BASEL BERN BRUGG DÜSSELDORF FRANKFURT A. M. FREIBURG I.BR. GENF HAMBURG KOPENHAGEN LAUSANNE MÜNCHEN STUTTGART WIEN ZÜRICH Big Data Konnektivität Einführung und Demos für die Platform Peter Welker (Trivadis GmbH) Berater / Partner
Transcript
BASEL BERN BRUGG DÜSSELDORF FRANKFURT A.M. FREIBURG I.BR. GENF HAMBURG KOPENHAGEN LAUSANNE MÜNCHEN STUTTGART WIEN ZÜRICH
Big Data KonnektivitätEinführung und Demos für die Pla tform
Peter Welker (Trivadis GmbH)Berater / Partner
Wer bin ich?
DOAG 2015 - Oracle Big Data Connectivity2 17.11.2015
Peter WelkerBerater (Trivadis Stuttgart)Partner
Hintergrundinfos – 23 Jahre IT / 17 Jahre DWH (meist Oracle)
– Architekturen, Performance
– Reviews, Evaluationen, PoCs
– DWH Appliances, MPP- & „Neue“ Plattformen
– Training, Artikel, Talks, Bücher
– Themenverantwortlicher „Big Data“
Aufgaben bei Trivadis
– Big Data – Solutions
– Business Intelligence Beratung und Entwicklung
Agenda
DOAG 2015 - Oracle Big Data Connectivity3 17.11.2015
1. Big Data @ Oracle –Statement of Direction
2. Eine umfassende analytische Plattform mit Oracle Produkten?
3. „Big Data Glue“ – Überblick Konnektivität
4. Konnektoren und mehr
5. ODI, Golden Gate & Big Data
6. Zusammenfassung
DOAG 2015 - Oracle Big Data Connectivity4 17.11.2015
Big Data @ Oracle „Statement of Direction “
Oracle Big Data Statement of Direction (1)http://www.oracle.com/technetwork/database/bigdata-appliance/overview/sod-bdms-2015-04-final-2516729.pdf
DOAG 2015 - Oracle Big Data Connectivity5 17.11.2015
Oracle: „Big Data Management Systeme bestehen aus“ …
Data Warehouse (Database)
Data ReservoirBigData „Ecosystem mit
Hadoop & NoSQL
(Big Data Appliance)
„FranchisedQuery Engine“Federation Tool
(Big Data SQL)
Oracle Big Data Statement of Direction (2)
DOAG 2015 - Oracle Big Data Connectivity6 17.11.2015
Aktueller Fokus auf vier Bereichen
– Global Metadata Services a single view of all available data across multiple data stores, exposed in a format similar to Oracle’s data dictionary .
– Global Query Routing and Processingoptimized query execution across multiple data store s. A single query may possibly merge data from multiple data stores. A variety of query optimization and caching techniques will be applied to optimize performance.
– Global Resource Monitoring and Managementprioritization of workloads across the entire BDMS ecosystem.
– Global Data Optimizationthe ability to automatically move data from one repository to anot her (for example, from a data warehouse to a data reservoir or vice versa) based on query performance requirements and/or storage costs .
Oracle Big Data Statement of Direction (3)
DOAG 2015 - Oracle Big Data Connectivity7 17.11.2015
Ein paar Aussagen
“Oracle will provide fast, integrated, secure access to all data – not on ly data stored in […] Exadata […] or Oracle Big Data Appliance , but also data stored in operational NoSQL databases, transactional relational databases, streaming data sources, and more.”
“Oracle will provide a framework for easily incorporating new data sourc es, ensuring that these new data sources can be seamlessly accessed and managed”
“Strategy is to extend its existing in-database features (such as its data dictionary, SQL query engine, query optimizer, resource manager, and data optimization) in order to manage the entire Big Data Management System ”
Oracle Big Data Statement of Direction (4)
DOAG 2015 - Oracle Big Data Connectivity8 17.11.2015
“A favorite hobby of new entrants to the database market is to paint Oracle , the market-leading database, as inflexible and promote their product on the basis that Oracle will never be able to provide the same type of functionality as their new platform. Such vendors pursue this positioning at their peril: object-oriented databases, massively-parallel databases, columnar databases, data warehouse appliances and other trends have been outed as replacements for Oracle Database only to later s ee their core benefits subsumed by the Oracle platform. ”
DOAG 2015 - Oracle Big Data Connectivity9 17.11.2015
Eine umfassende analytische Plattform mit Oracle Produkten?
Das Traditionelle / Klassische DWH
DOAG 2015 - Oracle Big Data Connectivity10 17.11.2015
RDBMS + OLAP
Hoher ETL Aufwand
Hoher Integrationsgrad
OLTP Quellen
Tagesaktuell
Core = SPOT
Marts dimensional
BI Suite obendrauf
Power-User Direktzugriff
…
Auswahl häufiger „moderner“ DWH Anforderungen
DOAG 2015 - Oracle Big Data Connectivity11 17.11.2015
OperativEinbindung direkt in operative Prozesse – nicht nur analytisch / dispositiv
„ODS“1:1 Abbild der Quellsysteme – manchmal historisiert – als Teil der Staging Area
„Echtzeit“Latenz von Stunden oder Minuten – sehr selten wirklich „Echtzeit“
Self Service BIAnsätze zur Flexibilisierung – Sandboxes, BI Tool-Features, einfache ETL Tools, Federation auf OLTP Systeme
Unified AnalysisEinbindung/Zusammenspiel mit Big Data Lösungen/Plattformen + Federation
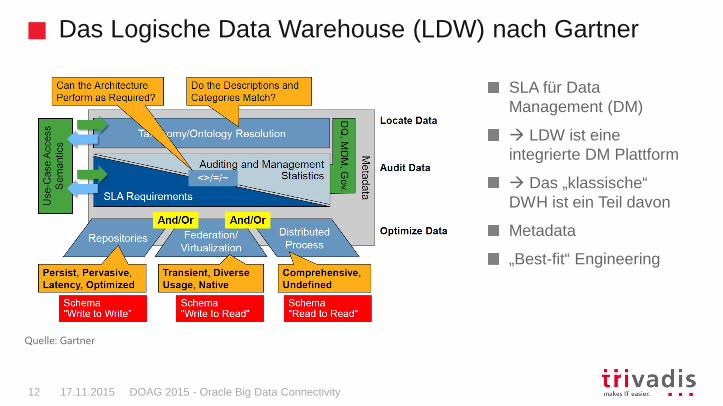
Das Logische Data Warehouse (LDW) nach Gartner
DOAG 2015 - Oracle Big Data Connectivity12 17.11.2015
SLA für Data Management (DM)
� LDW ist eine integrierte DM Plattform
� Das „klassische“ DWH ist ein Teil davon
Metadata
„Best-fit“ Engineering
Quelle: Gartner
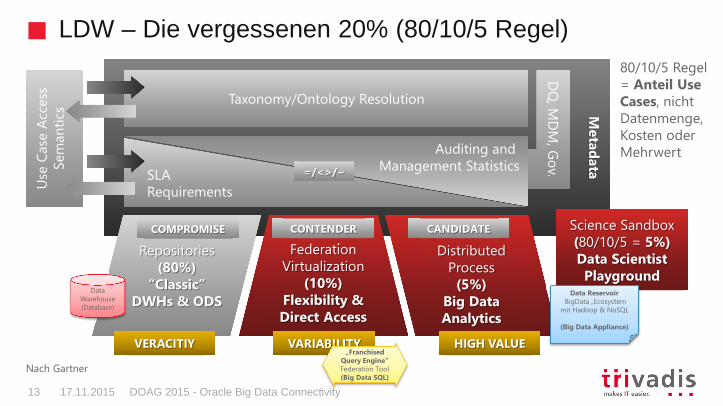
LDW – Die vergessenen 20% (80/10/5 Regel)
DOAG 2015 - Oracle Big Data Connectivity13 17.11.2015
80/10/5 Regel = Anteil UseCases, nicht Datenmenge, Kosten oder Mehrwert
VERACITIY VARIABILITY HIGH VALUE
Data Warehouse (Database)
Data ReservoirBigData „Ecosystem
mit Hadoop & NoSQL
(Big Data Appliance)
„FranchisedQuery Engine“Federation Tool(Big Data SQL)
DOAG 2015 - Oracle Big Data Connectivity14 17.11.2015
„Big Data Glue“Überblick Konnektivität
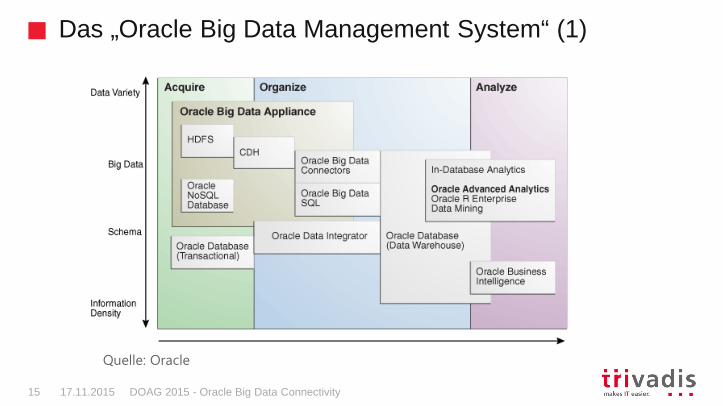
Das „Oracle Big Data Management System“ (1)
DOAG 2015 - Oracle Big Data Connectivity15 17.11.2015
Quelle: Oracle
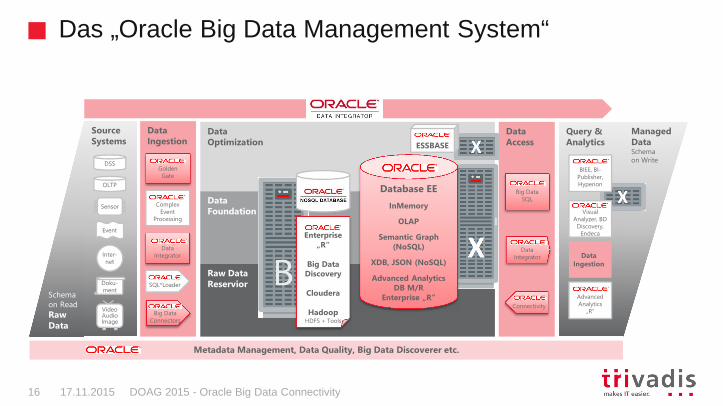
Das „Oracle Big Data Management System“
DOAG 2015 - Oracle Big Data Connectivity16 17.11.2015
Source Systems
OLTP
Doku-ment
Inter-net
DSS
Event
Sensor
VideoAudioImage
Data Ingestion
Data Optimization
Raw Data Reservior
Data Foundation
Data Access
Query & Analytics
Schema on Read
RawData
ManagedDataSchema on Write
Data Integration
Metadata Management, Data Quality, Big Data Discoverer etc.
Data Ingestion
SQL*Loader
Big Data Connectors
AdvancedAnalytics
„R“
Big Data SQL
Data Integrator
NoSQLKey Value
Database EE
InMemory
OLAP
Semantic Graph (NoSQL)
XDB, JSON (NoSQL)
Advanced AnalyticsDB M/R
Enterprise „R“
ESSBASE
Enterprise „R“
Big Data Discovery
Cloudera
HadoopHDFS + Tools
Data Integrator
Connectivity
Golden Gate
ComplexEvent
Processing
BIEE, BI-Publisher, Hyperion
Visual Analyzer, BD
Discovery, Endeca
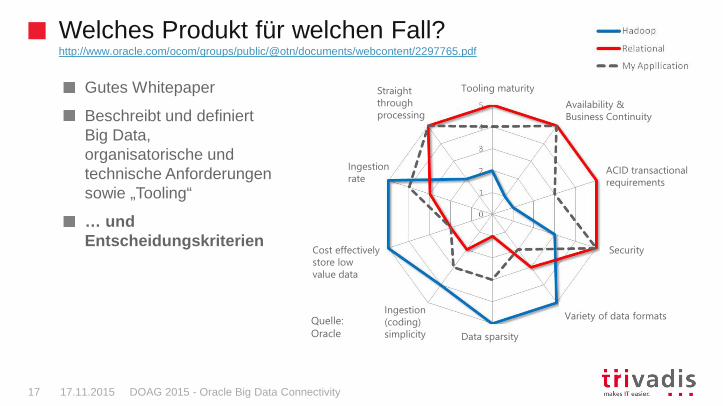
Welches Produkt für welchen Fall?http://www.oracle.com/ocom/groups/public/@otn/documents/webcontent/2297765.pdf
DOAG 2015 - Oracle Big Data Connectivity17 17.11.2015
Gutes Whitepaper
Beschreibt und definiert Big Data, organisatorische und technische Anforderungen sowie „Tooling“
… und Entscheidungskriterien
Tooling maturity
Availability & Business Continuity
ACID transactionalrequirements
Security
Variety of data formats
Data sparsity
Ingestion (coding) simplicity
Cost effectivelystore lowvalue data
Ingestion rate
Straight throughprocessing
Quelle: Oracle
DOAG 2015 - Oracle Big Data Connectivity18 17.11.2015
Konnektoren und mehr
Oracle Big Data Connectors
DOAG 2015 - Oracle Big Data Connectivity19 17.11.2015
Oracle SQL Connector for HDFS (OSCH)
Oracle Loader for Hadoop (OLH)
Oracle XQuery for Hadoop
Oracle „R“ Advanced Analytics for Hadoop
OSCH
OLH
OXH
ORH
Oracle SQL Connector for HDFS (OSCH)
DOAG 2015 - Oracle Big Data Connectivity20 17.11.2015
“ Read Only HDFS Zugriff auf Oracle Data Pump files, Delimited text files und Delimited text files in Apache Hive Tabellen aus einer Oracle Datenbank heraus”
„Einfachste“ Variante für Zugriff auf HDFS und Hive aus der Datenbank heraus
Nutzt External Tables und ET Präprozessor zum Zugriff auf HDFS und Hive via SQL
Ermöglicht Zugriff auf
– Apache Hadoop ab Version 2.2.0 (bspw. Cloudera 4 und 5)
– Hive Versionen 0.10.0, 0.12.0, 0.13.0, 0.13.1 oder 1.1.0
Benötigt DB ab 10.2.0.5, 11.2.0.2 oder 12
– Nur für Linux x86-64
OSCH
OSCH Setup
DOAG 2015 - Oracle Big Data Connectivity21 17.11.2015
Installation von Hadoop Client und OSCH auf DB Server
Danach generiert OSCH Zugriffsmechanismen und -objekte
CONNECT / AS sysdba;CREATE USER hdfsuser IDENTIFIED BY password
DEFAULT TABLESPACE hdfsdata -- Nur für Schreibvor-QUOTA UNLIMITED ON hdfsdata; -- gänge in die DB
GRANT CREATE SESSION, CREATE TABLE, CREATE VIEW TO hdfsuser;GRANT EXECUTE ON sys.utl_file TO hdfsuser; -- UTL_FILE Zugriff!GRANT READ, EXECUTE ON DIRECTORY osch_bin_path TO hd fsuser; -- OSCH binariesGRANT READ, WRITE ON DIRECTORY external_table_dir TO hdfsuser; -- External Tables
OSCH
Local Linux
Oracle Database
Hadoop
HiveTableFiles
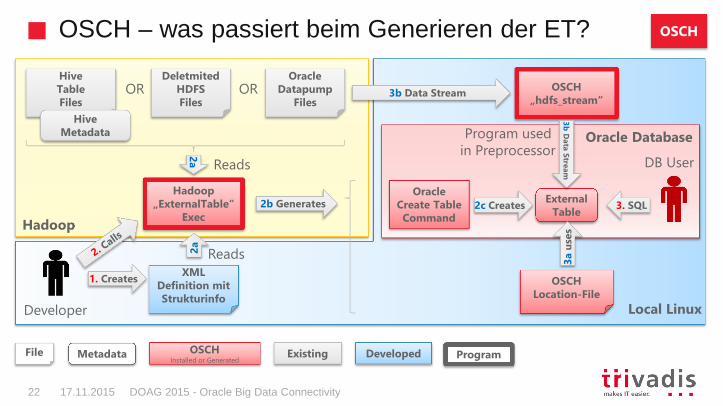
OSCH – was passiert beim Generieren der ET?
DOAG 2015 - Oracle Big Data Connectivity22 17.11.2015
XML Definition mit Strukturinfo
Hadoop„ExternalTable“
Exec
HiveMetadata
Oracle Create Table Command
OSCH Location-File
2b Generates ExternalTable
2c Creates2
a
2a
3. SQL
Developer
DB UserReads
Reads
1. Creates
DeletmitedHDFS Files
Oracle Datapump
FilesOR OR OSCH
„hdfs_stream“
3b
Data
Stre
am
Program usedin Preprocessor
3b Data Stream
File ProgramMetadata OSCHInstalled or Generated
Existing Developed
3a u
ses
OSCH
OSCH ExternalTable Setup
DOAG 2015 - Oracle Big Data Connectivity23 17.11.2015
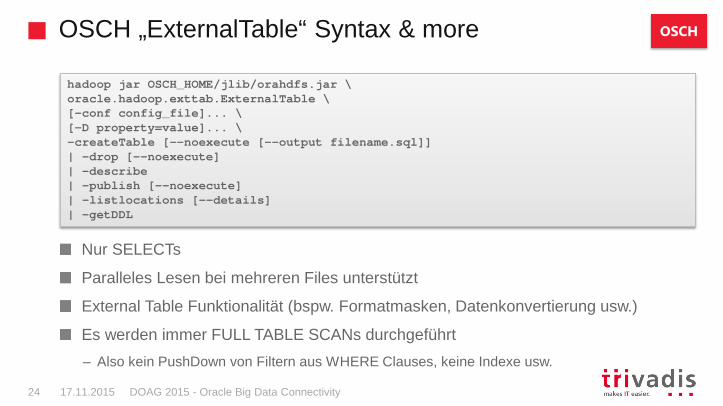
Achtung: Hier handelt es sich um das OSCH CommandLine Tool „ExternalTable“ , nicht um den Oracle Database Befehl
ExternalTable Tool in Hadoop ausführen
– Provide ET with information about the Hadoop data source and a schema in the Oracle Database either as part of the CREATE ET command or in a separate XML file
– Achtung: Außerhalb DB statt – es ist ein Aufruf eines Java Programms mittels des Hadoop client
Das Tool generiert den passenden Create External Table Befehl für die Datenbank
Der Zugriff geschieht über einen generischen Präprozessor
hadoop jar \ -- hadoop Befehl$OSCH_HOME/jlib/orahdfs.jar \ -- Tool aus folgender Bibliothekoracle.hadoop.exttab.ExternalTable \ -- Name des Tools (Java Programm)-conf /home/oracle/movies/moviefact_hdfs.xml \ -- Param: XML mit ET Definition-createTable -- Param: Befehl im Tool
OSCH
OSCH „ExternalTable“ Syntax & more
DOAG 2015 - Oracle Big Data Connectivity24 17.11.2015
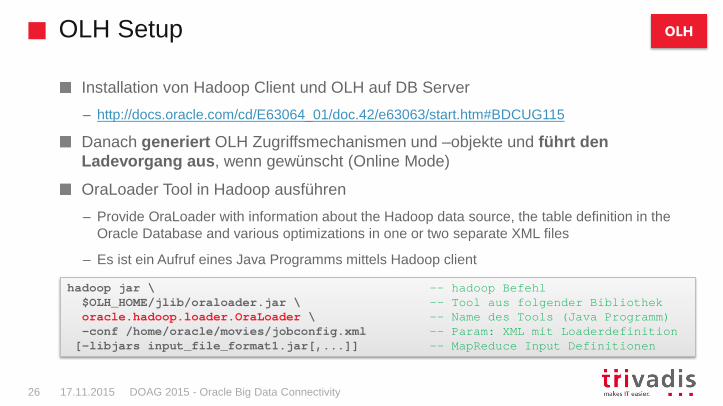
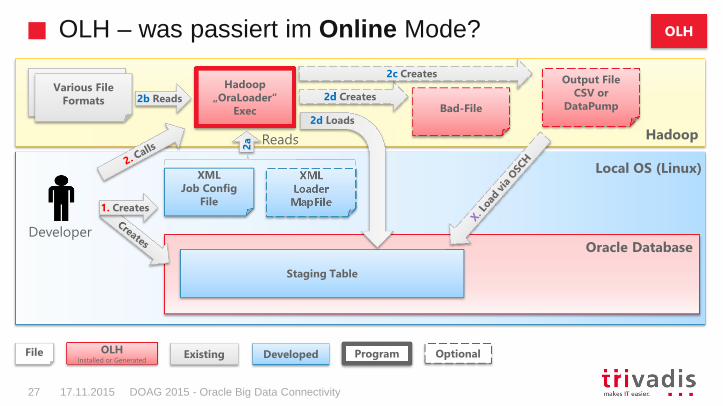
Danach generiert OLH Zugriffsmechanismen und –objekte und führt den Ladevorgang aus , wenn gewünscht (Online Mode)
OraLoader Tool in Hadoop ausführen
– Provide OraLoader with information about the Hadoop data source, the table definition in the Oracle Database and various optimizations in one or two separate XML files
– Es ist ein Aufruf eines Java Programms mittels Hadoop client
hadoop jar \ -- hadoop Befehl$OLH_HOME/jlib/oraloader.jar \ -- Tool aus folgender Bibliothekoracle.hadoop.loader.OraLoader \ -- Name des Tools (Java Programm)-conf /home/oracle/movies/jobconfig.xml -- Param: XML mit Loaderdefinition
DOAG 2015 - Oracle Big Data Connectivity27 17.11.2015
XML Job Config
File
Hadoop„OraLoader“
Exec
2a
2b Reads
Developer
Reads
File ProgramOLHInstalled or Generated
Existing Developed
XML LoaderMapFile
Various File Formats
Staging Table
2d Loads
2d Creates
2c Creates
Bad-File
Output FileCSV or
DataPump
1. Creates
Optional
OLH
Local OS (Linux)
Oracle Database
Hadoop
Various File Formats
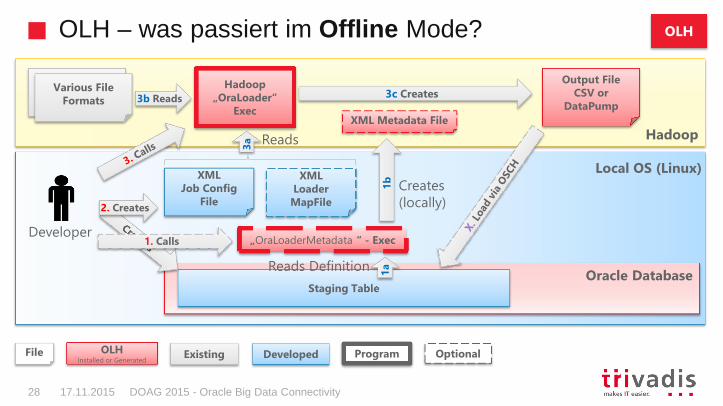
OLH – was passiert im Offline Mode?
DOAG 2015 - Oracle Big Data Connectivity28 17.11.2015
XML Job Config
File
Hadoop„OraLoader“
Exec
3a
3b Reads
Developer
Reads
File ProgramOLHInstalled or Generated
Existing Developed
XML LoaderMapFile
Various File Formats
Staging Table
3c Creates
Output FileCSV or
DataPump
2. Creates
Optional
„OraLoaderMetadata “ - Exec
1aReads Definition
XML Metadata File
1b Creates
(locally)
1. Calls
OLH
OLH – Input Formate
DOAG 2015 - Oracle Big Data Connectivity29 17.11.2015
„Simple Delimited Text File “ – Newline separiert Records, ein Zeichen separiert Felder
„Complex Delimited Test Files “ – Regular Expression separiert Felder
„Hive Tables “ – Konvertiert Hive Tabellen in das Avro-Format und lädt dieses
„Avro “ – Lädt Avro Formate
„Oracle NoSQL DB “ – Lädt „Values“ aus der NoSQL DB. Java Programmierung erforderlich, um auch die Keys zu laden
„Custom Input Formats “ – InputFormat Klasse von MapReduce muss erweitert werden
OLH
OLH – Output Formate
DOAG 2015 - Oracle Big Data Connectivity30 17.11.2015
Nur Online Load
– JDBC Output Format � Configdatei-Parameter mapreduce.outputformat.class = oracle.hadoop.loader.lib.output.JDBCOutputFormat
o Batch Inserts – ohne vollständige Fehlerbehandlung
– OCI Direct Path Output Format � Configdatei-Parametermapreduce.outputformat.class = oracle.hadoop.loader.lib.output.OCIOutputFormat
o Nur wenn Hadoop auf Linux x86-64 läuft
o Zieltabelle muss partitioniert sein
o Parallelität = Anzahl Reducer im MapReduce Job
Files (Online und Offline)
– Delimited Te xt Output Format Files auf dem Hadoop Cluster
– Data Pump Output Format Files auf dem Hadoop Cluster
OLH
OLH – Details
DOAG 2015 - Oracle Big Data Connectivity31 17.11.2015
DB Mapping – Auto Mode
– Im Online-Mode holt der OraLoader die DB Tabellenmetadaten direkt aus der DB
– Im Offline-Mode kann mit dem lokalen Java Program OraLoaderMetadata vorab ein Oracle Metadata XML File erzeugt werden. Dies muss vorab auf den Hadoop Cluster kopiert werden
– Automatisches Mapping möglich, sofern alle Spalten geladen und nur gleiche Spaltennamen sowie nur ein Date-Format verwendet wird
DB Mapping – Manual Mode
– Loadermap XML Datei muss erstellt werden
OLH
Oracle XQuery for Hadoop (OXH) – Überblick
DOAG 2015 - Oracle Big Data Connectivity32 17.11.2015
“Oracle XQuery for Hadoop runs transformations expressed in the XQuery language by translating them into a series of MapReduce jobs , which are executed in parallel on an Apache Hadoop cluster”
Input Formate: HDFS files oder Oracle NoSQL DB
Adapter für Avro, JSON, Oracle DB (OCI & JDBC + Datapump und Delimited Text als Output), Oracle NoSQL DB, Sequence Files, Solr, Text Files und XML
„XML Extensions for Hive“ liest XML Dateien als Hive Tabellen oder XML in HiveTabellen
„Apache Tika“ Adapter erlaubt die Programmierung weiterer Formate
com.oracle.bigdata.tablename: order_db.order_summar ycom.oracle.bigdata.colmap: {"col":"ITEM_CNT", field ":„oli_count"}... )
);
OBDS
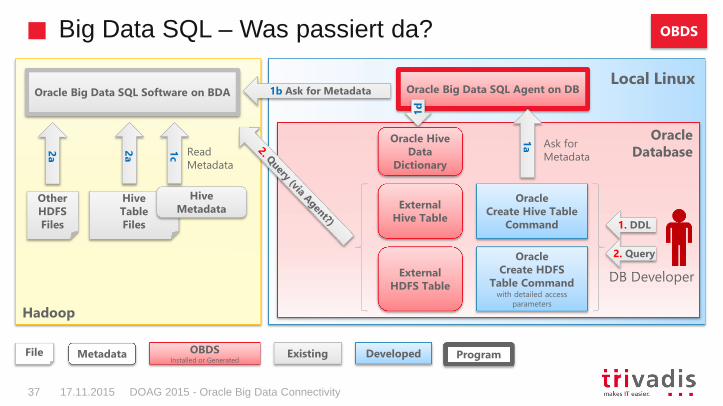
Big Data SQL – Mehr zu ORACLE_HIVE
DOAG 2015 - Oracle Big Data Connectivity40 17.11.2015
Zur „Create Table“ DDL Ausführungszeit werden die Hive Metadaten gelesen
Typen werden bei Bedarf automatisch konvertiert
– Bei external Hive Daten sogar bis zu zweimal: 1. via SerDe ins Hive Format und 2. von dort ins Oracle Format
Auch Zugriff auf Oracle NoSQL oder HBase ist möglich
– Schritt 1: Hive External Table auf KVStore von Oracle NoSQL bzw. HBase erstellen
– Schritt 1: Oracle External Table auf diese Hive Table erstellen
OBDS
Big Data SQL – „Copy to BDA“ Tool
DOAG 2015 - Oracle Big Data Connectivity41 17.11.2015
Bietet Hive-Zugriff auf einzelne, via CTAS-DP (siehe unten) erzeugte Dateien
Dazu erstellt man via CREATE TABLE … EXTERNAL (TYPE ORACLE _DATAPUMP) DP Dateien mit einer Tabelle als Inhalt
Kopiert diese nach HDFS
… und erstellt eine External Hive Table mit dem SERDE oracle.hadoop.hive.datapump.DPSerDe
OBDS
„Umsonst und draußen“: Oracle Database Gateway
DOAG 2015 - Oracle Big Data Connectivity42 17.11.2015
Erzeugt Database Links zu anderen Datenbanken (SQL Server, Teradata usw.)
– Gerne kostenintensiv
Kostenfrei ist aber die GENERIC OCBD Variante
– https://community.oracle.com/thread/2292321
Erzeugt einen DB Link via ODBC Treiber bspw. zu Hive
Was ist die Idee?
Oracle Konnektoren meiden die Nutzung anderer SQL Query Engines wie Hive oder Impala (auch wenn sie gerne die Hive Metadaten verwenden)
Mit ODG tun wir das aber – mit allen Vor- und Nachteilen
ODG
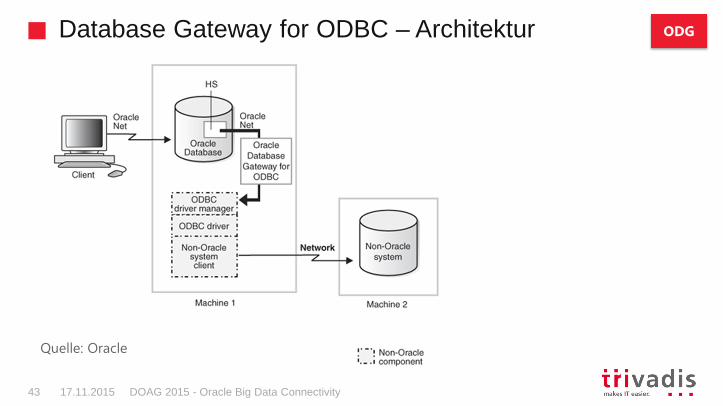
Database Gateway for ODBC – Architektur
DOAG 2015 - Oracle Big Data Connectivity43 17.11.2015
ODG
Quelle: Oracle
Database Gateway for ODBC – Setup
DOAG 2015 - Oracle Big Data Connectivity44 17.11.2015
1. Passenden OBCD Treiber installieren und konfigurieren
2. ODBC Gateway Installieren
3. listener.ora und tnsnames.ora anpassen
4. In ORACLE_HOME\hs\admin neue Datei erzeugen
5. Public Database Link erzeugen
6. … loslegen
ODG
DOAG 2015 - Oracle Big Data Connectivity45 17.11.2015
ODI, Golden Gate & Big Data
Oracle Big Data Capturing & Integration
DOAG 2015 - Oracle Big Data Connectivity46 17.11.2015
Oracle Data Integrator
Oracle Golden Gate
ODI
OGG
Oracle Data Integrator – Überblick
DOAG 2015 - Oracle Big Data Connectivity47 17.11.2015
Big Data Option (separate Lizenz!)
Native Code Generierung für Pig Latin, Spark (PySpark) und Oozie
Auswahl aus dem traditionellen ODI Agent oder Apache Oozie als Orchestrierungs-Engine
WebLogic Hive JDBC Driver
Zahlreiche Direct Load KMs (LKM = Loading Knowledge Modules kombiniert mit anderen KMs in einem Mapping einsetzbar) bspw. für Sqoop etc.
Oracle Data Integrator Application Adapter for Hadoop
Part of the Oracle Big Data Connectors (uses OLH/OSCH)
There is also a Big Data SQL Integration to ODI
ODI
Oracle Golden Gate
Oracle Golden Gate for Big Data – Überblick
DOAG 2015 - Oracle Big Data Connectivity48 17.11.2015
OGG
Adapted from Oracle
Cap
ture
Tra
il
Pu
mp
Ro
ute
Deli
ver
ForBig
Data
Oracle Golden Gate for Big Data – Überblick (2)
DOAG 2015 - Oracle Big Data Connectivity49 17.11.2015
Oracle Golden Gate for Big Data
Provides GoldenGate delivery to Flume , HDFS, Hive and HBase
Includes GoldenGate for Java, enabling integration to others such as Oracle NoSQL, Apache Kafka, Apache Storm, Apache Spark etc.
Key component of Oracle’s big data integration offering along with Oracle Data Integrator 12c
Oracle GoldenGate supports log-based capture from, and delivery to, Oracle, DB2 for z/OS, i Series, & LUW (Linux, Unix, Windows), SQL Server, MySQL, Informix, Sybase ASE, SQL/MX, JMS messaging systems and more. Oracle GoldenGate’sdelivery capabilities also include Oracle TimesTen In Memory Database andPostgreSQL, in addition to Hadoop-based big data systems
OGG
DOAG 2015 - Oracle Big Data Connectivity50 17.11.2015
Zusammenfassung
Zusammenfassung
DOAG 2015 - Oracle Big Data Connectivity51 17.11.2015
Konnektivität Datenbank � Big Data Plattform steht im Zentrum der Oracle BigDataAktivitäten
– Oracle Big Data Connectors (OLH, OSCH, OXH usw.) schon länger verfügbar
– Big Data SQL vereinfacht und beschleunigt Konnektivität deutlich, ist äußerst vielversprechend – aber lizenzmäßig extrem limitiert und daher für die meisten Kunden heute irrelevant
– Oracle Generic ODBC Database Gateway ist eine kostengünstige und einfache Option für Verbindungen ohne besondere Ansprüche an Durchsatz und Kompatibilität
ODI hat zahlreiche KMs rund um Hadoop und Co.– Mit der Big Data Option ist die Nutzung von Hadoop als Datenintegrationsplattform greifbar
Golden Gate erlaubt Hadoop & Co als Replikationsziel– Real-Time DI für Hive mag eingeschränkten Nutzen haben, aber Flume, Storm etc. sind