x 6= y. Ange-
nommen, es ware f (x) = f (y), dann folgt der Widerspruch
x = idM(x) = (g◦ f )(x) = g( f (x)) = g( f (y)) = (g◦ f )(y) = idM(y) = y.
Somit ist die Injektivitat der Funktion f auch bewiesen, und damit ihre Bijektivitat.
�
Achtung!
Es ist zu beachten: Sowohl die Umkehrabbildung von f als auch das Urbild un-
ter f werden mit f−1 gekennzeichnet. Aus dem Zusammenhang muss man ggf.
entscheiden, um welche von den beiden sich handeln. Diese Schreibweise ist so
verbreitet, dass wir sie auch so annehmen sollen.
Definition. Eine Funktion f : D → R heißt monoton wachsend (bzw. streng mo-
noton wachsend), wenn fur alle x,y ∈ D mit x < y folgt, dass f (x) ≤ f (y) (bzw.
f (x)< f (y)). Analog definiert man fur f den Begriff (streng) monoton fallend.
Satz 9.6. Sei I ⊂ R ein Intervall und f : I → R eine stetige Funktion. Dann ist f
genau dann injektiv, wenn f streng monoton (wachsend oder fallend) ist.

74 Abschnitt 9
Beweis. Eine Richtung ist trivial. Nehmen wir an, dass die Funktion f injektiv ist.
Zunachst beweisen wir durch Widerspruch, dass fur
x,y,z ∈ I mit x < y < z
gilt entweder
f (x)< f (y)< f (z) oder f (x)> f (y)> f (z).
Angenommen nicht, also, angenommen x,y,z ∈ I mit x < y < z existierten mit
f (x)< f (y)> f (z). Sei ξ ∈ R so dass
max{ f (x), f (z)}< ξ < f (y).
Da f (x) < ξ < f (y) folgt aus dem Zwischenwertsatz fur die Funktion f |[x,y],dass ein c1 ∈]x,y[ existiert mit f (c1) = ξ . Analog folgt aus dem Zwischenwertsatz
fur f |[y,z], dass ein c2 ∈]y,z[ existiert mit f (c2) = ξ . Das ist ein Widerspruch zur
Injektivitat von f .
Es ist nur noch zu zeigen, dass die Umkehrfunktion von f die gleiche Mono-
tonie wie f besitzt. Dafur nehmen wir an, dass f nicht streng monoton fallend ist,
und zeigen, dass f dann streng monoton wachsend sein muss. Es existieren dann
x1,x2 ∈ I mit
x1 < x2 und f (x1)< f (x2)
(Zu beachten ist dabei, dass wir < und nicht ≤ aufgrund der Injektivitat von f
beschrieben haben!) Seien noch dazu x,y ∈ I beliebig so dass x < y. Wir mochten
zeigen, dass dann f (x)< f (y) gilt. Angenommen, es ist y < x1, dann muss
f (y)< f (x1)< f (x2)
gelten, und damit
f (x)< f (y)< f (x1),
speziell also f (x)< f (y). �
Satz 9.7. Sei I ⊂ R ein Intervall und f : I → R eine streng monoton wachsende
(bzw. fallende) stetige Funktion. Dann ist J := f (I) ein Intervall und die Umkehr-
funktion von f : I → J ist streng monoton wachsend (bzw. fallend) und stetig.
Beweis. Wir beweisen, dass die Umkehrfunktion f−1 von f stetig in jedem Punkt
y0 von J ist. OBdA betrachten wir den Fall, indem y0 keine Intervallgrenze ist. Sei
f−1(y0) = x0 ∈ I. Dann ist x0 auch keine Intervallgrenze von I. Angenommen, f
ist streng monoton wachsend. Dann ist f−1 auch streng monoton wachsend. Sei
ε > 0 vorgegeben. Wir durfen ein ε ′ > 0 so dass ε ′ < ε und [x0 − ε ′,x0 + ε ′] ⊂ I
nehmen. Seien y1 = f (x0 − ε ′) und y2 = f (x0 + ε ′). Da
x0 − ε ′ < x0 < x0 + ε ′
stellt das strenge Wachstum von f sicher, dass
y1 < y0 < y2

Der Zwischenwertsatz von Bolzano 75
gilt. Wir setzen
δ := min{|y1− y0|, |y2 − y0|}> 0,
und sei y ∈]y0 −δ ,y0 +δ [. Aus den Ungleichungen y1 < y < y2 folgt
f−1(y1) = x0 − ε ′ < f−1(y)< f−1(y2) = x0 + ε ′,
und daraus ergibt sich
| f−1(y)− x0|= | f−1(y)− f−1(y0)|< ε ′ < ε,
was die Stetigkeit von f−1 in J definitionsgemaß bedeutet. �
Beispiel. Wir betrachten die Funktion
f : [0,∞[→ R, x 7→ xn
fur ein n ∈ N, n > 0. Diese Funktion ist streng monoton wachsend und stetig. Es
ist
f ([0,∞[) = [0,∞[,
da der Wertebereich ein Intervall sein muss und wir wissen, dass f (0) = 0 sowie
limx→∞
xn = ∞.
Die Umkehrfunktion g von f existiert mit Definitionsbereich [0,∞[ nach Satz 9.7.
Es existiert also insbesondere zu jedem y ∈ [0,∞[ ein x mit y = xn und dieses x
ist eindeutig bestimmt. Wir nennen dieses x die n-te Wurzel von y und schreiben
hierfur x = n√
y. Der Satz 9.7 zeigt wieder, dass die Funktion
g : [0,∞[→ [0,∞[, y → n√
y
streng monoton wachsend und stetig ist.
Bevor wir die Begriffe von Differenzierbarkeit und Integrierbarkeit thematisie-
ren, widmen wir ein Abschnitt dem Studium von typischen, elementaren Funktio-
nen der Analysis. Insbesondere wird die Stetigkeit von solchen Funktionen disku-
tiert.


ABSCHNITT 10
Elementare Funktionen der Analysis
Elementarfunktionen der Analysis sind diejenigen Funktionen, die aufgrund ih-
rer guten, einfachen Eigenschaften eine grundlegende Rolle bei der Theorie spie-
len. In der ersten Linie sind die Polynomfunktionen und die rationalen Funktio-
nen zu erwahnen. Ihre wichtigste Eigenschaften sind uns aus der Mathematik-
unterricht vertraut. Insbesondere haben wir ihre Stetigkeit schon diskutiert. Die
Wurzelfunktion x 7→ n√
x wurde schon als Umkehrfunktion von x 7→ xn eingefuhrt
und ihre Stetigkeit untersucht. Selbst die Exponentialfunktion und ihre Funktional-
gleichung haben wir als Anwendung unseres Wissens uber Reihen definiert. Ziel
dieses Abschnittes ist, weitere Eigenschaften sowohl der Exponentialfunktion und
ihrer Umkehrfunktion—der Logarithmus, als auch der trigonometrischen Funk-
tionen und ihrer Umkehrfunktionen zu prasentieren, insbesondere hinsichtlich der
Stetigkeit.
Definition. Die Funktion R→ R, die durch
x 7→ exp(x) :=∞
∑n=0
xn
n!
gegeben ist, heißt (reelle) Exponentialfunktion.
Aus der Definition und der in Abschnitt 7 schon bewiesenen Funktionalglei-
chung exp(x+ y) = expx · expy (vgl. Satz 7.12) ergibt sich:
Satz 10.1. Die Exponentialfunktion erfullt folgende Eigenschaften:
(a) Es ist exp0 = 1.
(b) Fur jedes x ∈ R ist exp(−x) = (expx)−1. Insbesondere ist expx 6= 0.
(c) Fur jedes x ist expx > 0.
(d) Fur x > 0 ist expx > 1, und fur x < 0 ist expx < 1.
(e) Die reelle Exponentialfunktion ist streng monoton wachsend.
(f) Die reelle Exponentialfunktion ist stetig und stiftet eine Bijektion zwischen
R und R>0.
Beweis. (a) ergibt sich unmittelbar aus der Definition. (b) folgt aus der Funktio-
nalgleichung 7.12, denn
expx · exp(−x) = exp(x− x) = exp0 = 1.

78 Abschnitt 10
Die Nichtnegativitat von (c) folgt aus der Tatsache expx 6= 0 in (b) zusammen mit
expx = exp(x
2+
x
2
)= exp
x
2· exp
x
2=(
expx
2
)2
> 0.
(d) Fur x ∈R ist expx ·exp(−x) = 1 so dass nach (b) ein Faktor ≥ 1 und der andere
≤ 1 sein mussen. Fur x > 0 ist definitionsgemaß
expx = 1+ x+1
2x2 + . . . > 1.
(e) Fur reelle y > x ist y− x > 0 und nach (d) exp(y− x)> 1, also
expy = exp(y− x+ x) = exp (y− x) · expx > expx.
(f) Die Stetigkeit ergibt sich nach dem Satz 8.6. Nach (d) liegt das Bild in R>0
und ist nach dem Zwischenwertsatz 9.1 ein Intervall. Die Unbeschranktheit des
Bildes folgt aus (c), woraus wiederum wegen (b) sich ergibt, dass auch beliebig
kleine positive reelle Zahlen zum Bild gehoren. Daher ist das Bild gleich R>0. Die
Bijektivitat folgt aus (e) und dem Satz 9.6. �
Dank Satz 10.1 besitzt die Exponentialfunktion eine Umkehrfunktion R>0 →R:
Definition. Der naturliche Logarithmus
log : R>0 → R, x 7→ logx
ist als die Umkehrfunktion der reellen Exponentialfunktion definiert. Oft bezeich-
net man logx auch mit lnx.
Aus der Funktionalgleichung der Exponentialfunktion 7.12 zusammen mit den
Satzen 8.6 und 10.1 folgt:
Satz 10.2. Der naturliche Logarithmus ist eine stetige, streng wachsende Funkti-
on, die eine Bijektion zwischen R>0 und R stiftet. Außerden gilt log1 = 0 und die
Funktionalgleichung
log(x · y) = logx+ logy
fur alle x,y ∈ R>0.
Definition. Zu einer positiven reellen Zahl a 6= 1 definiert man die Exponential-
funktion zur Basis a als
ax := exp(x loga).
Dem Leser ist die Uberprufung der folgenden vier Eigenschaften uberlassen:
Satz 10.3. Seien a,b ∈ R>0 \{1} und x,y ∈ R. Es gilt:
(a) ax+y = ax ·ay.
(b) a−x = 1ax .
(c) (ax)y = axy.
(d) (ab)x = axbx.

Elementare Funktionen der Analysis 79
Als Anwendung zeigen wir:
Satz 10.4. Fur x ∈ R gilt
expx = ex.
Beweis. Nach der Definition der Exponentialfunktion zur Basis b = e ist ex =exp(x loge). Wegen exp1 = e ist loge = 1, und daraus folgt ex = exp(x loge) =expx. �
Definition. Zu einer positiven reellen Zahl a 6= 1 definiert man den Logarithmus
zur Basis a als
loga x :=logx
loga.
Es ist naturlich loge x = logx. Daruber hinaus:
Satz 10.5. Seien a,b ∈ R>0 \ {1} und x,y ∈ R. Fur den Logarithmus zur Basis b
gilt:
(a) Es ist logb bx = x und blogb y = y, d.h., der Logarithmus zur Basis b ist die
Umkehrfunktion zur Exponentialfunktion zur Basis b.
(b) logb x · y = logb x+ logb y.
(c) logb yu = u · logb y fur u ∈ R.
(d) loga y = loga blogb y = logb y · loga b.
Beweis. Vgl. Ubungsblatt 7. �
Satz 10.6.
(a) Fur jedes n ∈ Z ist limx→∞expx
xn = ∞.
(b) Es gilt limx→∞ logx = ∞.
(c) Es gilt limx↓0 logx =−∞.
Beweis. (a) Fur x > 1 gilt
expx
xn>
∑mk=0
xk+1
(k+1)!
xn>
xm+1
(m+1)!
xn=
xn
(m+1)!−→ ∞.
(b) Seien A > 0, B = expA. Aus x > B folgt logx > logB = A, wie gewunscht.
(c) Es ist zu zeigen: Zu A > 0 vorgegeben existiert ein δ > 0 so dass aus 0 <x < δ die Abschatzung logx < −A folgt. Es genugt, δ = exp(−A) auszuwahlen:
Ist 0 < x < δ , dann gilt
logx < logδ =−A,
woraus sich die Aussage ergibt. �
Ein Spezialfall der Exponentialfunktion sind die Hyperbelfunktionen:
Definition. Sei x ∈ R.
(a) Die Funktion x 7→ sinhx := 12(expx− exp(−x)) heißt Sinus hyperbolicus.

80 Abschnitt 10
(b) Die Funktion x 7→ coshx := 12(expx+ exp(−x)) heißt Kosinus hyperboli-
cus.
(c) Die Funktion x 7→ tanhx := sinhxcoshx
heißt Tangens hyperbolicus.
(d) Die Funktion x 7→ cothx := coshxsinhx
heißt Kotangens hyperbolicus.
Die Funktion Sinus hyperbolicus ist streng monoton wachsend und die Funk-
tion Kosinus hyperbolicus ist auf R≤0 streng monoton fallend und auf R≥0 streng
monoton wachsend. Weitere Eigenschaften sind:
(i) coshx+ sinhx = expx.
(ii) coshx− sinhx = exp(−x).(iii) (coshx)2 − (sinhx)2 = 1.
Der Sinus Hyperbolicus bildet R bijektiv auf R ab und besitzt deswegen eine
Umkehrfunktion. Diese nennen wir Areasinus hyperbolicus. Es gilt dabei:
arsinh(x) = log(x+√
x2 +1).
Der Kosinus Hyperbolicus bildet das Intervall [0,∞[ bijektiv auf [1,∞[, deshalb be-
sitzt er eine Umkehrfunktion im Intervall [0,∞[, die man Areakosinus hyperbolicus
nennt. Es gilt:
arcosh(x) = log(x+√
x2 −1).
Die Stetigkeit dieser Funktionen in ihren Definitionsbereichen ist aus ihrer Dar-
stellung mittels elementareren Funktionen klar.
Weitere wichtige Elementarfunktionen der Analysis sind die trigonometrischen
Funktionen Sinus und Kosinus. Sie werden wir—so wie die Exponentialfunktion—
als Reihen reeller Zahlen definieren:
Definition. Fur x ∈ R heißt die Reihe∞
∑k=0
(−1)k x2k
(2k)!= 1− x2
2!+
x4
4!− x6
6!± . . .
die Kosinusreihe, und die Reihe
∞
∑k=0
(−1)k x2k+1
(2k+1)!= x− x3
3!+
x5
5!− x7
7!± . . .
die Sinusreihe.
Das Vergleich mit der Exponentialfunktion zeigt sofort, dass beide Reihe abso-
lut konvergieren. Die entsprechenden Funktionen R→ R gegeben durch
cosx :=∞
∑k=0
(−1)k x2k
(2k)!und sinx :=
∞
∑k=0
(−1)k x2k+1
(2k+1)!
heißen Sinus und Kosinus. Wegen Satz 8.6 sind sie stetige Funktionen. Außerdem
gilt:

Elementare Funktionen der Analysis 81
Satz 10.7. Es gilt:
(a) cos0 = 1 und sin0 = 0.
(b) cos(−x) = cosx und sin(−x) =−sinx.
(c) Die Additionstheoreme
(i) cos(x+ y) = cosx · cosy− sinx · siny
(ii) cos(x− y) = cosx · cosy+ sinx · siny
(iii) sin(x+ y) = sinx · cosy+ cosx · siny
(iv) sin(x− y) = sinx · cosy− cosx · siny
Beweis. (a) und (b) folgen direkt aus der Definition. Die Additionstheoreme (i)
und (iii) in (c) erfolgen nach einer geschickten Anwendung des Cauchy-Produktes
von Reihen 7.11. Die anderen (ii) und (iv) nutzen sowohl (i) und (iii) als auch
(b). �
Satz 10.8. Es gilt:
(a) 1 = cos2 x+ sin2 x.
(b) sin2x = 2 · sinx · cosx und cos2x = cos2 x− sin2 x.
(c) Es ist |sinx| ≤ 1 und |cosx| ≤ 1 fur alle x ∈ R.
Beweis. (a) folgt aus Satz 10.7(a) und (c)(iii) wegen
1 = cos0 = cos(x− x) = cos2 x+ sin2 x,
genauso wie (b). Die Aussage (c) folgt unmittelbar aus (a). �
Bei der Aussagen (a) und (b) in Satz 10.8 wurde die ubliche Schreibweise
cos2 x := (cosx)2 und sin2 x := (sinx)2 verwendet. Weitere wichtige Eigenschaf-
ten der Kosinus- und Sinusfunktion halten wir auch fest:
Satz 10.9. Es gilt:
(a) Es ist sinx > 0 fur alle x ∈]0,2].(b) Die Funktion cosx ist auf [0,2] steng monoton fallend und besitzt dort ge-
nau eine Nullstelle a.
(c) Die Funktionen cosx und sinx bilden jeweils R (surjektiv) auf [−1,1] ab.
Beweis. (a) Sei die Reihe r = ∑∞k=1(−1)k x2k+1
(2k+1)! . Man uberlege sich
∣∣∣r
x
∣∣∣≤ |x|26
≤ 2
3fur 0 < x ≤ 2,
indem man analog zu den Abschatzungen vom Leibniz-Kriterium 7.5 vorgeht.
Dann ergibt sich fur diese x, dass
sinx = x+ r = x(
1+r
x
)≥ x(
1− 2
3
)=
x
3> 0.

82 Abschnitt 10
(b) Fur x,y ∈ [0,2], x > y setzen wir u = x+y2
und v = x−y2
. Dann gilt x = u+ v,
y = u− v und daher mittels der Additionstheoreme
cosx− cosy = cosu · cosv− sinu · sinv− cosu · cosv− sinu · sinv
= −2sinu · sinv =−2sin(x+ y
2
)sin(x− y
2
)< 0,
wobei die letzte Ungleichung sich aus (a) ergibt. Also ist die Kosinusfunktion auf
dem Intervall [0,2] streng monoton fallend. Wegen
cos2 ≤ 1− 22
2!+
24
4!= 1−2+
1
3< 0
und dem Zwischenwertsatz sieht man sofort, dass die Kosinusfunktion auf [0,2]genau eine Nullstelle a hat.
(c) Es ist sin2 a = 1−cos2 a = 1 und daher ist sina =±1. Wegen (a) gilt sina =1. Ferner ist sin(−a) =−sina =−1 und
|sinx| ≤ 1 fur alle x ∈ R
nach 10.8(c). Eine Anwendung des Zwischenwertsatztes 9.1 liefert, dass das Bild
der Sinusfunktion [−1,1] sein muss. Nun ist cos0 = 1 und cos2a = −1 nach
10.8(b). Eine weitere Anwendung des Zwischenwertsatzes ergibt, dass das Bild
der Kosinusfunktion auch [−1,1] ist. �
Definition. Sei a die Nullstelle der Kosinusfunktion im Intervall [0,2]. Dann defi-
nieren wir die Zahl π := 2a.
Eine weitere Anwendung der Additionstheoreme ergibt, dass cosx und sinx die
Periode 2π besitzen, d.h., fur x ∈ R gilt
cos(x+2π) = cosx und sin(x+2π) = sinx.
Daraus ergibt sich, dass sowohl die Sinus als auch die Kosinusfunktionen unend-
lich viele Nullstellen haben:
Satz 10.10.
(a) Es ist cosx = 0 genau dann, wenn x = π2+ kπ fur k ∈ Z.
(b) Es ist sinx = 0 genau dann, wenn x = kπ fur k ∈ Z.
Beweis. Wir stellen fest:
cos(π
2+ kπ) = 0 und sin(kπ) = 0.
Sei nun cosx = 0. Fur k =[
xπ
]gelten die Ungleichungen kπ ≤ x ≤ (k+ 1)π und
dann ist
cos(x− kπ) = cosx · coskπ + sinx · sinkπ = 0,

Elementare Funktionen der Analysis 83
da sinkπ = 0. Erstezen wir x durch x− kπ , dann konnen wir annehmen, dass 0 ≤x < π . Zu zeigen ist es noch, dass x = π
2. Es ist
cos(−x) = cosx = 0 und somit cos(−x+π) = 0.
Eine der beiden Zahlen, x oder −x+ π liegt im Intervall [0, π2]. Dort hat die Ko-
sinusfunktion nur die Nullstelle π2
, woraus automatisch x = π2
folgt. Die Aussage
uber die Nullstellen der Sinusfunktion ergibt sich aus der Gleichung
cos(
x+π
2
)= cosx · cos
π
2− sinx · sin
π
2=−sinx.
�
Tangens- und Kotangensfunktion sind nun zu definieren:
Definition. Seien D := {x ∈R : cosx 6= 0} und E := {x ∈ R : sinx 6= 0}.
(a) Die Tangensfunktion wird definiert durch
tan : D → R, x 7→ sinx
cosx.
(b) Die Kotangensfunktion wird definiert durch
cot : E → R, x 7→ cosx
sinx.
Sie sind jeweils stetige Funktionen auf ihren Definitionsbereichen.
Zum Abschluss behandeln wir die Frage, ob trigonometrische Funktionen um-
kehrbar sind. Das ist nicht der Fall auf ihren maximal moglichen Definitionsberei-
chen, durch Wahl geeignete Intervalle, auf denen sie streng monoton sind, konnen
wir aber ihre Umkehrfunktionen definieren:
Satz 10.11.
(a) Die Kosinusfunktion ist auf [0,π] streng monoton fallend und es gilt
cos([0,π]) = [−1,1].(b) Die Sinusfunktion ist auf [−π/2,π/2] streng monoton wachsend und es gilt
sin([−π/2,π/2]) = [−1,1].(c) Die Tangensfunktion ist auf ]−π/2,π/2[ streng monoton wachsend und es
gilt tan(]−π/2,π/2[) = R.
(d) Die Kotangensfunktion ist auf ]0,π[ streng monoton fallend und es gilt
cot(]0,π[) = R.
Beweis. (a) In Satz 10.9(b) haben wir gesehen, dass cosx auf [0,2] streng monoton
fallend ist, dann erst recht auf [0,π/2]. Wegen
−cos(π − x) =−cosπ · cosπ/2+ sinπ · sin(−x) = cosx
sehen wir, dass die Kosinusfunktion auf [0,π] streng monoton fallend ist. Die Be-
hauptung cos([0,π]) = [−1,1] haben wir schon in Satz 10.9(c) uberlegt.

84 Abschnitt 10
(b) Es gilt
−cos(x+π
2) =−cosx · cos
π
2+ sinx · sin
π
2= sinx,
woraus die Behauptung uber die Monotonie folgt. Dass sin([−π/2,π/2]) = [−1,1]ist, haben wir schon in Satz 10.9(c) gezeigt.
(c) Fur x,y ∈]−π/2,π/2[ gilt tanx = tany genau dann, wenn
0 = sinx · cosy− cosx · siny = sinx · cos(−y)+ cosx · sin(−y) = sin(x− y).
Aus Satz 10.10(b) folgt nun, dass x− y = kπ fur k ∈ Z. Das ist aber wegen der
Wahl von x,y nur fur k = 0 moglich, und daher ergibt sich x = y. Also ist die
Tangensfunktion auf ]−π/2,π/2[ injektiv. Es gilt weiterhin
limx ↑ π
2
sinx
cosx= ∞ und lim
x ↓ −π2
sinx
cosx=−∞,
also die Tangensfunktion muss streng monoton wachsend sein, und aus dem Zwi-
schenwertsatz 9.1 folgt, dass das Bild von tanx auf dem Intervall den ganzen Rist.
(d) zeigt man analog zu (c). �
Die durch den Satz existierenden Umkehrfunktionen von Kosinus, Sinus, Tan-
kens und Kotangens bzgl. der eingeschankten Definitionsbereiche sind
(i) Die Funktion arccos : [−1,1]→ [0,π], die Arcus-Kosinus heißt.
(ii) Die Funktion arcsin : [−1,1]→ [−π/2,π/2], die Arcus-Sinus heißt.
(iii) Die Funktion arctan : R→]−π/2,π/2[, die Arcus-Tangens heißt.
(iv) Die Funktion arccot : R→]0,π[, die Arcus-Kotangens heißt.
Wegen Satz 9.6 sind alle diese Funktionen stetig in ihren Definitionsbereichen. Es
ist noch zu bemerken, dass neben den vier besprochenen trigonometrischen Funk-
tionen gelegentlich, namentlich in der alteren Literatur, sind die beiden Funktionen
secx :=1
cosxund cosecx = cscx :=
1
sinx
namlich die Sekansfunktion und die Kosekansfunktion, zu finden.
In der Schule werden die trigonometrischen Funktionen in der Regel durch
Betrachtungen am rechtwinkligen Dreieck definiert. Das Problem bei dieser De-
finition ist, dass wir (noch) gar nicht genau wissen, was uberhaupt ein”Winkel”
sein soll. Deswegen haben wir sie durch konvergente Reihen eingefuhrt. Wenn Sie
sich aus Ihrem Mathematikunterricht daran erinnern, was ein Winkel ist, konnen
Sie weiter lesen.
In der Geometrie wird ein Winkel α haufig im Bogenmaß gemessen, der wie
folgt definiert ist. Wir betrachten einen Kreis K im R2 mit Mittelpunkt (0,0). Ist
nun ℓ die Lange des Kreisbogens eines Kreissektors und r der Radius des Kreises,

Elementare Funktionen der Analysis 85
dann gilt α = ℓ fur den induzierten Winkel. Nehmen wir noch an, dass K der
Einheitskreis r ist (d.h. r = 1), dann folgt α = ℓ im Bogenmaß. Es ist dabei zu
merken: 360◦ = 2π .
Dies stellt eine gewisse Verbindung zwischen unserer Definitionen der trigono-
metrischen Funktionen und der Definition mittels eines rechtwinkligen Dreiecks.
Zum Schluss prasentieren wir ein Bild, indem die sechs trigonometrischen Funk-
tionen eines Winkels α am Einheitskreis zu erkennen sind1:
sec α
cotα
tanα
α
1
1
cosα0
sinαcsc α
Trigonometrische Funktionen des Winkels α in Einheitskreis
Diese Darstellung hat auch viele Vorteile: Z. B. kann man sofort sehen, dass
sowohl cos(−α) = cosα und sin(−α) =−sinα als auch sinα2 + cosα2 = 1 fur
α ∈ [0,2π] gilt; Auch die Periodizitat von Sinus und Kosinus, und viele bedeutende
Werte, die die Funktionen annehmen:
sin0 = 0, sinπ
4=
√2
2, sin
π
2= 1, sin(−π
4) =
√2
2, sin(−π) = 0;
und
cos0 = 1, cosπ
4=
√2
2, cos
π
2= 0, cos(−π
4) =−
√2
2, cos(−π) =−1.
Wir haben unser Repertoire an Funktionen deutlich erweitert, so dass die Un-
tersuchung der Diffferential- und Integralrechnung reeller Funktionen ordentlich
gemacht werden kann. Diese sind die zwei letzten Themen der Infinitesimalrech-
nung, bevor wir mit der linearen Algebra anfangen.
1Es ist zugleich eine attraktive geometrische Aufgabe, sich zu uberlegen, warum das so ist!


ABSCHNITT 11
Differenzierbarkeit reeller Funktionen
Die Schopfung der Differenzialrechnung im 17. Jahrhundert von Newton und
Leibniz ist das Resultat intensiven Nachdenkens, das uber Jahrhunderte zuruck-
geht, bezogen auf folgende Problemensorten:
• Die Bestimmung der Momentangeschwindigkeit und -beschleunigung.
• Die Bestimmung der Tangenten an Kurven, die auch wichtig fur die Her-
stellung von Linsen war.
• Die Berechnung von Funktionenextrema, die eine große Rolle bei ballisti-
schen Kurven und dem Studium der Planeten Bewegung gespielt hat.
• Die Berechnung von Kurvenlangen, auch im Kontext von Planetenbahnen.
Die beste Annaherung zum Begriff der Differenzierbarheit kommt geometrisch
durch die Tangente auf. Sei I eine Teilmenge von R. Seien a ∈ I ein Punkt und
f : I → R eine Funktion. Fur einen weiteren Punkt x ∈ I kann man die Sekan-
te durch die Punkte (a, f (a)) und (x, f (x)) des Funktionsgraphen ziehen. Lassen
wir x gegen a laufen, so wird aus den Sekanten anschaulich eine Tangente. Die
Prazisierung dieses Grenzwertprozesses fuhrt letztlich zum Begriff der Differen-
zierbarkeit.
f (x)
x=x0x1xna
f (a)x−a
f (x)− f (a)

88 Abschnitt 11
Zu x ∈ I, x 6= a, heißt die Zahl
f (x)− f (a)
x−a
der Differenzquotient von f zu a und x. Sie ist die Steigung der Sekante am Graph
durch die beiden Punkte (a, f (a)) und (x, f (x)). Fur x = a ist dieser Quotient nicht
definiert, aber es existiert der Grenzwert fur x → a. Dieser reprasentiert dann die
Steigung der Tangente an f im Punkt (a, f (a)) (oder an der Stelle a):
Definition. Sei I ⊂ R ein Intervall, a ∈ I und f : I → R eine Funktion. Man sagt,
dass die Funktion f differenzierbar in a ist, wenn der Limes
limx∈I\{a},x→a
f (x)− f (a)
x−a
existiert und endlich ist. In diesem Fall heißt der Limes die Ableitung von f in
a, geschrieben f ′(a). Existiert die Ableitung in einem Punkt a, ist sie eine reelle
Zahl. Haufig nimmt man die Differenz h := x− a als Parameter fur den Limes
des Differenzenquotienten, und lasst h gegen 0 gehen, d.h. man betrachtet den
Grenzwert
limh→0
f (a+h)− f (a)
h,
wobei die Bedingung x∈ I\{a} zur Bedingung a+h∈ I, h 6= 0 wird. Diese werden
wir ab jetzt nicht mehr kennzeichen, und wir werden limx→a statt limx∈I\{a}, x→a
schreiben.
Beispiele.
(i) Seien α,β ∈R, und sei die Funktion f :R→R gegeben durch x 7→αx+β .
Die Ableitung von f im Punkt a ∈ R wird durch den Quotient
(αx−β )− (αa−β )
x−a=
α(x−a)
x−a= α
bestimmt. Dieser ist konstant gleich α , dann existiert der Limes fur x → a
und ist gleich α , d.h., die Ableitung von f existiert im Punkt a und ist
gleich α .
(ii) Wir betrachten die Funktion g : R→ R, x 7→ x2. Der Differenzquotient zu
x und a ist
g(x)−g(a)
x−a=
(x)2 −a2
x−a=
(x+a)(x−a)
x−a= x+a.
Der Grenzwert davon fur x → a existiert offensichtlich. Daher ist
g′(a) = limh→0
g(a+h)−g(a)
h= lim
x→ax+a = 2a.
Eine Charakterisierung der Differenzierbarkeit einer Funktion in einem Punkt
ist gegeben durch:

Differenzierbarkeit reeller Funktionen 89
Satz 11.1. Sei I ⊂ R ein offenes Intervall, a ∈ I ein Punkt und f : I → R eine
Funktion. Dann ist f in a genau dann differenzierbar, wenn es ein s ∈ R und eine
Funktion ρ : I → R gibt mit ρ stetig in a und ρ(a) = 0 und mit
f (x) = f (a)+ s · (x−a)+ρ(x)(x−a).
Beweis. Wenn f in a differenzierbar ist, so setzen wir s := f ′(a). Fur die Funktion
ρ muss notwendigerweise
ρ(x) =
{f (x)− f (a)
x−a− s fur x 6= a,
0 fur x = a,
gelten, um die Bedingungen zu erfullen. Aufgrund der Differenzierbarkeit existiert
der Limes
limx→a
ρ(x) = limx→a
(f (x)− f (a)
x−a− s
)
und hat den Wert 0. Das bedeutet, dass ρ in a stetig ist. Es existieren umgekehrt s
und ρ mit den angegebenen Eigenschaften, so gilt fur x 6= a die Beziehung
f (x)− f (a)
x−a= s+ρ(x).
Da ρ stetig in a ist, muss auch der Limes links fur x → a existieren. �
Der Satz 11.1 hat eine klare geometrische Bedeutung. Die Gleichung
f (x) = f (a)+ s · (x−a)+ρ(x)(x−a)
lasst sich schreiben als f (x)−g(x) = (x−a)ρ(x), mit g(x) = f (a)+ f ′(a)(x−a).Anschaulich:
f (x)
g(x)
xa
f (a)
g(x)
f (x)f (x)− f (a)

90 Abschnitt 11
Das heißt: Die Differenz zwischen der Funktion f und ihrer Tangente lauft
gegen 0 fur x → a schneller als x gegen a.
Aus dem Satz 11.1 folgt unmittelbar:
Satz 11.2. Sei I ⊂ R ein offenes Intervall, a ∈ I ein Punkt und f : I → R eine
Funktion, die im Punkt a differenzierbar ist. Dann ist f stetig in a.
Beweis. Es gilt f (x)− f (a) = f ′(a)(x−a)+ρ(x)(x−a)→ 0 fur x → a, und damit
limx→a
f (x) = f (a). �
Beispiel. Die Umkehrung des Satzes 11.2 gilt nicht. Zum Beispiel betrachten wir
die Funktion f : R→ R, x 7→ |x|. Die Funktion ist stetig im Nullpunkt, aber nicht
differenzierbar, denn
f (x)− f (0)
x−0=
{xx= 1, falls x ≥ 0
−xx=−1 falls x < 0.
Es gelten die folgenden Rechenregeln fur differenzierbare Funktionen
Satz 11.3. Sei I ein offenes Intervall, a ∈ I und f ,g : I → R zwei Funktionen.
(a) Ist f konstant auf I, dann ist f differenzierbar auf I mit f ′(x) = 0 fur alle
x ∈ I.
(b) Sind f und g differenzierbar im Punkt a, und α,β ∈ R, dann
(i) ist α f ± βg differenzierbar in a mit (α f ± βg)′(a) = α f ′(a)±βg′(a).
(ii) ist f ·g differenzierbar in a mit ( f ·g)′(a) = f ′(a)g(a)+ f (a)g′(a).(iii) ist f/g differenzierbar in a falls g(a) 6= 0 und es gilt
( f
g
)′=
f ′(a)g(a)− f (a)g′(a)(g(a))2
.
Beweis. Zu (a): Die Aussage folgt aus dem obigen Beispiel fur α = 0.
Zu (b): Die erste Aussage lasst sich einfach nachrechnen. Zu (ii) gilt definitions-
gemaß
( f ·g)′(a) = limx→a
( f ·g)(x)− ( f ·g)(a)x−a
= limx→a
f (x)g(x)− f (a)g(a)
x−a
= limx→a
f (x)g(x)− f (x)g(a)+ f (x)g(a)− f (a)g(a)
x−a
= limx→a
f (x)(g(x)−g(a))
x−a+ lim
x→a
g(a)( f (x)−g(a))
x−a
= f (a)g′(a)+g(a)+ f ′(a).

Differenzierbarkeit reeller Funktionen 91
Fur die Regel der Quotient (iii) betrachten wir zuerst den Fall f = 1:
(1
g)′(a) = lim
x→a
1g(x)− 1
g(a)
x−a= lim
x→a
1g(x)
− 1g(a)
x−a
= limx→a
1
g(x)g(a)· g(a)−g(x)
x−a=
1
(g(a))2· (−g′(a)).
Es gilt nun im Allgemeinen nach Anwendung von (ii):
(f
g)′(a) = ( f · 1
g)′(a) = f (a)(
1
g)′(a)+(
1
g)(a) f ′(a)
= f (a)1
(g(a))2(−g′(a))+ f ′(a)
1
g(a)
=− f (a)g′(a)+ f ′(a)g(a)
(g(a))2.
�
Nach dem Satz 11.3 und mit Hilfe der vollstandigen Induktion kann man be-
weisen:
Satz 11.4. Jede Polynomfunktion f = f (x) = anxn+ . . .+a0 ist auf R differenzier-
bar mit
f ′(x) = nanxn−1 +(n−1)an−1xn−2 + . . .+a1.
Ferner ist jede rationale Funktionf (x)g(x) mit f ,g Polynomfunktionen und g 6= 0 auf
ihrem Definitionsbereich differenzierbar.
Die Hintereinanderschaltung von Funktionen lasst sich auch differenzieren wie
folgender Satz andeutet:
Satz 11.5 (Kettenregel). Seien I,J ⊂ R zwei offene Intervalle, a ∈ I und f : I →R, g : J → R Funktionen mit f (I) ⊂ J und f (a) =: b. Setzen wir auch voraus,
dass f in a diferenzierbar ist, und dass g in b differenzierbar ist. Dann ist g ◦ f
differenzierbar in a mit
(g◦ f )′(a) = g′( f (a)) · f ′(a) = g′(b) · f ′(a).
Beweis. Nach Satz 11.1 ist
f (x) = f (a)+(x−a)(s1+ρ1(x))
g(y) = g(b)+(y−b)(s2+ρ2(y))

92 Abschnitt 11
mit f (x) := s1 +ρ1(x) bzw. g(x) := s2 +ρ2(y) stetig in a bzw. in b auf I bzw. J.
Damit ergibt sich
g( f (x)) = g(b)+( f (x)−b)g( f (x))
= g( f (a))+( f (a)+(x−a) f (x)− f (a))g( f (x))
= g( f (a))+(x−a) f (x)g( f (x)).
Da f · (g◦ f ) im Punkt a stetig ist, sind wir wegen Satz 11.1 fertig. �
Die Differenzierbarkeit der Umkehrfunktion lasst sich wie folgt beweisen:
Satz 11.6. Seien I ⊂ R ein offenes Intervall, a ∈ I ein Punkt, und f : I → R eine
injektive, stetige, in a differenzierbare Funktion mit f ′(a) 6= 0. Dann ist die Um-
kehrfunktion f−1 von f in b = f (a) differenzierbar mit
( f−1)′(b) =1
f ′( f−1(b))=
1
f ′(a).
Beweis. Es ist die Existenz des Grenzwertes
limy→b
f−1(y)− f−1(b)
y−b
zu rechtfertigen. Nach dem Satz 9.7 ist f−1 stetig in b, und daher gilt
limy→b
f−1(y) = f−1(b) = a.
Wenn wir x = f−1(y) setzen, dann ist
limy→b
f−1(y)−a
y−b= lim
x→a
x−a
f (x)− f (a)= lim
x→a
1f (x)− f (a)
x−a
=1
f ′(a).
�
Beispiel. Fur n ∈ N, n ≥ 1 betrachten wir die Funktionen f ,g gegeben durch
f : [0,∞[→R, x 7→ xn
g : [0,∞[→R, x 7→ n√
x.
Fur a > 0 ist f ′(a) = nan−1 6= 0. Daher ist g an jeder Stelle b > 0 differenzierbar
mit
g′(b) =1
f ′(g(b))=
1
n( n√
b)n−1=
1
nb
1n−1.
Wegen f ′(0) = 0 ist g fur n ≥ 2 im Nullpunkt nicht differenzierbar.
Die Ermittlung von Grenzwerten der Form limx→a
f (x)/g(x) mittels der Differen-
tialrechnung beschreibt der folgende Satz:

Differenzierbarkeit reeller Funktionen 93
Satz 11.7 (Regel von L’Hopital1). Sei I ein offenes Intervall. Seien f ,g differen-
zierbare Funktionen auf I mit g(x) 6= 0 und g′(x) 6= 0 fur alle x ∈ I. Sei a ein
Haufungspunkt von I. Dann gilt: Ist eine der Voraussetzungen
(a) limx→a
f (x) = limx→a
g(x) = 0
(b) limx→a
g(x) = ∞ (oder −∞)
erfullt, dann ist
limx→a
f (x)
g(x)= lim
x→a
f ′(x)g′(x)
,
falls der rechtsstehende Grenzwert existiert.
Eine analoge Aussage gilt, falls I ein offenes Intervall ist, a ∈ I und f ,g diffe-
renzierbar auf I \{a} sind mit g(x) 6= 0, g′(x) 6= 0 fur alle x ∈ I \{a}.
Beweis. Wir betrachten nur die leichtere Situation (a) (der interessierte Leser wird
fur (b) auf [Heu] verwiesen.) Sei also
limx→a
f (x) = limx→a
g(x) = 0.
Die Strategie ist: Wir beweisen die Aussage fur a ∈ R und versuchen dies in der
Situation b = ∞ anzuwenden.
(i) Angenommen wird zunachst, dass a∈R ist. Dann besagt die Voraussetzung:
f und g sind in a stetig mit dem Wert 0, was uns f (a) = g(a) = 0 zu schreiben
erlaubt. Dann ist
limx→a
f (x)
g(x)= lim
x→a
f (x)−0
g(x)−0= lim
x→a
f (x)− f (a)
g(x)−g(a)= lim
x→a
f (x)− f (a)x−a
g(x)−g(a)x−a
= limx→a
f ′(x)g′(x)
,
aufgrund der fur unsere Zwecke gunstigen Voraussetzungen.
(ii) Angenommen, es ist a = ∞ (fur −∞ verlauft es analog). Dann gibt es ein
b> 0 mit ]b,∞[⊂ I. Sei nun die Hilfsfunktion h(y) = 1y, und das Intervall J :=]0, 1
b[.
Dann ist f (J)⊂ I, und die Funktionen
f := f ◦h|J und g := g◦h|Jsind auf J differenzierbar, mit g(y) 6= 0 und g′(y) 6= 0 fur alle y ∈ J.
1”...tout a fait au-dessus de la vaine gloire, que la plupart des Scavans reserchent avec tant d’avidite...”.
Fontenelles Meinung uber Guillaume-Francois-Antoine de L’Hopital, Marquis de Sainte-Mesme et du Mon-
tellier, Comte d’Antremonts, Seigneur d’Ouques, 1661–1704. 1696 sagte er von ihm selber:”Au reste je
reconnois devoir beaucoup aus lumieres de Mrs Bernoulli, sur tout a celles du jeune presentement Profes-
seur a Groningue. Je me suis servi sans facon de leurs decouvertes...”.

94 Abschnitt 11
Sie erfullen weiterhin die Voraussetzung (a) mit (dortigem) a = 0. Dann durfen
wir (i), und die Kettenregel, anwenden:
limx→∞
f (x)
g(x)= lim
y→0
f (1/y)
g(1/y)= lim
y→0
f (y)
g(y)
(i)= lim
y→0
f ′(y)g′(y)
= limy→0
f ′(1/y)(−1/y2)
g′(1/y)(−1/y2)
= limy→0
f ′(1/y)
g′(1/y)= lim
x→∞
f ′(x)g′(x)
.
�
Beispiel. Es ist limx→0
ex −1
x= 1, denn die Voraussetzung (a) in Satz 11.7 ist erfullt,
so dass
limx→0
ex −1
x= lim
x→0
ex
1= 1
gilt.
Es ist hierzu das Kommentar von H. Hauser anzubringen:”Der dem Anfanger so teure Glaube
an die Wunderkrafte der Regel von de l’Hospital, ist irrig und wird nicht selten mit entnervenden
Rechnungen gebußt.” (Vgl. [Heu], S. 290.)
Nun mochten wir die Differenzierbarkeit der Exponentialfunktion und der tri-
gonometrischen Funktionen zeigen.
Satz 11.8.
(a) exp ist auf R differenzierbar mit exp′ (a) = exp (a) fur alle a ∈ R.
(b) cos ist auf R differenzierbar mit cos′ (a) =−sin(a) fur alle a ∈ R.
(c) sin ist auf R differenzierbar mit sin′ (a) = cos(a) fur alle a ∈ R.
Beweis. Zu (a): Zunachst zeigen wir die Aussage fur a = 0. Es ist die Definition
von Ableitung im Nullpunkt anzuwenden. Es gilt also
exp′ (0) = limx→0
exp(x)−1
x−0= lim
x→0
ex −1
x= 1 = exp(0)
nach dem obigen Beispiel. Fur a ∈R beliebig gilt exp(x) = exp(a) ·exp(h(x)) mit
h : R→ R,x 7→ x−a differenzierbar auf R. Da exp in 0 = h(a) differenzierbar ist,
ist exp auch in a differenzierbar mit
exp′ (a) = exp(a) · exp′ (h(a)) ·h′(a) = exp (a).
Zu (b): Fur jedes a ∈ R gilt
sinx− sina
x−a=
2sin(x−a2)cos(x+a
2)
x−a=
sin(x−a2)
x−a2
cos(x+a
2)

Differenzierbarkeit reeller Funktionen 95
und es ist daher
limx→a
sinx− sina
x−a= lim
x→a
sin(x−a2)
x−a2
· limx→a
cos(x+a
2) = 1 · cos(
2a
2) = cos(a).
Zu (c): Fur jedes a ∈ R gilt analog zu (b):
cosx− cosa
x−a=
−2sin(x−a2)sin(x+a
2)
x−a=
sin(x−a2)
x−a2
(−sin(x+a
2))
und es ist daher
limx→a
cosx− cosa
x−a= lim
x→a
sin(x−a2)
x−a2
· limx→a
(−sin(
x+a
2))= 1 ·
(−sin(
2a
2))=−sin(a).
�
Die Funktion log :]0,∞[→ R ist differenzierbar und fur a ∈]0,∞[ gilt nach Satz
11.6 und Satz 11.8
log′ (a) =1
exp(log(a))=
1
a.
Die Umkehrfunktionen arccos bzw. arcsin von cos bzw. sin sind auf ]−1,1[ diffe-
renzierbar mit
arccos′(a) =−1√1− x2
und arcsin′(a) =1√
1− x2
fur jedes a ∈]−1,1[.Die Tangensfunktion ist auf R\{kπ + π
2: k ∈ Z} differenzierbar mit
tan′ (a) =1
cos2 (a)= 1+ tan2 (a)
fur jedes a aus ihrem Definitionsbereich. Analog ist die Kotangensfunktion auf
R\{kπ : k ∈ Z} differenzierbar mit
cot′ (a) =−1
sin2 (a)=−1− cot2 (a)
fur jedes a aus ihrem Definitionsbereich. Die Umkehrfunktionen arctan bzw. arccot
von tan bzw. cot sind auf R differenzierbar mit
arctan′(a) =1
1+a2= cos2 (arctan(a))
arccot′(a) =−1
1+a2=−cos2 (arctan(a)).
Zum Schluss wollen wir uns aus der Abhangigkeit des Punktes in der Definiti-
on von”Ableitung” befreien, indem wir die Ableitung als Funktion verstehen. Sei

96 Abschnitt 11
dazu I ⊂ R ein Intervall und f : I → R eine Funktion. Man sagt, dass f differen-
zierbar ist, wenn fur jeden Punkt a ∈ I die Ableitung f ′(a) von f in a existiert. Die
Abbildung
f ′ : I →R, x 7→ f ′(x)
heißt dann die Ableitung (oder Ableitungsfunktion) von f . Die Ableitung f ′ einer
in jedem Punkt differenzierbaren Funktion nennt man haufig auch die erste Ablei-
tung von f . Hohere Ableitungen werden rekursiv definiert:
Definition. Sei I ⊂R ein Intervall und sei f : I →R eine Funktion. Die Funktion f
heißt n-mal differenzierbar, wenn sie (n−1)-mal diferenzierbar ist und die (n−1)-te Ableitung von f , bezeichnet mit f (n−1), differenzierbar ist. Die Ableitung
f (n)(x) := ( f (n−1))′(x)
nennt man dann die n-te Ableitung von f . Die zweite Ableitung bezeichnet man
auch mit f ′′, die dritte mit f ′′′. Eine Funktion f heißt unendlich oft differenzierbar,
wenn sie n-mal differenzierbar ist fur jedes n ∈ N. Eine Funktion heißt unendlich
oft differenzierbar, wenn sie n-mal differenzierbar fur jedes n ∈N ist.
Eine differenzierbare Funktion ist stetig, aber ihre Ableitung muss nicht mehr
stetig sein. Insofern ergibt der folgende Begriff Sinn:
Definition. Sei I ⊂ R ein Intervall und sei f : I → R eine Funktion. Die Funktion
f heißt stetig differenzierbar, wenn f differenzierbar ist und ihre erste Ableitung
f ′ stetig ist. Eine Funktion heißt n-mal stetig differenzierbar, wenn sie n-mal dif-
ferenzierbar ist und die n-te Ableitung stetig ist.
Beispiele.
(i) Polynomfunktionen, die Exponentialfunktion, die Sinusfunktion und die
Kosinusfunktion sind unendlich oft differenziebar, sogar unendlich oft ste-
tig differenzierbar.
(ii) Sei f : R → R die Funktion gegeben durch f (x) = x · |x|. Falls a < 0, ist
f ′(a) = −2a. Falls a > 0 ist f ′(a) = 2a. Außerdem gilt f ′(0) = 0. Die
Funktion f ist dann in R differenzierbar, und ihre erste Ableitung ist die
Funktion f ′ : R→R gegeben durch f ′(x) = 2|x|. Die Funktion f ′ ist uber-
all stetig, und sie ist differenzierbar”nur” in R \ {0}. D.h. f ist einmal
differenzierbar, bloß nicht zweimal, da f ′ nicht weiter differenzierbar ist.
Ferner ist f (einmal) stetig differenzierbar, weil f ′ stetig ist.

ABSCHNITT 12
Mittelwertsatze der Differenzialrechnung
Unser Ziel ist die Integralrechnung. Aus fur uns noch unerfindlichen Grunden
mussen wir die Differenzierbarkeit vollstandig nachvollziehen. Bisher haben wir
eher technische Eigenschaften der Ableitungskunst betrachtet, und keine tieferen
Ergebnisse uber ihre geometrische Bedeutung und ihre Wichtigkeit beim Verstand-
nis des Wachstumsverhaltens einer Funktion. Diese Betrachtung wird in diesem
Abschnitt geschehen1.
Ein erstes Resultat liefert eine notwendige Bedingung fur die Bestimmung von
Extrema:
Satz 12.1. Sei f :]a,b[→ R eine Funktion, die in c ∈]a,b[ ein lokales Extremum
hat und dort differenzierbar ist. Dann ist f ′(c) = 0.
Beweis. OBdA durfen wir annehmen, dass f im Punkt c ein lokales Maximum
besitzt (fur lokale Minima verlauft der Beweis analog). D.h. definitionsgemaß exi-
stiert ein ε > 0 derart, dass f (y) ≤ f (c) fur alle y ∈]a,b[ mit |y− c| < ε . Sei nun
eine Folge in ]a,b[ mit xn < c und xn → c. Dann ist |xn − c|< ε fur alle n ≥ n0 bei
geeignetem n0 ∈ N. Daraus folgt
f ′(c) = limn→∞
f (xn)− f (c)
xn − c≥ 0,
da f (xn) ≤ f (c) ist fur n ≥ n0, und ferner xn < c gilt. Sei (yn) eine Folge in ]a,b[mit yn > c und yn → c. Dann ergibt sich analog
f ′(c) = limn→∞
f (yn)− f (c)
yn − c≤ 0,
insgesamt also f ′(c) = 0. �
Die Ableitung von f wird durch Grenzubergang aus dem Differenzenquotien-
ten hergeleitet. Dann ist klar, dass wir Eigenschaften der Ableitung aus den Ei-
genschaften des Differenzenquotienten schliessen konnen. Ist das umgekehrt auch
so? Die Antwort auf diese Frage wird vom Mittelwertsatz der Differentialrechnung
geliefert. Zunachst eine vereinfachte Form des Problems:
1Die Art, wie es heute Standard ist, in der wir diese Themen prasentieren, stammt aus dem”Traite de
Calcul differentiel et integral” von J.A. Serret, erstmal 1868 veroffentlicht. Serret verwies auf Bonnet als
Quelle:”la demostration qui precede est due a M. Ossian Bonnet”. Vgl. [Se], S. 19.

98 Abschnitt 12
Satz 12.2 (Rolle). Sei a < b und f : [a,b]→ R eine stetige, auf ]a,b[ differenzier-
bare Funktion mit f (a) = f (b). Dann gibt es ein c ∈]a,b[ mit
f ′(c) = 0.
Beweis. Ist die Funktion f konstant, dann gilt offensichtlich f ′(c) = 0 fur alle c ∈]a,b[. Ist f nicht konstant, so existiert ein x ∈]a,b[ mit f (x) 6= f (a). OBdA durfen
wir annehmen, dass f (x) > f (a) ist. Nach dem Satz von Weierstraß 9.4 nimmt f
in [a,b] ihr globales Maximum. Dieses wird weder in a noch in b angenommen,
denn es gilt f (x)> f (a) = f (b). Sei nun M dieses Maximum, und sei c ∈]a,b[ mit
f (c) = M. Die Funktion f nimmt also insbesondere ein lokales Maximum in c an,
und f ist nach Voraussetzung in c differenzierbar. Nach dem Satz 12.1 ist dann
f ′(c) = 0. �
Geometrisch erscheint die Aussage des Rolleschen Satzes außerordentlich ein-
leuchtend2. Denn der Kurvenbogen C gegeben durch die Gleichung y = f (x) geht
nach der Voraussetzung des Satzes durch die beiden Endpunkten der Strecke [a,b]auf der x-Achse. Behauptet wird dann, dass uber einem gewissen inneren Punkt
dieser Sekante eine Tangente an C zur x-Achse parallel ist:
C
ca b
Q
Dabei sind Sekante und Tangente waagerecht. Warum soll die”waagerechte”
Lage ausgezeichnet sein? Tatsachlich gibt es keinen Grund, wie Lagrange erkannt
hat:
Satz 12.3 (Mittelwertsatz der Differentialrechnung von Lagrange). Seien a < b
und f : [a,b]→ R eine stetige, auf ]a,b[ differenzierbare Funktion. Dann existiert
ein c ∈]a,b[ mit
f ′(c) =f (b)− f (a)
b−a.
2Michel Rolle (1652–1719) hat den Satz fur Polynomfunktionen gefunden, bei dem seine Aussage be-
sonders einfach lautet. Der Rollesche Satz gehort heute zum wesentlichen Ergebniss der Elementaranaly-
sis. Paradoxerweise, wie Ostrowski bemerkt hat, war Rolle selber einer der erbittertsten Gegner des”neuen
Kalkuls” der Infinitesimalrechnung (vgl. [Os], S. 152).

Mittelwertsatze der Differenzialrechnung 99
Beweis. Wir”drehen” die Funktion f so dass der Rollesche Satz 12.2 angewandt
werden kann. Sei dafur die Hilfsfunktion
g(x) := f (x)− f (b)− f (a)
b−a(x−a).
Nach den Rechenregeln fur stetige und differenzierbare Funktionen erfullt g die
Voraussetzungen von 12.2, und die Ableitung von g ist
g′(x) = f ′(x)− f (b)− f (a)
b−a.
Deshalb existiert nach dem Rollschen Satz 12.2 ein c ∈]a,b[ mit
0 = g′(c) = f ′(c)− f (b)− f (a)
b−a,
und daher ist f ′(c) = f (b)− f (a)b−a
. �
Das geometrische Gehalt des Mittelwertsatzes der Differentialrechnung von
Lagrange ist eine Verallgemeinerung des Rolleschen Satzes, namlich: Es moge
langs eines Bogens der stetigen Kurve y = f (x) eine Tangente vorhanden sein,
dann ist in einem gewissen inneren Punkte dieses Bogens die Tangente parallel zur
Sehne, die den Bogen spannt (vgl. die Sehne PP′ in der Aufzeichnung):
P
P′f (x) = x
4sin(x)+2
a bc1 c2
Wie man sieht, unterscheidet sich diese Aussage von derjenigen des Rollen-
schen Satzes nur dadurch, dass dort die Sehne PP′ auf der x-Achse lag.
Die Großef (b)− f (a)
b−areprasentiert die Steigung der Sekante durch P und P′;
f ′(c) reprasentiert, wie im vorausgegangenen Abschnitt gesprochen, die Steigung
der Tangente am Graph von f im Punkt c.
Beispiel. Seien a,b ∈ R. Es gilt |sinb− sina| ≤ |b− a|. OBdA wird a < b an-
genommen. Da die Sinusfunktion in [a,b] stetig, und in ]a,b[ differenzierbar ist,

100 Abschnitt 12
existiert nach Satz 12.3 ein c ∈]a,b[ so dass
sinb− sina
b−a= sin′ c = cosc
gilt. Aus |cosx| ≤ 1 fur alle x ∈ R ergibt sich
|sinb− sina|= |cosc||b−a| ≤ |b−a|.Es gibt doch eine weitere Verallgemeinerung des Mittelwertsatzes von Lagran-
ge:
Satz 12.4 (Mittelwertsatz der Differentialrechnung von Cauchy). Seien a < b und
f ,g : [a,b] → R stetige, auf ]a,b[ differenzierbare Funktionen. Dann existiert ein
c ∈]a,b[ mit
( f (b)− f (a))g′(c) = (g(b)−g(a)) f ′(c).
Daruber hinaus, wird eine der Voraussetzungen
(a) g′(x) 6= 0 fur alle x ∈]a,b[,(b) g(a) 6= g(b) und die Funktionen f ′ und g′ verschwinden nicht gleichzeitig,
erfullt, dann darf man schreiben:
f (b)− f (a)
g(b)−g(a)=
f ′(c)g′(c)
.
Beweis. Sei die Hilfsfunktion
h(x) := ( f (b)− f (a))g(x)− (g(b)−g(a)) f (x).
Die Funktion h ist stetig im ganzen Intervall [a,b] und differenzierbar auf ]a,b[.Ferner ist
h(a) = f (b)−g(a)− f (a)g(a)−g(b) f (a)+g(a) f (a) = f (b)g(a)−g(b) f (a)
h(b) = f (b)g(a)−g(b) f (a),
d.h., es gilt h(a) = h(b). Nach dem Rolleschen Satz 12.2 existiert ein c ∈]a,b[ so
dass h′(c) = 0, d.h., so dass
( f (b)− f (a))g′(c) = (g(b)−g(a)) f ′(c)
gilt.
Angenommen, es gilt (a): Einerseits ist g′(c) 6= 0; andererseits wurden g(a) und
g(b) ubereinstimmen, und so existierte ein d ∈]a,b[ nach dem Rolleschen Satz auf
g angewandt so dass g′(d) = 0, was ein Widerspruch ist.
Angenommen, es gilt (b): Einerseits ist g(b)−g(a) 6= 0; andererseits wurde g′(c)verschwinden, dann wurde sich auch f ′(c) annullieren, was ein Widerspruch zur
Tatsache ist, dass f ′ und g′ nicht zugleich verschwinden. �

Mittelwertsatze der Differenzialrechnung 101
Eine erste Anwendung des Mittelwersatzes von Lagrange ist der Schranken-
satz:
Satz 12.5 (Schrankensatz). Seien a< b und f : [a,b]→R eine stetige und auf ]a,b[differenzierbare Funktion. Fur alle x ∈]a,b[ gelte m ≤ f ′(x) ≤ M fur m,M ∈ R.
Dann gilt fur alle y,z ∈ [a,b] mit y ≤ z
m(z− y)≤ f (z)− f (y)≤ M(z− y).
Beweis. OBdA durfen wir y < z annehmen. Dann existiert nach Satz 12.3 ein c ∈]a,b[ mit
m ≤ f ′(c) =f (z)− f (y)
z− y≤ M.
�
Daraus folgt unmittelbar:
Satz 12.6. Seien a < b und f : [a,b] → R eine stetige, auf ]a,b[ differenzierbare
Funktion mit f ′(x) = 0 fur alle x ∈]a,b[. Dann ist f konstant.
Beweis. Es genugt m = M = 0 in Satz 12.5 einzusetzen. �
Der Mittelwertsatz von Lagrange hilft beim Verstandnis des Monotonieverhal-
tens einer Funktion.
Satz 12.7 (Monotonietest).
(i) Seien a < b und f : [a,b]→ R eine stetige, auf ]a,b[ differenzierbare Funktion.
Gilt fur alle x ∈]a,b[
f ′(x)> 0
f ′(x)< 0
f ′(x)≥ 0
f ′(x)≤ 0
so ist die Funktion f
streng monoton wachsend
streng monoton fallend
monoton wachsend
monoton fallend
au f [a,b].
(ii) Wenn die Funktion f : [a,b]→ R
monoton
{wachst
fallt
}, so ist
{f ′(x)≥ 0
f ′(x)≤ 0
}f ur alle x ∈ [a,b], in denen f diffe-
renzierbar ist.
Beweis. Zu (i): Falls f ′(x) > 0 ist fur alle x ∈]a,b[, folgt mit dem Mittelwertsatz
von Lagrange fur y,z ∈ [a,b], y < z und geeignetem x ∈]y,z[, dass
f (z)− f (y) = f ′(x)(z− y)> 0.
Analog erledigt man die anderen Falle.

102 Abschnitt 12
Zu (ii): Die Aussage folgt wie der Satz 12.2 durch direkte Betrachtung der
Differenzquotienten: Sie sind alle ≥ 0 falls f monoton wachsend ist, und alle ≤ 0
falls f monoton fallend ist. �
Bevor wir mit der Integralrechnung anfangen, mochten wir eine letzte Anwen-
dung der Differenzialrechnung einfuhren: Die Bestimmung der Konvexitat oder
Konkavitat einer differenzierbaren Funktion auf einem Intervall. Dies soll als Kom-
plemet betrachtet werden, da wir dies in der Vorlesung nicht thematisiert haben.
Definition. Sei I ⊂R ein Intervall. Sei f : I →R eine Funktion. Man sagt, dass die
Funktion f konvex auf I ist, wenn fur alle x,y ∈ I mit x < y, und fur alle λ ∈]0,1[gilt
f ((1−λ )x+λx)≤ (1−λ ) f (x)+λ f (y)).
Andererseits heißt das, wenn die Ungleichung
f ((1−λ )x+λx)≥ (1−λ ) f (x)+λ f (y)).
gilt, dann heißt die Funktion f konkav auf I.
Dazu zwei Bemerkungen:
(i) Es ist x < (1−λ )x+λy < y, falls λ ∈]0,1[.(ii) Die Funktion, die durch die Gerade, welche durch die Punkte (x, f (x)) und
(y, f (y)) lauft, definiert ist, nimmt in (1−λ )x+λy den Wert (1−λ ) f (x)+λ f (y) an.
Es ist nicht schwierig zu beweisen:
Satz 12.8. Seien I ⊂ R ein Intervall und f : I → R eine Funktion. Genau dann ist
f konvex auf I, wenn fur alle x,y,z ∈ I mit x < y < z gilt
f (y)− f (x)
y− x≤ f (z)− f (y)
z− y.
Fur differenzierbare Funktionen gibt es folgende Charakterisierung:
Satz 12.9. Seien ]a,b[ ein offenes Intervall und f : [a,b]→R eine stetige, auf ]a,b[differenzierbare Funktion. Genau dann ist f konvex auf [a,b], wenn f ′ monoton
wachsend in [a,b] ist.
Beweis. Angenommen, f ist konvex. Fur x,y ∈ [a,b] mit x < y ist zu zeigen, dass
f ′(x)≤ f ′(y). Sei hierzu x1 ∈]x,y[. Wegen Satz 12.8 gilt
f (x1)− f (x)
x1 − x≤ f (y)− f (x1)
y− x1
.
Lassen wir einerseits x1 gegen x laufen, dann wird f ′(x) ≤ f (y)− f (x)y−x
. Lassen wir
andererseits x1 gegen y laufen, so wird f ′(y) ≥ f (y)− f (x)y−x
. Insgesamt ergibt sich
f ′(x)≤ f ′(y).

Mittelwertsatze der Differenzialrechnung 103
Sei umgekehrt f ′ monoton wachsend in [a,b]. Ist zu zeigen, dass
f (y)− f (x)
y− x≤ f (z)− f (y)
z− y
fur x < y < z gilt. Nach dem Mittelwertsatz von Lagrange auf der Funktion f |[x,y]angewandt, existiert ein c1 ∈]x,y[ mit
f (y)− f (x)
y− x= f ′(c1).
Analoges Argument fur die Funktion f |[y,z] ergibt die Existenz eines c2 ∈]y,z[ mit
f (z)− f (y)
z− y= f ′(c2).
Da c1 < c2 und f ′ nach Voraussetzung monoton wachsend ist, dann erhalten wir ,
wie gewunscht f ′(c1)≤ f ′(c2). �
Die Kombination von Satz 12.9 mit dem Monotonietest 12.7 liefert folgendes
Kriterium:
Satz 12.10. Sei f : [a,b] → R stetig, zwei mal differenzierbar auf ]a,b[. Genau
dann ist f konvex in I, wenn f ′′(x)≥ 0 fur alle x ∈]a,b[.Die Punkte bei denen das Konvexitatsverhalten wechselt, heißen Wendepunkte:
Definition. Sei f : [a,b] → R eine stetige, auf ]a,b[ zweimal differenzierbare
Funktion. Ein Punkt c ∈ [a,b] heißt ein Wendepunkt von f wenn
f ′′(x)< 0 fur x < c und f ′′(x)> 0 fur x > c
oder
f ′′(x)> 0 fur x < c und f ′′(x)< 0 fur x > c
ist (wobei nur die x in einer gewissen Umgebung von c in Betracht gezogen wer-
den).
Dann muss f ′′(c)= 0 sein. Eine Erklarung dafur kann man aus einem Analogon
der Darbouxschen Eigenschaft fur Ableitungen schließen, namlich:
Satz 12.11 (Zwischenwertsatz fur Ableitungen). Sei f : [a,b]→R stetig, auf ]a,b[differenzierbar mit f ′(a) 6= f ′(b). Dann nimmt f ′ in ]a,b[ jeden Wert zwischen
f ′(a) und f ′(b).
Sein Beweis ist leicht nach den bishierigen Uberlegungen, und wir verzichten
darauf (vgl. [Heu], S. 285). Das heißt: Nur Nullstellen der zweiten Ableitung kom-
men als Wendepunkte in Frage, mussen aber keine sein, weil f ′′ beim Durchgang
durch eine solche Nullstelle keinen Vorzeichenwechsel zu erleiden braucht (vgl.
[Heu], S. 293). Die Bedingung f ′′′(c) 6= 0 wird dann die Bedenken auszuraumen.

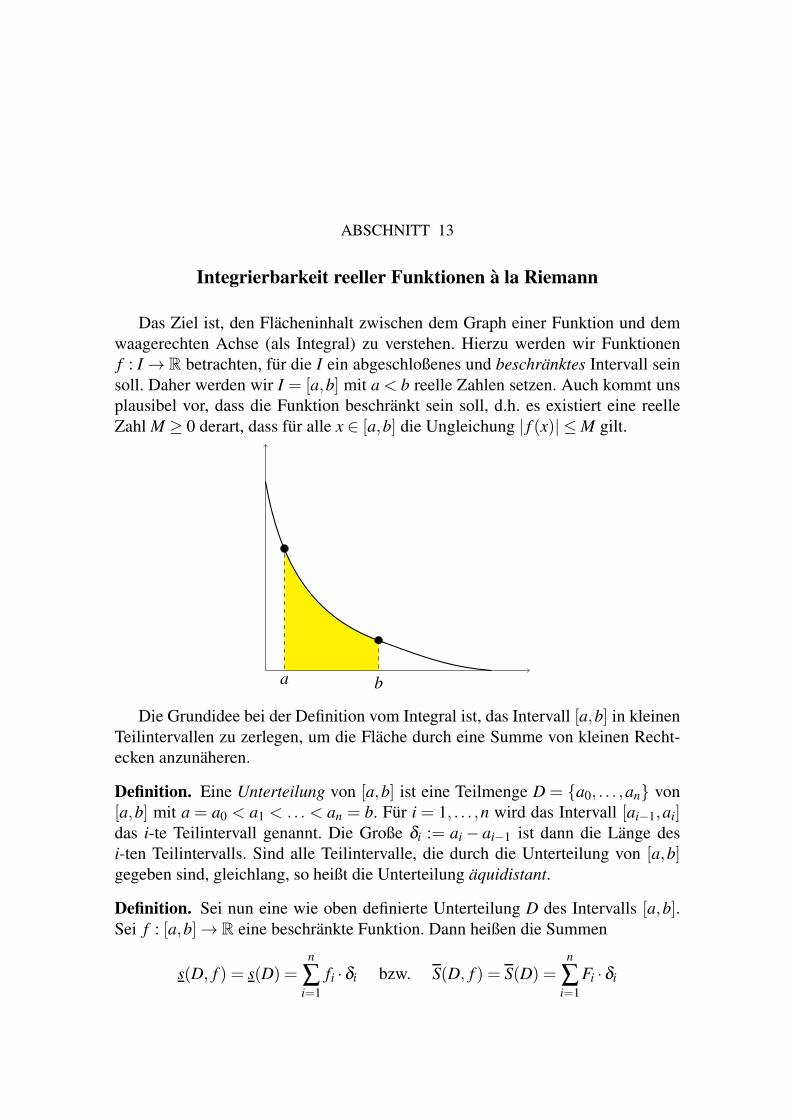
ABSCHNITT 13
Integrierbarkeit reeller Funktionen a la Riemann
Das Ziel ist, den Flacheninhalt zwischen dem Graph einer Funktion und dem
waagerechten Achse (als Integral) zu verstehen. Hierzu werden wir Funktionen
f : I → R betrachten, fur die I ein abgeschloßenes und beschranktes Intervall sein
soll. Daher werden wir I = [a,b] mit a < b reelle Zahlen setzen. Auch kommt uns
plausibel vor, dass die Funktion beschrankt sein soll, d.h. es existiert eine reelle
Zahl M ≥ 0 derart, dass fur alle x ∈ [a,b] die Ungleichung | f (x)| ≤ M gilt.
ba
Die Grundidee bei der Definition vom Integral ist, das Intervall [a,b] in kleinen
Teilintervallen zu zerlegen, um die Flache durch eine Summe von kleinen Recht-
ecken anzunaheren.
Definition. Eine Unterteilung von [a,b] ist eine Teilmenge D = {a0, . . . ,an} von
[a,b] mit a = a0 < a1 < .. . < an = b. Fur i = 1, . . . ,n wird das Intervall [ai−1,ai]das i-te Teilintervall genannt. Die Große δi := ai − ai−1 ist dann die Lange des
i-ten Teilintervalls. Sind alle Teilintervalle, die durch die Unterteilung von [a,b]gegeben sind, gleichlang, so heißt die Unterteilung aquidistant.
Definition. Sei nun eine wie oben definierte Unterteilung D des Intervalls [a,b].Sei f : [a,b]→R eine beschrankte Funktion. Dann heißen die Summen
s(D, f ) = s(D) =n
∑i=1
fi ·δi bzw. S(D, f ) = S(D) =n
∑i=1
Fi ·δi

106 Abschnitt 13
mit
fi := inf{ f (x) : x ∈ [ai−1,ai]} bzw. Fi := sup{ f (x) : x ∈ [ai−1,ai]}die Darbouxsche Untersumme bzw. die Darbouxsche Obersumme von f zur Un-
terteilung D.
Es ist nun klar: Eine vernunftige Definition des Integrals von f muss einen Wert
zwischen s(D, f ) und S(D, f ) ergeben.
Definition. Sei D eine Unterteilung von [a,b]. Eine weitere Unterteilung D′ von
[a,b] heißt eine Verfeinerung von D, wenn es D′ ⊃ D gilt.
Satz 13.1. Ist D′ eine Verfeinerung einer Unterteilung D von [a,b], so gilt
s(D)≤ s(D)≤ S(D)≤ S(D)
Beweis. Fugen wir eine Punkt zur Unterteilung D hinzu, dann wird die Darboux-
sche Untersumme vergroßert (oder sie bleibt erhalten), und die Darbouxsche Ober-
summe verkleinert (oder erhalten). Das Hinzufugen von weiteren Punkten liefert
die Behauptung. �
Satz 13.2. Fur D1,D2 Unterteilungen von [a,b] gilt
s(D1)≤ S(D2)
Beweis. Sei D′ := D1 ∪D2 die Unterteilung von samtlichen Punkten aus D1 und
D2 (ohne Wiederholung). Da D′ eine Verfeinerung von sowohl D1 als auch D2 ist,
folgt die behauptete Ungleichung nach Satz 13.1. �
Fur eine beschrankte Funktion f folgt aus Satz 13.2, dass jede Darbouxsche
Obersumme eine Majorante der Menge aller Darbouxschen Untersummen ist (und
umgekehrt). D.h. die Menge {s(D) : D Unterteilungung von [a,b]} ist nach oben
beschrankt und die Menge {S(D) : D Unterteilung von [a,b]} ist nach unten be-
schrankt:
s(D) S(D)
ABBILDUNG 1. Darbouxsche Summen
Somit ergibt es Sinne, das Supremum von Untersummen und das Infimum von
Obersummen zu betrachten:
Definition. Sei f : I = [a,b]→ R eine beschrankte Funktion. Dann definiert man
das Oberintegral und das Unterintegral von f uber [a,b] durch∫ b
af (x)dx := inf{S(D) : D Unterteilung von [a,b]},

Integrierbarkeit reeller Funktionen a la Riemann 107
∫ b
af (x)dx := sup{s(D) : D Unterteilung von [a,b]}.
Wegen Satz 13.2 sieht man sofort, dass
∫ b
af (x)dx ≤
∫ b
af (x)dx
gilt. Fur”normale” Funktionen sollten diese beiden Integrale ubereinstimmen. Ist
das der Fall, so heißt die Funktion Riemann-integrierbar:
Definition. Sei f : [a,b]→ R eine beschrankte Funktion. Dann heißt f Riemann-
integrierbar auf [a,b], wenn Ober- und Unterintegral ubereinstimmen:
∫ b
af (x)dx =
∫ b
af (x)dx.
Dann nennen wir diese Zahl das bestimmte Integral von f uber [a,b] und schreiben
hierfur∫ b
a f (x)dx.
Ein erstes Kriterium fur die Integrierbarkeit einer Funktion ist:
Satz 13.3. Eine Funktion f : [a,b] → R ist genau dann Riemann-integrierbar,
wenn es gilt
∀ ε > 0 ∃ D Unterteilung von [a,b] mit S(D)− s(D)< ε.
Beweis. Definitiongemaß ist f genau dann Riemann-integrierbar, wenn die zwei
Mengen in Abbildung 1 beliebig nahe liegen. D.h. fur ε > 0 vorgegeben existieren
zwei Unterteilungen D1 und D2 von [a,b] mit S(D2)−s(D1)< ε nach Satz 13.2. Es
genugt jetzt, die Unterteilung D = D1 ∪D2 zu bilden und Satz 13.1 anzuwenden.
�
Beispiele.
(i) Wir nehmen die Funktion f : [a,b] → R gegeben durch f (x) = x. Sie ist
im Intervall [a,b] monoton wachsend, so ist f (u) = u das Minimum und
f (v) = v das Maximum von f uber jedes Teilintervall [u,v] ⊂ [a,b]. Fur
n > 0 betrachten wir die aquidistante Unterteilung
Dn ={
ai = a+ ih : i = 0,1, . . .n und h =b−a
n
}
={
ai = a+ i · b−a
n: i = 0,1, . . .n
}.

108 Abschnitt 13
Mit Hilfe von der Formel ∑ni=1 i = 1
2n(n+1) zeigt man nach einigen Rech-
nungen
s(Dn) =n
∑i=1
ai−1δi =b2
2− a2
2− (b−a)2
2n
S(Dn) =n
∑i=1
aiδi =b2
2− a2
2+
(b−a)2
2n,
und damit S(Dn)−s(Dn) =(b−a)2
n. Da diese Differenz eine Nullfolge bildet
fur n→∞, also fur n groß genug, so wird sie kleiner als jedes vorgegebenes
ε > 0. Dann ist f Riemann-integrierbart mit∫ b
af (x)dx =
b2 −a2
2.
(ii) Nun betrachten wir die Funktion g : [0,1] → R gegeben durch g(x) = x2.
Sie ist im Interval [0,1] monoton wachsend, so ist wie in (i) g(u) = u2
das Minimum und g(v) = v2 das Maximum von g uber jedes Teilintervall
[u,v] ⊂ [a,b]. Fur n > 0 betrachten wir die aquidistante Unterteilung von
[0,1]
Dn ={
ai = 0+ ih : i = 0,1, . . .n und h =1−0
n
}
={
ai = i · 1
n: i = 0,1, . . .n
}.
Mit Hilfe von der Formel ∑ni=1 i2 = 1
6n(n+1)(n+2) zeigt man nach einigen
Rechnungen
s(Dn) =n
∑i=1
ai−1δi =n
∑i=1
((i−1)1
n)2 1
n=
1
3− 1
2n+
1
6n2
S(Dn) =n
∑i=1
aiδi =n
∑i=1
(i1
n)2 1
n=
1
3+
1
2n+
1
6n2,
und damit S(Dn)− s(Dn) =1n. Da diese Differenz eine Nullfolge bildet fur
n groß genug, so wird sie kleiner als jedes vorgegebenes ε > 0. Dann ist f
Riemann-integrierbar mit∫ 1
0g(x)dx =
1
3.
Nicht jede Funktion ist Riemann-integrierbar:
Beispiel. Man betrachte die Dirichlet-Funktion, d.h. die Funktion f : [0,1] → Rmit f (x) = 1 fur x ∈ Q und f (x) = 0 fur x ∈ R \Q. Da Q und R \Q dicht in Rsind, gibt es fur jedes Intervall [ai−1,ai] zu jeder Unterteilung D von [0,1] sowohl

Integrierbarkeit reeller Funktionen a la Riemann 109
rationale als auch irrationale Zahlen mit fi = 0 und Fi = 1 fur alle i, also mit s(D) =0 und S(D) = 1 fur alle D. Daraus ergibt sich
∫ b
af (x)dx = 0 und
∫ b
af (x)dx = 1.
Somit ist f nicht Riemann-integrierbar.
Ferner gibt es Funktionen, von denen kaum zu denken ist, dass sie Riemann-
integrierbar sein konnen, obwohl sie es in der Tat sind:
Beispiel. Man betrachte die Funktion f : [0,1] → R gegeben durch f (x) = 0 fur
x = 0 oder x ∈ R\Q und f (x) = 1q
fur x = pq
mit ggT(p,q) = 1. Sei ε > 0 vorge-
geben. Es gibt nur endlich viele x-Werte, sagen wir k, so dass f (x)> ε . Sei D eine
Unterteilung von [0,1] mit δi =εk
so dass alle die k x-Werte, fur die f (x)> ε gilt,
im i-ten Teilintervall von [0,1] liegen. Da f (x)≤ 1 fur alle x ∈ [0,1], dann ist
S(D)≤ ε + k ·maxi{δi}< ε + ε = 2ε.
Da ferner s(D) = 0 gilt, ist die Funktion f Riemann-integrierbar mit∫ 1
0f (x)dx = 0.
Dazu bekommt man zumindest die Lehre, dass die Sache knifflig ist! 1875
schrieb Du Bois-Reymond:”ich fuhle indessen, dass die Art, wie das Criterium
der Integrirbarkeit formulirt wurde, etwas zu wunschen ubrig lasst”. In der Tat
bewies er noch zusammen mit Darboux folgendes Ergebnis:
Satz 13.4. Sei f : [a,b]→ R eine beschrankte Funktion. Zu h > 0 bezeichnen wir
mit Dh die Menge aller Unterteilungen von [a,b] mit der Eigenschaft maxi{δi}≤ h.
Genau dann ist f Riemann-integrierbar, wenn zu vorgegebenem ε > 0 ein δ > 0
existiert derart, dass fur alle Unterteilungen D ∈Dδ die Ungleichung
S(D)− s(D)< ε
gilt.
Beweis. Die Notwendigkeit ist eine Folgerung von Satz 13.3. Die Umkehrung ist
schwieriger, denn die gesuchte Unterteilung D so dass maxi δi ≤ δ mag sich viel
von der Unterteilung D aus Satz 13.3 unterscheiden. Sei dazu ein ε > 0 vorgegeben,
und sei D eine Unterteilung so dass ∆ := S(D)− s(D) < ε . Die Unterteilung D
besteht aus endlich vielen Punkten, D = {a0, a1, . . . , an}. Wir betrachten nun eine
beliebige Unterteilung D∈Dδ , und setzen ∆ := S(D)−s(D). Es ist zu zeigen, dass
∆ beliebig klein fur δ → 0 wird. Sei dann D′ := D∪ D mit ∆′ := S(D′)− s(D′). Die
Darbouxschen Summen fur D′ und D stimmen uberein, bis auf in jenen Intervallen,
welche Punkte aus D enthalten. Da es hochstens n−1 solcher Intervalle gibt, ihre

110 Abschnitt 13
Langen ≤ δ sind, und wegen der Beschrankheit der Funktion f mit −M ≤ f (x)≤M fur M := max{ f (x) : x ∈ [a,b]}, ergibt sich
∆ ≤ ∆′+2 · (n−1) ·δ ·M.
Da D′ eine Verfeinerung von D ist, dann gilt ferner ∆′ ≤ ∆ < ε . Insgesamt erhalten
wir ∆ < 2ε sofern δ ≤ ε2(n−1)M
ist. Das zeigt die hinreichende Bedingung. �
Bei der Definition der Darbouxschen Summen kann man sich fragen, inwiefern
wichtig ist, genau fi bzw. Fi in Betracht zu ziehen. Das ist in der Tat unerheblich:
Man konnte das Bild von jedem Punkt im Intervall [ai−1,ai] nehmen, nicht nur fi
oder Fi. Betrachten wir das Bild f (ξi) der Mittelpunkte ξi des Intervalls [ai−1,ai],so spricht man uber Riemannsche Summen, d.h., Summen der Gestalt
σ(D) =n
∑i=1
f (ξi)δi :
2 4 6 8 10
20
40
60
80
Es ist klar, dass fi ≤ f (ξi)≤ Fi gilt, und damit s(D)≤ σ(D)≤ S(D). Aus Satz
13.4 folgt dann das Konvergenzverhalten
n
∑i=1
f (ξi)δi −→∫ b
af (x)dx
fur maxi δi → 0, vorausgesetzt, dass die Funktion f : [a,b]→RRiemann-integrierbar
ist.
Dies liefert ein einfaches Werkzeug, um Eigenschaften des Integrals beweisen
zu konnen. Zum Beispiel folgt die Beziehung
∫ b
a(α f +βg)(x)dx = α
∫ b
af (x)dx+β
∫ b
ag(x)dx mit α,β ∈ R

Integrierbarkeit reeller Funktionen a la Riemann 111
nach Anwendung des Grenzwertes fur maxi δi → 0 auf die endlichen Summen
n
∑i=1
(α f (ξi)+βg(ξ )) ·δi = α ·n
∑i=1
f (ξ ) ·δi +β ·n
∑i=1
g(ξ ) ·δi,
vorausgesetzt, dass alle involvierten Funktionen Riemann-integrierbar seien. Fur f
und g konnen wir es annehmen. Wird dann die Summe f +g Riemann-integrierbar
sein? Die Erklarung von diesem und anderen Fallen mochten wir jetzt zum Aus-
druck bringen:
Satz 13.5. Seien f ,g : [a,b] → R Riemann-integrierbare Funktionen. Sei λ ∈ R.
Dann sind die Funktionen
(i) f +g, (ii) λ f , (iii) f ·g, (iv) | f |, (v) f/g (falls |g(x)| ≥C > 0)
Riemann-integrierbar.
Beweis. Das Hauptproblem bei der Begrundung ist zu realisieren, dass Fi − fi die
kleinste obere Schranke fur die Variationen von f (x) im Intervall [ai−1,ai] re-
prasentiert, d.h., dass es
Fi − fi = sup{ f (x)− f (y) : x,y ∈ [ai−1,ai]} (*)
gilt. Sei dazu ε > 0 vorgegeben. Nach den Definitionen von Fi bzw. fi existieren
ξ ,η ∈ [ai−1,ai] mit f (ξ )> Fi − ε bzw. f (η)< fi + ε , so dass die Ungleichung
f (ξ )− f (η)> Fi − fi −2ε
gilt. Damit ist Fi − fi nicht nur eine obere Schranke fur | f (x)− f (y)| sondern die
kleinste sogar.
Nun beweisen wir die Behauptungen. Zu (i): Sei h(x) = f (x)+ g(x), und be-
zeichnen wir mit Fi,Gi,Hi bzw. fi,gi,hi die Suprema bzw. die Infima der Funktio-
nen f ,g,h auf [ai−1,ai]. Fur x,y ∈ [ai−1,ai] ergibt sich nach (*) und der Dreiecks-
ungleichung
|h(x)−h(y)| ≤ | f (x)− f (y)|+ |g(x)−g(y)| ≤ (Fi − fi)+(Gi −gi).
Die Anwendung von (*) auf die Funktion h zeigt die Ungleichung
(Hi −hi)≤ (Fi − fi)+(Gi −gi),
und die Differenzen zwischen Darbouxschen Ober- und Untersummen erfullen
weiterhin
∑i
(Hi −hi)δi ≤ ∑i
(Fi − fi)δi +∑i
(Gi −gi)δi. (**)
Fur vorgegebenes ε > 0 wahlen wir nach Satz 13.3 eine Unterteilung D so geschaft,
dass jedes Glied in der rechtsstehenden obigen Summe (**) kleiner als ε sei. (In
der Tat hat man da zwei verschiedene Unterteilungen, fur f und fur g; man kann

112 Abschnitt 13
aber die Vereinigung von den beiden bilden und damit weiter arbeiten). Daraus
folgt, dass
∑i
(Hi −hi)δi < 2ε
ist, und die Funktion h(x) = f (x)+g(x) ist Riemann-integrierbar wegen Satz 13.3.
Zu (ii): Fur h(x) = λ f (x) muss man die Gleichung
|h(x)−h(y)|= |λ | · | f (x)− f (y)|nutzen, um zu zeigen, dass (hi −hi)≤ |λ | · (Fi − fi) ist, und wie oben die Aussage
schließen. Zu (iii): Fur h(x) = f (x) ·g(x) nutzen wir die Ungleichung
|h(x)−h(y)| ≤ | f (x)||g(x)−g(y)|+ |g(y)|| f (x)− f (y)|≤ M · |g(x)−g(y)|+N · | f (x)− f (y)|
(die Funktionen f und g sind beschrankt, d.h es gilt | f (x)| ≤ M und |g(x)| ≤ N fur
alle x ∈ [a,b]). Zu (v): Da f (x)/g(x) = f (x) · (1/g(x)) ist, nach Anwendung von
(iii) reicht es uns, die Aussage fur 1/g(x) zu zeigen. Fur h(x) = 1/g(x) ist
|h(x)−h(y)|= |g(y)−g(x)||g(y)| · |g(x)| ≤
|g(x)−g(y)|C2
.
�
Beispiel. Dass | f |Riemann-integrierbar ist, impliziert nicht, dass f auch Riemann-
integrierbar ist. Dazu betrachten wir die Funktion f : [a,b]→ R gegeben durch
f (x) ={
1, wenn x ∈Q∩ [a,b];−1, wenn x ∈ (R\Q)∩ [a,b].
Die Funktion f ist nicht Riemann-integrierbar, aber die Funktion | f | schon, denn
| f |(x) = 1 fur alle x ∈ [a,b].
Insbesondere schließt man aus Satz 13.5, dass Polynomfunktionen Riemann-
integrierbar sind. Im Allgemeinen ist jede stetige Funktion Riemann-integrierbar:
Satz 13.6. Ist f : [a,b]→R eine stetige Funktion, so ist sie Riemann-integrierbar.
Beweis. Die Begrundung kann nicht auf dem Begriff der”gleichmaßigen Stetig-
keit” verzichten, den wir in dieser Vorlesung nicht betrachtet haben. Der interes-
sierte Leser wird auf die zahlreiche Literatur verwiesen. �
Satz 13.7. Seien a,b,c ∈ R mit a < b < c. Sei f : [a,c]→ R eine Funktion derart,
dass ihre Einschrankungen auf die Intervalle [a,b] und [b,c] Riemann-integrierbar
sind. Dann ist f auf [a,c] Riemann-integrierbar mit∫ c
af (x)dx =
∫ b
af (x)dx+
∫ c
bf (x)dx.

Integrierbarkeit reeller Funktionen a la Riemann 113
Beweis. Die Behauptung gilt deshalb, weil die Addition der Darbouxschen Sum-
men fur die Einschrankungen von f auf [a,b] und [b,c] eine Darbouxsche Summe
fur [a,c] ist. �
Definition. Fur a > b oder a = b definieren wir∫ b
af (x)dx :=−
∫ a
bf (x)dx und
∫ a
af (x)dx = 0
so dass die Gleichung aus Satz 13.7 fur beliebige a,b,c ∈ R erhalten bleibt.
Satz 13.8. [Monotonie des Integrals] Seien a < b und f ,g : [a,b] → R eine
Riemann-integrierbare Funktion. Gilt f (x)≤ g(x) fur alle x ∈ [a,b], dann ist
∫ b
af (x)dx ≤
∫ b
ag(x)dx.
Beweis. Fur f ≤ g gilt 0 ≤ g− f und daraus folgt s(D,g− f )≥ 0 fur alle Unter-
teilungen D von [a,b]. Da g− f Riemann-integrierbar ist nach Satz 13.5 erhalten
wir
0 ≤ s(D,g− f )≤∫ b
a(g− f )(x)dx =
∫ b
ag(x)dx−
∫ b
af (x)dx.
�
Satz 13.9. Seien a< b und sei f : [a,b]→R eine Riemann-integrierbare Funktion.
Dann gilt∣∣∣∫ b
af (x)dx
∣∣∣≤∫ b
a| f (x)|dx.
Beweis. Da f Riemann-integrierbar ist, ist f beschrankt, und somit auch | f |. Fur
eine Unterteilung D = {a = a0,a1, . . .an = b} von [a,b] ist
S(D, f )− s(D, f ) =n
∑i=1
(Fi − fi)δi
S(D, | f |)− s(D, | f |) =n
∑i=1
(F ′i − f ′i )δi
mit
Fi − fi = sup{| f (x)− f (y)| : x,y ∈ [ai−1,ai]} fur alle i
F ′i − f ′i = sup{|| f (x)|− | f (y)|| : x,y ∈ [ai−1,ai]} fur alle i.
Es gilt F ′i − f ′i ≤ Fi − fi fur jedes i wegen || f (x)| − | f (y)|| ≤ | f (x)− f (y)|, und
daher
S(D, | f |)− s(D, | f |)≤ S(D, f )− s(D, f )

114 Abschnitt 13
fur jede Unterteilung D. Nach Satz 13.3 ist | f | Riemann-integrierbar wenn f
Riemann-integrierbar ist. Daruber hinaus, wegen f ≤ | f | und − f ≤ | f | und Satz
13.5 und Satz 13.8 gilt∫ b
af (x)dx ≤
∫ b
a| f (x)|dx und
∫ b
a(− f (x))dx =−
∫ b
af (x)dx ≤
∫ b
a| f (x)|dx,
und daher∣∣∣∫ b
af (x)dx
∣∣∣= max{∫ b
af (x)dx,−
∫ b
af (x)dx
}≤∫ b
a| f (x)|dx.
�
Anmerkung. Sei f eine Riemann-integrierbare Funktion. Zwischen die bestimm-
te Integrale von f und | f | gilt im Allgemeinen die Ungleichung
∣∣∣∫ b
af (x)dx
∣∣∣≤∣∣∣∫ b
a| f (x)|dx
∣∣∣.
Zu einer Riemann-integrierbaren Funktion f : [a,b]→ R kann man den Wert∫ b
a f (x)dx
b−a
als die Durchschnittshohe der Funktion ansehen: Wenn wir dieser Wert mit der
Lange des Grundintervalls multiplizieren, ergibt sich den Flacheninhalt. Der Mit-
telwertsatz der Integralrechnung besagt, dass fur eine stetige Funktion dieser
Durchschnittswert (oder Mittelwert) von der Funktion auch angenommen wird:
Satz 13.10 (Mittelwertsatz der Integralrechnung). Seien a < b und f : [a,b]→ Reine stetige Funktion. Dann gibt es ein c ∈ [a,b] mit
∫ b
af (x)dx = f (c)(b−a).
Beweis. Die Funktion f ist auf [a,b] beschrankt nach dem Satz von Weierstraß 9.4:
Sei m bzw. M ihr Minimum bzw. Maximum. Dann gilt speziell m ≤ f (x)≤ M fur
alle x ∈ [a,b] und
m · (b−a)≤∫ b
af (x)dx ≤ M · (b−a).
Daher gilt∫ b
af (x)dx = ξ · (b−a)
fur ξ ∈ [m,M], und nach dem Zwischenwertsatz 9.1 existiert ein c ∈ [a,b] mit
f (c) = ξ . �

Integrierbarkeit reeller Funktionen a la Riemann 115
Satz 13.11. Sei f : [a,b] → R eine stetige Funktion. Sei g : [a,b] → R eine
Riemann-integrierbare Funktion so dass g uberall positive (oder uberall nega-
tive) Werte annimmt. Dann existiert ein ein c ∈ [a,b] mit∫ b
af (x) ·g(x)dx = f (c) ·
∫ b
ag(x)dx.
Beweis. Wir zeigen die Behauptung in der Situation g(x)≥ 0 fur alle x ∈ [a,b] (der
andere Fall ergibt sich nach Ersetzen von g durch −g). Es gilt
m ·g(x)≤ f (x) ·g(x)≤ M ·g(x)fur alle x ∈ [a,b], wobei m bzw. M das Minimum bzw. das Maximum von f auf
[a,b] ist. Nun folgt der Rest des Beweises wie bei Satz 13.10. �
Beispiel. Sei 1 < a < b. Fur jedes x ∈ [a,b] gilt
1 ≤ x+√
x
x−√x=
√x+1√x−1
= 1+2√
x−1≤ 1+
2√a−1
.
Daraus folgt
1 ≤ 1
b−a
∫ b
a
x+√
x
x−√x
dx ≤ 1+2√
a−1.
Beispiel. Seien f ,g : [a,b]→ R stetig mit∫ b
af (x)dx =
∫ b
ag(x)dx.
Es ist zu zeigen, dass ein c ∈ [a,b] existiert so dass f (c) = g(c). In der Tat ist dann
f −g eine stetige Funktion auf [a,b], und ergibt sich∫ b
a( f −g)(x)dx = 0
Nach Anwendung des Mittelwertsatzes existiert ein c ∈ [a,b] so dass
0 =
∫ b
a( f −g)(x)dx = ( f −g)(c) · (b−a).
Da b−a 6= 0 muss ( f −g)(c) = 0 sein, d.h. es ist f (c) = g(c).
Mit dem Riemannschen Integral sind wir noch nicht fertig: Im nachsten Ab-
schnitt mochten wir die Beziehung zwischen der Differential- und der Integral-
rechnung erklaren.


ABSCHNITT 14
Der Hauptsatz der Infinitesimalrechnung
Alles, was bisher in den Abschnitten der Infinitesimalrechnung betrachtet wur-
de, hilft dabei, die Beziehung zwischen Differenzierbarkeit und Integrierbarkeit
nachvollziehen zu konnen: Der sogenannte Hauptsatz der Differenzial- und In-
tegralrechnung, oder kurzer gesagt, der Hauptsatz der Infinitesimalrechnung. Als
Korollar ergibt sich die Regel von Barrow, die ermoglicht, bestimmte Integrale
durch den Begriff von Stammfunktion leicht zu berechnen. Das ist einfach, voraus-
gesetzt, dass die Berechnung von Stammfunktionen vorhanden ist. Deshalb werden
wir uns diese zum Schluss in Erinnerung zu rufen.
Definition. Seien I ⊂R ein Intervall, a∈ I und f : I →R eine Riemann-integrierbare
Funktion. Dann heißt die Funktion
I → R, x 7−→∫ x
af (x)dx
die Integralfunktion, oder auch das unbestimmte Integral, zu f zum Startpunkt a.
Satz 14.1 (Hauptsatz der Infinitesimalrechnung). Seien I ⊂ R ein Intervall, a ∈ I
und f : I → R eine stetige Funktion. Sei weiterhin
F(x) :=
∫ x
af (x)dx
das zugehorige unbestimmte Integral. Dann ist F differenzierbar mit
F ′(x) = f (x) fur alle x ∈ I.
Beweis. Sei x0 ∈ I. Der Differenzquotient zu F und x0 ist
F(x0 +h)−F(h)
h=
1
h
(∫ x0+h
af (x)dx−
∫ x0
af (x)dx
)=
1
h
∫ x0+h
x0
f (x)dx
Es ist zu zeigen: Der Limes des Differenzenquotienten existiert und ist gleich f (x)fur h → 0. Aquivalent dazu, der Limes von
1
h
(∫ x0+h
x0
f (x)dx−h f (x0))
fur h → 0 existiert und gleicht 0. Da f (x0) eine Konstante ist, gilt
h f (x0) =
∫ x0+h
x0
f (x0)dx.

118 Abschnitt 14
Dann betrachten wir1
h
∫ x0+h
x0
( f (x)− f (x0))dx.
Durch Betrachtung der Funktion g(x) = f (x)− f (x0) kann man OBdA annehmen,
dass f (x0) = 0 ist. Wegen der Stetigkeit von f gibt es zu jedem ε > 0 ein δ > 0
derart, dass fur alle x ∈ [x0 − δ ,x0 + δ ] die Abschatzung | f (x)|< ε gilt. Dann gilt
fur h ∈ [−δ ,δ ] die Abschatzung∣∣∣∫ x0+h
x0
f (x)dx
∣∣∣≤∣∣∣∫ x0+h
x0
| f (x)|dx
∣∣∣<∣∣∣∫ x0+h
x0
εdx
∣∣∣= |h|ε,
und daher ∣∣∣1
h
∫ x0+h
x0
f (x)dx
∣∣∣< ε.
�
Beispiel. Wir mochten den Grenzwert
L := limx→0
1
x
(∫ x
0e−t2
dt).
berechnen. Es gilt
L =
∫ x0 e−t2
dt
x=
F(x)
G(x),
mit F differenzierbar auf R nach dem Hauptsatz der Infinitesimalrechnung, wobei
F und G die Voraussetzungen der Regel von l’Hopital erfullen. Dann wenden wir
diese Regel an und wir erhalten
L = limx→0
F ′(x)G′(x)
= limx→0
e−x2
1= 1.
Dies kann man auch anders sehen. Da F(0) = 0, ergibt sich
L =
∫ x0 e−t2
dt −0
x−0= F ′(0) = e−0 = 1.
Definition. Sei I ⊂ R ein Intervall, und f : I → R eine Funktion. Eine Funktion
F : I → R heißt Stammfunktion zu f , wenn F auf I differenzierbar ist und F ′(x) =f (x) fur alle x ∈ I gilt.
Die Existenz von Stammfunktionen ist folgendermaßen gewahrleistet:
Satz 14.2. Seien I ⊂ R ein Intervall und f : I → R eine stetige Funktion. Dann
besitzt f eine Stammfunktion.
Beweis. Sei a ∈ I ein Punkt. Nach Satz 13.6 existiert das bestimmte Integral
F(x) =
∫ x
af (x)dx,

Der Hauptsatz der Infinitesimalrechnung 119
und nach dem Hauptsatz der Infinitesimalrechnung 14.1 ist F ′(x) = f (x), d.h., F
ist eine Stammfunktion von f . �
Stammfunktionen einer vorgegebenen Funktion unterscheiden sich in einer
Konstanten:
Satz 14.3. Sei I ⊂ R ein Intervall, f : I → R eine Funktion. Seien F und G zwei
Stammfunktionen von f . Dann ist F −G eine konstante Funktion.
Beweis. Es ist (F − G)′ = F ′ −G′ = f − f = 0, und nach Satz 12.6 ist F −G
konstant. �
Satz 14.4 (Regel von Barrow). Sei I ⊂ R ein Intervall, und f : I → R eine stetige
Funktion, fur die G eine Stammfunktion ist. Dann gilt fur jede zwei Punkte a,b ∈ I
mit a < b die Gleichheit∫ b
af (x)dx = G(b)−G(a) =: G(x)
∣∣∣b
a.
Beweis. Sei F die Integralfunktion zu f mit Startpunkt a. Wegen der Stetigkeit von
f auf [a,b] ist F auch eine Stammfunktion von f in [a,b]. Nach dem Mittelwertsatz
der Differentialrechnung unterscheiden sich F und G in einer Konstanten in [a,b].Das heißt, es ist F(x)−G(x) = c fur alle x ∈ [a,b], c ∈R. Daraus folgt unmittelbar
F(x) =
∫ x
af (t)dt + c.
Fur x = b bzw. x = a ist
F(b) =
∫ b
af (t)dt + c bzw. F(a) =
∫ a
af (t)dt + c = c,
woraus folgt
F(b)−F(a) =
∫ b
af ( f )dt.
�
Beispiel. Es ist das bestimmte Integral∫ 5
1 (2x4 − 3x2 − 1)dx zu berechnen. Eine
Stammfunktion von 2x4 − 3x2 − 1 ist einfach zu bestimmen, insofern ergibt sichsofort:
∫ 5
1(2x4 −3x2 −1)dx = 2
∫ 5
1x4dx−3
∫ 5
1x2dx−
∫ 5
1dx
= 2 · x5
5
∣∣∣5
1−3 · x3
3
∣∣∣5
1− x
∣∣∣5
1
= 2 ·(55
5− 1
5
)−(
53 −1)− (5−1)
= 2 · 3124
4−124−4 =
5608
5.

120 Abschnitt 14
Satz 14.5 (Partielle Integration). Seien f ,g : [a,b]→R zwei differenzierbare Funk-
tionen. Es gilt∫ b
af (x)g′(x) = f (b)g(b)− f (a)g(a)−
∫ b
af ′(x)g(x)dx.
Beweis. Es ist zunachst zu begrunden, dass∫
f (x)g′(x) dx = f (x)g(x)−∫
f ′(x)g(x) dx.
gilt. Da f und g differenzierbar sind, ergibt sich ( f g)′ = f ′g+ f g′, d.h., f g′ =( f g)′− f ′g. Dann ist
∫( f g′) dx =
∫(( f g)′− f ′g) dx = f g−
∫f ′g dx.
Nun folgt die Behauptung nach Anwendung der Regel von Barrow 14.4. �
Beispiel. Es ist das bestimmte Integral∫ π
0 xsinx dx zu berechnen. Es handelt sichum ein Produkt von Funktionen, daher scheint die partielle Integration wirksam zusein. Mit der Bezeichnung im obigen Satz machen wir f (x) = x und g′(x) = sinx.Dann ist f ′(x) = 1+ c und g(x) =
∫sinx = −cosx+ c′ (mit c,c′ ∈ R). Der Satz
besagt∫ π
0xsin x dx = (−xcos x)
∣∣∣π
0−∫ π
0(−cosx) dx =−π cosπ + sinx
∣∣∣π
0= π.
Satz 14.6 (Substitution). Sei f : [a,b]→R eine stetige Funktion. Sei ϕ : [c,d]→Reine stetig differenzierbare Funktion mit ϕ([c,d])⊂ [a,b]. Dann gilt
∫ ϕ(d)
ϕ(c)f (x) dx =
∫ d
cf (ϕ(t)) ·ϕ ′(t) dt.
Beweis. Da ϕ auf [c,d] stetig ist, so ist ϕ([c,d]) ein abgeschloßenes und be-
schranktes Intervall. Wegen der Stetigkeit von f auf [a,b] besitzt f eine Stamm-
funktion F : [a,b] → R nach dem Hauptsatz, die differenzierbar auf [a,b] ist mit
F ′(x) = f (x) fur alle x ∈ [a,b]. Nach der Regel von Barrow gilt∫ ϕ(d)
ϕ(c)f (x) dx = F(ϕ(d))−F(ϕ(c)) = (F ◦ϕ)(d)− (F ◦ϕ)(c).
Die Funktion F ◦ϕ : [c,d]→ R ist differenzierbar, und nach der Kettenregel gilt
(F ◦ϕ)′(t) = F ′(ϕ(t)) ·ϕ ′(t) = (( f ◦ϕ) ·ϕ ′)(t)
fur alle t ∈ [c,d]. Die Funktion F ◦ϕ ist also eine Stammfunktion von ( f ◦ϕ) ·ϕ ′
in [c,d] mit ∫ d
c( f ◦ϕ) ·ϕ ′ = (F ◦ϕ)(d)− (F ◦ϕ)(c).
Insgesamt ergibt sich die Behauptung. �

Der Hauptsatz der Infinitesimalrechnung 121
Beispiel. Wir mochten das bestimmte Integral∫ 3
053
√9− x2 dx berechnen. Wir
wenden die Substitutionsmethode an, und zwar mit ϕ(t) = 3sin t. Dabei ist ϕ ′(t) =3cos t +c, c ∈R und t = arcsin x
3. D.h.., fur x = 0 ist t = arcsin0 = 0 und fur x = 3
ist t = arcsin1 = π2
. Nun ist es einfach:∫ 3
0
5
3
√9− x2 dx =
5
3
∫ π/2
0
√9−9sin2 t ·3 · cos t dt
= 5 ·∫ π/2
0
√9(1− sin2 t) · cos t dt = 5 ·
∫ π/2
0
√9(cos2 t) · cos t dt
= 5 ·∫ π/2
03cos2 t dt = 15 ·
∫ π/2
0cos2 t dt
= 15 ·∫ π/2
0
1+ cos2t
2dt = 15
[1
2
∫ π/2
0dt +
1
2
∫ π/2
0cos2t dt
]
= 15
[1
2t
∣∣∣π/2
0+ sin2t
∣∣∣π/2
0
]= 15
[π
4+0
]=
15π
4.
Wir realisieren, dass es wichtig ist, die Berechnung von Stammfunktionen zubeherrschen. Dabei muss man zunachst die Grundtypen kennen, die wir nun ohneAnspruch auf Vollstandigkeit kurz vorstellen:
(a) Potenzen:
(i)∫
u(x)au′(x) dx = 1a+1
u(x)a+1 +K, a 6=−1.
(ii)∫ u′(x)
u(x) dx = log |u(x)|+K
(b) Exponentialfunktionen:
(i)∫
eu(x)u′(x) dx = eu(x)+K
(ii)∫
au(x)u′(x) dx = 1loga
au(x)+K, a > 0, a 6= 1.
(c) Trigonometrische Funktionen:
(i)∫
cos (u(x))u′(x) dx = sin(u(x))+K
(ii)∫
sin(u(x))u′(x) dx =−cos (u(x))+K
(iii)∫ u′(x)
cos2 (u(x))dx =
∫sec2 (u(x))u′(x) dx =
∫(1+ tan2 u(x))u′(x) dx = tan (u(x))+K
(iv)∫ u′(x)
sin2 (u(x))dx=
∫csc2 (u(x))u′(x) dx=
∫(1+cot2 u(x))u′(x) dx=−cot (u(x))+K
(d) Umkehrfunktionen der trigonometrischen Funktionen (”Arcus-Funktionen”):
(i)∫ u′(x)√
1−u(x)2dx = arcsin (u(x))+K =−arccos (u(x))+K
(ii)∫ u′(x)
1+u(x)2 dx = arctan (u(x))+K =−arccot(u(x))+K
(e) Hyperbelfunktionen:
(i)∫
cosh (u(x))u′(x) dx = sinh(u(x))+K
(ii)∫
sinh (u(x))u′(x) dx = cosh(u(x))+K
(iii)∫ u′(x)
cosh2 (u(x))dx = tanh(u(x))+K
(iv)∫ u′(x)
sinh2 (u(x))dx =−coth(u(x))+K
(f) Umkehrfunktionen der Hyperbelfunktionen (”Area-Funktionen”):
(i)∫ u′(x)√
u(x)2+1dx = arsinh(u(x))+K = logu(x)+
√u(x)2 +1+K
(ii)∫ u′(x)√
u(x)2−1dx = arcosh(u(x))+K = log |u(x)+
√u(x)2 −1|+K

122 Abschnitt 14
(iii)∫ u′(x)
1−u(x)2 dx = artanh(u(x))+K = 12
log
∣∣∣ 1+u(x)1−u(x)
∣∣∣+K
Eine Stammfunktion eines Produktes von zwei Funktionen kann man durchpartielle Integration erledigen:
∫xcos x dx = xsin x−
∫sinx dx = xsinx+ cosx+K.
Manchmal ist das trickreich:∫
logx dx =∫
1 · logx dx = x log x− ∫ x · 1x
dx = x log x− x+K
∫arctan x dx =
∫1 · arctan x dx = xarctan x− ∫ x
1+x2 dx = xarctan x− 12
log(1+ x2)+K
Substitution ist auch oft nutzlich:
∫1
x√
x−1dx = 2
∫t
(t2+1)tdt = 2
∫1
1+t2 dt = 2arctan t +K = 2arctan√
x+1+K∫
1√3−x2
dx =∫ √
3cos t√3−3sin2 t
dt =∫ √
3cos t√3√
1−sin2 tdt =
∫dt = t +K = arcsin ( x√
3)+K
Bei manchen Ausdrucken, die trigonometrische Funktionen involvieren, ist eineSubstitution der Art t = tan( x
2) geeignet, denn es gilt
sinx =2tan( x
2)
1+ tan2 ( x2)=
2t
1+ t2cosx =
1− tan2 ( x2)
1+ tan2 ( x2)=
1− t2
1+ t2,
wie im folgenden Beispiel:∫
1
1+ sinx+ cosxdx =
∫1
1+ 2t1+t2 +
1−t2
1+t2
· 1
1+ t2dt =
∫1
2t +2dt
=1
2
∫1
1+ tdt =
1
2log |t +1|+K =
1
2log (tan(
x
2)+1)+K.
Je mehr Kenntnisse man in der Trigonometrie hat, desto einfacher werden die
Berechnungen:∫
1sinxcosx
dx =∫
cos2 x+sin2 xsinxcosx
dx =∫
cos2 xsinxcosx
dx+∫
sin2 xsinxcosx
dx
=∫
cosxsinx
dx−∫ −sinx
cosxdx = log |sinx|− log |cosx|+K.
Gebrochen rationale Funktionen sind ein wichtiger Typus: Quotienten von Po-
lynomfunktionenp(x)q(x)
mit q 6= 0. Ist grad( p(x))≥ grad(q(x)), kann man”Polynom-
division” durchfuhren so dass
p(x)
q(x)= h(x)+
p(x)
q(x),
mit h(x) eine Polynomfunktion und grad( p(x))< grad(q(x)) gilt. Dann hangt die
Berechnung einer Stammfunktion davon ab, was fur Nullstellen der Nenner q(x)besitzt. Ausfuhrliche Erklarungen sind in der Ubung erklart worden, und eine Zu-
sammenfassung ist bei Stud.IP herunterzuladen. Hier betrachten nur zur Illustrati-
on zwei Beispiele:
Beispiele.

Der Hauptsatz der Infinitesimalrechnung 123
(a) Die Polynomfunktion x2 − x + 1 hat keine reelle Nullstellen. Man kann
leicht ahnen, dass eine Stammfunktion von 1/(x2 − x + 1) der Formarctanu(x) fur geeignete u(x) ist. In der Tat gilt:
∫1
x2 − x+1dx =
∫1
34+(x− 1
2)2
dx =
∫4/3
1+(x− 1
2)2
3/4
dx =2√3
∫2/√
3
1+(x− 1
2√3/2
)2dx
=2√3
∫2/√
3
1+(2x−1√3)2
dx =2√3
arctan2x−1√
3+K
(b) Es ist x3 −2x2 + x = x(x−1)2, und deswegen gilt fur A,B,C ∈ R
2x2 −4x+1
x(x−1)2=
A
x+
B
x−1+
C
(x−1)2=
(A+B)x2 +(−2A−B+C)x+A
x(x−1)2.
Koeffizientenvergleich liefert einem linearen Gleichungssystem, dessenLosung A = B = 1 und C =−1 ist. Somit ist
∫2x2 −4x+1
x3 −2x2 + xdx =
∫1
xdx+
∫1
x−1dx+
∫ −1
(x−1)2dx
= log |x|+ log |x−1|+ 1
x−1+K.
Bei dem Koeffizientenvergleich stellt sich als Wichtiges heraus, lineare Glei-
chungssysteme losen zu konnen. Im nachsten Abschnitt werden wir diese Theorie
allgemein darstellen.


ABSCHNITT 15
Ein Ruckblick auf die Infinitesimalrechnung
”Die Mathematik ist eine Art Spielzeug, welches die Natur uns zuwarf zum
Troste und zur Unterhaltung in der Finsternis”, schrieb der Franzose Jean-Baptist le
Rond d’Alembert (1717-1783). Diese Gedanken haben Sie, lieber Leser, vielleicht
nicht gespurt. Von Trost war moglicherweise nicht die Rede, sondern eher von
Finsternis. Die Unterhaltungsthemen waren bloß ganz andere. Sie mussten einfach
nur Mathematik lernen.
Moglichst schnell wurden viele neue Begriffe gelesen, aber gar nicht ver-
daut. Als Folgerung, optimistisch gesehen, eine Buchstabensuppe—gelegentlich
ein paar Zahlen: Formel und Sazte qualen Ihren Kopf, ohne ein Zuhause finden
zu konnen; es ist Zeit, die mathematischen Gedanken in Ordnung zu bringen.
In diesem Abschnitt werden wir eine kleine Zusammenfassung des analytischen
Teils dieser Vorlesung darstellen. Er sollte eine Motivation dafur sein, dass Sie
die vorherigen Abschnitte nochmal lesen. Eine tiefere Lekture, mit Bleistift und
Schmierzettel dabei. Und mit der Vorstellung von Gauß:”Pauca sed matura”, d.h.
wenig aber gut gemacht.
Wir haben nun einen erheblichen Teil der Vorlesung, namlich die Abschnitte 4
bis 14, der Infinitesimalrechnung gewidmet. Das Wort”Infinitesimal” ist als belie-
big klein zu verstehen, und das haben wir tatsachlich gemacht, wenn wir Grenz-
wertsprozesse in der Umgebung eines Punktes betrachtet haben.
Zentral ist also in dieser Theorie der Begriff von Grenzwert, auch Limes ge-
nannt. Wir haben ihn zunachst fur Folgen reeller Zahlen definiert, welche implizit
auch die Definition von reellen Zahlen voraussetzen. Das heißt, wir haben die Infi-
nitesimalrechnung mit dem Begriff der reellen Zahl angefangen. Die Situation ist
in der Einfuhrung zum Kapitel III in [HW, S. 170-171] wirklich gut beschrieben:
In 1821, Cauchy establishes new requirements of rigor in his fa-
mous”Cours d’Analyse”. The questions are the following:
- What is a derivative really? Answer: a limit.
- What is an integral really? Answer: a limit.
- What is an infinite series a1 +a2 +a3+ . . . really? Answer: a
limit.
This leads to

126 Abschnitt 15
- What is a limit? Answer: a number.
And, finally, the last question:
- What is a number?
Die reellen Zahlen wurden unbewusst seit langem bekannt. Eine antike Le-
gende besagt, dass der Pythagoreer Hippasos von Metapont entdeckt hat, dass√
2
keine rationale Zahl ist. Das wurde als Geheimnisverrat betrachtet, und der arme
Hipassos wurde ertrunken. Das geschah im 5. Jahrhundert v. Chr., und wir haben
sein Argument—diesmal schon ohne so besonders schlimme Wirkungen—in der
Vorlesung gezeigt (vgl. Satz 4.1).
Das ist aber noch nicht gut genug, um einen neuen Zahlenbereich einfuhren zu
konnen, denn es stellt sich sofort allerlei Fragen: Gibt es mehr irrationale Zahlen?
Wie viele? Wieso sind sie interessant? Die Zeit verging, und irgendwann um die
Neuzeit kamen Unbestimmten und Gleichungen in der Mathematik auf. Die Geo-
metrie wurde Algebra. Insbesondere wurden die Zahlen als Losungen von Glei-
chungen interpretiert. Die rationale Zahlen Q waren dann nicht mehr besonders,
sondern einfach nur ein Beispiel vom Zahlbereich, genauso wie die reellen Zahlen
R.
Sowohl Q als auch R sind doch Mengen, die mit der Summe und der Multipli-
kation versehen eine spezielle Struktur besitzen: Sie sind Korper (ein merkwurdi-
ges Wort von Richard Dedekind eingefuhrt; ein anderer Zeitgenosse, Leopold
Kronecker, mochte lieber das Wort”Rationalitatsbereich” verwenden; es ist nicht
mehr im Gebrauch). Beide lassen sich vernunftig anordnen. Bloß sind sie nicht das
Gleiche (vgl. Satz 4.5): Karl Weierstraß, ein Westphaler, der Professor in Berlin
wurde, und seine Kollegen Eduard Heine und Georg Cantor haben erkannt, dass Rder Vollstandigkeitsaxiom erfullt:
Jede nach oben beschrankte Teilmenge A 6= /0 von R besitzt ein Supremum.
Es ist aber doch mehr als das: Dieser Axiom definiert R als angeordneter
Korper! Im folgenden Sinne: Jeder angeordneter Korper K, der vollstandig ist,
ist isomorph zu R. Das Wort”isomorph” ist hier1 so zu interpretieren: Was die
Korperstruktur angeht, sind K und R voneinander nicht unterscheidbar. Insbeson-
dere besitzt R die Archimedische Eigenschaft 4.7, namlich
...dass jede reelle Zahl sich durch gewisse naturliche Zahlen ubertreffen lasst.
Und die Tatsache, dass Q (und R\Q) dicht in R ist (vgl. Satz 4.8):
1Das ist ein Oberbegriff in der Mathematik. Wir werden spater Isomorphismen zwischen Vektorraume
sehen.

Ein Ruckblick auf die Infinitesimalrechnung 127
Jede reelle Zahl hat um sich herum eine beliebig kleine Umgebung,
die eine rationale Zahl enthalt.
Die Frage nach dem Begriff von”reeller Zahl”, die Cauchy nicht zufriedenstel-
lend betrachten konnte, wurde von der Berliner Schule, plus Charles Meray in Di-
jon (Frankreich) und Richard Dedekind in Braunschweig um die Jahre 1870–1872
beantwortet. Die Einleitung von Konrad Knopp (vgl. [Kn], S. 1–2) ist durchaus
erleutend:
Heute gilt die Strenge gerade in bezug auf den zugrunde liegenden
Zahlbegriff als die wichtigste Forderung, die an die Behandlung
jedweden mathematischen Gegenstandes zu stellen ist, und seit den
letzten Jahrzehnten des vergangenen Jahrhunderts – in den 60er
Jahren wurde von WEIERSTRASS in seinen Vorlesungen und im
Jahre 1872 von CANTOR und von DEDEKIND sozusagen das letzte
Wort in der Sache gesprochen — kann keine Vorlesung, kein Werk,
das die grundlegenden Kapitel der hoheren Analysis behandelt, An-
spruch auf Gultigkeit machen, wenn es nicht von dem gereinigten
Begriff der reellen Zahl seinen Ausgangspunkt nimmt.
Die reellen Zahlen wurden verstanden, und damit viele Prozesse, die einen
Ubergang zur Unendlichkeit involvierten: Unendlich groß, aber auch unendlich
klein. Typische Beispiele dieser Prozesse waren die Folgen reeller Zahlen. Sie sind
seit sehr langem bekannt. Beispielsweise hat Archimedes schon die Folge
1,1+1
2,1+
1
2+(1
2
)2
,1+1
2+(1
2
)2
+(1
2
)3
, . . . ,1+1
2+(1
2
)2
+ . . .+(1
2
)n+1
+ . . .
betrachtet, und gesagt, dass sie konvergent ist. Das Wort”konvergent” tritt ubrigens
erst mit James Gregory im Jahr 1667 auf. D’Alembert um 1765 und vor allem
Cauchy in seinem Cours d’Analyse (1821) danken wir die Definition: Eine Folge
(an)n∈N reeller Zahlen ist gegen eine reelle Zahl a konvergent, wenn gilt:
∀ε > 0 ∃n0 ∈ N so dass |an −a|< ε fur alle n ≥ n0.
Tatsachlich ist diese Definition von d’Alembert in der Encyclopedie, 9. Band zu
lesen:”On dit qu’une grandeur est la limite d’une autre grandeur, quand la seconde
peut approcher de la premiere plus pres que d’une grandeur donnee, si petite qu’on
la puisse supposer...”. Cauchy fuhrte die Bezeichnung lim ein:
Lorsqu’une quantite variable converge vers une limite fixe, il est
souvent utile d’indiquer cette limite par une notation particuliere,
c’est ce que nous ferons, en placant l’abreviation
lim
devant la quantite variable dont il s’agit...

128 Abschnitt 15
Folgen reeller Zahlen haben dabei geholfen, die reellen Zahlen zu definieren!
Cauchy hat seinen eigenen Begriff von Konvergenz betrachtet, die Cauchy-Folge,
der gleichbedeutend zu dem ublichen war, aber nur fur reelle Zahlen (vgl. Satze
6.5 und 6.6). Beispiele wie das schon Ende des Abschnittes 6 betrachtete
1, 1.4, 1.41, 1.414, 1.4142, 1.41421, . . .
waren Jahrelang nicht verstanden. Auf einmal kam die Losung aus mehreren un-
abhangigen Seiten (Cantor, Heine, Meray und Dedekind): Die ganze Cauchy-Folge
wird als reelle Zahl erklart: Einer Cauchy-Folge rationaler Zahlen wird eine reelle
Zahl zugeordnet. Wie Cantor 18892 schrieb:
√3 ist also nur ein Zeichen fur eine Zahl, welche erst noch gefun-
den werden soll, nicht aber deren Definition. Letztere wird jedoch
in meiner Weise, etwa durch
(1.7, 1.73, 1.732, . . .)
befriedigend gegeben.
Folgen sind eng verbunden mit Reihen reeller Zahlen. Summen von unendlich
vielen Zahlen brachten schon in der Antike zum Nachdenken, wie die Paradoxe
von Zenon von Elea (um 490–430 v. Chr.) zeigen. Ein Beispiel davon ist der Para-
doxon von Achilles und der Schildkrote: Darin wird versucht zu belegen, dass ein
schneller Laufer wie Achilles bei einem Wettrennen eine Schildkrote niemals ein-
holen konne, wenn er ihr einen Vorsprung gewahre. In mathematischer Sprache,
hat Zenon nicht berucksichtigt, dass Reihen reeller Zahlen auch”konvergieren”
konnen. Es ist nichts ihm vorzuwerfen, denn die Reihen reeller Zahlen wurden
erst im zweiten Teil des 19. Jahrhunderts vollstandig verstanden. Der norwegische
Mathematiker Niels Henrik Abel (1802-1829) kritisierte sogar Cauchy in dieser
Richtung:
Cauchy est fou, et avec lui il n’y a pas moyen d s’entendre, bien
que pour le moment il soit celui qui sait comment les matematiques
doivent etre traitees. Ce qu’il fait est excellent, mais tres brouille...
Cauchy hat ubrigens eine riesige Arbeit im Bereich von Reihen gemacht: Das
Cauchysche Verdichtungskriterium (vgl. Aufgabe 24), Das Quotienten- und das
Wurzelkriterium (Satze 7.9 und 7.10), das Cauchysche Produkt (Satz 7.11) sind
Beispiele dazu. Er konnte aber noch nicht vollig korrekt das Verstausch von Limi-
ten und (unendlichen) Summen handeln.
2Bemerkung mit Bezug auf den Aufsatz: Zur Weierstraß-Cantorschen Theorie der Irrationalzahlen.
Math. Annalen 33 (1889), S. 476.

Ein Ruckblick auf die Infinitesimalrechnung 129
Eine Folge reeller Zahlen ist ein Beispiel von Funktion, namlich eine Abbil-
dung N → R. Der Begriff von Funktion wird erst Ende 18. Jahrhundert im heu-
tigen Sinne verstanden (bis dahin war die Vorstellung etwa, es ware ein Quotient
zwischen Unbekannten). 1837 schrieb Dirichlet ganz prazise (bei der damaligen
Standard):
”Entspricht nun jedem x ein einziges, endliches y, ... so heisst y eine
... Function von x fur dieses Intervall. ... Diese Definition schreibt
den einzelnen Theilen der Curve kein gemeinsames Gesetz vor;
man kann sich dieselbe aus den verschiedenartigsten Theilen zu-
sammengesetzt oder ganz gesetzlos gezeichnet denken”.
Heute sagen wir, dass eine Funktion f : A → B eine Korrespondenz ist, die aus
zwei Mengen A und B besteht, namlich den Definitionsbereich A und den Wertebe-
reich B, und aus einer Vorschrift, die jedes Element x ∈ A einem einzigen Element
y ∈ B zuordnet. Diese Korrespondenz bezeichnen wir mit
y = f (x) oder x 7→ f (x).
Wir sagen, dass y das Bild von x unter f ist, oder dass x das Vorbild von y ist.
Die Stetigkeit einer Funktion in einem Punkt war ein weiteres Aspekt der neuen
Fragestellung. Die Losung wurde mittels Grenzwertubergangsprozesse vermittelt.
Fur Cauchy lautet
”... f (x) sera fonction continue, si ... les valeurs numeriques de la
difference
f (x+α)− f (x)
decroit indefiniment avec celle de α ...”
Bei Weierstraß konnte man 1874 schon lesen:
”Wir nennen dabei eine Grosse y eine stetige Funktion von x, wenn
man nach Annahme einer Grosse ε die Existenz von δ beweisen
kann, sodass zu jedem Wert zwischen x0−δ . . .x0+δ der zugehori-
ge Wert von y zwischen y0 − ε . . .y0 + ε liegt.”
In der heutigen Interpretation ist das auch gleichbedeutend mit der Existenz der
seitigen Limiten, wie wir auch gezeigt haben:
Eine Funktion f : A →R ist in einem Punkt a ∈ A ⊂R stetig, wenn
die links- und rechtsseitigen Limiten limx↑a f (x) und limx↓a f (x)existieren und ubereinstimmen.

130 Abschnitt 15
Das ist im Wesentlichen wieder Weierstraß dankt. Wie Pringsheim3 1899 er-
kannte”Der Begriff des Grenzwertes einer Funktion ist wohl zuerst von Weier-
strass mit genugender Scharfe definiert worden”.
Bernhard Bolzano4 (1781–1848), Priester und Mathematiker aus Prag, fuhrte
den Geist fur die ε −δ -Definition der Stetigkeit ein:
”Nach einer richtigen Erklarung ... versteht man unter der Redens-
art, dass eine Funktion f x fur alle Werthe von x, die inner- oder
ausserhalb gewisser Grenzen liegen, nach dem Gesetze der Stetig-
keit sind andre nur so viel, dass, wenn x irgend ein solcher Werth
ist, der Unterschied f (x+ω)− f x kleiner als jede gegebene Grosse
gemacht werde konne, wenn man ω so klein, als man nur immer
will, annehmen kann ... [wenn man so klein genug nimmt]”.
Wir lernen heute:
Zu jedem ε > 0 vorgegeben existiert ein δ > 0 so dass
wenn |x−a|< δ ist, so ist | f (x)− f (a)|< ε .
Die Stetigkeit ist damit eine lokale Eigenschaft, so wie die Differenzierbarkeit:
Sie ist wieder durch einen Grenzwertubergang formalisiert:
Eine Funktion f : A →R ist differenzierbar in einem Punkt a∈ A ⊂R, falls der Limes limx→a
f (x)− f (a)x−a
existiert (und endlich ist).
Alternativ wird manchmal der Limes limh→0f (x+h)− f (h)
hbetrachtet.
Die ersten Eigenschaften von der Stetigkeit und der Differenzierbarkeit laufen
auf den entsprechenden Eigenschaften von Grenzwerten 5.4 hinaus: Dass die Sum-
me, Produkt, usw. zweier stetigen bzw. differenzierbaren Funktionen wieder eine
stetige bzw. differenzierbare Funktion ist (vgl. 8.3, 11.3).
Dabei ist naturlich besonders wichtig das Miteinander zwischen Stetigkeit und
Differenzierbarkeit: Dass die Differenzierbarkeit die Stetigkeit impliziert, aber
nicht umgekehrt, wie uns die Betrachtung der Absolut-Betrag Funktion im Null-
punkt lehrt (vgl. 11.2).
Der Stetigkeit und der Differenzierbarkeit sind viele Ergebnisse mit Eigenna-
men zugeordnet—Satze mit Eigennamen sind immer wichtig. Der Zwischenwert-
satz 9.1 ist davon der erste Satz, den wir gesehen haben, dessen Inhalt lautet:
3Enzyklopadie der Math. Wiss., Band II.1, S. 13.4Bolzano ist weniger bekannt, aber hat tiefsinnig die analytischen Fragestellungen seiner Zeit ver-
standen. Von ihm sagt Dieudonne:”Parmi les mathematiciens du debut du dix-neuvieme siecle, ce fut
probablement Bolzano qui posa les questions les plus profondes a propos des fondements de l’analyse”.

Ein Ruckblick auf die Infinitesimalrechnung 131
Jede reelle stetige Funktion f : [a,b]→ R nimmt alle Werte zuwi-
schen f (a) und f (b) an.
Bolzano realisierte diese Tatsache zuerst, die eine offensichliche Konsequenz
hat:
Ist f (a)≤ 0 und f (b)≥ 0 (oder umgekehrt), so besitzt die Funktion
eine Nullstelle im Intervall [a,b].
Traditionell wird diese Folgerung die Darbouxche Eigenschaft (vgl. 9.2) ge-
nannt, nach dem Franzosen Gaston Darboux (1842–1917).
Der Zwischenwertsatz hat noch zwei wichtige Korollare: Erstens, dass das Bild
eines Intervalles durch eine stetige Funktion wieder ein Intervall ist (vgl. 9.3);
zweitens, der Extremwertsatz 9.4, der von Weierstraß in seiner Vorlesung 1861
bewiesen wurde (und von Cantor 1870 veroffenlicht wurde): Jede stetige Funktion
f : [a,b]→R nimmt ihr Maximum und ihr Minimum an (dabei spielt eine wesent-
liche Rolle, dass das Intervall [a,b] abgeschloßen und beschrankt ist!) Hier lassen
wir David Hilbert (1862–1943) reden:
”In seinem Satze, dem zufolge eine stetige Funktion einer reel-
len Veranderlichen ihre obere und untere Grenze stets wirklich er-
reicht, d.h. ein Maximum und Minimum notwendig besitzt, schuf
WEIERSTRASS ein Hilfsmittel, dass heute kein Mathematiker bei
feineren analytischen oder arithmetischen Untersuchungen entbeh-
ren kann”.
Der Satz von Rolle 12.2 und die Mittelwertsatze der Differentialrechnung von
Lagrange und Cauchy 12.3 und 12.4 sind noch wichtige Ergebnisse der Differenti-
alrechnung. Sie besagen im Wesentlichen: Es moge langs eines Bogens der stetigen
Kurve y = f (x) eine Tangente vorhanden sein. Dann ist in einem gewissen inneren
Punkte dieses Bogens die Tangente parallel zur Sehne, die den Bogen spannt.
Die Mittelwertsatze besitzen eine zentrale Bedeutung fur die Analysis, die wohl
zuerst Cauchy erkannt hat: So Felix Klein (1849–1925):
”This was supplied by the mean value theorem; and it was Cauchy’s
great service to have recognized its fundamental importance... be-
cause of this, we adjudge Cauchy as the founder of exact infinitesi-
mal calculus”.
Als Folgerung der Differentialrechnung haben wir die Integralrechnung vor-
gestellt. Das ist historisch nicht genau richtig, aber es scheint didaktischer zu sein.
1823 beschrieb Cauchy das Integral einer stetigen Funktion als der Grenzwert einer
Summe. Fur allgemeinere Funktionen fragte sich 1854 Riemann:

132 Abschnitt 15
”Also zuerst: Was hat man unter
∫ ba f (x)dx zu verstehen?”
Fur Bernhard Riemann (1826–1866), wohl der genialste deutsche Mathemati-
ker laut Ostrowski, war die Antwort auf diese Frage eine Anmerkung in seinem Ha-
bilitationsschrift. Spater verallgemeinerten die Franzosen Emil Heinrich Du Bois-
Reymond (1818–1896) und Darboux die Definitionen von Cauchy und Riemann.
Die Integralrechnung ist aber ziemlich alter. Der Fundamentalsatz der Infinite-
simalrechnung 14.1 und seine Folgerungen, wie z. B. die Regel von Barrow 14.4
(nach Isaac Barrow (1630–1677), der akademische Lehrer Newtons), durch die
der Zusammenhang zwischen den Prozessen der Differentiation und der Integrati-
on hergestellt wird, wurden von Newton und Leibniz unabhangig aufgestellt. Wer
das zuerst entdeckt hat, war jahrelang ein großes Thema:
Newton besass zwar diese Satze lange vor Leibniz, hat sie aber erst
nach Leibniz veroffentlicht. Uber die Prioritat dieser Entdeckung
spielte sich ein sehr unerquicklicher Streit ab, der in den Jahren
1699–1722 sehr viel Staub in der gebildeten Welt Europas aufge-
wirbelt hat. Heute kann man vielleicht als das eine erfreuliche Re-
sultat dieses Streites wenigstens die Auffassung nennen, dass es ein
Verstoss gegen die Interessen der Wissenschaft ist, wissenschaftli-
che Entdeckungen, oder Methoden, die zu solchen Entdeckungen
fuhren, geheim zu halten oder nur innerhalb eines kleinen Kreises
bekannt zu geben5.
Hoffentlich haben Sie sich die wichtigste Konzepte und Ergebnisse der Infi-
nitesimalrechnung nach diesem historischen Intermezzo im Skript in Erinnerung
gerufen. Vielleicht haben Sie den Eindruck bekommen, dass die Mathematik le-
bendig ist, und nicht einfach ein dusterer Himmel, eine trockene Haufung von Re-
sultaten. Zur Mathematik gehort viel Geduld, aber als menschliche Schopfung ist
viele Leidenschaft dabei.
5Vgl. [Os], S. 180.

ABSCHNITT 16
Lineare Gleichungssysteme
Bei der Bestimmung von Stammfunktionen rationaler Funktionen haben wir
uns”ad hoc” mit dem Problem, wie lost man lineare Gleichungssysteme, getroffen.
Dies mochten wir jetzt systematisch betrachten.
Wir fangen klein an: Seien a,b ∈ R. Was ist die Menge aller x ∈ R so dass die
lineare Gleichung
ax = b
erfullt wird? Diese Sondersituation ist bereits lehrreicht:
(a) Ist a 6= 0, so besitzt die Gleichung genau eine Losung, namlich x = ba.
(b) Ist a = 0 und b 6= 0, so besitzt die Gleichung gar keine Losung: Es existiert
kein x ∈ R mit 0 · x = b 6= 0.
(c) Ist a = 0 und b = 0, so hat die Gleichung unendlich viele Losungen: Jedes
x ∈ R ist eine Losung, denn es gilt:
a · x = 0 · x = 0 = b fur alle x ∈R.
Lassen wir uns einen Schritt weiter gehen, und betrachten zwei lineare Glei-
chungen mit zwei Unbestimmten x und y:
a1x+b1y = c1
a2x+b2y = c2
mit ai,bi,ci ∈ R fur i = 1,2. Es ist nun die Frage: Wie findet man –falls moglich –
eine Losung der ersten und der zweiten Gleichung? D.h., wir suchen nach Paaren
(x,y) ∈ R×R, welche das Gleichungssystem erfullen.
Zunachst konnen wir die Unbestimmte y”eliminieren”, indem wir die erste
Ungleichung mit b2, die zweite mit b1 multiplizieren, und danach von der ersten
Gleichung die zweite substrahieren:
b2a1x + b2b1y = b2c1
−[b1a2x + b1b2y = b1c2](a1b2 − a2b1)x = b2c1 −b1c2.
Wir konnen analog vorgehen, um x zu eliminieren:
−[a2a1x + a2b1y = a2c1]a1a2x + a1b2y = a1c2
(a1b2 − a2b1)x = a1c2 −a2c1.

134 Abschnitt 16
Erfullen die Konstanten a1,a2,b1,b2 ∈ R die Ungleichung
a1b2 −a2b1 6= 0,
dann ist die Losung des linearen Gleichungssystems
x =b2c1 −b1c2
a1b2 −a2b1, y =
a1c2 −a2c1
a1b2 −a2b1.
Durch Einsetzen in das ursprungliche lineare Gleichungssystem sieht man sofort,
dass diese x und y das System erfullen:
a1x+b1y =a1(b2c1 −b1c2)+b1(a1c2 −a2c1)
a1b2 −a2b1
= c1
a2x+b2y =a2(b2c1 −b1c2)+b2(a1c2 −a2c1)
a1b2 −a2b1= c2
Ist a1b2 − a2b1 = 0, so hat das lineare Gleichungssystem entweder keine Losung
oder unendlich viele, je nachdem wie sich die Konstanten c1 und c2 im Bezug auf
ai,bi verhalten. Speziell gilt: Ist c1 = c2 = 0, so hat das lineare Gleichungssystem
mindestens die Losung x = y = 0. Sie ist die einzige, wenn a1b2 −a2b1 6= 0.
Lineare Gleichungssysteme haben eine einfache geometrische Bedeutung, die
wir fur zwei Unbestimmte anhand von drei Beispielen erklaren.
Beispiele.
(a) Betrachte das lineare Gleichungssystem
x + y = 1
x − y = 1
Da a1b2 − a2b1 = −2 6= 0, besitzt das Gleichungssystem genau eine
Losung, namlich (x,y) = (1,0). Dieser entspricht der Schnittpunkt der
Geraden mit Gleichungen x+ y = 1 und x− y = 1 in R2.
(b) Sei nun
x + y = 1
3x + 3y = 4
Ware (x, y) eine Losung, so gelte 3x+3y = 3 und 3x+3y = 4, also 3 = 4,
was ein Widerspruch ist. Die Geraden mit den Gleichungen x+ y = 1 und
3x+3y = 4 sind parallel, daher schneiden sie sich nicht. Die Losungsmen-
ge des linearen Gleichungssystems ist dann /0.
(c) Betrachte das lineare Gleichungssystem
x + 2y = 1
3x + 6y = 3
Die beiden Gleichungen entsprechen derselben Gerade, daher ist diese die
Losungsmenge des Gleichungssystems: Die Losungsmenge besteht also

Lineare Gleichungssysteme 135
aus den Punkten (x,−1
2x+
1
2
)
fur x ∈ R beliebig.
Im Allgemeinen hat ein lineares Gleichungssystem die folgende Gestalt:
a11x1 + · · ·+ a1nxn = b1...
...... (∗)
am1x1 + · · ·+ amnxn = bm
wobei m,n beliebige naturliche Zahlen sind:
- m ist die Anzahl der Gleichungen
- n ist die Anzahl der Unbekannten x1,x2, . . . ,xn
- die m ·n reellen Zahlen ai j heißen die Koeffizienten des Gleichungssystems
- die m reellen Zahlen bi heißen die konstante Terme des Gleichungssystems
Falls bi = 0 fur alle i = 1, . . . ,m heißt das lineare Gleichungssystem homogen.
Anderenfalls, d.h., falls ein i ∈ {1, . . . ,m} existiert mit bi 6= 0, so heißt das lineare
Gleichungssystem inhomogen.
Ein n-Tupel ξ 0 = (ξ 01 , . . . ,ξ
0n ) reeller Zahlen heißt Losung des linearen Glei-
chungssystems, wenn die i-ten Komponenten ξ 0i von ξ 0 das lineare Gleichungssy-
stem erfullen.
Ein lineares Gleichungssystem heißt dann
(a) losbar, wenn es mindestens eine Losung hat;
(b) nicht losbar oder unlosbar, wenn es keine Losung hat;
(c) eindeutig losbar, wenn es genau eine Losung hat.
Die Koeffizienten eines linearen Gleichungssystems werden oft in einer Tabelle
angeordnet. Wir schreiben
A = (ai j)1≤i≤m1≤ j≤n
= (ai j) =
a11 · · · a1n...
...
am1 · · · amn
Diese Tabelle heißt eine m× n-Matrix. Dann ist A die zum vorgegebenen linea-
ren Gleichungssystem (∗) gehorige Matrix. Fugt man die konstanten Terme des
Gleichungssystems zu A hinzu, so erhalt man eine m× (n+1)-Matrix
(A,b) =
a11 · · · a1n b1...
......
am1 · · · amn bm
.
Diese neue Matrix heißt die erweiterte Matrix des obigen linearen Gleichungssy-
stems (∗).

136 Abschnitt 16
Betrachten wir nun ein weiteres lineares Gleichungssystem
a′11x1 + · · ·+a′1nxn = b′1...
......
a′k1x1 + · · ·+ a′knxn = b′kmit k Ungleichungen und n Unbekannten, und mit erweiterter Matrix
(A′,b′) =
a′11 · · · a′1n b′1...
......
a′k1 · · · a′kn b′k
.
Definition. Die zwei lineare Gleichungssysteme mit zugehorigen erweiterten Ma-
trizen (A,b) und (A′,b′) heißen aquivalent, wenn sie dieselbe Losungsmenge be-
sitzen. Wir schreiben dann (A,b)∼= (A′,b′).
Die Anwendung von folgenden Transformationen, elementare Umformungen
genannt, lassen lineare Gleichungssysteme aquivalent:
(a) Umformungen von Typ I:
Ti j : Vertausche die i-te und die j-te Gleichung.
(b) Umformungen von Typ II:
Ti j(c) : Ersetze die i-te Gleichung durch die Gleichung
(ai1 + ca j1)x1 +(ai2 + ca j2)x2 + . . .+(ain + ca jn)xn = bi + cb j
mit j ∈ {1, . . . ,m}, j 6= i, c ∈ R.
(c) Umformungen von Typ III:
Ti(c) : Ersetze die i-te Gleichung durch die Gleichung
cai1x1 + cai2x2 + . . .+ cainxn = cbi
mit c ∈ R\{0}.
(d) Umformungen von Typ IV:
Ti : Weglassen der i-ten Gleichung, falls diese Null ist, d. h.
falls bi = 0 und ai j = 0 fur alle j.
Beispiel. Man wendet elementare Umformungen auf das erste Gleichungssystem
an, um dieses zu vereinfachen:
2x1 + x2 + x3 = 1
x1 +2x2 +2x3 = 2
x1 + x2 + x3 = 0
T12−→x1 +2x2 +2x3 = 2
2x1 + x2 + x3 = 1
x1 + x2 + x3 = 0
T21(−2)−→x1 +2x2 +2x3 = 2
−3x2 −3x3 =−3
x1 + x2 + x3 = 0
T31(−1)−→x1 +2x2 +2x3 = 2
−3x2 −3x3 =−3
− x2 − x3 =−2
T32
(− 1
3
)−→
x1 +2x2 +2x3 = 2
−3x2 −3x3 =−3
0x3 =−1

Lineare Gleichungssysteme 137
Das letzte lineare Gleichungssystem ist nicht losbar: Die Gleichung
0 · x3 =−1
kann fur kein x3 ∈ R erfullt werden. Damit ist das ursprungliche lineare Glei-
chungssystem auch nicht losbar, wie das folgende Ergebnis sicherstellt:
Satz 16.1. Zwei lineare Gleichungssysteme sind aquivalent, wen das eine aus dem
anderen durch eine endliche Folge von elementaren Umformungen hervorgegan-
gen ist.
Beweis. Es ist klar, dass elementare Umformungen von Typen I, III und IV die
Losungsmenge nicht andern. Zu untersuchen ist noch, dass dies auch fur elemen-
tare Umformungen vom Typ II der Fall ist. Sei dazu (A′,b′) aus (A,b) durch solche
elementare Umformung Ti j(c) entstanden. Ist ξ 0 eine Losung von (A,b) so gilt
speziell
ai1ξ 01 + · · ·+ ainξ 0
n = bi
a j1ξ 01 + · · ·+ a jnξ 0
n = b j
und damit auch
(ai1 + ca j1)ξ01 + · · ·+(ain + ca jn)ξ
0n = bi + cb j
ai1ξ 01 + · · ·+ainξ 0
n + c(a j1ξ 01 + · · ·+a jnξ 0
n ) = bi + cb j
d.h., ξ 0 = (ξ 01 , . . . ,ξ
0n ) ist auch eine Losung von (A′,b′). Umgekehrt sei angenom-
men, dass (A,b) aus (A′,b′) durch die elementare Umformung Ti j(−c) entstanden.
Dann gilt auch: Ist ξ 0 eine Losung von (A′,b′), so ist ξ 0 auch eine Losung von
(A,b). �
Definition. Lineare Gleichungssysteme mit erweiterter Matrix der Form (A′,b′)mit n Unbekannten und k Gleichungen so dass eine Zahl r mit 0 ≤ r ≤ k, und
Indizes 1 ≤ j1 < j2 < .. . jr ≤ n gibt mit der Eigenschaft
a′i j = 0 fur{
i = 1, . . .r, j < jii > r, j = 1, . . .n
und
a′1 j1, . . . ,a′r jr
6= 0
heißen lineare Gleichungssysteme in Zeilenstufenform.
Damit kann man zeigen:

138 Abschnitt 16
Satz 16.2. Jedes lineares Gleichungssystem ist zu einem linearen Gleichungssy-
stem mit erweiterter Matrix (A′,b′) gleich
0 · · · 0 a′1 j1a′1 j1+1 · · · ∗ ∗ ∗ · · · ∗ ∗ · · · ∗ ∗ · · · a′1n b′1
0 · · · 0 0 0 · · · 0 a′2 j2a′2 j2+1 · · · ∗ ∗ · · · ∗ ∗ · · · a′2n b′2
0 · · · 0 0 0 · · · 0 0 0 · · · 0 a′3 j3· · · ∗ ∗ · · · a′3n b′3
......
......
......
......
... · · · ......
......
......
......
......
...... · · · ∗ ∗ · · · ∗ b′r−1
0 · · · 0 0 0 · · · 0 0 0 0 0 0 a′r jr∗ · · · a′rn b′r
0 · · · · · · · · · 0 b′r+1...
...
0 · · · · · · · · · 0 b′k
aquivalent. (Fur i = 1, . . . ,r hnagt die i-te Gleichung nur von Unbekannten x j mit
j > ji ab.)
Beweis. Sei (A,b) ein lineares Gleichungssystem. Durch Anwendung von elemen-
taren Umformungen von Typen I und II wird (A,b) auf Zeilenstufenform gebracht
werden.
Schritt 1: Sind ai j = 0 fur alle i, j, so liegt die gesunechte Zeilenstufenform vor.
Angenommen, ai j 6= 0 fur mindestens ein Indexpaar (i, j). Sei j1 ∈ {1, . . . ,n} der
kleinste Index so dass die j1-Spalte von A nicht nur aus Nullen besteht. Anwendung
elementarer Umformungen von Typ I liefert a1 j1 6= 0. Fur i = 2, . . . ,m wenden wir
die elementare Umformung
Ti1
(− ai j1
a1 j1
)
an. So erhalten wir ein lineares Gleichungssystem dessen j1-te Spalte die Form
ai j1
0...
0
hat, indem x j1 also nur in der ersten Gleichung vorkommt. (Die Unbekannten
x1, . . . ,x j1−1 kommen im linearen Gleichungssystem nicht vor, falls j1 > 1 ist.)

Lineare Gleichungssysteme 139
Wir haben also erreicht
0 · · · 0 a′1 j1a′1 j1+1 a′1 j1+2 · · · a′1n b′1
0 · · · 0 0 a′2 j1+1 a′2 j1+2 · · · a′2n b′20 · · · 0 0 a′3 j1+1 a′3 j1+2 · · · a′3n b′3... · · · ...
......
... · · · ......
0 · · · 0 0 a′r j1+1 a′r j1+2 · · · a′rn b′r0 · · · 0 0 a′r+1 j1+1 a′r+1 j1+2 · · · a′r+!n b′r+1... · · · ...
......
... · · · ......
0 · · · 0 0 a′k j1+1 a′k j1+2 · · · a′kn b′k
Die Matrix entspricht also dem linearen Gleichungssystem
a′1 j1x j1 + a′1 j1+1x j1+1 + · · · + a′1nxn = b′1
a′2 j1+1x j1+1 + · · · + a′2nxn = b′2a′3 j1+1x j1+1 + · · · + a′3nxn = b′3
... · · · ......
a′k j1+1x j1+1 + · · · + a′knxn = b′k
Schritt 2: Wie im Schritt 1 behandeln wir nun das lineare Gleichungssystem
a′2 j1+1x j1+1 + · · · + a′2nxn = b′2a′3 j1+1x j1+1 + · · · + a′3nxn = b′3
... · · · ......
a′k j1+1x j1+1 + · · · + a′knxn = b′k
und wiederholen das obige Argument. Nach spatestens m Schritten erreichen wir
die gewunschte Zeilenstufenform. �
Beispiel. Wir suchen die Losungsmenge des linearen Gleichungssystems
−x1 + 2x2 + x3 = −2
3x1 − 8x2 − 2x3 = 4
x1 + 4x3 = −2
die zugehorige erweiterte Matrix ist
(A1,b1) =
−1 2 1 −2
3 −8 −2 4
1 0 4 −2
.

140 Abschnitt 16
Auf A1 wenden wir das Gaußsche Eliminationsverfahren an:
−1 2 1 −2
3 −8 −2 4
1 0 4 −2
T31(1)−→
−1 2 1 −2
3 −8 −2 4
0 2 5 −4
T21(3)−→
−1 2 1 −2
0 −2 1 −2
0 2 5 −4
T32(1)−→
−1 2 1 −2
0 −2 1 −2
0 0 6 −6
.
Sofort sieht man: Das System ist eindeutig losbar mit 6x3 =−6, also x3 =−1,
−2x2 =−2− x3 =−1, also x2 =12
und x1 = 2−2x2 − x3 = 2−1+1 = 2.
Beispiel. Betrachten wir das lineare Gleichungssystem
x1 + x2 + x3 + x4 = 1
2x1 + x2 − 2x3 + 2x4 = 2
4x1 − 3x2 + 2x3 = 30
die zugehorige erweiterte Matrix ist
(A2,b2) =
1 1 1 1 1
2 1 −2 2 2
4 −3 2 0 30
.
Anwendung des Gaußschen Eliminationsverfahrens liefert seine Zeilenstufenform:
1 1 1 1 1
2 1 −2 2 2
4 −3 2 0 30
T31(−4)−→
1 1 1 1 1
2 1 −2 2 2
0 −7 −2 −4 26
T21(−2)−→
1 1 1 1 1
0 −1 −4 0 0
0 −7 −2 −4 26
T32(−7)−→
1 1 1 1
1
0 −1 −4 0
0
0 0 26 −4
26
.
Das heißt, wir haben folgendes lineares Gleichungssystem in Zeilenstufenform
erreicht:x1 + x2 + x3 + x4 = 1
− x2 − 4x3 = 0
26x3 − 4x4 = 26
Definition. Betrachten wir ein lineares Gleichungssystem mit m Gleichungen
und n Unbekannten x1, . . .xn in Zeilenstufenform gegeben. Die Unbekannten
x j1, . . . ,x jr heißen Hauptvariable, und die Unbekannten xi mit i /∈ { j1, . . . jr} hei-
ßen freie Variable oder auch Parameter des linearen Gleichungssystems.

Lineare Gleichungssysteme 141
Beispiel. Im obigen Besipiel mit erweiterter Matrix (A1,b1) sind x1, x2 und x3
Hauptvariable. Im Beispiel mit erweiterter Matrix (A2,b2) sind x1, x2 und x3 Haupt-
variablen, x4 aber eine freie Variable.
Satz 16.3. Betrachten ein lineares Gleichungssystem mit erweiterter Matrix (A′,b′)in Zeilenstufenform gegeben.
(a) Das System ist genau dann losbar, wenn b′r+1 = . . .= b′k = 0 gilt.
(b) Sei (A,b) die erweitete Matrix eines losbaren linearen Gleichungssystem.
Dann gilt:
(i) Zu jeder beliebigen Wahl α j, j /∈ { j1, . . . , jr} von Werten fur die
freien Variable der Zeilenstufenform von (A,b) gibt es genau eine
Losung ξ 0 = (ξ 01 , . . . ,ξ
0n ) des Gleichungssystems mit ξ 0
j = α j fur
j /∈ { j1, . . . , jr}. Außerdem: Durch die r-te Gleichung des Systems
liegt dann die Hauptvariable x jr fest:
x jr = ξ 0jr
:=1
a′r jr
(b′r −a′r jr+1ξ 0
jr+1 − . . .−a′rnξ 0n
).
Aus der (r − 1)-ten Gleichung ergibt sich die Hauptvariable x jr−1
usw.
(ii) Das System mit Matrix (A,b) ist genau dann eindeutig losbar, wenn
r = n und b′r+1 = . . .= b′k = 0 in der Stufenform. (Insbesondere muss
dann m ≥ n gelten.)
Beweis. Gilt b′ν 6= 0 fur ν ∈ {r+1, . . . ,k}, dann ist die zugehorige ν-te Gleichung
0x1 + . . .+0xn = b′ν ,
die keine Losung besitzt, und damit das ganze lineare Gleichungssystem nicht. Gilt
b′r+1 = . . . = b′k = 0, so sind alle angegebene (ξ 01 , . . .ξ
0n ) Losungen des linearen
Gleichungssystems. �
Eine Zeilenstufenform lasst sich weiter vereinfachen, indem man elementare
Umformungen vom Typ III
Ti(a−1i ji)
fur i = 1, . . . ,r anwendet. Die i-te Gleichung, i ≤ r, hat dann die Gestalt
x ji +a′′i ji+1x ji+1 + . . .+a′′inxn = b′′i .
Dann machen wir dies mit der ersten Gleichung
x j1 +a′′1 j1+1x j1+1 + . . .+a′′1 j2−1x j2−1 +a′′1 j2+1x j2+1 + . . .= b′′1
(hier kommen naturlich x j1 und hochstens die n−r freien Variablen xi, i 6= j1, . . . jrvor.)

142 Abschnitt 16
Aus dieser ersten Gleichung kann man nun die Unbekannte x j2 eliminieren: Es
reicht, das a′′1 j2-fache der 2. Gleichung von der ersten abzuziehen. Insgesamt kann
man die Variable x jν fur ν = 2, . . . ,k aus der 1. Gleichung eliminieren. Man setzt
dies fort.
Schließlich kann man die Unbekannte x jr aus den ersten r − 1 Gleichungen
eliminieren, und Gleichungen der Art
0 = 0
weglassen (dank elementaren Umformungen vom Typ IV).
Ubrig bleiben genau r Gleichungen, wenn das lineare Gleichungssystem losbar
ist, welche sofort eine Losung liefern.
Somit erhalten wir eine sogenante reduzierte Zeilenstufenform des linearen
Gleichungssystems mit Matrix:
A′ =
0 · · · 0 1 ∗ · · · ∗ 0 ∗ · · · ∗ 0 · · · 0 ∗ · · · ∗0 · · · 0 0 0 · · · 0 1 ∗ · · · ∗ 0 · · · 0 ∗ · · · ∗0 · · · 0 0 0 · · · 0 0 0 · · · 0 1 · · · 0 ∗ · · · ∗...
......
......
......
...... · · · ...
......
......
......
......
......
... · · · 0 ∗ · · · ∗0 · · · 0 0 0 · · · 0 0 0 0 0 0 1 ∗ · · · ∗0 · · · · · · · · · 0...
...
0 · · · · · · · · · 0
r →
j1↓
j2↓
j3↓
. . . jr↓
(Dabei steht ∗ fur ein beliebiges Element aus K.)
Ist das lineare Gleichungssystem nicht losbar, so erhalt man eine widerspruchli-
che (r+1)-te Gleichung
0 = 1.
Beispiel. Wir betrachten das lineare Gleichungssystem des letzten Beispiels mit
Zeilenstufenform
x1 + x2 + x3 + x4 = 1
− x2 − 4x3 = 0
26x3 − 4x4 = 26

Lineare Gleichungssysteme 143
Davon rechnen wir die reduzierte Zeilenstufenform:
1 1 1 1 1
0 −1 −4 0 0
0 0 26 −4 26
T2(−1)−→
1 1 1 1 1
0 1 4 0 0
0 0 26 −4 26
T3(126 )−→
1 1 1 1 1
0 1 4 0 0
0 −0 1 − 213
1
T12(−1)−→
1 0 −3 1 1
0 1 4 0 0
0 −0 1 − 213
1
T13(3)−→
1 0 0 713
1913
0 1 4 0 0
0 −0 1 − 213
1
T23(−4)−→
1 0 0 713
1913
0 1 0 813
− 813
0 −0 1 − 213
1
Damit ist die Losungsmenge fur x4 = 13t, fur t ∈ R genau
x3 = 1+ 213
x4 = 1+2t
x2 = − 813− 8
13x4 = − 8
13−8t
x1 = 193− 7
13x4 = 19
13−7t
(d.h., eine Gerade des R3.)
Im nachsten Abschnitt betrachten wir axiomatisch die allgemeine Struktur,
welche die Losungsmenge homogener linearer Gleichungssysteme besitzen: Die
Struktur von Vektorraum.


ABSCHNITT 17
Vektorraume
Betrachten wir die Gleichung x+ y = 0. Sie liefert ein einfaches Beispiel vom
homogenen linearen Gleichungssystem. Seine Losungsmenge ist ubrigens
L :={(
x
−x
)∈R2 : x ∈R
}={(
0
0
)+(
1
−1
)t : t ∈R
}={(
1
−1
)t : t ∈R
}.
Es fallen folgende Tatsachen auf: L besitzt die Losung x= y= 0, die Summe zweier
Losungen ist wieder eine Losung, das Produkt von einer Losung mit einem reellen
Zahl ist weiterhin eine Losung. Das heizunachst einmal, dass die Losungsmenge
eines homogenen linearen Gleichungssystems eine Struktur besitzt, d.h., sie ist
mehr als einfach eine Menge: Man wird hierzu vom Losungsraum besprochen.
Diese Struktur (diese Raume) ist eine allgemeine Befund in der Mathematik: Die
Struktur vom Vektorraum.
Die Lineare Algebra, mit der wir uns in der Rest dieser Vorlesung hauptsachlich
beschaftigen werden, ist die Theorie der Vektorraume. Genau wie die Begriffe
”Gruppe“ und
”Korper“ in Abschnitt 3 fuhren wir auch den Begriff
”Vektorraum“
axiomatisch1 ein.
Definition. Ein Vektorraum uber einem Korper (K,+K, ·K) ist eine Menge V ver-
sehen mit
einer Verknupfung +V : V ×V →V , genannt Addition,
und einer Abbildung ·V : K ×V →V , genannt skalare Multiplikati-
on,
die folgenden Bedingungen genugen:
(a) V ist bezuglich der Addition eine abelsche Gruppe, d.h. fur alle u,v,w ∈V
gilt
(V1) u+V (v+V w) = (u+V v)+V w,
(V2) Es existiert 0V ∈V mit v+V 0V = 0V +V v = v,
(V3) Zu jedem v ∈V gibt es ein −v ∈V mit v+V (−v) = 0V ,
(V4) u+V v = v+V u.
(b) fur alle a, b ∈ K und v, w ∈V ist
1Wie Guiseppe Peano 1888 machte, allerdings erst ohne große Resonanz: Diese neue Sprache war
noch nicht notig, um die laufenden Forschungsprobleme zu betrachten. Es war erst im 20. Jahrhundert, als
die Funktionalanalysis, zusammen mit der Tendenz der modernen Algebra, alle Begriffe axiomatisch zu
strukturieren, dem Konzept von Vektorraum seinen Platz gegeben hat, den er noch heute besitzt.

146 Abschnitt 17
(V5) a ·V (b ·V v) = (a ·K b) ·V v,
(V6) 1 ·V v = v,
(V7) a ·V (v+V w) = a ·V v+V a ·V w,
(V8) (a+K b) ·V v = a ·V v+V b ·V v.
Die Unterscheidung zwischen +V und +K bzw. ·V und ·K, so wie zwischen 0V
und 0K immer wieder zu machen ist eine enorme Belastung fur die Bezeichnung.
In keinem Lehrbuch ist das so zu finden. Es ist also unvermeidlich, dass wir das
Symbol + sowohl fur die Addition in K, als auch fur die in V benutzen, ebenso
wie die Produktschreibweise innerhalb von K und fur die skalare Multiplikation
verwandt wird. Letzten Endes ware es auch nicht sehr hilfreich, wenn wir etwa
0 ∈ K und 0 ∈ V typografisch unterscheiden wurden. Deswegen werden wir dies
auch nicht tun, und wird dem Leser uberlassen, zu unterscheiden, wann die einen
oder die anderen gebraucht wird.
Einfach zu begrunden sind folgende Rechenregeln fur Vektorraume: Fur a ∈ K,
v ∈V ist
(a) 0v = 0
(b) (−a)v = a(−v) =−av
(c) av = 0 ⇐⇒ a = 0 oder v = 0.
Beispiele. (a) Obwohl es uns nichts Neues bringt, ist bereits das Beispiel V = K
nutzlich: K ist in offensichtlicher Weise ein Vektorraum uber sich selbst.
(b) Das fundamentale Beispiel eines Vektorraums ist V = Kn. Dazu definieren
wir fur
v =
a1...
an
, w =
b1...
bn
∈ Kn und α ∈ K :
v+w =
a1 +b1...
an +bn
, αv =
αa1...
αan
.
Die Vektoren des Kn werden wir als Spaltenvektoren schreiben. Dass Kn mit diesen
Operationen ein Vektorraum ist, kann man direkt nachrechnen. So ist etwa 0 =
0...
0
das neutrale Element bezuglich +, und
−a1...
−an
das Inverse von
a1...
an
bezuglich +.
(c) R ist ein Q-Vektorraum, wie aus den Korperaxiome von R folgt. Ebenso
ist C sowohl ein R-Vektorraum als auch ein Q-Vektorraum. (Allgemein gilt: Es
ist L ein Korper, der K als”Teilkorper” enthalt, so ist L ist in naturlicher Weise
ein Vektorraum uber K: Man beschrankt die Multiplikation L × L → L einfach

Vektorraume 147
auf K × L → L. Sogar noch allgemeiner gilt dies fur jeden L-Vektorraum V : Die
Einschrankung der skalaren Multiplikation auf Elemente von K macht ihn zum
K-Vektorraum.)
(d) Wir betrachten ein”merkwurdiges“ Beispiel:
V = R>0 = {x ∈ R : x > 0}
mit der Addition x⊕y = xy und der Skalarmultiplikation α ∗x = xα , α ∈R, ist ein
R-Vektorraum.
(e) In der Geometrie und vor allem in Physik und Technik sind Vektoren Gro-
ßen, die eine”Richtung“ und einen
”Betrag“ haben, z.B. Geschwindigkeit, oder
Kraft, wahrend”Skalare“ Großen sind, denen keine Richtung zukommt, z.B. Ener-
gie.
Wir wollen kurz erlautern, wie elementargeometrische Uberlegungen zum Be-
griff des Vektorraums fuhren. In der Ebene E der anschaulichen Geometrie zeich-
nen wir einen Punkt O aus, den”Ursprung“. Zu jedem Punkt P ∈ E gehort dann
eine gerichtete Strecke−→OP
O
P
Q
−→OP
−→OQ
−→OP+
−→OQ
Die Addition von solchen gerichteten Strecken erfolgt mittels der Parallelogramm-
Regel, wahrend fur r ∈ R, r ≥ 0, die Strecke r−→OP die gleiche Richtung wie
−→OP,
aber die r-fache Lange hat (bei r < 0 erfolgt Richtungsumkehr).
O
12
−→OP
P
2−→OP
−−→OP
−2−→OP
Nachdem man Koordinaten eingefuhrt hat (mit O als Ursprung des Koordina-
tensystems), ist der soeben konstruierte Vektorraum der”Ortsvektoren“ gerade der

148 Abschnitt 17
R2. Analog erhalt man den R3 als Vektorraum der Ortsvektoren des Anschauungs-
raums.
Wir betonen aber ausdrucklich, dass fur uns die Elemente eines Vektorraums
nicht etwa Wesen sind, die sich dadurch auszeichnen, dass sie eine Richtung und
einen Betrag haben. Bei den vorangegangenen Beispielen (c) und (d) und dem fol-
genden Beispiel (f) ist diese Betrachtungsweise weder naheliegend noch nutzlich.
(f) Sei V ein K-Vektorraum und M eine Menge. Sei Abb(M,V ) die Menge aller
Abbildungen von M nach V . Fur f , g ∈ Abb(M,V ) und α ∈ K definieren wir
f +g ∈ Abb(M,V ) durch ( f +g)(x) = f (x)+g(x),
α f ∈ Abb(M,V ) durch (α f )(x) = α f (x),
x ∈ M. Man uberpruft sofort, dass Abb(M,V ) mit diesen Operationen ein K-
Vektorraum ist. Die Axiome lassen sich”punktweise“ uberprufen; daher ubertragt
sich ihre Gultigkeit von V auf Abb(M,V ).(g) Insbesondere ist die Menge K[X ] aller Polynomfunktionen mit Koeffi-
zienten in einem Korper K, versehen mit der ublichen Addition von Polynom-
funktionen und mit der skalaren Multiplikation K ×K[X ] → K[X ], (α, p(X)) 7→(α p)(X) := α · p(X), ein Vektorraum uber K.
Teilmengen eines Vektorraumes, die wiederum die Struktur vom Vektorraum
besitzen, sind so gekennzeichnet:
Definition. V sei ein K-Vektorraum. Eine Teilmenge U von V heißt Untervektor-
raum, wenn gilt:
(U1) U 6= /0.
(U2) Fur alle u, v ∈U ist auch u+ v ∈U .
(U3) Fur alle u ∈U , α ∈ K ist αu ∈U .
Bemerkung 17.1. Ein Untervektorraum U von V ist selber ein K-Vektorraum.
Beweis. Nach (U1) existiert ein u ∈ U so dass wegen 0u = 0 gilt 0 ∈ U nach (b),
und ebenso ist −u = (−1)u ∈ U . Alle anderen Forderungen sind ohnehin fur be-
liebige Elemente von V erfullt. �
In unserer elementargeometrischen Interpretation sind Beispiele von Untervek-
torraumen gegeben durch die Geraden des R2, die den Ursprung enthalten, und
durch ebensolche Geraden und Ebenen des R3.
Beispiele von Untervektorraumen sind auch allgemein sehr leicht zu geben:
(a) In jedem Vektorraum V sind zunachst {0} und V Untervektorraume.

Vektorraume 149
(b) Seien U1, U2 ⊂V Untervektorraume. Dann ist U1∩U2 ein Untervektorraum
(aber U1∪U2 i.a. nicht!):
v,w ∈U1 ∩U2 =⇒ v,w ∈U1 und v,w ∈U2
=⇒ αv,v+w ∈U1 und αv,v+w ∈U2
=⇒ αv,v+w ∈U1 ∩U2.
(c) Genauso sieht man: Der Durchschnitt endlich vieler Untervektorraume
U1, . . . ,Un oder sogar beliebig vieler Untervektorraume ist ein Untervek-
torraum.
(d) Die Menge U ={(
x
y
)∈R2 : x+y= 0
}ist ein Untervektorraum von R2,
wie es in der einleitenden Motivation dieses Abschnittes begrundet wurde.
(e) Manchmal trug der Schein: Es gibt Untervektorraume, die durch nicht li-
neare Gleichungen gegeben werden: Die Menge
U ′ ={(
x
y
)∈ R2 : x2 + y4 = 0
}
ist ein Untervektorraum des R2. Es ist naturlich deshalb so, weil U ′ ={(0
0
)}ist.
(f) Die Menge W ={(
x
y
)∈R2 : x2+y2 ≤ 1
}ist kein Untervektorraum von
R2: Der Punkt(
1/2
1/2
)ist in W enthalten, aber 2 ·
(1/2
1/2
)=(
1
1
)/∈ W
(der Axiom (U3) ist damit verletzt).
Definition. Sei V ein K-Vektorraum, und seien v1, . . . ,vn ∈V . Ein Element w ∈V
ist Linearkombination von v1, . . . ,vn, wenn α1, . . . ,αn ∈ K existieren mit
w = α1v1 + · · ·+αnvn.
Seien w = α1v1 + · · ·+αnvn und z = β1v1 + · · ·+ βnvn Linearkombinationen
von v1, . . . ,vn. Dann sind auch
w+ z = (α1 +β1)v1 + · · ·+(αn +βn)vn,
λw = (λα1)v1 + · · ·+(λαn)vn, fur λ inK
Linearkombinationen von v1, . . . ,vn. Sei
L(v1, . . . ,vn) ={
w ∈V : w ist Linearkombination von v1, . . . ,vn
}.
Wir haben gesehen, dass L(v1, . . . ,vn) ein Untervektorraum von V ist. Er heißt
lineare Hulle von v1, . . . ,vn.

150 Abschnitt 17
Beispiel. Sei etwa V = Kn. Dann verwenden wir die Standardbezeichnung
ei =
0...
1...
0
mit dem Eintrag 1 and der i-ten Stelle und lauter Nullen sonst. Damit gilt
Kn = L(e1, . . . ,en),
denn fur v =
α1...
αn
∈ Kn ist
v = α1e1 + · · ·+αnen.
Beispiel. Die wichtigste Anwendung der linearen Algebra ist die Theorie der li-
nearen Gleichungssysteme. Sei z.B. fur K = R folgendes Gleichungssystem gege-
ben:
− x1 +3x2 +4x3 = 2
5x1 + x2 −3x3 = 0
x1 + x2 + x3 =−1.
Um den Zusammenhang zu den Linearkombinationen herzustellen, schreiben wir
Elemente des R3 im Folgenden als Spaltenvektoren. Wir setzen
v1 =
−1
5
1
, v2 =
3
1
1
, v3 =
4
3
1
, b =
2
0
−1
.
Eine Losung des obigen Gleichungssystems zu finden, ist dann gleichbedeutend
damit, x1, x2, x3 ∈ R zu finden, fur die
x1v1 + x2v2 + x3v3 = b
ist. Genau dann ist das Gleichungssystem losbar, wenn b ∈ L(v1,v2,v3).
Sei nun V ein K-Vektorraum und S eine beliebige Teilmenge von V . Dann set-
zen wir
L(S) ={
w ∈V : es existieren v1, . . . ,vn ∈ S mit w ∈ L(v1, . . . ,vn)}
und nennen L(S) die lineare Hulle von S.

Vektorraume 151
Anmerkung.
(a) Ist S endlich, etwa S = {v1, . . . ,vn}, dann ist
L({v1, . . . ,vn}) = L(v1, . . . ,vn).
(b) L(S) ist stets ein Untervektorraum:
w ∈ L(v1, . . . ,vn)z ∈ L(u1, . . . ,um)
}=⇒ w+ z ∈ L(v1, . . . ,vn,u1, . . . ,um),
αw ∈ L(v1, . . . ,vn), α ∈ K.
(c) Es ist zweckmaßig, L( /0) = {0} zu setzen.
Definition. Wenn U = L(S) ist, sagen wir auch, U sei der von S erzeugte Unter-
vektorraum, oder U sei der von S aufgespannte Untervektorraum, oder S sei ein
Erzeugendensystem von U .
Ist S also ein Erzeugendensystem von einem K-Vektorraum V , dann gibt es zu
jedem v ∈ V ein m ∈ N>0 so wie Elemente v1, . . . ,vm ∈ S und α1, . . . ,αm ∈ K mit
v = α1v1 + . . .+αmvm.
Ist V = L(S) mit S einer endlichen Menge, so heißt V endlich erzeugt. In dieser
Vorlesung werden wir nur solche systematisch betrachten. Das ist aber nicht immer
ausreichend, wie das folgende Beispiel zeigt:
Beispiel. Sie V = K[X ]. Jede Polynomfunktion f = a0 + a1X + · · ·+ anXn ist ei-
ne Linearkombination der Potenzen 1 = X0,X ,X2,X3, . . . der Unbestimmten X .
Also ist die Menge S dieser Potenzen ein Erzeugendensystem von K[X ] als K-
Vektorraum. Aber keine echte und schon gar keine endliche Teilmenge von S er-
zeugt K[X ]: fur kein m ist Xm Linearkombination der anderen Potenzen.
Der Durschnitt U1 ∩U2 zweier Untervektorraume U1 und U2 eines Vektorrau-
mes V ist die großte Menge, die sowohl in U1 als auch in U2 enthalten ist, und
damit naturlich auch der großte gemeinsame Untervektorraum von U1 und U2.
Welches ist der kleinste Untervektorraum, der sowohl U1 als auch U2 enthalt?
Die erste Antwort, die uns einfallt, ist nicht richtig:
Anmerkung. Die Vereinigung U1 ∪U2 zweier Untervektorraume U1, U2 eines
Vektorraumes V ist kein Untervektorraum: Seien dazu
U1 :={(
x
y
)∈ R2 : y = 0
}und U2 :=
{(x
y
)∈ R2 : x = 0
}.
Es ist(
0
1
),(
1
0
)∈U1∪U2, aber
(0
1
)+(
1
0
)=(
1
1
)/∈U1∪U2, so dass der
Axiom (U2) verletzt wird.
Wenn W ⊃U1 ∪U2 ein Untervektorraum sein soll, dann muss u1 +u2 ∈W fur
alle u1 ∈U1, u2 ∈U2. gelten. Insofern konnen wir setzen
U1 +U2 = {u1 +u2 : u1 ∈U1,u2 ∈U2}.

152 Abschnitt 17
Nun ist leicht zu zeigen, dass U1 +U2 ein Untervektorraum ist: Fur u1,u′1 ∈ U1,
u2,u′2 ∈U2 und α ∈ K ist
(u1 +u2)+(u′1+u′2) = (u1 +u′1)+(u2+u′2) ∈U1 +U2
α(u1 +u2) = αu1 +αu2 ∈U1 +U2.
Wir haben soeben gezeigt: Jeder U1 und U2 umfassende Untervektorraum enthalt
U1 +U2. Dann ist U1 +U2 der kleinste Untervektorraum, der U1 und U2 enthalt.
Wie man den Durchschnitt beliebig vieler Untervektorraume bilden kann, so
kann man auch die Summe beliebig vieler Untervektorraume bilden. Fur eine Fa-
milie (Ui)i∈I von Untervektorraumen setzen wir
∑i∈I
Ui = {ui1 + · · ·+uin : ui j∈Ui j
,n ∈ N}.
Da die Addition in einem Vektorraum V assoziativ und kommutativ ist, kommt es
nicht darauf an, die Ui irgendwie zu ordnen.
Mit dieser Schreibweise konnen wir die lineare Hulle einer Teilmenge S ⊂ V
auch so angeben:
L(S) = ∑v∈S
L(v).
Zerlegt ein Vektorraum V in Summe zweier Untervektorraume, etwa
V =U1 +U2,
lassen sich Vektoren v ∈V schreiben als Summe v = u1 +u2 mit u1 ∈U1,u2 ∈U2.
Leider ist diese Summe nicht eindeutig.
Zum Schluß wollen wir zeigen, unter welche Bedingungen ist diese Schreib-
weise eindeutig.
Satz 17.2. Seien U1,U2 Untervektorraume eines K-Vektorraumes V , und sei U =U1 +U2. Dann sind folgende Aussagen aquivalent:
(i) Ist u1 +u2 = 0 fur u1 ∈U1, u2 ∈U2, dann ist u1 = u2 = 0.
(ii) Fur jedes u ∈U ist die Darstellung u = u1 +u2 eindeutig.
(iii) U1 ∩U2 = {0}.
Beweis.
(i)⇒ (ii) Sei u ∈ U mit u = u1 +u2 = u′1 +u′2 fur u1,u′1 ∈ U1, u2,u
′2 ∈ U2. Es ist zu
zeigen: u1 = u′1 und u2 = u′2. Das ist aber einfach, denn aus
u = u1 +u2 = u′1 +u′2folgt, dass (u1 − u′1) + (u2 − u′2) = 0 sein muss, wobei u1 − u′1 ∈ U1 und
u2 −u′2 ∈U2 sind. Nach (i) ist dann
u1 −u′1 = 0 und u2 −u′2 = 0,
also u1 = u′1 und u2 = u′2.

Vektorraume 153
(ii)⇒ (iii) Sei u ∈U1 ∩U2. Es ist
u = 0+u = u+0,
und wegen (ii) muss u = 0 gelten.
(iii)⇒ (i) Seien u1 ∈U1 und u2 ∈U2 mit u1 +u2 = 0. Dann ist
u1 =−u2 ∈U2 und u2 =−u1 ∈U1,
und damit
u1,u2 ∈U1 ∩U2 = {0},also u1 = u2 = 0.
�
Definition. Seien U1,U2 Untervektorraume eines K-Vektorraumes. Dann heißt die
Summe U1+U2 die direkte Summe von U1 und U2, falls eine der Bedingungen (und
damit alle) aus Satz 17.2 erfullt sind. Wir schreiben dann
U1 ⊕U2.
Ein einfaches Beispiel dazu:
Beispiel. Sei V = K2. Es ist V = L(e1)⊕L(e2), denn es gilt einerseits
V = L(e1)+L(e2)
d.h., jeder Vektor aus V lasst sich als Summe von einem Vielfachen von e1 plus
einem Vielfachen von e2 darstellen, und andererseits
L(e1)∩L(e2) ={
v ∈V : v =( λ
0
),λ ∈R
}∩{
v ∈V : v =(
0
λ
),λ ∈R
}= {0}.
Im nachsten Abschnitt mochten wir uns klar machen, ob und wie Vektorraume
nach ihren”Großen” unterschieden werden konnen. Es ist zunachst einmal offen-
sichtlich, dass die Anzahl von Elementen in der grundlegenden Menge kein Krite-
rium dafur sein kann, weil dies nicht die zusatliche Struktur, die durch die Addition
und die skalare Multiplikation einbezogen ist, berucksichtigt.


ABSCHNITT 18
Basen und Dimension
Sei K ein Korper und V = Kn. Wir wissen bereits, dass e1, . . . ,en den Vektor-
raum V erzeugen: Zu jedem v =
α1...
αn
∈V existieren β1, . . . ,βn ∈ K mit
v = β1e1 + · · ·+βnen,
namlich β1 = α1, . . . ,βn = αn. Außerdem sind β1, . . . ,βn eindeutig bestimmt: Wir
mussen βi = αi wahlen, weil β1e1 + · · ·+βnen =
β1...
βn
.
Sei andererseits V = K2, w1 = e1, w2 = e2, w3 = e1 + e2. Auch dann existieren
zu jedem v =( α1
α2
)∈ K2 Elemente β1, β2, β3 ∈ K mit v = β1w1 +β2w2 +β3w3.
Wir konnen z.B. β1 = α1, β2 = α2, β3 = 0 wahlen, aber genauso β1 = α1+1, β2 =α2+1, β3 =−1. In diesem Fall sind die Koeffizienten β1, β2, β3 in der Darstellung
von v nicht eindeutig bestimmt. Um zwischen Systemen wie e1, . . . ,en ∈ Kn und
w1, w2, w3 ∈ K2 unterscheiden zu konnen, trifft man folgende
Definition. V sei ein K-Vektorraum. Die Vektoren v1, . . . ,vn ∈ V heißen linear
abhangig, wenn es α1, . . . ,αn ∈ K gibt, so daß αi 6= 0 fur mindestens ein i, aber
α1v1 + · · ·+αnvn = 0
ist. Sonst heißen v1, . . . ,vn linear unabhangig. Mit anderen Worten: v1, . . . ,vn sind
linear unabhangig, wenn
α1v1 + · · ·+αnvn = 0 =⇒ α1 = · · ·= αn = 0
gilt.
Wir betonen ausdrucklich, dass wir nicht von der linearen Unabhangigkeit der
Menge {v1, . . . ,vn} sprechen. Zwar kommt es fur die lineare Unabhangigkeit von
v1, . . . ,vn nicht auf die Reihenfolge an, aber man sollte nicht von vornherein aus-
schliessen, dass unter den vi ein Element doppelt vorkommt; ferner spielt beim
spater definierten Begriff”Basis“ die Reihenfolge sehr wohl eine Rolle. Um die
spadere Betrachtung zu vereinfachen fıhren wir doch den Begriff von linear un-
abhangiger Teilmenge eines K-Vektorraumes V :

156 Abschnitt 18
Definition. Eine Teilmenge S eines K-Vektorraumes V heißt linear unabhanging,
wenn jede endliche Teilmenge von S aus linear unabhangingen Vektoren besteht.
Beispiele.
(a) Die leere Menge /0 ist linear unabhangig.
(b) Der Nullvektor ist linear abhangig, da 1 ·0 = 0 gilt.
(c) Jede Menge, die den Nullvektor enthalt, ist linear abhangig.
(d) Die Vektoren v1 =( −2
2
), v2 =
(1
−1
)des R2 sind linear abhangig, denn
v1 +2v2 = 0.
(e) Die Vektoren w1 =(
1
1
)und w2 =
(1
0
)sind linear unabhangig in R2,
denn aus der Gleichung
λ1
(1
1
)+λ2
(1
0
)=(
0
0
),
d.h., aus dem linearen Gleichungssystem mit Gleichungen λ1+λ2 = 0 und
λ1 +0λ2 = 0 folgt λ1 = λ2 = 0 als einzige Losung.
(f) Sei V ein K-Vektorraum. Sei v ∈ V , v 6= 0. Dann ist v linear unabhangig,
denn es gilt: Aus v = 0 folgt λ = 0.
(g) Die Vektoren e1, . . . ,en des Kn sind linear unabhangig.
Das vierte Beispiel besagt: Man kann v1 = −2v2 schreiben, d.h., man kann v1
als Linearkombination der ubrigen Vektoren (in diesem Beispiel ist v2 der einzige
ubrige Vektor) darstellen. Das charakterisiert die lineare Abhangigkeit:
Satz 18.1. Die Vektoren v1, . . . ,vn sind genau dann linear abhangig, wenn es min-
destens ein j mit j ∈ {1, . . . ,n} gibt, so dass v j als Linearkombination der ubrigen
Vektoren
v1, . . . ,v j−1,v j+1, . . . ,vn
dargestellt werden kann.
Beweis.”⇐=“ Seien v1, . . . ,vn linear abhangig. Dann gibt es λ1, . . . ,λn ∈ K mit
λ1v1 + . . .+λnvn = 0 und λ j 6= 0 fur mindestens ein j ∈ {1, . . . ,n}. Daraus folgt
v j =−λ1
λ j
v1 − . . .− λ j−1
λ j
v j−1 − j+1
λ j
v j+1 − . . .− n
λ j
vn.
”=⇒“ OBdA wird j = 1 angenommen. Dann folgt v1 = λ2v2+ . . .+λnvn, und
daher gilt
λ1v1 −λ2v2 − . . .−λnvn = 0 mit λ1 = 1 6= 0.
�
Definition. Sei V ein K-Vektorraum. Eine Familie B von Vektoren aus V heißt
Basis von V , falls

Basen und Dimension 157
(B1) Die Vektoren aus B bilden ein Erzeugendensystem von V .
(B2) Die Vektoren aus B sind linear unabhangig.
Anmerkung. Absichtlich haben wir das Wort”Menge” vermieden, und statt-
dessen das Wort”Familie” verwendet: Wir mochten z. B. die Familie (v1,v2)
aus (v2,v1) unterscheiden. Als Mengen waren diese dasselbe Objekt: {v1,v2} ={v2,v1}. Deswegen verwenden wir runde Klammer (. . .) in der Bezeichnung.
Beispiele.
(a) /0 ist eine Basis von {0}.
(b) Die Vektoren e1, . . . ,en bilden eine Basis des Kn. Sie heißt die Standardba-
sis oder die kanonische Basis von Kn.
(c) Die Vektoren b1 =(
1
1
)und b2 =
(1
0
)bilden eine Basis des R2. Wir
haben oben gesehen, dass diese linear unabhangig sind. Sie bilden ferner
ein Erzeugendensystem von R2: Sei dazu v=(
v1
v2
)∈R2. Es ist zu zeigen:
v lasst sich schreiben als Linearkombination von b1 und b2. D.h., es muss
gelten:
v =(
v1
v2
)= λ1
(1
1
)+λ2
(1
0
)=( λ1
λ1
)+( λ2
0
)=( λ1 +λ2
λ1
).
Es muss also v1 = λ1 + λ2 und v2 = λ1 gelten. Kann mann also dann λ1
und λ2 fur jedes vorgegebenes Paar v1,v2 finden? Das ist genau dann der
Fall, wenn das lineare Gleichungssystem
v1 = λ1 +λ2
v2 = λ1
mit Unbekannten λ1 und λ2 losbar ist. Das ist doch der Fall mit λ1 = v2
und λ2 = v1−v2. Man kann also jeden Vektor v =(
v1
v2
)∈R2 als Linear-
kombination von (1,1) und (1,0) darstellen, namlich
v =(
v1
v2
)= v2
(1
1
)+(v1− v2)
(1
0
)
und damit bilden die Vektoren b1 und b2 ein Erzeugendensystem des R2.
Anmerkung. Sprachliche Verwendungen sind heutzutage im Alltag nicht mehr
so gepflegt; fur die Mathematik sind sie aber sehr wichtig: Wir haben von einer
Basis eines Vektorraumes gesprochen, nicht von der Basis. Damit ist geaußert,
dass Basen von Vektorraumen nicht eindeutig bestimmt sind.

158 Abschnitt 18
Satz 18.2 (Eindeutigkeit der Basisdarstellung). Sei V ein endlich erzeugter K-
Vektorraum. Sei (v1, . . . ,vn) eine Basis von V . Jeder Vektor v ∈ V lasst sich ein-
deutig als Linearkombination
v = λ1v1 + . . .+λnvn mit λi ∈ K
schreiben.
Beweis. Da (v1, . . . ,vn) eine Basis ist, existieren λ1, . . . ,λn ∈ K so dass
v = λ1v1 + . . .+λnvn.
Sei v = µ1v1 + . . .+µnvn, µi ∈ K eine weitere Darstellung von v als Linearkombi-
nation von v1, . . . ,vn. Damnn ist
0 = v− v = (λ1 −µ1)v1 + . . .+(λn −µn)vn.
Da v1, . . . ,vn linear unabhangig sind, folgt λi − µi = 0 fur alle i, also λi = µi fur
alle i = 1, . . . ,n. �
Definition. Sei V ein K-Vektorraum. Sei B ⊂V eine Teilmenge.
(a) Man sagt, dass B ein minimales Erzeugendensystem ist, wenn die Vekto-
ren aus B ein Erzeugendensystem von V bilden, aber nicht die Vektoren
die in echten Teilmengen von B enthalten sind.
(b) Man sagt, dass B eine maximale linear unabhangige Familie ist, falls die
Vektoren aus B linear unabhangig sind, aber nicht mehr die Vektoren die
in echten Obermengen von B enthalten sind.
Eine Basis eines K-Vektorraumes kann man folgendermaßen charakterisieren:
Satz 18.3. V sei ein K-Vektorraum, v1, . . . ,vn ∈ V. Dann sind folgende Aussagen
aquivalent:
(a) v1, . . . ,vn ist eine Basis von V .
(b) v1, . . . ,vn ist ein minimales Erzeugendensystem von V .
(c) v1, . . . ,vn ist maximal linear unabhangig in V .
Beweis. Eine Basis besitzt die in (b) und (c) behaupteten Eigenschaften: Sie ist ein
Erzeugendensystem nach Definition und minimal, weil eine Gleichung
vi = λ1v1 + · · ·+λi−1vi−1 +λi+1vi+1 + · · ·+λnvn
gegen die lineare Unabhangigkeit verstoßen wurde. Sie ist linear unabhangig nach
Definition und maximal, weil es zu jedem w ∈V eine Darstellung
w = λ1v1 + · · ·+λnvn
gibt: v1, . . . ,vn,w sind linear abhangig. Ein minimales Erzeugendensystem ist line-
ar unabhangig nach Satz 18.1 und damit eine Basis.

Basen und Dimension 159
Sei nun v1, . . . ,vn maximal linear unabhangig. Fur jedes w ∈ V hat man daher
eine nichttriviale Darstellung
0 = λ1v1 + · · ·+λnvn +βw.
Ware β = 0, so ware v1, . . . ,vn linear abhangig. Also muss β 6= 0 sein, und wir
erhalten
w =
(−λ1
β
)v1 + · · ·+
(−λn
β
)vn ∈ L(v1, . . . ,vn).
Somit ist v1, . . . ,vn ein Erzeugendensystem von V und damit eine Basis. �
Wenn man neue Objekte in der Mathematik einfuhrt, sollte man sich Gedake
daruber machen, dass sie tatsachlich existieren. Unser Ziel nun ist zu begrunden,
dass jeder Vektorraum immer mindestens eine Basis besitzt. Eine Voruberlegung
zuerst:
Satz 18.4. Dei V ein K-Vektorraum. Seien M,S Teilmengen aus V mit M ⊂ S ⊂V
so dass M linear unabhangig ist und S ein Erzeugendensystem von V ist. Dann
existiert eine Basis B von V mit M ⊂ B ⊂ S.
Beweis. Nach Satz 18.3 reicht es uns, unter alle Familien von Vektoren T , die
in V enthalten sind mit M ⊂ T ⊂ S, nach einer maximal linear unabhangigen zu
suchen. Ist S endlich, so gibt es sicherlich eine Basis B von V mit M ⊂B ⊂V . Ist
S unendlich, brauchen wir das Lemma von Zorn. Auf eine ausfuhrliche Erklarung
werden wir in dieser Vorlesung verzichten. �
Wahlen wir M = /0 und S =V in Satz, so erhalten wir:
Satz 18.5. Jeder Vektorraum besitzt eine Basis.
Aus besonderen Teilmengen ist es leicht, eine Basis zu bilden:
Satz 18.6 (Basiserganzungssatz). Sei V ein K-Vektorraum. Seien M eine linear
unabhangige Teilmenge von V und E ein Erzeugendensystem von V . Dann lasst
sich M durch Elemente aus E zu einer Basis von V erganzen.
Beweis. Man wendet Satz 18.4 auf M und S = M∪E an. �
Beispiel. Wir wollen eine Basis fur U = L(v1,v2,v3)⊂ R3 mit
v1 =
1
0
1
,v2 =
2
1
0
,v3 =
1
−1
3
finden, und diese zu einer Basis des R3 erganzen. Man uberpruft hierzu leicht,
dass v1,v2,v3 sind linear abhangig, aber v1 und v2 sind linear unabhangig, daher
bilden sie eine Basis von U . Um (v1,v2) zu einer Basis des R3 erganzen zu konnen,
suchen wir nach einem Vektor w ∈R3 in bekannten Erzeugendensystemen des R3,

160 Abschnitt 18
zum Beispiel (!) e1,e2,e3. Man pruft leicht nach, dass mit der Wahl w = e3 ist
(v1,v2,w = e3) eine Basis des R3.
Im Folgenden werden wir uns auf endlich erzeugte Vektorraume einschranken.
Konnen wir die Wahl von w im obigen Beispiel systematisieren? Die Wahl w =e3 war deshalb einfach, weil wir unter drei Vektoren suchen mussten. Was wenn
wir in R100 suchen hatten mussen? Wir versuchen diese Fragestelleung im endlich
erzeugten Fall zu klaren.
Sei V ein endlich erzeugter K-Vektorraum. Nach Satz 18.5 hat er eine Basis
B =(v1, . . . ,vn). Wie finden wir eine? Sei S⊂V ein Erzeugendensystem. Sei v∈ S,
v 6= 0. Wir fugen solange Vektoren aus S zu B hinzu, bis die Aufnahme eines jeden
weiteren Vektors aus S zu linearer Abhangigkeit fuhrt.
Es ist auch klar: Die Basis B hangt von der Wahl der Vektoren ab. Trotzdem
bleibt etwas fur alle Bases eines selben Vektorraumes erhalten: Die Anzahl ihrer
Elemente. Dies mochten nun begrunden.
Satz 18.7 (Austauschsatz von Steinitz). Sei V ein K-Vektorraum mit Basis (v1, . . . ,vn).Ist v ∈V, v 6= 0, dann existiert ein j ∈ {1, . . . ,n} so dass auch die Vektoren
(v1, . . . ,v j−1,v,v j+1, . . . ,vn)
eine Basis von V bilden. Dabei kann man als j jeden Index wahlen, fur den λ j 6= 0
ist in der Basisdarstellung v = λ1v1 + . . .+λnvn mit λ1, . . . ,λn ∈ K.
Beweis. Wir schreiben v als Linearkombination von v1, . . . ,vn, also
v = λ1v1 + . . .+λnvn fur λi ∈ K.
Da v 6= 0 ist, existiert ein Index j mit λ j 6= 0. OBdA durfen wir j = 1 annehmen
(sonst vertauschen wir v1 und v j). Zu zeigen ist, dass die Vektoren v,v2, . . . ,vn eine
Basis von V bilden. Zunachst zeigen wir, dass v1,v2, . . . ,vn linear unabhangig sind.
Sei dafur eine nichttriviale Darstellung
µ1v+µ2v2 + . . .+µnvn = 0 mit µi ∈ K.
Setzen wir die obige Darstellung des Vektors v ein, so erhalten wir
µ1(λ1v1 + . . .+λnvn)+µ2v2 + . . .+µnvn = 0,
also
µ1λ1v1 +(µ1λ2 +µ2)v2 + . . .+(µ1λn +µn)vn = 0
Da v1, . . . ,vn linear unabhangig sind, ergibt sich erstens
µ1λ1 = 0
und daraus µ1 = 0, da λ1 vorausgesetzt ist; und zweitens gilt auch
µ1λi +µi = 0 fur alle i = 2, . . . ,n,
also µi = 0 fur alle i = 2, . . . ,n, wie gewunscht.

Basen und Dimension 161
Es ist nur noch zu zeigen, dass v,v1, . . . ,vn ein Erzeugendensystem von V bil-
den. Da
v = λ1v1 + . . .+λnvn mit λ1 6= 0
gilt, folgt
v1 =1
λ1(v−λ2v2 − . . .−λnvn).
Ist w ∈V beliebig, so lasst sich w schreiben als Linearkombination von v1, . . . ,vn,
w = µ1v1 + . . .+µnvn fur µi ∈ K,
da die Vektoren v1, . . . ,vn eine Basis von V bilden. Setzten wir die Darstellung von
v1 herein, so sind wir fertig, denn wir erhalten
w =µ1
λ1
v+
(µ2 −
µ1λ2
λ1
)v2 + . . .+
(µn −
µ1λn
λ1
)vn,
also eine Linearekombination von v,v2, . . . ,vn. �
Als Folgerung ergibt sich:
Satz 18.8. Besitzt V eine Basis, die aus n Vektoren besteht, dann sind je m Vektoren
aus V mit m > n linear abhangig. Insbesondere gilt: In einem endlich erzeugten
K-Vektorraum haben je zwei Basen dieselbe Anzahl von Elementen.
Beweis. Sei B = (v1, . . . ,vn) eine Basis von V . Durch Widerspruch wollen wir
die erste Behauptung zeigen. Dafur nehmen wir an, wir hatten w1, . . . ,wm ∈V mit
m > n linear unabhangig. Nach dem Austauschsatz 18.7 erhalten wir eine neue
Basis
(v1, . . . ,v j−1,w1,v j+1, . . . ,vn).
Dann kann man w2 schreiben als
w2 = λ1v1 + . . .+λ j−1v j−1 +µ1w1 +λ j+1v j+1 + . . .+λnvn
mit allen λi,µ j ∈K. Dabei existiert ein Index k mit λk 6= 0 (sonst ware w2−µ1w1 =0, also Widerspruch zur Annahme, dass w1 und w2 linear unabhangig sind).
Nach dem Austauschsatz erhalten wir eine neue Basis, die aus w1, w2 und der
ubrigen n− 2 Vektoren aus der alten Basis besteht mit v = w2 und j = k (in der
Bezeichnung der Austauschsatz 18.7).
Rekursiv finden wir eine Basis B′ = (w1, . . . ,wn) von V in der alle n Vektoren
der Basis B ausgetauscht sind gegen Elemente von
(w1, . . . ,wn, . . . ,wm).
Wegen m> n kann man wm als Linearkombination der Elemente von B′ darstellen,
also Widerspruch! Die zweite Behauptung folgt unmittelbar aus der ersten. �

162 Abschnitt 18
Definition. Sei V ein endlich erzeugter K-Vektorraum. Dann heißt die Anzahl der
Elemente einer Basis von V die Dimension von V . Wir schreiben dimK V . Wir
nennen V einen endlichdimensionalen Vektorraum. Oft wird es mit dimK V < ∞bezeichnet.
Ist V nicht endlich erzeugt, dann schreiben wir dimK V = ∞ und sagen wir, dass
V unendlichdimensional ist.
Beispiele.
(a) dimK Kn = n: klar, denn e1, . . . ,en ist eine Basis.
(b) dimK{0}= 0: klar, denn /0 ist eine Basis.
(c) Der Erweiterungskorper C von R hat als R-Vektorraum die Dimension 2,
denn (1, i) ist eine Basis von C uber R. Also dimRC = 2. Dagegen ist
dimCC= 1. Jeden C-Vektorraum V konnen wir auch als R-Vektorraum be-
trachten. Ist v1, . . . ,vn eine Basis von V uber C, so ist v1, iv1, . . . ,vn, ivn of-
fensichtlich eine Basis von V uber R . (Der Leser moge dies genau prufen.)
Daher gilt dimRV = 2dimCV .
(d) Als Q-Vektorraum besitzt R unendliche Dimension.
Folgerungen: Sei V ein n-dimensionaler K-Vektorraum:
(1) Weniger als n Vektoren konnen kein Erzeugendensystem bilden (nach
18.3).
(2) Mehr als n Vektoren sind linear abhangig (nach 18.8).
(3) Jedes Erzeugendensystem mit n Vektoren ist linear unabhangig und damit
eine Basis (nach (1) und 18.1).
(4) Jede linear unabhangige Familie mit n Vektoren ist auch ein Erzeugenden-
system und damit eine Basis (nach 18.6 und 18.8).
Beispiel. Wir wissen: dimRR3 = 3. Somit: Haben wir im R3 drei linear un-
abhangige Vektoren gefunden, so wissen wir, dass diese eine Basis bilden. Der
Axiom (B1) mussen wir dann nichr mehr nachweisen. beispiel
Satz 18.9 (Dimension eines Vektorraumes). V sei ein endlichdimensionaler K-
Vektorraum und U ein Untervektorraum von V. Dann ist auch U endlichdimensio-
nal. Es gilt dimU ≤ dimV. Genau dann ist dimU = dimV, wenn U =V.
Beweis. Sei
m = max{p : es existieren linear unabhangige u1, . . . ,up ∈U}.Da p ≤ dimV , wenn u1, . . . ,up ∈ U ⊂ V linear unabhangig, ist m eine wohldefi-
nierte naturliche Zahl ≤ dimV . Seien nun w1, . . . ,wm ∈U linear unabhangig. Dann
sind w1, . . . ,wm maximal linear unabhangig in U und somit nach Satz 18.3 eine
Basis von U . Es folgt m = dimU .

Basen und Dimension 163
Dass m ≤ dimV , haben wir bereits festgestellt, und dass U = V aus dimU =dimV folgt, ist Teil von Satz 18.8: Im Falle m = dimV gilt (4) aus den obigen
Folgerungen. �
Haufig wendet man Satz 18.9 in folgender Situation an: U1, U2 sind Untervek-
torraume eines endlichdimensionalen K-Vektorraums V . Man weiß, dass U1 ⊂ U2
und dimU1 = dimU2. Dann folgt U1 =U2, indem man Satz 18.9 zuerst mit U =U2
anwendet (U2 ist endlichdimensional) und dann mit V =U2, U =U1.
Satz 18.9 bringt unsere geometrische Vorstellung zum Ausdruck, dass die”Un-
terraume“ eines”Raums“ nach ihrer Dimension gestuft sind: Punkte, Geraden,
Ebenen, . . . , der gesamte Raum.
Zum Abschluss dieses Abschnitts beweisen wir noch eine wichtige Dimensi-
onsformel:
Satz 18.10 (Dimensionsformel). Seien U1, U2 Untervektorraume eines endlichdi-
mensionalen K-Vektorraums V . Dann ist
dim(U1 +U2) = dimU1 +dimU2 −dim(U1 ∩U2).
Beweis. Sei (u1, . . . ,up) eine Basis von U1∩U2. Wir erganzen sie gemaß Satz 18.6
zum einen durch v1, . . . ,vm zu einer Basis (u1, . . . ,up, v1, . . . ,vm) von U1, zum an-
deren durch w1, . . . ,wn zu einer Basis (u1, . . . ,up, w1, . . . ,wn) von U2.
Die Behauptung folgt, wenn wir gezeigt haben, dass
(u1, . . . ,up, v1, . . . ,vm, w1, . . . ,wn)
eine Basis von U1 +U2 ist.
Sei W = L(u1, . . . ,up,v1, . . . ,vm,w1, . . . ,wn). Dann gilt U1 ⊂W , U2 ⊂W , mithin
U1 +U2 ⊂ W . Umgekehrt gilt ui, v j, wk ∈ U1 +U2 fur alle i, j, k, und damit ist
W ⊂U1+U2, so dass insgesamt W =U1+U2 folgt. Diese Gleichung besagt gerade,
dass u1, . . . ,up, v1, . . . ,vm, w1, . . . ,wn ein Erzeugendensystem von U1 +U2 ist.
Sei nun
λ1u1 + · · ·+λpup +µ1v1 + · · ·+µmvm + γ1w1 + · · ·+ γnwn = 0.
Dann gilt fur z = µ1v1 + · · ·+µmvm ∈U1:
z = µ1v1 + · · ·+µmvm =−(λ1u1 + · · ·+λpup)− (γ1w1 + · · ·+ γnwn),
also z ∈ U1 ∩U2. Somit existieren λ ′1, . . . ,λ
′p mit z = λ ′
1u1 + · · ·+ λ ′pup, und wir
erhalten
0 = z− z = λ ′1u1 + · · ·+λ ′
pup −µ1v1 −·· ·−µmvm.
Da u1, . . . ,up, v1, . . . ,vm linear unabhangig sind, folgt λ ′1 = · · ·= λ ′
p = µ1 = · · · =µm = 0, speziell z = 0, und dann λ1 = · · · = λp = γ1 = · · · = γn = 0, weil auch
u1, . . . ,up, w1, . . . ,wn linear unabhangig sind. �


ABSCHNITT 19
Lineare Abbildungen
Zu den wesentlichen Bausteinen vieler mathematischer Theorien gehoren eine
Klasse von Objekten – im Fall der linearen Algebra sind dies die Vektorraume –
und eine Klasse von Abbildungen, die die den Objekten innewohnenden Strukturen
respektieren. In der Algebra werden solche Abbildungen in der Regel Homomor-
phismen genannt.
Definition. Sei K ein Korper, und seien V , W K-Vektorraume. Eine Abbildung ϕ:
V →W heißt K-linear (oder ein Homomorphismus von K-Vektorraumen, oder kurz
linear), wenn gilt:
(L1) ϕ(u+ v) = ϕ(u)+ϕ(v) fur alle u,v ∈V,
(L2) ϕ(λu) = λϕ(u) fur alle u ∈V,λ ∈ K.
D ie folgenden zwei Eigenschaften lassen sich leicht uberprufen:
(i) ϕ(0) = 0, denn: ϕ(0) = ϕ(0 ·0) = 0 ·ϕ(0) = 0.
(ii) ϕ(−v) = −ϕ(v) fur alle v ∈ V , denn: ϕ(−v) = ϕ(−1 · v) = −1 ·ϕ(v) =−ϕ(v).
Beispiele.
(a) Die Indentitat idV ist K-linear.
(b) Die Nullabbildung ϕ: V →{0}, ϕ(v) = 0 fur alle v ∈V ist K-linear
(c) Durch Induktion zeigt man leicht, dass fur eine lineare Abbildung ϕ: V →W , Vektoren v1, . . . ,vn ∈V und Koeffizienten λ1, . . . ,λn ∈ K gilt
ϕ(λ1v1 + · · ·+λnvn) = λ1ϕ(v1)+ · · ·+λnϕ(vn).
(d) Die Abbildung ϕ :R2 →R gegeben durch(
x
y
)7→ x+y ist R-linear, denn
es gilt:
(L1) ϕ((
x
y
)+(
x′
y′)) = ϕ(
(x+ x′
y+ y′)) = x+ x′+ y+ y′ =
x+ y+ x′+ y′ = ϕ((
x
y
))+ϕ(
(x′
y′))
(L2) ϕ(λ(
x
y
)) = ϕ(
( λx
λy
)) = λx + λy = λ (x + y) = λϕ(
(x
y
)) fur
λ ∈ R.

166 Abschnitt 19
(e) Die Abbildung ϕ : R2 → R gegeben durch(
x
y
)7→ x+ y+2 ist nicht R-
linear, denn ϕ((
0
0
)) = 2 6= 0.
(f) Die Abbildung ϕ : C→C gegeben durch z 7→ z (mit z= a−bi der komple-
xen Konjugierten von z = a+bi) ist R-linear, da zu z = a+bi,z′ = a′+b′igilt:
(L1) ϕ(z+ z′) = (a+a′)− (b+b′)i = ϕ(z)+ϕ(z′)(L2) ϕ(λ z) = ϕ(λa+λbi) = λx−λbi = λϕ(z) fur λ ∈ R.
(g) Die Abbildung ϕ : C→ C gegeben durch z 7→ z ist nicht C-linear, denn es
gilt:
ϕ(i · i) = ϕ(i2) = ϕ(−1) =−1 6= 1 =−(−1) =−i2 = i · (−i) = i ·ϕ(i).Lineare Abbildungen sind nach der Auswahl einer Basis folgendermaßen be-
stimmt:
Satz 19.1. Seien V,W zwei K-Vektorraume. Sei (v1, . . . ,vn) eine Basis von V . Dann
gibt es zu beliebig vorgegebenen Vektoren w1, . . . ,wn ∈ W genau eine K-lineare
Abbildung ϕ : V →W mit ϕ(vi) = wi fur i = 1, . . . ,n.
Beweis. Da (v1, . . . ,vn) eine Basis von V ist, gibt es zu jedem v ∈ V eindeutig
bestimmte λ1, . . . ,λn ∈ K so dass
v = λ1v1 + . . .+λnvn.
Zu zeigen ist die Existenz und Eindeutigkeit der o.g. K-linearen Abbildung. Setzen
wir ϕ(v) = λ1w1+ . . .+λnwn, so erhalten wir eine K-lineare Abbildung ϕ : V →W
mit ϕ(vi) = wi fur i = 1, . . . ,n. Die Eindeutigkeit ist nun fast geschenkt: Ist ϕ eine
solche K-lineare Abbildung, so folgt
ϕ(v) = ϕ(λ1v1 + . . .+λnvn) = λ1ϕ(v1)+ . . .+λnϕ(vn) = λ1w1 + . . .+λnwn.
�
Beispiel. Sei (b1,b2) eine Basis des R2 mit b1 =(
1
1
)und b2 =
(1
0
). Seien
c1 =
3
5
0
und c2 =
0
0
2
zwei Vektoren aus R3. Wegen Satz 19.1 ist die
Abbildung ϕ : R2 → R3 gegeben durch ϕ(b1) = c1 und ϕ(b2) = c2 R-linear und
eindeutig bestimmt. Daruber hinaus wurden wir auch gerne eine Vorschrift fur
ϕ((
x1
x2
)), fur beliebiges
(x1
x2
)∈ R2, angeben konnen. Dafur beobachten wir
e1 =(
1
0
)= b2 und e2 =
(0
1
)= b1 −b2.

Lineare Abbildungen 167
Dann gilt ϕ(e1) = ϕ(b2) = c2 und
ϕ(e2) = ϕ(b1 −b2) = ϕ(b1)−ϕ(b2) =
3
5
0
−
0
0
2
=
3
5
−2
.
Somit erhalten wir die gewunschte Vorschrift:
ϕ((
x1
x2
)) = x1ϕ(e1)+ x2ϕ(e2) = x1 ·
0
0
2
+ x2 ·
3
5
−2
=
−3x2
5x2
2x1 −2x2
.
Lineare Abbildungen respektieren Untervektorraume:
Satz 19.2. Sei ϕ: V →W eine lineare Abbildung. Dann ist fur jeden Untervektor-
raum U von V die Bildmenge ϕ(U) ein Untervektorraum von W. Umgekehrt ist fur
jeden Untervektorraum N von W die Urbildmenge ϕ−1(N) ein Untervektorraum
von V.
Beweis. Man rechnet dies direkt mittels der Definition des Begriffes”Untervektor-
raum“ nach. �
Von besonderem Interesse bei einer linearen Abbildung ϕ: V → W sind die
Untervektorraume
Kernϕ = ϕ−1(0) = {v ∈V : ϕ(v) = 0} von V und
Bildϕ = ϕ(V ) = {w ∈W : ∃v ∈V mit ϕ(v) = w} von W.
Satz 19.3. Seien V,W zwei K-Vektorraume, sei ϕ : V → W eine K-lineare Abbil-
dung. Dann sind Kern bzw. Bild tatsachlich Untervektorraume von V bzw. W.
Beweis. Der Kern von ϕ ist ein Untervektorraum von V , denn es gilt:
(i) 0 ∈ Kern(ϕ), denn ϕ(0) = 0.
(ii) Seien u,v ∈ Kern(ϕ). Dann ist 0 = 0+ 0 = ϕ(u)+ϕ(v) = ϕ(u+ v), und
damit u+ v ∈ Kern(ϕ).(iii) Seien λ ∈ K,v ∈ Kern(ϕ). Dann ist
ϕ(λv) = λϕ(v) = λ0 = 0,
und so ist λv ∈ Kern(ϕ).
Analog ist Bild(ϕ) ein Untervektorraum von W :
(i) 0 ∈ Bild(ϕ), da fur 0 ∈W ist ϕ(0) = 0.
(ii) Seien u,v∈Bild(ϕ). Dann existieren u′,v′ ∈V mit ϕ(u′) = u und ϕ(v′)= v.
Somit ist u+ v = ϕ(u′+ v′) und so u+ v ∈ Bild(ϕ).(iii) Seien λ ∈ K, v ∈ Bild(ϕ). Dann existiert v′ ∈ V mit ϕ(v′) = v, und so
λv = λϕ(v′) = ϕ(λv′), also λv ∈ Bild(ϕ).
�

168 Abschnitt 19
Beispiele.
(i) Sei o : V → {0} die Nullabbildung. Dann ist Kern(o) = V und Bild(o) ={0}.
(ii) Sei ϕ : R2 → R gegeben durch(
x
y
)7→ x+ y. Es ist
Kern(ϕ) ={(
x
y
)∈ R2 : x+ y = 0
},
also die Gerade des R2 mit der Gleichung x+ y = 0, und
Bild(ϕ) ={
t ∈ R : ∃(
x
y
)∈ R2 mit x+ y = t
}= R.
Nach Definition ist ϕ genau dann surjektiv, wenn Bildϕ =W gilt. Die Injekti-
vitat konnen wir mittels des Kerns testen. Das fassen wir nun zusammen:
Satz 19.4. Seien V,W zwei K-Vektorraume, sei ϕ : V → W eine K-lineare Abbil-
dung. Dann gilt:
(i) ϕ ist injektiv genau dann, wenn Kern(ϕ) = {0}.
(ii) ϕ ist surjektiv genau dann, wenn Bild(ϕ) =W.
Beweis. Die zweite Aussage ist offensichtlich. Wir zeigen also nur die erste. Sei
ϕ injektiv. Zu zeigen ist zunachst, dass Kern(ϕ) = {0} ist. Die Inklusion {0} ⊂Kern(ϕ) gilt immer, da der Kern ein Untervektorraum ist. Es ist also zu zeigen,
Kern(ϕ)⊂ {0}. Sei dazu v ∈ Kern(ϕ). Dann ist ϕ(v) = 0 = ϕ(0), und wegen der
Injektivitat von ϕ folgt, dass v = 0 sein muss.
Seien umgekehrt v,v′ ∈ V mit ϕ(v) = ϕ(v′). Zu zeigen ist v = v′. Aus ϕ(v) =ϕ(v′) und der Linearitat von ϕ folgt 0 = ϕ(v)−ϕ(v′) = ϕ(v− v′). D.h., v− v′ ∈Kern(ϕ) = {0}, und damit v− v′ = 0, also v = v′, wie gewunscht. �
Die Dimensionen vom Kern und Bild addieren die Dimension des gesamten
Raums auf:
Satz 19.5. Sei V ein endlichdimensionaler K-Vektorraum und W ein beliebiger
K-Vektorraum, ϕ: V →W eine lineare Abbildung. Dann gilt
dimKernϕ +dimBildϕ = dimV.
Beweis. Wir wahlen eine Basis (u1, . . . ,um) von Kernϕ , eine Basis (w1, . . . ,wr)von Bildϕ , sowie Elemente v1, . . . ,vr ∈V mit ϕ(vi) =wi. Es genugt zu zeigen, dass
(u1, . . . ,um,v1, . . . ,vr) eine Basis von V ist. Sei v ∈V . Dann existieren µ1, . . . ,µr ∈K mit
ϕ(v) = µ1w1 + · · ·+µrwr.

Lineare Abbildungen 169
Es folgt
ϕ(v− (µ1v1 + · · ·+µrvr)) = ϕ(v)−ϕ(µ1v1 + · · ·+µrvr)
= (µ1w1 + · · ·+µrwr)− (µ1w1 + · · ·+µrwr)
= 0.
Also existieren λ1, . . . ,λm ∈ K mit
v− (µ1v1 + · · ·+µrvr) = λ1u1 + · · ·+λmum,
so dass
v = λ1u1 + · · ·+λmum +µ1v1 + · · ·+µrvr.
Damit ist (u1, . . . ,um,v1, . . . ,vr) ein Erzeugendensystem von V . Fur die lineare Un-
abhangigkeit wenden wir ϕ auf eine Gleichung
λ1u1 + · · ·+λmum +µ1v1 + · · ·+µrvr = 0
an und erhalten
µ1ϕ(v1)+ · · ·+µrϕ(vr) = 0.
Da w1, . . . ,wr linear unabhangig sind, folgt µ1 = · · · = µr = 0 und sodann λ1 =· · ·= λm = 0 wegen der linearen Unabhangigkeit von u1, . . . ,um. �
Man nennt dimBildϕ auch den Rang von ϕ und schreibt
rangϕ = dimBildϕ.
Wir fuhren noch ein Paar Termini technici ein:
Definition. Eine K-lineare Abbildung heißt
(a) Monomorphismus, falls sie injektiv ist.
(b) Epimorphismus, falls sie surjektiv ist.
(c) Isomorphismus, falls sie bijektiv ist.
Lineare Selbstabbildungen ϕ: V →V nennt man Endomorphismen von V . Bijekti-
ve Endomorphismen nennt man Automorphismen.
Die Charakterisierung von Injektivitat und Surjektivitat nach Satz 19.4, zusam-
men mit der Dimensionsformel 19.5 ergibt:
Satz 19.6. Seien V,W zwei endlichdimensionale K-Vektorraume so dass dimK V =dimK W. Dann sind fur jede K-lineare Abbildung ϕ : V →W aquivalent:
(1) ϕ ist ein Monomorphismus,
(2) ϕ ist ein Epimorphismus,
(3) ϕ ist ein Isomorphismus.
Beweis.”(1) =⇒ (2)“ Aus der Injektivitat von ϕ folgt Kern(ϕ) = {0} wegen
19.4. Aus der Dimensionsformel 19.5 und der Voraussetzung ergibt sich
dimK Bild(ϕ) = dimK V = dimK W.

170 Abschnitt 19
Aus Satz 18.9 folgt nun Bild(ϕ) =W , d.h., ϕ ist surjektiv.
”(2) =⇒ (1)“ Aus der Surjektivitat von ϕ und der Voraussetzung folgt
dimK Bild(ϕ) = dimK W = dimK V.
Nach Satz 19.5 ist dann dimK Kern(ϕ) = 0, und daher ist ϕ injektiv nach 19.4.
”(3) =⇒ (1)“ ist klar nach dem Obigen und der Definition der Bijektivitat. �
Satz 19.7. Seien U, V , W K-Vektorraume, ϕ: U → V, ψ: V → W lineare Abbil-
dungen.
(a) Dann ist auch ψ ◦ϕ : U →W linear.
(b) Wenn ϕ und ψ Isomorphismen sind, sind auch ψ ◦ϕ , ϕ−1 und ψ−1 Iso-
morphismen.
Beweis. (a) Man rechnet dies einfach aus: Fur u,v ∈U , α ∈ K ergibt sich
(ψ ◦ϕ)(u+ v) = ψ(ϕ(u+ v)) = ψ(ϕ(u)+ϕ(v)) = ψ(ϕ(u))+ψ(ϕ(v))
= (ψ ◦ϕ)(u)+(ψ ◦ϕ)(v),
ebenso
(ψ ◦ϕ)(λv) = ψ(ϕ(λv)) = ψ(λϕ(v)) = λψ(ϕ(u)) = λ (ψ ◦ϕ)(v).
(b) Die Bijektivitat von ψ ◦ϕ , ϕ−1 und ϕ−1 ist klar. Damit ist ψ ◦ϕ nach (a)
ein Isomorphismus. Die Linearitat von ϕ−1 sieht man so: Fur v, v′ ∈V ist
ϕ(ϕ−1(v+ v′)
)= v+ v′ = ϕ(ϕ−1(v))+ϕ(ϕ−1(v′))
= ϕ(ϕ−1(v)+ϕ−1(v′)
).
Anwendung von ϕ−1 auf diese Gleichung liefert ϕ−1(v+ v′) = ϕ−1(v)+ϕ−1(v′).Ebenso ergibt sich ϕ−1(λv) = λϕ−1(v) fur λ ∈ K. �
Definition. V , W seien K-Vektorraume. Eine bijektive lineare Abbildung ϕ heißt
Isomorphismus (von K-Vektorraumen). Wenn es einen Isomorphismus ϕ: V →W
gibt, nennt man V und W isomorph. Wir schreiben V ∼=W .
Das Wort”isomorph“ bedeutet
”von gleicher Gestalt“ und dies vermittelt sehr
genau die mathematische Bedeutung dieses Begriffs: Isomorphe Vektorraume be-
sitzten die gleiche Struktur. Jede Aussage der linearen Algebra, die fur V gilt, gilt
auch fur jeden zu V isomorphen Vektorraum W und umgekehrt: man”transportiert“
sie mittels eines Isomorphismus ϕ von V nach W , ebenso wie ϕ−1, das sich auch
als Isomorphismus erweist, die”lineare Struktur“ von W nach V ubertragt. Isomor-
phe Objekte einer algebraischen Theorie sind innerhalb dieser Theorie gleichwer-
tig. Sie konnen sich gegenseitig ersetzen, und haufig braucht man zwischen ihnen
nicht zu unterscheiden.
Beispiel. R2 und C sind isomorph als R-Vektorraume.

Lineare Abbildungen 171
Wir beweisen nun, dass jeder n-dimensionale K-Vektorraum zu Kn isomorph
ist. Damit zeigen wir: Fur die Lineare Algebra haben alle Vektorraume der Di-
mension n die gleiche Struktur. Insofern spricht man uber eine Klassifikation fur
endlichdimensionale Vektorraume.
Satz 19.8. Seien V,W endlich dimensionalen K-Vektorraume. Dann gilt:
dimK V = dimK W ⇐⇒V ∼=W.
Insbesondere ist jeder K-Vektorraum der Dimension n zu Kn isomorph.
Beweis. Sei B = (v1, . . . ,vn) eine Basis von V .
”=⇒ “ Sei C = (w1, . . . ,wn) eine Basis von W . Nach 19.1 gibt es genau eine
K-lineare Abbildung f : V → W mit f (vi) = wi fur alle i = 1, . . . ,n. Da C ein
Erzeugendensystem von W ist, gibt es zu jedem w ∈ W Skalare λ1, . . . ,λn ∈ K so
dass
w = λ1w1 + . . .+λnwn
gilt. Daraus folgt w = f (v) mit v = λ1v1+ . . .+λnvn ∈V ; daher ist f surjektiv. Die
Abbildung f ist auch injektiv: Ist w = 0, so folgt λ1 = . . . = λn = 0, also v = 0,
da die Vektoren aus C linear unabhangig sind. Damit ist f injektiv nach 19.4.
Insgesamt erhalt man V ∼=W .
”⇐=“ Sei f : V → W ein Isomorphismus. Ist w ∈ W , so existiert v ∈ V mit
w = f (v) wegen der Surjektivitat von f . Es gilt
v = λ1v1 + . . .+λnvn mit λ1, . . . ,λn ∈ K,
da B ein Erzeugendensystem von V ist. Daraus folgt
w = f (v) = λ1 f (v1)+ . . .+λn f (vn)
und B′ = ( f (v1), . . . , f (vn)) ist also ein Erzeugendensystem von W . Ist ferner
f (v) = 0, so ist v = 0 wegen der Injektivitat von f . Da v1, . . . ,vn linear unabhangig
sind, mussen f (v1), . . . , f (vn) auch linear unabhangig sein. Daraus folgt dann die
Behauptung dimK W = n = dimK V . �
Im nachsten Abschnitt betrachten wir eine nutzliche Darstellung einer linearen
Abbildung: Eine Matrix.


ABSCHNITT 20
Matrizenrechnung (I): Der Rang einer linearen Abbildung
Sei V ein endlich dimensionaler K-Vektorraum. Sei (v1, . . . ,vn) eine Basis von
V . Wir wissen schon: Zu jedem Vektor v ∈ V existieren Skalare λ1, . . . ,λn ∈ K so
dass v sich eindeutig als Linearkombination
v = λ1v1 + . . .+λnvn
von v1, . . . ,vn darstellen lasst. Der Vektor
λ1...
λn
∈ Kn
nennen wir den Koordinatenvektor zu V bezuglich der Basis (v1, . . . ,vn).Sei nun (e1,e2) die Standardbasis des R2. Sei ϕ : R2 → R2 ein Endomorphis-
mus des R2. Dann ist ϕ durch Angabe von ϕ(e1) und ϕ(e2) nach Satz 19.1 ein-
deutig bestimmt. Es ist
ϕ(e1) = a11e1 +a21e2
ϕ(e2) = a12e1 +a22e2
fur ai j ∈ R, i, j = 1,2. Die Koordinatenvektoren(
a11
a21
)bzw.
(a21
a22
)zu ϕ(e1)
bzw. ϕ(e2) konnen wir durch ein rechteckiges Schema
(a11 a12
a21 a22
)
beschreiben. Das nennen wir eine 2×2-Matrix. Im Allgemeinen:
Definition. Sei K ein Korper. Eine m×n-Matrix uber K (oder mit Eintragen in K)
ist eine Anordnung von m×n Elementen aus K nach folgendem Schema:
A = (ai j)1≤i≤m1≤ j≤n
= (ai j) =
a11 · · · a1n...
...
am1 · · · amn

174 Abschnitt 20
Wir nennen die waagerecht geschriebene n-Tupel (ai1, . . . ,ain) die i-te Zeile
und die senkrecht geschriebene m-Tupel
a1 j...
am j
die j-te Spalte der Matrix. Ei-
ne n×n-Matrix heißt quadratisch. Eine quadratische Matrix heißt diagonal, wenn
ai j = 0 fur alle i 6= j. Die Menge aller m×n-Matrizen uber K bezeichnen wir mit
Mm×n(K).
Wie man m×n-Matrizen addiert und mit Skalaren multipliziert, ist offensicht-
lich. Versehen mit diesem Verknupfungen besitzt Mm×n(K) die Struktur von K-
Vektorraum.
So wie im Obigen kann man im Allgemeinen einer linearen Abbildung eine
Matrix zuordnen: Sei ϕ : V →W eine lineare Abbildung endlichdimensionaler K-
Vektorraume mit Basen B = (v1, . . . ,vn) bzw. C = (w1, . . . ,wm). Nach 19.1 ist ϕdurch ϕ(v1), . . . ,ϕ(vn) eindeutig bestimmt. Die Elemente ϕ(v1), . . . ,ϕ(vn) wieder-
um sind durch ihre Koordinatenvektoren
a1 j...
am j
, j = 1, . . . ,n
eindeutig bestimmt. Wir schreiben diese Koordinatenvektoren als Spalten einer
m×n-Matrix
MCB = MC
B(ϕ) =
a11 · · · a1n
......
am1 · · · amn
(Merke: Die Spalten sind die Koordinatenvektoren der Bildvektoren.) Diese Matrix
MCB(ϕ) bestimmt ϕ vollstandig, nachdem die Basen B = (v1, . . . ,vn) von V und
C = (w1, . . . ,wm) von W gewahlt worden sind.
Definition. Die Matrix MCB(ϕ) heißt Matrix von ϕ bezuglich der Basen B von V
und C von W .
Wir haben gerade einer linearen Abbildung eine Matrix zugeordnet. Diesen
Vorgang konnen wir auch umkehren: Wir ordnen einer Matrix
A =
α11 · · · α1n
......
αm1 · · · αmn
diejenige lineare Abbildung ϕA: V → W zu, fur die die Koordinatenvektoren von
ϕ(v1), . . . ,ϕ(vn) bezuglich (w1, . . . ,wm) gerade die Spalten von A sind. Insgesamt
erhalten wir somit eine bijektive Abbildung von der Menge der linearen Abbildun-
gen von V nach W auf die Menge der m×n Matrizen uber K.

Matrizenrechnung (I): Der Rang einer linearen Abbildung 175
Da die Menge Hom(V,W) aller K-linearen Abbildungen von V nach W auch
die Struktur von K-Vektorraum besitzt, erhalten wir:
Satz 20.1. Sei K ein Korper, V und W seien K-Vektorraume der Dimensionen n
bzw. m. Seien Basen B(v1, . . . ,vn) von V und C = (w1, . . . ,wm) von W gewahlt.
Dann ist die Abbildung
MCB
: Hom(V,W) −→ Mm,n(K)ϕ 7→ MC
B(ϕ),
die jeder linearen Abbildung ihre Matrix bezuglich der Basen B und C zuordnet,
ein Isomorphismus von K-Vektorraumen.
Beweis. Die Bijektivitat von MCB
haben wir uns oben uberlegt. Die Linearitat rech-
net man unmittelbar nach. �
Seien Vektorraume U , V , W gegeben mit Basen A = (u1, . . . ,up), B =(v1, . . . ,vn) bzw. C = (w1, . . . ,wm), ferner lineare Abbildungen ϕ : U → V , ψ:
V → W . Seien A = MBA(ϕ) ∈ Mn×p(K) und B = MB
B(ψ) ∈ Mm×n(K) die Matri-
zen von ϕ und ψ bezuglich der gegebenen Basen und C =MCA(ψ ◦ϕ)∈Mm×p(K)
die Matrix von ψ ◦ϕ . Wie ergibt sich C aus A und B? Um die Koeffizienten einer
Matrix zu benennen, schreiben wir kurz z.B.
A = (α jk), B = (βi j), C = (γik).
Es gilt
ϕ(uk) =n
∑j=1
α jkv j, ψ(v j) =m
∑i=1
βi jwi
und
(ψ ◦ϕ)(uk) = ψ
(n
∑j=1
α jkv j
)=
n
∑j=1
α jkψ(v j)
=n
∑j=1
α jk
m
∑i=1
βi jwi
=m
∑i=1
(n
∑j=1
βi jα jk
)wi.
Der Koordinatenvektor von (ψ ◦ϕ)(uk) bezuglich w1, . . . ,wm ist also(
n
∑j=1
β1 jα jk, . . . ,n
∑j=1
βm jα jk
), k = 1, . . . , p.

176 Abschnitt 20
Dies ist gerade die k-te Spalte von C. Wir erhalten also
γik =n
∑j=1
βi jα jk, i = 1, . . . ,m, k = 1, . . . , p.
Definition. Sei K ein Korper, A = (α jk) eine n× p-Matrix uber K, B = (βi j) eine
m×n-Matrix. Dann heißt die m× p-Matrix C = (γik) mit
γik =n
∑j=1
βi jα jk, i = 1, . . . ,m, k = 1, . . . , p
das Produkt von B und A,
C = BA
(in dieser Reihenfolge!).
Zu bemerken ist folgendes:
(a) Das Produkt von B und A lasst sich nur bilden, wenn die Spaltenzahl von
B und die Zeilenzahl von A ubereinstimmen.
(b) Man kann die Matrizenmultiplikation schematisch so darstellen:
bi1 . . . bin
a1k
...
ank
=
cik
(c) Die Matrizenmultiplikation ist nicht kommutativ: Auch wenn wir die Pro-
dukte BA und AB bilden konnen, ist i.a. BA 6= AB. Zum Beispiel gilt(
0 1
0 0
)(0 0
1 0
)=
(1 0
0 0
)
(0 0
1 0
)(0 1
0 0
)=
(0 0
0 1
)
Wir haben das Matrizenprodukt BA so definiert, dass BA die Matrix von ψ ◦ϕist. Genauer gilt:
Satz 20.2. Seien U, V , W K-Vektorraume mit den Basen u1, . . . ,up, v1, . . . ,vn und
w1, . . . ,wm. Seien ϕ: U → V, ψ: V → W lineare Abbildungen. Wenn A die Ma-
trix von ϕ bezuglich u1, . . . ,up und v1, . . . ,vn und B die Matrix von ψ bezuglich
v1, . . . ,vn und w1, . . . ,wm ist, so ist BA die Matrix von ψ ◦ϕ bezuglich u1, . . . ,up
und w1, . . . ,wm.

Matrizenrechnung (I): Der Rang einer linearen Abbildung 177
Die n×n-Matrix
En =
1 0 · · · 0
0. . .
. . ....
.... . .
. . . 00 · · · 0 1
heißt n-reihige Einheitsmatrix. Sie ist die Matrix der identischen Abbildung eines
beliebigen n-dimensionalen K-Vektorraums V bezuglich einer beliebigen Basis B,
d.h En = MBB(idV ).
Wir haben oben gesehen, dass die Matrizenmultiplikation nicht kommutativ ist.
Hingegen gelten die ubrigen uns vertrauten Rechenregeln:
Satz 20.3. A und B seien n× p-Matrizen, C und D seien m×n-Matrizen uber K.
F sei eine (k×m)-Matrix. Dann gilt:
(a) EnA = AEp = A,
(b) F(CA) = (FC)A,
(c) (C+D)A =CA+DA, C(A+B) =CA+CB.
Beweis. Man kann dies direkt ausrechnen. Es ist aber viel eleganter, die Rechenre-
geln fur Matrizen auf die entsprechenden Regeln fur Abbildungen zuruckzufuhren.
Als Beispiel betrachten wir (b). Sind χ , ψ , ϕ die durch F , C, A gegebenen linearen
Abbildungen, so gilt
χ ◦ (ψ ◦ϕ) = (χ ◦ψ)◦ϕ,
F(CA) ist die Matrix von χ ◦(ψ ◦ϕ), und (FC)A ist die Matrix von (χ ◦ψ)◦ϕ . �
Bei einem Endomorphismus ϕ: V → V hat man es bei Definitions- und Bild-
bereich mit ein und demselben Vektorraum zu tun. Dementsprechend betrachtet
man auch nur eine Basis v1, . . . ,vn, wenn nichts anderes ausdrucklich vorausgesetzt
wird. Daher kann man kurz von der Matrix von ϕ bezuglich v1, . . . ,vn sprechen.
Die Spalten einer Matrix A lassen sich nach der obigen Diskussion als Bilder
von Vektoren durch eine lineare Abbildung ϕA interpretieren. Es ist aber sehr na-
heliegend sich zu fragen, ob es eine Verbindung zwischen den Spalten der Matrix
und dem Rang von ϕA gibt.
Definition. Die Dimension des von den Spalten von A erzeugten Untervektor-
raums in Km nennt man den Spaltenrang von A; der wird mit rgs(A) bezeichnet.
Wenn wir den Begriff Spaltenrang eingefuhrt haben, warum nicht auch den
Zeilenrang?
Definition. Die Dimension des von den Zeilen von A erzeugten Untervektorraums
in Kn (wobei wir die Elemente von Kn hier als Zeilenvektoren auffassen) nennt man
den Zeilenrang von A; dieser wird mit rgz(A) bezeichnet.

178 Abschnitt 20
Satz 20.4. Fur Matrizen A ∈ Mm×n(K) gilt
rgs(A) = rgz(A) = rang(ϕA).
Insbesondere stimmen Spalten- und Zeilenrang uberein.
Dann werden wir von nun an rang(A) anstelle von rgs(A) bzw. rgz(A) schreiben
und diese Zahl als den Rang der Matrix A bezeichnen.
Der Rang einer Matrix lasst sich leicht mit Hilfe von dem Gaußschen Elimina-
tionsverfahren nachrechnen:
Satz 20.5. Seien A∈Mm×n(K). Sei B ∈Mm×n(K) eine weitere Matrix, die mittels
elementarer Zeilenumformungen aus A hervorgeht. Dann erzeugen die Zeilenvek-
toren von A den gleichen linearen Untervektorraum in Kn wie die Zeilen von B.
Insbesondere ist der Zeilenrang einer Matrix invariant unter elementaren Zeile-
numformungen.
Algorithmisch bedeutet das: Man bringt die Matrix A mittels elementarer Zei-
lenumformungen auf Zeilenstufenform. Dann ist die Anzahl von der von Null ver-
schiedenen Zeilen der Rang von A. Ubrigens: Man kann auch uber den Kern von
A sprechen. Damit ist Kern(ϕA) gemeint.
Beispiel. Die Matrix A in der folgenden Umformungen
A :=
0 0 1 2 1
1 2 1 3 1
1 2 2 5 2
T12−→
1 2 1 3 1
0 0 1 2 1
1 2 2 5 2
T31(−1)−→
1 2 1 3 1
0 0 1 2 1
0 0 1 2 1
T32(−1)−→
1 2 1 3 1
0 0 1 2 1
0 0 0 0 0
hat den Rang 2.
Matrizen haben wir schon im Abschnitt 16 a propos der linearen Gleichungs-
systeme betrachtet. Wir wollen nun diese Interpretation der linearen Gleichungs-
systeme in der Welt der linearen Abbildungen erklaren. Sei dafur A ∈ Mm×n(K)eine Matrix mit Spaltenvektoren
a1 =
a11...
am1
, a2 =
a12...
am2
, . . . ,an =
a1n...
amn
∈ Km.
Sei b =
b1...
bm
∈ Km. Wir betrachten das lineare Gleichungssystem
Ax = b.

Matrizenrechnung (I): Der Rang einer linearen Abbildung 179
Die Matrix A entspricht der linearen Abbildung ϕA : Kn →Km (bezuglich der Stan-
dardbasen von Kn und Km). Speziell gilt
ϕA(
x1...
xn
) = A
x1...
xn
= x1a1 + . . .+ xnan
fur
x1...
xn
∈ Kn.
Sei L (A,b) die Menge aller Losungen des linearen Gleichungssystems Ax= b.
Man uberlegt sich sofort:
(a) Ax = b besitzt eine Losung genau dann, wenn b ∈ Bild(ϕA).(b) Fur x ∈ Kn gilt: x ∈ L (A,b) genau dann, wenn ϕA(x) = b.
(c) Die Losungsmenge L (A,0) eines homogenen linearen Gleichungssystem
ist ein Untervektorraum des Kn.
(d) Fur x ∈ Kn gilt: x ∈ L (A,0) genau dann, wenn x ∈ Kern(ϕA)
Auf diese Feststellungen basiert folgender Satz:
Satz 20.6. Seien A ∈Mm×n(K), b ∈ Kn. Sei (A,b) die erweiterte Matrix des linea-
ren Gleichungssystems Ax = b.
(a) Fur Ax = b gilt L (A,b) 6= /0 genau dann, wenn
rang(A) = rang(A,b).
(b) Fur das homogene lineare Gleichungssystem Ax = 0 gilt:
dimK L (A,0) = dimK Kern(A) = n− rang(A).
(c) Ist u ∈ L (A,b), dann gilt
L (A,b) = u+L (A,0) = {u+ v : v ∈ L (A,0)}= u+Kern(A).
Fur eine Basis u1, . . . ,us von L (A,0) = Kern(A) mit s = n− rang(A) lasst
sich insbesondere jede Losung x ∈ L (A,b) eindeutig schreiben als
v = u+λ1u1 + . . .+λsus.
Beispiel. Wir betrachten das lineare Gleichungssystem
x3 + 2x4 = 1
x1 + 2x2 + x3 + 3x4 = 1
x1 + 2x2 + 2x3 + 5x4 = 2
Aus Satz 20.6 ist es genau dann losbar, wenn den Rang der assozierten Matrix
A =
0 0 1 2
1 2 1 3
1 2 2 5

180 Abschnitt 20
mit dem Rang der erweiterten Matrix
(A,b) =
0 0 1 2 1
1 2 1 3 1
1 2 2 5 2
ubereinstimmt. Aus dem letztem Beispiel sieht man sofort:
rang(A) = rang(A,b) = 2.
Die Losungsmenge bestimmen wir indem wir eine spezielle Losung des inhomo-
genen Systems berechnen und dann die Losungsmenge des assozierten homogenen
Gleichungssystems, d.h., den Kern von A.
Nach den im obigen Beispiel durchgefuhrte elementaren Umformungen ist das
Gleichungssystem
x1 + 2x2 + x4 = 0
x3 + 2x4 = 1
zu betrachten. Eine spezielle Losung dieses inhomogenen linearen Gleichungssy-
stems berechnen wir, wenn wir x2 = x4 = 0 setzen, und bekommen x1 = 0 und
x3 = 1. Das heißt, eine spezielle Losung ist
0
0
1
0
. Nun mussen wir noch den
Kern von A berechnen. Es ist also das homogene lineare Gleichungssystem
x1 + 2x2 + x4 = 0
x3 + 2x4 = 0
zu losen. Der Losungsraum (d.h. gleichzeitig, der gesuchte Kern) ist
L (A,0) = Kern(A) = L(
−2
1
0
0
,
−1
0
−2
1
),
wie man leicht nachprufen kann. Dann ist die Losungsmenge des ursprunglichen
linearen Gleichungssystems
L (A,b) =
0
0
1
0
+L
(
−2
1
0
0
,
−1
0
−2
1
).
Wir sind mit dem zusammenhang zwischen linearen Abbildungen und Matrizen
nocht nicht fertig. Im nachsten Abschnitt betrachten wir noch die Matrix, die zur
Umkehrabbildung –falls sie existiert– gehort, und das Problem des Basiswechsels:
Wie kann man von einer Basis zu einer anderen eines Vektorraumes ubergehen?

ABSCHNITT 21
Matrizenrechnung (II): Basiswechsel
Sei A eine n× n-Matrix. Die durch A gegebene lineare Abbildung ist genau
dann ein Automorphismus, wenn rangA= n; siehe Satz 19.6. In diesem Fall besitzt
ϕ ein Inverses ϕ−1, dessen Matrix wir mit A−1 bezeichnen. Da
ϕ ◦ϕ−1 = ϕ−1 ◦ϕ = idKn,
ist AA−1 = A−1A = En.
Definition. Sei A eine n×n-Matrix des Ranges n. Die soeben beschriebene Matrix
A−1 heißt die zu A inverse Matrix.
Ist A eine n × n-Matrix, zu der es eine n × n-Matrix A′ mit A′A = En oder
AA′ = En gibt, so muss bereits rangA = n gelten: Fur die durch A′ gegebene li-
neare Abbildung ϕ ′ ist
ϕ ′ ◦ϕ = idKn oder ϕ ◦ϕ ′ = idKn .
Im ersten Fall ist ϕ injektiv, also ein Automorphismus von Kn gemaß Satz 19.6,
im zweiten Fall ist ϕ surjektiv und damit ebenfalls ein Automorphismus. Es folgt
ϕ ′ = ϕ−1 und somit A′ = A−1.
Wir fassen diese Erkenntnisse zusammen:
Satz 21.1. A sei eine n×n-Matrix uber K und ϕ der durch A gegebene Endomor-
phismus des Kn. Dann sind aquivalent:
(a) ϕ ist ein Automorphismus;
(b) rangA = n;
(c) es existiert eine n×n-Matrix A′ mit A′A = En oder AA′ = En.
In diesem Fall ist A′ = A−1 die Matrix von ϕ−1, und man nennet A eine inver-
tierbare Matrix.
Satz 21.2. Dei invertierbaren n× n-Matrizen uber einem Korper K bilden eine
Gruppe bezuglich der Matrizenmultiplikation, die man mit
GL(n,K)
bezeichnet.
Dafur ist allenfalls noch zu beweisen, dass das Produkt invertierbarer Matrizen
invertierbar ist, aber dies folgt aus AB((B−1A−1) = En.

182 Abschnitt 21
Die Bestimmung von A−1 ist mit unserem Verfahren zum Losen linearer Glei-
chungssysteme (prinzipiell) sehr einfach. Sei
AB = En.
Dann erfullt die j-te Spalte von B das lineare Gleichungssystem
(A,e j)
dessen rechte Seite die j-te Spalte der Einheitsmatrix ist. Also haben wir insgesamt
n lineare Gleichungssysteme gleichzeitig zu losen. Sie alle haben die”linke Seite“
A, und daher konnen wir mit allen rechten Seiten simultan arbeiten.
Beispiel.
A =
1 0 1 1
1 1 2 1
0 −1 0 1
1 0 0 2
1 0 1 1 1 0 0 0
1 1 2 1 0 1 0 0
0 −1 0 1 0 0 1 0
1 0 0 2 0 0 0 1
1 0 1 1 1 0 0 0
0 1 1 0 −1 1 0 0
0 −1 0 1 0 0 1 0
0 0 −1 1 −1 0 0 1
1 0 1 1 1 0 0 0
0 1 1 0 −1 1 0 0
0 0 1 1 −1 1 1 0
0 0 −1 1 −1 0 0 1
1 0 0 0 2 −1 −1 0
0 1 0 1 0 0 −1 0
0 0 1 1 −1 1 1 0
0 0 0 2 −2 1 1 1
1 0 0 0 2 −1 −1 0
0 1 0 0 −1 1/2 −1/2 1/2
0 0 1 0 0 1/2 1/2 −1/2
0 0 0 1 −1 1/2 1/2 1/2
A−1 =
2 −1 −1 0
−1 1/2 −1/2 1/2
0 1/2 1/2 −1/2
−1 1/2 1/2 1/2
Auf der rechten Seite konnen wir jetzt die Losungen unserer vier Gleichungssyste-
me, d.h. aber A−1, direkt ablesen.
Wir wollen nun das Problem des Basiswechsels betrachten: Wir wissen schon,
dass man K-lineare Abbildungen zwischen endlich dimensionalen Vektorraumen
bei Festlegung von Basen durch Matrizen beschreiben kann. Jetzt wollen wir ver-
stehen, wie sich die beschreibende Matrix andert, wenn man zu anderen Basen
ubergeht. Wir fangen klein mit einem Beispiel an.
Sei V ein K-Vektorraum der Dimension 2. Wegen Satz 19.8 identifizieren wir
V mit K2. Sei v ∈K2, v 6= 0, ein Vektor der Lange√
8:

Matrizenrechnung (II): Basiswechsel 183
0
v
Wie kann man v unter allen Vektoren aus dem K2 der Lange√
8 kennzeichen?
Wegen der Eindeutigkeit der Basisdarstellung 18.2 konnen wir das nach Angabe
einer Basis des K2 tun. Betrachten wir die Standardbasis E = (e1,e2) des K2, so
lasst sich v durch E eindeutig beschreiben als v = 2e1 +2e2.
0
v
2e1e1
2e2
e2
Die Basis E haben wir ausgewahlt. Suchen wir eine weitere Basis B = (b1,b2)aus, so lasst sich v anders darstellen, z.B. v = 2b1 +0b2:
0
v
b1
b2
Zu v gehort ein (eindeutig bestimmte nach der Wahl einer Basis) Koordinaten-
vektor des K2 je nachdem, welche Basis wir aussuchen:
(a) Bezuglich E hat v den Koordinatenvektor(
2
2
)
(b) Bezuglich B hat v den Koordinatenvektor(
2
0
)
Da dies fur jeden Vektor des K2 vorkommt, stellt sich die allgemeine Frage: Wie
konnen Koordinatenvektoren in der Basis E zu Koordinatenvektoren in der Basis
B, und umgekehrt, ubergehen? Dieser Prozess entspricht einem Automorphismus
des K2:

184 Abschnitt 21
(a) Fur λ i1,λ
12 ∈ K stellt die Abbildung
τEB= τ : K2 −→ K2
bi 7→ τ(bi) = λ i1e1 +λ i
2e2
die Vektoren von B in Koordinaten bezuglich E dar.
(b) Fur µ i1,µ
12 ∈ K stellt die Abbildung
τBE
= (τEB)−1 = τ−1 : K2 −→ K2
ei 7→ τ−1(ei) = µ i1b1 +µ i
2b2
die Vektoren aus E in Koordinaten bezuglich B dar.
Die linearen Abbildungen τ und τ−1 lassen einen Vektor v invariant, es wird
sich bloß nur seine Darstellung mittels einer angegebenen Basis andern: Insofern
sind τ und τ−1 identischen Abbildungen. Wir werden oft τ = τEB= idE
B und τ−1 =
idBE schreiben.
Die Abbildung τ = idEB ist im Beispiel so definiert:
τ = idEB : K2 −→ K2
b1 7→ τ(b1) = e1 + e2
b2 7→ τ(b2) = e1 − e2
Die Matrix dieser linearen Abbildung ist dann
MEB =
(1 1
1 −1
).
Sie transformiert die Basis E in die Basis B:(
1 1
1 −1
)(1
0
)=
(1
1
)
(1 1
1 −1
)(0
1
)=
(1
−1
)
Dann nennen wir MEB(id) die Ubergangsmatrix von der Basis E zur Basis B.
Es ist noch zu beachten: Diese Matrix MEB(id) transformiert Koordinatenvektoren
bezuglich der Basis B in Koordinatenvektoren bezuglich der Basis E :(
1 1
1 −1
)(2
0
)=
(2
2
)
Der zu v assoziierte Koordinatenvektor bezuglich B ist
(2
0
), und der bezuglich
E ist
(2
2
), wir wir uns oben schon uberlegt haben.

Matrizenrechnung (II): Basiswechsel 185
Die Abbildung τ−1 = idBE ist folgendermaße definiert:
τ−1 = idBE : K2 −→ K2
e1 7→ τ−1(b1) =12b1 +
12b2
e2 7→ τ−1(b2) = b1 − e1 =12b1 − 1
2b2
Die Matrix dieser linearen Abbildung ist dann
MBE (id) =
1
2
(1 1
1 −1
).
Sie transformiert die Basis B in die Basis E :
1
2
(1 1
1 −1
)(1
1
)=
(1
0
)
1
2
(1 1
1 −1
)(1
−1
)=
(0
1
)
Dann ist MBE(id) die Ubergangsmatrix von der Basis B zur Basis E . Die Matrix
MBE(id) transformiert dann Koordinatenvektoren bezuglich der Basis E in Koordi-
natenvektoren bezuglich der Basis B dargestellt:
1
2
(1 1
1 −1
)(2
2
)=
(2
0
)
(Der Koordinatenvektor
(2
2
)zu v bezuglich E wird in den Koordinatenvektor
(2
0
)zu v bezuglich B umgewandelt.) Eine Tatsache fallt uns auf:
(1/2 1/2
1/2 −1/2
)−1
=
(1 1
1 −1
),
also
(MBE (id))−1 = ME
B(id).
Das ist naturlich ein allgemeines Sachverhalten:
Satz 21.3. Sei V ein K-Vektorraum der endlichen Dimension n. Seien B und B′
zwei Basen von V . Dann ist die Matrix
T := MBB′(id) ∈ Mn×n(K)
invertierbar, und es ist
T−1 = MB′B (id)
Beweis. Es ist
MB′B (id) ·MB
B′(id) = MB′B′ (id) = En.
�

186 Abschnitt 21
Definition. Die Matrix T = MBB′(id) nennen wir die Matrix des Basiswechsels,
oder die Ubergangsmatrix, von B zu B′.
Naheliegend ist das Problem: Was ist das Verhalten von einer Matrix einer
linearen Abbildung nach Koordinatenwechsel im Definitions- und Wertebereich
(d.h., im Start- und Zielvektorraum)?
Sei ϕ : R2 → R2 gegeben durch(
x
y
)7→(
x
3x+2y
).
Die Abbildung ϕ ist R-linear mit
ϕ(
(1
0
)) =
(1
3
)= e1 +3e2
ϕ(
(0
1
)) =
(0
2
)= 2e2.
Bezeichnen wir wieder mit E = (e1,e2) die Standardbasis des R2, so liest man
unmittelbar daraus:
MEE (ϕ) =
(1 0
3 2
).
Nehmen wir an, wir haben noch die Basis B = (b1,b2) mit b1 = e1 + e2 und b2 =e1 − e2 wie im obigen Beispiel zur Verfugung. Was ist nun die Matrix MB
E(ϕ)?
Diese Matrix lasst sich berechnen, indem wir in R2 im Wertebereich einen Ba-
siswechsel durchfuhren:
R2 ϕ−→ R2 τ−1
−→ R2
e1 7→ ϕ(e1) = e1 +3e2 7→ 12b1 +
12b2 +
32b1 − 3
2b2 = 2b1 −b2
e2 7→ ϕ(e2) = 2e2 7→ b1 −b2
Wir mussen noch die Vektoren e1 +3e2 und 2e2 mittels der Basis B = (b1,b2)ausdrucken. Dies bekommen wir, wenn wir die Abbildung τ−1 des obigen Bei-
spiels anwenden, d.h., wenn wir die Matrix MBE(id) des Basiswechsels von B
nach E betrachten. Es gilt tatsachlich:
MBE (id)
(1
3
)=
1
2
(1 1
1 −1
)(1
3
)=
(2
−1
)
MBE (id)
(0
2
)=
1
2
(1 1
1 −1
)(0
2
)=
(1
−1
).
Insgesamt ergibt sich
MBE (id◦ϕ)=MB
E (ϕ)=MBE (id)ME
E (ϕ)=1
2
(1 1
1 −1
)(1 0
3 2
)=
(2 1
−1 −1
).

Matrizenrechnung (II): Basiswechsel 187
Genauso kann man sich fragen, wie wirkt es aus, wenn wir einen Basiswechsel
im Definitionsbereich von ϕ durchfuhren, also etwa nun die Frage, welche ist die
Matrix MEB(ϕ). Diesmal kommt die Abbildung τ , die die Basis B in die Basis E
transformiert, im Einsatz. Wir haben:
R2 τ−→ R2 ϕ−→ R2
b1 7→ τ(b1) = e1 + e2 7→ e1 +5e2
b2 7→ τ(b2) = e1 − e2 7→ e1 + e2
Tatsachlich gilt:
MEB(ϕ) = ME
B(ϕ ◦ id) = MEE (ϕ)M
EB(id).
Wenn wir zum Schluß direkt die Matrix MBB(ϕ) berechnen wollen, mussen wir
nur die zwei obigen Teile zusammenbringen:
R2 τ−→ R2 ϕ−→ R2 τ−1
−→ R2
b1 7→ τ(b1) 7→ ϕ((τ(b1)) 7→ τ−1(ϕ((τ(b1)))b2 7→ τ(b2) 7→ ϕ((τ(b2)) 7→ τ−1(ϕ((τ(b2))).
Mit Matrizen druckt sich das Obige so aus:
MBB (ϕ) = MB
E (τ−1)MEE (ϕ)M
EB(τ)
= (MEB(τ−1))−1ME
E (ϕ)MEB(τ)
Im Allgemeinen ergibt sich:
Satz 21.4. Seien V,W zwei endlich dimensionale K-Vektorraume der Dimensionen
m resp. n. Seien B und B′ zwei Basen von V , und C und C ′ zwei Basen von W.
Sind
T := MBB′(idV ) ∈ Mm×m(K) und S := MC
C ′(idW ) ∈ Mn×n(K),
so gilt
MC ′B′(ϕ) = S−1MC
B(ϕ)T
fur jede K-lineare Abbildung ϕ : V →W.
Beweis. Nach dem letzten Satz 21.3 ist S−1 = MC ′C(idW ). Es folgt:
S−1MCB(ϕ)T = (MC ′
C (idW ) ·MCB(ϕ)) ·MB
B′(idV )
= MC ′B (ϕ) ·MB
B′(idV ) = MC ′B′(ϕ).
�
Ist speziell V =W , dann folgt aus dem Satz 21.4 fur B = C und B′ = C ′
Satz 21.5. Es ist MB′B′ (ϕ) = T−1MB
B(ϕ)T .
(Das war die Situation des obigen Beispiels mit B = E und B′ = B).


ABSCHNITT 22
Determinanten
Wir betrachten ein lineares Gleichungssystem
a1x+b1y = c1
a2x+b2y = c2
mit
rang
(a1 b1
a2 b2
)= 2.
Wir kennen ein Verfahren zur Losung solcher Gleichungssysteme. Gibt es auch
eine”Formel“ fur x und y, vergleichbar etwa der
”p-q-Formel“ fur quadratische
Gleichungen?
Durch Umformen erhalten wir zunachst:
(a1b2 −b1a2)x = c1b2 −b1c2
(a1b2 −b1a2)y = a1c2 − c1a2.
Wegen rangA = 2 muss a1b2 −b1a2 6= 0 sein (!), und wir erhalten
x =c1b2 −b1c2
a1b2 −b1a2und y =
a1c2 − c1a2
a1b2 −b1a2.
Auffallig ist, dass die Terme c1b2 − b1c2, a1b2 − b1a2, a1c2 − c1a2 alle von der
gleichen Bauart sind. Wenn wir fur eine 2×2-Matrix
A =
(α11 α12
α21 α22
)
detA = α11α22 −α12α21 setzen, so gilt
a1b2 −b1a2 = det
(a1 b1
a2 b2
), c1b2 −b1c2 = det
(c1 b1
c2 b2
), a1c2 − c1a2 = det
(a1 c1
a2 c2
).
Der nachste Schritt ware nun, lineare Gleichungssysteme mit drei Unbestimm-
ten zu untersuchen und herauszufinden, ob es dort ahnliche Gesetzmaßigkeiten
gibt. Wir werden sehen, dass dies zutrifft und dass die in Zahler und Nenner der
Auflosungsformel auftretenden Großen”Determinanten“ gewisser Matrizen sind.
Naturlich mussen wir Determinanten erst noch definieren. Dabei gehen wir rekur-
siv vor.

190 Abschnitt 22
Fur eine quadratische n-reihige Matrix A = (ai j) sei Ai diejenige Matrix, die
aus A durch Streichen der ersten Spalte und i-ten Zeile entsteht:
Ai =
a11 a12 · · · a1n...
......
ai1 ai2 ain...
......
an1 an2 · · · ann
Die Matrizen Ai haben das Format (n−1)× (n−1).
Definition. Sei A eine n×n-Matrix. Wir setzen
detA =
{a, wenn n = 1 und A = (a),
∑ni=1(−1)i+1ai1 detAi fur n > 1.
Mit dieser Definition ergibt sich fur n = 2:
det
(a b
c d
)= ad− cb.
Fur n = 3,
A =
α1 β1 γ1
α2 β2 γ2
α3 β3 γ3
erhalt man:
detA =α1 det
(β2 γ2
β3 γ3
)−α2 det
(β1 γ1
β3 γ3
)+α3 det
(β1 γ1
β2 γ2
)
=α1(β2γ3 −β3γ2)−α2(β1γ3 −β3γ1)+α3(β1γ2 −β2γ1)
=α1β2γ3 −α1β3γ2 −α2β1γ3 +α2β3γ1 +α3β1γ2 −α3β2γ1.
Wir haben nun zwar die Determinante einer beliebigen n×n-Matrix definiert, aber
mit der Definition allein kann man nicht viel mehr anfangen, als Determinanten
auszurechnen. Zunachst wollen wir wichtige Eigenschaften der Determinante fest-
halten. Dazu betrachten wir die Matrix A als Zusammensetzung ihrer Zeilenvekto-
ren v1, . . . ,vn und schreiben auch
(v1, . . . ,vn) oder
v1...
vn
fur A.
In der Regel berechnet man Determinanten mittels Matrix-Umformungen, die
wir im Folgenden diskutieren werden. Dabei braucht man nur solange zu rechnen,
bis man A in eine obere Dreiecksmatrix umgeformt hat:

Determinanten 191
Satz 22.1. Sei A eine n-reihige obere Dreiecksmatrix, d.h. von der Form
d1 ∗ · · · ∗0
. . .. . .
......
. . .. . . ∗
0 · · · 0 dn
.
Dann ist detA = d1 · · ·dn.
Dies folgt per Induktion direkt aus der Definition der Determinante. Wir halten
nun wichtige Eigenschaften der Determinante fest.
Satz 22.2. (a) Die Funktion det ist linear in jeder Zeile, d.h.
det(v1, . . . ,v j−1,v j + v′j,v j+1, . . . ,vn)
= det(v1, . . . ,v j−1,v j,v j+1, . . . ,vn)+det(v1, . . . ,v j−1,v′j,v j+1, . . . ,vn)
det(v1, . . . ,v j−1,αv j,v j+1, . . . ,vn) = α det(v1, . . . ,vn).
(b) Wenn eine der Zeilen von A der Nullvektor ist, so gilt detA = 0.
(c) detEn = 1 fur alle n ≥ 1.
Beweis. Fur jedes v ∈ Kn sei v der um die erste Komponente gekurzte Vektor: Fur
v = (ξ1, . . . ,ξn) ist v = (ξ2, . . . ,ξn). Die vk, k 6= i, sind ja gerade die Zeilen der Ma-
trizen Ai. Wir beweisen (a) durch Induktion uber n; der Fall n = 1 ist offensichtlich
richtig. Sei
A′ = (v1, . . . ,v j−1,v′j,v j+1, . . . ,vn),
A′′ = (v1, . . . ,v j−1,v j + v′j,v j+1, . . . ,vn).
Fur j 6= i ist a′′i1 = a′i1 = ai1 und
detA′′i = det(v1, . . . ,vi−1,vi+1 . . . ,v j−1,v j + v′j,v j+1, . . . ,vn)
= det(v1, . . . ,vi−1,vi+1, . . . ,v j−1,v j,v j+1, . . . ,vn)
+det(v1, . . . ,vi−1,vi+1, . . . ,v j−1,v′j,v j+1, . . . ,vn)
= detAi +detA′i
nach Induktionsvoraussetzung.
Fur j = i ist A′′i = A′
i = Ai, aber es gilt
a′′i1 = ai1 +a′i1.

192 Abschnitt 22
Damit ergibt sich:
detA′′ =n
∑i=1
(−1)i+1a′′i1 detA′′i
=n
∑i=1
(−1)i+1ai1(detAi +detA′i)+(−1) j+1(α j1 +a′j1)detA j
=∑i6= j
(−1)i+1ai1 detAi +n
∑i=1
(−1)i+1a′i1 detA′i
=detA+detA′.
Dies ist die erste Behauptung in (a). Genauso beweist man die zweite Behauptung.
(b) Sei etwa vi = 0. Dann ist nach (a)
det(v1, . . . ,vn) = det(v1, . . . ,vi−1,0 · vi,vi+1, . . . ,vn) = 0 ·det(v1, . . . ,vn).
(c) Dies ergibt sich sofort nach dem Satz 22.1. �
Bis jetzt hat die Wahl (−1)i+1 der Vorzeichen in der Definition der Determi-
nante keine Rolle gespielt. Ihre Bedeutung ergibt sich aus dem folgenden Satz:
Satz 22.3. (a) Wenn zwei Zeilen v j, vk ubereinstimmen, ist
det(v1, . . . ,vn) = 0.
(b) Bei Vertauschung von zwei Zeilen wird die Determinante mit −1 multipli-
ziert:
det(v1, . . . ,v j−1,vk,v j+1, . . . ,vk−1,v j,vk+1, . . . ,vn) =−det(v1, . . . ,vn).
(c) Die Determinante andert sich nicht bei elementaren Zeilentransformatio-
nen:
det(v1, . . . ,v j−1,v j +αvk,v j+1, . . . ,vn) = det(v1, . . . ,vn).
Beweis. Wir beweisen (a) und (b) gleichzeitig durch Induktion uber n. Im Fall
n = 1 sind beide Behauptungen”leer“ – es gibt ja nur eine Zeile – und damit
automatisch richtig.
Sei n > 1. Dann ist (mit A = (v1, . . . ,vn))
detA =n
∑i=1
(−1)i+1ai1 detAi.
Die Induktionsvoraussetzung fur (a) ergibt, dass Ai = 0 fur i 6= j, k. Also ist
detA = (−1) j+1a j1 detA j +(−1)k+1ak1 detAk.
Die Matrizen A j und Ak haben die gleichen Zeilen, allerdings in verschiedenen
Reihenfolgen. Bei A j steht vk = v j auf dem (k−1)-ten Platz, bei Ak steht v j = vk

Determinanten 193
auf dem j-ten Platz, und die anderen Zeilen sind entsprechend verschoben:
A j =
v1...
v j−1
v j+1...
vk−1
v j
vk+1...
vn
Ak =
v1............
vk−1
vk+1......
vn
Mittels k− j−1 Zeilenvertauschungen konnen wir Ak in A j uberfuhren (oder um-
gekehrt). Also ist
detA j = (−1)k− j−1 detAk,
wie sich aus der Induktionsannahme fur (b) ergibt. Wegen a j1 = ak1 folgt
detA = (−1) j+1a j1 detA j +(−1)k+1ak1 detAk
=((−1) j+1(−1)k− j−1 +(−1)k+1
)ak1 detAk
=((−1)k +(−1)k+1
)ak1 detAk
= 0.
Nun ist noch (b) zu zeigen. Dabei brauchen wir die Induktionsvoraussetzung nicht
zu bemuhen, sondern konnen dies direkt aus (a) herleiten. Nach (a) und 22.2 ist
0 = det(. . . ,v j + vk, . . . ,v j + vk, . . .)
= det(. . . ,v j, . . . ,v j + vk, . . .)+det(. . . ,vk, . . . ,v j + vk, . . .)
= det(. . . ,v j, . . . ,v j, . . .)+det(. . . ,v j, . . . ,vk, . . .)+
det(. . . ,vk, . . . ,v j, . . .)+det(. . . ,vk, . . . ,vk, . . .)
= det(. . . ,v j, . . . ,vk, . . .)+det(. . . ,vk, . . . ,v j, . . .).
(c) Es ist
det(. . . ,v j +αvk, . . .) = det(v1, . . . ,vn)+α det(. . . ,vk, . . . ,vk, . . .)
= det(v1, . . . ,vn)
gemaß 22.2 und Teil (a). �
Die fundamentale Bedeutung der Determinante ergibt sich aus dem folgenden
Satz, der uns zeigt, was durch die Determinante determiniert wird:

194 Abschnitt 22
Satz 22.4. Sei A eine n×n-Matrix. Dann gilt:
detA 6= 0 ⇐⇒ rangA = n.
Beweis. Sei zunachst rangA < n. Dann sind gemaß Satze20.4–20.6 die Zeilen von
A linear abhangig. Da Zeilenvertauschungen die Determinante nur um den Faktor
−1 andern, durfen wir annehmen, dass
vn =n−1
∑i=1
βivi.
Nach 22.2 und 22.3 ist
detA = det(v1, . . . ,vn−1,n−1
∑i=1
βivi)
=n−1
∑i=1
βi det(v1, . . . ,vn−1,vi) = 0.
Sei nun rangA = n. Dann zeigen die Uberlegungen nach dem Satz 16.3, welche
die Einfuhrung der reduzierten Zeilenstufenform eines linearen Gleichungssystems
rechtfertigen, dass wir A durch elementare Umformungen, Zeilenvertauschungen
und Multiplikation mit von 0 verschiedenen Elementen von K in die Einheitsma-
trix uberfuhren konnen. Jeder Umformungsschritt andert die Determinante nur um
einen von 0 verschiedenen Faktor. Da detEn = 1, folgt detA 6= 0. �
Bei der Definition der Determinante erscheint es recht willkurlich, in der Re-
kursion von der ersten Spalte Gebrauch zu machen. Man hatte auch”nach einer
anderen Spalte entwickeln konnen“ oder gar”nach einer Zeile“. Dies hatte aber
nicht zu einem anderen Resultat gefuhrt, denn die Determinante ist durch wenige
Forderungen eindeutig bestimmt.
Wir sagen, ∆ : M(n,n) → K sei eine Determinantenfunktion, wenn folgende
Bedingungen erfullt sind:
(a) ∆ ist linear in jeder Zeile im Sinne von 22.2 (a);
(b) wenn A zwei gleiche Zeilen besitzt, ist ∆(A) = 0.
Satz 22.5. ∆ : M(n,n)→ K sei eine Determinantenfunktion mit ∆(En) = 1. Dann
ist ∆(A) = detA fur alle A ∈ M(n,n).
Beweis. Beim Beweis der Tatsache, dass detA= 0 ist, wenn die Zeilen von A linear
abhangig sind, haben wir nur von den Eigenschaften (a) und (b) oben Gebrauch
gemacht. Also ist ∆(A) = 0 im Falle rangA < n.
Der Beweis von Satz 22.4 zeigt weiter, dass jede Determinantenfunktion die
Eigenschaften besitzt, die in 22.3, (b) und (c) beschrieben sind. Wenn wir also A

Determinanten 195
in die Einheitsmatrix transformieren, so andert sich dabei ∆(A) um den gleichen
Faktor α 6= 0 wie detA. Es ergibt sich
α∆(A) = ∆(In) = detEn = α detA. �
Fur eine n×n-Matrix A = (ai j) setzen wir
Apq =
a11 · · · a1q · · · a1n... . . .
...
ap1 apq apn... . . .
...
an1 · · · anq · · · ann
Apq geht also durch Streichen der p-ten Zeile und der q-ten Spalte aus A hervor.
Mit dieser Bezeichnung konnen wir den Spaltenentwicklungssatz formulieren:
Satz 22.6. Sei A = (ai j) eine n×n-Matrix. Dann ist fur alle q, 1 ≤ q ≤ n:
detA =n
∑p=1
(−1)p+qapq detApq.
Beweis. Wie im Fall q= 1, den wir zur Definition der Determinante benutzt haben,
zeigt man, dass
∆q(A) =n
∑p=1
(−1)p+qapq detApq
eine Determinantenfunktion ist. Die Vorzeichen sind so gewahlt, dass ∆q(E) = 1.
Nach 22.5 ist mithin ∆q(A) = detA fur alle q. �
Eine wichtige Operation ist das Transponieren von Matrizen.
Definition. Sei A= (ai j) eine m×n-Matrix. Dann ist A⊤ = (a ji) die Transponierte
von A. Deutlicher: Die i-te Spalte von A⊤ ist gerade die i-te Zeile von A, die j-te
Zeile von A⊤ ist die j-te Spalte von A.
Satz 22.7. Sei A eine n×n-Matrix. Dann ist detA = detA⊤.
Beweis. Da die Zeilen von A⊤ die Spalten von A sind, zeigen unsere bisherigen
Uberlegungen: Die Funktion δ : M(n,n)→ K, δ (A) = detA⊤, besitzt folgende Ei-
genschaften:
(a) Sie ist linear in jeder Spalte;
(b) δ (A) = 0, wenn zwei Spalten von A ubereinstimmen;
(c) δ (En) = 1.
Ferner ist δ die einzige Funktion mit dieser Eigenschaft.
Aber auch det besitzt die Eigenschaften (a), (b), (c). Fur (c) ist dies hinlanglich
bekannt. Wenn zwei Spalten von A ubereinstimmen, gilt detA = 0, weil dann
rangA < n; vgl. 22.4. Somit ist (b) erfullt.

196 Abschnitt 22
Schließlich gilt auch (a). Um die Linearitat in der q-ten Spalte zu beweisen,
betrachten wir einfach die Entwicklung nach dieser Spalte. Wenn a′′pq = apq +a′pq
fur p= 1, . . . ,n und a′′i j = ai j = a′i j fur j 6= q, so gilt Apq =A′pq =A′′
pq fur p= 1, . . . ,nund wir erhalten
detA′′ =n
∑p=1
(−1)p+q(apq +a′pq)A′′pq
=n
∑p=1
(−1)p+qapqApq +n
∑p=1
(−1)p+qa′pqA′pq
= detA+detA′.
Genauso zeigt man detA′ = β detA wenn
a′pq = βapq fur p = 1, . . . ,n und ai j = a′i j sonst.
Da die Funktion δ mit den Eigenschaften (a), (b) und (c) eindeutig bestimmt ist,
muss δ (A) = detA fur alle A ∈ M(n,n) gelten. �
Durch Anwenden der Spaltenentwicklung auf detA⊤ erhalten wir wegen 22.7
den Zeilenentwicklungssatz fur detA:
Satz 22.8. Fur alle n×n-Matrizen A und alle p = 1, . . . ,n gilt
detA =n
∑q=1
(−1)p+qapq detApq.
Ebenso ergibt sich, dass wir elementare Spaltenumformungen, Spaltenvertau-
schungen usw. zur Berechnung der Determinante heranziehen konnen.
Als nachstes untersuchen wir, wie sich die Determinante des Produktes zweier
Matrizen berechnen lasst:
Satz 22.9. Fur alle n×n-Matrizen A, B ist
detAB = (detA)(detB).
Beweis. Sei zunachst rangB< n. Dann ist auch rangAB< n. Um dies zu beweisen,
betrachte man die A, B entsprechenden Endomorphismen des Kn. Es ist
dimBildϕ ◦ψ = dimϕ(Bildψ)≤ dimBildψ = rangψ,
und damit rangAB ≤ rangB. Im Fall rangB < n ist detB = 0, und nach dem soeben
Bewiesenen ist auch detAB = 0.
Sei nun rangB = n. Wir betrachten die durch
δ (A) = (detB)−1(detAB)
definierte Abbildung δ : M(n,n)→ K. (Dabei ist B festgehalten.)

Determinanten 197
Wir schreiben im Folgenden eine n×n-Matrix in der Form
v1...
vn
,
wobei v1, . . . ,vn die Zeilen von A sind. Es gilt
v1...
v j + v′j...
vn
B =
v1B...
(v j + v′j)B...
vnB
=
v1B...
v jB+ v′jB...
vnB
.
Also ist
det
v1...
v j + v′j...
vn
B = det
v1...
v j...
vn
B+det
v1...
v′j...
vn
B,
und durch Multiplikation mit (detB)−1 ergibt sich
δ
v1...
v j + v′j...
vn
= δ
v1...
v j...
vn
+δ
v1...
v′j...
vn
.
Genauso folgt
δ
v1...
βv j...
vn
= βδ
v1...
v j...
vn
.
Dies zeigt: δ ist linear in jeder Zeile. Falls A zwei gleiche Zeilen besitzt, besitzt
auch AB zwei gleiche Zeilen, woraus detAB= 0 und somit δ (A) = 0 folgt. Schließ-
lich ist
δ (En) = (detB)−1(detEnB) = (detB)−1(detB) = 1.
Insgesamt konnen wir mit Satz 22.5 schließen: δ (A) = detA fur alle A. Also ist
detAB = (detB)δ (A) = (detB)(detA)
wie zu beweisen war. �

198 Abschnitt 22
Als Folgerung ergibt sich
Satz 22.10. Sei A eine n×n-Matrix des Ranges n. Dann ist
detA−1 = (detA)−1.
In der Tat ist (detA−1)(detA) = detEn = 1.
Ausgangspunkt unserer Uberlegungen war die Suche nach einer”Formel“ fur
die Losung eines eindeutig losbaren linearen Gleichungssystems mit n Unbe-
stimmten in n Gleichungen. Diese geben wir in 22.12 an; zunachst bestimmen wir
die Inverse einer Matrix mit Hilfe von Determinanten.
Satz 22.11. A sei eine n×n-Matrix des Ranges n. Dann gilt
A−1 =1
detAB
mit B = (bi j) und bi j = (−1)i+ j detA ji (es ist hierzu die Transposition A ji, und
nicht Ai j zu beachten!!)
Wir erinnern daran, dass sich A ji durch Streichen der j-ten Zeile und i-ten Spal-
te aus A ergibt. Fur eine 2×2-Matrix bedeutet Satz 22.11:(
a b
c d
)−1
=1
ad −bc
(d −b
−c a
).
Beweis von Satz 22.11. Wir betrachten das Produkt
C = AB.
Es ist C = (ckm) mit
ckm =n
∑i=1
akibim =n
∑i=1
aki(−1)i+m detAmi =
{detA, falls k = m
0, falls k 6= m.
Zur Begrundung der letzten Gleichung: Im Falle k = m istn
∑i=1
aki(−1)i+k detAki
einfach die Entwicklung von detA nach der k-ten Spalte; im Falle k 6= m ist es die
Entwicklung von detA′ nach der k-ten Spalte, wobei sich A′ aus A dadurch ergibt,
dass wir die m-te Spalte von A durch die k-te ersetzen. Also ist detA′ = 0.
Insgesamt ergibt sich
A1
detAB =
1
detAC = En, somit A−1 =
1
detAB. �
Beispiel. Wir mochten die Matrix A invertieren, fass dies moglich ist:
A =
1 −1 1
2 1 2
0 0 1
.

Determinanten 199
Da detA = 3 6= 0, dann ist A invertierbar. Dazu betrachten wir die Matrix B in Satz
22.11:
A =
det
(1 2
0 1
)−det
(2 2
0 1
)det
(2 1
0 0
)
−det
(−1 1
0 1
)det
(1 1
0 1
)−det
(1 −1
0 0
)
det
(−1 1
1 2
)−det
(1 1
2 2
)det
(1 −1
2 1
)
⊤
=
1 −2 0
1 1 0
−3 0 3
⊤
=
1 1 −3
−2 1 0
0 0 3
.
Aus Satz 22.11 ergibt sich dann
A−1 =1
detA=
1
3
1 1 −3
−2 1 0
0 0 3
=
1/3 1/3 −1
−2/3 1/3 0
0 0 1
.
Der kronende Abschluss dieses Paragraphen ist die Cramersche Regel, die un-
ser eingangs gestelltes Problem lost:
Satz 22.12. A sei eine n×n-Matrix des Ranges n und b ∈ Kn. Dann ist die eindeu-
tig bestimmte Losung (ξ1, . . . ,ξn) des linearen Gleichungssystems (A,b) gegeben
durch
ξi =detBi
detA, i = 1, . . . ,n,
wobei hier Bi diejenige Matrix ist, die sich aus A ergibt, wenn man die i-te Spalte
durch b ersetzt.
Beweis. Wir betrachten die Matrix A′ mit den Spalten
v1, . . . ,ξivi −b, . . . ,vn.
A′ hat Rang < n, weil ξivi −b Linearkombination von v1, . . . ,vi−1,vi+1, . . . ,vn ist.
Somit ist
detA′ = ξi detA−detBi = 0.
Auflosen nach ξi ergibt die gesuchte Gleichung. �
Beispiel. Wir losen das folgende lineare Gleichungssystem mittels der Cramer-
schen Regel:
x1 + x2 + x3 = 1
x1 −2x2 +3x3 = 2
x1 + x3 = 5

200 Abschnitt 22
Dabei sind
A =
1 1 1
1 −2 3
1 0 1
und b =
1
2
5
.
Mit der Bezeichnung aus Satz 22.12 ist detA = 2 und
detB1 = det
1 1 1
2 −2 3
5 0 1
= 21,
detB2 = det
1 1 1
1 2 3
1 5 1
=−8,
detB3 = det
1 1 1
1 −2 2
1 0 5
=−11.
Nun ist wegen Satz 22.12 die eindeutig bestimmte Losung des ursprunglichen
linearen Gleichungssystems
x1 = 212
x2 = −4
x3 = −112.

ABSCHNITT 23
Eigenwerte und Eigenvektoren
Um einem Endomorphismus eines endlichdimensionalen Vektorraums eine
Matrix zuzuordnen, mussen wir erst eine Basis fixieren. Wie diese Matrix aus-
sieht, hangt (fast immer) von der Wahl der Basis ab. In diesem Abschnitt ist es
unser Ziel, zu einem gegebenen Endomorphismus f eines endlichdimensionalen
K-Vektorraums V eine Basis von V zu bestimmen, bezuglich der die Matrix von f
eine moglichst einfache Gestalt hat.
Bevor wir uns dem schwierigen Problem der Endomorphismen zuwenden, be-
trachten wir lineare Abbildungen f : V → W . Die wesentliche Vereinfachung be-
steht darin, dass wir Basen in V und W unabhangig voneinander wahlen konnen.
Satz 23.1. Sei K ein Korper, V seien endlichdimensionale K-Vektorraume und
f : V → W eine lineare Abbildung. Dann existieren Basen (v1, . . . ,vn) von V
und (w1, . . . ,wm) von W, so dass die Matrix von f bezuglich (v1, . . . ,vn) und
(w1, . . . ,wm) gerade
Ar =
1 0. . . 0
0 1
0 0
ist mit r = rang f .
Beweis. Es gilt r = rang f = dimBild f . Wir wahlen eine Basis (w1, . . . ,wr) von
Bild f und erganzen sie durch wr+1, . . . ,wm zu einer Basis von W . Dann wahlen
wir v1, . . . ,vr ∈ V so, dass f (vi) = wi. Es gilt dimKern f = dimV − dimBild f
gemaß 19.5. Daher konnen wir eine Basis von Kern f mit vr+1, . . . ,vn bezeich-
nen. Wir haben bereits beim Beweis von 19.5 gesehen, dass nun (v1, . . . ,vn) eine
Basis von V ist.
Bezuglich der Basen (v1, . . . ,vn) und (w1, . . . ,wm) besitzt f gerade die behaup-
tete darstellende Matrix. �
Matrizen von linearen Abbildungen f : V → W besitzen also bezuglich geeig-
neter Basen eine sehr einfache Gestalt.

202 Abschnitt 23
Definition. Sei K ein Korper. Zwei Matrizen A,B ∈ Mn×n(K) heißen ahnlich,
wenn es eine invertierbare Matrix T ∈ Mn×n(K) gibt mit
B = T−1AT.
Falls A ahnlich zu einer Diagonalmatrix ist, heißt A diagonalisierbar. Ein Endomor-
phimus ϕ : V → V eines endlich dimensionalen K-Vektorraumes heißt diagonali-
sierbar, wenn es eine Basis B von V gibt, so dass die Darstellungsmatrix MBB(ϕ)
eine Diagonalmatrix ist.
Fur Endomorphismen wird man sicherlich eine Diagonalmatrix als”einfach“
ansehen. Nehmen wir einmal an, f besaße bezuglich v1, . . . ,vn Diagonalform,
A =
d1 0
. . .
0 dn
sei die Matrix von f . Dann gilt fur i = 1, . . . ,n
f (vi) = divi,
vi wird also von f auf ein Vielfaches von sich selbst abgebildet.
Definition. Sei V ein K-Vektorraum und f ein Endomorphismus von V . Wenn fur
v ∈V , v 6= 0,
f (v) = λv
mit λ ∈ K gilt, heißt v ein Eigenvektor und λ der zugehorige Eigenwert von f .
Genau dann ist 0 ein Eigenwert von f , wenn f nicht injektiv ist, und die Ei-
genvektoren zum Eigenwert 0 sind gerade die von 0 verschiedenen Elemente des
Kerns.
Genau dann gilt f (v) = λv, wenn
(λ id− f )(v) = 0,
denn (λ id− f )(v) = (λ id)(v)− f (v) = λv− f (v). Die Eigenvektoren zum Eigen-
wert λ sind also die von 0 verschiedenen Elemente des Untervektorraums
Eigλ ( f ) := Kern(λ id− f ).
Wir nennen Eigλ ( f ) den Eigenraum von f zum Eigenwert λ . Die Dimension von
Eigλ ( f ) heißt geometrische Vielfachheit des Eigenwertes λ .
Der folgende Satz informiert uns uber die Beziehungen zwischen den Eigen-
raumen und die Zahl der moglichen Eigenwerte.
Satz 23.2. Seien V ein Vektorraum der Dimension n und f ein Endomorphis-
mus von V . Seien λ1, . . . ,λm paarweise verschiedene Eigenwerte von f und U =Eigλ1
( f )+ · · ·+Eigλm( f ). Dann gilt

Eigenwerte und Eigenvektoren 203
(a) U ist die direkte Summe von Eigλ1( f ), . . . ,Eigλm
( f ),
U = Eigλ1( f )⊕·· ·⊕Eigλm
( f ).
(b) Speziell ist ∑mi=1 dimEigλi
( f )≤ dimV und erst recht m ≤ dimV.
Beweis. Dass U direkte Summe der Eigλi( f ) ist, heißt ja folgendes: Die lineare
Abbildung
Eigλ1( f )⊕·· ·⊕Eigλm
( f )→V, (v1, . . . ,vm) 7→ v1 + · · ·+ vm,
bildet die”externe“ direkte Summe Eigλ1
( f )⊕·· ·⊕Eigλm( f ) isomorph auf U ab.
Nach Definition von U ist U das Bild. Fur die Injektivitat ist zu zeigen:
v1 + · · ·+ vm = 0 =⇒ v1, . . . ,vm = 0.
Wir beweisen dies durch Induktion uber m. Im Fall m= 1 ist die Behauptung trivial.
Sei m > 1. Es gilt
0 = f (v1+ · · ·+ vm) = λ1v1 + · · ·+λmvm.
Damit ergibt sich mittels Subtraktion von λm(v1 + · · ·+ vm) = 0:
(λ1 −λm)v1 + · · ·+(λm−1 −λm)vm−1 = 0.
Auf v′1 = (λ1 − λm)v1, . . . ,v′m−1 = (λm−1 − λm)vm−1 konnen wir die Induktions-
voraussetzung anwenden, und wegen λi − λm 6= 0 fur i 6= m ergibt sich dann
v1, . . . ,vm−1 = 0 und somit auch vm = 0.
Teil (b) folgt aus ∑mi=1 dimEigλi
( f ) = dimU ≤ dimV . �
Fur die Bestimmung der Eigenwerte beachten wir, dass die Definition von
Eigλ ( f ) fur beliebiges λ ∈ K Sinn ergibt. Es gilt offensichtlich
λ Eigenwert von f ⇐⇒ Eigλ ( f ) 6= 0 ⇐⇒ λ id− f nicht injektiv.
Wir wahlen eine Basis (v1, . . . ,vn) von V . Sei A die Matrix von f bezuglich
(v1, . . . ,vn) Sei En die n × n-Einheitsmatrix. Dann ist λEn − A die Matrix von
λ id− f , und genau dann ist λ id− f nicht injektiv, wenn rang(λEn − A) < n,
aquivalent, wenn
det(λEn −A) = 0.
Mit A = (αi j) ist
λEn −A =
λ −α11 −α12 . . . −α1n
−α21. . .
. . ....
.... . .
. . . −αn−1n
−αn1 . . . −αnn−1 λ −αnn
.
Es ist nicht schwierig zu zeigen, dass
det(λEn −A) = λ n + cn−1λ n−1 + · · ·+ c0

204 Abschnitt 23
eine polynomiale Funktion von λ ist. Wir erweitern den Korper K zum Korper der
rationalen Funktionen K(X). Dann konnen wir die Determinante
det(XEn −A) = det
X −α11 −α12 . . . −α1n
−α21. . .
. . ....
.... . .
. . . −αn−1n
−αn1 . . . −αnn−1 X −αnn
bilden. Es gilt
det(XEn −A) = Xn + cn−1Xn−1 + · · ·+ c0
und
det(λEn −A) =(det(XEn −A)
)(λ ).
Definition. Sei A eine n×n-Matrix. Das Polynom
χA(X) := det(XEn −A)
heißt charakteristisches Polynom von A.
Wie wir gesehen haben, ist χA ein normiertes Polynom vom Grad n.
Sei (w1, . . . ,wn) eine weitere Basis von V . Dann ist f bezuglich (w1, . . . ,wn)durch die Matrix
B =CAC−1
gegeben, wobei C die Matrix des Ubergangs von (v1, . . . ,vn) zu (w1, . . . ,wn) ist. Es
gilt (detC)(detC−1) = 1. Also ist
χA = det(XEn−A) = (detC)det(XEn −A)(detC−1)
= det(C(XEn −A)C−1) = det(XCEnC−1 −CAC−1)
= det(XEn −B) = χB.
Wir haben damit gezeigt:
Satz 23.3. Sei V ein n-dimensionaler Vektorraum und f ein Endomorphismus von
V . Dann besitzen alle Matrizen A, die f bezuglich einer Basis von V darstellen,
das gleiche charakteristische Polynom χA.
Wegen Satz 23.3 durfen wir χA das charakteristische Polynom von f nennen
und mit χ f bezeichnen. Seine Nullstellen sind gerade die Eigenwerte von f .
Eine zu Satz 23.3 aquivalente Aussage ist, dass ahnliche Matrizen das gleiche
charakteristische Polynom besitzen. Wenn wir von einer n×n-Matrix A ausgehen,
dann heißen die Eigenwerte des von A bezuglich der kanonischen Basis von Kn
dargestellten Endomorphismus f die Eigenwerte von A. Entsprechendes soll fur
die Eigenvektoren und Eigenraume gelten.

Eigenwerte und Eigenvektoren 205
Es ist unser Ziel, die Klassen ahnlicher Matrizen durch Invarianten zu beschrei-
ben. Eine Invariante, die wir nun gefunden haben, ist das charakteristische Poly-
nom. Zwei seiner Koeffizienten wollen wir uns naher ansehen. Sei
χA = Xn + cn−1Xn−1 + · · ·+ c0.
Dann gilt
c0 = χA(0) = det(0En −A) = det(−A) = (−1)n detA.
Damit ist c0 identifiziert. Man kann sich auch uberlegen:
cn−1 =−α11 −·· ·−αnn.
Man nennt −cn−1 = α11 + · · ·+αnn die Spur von A.
Da zu einem gegebenen Endomorphismus f das charakteristische Polynom χ f
unabhangig von der Wahl einer Matrix A fur f ist, durfen wir von der Determinante
und Spur von f sprechen.
Wenn auch ahnliche Matrizen das gleiche charakteristische Polynom haben, so
ist die Umkehrung doch falsch. Die Matrizen
E2 =
(1 0
0 1
)und A =
(1 1
0 1
)
haben beide das charakteristische Polynom (X − 1)2, aber die Einheitsmatrix ist
nur zu sich selbst ahnlich.
Ferner gilt dimEig1(E2) = 2, aber dimEig1(A) = 1. Obwohl in beiden Fallen
1 doppelte Nullstelle des charakteristischen Polynoms ist, haben die Eigenraume
zum Eigenwert 1 verschiedene Dimensionen.
Den Zusammenhang zwischen der Dimension von Eigλ ( f ) und der Vielfach-
heit von λ als Nullstelle von χ f nennt der nachste Satz. Außerdem gibt er ein
einfaches Kriterium fur Diagonalisierbarkeit: Ein Endomorphismus heißt diago-
nalisierbar, wenn er bezuglich einer geeigneten Basis durch eine Diagonalmatrix
dargestellt wird; eine Matrix heißt diagonalisierbar, wenn sie zu einer Diagonal-
matrix ahnlich ist.
Satz 23.4. Sei f ein Endomorphismus des endlichdimensionalen K-Vektorraums
V . Seien λ1, . . . ,λm die paarweise verschiedenen Eigenwerte von f und e1, . . . ,em
ihre Vielfachheiten als Nullstellen von χ f .
(a) Es gilt dimEigλi( f )≤ ei fur i = 1, . . . ,m.
(b) Folgende Aussagen uber f sind aquivalent:
(i) f ist diagonalisierbar.
(ii) V besitzt eine Basis aus Eigenvektoren von f .
(iii) χ f zerfallt in Linearfaktoren, und es gilt dimEigλi( f ) = ei fur i =
1, . . . ,m.

206 Abschnitt 23
Beweis. (a) Sei λ ein Eigenwert. Wir wahlen eine Basis v1, . . . ,vr von Eigλ ( f ) und
erganzen sie zu einer Basis v1, . . . ,vn von V . Die Matrix von f bezuglich v1, . . . ,vn
hat dann die Gestalt
A =
λ 0 ∗ · · · ∗. . .
0 λ
0
∗ · · · ∗
.
Sukzessive Entwicklung von det(XEn −A) nach den Spalten 1, . . . ,r ergibt
χ f = χA = (X −λ )r ·gmit einem Polynom g ∈ K[X ]. Daraus folgt unmittelbar Teil (a).
(b) Die Aquivalenz von (i) und (ii) haben wir bereits zu Beginn des Abschnitts
gesehen.
Wenn f eine Basis aus Eigenvektoren (v1, . . . ,vn) mit den Eigenwerten λ1, . . . ,
λn besitzt, gilt
χ f = (X − λ1) · · ·(X − λn),
χ f zerfallt also in Linearfaktoren. Unter λ1, . . . , λn kommt λi genau ei-mal vor.
Also ist dimEigλi( f )≥ ei und dann dimEigλi
( f ) = ei gemaß (a). Dies beweist die
Implikation (ii) ⇒ (iii).
Die Umkehrung (iii) ⇒ (ii) ergibt sich aus 23.2: Wenn dimEigλi( f ) = ei fur
i = 1, . . . ,m und χ f in Linearfaktoren zerfallt, dann ist
m
∑i=1
dimEigλi( f ) =
m
∑i=1
ei = grad χ f = dimV.
Mit den Bezeichnungen von 23.2 gilt also
V =U = Eigλ1( f )⊕·· ·⊕Eigλm
( f ). �
Eine unmittelbare Folgerung aus Satz 23.4:
Satz 23.5. Sei f ein Endomorphismus des K-Vektorraums V mit n = dimV < ∞.
Wenn χ f n paarweise verschiedene Nullstellen besitzt, so ist f diagonalisierbar.
Zur Bestimmung der Eigenwerte haben wir die Nullstellen des charakteristi-
schen Polynoms zu ermitteln.
Wenn uns dies gelungen ist, finden wir den Eigenraum zu einem Eigenwert
λ als Losung eines homogenen linearen Gleichungssystems: Wenn A die Matrix
von f bezuglich einer Basis (v1, . . . ,vn) ist, so bilden die Losungen des homoge-
nen linearen Gleichungssystems λEn −A = 0 gerade die Koordinatenvektoren der
Eigenvektoren von f zum Eigenwert λ bezuglich (v1, . . . ,vn).

Eigenwerte und Eigenvektoren 207
Bei den folgenden Beispielen ist der betrachtete Endomorphismus stets der von
der jeweiligen Matrix A bezuglich der kanonischen Basis des Kn bestimmte Endo-
morphismus.
(a) K =Q (oder R oder C)
A =
(1 −4
−1 1
) χA = (X −1)2 −4 = X2 −2X −3
Eigenwerte: λ1 =−1, λ2 = 3
Basis von Eig−1(A): (1,1/2)Basis von Eig3(A): (1,−1/2)
A ist diagonalisierbar.
(b) K = R,
A =
(0 1
−1 0
)χA = X2 +1
A besitzt keinen Eigenwert.
(c) K = C,
A =
(0 1
−1 0
) χA = X2 +1
Eigenwerte: λ1 = i, λ2 =−i
Basis von Eigi(A): (1, i)Basis von Eig−i(A): (1,−i).
Die Matrix A ist also uber C diagonalisierbar, besitzt aber keinen reellen
Eigenwert.
(d) K beliebig,
A =
(1 1
0 1
) χA = (X −1)2
Eigenwert: λ1 = 1
Basis von Eig1(A): (1,0)
Uber keinem Korper K ist A diagonalisierbar.
Wir rechnen noch ein etwas komplizierteres Beispiel:
A =
−1 2 −1
1 0 −1
−1 −2 −1
χA = det
X +1 −2 1
−1 X 1
1 2 X +1
= X3 +2X2 −4X −8
= (X −2)(X +2)2.
Eigenwerte: λ1 = 2, λ2 =−2.
Losen des linearen Gleichungssystems 2En −A = 0:
3 −2 1 1 2 3 1 2 3 1 0 1
−1 2 1 0 4 4 0 1 1 0 1 1
1 2 3 0 −8 −8 0 0 0 0 0 0

208 Abschnitt 23
Basis von Eig2(A): v = (−1,−1,1).Losen des linearen Gleichungssystems −2En −A = 0:
−1 −2 1 1 +2 −1
−1 −2 1 0 0 0
1 2 −1 0 0 0
Basis von Eig−2(A): w1 = (−2,1,0), w2 = (1,0,1).
Wir betrachten noch kurz die Falle K = C und K = R. Da nach dem Funda-
mentalsatz der Algebra jedes nicht konstante Polynom f ∈ C[X ] eine Nullstelle
besitzt, hat jeder Endomorphismus eines endlichdimensionalen C-Vektorraums V
mindestens einen Eigenwert (außer im trivialen Fall V = {0}):
Satz 23.6. Sei V ein C-Vektorraum mit 0 < dimV < ∞ und f : V → V ein Endo-
morphismus. Dann besitzt f einen Eigenwert.
Anmerkung. Dass die Aussage von 23.6 fur K = R nicht gilt, haben wir oben
gesehen.

Nachwort
Dann sprach sie wieder.
≫Schade, dass der Weg nicht langer war. Findest du nicht?≪
≫Fruher oder spater waren wir ohnehin ans Ende gelangt.≪
Pakhi sah mich an, und ihre Augen glanzten im Mondlicht. Dann wandte sie
den Blick ab und fragte:
≫Woran hast du die ganze Zeit gedacht? ≪
≫Keine Ahnung. ≪
≫Ich habe daran gedacht, wie schon es ist zu gehen, und doch bereitet das
Gehen dem Weg ein Ende. ≪
Damals lachte ich uber ihre Worte. Aber jetzt denke ich, dass dieses vier-
zehnjahrige Madchen, ohne es zu wissen, eine Wahrheit erkannt hatte. Denn so
ist es doch: Indem wir leben, brauchen wir unser Leben auf. Die Wege, die wir
gern beschreiten, enden, weil wir sie abschreiten.
Aus dem Buch: Das Madchen meines Herzens, von Buddhadeva Bose.
List Taschenbuch, 2012. Seite 61.


Literaturverzeichnis
[Art] Artin, M.: Algebra. Birkhauser, Basel 1993
[Bre] Brenner, H.: Mathematik fur Anwender I, Skript, Osnabruck WS 2011/12
[Bri] Brieskorn, E.: Lineare Algebra und analytische Geometrie I, II. Vieweg, Braun-
schweig 1985
[Bru1] Bruns, W.: Lineare Algebra 1, Skript, Osnabruck WS 2011/12
[Bru2] Bruns, W.: Analysis I, Skript, Osnabruck.
[Fis] Fischer, G.: Lineare Algebra. Vieweg, Braunschweig 1997
[HW] Hairer, E. ind Wanner, G.: Analysis by Its History. Springer, New York, 1996
[Heu] Heuser, H.: Lehrbuch der Analysis. Teil 1. 17., aktualisierte Auflage. View-
eg+Teubner, Wiesbaden 2009
[Jan] Janich, K.: Lineare Algebra. Springer, Berlin 1998
[Ker] Kersten, I.: Analytische Geometrie und Lineare Algebra 1. Universitatsdrucke
Gottingen 2005
[Kn] Knopp, K.: Theorie und Anwendung der unendlichen Reihen. 5. Aufl. Springer,
Berlin, 1964
[Kow] Kowalsky, H.-J.: Lineare Algebra. de Gruyter, Berlin 1995
[Lan] Lang, S.: Linear Algebra. Springer, Berlin 1993
[Lip] Lipschutz, S.: Linear Algebra. McGraw-Hill, New York 1974
[Lor] Lorenz, F.: Lineare Algebra I, II. Spektrum, Heidelberg 1996
[Os] Ostrowski, A.: Vorlesungen uber Differential- und Integralrechnung. Band I.
Birkhauser, Basel, 1952
[Se] Serret, J.A.: Calcul differentiel et integral, tome premier. Gauthier-Villars, Paris,
1900
[Smi] Smith, L.: Linear Algebra. Springer, New York 1978
[StG] Stoppel, H. und Griese, B.: Ubungsbuch zur Linearen Algebra. Vieweg, Braun-
schweig 1998.
[StW] Storch, U. und Wiebe, H.: Lehrbuch der Mathematik, Band 2. Spektrum, Heidel-
berg 1999
[Tra] Trapp, H.-W.: Einfuhrung in die Algebra. Rasch, Osnabruck 1995

















