

Sommersemester 2013Anika Groß, Dr. Michael HartungUniversität Leipzig, Institut für Informatik, Abteilung Datenbankenhttp://dbs.uni-leipzig.de
Bio Data Management
Kapitel 7Datenintegration - Ansätze und Systeme

Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
Vorläufiges Inhaltsverzeichnis
1. Motivation und Grundlagen2. Bio-Datenbanken3. Datenmodelle und Anfragesprachen4. Modellierung von Bio-Datenbanken5. Sequenzierung und Alignments6. Genexpressionsanalyse7. Datenintegration: Ansätze und Systeme8. Matching9. Annotationen10. Versionierung von Datenbeständen

Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
KontextBeschreibung des Unter-suchungsgegenstandes
Beschreibung des experimentellen Designs und Prozesses
experimentelleMetadaten
experimentelle Daten
Experiment
Analyse
Analysergebnisse
Interpretation und Ergebnispräsentation
Datenintegration
private und öffentlich zugängliche Datenzur Beschreibungen von Genen
Gewebeprobe / selektierte Zelle Hypothese

Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
Lernziele
• Verstehen und Begreifen von generellen Ansätzen zur Datenintegration• Anwendung in Abhängigkeit von Kontext und Daten• Beurteilung der Ansätze
• Kennen von speziellen Datenintegration-lösungen sowie deren Verwendung

Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
Gliederung
1) Motivation2) Datencharakteristik3) Schema- und Instanzdatenintegration4) Ausgewählte Lösungskonzepte

Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
Problembereich: Datenintegration
Aufgabenspektrum:
Klinische Datenz.B. Patientendaten
Daten über biol. Objekte,z.B. Gene, Proteine
• Selektion von interessanten Daten,• übergreifenden Datenanalyse und • Interpretation von Analyseergebnissen
Experimentelle Datenz.B. Microarray-Daten
...
Differentiell exprimierte STAT3 Gene beimalignen Lymphomen von Patienten,
die älter als 50 Jahre sind?

Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
• Verschiedene Arten von Analysen • Analyse von Sequenzdaten (z.B. multiple alignments)• Identifikation von Transkriptionsfaktorbindungsstellen• Genexpressionsanalyse• Transkriptionsanalyse, z.B. ENCODE Projekt
(http://www.genome.gov/ENCODE)• Functional profiling• Pathway Analyse und Rekonstruktion
• Viele heterogene Datenquellen • Experimentdaten, z.B. von Chip-basierten Techniken• Experimentbeschreibung (Metadaten eines Experiments)• Klinische Daten• Viele miteinander verbundene Webdatenquellen und Ontologien• Private vs. öffentliche Daten
Motivation

Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
Datenintegration
• Datenintegration = Informationsintegration• Korrekte, vollständige und effiziente Zusammenführung von
Daten und Inhalt verschiedener, heterogener Quellen zu einer einheitlichen und strukturierten Infomenge zur effektiven Interpretation durch Nutzer und Anwendungen*
• = Zusammenfügung von Metadaten und Instanzdaten
*Leser, Naumann: Informationsintegration, dpunkt.verlag, 2007.
Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
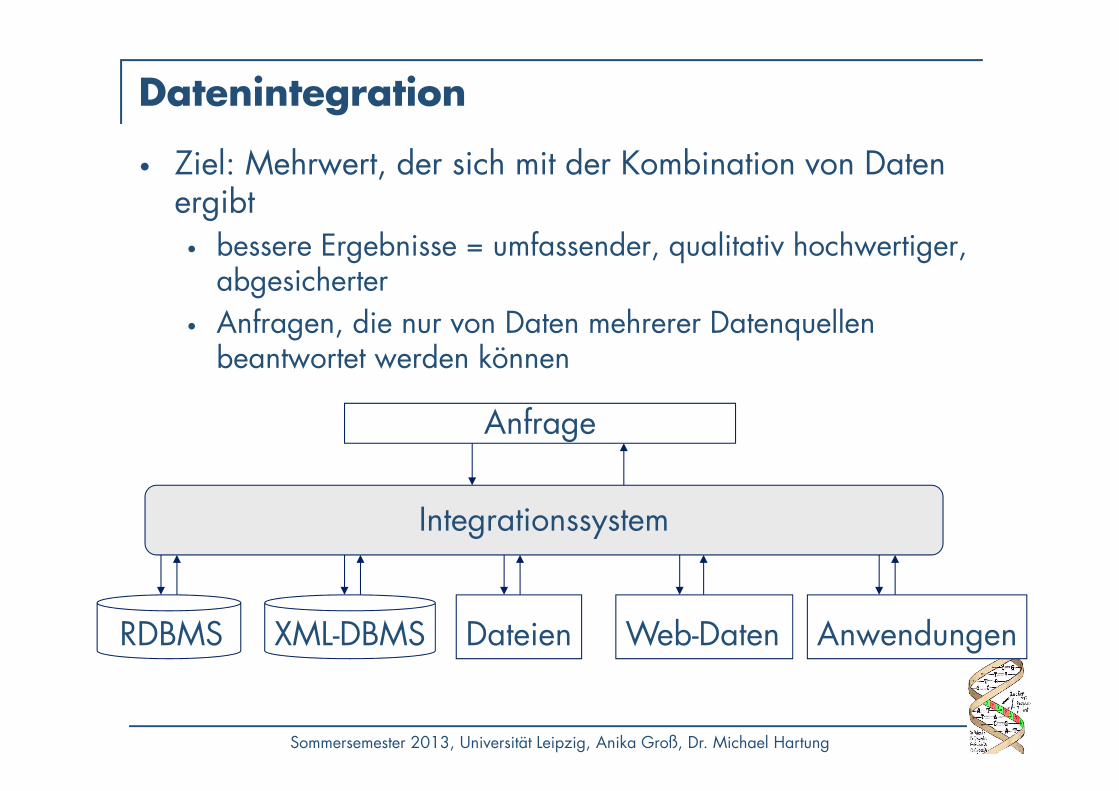
Datenintegration
• Ziel: Mehrwert, der sich mit der Kombination von Daten ergibt
• bessere Ergebnisse = umfassender, qualitativ hochwertiger, abgesicherter
• Anfragen, die nur von Daten mehrerer Datenquellen beantwortet werden können
Anfrage
RDBMS XML-DBMS
Integrationssystem
Dateien Web-Daten Anwendungen

Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
Probleme bei einer Datenintegration
• Komplexe Fragestellungen � Nutzung vieler verschiedener Datenquellen
• Weite Verteilung der Daten• Hohe Redundanz• Heterogenität der Datenquellen bzgl.
• Syntax• Schema/Struktur• Semantik• Schnittstellen
• Evolution von Daten und Schemata
Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
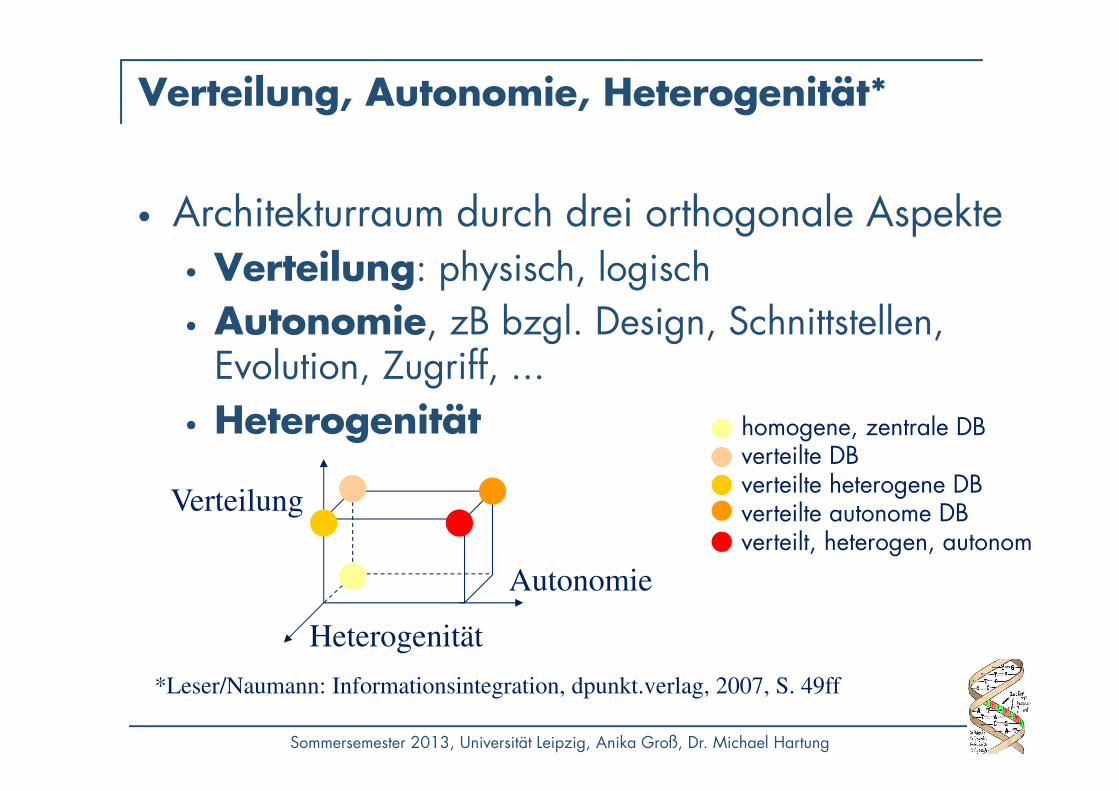
Verteilung, Autonomie, Heterogenität*
• Architekturraum durch drei orthogonale Aspekte• Verteilung: physisch, logisch• Autonomie, zB bzgl. Design, Schnittstellen,
Evolution, Zugriff, ...• Heterogenität
*Leser/Naumann: Informationsintegration, dpunkt.verlag, 2007, S. 49ff
homogene, zentrale DBverteilte DBverteilte heterogene DBverteilte autonome DBverteilt, heterogen, autonom
Autonomie
Verteilung
Heterogenität

Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
Architekturvarianten im Überblick
• Monolithische Datenbanken• Förderierte Datenbanken• Mediator-basierte Systeme• Peer-Daten-Management-Systeme
• Suchmaschinen• Portale
• ...
Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
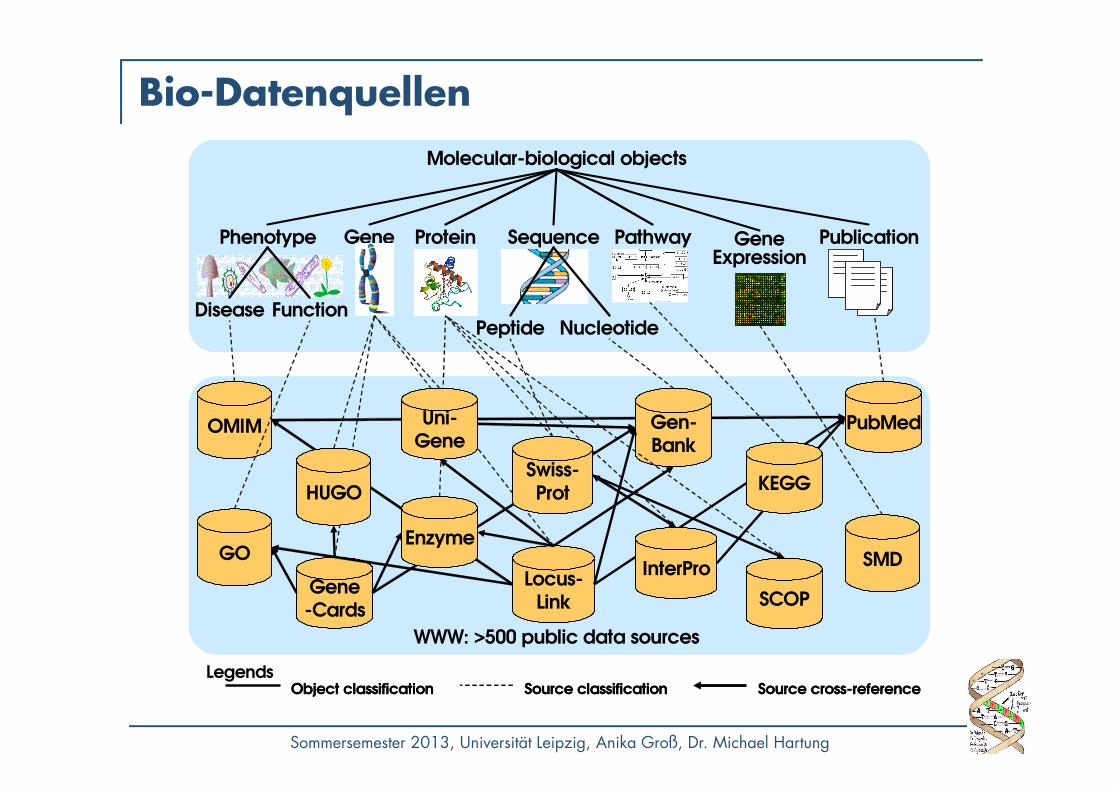
Bio-Datenquellen
OMIM
GO
Gen-Bank
Locus-Link
SMD
Molecular-biological objects
SequenceGenePhenotype Gene Expression
Peptide NucleotideDisease Function
Protein Pathway
SCOPGene-Cards
Publication
PubMedUni-Gene
Swiss-Prot
InterPro
KEGGHUGO
Enzyme
LegendsObject classificationObject classification Source classificationSource classification Source cross-referenceSource cross-reference
WWW: >500 public data sources

Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
Verschiedene Arten von Webdatenquellen
• Genomdatenquellen: Ensembl, NCBI Entrez, UCSC Genome Browser, ...
• Objekte: Gene, Transkripte, Proteine etc. verschiedener Spezies
• Objektspezifische Datenquellen• Proteine: UniProt (SwissProt, Trembl), Protein Data Bank (PDB),...• Proteininteraktionen: BIND, MINT, DIP, ...• Gene: HUGO (standardisierte Gensymbole für humanes
Genom), MGD, ...• Pathways: KEGG (metabolische & regulatorische Pathways),
GenMAPP, ...• ...

Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
Verschiedene Arten von Webdatenquellen II
• Publikationsquellen: Medline / Pubmed (>16 Mio Einträge)
• Ontologien• Verwendung zur einheitlichen und semantischen
Beschreibung von Eigenschaften biol. Objekte• Kontrollierte Vokabulare zur Reduzierung terminologischer
Variationen• Populäre Bespiele : Molekulare Funktionen, Biologische
Prozesse, Zelluläre Komponenten (Gene Ontology)• Ontologie-Sammlung: Open Biomedical Ontologies (OBO)
Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
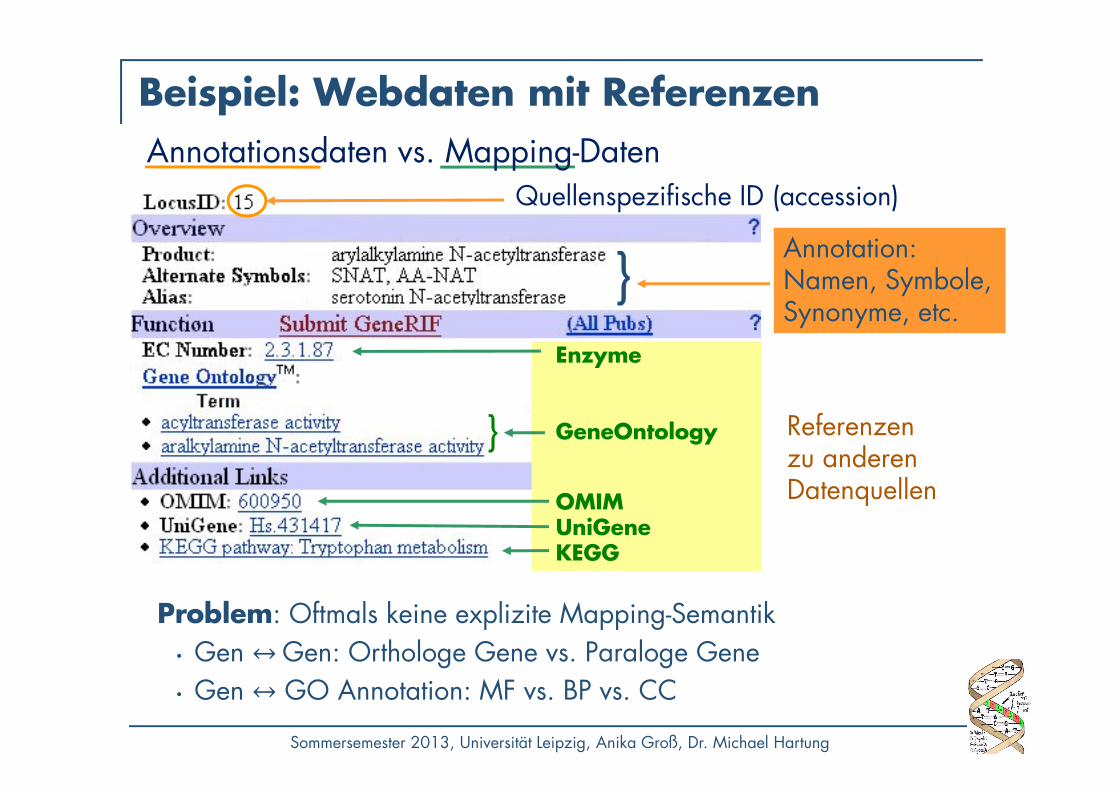
Enzyme
GeneOntology
OMIMUniGeneKEGG
} Referenzen zu anderen Datenquellen
Quellenspezifische ID (accession)
Annotation: Namen, Symbole, Synonyme, etc.
}
Problem: Oftmals keine explizite Mapping-Semantik• Gen ↔ Gen: Orthologe Gene vs. Paraloge Gene• Gen ↔ GO Annotation: MF vs. BP vs. CC
Annotationsdaten vs. Mapping-Daten
Beispiel: Webdaten mit Referenzen

Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
• Heterogenität• Schema• Syntax (Format)• Semantik
• Viele, hochverbundene Datenquellen und Ontol.
• Häufige Änderungen• Daten• Schema und Formate• Schnittstellen
• Unvollständige Quellen• Forschung�#Tupel• Zielstellung der Quelle:
Spezifische Attribute
• Überlappende Quellen
Verteilte molekularbiologische Daten
Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
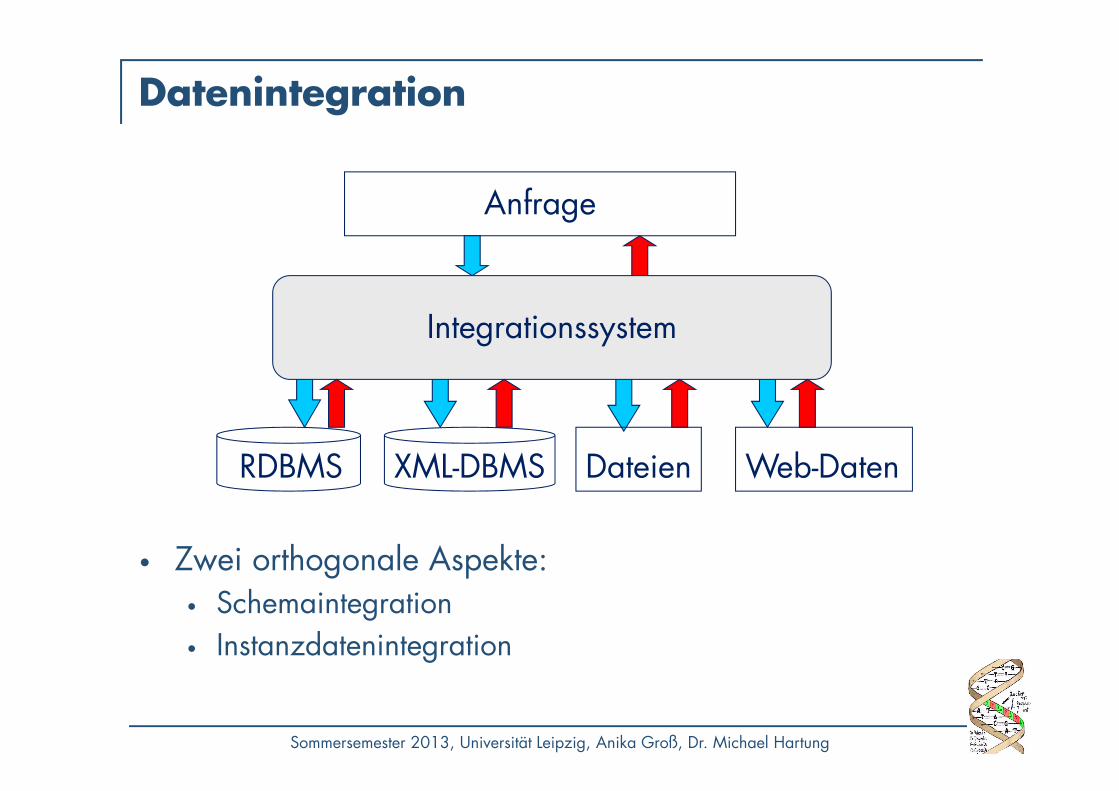
Datenintegration
• Zwei orthogonale Aspekte:• Schemaintegration• Instanzdatenintegration
Anfrage
RDBMS XML-DBMS
Integrationssystem
Dateien Web-Daten

Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
Schemaintegration
• Schemaintegration = Metadatenintegration• Ziel: Erstellung einer 'homogenisierten Sicht' (globales
Schema) auf die zu integrierenden Datenquellen
• Globales Schema:• Enthält alle relevanten Schemaelemente der zu
integrierenden Datenquellen• Schema-Mappings zwischen globalem und
Quellenschemata
Globales Schema SG
Quellenschema S1 Quellenschema S2 Quellenschema Sn...
M1: S1 x SG M2: S2 x SG Mn: Sn x SG

Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
Schema-Mapping
• Entstehung durch Schema-Matching (Prozess)• Eingabe: Schemata Source, Target ∈ S1,...,n, Algorithmus• Ausgabe: Schema-Mapping M: S x T
• Eigenschaften des Mapping:• bidirektional • Semantik: oftmals Äquivalenzrelation• Suche nach 1:1 Beziehung zwischen den Elementen (aber
nicht immer möglich: Name ↔ Vorname, Nachname)• vielfach weder injektiv noch surjektiv (und damit auch nicht
bijektiv)• Problem: Transformationen, zB Aggregation von Daten
Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
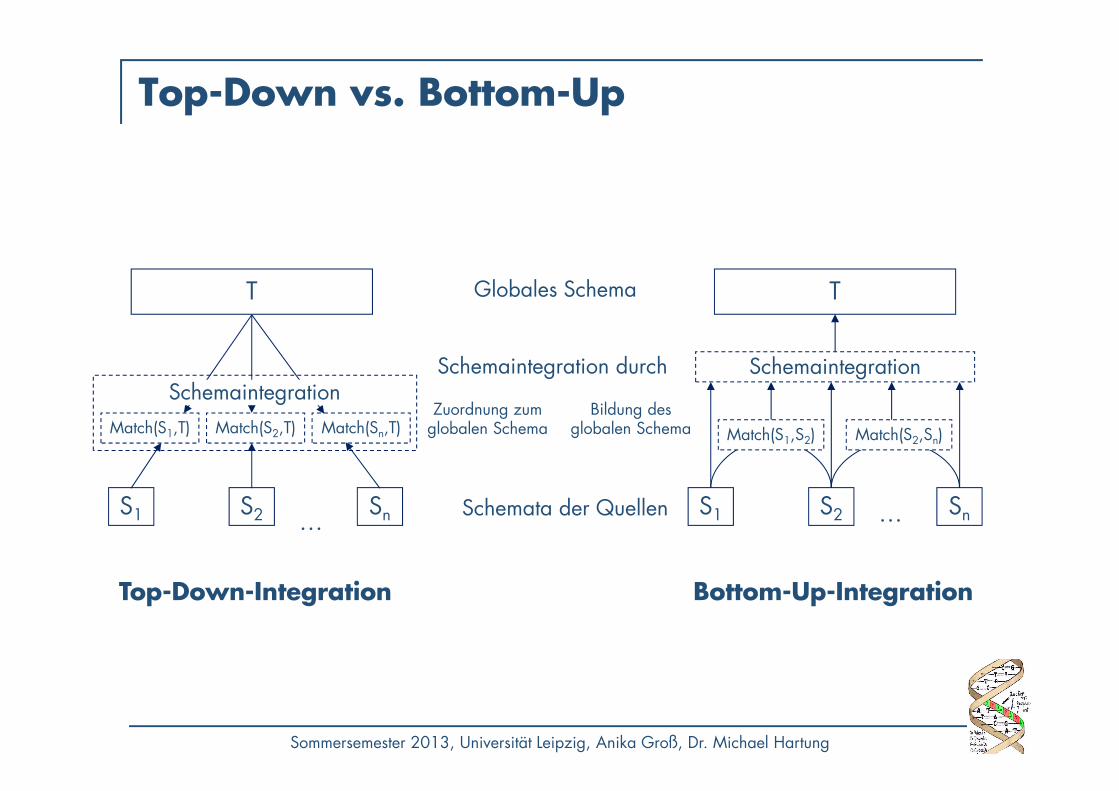
Top-Down vs. Bottom-Up
Globales Schema
Schemata der Quellen
Bottom-Up-IntegrationTop-Down-Integration
T
S1 S2 Sn…
T
S1 S2 Sn…
Schemaintegration
Match(S1,S2) Match(S2,Sn)
Bildung desglobalen Schema
Zuordnung zumglobalen SchemaMatch(S1,T) Match(S2,T) Match(Sn,T)
SchemaintegrationSchemaintegration durch

Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
Instanzdatenintegration
• Instanzdatenintegration: Zusammenfügen der Daten aus den verschiedenen Datenquellen
• Virtuell: zur Beantwortung einer Anfrage• Materialisiert: Prozess der Vorverarbeitung (ETL)
• Basis: Schema-Mappings
Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
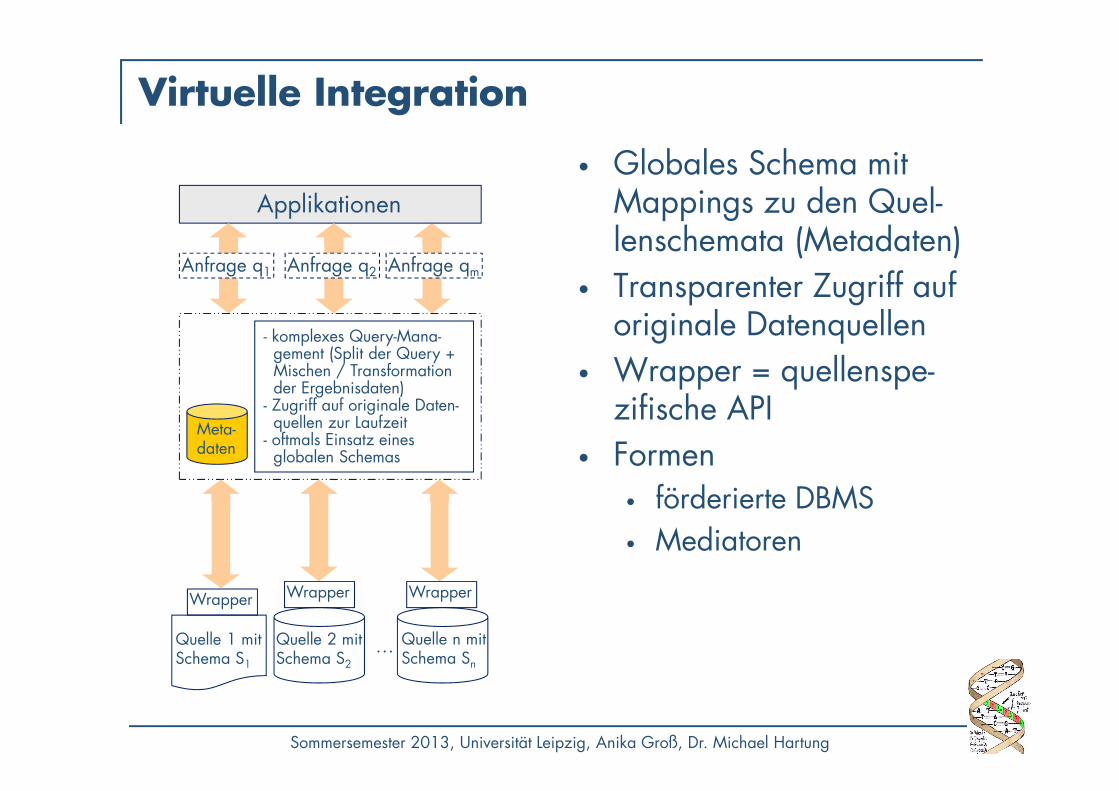
Virtuelle Integration
• Globales Schema mit Mappings zu den Quel-lenschemata (Metadaten)
• Transparenter Zugriff auf originale Datenquellen
• Wrapper = quellenspe-zifische API
• Formen• förderierte DBMS• Mediatoren
Anfrage q1 Anfrage qm
Applikationen
Anfrage q2
Meta-daten
Quelle 1 mit Schema S1
Quelle n mitSchema Sn
…Quelle 2 mit Schema S2
- komplexes Query-Mana-gement (Split der Query +Mischen / Transformationder Ergebnisdaten)
- Zugriff auf originale Daten-quellen zur Laufzeit
- oftmals Einsatz eines globalen Schemas
WrapperWrapperWrapper
Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
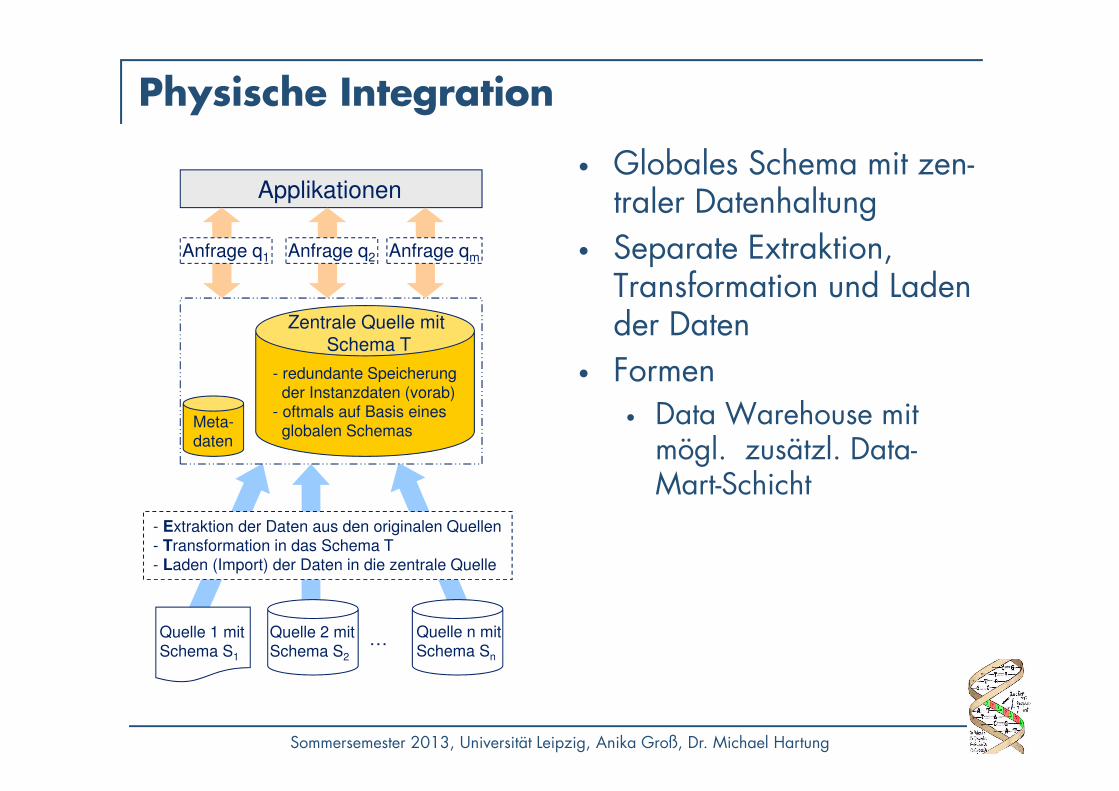
Physische Integration
• Globales Schema mit zen-traler Datenhaltung
• Separate Extraktion, Transformation und Laden der Daten
• Formen• Data Warehouse mit
mögl. zusätzl. Data-Mart-Schicht
Anfrage q1 Anfrage qm
Applikationen
Meta-
daten
- redundante Speicherung
der Instanzdaten (vorab)
- oftmals auf Basis eines
globalen Schemas
Quelle 1 mit
Schema S1
Quelle n mit
Schema Sn
…Quelle 2 mit
Schema S2
Zentrale Quelle mit
Schema T
- Extraktion der Daten aus den originalen Quellen
- Transformation in das Schema T
- Laden (Import) der Daten in die zentrale Quelle
Anfrage q2
Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
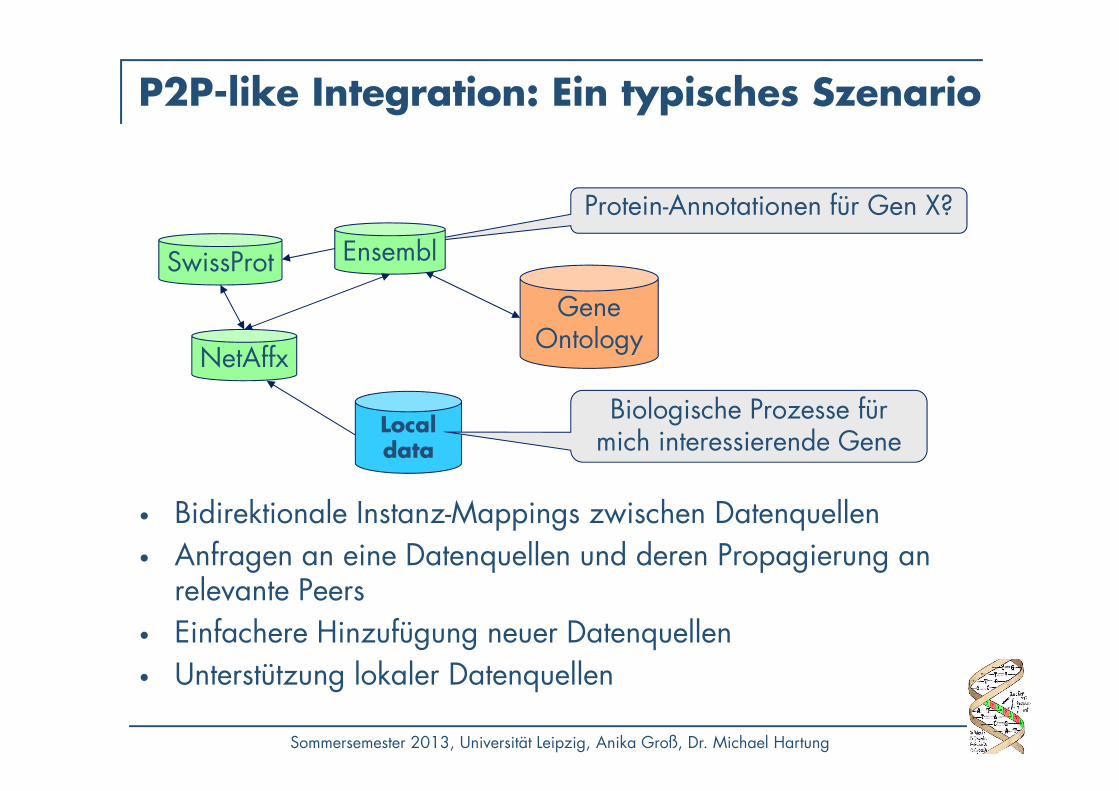
P2P-like Integration: Ein typisches Szenario
• Bidirektionale Instanz-Mappings zwischen Datenquellen• Anfragen an eine Datenquellen und deren Propagierung an
relevante Peers• Einfachere Hinzufügung neuer Datenquellen• Unterstützung lokaler Datenquellen
Gene Ontology
Protein-Annotationen für Gen X?
Local data
Biologische Prozesse fürmich interessierende Gene
SwissProt Ensembl
NetAffx
Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
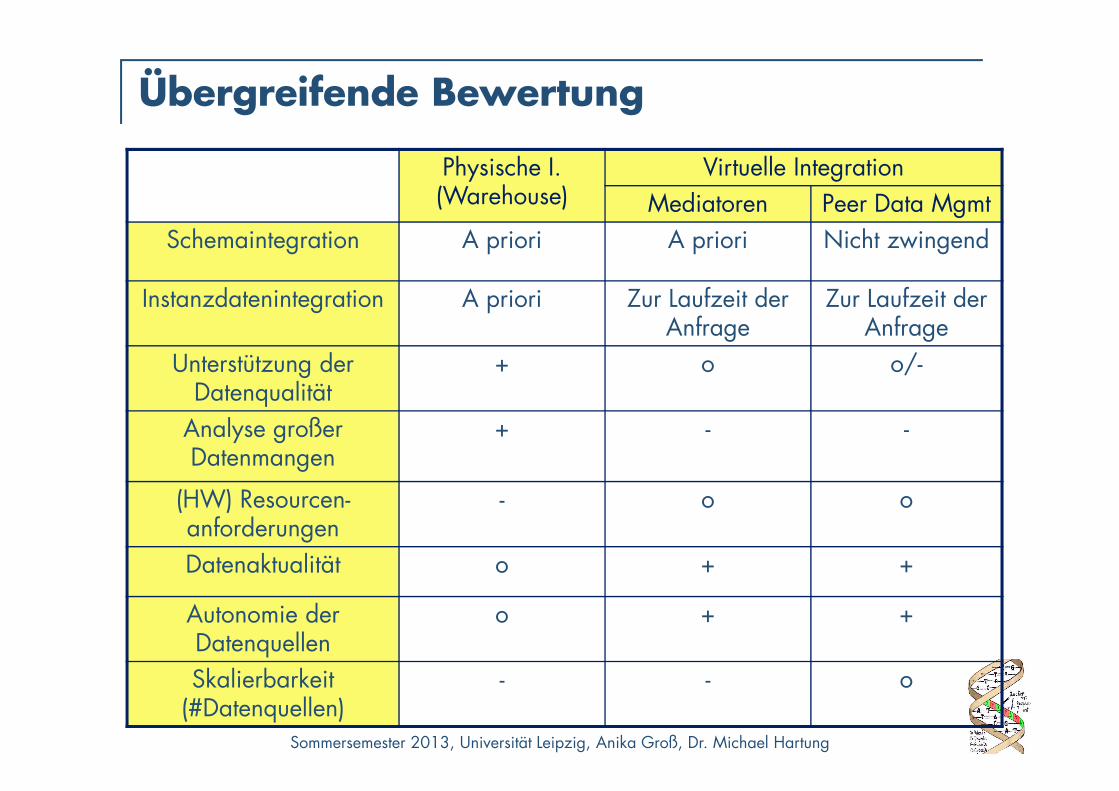
Übergreifende Bewertung
Physische I. (Warehouse)
Virtuelle IntegrationMediatoren Peer Data Mgmt
Schemaintegration A priori A priori Nicht zwingend
Instanzdatenintegration A priori Zur Laufzeit der Anfrage
Zur Laufzeit der Anfrage
Unterstützung der Datenqualität
+ o o/-
Analyse großer Datenmangen
+ - -
(HW) Resourcen-anforderungen
- o o
Datenaktualität o + +
Autonomie der Datenquellen
o + +
Skalierbarkeit(#Datenquellen)
- - o

Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
Gliederung
1) Motivation2) Datencharakteristik3) Schema- und Instanzdatenintegration4) Ausgewählte Lösungskonzepte
Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
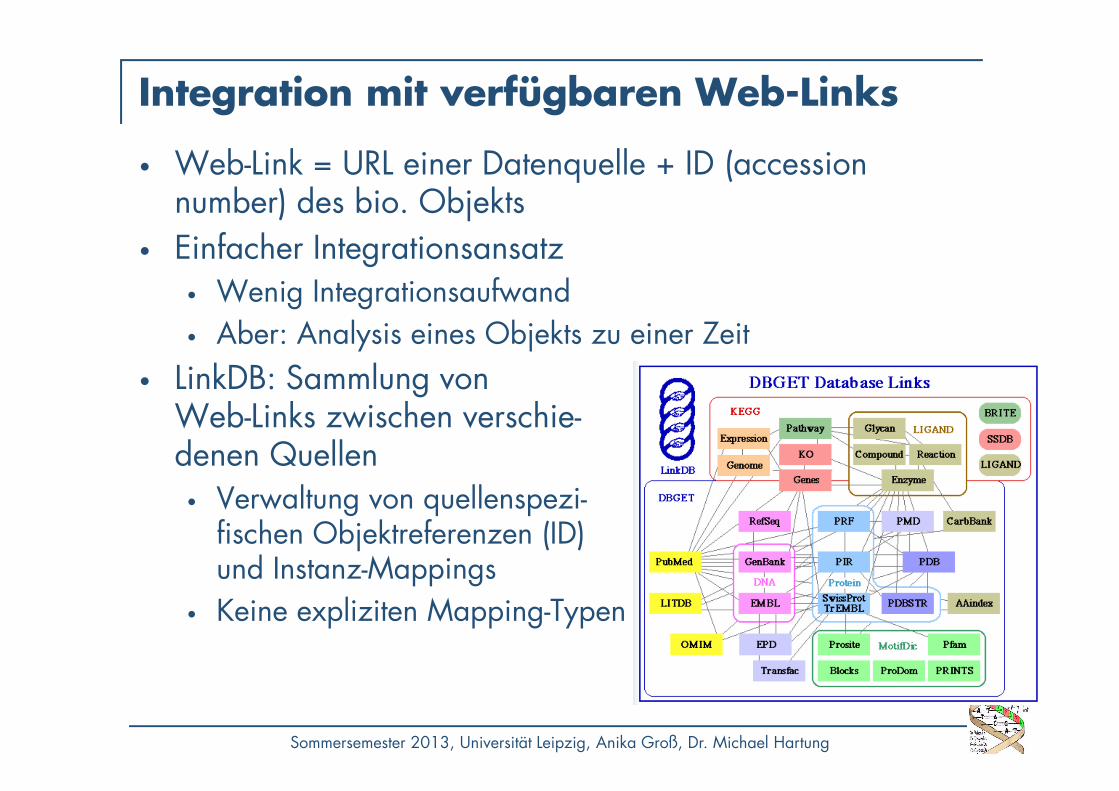
• Web-Link = URL einer Datenquelle + ID (accession number) des bio. Objekts
• Einfacher Integrationsansatz• Wenig Integrationsaufwand• Aber: Analysis eines Objekts zu einer Zeit
• LinkDB: Sammlung von Web-Links zwischen verschie-denen Quellen
• Verwaltung von quellenspezi-fischen Objektreferenzen (ID) und Instanz-Mappings
• Keine expliziten Mapping-Typen
Integration mit verfügbaren Web-Links

Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
Sequence Retrieval System (SRS)
• Integration mittels Indexierung von Datenquellen• Entwickelt am EMBL für den Zugriff auf biol. Objekte /
Sequenzdaten• Kommerziell erweiterte Version von BioWisdom (zuvor:
Lion Bioscience)• Datenintegration primär für dateibasierte Quellen, aber
Erweiterungen für Zugriff auf RDBMS und Analysetools• Mapping-basierte Integration, kein globales Schema• Lokale Installation der Quellen notwendig (Download!)• Indexierung bzgl. Anfrageattribute von dateibasierten
Quellen• Definition von Hub-Tabellen und Anfrageattributen für
Integration von relationalen Datenquellen
Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
Sequence Retrieval System (SRS) II
• Umfangreiche Wrapper-Bibliothek verfügbar für öffentliche Datenquellen
• Proprietäre Wrapper-Sprache: Icarus• Keine generischen Wrapper, z.B. zur Integration privater
Datenquellen
Source: Lion BioScience
Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
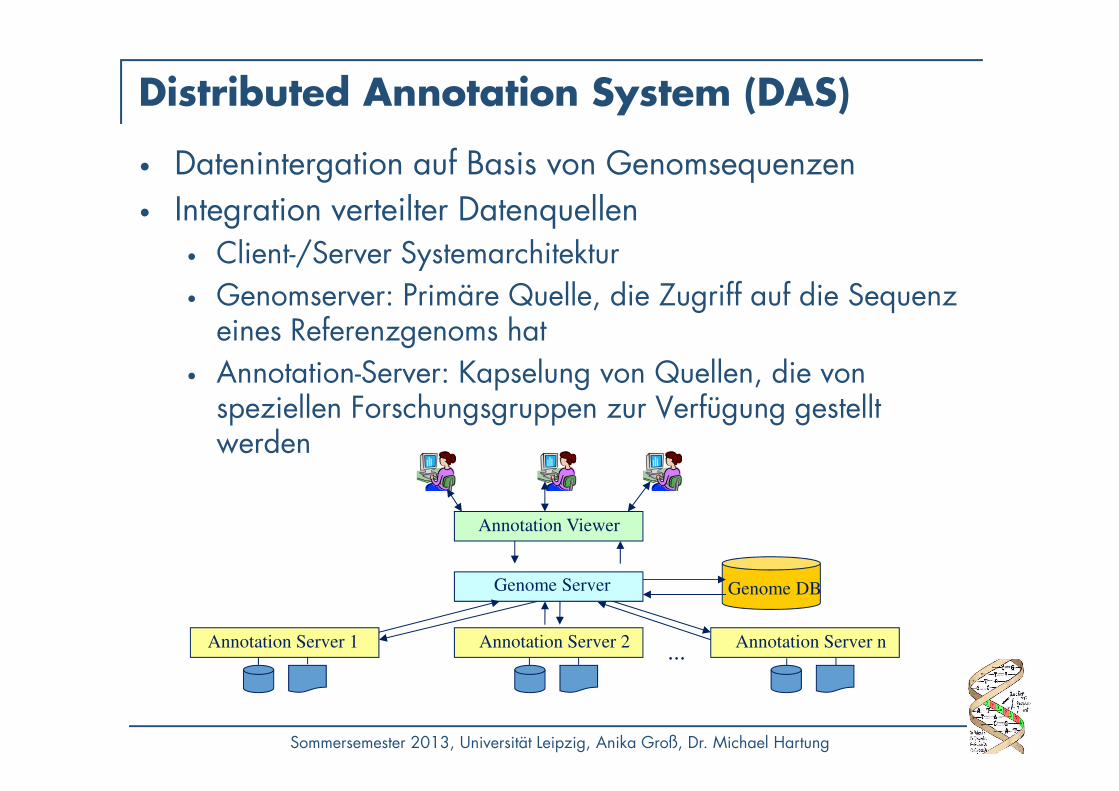
Distributed Annotation System (DAS)
• Datenintergation auf Basis von Genomsequenzen• Integration verteilter Datenquellen
• Client-/Server Systemarchitektur• Genomserver: Primäre Quelle, die Zugriff auf die Sequenz
eines Referenzgenoms hat• Annotation-Server: Kapselung von Quellen, die von
speziellen Forschungsgruppen zur Verfügung gestellt werden
Annotation Viewer
Genome Server
Annotation Server 1
Genome DB
Annotation Server 2 Annotation Server n...

Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
Distributed Annotation System (DAS) II
• Ausrichtung der Beschreibungen (Annotationen) an der Sequenz eines Referenzgenoms
• Einfaches Hinzufügen neuer Quellen, aber dann meist für alle Benutzer sichtbar
• Sequenzkoordinaten für Zugriff auf Annotationen notwendig: Spezies, Chromosom, Start-, Stoppposition, Richtung (strand)
• Problem: Neuberechnung aller Annotationen im Falle die zugrunde liegende Referenzsequenz ändert sich

Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
EnsMart
• Data-Warehouse-basierte Datenintegration• Data Mart auf Basis von Ensembl• Gezielte Suche und Wiedergabe von
• Ensembl-eigenen bio. Objekten: Gene, Transkripte und Polypetide
• Assoziierten Annotationen• Referenzierte biol. Objekte
• Multidimensionales Schema• Ensembl-eigene bio. Objekte als "Fakten"• Instanz-Mappings zu referenzierten Objekten als
beschreibende Dimensionen
• Spezies-spezifische Data Marts, die über Homologie-Mappings verbunden sind
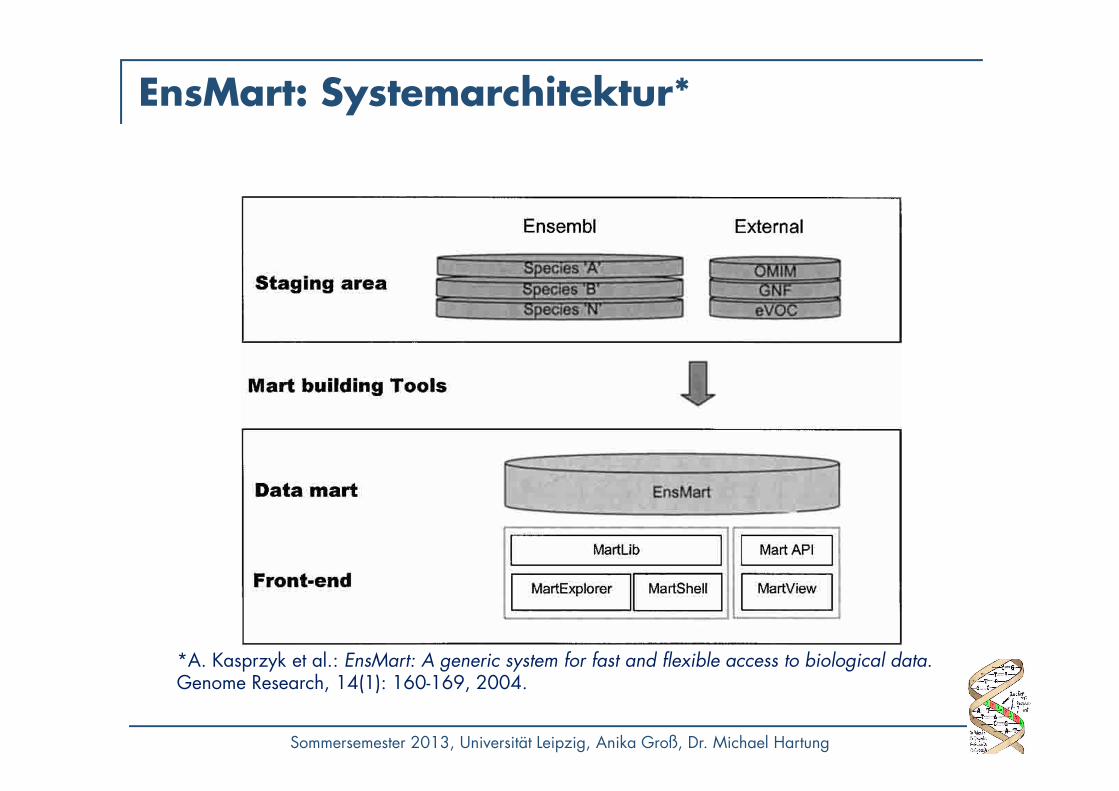
Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
EnsMart: Systemarchitektur*
*A. Kasprzyk et al.: EnsMart: A generic system for fast and flexible access to biological data.Genome Research, 14(1): 160-169, 2004.
Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
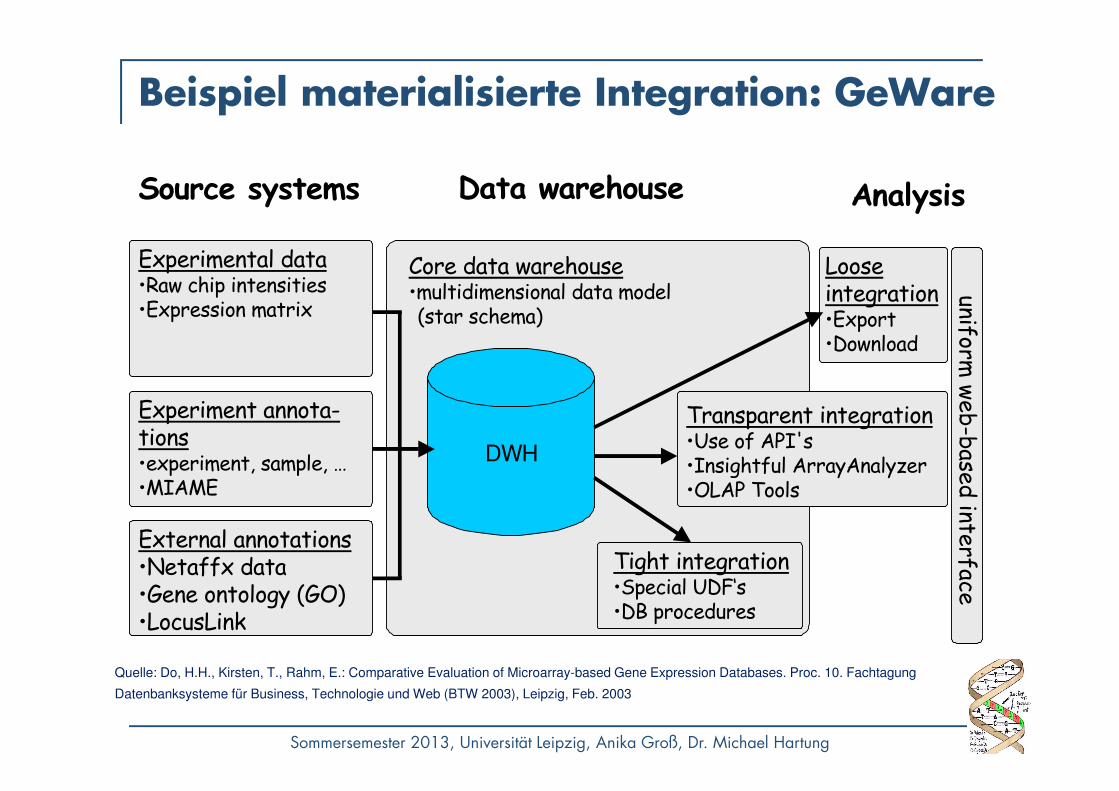
Beispiel materialisierte Integration: GeWare
Experimental data•Raw chip intensities•Expression matrix
Data warehouse
External annotations•Netaffx data•Gene ontology (GO)•LocusLink
Experiment annota-tions•experiment, sample, …•MIAME
Source systems Analysis
Core data warehouse•multidimensional data model (star schema)
Tight integration•Special UDF‘s•DB procedures
Loose integration•Export•Download
Transparent integration•Use of API's•Insightful ArrayAnalyzer•OLAP Tools
DWH
uniform w
eb-b
ased
interface
Quelle: Do, H.H., Kirsten, T., Rahm, E.: Comparative Evaluation of Microarray-based Gene Expression Databases. Proc. 10. Fachtagung
Datenbanksysteme für Business, Technologie und Web (BTW 2003), Leipzig, Feb. 2003

Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
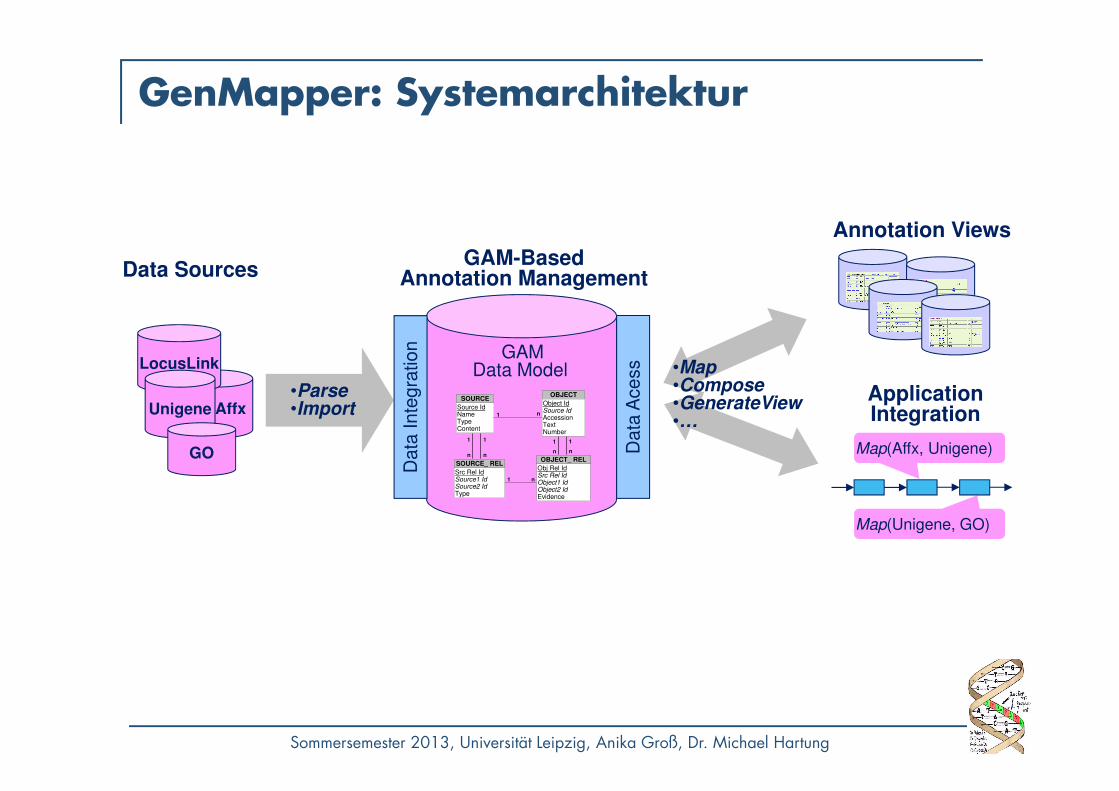
GenMapper*
• Data-Warehouse-basierte Datenintegration• Generisches Schema: GAM
• Einheitliche Repräsentation von Annotationsdaten• Flexibilität bzgl. Heterogenität und Integration
• Nutzung existierender Instanz-Mappings zwischenObjekten/Quellen
• High-level Operatoren zur Datenintegration und Anfrageformulierung / -verarbeitung
• Sichtenkonzept: Annotation Views für spezifischeAnalyseanforderungen
*Do, H.H.; Rahm, E.: Flexible integration of molecular-biological annotation data: The GenMapper approach. Proc. 9th EDBT Conf., 2004
Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
GenMapper: Systemarchitektur
NetAffx
GAMData Model
GAM-BasedAnnotation ManagementData Sources
LocusLink
Annotation Views
Application Integration
•Map•Compose•GenerateView•…
Map(Unigene, GO)
Da
ta In
teg
ration
Da
ta A
ce
ss
Unigene
Map(Affx, Unigene)
•Parse•Import
GO
Source IdNameTypeContent
SOURCE
Source IdNameTypeContent
SOURCE
Obj Rel IdSrc Rel IdObject1 IdObject2 IdEvidence
OBJECT_ REL
Obj Rel IdSrc Rel IdObject1 IdObject2 IdEvidence
OBJECT_ REL
n1
n1
11
n nn n
1 1
Object IdSource IdAccessionTextNumber
OBJECT
Object IdSource IdAccessionTextNumber
OBJECT
Src Rel IdSource1 IdSource2 IdType
SOURCE_ REL
Src Rel IdSource1 IdSource2 IdType
SOURCE_ REL
Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
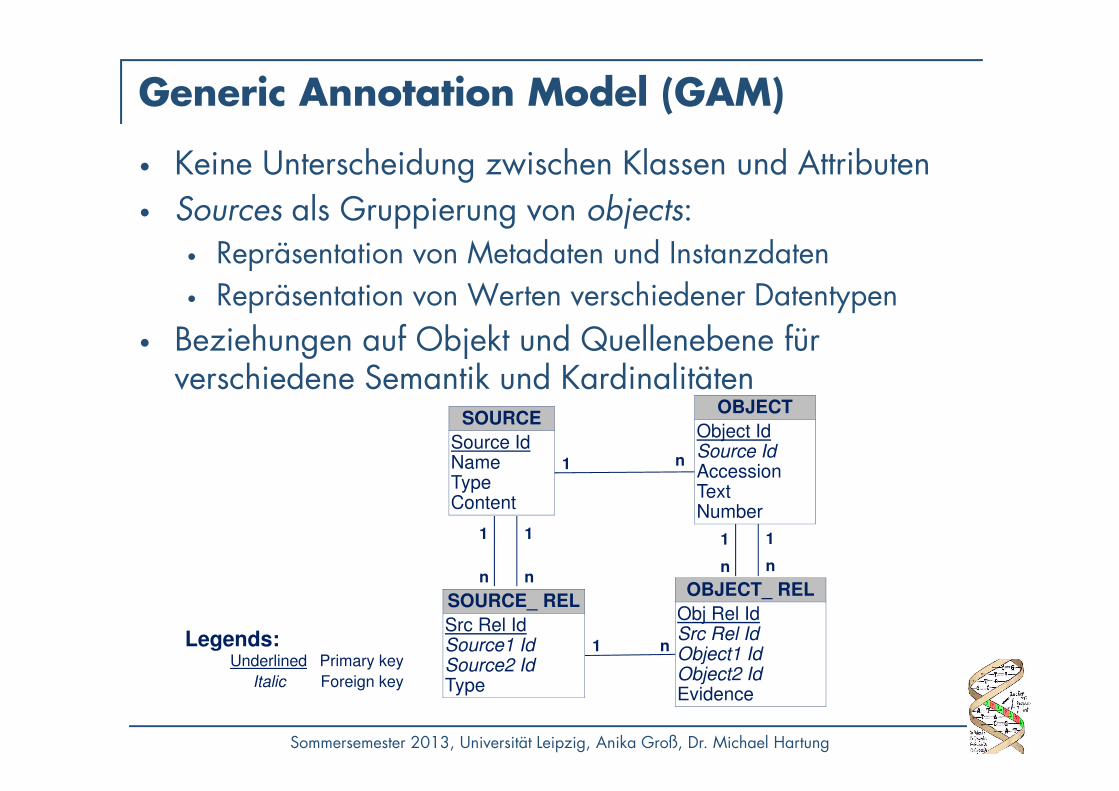
Generic Annotation Model (GAM)
• Keine Unterscheidung zwischen Klassen und Attributen• Sources als Gruppierung von objects:
• Repräsentation von Metadaten und Instanzdaten• Repräsentation von Werten verschiedener Datentypen
• Beziehungen auf Objekt und Quellenebene für verschiedene Semantik und Kardinalitäten
SOURCE
Source IdNameTypeContent
OBJECT_ REL
Obj Rel IdSrc Rel IdObject1 IdObject2 IdEvidence
n1
n1
11
n nn n
1 1
OBJECT
Object IdSource IdAccessionTextNumber
SOURCE_ REL
Src Rel IdSource1 IdSource2 IdType
Underlined Primary key
Legends:
Italic Foreign key
Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
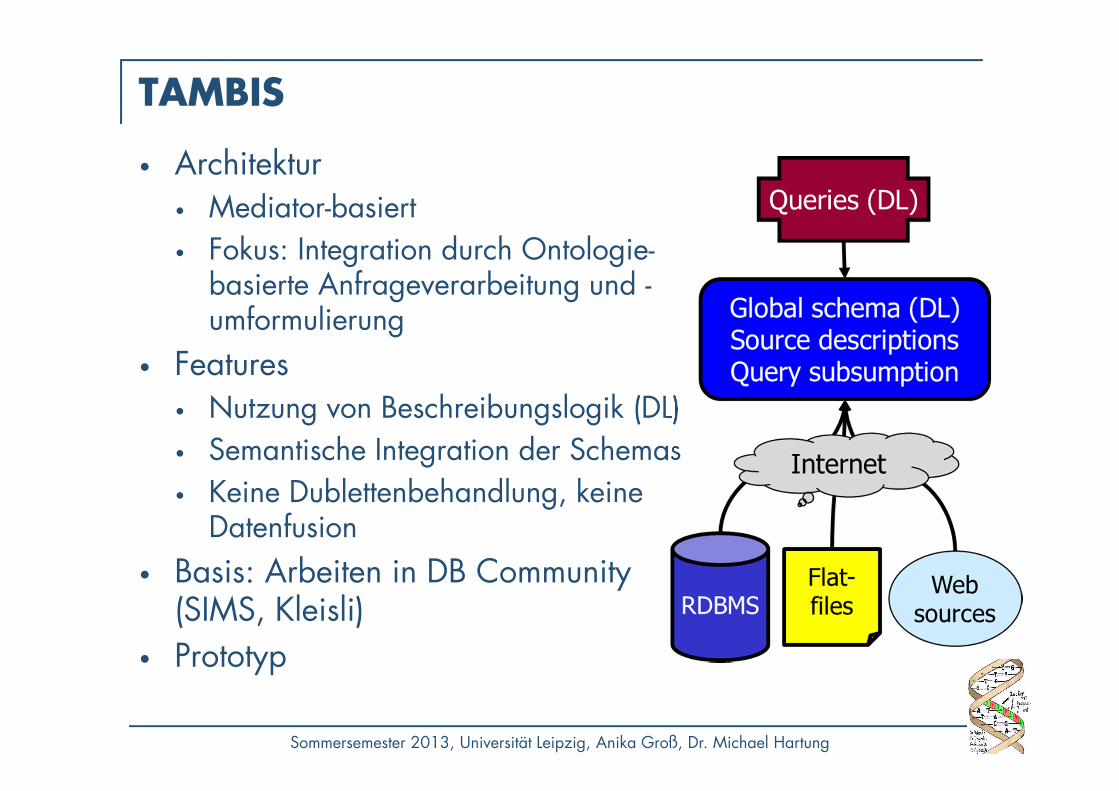
TAMBIS
• Architektur• Mediator-basiert• Fokus: Integration durch Ontologie-
basierte Anfrageverarbeitung und -umformulierung
• Features• Nutzung von Beschreibungslogik (DL)• Semantische Integration der Schemas• Keine Dublettenbehandlung, keine
Datenfusion
• Basis: Arbeiten in DB Community (SIMS, Kleisli)
• Prototyp
Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
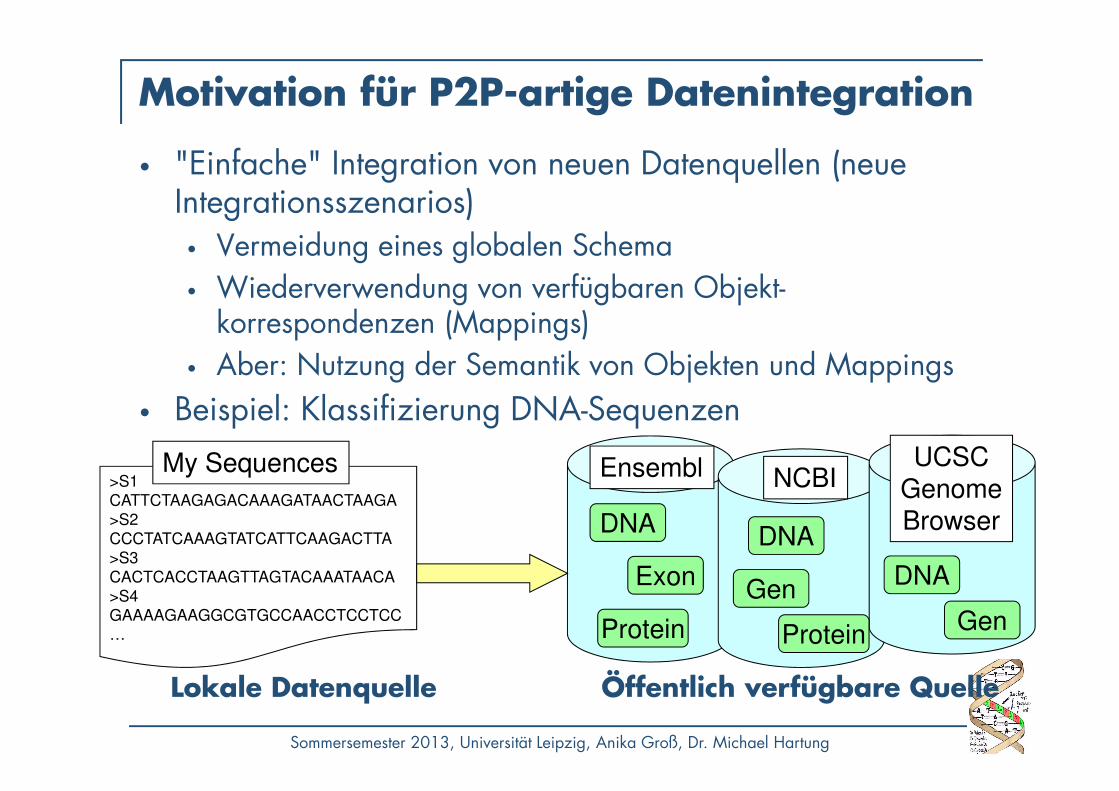
Motivation für P2P-artige Datenintegration
• "Einfache" Integration von neuen Datenquellen (neue Integrationsszenarios)
• Vermeidung eines globalen Schema• Wiederverwendung von verfügbaren Objekt-
korrespondenzen (Mappings)• Aber: Nutzung der Semantik von Objekten und Mappings
• Beispiel: Klassifizierung DNA-Sequenzen
>S1
CATTCTAAGAGACAAAGATAACTAAGA
>S2
CCCTATCAAAGTATCATTCAAGACTTA
>S3
CACTCACCTAAGTTAGTACAAATAACA
>S4
GAAAAGAAGGCGTGCCAACCTCCTCC
…
My SequencesNCBIEnsembl UCSC
Genome
BrowserDNA
Exon
Protein
DNA
GenDNA
GenProtein
Lokale Datenquelle Öffentlich verfügbare Quelle

Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
BioFuice*: P2P-artige Datenintegration
• Bioinformatics information fusion utilizing instance correspondences and peer mappings
• Bottom-up Integration• High-level Operatoren• P2P-artige Infrastruktur
• Mappings zwischen autonomen Datenquellen (Peers)• Mapping: Menge von Korrespondenzen zwischen Objekten• Einfach Integration neuer Datenquellen
• Mediator• Steuerung der Mapping- und Operatorausführung• Nutzung eines anwendungsspezifischen semantischen
Domänenmodells
*Kirsten, T; Rahm, E: BioFuice: Mapping-based data integration in bioinformatics. Proc. 3rd Intl. Workshop DILS, July 2006
Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
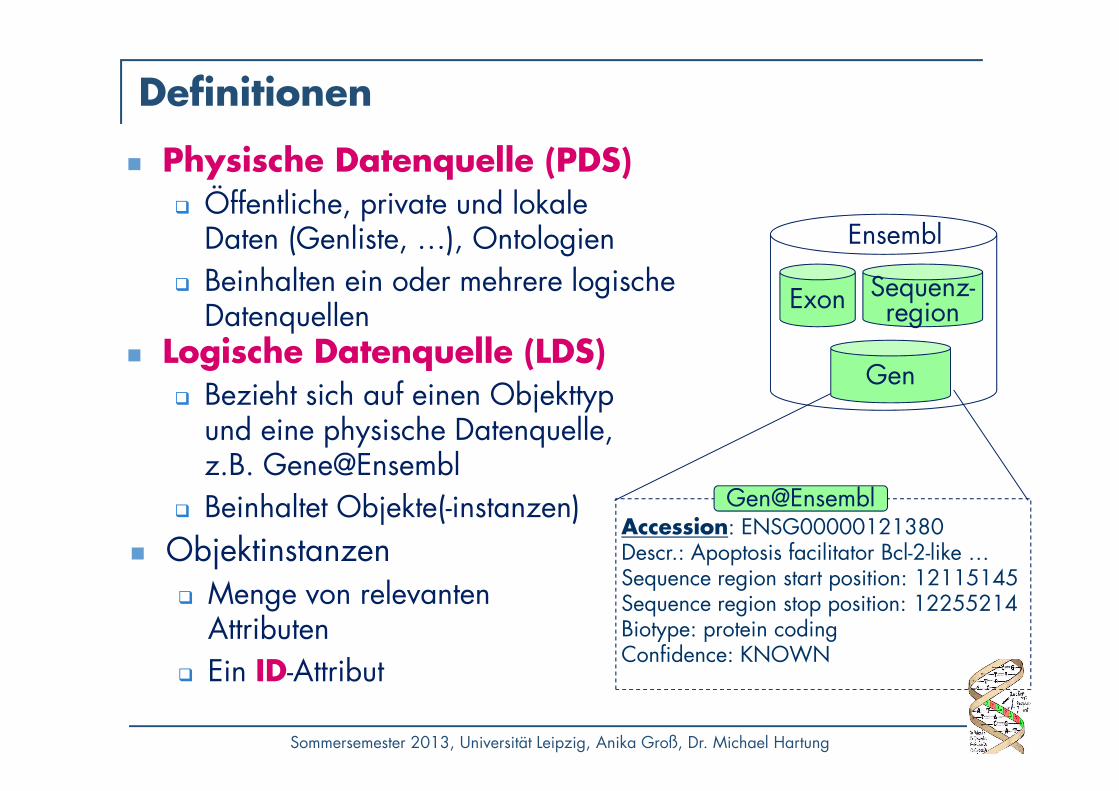
Definitionen
� Physische Datenquelle (PDS)� Öffentliche, private und lokale
Daten (Genliste, …), Ontologien� Beinhalten ein oder mehrere logische
Datenquellen
Ensembl
Accession: ENSG00000121380Descr.: Apoptosis facilitator Bcl-2-like …Sequence region start position: 12115145Sequence region stop position: 12255214Biotype: protein codingConfidence: KNOWN
Gen@Ensembl
� Objektinstanzen� Menge von relevanten
Attributen� Ein ID-Attribut
Gen
Sequenz-regionExon
� Logische Datenquelle (LDS)� Bezieht sich auf einen Objekttyp
und eine physische Datenquelle,z.B. Gene@Ensembl
� Beinhaltet Objekte(-instanzen)
Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
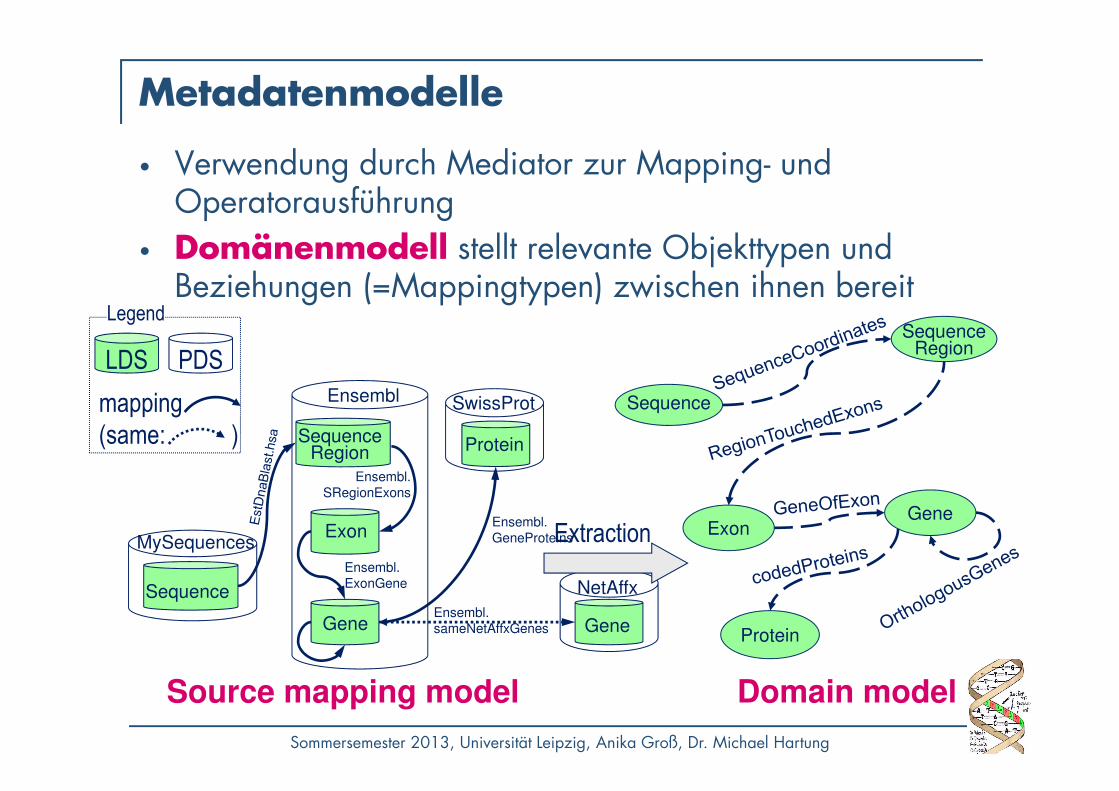
Metadatenmodelle
• Verwendung durch Mediator zur Mapping- und Operatorausführung
• Domänenmodell stellt relevante Objekttypen und Beziehungen (=Mappingtypen) zwischen ihnen bereit
Source mapping model
LDS PDS
mapping
(same: )
Legend
Ensembl SwissProt
MySequences
NetAffx
Ensembl.SRegionExons
Ensembl.ExonGene
Ensembl.GeneProteins
Ensembl.sameNetAffxGenes
Domain model
Extraction
SequenceRegion
Gene
Protein
Sequence
Exon
Sequence
SequenceRegion
Exon
Gene Gene
Protein

Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
Operatoren
• Mengenorientierte Operatoren• Eingabe: Menge von Objekten/Mappings
+ Parameter / Bedingungen• Ausgabe: Menge resultierender Objekte
⇒ Kombination von Operatoren in Skripten �Workflow-artige Ausführung
• Ausgewählte Operatoren:• Single source: queryInstances, searchInstances, …• Navigation: traverse, map, compose, …• Navigation + Aggregation: aggregate,
aggregateTraverse, …• Universell: diff, union, intersect, …

Sommersemester 2013, Universität Leipzig, Anika Groß, Dr. Michael Hartung
Zusammenfassung
• Viele verschiedene Datenquellen mit unterschiedlichem Fokus
• Hauptsächlich Heterogenität als Integrationsbarriere
• Virtuelle vs. physische Integration• Virtuell: Mediator-Systeme, förderierte DBMS• Physisch: Data Warehouse
• Schemaintegration: Top-down vs. Bottom-Up• Neuere Ansätze: PDMS und P2P-like Integration
• Systeme: SRS, DAS, GenMapper, EnsMart, Geware, BioFuice, ...
• Mehr Details: VL Datenintegration







