

1© Marcus Hudec
Univariate HäufigkeitstabellenTabellarische und graphische Aufbereitung von Daten
Statistik 1 für SoziologInnen
Tabellarische und graphische Aufbereitung von Daten
Univ.Prof. Dr. Marcus Hudec
Absolute Häufigkeiten diskreter Merkmale
X sei ein diskretes Merkmal mit den Realisationsmöglichkeiten xi, wobei i=1,...,k
X sei ein qualitatives Merkmal, das entweder eine Nominal- oder eine Ordinalskala aufweist
Die Anzahl des Vorkommens von xi in einer Population heißt absolute Häufigkeit:
n(X=xi) bzw. kurz ni
n()…Zählfunktion
2 Statistik 1 - Univariate Häufigkeitstabellen

2© Marcus Hudec
Beispiel: Personalbeurteilung (Schlittgen p.13 ff)
n=120 BeurteilungsbögenMerkmal: "Produktives Denken"Ausprägungen xi (k=10):0 ... sehr gering
bis 9 ... sehr gut ausgeprägtSkalenniveau: OrdinalUrliste:Urliste:5 6 8 7 5 5 ...
... 6 5 5 4
3 Statistik 1 - Univariate Häufigkeitstabellen
Häufigkeitstabelle (absolute Häufigkeiten)
i xi ni
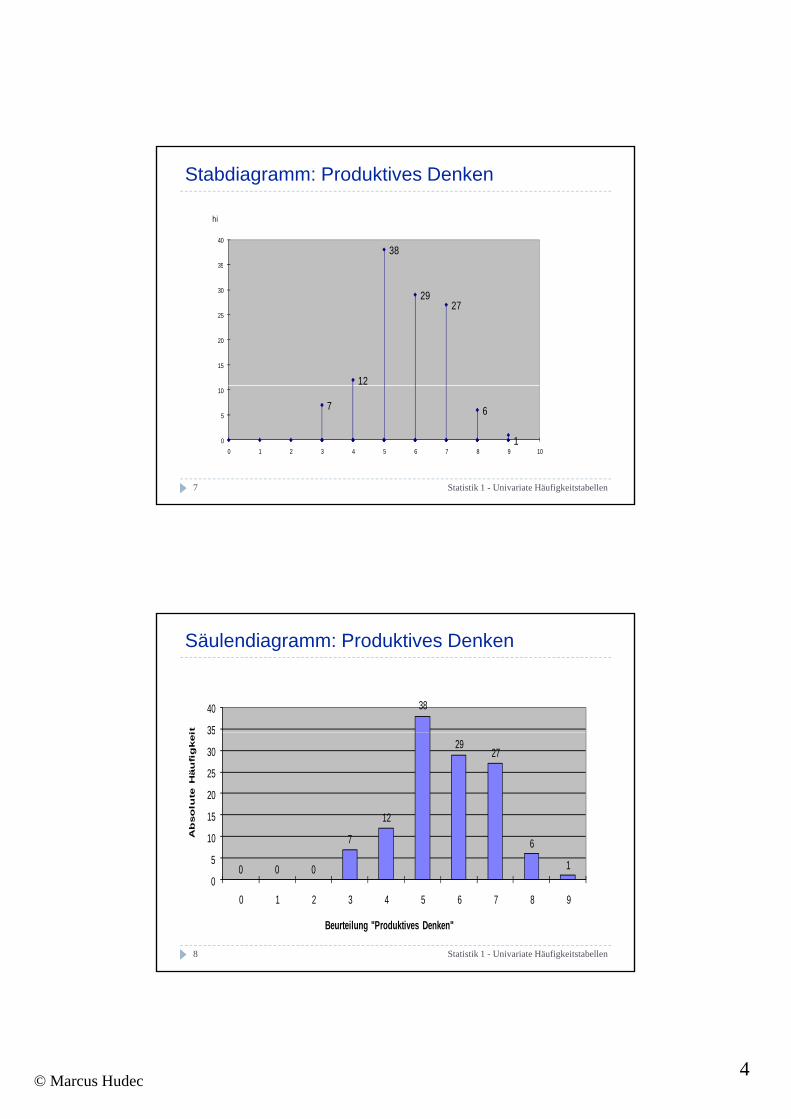
1 0 02 1 02 1 03 2 04 3 75 4 126 5 387 6 298 7 27
Statistik 1 - Univariate Häufigkeitstabellen4
8 7 279 8 6
10 9 1Gesamt 120
i … laufender Index
xi …Ausprägungen
ni … Häufigkeiten

3© Marcus Hudec
Relative Häufigkeiten diskreter Merkmale
Die relative Häufigkeit hi von einer Merkmalsausprägung xi ist:die absolute Häufigkeit n der Merkmalsausprägung xdie absolute Häufigkeit ni der Merkmalsausprägung xidividiert durch die Gesamtzahl der Merkmalsträger n
≡==
≡= iii
i hnn
nxXnxXh )(
)(
∑∑==
==k
ii
k
ii hnn
111
5 Statistik 1 - Univariate Häufigkeitstabellen
Häufigkeitstabelle (absolute & relative Häufigkeiten)
i xi ni hi hi in %1 0 0 0,00 0,00%2 1 0 0,00 0,00%3 2 0 0,00 0,00%4 3 7 0,06 5,83%5 4 12 0,10 10,00%6 5 38 0,32 31,67%7 6 29 0,24 24,17%8 7 27 0,23 22,50%9 8 6 0 05 5 00%9 8 6 0,05 5,00%
10 9 1 0,01 0,83%Gesamt 120 1 100,00%
6 Statistik 1 - Univariate Häufigkeitstabellen
In der Praxis werden die relativen Häufigkeiten oft mit 100 multipliziert und als Prozentwerte dargestellt
4© Marcus Hudec
Stabdiagramm: Produktives Denken
3835
40
hi
12
2927
15
20
25
30
35
7 6
10
5
10
0 1 2 3 4 5 6 7 8 9 10
7 Statistik 1 - Univariate Häufigkeitstabellen
Säulendiagramm: Produktives Denken
38
35
40
t
7
12
2927
610
15
20
25
30
35
Ab
so
lute
Häu
fig
kei
0 0 0 10
5
0 1 2 3 4 5 6 7 8 9
Beurteilung "Produktives Denken"
8 Statistik 1 - Univariate Häufigkeitstabellen
5© Marcus Hudec
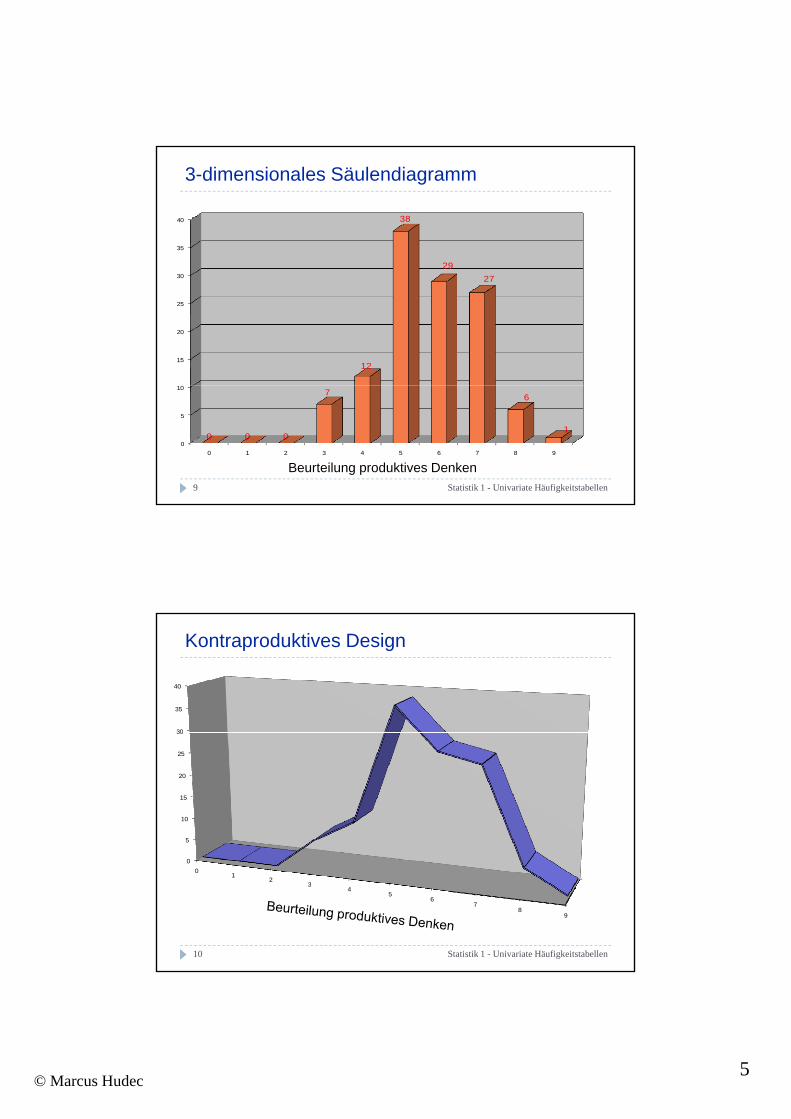
3-dimensionales Säulendiagramm
35
40 38
29
15
20
25
30
12
2927
0
5
10
0 1 2 3 4 5 6 7 8 9
0 0 0
7 6
1
9 Statistik 1 - Univariate Häufigkeitstabellen
Beurteilung produktives Denken
Kontraproduktives Design
30
35
40
5
10
15
20
25
30
Datenreihen1
00
12
34
56
78
9
10 Statistik 1 - Univariate Häufigkeitstabellen

6© Marcus Hudec
4 Leitregeln für statistische Graphiken
Eine statistische Graphik sollte möglichst selbsterklärend sein.
Möglichst exakte Angabe der Datenquelle bzw. der Grundgesamtheit.
Es sollte möglich sein, auf die zugrundeliegenden numerischen Daten rückschließen zu können
Gitterlinien, WertangabenDie erste optische Wahrnehmung muss die tatsächlichen Größenordnungen korrekt widerspiegeln.
Menschen nehmen Flächen wahr Flächen müssen dieMenschen nehmen Flächen wahr Flächen müssen die Quantität reflektieren
Die Graphik soll optisch attraktiv sein, aber eine klare Botschaft vermitteln.
Erwecken des Interesses des Betrachters
11 Statistik 1 - Univariate Häufigkeitstabellen
Vier zentrale Prinzipien statistischer Graphiken
Selbsterklärend(Qualitative Information)Numerische TransparenzNumerische Transparenz (Quantitative Information)Graphische Integrität(Korrektheit der Information)Optische Attraktivität(Anziehungskraft)
Statistik 1 - Univariate Häufigkeitstabellen12
(Anziehungskraft)
Mehr dazu im Kapitel 3. Statistische Graphiken

7© Marcus Hudec
Daten aus Kühnel & Krebs p.44
Frage nach der Einschätzung der Wirtschaftlage in Deutschland (1996)
Ausprägung Code Häufigkeitsehr gut 1 30gut 2 435teils/teils 3 1710schlecht 4 1087schlecht 4 1087sehr schlecht 5 232keine Antwort -99 24
13 Statistik 1 - Univariate Häufigkeitstabellen
Daten aus Kühnel & Krebs p.44 - mit Excel aufbereitet
Gültige Kumulierte
Frage nach der "Einschätzung der allgemeinen Witschaftslage in der Bundesrepublik Deutschland"
Ausprägung Code Häufigkeit ProzenteGültige
ProzenteKumulierte Prozente
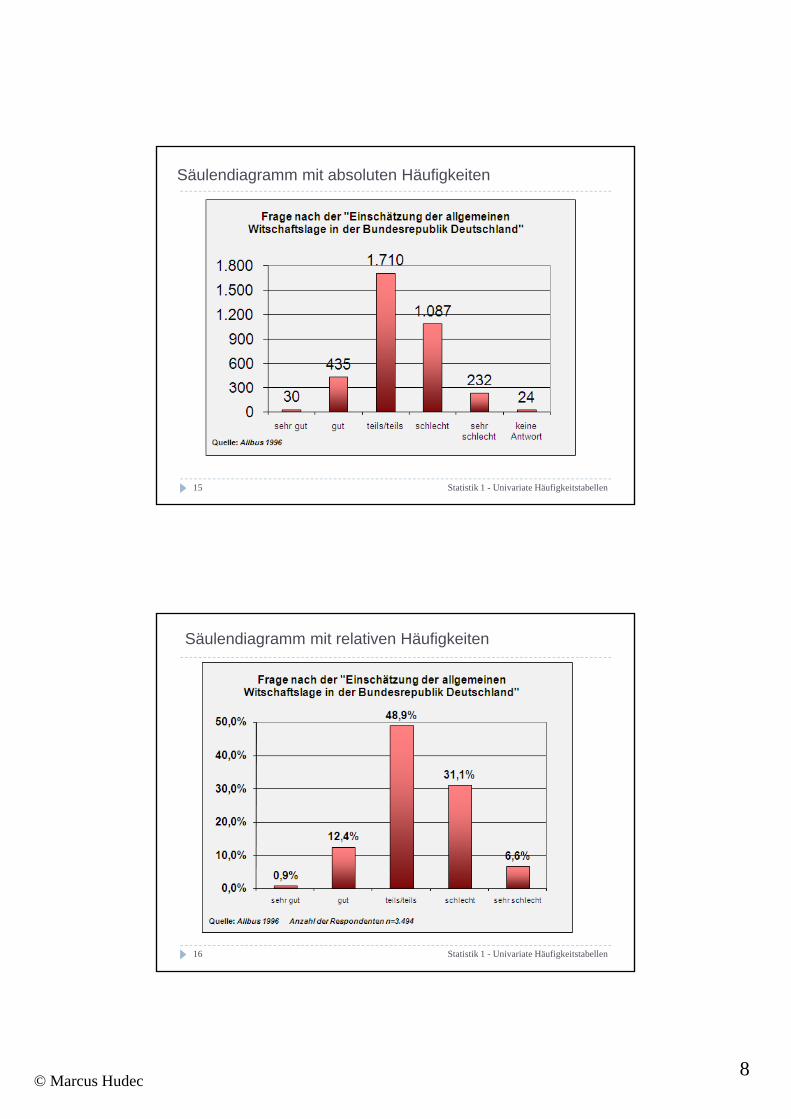
sehr gut 1 30 0,9% 0,9% 0,9%gut 2 435 12,4% 12,4% 13,3%teils/teils 3 1.710 48,6% 48,9% 62,2%schlecht 4 1.087 30,9% 31,1% 93,4%sehr schlecht 5 232 6,6% 6,6% 100,0%keine Antwort -99 24 0,7% MissingTotal 3.518 100,0% 100,0%Gültige Fälle: 3.494 Fehlende Fälle: 24g
Quelle: Allbus 1996
14 Statistik 1 - Univariate Häufigkeitstabellen
Die gültigen Prozentwerte beziehen die absolute Häufigkeit gültiger Antworten auf die Gesamtzahl aller gültigen Antworten
8© Marcus Hudec
Säulendiagramm mit absoluten Häufigkeiten
15 Statistik 1 - Univariate Häufigkeitstabellen
Säulendiagramm mit relativen Häufigkeiten
16 Statistik 1 - Univariate Häufigkeitstabellen
9© Marcus Hudec
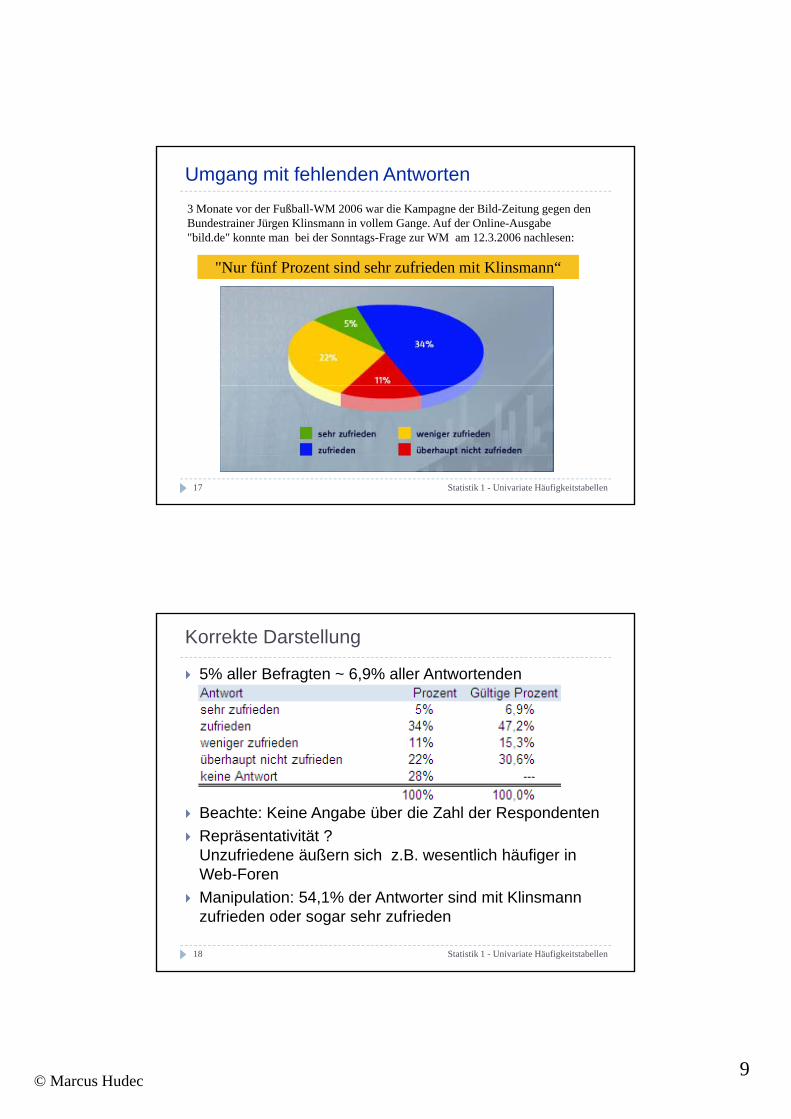
Umgang mit fehlenden Antworten3 Monate vor der Fußball-WM 2006 war die Kampagne der Bild-Zeitung gegen den Bundestrainer Jürgen Klinsmann in vollem Gange. Auf der Online-Ausgabe "bild.de" konnte man bei der Sonntags-Frage zur WM am 12.3.2006 nachlesen:
"Nur fünf Prozent sind sehr zufrieden mit Klinsmann“"Nur fünf Prozent sind sehr zufrieden mit Klinsmann
Statistik 1 - Univariate Häufigkeitstabellen17
Korrekte Darstellung
5% aller Befragten ~ 6,9% aller Antwortenden
Beachte: Keine Angabe über die Zahl der RespondentenRepräsentativität ? Un friedene ä ßern sich B esentlich hä figer in
Statistik 1 - Univariate Häufigkeitstabellen18
Unzufriedene äußern sich z.B. wesentlich häufiger in Web-ForenManipulation: 54,1% der Antworter sind mit Klinsmann zufrieden oder sogar sehr zufrieden

10© Marcus Hudec
Imputation fehlender Werte
Imputationsmethoden haben das Ziel fehlende Werte möglichst sinnvoll zu ergänzenGrundgedanke ist dabei das Ausnützen vonGrundgedanke ist dabei das Ausnützen von Abhängigkeiten zwischen MerkmalenUnterschiedliche Ergebnisse bei politischen Meinungsumfragen unterscheiden sich häufig nur in der methodischen Behandlung fehlender Werte:Wie werden die Unschlüssigen bzw. die Antwortverweigerer aufgeteilt?
Statistik 1 - Univariate Häufigkeitstabellen19
g gVergleiche in der jüngeren österreichischen Geschichte die Unterschätzung der FPÖ unter J. Haider in vielen Meinungsumfragen vor Wahlen
Absolute oder relative Häufigkeiten?
Für Vergleichszwecke eignen sich relative Häufigkeiten natürlich besserBei Stichproben interessieren meist die AnteileBei Stichproben interessieren meist die Anteile (~relativen Häufigkeiten), aber der Umfang der Stichprobe muss unbedingt kommuniziert werden, um die Relevanz der Ergebnisse beurteilen zu können.Absolute Häufigkeiten kommunizieren stärker die Betroffenheit:
Statistik 1 - Univariate Häufigkeitstabellen20
Im Jahresdurchschnitt 2006 gab es in Österreich laut AMS 239.000 als arbeitslos vorgemerkte Personen Im Jahresdurchschnitt 2006 betrug laut AMS die Arbeitslosenquote 6,8%
11© Marcus Hudec
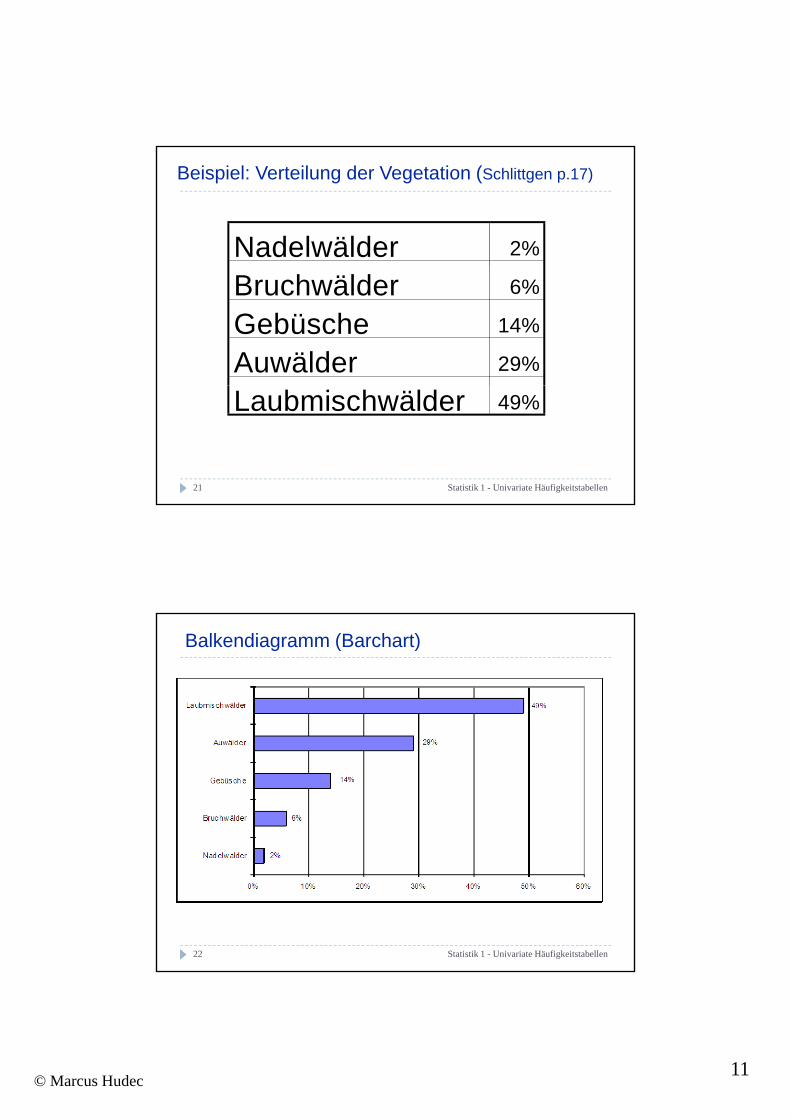
Beispiel: Verteilung der Vegetation (Schlittgen p.17)
Nadelwälder 2%
Bruchwälder 6%
Gebüsche 14%
Auwälder 29%
Laubmischwälder 49%
21 Statistik 1 - Univariate Häufigkeitstabellen
Balkendiagramm (Barchart)
22 Statistik 1 - Univariate Häufigkeitstabellen

12© Marcus Hudec
Tortendiagramm (Piechart)
Nadelwälder2% Bruchwälder
6%
Gebüsche14%14%
Laubmischwälder49%
Auwälder29%
23 Statistik 1 - Univariate Häufigkeitstabellen
Häufigkeitsverteilung bei einem stetigen MerkmalStetiges Merkmal X mit vielen unterschiedlichen AusprägungenGrundgesamtheit von n Merkmalsträgern
nxxx ,,, 21 …
Urliste der Körpergröße von 100 Studenten:
170 183 154 186 165 180 177 178 184 176 178 175 188 153 183 180 165 180 180 196 174 167 181 168 166 187 187 195 164 177 197 161 187 170 171 184 170 187 167 160 162 182 173 168 182 185 155 176 172 164 166 163 170 164 171 173 179 174 180 172 177 175 157 167 165 160 170 173 166 173 166 178 172 176 169 160 169 171 179 179 175 175 190 182 177 185 173 174 172 186 173 173 176 162 174 182 188 188 174 177
24 Statistik 1 - Univariate Häufigkeitstabellen
13© Marcus Hudec
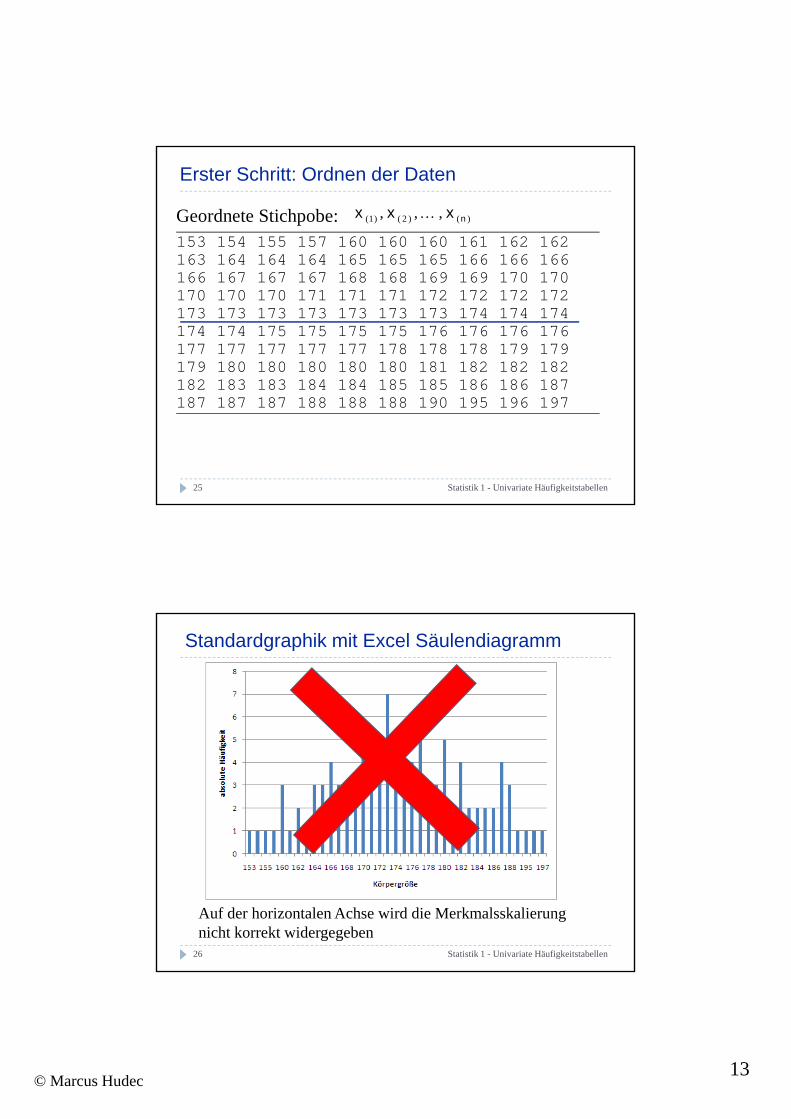
Erster Schritt: Ordnen der Daten
Geordnete Stichpobe:153 154 155 157 160 160 160 161 162 162163 164 164 164 165 165 165 166 166 166
)()2()1( ,,, nxxx …
166 167 167 167 168 168 169 169 170 170170 170 170 171 171 171 172 172 172 172173 173 173 173 173 173 173 174 174 174174 174 175 175 175 175 176 176 176 176177 177 177 177 177 178 178 178 179 179179 180 180 180 180 180 181 182 182 182182 183 183 184 184 185 185 186 186 187182 183 183 184 184 185 185 186 186 187187 187 187 188 188 188 190 195 196 197
25 Statistik 1 - Univariate Häufigkeitstabellen
Standardgraphik mit Excel Säulendiagramm
Statistik 1 - Univariate Häufigkeitstabellen26
Auf der horizontalen Achse wird die Merkmalsskalierung nicht korrekt widergegeben
14© Marcus Hudec
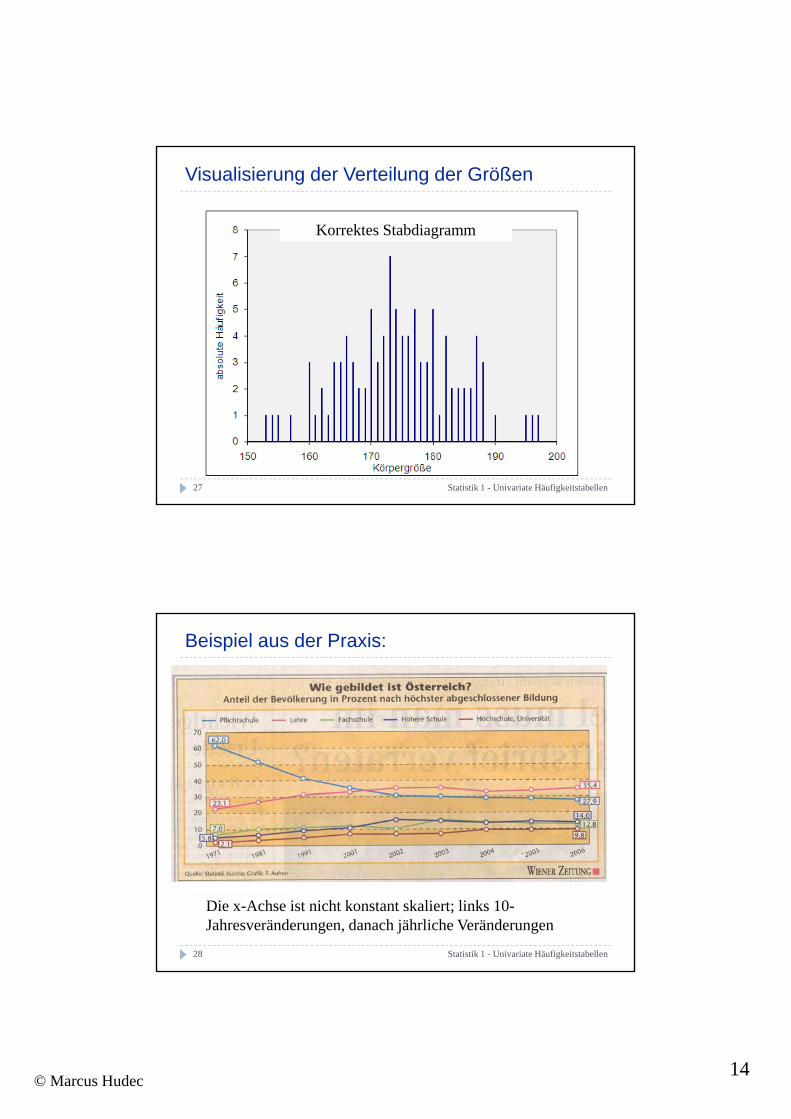
Visualisierung der Verteilung der Größen
Korrektes Stabdiagramm
27 Statistik 1 - Univariate Häufigkeitstabellen
Beispiel aus der Praxis:
Statistik 1 - Univariate Häufigkeitstabellen28
Die x-Achse ist nicht konstant skaliert; links 10-Jahresveränderungen, danach jährliche Veränderungen

15© Marcus Hudec
Visualisierung der Verteilung der Größen
Ein Dot-Plot ist eine einfache statistische Graphik für die Darstellung der Verteilung kleinerer bis mittlerer Datensätze.
Visualisierung von Werte-Cluster bzw. von Lücken in der Verteilung sowie für das Aufzeigen extremer
29 Statistik 1 - Univariate Häufigkeitstabellen
Einzelbeobachtungen (Ausreißer).
Körpergröße
Stem & Leaf-Diagram (Stengel-Blatt Diagramm)N = 100 Median = 174
Spaltenwerte in Einheiten von 10
Semigraphische Technik:
Systematisches Aufschreiben der Werte so dass sich 15 : 34
15 : 57 16 : 0001223444 16 : 55566667778899 17 : 000001112222333333344444 17 : 5555666677777888999
der Werte, so dass sich ein Bild der Verteilung ergibt
Alle Einzelwerte bleiben exakt erhalten
Nur für kleinere Datensätze geeignet
18 : 00000122223344 18 : 55667777888 19 : 0 19 : 567
geeignet
30 Statistik 1 - Univariate Häufigkeitstabellen

16© Marcus Hudec
Stemleaf-Diagramm mit HäufigkeitenN = 100 Median = 174
Spaltenwerte in Einheiten von 10
2 2 15 : 34 2 2 15 : 34 4 2 15 : 57 14 10 16 : 0001223444 28 14 16 : 55566667778899 24 17 : 000001112222333333344444 48 19 17 : 5555666677777888999 29 14 18 : 00000122223344 15 11 18 : 55667777888
4 1 19 : 0 3 3 19 : 567 Absolute Häufigkeiten
Kumulierte Häufigkeiten31 Statistik 1 - Univariate Häufigkeitstabellen
Stemleaf-Diagramm
Abstrahiert man von den konkreten Werten undkonkreten Werten und achtet nur auf die Form der Verteilung, ergibt sich das Histogramm
32 Statistik 1 - Univariate Häufigkeitstabellen

17© Marcus Hudec
Histogramm
Das Bild erinnert an ein Sä l diSäulendiagramm.
Im Gegensatz dazu kommt aber der horizontalen Achse eine geänderte Bedeutung zu.
Statistik 1 - Univariate Häufigkeitstabellen33
Numerische Skala!
Häufigkeitstabelle bei stetigen Merkmalen
Klassierung (Klassifizierung):Einteilung des Wertevorrates (Realisationsmöglichkeiten der Merkmalsausprägungen) in nicht überschneidende p g g )angrenzende KlassenNach Möglichkeit gleiche Breite !Absolute Häufigkeit der Klasse ist die Anzahl der Realisationen mit Werten, die zu dieser Klasse gehören:
Klasse i sei definiert durch (ui,oi]( )n(ui<X ≤oi)=ni
eindeutige Zuordnung durch halboffene IntervalleRelative Häufigkeit der Klasse
h(ui<X ≤oi)=ni/n=hi
34 Statistik 1 - Univariate Häufigkeitstabellen

18© Marcus Hudec
Häufigkeitstabelle für klassifizierte Daten
Bereich ni hi
150+ bis 155 3 0,03155+ bis 160 4 0,04160+ bis 165 10 0,10165+ bis 170 16 0,16170+ bis 175 23 0,23175+ bis 180 20 0,20180+ bis 185 11 0,11185+ bis 190 10 0 10185+ bis 190 10 0,10190+ bis 195 1 0,01195+ bis 200 2 0,02Gesamt 100 1
35 Statistik 1 - Univariate Häufigkeitstabellen
Histogramm
Ein Histogramm ist die graphische Darstellung einer Häufigkeitstabelle, die sich durch die Klassierung eines stetigen Merkmals in Intervalle ergibt
10
15
20
25
Statistik 1 - Univariate Häufigkeitstabellen36
0
5
140 150 160 170 180 190 200 210Körpergröße

19© Marcus Hudec
Histogramm mit Polygonzug
20
25
5
10
15
20
0140 150 160 170 180 190 200 210
37 Statistik 1 - Univariate Häufigkeitstabellen
Polygonzug
20
25
5
10
15
20
0140 150 160 170 180 190 200 210
38 Statistik 1 - Univariate Häufigkeitstabellen

20© Marcus Hudec
Tabellen in der Praxis
In der Praxis sind Häufigkeitstabellen oft der Ausgangspunkt einer empirischen Untersuchung (Sekundärdaten)( )Achtung: Klassierte Daten haben nicht 1:1 den selben Informationsgehalt wie die Originaldaten, da die Verteilung innerhalb der Klassen unbekannt ist (vgl. Informationsgehalt von Stem & Leaf-Diagramm und Histogramm)Problem offener Klassen:z.B.: monatl. Einkommen größer als 100.000,-Generell: Ungleich große Klassenbreiten erfordern eine adäquate graphische Darstellung
39 Statistik 1 - Univariate Häufigkeitstabellen
Zusammenfassung von Klassen
Bereich ni hi
150+ bis 160 7 0,07,160+ bis 165 10 0,10165+ bis 170 16 0,16170+ bis 175 23 0,23175+ bis 180 20 0,20180 bi 185 11 0 11180+ bis 185 11 0,11185+ bis 200 13 0,13Gesamt 100 1
40 Statistik 1 - Univariate Häufigkeitstabellen

21© Marcus Hudec
Fehlerhafte Modifikation des Histogramms
25
5
10
15
20
41 Statistik 1 - Univariate Häufigkeitstabellen
0140 150 160 170 180 190 200 210
Fehlerhafte Modifikation des Histogramms
42 Statistik 1 - Univariate Häufigkeitstabellen

22© Marcus Hudec
Korrekte Modifikation des Histogramms
Fläche muss konstant bleiben
43 Statistik 1 - Univariate Häufigkeitstabellen
Korrektes Histogramm nach Aggregation
falsch
44 Statistik 1 - Univariate Häufigkeitstabellen
Fläche muss konstant bleiben Prinzip der Flächentreue
korrekt

23© Marcus Hudec
Histogramm <==> Dichtedarstellung
Prinzip der Flächentreue:Der Flächeninhalt der Histogramm-Blöcke muss proportional zur Häufigkeit seinp p gDie Höhe der Histogramm-Blöcke muss dann die Dichte darstellen Dichte ist allgemein eine Häufigkeit bezogen auf eine Einheit z.B. Bevölkerungsdichte Anzahl Einwohner je km²Häufigkeitsdichte ist die relative Häufigkeit dividiert durch die KlassenbreiteFläche = Höhe*Breite Fläche ~ HäufigkeitBei Klassen konstanter Breite ist diese Unterscheidung für die Visualisierung irrelevant
45 Statistik 1 - Univariate Häufigkeitstabellen
Berechnung der Häufigkeitsdichte
Bereich ni hi bi di=hi/bi
150+ bis 160 7 0,07 10 0,007, ,160+ bis 165 10 0,10 5 0,020165+ bis 170 16 0,16 5 0,032170+ bis 175 23 0,23 5 0,046175+ bis 180 20 0,20 5 0,040180 bi 185 11 0 11 5 0 022180+ bis 185 11 0,11 5 0,022185+ bis 200 13 0,13 15 0,009Gesamt 100 1
46 Statistik 1 - Univariate Häufigkeitstabellen
24© Marcus Hudec
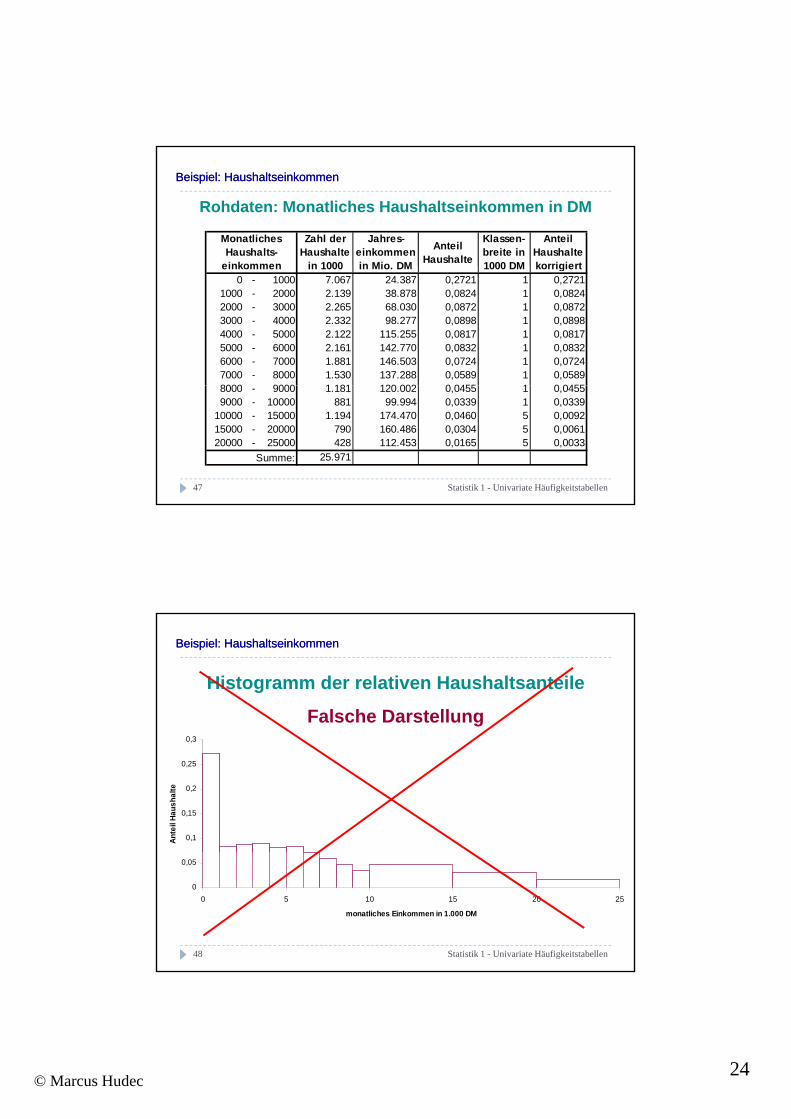
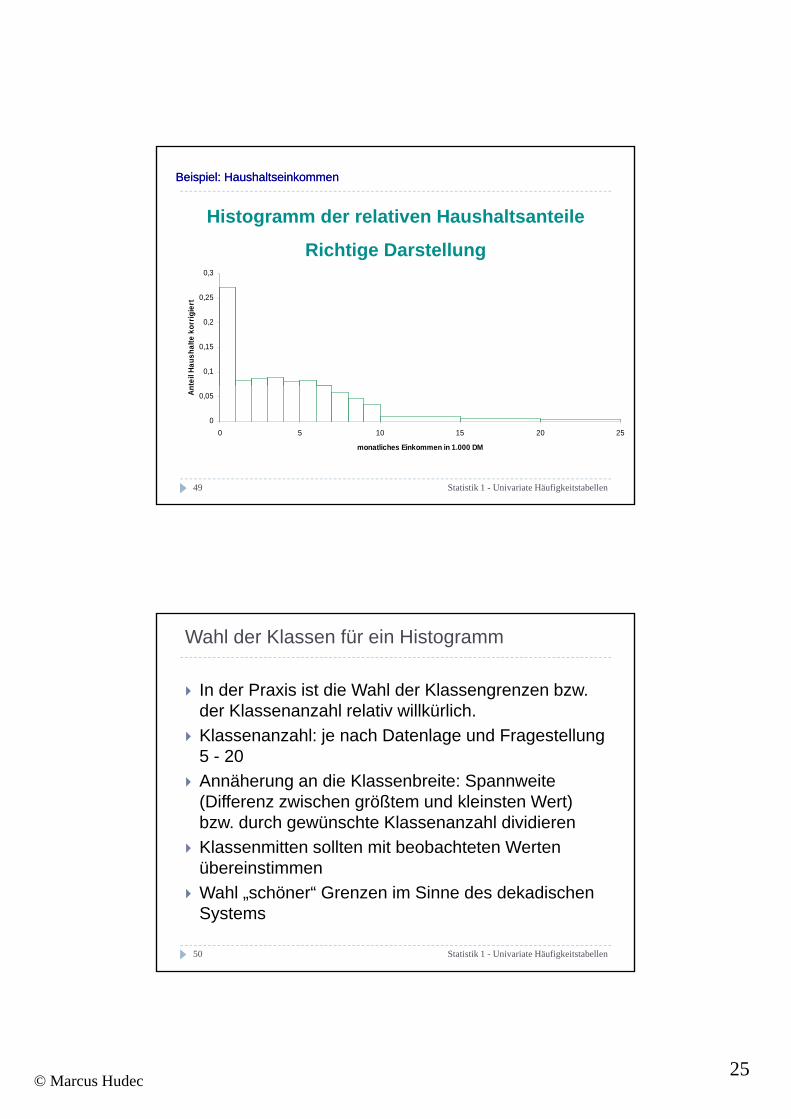
Beispiel: HaushaltseinkommenBeispiel: Haushaltseinkommen
Rohdaten: Monatliches Haushaltseinkommen in DM
Zahl der Haushalte
in 1000
Jahres-einkommen in Mio DM
Anteil Haushalte
Klassen-breite in 1000 DM
Anteil Haushalte korrigiert
Monatliches Haushalts-
einkommen in 1000 in Mio. DM 1000 DM korrigiert0 - 1000 7.067 24.387 0,2721 1 0,2721
1000 - 2000 2.139 38.878 0,0824 1 0,08242000 - 3000 2.265 68.030 0,0872 1 0,08723000 - 4000 2.332 98.277 0,0898 1 0,08984000 - 5000 2.122 115.255 0,0817 1 0,08175000 - 6000 2.161 142.770 0,0832 1 0,08326000 - 7000 1.881 146.503 0,0724 1 0,07247000 - 8000 1.530 137.288 0,0589 1 0,05898000 9000 1 181 120 002 0 0455 1 0 0455
einkommen
8000 - 9000 1.181 120.002 0,0455 1 0,04559000 - 10000 881 99.994 0,0339 1 0,0339
10000 - 15000 1.194 174.470 0,0460 5 0,009215000 - 20000 790 160.486 0,0304 5 0,006120000 - 25000 428 112.453 0,0165 5 0,0033
25.971Summe:
47 Statistik 1 - Univariate Häufigkeitstabellen
Beispiel: HaushaltseinkommenBeispiel: Haushaltseinkommen
Histogramm der relativen Haushaltsanteile
Falsche Darstellung
0,1
0,15
0,2
0,25
0,3
Ante
il Ha
usha
lte
0
0,05
0 5 10 15 20 25
monatliches Einkommen in 1.000 DM
48 Statistik 1 - Univariate Häufigkeitstabellen
25© Marcus Hudec
Beispiel: HaushaltseinkommenBeispiel: Haushaltseinkommen
Histogramm der relativen Haushaltsanteile
Richtige Darstellung
0,1
0,15
0,2
0,25
0,3
teil
Haus
halte
kor
rigie
rt
0
0,05
0 5 10 15 20 25
monatliches Einkommen in 1.000 DM
An
49 Statistik 1 - Univariate Häufigkeitstabellen
Wahl der Klassen für ein Histogramm
In der Praxis ist die Wahl der Klassengrenzen bzw. der Klassenanzahl relativ willkürlich.Klassenanzahl: je nach Datenlage und FragestellungKlassenanzahl: je nach Datenlage und Fragestellung 5 - 20Annäherung an die Klassenbreite: Spannweite (Differenz zwischen größtem und kleinsten Wert) bzw. durch gewünschte Klassenanzahl dividieren Klassenmitten sollten mit beobachteten WertenKlassenmitten sollten mit beobachteten Werten übereinstimmenWahl „schöner“ Grenzen im Sinne des dekadischen Systems
50 Statistik 1 - Univariate Häufigkeitstabellen

26© Marcus Hudec
Typisierung von Verteilungen
Unimodal Distribution
Unimodale Verteilung
Bimodal Distribution
Bimodale Verteilung
Statistik 1 - Univariate Häufigkeitstabellen51
Multimodal Distribution
Multimodale Verteilung
Schiefe einer Verteilung
Unimodale symmetrische Verteilung
Statistik 1 - Univariate Häufigkeitstabellen52
rechtsschief linksschief

27© Marcus Hudec
Kritik am klassischen Histogramm
Das resultierende Bild von der Gestalt der Verteilung hängt von der letztlich willkürlichen Wahl der Anzahl der Intervalle und vom Startpunkt der Intervallbildungder Intervalle und vom Startpunkt der Intervallbildung ab
Statistik 1 - Univariate Häufigkeitstabellen53
Beispiel: Altersverteilung einer Kohorte
Histogram of Age
uenc
y 2030
Histogram of Age
uenc
y
015
20
Age
Freq
u
20 40 60 80
05
10
Age
Freq
u
20 30 40 50 60 70 80
05
10
Histogram of Age
50
Histogram of Age
10
Statistik 1 - Univariate Häufigkeitstabellen54Age
Freq
uenc
y
0 20 40 60 80 100
010
2030
40
Age
Freq
uenc
y
20 30 40 50 60 70 80
02
46
8

28© Marcus Hudec
Verschieben der Klassen-IntervalleHistogram of Age
quen
cy
1015
20
Histogram of Age
quen
cy 1015
Age
Freq
20 40 60 80
05
Age
Freq
20 40 60 80
05
Histogram of Age
20
Histogram of Age
15
Statistik 1 - Univariate Häufigkeitstabellen55
Age
Freq
uenc
y
20 40 60 80
05
1015
Age
Freq
uenc
y
20 40 60 80
05
10
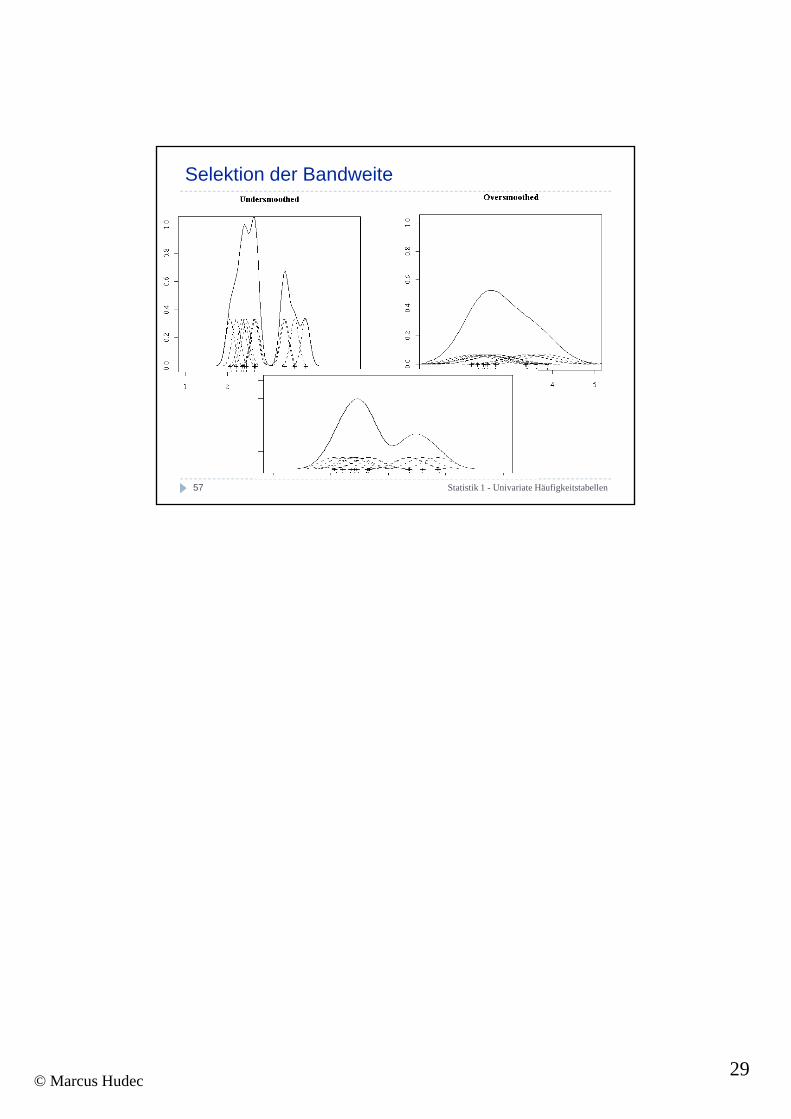
Alternative: Kernschätzer
56 Statistik 1 - Univariate Häufigkeitstabellen
Ein Kern bezeichnet eine symmetrische Funktion, die rund um den empirischen Datenpunkt aufgetragen wird. Das Bild der Verteilung ergibt sich dann durch die Summe über alle Funktionswerte im gesamten Bereich der x-Achse
29© Marcus Hudec
Selektion der Bandweite
Statistik 1 - Univariate Häufigkeitstabellen57







