

5. Information Retrieval

2
Inhalt
§ 5.1 Information Retrieval
§ 5.2 Vorverarbeitung der Dokumente
§ 5.3 Boolesches Retrieval
§ 5.4 Vektorraum-Modell
§ 5.5 Evaluation
§ 5.6 Implementierung
§ 5.7 Websuche
Datenbanken & Informationssysteme / Kapitel 5: Information Retrieval

3
5.1 Information Retrieval
§ Information Retrieval ist ein Fachgebiet in der Schnittmenge von Informationswissenschaft,Informatik und Computerlinguistik
§ Weitgehend unabhängige, parallele Entwicklung zum Fachgebiet Datenbanken der Informatik mitnun zunehmendem Ideenaustausch
Datenbanken & Informationssysteme / Kapitel 5: Information Retrieval
Information Retrieval (IR) is finding material (usually documents) of an
unstructured nature (usually text)that satisfies an information need from within
large collections (usually stored on computers)
[Manning 2008]

4
Information Retrieval
§ Information Retrieval befasst mit Suche nach Inhalten
§ Artikel (z.B. aus Wissenschaft und Presse)
§ Webseiten
§ Office-Dokumente (z.B. Präsentationen und Spreadsheets)
§ E-Mails
§ Benutzerprofile (z.B. auf Facebook oder XING)
Datenbanken & Informationssysteme / Kapitel 5: Information Retrieval
Information Retrieval (IR) is finding material (usually documents) of an
unstructured nature (usually text)that satisfies an information need from within
large collections (usually stored on computers)
[Manning 2008]

5
Information Retrieval
§ Daten haben meist keine oder nur wenig Struktur
§ Einfache Textdokumente (keine Struktur)
§ HTML (Überschriften und Absätze markiert)
§ JSON und XML (semistrukturiert)
§ RDBMSs, im Gegensatz, betrachten strukturierte Daten
Datenbanken & Informationssysteme / Kapitel 5: Information Retrieval
Information Retrieval (IR) is finding material (usually documents) of an
unstructured nature (usually text)that satisfies an information need from within
large collections (usually stored on computers)
[Manning 2008]

6
Information Retrieval
§ Informationsbedürfnis des Benutzers als Ausgangspunkt
§ selten präzise (z.B. Was kann man in Berlin unternehmen?)
§ ungenau als Anfrage formuliert (z.B. berlin sights)
§ RDBMSs, im Gegensatz, bieten Anfragesprache mitgenau definierter Semantik (z.B. relationale Algebra)
Datenbanken & Informationssysteme / Kapitel 5: Information Retrieval
Information Retrieval (IR) is finding material (usually documents) of an
unstructured nature (usually text)that satisfies an information need from within large collections (usually stored on computers)
[Manning 2008]

7
Information Retrieval
§ Große Datenmengen mit rapidem Wachstum
§ Desktop ~ 100.000 Dokumente
§ The New York Times (1987–2007) ~ 2.000.000 Dokumente
§ WWW im Jahr 1998 ~ 800.000.000 Dokumente
§ WWW im Jahr 2008 ~ 1.000.000.000.000 Dokumente
Datenbanken & Informationssysteme / Kapitel 5: Information Retrieval
Information Retrieval (IR) is finding material (usually documents) of an
unstructured nature (usually text)that satisfies an information need from within
large collections (usually stored on computers)
[Manning 2008]

8
Historisches
§ Bibliotheken (seit ca. 2000 v. Chr.)
§ Katalogisierung nach Titel, Erscheinungsjahr,Autoren oder Schlagwörtern
§ Klassifikationsschemata zur inhaltlichenEinordnung (z.B. Dewey-Dezimalklassifikation)
§ Vannevar Bushs Memex (1945) [3]
§ erweitertes Gedächtnis (memory extender)
§ Verknüpfung und Annotation von Inhalten
Datenbanken & Informationssysteme / Kapitel 5: Information Retrieval
© JMC Photos@flickr

9
Historisches
§ SMART System von Salton et al. (1960er)
§ Rangordnung der Ergebnisse
§ Berücksichtigung von Rückmeldungen des Benutzers
§ TREC und andere Benchmark-Initiativen (seit 1992)
§ Google und andere Suchmaschinen (seit frühen 1990er)
Datenbanken & Informationssysteme / Kapitel 5: Information Retrieval

10
IR vs. DBMSs
§ IR-Systeme und DBMSs unterscheiden sich wie folgt
§ unstrukturierte vs. strukturierte Daten
(z.B. Zeitungsartikel vs. Attribute eines Produkts)
§ vages vs. genau definiertes Informationsbedürfnis
(z.B. Berichte über Berlin vs. meistverkauftes Produkt)
§ vage vs. genau definierte Semantik der Anfragen
(z.B. Schlüsselwortanfragen vs. Relationale Algebra)
§ Rangordnung vs. keine Rangordnung der Ergebnisse
(z.B. Berichte über Berlin vs. Studenten im dritten Semester)
§ Mensch vs. Anwendung als typischer Anwender
Datenbanken & Informationssysteme / Kapitel 5: Information Retrieval

11
IR in DBMSs
§ DBMSs integrieren zunehmend IR-Funktionalität
§ Volltextsuche (z.B. in MS SQL Server und PostgreSQL)auf textuellen Attributen mit linguistischer Vorverarbeitung,sowie Rangordnung der Ergebnisse
§ IR-Systeme werden zunehmend als DBMSs eingesetzt
§ Elasticsearch und Apache Solr erweitern Apache Lucene
als traditionelles IR-System zur Indexierung und Suche von
semi-strukturierten Dokumenten (z.B. in JSON oder XML)und können je nach Anwendung ein (R)DBMS ersetzen
Datenbanken & Informationssysteme / Kapitel 5: Information Retrieval

12
Gütemaße im Information Retrieval
§ Informationsbedürfnis des Benutzers undSemantik der Anfragen sind vage
§ Gütemaße messen inwiefern das von einem IR-Systemzurückgelieferte Ergebnis das Informationsbedürfnis
des Benutzers befriedigen kann
§ Alle Dokumente in der Dokumentensammlung werden hierzu als relevant bzw. nicht-relevant für das Informationsbedürfnis des Benutzers klassifiziert
Datenbanken & Informationssysteme / Kapitel 5: Information Retrieval
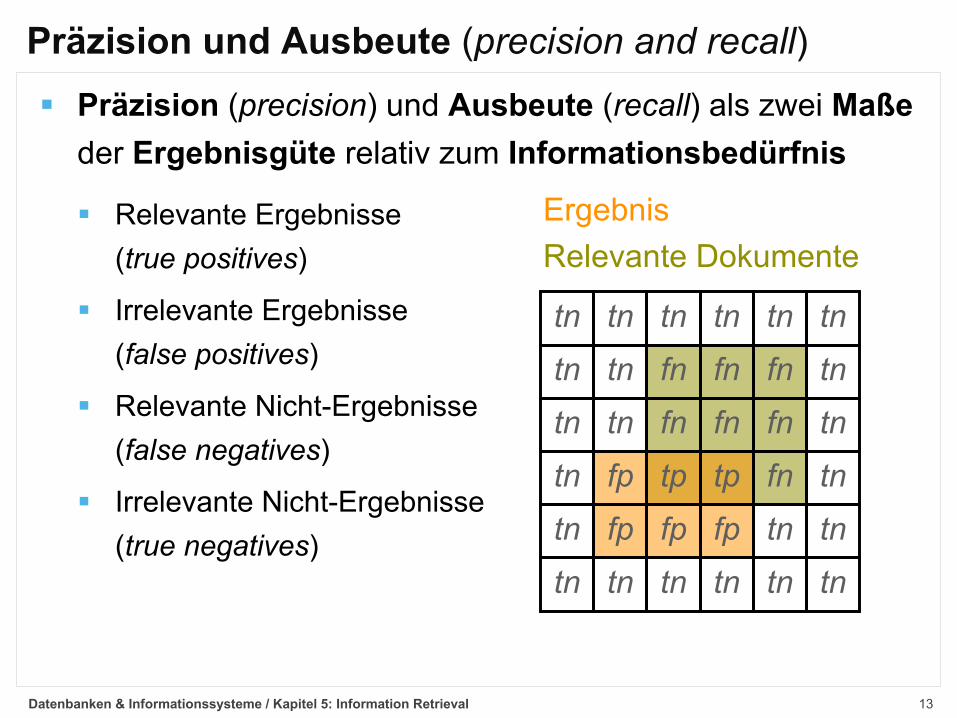
13
Präzision und Ausbeute (precision and recall)§ Präzision (precision) und Ausbeute (recall) als zwei Maße
der Ergebnisgüte relativ zum Informationsbedürfnis
§ Relevante Ergebnisse(true positives)
§ Irrelevante Ergebnisse(false positives)
§ Relevante Nicht-Ergebnisse(false negatives)
§ Irrelevante Nicht-Ergebnisse(true negatives)
Datenbanken & Informationssysteme / Kapitel 5: Information Retrieval
tn tn tn tn tn tn
tn tn
tn tn
tn
tn
tn tn tn tn tn tn
tn tn
tn
tn
tn
fp
fp fp fp
tptp
fn fn fn
fn
fnfnfn
Relevante DokumenteErgebnis

14
Präzision und Ausbeute (precision and recall)§ Präzision (precision)
misst Fähigkeit nur relevante Dokumente zu liefern
§ Ausbeute (recall)
misst Fähigkeit alle relevanten Dokumente zu liefern
Datenbanken & Informationssysteme / Kapitel 5: Information Retrieval
#tp
#tp + #fn=
# relevanter Dokumente im Ergebnis
# relevanter Dokumente
#tp
#tp + #fp=
# relevanter Dokumente im Ergebnis
# Dokumente im Ergebnis

15
Literatur
§ C. D. Manning, P. Raghavan, H. Schütze:Introduction to Information Retrieval,Cambridge University Press, 2008[PDF]
§ W. Bruce Croft, D. Metzler, T. Strohman:Search Engines – Information Retrievalin Practice, Pearson Education, 2010[PDF]
Datenbanken & Informationssysteme / Kapitel 5: Information Retrieval

16
5.2 Vorverarbeitung der Dokumente
§ Dokumente durchlaufen Vorverarbeitung (preprocessing),bevor sie indexiert werden, um dann mit Hilfe des Index Anfragen bearbeiten zu können, z.B.
§ Entfernen von Formatierungen (z.B. HTML-Tags)
§ Zerlegung (tokenization) in Bestandteile (tokens)
§ Normalisierung der Bestandteile zu Termen (terms)
Datenbanken & Informationssysteme / Kapitel 5: Information Retrieval

17
Zerlegung (tokenization)§ Dokumente werden in Bestandteile (tokens) zerlegt, indem
das Dokument u.a. an Leerzeichen (white spaces) aufgeteilt wird und Satzzeichen entfernt werden
§ Zusätzlich kann eine Aufteilung von Mehrwortgruppen
(compound splitting) vorgenommen werden(z.B. bodenseeschifferpatentantrag)
Datenbanken & Informationssysteme / Kapitel 5: Information Retrieval

18
Normalisierung (normalization)§ Normalisierung der Bestandteile führt zu Termen
(terms), die indexiert und gesucht werden können, z.B.
§ Umwandlung in Kleinbuchstaben (lower casing)
§ Vereinheitlichung von Umlauten (z.B. ä wird zu ae)
§ Vereinheitlichung von Datumsangaben (z.B. 2011/05/21)
Datenbanken & Informationssysteme / Kapitel 5: Information Retrieval

19
Wortreduktion (stemming, lemmatization)§ Wörter kommen in verschiedenen Beugungsformen vor
§ Konjugation bei Verben
(z.B. go, gone, went)
§ Deklination bei Substantiven und Adjektiven
(z.B. boat, boats, mouse, mice)
§ Komparation bei Adjektiven
(z.B. cheap, cheaper, cheapest)
§ Wörter können zudem den gleichen Wortstamm haben(z.B. work, worker, working, drive, driver, driven)
Datenbanken & Informationssysteme / Kapitel 5: Information Retrieval

20
Grundformreduktion
§ Reduktion auf Grundform (auch: Lemmatisierung) (lemmatization) erfolgt immer auf ein existierendes Wort
§ Nominativ Singular bei Substantiven und Adjektiven
(z.B. boat und boats wird zu boat)
§ Infinitiv bei Verben
(z.B. go, gone und went wird zu go)
§ Bestimmung der korrekten Grundform ist oft schwierig
und bedarf zusätzlicher Information in Form von
§ Kontext oder Wortart (part of speech)
§ Wörterbuch (z.B. um mice auf mouse abzubilden)
Datenbanken & Informationssysteme / Kapitel 5: Information Retrieval

21
Stammformreduktion
§ Reduktion auf Stammform (stemming) erfolgt auf Wortstamm, der kein existierendes Wort sein muss
(z.B. boats auf boa und vegetation auf veget)
§ Regelbasierte Ansätze zur sukzessiven Suffixentfernungfür schwach gebeugte (flektierte) Sprachen wie Englisch
Datenbanken & Informationssysteme / Kapitel 5: Information Retrieval

22
Porters Algorithmus
§ Porters Algorithmus entfernt Suffixe in fünf Schritten
§ Schritt 1a: Wende Regel für längst mögliches Suffix an§ sses → ss§ ies → i§ s → _
§ …
§ Schritt 2: Falls Token aus zwei oder mehr Silben besteht§ ational → ate§ tional → tion§ enci → ence§ izer → ize§ …
Datenbanken & Informationssysteme / Kapitel 5: Information Retrieval

23
Porters Algorithmus
Datenbanken & Informationssysteme / Kapitel 5: Information Retrieval
He is the author of the multi-volume work The Art of Computer Programming. He contributed to the development of the rigorous analysis of the computational complexity of algorithms and systematized formal mathematical techniques for it. In the process he also popularized the asymptotic notation. In addition to fundamental contributions in several branches of theoretical computer science, Knuth is the creator of the TeX computer typesetting system, the related METAFONT font definition language and rendering system, and the Computer Modern family of typefaces.
He is the author of the multi volum work The Art of Comput Program He contribut to the develop of the rigor analysi of the comput complex of algorithm and systemat formal mathemat techniqu for it In the process he also popular the asymptot notat In addit to fundament contribut in sever branch of theoret comput scienc Knuth is the creator of the TeX comput typeset system the relat METAFONT font definit languag and render system and the Comput Modern famili of typefac
Quelle: https://en.wikipedia.org/wiki/Donald_Knuth

24
Porters Algorithmus
§ Implementierung unter http://snowball.tartarus.org/algorithms/porter/stemmer.html
§ Online-Demo unterhttp://9ol.es/porter_js_demo.html
Datenbanken & Informationssysteme / Kapitel 5: Information Retrieval

25
Wortreduktion
§ Durch eine Reduktion von Wörtern auf ihre Grundform
oder Stammform kann man erreichen
§ tolerantere Suche (z.B. beim Booleschen Retrieval),die nicht mehr von spezifischer Wortform abhängt
§ geringere Anzahl zu indexierender Terme
§ Verbesserung des Recall
(z.B. für working conditions chinese factories)
§ Verschlechterung der Präzision
(z.B. für marine vegetation)
§ Nutzen der Wortreduktion für IR ist umstritten, tendenziell größer für stark flektierte Sprachen (z.B. Deutsch)
Datenbanken & Informationssysteme / Kapitel 5: Information Retrieval

26
Zipf‘sches Gesetz (Zipf‘s law)§ George K. Zipf (1902–1950) beobachtete,
dass für natürlichsprachliche Text gilt,dass die Häufigkeit eines Wortes f(w)umgekehrt proportional zu seinemHäufigkeitsrang r(w) ist, d.h.:
§ Das häufigste Wort kommt somit
§ doppelt so oft vor wie das zweithäufigste Wort
§ zehnmal so oft vor wie das Wort auf Rang 10
§ hundertmal so oft vor wie das Wort auf Rang 100
Datenbanken & Informationssysteme / Kapitel 5: Information Retrieval
Quelle: http://en.wikipedia.org
f(w) Ã 1r(w) –
mit – ¥ 1
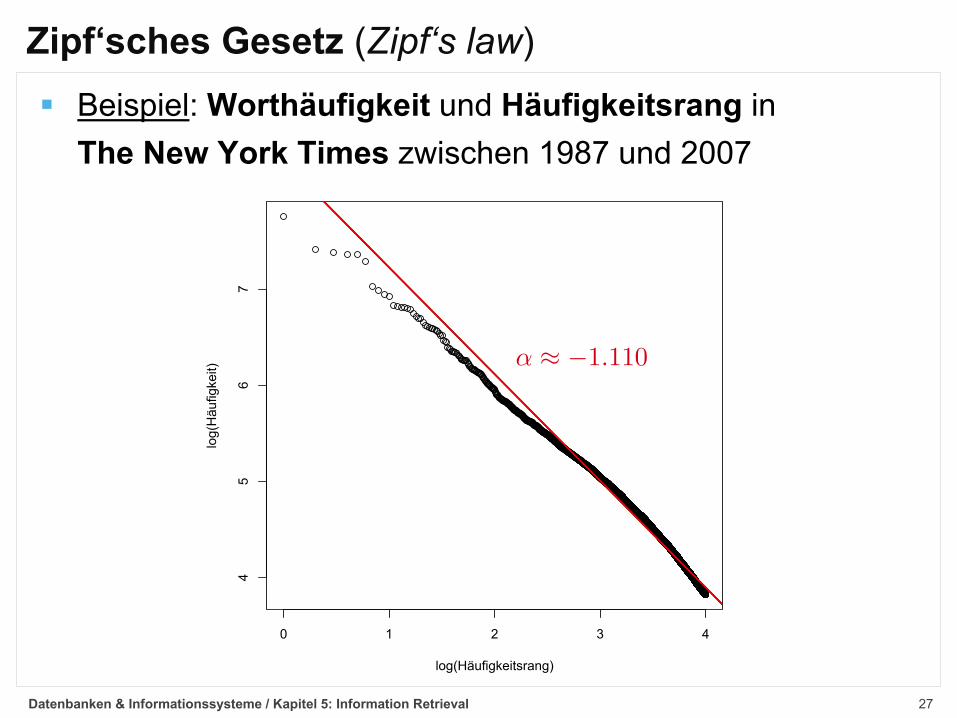
27
Zipf‘sches Gesetz (Zipf‘s law)§ Beispiel: Worthäufigkeit und Häufigkeitsrang in
The New York Times zwischen 1987 und 2007
Datenbanken & Informationssysteme / Kapitel 5: Information Retrieval
0 1 2 3 4
45
67
log(Häufigkeitsrang)
log(Häufigkeit)
– ¥ ≠1.110

28
Stoppworteliminierung (stopword removal)§ Stoppwörter (z.B. a, the, of) sind Wörter, die nur wenig
Information beinhalten, da sie z.B. in sehr vielen
Dokumenten vorkommen und somit von geringem Nutzen für die Beantwortung von Anfragen sind
§ Eliminierung von Stoppwörtern
§ reduziert den zur Indexierung benötigten Speicherplatz
§ verbessert die Antwortzeiten
§ kann Ergebnisgüte verbessern
(z.B. a song of fire and ice)
§ kann Ergebnisgüte verschlechtern (z.B. the who)
Datenbanken & Informationssysteme / Kapitel 5: Information Retrieval

29
Stoppworteliminierung (stopword removal)§ Stoppworteliminierung anhand einer manuell definierten
Stoppwortliste, evtl. mit themenspezifischen Stoppwörtern
§ Stoppwortliste kann alternativ automatisch erstellt
werden und alle Wörter enthalten, die in mehr als einem
bestimmten Anteil der Dokumente vorkommen
Datenbanken & Informationssysteme / Kapitel 5: Information Retrieval
a, an, and, are, as, at, be, by, for,has, he, in, is, it, its, of, on, that,
the, to, was, where, will, with

30
Bag-of-Words
§ Vorverarbeitung wandelt Dokument in eine Multimenge
von Wörtern (bag of words) um, d.h. die Information wie oft ein Wort im Dokumente vorkommt bleibt erhalten
Datenbanken & Informationssysteme / Kapitel 5: Information Retrieval

31
5.3 Boolesches Retrieval
§ Boolesches Retrieval als früher Ansatz, der noch Anwendung (z.B. Katalogsuche in Bibliotheken) findet
§ Dokumente als Belegungen Boolescher Variablen, die anzeigen, ob ein Term im Dokument vorkommt oder nicht
§ Anfragen als Boolesche Ausdrücke, welche Terme mit den Operatoren AND, OR und NOT verknüpfen
Datenbanken & Informationssysteme / Kapitel 5: Information Retrieval

32
Boolesches Retrieval
§ Beispiel: Dokumente über George Martin oder Neil Gaiman
mit Darstellung der Dokumentensammlungals Term-Dokument-Matrix
Datenbanken & Informationssysteme / Kapitel 5: Information Retrieval
(george AND martin) OR (neil AND gaiman)
george martin neil gaiman
d1 1 0 0 1d2 1 1 1 0d3 0 1 1 1d4 0 1 1 0d5 0 0 1 1
✖
✔
✔
✖
✔

33
Erweiterungen
§ Boolesches Retrieval kann erweitert werden durch
§ Aufteilung der Dokumenten in Felder (z.B. Titel, Abstract)
§ zusätzliche Operatoren basierend auf Wortposition (NEAR)
§ Vorteil:
§ Semantik von Anfragen (d.h. erwartetes Ergebnis)ist eindeutig definiert
§ Nachteil:
§ keine Rangordnung des Ergebnissesnach Relevanz (ranking)
Datenbanken & Informationssysteme / Kapitel 5: Information Retrieval

34
Zusammenfassung
§ Information Retrieval als Fachgebiet in der Schnittmenge zwischen Informationswissenschaft, Informatik
und Computerlinguistik
§ Präzision und Ausbeute als elementare Gütemaße
§ Zerlegung und Normalisierung der Dokumente
(z.B. Eliminierung von Stoppwörtern, Wortreduktion)
§ Boolesches Retrieval als früher Ansatz, der noch immer Anwendung findet und Grundlage moderner Ansätze ist
Datenbanken & Informationssysteme / Kapitel 5: Information Retrieval

35
Literatur
[1] C. D. Manning, P. Raghavan, H. Schütze:
Information Retrieval, Cambridge University Press, 2008(Kapitel 1 & 2)
[2] W. B. Croft, D. Metzler, T. Strohman:
Search Engines – Intelligent IR in Practice,Pearson, 2010(Kapitel 1 & 4)
[3] V. Bush: As We May Think, The Atlantic, 1945http://www.theatlantic.com/magazine/archive/1945/07/as-we-may-think/303881/
Datenbanken & Informationssysteme / Kapitel 5: Information Retrieval







