

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 1
Einführung in die Informationswissenschaft

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 2
Einführung in die Informationswissenschaft
Zielgruppen:
1. Studierende der Informationswissenschaft (B.A. – 1. Semester)
2. Studierende der Kulturwissenschaft und Medien (B.A. – 3. Semester)
3. Studierende anderer Fächer im Wahlbereich
Scheine:Beteiligungsnachweis (B.A.): regelmäßige aktive Teilnahme sowie kurze Klausur am Semesterende

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 3
Einführung in die Informationswissenschaft
Zentrales Thema dieser Vorlesung:Information Retrieval
Wer befasst sich mit Information Retrieval?Konferenzen – Messen. Zeitschriften. Wie findet man Literatur?
Kurze Geschichte des Information Retrieval
Grundlagen:Informationsvermittlung - Relevanz – Pull / Push – konkreter vs.
problemorientierter Informationsbedarf – Recall und Precision –Suche nach Datensätzen („Nadel-im-Heuhaufen“-Syndrom) –Berrypicking - informetrische Suchen – Informationsfilter –Informationsbarrieren – Typologie von Retrievalsystemen:
Boolesche Systeme und natürlichsprachige Systeme –Weltregionen im Internet – Feldschema (Datenbankdesign) -
invertierte Dateien

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 4
Einführung in die Informationswissenschaft
Funktionalität Boolescher Retrievalsysteme:Datenbankaufruf - feldspezifische Suche - Suche im Basic Index -
Blättern im Wörterbuch - Fragmentierung - mengentheoretische Operatoren - Abstandsoperatoren - Häufigkeitsoperatoren -
hierarchische Suche – datenbankübergreifende Suche -Umformulierung von Suchergebnissen zu Suchargumenten –Anzeigen von Suchergebnissen - Bestellen von Volltexten -
Suchprofile / SDI – Menüführung vs. Befehlssprache
Gewichtetes Retrieval:Intellektuelles Gewichten von Schlagworten – Gewichten durch
„Cracken“ von Ketten beim syntaktischen Indexieren –Relevance Ranking bei Booleschen Operatoren

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 5
Einführung in die Informationswissenschaft
Informationslinguistik:Erkennen von Worten – Stoppworte – Morphologie -
Wortstammanalyse – Lemmatisierung - Phrasenerkennung –Homonyme – Synonyme - semantisches Umfeld – WORDNET –
Anaphora(-auflösung) - Fehlertoleranz – SOUNDEX –phonetische Suche - Besonderheiten der deutschen Sprache –
MORPHY

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 6
Einführung in die Informationswissenschaft
Textstatistik (Relevance Ranking I):Worthäufigkeiten – dokumentspezifische Wortgewichtung –
Position im Dokument – inverse Dokumenthäufigkeit –FREESTYLE – Vektorraummodell – SMART - probabilistisches
Modell – Anreichern von Suchargumenten – RelevanceFeedback
Link-Topologie (Relevance Ranking II):Zitationsindexierung – Link-Analyse – Hubs und Authorities –
Kleinberg-Algorithmus – TEOMA – ALTAVISTA – PageRank –kontextspezifischer PageRank – Nutzungsanalyse – GOOGLE

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 7
Einführung in die Informationswissenschaft
Basisliteratur:Reginald Ferber: Information Retrieval. Suchmodelle und Data-Mining-Verfahren für Textsammlungen und das Web. – Heidelberg: dpunkt.verlag, 2003.William B. Frakes; Ricardo Baeza-Yates (Hrsg.): Information Retrieval. Data Structure & Algorithms. – Upper Saddle River, NJ: Prentice Hall PTR, 1992.Rainer Kuhlen; Thomas Seeger; Dietmar Strauch (Hrsg.): Grundlagen der praktischen Information und Dokumentation. – München: Saur, 5. Aufl., 2004.Eleonore Poetzsch: Information Retrieval. Einführung in Grundlagen und Methoden. – Potsdam: Verl. für Berlin-Brandenburg, 3. Aufl., 2002.Karen Sparck-Jones; Peter Willett (Hrsg.): Readings in Information Retrieval. – San Francisco: Morgan Kaufmann, 1997.Wolfgang G. Stock: Informationswirtschaft. Management externen Wissens. – München; Wien: Oldenbourg, 2000.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 8
Einführung in die Informationswissenschaft
Ein Klassiker des Wissensmanagements: Das Matthäus-Evangelium:10 Die Jünger kamen zu Jesus und fragten: "Warum sprichst du in Gleichnissen,
wenn du zu den Leuten redest?“
11 Jesus antwortete: "Euch hat Gott die Geheimnisse seines Planes erkennen lassen, nach dem er schon begonnen hat, seine Herrschaft in der Welt aufzu-richten; den anderen hat er diese Erkenntnis nicht gegeben.
12 Denn wer viel hat, dem wird noch mehr gegeben werden, so dasser übergenug haben wird. Wer aber wenig hat, dem wird auch noch das wenige genommen werden, das er hat.
13 Mit diesem Grund rede ich in Gleichnissen, wenn ich zu ihnen spreche. Denn sie sehen zwar, aber erkennen nichts; sie hören zwar, aber verstehen nichts. ...“Der Bezug in Matthäus 13:12 ist die Erkenntnis, also Wissen. Werviel Wissen hat, dem wird noch mehr gegeben; wer wenig Wissen hat, der verliert im Laufe der Zeit auch noch das wenige.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 9
Wer befasst sich mit Information Retrieval?

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 10
Information Retrieval
Informatik
Informationswissenschaft
Linguistik
Retrievalsoftware
Kommerzielle Datenbanken und Hosts
Suchmaschinen im Internet

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 11
Information Retrieval
Konferenzen
• ACM SIGIR Conference on Research and Development in Information Retrieval (seit 1977; Fokus: informatische, computerlinguistische und informationswissenschaftliche Grundlagen) – ACM: Association for Computing Machinery – SIGIR: Special Interest Group on Information Retrieval
• TREC (seit 1992; Fokus: Evaluation von Retrievalsystemen) – Text REtrieval Conference
• World Wide Web Conference (seit 1994; Fokus: Retrieval-systeme im Internet)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 12
Information Retrieval
Messen (mit Tagungen)• Online Information (London)• National Online Meeting (USA)• DGI-Online-Tagung (Frankfurt/M.) (Fokus: jeweils auf
kommerzielle Datenbanken und Hosts)
Verbände in Deutschland• Fachgruppe Information Retrieval der Gesellschaft für
Informatik• Online-Benutzergruppe in der DGI (OLBG) – DGI: Deutsche
Gesellschaft für Informationswissenschaft und Informationspraxis

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 13
Information Retrieval
Zeitschriften:• Journal of the American Society for Information Science
and Technology (JASIST)
• Communications of the ACM
• Information Processing & Management
• Information Retrieval
• Journal of Documentation
Spezialsuchmaschine:• CiteSeer von NEC Research
Institute (citeseer.com)
C. Lee Giles; Kurt D. Bollacker; Steve Lawrence: CiteSeer: An Automatic Citation Indexing System. – In:Digital Libraries 98. – New York: ACM, 1998, 89-98.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 14
Information Retrieval
Eine kurze Geschichte des Information Retrieval:Beginn der Forschungen: Anfang der 60er Jahre
– Experimente mit natürlichsprachigen Systemen: Gerard Salton (1927 – 1995) – Vektorraummodell, SMART
– Vorbereitungen kommerzieller Online-Systeme: Roger Kent Summit (geb. 1930) – DIALOG

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 15
Information Retrieval
Eine kurze Geschichte des Information Retrieval:Theoriebildungen / erste Anwendungen: 70er Jahre
– Erstes Online-System: DIALOG 1972
– Theoretische Grundlagen, Gewichtungsverfahren: Karen Sparck-Jones / Donna Harman / C.J. „Keith“ van Rijsbergen (geb. 1943)
– Probabilistisches Modell: Stephen E. Robertson
vanRijsbergen
Robertson
Sparck-Jones

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 16
Information Retrieval
Eine kurze Geschichte des Information Retrieval:Erfolg der Booleschen Online-Systeme in Praxis einsetzbare natürlichsprachige Systeme (nur moderat erfolgreich): 80er Jahre– diverse Online-Hosts, auch in Deutschland: GENIOS, GBI u.a.
– natürlichsprachige Systeme: OKAPI, INQUERY; in Deutschland: AIR/PHYS: Gerhard Lustig, Norbert Fuhr, Gerhard Knorz
Fuhr Knorz

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 17
Information Retrieval
Eine kurze Geschichte des Information Retrieval:Boom durch Word Wide Web: 90er Jahre
– großangelegte Retrievaltests: TREC (Donna Harman)– natürlichsprachige Oberflächen auch bei Online-Hosts: Freestyle, WIN– Retrievaltechniken für‘s Web: Technologieführer bei „klassisch“
orientierten Systemen: AltaVista (Louis Monier)– Technologieführer bei Systemen unter Nutzung der Web-Topologie:
Google (Lawrence „Larry“ Page; Sergey Brin)
Brin (li.)
PageMonier

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 18
Grundlagen des Information Retrieval

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 19
Grundlagen des Information Retrieval
(gemeintes)Wissen
(verstandenes)Wissen
Informations-sender
Informations-empfänger
Informations-kanal
Informationsübermittlung: In Bewegung gesetztes Wissen

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 20
Grundlagen des Information Retrieval
• Wissen– subjektiv (an menschliches Denken gebunden;
Poppers „Welt 2“)– objektiv (unabhängig von menschlichem Denken gespeichert;
Poppers „Welt 3“)• Information
– „Wissen in Aktion“ (gemäß Kuhlen)– aber auch: andere epistemische Gegenstände (z.B. Annahmen
oder Lügen) „in Aktion“• Semiotik der Information
– Syntax (Zeichenebene)– Semantik (Bedeutung der Zeichen: Beziehung zwischen
Zeichen und Gegenständen)– Pragmatik (Handlungsrelevanz der Zeichen: Beziehung
zwischen Zeichen und Benutzer)
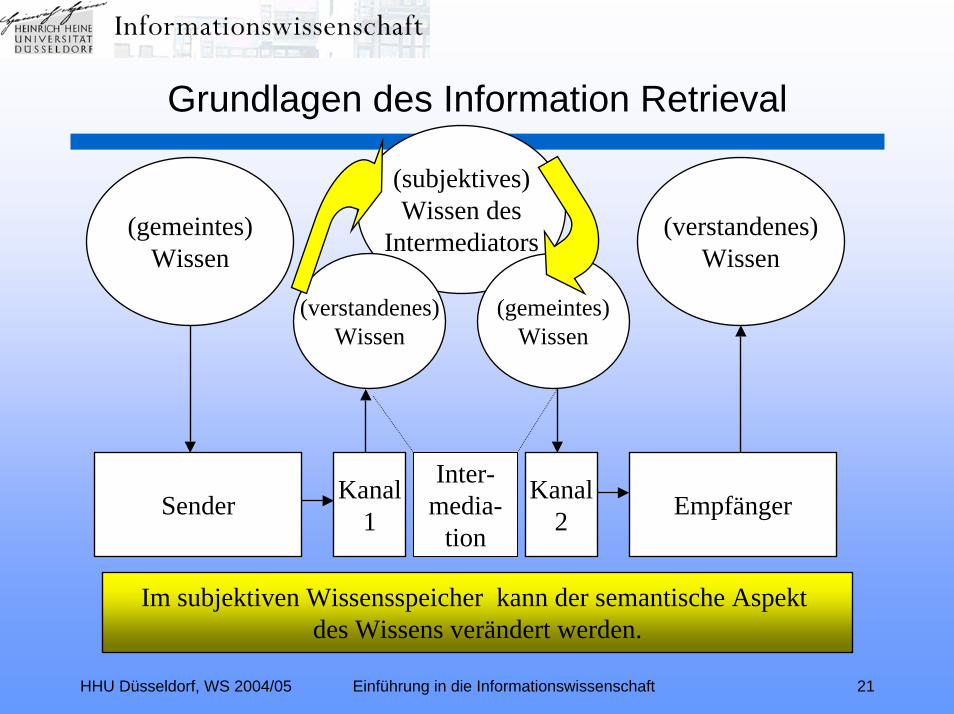
HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 21
Grundlagen des Information Retrieval
(gemeintes)Wissen
(subjektives)Wissen des
Intermediators (verstandenes)Wissen
Sender EmpfängerKanal1
Kanal2
(verstandenes)Wissen
(gemeintes)Wissen
Inter-media-
tion
Im subjektiven Wissensspeicher kann der semantische Aspekt des Wissens verändert werden.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 22
Grundlagen des Information Retrieval
(gemeintes)Wissen
(objektives)Wissen
(verstandenes)Wissen
Sender EmpfängerKanal1
Kanal2
Informa-tions-
speicher
Im objektiven Wissensspeicher wird der semantische Aspekt des Wissens nicht verändert.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 23
Grundlagen des Information Retrieval
• Dokumentarische Bezugseinheit (DBE)stets gleichbleibende Einheit der Vorlagen, die in einen Informationsspeicher aufgenommen werden, hierbei ggf. analytische „Zerlegung“ der VorlagenBeispiele:Buch (als Ganzes) - Buchkapiteldto. - Abbildung; TabelleZeitschrift (als Ganzes) - ArtikelKorrespondenz - einzelner BriefFilm - Filmsequenz

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 24
Grundlagen des Information Retrieval
• Dokumentationswürdigkeit Kriterienkatalog, der die Entscheidung fundiert, ob eine bestimmte DBE in den Informationsspeicher aufgenommen wird oder nichtAspekte:– Informationsbedarf der Nutzer– thematische Kriterien– formale Kriterien (Bsp.: nur wissenschaftliche Artikel;
nur HTML-Dateien) – Finanzrahmen - Personalressourcen - Zeit– ggf.: Neuigkeit– ggf.: kritische Prüfung des Inhalts

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 25
Grundlagen des Information Retrieval
• Dokumentationseinheit
Repräsentant der DBE in einem InformationsspeicherBestandteile:– formale Beschreibung – inhaltliche Beschreibung– (nicht immer) dokumentarische Bezugseinheit in
Vollform

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 26
Grundlagen des Information Retrieval
• Information Indexing: Erarbeitung des informationellen Mehr-wertes beim Input. Abbildung der formalen und inhaltlichen Aspekte einer DBE auf eine DE– Datenstrukturierung (Dokumentstruktur, Feldschema,
feldspezifische Datendefinition)– inhaltliche Erschließung (Abbildung der thematisierten
Gegenstände)• Information Retrieval: Erarbeitung des informationellen Mehr-
wertes beim Output. Abbildung einer Suchfrage nach DE mit dem Ziel, über die formalen oder inhaltlichen Aspekte die “richtigen” DBE zu finden– Suchen nach relevanten DBE - Pull-Ansatz– Übermitteln relevanter DE oder DBE - Push-Ansatz– Verdichtungen der Informationen der DE durch informetrische
Verfahren• Weiterverarbeitung der relevanten Informationen

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 27
(gemeintes)Wissen
(subjektives)Wissen
des Indexers (objektives)Wissen
Autor DBE
(verstandenes)Wissen
(Indexer)
(gemeintes)Wissen
(Indexer)
Grundlagen des Information Retrieval
DE (physikalischer)WissensspeicherIndexer
Wissensrepräsentation I / Inputbereich:Information Indexing

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 28
Grundlagen des Information Retrieval
(objektives)Wissen
(subjektiver)Wissensspeicher
des Recher-cheurs
(verstandenes)Wissen
DE
(verstandenes)Wissen
(Recher-cheur)
(gemeintes)Wissen
(Recher-cheur)
DBE(physikalischer)Wissensspeicher
EmpfängerRecher-cheur
Wissensrepräsentation II / Outputbereich:Information Retrieval

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 29
Grundlagen des Information Retrieval
(subjektives)Wissen
des Nutzers(im günstigenFall): neues
Wissen(verstandenes)
Wissen(Nutzer)
(gemeintes)Wissen
(Nutzer)
EmpfängerNutzer Handlungen neue
Informationen
Wissensrepräsentation III / Weiterverarbeitung:Handlungsrelevanz der Information
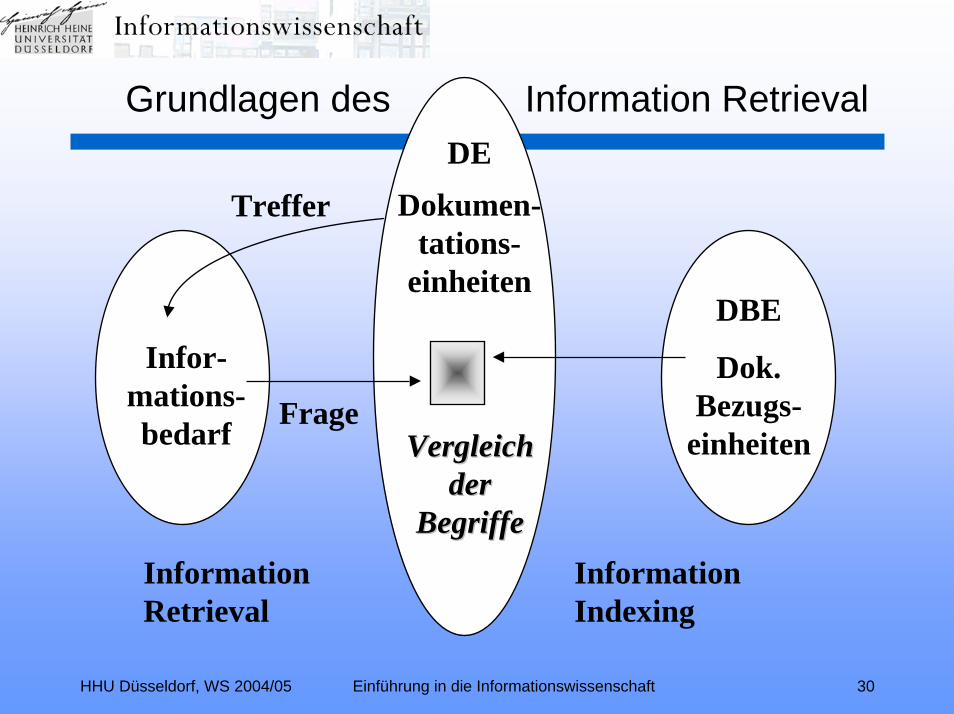
HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 30
Grundlagen des Information Retrieval
Infor-mations-bedarf
DBE
Dok. Bezugs-
einheiten
DEDokumen-
tations-einheiten
Frage
Treffer
Information Retrieval
Information Indexing
Vergleich Vergleich der der
BegriffeBegriffe

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 31
Grundlagen des Information Retrieval
Relevanz - PertinenzRelevanz: Wann ist ein Dokument für ein Suchargument relevant?– (1) wenn es objektiv zur Vorbereitung einer Entscheidung
dient– (2) wenn es objektiv eine Wissenslücke schließt– (3) wenn es objektiv eine Frühwarnfunktion erfüllt
Pertinenz: Wann ist ein Dokument für einen Nutzer pertinent?– (1) wenn es subjektiv zur Vorbereitung der Entscheidung eines
Nutzers dient– (2) wenn es subjektiv eine Wissenslücke des Nutzers schließt– (3) wenn es subjektiv eine Frühwarnfunktion für den Nutzer
erfüllt

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 32
Grundlagen des Information Retrieval
Relevanz - PertinenzZiele des Information Retrieval:– Gewinnung relevanter / pertinenter Dokumente, die
objektives Wissen enthalten– Umwandlung des gefundenen objektiven Wissens in
subjektives Wissen beim Nutzer (was auch heißt: der Nutzer muss die Fähigkeit haben, das entsprechende Wissen zu verstehen)
– Ableitung von Handlungen – aus dem gefundenen Wissen auf der Basis der eigenen Vorkenntnisse neues, handlungsrelevantes Wissen zu kreieren

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 33
Grundlagen des Information Retrieval
Relevanz - PertinenzVoraussetzungen für erfolgreiches Retrieval:– das richtige Wissen– zum richtigen Zeitpunkt („just in time“)– am richtigen Ort– im richtigen Umfang– in der richtigen Form– mit der richtigen Qualität,
wobei „richtig“ heißt:– (1) Wissen, Zeitpunkt usw. haben (objektiv betrachtet)
Relevanz– (2) Wissen, Zeitpunkt usw. werden vom Nutzer
(subjektiv betrachtet) als passend eingeschätzt: haben Pertinenz

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 34
Grundlagen des Information Retrieval
Retrieval: Pull und Push– Pull-Service: zur Befriedigung von ad-hoc auftretendem
Informationsbedarf sucht ein Nutzer aktiv in Informationssystemen nach Wissen
– Push-Service: zur Befriedigung eines (über einen gewissen Zeitraum) andauernden Informationsbedarf wird ein Nutzer vom Informationssystem mit jeweils aktuellem, neuem Wissen versorgt. Push-Services sorgen für current awareness
• Arbeitsschritt 1: Festlegen eines Informationsprofils (führt Nutzer oder Information Professional durch)
• Arbeitsschritt 2: Periodische Lieferung von Wissen (führt Informationssystem automatisch durch) – „SDI“ (selective dissemination of information) oder „Alert“

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 35
Grundlagen des Information Retrieval
allgemeine Infor-mationen
exklusive Infor-mationen
zielgruppen-spezifische Informationen
Pull-Service
Push-Service
Pass-wörter
Benutzer-sichten
freier Zugang
(a) E-Mail-Verteiler (b) personalisiert auf Homepage

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 36
Grundlagen des Information Retrieval
Themenbearbeitungszeit
bekannte Informationen
gedeckter Informationsbedarf
unbekannte Informationen
ungedeckter Informationsbedarf
t1
t2
erhalten durch Push-Service
erhalten durch Pull-Service
R.Schönfelder: Inhaltliche und methodische Probleme einer rationellen Informationsplanung in Forschung und Entwicklung. – In: Informatik 22 (1975) 6, 49-52.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 37
Grundlagen des Information Retrieval
Frage- und Antworttypen– Konkreter Informationsbedarf (Faktenfrage)
• Welchen Umsatz hatte Unternehmen X im Dezember 1998 in der Region Z?
• Wo liegt der Schmelzpunkt von Kupfer?• Wie schloß der Dollarkurs letzten Freitag an der
Frankfurter Börse?• Wann hat mein Geschäftspartner X Geburtstag?
– Problemorientierter Informationsbedarf (Literatur)• Welche Methoden der fuzzy logic lassen sich beim Data
Mining einsetzen?• Wie hängen Marketing und Qualitätsmanagement
zusammen?• Wie bewerten Analysten das Unternehmen X?• Wie beschreiben Marktforscher das Konsumklima für
ausländischen Wein in Ungarn?Valery I. Frants; Jacob Shapiro; Vladimir G. Voiskunskii: Automated Information Retrieval. – San Diego [u.a.]:
Academic Press, 1997. - Kap. 2.3: The information need, 34-40.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 38
Grundlagen des Information Retrieval
Problemorientierter Informationsbedarf
– 1. Thematische Grenzen sind nicht exakt.
– 2. Die Suchfrageformulie-rung läßt terminologische Varianten zu.
– 3. Es müssen diverse Doku-mente aus unterschiedlichen Quellen beschafft werden.
– 4. Mit der Übermittlung der Literaturinformation wird ggf. das Informationsproblem modifiziert oder ein neuer Bedarf entdeckt.
Konkreter Informationsbedarf
– 1. Thematische Grenzen sind klar angesteckt.
– 2. Die Suchfrageformulie-rung ist durch exakte Terme ausdrückbar.
– 3. Eine Faktenfrage reicht aus, um den Bedarf zu decken.
– 4. Mit der Übermittlung der Fakteninformation ist das Informationsproblem erledigt.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 39
Grundlagen des Information Retrieval
Aspekte der Relevanz:– Haben wir alle Datensätze gefunden, die handlungs-
relevantes Wissen beinhalten? (Vollständigkeit; Recall)Recall = a / (a + c)
– Haben wir nur solche Datensätze gefunden? (Genauigkeit, Precision)Precision = a / (a + b)
a =: gefundene relevante Trefferb =: nichtrelevante Datensätze, die in der Treffermenge enthalten sind (Ballast)c =: relevante Datensätze in der Datenbank, die nicht gefunden wurden

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 40
Grundlagen des Information Retrieval
• Recall und Precision beim konkreten InformationsbedarfRecall = 1Precision = 1
• Recall und Precision beim problemorientierten Informationsbedarfinverse Relation zwischen Recall und Precision– bei Erhöhung des Recall: Absinken der Precision– bei Erhöhung der Precision: Absinken des Recallempirischer Schätzwert: Recall + Precision = 1
• Achtung Problem: dies ist ein theoretisches Modell; genaue Messergebnisse sind unmöglich, da der Wert c in großen Datenbanken prinzipiell unbekannt ist.
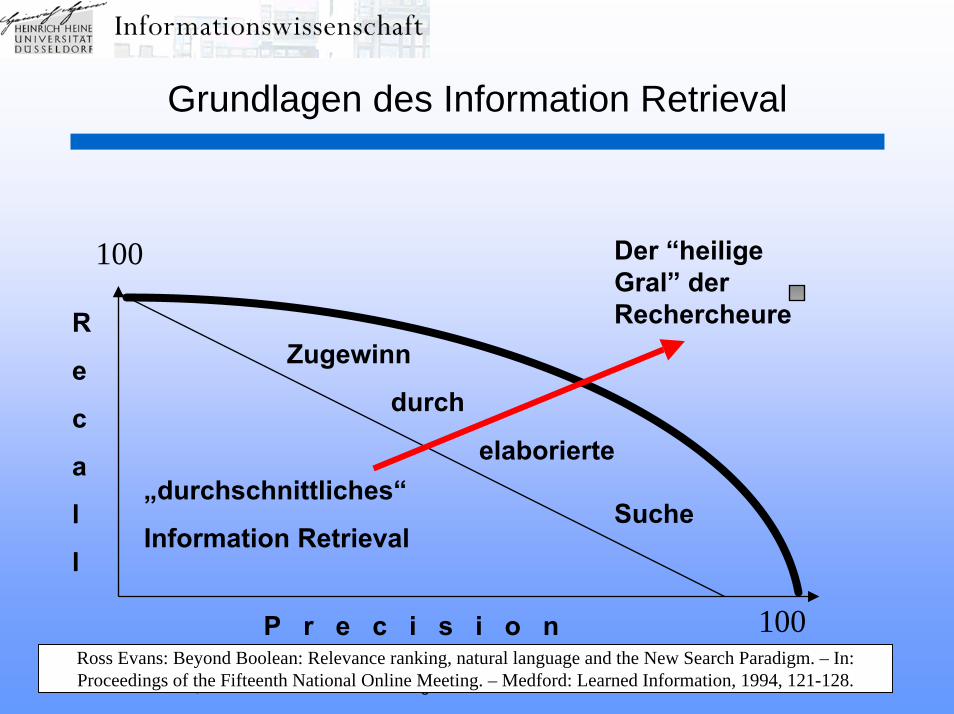
HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 41
Grundlagen des Information Retrieval
100
R
e
c
a
l
l
100P r e c i s i o n
„durchschnittliches“
Information Retrieval
Der “heilige Gral” der Rechercheure
Zugewinn
durch
elaborierte
Suche
Ross Evans: Beyond Boolean: Relevance ranking, natural language and the New Search Paradigm. – In:Proceedings of the Fifteenth National Online Meeting. – Medford: Learned Information, 1994, 121-128.
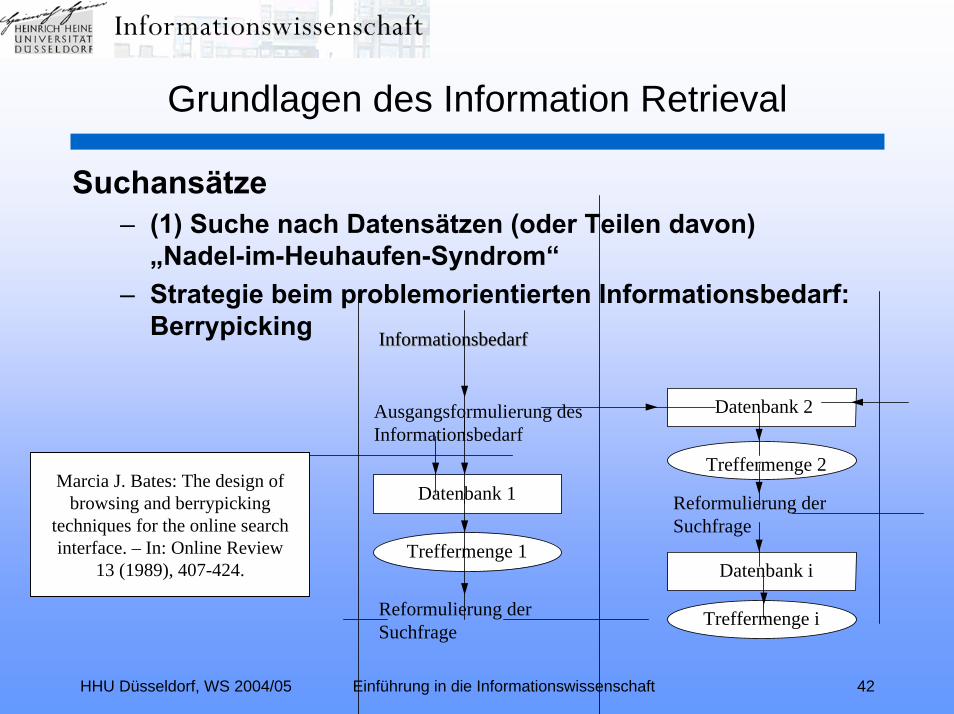
HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 42
Grundlagen des Information Retrieval
Suchansätze– (1) Suche nach Datensätzen (oder Teilen davon)
„Nadel-im-Heuhaufen-Syndrom“– Strategie beim problemorientierten Informationsbedarf:
Berrypicking InformationsbedarfInformationsbedarf
Ausgangsformulierung desInformationsbedarf
Datenbank 1
Datenbank 2
Datenbank iTreffermenge 1
Treffermenge 2
Reformulierung derSuchfrage
Treffermenge iReformulierung derSuchfrage
Marcia J. Bates: The design ofbrowsing and berrypicking
techniques for the online searchinterface. – In: Online Review
13 (1989), 407-424.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 43
Grundlagen des Information Retrieval
Suchansätze– (2) informetrische Suche
Charakterisierung ganzer „Heuhaufen“, d.h. von Treffermengen
– Faktenextraktion aus Datenbanken. Generierung von neuartigen Informationen durch das Retrieval
• Rangordnungen• Zeitreihen• semantische Netze• Informationsflussgraphen
• Hinweis: informetrische Suchen werden in der Vorlesung „Empirische Informationswissenschaft“ behandelt.
Wolfgang G. Stock: Wirtschaftsinformationen aus informetrischen Online-Recherchen. – In:Nachrichten für Dokumentation 43 (1992), 301-315.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 44
Grundlagen des Information Retrieval
Informationsfilterung (erwünschte Einschränkung auf relevante / pertinente Dokumente)
• durch Strukturierung der Dokumente• durch Indexieren (Informationsfilter i.e.S.)
– Thesaurus– Klassifikation– Textwortmethode– Zitationsindexierung– usw.
• durch Informationsverdichtung– Abstracts– Ontologien– Topic Maps

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 45
Grundlagen des Information Retrieval
Informationsbarrieren (unerwünschte Einschränkung auf Teilmengen der relevanten / pertinentenDokumente)
• politisch-ideologische Barriere• Eigentumsbarriere• Gesetzesbarriere• Zeitbarriere• Effektivitätsbarriere• Finanzierungsbarriere• Terminologiebarriere• Fremdsprachenbarriere• Zugangsbarriere• Barrieren durch Mängel beim Information Retrieval• Bewusstheitsbarriere• Resonanzbarriere
Heinz Engelbert: Der Informationsbedarf in derWissenschaft. – Leipzig: Bibliographisches Institut, 1976. –
Kap. 4: Informationsbarrieren, 59-72.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 46
Grundlagen des Information Retrieval
Informationsbarrieren
Wolfgang G. Stock: Informationswissenschaftund –praxis in der
Deutschen Demokratischen Republik. – Frankfurt:IDD Verl. Werner Flach, 1986, S. 64.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 47
Grundlagen des Information Retrieval
• Typologie von Retrievalsystemen– (1) Boolesche Systeme
George Boole (1815 – 1864), englischer Mathematiker und Logiker
(„Boolesche Algebra“)
– Boolesche Systeme erfordern die Übersetzung einer Anfrage in eine formale Sprache.
– Country AND Western ANDNOT „Garth Brooks“

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 48
Grundlagen des Information Retrieval
• Typologie von Retrievalsystemen– (2) Natürlichsprachige Systeme
Natürlichsprachige Systeme erwarten Anfragen in gewöhnlicher Sprache (mittels ganzer Sätze, einzelner Terme oder auch ganzer Musterdokumente).Beispiele: kommerzielle Content-Aggregatoren mit natürlichsprachiger Suche: WIN (Westlaw), Target (DIALOG), Freestyle (Lexis-Nexis); Content-Aggregatoren mit natürlichsprachiger automatischer Indexierung: FACTIVA, Dialog Profound, Dialog NewsEdge; alle Suchmaschinen im WWWKomponenten:a) Informationslinguistik (Abgleich Suchargument –Dokumente)b) Informationsstatistik (Relevance Ranking)c) nicht immer: Ordnungssysteme (terminologische Kontrolle)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 49
Grundlagen des Information Retrieval
• Typologie von Retrievalsystemen– (3) Kombinierte Systeme
Boolesches und natürlichsprachiges Retrieval in Kombination(a) zuerst Boolesches Retrieval, danach in Treffermenge Relevance RankingBeispiele: diverse Content-Aggregatoren, AltaVista(b) zuerst Informationslinguistik, danach in Treffermenge Feinrecherche mittels Boolescher OperatorenBeispiel: Lexis-Nexis

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 50
Grundlagen des Information Retrieval
Weltregionen des Internet:Die „Oberfläche“
– digitale Dokumente im Web– (prinzipiell) auffindbar durch Suchwerkzeuge– Dokumente sind u.U. unerwünschter Ballast („Spam“)
• Suchwerkzeuge / Typen:– Suchmaschinen– Webkataloge– Meta-Suchmaschinen– Portale

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 51
Grundlagen des Information Retrieval
Suchmaschinen (Search Engines)
Mechtild Stock; Wolfgang G. Stock: Informationslinguistik und -statistik: AltaVista, FAST und Northern Light. – In: Password Nr.1 (2001), 16-24. - Mechtild Stock; Wolfgang G. Stock: Relevance
Ranking nach „Popularität“ von Webseiten: Google. – In: PasswordNr. 2 (2001), 20-27.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 52
Grundlagen des Information Retrieval
Suchmaschinen (Search Engines)• Gegenstand: Dokumente im Internet (WWW, Newsgroups),
gerichtet auf einzelne Webseiten• automatisches Einsammeln der Dokumente mittels Crawler• automatisches Aktualisieren der Datenbasis• Kopieren der Dokumente (oder von Teilen) in die eigene
Datenbank• automatisches Indexieren der kopierten Dokumente• eher große Datenbasis (mehrere Mrd. Dokumente)• Suchsystem mit natürlichsprachiger Eingabe und mit Profi-
Oberfläche

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 53
Grundlagen des Information Retrieval
Webkataloge (Web-Directories)
Mechtild Stock; Wolfgang G. Stock: Klassifikation und terminologi-sche Kontrolle: Yahoo!, Open Directory und Oingo im Vergleich. –
In: Password Nr. 12 (2000), 26-33.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 54
Grundlagen des Information Retrieval
Webkataloge (Web-Directories)• Gegenstand: Dokumente im WWW (z.T. zusätzlich exklusive
Dokumente, z.B. News), gerichtet vor allem auf Einstiegs-seiten in Websites
• intellektuelle Auswahl• intellektuelles Indexieren (i.d.R. Klassifikation)• Datenbasis: „Titel“ der Dokumente (vom Webkatalog oder
vom Anmeldenden vergeben) und URL• eher kleine Datenbasis (einige Mio. Dokumente)• unregelmäßiges Update• Suchsysteme mit Klassifikationshierarchien und
natürlichsprachiger Suche (über die Klassenbezeichnungen und die Dokumenten“titel“)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 55
Grundlagen des Information Retrieval
Meta-Suchmaschinen

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 56
Grundlagen des Information Retrieval
Meta-Suchmaschinen• keine Datenbasis; greifen auf die Datenbasen anderer
Suchwerkzeuge zurück („Schmarotzer“)
– a) Metasuchmaschinen ohne eigenen informationellen
Mehrwert (außer der Abfrage diverser Suchwerkzeuge
und ggf. Dublettenelimination)
– b) Metasuchmaschinen mit Angebot von
Dokumentationssprachen (z.B. Thesaurus)
– c) mit Bearbeitung eingesammelter Dokumente

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 57
Grundlagen des Information Retrieval
Portal• einheitlicher Einstiegspunkt in das WWW
(allgemein: „horizontales Portal“; fachspezifisch: „vertikales“ Portal)
• Simplizität• Bereitstellung von Suchwerkzeugen
(Suchmaschine und Katalog)• allgemein interessierende bzw. fachspezifische
(möglichst) exklusive Inhalte (News, Aktienkurse)• Zusatzfunktionalitäten (Tools mit
benutzerspezifischem Gebrauchswert, z.B. Übersetzungsprogramme, Kalender, Adressbuch)
• Personalisierung (Verwalten von Informationsprofilen – „MyXXX“)
• Kommunikation (E-Mail-Accounts, themenspezifische Chatrooms, Platz für benutzereigene Homepage o.ä.)
Hermann Rösch: Internetportal, Unternehmensportal,Wissenschaftsportal. – In: Gerhard Knorz; Rainer Kuhlen
(Hrsg.): Informationskompetenz – Basiskompetenz inder Informationsgesellschaft. – Konstanz: UVK, 2000,
245-264.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 58
Grundlagen des Information Retrieval
Weltregionen des Internet: Das „Deep Web“ (oder „Invisible Web“)– digitale Dokumente, die nicht direkt im Web liegen, aber via Web
erreichbar sind– derzeit nicht auffindbar durch Suchwerkzeuge– Dokumente sind (meist) qualitätsgeprüft– Terminologie: „invisible Web“ – Sherman & Price
„Deep Web“ – Bergman (Schätzung: Deep Web ist 500mal größer als das Oberflächenweb – wahrscheinlich stark überschätzt)
• Typen:– Kostenfreie singuläre Datenbanken– Kommerzielle Informationsanbieter
• Selbstvermarkter• Content-Aggregatoren (Online-Hosts)
Chris Sherman; Gary Price: The Invisible Web. – Medford: Information Today, 2001.Michael K. Bergman: The Deep Web: Surfacing Hidden Value. – In: The Journal of Electronic Publishing
7 (2001) Iss.1

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 59
Grundlagen des Information Retrieval
(Kostenfreie) Singuläre Datenbanken im Web– thematisch orientierte Datenbanken– (i.d.R.) aufgebaut von öffentlichen Einrichtungen (durch
öffentliche Mittel bereits finanziert)– mehrere tausend Datenbanken via Web erreichbar

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 60
Grundlagen des Information Retrieval
(Kommerzielle) Singuläre Datenbanken im Web –„Selbstvermarkter“– thematisch orientierte Datenbanken– (i.d.R.) aufgebaut von Privatunternehmen mit dem
Zweck der Erzielung von Gewinnen– teilweise auch zusätzlich bei Content-Aggregatoren
aufgelegt
Mechtild Stock; Wolfgang G. Stock: Professionelle Informationen über deutsche Unternehmen im Internet. –In: Password Nr. 11 (2001), 26-33, und Nr. 12 (2001), 18-25.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 61
Grundlagen des Information Retrieval
Content-AggregatorenWirtschaft
– Bündelung wirtschaftsrelevanter Datenbasen unter einer Oberfläche
– Wirtschaftsnachrichten, Firmeninformationen, Wirtschaftswissenschaft, Marktdaten usw.
Mechtild Stock; Wolfgang G. Stock:GBI – the contentmachine. Wirtschaftsinformationen für Hochschulen, Unternehmen und Internet-
Surfer. – In: Password Nr. 2 (2003), 8-17; dies. : Dialog / DataStar. One-Stop-Shops internationaler Fachinformationen. – In: Password Nr. 4 (2003), 22-29. – dies. :
Dialog Profound / NewsEdge: Dialogs Spezialmärkte für Marktforschung und News. – In: Password Nr. 5 (2003);dies.: GENIOS Wirtschaftsdatenbanken. Bündelung deutscher und internationaler Informationen als Wettbewerbs-
Vorteil. – In: Password Nr. 6 (2003), 14-22.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 62
Grundlagen des Information Retrieval
Content-AggregatorenNews
– Bündelung von Nachrichten-Datenbasen unter einer Oberfläche
– (real-time)-Informationen von Nachrichtenagenturen, Zeitungen, Zeitschriften
Mechtild Stock: Factiva.com. Neuigkeiten auf der Spur. – In: Password Nr. 5 (2002), 31-40. - Mechtild Stock;Wolfgang G. Stock: Von Factiva.com zu Factiva Fusion. Globalität und Einheitlichkeit mit Integrationslösungen. –
In: Password Nr. 3 (2003), 19-28. – Mechtild Stock: ASV Infopool. Boulevard online. – In: Password Nr. 10(2002), 22-27.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 63
Grundlagen des Information Retrieval
Content-AggregatorenWTM (Wissenschaft – Technik – Medizin)
– Bündelung von Wissenschaftsdatenbasen unter einer Oberfläche
– disziplinspezifische bibliographische Datenbasen, Volltexte von Wissenschaftszeitschriften, Zitationsdatenbanken
Schwerpunkt Technik / Patente: FIZ Technik –Questel-Orbit
Mechtild Stock, Wolfgang G. Stock: FIZ Technik. „Kreativplattform“ des Ingenieurs durch Technikinformation. –In: Password Nr. 3 (2004), 22-29; – dies.: Questel-Orbit. Patente, Warenzeichen und Domain-Namen professionell
suchen. – In Password Nr. 2 (2004), 16-24.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 64
Grundlagen des Information Retrieval
WTM (Wissenschaft – Technik – Medizin)Schwerpunkt Medizin: DIMDI – OVID
Schwerpunkt Naturwissenschaft: STN - WoK
Mechtild Stock, Wolfgang G. Stock: DIMDI. Eine deutsche Informationsbehörde für Gesundheit und Medizin. –In: Password Nr. 9 (2003), 18-27. – dies.:Ovid Technologies. Medizininformationen: Literaturnachweise,
Volltexte und klinische Entscheidungen aus einer Hand. – In Password Nr. 10 (2004).
Mechtild Stock, Wolfgang G. Stock: Web of Knowledge. Wissenschaftliche Artikel, Patente und deren Zitationen. –In: Password Nr. 10 (2003), 30-37; – dies.:FIZ Karlsruhe. STN Easy: WTM-Informationen „light“. –
In Password Nr. 11 (2003), 22-29; dies.: STN on the Web und der Einsatz einer Befehlssprache. Quo vadis, STNund FIZ Karlsruhe? – In: Password Nr. 12 (2003), 14-21.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 65
Grundlagen des Information Retrieval
WTM (Wissenschaft – Technik – Medizin)Schwerpunkt Volltexte akademischer Zeitschriften:Reed-Elsevier (Science Direct – Scirus) –WoltersKluwer (via OVID)Springer (SpringerLink)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 66
Grundlagen des Information Retrieval
Content-AggregatorenRecht
– Bündelung von juristischen Datenbasen unter einer Oberfläche
– Urteile, Volltexte juristischer Zeitschriften, bibliographische Datenbanken
Ulrich Noack; Michael Beursken; Sascha Kremer: Die großen Fünf: Professionelle Online-Dienste fürJuristen im Test. – Düsseldorf: Zentrum für Informationsrecht, 2004.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 67
Grundlagen des Information Retrieval
Weltregionen des InternetGrenzüberschreitungen
– Hybrid-Suchmaschine (Content-Aggregator und WWW-Suchmaschine)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 68
Grundlagen des Information Retrieval
Weltregionen des Internet / Grenzüberschreitungen– Querweltein-Ergänzungen
Suchmaschinen mit Links ins Deep Web. Beispiel: AltaVista (Oberflächenweb) – Wer liefert was? (Deep Web)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 69
Grundlagen des Information Retrieval
Weltregionen des Internet / Grenzüberschreitungen– „Pervertierte“ Querweltein-Ergänzungen / „Teaser“
Suchmaschinen mit (ggf. unerwünschten) Links ins Deep Web. Beispiel: Google (Oberflächenweb) – Koenigstraum.de (Deep Web)
– Erstellung von „Brückenseiten“, die ein (kostenpflichtiges) Dokument in einer Datenbank beschreiben – in der Hoffnung, dass diese Brückenseiten von Spidern gefunden werden
– Treffer bei Suchmaschine: Brückenseite; von hier aus Link zur Kasse und erst dann zum eigentlichen Datensatz
– Das „Unethische“ hieran ist nicht die Brückenseite als solche, sondern dass die Suchmaschinen – ohne es zu wissen und ohne Preise berechnen zu können – instrumentalisiert werden.
Christian Heinisch: Teaser: Suchmaschinen als Wegweiser zu Inhalten des „Invisible Web“. – In: PasswordNr. 4 (2003), 31-33.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 70
Grundlagen des Information Retrieval
Weltregionen des Internet / Grenzüberschreitungen– „Pervertierte“ Querweltein-Ergänzungen / „Teaser“
Suche nach „Zettelflut“ bei Google
hier: der 1. Treffer ist eine Brückenseite

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 71
Grundlagen des Information Retrieval
Weltregionen des Internet / Grenzüberschreitungen– „Pervertierte“ Querweltein-Ergänzungen / „Teaser“
die Brückenseite von Koenigstraum
(früher: Verlag Norman Rentrop)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 72
Grundlagen des Information Retrieval
Weltregionen des Internet / Grenzüberschreitungen– „Pervertierte“ Querweltein-Ergänzungen / „Teaser“
... und jetzt soll kassiert werden:
EUR 577,68

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 73
Grundlagen des Information Retrieval
Weltregionen des Internet / Grenzüberschreitungen– Querweltein-Ergänzungen
Deep Web-Datenbank mit Links ins OberflächenwebBeispiel: HWWA-Wirtschaftsdatenbank

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 74
Grundlagen des Information Retrieval
Weltregionen des Internet / Überblick
Wolfgang G. Stock: Weltregionen des Internet: Digitale Informationen im WWW und via WWW. – In: PasswordNr. 2 (2003), 26-28.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 75
Grundlagen des Information Retrieval
Weltregionen des Internet und die Welt gedruckter Dokumente... wenn die benötigten Dokumente nur in Printausgaben vorliegen:
Nutzung von Document Delivery Services

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 76
Grundlagen des Information Retrieval
Typische Dokumente: Wirtschafts-information
Beispiel:Firmendossier (Creditreform Online) - 1 -

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 77
Grundlagen des Information Retrieval
Beispiel:Firmendossier (Creditreform Online) - 2 -

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 78
Grundlagen des Information Retrieval
Beispiel:Firmendossier (Creditreform Online) - 3 -

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 79
Grundlagen des Information Retrieval
Beispiel:Firmendossier (Creditreform Online) - 4 -

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 80
Grundlagen des Information Retrieval
Typische Dokumente: News
Beispiel:Zeitungsartikel bei Factiva- 1 -

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 81
Grundlagen des Information Retrieval
Beispiel:Zeitungsartikel bei Factiva- 2 -

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 82
Grundlagen des Information Retrieval
Typische Dokumente: WTM (1)
Beispiel:Bibliographischer Nachweis / MEDLINE bei DIMDI

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 83
Grundlagen des Information Retrieval
Typische Dokumente: WTM (2)
Beispiel:PatentnachweisDerwent bei DIALOG - 1 -

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 84
Grundlagen des Information Retrieval
Beispiel:PatentnachweisDerwent bei DIALOG - 2 -

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 85
Grundlagen des Information Retrieval
Typische Dokumente: WTM (3)
Beispiel:Beilstein bei STN International

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 86
Grundlagen des Information Retrieval
Typische Dokumente: Rechts-information
Beispiel:Grundsatzurteil (Juris) - 1 -

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 87
Grundlagen des Information Retrieval
Beispiel:Grundsatzurteil (Juris) - 2 -

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 88
Grundlagen des Information Retrieval
Typische Dokumente: WWW

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 89
Grundlagen des Information Retrieval
Dateien– Dokumentenspeicher (sequentielle Aufnahme aller
Daten eines Dokumentes) – Zuordnung einer eindeutigen Dok.-Nr.
– Invertierte Dateien: feldspezifische (i.d.R. alphabetische) Listen aller Einträge eines Feldes aller Dokumente – unter Zuordnung der Dok.-Nr. und weiterer Angaben
– Basic Index: Invertierte Datei über bestimmte Felder (je nach System alle Felder oder Auswahl)
– Wortindex: jedes einzelne Wort ist IndexeintragPhrasenindex: zusammengehörige Phrasen bilden einen Indexeintrag

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 90
Grundlagen des Information Retrieval
Invertierte Dateien. Jeder Eintrag enthält:– eigene Adresse im Speicher– Dokumentnummer(n) bzw. deren Adresse(n)– Häufigkeit in Gesamtdatenbank
• Anzahl der Dokumente, in denen der Eintrag (min. einmal) vorkommt
• Gesamtanzahl des Vorkommens in der Datenbank– Position(en) im Dokument
• Wortnummer(n)• Vorkommen in Satz/Sätzen Nummer(n) X, X‘, ...• Vorkommen in Absatz/Absätzen Nummer(n) Y, Y‘, ...• beim Einsatz syntaktischen Indexierens: Vorkommen in
Themenkette(n) T, T‘, ...– ggf.: Kennzeichen auf Position (z.B. Größe des
Druckerfonts)– ggf.: Gewichtungswert– ggf. jeder Eintrag zweimal: normale Buchstabenfolge
und zusätzlich rückläufig

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 91
Grundlagen des Information Retrieval
Invertierte Dateien. Beispiel (Textbody)
Eintrag: Unternehmen / nemhenretnU
Dok.-Nr. 2, 23, 45, 56# Dok. 4# insg. 7Wort-Nr. (2: 4, 28), (23: 99), (45: 13, 17, 55), (56: 432)Satz-Nr. (2: 1, 3), (23: 15), (45: 9, 9, 15), (56: 58)Absatz-Nr. (2: 1, 1), (23: 1), (45: 1, 1, 2), (56: 4)Font (2.4: 28), (2.28: 10), (23.99: 12), (45.13: 72),
(45.17: 12), (45.55: 12), (56.432: 20)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 92
Grundlagen des Information Retrieval
Invertierte Dateien. Beispiel (Deskriptorfeld)
Eintrag: Just in Time-Logistik / kitsigoL-emiT ni tsuJ
Dok.-Nr. 44, 1204# Dok. 2# insg. 8Kette-Nr. (44: 1, 3, 9), (1204: 1-5)Gewichtung (44: 33), (1204: 100)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 93
Grundlagen des Information Retrieval
Wie kommen die Datenbanken zu ihren Dokumenten?
– (1) intellektuelle Auswahl nach Kriterien der Dokumentationswürdigkeit
– (2) automatisches Einsammeln durch Crawler (Spider, Robots)
• Verfolgen der Links in bereits gesammelten Dokumenten
• Beachtung von Robot Exclusion Standards
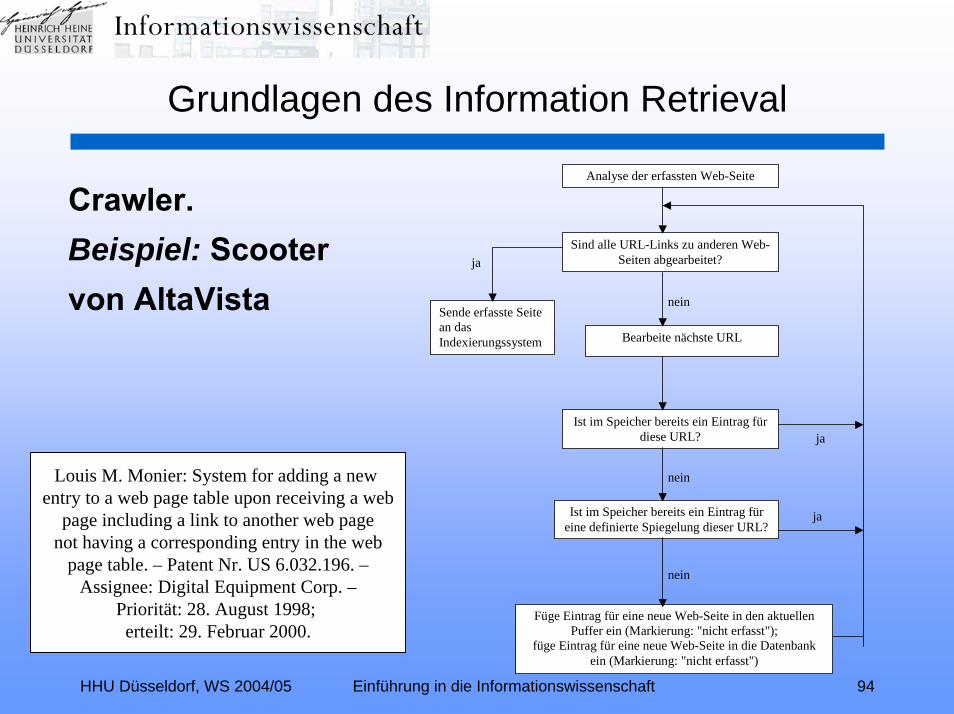
HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 94
Grundlagen des Information Retrieval
ja
nein
ja
nein
ja
nein
Analyse der erfassten Web-Seite
Sind alle URL-Links zu anderen Web-Seiten abgearbeitet?
Sende erfasste Seitean dasIndexierungssystem Bearbeite nächste URL
Ist im Speicher bereits ein Eintrag fürdiese URL?
Ist im Speicher bereits ein Eintrag füreine definierte Spiegelung dieser URL?
Füge Eintrag für eine neue Web-Seite in den aktuellenPuffer ein (Markierung: "nicht erfasst");
füge Eintrag für eine neue Web-Seite in die Datenbankein (Markierung: "nicht erfasst")
Crawler. Beispiel: Scooter von AltaVista
Louis M. Monier: System for adding a new entry to a web page table upon receiving a web
page including a link to another web pagenot having a corresponding entry in the web
page table. – Patent Nr. US 6.032.196. –Assignee: Digital Equipment Corp. –
Priorität: 28. August 1998; erteilt: 29. Februar 2000.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 95
Funktionalität Boolescher Retrievalsysteme

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 96
Funktionalität Boolescher Retrievalsysteme
Einsatz boolescher Systeme bei:• bibliographischen Datenbanken• Volltextdatenbanken• Faktendatenbanken• z.T. bei Suchmaschinen im WWW
Varianten:• befehlsorientiert (für Information Professionals)• menügeführt (für Laien)
Wolfgang G. Stock: Informationswirtschaft. – München; Wien: Oldenbourg. 2000. - Kap. 4: Retrieval von elektronischen Informationen: Techniken und Strategien, 90-118.
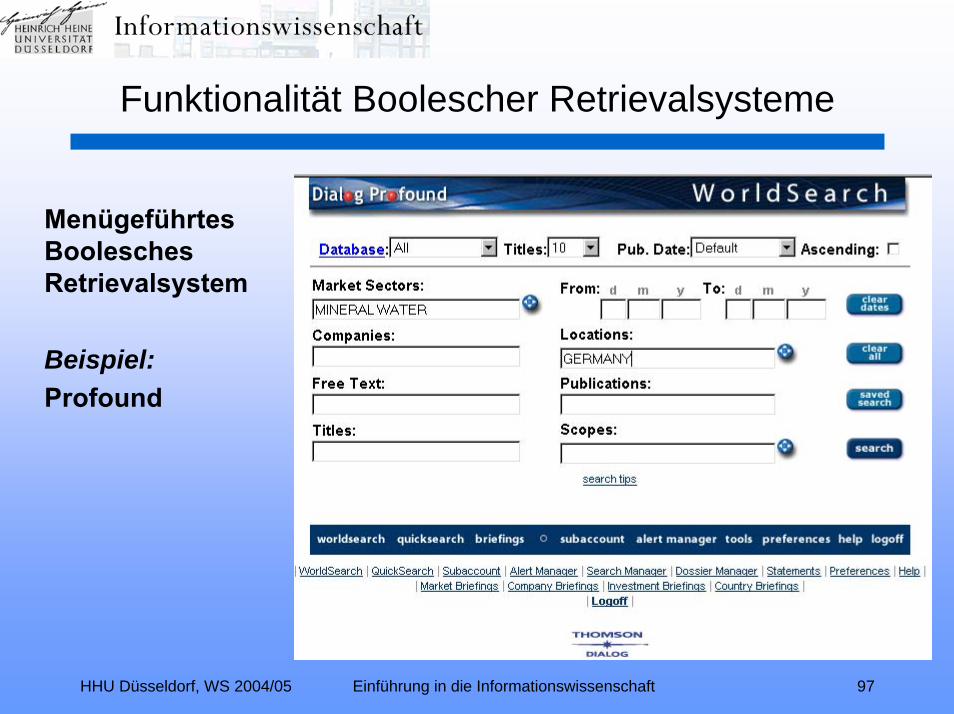
HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 97
Funktionalität Boolescher Retrievalsysteme
Menügeführtes Boolesches Retrievalsystem
Beispiel:Profound

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 98
Funktionalität Boolescher Retrievalsysteme
Befehls-orientiertesBoolesches Retrievalsystem
Beispiel:DialogWeb

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 99
Funktionalität Boolescher Retrievalsysteme
Arbeiten mit booleschen Retrievalsystemen– Suchen nach den bestpassenden Datenbanken (Nadel-im-
Heuhaufen-Syndrom – Phase 1)Derzeit existieren mehrere zehntausend fachspezifische Datenbanken. (Hinweis: recht vollständig ist der Datenbankführer von GALE)
– Suchen nach den bestpassenden Dokumenten (Nadel-im-Heuhaufen-Syndrom – Phase 2)Derzeit existieren (außerhalb des WWW) mehrere zehnmilliarden Dokumente.
– Ausgeben der gefundenen Dokumente– Initiierung eines Pushdienstes

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 100
Funktionalität Boolescher Retrievalsysteme
Suchen nach bestpassenden Datenbanken (Nadel-im-Heuhaufen-Syndrom – Phase 1)– „Bluesheets“: Detaillierte Datenbankbeschreibungen

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 101
Funktionalität Boolescher Retrievalsysteme
Datenbankindex: Suchen der bestpassenden Datenbanken (befehlsorientierte Variante)
• Öffnen der Indexdatenbank (bei DIALOG: b 411)• Einschränken auf thematischen Bereich / SET FILES
(sf papersmj, 47, not 703)• Suchargument eingeben / SELECT (s XXX)• ggf. Suchargument speichern / SAVE TEMP (save temp
Name)• Rangordnung der Datenbanken nach Treffern zum
Suchargument / RANK FILES (rf)• Aussuchen der Datenbanken; Aufrufen entweder mit File-
Name oder mit Ausgabenummer (N1, N2, ...) / BEGIN (b N1-N9)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 102
Funktionalität Boolescher Retrievalsysteme
Datenbankindex: Beispiel DIALOG (1)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 103
Funktionalität Boolescher Retrievalsysteme
Datenbankindex: Beispiel DIALOG (2)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 104
Funktionalität Boolescher Retrievalsysteme
Datenbankindex: Suchen der bestpassenden Datenbanken (menügeführte Variante)Beispiel: GBI (CROSS)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 105
Funktionalität Boolescher Retrievalsysteme
Suchen nach bestpassenden Dokumenten (Nadel-im-Heuhaufen-Syndrom – Phase 2)Zugang zu Datenbanken
– Öffnen einer Datenbank / BEGIN 3– Öffnen von Segmenten einer Datenbank (etwa: nur die
letzten zwei Jahrgänge) / BEGIN 3 CURRENT 2– Öffnen mehrerer (gleich strukturierter) Datenbanken
gleichzeitig / Einzelauswahl / BEGIN 3, 45, 47– Öffnen mehrerer Datenbanken eines vordefinierten
Datenbankclusters / BEGIN PAPERS

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 106
Funktionalität Boolescher Retrievalsysteme
Feldspezifische Suche– alphanumerische Felder (wie AU, CT, TI, ...) / SELECT
S AU=Marx, Karl (bei Phrasenindex)S AU=Marx AND AU=Karl (bei Wortindex)
– numerische Felder (wie YR, UM, PL, ...) / algebraische Operatoren (gleich, größer, kleiner)YR=2003; YR>1999; YR<1999
– Basic Index / Suchen ohne FeldkürzelS Marx
Blättern im Wörterbuch– Einstieg in die invertierten Dateien / EXPAND
E AU=Marx– Anzeige der (alphabetischen) Umgebung mit lfd. Nr.
(etwa: T3 Marx, Karl)– Übernahme der lfd. Nr. / S T3

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 107
Funktionalität Boolescher Retrievalsysteme
Schreibvarianten (Beispiele: Lexis-Nexis)– ohne weitere Befehle: je nach System: nicht
zeichensensitiv, automatische Pluralbildung, automatische Weiterleitung zum Deskriptor
– nur Großbuchstaben suchen: ALLCAPS ALLCAPS aids (findet AIDS)
– nur Kleinbuchstaben suchen: NOCAPSNOCAPS aid (findet aid)
– erster Buchstabe groß: CAPS CAPS aid (findet Aid)
– nur Pluralform suchen: PLURALPLURAL job (findet jobs)
– nur Singularform suchen: SINGULARSINGULAR job (findet job)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 108
Funktionalität Boolescher Retrievalsysteme
Fragmentierung (Truncation)– Links-, Mitte-, Rechtsfragmentierung– offene Fragmentierung (beliebig viele Zeichen werden
ersetzt) / $Unternehm$ findet Unternehmen, Unternehmung, Unternehmensgeschichtsschreibungstheorie, ...$unternehmen findet Bauunternehmen, Chemieunternehmen, Stahlunternehmen
– begrenzte Fragmentierung (genau ein Zeichen wird ersetzt) / *Unternehm*** findet Unternehmen, Unternehmung, aber nicht längere TermeMa*er findet Maier, Mayer, Majer (aber auch Maler)
– Je nach System müssen n Zeichen (oft: 3 oder 5) vor oder nach dem Jokerzeichen vorhanden sein
– Achtung bei großzügiger Fragmentierung: $affe$

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 109
Funktionalität Boolescher Retrievalsysteme
SchnittmengeA UND B
1. Invertierter Index: Suche nach A nebst Dok.-Nr. Die Menge der Dok.-Nummern sei „Menge 1“.
2. Invertierter Index: Suche nach B nebst Dok.-Nr. Die Menge der Dok.-Nummern sei „Menge 2“.
3. Bestimme Schnittmenge aus „Menge1“ und „Menge 2“. Entstehende Menge sei „Menge 3“.
4. Folge den Verweisen aus „Menge 3“ zu den Dokumenten, kopiere diese zur Ausgabe!
Gerard Salton; Michael McGill: Information Retrieval – Grundlegendes für Informationswissenschaftler. –Hamburg [u.a.]: McGraw-Hill, 1983. – Kap.2: Invertierte Dateisysteme, 27-55.
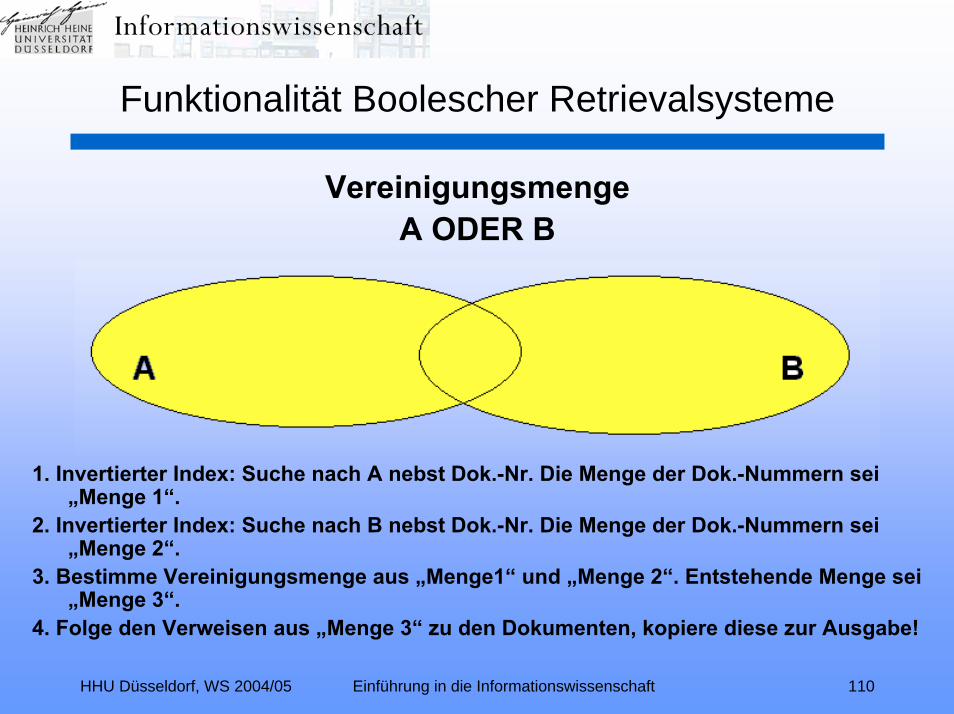
HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 110
Funktionalität Boolescher Retrievalsysteme
VereinigungsmengeA ODER B
1. Invertierter Index: Suche nach A nebst Dok.-Nr. Die Menge der Dok.-Nummern sei „Menge 1“.
2. Invertierter Index: Suche nach B nebst Dok.-Nr. Die Menge der Dok.-Nummern sei „Menge 2“.
3. Bestimme Vereinigungsmenge aus „Menge1“ und „Menge 2“. Entstehende Menge sei „Menge 3“.
4. Folge den Verweisen aus „Menge 3“ zu den Dokumenten, kopiere diese zur Ausgabe!
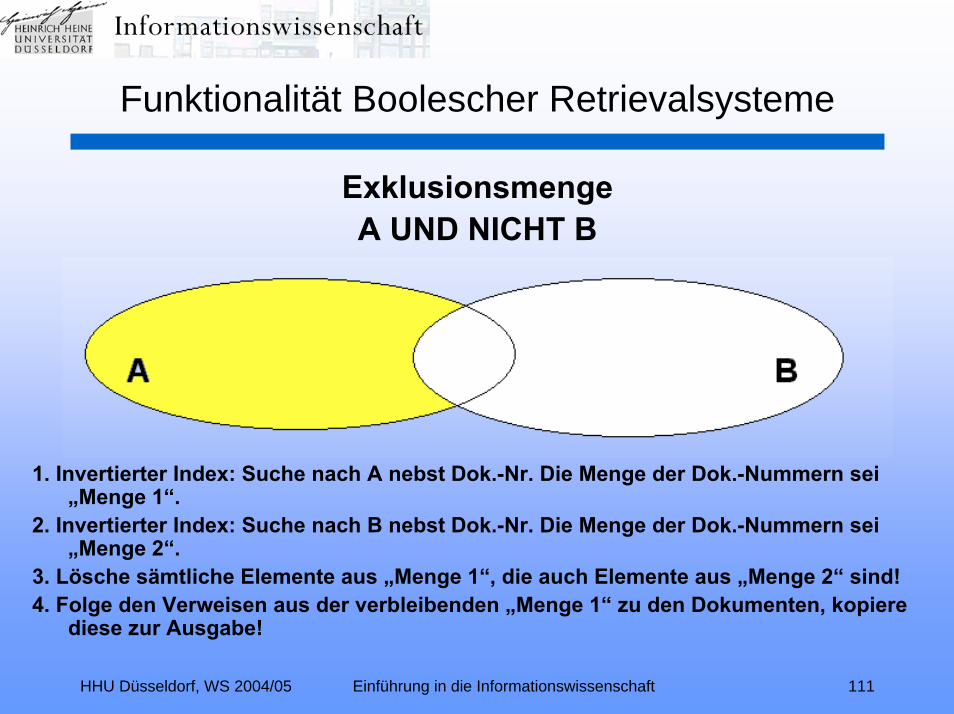
HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 111
Funktionalität Boolescher Retrievalsysteme
ExklusionsmengeA UND NICHT B
1. Invertierter Index: Suche nach A nebst Dok.-Nr. Die Menge der Dok.-Nummern sei „Menge 1“.
2. Invertierter Index: Suche nach B nebst Dok.-Nr. Die Menge der Dok.-Nummern sei „Menge 2“.
3. Lösche sämtliche Elemente aus „Menge 1“, die auch Elemente aus „Menge 2“ sind!4. Folge den Verweisen aus der verbleibenden „Menge 1“ zu den Dokumenten, kopiere
diese zur Ausgabe!

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 112
Funktionalität Boolescher Retrievalsysteme
Ausschließende ExklusionsmengeA XOR B
1. Invertierter Index: Suche nach A nebst Dok.-Nr. Die Menge der Dok.-Nummern sei „Menge 1“.2. Invertierter Index: Suche nach B nebst Dok.-Nr. Die Menge der Dok.-Nummern sei „Menge 2“.3. Bestimme Vereinigungsmenge aus „Menge1“ und „Menge 2“. Entstehende Menge sei „Menge 3“.4. Bestimme Schnittmenge aus „Menge1“ und „Menge 2“. Entstehende Menge sei „Menge 4“.5. Lösche alle Elemente aus „Menge 3“, die auch Element von „Menge 4“ sind!6. Folge den Verweisen aus der verbleibenden „Menge 3“ zu den Dokumenten, kopiere diese zur
Ausgabe!

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 113
Funktionalität Boolescher Retrievalsysteme
Boolesche Funktoren in aussagenlogischer Deutung
A B A UND B A ODER B A UND NICHT B A XOR B
w w w w f fw f f w w wf w f w f wf f f f f f
Konjunktion Disjunktion Postsektion Kontravalenz„beides“ „mindestens eines“ „das eine „entweder das eine oder
ohne das andere“ das andere“
I.M.Bochenski; Albert Menne: Grundriß der Logistik. – Paderborn: Schöningh, 1973, 27-35.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 114
Funktionalität Boolescher Retrievalsysteme
Abstandsoperatoren (Verschärfung des Booleschen UND)– (1) direkte Nachbarschaft:
• Phrasen: „Miranda Otto“• benachbarte Worte in Reihenfolge: Miranda ADJ Otto findet
Miranda Otto• benachbarte Worte ohne Beachtung der Reihenfolge: Miranda (N)
Otto findet Miranda Otto und Otto, Miranda– (2) numerische Abstandsoperatoren:
• Suche nach Worten im Abstand von n Worten (n frei wählbar): Miranda (N) Otto W/25 Eowyn findet alle Texte, in denen die Namen im Abstand von max. 25 Worten vorkommen
– mehrfache Anwendung von W/n findet (bei geschickt gewähltem n) hochrelevante Texte: Auenland W/25 Auenland W/25 Auenland
• Suche nach Worten im Abstand von n Worten (n fest, i.d.R. 10): Eowyn NEAR Aragorn findet Texte, in denen die Namen im Abstand von max. 10 Worten vorkommen

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 115
Funktionalität Boolescher Retrievalsysteme
Abstandsoperatoren (Verschärfung des Booleschen UND)– (3) grammatische Nachbarschaft:
• (nicht) im gleichen Satz (auch bei thematischen Ketten des syntaktischen Indexierens)
– A UND.S B– A NICHT.S B
• (nicht) im gleichen Absatz– A UND.P B– A NICHT.P B
• (nicht) im gleichen Feld– A UND.F B– A NICHT.F B
• Satzanfang: #A (A steht am Satzanfang)– Probleme mit Anaphora (... Miranda Otto ... . Sie spielt die Eowyn.)
Häufigkeitsoperator (Angabe der Minimalhäufigkeit)– ATLEAST 20 (A): A muss min. 20mal vorkommen

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 116
Funktionalität Boolescher Retrievalsysteme
Hierarchische Suche
UND
Marketing Dienstleister
UB1 UB2 UB3
Werbung
UB1 UB2 UB3
Consultant

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 117
Funktionalität Boolescher Retrievalsysteme
Hierarchische Suche• bei Klassifikationen durch Rechtsfragmentierung
– DDC=382 findet alles zur Klasse 382– DDC=382* findet alles zu 382 und zu den Unterbegriffen
der nächsten Hierarchieebene– DDC=382** findet alles zu 382 und zu den Unter-
begriffen der nächsten zwei Hierarchieebenen– DDC=382$ findet alles zu 382 nebst allen Unterbegriffen
• bei Thesauri – DOWN-Operator (findet alles zum Deskriptor nebst aller
Unterbegriffe)DE DOWN Hepatitis findet alles zu Hepatitis und zu allen Unterbegriffen (bis zu den Bottomterms) im unterlegten Thesaurus
– NÄCHSTE EBENE (findet alles zum Deskriptor sowie zu den Unterbegriffen der nächsten Hierarchieebene)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 118
Funktionalität Boolescher Retrievalsysteme
Hierarchische Suche
Beispiel:GBI

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 119
Funktionalität Boolescher Retrievalsysteme
Hierarchische Suche
Beispiel:STN

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 120
Funktionalität Boolescher Retrievalsysteme
Klammersetzung / Bindungsstärke der Operatoren– je nach System binden die Operatoren jeweils stärker
als andere; Beispiel: UND stärker ODER– Umgehen der Bindungsstärke durch Klammern; die
Systeme arbeiten die Klammern von innen nach außen ab
– Gesucht: Artikel von Ernst Meier (oder Maier?) aus den Jahren 1998 und 1999 über Mineralwasser sowie Soft Drinks:AU=M*ier, Ernst UND (YR=1998 ODER YR=1999) UND (DE=Mineralwasser ODER DE=Soft Drinks)
– Gesucht: Unternehmen im Postleitzahlbereich Köln, die Anwendersoftware anbieten und die entweder mehr als 30 Mitarbeiter oder mehr als 20 Mio. EURO Jahresumsatz haben. Wir wollen dabei nichts mit Unternehmen zu tun haben, die Software für militärische Zwecke erstellen.(PL=5$ UND PC=7372002 UND (MI>30 ODER UM>20)) UND NICHT PC=7372003

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 121
Funktionalität Boolescher Retrievalsysteme
Datenbankübergreifende Suche– Dubletten können vorkommen und sollten gelöscht werden– Aufruf der Datenbanken in der Reihenfolge ihrer Qualität (damit die
besten Datensätze erhalten bleiben)– nach Abschluss der Suche:
• Identifizieren der Dubletten / IDENTIFY DUPLICATES• Löschen der Dubletten / REMOVE DUPLICATES
– ggf. Aufsplitten der Ergebnisse in die einzelnen Daten-banken
– Beispiel: DataStar

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 122
Funktionalität Boolescher Retrievalsysteme
Umformulierung von Suchergebnissen zu Suchargumenten (MAPPING)– Suchschritt 1: Suche nach Argumenten für (den
eigentlich erwünschten) Suchschritt 2– Interesse besteht nur an den gefundenen Inhalten
gewisser Felder; Zwischenspeichern / MAP (ggf. Feldkürzel verändern)
– Suchschritt 2: ggf. Aufruf einer neuen Datenbank, Ausführen des gespeicherten Sucharguments
– Beispiel: Suche nach Literatur zu „Aspirin“ – chemische Bezeichnungen unbekannt: (1) Aufruf einer Synonymdatenbank für chemische Bezeichnungen; Suche nach Aspirin; MAP RN (RN: Feld mit den Bezeichnungen) Suchergebnis wird zwischengespeichert – (2) Aufruf einer Chemie-Literaturdatenbank; Auslösen des Zwischenspeichers EXECUTE STEPS

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 123
Funktionalität Boolescher Retrievalsysteme
Graphische Suche – realisiert für Retrieval nach chemischen Strukturen und Reaktionen
bei STN und Web of Knowledge

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 124
Funktionalität Boolescher Retrievalsysteme
Ausgeben der gefundenen Dokumente– Anzeigen / TYPE [Suchschritt]/[Format]/[Dokumente]
TYPE S3/5/1-5,9– bisherige Suchgeschichte / DISPLAY SET
– Sortieren / SORT [Suchschritt]/[Dokumente]/[Feld(er)]/ [Sortierrichtung] / SORT S3/all/yr,au/d
– Bilden einer Rangordnung nach Feldinhalten / RANK– Bestellen von Volltexten (die nicht direkt im PDF-Format
vorliegen) / ORDER

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 125
Funktionalität Boolescher Retrievalsysteme
Einrichten eines Pushdienstes– Suchargument ist vorhanden; Treffermenge
zufriedenstellend– Name des
Suchprofils definieren
– Periodizität festlegen
– Lieferanschrift eingeben hier: E-Mail (GBI)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 126
Funktionalität Boolescher Retrievalsysteme
Einrichten eines Pushdienstes– auf Homepage ausliefern (Beispiel: Factiva)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 127
Funktionalität Boolescher Retrievalsysteme
Auslieferung des Pushdienstes auf Homepage

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 128
Gewichtetes Retrieval

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 129
Gewichtetes Retrieval
Gewichten von Schlagworten (Deskriptoren, Notationen, Textworten) - Varianten– intellektuelle Zuordnung von Gewichtungswerten
• Zwei-Klassen-Verfahren: Klasse 1 – Schlagworte (besonders wichtig / relevant für das Dokument); Klasse 2 – Schlagworte (nicht so relevant wie die Klasse 1 –Schlagworte, aber auch wichtig)
• numerische Werte (Zuteilung von Werten aus einem Wertebereich [etwa: > 0 und 1] zu jedem Schlagwort nach Wichtigkeit im Dokument
– automatische Zuordnung von Gewichtungswerten• Basis: syntaktisches Indexieren mit Ketten

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 130
Gewichtetes Retrieval
Intellektuelles Gewichten von Schlagworten mittels Zwei - Klassen – Verfahren
• Beispiel 1: MedlineBeschränkung auf Klasse 1 - Dokumente
MAJR

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 131
Gewichtetes Retrieval
Intellektuelles Gewichten von Schlagworten mittels Zwei-Klassen – Verfahren
• Beispiel 1: Medline
• Indexierung:
Deskriptoren mit Sternchen *: Klasse 1 („major“)
Deskriptoren ohne Sternchen: Klasse 2

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 132
Gewichtetes Retrieval
Intellektuelles Gewichten von Schlagworten mittels Zwei-Klassen – Verfahren
• Beispiel 2: PatenteHauptanspruch des Patentes in ICM.Weitere Ansprüche / Informationen in
ICS, ICA und ICI

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 133
Gewichtetes Retrieval
Intellektuelles Gewichten von Schlagworten mittels numerischer Werte– beim Indexieren (also beim Input): Zuordnung von
numerischen Werte zu den Schlagworten (Deskriptoren, Notationen, Textworten)
– Beispiel: Information Retrieval (1,0); Boolesches System (0,5); natürlichsprachiges System (0,5); gewichtetes Retrieval (0,3); Informationslinguistik (0,4); Phrasenerkennung (0,1); Fehlertoleranz (0,1).
– „Information Retrieval“ wäre demnach in diesem Dokument zehnmal so wichtig wie „Phrasenerkennung“ (weil etwa zehnmal so viele Seiten darüber handeln)
– In der derzeitigen Informationspraxis werden solche Systeme nicht beachtet.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 134
Gewichtetes Retrieval
Boolesches Retrieval bei numerischen Gewichtungswerten– A und B seien Schlagworte, p und q Gewichtungswerte
(zwischen 0 und 1). p, q werden als „mindestens Gewicht von ...“ verstanden
– Schnittmenge Ap UND Bq
• 1. Invertierter Index: Suche alle Dokumente, bei denen Gew(A) ≥ p und Gew(B) ≥ q ist!
• 2. Bilde die Summe Gew(A) + Gew(B) für alle Dokumente aus Schritt 1!
• 3. Sortiere die Dokumente absteigend nach der Summe Gew(A) + Gew(B)!

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 135
Gewichtetes Retrieval
Boolesches Retrieval bei numerischen Gewichtungswerten– Vereinigungsmenge Ap ODER Bq
• 1. Invertierter Index: Suche alle Dokumente, bei denen Gew(A) ≥ p oder Gew(B) ≥ q (oder beides) ist!
• 2.a. wenn nur 1 Suchargument: berücksichtige Gew(A) bzw. Gew(B)!
• 2.b. wenn mehr als 1 Suchargument: berücksichtige das jeweils höchste Gewicht (Maximum)
– Gew(A) ≥ Gew(B) Gew(A)– Gew(A) < Gew(B) Gew(B)
• 3. Sortiere die Dokumente absteigend nach dem Maximum (Gew(A), Gew(B))!

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 136
Gewichtetes Retrieval
Boolesches Retrieval bei numerischen Gewichtungswerten– Exklusionsmenge Ap UND NICHT Bq
• 1.a. Invertierter Index: Suche alle Dokumente, bei denen Gew(A) ≥ p ist!
• 1.b. Schließe alle Dokumente aus der nach 1.a. gefundenen Menge aus, bei denen Gew(B) ≥ q ist! Alternative?: behalte nur, wenn Gew(B) < 1-q ?
• 2. Bilde Summe Gew(A) – Gew(B) für alle Dokumente aus 1.b.!
• 3. Sortiere die Dokumente absteigend nach der Summe Gew(A) – Gew(B)!

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 137
Gewichtetes Retrieval
Exklusionsmenge Ap UND NICHT Bq. Welche Alternative wählen?
Welche Dokumente bleiben in Treffermenge?q Variante 1: Ausschluss Variante 2: Verknüpfung mit
bei Gew(B) ≥ q B, wobei Gew(B) < 1 - q1,0 < 1,0 keines mit B0,9 < 0,9 < 0,10,8 < 0,8 < 0,20,7 < 0,7 < 0,3...0,2 < 0,2 < 0,80,1 < 0,1 < 0,90,0 keines mit B < 1,0

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 138
Gewichtetes Retrieval
Boolesches Retrieval bei numerischen Gewichtungswerten– bei mehreren Booleschen Operatoren: nacheinander
Abarbeiten der Anweisungen– Beispiel: 5 Dokumente
Dok1 A(0,9) B(0,5) C(0,3) D(0,1)Dok2 A(1,0) B(0,1) C(0,1)Dok3 A(0,5) B(1,0) C(0,3) D(0,4)Dok4 B(0,3) C(1,0) D(0,5)Dok5 A(1,0) B(0,2) C(0,1) D(1,0)
(A(0,5) UND [B(0,5) ODER D(0,5)]) UND NICHT C (0,4)Welche Dokumente in welcher Reihenfolge?

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 139
Gewichtetes Retrieval
Boolesches Retrieval bei numerischen Gewichtungswerten
(A(0,5) UND [B(0,5) ODER D(0,5)]) UND NICHT C (0,4)
1(0,9) 1,4 1(0,5) 0,5 1,1 1(0,3)
2(1,0) 2(0,1)
3(0,5) 1,5 3(1,0) 1,0 1,2 3(0,3)
0,5 4(0,5)
5(1,0) 2,0 1,0 5(1,0) 1,9 5(0,1)
Schritt: 1 5 2 4 3 7 6

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 140
Gewichtetes Retrieval
Gewichten durch „Cracken“ von Ketten beim syntaktischen IndexierenBeispiel eines Indexats mit thematischen Ketten (Textwortmethode nach Henrichs)
Hegel, Georg Wilhelm Friedrich (3); Dilthey, Wilhelm (6)
Geisteswissenschaft (1-7); Geist (2-3,5); Naturwissenschaft (1); Logik (1); Mathematik (1); Weltanschauungsphilosophie (2,7-8); Dogmatik (2,8); Erfahrungswissenschaft (4); Psychologie (4); Wertordnung (5); Wert (5); Historismus (6); Philosophie, wissenschaftliche (7); Kunde (8).
8 Ketten: Kette 1: Geisteswissenschaft – Naturwissenschaft – Logik –Mathematik; Kette 2: Geisteswissenschaft – Geist – Weltanschauungs-philosophie – Dogmatik; Kette 3: Geisteswissenschaft – Hegel usw.
Norbert Henrichs: Benutzungshilfen für das Retrieval bei wörterbuchunabhängig indexiertem Textmateriall. – In:Rainer Kuihlen (Hrsg.): Datenbasen – Datenbanken – Netzwerke. Band 3: Nutzung und Bewertung von
Retrievalsystemen. – München [u.a.]: Saur, 1980, 157-168.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 141
Gewichtetes Retrieval
Gewichten durch „Cracken“ von Ketten beim syntaktischen Indexieren– Primitivvariante: Gewichten
als Zuordnung der relativen Häufigkeiten in den Ketten zu den Schlagworten
– im Beispiel: 8 Ketten• Hegel <0,125> • Dilthey <0,125>• Geisteswissenschaft
<0,875>• Geist <0,375>• Naturwissenschaft <0,125>
• Logik <0,125>• Mathematik <0,125>• Weltanschauungsphilosophie
<0,375>• Dogmatik <0,250>• Erfahrungswissenschaft <0,125>• Psychologie <0,125>• Wertordnung <0,125>• Wert <0,125>• Historismus <0,125>• Philosophie, wissenschaftliche
<0,125>• Kunde <0,125>

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 142
Gewichtetes Retrieval
Gewichten durch „Cracken“ von Ketten Kritik an der Primitivvariante. Henrichs: Es muss berücksichtigt werden:
• 1. Häufigkeit des Schlagwortes (Anzahl der Themenketten, in denen das Schlagwort vorkommt) – „Schlagwortwert“
• 2. Mächtigkeit der Themenkette (Anzahl der Schlagworte in den jeweiligen Themenketten) – „Indexkettenwert“
• 3. Komplexität des Dokuments (Anzahl aller Schlagworte, d.h. Summe der Indexkettenwerte; normiert auf 100) –„Dokumentwert“

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 143
Gewichtetes Retrieval
Errechnen der Schlagwortwerte (SWW)Hegel Index: 3 SWW 1Dilthey 6 1Geisteswissenschaft 1-7 7Geist 2-3,5 3Naturwissenschaft 1 1Logik 1 1Mathematik 1 1Weltanschauungsphilosophie 2,7-8 3Dogmatik 2,8 2Erfahrungswissenschaft 4 1Psychologie 4 1Wertordnung 5 1Wert 5 1Historismus 6 1Philosophie, wissenschaftliche 7 1Kunde 8 1

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 144
Gewichtetes RetrievalErrechnen der Indexkettenwerte Themenkette: 1 2 3 4 5 6 7 8Hegel 1 Dilthey 1Geisteswissenschaft 7 7 7 7 7 7 7Geist 3 3 3Naturwissenschaft 1Logik 1Mathematik 1Weltanschauungsphilosophie 3 3 3Dogmatik 2 2Erfahrungswissenschaft 1Psychologie 1Wertordnung 1Wert 1Historismus 1Philosophie, wissenschaftliche 1Kunde 1Indexkettenwert 10 15 11 9 12 9 11 6 Σ= 83

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 145
Gewichtetes RetrievalThemenkette: 1 2 3 4 5 6 7 8Hegel 11 Σ= 11Dilthey 9 Σ= 9Geisteswissenschaft 10 15 11 9 12 9 11 Σ= 77Geist 15 11 12 Σ= 38Naturwissenschaft 10 Σ= 10Logik 10 Σ= 10Mathematik 10 Σ= 10Weltanschauungsphilosophie 15 11 6 Σ= 32Dogmatik 15 6 Σ= 21Erfahrungswissenschaft 9 Σ= 9Psychologie 9 Σ= 9Wertordnung 12 Σ= 12Wert 12 Σ= 12Historismus 9 Σ= 9Philosophie, wissenschaftliche 11 Σ= 11Kunde 6 Σ= 6Indexkettenwert 10 15 11 9 12 9 11 6
HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 146
Gewichtetes Retrieval
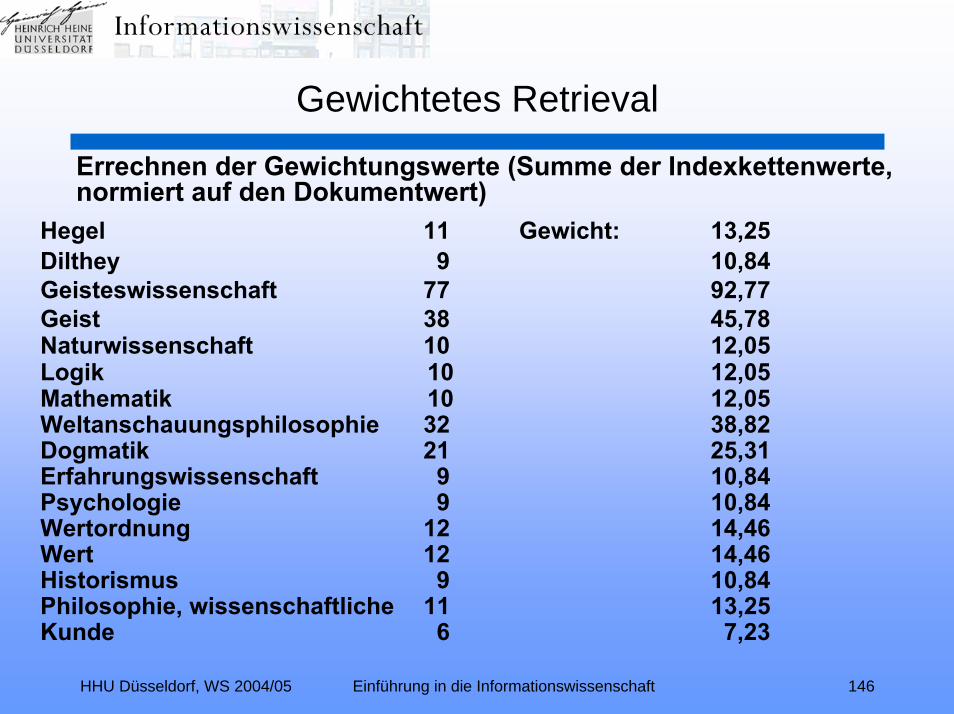
Errechnen der Gewichtungswerte (Summe der Indexkettenwerte, normiert auf den Dokumentwert)
Hegel 11 Gewicht: 13,25Dilthey 9 10,84Geisteswissenschaft 77 92,77Geist 38 45,78Naturwissenschaft 10 12,05Logik 10 12,05Mathematik 10 12,05Weltanschauungsphilosophie 32 38,82 Dogmatik 21 25,31Erfahrungswissenschaft 9 10,84Psychologie 9 10,84Wertordnung 12 14,46Wert 12 14,46Historismus 9 10,84Philosophie, wissenschaftliche 11 13,25Kunde 6 7,23

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 147
Gewichtetes RetrievalFazit.– Intellektuelle Gewichtungen beschränken sich in der
derzeitigen Informationspraxis auf das Zwei-Klassen-Verfahren.
– Zur automatischen Berechnung von Gewichtungswerten eignen sich Dokumente mit syntaktischer Indexierung (mittels Themenketten).
– Ein Primitivverfahren errechnet die relative Häufigkeit eines Schlagwortes in den Themenketten eines Dokuments.
– Ein elaborierteres Verfahren (nach Henrichs) berücksichtigt neben der Auftretenshäufigkeit die Zusammenhänge in der Gesamtstruktur der Themenketten eines Dokuments.
– Boolesche Operatoren werden durch die Gewichtungswerte modifiziert eingesetzt. (Ist das Schlagwort vorhanden underreicht es min. den angegebenen Gewichtungswert?)
– Ein Relevance Ranking wird möglich (UND: Summe; ODER: Maximum; UND NICHT: Differenz).

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 148
Informationslinguistik

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 149
Informationslinguistik
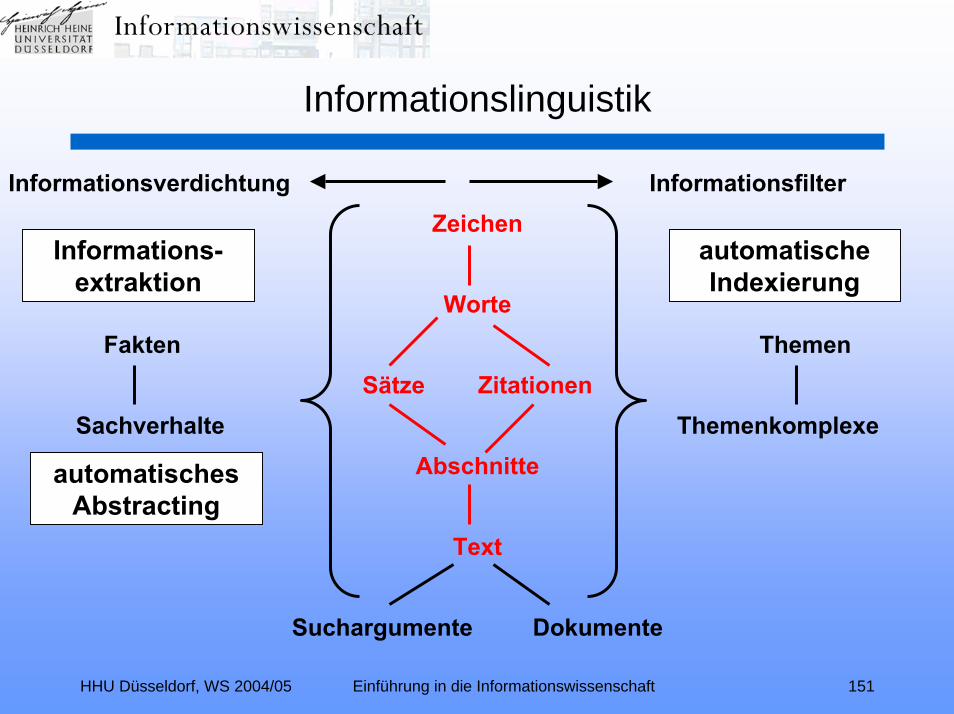
Linguistische Teilgebiete und deren Relevanz für das Information Retrieval (IR)– Worterkennung
• gesprochene Sprache: Phonetik (wichtig bei Systemen, an die Anfragen auch mündlich gestellt werden; Beispiel:Intranet-Schnittstelle im Auto)
• geschriebene Sprache: Zeichenerkennung / OCR (wichtig bei Systemen, bei denen nicht-digitale Dokumente aufgenommen werden)
• digital vorliegende Sprache: Wortidentifikation; alternativ: n-Gram – Methode (zentral für IR bei der Bearbeitung von Anfragen wie Dokumenten)
– Morphologie: Wortebene: Flexionsformen, Präfixe, Suffixe, Wortstämme, Zerlegung von Mehrwortbegriffen, Zusammen-fassen von Phrasen (zentral für IR)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 150
Informationslinguistik
Linguistische Teilgebiete und deren Relevanz für das Information Retrieval (IR)– Lexikon: Wortebene: Lexeme / Lemmatisierung; Synonyme;
Ober- und Unterbegriffe; verwandte Begriffe (zentral für IR)
– Syntax: Satzebene: grammatische Struktur eines Satzes
– Semantik: Satzebene: Bedeutung des Satzes; Klärung möglicher Mehrdeutigkeiten (letzteres mit großer Bedeutung für IR)
– Diskursanalyse: Textebene: Struktur und Bedeutung über Satzgrenzen hinweg; Art des Diskurses (Einleitung, Methodenteil,Ergebnisse, ...); Anaphora (große Bedeutung für IR)
– Pragmatik: Textebene: Zweck eines Textes; Einordnung in Kontexte (auch in Wissensgebiete) (große Bedeutung für IR)
Elizabeth D. Liddy: Enhanced text retrieval using natural language processing. – In: Bulletin of the AmericanSociety for Information Science April/May 1998.
HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 151
Informationslinguistik
Informationsverdichtung InformationsfilterZeichen
WorteFakten Themen
Sätze ZitationenSachverhalte Themenkomplexe
Abschnitte
Text
Suchargumente Dokumente
Informations-extraktion
automatischesAbstracting
automatischeIndexierung

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 152
Informationslinguistik
Englische Sprache– (vorwiegend) regelmäßige Endungen (Bsp.: -ed, -ing)– Wortstammbildung (stemming)– zusammengesetzte Begriffe durch mehrere Einzelworte (Bsp.:
„information science“, „high school“); Problem: Erkennung der Phrasen
Deutsche Sprache– sehr viele Regeln für Flexionen; diverse Ausnahmen– Grundformbildung (Lemmatisierung)– zusammengesetzte Begriffe durch EIN Einzelwort (Bsp.:
Informationswissenschaft; Hochschule); Problem: Zerlegung der Mehrwortbegriffe
– weitere Spezifika: etwa: Bindestrichergänzungalso: keine allgemeine Informationslinguistik, sondern sprachspezifische Varianten

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 153
Informationslinguistik
Grundansatz: Worte vs. N-Gramme– Zerlegen der Dokumente / Suchanfragen in Worte
und/oder N-Gramme
– Wortidentifikation: ein Wort ist eine Zeichenfolge zwischen zwei Leerstellen oder Satzzeichen bzw. dem Anfang eines Feldeintrags und einer Leerstelle/einem Satzzeichen
– N-Gramm: Zerlegung eines Textes in Zeichenfolgen mit n Zeichen (etwa: n=3 oder n=5).
– Zuordnung einer Wort- bzw. N-Gramm-Position (und ggf. weiterer Merkmale) in der invertierten Datei
– bei nicht-zeichensensitiven Systemen: Übertragung aller Buchstaben in eine Form (etwa: alles Großschreibung)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 154
Informationslinguistik
N-Gramme• Geschichte
– geht auf Claude Shannon (1948) zurück
– für das Information Retrieval nutzbar gemacht u.a. von Norbert Henrichs (1975) und M.Damashek (1995)
– es gibt diverse IR-Systeme auf N-Gramm-Basis; z.B. HAIRCUT (Hopkins Automated Information Retriever for Combing Unstructured Text) von James Mayfield et al. 2000
– besonders stark bei asiatischen Sprachen (wegen der nicht eindeutigen Leerzeichen)
Claude Shannon: A mathematical theory of communication.- In: Bell System Technical Journal 27 (1948),379-423 und 623-656.
M. Damashek: Gauging similarity with n-grams. Language-independent categorization of text. – In: Science267 (1995), 843-848.
J. Mayfield; P. McNamee; C. Piatko: The JHU/APL HAIRCUT system at TREC-8. – In: E.M. Voorhees;D.K. Harman (Hrsg.): Proceedings of the 8th Text REtrieval Conference. – Gaithersbury: NTIS, 2000, 445-452.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 155
Informationslinguistik
N-Gramme• Zerlegung von Buchstabenfolgen innerhalb eines Textes
(einschl. Leerzeichen) in Folgen von n Zeichen
• Anzahl der N-Gramme ist begrenzt: |Alphabet|n
Bsp.: deutsches Alphabet: 26 Zeichen plus Leerzeichen
bei n=3 273 = 19.683 3-Gramme
bei n=4 274 = 531.441 4-Gramme
bei n=5 275 = 14.348.907 5-Gramme
• Vergleich: arbeitet man mit Worten, so ist deren Anzahl (zumindest prinzipiell) unendlich groß

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 156
Informationslinguistik
N-Gramme• Vorteile der N-Gramme gegenüber Worten:
– überschaubares, endliches Material
– keine weiteren Algorithmen wie bei der Wortbearbeitung (Morphologie, Zerlegung von Mehrwortausdrücken usw.)
– da sprachungebunden: mehrsprachiges Retrieval gegeben
– kostengünstig
• Nachteile:– semantische „Fallen“ sind möglich
– Präzision suboptimal (allerdings nur im Vergleich mit hochentwickelten Algorithmen der Wortbearbeitung)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 157
Informationslinguistik
N-Gramme. Beispiel: Pentagramm (n=5)_Wide reihe
Wider eihei
iders iheit
dersp heits
erspr eitsb
rspru itsbe
spruc tsbew
pruch sbewe
ruchs bewei
uchsf eweis
chsfr weis_
hsfre
sfrei
freih „Widerspruchsfreiheitsbeweis“
Semantische Fallensind möglich.
Norbert Henrichs: Sprachproblemebeim Einsatz von Dialog-Retrieval-
Systemen. – In: DeutscherDokumentartag 1974, Bd. 2. –
München [u.a.]: Verl. Dokumentation, 1975, 219-232

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 158
Informationslinguistik
N-Gramme• alle Zeichen innerhalb eines Satzes werden in N-Gramme
zerlegt (dies wird für alle Sätze eines Textes wiederholt)• Probleme:
– Überzerlegung (wie „Reihe“ bei „Widerspruchsfreiheits-beweis“ in einem 5-Gramm)
– Zeichenfolge mit n-2 Zeichen (und weniger) werden durch ein n-Gramm nicht erkannt (wie „IBM“ bei einem 6-Gramm)
– Entstehung von Mehrdeutigkeiten durch die n-Gramm-Zerlegung (Bsp.: Treffer „prime minister“ für den Satz „The foreign minister ate prime rib for lunch“: Such-4-Gramme „prim“, „rime“, „mini“, „inis“, „nist“, „iste“, „ster“ kommen alle im Satz vor. Lösung: Einbeziehen von Leerzeichen: „me_m“, „e_mi“ – diese kommen im Satz nicht vor)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 159
Informationslinguistik
N-Gramme• N-Gramm-Retrieval bei HAIRCUT: (1.) Berechnung eines
Ähnlichkeitswertes zwischen Such-N-Grammen und N-Grammen in Texten
• P: Wahrscheinlichkeit für Relevanz (rechte Gleichungs-seite: relative Häufigkeit)
• D: Dokument (Text)• C: gesamte Datenbank (collection)• Q: Suchanfrage; q: N-Gramm aus Suchanfrage• α: Konstante (Glättungsparameter)
P(D|Q) = [α*P(q1|D) + (1- α)*P(q1|C)] * ... * [α*P(qn|D) + (1- α)*P(qn|C)]

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 160
Informationslinguistik
N-Gramm-Retrieval bei HAIRCUT: (2.) Relevance Feedback– Recherche nach der Ähnlichkeitsformel– Auswahl der Top N (i.d.R. 20) Dokumente– Gewichtung der N-Gramme in diesen Dokumenten nach
Formel
– Li: relative Häufigkeit des N-Gramms i in den Dokumenten– Ci: relative Häufigkeit des N-Gramms i in der gesamten
Datenbank– IDFi = inverse Dokumenthäufigkeit von i: (ld N / n) + 1 (N:
Anzahl der Dokumente in der Datenbank; n: Anzahl der Dokumente, in denen i vorkommt)
– K: Konstante– Selektion der Top M (i.d.R. 50) N-Gramme und neue Suche
mittels dieser 50 N-Grammen
(Li – Ci) * (IDFi)K

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 161
Informationslinguistik
N-Gramme: Welches N für welche Sprache?
Paul McNamee; James Mayfield: Character n-gram tokenization for European language text retrieval. - In:Information Retrieval 7 (2004), 73-97.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 162
Informationslinguistik
N-Gramme / Worte: Speicherung in invertierter Datei– alle N-Gramme bzw. alle Worte der Dokumente werden
in der invertierten Datei gespeichert
– zusätzlich wird die numerische Position im Dokument angegeben (d.h. die Worte werden durchnumeriert)
– zusätzlich: Angabe von Satz und Absatz
– Warum?
• Erkennen von benachbarten Worten bzw. von Phrasen
• Arbeit mit Abstandsoperatoren ermöglichen
• Rankingkriterium bei Relevance Ranking
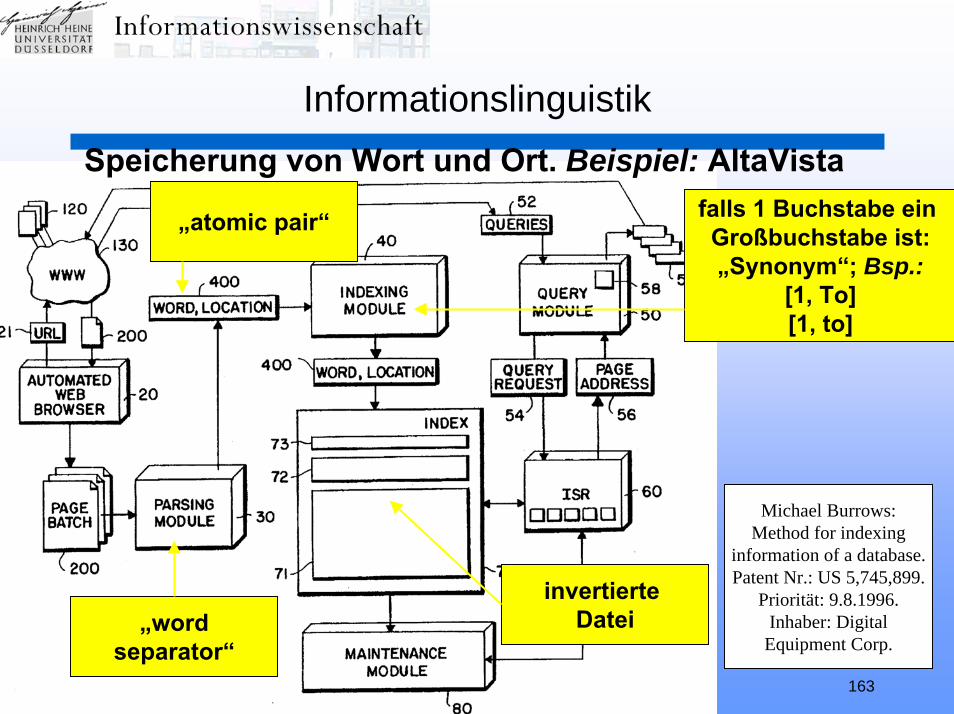
HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 163
InformationslinguistikSpeicherung von Wort und Ort. Beispiel: AltaVista
„wordseparator“
invertierte Datei
„atomic pair“ falls 1 Buchstabe ein Großbuchstabe ist:„Synonym“; Bsp.:
[1, To][1, to]
Michael Burrows:Method for indexing
information of a database.Patent Nr.: US 5,745,899.
Priorität: 9.8.1996.Inhaber: Digital
Equipment Corp.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 164
InformationslinguistikStoppwortliste:– Negativliste mit Begriffen, die (wahrscheinlich) im
Retrieval nicht gesucht werden.– Stoppworte sind i.d.R. häufig vorkommende Worte; ihre
Unterdrückung spart Speicherplatz.– Eine Elimination von Stoppworten ist wenig sinnvoll:
• bei gewissen Phrasen werden sie benötigt: „to be or not to be“
• u.U. wird gezielt nach Stoppworten gesucht: „Studien zum englischen Hilfsverb ‚to be‘“
• Pronomina sind eigentlich Stoppworte. Sie werden aber (theoretisch) bei der Informationsstatistik benötigt.
– Deshalb: Stoppworte markieren und von „normaler“ Suche ausschließen. Wenn Nutzer will, jedoch berücksichtigen.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 165
Informationslinguistik
Stoppwortliste: Beispiele von van Rijsbergen
C.J. van Rijsbergen: Information Retrieval. – 2nd. Ed. – London; Boston: Butterworth, 1979, S. 18.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 166
Informationslinguistik
Stoppwortliste: Markierung von Stoppworten; Einbezug von Stoppworten durch Suchsyntax.Beispiel: Google
Ausschluss einesStoppwortes
Einbezug einesStoppwortes durch
„+“

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 167
Informationslinguistik
Informationslinguistik: englische SpracheWortstammbildung (stemming)
ReduktionsformenWortstamm Grundform
Ausgangswort: retrieved
RETRIEV RETRIEVAL
Wortstammbildung durch Grundformbildung durchAbtrennen von Buchstaben Vergleich mit Wörterbuchnach gewissen Regeln (ggf. alternativ: nach
gewissen Regeln)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 168
Informationslinguistik
Informationslinguistik: englische SpracheWortstammbildung (stemming)
Präfixe – Suffixe
Rainer Kuhlen: Experimentelle Morphologie in der Informationswissenschaft. – München: Verl. Dokumentation,1977. – (DGD-Schriftenreihe; 5), S. 128 f.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 169
Informationslinguistik
Wortstammbildung (stemming)Einfaches Abtrennen mittels Präfix- bzw. Suffixliste
Ausschnitt aus einer Suffixliste (Anfangs-buchstabe: E)
zusätzlich: Längenregel (etwa: nur Suffix abschneiden, wenn mehr als 3 Buchstaben erhalten werden)
Bsp.: ring, red

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 170
Informationslinguistik
Wortstammbildung (stemming)Abtrennen / Bearbeiten nach dem Porter-AlgorithmusAbk.: C Konsonant: alles außer A, E, I, O, U; Y nur dann, wenn nicht
nach Konsonant (wie in Toy)V VokalCCC, ... sei CVVV, ... sei V[C]VCVC...[V] (allgemeine Form)(VC){m}(V) Anzahl der VC = m in einem Wort Bsp.: m=0 : tree, by
m=1 : trouble, treesm=2 : troubles, private
M.F.Porter: An algorithm for suffix stripping.- In: Program 14 (1980) 3, 130-137.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 171
Informationslinguistik
Abtrennen / Bearbeiten nach dem Porter-AlgorithmusRegel: (Bedingung) S1 S2: falls ein Wort mit dem Suffix S1 endet und der
Stamm vor S1 die Bedingung erfüllt, dann wird S1 durch S2 ersetztdie Bedingung wird durch m definiert; etwa: (m > 1)
Bsp.: (m>1) EMENT _S1 = EMENT; S2 = NullREPLACEMENT REPLAC
*S der Stamm endet mit „S“*V* der Stamm enthält einen Vokal*d der Stamm endet mit einem Doppelkonsonant (etwa: -TT, -SS)and, or, not : Kombinationen von Bedingungenbei mehreren Regeln in einem Schritt: nur eine anwenden, und zwar die mit
dem „longest match“

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 172
Informationslinguistik
Porter-Algorithmus
Schritt 1

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 173
Informationslinguistik
Porter-Algorithmus. Schritt 2

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 174
Informationslinguistik
Porter-AlgorithmusSchritt 3
HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 175
Informationslinguistik
Porter-Algorithmus
Schritt 4

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 176
Informationslinguistik
Porter-AlgorithmusSchritt 5

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 177
Informationslinguistik
Porter-Algorithmus: Leistungsfähigkeit

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 178
Informationslinguistik
Grundformenbildung nach dem Kuhlen-Algorithmus
• Abk.: % alle Vokale (einschließlich Y)• * alle Konsonanten• / oder• Ø Leerzeichen• ersetze zu
• 8 Regeln (mit Ausnahmen [hier übergangen] und Restriktionen)
Rainer Kuhlen: Experimentelle Morphologie in der Informationswissenschaft. – München: Verl. Dokumentation,1977. – (DGD-Schriftenreihe; 5), S. 71 f.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 179
Informationslinguistik
Kuhlen-Algorithmus

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 180
Informationslinguistik
Kuhlen-Algorithmus. Beispiele für die Regeln1. IES Y applies apply (3. Pers. Sing. auf Infinitiv);
activities activity (Plural auf Singular)falsch bei: Singular auf -IE. cookies cooky (richtig wäre: cookie)
2. ES Ø fishes fish (Plural auf Singular oder 3. Pers. Sing. auf Infinitiv)falsch bei: gewissen Verben. breaches breach (richtig wäre: breache)
3. S Ø lovers lover (Plural auf Singular)4. S‘, ES‘ Ø; IES‘ Y ladies‘ lady (Genitiv Plural auf Singular)5. ‘S, ‘ Ø mother‘s mother (Genitiv Sing. auf Nominativ Sing.)6. ING Ø wenn **/%/X: calling call
ING E wenn %*: having have (Partizip Präsenz auf Infinitiv)7. IED Y satisfied satisfy (Vergangenheit auf Infinitiv)8. ED Ø wenn **/%/X: called call
ED E wenn %*: hated hate (Vergangenheit auf Infinitiv)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 181
Informationslinguistik
Morphologie des Deutschen• Grundformbildung (Wortstammanalysen durch Abtrennen
eignen sich im Deutschen nicht) / Lemmatisierung• (1) Erstellung von Grundformenlexika für Wortformen
– Substantive– Adjektive– Verben (schwache / nicht-schwache)– Eigennamen– andere
• (2) Klassen von Flexionsendungen (für die Lexika)• (3) Beschreiben besonderer Merkmale (für die
Lexikoneinträge); etwa: Pluralbildung: NEIN (wie in „Laub“); Umlautung bei Plural („Mann“ – „Männer“)
• (4) Derivation (Relationen zwischen Wortformen); Bsp.:Lauf (Substantiv) – laufend (Adjektiv) – laufen (Verb)
• (5) Komposition / Zerlegung von Komposita

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 182
Informationslinguistik
Morphologie des Deutschen. Beispiel MORPHY• Grundformenlexika
– Wortstamm– Klasse der Flexionsendungen (MORPHY enthält 62 Klassen
für Substantive) / besondere Merkmale
Wolfgang Lezius: Morphologiesystem MORPHY. – In: R.Hausser (Hrsg.): Linguistische Verifikation. Dokumentation zur Ersten Morpholympics 1994. – Tübingen: Niemeyer, 1996, 25-35.
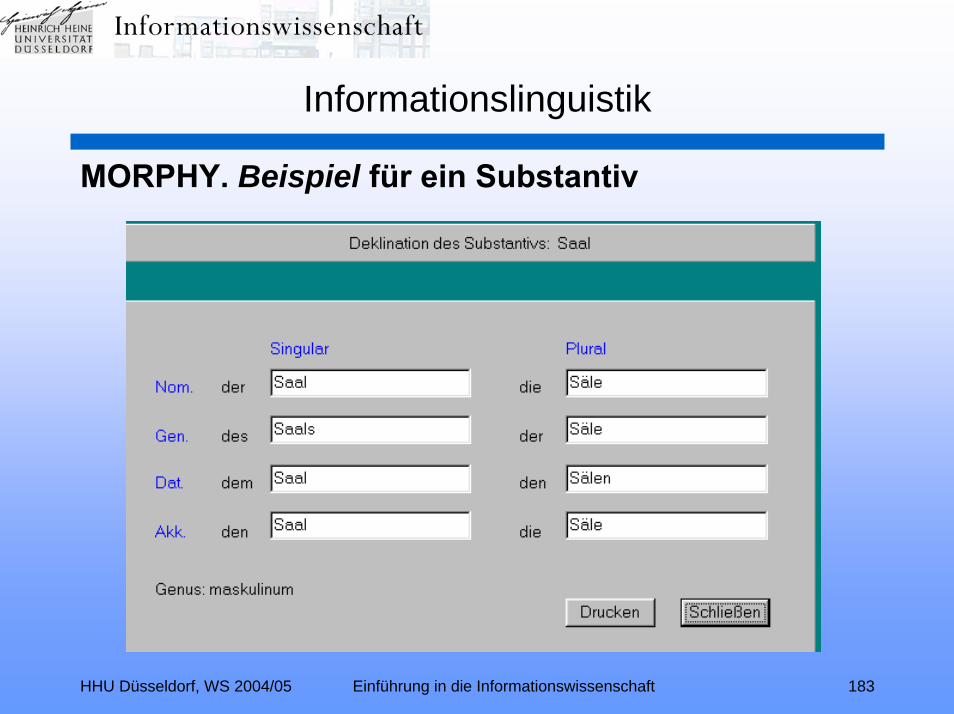
HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 183
Informationslinguistik
MORPHY. Beispiel für ein Substantiv

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 184
Informationslinguistik
MORPHY.
Beispielfür ein Adjektiv
(Positiv, Komparativ, Superlativ)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 185
Informationslinguistik
MORPHY.
Beispielfür ein Verb
(mit Prä-und Suffixen)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 186
Informationslinguistik
Komposition / Kompositazerlegeung• Fugenbildung unregelmäßig
– Komposition aus Singular- und aus Pluralform (Bsp.: „Haus-meister“ – „Häuser-meer“)
– Komposition mit und ohne Fugen-S (Bsp.: „Schwein-s-blase“ –„Schwein-e-bauch“ – „Schwein-kram“)
• Zerlegung nicht immer eindeutig– „Staubecken“ führt zu „Stau-becken“ oder „Staub-ecken“– „Baumangel“ führt zu „Bau-mangel“ oder „Baum-angel“– je nachdem, ob die Analyse links oder rechts beginnt
• MORPHY arbeitet nach dem longest-matching Verfahren von rechts, schneidet so lange von rechts ab, bis ein Wort gefunden wird (zerlegt also theoretisch zu „Staub-ecken“)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 187
Informationslinguistik
Komposition / Kompositazerlegeung• „Staubecken“ (von rechts nach links)• Staubecke-n kein Eintrag vorhanden• Staubeck-en kein Eintrag vorhanden• Staubec-ken kein Eintrag vorhanden• Staube-cken kein Eintrag vorhanden• Staub-ecken Eintrag „Staub“ vorhanden• Sta-ub kein Eintrag vorhanden• St-aub kein Eintrag vorhanden• S-taub kein Eintrag vorhanden• morphologische Analyse von „Ecken“: Plural „Ecke“• ecken Eintrag „Ecke“ vorhanden• ERGEBNIS: Staub - Ecke

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 188
Informationslinguistik
Komposition / Kompositazerlegeung• „Staubecken“ (von links nach rechts)• S-taubecken kein Eintrag vorhanden• St-aubecken kein Eintrag vorhanden• Sta-ubecken kein Eintrag vorhanden• Stau-becken Eintrag „Becken“ vorhanden
Eintrag „Stau“ vorhanden• b-ecken kein Eintrag vorhanden• be-cken kein Eintrag vorhanden• ... kein Eintrag vorhanden
• ERGEBNIS: Stau - Becken

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 189
Informationslinguistik
Komposition / Kompositazerlegeung• bei längeren Komposita: Zerlegung von rechts und von links• „Wellensittichfutter“• gefunden würden:
• Wellensittichfutter• Wellensittich (gefunden durch Abtrennung von rechts)• Futter• Sittichfutter (gefunden durch Abtrennung von links)• Welle falsch!• Sittich
• Zerlegungsverbote– partiell: Ausnahmen (wie hier „Welle“) müssen als Merkmal bei der
Grundform (hier: „Wellensittich“) hinterlegt sein – absolut: ebenfalls als Merkmal festhalten (Transport, Verbrechen)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 190
Informationslinguistik
Morphologische Analyse von MORPHY
Probleme bei MORPHY1. Mehrdeutigkeiten bleiben erhalten („gewohnt“)
2. Kontext im Satz nicht berücksichtigt („ausgehen“)
falsch
falsch
falsch

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 191
Informationslinguistik
Morphologische Analyse bei IDX• elaborierteres System als MORPHY: IDX (Fa. Softex)
• baut auf PRIMUS auf (Rechtschreibwörterbuch)
• eingesetzt bei– MILOS / KASCADE
(ULB Düsseldorf)
– dpa
• ursprünglich entwickelt von Harald H. Zimmermann (Universität des Saarlandes)
H.H.ZimmermannKlaus Lepsky: Maschinelle Indexierung von Titelaufnahmen zur Verbesserung der sachlichen Erschließung inOnline-Publikumskatalogen. – Köln: Greven, 1994. – (Kölner Arbeiten zum Bibliotheks- und Dokumentations-
wesen; 18)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 192
Informationslinguistik
Funktionalität von IDX– Grundformbildung– Elimination von (gewissen) Funktionsworten als Stoppworte– Kompositazerlegung– Derivation– Zusammenfügen diskontinuierlicher Verbalgruppenteile
(„ging ... weg“ – „weggehen“)– Erkennung fester Wendungen „steht ... zur Verfügung“ –
„zur Verfügung stehen“)– Auflösen von Auslassungstilden („Haus- und Hofwirtschaft“
– „Hauswirtschaft“)– Synonyme („Samstag“ – „Sonnabend“)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 193
Informationslinguistik
<10> Grundform Adjektiv< 6> Grundform Substantiv – falsch:23: Dekomposition:23t: hinterer Wortteil:4: Derivation von <6> auf <5> (Verb)<0> Stoppwort :4: Derivation von <7> auf <10>:103: unzulässige Dekomposition
(bleibt unberücksichtigt)
Zeile 757: problematische Dekomposition auf „legen“
Quelle: Lepsky 1994, 69

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 194
Informationslinguistik
Semantisches Umfeld (Relationen) von Worten• Voraussetzung: morphologische Analyse erfolgreich
abgeschlossen• Wortklassen
– Substantiv– Verb– Adjektiv– Adverb– (Funktionsworte)
• klassenspezifische Zuordnung von Relationen zu den Worten
• Beispiel: WordNetGeorge A. Miller: WORDNET: An on-line lexical database. – In: International Journal of Lexicography 3-4 (1990),235-312. – George A. Miller; Richard Beckwith; Christiane Fellbaum; Derek Gross; Katherine Miller: Introduction
to WordNet: An On-Line Lexical Database. – Princeton, 1993.www.cogsci.princeton.edu/~wn/5papers.pdf

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 195
Informationslinguistik
Wort-Bedeutungs-Matrix (WordNet)
Erkennen von Synonymen (hier: E1,1 und E1,2)Erkennen von Homonymen (hier: E1,2 und E2,2)
George A. Miller

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 196
Informationslinguistik
Relationen von Substantiven (WordNet)• Hyponymie (Abstraktionsrelation; Hyponym - Hypernym):
„kind of ...“– transitiv, asymmetrisch
• Meronymie (Teil-Ganzes-Relation; Meronym - Holonym): „part of ...“
– asymmetrisch– Problem: Meronymie ist z.T. transitiv oder z.T. nicht transitiv.
[Die Rinde ist Teil des Baumes. Der Baum ist Teil des Waldes. Kann man schließen: Die Rinde ist Teil des Waldes?]
• Antonymie (Gegensatz)– symmetrisch
• Ähnlichkeit (symmetrisch; nicht transitiv)
George A. Miller: Nouns in WordNet: A Lexical Inheritance System. – Princeton, 1993.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 197
Informationslinguistik
Meronymie• Variante 1: transitiv (z.B. Geographica)
• Variante 2: nicht transitiv– Es gibt Bäume im Wald;
aber auch welche außerhalb von Wäldern.
RindeBaumWald
Deutschland
NRW
D

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 198
Informationslinguistik
Relationen von Substantiven (WordNet)Beispiel

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 199
Informationslinguistik
Relationen von SubstantivenBeispiel (WWW-Version von WordNet): „Duck“
• In WordNet: 57.000 Substantive; 48.800 Bedeutungen

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 200
Informationslinguistik
Relationen von Substantiven (WordNet)
Bedeutungen
Unterbegriffe Abstraktions-relation

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 201
Informationslinguistik
Relationen von Verben (WordNet) • Verb-Hyponymie (Verb-Enthaltensein; Troponym –
Hypernym)• Troponym
– + Temporal Inclusion• + Troponymie („echte“ Abstraktion: talk – lisp)• - Troponymie (abhängige Tätigkeit: sleep – snore)
– - Temporal Inclusion– Backward Presupposition (try – succeed; auch:
Gegensätze: untie – tie)– Cause (have – give)
Christiane Fellbaum: English Verbs as a Semantic Net. – Princeton, o.J.
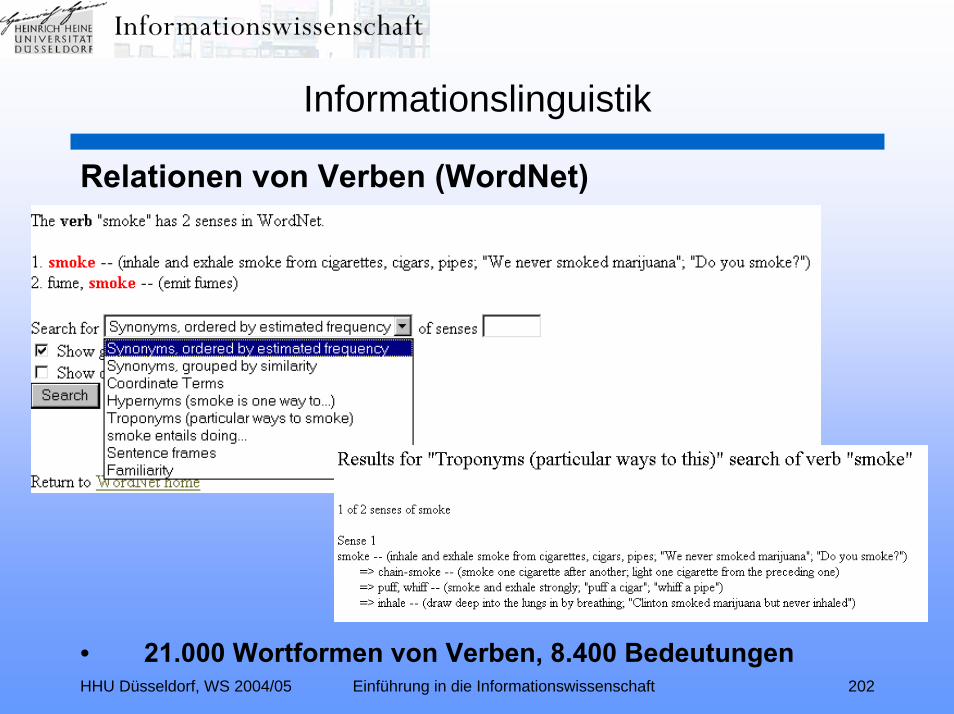
HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 202
Informationslinguistik
Relationen von Verben (WordNet)
• 21.000 Wortformen von Verben, 8.400 Bedeutungen

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 203
Informationslinguistik
Relationen von Adjektiven und Adverbien (WordNet) • Antonymie (nicht bei
Adverbien)
• Ähnlichkeit• abgeleitet von ...
• 19.500 Adjektive• 10.000 Bedeutungen
Christiane Fellbaum; Derek Gross; Katherine Miller: Adjectives in WordNet. – Princeton, 1993.
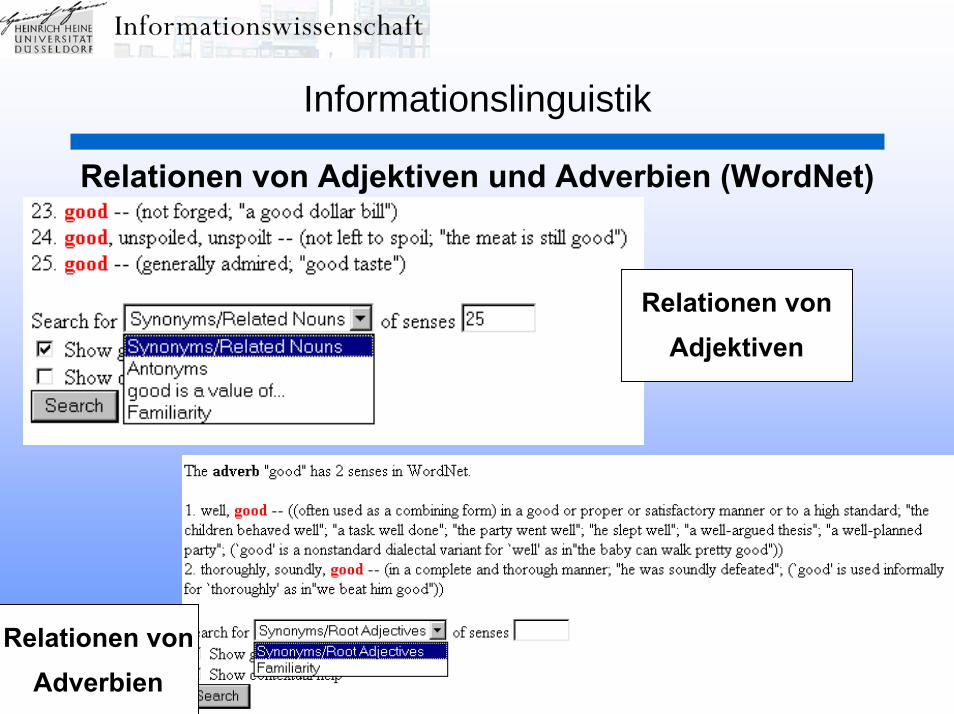
HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 204
Informationslinguistik
Relationen von Adjektiven und Adverbien (WordNet)
Relationen vonAdjektiven
Relationen vonAdverbien

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 205
Informationslinguistik
Überblick der Relationen in WordNet
symmetrische undasymmetrische Relationen

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 206
Informationslinguistik
Worte nach morphologischer und semantischer Analyse: Präzisierung und Erweiterung der Suchanfrage
• Dokumente und Anfragen werden morphologisch analysiert. Bei den Dokumenten werden die Wortstämme (oder die Grundformen) in einer invertierten Datei gelistet.
• Natürlichsprachige Anfragen werden wortweise semantisch analysiert.
• Bei Homonymen in der Anfrage: Rückfragen (System-Nutzer-Dialog)
• Bei Synonymen in der Anfrage: automatischer Einbezug aller Synonyme (oder System-Nutzer-Dialog)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 207
Informationslinguistik
Worte nach morphologischer und semantischer Analyse: Präzisierung und Erweiterung der Suchanfrage
• Anfrageerweiterung: Entweder automatisch oder nach System-Nutzer-Dialog werden die semantischen Umfeldterme in das Suchargument einbezogen.
• Strategien– (1) Einbezug von Hyponymen und Meronymen (bei
Substantiven) sowie von Troponymen (bei Verben) über n Ebenen (n = 1, 2, ...)
– (2) Einbezug von Hypernymen und Holonymen über n Ebenen
– (3) Einbezug von ähnlichen Worten – (4) Einbezug von abgeleiteten Adjektiven / Adverbien bzw.
umgekehrt– (5) ggf.: Einbezug von Antonymen (?)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 208
Informationslinguistik
Erweiterung der Suchanfrage: Beispiel„How dangerous is smoking of cigarettes?“
• Stoppworte markieren: How, is, of• morphologische Analyse:
– (1) dangerous [Adjektiv]– (2) smoke [Verb]– (3) cigarette [Substantiv]
• semantische Erweiterung (im Beispiel: bei 1 und 3: Synonyme, bei 2: Troponyme)„(dangerous, unsafe, unsecure, vulnerable, hazardous, risky) (smoke, „chain-smoke“, puff, whiff, inhale) (cigarette, cigaret, „coffin nail“, butt)
• „Inhaling coffins nails is hazardous for your health“ wird als Treffer gefunden.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 209
Informationslinguistik
„Thesaurus“• Lesart 1: im Sinne der Sprachwissenschaft (wie bei WordNet)
– Es werden semantische Umfeldbegriffe im allgemeinen Sprachgebrauch der Umgangssprache abgebildet.
– Fachsprachen kommen höchstens am Rande vor.– Probleme: Was tun bei Mehrdeutigkeiten (etwa: Homonymen)?
• Lesart 2: im Sinne einer Dokumentationsmethode („Standard-Thesaurus Wirtschaft“, ...)
– Es werden die semantischen Umfeldbegriffe in einer Fachsprache abgebildet.
– Thesauri (als Dokumentationsmethode) sind stets fachbezogen.– Ein Thesaurus im Sinne der Sprachwissenschaft kann in
fachlichen Umgebungen keine Dokumentationsmethode ersetzen.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 210
Informationslinguistik
Erkennung von Phrasen• Eigennamen („Miranda Otto“, „Heinrich-Heine-Universität
Düsseldorf“)• Mehrwortbegriffe (häufig im Englischen: „high school“, „soft
ice“; aber auch im Deutschen: „juristische Person“)• Phrasen müssen in den Dokumenten und in den
Suchanfragen erkannt werden; bzl. der Dokumente geht die Phrase (in Grundform) in die invertierte Datei ein
• Methoden der Phrasenerkennung– Abgleich mit Phrasenwörterbuch (dieses muss auf- und
ausgebaut werden; deshalb: Rückgriff auf weitere Methoden)– Textklumpen– Indikatorbegriffe (vor allem zur Identifikation von Eigennamen)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 211
Informationslinguistik
Erkennung von Phrasen durch Textklumpen (Lexis-Nexis-Methode)
• Stoppwortliste wird massiv erweitert– alle Adverbien– alle Hilfsverben– weitere Verben– weitere Worte (z.B. Monatsnamen)
• Stoppworte gelten als Einschnitte in Texte• Die (zwischen den Stoppworten bzw. Satzgrenzen)
übrigbleibenden Textteile sind Kandidaten für Phrasen (insofern mindestens zwei Worte übrig bleiben oder das Wort nur Großbuchstaben enthält)
Xin Allan Lu; David James Miller; John Richard Wassum: Phrase Recognition Method and Apparatus. – Patent Nr.US 5.819.260. – Priorität: 22.1.1996. – Inhaber: Lexis-Nexis.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 212
Informationslinguistik
Phrasenerkennung durch Textklumpen („Chunks“)Erweiterte Stoppwortliste (Partition List)
kleiner Ausschnitt

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 213
Informationslinguistik
Phrasenerkennung durch Textklumpen (Beispiel)Citing what is called newly conciliatory comments by the leader of the Irish Republican Army’s political wing, theClinton Administration announced today that it would issue him a visa to attend a conference on Northern Ireland in Manhattan on Tuesday.
gelb: 1-Wort-Klumpen; wird übergangenrot: Textklumpen; potentielle Phrase
erkannte Phrasen:conciliary comments
Irish Republican Armypolitical wing
Clinton AdministrationNorthern Ireland
HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 214
Informationslinguistik
Phrasen-erkennung durch Textklumpen
Lexis-Nexis

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 215
Informationslinguistik
Phrasenerkennung durch Textklumpen• Welche Phrasen werden erfasst?
– Substantiv-Phrasen („ice cream“)– Adjektiv-Substantiv-Phrasen („high school“)– Partizip-Substantiv-Phrasen („operating system“)– einige Eigennamen („Northern Ireland“)
• Zusatzverfahren für Eigennamen:– Indikatorbegriffe für
Unternehmen ProdukteOrganisationen Personen

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 216
Informationslinguistik
Phrasenerkennung durch Indikatorbegriffe
Indikatoren auf Unternehmen (Listenausschnitt A bis G)Vorgehen:
Kommt ein „Company Indicator“ in einer Phrase vor, werden die Worte hinter dem Indikator gelöschtIst die Phrase vor dem Indikator bereits vorhanden, wird diese als Synonym behandelt

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 217
Informationslinguistik
Phrasenerkennung durch Indikatorbegriffe
Indikatoren auf PersonennamenVorgehen:Kommt ein Vorname in einer Phrase vor, so werden die Worte vor dem Indikator gelöscht

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 218
Informationslinguistik
Erstellung eines PhrasenwörterbuchesSchwellenwerte für Listeneintrag:
1. dokumentspezifisch: Phrase mehr einmal (Ausnahme: Großbuchstaben)
2. datenbankspezifisch:Phrase in mehr als fünf Dokumenten

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 219
Informationslinguistik
• Anaphora – Ellipsen– Anaphora beziehen sich auf frühere Textelemente (Korrelate)
und haben deren Bedeutung („Kal does not have a dog but hewould like to.“)
– Ellipsen sind unvollständige Formulierungen („Kal does not have a dog but Ari does [have a dog].“)
– Probleme mit anaphorischen und elliptischen Wendungen:
– (1) beim Einsatz von Abstandsoperatoren
– (2) bei der Kreation der Zählbasis der Informationsstatistik
Ari Pirkola; Kalvero Jävelin: The effect of anaphora and ellipsis resolution on proximity searching in a textdatabase. – In: Information Processing & Management 32 (1996), 199-216.
Elisabeth Liddy: Anaphora in natural language processing and information retrieval. – In:Information Processing & Management 26 (1990), 39-52.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 220
Informationslinguistik
– Typen von Anaphora und Ellipsen• (1) Pronomen: Personalpronomen (er, sie, es, ...),
Possessivpronomen (mein, dein, ...), Reflexivpronomen (mich, sich), Demonstrativpronomen (diese, jene), Relativpronomen (die Studenten, die ...)
• (2) Nomen: Ersetzung (diese Frau), Abkürzungen (Kanzler Schröder), Metaphern, Metonymie (bildlicher Ausdruck: der Löwe aus Berlin), Paraphrase (Umschreibung)
• (3) Zahlwörter: (der zuerst Genannte, die beiden Länder)
• (4) Asyndeton (Auslassung des Nomens bzw. Pronomens: er kam, sah, siegte)
• (5) elliptische Weglassung (Egon hackte Holz, genau wie Rolf)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 221
Informationslinguistik
– Anaphoraauflösung• Ziel: eindeutige Zuordnung der Anaphora bzw. Ellipsen zu
ihren ursprünglichen Termen
• Beispiel 1: John hid Bill‘s car key. He was drunk. Zuordnung des „he“ zu „Bill“
• Beispiel 2: John hid Bill‘s car key. He was playing a joke on him. Zuordnung des „he“ zu „John“ und des „him“ zu „Bill“
– Es gibt Theorien und erste Prototypen für Anaphora-auflösung; zufriedenstellende Produkte (noch) nicht.
Shalom Lappin: A sequenced model of anaphora and ellipsis resolution. – London: King‘s College, 2003.(unveröffentl. Skript)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 222
Informationslinguistik
• Fehlertolerante Behandlung von SuchfragenIdentifikation und Korrektur von Eingabefehlern bei der Suche– Verfahren: Soundex (eingesetzt bei Okapi) - Basis:
Phonetik– Reduktion aller Worte auf einen Code.; für die Dokumente
Speicherung in invertierter Datei– Verfahrensschritte (Beispiel: „economics“)
• (1) erster Buchstabe bleibt erhalten E• (2) falls der zweite Buchstabe mit dem ersten identisch
ist, übergehe ihn• (3) falls zwei aufeinanderfolgende Buchstaben im
Ausgangswort identisch sind, übergehe den zweitenJacob R.Jacobs: Finding words that sound alike. The Soundex algorithm. – In: Byte 7 (1982) 3, 473-474. -
Stephen Walker; Richard M. Jones: Improving Subject Retrieval in Online Catalogues. – Boston Spa: BritishLibrary, 1987. – (British Library Research Paper; 24).

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 223
Informationslinguistik
– Soundex bei Okapi• (4) falls zwei aufeinanderfolgende Buchstaben im
entstehenden Codewort identisch sind, notiere beide• (5) Buchstaben aeiuoywh werden ignoriert
economics Ecnmcs• (6) Buchstaben cgjkqsxz werden als C dargestellt
economics ECnmCC• (7) Buchstaben bfpv werden als B dargestellt• (8) Buchstaben dt werden als D dargestellt• (9) Buchstaben mn werden als M dargestellt
economics ECMMCC• (10) Buchstaben l und r bleiben erhalten• (11) falls der letzte Buchstabe aiouy ist, wird y notiert

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 224
Informationslinguistik
• Fehlertolerante Behandlung von SuchfragenBeispiel: economics : ECMMCC
econimics : ECMMCC (wird gefunden)economisc : ECMMCC (wird gefunden)economy : ECMMY (wird nicht direkt gefunden)
– Bei fehlerhafter Eingabe wird ein Codevergleich durchgeführt • zunächst Suche nach direkten Treffern• dann nach Treffern mit bestmöglicher Übereinstimmung
– Dialog mit Nutzer:Can’t find “economisc” - closest match found is “economics”

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 225
Informationslinguistik
Phonetische Suche• Suche nach gleich klingenden Worten (Homophonen)• wichtig u.a. beim Retrieval nach Warenzeichen / Marken
(Microsoft – Mikrosaft) oder bei Namen (Meyer – Mayer –Meier)
• Soundex funktioniert in Grenzen (Meyer/Mayer/Meier – MR), bringt aber u.U. irrelevante Treffer (Maar/more/... – MR)
• Unscharfes Retrieval durch Austauschen einer gewissen Anzahl von Buchstaben (Methode von Questel-Orbit in den Warenzeichen-Datenbanken)– Definition einer Stelle im Wort, ab der unscharf gesucht wird
(etwa: ab der 3. Stelle)– Definition der Anzahl der Buchstaben, die unterschiedlich sein
dürfen (etwa: 2) – bei Questel-Orbit derzeit nur direkt benachbarte Zeichen

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 226
Informationslinguistik
Fazit• Informationslinguistik bringt einen Abgleich zwischen
(natürlichsprachlichen) Dokumenten und (natürlichsprachigen) Anfragen.
• Die Identifizierung von Worten geschieht entweder durch Leer-und Satzzeichen oder durch das N-Gram-Verfahren.
• In einer invertierten Datei werden (mindestens) Wort und Ort (im Dokument) gespeichert.
• Eine Stoppwortliste markiert häufig vorkommende Worte, die i.d.R. nicht im Retrieval benötigt werden.
• Aus den im Text vorkommenden flektierten Worten werden Wortstämme oder Grundformen abgeleitet.– im Englischen: Stemming durch Suffixabtrennen oder durch
Algorithmen (etwa dem Porter-Algorithmus)– im Deutschen: Lemmatisierung (Voraussetzung: Wörterbuch,
Flexionsendungen, Merkmale), Derivation, Kompositazerlegung

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 227
Informationslinguistik
Fazit• Ein Thesaurus (im sprachwissenschaftlichen Sinne) gibt den
Worten ihr umgangssprachliches semantisches Umfeld (Synonymie, Homonymie, bei Substantiven: Hyponymie und Meronymie, bei Verben: Troponymie).
• Phrasenerkennung geschieht durch das Bilden von Textklumpen sowie zusätzlich (bei Namen) durch Indikatorbegriffe.
• Anaphorische bzw. elliptische Wendungen müssten eigentlich ihren Nomen zugeordnet werden (wegen der Zählbasis bei der Informationsstatistik).
• Durch spezielle Algorithmen (Beispiel: Soundex) lassen sich fehlerhafte Sucheingaben identifizieren.
• Eine phonetische Suche lässt sich entweder mit Soundex oder einer anderen unscharfen Retrievalform realisieren.
Wolfgang G. Stock: Informationswirtschaft. Management externen Wissens. – München; Wien: Oldenbourg, 2000. –Kap. 6.1: Informationslinguistik, 149-159.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 228
Textstatistik
Relevance Ranking I

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 229
Textstatistik
Relevance Ranking• Sortierung der Dokumente (die durch informations-
linguistische Verfahren oder durch eine Boolesche Suche gefunden worden sind) nach der Relevanz zur Suchfrage
• Verfahren:– Textstatistik
– Linktopologie
• Vermutung: Die Verteilung der Dokumente zu einer Suchfrage verläuft typisch informetrisch (linksschief)
• damit: am Anfang einer Ausgabeliste stünden die zentralen Dokumente

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 230
Textstatistik
Das informetrische Verteilungsgesetz
f (x)
f (x) = _____C
xa
ca. 80 %
xca. 20%

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 231
Textstatistik
Precision bei Such-maschinen im WWW
Precision aufRangplatz n (P @ n) fürn = 1, ..., 20
David Hawking; Nick Craswell; Peter Bailey; Kathleen Griffiths: Measuring search engine quality. – In: Information Retrieval 4 (2001), 33-59.
Von einer typisch informetrischen Verteilung keineSpur. Lösungsalternativen: (1) unsere Vermutung
war falsch; (2) Relevance Ranking von Such-maschinen ist subopimal.
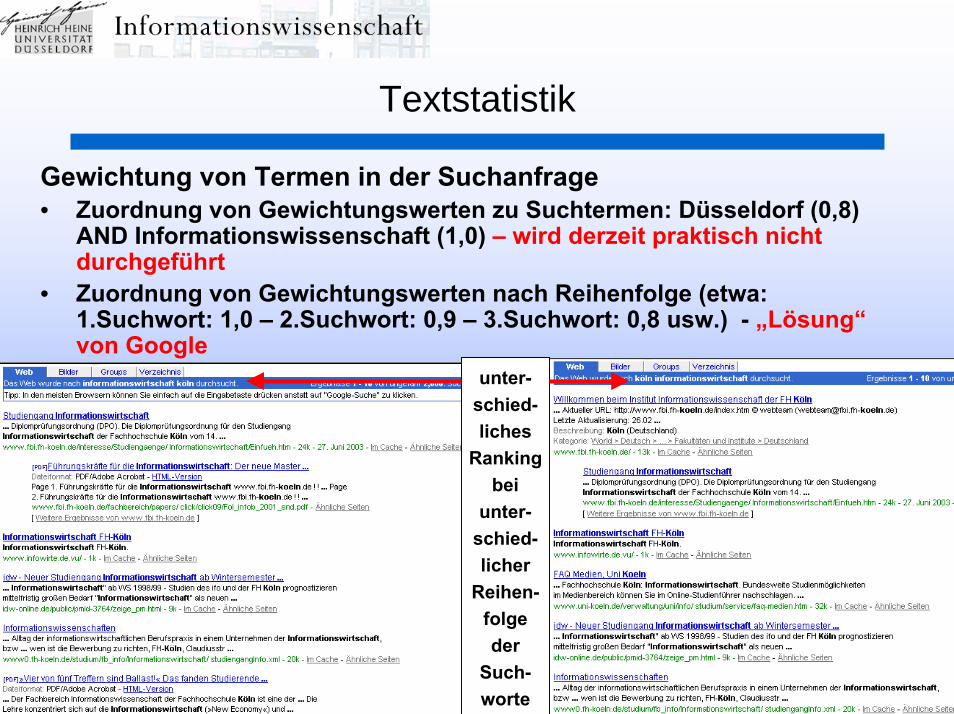
HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 232
Textstatistik
Gewichtung von Termen in der Suchanfrage• Zuordnung von Gewichtungswerten zu Suchtermen: Düsseldorf (0,8)
AND Informationswissenschaft (1,0) – wird derzeit praktisch nicht durchgeführt
• Zuordnung von Gewichtungswerten nach Reihenfolge (etwa: 1.Suchwort: 1,0 – 2.Suchwort: 0,9 – 3.Suchwort: 0,8 usw.) - „Lösung“ von Google
unter-schied-liches
Rankingbei
unter-schied-licher
Reihen-folgeder
Such-worte

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 233
Textstatistik
Übergang von einer Booleschen Anfragen zum Relevance Ranking• Variante 1: Suchterme werden mit Boolescher Logik
übernommen– 1.1 Nutzer wird nach Gewichtungen der Suchterme gefragt– 1.2 Gewichte werden automatisch auf jeweils 1 gesetzt
Die Resultate aus dem Relevance Ranking für die Dokumente werden als Gewichtungswerte interpretiert. (Weiter: Kapitel „Gewichtetes Retrieval“)
• Variante 2: 2 Teilsuchen: (a) Boolesche Anfrage, (b) RelevanceRanking ohne Boolesche Funktionalität (AltaVista-Lösung)
Schritt 1: Boole
Schritt 2: Ranking

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 234
Textstatistik
Übergang von einer Booleschen Anfragen zum Relevance Ranking• Variante 3: Suchterme werden ohne Boolesche Logik
übernommen – eigentlich unzulässig (diverse Suchmaschinen tun dies)– mit ODER bzw. UND verknüpfte Suchworte würden gleich
behandelt– mit UND NICHT verknüpfte Suchworte (soweit noch
vorhanden) würden positiv mitberücksichtigt• Vorsicht: Ein Übergang von Booleschen Anfragen zum
Relevance Ranking ist ausschließlich beim problemorientierten Informationsbedarf möglich, etwa bei Feldsuchen in Titel-, Abstract-, Schlagwort- oder Volltextfeldern (unzulässig beim konkreten Informationsbedarf, etwa bei Suchen im Autor- oder Jahrgangsfeld)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 235
Textstatistik
Textstatistik. Der Ausgangspunkt: Die These von Luhn• Die Häufigkeit des Auftretens von Worten in einem Dokument ist
ein Indikator auf deren Signifikanz im Dokument.
• Luhn: Einer der „Väter“ des Information Retrieval
• weitere Entwicklungen von Luhn:– SDI– KWIC / KWOC
• Forschungen und Entwicklungen bei IBM
Hans Peter Luhn (1896 – 1964)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 236
Textstatistik
Textstatistik. Der Ausgangspunkt: Die These von Luhn• keine „gute“ Signifikanz bei sehr häufig in einem Dokument
auftretenden Worten (wahrscheinlich Stoppworten)• keine „gute“ Signifikanz bei sehr selten in einem Dokument
auftretenden Worten • „gute“ Signifikanz haben die Worte dazwischen• „Wort“ bedeutet (nach van Rijsbergen) sowohl das (flektierte)
Textwort als auch – wichtiger – (a) den Wortstamm bzw. die Grundform sowie (b) eine Phrase (m.E. müssten (c) auch die Pronomina der Grundformen bzw. Phrasen beachtet werden)
Hans Peter Luhn: The automatic derivation of information retrieval encodements from machine-readable texts. – In:A.Kent (Hrsg.): Information Retrieval and Machine Translation, Vol. 3, Part 2. – New York: Interscience, 1961,
1021-1028. – Claire K.Schultz: H.P.Luhn: Pioneer of Information Science – Selected Works. – London: Macmillan, 1968. – C.J. van Rijsbergen: Information Retrieval. – 2nd Ed. – London [u.a.]: Butterworths, 1979, 15 f.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 237
Textstatistik
Die These von Luhn: Textworte mit „guter“ Signifikanz
Quelle: Schultz 1968, 210.
zu seltenzu häufig
„gute“ Signifikanz

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 238
Textstatistik
Textstatistik: Zählbasis• Häufigkeit eines Wortes (einer Grundform/eines
Wortstammes, einer Phrase zuzüglich der betreffenden Pronomina).Wort i im Dokument j: Freq(i,j)
• Position des Wortes im Dokument (P)– Wort und Ort– Wort in spezifischem Feld (bzw. Meta-Tag)
• Anzahl aller Worte in einem Dokument (L)• Anzahl aller Dokumente in einer Datenbank, in denen ein
bestimmtes Wort (mindestens einmal) vorkommt (n)• Gesamtanzahl der Dokumente in einer Datenbank (N)
Donna Harman: Ranking algorithms. – In: William B. Frakes; Ricardo Baeza-Yates (Hrsg.): Information Retrieval.Data Structures & Algorithms. – Upper Saddle River, NJ: Prentice Hall PTR, 1992, 363-392.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 239
Textstatistik
• einfaches Zählen der Worte: Freq(i,j):untaugliches Verfahren (Grund: lange Texte haben viele Worte und würden zu Unrecht nach oben sortiert)
• Gewichtung nach Position im Text (P)– Gewichtungsfaktor für Vorkommen in unterschiedlichen
Textteilen (Bsp.: 1.Abschnitt: 1,5 - Mitte: 0,8)– Gewichtungsfaktor für Vorkommen in unterschiedlichen
Feldern bzw. Meta-Tags (Bsp.: Titel: 2,5; - Abstract: 1,5 - Text: 1; title-tag: 2,5 – keywords-tag: 1,5)
– wenn das Wort mehr als einmal vorkommt: Übernahme des größten Wertes (Maximum) als Gewichtungsfaktor
– als alleiniger Wert untauglich (ein Vorkommen z.B. im Titel sagt allein nichts über die Signifikanz des Wortes im gesamten Text aus); u.U. einsetzbar in Verbindung mit WDF

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 240
Textstatistik
Dokumentspezifische Wortgewichtung (within-document frequency weight) WDF
•• relative Häufigkeit des Vorkommens eines Wortes in einem Dokument (je häufiger, desto größer WDF)
• i =: Wort; j =: Dokument• Freq(i,j) =: Häufigkeit von i in j; ld: Logarithmus dualis
Berechnungsformel nach Donna Harman:WDF(i) = (ld [Freq(i,j) + 1]) / ld L
Donna Harman: An experimental study of factors important in document ranking. – In: Proceedings of the ACMConference on Research and Development in Information Retrieval. – Pisa, 1986, 186-193.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 241
Textstatistik
Dokumentspezifische Wortgewichtung (within-document frequency weight) WDF
•• WDF(i) = (ld [Freq(i,j) + 1]) / ld L
Warum Häufigkeit „+1“?wenn Freq(i,j) = 0, dann steht im Zähler ld (0 + 1), also ld(1)ld(1) = 0 (und dies ist intuitiv zutreffend)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 242
Textstatistik
WDF - BeispieleBeispiel (1) nach Harman-Formel: Dokument 1 hat 1024 Worte; Wort A kommt 7mal vorWDF (A,1) = (ld [7+1]) / ld 1024 = 3 / 10 = 0,3Vergleich: relative Häufigkeit(A): 7/1024 = 0,7%
Beispiel (2) nach Harman-Formel: Dokument 1 hat 1024 Worte; Wort B kommt 15mal vorWDF (B,1) = (ld [15+1]) / ld 1024 = 4 / 10 = 0,4Vergleich: relative Häufigkeit(B): 15/1024 = 1,5%
Der Wertebereich nach Harman-Formel ist „gestauchter“ als die relative Häufigkeit in %.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 243
Textstatistik
Inverse Dokumenthäufigkeit (inverted document frequency weight) IDF
• relative Häufigkeit des Vorkommens eines Wortes in Dokumenten der gesamten Datenbank (je häufiger, desto kleiner IDF); je seltener ein Wort ist, desto diskriminierender ist es
Berechnungsformel nach Karen Sparck Jones:IDF (i) = (ld N / n) + 1
• Beispiel: Datenbank hat 3584 Datensätze; Wort A kommt in 7 Datensätzen vor
• IDF (A) = (ld 3584 / 7) + 1 = (ld 512) + 1= 9+1 = 10
Karen Sparck Jones: A statistical interpretation of term specificity and its application in retrieval – In: Journal of Documentation 28 (1972), 11-21.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 244
Textstatistik
Zusammenspiel der Gewichtungsfaktoren der Wörter
einfache Gewichtungsformel: Gewicht (i,j) = WDF * IDF * P
• Beispiel: Wort A in Dokument 1• A kommt u.a. im Titel vor: Gewichtungswert für Titelterme: 2,5.
P (A,1) = 2,5 • WDF (A,1) = 0,3• IDF (A) = 10• Gewicht (A,1) = 0,3 * 10 * 2,5 = 7,5
Wolfgang G. Stock: Informationswirtschaft. Management externen Wissens. – München; Wien: Oldenbourg, 2000. –Kap. 6.2: Informationsstatistik, 159-164.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 245
Textstatistik
Das Längengewicht• Ein zusätzlicher Gewichtungsfaktor für die deutsche Sprache?• intuitive Begründung: je länger ein Wort, desto wichtiger ist es im
Dokument– mit der Wortlänge steigt die Indexierungsspezifität (etwa: Gesetz und
Privatstraßenfinanzierungsgesetz)– wenn lange Worte vorkommen, sie diese auch i.d.R. einschlägig
thematisch (d.h. keine unspezifischen „Füllworte“)– lange Worte kommen eher selten vor (fallen also im WDF nicht auf)– deshalb: Gewichtungsfaktor für jedes (deutschsprachige) Wort nach
Länge (etwa: Grundform [ohne Dekomposition] < 10 Zeichen: Faktor1; 10-11 Zeichen: Faktor: 1,1; 12-13 Zeichen: Faktor 1,2 usw. Alternative: Gewichtung nach Anzahl der Worte pro Kompositum
– auch für das Englische bei Phrasen sinnvoll?
Hartmut Lohmann: KASCADE: Dokumentanreicherung und automatische Inhaltserschließung. – Düsseldorf: ULB,2000. – (Schriften der Universitäts- und Landesbibliothek Düsseldorf; 31), 36 f.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 246
Textstatistik
Sortierung nach Gewichtung. Variante 1: „ODER“– Schritt 1: Suche (in invertierter Datei) nach allen Suchworten
(bzw. Grundformen/Wortstämmen, Phrasen). Treffer ist, wenn das Dokument mindestens ein Suchwort enthält (analog einer ODER-Verknüpfung)
– Schritt 2: Ermittlung des Gewichtes für jedes Suchwort in allen Dokumenten, die in Schritt 1 gefunden worden sind
– Schritt 3: Bildung der Summe der Gewichte aller Suchworte pro Dokument; Zuordnung der Summe zum Dokument
– Schritt 4: Sortierung der Dokumente nach der Summe der Gewichtungswerte
– ggf. als Problem empfunden: in den gefundenen Dokumenten tauchen nicht alle Suchworte auf

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 247
Textstatistik
Sortierung nach Gewichtung. Variante 1: „ODER“
Ablauf
Donna Harman: Ranking algorithms. – In: William B. Frakes; Ricardo Baeza-Yates (Hrsg.): Information Retrieval.Data Structures & Algorithms. – Upper Saddle River, NJ: Prentice Hall PTR, 1992, 381.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 248
Textstatistik
Sortiervariante 1: „ODER“. Beispiel: Freestyle• Errechnung der Gewichtungen durch WDF und IDF; Elimination
von Stoppworten und von Hochfrequenzworten• Abbildung der Gewichtungswerte für die Dokumente auf eine
Skala von >0 bis 100• Schaffen von Transparenz für den Nutzer
– Angabe von Dokumentenanzahl und (normiertem) IDF für die Suchworte (.WHY)
– Angabe der top-gerankten Dokumente mit dem Vorkommen bzw. Nichtvorkommen der Suchworte (.WHERE)
Wolfgang G. Stock: Lexis-Nexis‘ Freestyle. Natürlichsprachige Suche – More like this! –In: Password Nr. 11 (1998), 21-28.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 249
Textstatistik
Sortiervariante 1: „ODER“. Beispiel: Freestyle• Anfragebeispiel: Wolfgang Clement‘s opinions for the future of
Rheinbraun in Hambach and Garzweiler (max. 50 Dokumente)
.WHY: Welche Gewichtungswerte erhalten die Suchargumente?

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 250
Textstatistik
Sortiervariante 1: „ODER“. Beispiel: Freestyle
.WHERE: Wo kommen die Suchargumente vor?

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 251
Textstatistik
Sortierung nach Gewichtung. Variante 2: „UND“– Schritt 1: Suche (in invertierter Datei) nach allen n
Suchworten (bzw. Grundformen/Wortstämmen, Phrasen). Treffer ist, wenn das Dokument alle Suchworte enthält (analog einer UND-Verknüpfung)
• Schritt 1.1: Ermittlung des Gewichtes für jedes Suchwort in allen Dokumenten, die in Schritt 1 gefunden worden sind
• Schritt 1.2: Bildung der Summe der Gewichte aller Suchworte pro Dokument; Zuordnung der Summe zum Dokument
• Schritt 1.3: Sortierung der Dokumente nach der Summe der Gewichtungswerte
• hiernach: entweder (a) Abbruch des Verfahrens oder (b) weiter, wenn bei Schritt 1 nichts gefunden oder (c) stets weiter:
– ggf. Schritt 2: Suche nach Dokumenten, die n-1 Suchworte enthalten
• Schritt 2.1 bis 2.3: analog wie bei 1.– ggf. Schritt 3: Suche nach Dokumenten, die n-2 Suchworte
enthalten (usw.)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 252
Textstatistik
Sortiervariante 2: „UND“– Einsatz bei diversen Suchmaschinen (u.a. AltaVista,
Alltheweb/FAST) – Variante: Abbruch nach Schritt 1
Risiko:Informations-
verlust(Boolesches
UNDzu restriktiv)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 253
Textstatistik
Vektorraummodell– Dokumente wie Anfragen werden als Vektoren in einem
n-dimensionalen Raum verstanden, wobei die Dimensionen Worten (Grundformen/Wortstämmen, Phrasen) entsprechen
– Relevance Ranking geschieht nach der „Nähe“ der Vektoren (genauer: nach dem Winkel, der zwischen dem Anfragevektor und den Dokument-vektoren liegt)
– entwickelt von Gerard Salton im Kontext des SMART-Systems (ab 1961 an der Harvard-University und ab 1965 Cornell-University, Ithaca) – SMART: System for the Mechanical Analysis and Retrieval of Text
Gerard Salton; A.Wong; C.S.Yang: A vector space model for automatic indexing. – In: Communications of the ACM18 (1975), 613-620.
Gerard Salton; eigentlich: Gerhard Anton Sahlmann

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 254
Textstatistik
Vektorraummodell• gegeben: Anfrage mit m Worten
ATERM(j,k) ist der Gewichtungswert des Wortes j in Anfrage k • gegeben: Dokumentenmenge mit n Dokumenten und t Deskriptoren
TERM(i,j) ist der Gewichtungswert des Wortes j im Dokument i• die m Worte aus den Anfragen und die t Deskriptoren aus den
Dokumenten werden jeweils als eine Dimension in einem m+t-dimensionalen Vektorraum angesehen
Dokument-Wort (Dimension)-Matrix
- TERM(i,j) sind numerische Gewichtungswerte
- kommt ein Wort in einem Dokument nicht vor, ist TERM = 0
Gerard Salton; Michael J. McGill: Information Retrieval – Grundlegendes für Informationswissenschaftler. –Hamburg [u.a.]: McGraw-Hill, 1983, 127 ff.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 255
Textstatistik
Vektorraummodell• ein Dokument wird durch den Vektor seiner Dimensionen (Worte)
unter Berücksichtigung der jeweiligen Gewichtung repräsentiert
Dimension (Wort) A
Gewichtungswert von A im Dokument 1
Dimension (Wort) BGewichtungswert von B im Dokument 1
Vektor von Dokument 1 (enthält die Worte A und B)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 256
Textstatistik
Vektorraummodell• Dokumentenraum (3 Dimensionen; 3 Dokumente)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 257
Textstatistik
Vektorraummodell• Ähnlichkeit zwischen Anfrage (genauer: Anfragevektor) und
Dokumenten (genauer: Dokumentvektoren)
• wenn die Vektoren übereinander liegen: Winkel: 0° • Cosinus 0° = 1

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 258
Textstatistik
Cosinus α = b : c (Ankathete : Hypothenuse)
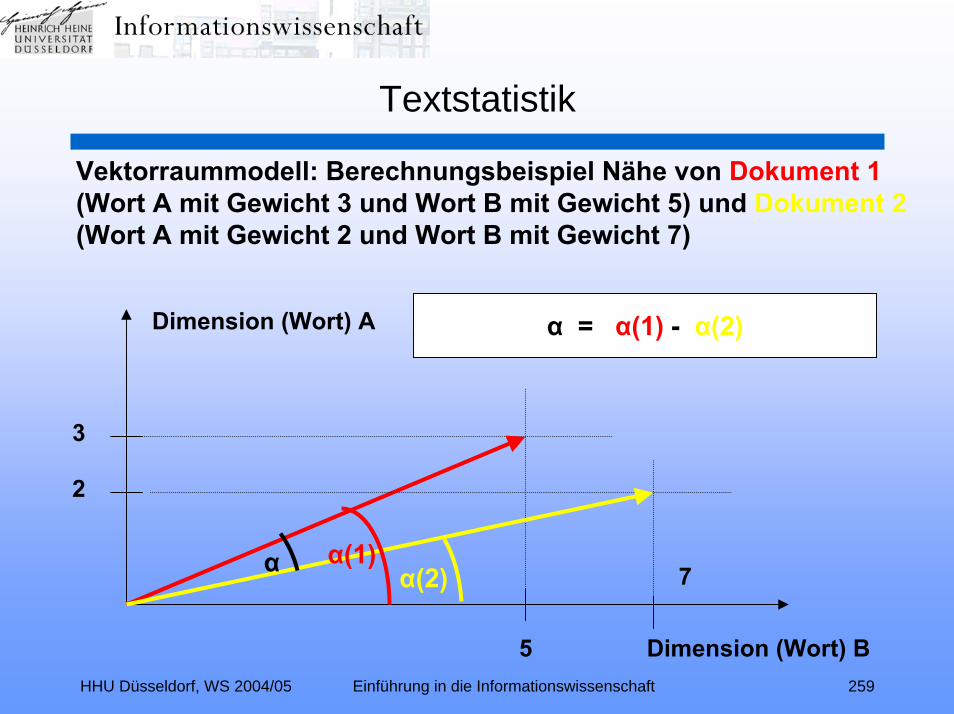
HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 259
Textstatistik
Vektorraummodell: Berechnungsbeispiel Nähe von Dokument 1(Wort A mit Gewicht 3 und Wort B mit Gewicht 5) und Dokument 2(Wort A mit Gewicht 2 und Wort B mit Gewicht 7)
Dimension (Wort) A
Dimension (Wort) B
3
2
7α(1)
α = α(1) - α(2)
α α(2)
5

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 260
Textstatistik
Dok1 (5 ׀ 3); Dok2 (7 ׀ 2); cos α = b : c (da c unbekannt, nach Pythagoras berechnen: a2 + b2 = c2)cos α = b : (a2 + b2)1/2
cos α(1) = 5 : (52 + 32)1/2 = 5 : (25+9)1/2 = 5 : 341/2 = 0,86 ~ α(1) = 30,68°cos α(2) = 7 : (72 + 22)1/2 = 7 : (49+4)1/2 = 7 : 531/2 = 0,96 ~ α(2) = 16,28°α = α(1) - α(2). α = 30,68° - 16,28° = 14,42°. cos α = 0,97
3
2
75α(1)α α(2)
oder direkt nach dem Additionstheorem berechnen:cos (α(1) – α(2)) = cos α(1) * cos α(2) + sin α(1) * sin α(2)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 261
Textstatistik
Dok1 (5 ׀ 3); Dok2 (7 ׀ 2); Berechnung nach Cosinus-Formel (Salton-Vorschlag)Zähler: (5 * 7) + (3 * 2) = 35 + 6 = 41Nenner: ((52 + 32) * (72 + 22))1/2 = ((25 + 9) * (49 + 4))1/2 = (34*53)1/2
= 1.8021/2 = 42,45cos α = 41 : 42,45 = 0,97
3
2
7
5
α(1)α α(2)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 262
Textstatistik
Einsatz des Vektorraummodells bei SMART– SMART: keine einheitliches System, sondern experimentelle
Umgebung mit diversen Varianten– Vorgehen bei der Indexierung eines Dokumentes
• (1) Identifikation der einzelnen Worte• (2) Stoppwortliste: Elimination von nicht sinntragenden
häufigen Worten (Variante: Schritt 2 übergehen)• (3) Grundform- bzw. Wortstammbildung • (4) Zählen der Häufigkeit der Grundformen bzw.
Wortstämme in einem Dokument; Bilden von drei Klassen: „gute“ Worte; zu häufige Worte; zu seltene Worte
Gerard Salton (Hrsg.): The SMART Retrieval System – Experiments in Automatic Document Processing. –Englewood Cliffs: Prentice-Hall, 1971.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 263
Textstatistik
Einsatz des Vektorraummodells bei SMART– (5) bei Hochfrequenzworten: Generierung von Phrasen
Kriterium: Komponenten sollen im Sinnzusammenhang des Dokuments stehen; Ziel: Erhöhung der Indexierungsspezifität häufig vorkommender Worte
Schritt 5Schritt 6

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 264
Textstatistik
Einsatz des Vektorraummodells bei SMART– (5) bei Hochfrequenzworten: Generierung von Phrasen– Arbeitsschritte: – (5.1) Übernahme aller Wortstämme/Grundformen aus
allgemeiner SMART-Prozedur– (5.2) Paarbildung aller Wortstämme/Grundformen, die im
Dokument innerhalb von n Worten stehen (etwa: n=4); dabei Bedingung: eines der Worte ist Hochfrequenzwort
– (5.3) Zusammenführen von Paaren mit gleichen Komponenten (A B – B A). Beispiel: [my] student[s‘] knowledge – [the] knowledge [of my] student[s]
– (5.4) Betrachtung der entstandenen Phrase als ein Wort bzw. als eine Dimension im n-dimensionalen Vektorraum (für die Berechnung von WDF, IDF, Position)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 265
Textstatistik
Einsatz des Vektorraummodells bei SMART– (5) bei Hochfrequenzworten: Generierung von Phrasen
Beispiel

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 266
Textstatistik
Einsatz des Vektorraummodells bei SMART– (6) bei Niedrigfrequenzworten: Bildung von Klassen von
„Synonymen“ (oder zumindest: von ähnlichen Worten)– Kriterium: Ähnlichkeit der Worte; Ziel: Verminderung der
Indexierungsspezifität selten vorkommender Worte– falls vorhanden: Einsatz eines Synonymwörterbuches oder
eines Thesaurus (daraus: Synonymie-Relation)– ansonsten: automatisch generieren – Problem: die seltenen Worte in einem Dokument (um diese
geht es hier) treten nicht oft gemeinsam auf (weil sie halt selten sind). Aus rhetorischen Gründen wird kaum jemand Synonyme häufig nebeneinander verwenden
– Lösungsansatz: Single-Linkage-Klassifikation

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 267
Textstatistik
Einsatz des Vektorraummodells bei SMART– (6) bei Niedrigfrequenzworten: Single-Linkage-Klassifikation– Arbeitsschritte:– (6.1) Bildung von Wortpaaren (Ti, Tj) auf der Basis von
Ähnlichkeitswerten (etwa: Häufigkeit gemeinsamen Auftretens innerhalb von n Worten oder innerhalb eines Satzes)
– (6.2) Zuordnung eines dritten Wortes Tk zur Klasse (Ti, Tj), wenn eine Ähnlichkeit zu mindestens einem der Ausgangs-worte vorliegt
– (6.3) usw. bis kein weiteres Wort in der Dokumenten-sammlung mehr gefunden wird, das zu einem Wort der Klasse (Ti, Tj, Tk, ...) ähnlich ist
– (6.4) Betrachtung der entstandenen Klasse als ein Wort bzw. als eine Dimension im n-dimensionalen Vektorraum (für die Berechnung von WDF, IDF, Position)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 268
Textstatistik
Einsatz des Vektorraummodells bei SMART
(6) bei Niedrig-frequenzworten: Generierung von Klassen
Beispiel

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 269
Textstatistik
Einsatz des Vektorraummodells bei SMART– (7) Errechnung von IDF und WDF (Variante: Einbeziehen
weiterer Gewichtungsfaktoren wie Position; im ursprünglichen SMART: binäre Indexierung, also nur durch 1 bzw. 0)
• für die „guten“ Worte mittlerer Häufigkeit• für die in Schritt 5 geformten Phrasen• für die in Schritt 6 geformten (Synonym-)Klassen
– (8) Vektorbildung („Einhängen“ des Dokumentes in den Vektorraum)
– (9) Zuordnung des neuen Dokuments zu einem bestehenden Dokumentencluster; ggf. Kreation eines neuen Clusters
– dabei: Vergleich des neuen Dokuments mit den Zentroid-Vektoren der Cluster

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 270
Textstatistik
Einsatz des Vektorraummodells bei SMART– Dokumentenraum mit Clustern
Zentroid: imaginäres Dokument, dessen Dimensionen den arithmetischen Mittelwert der Dokumentwerte beinhalten
Superzentroid: imaginäres Dokument, dessen Dimensionen den arithmetischen Mittelwerten der zugehörigen Zentroid-Vektoren beinhalten

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 271
Textstatistik
Einsatz des Vektorraummodells bei SMART– Suche bei SMART– (1) Indexierung der Suchanfrage– (2) Vergleich: Vektor der Suchanfrage mit Superzentroid-
Vektoren– (3) innerhalb des gefundenen Superclusters: Vergleich: Vektor
der Suchanfrage mit Zentroid-Vektoren– (4) innerhalb des gefundenen Clusters: Vergleich: Vektor der
Suchanfrage mit den Dokumentvektoren– (5) Ausgabe der Dokumente in der Reihenfolge ihrer
Ähnlichkeit (Cosinus) mit der Suchanfrage– (6) Nutzer wählt relevante Dokumente aus (gleichzeitig markiert
er damit auch – durch Übergehen – ihm nicht relevant erscheinende Dokumente)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 272
Textstatistik
Einsatz des Vektorraummodells bei SMART– Suche bei SMART– (7) Relevance Feedback– Dimensionen (Worte) der
relevanten Dokumente werden der Suchfrage hinzugefügt (oder höher gewichtet)
– Dimensionen (Worte) der irrelevanten Dokumente werden aus der ursprünglichen Such-frage entfernt (oder niedriger gewichtet)
– iteratives Verfahren: kann mehrfach wiederholt werden

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 273
Textstatistik
Vektorraummodell – Problem• Modell nimmt an, dass die Terme unabhängig voneinander
sind• dies ist falsch: Terme sind vielmehr vom Auftreten anderer
Terme abhängig – kommen also verstärkt gemeinsam vor (Bsp. Synonyme oder Homonyme in unterschiedlichen Kontexten)
• Lösungsmöglichkeit: Beachten von Werten des gemeinsamen Auftretens von Termen in Texten („co-occurences“)
Holger Billhardt; Daniel Borrajo; Victor Maojo: A context vector model for information retrieval. In:Journal of the American Society for Information Science and Technology 53 (2002), 236-249.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 274
Textstatistik
Das probabilistische Modell• „klassische“ Variante entwickelt von Maron und Kuhns 1960• Ansatz: Wie wahrscheinlich ist es, dass ein Dokument für eine
Suchanfrage relevant ist? Ausgabe der Dokumente im RelevanceRanking absteigend nach der Wahrscheinlichkeit
• Wahrscheinlichkeitstheorie: P(B ׀A) „bedingte Wahrscheinlich-keit“: Wie groß ist die Wahrscheinlichkeit, dass B eintritt, wenn A gegeben ist? Hier: A: Anfrage; B: Relevanz eines Dokuments
• Bayessches Theorem:
M.E.Maron; J.L.Kuhns: On relevance, probabilistic indexing and information retrieval. – In: Journal of the ACM7 (1960), 216-244.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 275
Textstatistik
Das probabilistische Modell• A: Anfrage besteht aus Worten W1, ..., Wn
• B: relevante Dokumente bestehen jeweils aus Worten W1, ..., Wm
• Die bedingte Wahrscheinlichkeit, dass ein Dokument B bei gegebener Anfrage A relevant ist, hängt ab:– von der Wahrscheinlichkeit der Suchworte P(A) – ist gegeben– von der Wahrscheinlichkeit der Worte in den relevanten Dokumenten
P(B) – ist (zumindest theoretisch) gegeben– von der Wahrscheinlichkeit, dass die Dokumente B zur Suchfrage A
relevant sind P(A׀B); d.h. es liegen Relevanzinformationen für die Dokumente in Bezug auf die Suchfrage vor – ist (ohne RelevanceFeedback) nicht gegeben

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 276
Textstatistik
Das probabilistische Modell• Das Modell geht davon aus, dass die Relevanz der einzelnen
Dokumente unabhängig voneinander ist (dies erfordert das Bayessche Theorem)
• „Relevanz“ muss unter Ausschluss des Nutzers definiert werden, also ohne „Pertinenz“ (oder „Usefulness“ nach Robertson)
• Sonst wäre das Modell nämlich faktisch falsch: Ein Nutzer, der bereits n Dokumente erhalten hat, orientiert sich bei der Relevanzeinschätzung des n+1sten Dokuments an den n vorangegangenen (ein Dokument, das weit oben platziert ist, hat größere Chancen, als relevant eingeschätzt zu werden, als eines,das weiter unten gereiht ist)
Stephen E. Robertson: The probability ranking principle in IR. – In: Journal of Documentation 33 (1977),294-304.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 277
Textstatistik
Das probabilistische Modell• Was tun, wenn keine Relevanzinformationen vorhanden sind?• Durchführen einer Suche nach einem anderen Modell (etwa dem
Vektorraummodell)• Annahme: die top gerankten Dokumente sind relevant (Nutzer wird
nicht gefragt)• Schätzung des Zusammenhangs der Dokumente (mit deren
Worten) und der Relevanz: Welche Worte kommen dort wie wichtig vor? „Verdecktes Relevance Feedback-Verfahren“
• neue Suche unter Einbezug der Worte und der (nunmehr errechneten) Gewichtungen aus den top gerankten Dokumenten
W.B.Croft; D.J.Harper: Using probabilistic models of document retrieval without relevance information. –In: Journal of Documentation 35 (1979), 285-295.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 278
Textstatistik
Das probabilistische Modell• Relevanzinformationen aus Stichprobe. Nutzer werden einige
Dokumente (etwa 10 bis 20) zur Beurteilung vorgelegt
• Vorkommen eines Wortes x=1 bzw. Nicht-Vorkommen von x (x=0) in Dokumenten der Stichprobe
• N (Anzahl der Dokumente in der Stichprobe); K (Anzahl der relevanten Dokumente); n Dokumente aus K enthalten das Wort xi, davon k relevant
Norbert Fuhr: Probabilistisches Indexing und Retrieval. – Eggenheim-Leopoldshafen: FIZ Karlsruhe, 1988.- (FIZ – KA – 14), 25.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 279
Textstatistik
Das probabilistische Modell• Relevanzinformationen aus Stichprobe. Ableitung von
Wahrscheinlichkeitswerten:• P1 (Vorkommen von xmi ist wesentlich für die Relevanz des
Dokuments) = k / K• P2 (Nicht-Vorkommen von xmi ist wesentlich für die Relevanz des
Dokuments) = (K - k) / K• P3 (Vorkommen von xmi ist wesentlich für die Nicht-Relevanz des
Dokuments) = (n - K) / N - K• P4 (Nicht-Vorkommen von xmi ist wesentlich für die Nicht-Relevanz
des Dokuments) = (N – K – n + k) / (N – K)• P2 = 1 - P1 P4 = 1 - P3
• rel. Häufigkeit der Dokumente mit xmi in der Stichprobe: n / N• Gewichtung (Dokument mit xmi ) = P1 / rel. Häufigkeit („einfache
Version“)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 280
Textstatistik
Beispiel für Relevanzbeurteilung
relevant nicht relevant
„Miranda“ = 1
k10
n-k1
n11
„Miranda“ = 0
K-k2
N-K-n+k7
N-n9
K12
N-K8
N20
Rel. Häufigkeit = n / N = 11 / 20 = 0,55
Gew(Dok mit „Miranda“) = 0,83 / 0,55 = 1,51
P1 = k/K = 10/12 = 0,83 P2 = (K-k)/K = 2/12 = 0,17P3 = (n-k)/(N-K) = 1/8 = 0,125 P4 = (N-K-n+k)/(N-K) = 7/8 = 0,875Algorithmus: Gewichte alle Dokumente der Datenbank, in denen „Miranda“ vorkommt, mit 1,51!

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 281
Textstatistik
Das probabilistische Modell• Berechnung der Gewichtungen nach Robertson / Sparck-
Jones• Notation: statt K,k (für relevante Dokumente) hier: R, r
• Errechnung des Gewichtungswertes für alle Worte aus der Stichprobe. Bildung der Summe für die vorkommenden Worte eines Dokuments. Ranking gemäß ODER
Stephen E. Robertson; Karen Sparck-Jones: Relevance weighting of search terms. – In:Journal of the American Society für Information Science 27 (1976), 129-146.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 282
Textstatistik
Das probabilistische Modell• Fortführung des Beispiels
10 / (12 – 10) 10 / 2• w(„Miranda“) = log ---------------------------------------- = log ------------ = log 35
(11 – 10) / (20 – 11 – 12 + 10) 1 / 7
= 1,54• Algorithmus: Gewichte alle Dokumente der Datenbank, in denen
„Miranda“ vorkommt, mit 1,54!

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 283
Textstatistik
Textstatistik (Relevance Ranking I). Fazit• Zuordnung von Gewichtungswerten bei Suchanfragen durch
Nutzer (bei Google: durch Reihenfolge der Suchworte)• Der Übergang zum Relevance Ranking ist sowohl aus Booleschen
Systemen als auch aus informationslinguistischen Komponenten automatisch indexierender Systeme möglich.
• Historischer Ausgang: These von Luhn: Häufig vorkommende Worte sind für ein Dokument auch wichtig (schlecht: zu häufige und zu seltene Worte)
• Grunddaten für Textstatistik:– Position eines Wortes im Text (im Titel wichtiger als in einer Fußnote)– WDF (Gewichtung nach Auftretenshäufigkeit im Dokument: je häufiger,
desto wichtiger)– IDF (Gewichtung nach Auftretenshäufigkeit in der gesamten
Datenbank: je mehr Dokumente das Wort enthalten, desto unwichtiger)– „einfacher“ Gewichtungswert (Wort im Dokument): P * WDF * IDF

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 284
Textstatistik
Textstatistik (Relevance Ranking I). Fazit• Sortierung nach „einfacher“ Gewichtung: ODER-Variante (Beispiel:
Freestyle von Lexis-Nexis) sowie UND-Variante (Beispiel:AlltheWeb)
• Vektorraummodell von Gerard Salton: Ein Dokument wird durch einen Vektor repräsentiert; die Dimensionen sind Wortstämme/ Grundformen oder Phrasen; die Werte auf den Dimensionen entstammen der „einfachen“ Gewichtung
• Ähnlichkeit zwischen Anfragen und Dokumenten bzw. zwischen Dokumenten untereinander: Cosinus
• eingesetzt bei SMART (Sonderbehandlung von Niedrig- und von Hochfrequenzworten)
• Errechnung von Zentroid- und Superzentroid-Vektoren• Relevance Feedback

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 285
Textstatistik
Textstatistik (Relevance Ranking I). Fazit• Probabilistisches Modell: Ranking nach der Wahrscheinlichkeit,
dass ein Dokument für eine Suchfrage relevant ist• Abschätzen der Wahrscheinlichkeit von Worten, die in relevanten
Dokumenten vorkommen– „verdecktes“ Relevance Feedback: Analyse von top gereihten
Dokumenten (mit anderem Verfahren geordnet)– „offenes“ Relevance Feedback: Analyse von Dokumenten (mit
anderem Verfahren geordnet), die vom Nutzer als relevant bzw. nicht relevant eingestuft worden sind
• Zuordnung der (neu errechneten) Gewichtungswerte zu den Dokumenten (analog zu IDF). Neue Suche

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 286
Link-Topologie
Relevance Ranking II
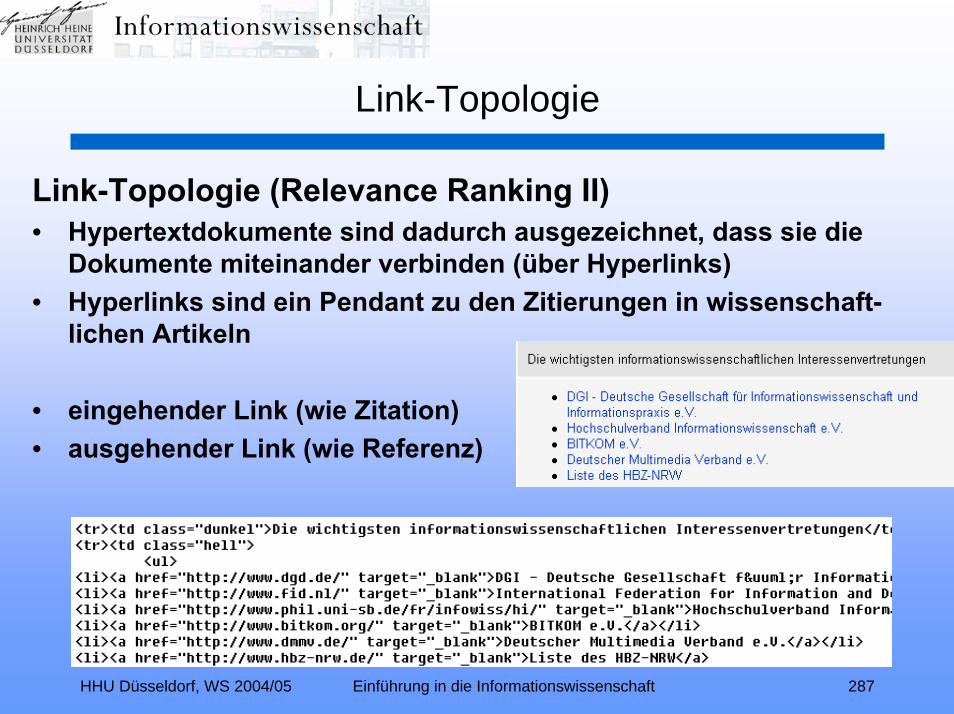
HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 287
Link-Topologie
Link-Topologie (Relevance Ranking II)• Hypertextdokumente sind dadurch ausgezeichnet, dass sie die
Dokumente miteinander verbinden (über Hyperlinks)• Hyperlinks sind ein Pendant zu den Zitierungen in wissenschaft-
lichen Artikeln
• eingehender Link (wie Zitation)• ausgehender Link (wie Referenz)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 288
Link-Topologie
Link-Topologie (Relevance Ranking II)• These: Die Linkstruktur in einer Hypertextumgebung (wie dem
WWW) sagt etwas aus über die Relevanz eines Dokuments• zwei grundlegende Ansätze
– Hubs und Authorities – Kleinberg-Algorithmus(Aspekte davon eingesetzt bei: AltaVista und Teoma)
– PageRank – Algorithmus von Brin und Page(eingesetzt bei: Google)
• Theoretische Basis: Zitationsanalyse– Bibliographic Coupling– Co-Citations

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 289
Link-Topologie
Zitationen und Referenzen:Analogie: eingehende und ausgehende Links
Link-Ausgang
Link-Eingang

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 290
Link-Topologie
Link-Topologie (Relevance Ranking II)• Theoretische Basis: Zitationsanalyse. Sind Web-Links wirklich
analog zu Zitationen und Referenzen?• Stichprobe: rund 10% aller Links sind gleich wie akademische
Zitationen; rund 20% können zumindest als analog gelten• D.h.: 80 – 90% aller Links sind nicht wie Zitationen benutzt,
sondern dienen der Navigation, sind Linklisten „verwandter Themen“ oder sind Werbung
• also: es ist Vorsicht geboten, Ergebnisse der Zitationsanalysen auf die Link-Topologie unkritisch zu übertragen!
Alastair G. Smith: Web links as analogues of citations. – In: Information Research 9 (2004) 4, paper 188.Online: http://informationr.net/ir/9-4/paper188.html
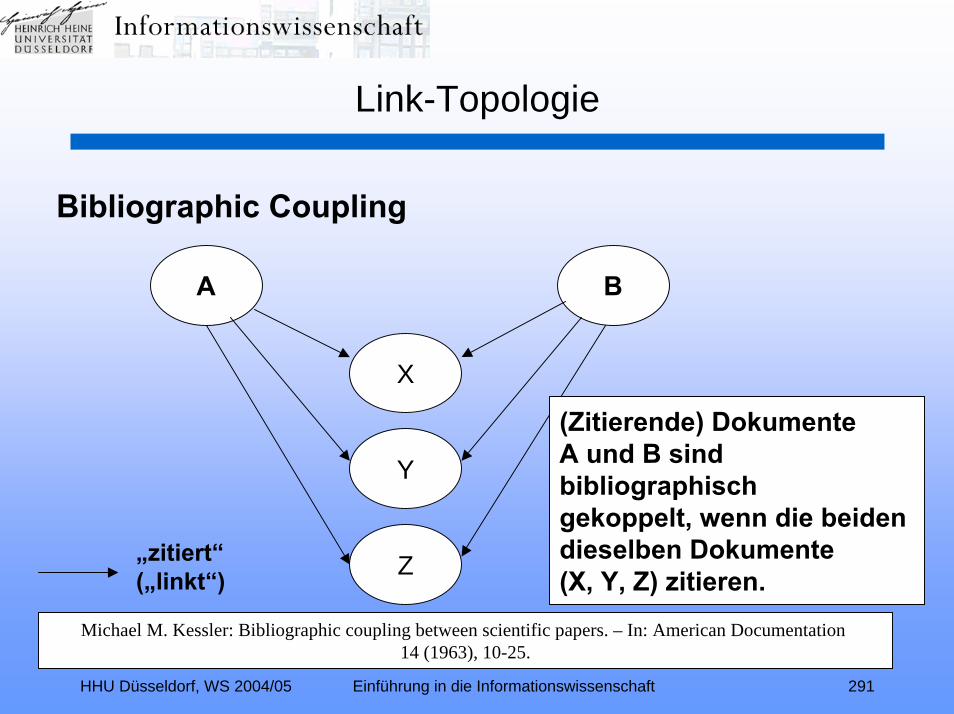
HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 291
Link-Topologie
Bibliographic Coupling
A
Z
Y
X
B
„zitiert“ („linkt“)
(Zitierende) Dokumente A und B sind bibliographisch gekoppelt, wenn die beidendieselben Dokumente(X, Y, Z) zitieren.
Michael M. Kessler: Bibliographic coupling between scientific papers. – In: American Documentation 14 (1963), 10-25.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 292
Link-Topologie
Zitationsstrukturen. Co-Zitationen von Artikeln
A B
Y
X
Z(Zitierte) Dokumente A und B sind co-zitiert, wenn die beidenim Zitationsapparat zitierender Dokumente (X, Y, Z) gemeinsam vorkommen.
Henry Small
„zitiert“ („linkt“)
Henry G. Small: Co-citation in scientific literature. – In: Journal of the American Society for Information Science24 (1973), 265-269. – Henry G. Small; Belver C. Griffith: The structure of scientific literature I: Identifying andgraphing specialties. – In: Science Studies 4 (1974), 17-30. – Belver C. Griffith; Henry G. Small; H.J.Stonehill;
S.Dey: The structure of scientific literature II: The macro- and micro-structure of science. – In ScienceStudies 4 (1974), 339-365.
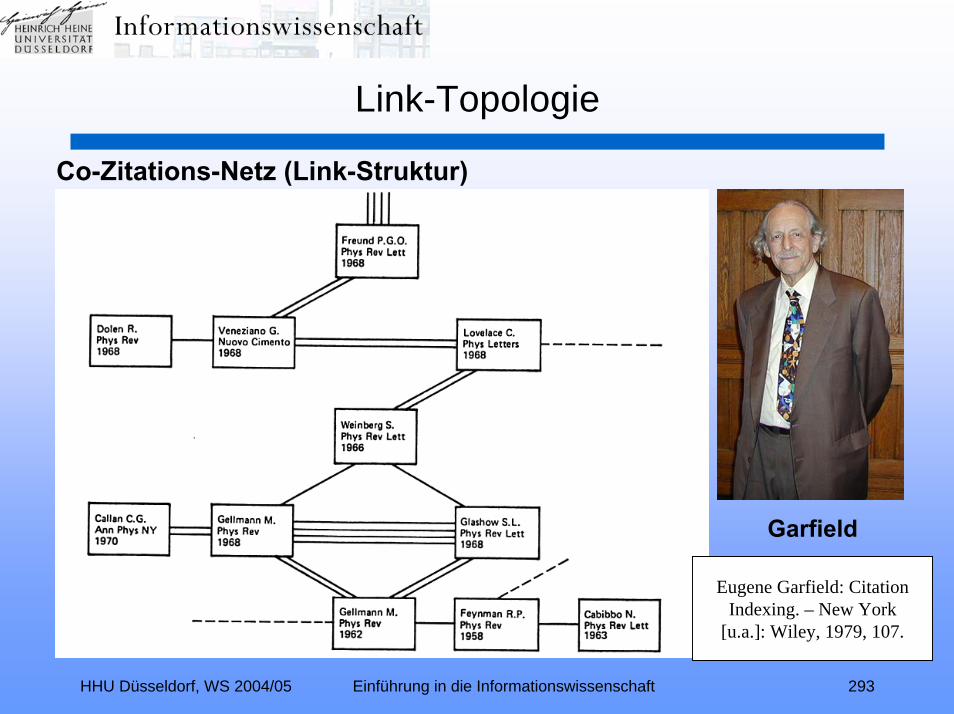
HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 293
Link-Topologie
Co-Zitations-Netz (Link-Struktur)
Eugene Garfield: CitationIndexing. – New York
[u.a.]: Wiley, 1979, 107.
Garfield

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 294
Link-Topologie
Hubs und Authorities. Der Kleinberg-AlgorithmusHITS (Hyperlink-Induced Topic Search)• „hub“ (Radnabe; Mittelpunkt): ein Dokument, von dem viele
Links ausgehen• „authority“: ein Dokument, auf das viele andere Dokumente
(aus anderen Websites) linken• „good hub“: hub, der auf viele gute authoritites
linkt (das „good“ ist ein Unterschied zur Zitatenanalyse, in der alle Zitierungen gleich sind)
• „good authority“: authority, die von vielen guten hubs gelinkt wird
• Ziel: kleine Menge einer „community“ von hubs und authorities: „high-quality pages“
Jon M. Kleinberg: Authoritative sources in a hyperlinked environment. – In: Journal of the ACM46 (1999), 604-632.
Kleinberg

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 295
Link-Topologie
Hubs und Authorities. Der Kleinberg-Algorithmus
„Referenzen“(ausgehende Links):
Zählbasis für hubs(y)
„Zitationen“(eingehende Links):
Zählbasis für authorities(x)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 296
Link-Topologie
Hubs und Authorities. Der Kleinberg-Algorithmus• Werte für x (eingehende Links) und y (ausgehende Links)
werden für alle Dokumente einer Treffermenge gezählt• hub-Gewicht (Dokument) = x2
• authority-Gewicht (Dokument) = y2
• Abbildung der Gewichtungswerte auf das Intervall [0, .., 1]• iteratives Vorgehen: y-Wert steigt, wenn x-Wert des gelinkten
Dokuments höher; x-Wert steigt, wenn y-Wert der linkenden Dokumente höher. Vorgehen:– für x-Wert von Dokument p: Summe der y-Werte– für y-Wert von Dokument p: Summe der x-Werte– Wiederholung des Verfahrens– Abbruch, wenn die entstehenden (x,y)-Paare einen Grenzwert
(x*, y*) erreicht haben

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 297
Link-Topologie
Hubs und Authorities. Der Kleinberg-Algorithmus• Ergebnis: c Dokumente mit den größten x*-Werten und c
Dokumente mit den größten y*-Werten (c: Konstante – soll klein gehalten werden)
-------------------------------------------------------------------------------------------• Anwendung bei einer Suchmaschine. Schritte
– (1) Suchfrage führt über informationslinguistische Bearbeitung zu einer ersten Treffermenge (root set S)
– (2) Erweiterung von S zu T: Einbeziehen aller Seiten, die auf ein Dokument aus S linken oder die von einem Dokument aus S gelinkt werden (Regel: Grenzwert der Anzahl eingebrachter Seiten pro Dokument wird nicht überschritten)

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 298
Link-Topologie
Hubs und Authorities. Der Kleinberg-Algorithmus
• (3) Aus T werden alle Links entfernt, die innerhalb einer Domain liegen (nur die Links nach „draußen“ bleiben erhalten)
• (4) Errechnung der hubs und authorities – wie beschrieben• (5) falls mehrere communities vorhanden („multiple
communities“): Anzeige zur Auswahl
Schritt 2Erweiterung von Root Set
S auf Menge T

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 299
Link-Topologie
Einsatz des Kleinberg-Algorithmus bei Teoma
„Teoma“ (gälisch): „Experte“wird betrieben von: Ask Jeeves, Inc.
zweistufige Suche:(1) Bestimmung der communities (mehrere Schritte möglich) –„Refine“(2) Ranking der Dokumente nach Autorität (hub – authority) für jedeCommunity – „Results“
communities
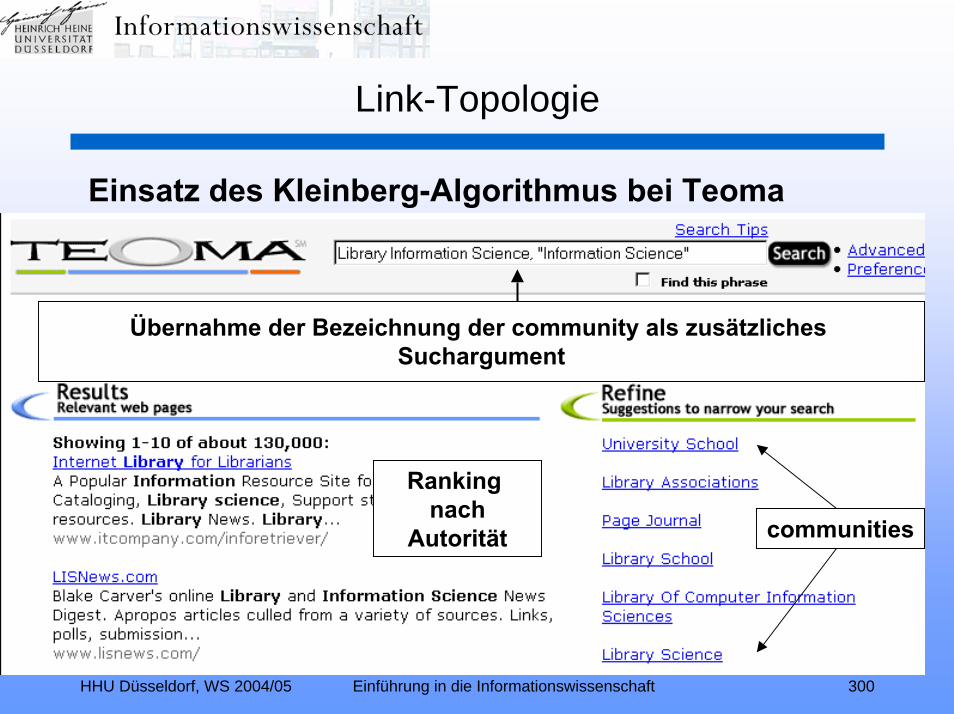
HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 300
Link-Topologie
Einsatz des Kleinberg-Algorithmus bei Teoma
Übernahme der Bezeichnung der community als zusätzliches Suchargument
communities
Ranking nach
Autorität

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 301
Link-Topologie
Hubs und Authorities. Eine Weiterentwicklung
• Einbeziehen von Co-Zitationen und bibliographic coupling• im Bild links: i und j sind co-zitiert; im Bild rechts: i und j sind
bibliographisch gekoppelt
Chris Ding; Xiaofeng He; Parry Husbands; Hongyuan Zha; Horst Simon: PageRank, HITS and a UnifiedFramework for Link Analysis. – Berkeley: Lawrence Berkeley National Laboratory, 2001. –
(LBNL Tech Report; 49372).

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 302
Link-Topologie
Co-Zitationen und bibliographic coupling bei HITS• Co-Zitationen und bibliographic coupling sind Ähnlichkeitsmaße
zwischen zwei Dokumenten. Hilfreich bei der Berechnung der communities.
• mögliche Maßzahlen: – Co-Zitations-Maß(A,B): g / (a + b – g)
a: Anzahl der Webseiten, die auf Seite A linken; b: Anzahl der Webseiten, die auf B linken; g: Anzahl der Seiten, die auf beideSeiten A und B linkenergänzt das authority-Maß
– Kopplungs-Maß(A,B): g‘ / (a‘ + b‘ – g‘)a‘: Anzahl der Webseiten, die eine Seite A linkt; b‘: Anzahl derWebseiten, die B linkt; g‘: Anzahl der Seiten, die sowohl Seite A als auch Seite B linkenergänzt das hub-Maß

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 303
Link-Topologie
HITS und andere Methoden im Zusammenspiel: AltaVista
• Ablauf der Indexierung gemäß Patent US 6,112,203• „connectivity“: gemäß Kleinberg-Algorithmus
– Bildung der „Nachbarschaftsgraphen“– endgültige Sortierung nach hub / authority
• „content analysis“– Vektorraummodell– probabilistisches Modell (Variante: verdecktes Relevance Feedback)
• zusätzlich: „pruning“ („beschneiden“ – „zusammenstreichen“). Definition von Grenzwerten– pruning beim Nachbarschaftsgraphen– pruning nach der content analysis
Krishna A. Bharat; Monika R. Henzinger: Method for ranking documents in a hyperlinked environment usingconnectivity and selective content analysis. – Patent Nr. US 6,216,203. – Patentinhaber: AltaVista Comp. –
Priorität: 9.4.1998.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 304
Link-TopologieAltaVista – automatische Indexierung gemäß Patent US 6,112,203

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 305
Link-Topologie
PageRank• das WWW wird als „citation graph“ (link graph) aufgefasst• nach der Stellung in diesem Graphen bekommt jede Webseite ihr
spezifisches Gewicht: den PageRank (nach Larry Page; Wort-spiel mit Web-Page)
• intuitive Begründung: „Zufallssurfer“ („random surfer“) klickt ausgehend von einer zufällig gewählten Seite durch das Web; er nutzt nie den Back-Button, kann aber irgendwann erneut eine Seite nach Zufall auswählen. Die Wahrscheinlichkeit, dass der Zufallssurfer eine Webseite besucht, ist deren PageRank.
Sergey Brin; Lawrence Page: The anatomy of a large-scale hypertextual Web search engine. – In: ComputerNetworks and ISDN Systems 30 (1998), 107-117.
Lawrence Page: Method for node ranking in a linked database. – Patent Nr. US 6,285,999. –Priorität: 9.1.1998. – Patentinhaber: The Board of Trustees of the Leland Stanford Junior University.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 306
Link-Topologie
PageRank• (1) eine Webseite hat einen hohen PageRank r, wenn viele andere
Seiten auf sie linken (analog zur Zitationsrate bei Garfield)• (2) eine Webseite hat einen hohen PageRank r, wenn Seiten mit
ihrerseits hohem PageRank auf sie linken (keine Analogie zur Zitationsrate)
Pfeile: Links Schritt 1. r(A) = r(C) (C linkt A und sonst nichts)Schritt 2. r(B) = r(A) / 2 (A linkt B und C,also insgesamt 2 Seiten)Schritt 3. R(C) = r(B) + r(A)/2Wahrscheinlichkeit des Zufallssurfers,auf A, B oder C zu stoßen, ist 1, also:r(A) + r(B) + r(C) = 1

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 307
Link-Topologie
PageRank
r(A) + r(B) + r(C) = 1da r(A) = r(C), folgt:2 r(C) + r(B) = 1da r(B) = r(A)/2 = r(C)/2, folgt:2 r(C) + ½ r(C) = 15/2 r(C) = 1r(C) = 2/5 = 0,4also: r(A) = 0,4r(B) = 0,2
Sergey Brin
Larry Page
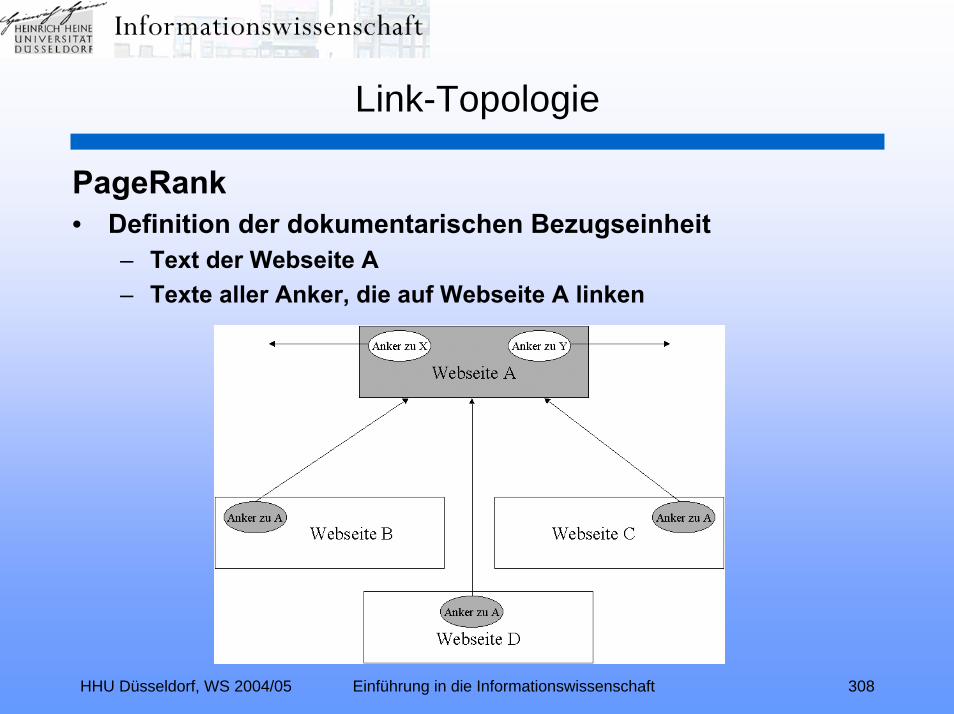
HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 308
Link-Topologie
PageRank• Definition der dokumentarischen Bezugseinheit
– Text der Webseite A– Texte aller Anker, die auf Webseite A linken

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 309
Link-Topologie
PageRank• Berechnungsformel für PageRank
PR(A) : PageRank der Seite A
d : Faktor (Wahrscheinlichkeit, mit der ein „Zufallsnutzer“ die Links einer Seite weiterverfolgt) – Wert im Intervall [0,1] -derzeit wird bei Google mit d = 0,85 gearbeitet
T : Texte, die einen Link auf A enthalten
C : Anzahl der Links, die von einer Seite T ausgehen
PR(A) = (1 - d) + d [PR(T1) / C(T1) + ... + PR(Tn) / C(Tn)]
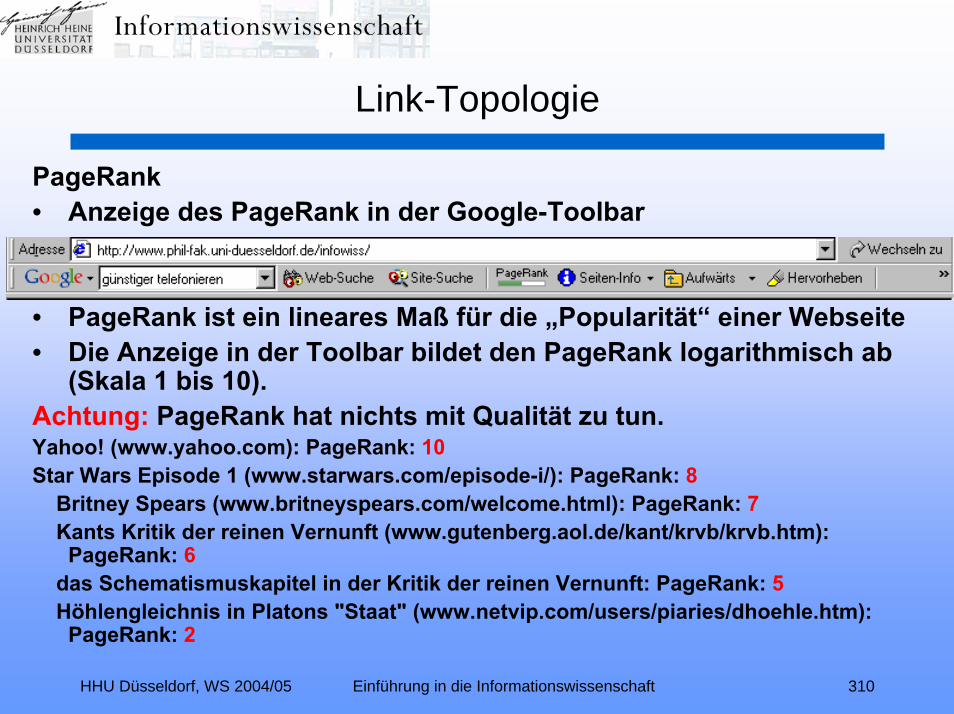
HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 310
Link-Topologie
PageRank• Anzeige des PageRank in der Google-Toolbar
• PageRank ist ein lineares Maß für die „Popularität“ einer Webseite• Die Anzeige in der Toolbar bildet den PageRank logarithmisch ab
(Skala 1 bis 10).Achtung: PageRank hat nichts mit Qualität zu tun.Yahoo! (www.yahoo.com): PageRank: 10Star Wars Episode 1 (www.starwars.com/episode-i/): PageRank: 8
Britney Spears (www.britneyspears.com/welcome.html): PageRank: 7Kants Kritik der reinen Vernunft (www.gutenberg.aol.de/kant/krvb/krvb.htm):
PageRank: 6das Schematismuskapitel in der Kritik der reinen Vernunft: PageRank: 5Höhlengleichnis in Platons "Staat" (www.netvip.com/users/piaries/dhoehle.htm):
PageRank: 2

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 311
Link-Topologie
Systemarchitektur von GoogleIndexer:für jedes Wort wird gespeichert:docIDPosition im DokumentDruckerfontGroßschreibungAnchors:Zuordnung von Wortenaus den Dokumentenund aus den AnkernBarrels:invertierte DateiLinks: Basis für die PageRank-Berechnung

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 312
Link-Topologie
PageRank und der Backlink-Crawler• Vorschlag: Crawler arbeitet nicht nur (wie z.B. bei AltaVista) die
Links einer aktuellen Seite ab, sondern folgt den Backlinks (also den Links, die auf die aktuelle Seite linken). Vor.: URL sind bekannt (also bei der Vorwärtssuche bereits gefunden)
• mögliche Methoden:– abarbeiten, wie es kommt (bei großen Datenmengen
ineffizient)– nach Anzahl der Backlinks (etwa bei > 100 Indikator auf
„heiße“ Seite)– nach PageRank der Seiten („excellent ordering metric“)
Junghoo Cho; Hector Garcia-Molina; Lawrence Page: Efficient crawling through URL ordering. –In: Proceedings of the 7th International World Wide Web Conference. – Brisbane, 1998.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 313
Link-Topologie
Relevance Ranking bei Google– bei mehreren Suchworten: Abstand (je dichter, desto
höher)
– Drucktype (je größer, desto höher)
– zentral: PageRank der einzelnen Webseiten
• Problem: der PageRank einer Seite steht fest – er hat nichts mit der aktuellen Suchfrage zu tun
• von Google vorgetragene Lösungsmöglichkeiten
– Re-Ranking von Seiten im Anschluss an eine Suche
– Einbeziehen von Nutzungsstatistiken

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 314
Link-Topologie
Re-Ranking• Ausgang: Bildung einer
Treffermenge
• 1. Schritt: Ranking nach PageRank (und anderen Komponenten): „Main Ranking Component“
• Zusatzschritt: Neuberechnung des Rangs innerhalb der Treffermenge: „Re-Ranking Component“
Krishna Bharat: Ranking search results by reranking the results based on local inter-connectivity. –Patent Nr. US 6,526,440. – Priorität: 30.1.2001. – Patentinhaber: Google, Inc., Mountain View.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 315
Link-Topologie
Re-Ranking• „old scores“ der Dokumente x in der
Treffermenge (aus invertierter Datei)
• u.U. Beschneiden der Treffermenge auf die top n Dokumente (etwa: n=1.000)
• Berechnen des „local score“ für die aktuelle Treffermenge
• neue Rangordnung als Funktion von „old score“ und „local score“

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 316
Link-Topologie
Re-Ranking• Identifikation aller Dokumente
in der Treffermenge, die auf eine Seite x linken: B(y)
• wenn x und y dem selben Host angehören, wird y aus B(y) entfernt
• falls mehrere Dokumente in B(y) dem selben Host angehören, wird das Dokument mit dem höheren score behalten
• Sortierung innerhalb B(y) nach old score

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 317
Link-Topologie
Re-Ranking• Beschneiden von B(y) auf die top gerankten k Dokumente:
„BackSet“ (etwa: k = 20)• Berechnung des „local score“ über die Summe der old scores der k
Dokumente im beschnittenen B(y). Ggf. mittels Exponent m gewichten (m = 1, 2 oder 3)
• Berechnung des „New Score“ für Dokument x aus dem Produkt des Quotienten a + local score(x) / MaxLS und b + old score(x) / MaxOS (Max: höchster Wert; a,b: Konstante, i.d.R. 1).

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 318
Link-Topologie
Ranking nach Nutzung• Verwenden von Informationen über die Zugriffshäufigkeit auf
Webseiten• Nutzungsinformationen als (weiteres) Rankingkriterium• Voraussetzung: Zugriff auf Nutzungsfälle. Google: durch
Toolbar (an Google gemeldet werden alle URL-Aufrufe); also: Stichprobe der Toolbar-Nutzer
• Vorgehen: Speicherung der (jeweils aktuellen) Anzahl der Visits einer Website sowie der Anzahl der Nutzer
• Filter: Nicht-Berücksichtigung gewisser Nutzer• Gewichtung: nach Nutzergruppen
Jeffrey A. Dean; Benedict Gomes; Krishna Bharat; Georges Harik; Monika R. Henzinger: Methods and apparatusfor employing usage statistics in document retrieval. – Patentanmeldung US 2002/0123988 A1. -
Priorität: 2.3.2001. – Patentinhaber: Google, Inc., Mountain View.

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 319
Link-Topologie
Ranking nach Nutzung• Visits
– Anzahl der Visits in Zeiteinheit
– Filter: Ausschluss von automatischen Agenten
– Gewichtung: nach Nutzergruppen (etwa: aus Deutschland höher als aus der Antarktis)
– Visit Score: ld[(1+ld(VF)/ld(MAXVF)]
– VF: visit frequency– MAX: Konstante
(Höchstwert; etwa: 2.000)
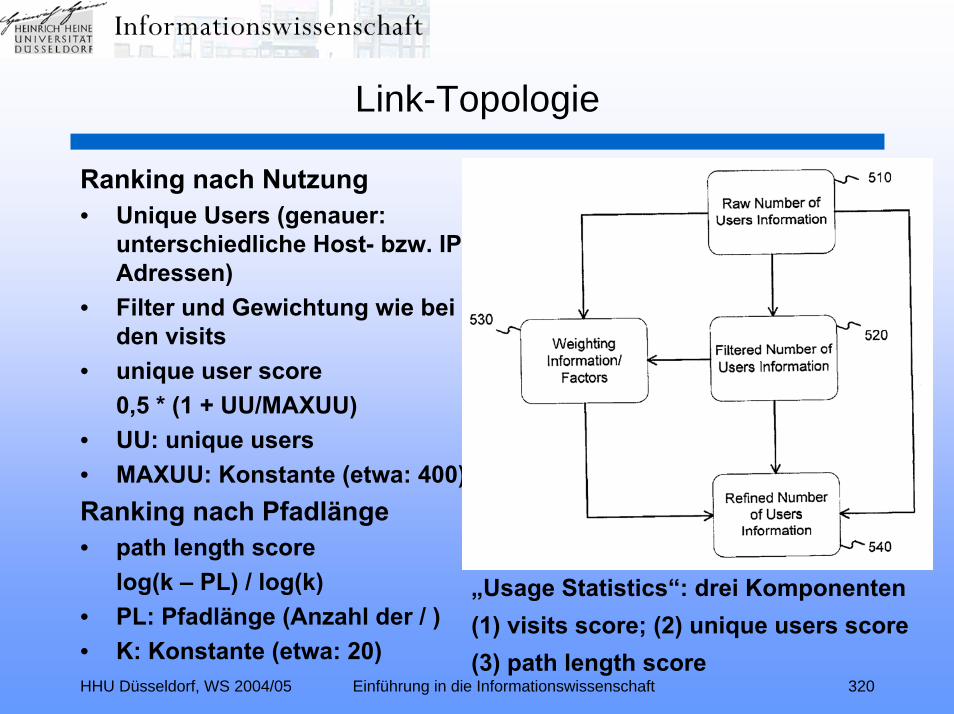
HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 320
Link-Topologie
Ranking nach Nutzung• Unique Users (genauer:
unterschiedliche Host- bzw. IP-Adressen)
• Filter und Gewichtung wie bei den visits
• unique user score0,5 * (1 + UU/MAXUU)
• UU: unique users• MAXUU: Konstante (etwa: 400)Ranking nach Pfadlänge• path length score
log(k – PL) / log(k)• PL: Pfadlänge (Anzahl der / )• K: Konstante (etwa: 20)
„Usage Statistics“: drei Komponenten(1) visits score; (2) unique users score(3) path length score

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 321
Link-Topologie
Usage Statistics• Beispiel: • 3 Dokumente 610, 620, 630• Pfeile: Links• Suchfrage: „weather“• Relevance Ranking nach
Textstatistik: 620 – 630 – 610• Relevance Ranking nach
PageRank: 630 – 610 – 620• Relevance Ranking nach Anzahl
der Visits: 610 – 620 – 630• Relevance Ranking nach gefilterter
und gewichteter Visit-Zahl (ohne Agenten; dt. Visits doppelt): 620 –610 - 630

HHU Düsseldorf, WS 2004/05 Einführung in die Informationswissenschaft 322
Link-Topologie
Link-Topologie (Relevance Ranking II). Fazit• Theoretische Basis der Link-Topologie ist die Zitationsanalyse
(mit ihren Zitationsraten, Co-Citations usw.)• Kleinberg-Algorithmus (HITS): Hubs und Authorities. Diese bilden
Community. Trefferliste zeigt Communities und für jede Community die „besten“ Hubs und Authorities (Einsatz bei Teoma)
• HITS im Zusammenspiel mit Vektorraummodell und probabilistischem Modell: AltaVista
• PageRank: objektiver (d.h. von einer Suchfrage unabhängiger) Gewichtungswert einer Webseite: abhängig von den eingehenden Links (Backlinks) und der Gewichtung der linkenden Seiten (Einsatz bei Google)
• Problem: PageRank einer Seite hat mit der Suchfrage nichts zu tun. Ergänzende Methoden: Re-Ranking innerhalb erster Treffer-menge / Einbeziehen von Nutzungsinformationen







