

Informationsintegration
Das Verborgene Web(Hidden Web)
09.02.2006
Felix Naumann

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 2
Überblick Motivation [Be01,To01]
Suche über das Web Begriffe und Definitionen
Auffinden von Hidden Web Informationsquellen Potentielle Hidden Web Quellen Finden [BC04] Themen extrahieren [IGS01] Klassifikation nach Themen [IGS01]
Anfragen an relevante Quellen des Hidden Web Anfragen geeignet verteilen [IGS01] Anfragesprache lernen [BC04]
(Ergebnisse integrieren)

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 3
Das Web
Surface web
Shallow web
Deep web (tiefes Netz)
Invi
sibl
e W
eb(u
nsic
htba
res
Net
z)
Quelle: [To01]
09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 4
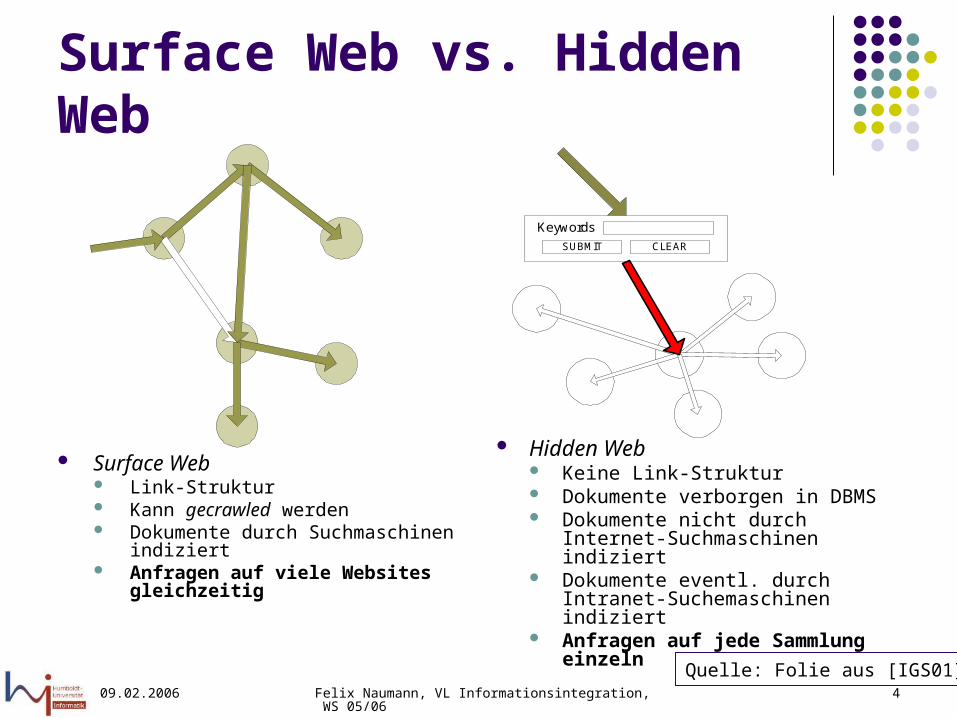
Surface Web vs. Hidden Web
Surface Web Link-Struktur Kann gecrawled werden Dokumente durch Suchmaschinen
indiziert Anfragen auf viele Websites
gleichzeitig
Hidden Web Keine Link-Struktur Dokumente verborgen in DBMS Dokumente nicht durch Internet-
Suchmaschinen indiziert Dokumente eventl. durch Intranet-
Suchemaschinen indiziert Anfragen auf jede Sammlung
einzeln
SUBMIT
Keywords
CLEAR
Quelle: Folie aus [IGS01]

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 5
Hidden Web: Beispiel
Suche in PubMed nach “diabetes” 178,975 Treffer
Google Suche: “diabetes site:www.ncbi.nlm.nih.gov” nur 119 matches
Weitere Beispiele:Database Query Matches Google
PubMed diabetes 178,975 119
U.S. Patents wireless network 16,741 0
Library of Congress visa regulations >10,000 0
… … … … Gegenbeispiel
Amazon: Hilft explizit bei Verlinkung Quelle: Folie aus [IGS01]

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 6
Suche über das Web
Kataloge Suchmaschinen Metacrawler Antwort Services Unsichtbares/Tiefes/Verborgenes Web

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 7
Kataloge Indices speichern URL,
Titel, Kategorien, und Zusammenfassung
Wartung durch Experten freiwillig, bezahlt, Selbst-
Registrierung Das Web (Stand 2001):
>5,000,000,000 Dateien Yahoo:
~2,000,000 Sites 1/2500th des bekannten
Webs
Quelle: [To01]
09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 8
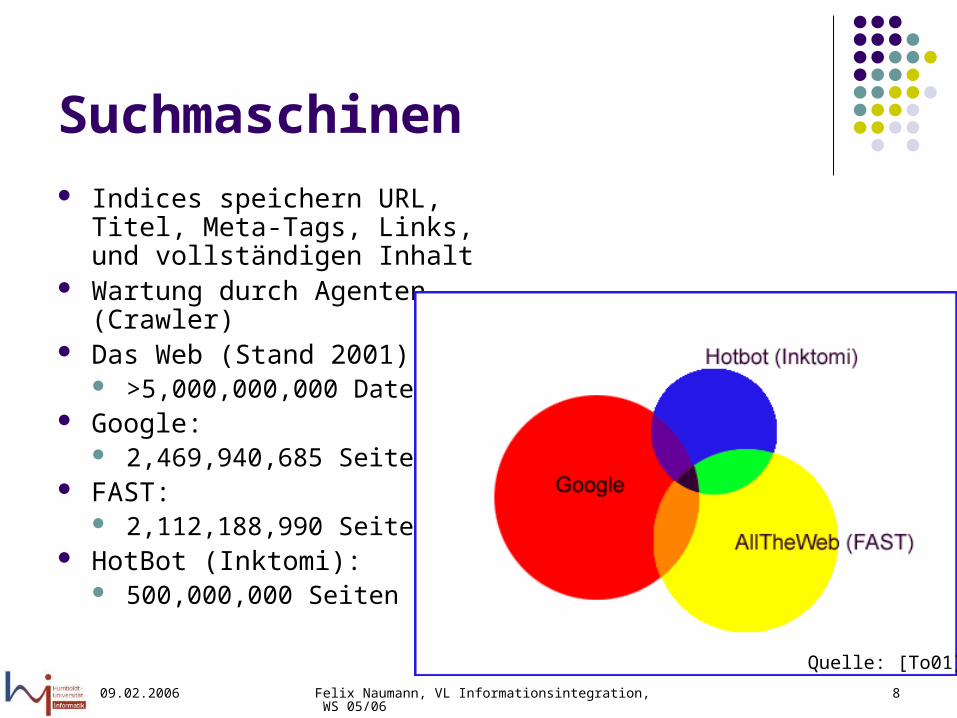
Suchmaschinen Indices speichern URL, Titel,
Meta-Tags, Links, und vollständigen Inhalt
Wartung durch Agenten (Crawler)
Das Web (Stand 2001): >5,000,000,000 Dateien
Google: 2,469,940,685 Seiten
FAST: 2,112,188,990 Seiten
HotBot (Inktomi): 500,000,000 Seiten
Quelle: [To01]

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 9
Meta-Suchmaschinen Haben keinen eigenen Katalog oder Index Nutzer geben Suchbegriff ein, der simultan an andere
Suchmaschinen weitergeleitet wird. Ergebnisse werden integriert und als eine Liste zurückgegeben. Vorteile:
Eine einzige Anfrage Geschwindigkeit
(parallel statt sequentiell) Nachteile:
Time-outs und unvollständige Suche
Anfragesyntax oft reduziert auf kleinsten gemeinsamen Nenner
Quelle: [To01]

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 10
Antwort Services
Datenbank mit gespeicherten häufigen Fragen Katalog von Ask Jeeves enthält 7,000,000 Fragen
Natürlich-sprachliche Suche
Suche in eigener DB und in fremden Katalogen/Indices
Kennt Spezial-Daten-quellen des Hidden Web
Gewichtung anerkannter Quellen (z.B. Almanache)
Quelle: [To01]

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 11
Invisible/Hidden/Deep Web
Quelle: [To01]
09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 12
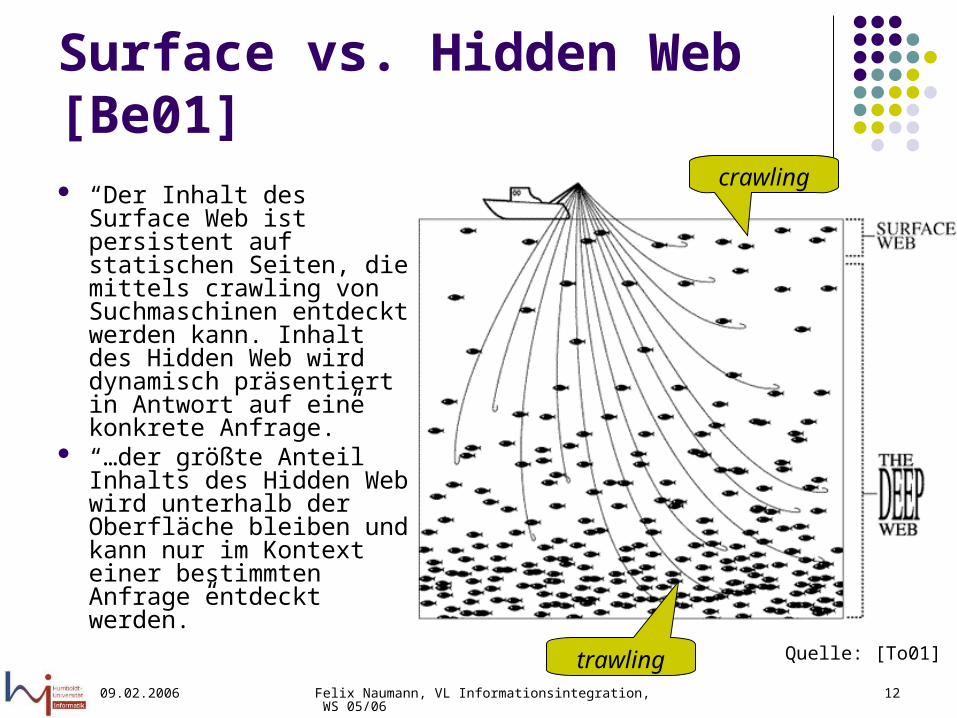
Surface vs. Hidden Web [Be01] “Der Inhalt des Surface
Web ist persistent auf statischen Seiten, die mittels crawling von Suchmaschinen entdeckt werden kann. Inhalt des Hidden Web wird dynamisch präsentiert in Antwort auf eine konkrete Anfrage.”
“…der größte Anteil Inhalts des Hidden Web wird unterhalb der Oberfläche bleiben und kann nur im Kontext einer bestimmten Anfrage entdeckt werden.”
Quelle: [To01]
crawling
trawling

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 13
Das Verborgene Web
Der Teil des Webs, der nicht durch Suchmaschinen indiziert wird. Oft gespeichert in Datenbanken Dynamisch generierte Web Seiten durch Anwendungen im
Server jsp, cgi, …
Sites und Seiten mit Passwort-geschütztem Inhalt Inhalt von Dateien, die nicht in Standard-Formaten
gespeichert werden *.pdf, *.ppt, *.doc Grafikformate
Quelle: [To01]

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 14
Begriffe / Synonyme Surface Web (Oberflächen-Web)
Inhalt für „normale“ Suchmaschinen sichtbar Shallow Web (Flaches Web)
„Normale“ Web-Seiten, die dynamisch generiert werden Anfragen durch Klicken auf Links
Hidden Web (verborgenes Web) Inhalt für „normale“ Suchmaschinen unsichtbar Invisible Web (unsichtbares Web)
Synonym mit Hidden web Deep Web (tiefes Web)
nach BrightPlanet, Synonym mit Hidden Web
Quelle: [To01]

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 15
Statistiken [Be01]
400 to 550 fach größer als Surface Web 7,500 Terabytes Informationen im Hidden Web 19 Terabytes Information im Surface Web 550 Milliarden Dokumente im Hidden Web 1 Milliarde Dokumente im Surface Web je nach dem, was man zählt…
Dynamische Seiten...
100,000 Hidden Websites ca. 84% sind auf Text Dokumente spezialisiert ca. 95% des Hidden Web ist öffentlich verfügbar.
Quelle: [To01]

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 16
Eigenschaften [Be01]
Hidden Websites haben thematisch oft „schmaleren“, aber „tieferen“ Inhalt.
Oft qualitativ bessere Informationen Meist relevanter Inhalt
Kein Spam Über die Hälfte aller Hidden Websites sind
thematisch spezialisiert. Am schnellsten wachsende Kategorie neuer
Informationen im InternetQuelle: [To01]
09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 17
Beispiel: CompletePlanet.com

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 18
Überblick Motivation [Be01,To01]
Suche über das Web Begriffe und Definitionen
Auffinden von Hidden Web Informationsquellen Potentielle Hidden Web Quellen Finden [BC04] Themen extrahieren [IGS01] Klassifikation nach Themen [IGS01]
Anfragen an relevante Quellen des Hidden Web Anfragen geeignet verteilen [IGS01] Anfragesprache lernen [BC04]
(Ergebnisse integrieren)

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 19
Auffinden von Hidden Web Quellen [BC04] Ziel: Finde Webseiten, die als Einstiegspunkt ins Hidden Web
dienen. Seiten mit HTML Formular
Einschränkungen Textuelle Formulare
mindestens ein Textinput Nicht nur radio buttons, menus, checkboxen...
Anfrageformulare Formulare, die Anfragen entgegennehmen und Informationen liefern Keine Login Seiten
„Hidden Web Formulare“ Keine Seiten mit komplexen Formularen (mehr als ein Inputfeld)
Aufgabe: Automatisches Finden und Erkennen von Hidden Web Formularen
André Bergholz, Xerox

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 20
Auffinden von Hidden Web Quellen [BC04] Manuell Automatisches Auffinden von Formularen
Google-Suche (nach Themen) Lokales breadth-first Crawling bis Formular gefunden
Innerhalb einer Site Bis zu einer festen Tiefe
Automatisches Erkennen von Hidden Web Formularen (Heuristiken) Testanfragen mit positiven und negativen Suchwörtern
Positiv: „passende“ Worte Negativ: Fantasieworte
Ergebnisse negativer Suchwörter immer gleich groß (Byte) Ergebnisse positiver Suchworte immer größer als negative
Berechnung der Größe durch „Subtraktion“ von Webseiten (als Baum)

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 21
Überblick Motivation [Be01,To01]
Suche über das Web Begriffe und Definitionen
Auffinden von Hidden Web Informationsquellen Potentielle Hidden Web Quellen Finden [BC04] Themen extrahieren [IGS01] Klassifikation nach Themen [IGS01]
Anfragen an relevante Quellen des Hidden Web Anfragen geeignet verteilen [IGS01] Anfragesprache lernen [BC04]
(Ergebnisse integrieren)
Panagiotis G. Ipeirotis, NYU

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 22
Suche im Hidden Web – Probleme
Auswahl relevanter Quellen für Anfrage Themen extrahieren
Content summary Nach Themen klassifizieren
Hidden Web Metasearcher
Library of Congress
Hidden Web
PubMed ESPN
Nieren 220,000 Steine 40,000...
Nieren 5 Steine 40...
Nieren 20 Steine 950...
Quelle: Folie aus [IGS01]

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 23
Klassifikation von Hidden Web Quellen
Klassifikation hier: Hierarchie über Kategorien und Subkategorien Zuordnung von Quellen ist nicht immer eindeutig.
Manuell Yahoo InvisibleWeb (www.invisibleweb.com) SearchEngineGuide (www.searchengineguide.com) Hierarchien sind einsehbar.
Automatisch Basierend auf Kategorie der Dokumente in der Quelle
09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 24
09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 25

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 26
Content Summaries
Statistiken, die den Inhalt einer Hidden Web Quelle beschreiben
Document-cardinality dc Anzahl der Dokumente
insgesamt Document-frequency df(w)
Pro Wort: Anzahl der Dokumente, die dieses Wort enthalten
Beispiel
KrebsDB
Document cardinality: 148.944
Wort Document frequency
Darm 121.134
Krebs 91.688
... ...
Vorschau zur Verwendung von content summariesAnfrage „Darm-Krebs“Anzahl Treffer = dc * df(Darm)/dc * df(Krebs)/dc = 74569

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 27
Suche im Hidden Web – Probleme
1. Wie extrahiert man content summaries?
2. Wie verwendet man content summaries?
Web Database
Web Database 1
MetasearcherKrebs
Basketball 4Krebs 4,532CPU 23
Basketball 4Krebs 4,532CPU 23
Web Database 2Basketball 4Krebs 60,298CPU 0
Web Database 3Basketball 6,340Krebs 2CPU 0
Quelle: Folie aus [IGS01]

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 28
Extraktion von Content Summaries – Probleme
Kein direkter Zugang zu den Dokumenten ohne konkrete Anfrage
Gebundene Variablen Deswegen: Anfrage-basiertes Dokument-
Sampling:1. „Sinnvolle“ Anfrage an Datenbank schicken (focussed
probing) Ergebnisliste mit Links (Ergebnisdokument)
2. Ergebnisdokumente aus Liste einholen (das „Sample“)3. Sample verwenden um content summary zu erstellen
Quelle: Folie aus [IGS01]

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 29
“Zufälliges” Anfrage-basiertes Sampling
1. Start mit leerem content summary Jedes Wort hat df(w) = 0.
2. Wähle ein Wort und schicke es als Anfrage an Hidden Web Quelle.
3. Wähle top-k Dokumente der Antwort (z.B. k=4).
4. Zähle df(w) für alle w in Sample um content summary zu füllen.
5. Wiederhole bis „genug“ (z.B. 300) Dokumente empfangen wurden
metallurgy
dna
aidsfootball
cancerkeyboardram
polo
Sample
Wort Häufigkeit in Sample
Krebs 150 (out of 300)
aids 114 (out of 300)
Herz 98 (out of 300)
…
Basketball 2 (out of 300)
Quelle: Folie aus [IGS01]

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 30
Zufälliges Sampling – Probleme df(w) zwischen 1 und Anzahl der
Dokumente Es wird nicht Document-frequency
ermittelt, sondern Sample-frequency. Absolute Zahlen sind nicht
aussagekräftig. Große Quellen haben ähnliche content
summary wie kleine Quellen. Zahlen sind nur relativ zu interpretieren
(als ranking). Viele Anfragen ohne oder nur mit
kleinem Ergebnis (Zipf‘s law) Viele, seltene Worte fehlen in der
content summary.
# documents
word rank
Zipf’s law
Viele Worte erscheinen nur in ein oder zwei Dokumenten.
Deshalb jetzt verbesserte LösungQuelle: Folie aus [IGS01]

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 31
Zufälliges Sampling – Verbesserung
Algorithmus: Überblick1. Trainiere Dokument-Klassifikatoren
Finde repräsentative Wörter für jede Kategorie.
2. Verwende Klassifikationsregeln um ein themenspezifisches Sample aus Quelle zu erhalten.
3. Schätze df(w) aller entdeckten Wörter.
Quelle: Folie aus [IGS01]
09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 32
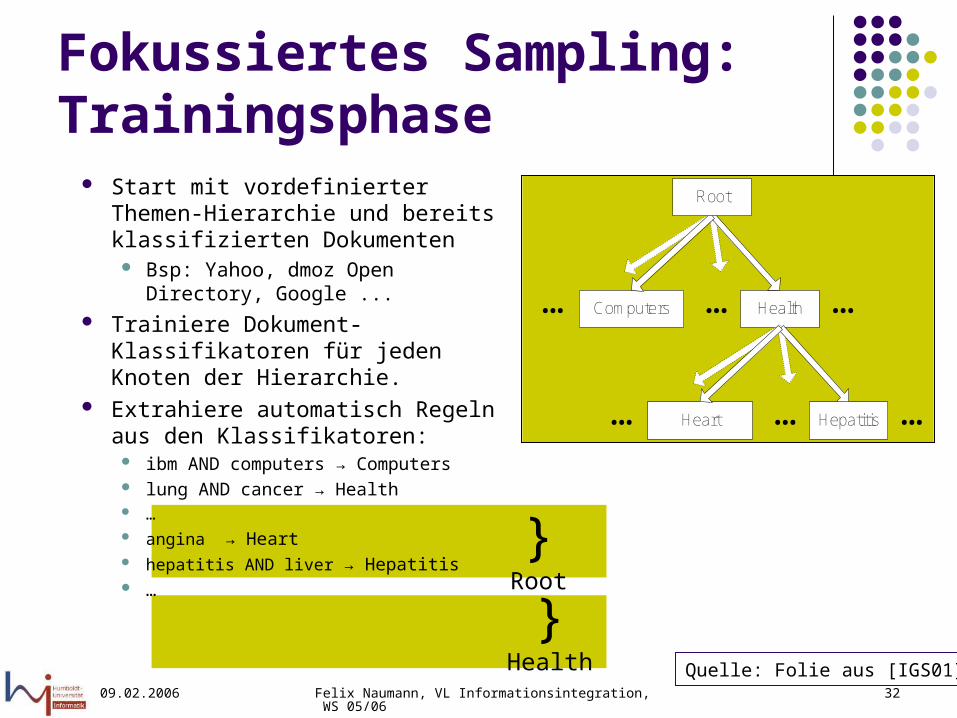
Fokussiertes Sampling: Trainingsphase
Start mit vordefinierter Themen-Hierarchie und bereits klassifizierten Dokumenten Bsp: Yahoo, dmoz Open Directory,
Google ... Trainiere Dokument-Klassifikatoren
für jeden Knoten der Hierarchie. Extrahiere automatisch Regeln aus
den Klassifikatoren: ibm AND computers → Computers lung AND cancer → Health … angina → Heart hepatitis AND liver → Hepatitis …
} Root
} Health
HealthComputers
Root
...... ...
HepatitisHeart ...... ...
Quelle: Folie aus [IGS01]
09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 33
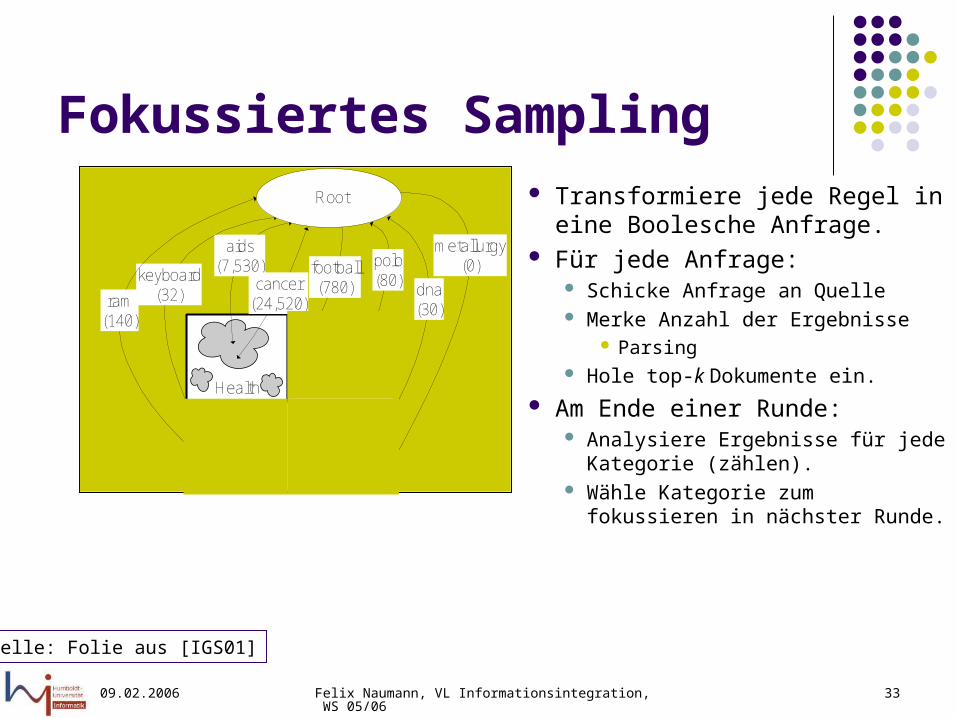
Fokussiertes Sampling Transformiere jede Regel in eine
Boolesche Anfrage. Für jede Anfrage:
Schicke Anfrage an Quelle Merke Anzahl der Ergebnisse
Parsing Hole top-k Dokumente ein.
Am Ende einer Runde: Analysiere Ergebnisse für jede
Kategorie (zählen). Wähle Kategorie zum fokussieren in
nächster Runde.
Health
Sports
Science
metallurgy(0)
dna(30)
Computers
aids(7,530) football
(780)cancer(24,520)
keyboard(32)ram
(140)
polo(80)
Root
Quelle: Folie aus [IGS01]
09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 34
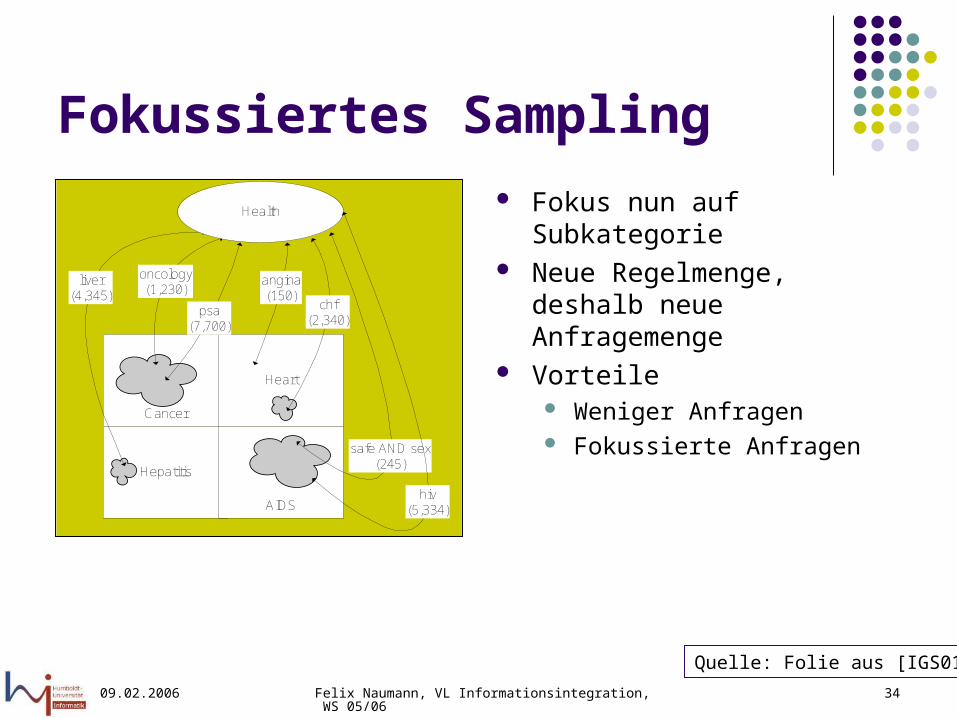
Fokussiertes Sampling
Cancer
Hepatitis
Heart
AIDS
oncology(1,230)
angina(150)
psa(7,700)
liver(4,345)
chf(2,340)
Health
safe AND sex(245)
hiv(5,334)
Fokus nun auf Subkategorie Neue Regelmenge, deshalb
neue Anfragemenge Vorteile
Weniger Anfragen Fokussierte Anfragen
Quelle: Folie aus [IGS01]
09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 35
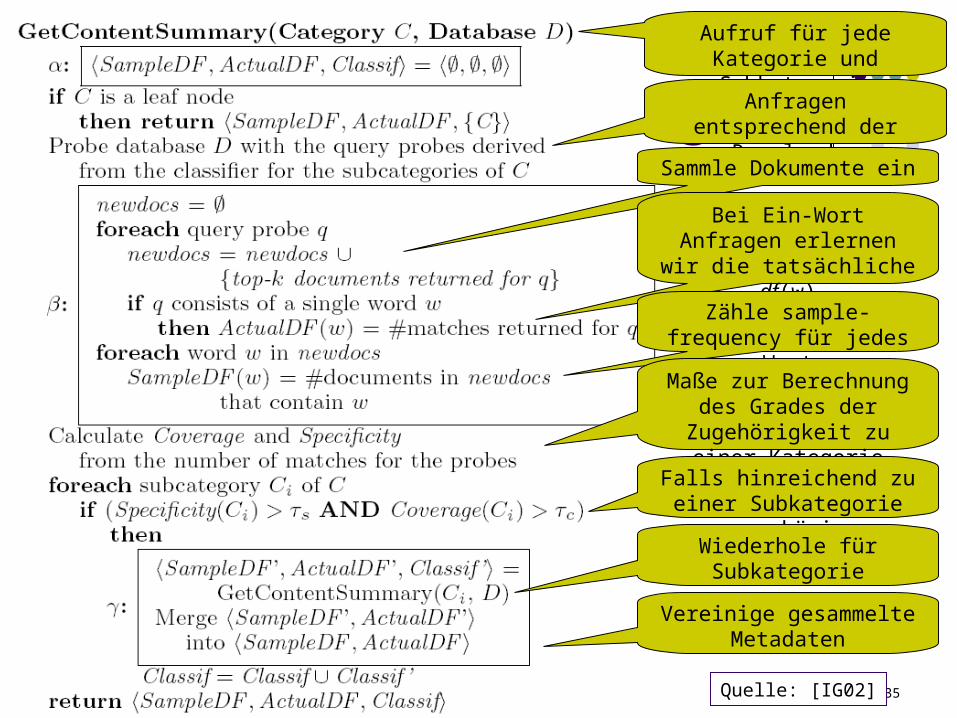
Fokussiertes Sampling
Aufruf für jede Kategorie und Subkategorie
Anfragen entsprechend der Regeln des Klassifikators
Sammle Dokumente ein
Bei Ein-Wort Anfragen erlernen wir die
tatsächliche df(w)
Zähle sample-frequency für jedes Wort
Maße zur Berechnung des Grades der Zugehörigkeit
zu einer Kategorie
Falls hinreichend zu einer Subkategorie zugehörig
Wiederhole für Subkategorie
Vereinige gesammelte Metadaten
Quelle: [IG02]

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 36
Zugehörigkeit von Hidden Web Quellen zu Kategorien Coverage (Abdeckung) –basierte
Klassifikation Quelle D wird allen Kategorien Ci
zugeordnet, für die D hinreichend viele Dokumente enthält.
Specificity (Spezifizität) –basierte Klassifikation Quelle D wird allen Kategorien Ci
zugeordnet, die eine hinreichende Menge von Dokumenten in D abdecken.
Wahl der Schwellwerte beeinflusst Klassifikation Hohe Specificity sammelt
spezialisierte (kleine) Quellen Hohe Coverage sammelt
allgemeinere (große) Quellen
Beispielkategorie: Fußball Sport.de vs. Frauenfussball.de Sport.de
Hohe coverage Alles über Fußball
Niedrige specificity Auch viel über andere Sportarten
Frauenfußball Niedrige coverage
Nur Teilausschnitt der Fußballwelt
Hohe specificity Nur Fußball
Quelle: Folie aus [IGS01]

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 37
Sample-frequency vs. Document-frequency Motivation:
Sample-frequencies sind nur relativ. Quelle mit ähnlichem Inhalt aber unterschiedlicher Größe haben gleiche content
summary. Sample Frequencies
“Leber” erscheint in 200 von 300 Dokumenten im Sample. “Niere” erscheint in 100 von 300 Dokumenten im Sample. “Hepatitis” erscheint in 30 von 300 Dokumenten im Sample.
Document-frequencies Anfrage “Leber” ergibt 140,000 Matches. Anfrage “Hepatitis” ergibt 20,000 Matches. “Niere” war kein Trainingswort… “Darm” und “Krebs” waren zwar Trainingsworte, aber nur gemeinsam.
Zur Abschätzung der (besseren) Document-frequencieswerden Infos der Ein-Wort Anfragen verwendet.
Quelle: Folie aus [IGS01]

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 38
?
?
?
Known Frequency
?Unknown Frequency
Frequency in Sample (always known)
... ...
cancer liver stomachkidneys
......
hepatitis... ...
...
20,000 matches
140,000 matches
60,000 matches
f = P (r+p) -B
?
?
?
Known Frequency
?Unknown Frequency
Frequency in Sample (always known)
... ...
cancer liver stomachkidneys
......
hepatitis... ...
...
20,000 matches
140,000 matches
60,000 matches
f = P (r+p) -B
?
?
?
Known Frequency
?Unknown Frequency
Frequency in Sample (always known)
... ...
cancer liver stomachkidneys
......
hepatitis... ...
...
20,000 matches
140,000 matches
60,000 matches
Frequency in Sample (always known)
... ...
cancer liver stomachkidneys
......
hepatitis... ...
...
Abschätzen der Document-frequencies
Bekannt aus Algorithmus Ranking r der Worte
nach Sample-frequencies
Document-frequency f der Worte aus Ein-Wort Anfragen
Mandelbrot’s Formel verfeinert Zipfs Formel:
f = P (r+p)-B
P, p und B sind Parameter der Quelle
Niedriger rank ergibt hohe frequency
Dann: Kurvenanpassung z.B.: P = 8*105, p =.25,
B = 1.15
r
f
Quelle: Folie aus [IGS01]http://www.math.yale.edu/mandelbrot/web_pdfs/9_E7rankSizePlots.pdf

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 39
Abschätzen der Document-frequencies
Algorithmus Sortiere Wörter absteigend nach Sample-
frequency Ermittle P, p und B durch Fokus auf Wörter mit
bekannter Document-frequency. (Kurvenanpassung)
Berechne df(wi) = P (ri+p)-B für alle anderen Wörter.
Quelle: Folie aus [IGS01]

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 40
Vorteile des Fokussierten Sampling
Wenige Anfragen (Fokus auf Thema) Vielversprechende Anfragen Klassifikation „along the way“
Nützlich für Auswahl relevanter Quellen Schätzung Document-frequency statt nur
Sample-frequency.
Quelle: Folie aus [IGS01]

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 41
Überblick Motivation [Be01,To01]
Suche über das Web Begriffe und Definitionen
Auffinden von Hidden Web Informationsquellen Potentielle Hidden Web Quellen Finden [BC04] Themen extrahieren [IGS01] Klassifikation nach Themen [IGS01]
Anfragen an relevante Quellen des Hidden Web Anfragen geeignet verteilen [IGS01] Anfragesprache lernen [BC04]
(Ergebnisse integrieren)
09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 42
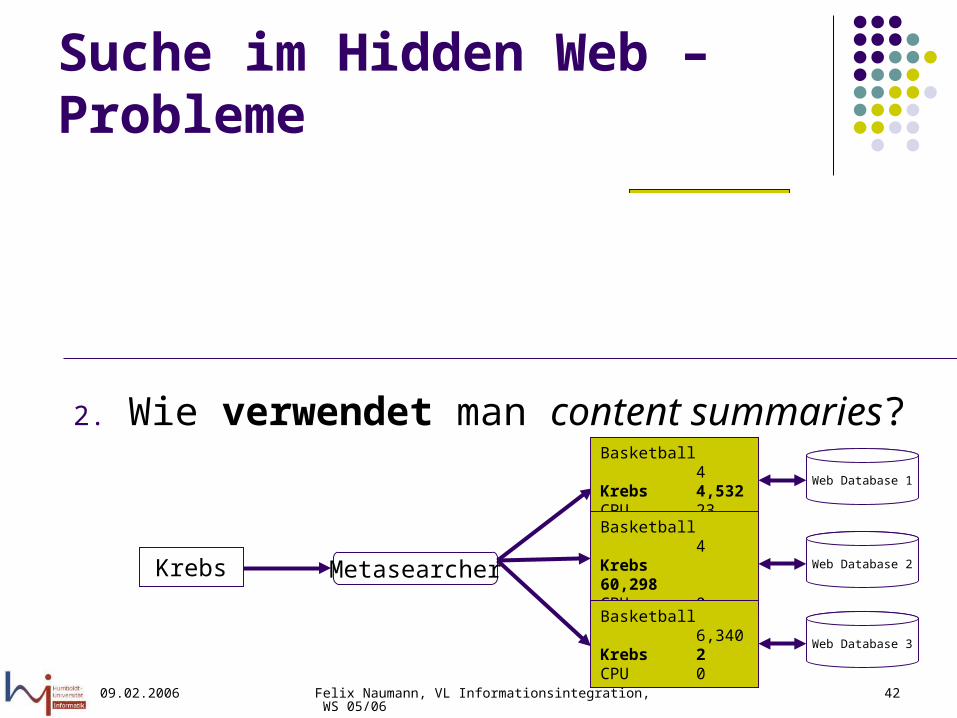
Suche im Hidden Web – Probleme
1. Wie extrahiert man content summaries?
2. Wie verwendet man content summaries?
Web Database
Web Database 1
MetasearcherKrebs
Basketball 4Krebs 4,532CPU 23
Basketball 4Krebs 4,532CPU 23
Web Database 2Basketball 4Krebs 60,298CPU 0
Web Database 3Basketball 6,340Krebs 2CPU 0

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 43
Quellenauswahl und Content Summaries
Quellenauswahl nimmt vollständige content summaries an. Falls unvollständig (das Suchwort fehlt), kann nicht
entschieden werden, ob die Quelle relevant ist. Content summaries aus Sampling sind immer
unvollständig. Idee: Klassifikation verwenden
Quellen gleicher Kategorie sollten auch ähnlich content summary haben.
Content summaries verschiedener Quellen gleicher Kategorie können sich komplementieren.

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 44
Content Summaries für Kategorien (statt für Quellen)
Anzahl der Quellen
Anzahl der Dokumente (Summe)
Document-frequencies (Summe)
Somit kann jede Kategorie als Hidden Web Quelle angesehen werden.
CANCERLIT
… ...breast 121,134… ...cancer 91,688… ...diabetes 11,344… …metastasis <not found>
CancerBACUP
… ...breast 12,546… ...cancer 9,735… ...diabetes <not found>… …metastasis 3,569
Category: CancerNumDBs: 2
Number of Documents: 166,272
… ...breast 133,680… ...cancer 101,423… ...diabetes 11,344
… …metastasis 3,569
Number of Documents: 148,944 Number of Documents: 17,328
Quelle: Folie aus [IGS01]
09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 45
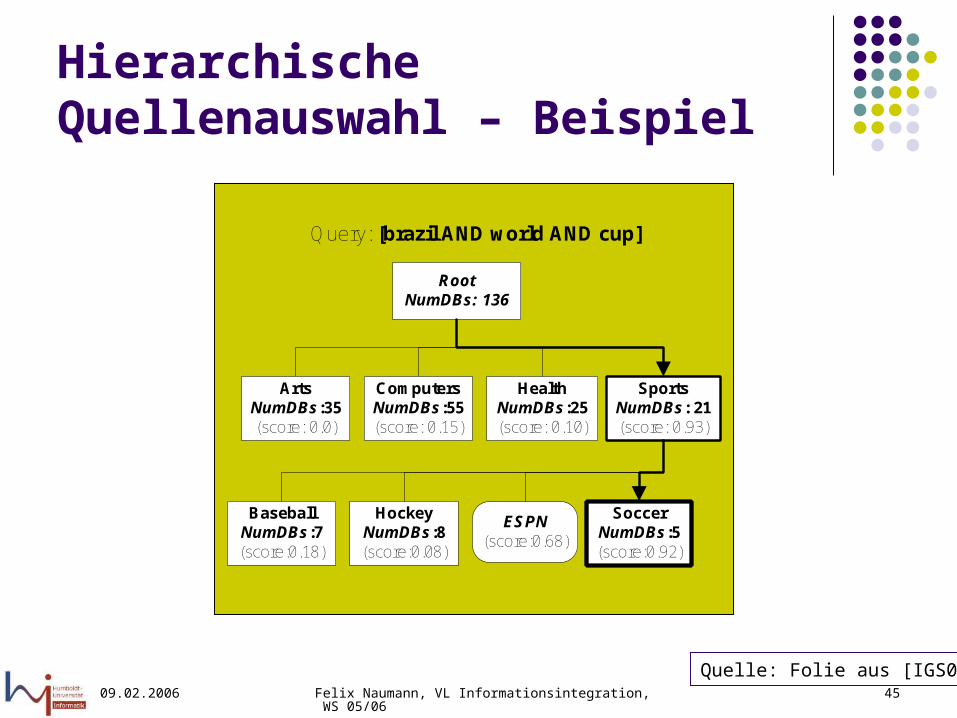
Hierarchische Quellenauswahl – Beispiel
RootNumDBs: 136
SportsNumDBs: 21(score: 0.93)
ArtsNumDBs:35(score: 0.0)
ComputersNumDBs:55(score: 0.15)
HockeyNumDBs:8(score:0.08)
BaseballNumDBs:7(score:0.18)
ESPN(score:0.68)
HealthNumDBs:25(score: 0.10)
SoccerNumDBs:5(score:0.92)
Query: [brazil AND world AND cup]
Quelle: Folie aus [IGS01]

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 46
Überblick Motivation [Be01,To01]
Suche über das Web Begriffe und Definitionen
Auffinden von Hidden Web Informationsquellen Potentielle Hidden Web Quellen Finden [BC04] Themen extrahieren [IGS01] Klassifikation nach Themen [IGS01]
Anfragen an relevante Quellen des Hidden Web Anfragen geeignet verteilen [IGS01] Anfragesprache lernen [BC04]
(Ergebnisse integrieren)

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 47
Anfragen an Quellen des Hidden Web
Hidden Web Quellen verwenden unterschiedliche Anfragesprachen (Schnittstellen-Heterogenität) Suchwörter Phrasen Boolesche Kombinationen
Es gilt, solche „Anomalien“ automatisch
zu entdecken.
Quelle [BC04]

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 48
Anfragesprache an Quellen des Hidden Web
Mögliche Operatoren O = {CASE, STEM, PHRASE, AND, OR, NOT}
Mögliche Syntax S = {wort, `*´, `_´, `“ “´, `AND´, `OR´, `NOT´, `+´, `-´}
Ziel Automatische Erkennung der unterstützten Operatoren Automatische Erkennung der Interpretation der Syntax

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 49
Maschinelles Lernen für Syntax Zielfunktion: T:S O
Zuordnung von Ausdrücken zu Operatoren Problem: Nicht jede Syntax wird unterstützt
Erweiterung von O zu O‘ O = {CASE, STEM, PHRASE, AND, OR, NOT} O‘ = O {ignored, literal, unknown}
Beispiel: Google Wort CASE, STEM `*´ ignored `_´ AND `“ “´ PHRASE `AND´ AND `OR´ OR `NOT´ ignored `+´ AND `-´ NOT literal, unknown
Google kann natürlich noch viel mehr~ SYNONYM

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 50
Maschinelles Lernen für Syntax Idee
Testanfragen verschicken und Ergebnisgrößen untersuchen. Machine Learning Methoden verwenden.
Wichtige Annahme: Man kann Ergebnisgröße herausparsen.
Training Hidden Web Quellen mit bekannter Syntax und bekannten Operatoren Testanfrage verschicken und Eigenschaften der Ergebnisse
(insbesondere Ergebnisgröße) beobachten. Testing
Unbekannte Hidden Web Quelle Gleiche Testanfragen verschicken und Eigenschaften vergleichen.
Welche Testanfragen? Welche Eigenschaften?

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 51
Testanfragen Beispiele
‘caSaBlancA’ (template ‘RandomCase(A)’) Einzelnes Wort
‘Bogart AND’ (template ‘B AND’) Nicht wohlgeformt
‘+Casablanca +Bogart’ (template ‘+A +B’) Kombination von Worten
Variationen ‘+Bogart +Casablanca ’ (template ‘+B +A’)
In [BC04]: 22 templates Templates füllen mit drei Sorten von Wortpaaren
Phrasen: A = information, B = retrieval Co-occurrence: A = information, B = knowledge Nicht verwandte Worte: A = China, B = Käse
Quelle [BC04]

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 52
Eigenschaften der Ergebnisse (Features) Für jede Anfrage qi
Extraktion der Trefferanzahl m(qi) Für jedes Paar von Anfragen qi, qj (231 Stück)
merke (zur Normalisierung) -1 falls m(qi) < m(qj) 0 falls m(qi) = m(qj) +1 falls m(qi) > m(qj)
Dies sind dreiwertige Machine Learning Features. Nun: Beliebiger Algorithmus für Maschinelles
Lernen verwenden Decision Trees, k-Nearest Neighbour, Support-Vector-
MachinesQuelle [BC04]

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 53
Weitere Probleme Stop-Wörter
a, the, on, in, ... Kontextsensitive Stop-Wörter
Google: ‚www‘ vs. ‚www database‘
Dynamische Interpretation CiteSeer: ‚www databases‘
(i) entspricht www AND databases (ii) entspricht www OR databases falls (i) leer
Ergebnisgröße oft nur geschätzt.
09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 54
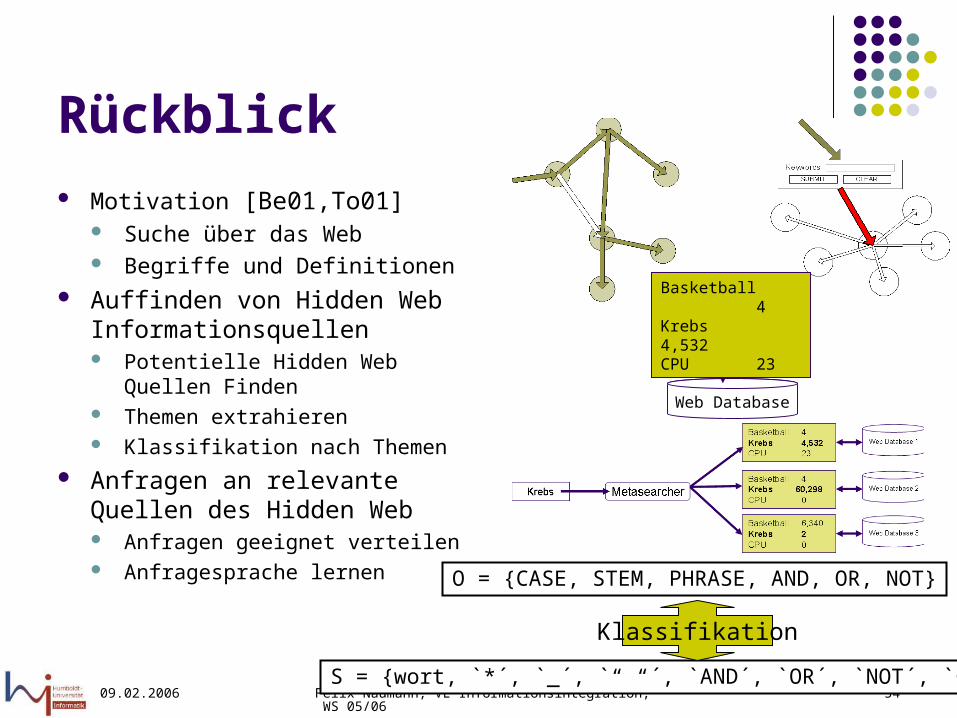
Rückblick Motivation [Be01,To01]
Suche über das Web Begriffe und Definitionen
Auffinden von Hidden Web Informationsquellen Potentielle Hidden Web Quellen
Finden Themen extrahieren Klassifikation nach Themen
Anfragen an relevante Quellen des Hidden Web Anfragen geeignet verteilen Anfragesprache lernen
Web Database
Basketball 4Krebs 4,532CPU 23
O = {CASE, STEM, PHRASE, AND, OR, NOT}
S = {wort, `*´, `_´, `“ “´, `AND´, `OR´, `NOT´, `+´, `-´}
Klassifikation
09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 55
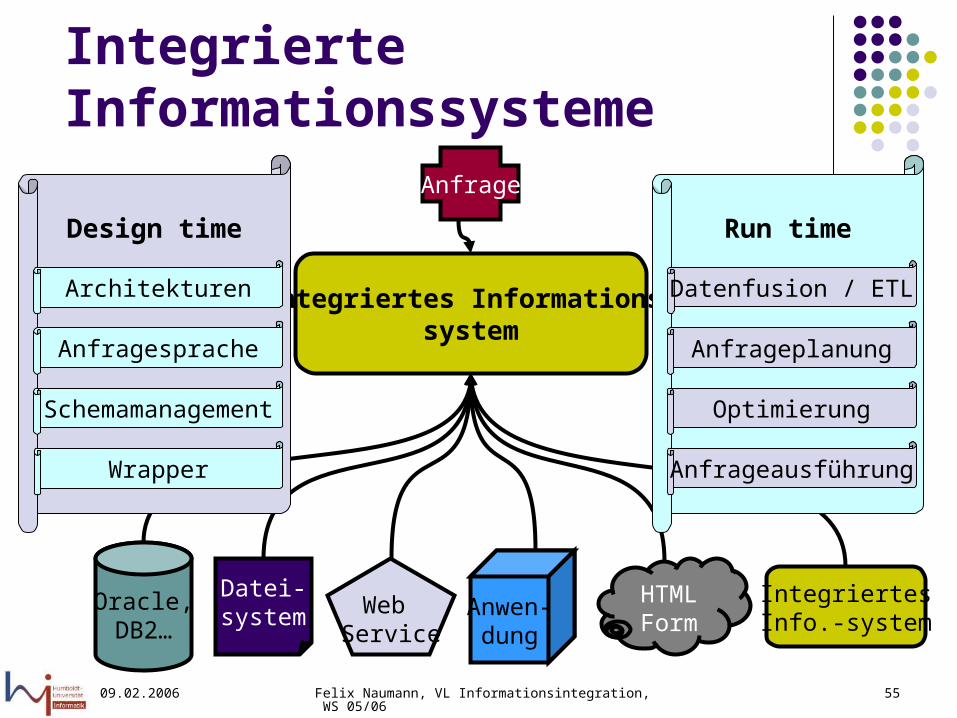
Integrierte Informationssysteme
Integriertes Informations-system
Oracle,DB2…
Design time
Web Service
Anwen-dung
HTML Form
IntegriertesInfo.-system
Datei-system
Anfrage
Architekturen
Anfragesprache
Schemamanagement
Wrapper
Run time
Anfrageausführung
Optimierung
Anfrageplanung
Datenfusion / ETL
09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 56
Semesterrückblick

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 57
Prüfungshinweise
Bereiten Sie ein Einstiegsthema vor. Besser: Bereiten Sie alle Themen vor.
Alle Referenzen schicke ich gerne per pdf zu bzw. verleihe das Buch.
Aufsätze zu ausgewählten Themen: http://www.informatik.hu-berlin.de/mac/lehre/WS04/VL_WS04_In
formationsintegration.html Prüfungsprotokolle
http://fachschaft.informatik.hu-berlin.de/pruefungsprotokolle/index.php
Selber schreiben! Sprechstunde Donnerstags 15 Uhr

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 58
Organisatorisches – Werbung Veranstaltungen im kommenden Semester
Ringvorlesung Seminar „Schema Matching“ Bei anderen
Prof. Freytag: Implementierung von Datenbanksystemen [DBS II] (HK) Informationssysteme – gestern, heute, morgen (HK)
Prof. Schweikardt: Datenbanktheorie (HK) Studien- und Diplomarbeiten Praktika Fuzzy Workshop
25.7. – 27.7. 2006

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 59
Evaluation

09.02.2006 Felix Naumann, VL Informationsintegration, WS 05/06 60
Literatur Wichtigste Literatur
[IGS01] Probe, Count, and Classify. P.G. Ipeirotis, L. Gravano, and M. Shami. SIGMOD 2001
[BC04] A. Bergholz and B. Chidlovskii. Learning Query Languages of Web Interfaces, SAC04
Weiteres [Be01] The Deep Web: Surfacing Hidden Value Michael K. Bergman,
Whitepaper at http://www.completeplanet.com/Tutorials/DeepWeb/index.asp
[To01] Foliensatz von Dawne Tortorella (BellCow) nach [Be01] [IG02] Distributed Search of the Hidden Web: Hierarchical Data
Sampling and Selection. P.G. Ipeirotis and L. Gravano in VLDB 2002.







