

Mathematische Statistik II
Volkmar LiebscherLMU München
WS 2004/2005Version 14. Oktober 2004, 18:48:40

Zusammenfassung
Statistik beschäftigt sich mit Fragestellungen, die die Erfassung und Aufbereitung von Daten betreffen.Die Mathematische Statistik speziell beschreibt und analysiert die verwendeten Methoden mit mathema-tischen Mitteln.
Die Vorlesung führt die Einführung in zentrale Konzepte, Modelle und Techniken der Mathemati-schen Statistik fort. Dazu gehören:
• asymptotische Statistik:
– Konsistenz und
– asymptotische Normalität;
• Statistik für das lineare Modell,
• Nichtparametrische Statistik,
• Robuste Statistik.
Interessenten sollten über Grundkenntnisse in der Wahrscheinlichkeitsrechnung verfügen und denInhalt der Vorlesung “Mathematische Statistik 1” verfügbar haben. Weitere Kenntnisse in Analysis, spe-ziell Funktionalanalysis und Maßtheorie sind hilfreich.

Inhaltsverzeichnis
VII Lineare Statistik im Linearen Modell 3VII.1 Literatur Lineares Modell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3VII.2 Das Lineare Modell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
Exkurs: Mehrdimensionale Normalverteilungen . . . . . . . . . . . . . . . . . . . . 3VII.3 Punktschätzung im linearen Modell . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
VII.3.1 Schätzung der Parameter . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5VII.3.2 Das Gauß-Markov-Theorem . . . . . . . . . . . . . . . . . . . . . . . . . . 6VII.3.3 Schätzung der Varianz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
VII.4 Tests im linearen Modell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
VIII Asymptotische Statistik 7VIII.1 Konvergenzarten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
Exkurs: Schwache Konvergenz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7VIII.2 U-Statistiken . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8VIII.3 M-Schätzer und ihre Asymptotik . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
VIII.3.1Definition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9VIII.3.2Konsistenz und Asymptotische Normalität vonM-Schätzern . . . . . . . . . 11Exkurs: Epikonvergenz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
VIII.4 Anwendung auf Maximum-likelihood Schätzer . . . . . . . . . . . . . . . . . . . . . 13VIII.4.1Konsistenz von ML-Schätzern . . . . . . . . . . . . . . . . . . . . . . . . . 13VIII.4.2Asymptotische Normalität von ML-Schätzern . . . . . . . . . . . . . . . . . 13
VIII.5 Asymptotische Testtheorie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14VIII.5.1Asymptotische Verteilung von Teststatistiken . . . . . . . . . . . . . . . . . 14VIII.5.2Der χ2-Anpassungstest . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14VIII.5.3Asymptotische Fehler von Tests . . . . . . . . . . . . . . . . . . . . . . . . 14
IX Ordnungsbasierte Nichtparametrische Verfahren 15IX.1 Lehrbücher Nichtparametrische Statistik . . . . . . . . . . . . . . . . . . . . . . . . 15IX.2 Empirische Verteilungsfunktion und Ordnungsstatistiken . . . . . . . . . . . . . . . . 15
IX.2.1 Der Hauptsatz der Statistik . . . . . . . . . . . . . . . . . . . . . . . . . . . 15IX.3 Nichtparametrische Tests . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15IX.4 L-Schätzer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
IX.4.1 Definition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15IX.4.2 Asymptotik vonL-Schätzern . . . . . . . . . . . . . . . . . . . . . . . . . . 16IX.4.3 R-Schätzer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
1

INHALTSVERZEICHNIS 2
X Kurvenschätzung 17X.1 Lehrbücher Kurvenschätzung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17X.2 Beispiele . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17X.3 Dichteschätzung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
X.3.1 Histogramm-Schätzer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17X.3.2 Kerndichteschätzer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
X.4 Nichtparametrische Regression . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17X.5 Adaptive Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
XI Robuste Statistik 18XI.1 Literatur Robuste Statistik . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18XI.2 Einführendes Beispiel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
XI.2.1 Modelle für Störungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21XI.3 Qualitative Robustheit und Hampels Theorem . . . . . . . . . . . . . . . . . . . . . 22XI.4 Robustheitsmaße . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
XI.4.1 Metriken für die schwache Konvergenz . . . . . . . . . . . . . . . . . . . . 23XI.4.2 Bruchpunkte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25XI.4.3 Die Einflussfunktion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27XI.4.4 EffizienteM-, L- undR-Schätzer . . . . . . . . . . . . . . . . . . . . . . . . 28XI.4.5 Skalen-Probleme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28

Kapitel VII
Lineare Statistik im Linearen Modell
Motivation In diesem Kapitel lernen wir einfache Techniken kennen, komplexe Sachverhalte statistischaufzudecken. Die Einfachheit der Mittel (die häufig unangemessen scheint) wird dabei kompensiert durchdie Möglichkeit, komplexeste Beziehungen abzubilden.
VII.1 Literatur Lineares Modell
[Pruscha] H. Pruscha.Angewandte Methoden der mathematischen Statistik. Lineare, loglineare, logisti-sche Modelle. Finite und asymptotische Methoden., 2. Aufl., Teubner Stuttgart, 1996.
[Nollau] V. Nollau.Statistische Analysen, 1975.
[Christensen] R. Christensen.Plane answers to complex questions. The theory of linear models.3. Aufl.Springer New York, 2002.
VII.2 Das Lineare Modell
Beispiel VII.1 lineare Regression:
Yi = aXi +b+ εi
Beispiel VII.2 3 verschiedene Bedingungen: keine Düngung, normale Düngung, doppelte Düngung:
Yi, j = µi + εi, j , (i = 1,2,3, j = 1, . . . ,ni)
µi mittlerer Ertrag bei keiner Düngung, normaler Düngung, doppelter Düngung
Exkurs: Mehrdimensionale Normalverteilungen
mehrdimensionale Normalverteilungen leben auf demRn.charakteristische Funktion
ϕY(t) = EeitTY, (t ∈ Rn)
Definition VII.1 Eine zufälliger Vektor Y∈Rn hat eine mehrdimensionale Normalverteilung fallsϕY(t)=eiµTt− 1
2tTΣt . a heißt Erwartungswertvektor undΣ Kovarianzmatrix. Bezeichnung:LY = N(µ,Σ)
3

KAPITEL VII. LINEARE STATISTIK IM LINEAREN MODELL 4
Lemma VII.1 Zu jedem µ∈ Rn und jeder positiv semidefiniten MatrixΣ ∈ Rn×n gibt esN(µ,Σ).
Lemma VII.2 Σ invertierbar⇒ N(µ,Σ)∼ `n mit Dichte
fµ,Σ(x) =1√
2detΣe−
12(x−µ)TΣ−1(x−µ)
Satz VII.1 Für einen normalverteilten zufälligen Vektor Y∈ Rn hat die KovarianzmatrixVY genaudann Diagonalgestalt (Yi sind unkorrelliert), wenn Yi , i = 1, . . . ,n unabhängig sind.
Satz VII.2 Y ∼ N(µ,Σ), A∈ Rm×n, b∈ Rm impliziert AY+b∼ N(Aµ+b,AΣAT)
Definition VII.2 Ein lineares Modell ist eine Familie von Verteilungen(Pϑ)ϑ∈Θ wobeiΘ = Rp und PXβ
die Verteilung eines Vektors Y∈ Rn ist mit
Y = Xβ+ ε
wobei die Verteilung vonε die BeziehungVε = σ2Id für ein σ > 0 erfüllt.Ist ε standardnormalverteilt, so heißt es normales lineares Modell.
Anmerkung Im ganzen Ansatz ist nur die Kovarianzstruktur vonε entscheidend. Diese reicht aus, alleErwartungswerte quadratischer Funktionen auszurechnen, wie für das Gauss-Risiko von linearen Funk-tionen nötig (und hinreichend), siehe unten. Natürlich beeinflußt die Verteilung vonε andere Qualitäts-merkmale von diesen und anderen Schätzern, dies wird zumeist ignoriert. Damit kann man genausogutannehmen, daß ein normales Modell vorliegt.
Wenn A invetierbar ist, dann kann man X′ = XA−1 und β′ = Aβ setzen und bekommt die gleicheFamile von Modellen (lineare Umparametrisierung). Wichtig ist eigentlich nur der lineare Teilraum
L = ImX = Xb : b∈ Rp
Beispiel VII.3 lineare Regression:
Yi = aXi +b+ εi
also p= 2, β =(
ab
)und
X =
X1 1X2 1...
...Xn 1
Beispiel VII.4 Varianzanalyse: X,β
VII.3 Punktschätzung im linearen Modell
Anmerkung Qualitätskriterium: Gauss-VerlustLassen nur lineare Schätzer zu.

KAPITEL VII. LINEARE STATISTIK IM LINEAREN MODELL 5
VII.3.1 Schätzung der Parameter
Definition VII.3 Sei(
PXβ
)β∈Rp
ein lineares Modell. Ein kleinster Quadrate Schätzer ist ein Schätzer
T : Rn 7−→ Rp mit der Eigenschaft
‖Y−XT(Y)‖2 = min‖Y−Xb‖2 : b∈ Rp
Satz VII.3 Sei(
PXβ
)β∈Rp
ein lineares Modell.
1. Dann gibt es einen Kleinste Quadrate Schätzer und jeder Kleinste Quadrate Schätzer erfüllt
XT(Y) = PrImXY
2. Jeder Kleinste Quadrate Schätzer erfüllt
XTXT(Y) = XTY
3. Falls X Rang p hat, ist der kleinste Quadrate Schätzer eindeutig gegeben durch
β = (XTX)−1XTY
und erfüllt
Eββ = β , Vββ = σ2(XTX)−1
Beweis:Ableiten.
Anmerkung Normalengleichung minimum least squares estimator (MLS)Falls rgX < p, istβ nicht identifizierbar, sodaß wegen PX
β = PXβ′ für geeigneteβ,β′ nicht β = EβT =
Eβ′T = β′ gelten kann.
Für normales Modell istβ auch MLE.
Satz VII.4 Sei(
PXβ
)β∈Rp
ein lineares Modell wobei X Rang p hat. Dann ist der Kleinste Quadrate
Schätzer der beste lineare unverfälschte Schätzer
Bezeichnung engl.: best linear unbiased estimator (BLUE)
Beweis:Bias-Variance Zerlegung.
R(T,β) = Eβ ‖T(Y)−β‖2 =∥∥EβAY−β
∥∥2 +SpVβAY
= ‖AXβ−β‖2 +SpVβAε
= ‖AXβ−β‖2 +SpA(Vβε)AT
= ‖AXβ−β‖2 +σ2SpAAT
erwartungstreu:AX= Id. Auf diesem affinen Teilraum soll∑p,ni=1, j=1A2
i j minimiert werden.A0 =(XTX)−1XT
ist die Lösung, da für alleA′ mit A′X = 0
ddλ
Sp(A0 +λA′)(A0 +λA′)T = 2SpA′A0T
= 2SpA′X(XTX)−1 = 0
womit A0 lokales, aus Gründen der strikten Konvexität auch globales Maximum ist.

KAPITEL VII. LINEARE STATISTIK IM LINEAREN MODELL 6
VII.3.2 Das Gauß-Markov-Theorem
Satz VII.5 Sei(
PXβ
)β∈Rp
ein lineares Modell. Dann ist ein lineares Funktional a(β) = cTβ genau dann
linear erwartungstreu schätzbar, wenn c∈ ImXT.
Beweis:EβaTY = aTXβ !=cTβ für alle β ∈ Rp. Damit mußXTa!=c gelten, oderc∈ ImXT.
Anmerkung Man nennt solche Funktionen auchschätzbare Funktionen
Satz VII.6 (Gauß-Markov-Theorem) Sei(
PXβ
)β∈Rp
ein lineares Modell und cTβ schätzbar. Dann ist
der beste lineare unverfälschte Schätzer gegeben durch
cTβ = cTβ = aTY
wobeiβ eine Kleinster Quadrate Schätzer ist bzw. a∈ ImX mit XTa = c.
Beweis:Es gilt VβaTY = VaTε = aTϑ2Ida = σ2‖a‖2. Von oben wissen wir, daßXTa = c gelten muß.Klarerweise giltXTa = XTPrImXa sodaß‖a‖ minimal wird, wenna∈ ImX.
Beispiel VII.5 (Einfache ANOVA) aus Pruscha
VII.3.3 Schätzung der Varianz
man schätzt
σ2 =1
n− rgX
∥∥∥Y−Xβ∥∥∥2
Lemma VII.3 Es giltEβσ2 = σ2.
leverage-Werte: Einfluß deri-ten Komponente auf den Schätzer.Beispiele
VII.4 Tests im linearen Modell
Motivation Ab jetzt: nur Normales lineares Modell.
Definition VII.4 Sei(
PXβ
)β∈Rp
ein lineares Modell. Einelineare Hypotheseist eine Nullhypothese der
Form Θ0 = β : β ∈ H für einen linearen Teilraum H⊂ Rp
Satz VII.7 Sei(
PXβ
)β∈Rp
ein normales lineares Modell. Dann hat die TeststatistikPrH⊥ eine χ2p−k-
Verteilung.

Kapitel VIII
Asymptotische Statistik
Qualität:asymptotischer Erwartungswert, Konsistenz, asymptotische Varianz, asymptotische relative Effizienz
VIII.1 Konvergenzarten
Anmerkung Zur Erinnerung: fast sicher und stochastische Konvergenz
Exkurs: Schwache Konvergenz
Definition VIII.1 (Xn)n∈N heißtasymptotisch normalverteiltmit Erwartungswert µn ∈ Rk und VarianzΣn, Σn invertierbar, falls
L(Σ−1/2(Xn−µn)) ===========⇒n→∞
N(0, IdRk)
Der folgende Satz ist nützlich
Satz VIII.1 (Skorohod) XnD
−−−−−−−−−−−→n→∞
X genau dann wenn es Wahrscheinlichkeitsraum(Ω′,F ′,P′) und
zufällige Größen(Yn)n∈N,Y mit PXn = P′Yn,PX = P′Y gibt, sodaß
Yn
P′−f.s.−−−−−−−−−−−−−−−→
n→∞Y
Folgerung (Xn)n∈N sei asymptotisch normalverteilt mit Erwartungswert µ∈ Rk und VarianzΣn, Σn in-vertierbar undΣn −−−−−−−−−−−→
n→∞0, sowie f: Rk 7−→Rl in µ differenzierbar mit f′(µ) 6= 0. Dann ist( f (Xn))n∈N
asymptotisch normalverteilt mit Erwartungswert f(µ) und Varianzen f′(µ)TΣn f ′(µ).
Beweis:Obiger Satz zeigt (auf anderem Wraum)
Xn = µ+Σ1/2n Yn
mit Yn →Y ∼ N(0, Id) P-f.s., also auchXn → µ P-f.s.Taylorentwicklung ergibtP-f.s.
f (Xn) = f (µ)+ f ′(µ)TΣ1/2n Yn +o(Σ1/2
n Yn)
= f (µ)+ f ′(µ)TΣ1/2n Y +Σ1/2
n(
f ′(µ)T(Y−Yn)+o(Y))︸ ︷︷ ︸
−−−−−−−−−−−→n→∞
0
7

KAPITEL VIII. ASYMPTOTISCHE STATISTIK 8
Weiterhin
Satz VIII.2 (Slutsky) Falls XnD
−−−−−−−−−−−→n→∞
X und YnP
−−−−−−−−−−−→n→∞
0 dann gilt Xn +YnD
−−−−−−−−−−−→n→∞
X.
Anmerkung gilt nicht mit reiner Verteilungskonvergenz
Wir demonstrieren dies an der asymptotischen Normalität der Momentenmethode.. Erinnerung: em-pirische Momente
mi(x) =n
∑j=1
(x j)i
Satz VIII.3 Seien(Xn)n∈N u.i.v. zufällige Größen mit Werten inX0 ⊂ R, wobei die Verteilungsannahme(Qϑ)ϑ∈Θ gelte, d.h. es gibt einϑ0 ∈Θ⊂Rl mit L (X1) = Qϑ0. Wenn für k∈N
R|t|2kQϑ(dt) < ∞ für alle
ϑ ∈Θ und die Abbildungϑ 7→ (m1(ϑ), . . . ,mk(ϑ)) mit
mi(ϑ) =Z
t iQϑ(dt)
ist eindeutig und differenzierbar inϑ0 mit invertierbarer Jacobimatrix J dann ist der Schätzer nach derMomentenmethode asymptotisch normalverteilt mit erwartungswertϑ0 und Kovarianzmatrix1nJ−1M(ϑ0)(J−1)T,wobei
M(ϑ)i j = mi+ j(ϑ)
Beweis:Anwendung des Satzes Satz VIII.2. Wir wissen aus dem Zentralen Grenzwertsatz daß(mi)ki=1
asymptotisch normalverteilt ist mit Kovarianzmatrix1nM(ϑ0). J−1 ist die Ableitung der Umkehrfunktion
vonm in ϑ0.
VIII.2 U-Statistiken
A(ϑ) =R
Pϑ(dt1, . . . , tk)h(t1, . . . , tk)
Definition VIII.2 Sei h: Rk 7−→ R eine symmetrische Funktion. Dann heißt Tn : Rn 7−→ R,
Tn(x1, . . . ,xn) =(
nk
)−1
∑i1<i2<···<ik
h(Xi1, . . . ,Xik)
U-Statistik der Ordnung k und h Kern der Ordnung k.
Satz VIII.4 Sei h ein Kern der Ordnung k und Tn die zugehörigen U−Statistiken. Falls(Xn)n∈N u.i.v.mit Eh2(X1, . . . ,Xk) < ∞ dann gilt
Tn(X1, . . . ,Xn)P
−−−−−−−−−−−→n→∞
Eh(X1, . . . ,Xk)
Satz VIII.5 Unter dieser Bedingung ist(Tn)n∈N asymptotisch normalverteilt mit ErwartungswertEh(X1, . . . ,Xk)und Varianz nk2VE(h(X1, . . . ,Xk)|X1).
Anmerkung Also schätzt U-Statistik a(ϑ) = Eϑh(X1, . . . ,Xk).

KAPITEL VIII. ASYMPTOTISCHE STATISTIK 9
VIII.3 M-Schätzer und ihre Asymptotik
VIII.3.1 Definition
Motivation Maximum-likelihood-Schätzer sind relativ leicht zu verstehen, deshalb verallgemeinern.(sogar weg vonA ⊆ R). Hier betrachten wir die negative Loglikelihoodfunktion.
Definition VIII.3 Ein M-Schätzer zu einer Funktionϕ : A×X0 7−→R ist ein Schätzer T: X n0 7−→A für
welchen gilt daß
n
∑i=1
ϕ(T(x1, . . . ,xn),xi) = minn
∑i=1
ϕ(a,xi) : a∈ A
Anmerkung M kommt von maximum-likelihood-artig.
Anmerkung Alternative fürA ⊆ Rd: von Maximum Likelihood zu likelihood-Gleichungen
∂∂ϑ
ln p(ϑ,x) = 0
Ein M-Schätzer zu einer Funktionψ : A ×X0 7−→ Rd ist ein Schätzer T: X n0 7−→ A für welchen gilt
daß
n
∑i=1
ψ(T(x1, . . . ,xn),xi) = 0
(heißt Schätzgleichung)
Bezeichnung Setzen
Φ(a,x1, . . . ,xn) =n
∑i=1
ϕ(a,xi)
Ψ(a,x1, . . . ,xn) =n
∑i=1
ψ(a,xi)
In der Literatur meistρ stattϕ.Außerdem bezeichnen wir Minimierermengen mit
argmina f (a) = a∈ A : f (a) = inf f (a′) : a′ ∈ A
Beispiel VIII.1 Mittelwert: ϕ(ϑ,x) = ‖x−ϑ‖2 maximum-likelihood Schätzer für Gauß-Familie
Beispiel VIII.2 Medianϕ(ϑ,x) = |x−ϑ| maximum-likelihood Schätzer für(Qϑ)ϑ∈Θ,
qϑ(x) = e−1/2|x−ϑ|
Was wird geschätzt?In der ersten Variante sollte geltenT(ν) ∈ argminϑ
Rϕ(ϑ,y)ν(dy) wegen Grenzwert
1n
n
∑i=1
ϕ(a,xi)P−f.s.−−−−−−−−−−−−−−→
n→∞
Zϕ(ϑ,y)ν(dy)
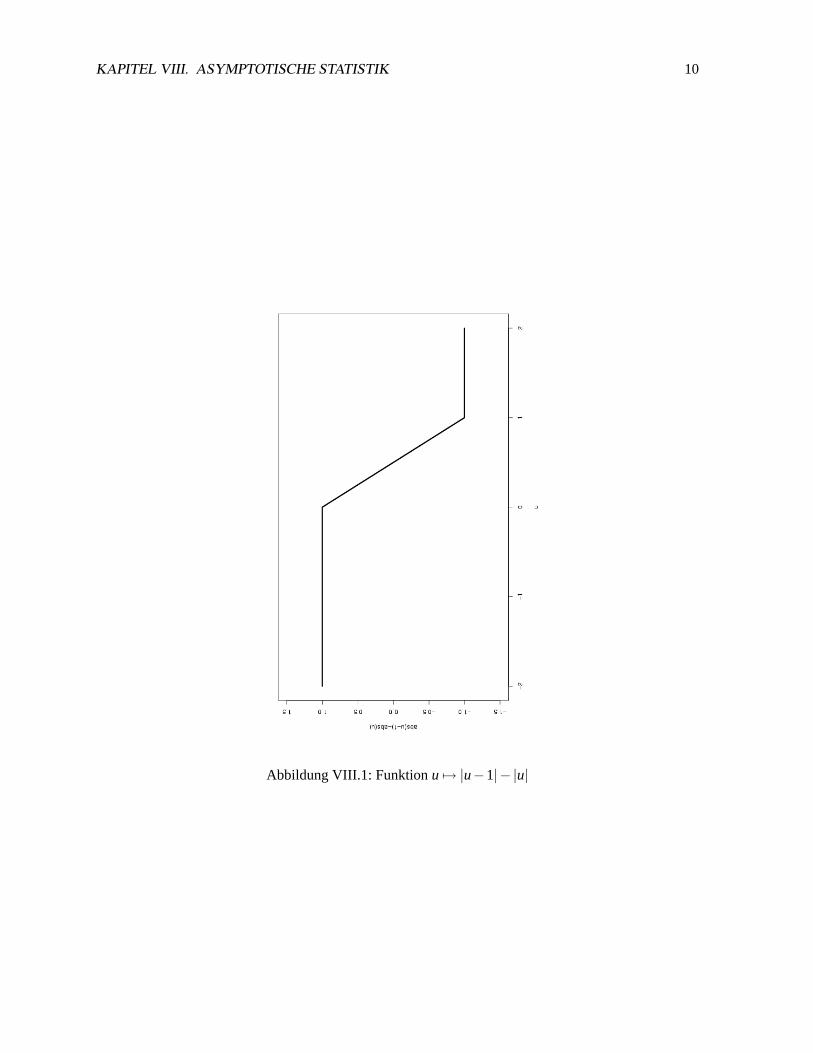
KAPITEL VIII. ASYMPTOTISCHE STATISTIK 10
Abbildung VIII.1: Funktionu 7→ |u−1|− |u|

KAPITEL VIII. ASYMPTOTISCHE STATISTIK 11
Gilt zumindest wennϕ(·,ϑ)∈Cb(R) oderR|ϕ(ϑ,y)|ν(dy) < ∞. Für Konvergenz der Minimierer ist aber
mehr nötig (s.u.)Problem wennϕ nicht beschränkt, aber ErsatzBeispiel Median:R|x− t|ν(dx)∼
R(|x− t|−|x|)ν(dx) wohldefiniert, dau 7→ |u−1|−|u| beschränkt (und stetig), siehe
Abb. Abb. VIII.1Im ψ-Bild weniger Probleme mit Konvergenz des Integrals, dafür Fixierung einer Lösung (s.u.)
Anmerkung Zur Berechnung von M-Schätzern:Variante 1: Minimierungsproblem
• Existiert eindeutiges (globales) Minimum? Konvexität, Stetigkeit vonϕ
• Gradientenverfahren:ϑn+1 = ϑn−cn∇Φ(ϑn) mit geeigneten Gewichten cn (steuern Schrittweite)
Guter Startpunkt nötig. Dafür Robustheit (hoher Bruchpunkt). 1-dim: Median meist gute Wahl
• Abbruchkriterium:0≥Φ(ϑn)−Φ(ϑn−1)≥−ε
• abhängig vom Beispiel explizitere Methoden (s.o., aber auch nächstes Bsp.)
Variante 2: Lösung nichtlinearer Gleichung. z.B. Newton-Verfahren, Sekanten-Verfahren, aber sonstgleiche Probleme.
Anmerkung Was lernen wir:
• Nichteindeutigkeit kann größeres Problem werden
• Probleme für numerische Algorithmen (aber: später!)
• Vergleiche mit getrimmten (siehe Bsp. XI.13) und winsorisiertem Mittel
mwin,α =1n
((k−1)(xk:n +xn−k:n)+
n−k
∑i=k
xi:n
)M-Schätzer istadaptiv, kein ad hocα. Aber: Problem mit Topfbreite, später.
VIII.3.2 Konsistenz und Asymptotische Normalität vonM-Schätzern
Exkurs: Epikonvergenz
aus Witting+PollardEinfachste Varianteϕ(x,ϑ) = ϕ(x−ϑ). Im weiteren setzen wir voraus:
(M) ψ(·) ist monoton wachsend und nimmt negative und positive Werte an.
ϕ(·) ist konvex und hat Punkte, in denen es streng monoton fällt.
Meist ψ = ϕ′.Dann gibt es (imψ-Bild)
T−n (x1, . . . ,xn) = supt : Ψ(t,x1, . . . ,xn) < 0
T+n (x1, . . . ,xn) = inft : Ψ(t,x1, . . . ,xn) > 0

KAPITEL VIII. ASYMPTOTISCHE STATISTIK 12
Satz VIII.6 (Konsistenz von 1dimM-Schätzern) Angenommen, für einψ ∈M 1(R) giltR
ν(dx)ψ(x−t) < ∞ für wenigstens ein t∈ R. Dann existiertλ : R 7−→ R∪±∞,
λ(t) =Z
ν(dx)ψ(x− t)
und ist monoton wachsend.Wenn es ein t0 ∈ R mit λ(t) ≶ 0 für t ≶ t0 gibt, dann gilt
T±n
ν∞−f.s.−−−−−−−−−−−−−−−−→
n→∞t0
Insbesondere gilt dann für jede Folge Tn von M-Schätzern bezüglichψ daß
Tn
ν∞−f.s.−−−−−−−−−−−−−−−−→
n→∞t0
Beweis:Monotonität klar (Monotonität der Integrale).Sei(Xi)i∈N u.i.v.∼ ν. Das starke Gesetz der großen Zahlen impliziert für festesε > 0
1n
n
∑i=1
ψ(Xi − (t0− ε))ν∞−f.s.−−−−−−−−−−−−−−−−→
n→∞λ(t0− ε) < 0
Daraus folgt für fast allen ∈ N T−n ≥ t0− ε. Analog gilt für fast allen ∈ N T+
n ≤ t0 + ε. T−n ≤ T+
nimpliziert das Verlangte.
Wir definieren in diesem Fall (ψ)
T(ν) =12(supt : λ(t) < 0+ inft : λ(t > 0))
Satz VIII.7 Angenommen,(M) gilt und
(M+1) λ ist in t0 differenzierbar mitλ′(t0) > 0
(M+2) σ2(t) =R
ν(dx)ψ(x, t)2−λ(t)2 ist in einer Umgebung von t0 stetig und in(0,∞).
Dann sind alle M-Schätzer Tn bezüglichψ asymptotisch normal mit Mittelwert t0 und Varianz σ2(t0)n(λ′(t0))2 .
Beweis:[Skizze](Xi)i∈N sei u.i.v. gemäßν. ZGWS zeigt:1n ∑ni=1 ψ(Xi− t) ist asymptotisch normalverteilt
für t in Umgebung vont0. Genauso gilt dies für1n ∑ni=1 ψ(Xi − (t0 + y/
√n)), y∈ R beliebig (man zeige
Lindeberg-Bedingung oder ähnliches). Dann gilt
P(T−n ≤ t0 +y/
√n) = P(
1n
n
∑i=1
ψ(Xi − (t0 +y/√
n))≥ 0)
= P(1/√
nn
∑i=1
(ψ(Xi − (t0 +y/√
n))−λ′(t0)y/√
n)≥−λ′(t0)y)
===========⇒n→∞
N(0,σ2(t0))(−λ′(t0)y,∞) = N(0,σ2(t0)λ′(t0)2)(−∞,λ′(t0)y)
was das Verlangte zeigt.
Beispiel VIII.3 Kleinste Quadrate Schätzer, Varianzanalyse: ni → ∞

KAPITEL VIII. ASYMPTOTISCHE STATISTIK 13
VIII.4 Anwendung auf Maximum-likelihood Schätzer
VIII.4.1 Konsistenz von ML-Schätzern
Hess, Wald
Satz VIII.8 (Wald) SeiΘ⊆Rd abgeschlossen und(X n0 ,Xn
0,(Qn
ϑ)
ϑ∈Θ)n∈N dominierte Standard statisti-sche Räume mit Qϑ 6= Qϑ′ für ϑ 6= ϑ′. Es gebe Dichten(qϑ)ϑ∈Θ mit folgenden Eigenschaften:
1. q· (x) ist für ν0-fast alle x stetig.
2. IstΘ beschränkt, so gelte mit w(ϑ,x,ε) = supq(ϑ′,x) : |ϑ−ϑ′|< ε daß für alleϑ 6= ϑ′ einε > 0existiert mit
Eϑ lnw(ϑ′,X1,ε)
q(X1,ϑ)< ∞.
3. Für unbeschränkteΘ sei zusätzlich q(x,ϑ)→ 0 für |ϑ| → ∞ außerhalb einer Nullmenge. Entspre-chend gelte mit w∞(x,M) = supq(ϑ′,x) : |ϑ′| ≥M daß für alleϑ ein M> 0 existiert mit
Eϑ lnw∞(X1,M)q(X1,ϑ)
< ∞
Falls dann(Tn)n∈N ML-Schätzer sind, so sind sie konsistent für a(ϑ) = ϑ.
VIII.4.2 Asymptotische Normalität von ML-Schätzern
Satz VIII.9 (Hauptsatz über ML-Schätzer) Seien(X n0 ,Xn
0,(Qn
ϑ)
ϑ∈Θ)n∈N dominierte Standard statisti-sche Räume mit dominierendem Maßν0n und einem IntervallΩ ⊆ R, für welchen Dichten(qϑ)ϑ∈Θexistieren sodaß
1. q(ϑ,x) > 0 für alle ϑ ∈Θ,
2. q( · ,x) ist zweifach stetig differenzierbar für alle x∈ X0,
3. ηϑ( · ) = ddϑ lnq(ϑ, · ) ∈ L2(Pϑ)∀ϑ ∈Θ.
4. Vertauschbarkeit: Zd
dϑq(ϑ,x)ν0(dx) = 0 =
Zd2
dϑ2 lnq(ϑ,x)Qϑ(dx)
5. Für jedesϑ gibt es Umgebung in der∣∣∣ d2
dϑ2 lnq(ϑ′,x)∣∣∣≤M(ϑ,x) f.s. für alleϑ′ aus der Umgebung
mit Eϑ(M(ϑ,X1)) < ∞
6. Es gilt0 < J(ϑ) = Eϑη2ϑ < ∞.
Dann gilt für jede konsistente Folge(Tn)n∈N von ML-Schätzern und jedesϑ ∈ Θ daß(Tn)n∈N asympto-tisch normalverteilt mit Ewertϑ und Varianz 1
nJ(ϑ) ist.
Anmerkung Es gibt auch eine mehrdimensionale Version.
Folgerung 1 Sei(Pϑ)ϑ∈Θ regulär. Dann ist jeder ML-Schätzer TML asymptotisch effizient.Ist T ein M-Schätzer zu einer Funktionϕ, dann ist asymptotischVϑT ≈ VϑTML nur dann wenn
ϕ(x,ϑ) = clogq(x,ϑ).

KAPITEL VIII. ASYMPTOTISCHE STATISTIK 14
VIII.5 Asymptotische Testtheorie
VIII.5.1 Asymptotische Verteilung von Teststatistiken
Asymptotischesχ2
VIII.5.2 Der χ2-Anpassungstest
Ohne & mit Schätzung der Parameter
VIII.5.3 Asymptotische Fehler von Tests
Large deviations, lokale Alternativen

Kapitel IX
Ordnungsbasierte NichtparametrischeVerfahren
IX.1 Lehrbücher Nichtparametrische Statistik
[Gibbons] Jean Dickinson Gibbons. Nonparametric statistical inference. McGraw-Hill New York , 1971.
[Hajek-Sidak] J. Hajek and Z. Sidak. Theory of rank tests. Academic Press New York-London, 1967.
IX.2 Empirische Verteilungsfunktion und Ordnungsstatistiken
IX.2.1 Der Hauptsatz der Statistik
Bezeichnung Zur Erinnerung:Pn = 1
n ∑ni=1 δxi empirisches Maß
Fn empirische Verteilungsfunktion.
Satz IX.1 (Glivenko-Cantelli) (Xi)i∈N u.i.v., FX1 = F. Dann gilt
supt∈R
|Fn(t)−F(t)|P−f.s.−−−−−−−−−−−−→
n→∞0
Folgerung Pn ===========⇒n→∞
L (X1) P− f.s.
IX.3 Nichtparametrische Tests
IX.4 L-Schätzer
IX.4.1 Definition
Motivation Man versuche, Median zu verallgemeinern:M-Schätzer: Median minimiertϑ 7→ ∑n
i=1 |xi −ϑ|L-Schätzer: Median ist xn/2:n oder 1
2(x(n−1)/2:n +x(n+1)/2:n).xk:n sind Ordnungsstatistiken
15

KAPITEL IX. ORDNUNGSBASIERTE NICHTPARAMETRISCHE VERFAHREN 16
Definition IX.1 Ein L-Schätzerist eine Abbildung T: Rn 7−→ R, für welche Gewichte ani ∈ R, i =1, . . . ,n und h: R 7−→ R existieren, so daß
T(x1, . . . ,xn) =n
∑i=1
anih(xi:n)
Anmerkung L lineareKombination von Ordnungsstatistiken
IX.4.2 Asymptotik von L-Schätzern
Motivation Was schätzt ein L-Schätzer? Am einfachsten versteht man dies an asymptotischen Betrach-tungen.
Zunächst beschäftigen wir uns mit den einfachstenL-Schätzern, den Ordnungsstatistiken.Translations-Invarianz für Lokations-Schätzer:O.B.d.A.h(u) = u.Weiterhin ist
T(x1, . . . ,xn) =Z
F−1n (s−0)Mn(ds)
wobei Mn = ∑ni=1aniδi/n ein signiertesMaß ist (d.h. eine u.U. auch negative Dichte bezüglich einem
gewöhnlichen Maß hat).Probleme mit Spiegelungs-Invarianz und Asymptotik löst man am besten mit folgendem Ansatz:
ani =12
M((i−1
n,
in))+
12
M([i−1
n,
in]),
wobeiM ein signiertes Maß auf[0,1] ist.Dann gilt
T(Q) =Z
F−1Q (s)M(ds)
mit der symmetrisierten VerteilungsfunktionF−1(s) = F−1(s−0)+F−1(s+0).
IX.4.3 R-Schätzer
Motivation R – Schätzer, die vonRang-Tests abgeleitet werden
s.o., aus Huber

Kapitel X
Kurvenschätzung
X.1 Lehrbücher Kurvenschätzung
[Silverman] B.W. Silverman. Density estimation for statistics and data analysis.Chapman and Hall, Lon-don - New York, 1986.
[Efromovich] Sam Efromovich. Nonparametric curve estimation. Springer New York, 1999
X.2 Beispiele
X.3 Dichteschätzung
Gütekriterien:
RF(F) = E∥∥F− F
∥∥∞
Kolmogoroff-Abstand oder
Rf ( f ) = MISE( f ) = EZ
( f (x)− f (x))2dx
mittlerer integrierter quadratischer Fehler
X.3.1 Histogramm-Schätzer
X.3.2 Kerndichteschätzer
Gegeben sei KernfunktionK : R 7−→ R mitR
K(x)dx = 1.Wir setzen fürh > 0 (Bandbreite) Kh(x) = 1
hK( xh)
X.4 Nichtparametrische Regression
Wieder MISE
X.5 Adaptive Verfahren
17

Kapitel XI
Robuste Statistik
XI.1 Literatur Robuste Statistik
[Hampel et.al.] F.R. Hampel, E.M. Ronchetti, P.J. Rousseeuw, W.A. Stahel.Robust statistics. The ap-proach based on influence functions. Wiley Series in Probability and Mathematical Statistics.John Wiley & Sons, Probability and Mathematical Statistics. New York etc., 1986.
[Huber] P.J. Huber.Robust statistics. Wiley Series in Probability and Mathematical Statistics. JohnWiley & Sons, New York etc., 1981.
[Jureckova] J. Jurecková und P.K. Sen.Robust statistical procedures: asymptotics and interrelations.Wiley Series in Probability and Mathematical Statistics. John Wiley & Sons Ltd, New York, NY,1996.
[Rey] W.J.J. Rey.Introduction to robust and quasi-robust statistical methods. Universitext. Springer-Verlag, Berlin etc., 1983.
[Rieder] H. Rieder. Robust asymptotic statistics. Springer Series in Statistics. Springer-Verlag, NewYork, NY, 1994.
XI.2 Einführendes Beispiel
Beispiel XI.1 (siehe [Huber])
Xi ∼ Pε,µ,σ = (1− ε)N(µ,σ2)+ εN(µ,9σ2)
Wollenσ schätzen, d.h. Skalen-Bestimmung.Zwei prominente Schätzer
dn =1n
n
∑i=1
|xi − x| sn =
(1n
n
∑i=1
(xi − x)2
)1/2
(mittlere absolute Abweichung und mittlere quadratische Abweichung)Zum Vergleich der Schätzer: asymptotische relative Effizienz, berechnet sich zu (!!!ÜA 1)
are(ε) = limn→∞
Var(sn)/(Esn)2
Var(dn)/(Edn)2 =3(1+80ε)/(1+8ε)2−1
4((π(1+8ε)/2(1+2ε)2)−1)
18
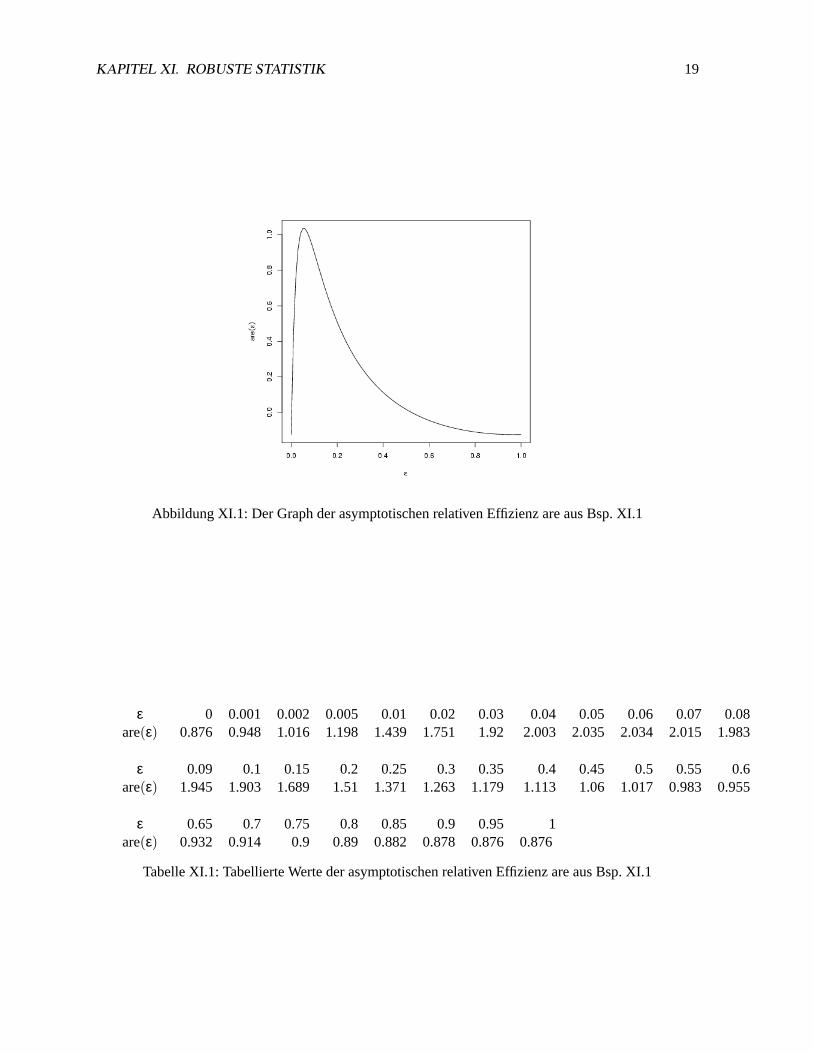
KAPITEL XI. ROBUSTE STATISTIK 19
Abbildung XI.1: Der Graph der asymptotischen relativen Effizienz are aus Bsp. XI.1
ε 0 0.001 0.002 0.005 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08are(ε) 0.876 0.948 1.016 1.198 1.439 1.751 1.92 2.003 2.035 2.034 2.015 1.983
ε 0.09 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.45 0.5 0.55 0.6are(ε) 1.945 1.903 1.689 1.51 1.371 1.263 1.179 1.113 1.06 1.017 0.983 0.955
ε 0.65 0.7 0.75 0.8 0.85 0.9 0.95 1are(ε) 0.932 0.914 0.9 0.89 0.882 0.878 0.876 0.876
Tabelle XI.1: Tabellierte Werte der asymptotischen relativen Effizienz are aus Bsp. XI.1
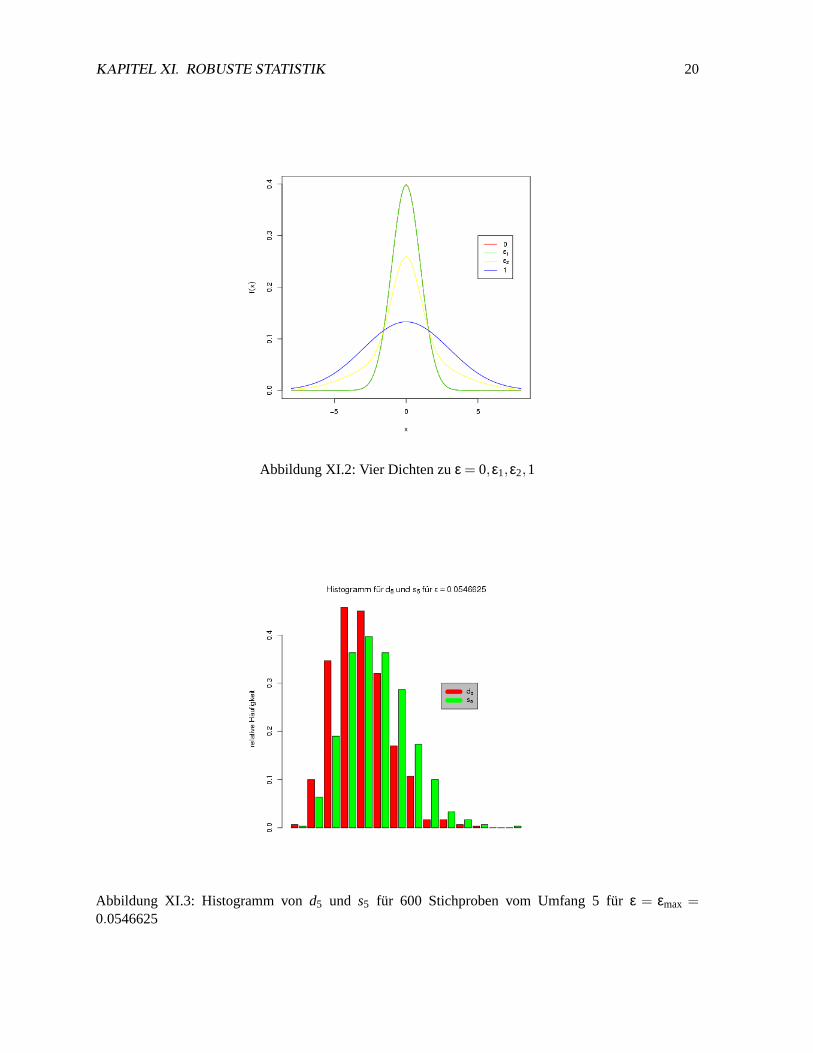
KAPITEL XI. ROBUSTE STATISTIK 20
Abbildung XI.2: Vier Dichten zuε = 0,ε1,ε2,1
Abbildung XI.3: Histogramm vond5 und s5 für 600 Stichproben vom Umfang 5 fürε = εmax =0.0546625

KAPITEL XI. ROBUSTE STATISTIK 21
Kurvendiskussion (Tabelle siehe Tab. XI.1, Plot siehe Bild Abb. XI.1) ergibtare(ε)= 1 für ε1 = 0.001763241undε2 = 0.523525704als auch Maximum von2.037618für εmax = 0.0546625. Eine Simulation findetsich in Bild Abb. XI.3.
Was sind Störungen?
• grobe Fehler (gross errors)Nur dies wird im weiteren behandelt
• Verletzung der Verteilungsannahmen
• Runden (unbedeutend, aber ...)
• Unabhängigkeit verletzt (nicht betrachtet)
Stabilität betrifft:
• qualitativ: Stetigkeit
• Bias
• Varianz
• Risiko
Wegen Unabhängigkeit können wir (Symmetrie) jede gute Statistik als Funktional der empirischenVerteilung schreiben,T(x1, . . . ,xn)∼= T(1
n ∑ni=1 δxi ). Dies macht Verallgemeinerung (außerhalb der para-
metrischen Familie) leicht.
XI.2.1 Modelle für Störungen
Motivation Die meisten Beobachtungen Y sind gestört, d.h. es gibt einen zufäligen Wert X, den wireigentlich sehen wollen und einen Störterm Z, unabhängig von X sowie eine Formel der Art
Y = X +Z
oder
Y = XZ
oder allgemein
Y = f (X,Z)
Dann gilt
PY(A) = P(Y ∈ A) =Z
PX(dx)PZ(dz)χA( f (x,z)) =Z
PX(dx)PZ(z : f (x,z) ∈ A)
Zur Erinnerung:Ein stochastischer (Markov,Bedingungs-)Kern von(Ω,F ) nach(Ω′,F ′) ist eine Abbildung K: Ω×
F ′ 7−→ [0,1] mit
1. K(x, ·) ist ein Wahrscheinlichkeitsmaß aufF ′ für alle x∈Ω.
2. K(·,A) ist F meßbar Funktion für alle A∈ F ′.

KAPITEL XI. ROBUSTE STATISTIK 22
Dann transformiert K Wahrscheinlichkeitsmaße aufΩ in solche aufΩ′ durch QK(A)=R
Q(dx)K(x,A)∀A∈F ′.
Beispiel XI.2 Nun Kurven
1. Kt(x, · ) = N(x, t), QKt = Q∗N(0, t), QKt Ks = QKt+s
2. Kt(x, · ) = e−tδx +(1−e−t)ν, QKt = e−tQ+(1−e−t)ν, wieder QKt Ks = QKt+s
3. Kt(x, · ) = Gl([x,x+ t])
Nun zu unserer Liste von Störungen.
Beispiel XI.3 grobe Fehler:Kl (x1, . . . ,xl , . . . ,xn, · ) = δ(x1,...,yl ,...,xn)Interpretation: jedes xl wird durch einen Wert yl ersetzt, der nichts mit xl zu tun hat.allgemeiner: xl1, . . . ,xlm → yl1, . . . ,ylm.
Beispiel XI.4 Runden: auch eine deterministische Trafo
Beispiel XI.5 Qnϑ →Qn
ε,ϑ = Qnϑ Kn
ε mit Qε,ϑ = Qϑ Kεε klein: kleine Störung
XI.3 Qualitative Robustheit und Hampels Theorem
Motivation qualitativ robust⇔ Stetigkeitaber: allgemeiner verschiedene Schätzer, Folge
FolgenTn, a beliebig.
Definition XI.1 (Tn)n∈N heißt qualitativ robust (bezüglich Prochorov-Abstand) in Q0, falls für alleε > 0es einδ > 0 und n0 ∈ N gibt mit
dP(Q0,Q)≤ δ⇒ dP(LQ0(Tn),LQ(Tn))≤ ε, (n≥ n0) (XI.1)
Anmerkung verschiedene Metriken können verschiedene Begriffe erzeugen, aber. . .
Nun: SchätzerTn = T(Pn), a = T wobei alsoT : M 1(X0,B(X0)) 7−→ A
Lemma XI.1 T schwach stetig in Q0 ⇒ Tn = T(Pn) ist konsistent in Q0
Beweis:Folgt direkt aus Satz IX.1.
Lemma XI.2 Tn = T(Pn) ist konsistent in Q0 ⇒ in (XI.1) kann man jede Metrik benutzen.
Beweis:
d(LQ0(Tn),LQ(Tn))≤ d(LQ0(Tn),δT(Q0))︸ ︷︷ ︸→0 wegen Konsistenz
+d( δT(Q0)︸ ︷︷ ︸fester Wert
,LQ(Tn))
+ Äquivalenzbegriff für Metriken

KAPITEL XI. ROBUSTE STATISTIK 23
Satz XI.1 Für A ⊆ R gilt:Sei T stetig in einer Umgebung von Q0. Dann ist(Tn)n∈N qualitativ robust in Q0.Ist (Tn)n∈N konsistent in einer Umgebung von Q0 und qualitativ robust in Q0. Dann ist T stetig in Q0.
Beispiel XI.6 T(Q) =R
Q(dx)ψ(x) ist stetig genau dann wennψ ∈Cb(E).Bew.:ψ(x) = T(δx) impliziert StetigkeitFalls ψ(xn)≥ n2, nehme Qn = (1− 1
n)δx0 + 1nδxn. Dann ist T(Qn)∼ n, aber Qn ===========⇒
n→∞δx0.
Beispiel XI.7 arithm. Mittel ist nicht qualitativ robust! (stetig auch nicht, siehe vorher)Methode: Kontamination Q= (1− ε)Q0 + εδx
Beispiel XI.8 U-statistik ist stetig genau dann wenn symmetrischer Kern stetig ist (Aufgabe k= 2).
Für Median noch ein paar Vorbereitungen:
Definition XI.2 Sei F : R 7−→ [0,1] Verteilungsfunktion. Dann ist dieQuantilfunktionF−1 definiertdurch
F−1(y) =
supx : F(x = 0) y = 0infx : F(x) > y y∈ (0,1)infx : F(x) = 1 y = 1
med(Q) =12(F−1
Q (12)+F−1
Q (12−0))
Beispiel XI.9 Median qualitativ robust in Q genau dann wenn FQ stetig in med(Q), d.h. F−1Q (1
2) =F−1
Q (12−0)
Für stetig genauso.
Weitere Bsp. kommen noch.
XI.4 Robustheitsmaße
XI.4.1 Metriken für die schwache Konvergenz
Bezeichnung Abstand von Histogrammen: verschiedene Varianten.
Sei(E,ρ) vollst. sep. metrischer Raum.
Bezeichnung Aε = x∈ E : infy∈A ρ(x,y)≤ ε
Definition XI.3 Prochorov-Abstand
dP(ν,ν′) = supε > 0 : ν(A)≤ ν′(Aε)+ ε∀A∈B(E)
Lemma XI.3 ν(A)≤ ν′(Aε)+δ∀A∈B(E) impliziert ν′(A)≤ ν(Aε)+δ∀A∈B(E).
Satz XI.2 dP ist eine Metrik aufM 1(E,B(E)), bezüglich welcher dieser vollständig und separabler ist.Seienνn,ν Wahrscheinlichkeitsmaße auf(E,ρ). Dann giltνn ===========⇒
n→∞ν genau dann wenn dP(νn,ν) −−−−−−−−−−−→
n→∞0.
Satz XI.3 Es sind äquivalent

KAPITEL XI. ROBUSTE STATISTIK 24
1. ν(A)≤ ν′(Aε)+δ∀A∈B(E)
2. Es gibt zufällige Größen X,Y mitL(X) = ν, L(Y) = ν′ und P(ρ(X,Y) > ε)≤ δ.
3. Es gibt stochastischen Kern K mitν′ = νK undR
ν(dx)K(x,Bε(x))≤ δ.
Beispiel XI.10 dP(δx,δy) = ρ(x,y)∧1
Anmerkung
Pε,δ(ν) = ν′ : ν(A)≤ ν′(Aε)+δ
wird auch Prochorov-Umgebung genannt.Alternative:ε = δ = 0 impliziert dT(ν,ν′) = sup|ν(A)−ν′(A)|,A∈B(E)Totalvariationsabstand, wissen: dT ≥ dP
Analog
Definition XI.4 ν,ν′ ∈ M 1(E,B(E)). ν ∈ M 1(E×E,B(E×E)) ist Kopplungvonν,ν′, ν ∈ C (ν,ν′),falls
ν(A×E) = ν(A) ν(E×A) = ν′(A), (A∈B(E)).
Seiρ beschränkt,∞ > p≥ 1. Die lp-Wasserstein Metrik ist definiert durch
dpW(ν,ν′) = inf
ν∈C (ν,ν′)(Z
ν(d(x,y))ρ(x,y)p)1/p
Anmerkung Transportkosten
ÜA 2Ist Metrik! Speziell:E = R
Definition XI.5 Levy-Metrik
dL(ν,ν′) = infε > 0 : Fν(t− ε)− ε≤ Fν′(t)∀t ∈ R
Kolmogoroff-Metrik
dK(ν,ν′) = sup|Fν(t)−Fν′(t)| : t ∈ R
Lemma XI.4 1. dL ≤ dK ≤ dT
2. dL ≤ dP ≤ dT
3. (dP)2 ≤ d1W ≤ 2dP
Anmerkung ÜA 3Man probiere alle möglichen Metriken anν = pδx +(1− p)δy!Erweiterung: Histogramme

KAPITEL XI. ROBUSTE STATISTIK 25
XI.4.2 Bruchpunkte
Motivation Wann versagt die Statistik völlig?D.h., wir haben ein Kontaminationsmodell und fragen, bei welcher Stärke der Kontamination wir
uns überhaupt nicht mehr auf die Statistik verlassen können.
Im folgenden sei(Pε)ε∈[0,1] ein Nachbarschaftssystem von Wahrscheinlichkeitsmaßen, d.h.Pε(Q) ⊆M 1(X ) mit
1. P0(Q) = Q
2. P1(Q) = M 1(X )
3. Pε(Q)⊆ Pε′(Q) falls ε ≤ ε′
4. Pε(Q) ist konvex
Beispiel XI.11 1. Pε(Q) = Q′ : d(Q,Q′)≤ ε für eine Metrik d. (Prohorov (auch verallgemeinert),Levy, Wasserstein Umgebung) Konvexität ist Eigenschaft der Metriken:
d(Q,λQ1 +(1−λ)Q2)≤ λd(Q,Q1)+(1−λ)d(Q,Q2)
Nachweis der Konvexität für diese Spezialfälle ist ÜA 4
2. Pε(Q) = (1− ε)Q+ εQ′ : Q′ ∈M 1(X ) (grobe Fehler „gross error“ Umgebung)
Version 1 für Bruchpunkte: (verteilungsfrei, Statistik ist punktweise nicht kontrollierbar)
Definition XI.6 Sei T : X n0 7−→ A eine Statistik. Definieren wir für x∈ X n
0 , y ∈ X k0 , i1 < · · · < ik ∈
1, . . . ,n einen neuen Vektor xyi1,...,ik
= (z1, . . . ,zn) wobei
zi =
yl wenn i= i lxi sonst
.
Der Bruchpunkt erster Artist
ε∗,I (T,x1, . . . ,xn) = infk/n : supρ(T(x1, . . . ,xn),T(xy,i1,...,ik)) : y∈ X k0= supρ(T(x1, . . . ,xn),a) : a∈ A
Für eine Folge(Tn)n∈N von Schätzern (z.B. Tn = T(Pn)) setzt man
ε∗,I ((Tn)n∈N) = liminfn→∞
infε∗I (Tn,x1, . . . ,xn) : x1, . . . ,xn ∈ X0
Beispiel XI.12 Median hat Bruchpunkt 0.5Mittelwert hat Bruchpunkt 0
Definition XI.7 Sei (x1, . . . ,xn) eine Stichprobe. Wir definieren die Ordnungsstatistiken(xk:n)k=1,...,n
durch
xk:n = F−1n (
kn−0)

KAPITEL XI. ROBUSTE STATISTIK 26
Beispiel XI.13 α-getrimmtes Mittel,α ∈ (0,0.5).
mα(Q) = 1/(1−2α)Z 1−α
α`(dt)F−1
Q (t)
hat Bruchpunktα.Es gilt
Tn(x1, . . . ,xn) =1
n(1−2α)
n
∑k=1
wα(k,n)xk:n
mit
wα(k,n) =
1 wennbnαc+1 < k < bn(1−α)c+1
(bnαc+1−nα)/n wenn k= bnαc+1(n(1−α)−bn(1−α)c)/n wenn k= bn(1−α)c+1
0 sonst
Version 2: (Verzerrung bleibt beschränkt)
Definition XI.8
bε(T,Q) = sup|T(Q′)−T(Q)| : Q′ ∈ Pε(Q)b′ε(n,T,Q) = sup|EQ′n(Tn)−EQn(Tn)| : Q′ ∈ Pε(Q)
ergibt Bruchpunkt zweiter Art:
ε∗,II (T,Q) = liminfn→∞
supε > 0 : b′ε(n,T,Q) < b′1(n,T,Q)
Anmerkung Andere Varianten:
ε∗ = supε > 0 : bε(T,Q) < b1(T,Q)ε∗ = supε > 0 : limsup
n→∞b′ε(n,T,Q) < limsup
n→∞b′1(n,T,Q)
ähnlich für die Varianz möglich, aber ungebräuchlich.
Version 3: (Abstand in Metrik)
Definition XI.9 Für n definiere
∆ε(n,T,Q) = supd(LQ(Tn),LQ′(Tn)) : Q′ ∈ Pε(Q)
und den Bruchpunkt
ε∗,III (T,Q) = liminfn→∞
supε > 0 : ∆ε(n,T,Q) < ∆1(n,T,Q)
Beispiel XI.14 Mittelwert: ε∗,III (T,Q) = 0
Version 4:

KAPITEL XI. ROBUSTE STATISTIK 27
Definition XI.10
ε∗,IV (T,Q) = supε > 0 :∃Kε $ Akompakt∀Q′ ∈ Pε(Q) : Q′n(Tn ∈ Kε) −−−−−−−−−−−→n→∞
1
Beispiel XI.15 A = R, dann äquivalent:∃rε:
Qn(|Tn| ≤ rε) −−−−−−−−−−−→n→∞
1
explizites Beispiel: Median fürε < 0.5 und Levy-Umgebung.
Anmerkung intuitiv klar: ε∗,IV ≥ ε∗,I
Problem: berechnen und fallsA „zu kompakt“:A = [0,∞) für eine Skala.Kε = [0, rε] ist kompakt, aber 0 schlechtähnliches Problem existiert aber auch für Bruchpunkt erster Art!
Beispiel XI.16 X0 = 0,1 Bernoulli-Verteilungen, T Mittelwert. Schwaches Gesetz der großen Zahlenergibt Bruchpunkt1!
Median wäre schlechte Statistik.
Anmerkung Falls Pε ⊆ Pε, dann giltε∗,i ≥ ε∗,i
XI.4.3 Die Einflussfunktion
Motivation infinitesimale Änderung einer Statistik verstehen (ganz geringe Störung)
Definition XI.11 Sei T: M 1(X0,B(X0)) 7−→ R. Falls existiert, sei
IF (x,T,Q) = limε↓0
T((1− ε)Q+ εδx)−T(Q)ε
Anmerkung ÜbergangR 7→ Rd kanonisch, damit wesentliche Beispiele erschlagen.
Beispiel XI.17 X0 = 1, . . . ,N partielle Ableitung!Schwache Diffbarkeitsforderung!allgemeiner:
dTdQ′ (Q) = lim
ε↓0
T((1− ε)Q+ εQ′)−T(Q)ε
ist affines Funktional in Q′, d.h. unter guten Bedingungen gilt
dTdQ′ (Q) =
ZQ′(dx)IF (x,T,Q)
insbesondere
0 =dTdQ
(Q) =Z
Q(dx)IF (x,T,Q)

KAPITEL XI. ROBUSTE STATISTIK 28
Beispiel XI.18 X0 = R: Mittelwert, T(Q) =R
Q(dy)y.
IF (x,T,Q) = limε↓0
(1− ε)R
Q(dy)y+ εx)−R
Q(dy)yε
= x−Z
Q(dy)y
unbeschränkt!Median:Falls Q= q· `, q stetig, dann
IF (x,T,Q) =sign(x−med(Q))
2q(med(Q))
Definition XI.12 gross-error-sensitivity
σ∗(T,Q) = sup|IF (x,T,Q)| : x∈ X0
T heißt B-robust, falls supσ∗(T,Q) : Q∈M 1(X0,B(X0))< ∞.
Definition XI.13 Sensitivitätskurve
SCn(x1, . . . ,xn)(x) = (n+1)(Tn+1(x1, . . . ,xn,x)−Tn(x1, . . . ,xn))
XI.4.4 Effiziente M-, L- und R-Schätzer
XI.4.5 Skalen-Probleme
Definition XI.14 Ist ν ∈M 1(R) undσ ∈ R dann istσν ∈M 1(R) definiert durch
σν(B) = ν(x : σx∈ B)
Ein Familie (Pϑ)ϑ∈Θ mit Θ ⊂ R heißt Skalenfamiliefalls Pϑ = ϑP0. Dann istΘ abgeschlosseneUnterhalbgruppe von(R, ·), meist:(0,∞), [0,∞),R\0,R.
Änderungen

Index
L-Schätzer, 14
asymptotischen NormalitätMomentenmethode, 8
Bandbreite, 16BLUE, 5Bruchpunkt, 24–26
empirische Verteilungsfunktion, 14empirisches Maß, 14
Fehlergrob, 24
Funktionschätzbar, 6
grober Fehler, 24
Kolmogoroff-Abstand, 16
lineares Modell, 3–6
MISE, 16mittlerer integrierter quadratischer Fehler, 16MLS, 5Momentenmethode
asymptotischen Normalität, 8
Normalengleichung, 5
Ordnungsstatistik, 15
Schätzerkleinste Quadrate, 5, 6
Skalen-Probleme, 27Skalenfamilie, 27
29

Übersetzungen
Deutsch=⇒ Englisch
grobe Fehler→ gross errors, 23Bandbreite→ bandwidth, 19bester lineare unverfälschte Schätzer→ best li-near unbiased estimator, 6grober Fehler→ gross error, 27Kleinste Quadrate Schätzer→ minimum leastsquares estimator, 6mittlerer integrierter quadratischer Fehler→meanintegrated square error, 19Normalengleichung→ normal equations, 6
Englisch=⇒ Deutsch
best linear unbiased estimator→ bester lineareunverfälschte Schätzer , 6bandwidth→ Bandbreite, 19gross error→ grober Fehler, 27gross errors→ grobe Fehler, 23mean integrated square error→ mittlerer inte-grierter quadratischer Fehler, 19minimum least squares estimator→Kleinste Qua-drate Schätzer, 6normal equations→ Normalengleichung, 6
30







