Leuphana Universität Lüneburg Statistik I Deskription Fakultät W Wirtschaftswissenschaften Professur 'Statistik und Freie Berufe' Univ.-Prof. Dr. Joachim Merz Übungs- und Klausuraufgaben mit Lösungen
Transcript
Leuphana Universität Lüneburg
Statistik I Deskription
Fakultät W Wirtschaftswissenschaften
Professur 'Statistik und Freie Berufe' Univ.-Prof. Dr. Joachim Merz
Übungs- und Klausuraufgaben
mit Lösungen
Zwölfte Auflage 2014
Impressum: Statistik I - Deskription, Übungs- und Klausuraufgaben
herausgegeben von der Leuphana Universität Lüneburg,
Fakultät W - Wirtschaftswissenschaften.
Univ.-Prof. Dr. Joachim Merz, Forschungsinstitut Freie Berufe,
Professur 'Statistik und Freie Berufe'.
Campus, Scharnhorststraße 1, Gebäude 5, 21335 Lüneburg
Gedruckt auf 100 % Altpapier, chlorfrei gebleicht.
Copyright 2014
Vorwort Für das 'aktive Lernen' des Stoffes aus der Vorlesung 'Statistik I – Deskription' sind in diesem Übungsbuch neue vorlesungsbegleitende Übungsaufgaben sowie neue Klau-suren jeweils mit Lösungen zusammengestellt. Grundlage für dieses Skriptum ist meine Vorlesung 'Statistik I – Deskription' an der Universität Lüneburg mit den zugehörigen Plenarübungen. Es empfiehlt sich, die Klausuren unter Examensbedingungen (Zeitvorgabe!) selbständig zu lösen. Bei der Erstellung der Übungsaufgaben waren meine Tutorinnen und Tutoren tatkräftig und selbständig beteiligt. Mein herzlicher Dank für die neue Auflage gilt Katja Bergstedt und besonders Lena Krüger, die schließlich auch die redaktionelle Arbeit getan hat. Danken möchte ich aber auch den Tutorinnen und Tutoren der voran-gegangenen Semester, die für dieses Übungsbuch Grundsteine gelegt haben, sowie Herrn Dipl.-Volksw. Paul Böhm für die generelle Unterstützung. Viel Spaß und Erfolg! Lüneburg, im August 2014 Univ.-Prof. Dr. Joachim Merz
STATISTIK I - Deskription
A ÜBUNGSAUFGABEN MIT LÖSUNGEN
1 Allgemeine Grundlagen und Wirtschafts- und Sozialstatistik ........................ 1
2 Statistische Analyse eines einzelnen Merkmals ............................................. 6
3 Konzentration einer Verteilung und statistische Analyse mehrerer Merkmale ...................................................................................................... 12
Aufgabenblatt 1: Allgemeine Grundlagen und Wirtschafts- und Sozialstatistik
1 Im Rahmen der Statistik I-Vorlesung findet seit letztem Semester regelmäßig eine Umfrage zu Wohnsituation der Studierenden statt. In dieser werden die Teilnehmer der Vorlesung zu Themen wie ihrer Wohnform, der Größe ihrer Wohnung und ähnlichem befragt. Klären Sie für diese Analyse die folgenden Begriffe:
2 Geben Sie die Skalierung der folgenden Merkmale an:
a) Geschlecht b) Studiengang (BWL, Uwi, Kuwi etc.) c) Wohnform (bspw. WG, Einzelwohnung) d) Entfernung der Wohnung von der Universität (drei Ausprägungen:
„nah“, „weit“, „sehr weit“) e) Wohnungsgröße (in m²) f) Zahl der Zimmer g) Miete (in €) h) Miete (drei Ausprägungen: „niedriger als die Durchschnittsmiete“,
„gleich der Durchschnittsmiete“, „höher als die Durchschnittsmiete“) i) Miete pro m² Wohnfläche j) Durchschnittliche Zimmergröße k) Zahl der Mitbewohner l) Zufriedenheit mit der Wohnung (drei Ausprägungen „sehr zufrieden“,
„geht so“, „bin weg, sobald ich irgendetwas anderes finde“) m) Durchschnittliche Temperatur im Sommer (in °C)
3 Welche der in Aufgabe 2 genannten Merkmale sind stetig bzw. diskret? 4 Üben Sie den Umgang mit Summenzeichen anhand folgender Beispiele:
i 1 2 3 4 5
ix 2 4 6 8 10
iy 20 40 80 160 320
2 Merz: Statistik I - Deskription
a) 5
1i
i
x=∑ b)
4
2j
j
y=∑
c) 21
n
jj
x y=∑ d)
5
21
ii
x y=
+∑
e) ( )5
1
2 2ii
x=
+∑ f) 5 2
1 1i j
i j
x y= =∑∑
5 Im Folgenden finden Sie wirtschaftliche Daten eines fiktiven Landes geteilt
nach Männern und Frauen sowie nach den beiden Regierungsbezirken Norden und Süden.
Erwerbstätige; In Klammern: abhängige Erwerbstätige
Norden 1,3 Mio. (75%) 0,75 Mio. (30%) Süden 1,36 Mio. (85%) 1,0 Mio. (40%)
a) Berechnen und interpretieren Sie das Geschlechterverhältnis. b) Berechnen und interpretieren Sie die Bevölkerungsdichte. c) Berechnen und interpretieren Sie die allgemeine Erwerbsquote für die
Männer.1 d) Wie viele abhängige Erwerbstätige gibt es im Süden?
6 Ordnen Sie folgende Personen in das Erwerbskonzept ein:
a) Peter Neururer, 50 Jahre, bis Ende Mai 2005 Trainer des Vfl Bochum, sucht eine neue Stelle als Bundesligatrainer, nicht bei der Agentur für Arbeit gemeldet
b) Stefan M., 27, nach abgeschlossenem Philosophie und Anthropologiestudium mit einem Zeitvertrag über drei Jahre bei einer Tageszeitung als Sportreporter beschäftigt
c) Herrmann K., 41, Angestellter der Stadt Hamburg, seit 4 Monaten mit schwerer Grippe im Krankenhaus, angeblich kein Simulant
d) Josef Ackermann, 57, Sprecher des Vorstands der Deutschen Bank AG e) Paul R, 40, ehemaliger Bäcker, wegen einer Mehlstauballergie
berufsunfähig, bezieht Arbeitslosengeld II und sucht über die Agentur für Arbeit eine Stelle als Lagerarbeiter
f) Peter R, 40, Bäcker in einer Großbäckerei, möchte sich beruflich verändern und sucht privat und über die Agentur für Arbeit eine Stelle als Lagerarbeiter
g) Hannelore B., 34, Hausfrau, macht in der Abendschule ihr Abitur nach
4 Merz: Statistik I - Deskription
Lösungen zu Aufgabenblatt 1:
Allgemeine Grundlagen und Wirtschafts- und Sozialstatistik
1 • statistische Einheit/Merkmalsträger: der einzelne (befragte) Student • Merkmal: bspw. die Wohnform • Ausprägungen (gleiches Beispiel): WG, Einzelwohnung,
Wohnheimzimmer, bei Eltern… 2 und 3
a) Geschlecht ⇒ männlich, weiblich ⇒ NOMINAL (diskret)
b) Studiengang ⇒ NOMINAL (diskret) c) Wohnform ⇒ WG etc. ⇒NOMINAL (diskret) d) Entfernung zu Uni ⇒ 3 Kategorien ⇒ ORDINAL (diskret) e) Wohnungsgröße ⇒ VERHÄLTNIS (stetig) f) Zahl der Zimmer ⇒ ABSOLUT (diskret) natürliche Einheit und Nullpunkt g) Miete (in €) ⇒ VERHÄLTNIS (appr. stetig), natürlicher Nullpunkt h) Miete (3 Ausprägungen) ⇒ ORDINAL (diskret) i) Miete pro m² ⇒ VERHÄLTNIS (approximativ stetig) j) Durchschnittliche Zimmergröße ⇒ VERHÄLTNIS (stetig) k) Zahl der Mitbewohner ⇒ ABSOLUT (diskret) l) Zufriedenheit ⇒ ORDINAL (diskret) m) Durschnittstemperatur ⇒ INTERVALL (stetig)
Aufgabenblatt 2: Statistische Analyse eines einzelnen Merkmals
1 In der autofreien Stadt Klauingen steigt die Fahrraddiebstahlquote immer
weiter an. Die Arbeitsgruppe „Statistik“ der Klauinger Gesamtschule, die sich seit je her mit dem Fahrverhalten der Einwohner beschäftigt, nahm dieses zum Anlass für eine neue Umfrage. Sie befragten 20 Bewohner nach der Anzahl der ihnen gestohlener Fahrräder in den letzten 5 Jahren. Die Gruppe kam zu folgendem Ergebnis:
0 8 5 6 1 5 2 7 4 6 4 3 1 5 4 7 5 3 6 5
a) Auf welcher Skala wird dieses Merkmal gemessen? Handelt es sich um
ein stetiges oder diskretes Merkmal? b) Ermitteln sie die absoluten und relativen Häufigkeiten und die
Verteilungsfunktion anhand einer Tabelle. c) Wie vielen der Befragten wurden weniger als 5 Räder entwendet? d) Berechnen Sie den Median (Z) und den Modus (D). e) Bestimmen Sie die Spannweite (R).
2 Des Weiteren interessierte sich die Statistikgruppe für die im letzten Jahr zurückgelegten Kilometer der Stadtbewohner. Sie kamen zu folgenden erstaunlichen Ergebnissen:
a) Bestimmen Sie die absoluten und relativen Häufigkeiten unter
b) Ermitteln Sie des Weiteren die Verteilungs- und die Dichtefunktion. c) Errechnen Sie die modale Klasse, den Median sowie das arithmetische Mittel. d) Errechnen Sie das obere und untere Quartil, sowie die
Quartilsabweichung und zeichnen sie ein “Box and Whiskers“ Plot. e) Ermitteln Sie außerdem die Varianz und die Standardabweichung. f) Errechnen und interpretieren sie die standarisierte Schiefe und die
a) Der Fechnerschen Lageregel zur Folge gilt für eine asymmetrische Verteilung: Arithmetisches Mittel = Median = Modus.
b) Ein Merkmal des arithmetischen Mittels ist es, dass die Summe der quadrierten Abweichungen der Merkmalswerte vom arithmetischen Mittel gleich 0 ist.
c) Das geometrische Mittel wird zur Berechnung von Durchschnittsgeschwindigkeiten herangezogen, da es in diesem Zusammenhang genauer ist, als das arithmetische Mittel.
d) Bei gruppiertem Datenmaterial ist der Modus immer gleich dem Mittelwert.
e) Eine Verteilungsfunktion kann auch einen Wert größer 1 annehmen. f) Je größer der Exzess, desto flacher ist die Verteilung. g) Je stärker negativ das dritte Moment ( Schiefe ) ist, desto linkssteiler ist
die Verteilung.
8 Merz: Statistik I - Deskription
Lösungen zu Aufgabenblatt 2: Statistische Analyse eines einzelnen Merkmals
c) gesucht: ( ) ( 5) ( 4) 4 0, 45 45%h x h x F< = ≤ = = =
d) Modus (D): Bei metrisch skalierten, ungruppierten Merkmalen, ist der Modus der Merkmalswert x, bei dem die relative Häufigkeit ihr Maximum annimmt.
5D = Median (Z): Der Median halbiert das Datenmaterial, so dass 50% darüber und 50% darunter liegen. hier ist n = 20 (wichtig: 20 ist eine gerade Zahl)
Da die standardisierte Schiefe kleiner 0 ist, handelt es sich um eine rechtssteile bzw. um eine linksschiefe Verteilung. Die standardisierte Wölbung ist gleich 2,0651. Dieser Wert lässt sich normieren sm4= m4/s
4 - 3 = -0,9349. Damit lässt sich nun sagen, dass die hier vorliegende Verteilung spitzer ist, als die Normalverteilung.
Merz: Statistik I - Deskription 11
3
a) Falsch. Der Fechnerschen Lageregel zur Folge gilt für eine asymmetrische Verteilung: arithmetisches Mittel ≠ Z ≠ D . D < Z < arithmetisches Mittel = linkssteile Verteilung und arithmetisches Mittel < Z< D. (nur bei einer Uni-modalen Verteilung sinnvoll).
b) Falsch. Die Summe der quadrierten Abweichungen der Merkmalswerte vom arithm. Mittel ist ein Minimum.
c) Falsch. Das geometrische Mittel wird bei Wachstumsraten herangezogen, bei der
Berechnung von Durchschnittsgeschwindigkeiten hilft das harmonische Mittel.
d) Falsch. e) Falsch.
Die Verteilungsfunktion besteht aus den aufsummierten Wahrscheinlichkeiten und kann somit nicht über 1 steigen.
f) Richtig. g) Falsch.
Je stärker negativ das dritte Moment ist, desto rechtssteiler ist die Verteilung.
12 Merz: Statistik I - Deskription
Aufgabenblatt 3: Konzentration einer Verteilung und statistische Analyse mehrerer
Merkmale
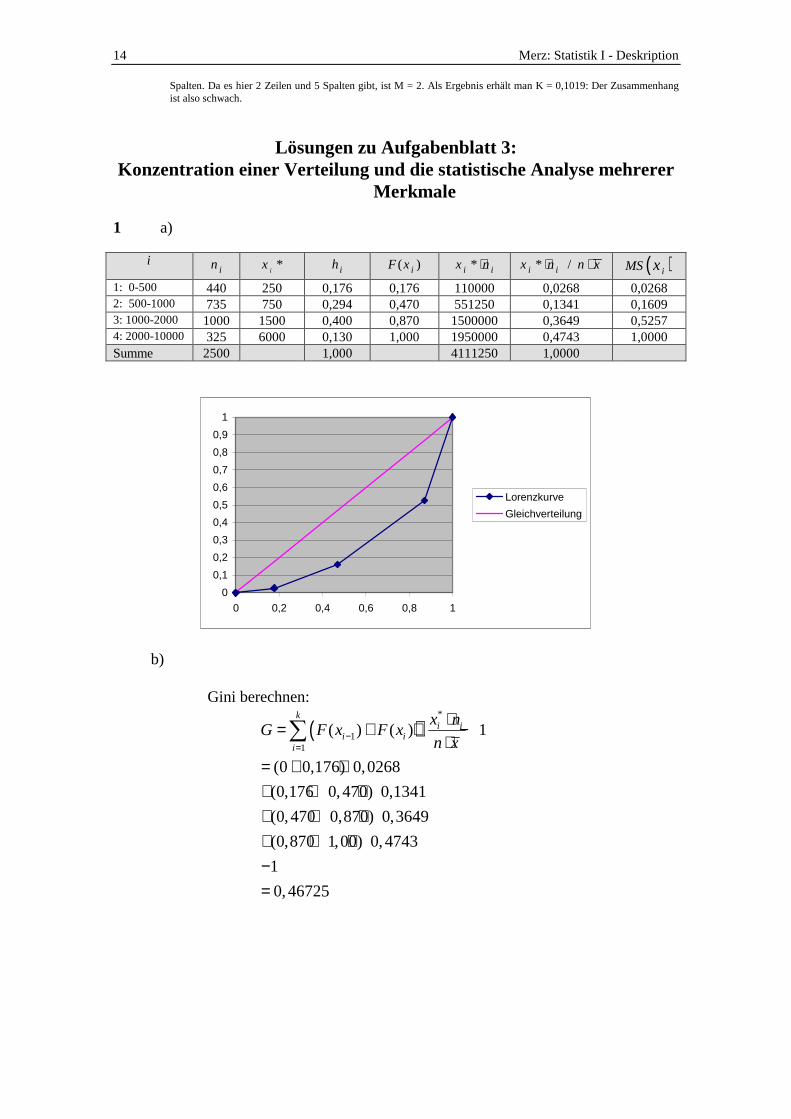
1 Sie wollen das Nettoeinkommen der Deutschen analysieren. Eine Befragung (Quelle: Allbus 2004) ergab folgende Einkommensverteilung:
Monatliches Nettoeinkommen in € 0-500 500-1000 1000-2000 2000-10000
Anzahl der Personen 440 735 1000 325
a) Ermitteln Sie die kumulierte relative Merkmalssumme und tragen Sie
diese mit der kumulierten Häufigkeit zusammen in einem Diagramm (Lorenzkurve) ab.
b) Beurteilen Sie, ob die deutsche Einkommensverteilung gleichverteilt ist. Berechnen Sie hierzu ein geeignetes statistisches Maß.
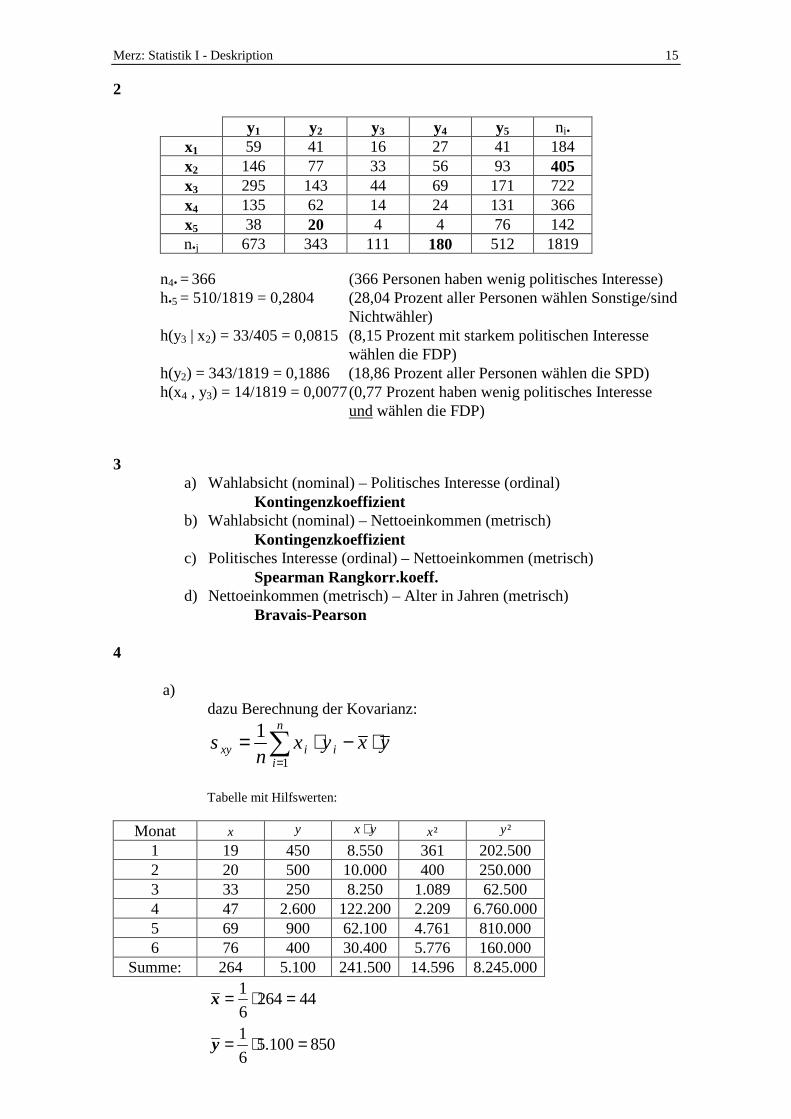
2 Ihr Kommilitone ist Politikstudent und soll den Zusammenhang zwischen dem
politischen Interesse und der Wahlabsicht analysieren. Das politische Interesse x wurde als ordinales Merkmal erfasst (1:sehr stark; 2:stark; 3:mittel; 4:wenig; 5:überhaupt nicht). Bei der Wahlabsicht y wurde nach folgenden Parteien gefragt:
1: CDU/CSU 2: SPD 3: FDP 4: Die Grünen 5: Sonstige/Nichtwähler
a) Ermitteln Sie die fehlenden Werte in der Tabelle sowie die
Randverteilungen. b) Berechnen und interpretieren Sie die Ausdrücke n4•, h•5, h(y3 | x2), h(y2),
h(x4 , y3)
3 Da Sie völlig begeistert über die im „Allbus 2004“ erhobenen Daten sind, wollen Sie den Zusammenhang zwischen einigen Merkmalen analysieren. Welches Zusammenhangsmaß wählen Sie?
a) Wahlabsicht – Politisches Interesse b) Wahlabsicht – Nettoeinkommen c) Politisches Interesse – Nettoeinkommen d) Nettoeinkommen – Alter in Jahren
Merz: Statistik I - Deskription 13
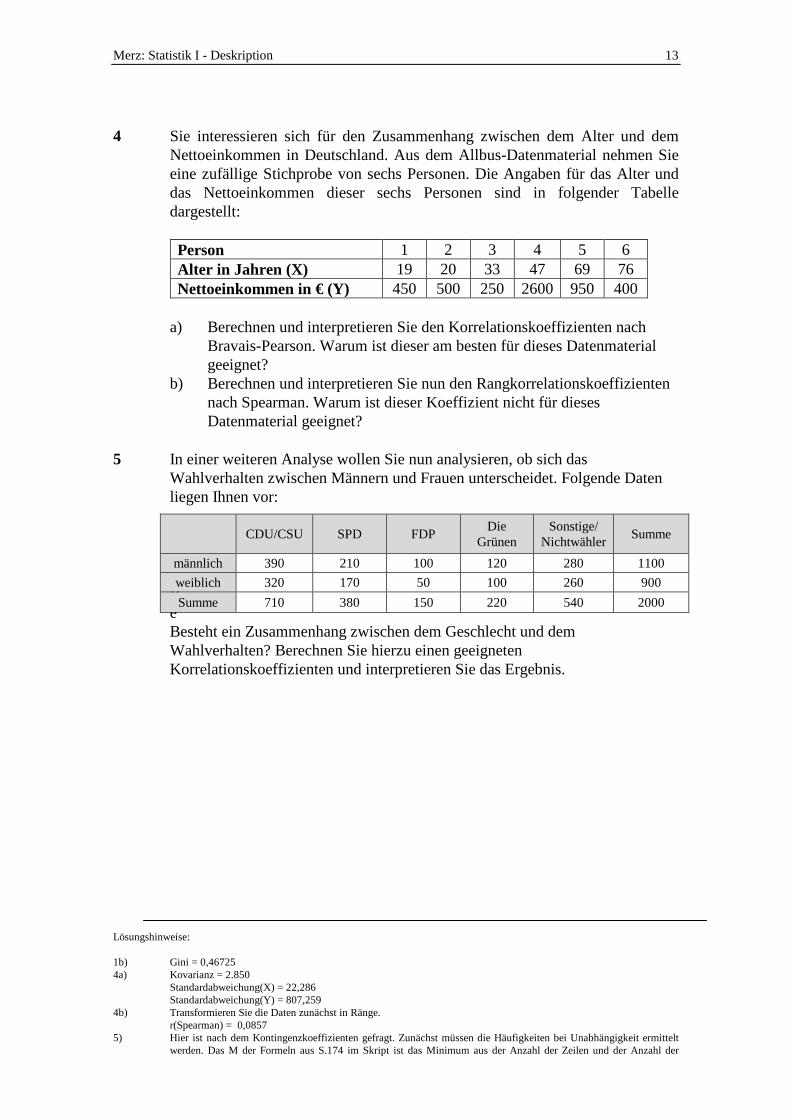
4 Sie interessieren sich für den Zusammenhang zwischen dem Alter und dem Nettoeinkommen in Deutschland. Aus dem Allbus-Datenmaterial nehmen Sie eine zufällige Stichprobe von sechs Personen. Die Angaben für das Alter und das Nettoeinkommen dieser sechs Personen sind in folgender Tabelle dargestellt:
Person 1 2 3 4 5 6 Alter in Jahren (X) 19 20 33 47 69 76 Nettoeinkommen in € (Y) 450 500 250 2600 950 400
a) Berechnen und interpretieren Sie den Korrelationskoeffizienten nach
Bravais-Pearson. Warum ist dieser am besten für dieses Datenmaterial geeignet?
b) Berechnen und interpretieren Sie nun den Rangkorrelationskoeffizienten nach Spearman. Warum ist dieser Koeffizient nicht für dieses Datenmaterial geeignet?
5 In einer weiteren Analyse wollen Sie nun analysieren, ob sich das
Wahlverhalten zwischen Männern und Frauen unterscheidet. Folgende Daten liegen Ihnen vor:
BeBesteht ein Zusammenhang zwischen dem Geschlecht und dem Wahlverhalten? Berechnen Sie hierzu einen geeigneten Korrelationskoeffizienten und interpretieren Sie das Ergebnis.
Lösungshinweise: 1b) Gini = 0,46725 4a) Kovarianz = 2.850 Standardabweichung(X) = 22,286 Standardabweichung(Y) = 807,259 4b) Transformieren Sie die Daten zunächst in Ränge. r(Spearman) = 0,0857 5) Hier ist nach dem Kontingenzkoeffizienten gefragt. Zunächst müssen die Häufigkeiten bei Unabhängigkeit ermittelt
werden. Das M der Formeln aus S.174 im Skript ist das Minimum aus der Anzahl der Zeilen und der Anzahl der
CDU/CSU SPD FDP Die
Grünen Sonstige/
Nichtwähler Summe
männlich 390 210 100 120 280 1100
weiblich 320 170 50 100 260 900
Summe 710 380 150 220 540 2000
14 Merz: Statistik I - Deskription
Spalten. Da es hier 2 Zeilen und 5 Spalten gibt, ist M = 2. Als Ergebnis erhält man K = 0,1019: Der Zusammenhang ist also schwach.
Lösungen zu Aufgabenblatt 3:
Konzentration einer Verteilung und die statistische Analyse mehrerer Merkmale
n4• = 366 (366 Personen haben wenig politisches Interesse) h•5 = 510/1819 = 0,2804 (28,04 Prozent aller Personen wählen Sonstige/sind
Nichtwähler) h(y3 | x2) = 33/405 = 0,0815 (8,15 Prozent mit starkem politischen Interesse
wählen die FDP) h(y2) = 343/1819 = 0,1886 (18,86 Prozent aller Personen wählen die SPD) h(x4 , y3) = 14/1819 = 0,0077 (0,77 Prozent haben wenig politisches Interesse
und wählen die FDP) 3
a) Wahlabsicht (nominal) – Politisches Interesse (ordinal) Kontingenzkoeffizient
b) Wahlabsicht (nominal) – Nettoeinkommen (metrisch) Kontingenzkoeffizient
c) Politisches Interesse (ordinal) – Nettoeinkommen (metrisch) Spearman Rangkorr.koeff.
d) Nettoeinkommen (metrisch) – Alter in Jahren (metrisch) Bravais-Pearson
Die Kovarianz misst, ob ein linearer Zusammenhang zwischen Variablen besteht. Das Vorzeichen gibt die Richtung des Zusammenhangs an: es besteht also ein positiver Zusammenhang. Die Stärke des Zusammenhangs lässt sich anhand der Kovarianz allerdings nicht bemessen, da ihr Wertebereich nicht normiert ist. Hierfür benötigt man den Bravais-Pearson-
Korrelationskoeffizienten.
2 2 2
1
2 2 2
1
1 114596 44 22,286
6
1 18.245.000 850 807,259
6
28500,1584
22,286 807,259
=
=
=⋅
= ⋅ − = ⋅ − =
= ⋅ − = ⋅ − =
= =⋅
∑
∑
xy
x y
n
x ii
n
y ii
sr
s s
s x xn
s y yn
r
Es liegt also ein schwacher positiver Zusammenhang vor.
Es liegt also ebenfalls ein schwacher positiver Zusammenhang vor. Allerdings sollte man den BP-Koeffizienten berechnen, weil bei der Spearman–Methode durch die Transformation in Ränge Informationen verloren gehen.
5
Zunächst Berechnung der Häufigkeiten bei Unabhängigkeit (in Klammern)
M: Minimum aus [Anzahl der Zeilen & Anzahl der Spalten] Es besteht also nur ein schwacher Zusammenhang zwischen dem Geschlecht und der Wahlabsicht.
18 Merz: Statistik I - Deskription
Aufgabenblatt 4: Regressionsrechnung
1 Einfachregression
Die folgende Tabelle enthält eine Zufallsauswahl von 10 Fällen aus der im lezten Semester stattgefundenen Umfrage „Wohnst du noch oder studierst du schon?“. Anhand dieser Daten soll die übliche Vermutung, dass größere Wohnungen teurer sind als kleine (dass es also einen kausalen Zusammenhang zwischen Wohnfläche und Monatsmiete gibt) überprüft werden.
a) Erstellen Sie einen geeigneten und sinnvollen Regressionsansatz nach dem Schema 0 1= + +y xi i iβ β ε . Achten Sie dabei vor allem auf die Wahl
der abhängigen und der unabhängigen Variablen. b) Ermitteln und interpretieren Sie die lineare Regressionsfunktion des Typs
i iy = b b x0 1+ ⋅ nach der Methode der kleinsten Quadrate unter Verwendung
der Summenformeln (S. 185 Skript). c) Ermitteln und interpretieren Sie die lineare Regressionsfunktion des Typs
i iy = b b x0 1+ ⋅ nach der Methode der kleinsten Quadrate. Verwenden Sie
diesmal die Matrizenrechnung. - Erstellen und interpretieren Sie X'X und X'y.
- Berechnen und interpretieren Sie ( ) 1'X X
− und ( ) 1
' 'b X X X y−= ⋅ .
d) Berechnen und interpretieren Sie das Bestimmtheitsmaß R². e) Prognostizieren Sie mit ihrer Regressionsfunktion aus c) den Mietpreis
für Wohnungen mit 29 bzw. 110 m² Wohnfläche und nehmen Sie zu Ihrer Prognose kritisch Stellung.
Merz: Statistik I - Deskription 19
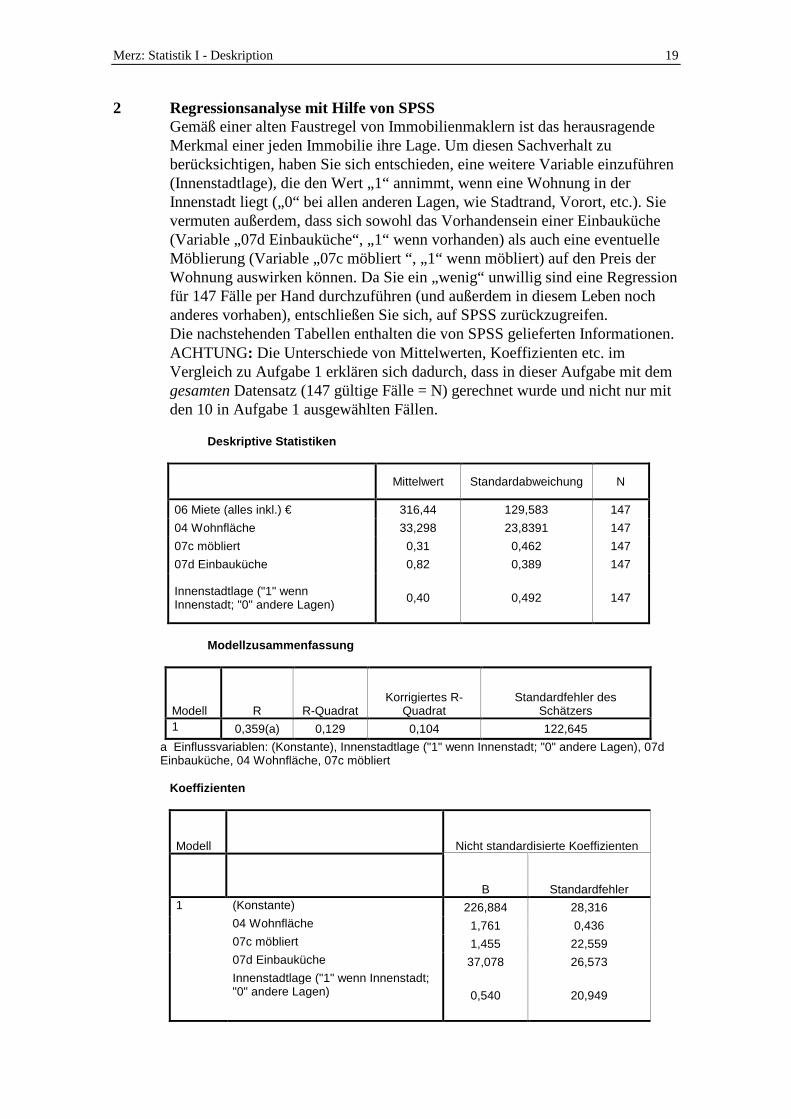
2 Regressionsanalyse mit Hilfe von SPSS
Gemäß einer alten Faustregel von Immobilienmaklern ist das herausragende Merkmal einer jeden Immobilie ihre Lage. Um diesen Sachverhalt zu berücksichtigen, haben Sie sich entschieden, eine weitere Variable einzuführen (Innenstadtlage), die den Wert „1“ annimmt, wenn eine Wohnung in der Innenstadt liegt („0“ bei allen anderen Lagen, wie Stadtrand, Vorort, etc.). Sie vermuten außerdem, dass sich sowohl das Vorhandensein einer Einbauküche (Variable „07d Einbauküche“, „1“ wenn vorhanden) als auch eine eventuelle Möblierung (Variable „07c möbliert “, „1“ wenn möbliert) auf den Preis der Wohnung auswirken können. Da Sie ein „wenig“ unwillig sind eine Regression für 147 Fälle per Hand durchzuführen (und außerdem in diesem Leben noch anderes vorhaben), entschließen Sie sich, auf SPSS zurückzugreifen.
Die nachstehenden Tabellen enthalten die von SPSS gelieferten Informationen. ACHTUNG: Die Unterschiede von Mittelwerten, Koeffizienten etc. im Vergleich zu Aufgabe 1 erklären sich dadurch, dass in dieser Aufgabe mit dem gesamten Datensatz (147 gültige Fälle = N) gerechnet wurde und nicht nur mit den 10 in Aufgabe 1 ausgewählten Fällen.
Deskriptive Statistiken
Mittelwert Standardabweichung N
06 Miete (alles inkl.) € 316,44 129,583 147
04 Wohnfläche 33,298 23,8391 147
07c möbliert 0,31 0,462 147
07d Einbauküche 0,82 0,389 147
Innenstadtlage ("1" wenn Innenstadt; "0" andere Lagen) 0,40 0,492 147
Modellzusammenfassung
Modell R R-Quadrat Korrigiertes R-
Quadrat Standardfehler des
Schätzers 1 0,359(a) 0,129 0,104 122,645
a Einflussvariablen: (Konstante), Innenstadtlage ("1" wenn Innenstadt; "0" andere Lagen), 07d Einbauküche, 04 Wohnfläche, 07c möbliert
Die Regressionsfunktion lautet:ˆ 124, 0457866 4,81770354y x= + ⋅
Der Koeffizient 1b sagt aus, wie sich eine Veränderung von x auf y aus-wirkt: pro Quadratmeter Wohnfläche steigt der durschnittliche Wohnungspreis um 4,82 €
Der Koeffizient 0b gibt den Schnittpunkt mit der y-Achse an, in diesem Fall eine "Basismiete" bei einer Wohnungsgröße von 0 m². Für das Beispiel ist der Wert jedoch nicht interpretierbar, da er weit außerhalb des Stützbereichs für die Regressionsfunktion liegt.
24 Merz: Statistik I - Deskription
d) Berechnung des Bestimmtheitsmaßes:
ˆerklärte Varianz von y (Varianz von y)
Gesamtvarianz (Varianz von y)
ˆ% der Varianz von Merkmal y werden erklärt duch die Varianz der geschätzten Merkmalswerte y
0 B 1
B
x
=
→ ≤ ≤→
2
1
2 2 2 2
1 1
2
2
1
1 1
n
i i
i
n n
i i
i i
xy
x y
x y x yn
B
x x y yn n
sr
s s=
= =
⋅ ⋅ − ⋅= =
⋅ − ⋅ ⋅ −
=
∑
∑ ∑
2
2
190.434 29,9 271
10
1 110.818 29, 2 800.812 271²
10 10
B
⋅ − ⋅=
⋅ − ⋅ ⋅ −
20, 762428 0,581296B = =
Durch die Regressionsfunktion werden 58,13 % der Gesamtstreuung der
Wohnungsmieten erklärt, es liegt eine (für ein derart einfaches Modell) recht hohe Anpassung vor, allerdings bleibt genug nicht erklärte Varianz um die Aufnahme zusätzlicher Variablen zu erwägen
Die Prognose für eine Wohnung mit 110 m² ist mit einer gewissen
Vorsicht zu genießen. Die größte Wohnung im Datensatz hat eine Größe von 68 m², so dass 110 m² recht weit ausserhalb des Datenmaterials liegt und eigentlich nicht zu interpretieren ist. Zudem hängt die Prognose ja nicht ausschließlich von der Größe ab (vergl. Aufgabenteil d).
2 Regressionsanalyse mit Hilfe von SPSS a) Deskriptive Informationen = Mittelwert und Standardabweichung
- abhängige Variable: y (Miete):
316, 44 316,44 €
129, 583 129,58 € 316,44 €
Wohnungen kosten im Durchschnitt
Die Miete weicht durchschnittlich um vom Mittelwert ab
y
y
s
=
= →
→
Merz: Statistik I - Deskription 25
- unabhängige Variablen: -
1
x (Wohnungsgröße): 11
33, 289; 23,8391 xx s= =
2
x (Wohnung möbliert/Dummy): 22 0, 31 0, 462; xx s= = → 31% der
Wohnungen sind möbliert
3x (Einbauküche/Dummy):
33 0, 82 0, 389; xx s= = → 82 % der Wohnungen
haben eine EBK 4x (Innenstadtlage):
34 0, 4 0, 492; xx s= = → 40% der Befragten haben eine
Innenstadtwohnung
b) Regressionsansatz:
0
1
2
3
4
( / )
( / )
( / )
i
i
i
i
i i
Wohnungsmiete
Wohnungsgröße
möbliert ja nein
EBK ja nein
Innenstadtlage ja nein
β
β
β
β
β ε
=
+ ⋅
+ ⋅
+ ⋅
+ ⋅ +
c) Regressionsfunktion:
1 2 3 4ˆ 266,884 1, 761 1, 455 37, 078 0,540
i i i i iy x x x x= + ⋅ + ⋅ + ⋅ + ⋅
Die „Basismiete“ beträgt 266,884 €.
Die Miete erhöht sich um durchschnittlich 1,761 € pro zusätzlichem m² Wohnfläche; sie erhöht sich um 1,455 €, wenn die Wohnung möbliert ist und um 37,078 € wenn es eine EBK gibt. Eine Innenstadtlage erhöht die Miete um 0,540 €.
Die Anpassungsgüte der Regressionsfunktion an die gegebenen y-Werte
ist nicht sonderlich gut: Nur 12,9 % der Varianz der Wohnungsmieten werden durch das Modell erklärt.
Bei der Interpretation des etwas „seltsamen“ Koeffizienten
(Innenstadtlage) sollte man auf andere relevante erklärende Variablen hinweisen:
Straßennähe der Wohnung, Wohnort (HH versus LG). Vielleicht gibt es aber auch andere inhaltliche Erklärungen.
26 Merz: Statistik I - Deskription
Aufgabenblatt 5:
Verhältnis- und Indexzahlen und Hochrechnung
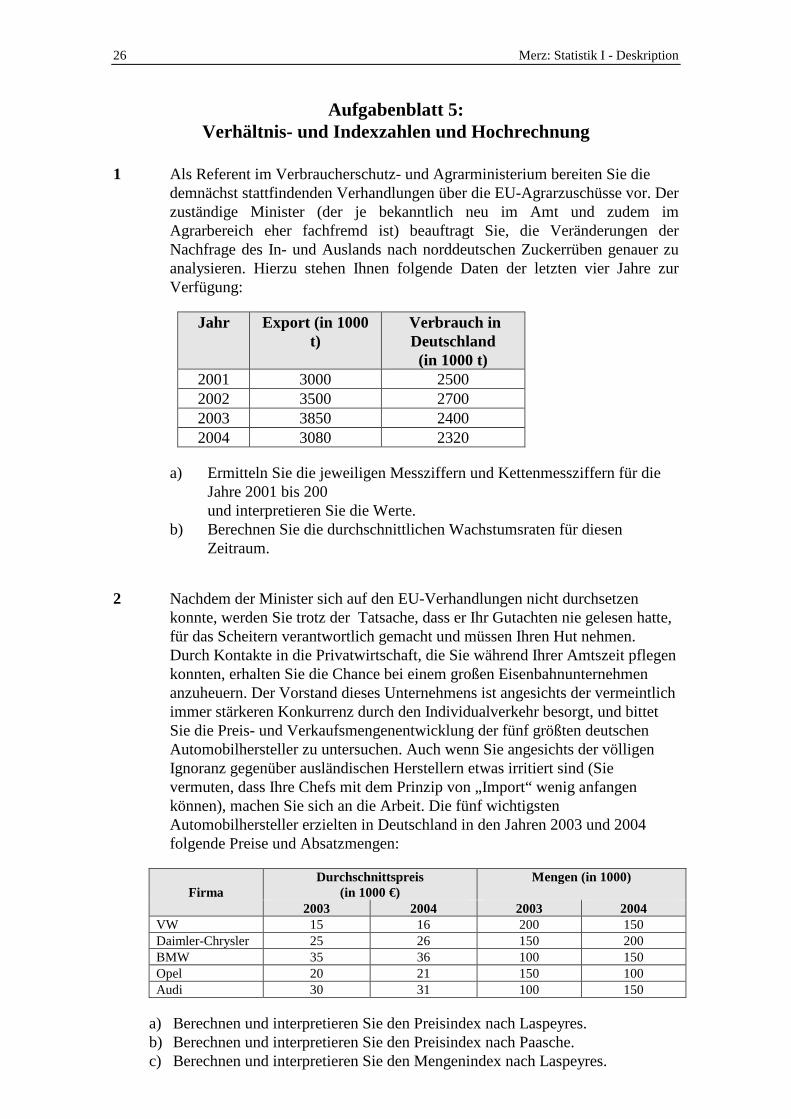
1 Als Referent im Verbraucherschutz- und Agrarministerium bereiten Sie die demnächst stattfindenden Verhandlungen über die EU-Agrarzuschüsse vor. Der zuständige Minister (der je bekanntlich neu im Amt und zudem im Agrarbereich eher fachfremd ist) beauftragt Sie, die Veränderungen der Nachfrage des In- und Auslands nach norddeutschen Zuckerrüben genauer zu analysieren. Hierzu stehen Ihnen folgende Daten der letzten vier Jahre zur Verfügung:
a) Ermitteln Sie die jeweiligen Messziffern und Kettenmessziffern für die Jahre 2001 bis 200 und interpretieren Sie die Werte. b) Berechnen Sie die durchschnittlichen Wachstumsraten für diesen Zeitraum.
2 Nachdem der Minister sich auf den EU-Verhandlungen nicht durchsetzen konnte, werden Sie trotz der Tatsache, dass er Ihr Gutachten nie gelesen hatte, für das Scheitern verantwortlich gemacht und müssen Ihren Hut nehmen. Durch Kontakte in die Privatwirtschaft, die Sie während Ihrer Amtszeit pflegen konnten, erhalten Sie die Chance bei einem großen Eisenbahnunternehmen anzuheuern. Der Vorstand dieses Unternehmens ist angesichts der vermeintlich immer stärkeren Konkurrenz durch den Individualverkehr besorgt, und bittet Sie die Preis- und Verkaufsmengenentwicklung der fünf größten deutschen Automobilhersteller zu untersuchen. Auch wenn Sie angesichts der völligen Ignoranz gegenüber ausländischen Herstellern etwas irritiert sind (Sie vermuten, dass Ihre Chefs mit dem Prinzip von „Import“ wenig anfangen können), machen Sie sich an die Arbeit. Die fünf wichtigsten Automobilhersteller erzielten in Deutschland in den Jahren 2003 und 2004 folgende Preise und Absatzmengen:
Firma Durchschnittspreis
(in 1000 €) Mengen (in 1000)
2003 2004 2003 2004
VW 15 16 200 150 Daimler-Chrysler 25 26 150 200 BMW 35 36 100 150 Opel 20 21 150 100 Audi 30 31 100 150
a) Berechnen und interpretieren Sie den Preisindex nach Laspeyres. b) Berechnen und interpretieren Sie den Preisindex nach Paasche. c) Berechnen und interpretieren Sie den Mengenindex nach Laspeyres.
Merz: Statistik I - Deskription 27
d) Berechnen und interpretieren Sie den Umsatzindex. e) Gehen Sie davon aus, dass im Jahr 2003 genauso viele Autos im Inland wie in
den USA abgesetzt wurden und der Gesamterlös der fünf deutschen Automobilhersteller in den USA bei 15 Mrd. US$ lag. Berechnen Sie die Verbrauchergeldparität. Beurteilen Sie das Ergebnis auch im Hinblick auf den offiziellen Wechselkurs.
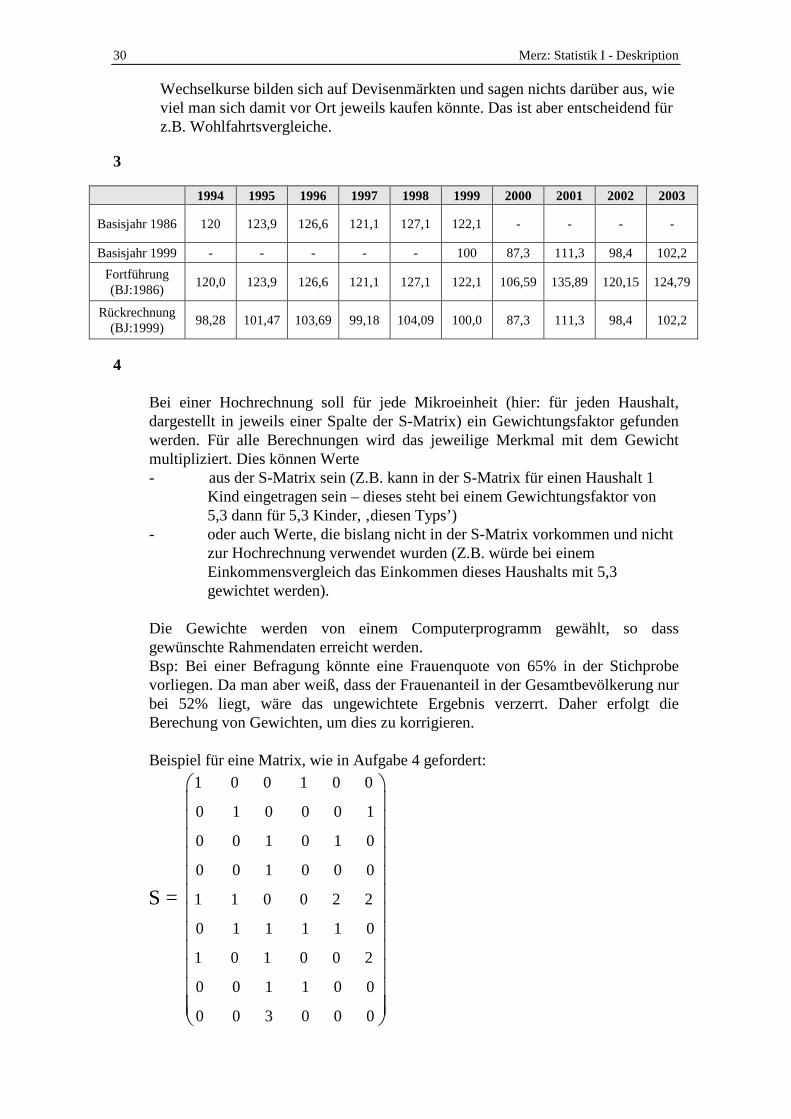
3 Erschüttert von den steigenden Verkaufszahlen der automobilen Konkurrenz entscheidet sich der Vorstand ihre Abteilung zu schließen, da diese „ohnehin nur für schlechte Nachrichten sorgt“. (Sollten Sie sich in Aufgabe 2c verrechnet und sinkende Verkaufszahlen errechnet haben, stellen Sie sich einfach vor, dass Sie deswegen entlassen werden). Da Sie derartiges schon geahnt hatten, haben Sie erfreulicherweise (für Sie) vorgesorgt und kommen bei einem großen Kaufhaus unter. Dieses hat die Verkaufszahlen seines beliebtesten Produktes (eines singenden Teddybären für Kinder im Vorschulalter) bisher als Index mit Basisjahr 1986 (dem Jahr der Einführung) erfasst. Da im Jahr 1999 ein Wechsel des Produktmanagers stattgefunden hat, dessen Beurteilung vereinfacht werden sollte), wurde in diesem Jahr ein neuer Index begonnen.
a) Berechnen und interpretieren Sie die Werte des gemeinsamen Indexes
mit dem Basisjahr 1986 (Fortführung). b) Berechnen und interpretieren Sie die Werte des gemeinsamen Indexes
mit dem Basisjahr 1999 (Rückrechnung) 4 Für die repräsentative Gewichtung einer Stichprobe wird eine simultane
Hochrechnung z.B. nach dem Minimum Information Loss (MIL)-Prinzip durchgeführt. Erstellen Sie für n=6 Haushalte eine sinnvolle S-Matrix bei einem gegebenen Vektor der anzustrebenden Rahmenbedingung:
R1: 100000 Einpersonenhaushalte R2: 85000 Zweipersonenhaushalte R3: 60000 Mehr als Zweipersonenhaushalte R4: 250000 Familien R5 60000 Erwerbstätige Frauen R6: 120000 Erwerbstätige Männer R7: 40000 Frauen älter als 40 Jahre R8: 35000 Männer älter als 40 Jahre R9: 25000 Kinder
Laspeyres: Der Warenkorb der Basisperiode ist in der Berichtsperiode veraltet (Substitution von Produkten) und muss regelmäßig aktualisiert werden, was einen Bruch in der Vergleichbarkeit zu den Vorperiodenwerten darstellt. Paasche: Das Problem des veralteten Warenkorbes besteht hier nicht. Aber: - Bestimmte Waren, auf die man den Index zurückrechnet gab es, oftmals
in früheren Perioden noch gar nicht. - hoher zeitlicher und kostenmäßiger Aufwand zur Bestimmung des neuen
Warenkorbes in jeder Periode. c) Mengenindex nach Laspeyres
Der Mengenindex hat die Aufgabe, die Mengenentwicklung der Gesamtheit von Gütern zwischen der Berichts- und Basisperiode anzugeben. Die Gewichtung erfolgt über die alten Preise.
Es wurden von allen Herstellern 21,53% mehr Umsatz gemacht
e) Gesamterlös Deutschland 2003: 16,25 Mrd. € → Angaben in Tabelle in
1000 € ( 0 01
.=∑
ni i
i
p q )
Gesamterlös USA 2003:15,00 Mrd. US$
$,
,$
15, 00 . $ $0,92308
16, 25 .
16, 25 .1, 08333
15, 00 . $ $
= =
= =
EUR
EUR
Mrd US USVG
Mrd EUR EUR
Mrd EUR EURVG
Mrd US US
Man braucht 1,083 € um sich den Gegenwert von 1 $ kaufen zu können → Kaufkraft der Währung. Offizieller Wechselkurs = Marktpreis von Währungen, spiegelt aber nicht wieder, wie viel das wirklich in dem Land der anderen Währung wert ist
30 Merz: Statistik I - Deskription
Wechselkurse bilden sich auf Devisenmärkten und sagen nichts darüber aus, wie viel man sich damit vor Ort jeweils kaufen könnte. Das ist aber entscheidend für z.B. Wohlfahrtsvergleiche.
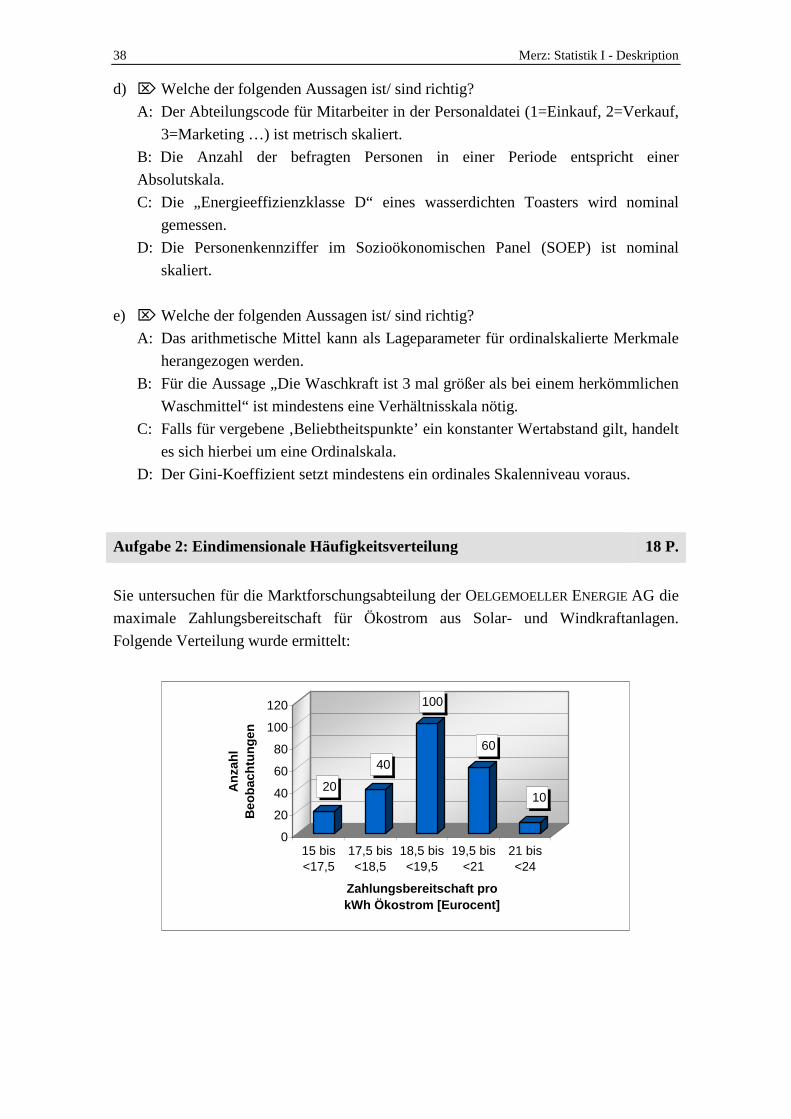
Bei einer Hochrechnung soll für jede Mikroeinheit (hier: für jeden Haushalt, dargestellt in jeweils einer Spalte der S-Matrix) ein Gewichtungsfaktor gefunden werden. Für alle Berechnungen wird das jeweilige Merkmal mit dem Gewicht multipliziert. Dies können Werte - aus der S-Matrix sein (Z.B. kann in der S-Matrix für einen Haushalt 1
Kind eingetragen sein – dieses steht bei einem Gewichtungsfaktor von 5,3 dann für 5,3 Kinder, ‚diesen Typs’)
- oder auch Werte, die bislang nicht in der S-Matrix vorkommen und nicht zur Hochrechnung verwendet wurden (Z.B. würde bei einem Einkommensvergleich das Einkommen dieses Haushalts mit 5,3 gewichtet werden).
Die Gewichte werden von einem Computerprogramm gewählt, so dass gewünschte Rahmendaten erreicht werden. Bsp: Bei einer Befragung könnte eine Frauenquote von 65% in der Stichprobe vorliegen. Da man aber weiß, dass der Frauenanteil in der Gesamtbevölkerung nur bei 52% liegt, wäre das ungewichtete Ergebnis verzerrt. Daher erfolgt die Berechung von Gewichten, um dies zu korrigieren.
Beispiel für eine Matrix, wie in Aufgabe 4 gefordert:
1 0 0 1 0 0
0 1 0 0 0 1
0 0 1 0 1 0
0 0 1 0 0 0
1 1 0 0 2 2
0
S = 1 1 1 1 0
1 0 1 0 0 2
0 0 1 1 0 0
0 0 3 0 0 0
Merz: Statistik I - Deskription 31
Aufgabenblatt 6: Zeitreihen- und Querschnittsanalyse
1 Als Mitarbeiter in dem Stahlunternehmen HEAVY METAL gelangen Sie
zufällig an Informationen über die Gewinnsituation eines Konkurrenten und untersuchen diese neugierig.
Beurteilen und interpretieren Sie die Gewinnsituation des Konkurrenten anhand der folgenden Instrumente
a) Bestimmen Sie die glatte Komponente mit Hilfe der Methode der
gleitenden Durchschnitte (beachten Sie die Quartalseinteilung). b) Bereinigen Sie die Zeitreihe ausgehend von einer konstanten Saisonfigur
um den saisonalen Einfluss.
2 Die Kosten Ihrer Rechtsabteilung werden von Jahr zu Jahr höher. Treffen Sie eine Prognose für die Höhe der Kosten für das Jahr 2007 mit Hilfe der exponentiellen Glättung 2. Ordnung. Für den Glättungsfaktor a gelte: a = 0,4.
Jahr Kosten in Mio 1999 8,6 2000 9,1 2001 9,2 2002 10,4 2003 11,3 2004 12,9
3 Traditionell rodeln die Lüneburger jedes Jahr am 1. Januar den Kalkberg hinab. Der Gewinner darf dann (als Zuschauer) die deutschen Rodelmeisterschaften besuchen.
Obwohl es sich bei dem Turnier um ein Freizeitsportereignis handelt, strengen sich die Lüneburger sehr an. Seit 2001 werden nun auch die Jahresbestzeiten dokumentiert. Es ist zu beobachten, dass sich die Zeiten jährlich verbessern.
a) Sie möchten in den nächsten Jahren in diesen Sport einsteigen und
interessieren sich deshalb für die zukünftige Entwicklung der Zeiten, um ihr Trainingsprogramm darauf abzustimmen. Berechnen Sie die lineare Trendfunktion der Zeitreihe nach der Methode der kleinsten Quadrate.
b) Ein Insider und mehrfacher Gewinner dieses Events will mit ihnen wetten, dass die Bestzeit im Jahr 2008 unter 2 Minuten liegt. Wetten sie dagegen?
c) Erstellen Sie ein Box-and-Whisker-Diagramm für die vorliegenden Daten.
Berechnen Sie hierfür zunächst alle notwendigen Parameter und beschriften Sie
Ihren Plot mit diesen.
d) Berechnen Sie die Schiefe für die Verteilung der Zahlungsbereitschaft. Im Vorjahr
betrug die Schiefe m3=-0,52. Welche Schlüsse können Sie aus dem vergleich der
aktuellen Schiefe mit der des Vorjahres ziehen?
e) ⌦ Welche der folgenden Aussagen ist/ sind richtig?
A: Ein p-Quantil ist die relative Häufigkeit eines bestimmten Merkmals.
B: Das harmonische Mittel wird zur Mittelung von Wachstumsraten herangezogen.
C: Zwischen x0,25 und x0,75 liegen 50% aller Merkmalsträger.
D: Bei einer symmetrischen Verteilung sind Modus und Median gleich groß.
Aufgabe 3: Konzentration 18 P.
Sie möchten die Informationen über die Zahlungsbereitschaft für Ökostrom der
OELGEMOELLER ENERGIE AG (Siehe Aufgabe 2) hinsichtlich der Verteilung und
Konzentration genauer analysieren.
a) Berechnen Sie die Verteilungsfunktion der Stromkunden sowie die kumulierte
relative Merkmalssumme für die Zahlungsbereitschaft und stellen Sie Ihre
Ergebnisse in einer passenden Grafik dar.
b) Berechnen Sie den Gini-Koeffizienten für die Verteilung der Zahlungsbereitschaft.
Welche Aussagen können Sie aufgrund Ihres Ergebnisses machen?
c) ⌦ Welchen Wert könnte der Gini-Koeffizient maximal annehmen, wenn bei der
vorliegenden Stichprobe die Konzentration immer weiter zunehmen würde?
A: 0,500 B: 0,824 C: 0,996 D: 1,000
d) ⌦ Welche der folgenden Aussagen ist/ sind richtig?
A: Die Lorenzkurve kann niemals über der Gleichverteilungsgeraden liegen.
B: Zwei Lorenzkurven verschiedener Verteilungen lassen sich nur vergleichen,
wenn sich diese nicht schneiden.
C: Der Gini-Koeffizient ist die Fläche unterhalb der Lorenzkurve.
40 Merz: Statistik I - Deskription
D: Das erste Dezil ist betragsmäßig immer kleiner (oder höchstens gleich groß) als
das letzte Dezil.
Aufgabe 4: Zweidimensionale Häufigkeiten und Korrelation 20 P.
In einer weiteren Umfrage unter den Kunden der OELGEMOELLER ENERGIE AG über die
Zahlungsbereitschaft für Ökostrom haben Sie Einzeldaten erhoben. Ihnen liegen
Informationen über die Zahlungsbereitschaft und über zusätzliche soziodemografische
Merkmale vor:
Zahlungs-bereitschaft [Eurocent]
Monatliches Netto-
einkommen [€]
Kinder im Haushalt
Alter Wohngegend
15,5 1.400 Nein 35 Ländlich
21,0 2.500 Ja 48 Kleinstadt
20,0 2.600 Ja 42 Stadt
19,5 2.100 Nein 39 Ländlich
16,5 1.200 Ja 32 Ländlich
17,5 1.600 Ja 24 Stadt
17,0 1.100 Nein 21 Stadt
21,5 2.000 Nein 50 Kleinstadt
16,0 2.000 Nein 32 Stadt
a) Erstellen Sie auf Grundlage des Datenmaterials eine Kreuztabelle, die die Verteilung
der absoluten Häufigkeiten der Stromkunden zwischen Altersgruppen („Personen
bis 40 Jahren“ und „Personen über 40 Jahren“) und dem Wohnort darstellt.
Berechnen Sie hierfür die Randverteilungen.
b) Berechnen und interpretieren Sie die Werte h(Stadt, alt), h(Stadt | jung) und h(alt).
c) ⌦ Welche der folgenden Aussagen ist/ sind richtig?
A: Die Korrelation zwischen Alter und Zahlungsbereitschaft ist mit dem Bravais-
Pearson Korrelationskoeffizienten zu berechnen.
B: Im Gegensatz zur quadratischen Kontingenz (χ²) kann der normierte
Kontingenzkoeffizient K* die Richtung eines Zusammenhangs bestimmen.
C: Der Bravais-Pearson-Korrelationskoeffizient ist grundsätzlich höher als der
Spearman’sche Rangkorrelationskoeffizient.
D: Der Zusammenhang zwischen der Wohngegend und der Zahlungsbereitschaft
kann mit dem Rangkorrelationskoeffizienten nach Spearman berechnet werden.
Merz: Statistik I - Deskription 41
d) Berechnen und interpretieren Sie auf der Grundlage des gegebenen Datenmaterials
ein geeignetes Korrelationsmaß für die Zahlungsbereitschaft und das Einkommen
der befragten Kunden.
Aufgabe 5: Regression 21 P.
Führen Sie auf der Basis der Daten aus Aufgabe 4 eine Regression mit der Methode der
kleinsten Quadrate durch, um eine Aussage darüber machen zu können, inwieweit die
Zahlungsbereitschaft für Ökostrom von dem Alter der Kunden der OELGEMOELLER
ENERGIE AG abhängt. Verwenden Sie hierfür die Matrixrechnung, um folgende
Teilaufgaben beantworten zu können:
a) ⌦ Welche Aussage über X’X ist richtig?
A:
⋅= 4102379,1323
3239' XX B:
=
3239
12379323' XX
C:
=
25,30475,164
5,1649' XX D:
=
25,30475,164
5,1649' XX
b) ⌦ Welche Aussage(n) kann/ können auf der Grundlage von X’X und X’y im
vorliegenden Fall gemacht werden?
A: Insgesamt würden alle Kunden der Stichprobe zusammen 12.379 Euro im Jahr
für Strom ausgeben.
B: Sie Summe der quadrierten Zahlungsbereitschaften beläuft sich auf 3047,25.
C: Das durchschnittliche Alter kann man berechnen aus (X’X)1,2 : (X’X) 1,1
D: Die durchschnittliche Zahlungsbereitschaft berechnet sich aus (X’y)1 : (X’X) 1,1
c) ⌦ Welches ist die Inverse von X’X zur Berechnung der Regressionsgeraden?
A:
−−
025,0451,0
451,0349,8 B:
−−
0013,0046,0
046,0748,1
C:
−−⋅ −
784,1046,0
046,010271,1 3
D:
−−⋅ −
0025,0451,0
451,010349,8 3
42 Merz: Statistik I - Deskription
d) ⌦ Welche der folgenden Aussagen ist/ sind richtig?
A: xy ⋅+= 093,024,20ˆ
B: Mit jedem zusätzlichen Euro Netto-Monatseinkommen steigt die
Zahlungsbereitschaft um ca. 0,0018 €.
C: Bei einem 35-jährigen Kunden wird die Zahlungsbereitschaft auf ca. 18 Eurocent
geschätzt .
D: Bei einem ca. 12-jährigen (genauer: 11,926-jährigen) beträgt die
Zahlungsbereitschaft 0 Euro.
Für die folgenden Teilaufgaben wurde die Regressionsanalyse auf weitere Merkmale
und zusätzliche Beobachtungen ausgeweitet und mit Hilfe des Computerprogramms ET
(Econometric Toolkit) ausgewertet. Neben der Zahlungsbereitschaft für Ökostrom [ZB;
in Euro pro kWh] als abhängige Größe sind die Variablen Alter [ALTER; in Jahren],
Geschlecht [MANN; 1=Mann, 0=Frau] und Wohnort [STADT; 1=Stadt, 0=Land] sowie
das monatliche Bruttoeinkommen [EINKOMM; in Euro] als erklärende Größen in das
Modell aufgenommen worden.
Ordinary Least Squares --------------------------------------------------- --------------------------- Dependent Variable ZB Number of O bservations 15 Mean of Dep. Variable 19.000 Std. Dev. o f Dep. Var. 2.236068 Std. Error of Regr. .4754 Sum of Squa red Residuals 2.26089 R - squared .96770 Adjusted R - squared .95478 F( 4, 10) 74.900 Prob. Value for F .00000 --------------------------------------------------- --------------------------- Variable Coefficient Std. Error t-ratio Prob•t•> x Mean of X Std.Dev.of X --------------------------------------------------- --------------------------- Constant 21.2215 2.1952 9.667 .0000 0 ALTER -.184211 .4289E-01 -4.294 .0016 30.866667 2.23607 MANN .785619E-01 .2566 .306 .7657 .60000000 .50709 STADT .183516 .2740 .670 .5182 .53333333 .51640 EINKOMM .183056e-02 .5424E-03 3.375 .0071 1813.3333 551.44831
e) ⌦ Welche der folgenden Aussagen ist/ sind richtig?
A: Die Regressionsebene beschreibt die Punktwolke recht gut, da über 96% der
Varianzen erklärt werden können.
B: Das „adjustet R-squared“ ist immer kleiner als das unkorrigierte „R-squared“.
C: Grundlage dieser Regressionsschätzung ist eine Stichprobe mit n=15.
D: „Sum of Squared Residuals“ besagt, dass sich alle quadrierten Abweichungen
zwischen beobachteten und geschätzten Zahlungsbereitschaften auf 2,26
Eurocent² aufsummieren.
Merz: Statistik I - Deskription 43
f) ⌦ Welche der folgenden Aussagen ist/ sind richtig?
A: Wären alle unabhängigen Variablen der Regressionsgleichung Null, so läge rein
rechnerisch die Zahlungsbereitschaft bei 21,2 Eurocent pro kWh Ökostrom.
B: Sinkt das Alter eines Stromkunden um gerundet 0,18 Jahre, so steigt die
Zahlungsbereitschaft um 1 Eurocent.
C: Ein Mann ist bereit 0,0786 Eurocent mehr pro kWh zu bezahlen als eine Frau.
D: Eine 30-jährige, in einer Stadt lebende Frau mit einem Monatseinkommen von
2.000 Euro wäre nach dieser Schätzung bereit ca. 19,5 Eurocent pro kWh
Ökostrom zu bezahlen.
g) ⌦ Welche der folgenden Aussagen ist/ sind richtig?
A: Das Monatseinkommen in der Stichprobe betrug durchschnittlich 1813 €.
B: In der Stichprobe betrug der Anteil der Stadtbevölkerung 51,6%.
C: Bezüglich des Wohnortes und des Geschlechts kann keine sichere Aussage
gemacht werden, da dieser Koeffizient nicht signifikant ist. Hierfür muss nach
der ‚Daumenregel’ der t-Wert betragsmäßig über 3 liegen.
D: Die durchschnittliche Zahlungsbereitschaft in der Stichprobe lag bei 21,2215
(siehe „Constant“) Eurocent pro kWh.
Aufgabe 6: Indizes und Hochrechnung 15 P.
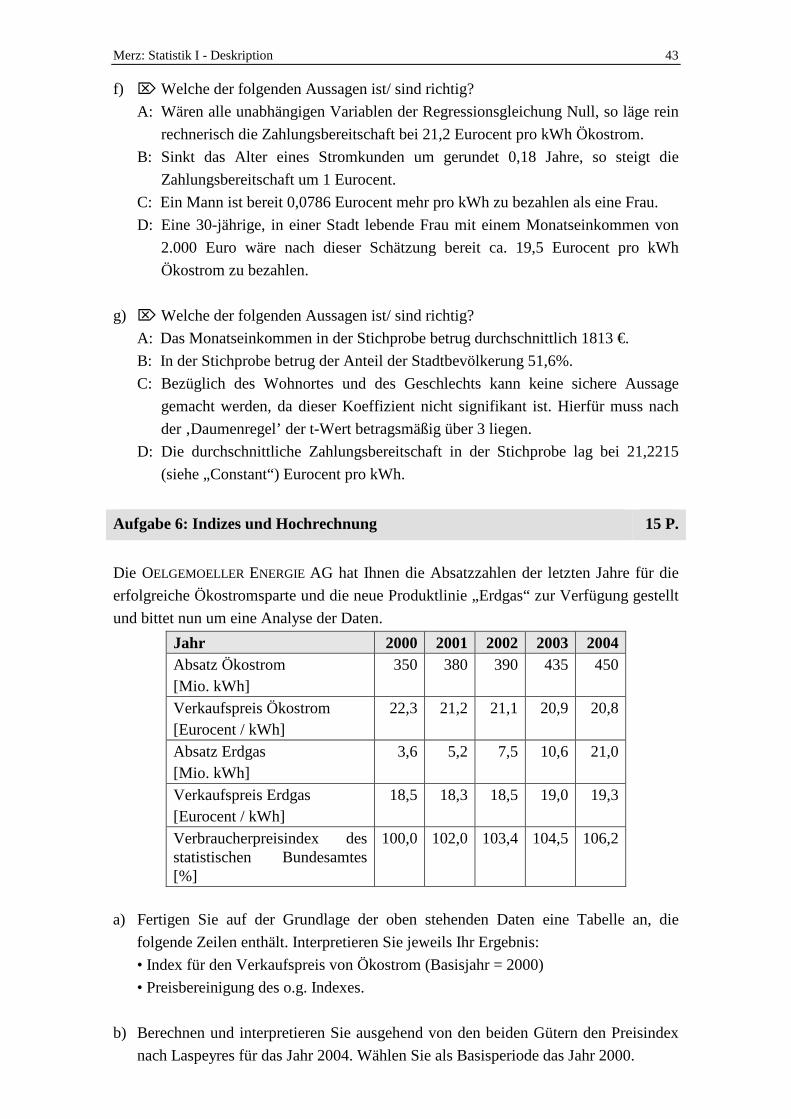
Die OELGEMOELLER ENERGIE AG hat Ihnen die Absatzzahlen der letzten Jahre für die
erfolgreiche Ökostromsparte und die neue Produktlinie „Erdgas“ zur Verfügung gestellt
und bittet nun um eine Analyse der Daten.
Jahr 2000 2001 2002 2003 2004 Absatz Ökostrom [Mio. kWh]
350 380 390 435 450
Verkaufspreis Ökostrom [Eurocent / kWh]
22,3 21,2 21,1 20,9 20,8
Absatz Erdgas [Mio. kWh]
3,6 5,2 7,5 10,6 21,0
Verkaufspreis Erdgas [Eurocent / kWh]
18,5 18,3 18,5 19,0 19,3
Verbraucherpreisindex des statistischen Bundesamtes [%]
100,0 102,0 103,4 104,5 106,2
a) Fertigen Sie auf der Grundlage der oben stehenden Daten eine Tabelle an, die
folgende Zeilen enthält. Interpretieren Sie jeweils Ihr Ergebnis:
• Index für den Verkaufspreis von Ökostrom (Basisjahr = 2000)
• Preisbereinigung des o.g. Indexes.
b) Berechnen und interpretieren Sie ausgehend von den beiden Gütern den Preisindex
nach Laspeyres für das Jahr 2004. Wählen Sie als Basisperiode das Jahr 2000.
44 Merz: Statistik I - Deskription
c) Berechnen und interpretieren Sie ausgehend von den beiden Gütern den
Mengenindex nach Paasche für das Jahr 2004. Wählen Sie als Basisperiode das Jahr
2000.
d) ⌦ Ausgehend vom Jahr 2004 hätte die gleiche Menge Erdgas zum
Endverbraucherpreis in den USA 4,46 Mio. US$ gekostet. Welche der folgenden
Aussagen trifft auf die Verbrauchergeldparität VGD,US zu?
A: VGD,US = 1,20 $/€
B: VGD,US = 0,83 $/€
C: VGD,US = 1,10 $/€
D: Keine der oben genannten.
Aufgabe 7: Zeitreihenanalyse 13 P.
Die OELGEMOELLER ENERGIE AG beliefert die PICKENPACK-GEDÄCHTNISUNIVERSITÄT in
Uelzen mit Erdgas. Folgender Tabelle können Sie die Absatzmengen der letzten
Semester entnehmen:
Quartal Winter 03
Sommer 03
Winter 04
Sommer 04
Winter 05
Sommer 05
Erdgaslieferung [1.000 kWh]
65,2 31,0 60,1 30,2 58,6 29,3
Führen Sie eine Saisonbereinigung dieser Zahlen durch. Bestimmen Sie hierfür zunächst
die Glatte Komponente mit Hilfe der Methode der exponentiellen Glättung 1. Ordnung
und einem Glättungsfaktor von 0,2. Unterstellen Sie aus Mangel an Daten für y’Sommer 02
= 48,1. Berechnen Sie die Saisonindexziffer mit einer konstanten Saisonfigur.
Merz: Statistik I - Deskription 45
Lösung der Klausur WS 05/06
Aufgabe 1: Allgemeines, Wirtschafts- und Sozialstatistik a) A: richtig
- realer Index fällt - preisbereinigter Indes fällt nur von 2000 auf 2001, danach steigt er
b) ( )i i
t 0
i
i i
0 0
i
L00,04I
p q20,8 350 19,3 3, 6 7.349, 48
p 0,933722,3 350 18,5 3, 6 7.871, 6p q
⋅⋅ + ⋅
= = = =⋅ + ⋅⋅
∑
∑
Warenkorb von „damals“ ist mit heutigen Preisen nur 93 % wert.
Merz: Statistik I - Deskription 49
c) ( )i i
t t
i
i i
t 0
i
P00,04I
p q20,8 450 19,3 21 9.765,3
q 1,32920,8 350 19,3 3, 6 7.349, 48p q
⋅⋅ + ⋅
= = = =⋅ + ⋅⋅
∑
∑
Die Menge ist – bewertet mit heutigen Preisen – um fast 33 % im Vergleich zu 2000 gestiegen.
d) D,USVG4, 46$ $
1,104, 053€ €
= =
Aufgabe 7: Zeitreihenanalyse
a = 0,2 ( )t t t 1
y ' a y 1 a y '−= ⋅ + − ⋅
2003 2004 2005 ty
ty ' ty
ty ' ty
ty '
W 65,2 51,52 60,1 49,953 58,6 48,52192 S 31 47.416 30,2 46,002 29,3 44,6775
y* y y '= − y * y *
W 13,68 10,147 10,07808 S -16,416 -15,8024 -15,3775
( )W
1S 11,3 13, 68 10,147 10, 07808
3= → ⋅ + +ɶ
( )S
1S 15,87 16, 416 15,8024 15,3775
3= − → ⋅ − − −ɶ
S S 2, 285= +ɶ
S 11,3 2, 285 13,585= + =
S 15,87 2, 285 13,585= − + = − 2003 2004 2005
W 51,615 46,515 45,015 S 44,585 43,785 42,885
50 Merz: Statistik I - Deskription
Univ.-Prof. Dr. Joachim Merz
Statistik I – Deskription Klausur zum Wintersemester 2004 / 2005
16. Februar 2005
Aufgabe 1: Allgemeines, Wirtschafts- und Sozialstatistik 12 P.
a) ⌦ Welche der folgenden Aussagen ist/ sind richtig?
A: Das BIP in Deutschland im Jahr 2004 lag bei 2178 Milliarden €. B: Das BIP in Deutschland im Jahr 2004 lag bei 2178 Billionen €.
C: Das BIP gibt an, wie viel Einkommen im Inland erwirtschaftet wurde. D: Das BIP gibt an, wie viel Einkommen von ‚Inländern’ erwirtschaftet wurde.
b) ⌦ Welche der folgenden Aussagen ist/ sind richtig?
A: Die Telefonnummer ist verhältnisskaliert.
B: Die Note in dieser Statistik-Klausur ist ordinal skaliert.
C: Die Anzahl der Klausuren je Semester ist absolut skaliert. D: Das Nettoeinkommen ist absolut skaliert.
c) ⌦ Welche der folgenden Aussagen ist/ sind richtig?
A: Je kleiner die allgemeine Fertilitätsrate, desto größer ist die allgemeine
Bevölkerungsdichte.
B: Eine Nettoreproduktionsrate, die kleiner als Eins ist, führt zum Schrumpfen der Bevölkerung. C: Die Fertilitätsrate entspricht der durchschnittlichen Kinderanzahl einer Frau.
D: Liegt das Geschlechterverhältnis bei 962, so gibt es 3,8 Prozent mehr Männer
als Frauen.
d) ⌦ Welche der folgenden Aussagen ist/ sind richtig?
A: Ein Zivildienstleistender gehört zur Gruppe der Nichterwerbspersonen.
B: Ein selbständiger Wirtschaftsberater mit einem Nettoeinkommen von monatlich 339€ ist erwerbstätig. C: Ein Wehrdienstleistender im Auslandseinsatz ist eine Erwerbsperson. D: Ein Arbeitsloser gehört zur Gruppe der Nichterwerbspersonen.
Merz: Statistik I - Deskription 51
Aufgabe 2: Eindimensionale Häufigkeitsverteilung 24 P.
Als Marketingchef der Deutschen Eisenbahn führen Sie eine Umfrage zur
Kundenzufriedenheit unter zehn zufällig ausgewählten Bahnkunden durch. Die
Befragung ergab folgenden Datensatz. (Beachten Sie bei der Beantwortung der
folgenden Fragen, dass das Jahresnettoeinkommen in 1.000€ angegeben ist!!!)
Person
ennum
mer
Jährliche
Ausgaben
für Bahnfahrten
(in €)
Jahresnettoein
kom-men (in
1.000 €)
Qualität des
Zugpersonals (1:
sehr gut/....../6: sehr
schlecht)
Wohnort
(1: Ost/0:
West)
1 900 15 1 1
2 600 20 3 0
3 2500 40 4 0
4 200 10 6 1
5 600 5 2 1
6 600 13 4 0
7 5000 17 3 0
8 2000 24 2 0
9 1500 22 4 0
10 100 14 2 1
a) ⌦ Das arithmetische Mittel des Jahresnettoeinkommens beträgt:
A: 180000€ B: 18000€ C: 17000€ D: 18€
b) ⌦ Die Standardabweichung des Jahresnettoeinkommens beträgt:
A: 82400000€ B: 9077,44€ C: 82,40€ D: 9,08€
c) ⌦ Welche der folgenden Aussagen ist/ sind richtig?
A: Der Variationskoeffizient beinhaltet Informationen über die Schiefe einer
Verteilung.
B: Ist der Variationskoeffizient größer als 3, so spricht man von der Wölbung
einer Verteilung.
C: Der Variationskoeffizient dient dem Vergleich der Streuung zweier
Verteilungen.
D: Um den Variationskoeffizienten berechnen zu können, wird die
Quartilsabweichung benötigt.
d) Erstellen Sie ein Box-and-Whisker-Diagramm für die „jährlichen Ausgaben für
Bahnfahrten“ Berechnen Sie hierfür zunächst alle notwendigen Parameter und
beschriften Sie Ihren Plot mit diesen.
52 Merz: Statistik I - Deskription
e) ⌦ Welche der folgenden Aussagen ist/sind richtig?
A: Die Verteilung aller Einkommen in Deutschland ist rechtssteil.
B: Die Verteilung aller Einkommen in Deutschland ist linkssteil.
C: 50% aller Merkmalswerte liegen unterhalb des Modus.
D: Der Median entspricht dem arithmetischen Mittel aus dem unteren und oberen
Quartil.
f) ⌦ Der Umsatz der Deutschen Eisenbahn nahm vom 2000 bis 2003 um jeweils
10 Prozent pro Jahr zu, von 2003 bis 2004 betrug die Wachstumsrate nur noch 5
Prozent. Wie groß ist die durchschnittliche Wachstumsrate des Umsatzes von
2000-2004?
A: 1,0875% B: 8,750% C: 7,471% D: 8,728%
g) ⌦ Welche der folgenden Aussagen ist/sind richtig?
A: Das dritte Moment ist ein Maß für die Schiefe.
B: Das dritte Moment ist ein Moment für die Wölbung.
C: Ist das vierte Moment negativ, so ist die Verteilung ‚gewölbter’ als die
Normalverteilung.
D: Ist das vierte Moment positiv, so ist die Verteilung flacher als die
Normalverteilung.
Aufgabe 3: Konzentration 17 P.
a) Berechnen Sie - ausgehend von der Datentabelle in Aufgabe 2 - die
Verteilungsfunktion der „jährlichen Ausgaben für Bahnfahrten“ sowie die
kumulierte relative Merkmalssumme und stellen Sie Ihre Ergebnisse in einer
passenden Grafik dar. Runden Sie gegebenenfalls auf 3 Dezimalstellen.
b) Berechnen und interpretieren Sie die 90/10-Relation für die „jährlichen
Ausgaben für Bahnfahrten“.
c) Berechnen Sie den Gini-Koeffizienten für die Verteilung der „jährlichen
Ausgaben für Bahnfahrten“. Welche Aussagen können Sie aufgrund Ihres
Ergebnisses machen?
Merz: Statistik I - Deskription 53
d) ⌦ Welche der folgenden Aussagen ist/ sind richtig?
A: Es gilt immer, dass F(x) MS(x)≥ .
B: Bei vollständiger Gleichverteilung ist der Ginikoeffizient gleich Eins.
C: Zwei Lorenzkurven verschiedener Verteilungen lassen sich nur vergleichen, wenn sich diese nicht schneiden.
D: Die 90/10-Relation ist immer größer als 9.
Aufgabe 4: Zweidimensionale Häufigkeiten und Korrelation 17 P.
a) Erstellen Sie auf Grundlage des Datenmaterials aus Aufgabe 2 eine Kreuztabelle,
die die absoluten Häufigkeiten der 10 Personen nach ihrem Wohnort (X) und
ihrer Bewertungsnote des Zugpersonals (Y:„Qualität des Zugpersonals“)
darstellt.
b) Berechnen und interpretieren Sie die Werte h(X=1, Y=2), h(X=1|Y=2),
h(Y=2|X=1) und F(X=0, Y=4).
c) ⌦ Welche der folgenden Aussagen ist/ sind richtig?
A: Die Korrelation zwischen dem Wohnort und dem Jahresnettoeinkommen wird
mit dem Kontingenzkoeffizienten berechnet.
B: Der normierte Kontingenzkoeffizient gibt Auskunft über Richtung und Stärke
eines Zusammenhangs.
C: Ein sehr starker Zusammenhang zwischen zwei Variablen liegt vor, wenn der
Kontingenzkoeffizient gleich –1 ist
D: Ist der Rangkorrelationskoeffizient nach Spearman gleich Eins, so liegt ein
starker positiver Zusammenhang zwischen den beiden Merkmalen vor.
d) Berechnen und interpretieren Sie auf der Grundlage des Datenmaterials aus
Aufgabe 2 ein geeignetes Korrelationsmaß, um den Zusammenhang zwischen
dem „Jahresnettoeinkommen“ und den „jährlichen Ausgaben für Bahnfahrten“
zu bewerten.
54 Merz: Statistik I - Deskription
Aufgabe 5: Regression 22 P.
Sie vermuten, dass die „jährlichen Ausgaben für Bahnfahrten (in €)“ (Y) zum einen vom
„Jahresnettoeinkommen (in 1000€)“ (X1) und zum anderen vom Wohnort (X2)
abhängen. Hierzu stehen Ihnen folgende Informationen zur Verfügung:
10 180 4
X 'X 180 4064 44
4 44 4
=
( ) 1
1,200 -0,046 -0,698
X 'X -0,046 0,002 0,023
-0,698 0,023 0,690
− =
a) Berechnen Sie X’y mit Hilfe der Angaben der Datentabelle aus Aufgabe 2.
b) Ermitteln Sie aufgrund der obigen Matrizen das durchschnittliche
Nettoeinkommen der Ostdeutschen. Wie kann man den Wert „4064“ in X’X
interpretieren?
c) Berechnen und interpretieren Sie die geschätzten Regressionskoeffizienten.
d) Ihre Tante arbeitet und wohnt seit drei Monaten in Dresden und verdient dort
1.500€ im Monat. Was erwarten Sie aufgrund der Regressionsergebnisse, wie
viele Euros Ihre Tante jährlich für Bahnfahrten ausgibt?
Es interessiert Sie nun, wie das Regressionsergebnis aussieht, wenn die „jährlichen
Ausgaben für Bahnfahrten (in €)“ (Y) nur noch vom „Jahresnettoeinkommen (in
1000€)“ (X) abhängen und nicht mehr vom Wohnort.
e) Ermitteln Sie X’X und die Inverse von X’X.
f) Was besagt das Bestimmtheitsmaß? Beurteilen Sie das Bestimmtheitsmaß der
Regression im unten dargestellten ET-Ausdruck.
Ordinary Least Squares ------------------------------------------------------------------------------ Dependent Variable AUSGABEN Number of Observations 10 Mean of Dep. Variable 1400 Std. Dev. of Dep. Var. 1484.737 Std. Error of Regr. 1429,177 Sum of Squared Residuals 16340376.2 R - squared 0.176 Adjusted R - squared .073 F( 1, 8) 1.713 Prob. Value for F .227 ------------------------------------------------------------------------------ Variable Coefficient Std. Error t-ratio Prob5t5>x Mean of X Std.Dev.of X ------------------------------------------------------------------------------ Constant 226.942 1003.689 0.226 0.827 EINK 65.170 49.788 1.309 0.227
Merz: Statistik I - Deskription 55
Aufgabe 6: Indizes 12 P.
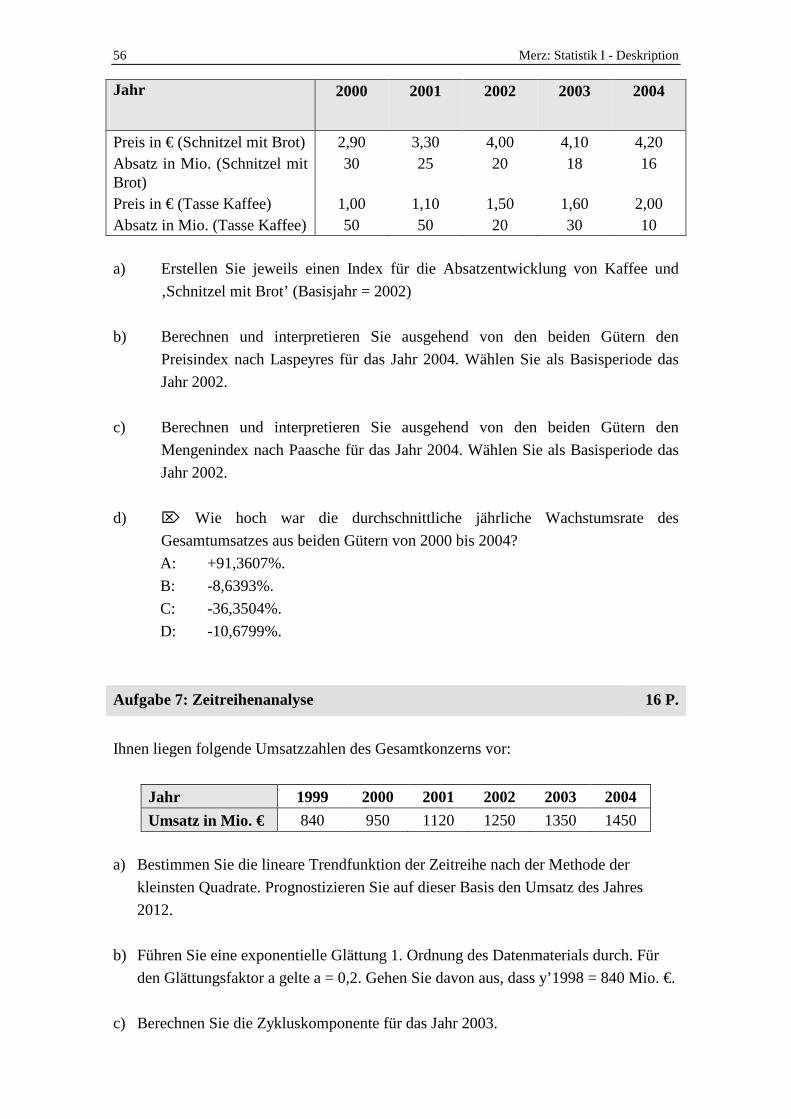
Die Verkaufszahlen in den Speisewagen der Deutschen Eisenbahn stagnieren. Sie erhalten den Auftrag, die Ursachen dafür eingehender zu analysieren. Hierzu stehen Ihnen folgende Daten zur Verfügung.
56 Merz: Statistik I - Deskription
Jahr 2000 2001 2002 2003 2004
Preis in € (Schnitzel mit Brot) 2,90 3,30 4,00 4,10 4,20 Absatz in Mio. (Schnitzel mit Brot)
30 25 20 18 16
Preis in € (Tasse Kaffee) 1,00 1,10 1,50 1,60 2,00 Absatz in Mio. (Tasse Kaffee) 50 50 20 30 10
a) Erstellen Sie jeweils einen Index für die Absatzentwicklung von Kaffee und
‚Schnitzel mit Brot’ (Basisjahr = 2002)
b) Berechnen und interpretieren Sie ausgehend von den beiden Gütern den
Preisindex nach Laspeyres für das Jahr 2004. Wählen Sie als Basisperiode das
Jahr 2002.
c) Berechnen und interpretieren Sie ausgehend von den beiden Gütern den
Mengenindex nach Paasche für das Jahr 2004. Wählen Sie als Basisperiode das
Jahr 2002.
d) ⌦ Wie hoch war die durchschnittliche jährliche Wachstumsrate des
Gesamtumsatzes aus beiden Gütern von 2000 bis 2004?
A: +91,3607%.
B: -8,6393%.
C: -36,3504%.
D: -10,6799%.
Aufgabe 7: Zeitreihenanalyse 16 P.
Ihnen liegen folgende Umsatzzahlen des Gesamtkonzerns vor:
Jahr 1999 2000 2001 2002 2003 2004
Umsatz in Mio. € 840 950 1120 1250 1350 1450
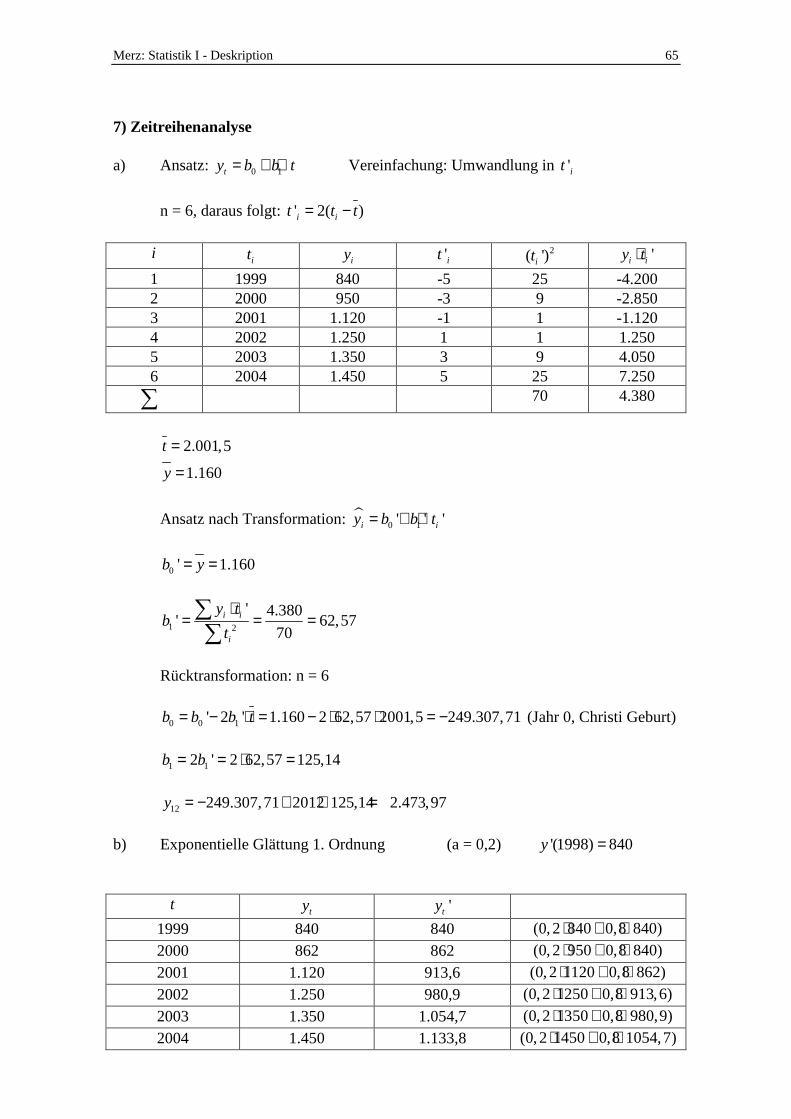
a) Bestimmen Sie die lineare Trendfunktion der Zeitreihe nach der Methode der
kleinsten Quadrate. Prognostizieren Sie auf dieser Basis den Umsatz des Jahres
2012.
b) Führen Sie eine exponentielle Glättung 1. Ordnung des Datenmaterials durch. Für
den Glättungsfaktor a gelte a = 0,2. Gehen Sie davon aus, dass y’1998 = 840 Mio. €.
c) Berechnen Sie die Zykluskomponente für das Jahr 2003.
Merz: Statistik I - Deskription 57
Lösung Klausur WS 04/05 1) Allgemeines, Wirtschafts- und Sozialstatistik a) richtig sind A,C b) richtig sind C,B c) richtig ist B d) richtig sind B,C 2) Eindimensionale Häufigkeitsverteilung
a) richtig ist B (18.000,- €)
1
1 n
ii
X Xn =
= ∑ = 1
(15 ...14)10
+ = 18 (in Tausend)
b) richtig ist B (9077,44 €)
2 2
1
1( )
n
ii
s s X Xn =
= = −∑ = 2 21((15 18) ... (14 18) )
10− + + −
c) richtig ist C
d) Box-and-whisker-plot für die „jährlichen Aufgaben für Bahnfahrten“
F ( 25 ) = 10 * 0,25 = 2,5 (X3 = 600, da 2,5 ungerader Wert) F ( 50 ) = 10 * 0,5 = 5 (½ X5 + ½ X6 = ½ (600 + 900) = 750) F ( 75 ) = 10 * 0,75 = 7,5 (X8 = 2000, da 7,5 ungerader Wert)
Die Whisker enden beim 1,5-fachen der Boxbreite, jedoch keine Werte < 0
e) richtig ist B
f) richtig ist D ( 8,728%) 1 2 ...nnGM x x x= ⋅ ⋅ ⋅ = 4 1,1 1,1 1,1 1,05⋅ ⋅ ⋅
g) richtig ist A
58 Merz: Statistik I - Deskription
3) Konzentration a) Ungruppierte Daten (Einzeldaten liegen vor, ordnen)
G ist relativ groß, ungleiche Verteilung der Ausgaben d) richtig sind A,C 4) Zweidimensionale Häufigkeitsverteilung und Korrelation a) Kreuztabelle der absoluten Häufigkeiten: Wohnort West (0) Wohnort Ost (1) Randverteilungen
Randverteilungen 6 4 10 b) h (X = 1, Y = 2) = 2/10 (20 % von allen wohnen im Osten und geben die Note 2)
h (X = 1/ Y = 2) = 2/3 (66,67 % der Leute, die die Note 2 geben, wohnen im Osten)
h (Y = 2/ X = 1) = 2/4 (50 % der Leute, die im Osten wohnen, geben die Note 2)
60 Merz: Statistik I - Deskription
F (X = 0, Y = 4) = 60 % haben höchstens eine 4 (oder besser) gegeben und wohnen (höchstens) in Ostedeutschland
c) richtig sind A,D d) Berechnung eines geeigneten Korrelationsmaßes zwischen
„Jahresnettoeinkommen“ und den „jährlichen Ausgaben für Bahnfahrten“ Jahresnettoeinkommen (metrisch), Jährliche Ausgaben für Bahnfahrten
(metrisch). Bei zwei metrischen Merkmalen wird der „Bravais-Pearson-Korrelationskoeffizient“ verwendet. Hilfstabelle:
i xi yi xi*y i
1 900 15.000 13.500.000
2 600 20.000 12.000.000
3 2.500 40.000 100.000.000
4 200 10.000 2.000.000
5 600 50.000 3.000.000
6 600 13.000 7.800.000
7 5.000 17.000 85.000.000
8 2.000 24.000 48.000.000
9 1.500 22.000 33.000.000
10 100 14.000 1.400.000
Summe 14.000 180.000 305.700.000
2
1
1( ) 1.408,55
n
x ii
s X Xn =
= − =∑ 1
1 1(900 ... 100)
10
n
ii
X Xn =
= = + +∑ = 1.400
2
1
1( ) 9.077,44
n
y ii
s y yn =
= − =∑ 1
1 1(15000 ... 14000)
10
n
ii
Y yn =
= = + +∑ =
18.000
1
1305.700.000 1.400 18.000 5.370.000
10
n
xy i ii
S X Y XY=
= − = ⋅ − ⋅ =∑
5.370.000
1.408,55 9077,44xy
x y
sr
s s= =
⋅ ⋅= 0,42 1 1r− ≤ ≤
Hier liegt ein positiver Zusammenhang vor.
Merz: Statistik I - Deskription 61
5) Regression a) x1 = Jahreseinkommen, x2 = Wohnort, y = Ausgaben für Bahnfahrten
X’y =
1 1 1 1 1 1 1 1 1 1
15 20 40 10 5 13 17 24 22 14
0 0 0 0 0 01 1 1 1
900
600
2.500
200
600
600
5.000
2.000
1.500
100
=
14.000
305.700
1.800
b) Durchschnittliches Einkommen = 44.000
4= € 11.000,-
4064 = 21
1
n
i
X=∑ = Summe der Quadrate der Einkommen der Ostdeutschen
c) Bestimmung der Regressionskoeffizienten b = (X’X)-1X’y
b =
1,200 0,046 0,698 14.000 1.481,4
0,046 0,002 0,023 305.700 8,8
0,698 0,023 0,690 1.800 1.498,9
− − − = − −
=0
1
2
b
b
b
y = 1.481,4 + 8,8 x1 – 1498,9 x2
- Grundsätzlich gibt jeder € 1.481,40 für Bahnfahrten p.a. aus - Steigt das Einkommen um € 1.000,-, steigen die Ausgaben um € 8,80 - Die Ostdeutschen geben durchschnittlich € 1.489,90 p.a. weniger aus
f) B = r2 = Anteil der durch die Regression erklärte Varianz der y-Werte. Je höher
B, desto besser. 0 ≤ B ≤ 1. B im Ausdruck beträgt 0,176, d.h. 17,6 % der der Gesamtstreuung wird durch die Regression erklärt. Dies ist ein relativ schwacher Wert.
Exkurs: Summen, Doppelsummen Häufig hat man es mit Summen endlich vieler Sumanden zu tun. Um die Schreibweise
zu vereinfachen, können sie mit dem griechischen Sigma ∑ abgekürzt werden.
Definition: Das Summenzeichen steht als als Wiederholungszeichen für die fortgesetzte Addition:
1 ...m
i k k mi k
a a a a+=
= + + +∑ , , ,i k m N
k m
∈<
wobei: i = Summationsindex k = untere Summationsgrenze m= obere Summationsgrenze
ia = allg. Summationsglied
Merz: Statistik I - Deskription 69
Beispiele:
a) 3
2 2 2 2
1
1 2 3i
i=
= + +∑
b) 4
1
4c c c c c c= + + + =∑
c) 4
1 2 3 4
1
i
i
x x x x x=
= + + +∑
Zerlegungsregeln für einfache Summen 1. Summe gleicher Summanden
( 1)m
i k
a m k a=
= − +∑ , 1
n
i
a na=
=∑
2. Summen mit gleicher Summationsvorschrift
( )m m m
i i i ii k i k i k
a b a b= = =
+ = +∑ ∑ ∑
3. Summen mit additiven Konstanten
( ) ( 1)m m
i ii k i k
a c a m k c= =
+ = + − +∑ ∑
4. Summen mit multiplikativen Konstanten
m m
i ii k i k
ca c a= =
=∑ ∑
5. Summenzerlegung
1
m l m
i i ii k i k i l
a a a= = = +
= +∑ ∑ ∑ , k ≤ l ≤ m
70 Merz: Statistik I - Deskription
II Eindimensionale Häufigkeitsverteilungen
Qualitative (nominalskalierte) Merkmale
Ausprägung eines qualitativen Merkmals A i
absolute Häufigkeit eines Merkmals n Ai i= n( )
Anzahl der verschiedenen Ausprägungen k
Anzahl der Beobachtungen n nii
k
==∑
1
relative Häufigkeit eines Merkmales h Anni
i( ) =
(Häufigkeitsverteilung)
Quantitative (metrisch skalierte) Merkmale
Diskrete Merkmale
Merkmalswert x i
absolute Häufigkeit eines Merkmals n n xi i= ( )
Anzahl der verschiedenen Merkmalswerte k
Anzahl der Beobachtungen n nii
k
==∑
1
relative Häufigkeit eines Merkmalswertes(Häufigkeitsfunktion, - verteilung) h x
nni
i( ) =
kumulierte absolute Häufigkeit n x x ni jj
i
( )≤ ==∑
1
kumulierte relative Häufigkeit h x x h xi jj
i
( ) ( )≤ ==∑
1
Verteilungsfunktion
F x h x x h x ii i jj
i
( ) ( ) ( ), ,= ≤ = ==∑
1
1 ... , k
Stetige Merkmale
Merkmalswert x
Klassenuntergrenze der Merkmalsklasse i x iu
Klassenobergrenze der Merkmalsklasse i x io
Klassenbreite ∆x x xi io
iu= −
Merz: Statistik I - Deskription 71
absolute Häufigkeit der in der Klasse iliegenden Merkmalswerte n n x xi i
u= ≤( <x io )
Anzahl der Klassen k
Anzahl der Beoachtungen n nii
k
==∑
1
relative Häufigkeit der in der Klasse iliegenden Merkmalswerte(Häufigkeitsverteilung, i = 1,..., k)
h x h x xi iu( ) (= ≤ <x
nni
o i) =
normierte relative Häufigkeit(Dichtefunktion, i = 1, ... , k) f x
n
n xii
i
( ) =∆
kumulierte relative Häufigkeit h x x h xio
jj
i
( ) ( )≤ ==∑
1
Interpolation innerhalb der Klasse i F x F xx x
xh xi
u iu
ii( ) ( ) ( )= + − ⋅
∆
72 Merz: Statistik I - Deskription
III Lageparameter
Mittelwerte
Häufigster Wert (Modus)
- ungruppiertes Datenmaterial
D xn x
nii= =( )
max
- gruppiertes Datenmaterial
D xn
n xii
i
= =* max∆
Median (Zentralwert)
- ungruppiertes Datenmaterial
falls n ungerade Z x n= +1
2
falls n gerade Z x xn n= ++
1
22 2
1( )
- gruppiertes Datenmaterial: Der Median ist nur approximativ mit Hilfe der Verteilungsfunktion erhältlich. Es gilt: h x Z F Z( ) ( ) ,≤ = = 0 5
lineare Interpolation bei metrisch skalierten, stetigen Merkmalen:
Z xF Z F x
hxi
u iu
ii= + −( ) ( ) ∆
Arithmetisches Mittel
- ungruppiertes Datenmaterial
xn
x ii
n
==∑
1
1
- gruppiertes Datenmaterial
bekannte Gruppenmittel ( )* *
1 1
1 k k
i i i ii i
x x n x h xn = =
= = ⋅∑ ∑
unbekannte Gruppenmittel xn
x nii
k
i==∑
1
1
* mit x x xi iu
io* ( )= +1
2
Merz: Statistik I - Deskription 73
Geometrisches Mittel
GM x xii
n
n i==
∏1
, ( >0)
log log GMn
x ii
n
==∑
1
1
Harmonisches Mittel
HMn
x ii
n=
=∑
1
1
Streuungsmaße
Spannweite (range) R
R x x x xn= − = −max min ( ) ( )1
Quartilsabweichung
QA x x= −12 0 75 0 25 ( ), ,
p-Quantile
Interpolationsformel bei gruppiertem Datenmaterial:
x xF x F x
nn
xp iu p i
u
ii= +
−⋅
( ) ( )∆
Mittlere absolute Abweichung
- ungruppiertes Datenmaterial
dn
x xii
n
= −=∑
1
1
- gruppiertes Datenmaterial
dn
x x n x x h xii
k
i ii
k
i i= − ⋅ = − ⋅= =∑ ∑
1
1 1
* * *, = Klassenmitte der Klasse i
74 Merz: Statistik I - Deskription
Varianz
- ungruppiertes Datenmaterial
sn
x xn
x xii
n
ii
n2 2
1
2 2
1
1 1= − = −= =∑ ∑( )
- gruppiertes Datenmaterial
sn
x x n x n x xii
k
i ii
k
i i2 2
1
2
1
21 1= − ⋅ = ⋅ −= =∑ ∑( ) ( )* * *
n = Klassenmitte der Klasse i
Standardabweichung
s s= 2
Variationskoeffizient
Vsx
= ⋅100(%)
Konzept der Momente
Durchschnittliche potenzierte Abweichungen der Merkmalswerte um einen Bezugspunkt a: Bezugspunkt Null ( )a = 0 Momente um Null Bezugspunkt arithmetisches Mittel ( )a x= Momente um das arithmetische Mittel
- ungruppiertes Datenmaterial
mn
x ara
ir
i
n
= −=∑
1
1
( )
- gruppiertes Datenmaterial
mn
x a n xra
ir
ii
k
i= − ⋅=∑
1
1
( ) ,* * = Klassenmitte der Klasse i
Standardisierte Schiefe
Momente 3. Ordnung (r=3) ergeben die Schiefe. Die Schiefe (skewness) ist ein Asymmetriemaß
( )
( )
3
3 13 33
2
1
1
1
n
ii
n
ii
x xm n
sms
x xn
=
=
−= =
−
∑
∑
Merz: Statistik I - Deskription 75
Exzeß (Kurtosis, Wölbung)
Momente 4. Ordnung (r=4) ergeben die Wölbung
( )
( )
4
144 44
2
1
1
1
n
ii
n
ii
x xm n
sms
x xn
=
=
−= =
−
∑
∑
Konzentration einer Verteilung
Die Merkmale werden für Konzentrationsanalysen grundsätzlich nach ihrer Größe geordnet
erteilungsfunktion:
Abszissenwerte der Lorenzkurve
V F x
n
nji
i
j
( ) ==∑
1
kumulierte relative Merkmalssumme:Ordinatenwerte der Lorenzkurve MS x
x n
nxj
i ii
j
( )
*
=⋅
=∑
1
Gini Koeffizient:
Gruppiert: ( ) ( )*
11
1k
i ii i
i
n xG F x F x
n x−=
⋅= + ⋅ − ⋅ ∑
Ungruppiert (xi geordnet!) ( )
1 1
1
2 1n n
i ii i
n
ii
i x n xG
n x
= =
=
⋅ ⋅ − + ⋅=
⋅
∑ ∑
∑
76 Merz: Statistik I - Deskription
IV Zweidimensionale Häufigkeitsverteilung
Darstellung
Ausprägung des 1. Merkmals (x) x i ki = 1,...,
Ausprägung des 2. Merkmals (y) y j mj = 1,...,
absolute Häufigkeit des Merkmalspaares ( , )x yi j
n n x yij i j= ( , )
Anzahl der Beobachtungen
n nijj
m
i
k
===∑∑
11 relative Häufigkeit des Merkmalspaares ( , )x yi j
h x yn
ni jij( , ) =
Randverteilung des 1. Merkmals (x) (Zeilensumme)
marginale absolute Häufigkeiten n ni ijj
m
⋅=
=∑1
marginale relative Häufigkeiten hnni
i⋅
⋅=
Randverteilung des 2. Merkmals (y) (Spaltensummen)
marginale absolute Häufigkeiten n nj iji
k
⋅=
=∑1
marginale relative Häufigkeiten hn
njj
⋅⋅=
Häufigkeitsverteilung von x bei gegebenem y (bedingte Verteilung)
h x yi j( ) =n
nij
j⋅
Häufigkeitsverteilung von y bei gegebenem x (bedingte Verteilung)
h y xj i( ) =n
nij
i ⋅
Merz: Statistik I - Deskription 77
Korrelationsrechnung
Häufigkeit bei Unabhängigkeit
i jij
n nn
n⋅ ⋅⋅
=ɶ
Quadratische Kontingenz
22
1 1
( )k mij ij
i j ij
n n
nχ
= =
−=∑∑
ɶ
ɶ
Kontingenzkoeffizient
Kn
M
MM* min=
+⋅
−=χ
χ
2
2 1 (k, m)
Rangkorrelationskoeffizient nach Spearman
R Rangnummer
R R
n n nr
i
i ii
n
sp
des 1. Merkmals (ordinalskaliert)
R Rangnummer des 2. Merkmals (ordinalskaliert)
r
i'
sp = −⋅ −
− +− ≤ ≤ +=
∑1
6
1 11 1
2
1
( )
( ) ( ), ( )
'
Kovarianz
- ungruppiertes Datenmaterial
sn
x x y yn
x y x yxy i ii
n
i ii
n
= − ⋅ − = ⋅ − ⋅= =∑ ∑
1 1
1 1
( ) ( )
- gruppiertes Datenmaterial
( )* * * *
1 1
1 1( )
k k
xy i i i i i ii i
s x x y y n x y n xyn n⋅ ⋅
= == − − ⋅ = ⋅ −∑ ∑
Bravais-Pearson-Korrelationskoeffizient
rs
s srxy
x y
= − ≤ ≤ +, ( )1 1
78 Merz: Statistik I - Deskription
Regressionsrechnung
beobachtete Werte y x xi i i, , , ...1 2
unterstellte funktionale Abhängigkeit y f x x= ( , ,1 2 ...)
Regressionskoeffizienten β β β0 1 2, , , ...
Schätzwerte für 0 1 2,, , ...β β β b b b0 1 2, , , ...
Modell der linearen Regression (stochastischer Ansatz)
y x x xK K= + + + + +β β β β ε0 1 1 2 2 ... Deterministischer Ansatz
0 1 1 2 2ˆ ... K Ky b b x b x b x= + + + +
Methode der kleinsten Quadrate (Ordinary Least Squares -OLS)
n2 2
0 1 1 2 21 1
ˆ( ) ( ...) min!n
i i i i ii i
Q y y y b b x b x= =
= − = − − − − =∑ ∑
⇒ = = =∂∂
∂∂
∂∂
Qb
Qb
Qb0 1 2
0 0 0, , , ...
Schätzwerte bei einfacher linearer Regression
b y b x0 1= −
bn
x y x y
nx x
s
sr
s
s
i ii
n
ii
nxy
x
y
x1
1
2 2
1
2
1
1=
− ⋅
−= = ⋅=
=
∑
∑
OLS-Schätzer bei multipler Regression
b X X X y= −( ' ) '1 Bestimmtheitsmaß bei einfacher linearer Regression
Bs
s
y y
y y
ry
y
ii
n
ii
n= =−
−==
=
∑
∑
ɵ
( ɵ )
( )
2
2
2
1
2
1
2
Merz: Statistik I - Deskription 79
V Indexzahlen
Preis des Gutes i zur Basiszeit pi
0
Preis des Gutes i zur Berichtszeit pti
Menge des Gutes i zur Basiszeit q i0
Menge des Gutes i zur Berichtszeit q ti
Preisindex
- nach Laspeyres
( ) 10,
01
100
ni it
it n
i i
i
p qI p
p q
=
=
⋅= ⋅
⋅
∑
∑
0L
0
- nach Paasche
10,
01
( ) 100
ni it t
it n
i i
i
p qI p
p q
=
=
⋅= ⋅
⋅
∑
∑
P
t
Mengenindex
- nach Laspeyres
10,
01
( ) 100
ni i
ti
t ni i
i
p qI q
p q
=
=
⋅= ⋅
⋅
∑
∑
0L
0
- nach Paasche
10,
01
( ) 100
ni i
ti
t ni i
i
p qI q
p q
=
=
⋅= ⋅
⋅
∑
∑
tP
t
80 Merz: Statistik I - Deskription
Umsatzindex (Wertindex)
I p q
p q
p qt
ti
ti
i
n
i i
i
n01
0 01
100, ( , ) =⋅
⋅⋅=
=
∑
∑
Umbasierung von Basisjahr 1 auf Basisjahr 2
Basisjahr 1 01 Basisjahr 2 02
II
Itt
0201
01 02
100,,
,
= ⋅
Merz: Statistik I - Deskription 81
VI Zeitreihenanalyse
Zeitreihenwerte yi
Zeitpunkte t i
Trendgerade
y t= + +β β ε0 1 Ermittlung der Trendgeraden nach der Methode der kleinsten Quadrate
0 1
0 1
y b b t
b y b t
= +
= −
bn
t y ty
nt t
i ii
n
ii
n11
2 2
1
1
1=
−
−
=
=
∑
∑
transformierte Zeitwerte
bei ungeradem n t t ti i' = −
bei geradem n t t ti i' ( )= −2
wenn t ii
n'
=∑ =
1
0 gilt, folgt die Vereinfachung für die Ermittlung der Trendgeraden:
0'b y=
'
11
'2
1
'
n
i ii
n
ii
y tb
t
=
=
=∑
∑
Methode der gleitenden Durchschnitte
geschätzter Trendwert zum Zeitpunkt t yt'
Anzahl der Zeitreihenwerte vor und nach k dem Zeitpunkt t, die in die Berechnung von yt
' einbezogen werden.
- ungerade Ordnung
yk
y t k k n ktt k
t k' , , , ... ,=
+= + + −
= −
+
∑1
2 11 2τ
τ
82 Merz: Statistik I - Deskription
- gerade Ordnung
( 1)'
( 1)
1 1 1, 1, 2, ... ,
2 2 2
t k
t t k t kt k
y y y y t k k n kk τ
τ
+ −
− += − −
= + + = + + −
∑
Exponentielle Glättung
Glättungsfaktor a a; 0 1≤ ≤
- 1. Ordnung
y ay a yt t t' '( )= + − −1 1
- 2. Ordnung
y ay a yt t t" ' "( )= + − −1 1
Prognose mit exponentieller Glättung
- 1. Ordnung
ɵ'y yt t+ =1
- 2. Ordnung
ɵy r mitt r t t+ = +α β ta
ay y
ty yt
t tt t t= − = − = −1
2, ,' "
' " β α
Saisonbereinigung bei konstanter Saisonfigur
um die glatte Komponente bereinigte Zeitreihe y y i Jahr j Monati j i j, ,' ,− = =
Saisonindexziffer ( )'j , i,j
1
1S - y
jm
i jij
ym =
= ∑ɶ
normierte Saisonindexziffer ɵ ɶ ɶS S S mitj j ji
= −=∑
1
1λ
λ
λ = Ordnungder gleitenden Durchschnitte
saisonbereinigte Zeitreihe y Si j j,ɵ−
Merz: Statistik I - Deskription 83
Saisonbereinigung bei variabler Zeitreihe
um die glatte Komponente bereinigte Zeitreihe y
yi j
i j
,
,'
Saisonindexziffer ɶ ,
,'I
m
y
yj
j
i j
i ji
mj
==∑
1
1
normierte Saisonindexziffern ɵ ɶ
ɶ
I I
Ij j
jj
= ⋅
=∑
λλ
1
saisonbereinigte Zeitreihe y
Ii j
j
,
ɵ
84 Merz: Statistik I - Deskription
Literatur
A EINIGE STANDARDWERKE
Anderson, Davi, R., Sweeney, Dennis, J., Williams, Thomas, A., Freeman, Jim und Essie Shoesmith (2007), Statistics for Business and Economics, Thomson Publisher, London (mit CD)
Anderson, O., Popp, W., Schaffranek, M., Stenger, H. und K. Szameitat (1988), Grundlagen der Statistik, Springer-Verlag, 2. Auflage, Berlin
Bamberg, G. und F. Baur (2002), Statistik, R. Oldenbourg Verlag, 12. Auflage, München
Bleymüller, J., Gehlert, G. und H. Gülicher (2004), Statistik für Wirtschafts-wissenschaftler, 14. Auflage, Vahlen, München
Blossfeld, H.-P., Hamerle, A. und K. U. Mayer (1986), Ereignisanalyse: Statistische Theorie und Anwendung in den Wirtschafts- und Sozialwissenschaften, Campus-Verlag, Frankfurt/New York
Bortz, Jürgen (2004), Statistik für Human- und Sozialwissenschaftler, Springer-Verlag, Berlin
Buttler G. und N. Fickel (2002), Statistik mit Stichproben, Rowohlt Taschenbuch Verlag, Reinbeck bei Hamburg
Fahrmeier, L., Künstler, R., Pigeot, I. und G. Tutz (2004), Statistik - Der Weg zur Datenanalyse, 5. verbesserte Auflage, Springer-Verlag, Berlin
Ferschl, F. (1985), Deskriptive Statistik, Physica-Verlag, 3., korrigierte Auflage, Würzburg
Grohmann, H. (1986a), Statistik - Allgemeine Methodenlehre I (ohne Wahrscheinlichkeitsrechnung), 2. Auflage, dipa-Verlag, Frankfurt a.M.
Hansen, G. (1985), Methodenlehre der Statistik, 3. Auflage, München, Vahlen
Hartung, J., Elpelt, B. und K.-H. Klösener (2005), Statistik: Lehr- und Handbuch der angewandten Statistik, 14., unwesentlich veränderte Auflage, R. Oldenbourg Verlag, München
Hochstädter, D. (1996), Statistische Methodenlehre, 8., überarbeitete Auflage, Verlag Harri Deutsch, Frankfurt a.M.
Hujer, R. (2001), Statistik - Manuskript zur Vorlesung, Frankfurt a.M.
Hujer, R. und R. Cremer (1998), Methoden der empirischen Wirtschaftsforschung, 2. Auflage, Vahlen, München
Kellerer, H. (1976), Statistik im modernen Wirtschafts- und Sozialleben, 14. Auflage, Rowohlt, Reinbek bei Hamburg
Kommission zur Verbesserung der informationellen Infrastruktur zwischen Wissenschaft und Statistik (Hrsg.) (2001), Wege zu einer besseren informationellen Infrastruktur. Gutachten der vom Bundesministerium für Bildung und Forschung eingesetzten Kommission zur Verbesserung der informationellen Infrastruktur zwischen Wissenschaft und Statistik, Baden-Baden.
Merz: Statistik I - Deskription 85
Kreyszig, E. (1989), Statistische Methoden und ihre Anwendungen, 7. Auflage, Vandenhoeck & Ruprecht, Göttingen
Krug, W. und M. Nourney (2001), Wirtschafts- und Sozialstatistik: Gewinnung von Daten, R. Oldenbourg Verlag, 6. Auflage, München
Kunz, D. (1987), Praktische Wirtschaftsstatistik, Kohlhammer, Stuttgart.
Lippe von der, P. (1996), Wirtschaftsstatistik, 5., völlig neubearbeitete und erweiterte Auflage, Lucius & Lucius, Stuttgart
Litz, H.P. (2003), Statistische Methoden in den Wirtschafts- und Sozialwissenschaften, 3., vollständig überarbeitete und erweiterte Auflage, R. Oldenbourg Verlag, München, Wien
Merz, J. (2009), Statistik I - Deskription, Skriptum zur Vorlesung, 9. erweiterte Auflage, Lüneburg
Mittag, H.J. und D. Stemann, Statistik – Beschreibende Statistik und explorative Datenanalyse, 5., verbesserte und erweiterte Auflage, Fachbuchverlag Leipzig im Carl-Hanser-Verlag, Leipzig
Moore, D.S. (1997), Statistics – Concepts and Controversies, 5. Auflage, W.H. Freeman and Company, New York
Neubauer, W., Bellgardt, E. und A. Behr (2002), Statistische Methoden, 2. Auflage, Vahlen, München
Pfanzagl, J. (1983), Allgemeine Methodenlehre der Statistik I, 6., verbesserte Auflage, Walter de Gruyter, Berlin/New York
Sachs, L. (2004), Angewandte Statistik - Anwendung statistischer Methoden, 11., überarbeitete und aktualisierte Auflage, Springer Verlag, Berlin
Scharnbacher, K. (2004), Statistik im Betrieb - Lehrbuch mit praktischen Beispielen, 14., aktualisierte Auflage, Gabler Verlag, Wiesbaden
Schira, J. (2009), Statistische Methoden der VWL und BWL Theorie und Praxis, 3. aktualisierte Auflage, Pearson Studium, München
Schlittgen, R. (2003), Einführung in die Statistik, 10., durchgesehene Auflage, R. Oldenbourg Verlag, München, Wien
Schwarze, J. (2005), Grundlagen der Statistik I - Beschreibende Verfahren, 10. Auflage, Verlag Neue Wirtschafts-Briefe, Herne/Berlin
Wetzel, W. (1971, 1973), Statistische Grundausbildung für Wirtschaftswissenschaftler, Teil I und Teil II, Walter de Gruyter, Berlin
Yamane, T. (1981), Statistik - Ein einführendes Lehrbuch, Teil I und Teil II, Fischer Taschenbuch Verlag, Frankfurt
Zöfel, P. (1992), Statistik in der Praxis, 3., überarbeitete und ergänzte Auflage, UTB 1293, Stuttgart
B BÜCHER MIT ÜBUNGSAUFGABEN
Bamberg, G. und F. Baur (2000), Statistik Arbeitsbuch: Übungsaufgaben, Fallstudien, Lösungen, 6. Auflage, R. Oldenbourg Verlag, München
86 Merz: Statistik I - Deskription
Bihn, W.R. und K.A. Schäffer (1986), Übungsaufgaben zur Grundausbildung in Statistik für Wirtschaftswissenschaftler, J.C. Witsch Nachf., Köln
Fahrmeier, L., Künstler, R., Pigeot, I., Tutz, G., Caputo, A. und S. Lang (2003), Arbeitsbuch Statistik, 3., überarbeitete und erweiterte Auflage, Springer-Verlag, Berlin
Hartung, J. und B. Heine (1999), Statistik Übungen: Deskriptive Statistik, 6. Auflage, R. Oldenbourg Verlag, München
Hochstädter, D. (1993), Aufgaben mit Lösungen zur statistischen Methodenlehre, 2. Auflage, Verlag Harri Deutsch, Frankfurt
Lippe von der, P. (1999), Klausurtraining in Statistik, R. Oldenbourg Verlag, 5. Auflage, München/Wien
Merz, J. (2009), Statistik I - Deskription, Übungs- und Klausuraufgaben mit Lösungen, 9. Auflage, Lüneburg
Spiegel, M.R. (1990), Statistik, 2. Auflage, Mc Graw Hill, Düsseldorf
C FORMEL- UND TABELLENWERKE
Bihn, E.R. und K.A. Schäffer (1987), Formeln und Tabellen zur Grundausbildung in Statistik für Wirtschaftswissenschaftler, J.C. Witsch Nachf., Köln
Bleymüller, J. und G. Gehlert (1999), Statistische Formeln, Tabellen und Programme, 9. Auflage, Verlag Franz Vahlen, München
Bohley, P. (1998), Formeln, Rechenregeln und Tabellen zur Statistik, R. Oldenbourg Verlag, 7. Auflage, München
Rinne, H. (1997), Statistische Formelsammlung, 2. Auflage, Verlag Harri Deutsch, Frankfurt
Vogel, F. (2000), Beschreibende und schließende Statistik - Formeln, Definitionen, Erläuterungen, Stichwörter und Tabellen, R. Oldenbourg Verlag, 12. Auflage, München
D WEITERFÜHRENDE LITERATUR
Allgemeines Statistisches Archiv (1992), Band 76
Arminger, G. und F. Müller (1990), Lineare Modelle zur Analyse von Paneldaten, Opladen
Backhaus, K., Erichson, B., Pinke, W., Schuchard-Fischer, Chr. und R. Weiber (2006), Multivariate Analysemethoden, 11., überarbeitete Auflage, Springer Verlag, Berlin/Tokyo
Bates, B.C., Z.W. Kundzewicz, S. Wu, J.P. Palutikof, Eds. (2008), Climate Change and Water. Technical Paper of Ingovernmental Panel on Climate Change, IPCC Secretariat, 210 pp., Geneva
Berntsen, R. (1991), Dynamik in der Einkommensverteilung. Eine empirische Längsschnittuntersuchung der Strukturen der Einkommensverteilung privater Haushalte in der Bundesrepublik Deutschland, Dissertation, Frankfurt
Merz: Statistik I - Deskription 87
Diewald, M. (1984), Das 'SPES-Indikatoren-Tableau' 1976 - Fortschreibung bis zum Jahr 1982, Sfb 3-Arbeitspapier Nr. 150, Frankfurt/Mannheim
Esenwein-Rothe (1978), Modelle für eine Bevölkerungsprojektion und die Grenzen der Aus-sagekraft, in: Jahrbuch für Nationalökonomie und Statistik, Band 193, Heft 1
Esser, H., Grohmann, H., Müller, W. und K.A. Schäffer (1989), Mikrozensus im Wandel - Untersuchungen und Empfehlungen zur inhaltlichen und methodischen Gestaltung, Forum der Bundesstatistik, Bd. 11, Metzler-Poeschel Verlag, Stuttgart
Galler, H.P. and G. Wagner (1986), The Microsimulation Model of the Sfb 3 for the Analysis of Economic and Social Policies, in: Orcutt, G.H., Merz, J. and H. Quinke (eds.), Microanalytic Simulation Models to Support Social and Financial Policy, S. 227-247, North Holland, Amsterdam
Galler, H.P. und N. Ott (1994), Das dynamische Mikrosimulationsmodell des Sonderforschungsbereichs 3, in: Mikroanalytische Grundlagen der Gesellschaftspolitik, Deutsche Forschungsgemeinschaft, Bd. 2, Akademie Verlag, Berlin
Glatzer, W. und W. Zapf (Hrsg.) (1984), Lebensqualität in der Bundesrepublik, Frank-furt/New York
Goldberger, A.S. (1991), A Course in Econometrics, Harvard University Press, London
Greene, W. (1991), Econometric Analysis, Macmillan Publishing Company, New York
Greene, W. (1992), ET - The Econometrics Toolkit, Version 3.0, Econometric Software, Inc., New York
Grohmann, H. (1986b), Bevölkerungs- und Wirtschaftsstatistik, dipa-Verlag, 2. Auflage, Frankfurt a.M.
Habich, R., und H.-H. Noll unter Mitarbeit von W. Zapf (1993), Soziale Indikatoren und Sozialberichterstattung - Internationale Erfahrungen und gegenwärtiger Forschungsstand, Berlin/Mannheim
Hamer, G. und C. Stahmer (1992), Integrierte Volkswirtschaftliche- und Umwelt-gesamtrechnung (I): Konzeption, in: ZfU, Heft 1, S. 85-117; Integrierte Volkswirtschaftliche- und Umweltgesamtrechnung (II): (Zahlen-)Beispiel und Realisierungsmöglichkeiten, in: ZfU, Heft 2, S. 237-256
Hansen, G. (1993), Quantitative Wirtschaftsforschung, Franz Vahlen, München
Hsiao, C. (1986), Analysis of Panel Data, Cambridge (Mass.)
Huff, D. (1978), How to Lie with Statistics, Penguin Books, Harmondsworth (UK)
Johnson, J.D. (1992), Applied Multivariate Data Analysis – Volume II: Categorical and Multivariate Methods, Springer Verlag, New York
Krämer, W. (1991), So lügt man mit Statistik, Campus-Verlag, Frankfurt/New York
Krupp, H.-J. und W. Zapf (1977), Sozialpolitik und Sozialberichterstattung, Frankfurt/New York
Leipert, C. (1975), Unzulänglichkeiten des Sozialprodukts in seiner Eigenschaft als Wohlstandsmaß, Tübingen
Leipert, C. (1989), Die heimlichen Kosten des Fortschritts, Frankfurt
Maddala, G.S., Rao, C.R. und H.D. Vinod (Hrsg.) (1993), Econometrics, 11. Auflage, North-Holland, New York
88 Merz: Statistik I - Deskription
Malinvaud, E. (1980), Statistical Methods in Econometrics, 3. Auflage, American Elsevier, New York
Mátyás, L. und P. Sevestre (1992), The Econometrics of Panel Data, Handbook of Theory and Applications, Kluwer academic publishers, Dortrecht
Merz (2002), Freie Berufe im Wandel der Märkte, FFB-Schriftenreihe, Band 13, Nomos Verlag, Baden-Baden
Merz, J. (1980a), Die Ausgaben privater Haushalte - Ein mikroökonometrisches Modell für die Bundesrepublik Deutschland, Frankfurt/New York
Merz, J. (1980b), Prognosegüte und Spektraleigenschaften ökonomischer Modelle, in: Stöppler, S. (Hrsg.), Dynamische ökonomische Systeme - Analyse und Steuerung, 2. Auflage, Gabler-Verlag, Wiesbaden, S. 31-66
Merz, J. (1987), Mathematik II für Wirtschaftswissenschaftler, Skriptum zur Vorlesung, Johann Wolfgang Goethe-Universität Frankfurt, Frankfurt a.M.
Merz, J. (1991a), Markt- und nichtmarktmäßige Aktivitäten privater Haushalte - Theoretischer Ansatz, repräsentative Mikrodaten, mikroökonometrische Analyse und Mikrosimulation wirtschafts- und sozialpolitischer Maßnahmen für die Bundesrepublik Deutschland, Frankfurt a.M.
Merz, J. (1991b), Microsimulation - A Survey of Principles, Developments and Applications, in: International Journal of Forecasting, 7, S. 77-104
Merz, J. (1994a), Statisches Mikrosimulationsmodell: Mainframe und PC-Version, in: Hauser, R., Ott, N. und G. Wagner (eds.), Deutsche Forschungsgemeinschaft: Mikroanalytische Grundlagen der Gesellschaftspolitik - Erhebungsverfahren, Analysemethoden und Mikrosimulation, Akademie Verlag, Berlin
Merz, J. (1994b), Microdata Adjustment by the Minimum Information Loss Principle, Forschungsinstitut Freie Berufe der Universität Lüneburg, FFB-Diskussionspapier Nr. 10, Lüneburg
Merz, J. (2008), Statistik II - Wahrscheinlichkeitsrechnung und induktive Statistik, Skriptum zur Vorlesung, 7. verbesserte Auflage, Lüneburg
Merz, J. und H. Stolze (2006), Adjust for Windows Version 1.1 - A Software Package to Achieve Representative Microdata by the Minimum Information Loss Principle - Manual, FFB-Dokumentation Nr. 13, Forschungsinstitut Freie Berufe, Fakultät II Wirtschafts-, Verhaltens- und Rechtswissenschaften, Universität Lüneburg, Lüneburg
Merz, J. und J. Faik (1992), Equivalence Scales Based on Revealed Preference Consumption Expenditure Microdata - The Case of West Germany, Forschungsinstitut Freie Berufe der Universität Lüneburg, FFB-Diskussionspapier Nr. 3, Lüneburg
Merz, J., Helberger, C. und H. Schneider (1985), Nebenerwerbstätigkeitsumfrage 1984, Dokumentation, bearbeitet von Klaus Wolff, Frankfurt
Merz, J., Stolze, H. und M. Zwick (2002), Professions, entrepreneurs, employees and the new German tax (cut) reform 2000 - A MICSIM microsimulation analysis of distributional impacts, Forschungsinstitut Freie Berufe der Universität Lüneburg, FFB-Diskussionspapier Nr. 34, Lüneburg
Mueller, U. (1993), Bevölkerungsstatistik und Bevölkerungsdynamik, Walter de Gruyter, Berlin/New York
Merz: Statistik I - Deskription 89
Noll, H.-H. (1990), Sozialindikatorenforschung in der Bundesrepublik - Konzepte, For-schungsansätze und Perspektiven, in: Timmermann, H. (Hrsg.), Lebenslagen, Sozialindikatorenforschung in beiden Teilen Deutschlands, S. 69-87, Saarbrücken
Noll, H.-H. (1993), Lebensbedingungen in der Europäischen Gemeinschaft gleichen sich nur langsam an - ökonomische und soziale Indikatoren im EG-Vergleich, in: ZUMA, Informationsdienst Soziale Indikatoren (ISI), Heft 4, S. 11-15
Noll, H.-H. (Hrsg.) (1997), Sozialberichterstattung in Deutschland - Konzepte, Methoden und Ergebnisse für Lebensbereiche und Bevölkerungsgruppen, Juventa, Weinheim und München
Nullau, B. u.a. (1969), Das Berliner Verfahren, DIW- Beiträge zur Strukturforschung, Berlin
Orcutt, G., Merz, J. and H. Quinke (eds.) (1986), Microanalytic Simulation Models to Support Social and Financial Policy, North Holland, Amsterdam
Rapin, H. (Hrsg.) (1990), Der private Haushalt - Daten und Fakten, Stiftung 'Der Private Haushalt', Campus, Frankfurt a.M.
Rinne, H. (1994), Wirtschafts- und Bevölkerungsstatistik - Erläuterungen, Erhebungen, Ergebnisse, R. Oldenbourg Verlag, München/Wien
Rockwell, R. (1986/87), Prospects for Social Reporting in the United States: A Receding Horizion, in: The Tocqueville Review, Vol. 8, S. 251-262
Schlittgen, R. und B.H.J. Streitberg (1987), Zeitreihenanalyse, 2. Auflage, R. Oldenbourg Verlag, München/Wien
Schwarze, J. (2006), Grundlagen der Statistik II – Wahrscheinlichkeitsrechnung und induktive Statistik, Verlag Neue Wirtschafts-Briefe, 8. Auflage, Herne/Berlin
Sheldon, E. B. and R. Park (1975), Social Indicators, in: Science, American Association for the Advancement of Science, Vol. 188, S. 693-699
Sheldon, E. B. and W.E. Moore (eds.) (1968), Indicators of Social Change, Concepts and Measurement, New York
Spanos, A. (1986), Statistical Foundation of Econometric Modelling, Cambridge
Stahmer, C. (1992), Integrierte Volkswirtschaftliche- und Umweltgesamtrechnung, in: Wirtschaft und Statistik, Heft 9, S. 577-593
Statistisches Bundesamt (1980), Fachserie 14, Reihe 7.3, Finanzen und Steuern, Lohnsteuern, Wiesbaden
Statistisches Bundesamt (1990), Fachserie 1, Reihe 4.1.1, Bevölkerung und Erwerbstätigkeit, Wiesbaden
Statistisches Bundesamt (Hrsg.) (1988), Das Arbeitsgebiet der Bundesstatistik, W. Kohlhammer, Stuttgart/Mainz
Statistisches Bundesamt (Hrsg.) (1992). Datenreport 1992, in Zusammenarbeit mit dem Wissenschaftszentrum für Sozialforschung, Berlin und dem Zentrum für Umfragen, Methoden und Analysen, Mannheim, Wiesbaden
Statistisches Bundesamt, Statistisches Jahrbuch, verschiedene Jahrgänge, Wiesbaden
Steger, A. (1980), Haushalte und Familien bis zum Jahre 2000 ,Campus, Frank-furt a.M./New York).
90 Merz: Statistik I - Deskription
Stobernack, M. (1989), Die Bedeutung der Arbeitslosenversicherung für Arbeitslosigkeit und Arbeitsangebot unter Einbeziehung eines empirischen Arbeitsangebotsvergleichs zwischen der Bundesrepublik und den USA, Berlin.
United Nations Development Programme (UNDP) (1991), Human Development Report 1991, Oxford
Vogel, J. (1990), Social Indicators - A Swedish Perspective, in: Journal of Public Policy, Vol. 9, S. 439-444
Yang, M.C.K. and D. Robinson (1986), Understanding and Learning Statistics by Computer, World Scientific, Singapore
Zapf, W. (1972), Zur Messung der Lebensqualität, in: Zeitschrift für Soziologie, 1. Jg., S. 353-367
Zapf, W. (1977), Einleitung in das SPES-Indikatorensystem, in: Zapf, W. (Hrsg.), Lebensbedingungen in der Bundesrepublik. Sozialer Wandel und Wohlfahrtsentwicklung, S. 11-27, Frankfurt/New York
Zapf, W. (1990), Einleitung, in: WZB-AG Sozialberichterstattung (Hrsg.), Sozialreport 1990, Dokumentation eines Workshops am Wissenschaftszentrum Berlin für Sozialforschung, Arbeitspapier P90-102, Berlin
E SONSTIGE LITERATUR
Berger-Schmitt, R. (2002), Unterschiede in den Lebensbedingungen in der Europäischen Union kaum verringert, in: Informationsdienst Soziale Indikatoren (ISI), Ausgabe 27, Januar 2002, S. 2
Club of Rome (1991), Der Blick in die Zukunft, in: natur, Heft 9, S. 31-32
Der siebte Tag (30.11.2002), Wochenendbeilage zur Hannoverschen Allgemeinen Zeitung, November 2002, Madsack-Verlag, Hannover
Die ZEIT (02.09.1994), Nr. 36, ZEITVERLAG, Hamburg
Gonick, L. and W. Smith (1993), The Cartoon Guide to Statistics, HarperCollins Publishers, New York
Kuhn, T. (1970), Structure of Scientific Revolutions, 2. Auflage, Chicago
Meadows, D., Randers, D. und J. Randers (1992), Die neuen Grenzen des Wachstums - Die Lage der Menschheit: Bedrohung und Zukunftschancen, Stuttgart
Merz, J., Rauberger, T.K. und A. Rönnau (1994), Freie Berufe in Rheinland-Pfalz und in der Bundesrepublik Deutschland: Struktur, Entwicklung und wirtschaftliche Bedeutung, Schriften des Forschungsinstituts Freie Berufe der Universität Lüneburg Nr. 7, Lüneburg
Myers, N. (Hrsg.) (1985), gaia - der öko-Atlas unserer Erde, Fischer Verlag, Frankfurt
Schwarze, J. (1977), Bibliographie zur Statistik in der Weiterbildung, 2. Auflage, Pädagogische Arbeitsstelle des Deutschen Volkshochschulverbandes, Holzhausenstr. 21, 6000 Frankfurt, Frankfurt/Bonn
Sozio-ökonomisches Panel (Welle I (1) 1984, Welle I (9), 1992), des Sonderforschungs-bereichs 3, Frankfurt/Mannheim und des DIW, Berlin
Merz: Statistik I - Deskription 91
Statistisches Bundesamt (1986), Volkszählung '87: Zehn Minuten, die allen helfen - Materialien, Abschnitt 2.2, Wiesbaden
Statistisches Bundesamt (2003), Energieverbrauch und Luftemissionen des Sektors Verkehr, Band 12 der Schriftenreihe zu den Umweltökonomischen Gesamtrechnungen - Kurzfassung
Statistisches Bundesamt (2005), Verbraucherpreisindex und Index der Einzelhandelspreise - Jahresdurchschnitte ab 1948, Wiesbaden
Statistisches Bundesamt (Hrsg.) (1988), Das Arbeitsgebiet der Bundesstatistik 1988, Mainz, Kohlhammer
United Nations (2005), Population Challenges and Development Goals, Department of Economic and Social Affairs, Population Division, New York
United Nations Development Programm (UNDP) (Hrsg.), Human Development Report 1991, New York, Oxford, 1991,Oxford University Press
United Nations Development Programm (UNDP) (Hrsg.), Human Development Report 2003, New York, Oxford, 2003,Oxford University Press
Wolffs, M. (2002), Bevölkerung zwischen Dynamik und Stillstand - Demographische Entwicklungen im Längschnitt, Sankt Augustin, Arbeitspapier der Konrad-Adenauer-Stiftung e.V.
ZEIT-Punkte (1994), Weltbevölkerung - Wird der Mensch zur Plage?, Nr. 4/1994, ZEITVERLAG, Hamburg