76
Statistik Vorlesung 6 (Tests II) K.Gerald van den Boogaart http://www.stat.boogaart.de Statistik – p. 1/57

StatistikVorlesung 6 (Tests II)
K.Gerald van den Boogaart
http://www.stat.boogaart.de
Statistik – p. 1/57
Sümpfe des multiplen Testens
Rangviertel
Die unwegsamen Ausreißerberge
Die Datenminen
Todeswüste, der nicht erfüllten Voraussetzungen
Steig der
Nich
tparametrik
Gle
tsch
ersp
alt
e der
glei
chen
Mes
swer
te
Nacht der angenommen Hypothesen
Klippe
der
unüber
prü
fbare
n
Vor
auss
etzu
nge
n Klippe der unüberprüfbaren
Voraussetzungen
robuster Weg
Momentenmethoden u.Lineare Modelle
ML-CityBayes-Land
t-DorfModell-Platz
Statistika
Vertrauensbereich
Normalviertel
Vorhersagebereich
Steppe der unwesentlich verletzten Voraussetzungen
Schätzervorstadt
Schlaraffia oder das Land des gelungen statistischen Nachweis Land des offenen Betrugs
BonferroniPassage
BenjaminiPassage
Sequenzielle Passage
Posthoc
Mathe
Schätzung
Daten
Test
Aussichtsturm
Grafingen
Riesige Halde mit nichtrepräsentativen
Daten
Statistik – p. 2/57

Konstruktion eines Tests
Je größer der Messwert, deso eher wurde der Grenzwertüberschritten:
T (X) =
{
0, falls X < k
1, falls X ≥ k
k heißt kritischer Wert.
Wähle k so, dass (wenn die Hypothese stimmt)
P (X > k) = α = 0.05
Falls X normalverteilt mit Mittelwert 7,5 undStandardabweichung 1 so ist
k = FN(7.5,1)(1 − α) = 9.14485362695147Statistik – p. 3/57

Ein Test hat
Namen(hier: einfacher einseitiger Gauss-Test)
Statistik – p. 4/57

Ein Test hat
Namen
AnwendungssituationÜberprüfen ob der wahre Erwartungswert einen festenWert (hier 7,5) übersteigt, wenn eine normalverteilteMessung mit bekannter Varianz σ2 (hier 1) vorliegt.
Statistik – p. 4/57

Ein Test hat
Namen
Anwendungssituation
Hypothese und AlternativeH0 : µ = 7, 5 vs. H1 : µ > 7, 5
Statistik – p. 4/57

Ein Test hat
Namen
Anwendungssituation
Hypothese und Alternative
VoraussetzungenX ∼ N(µ, σ2
0)
Statistik – p. 4/57

Ein Test hat
Namen
Anwendungssituation
Hypothese und Alternative
Voraussetzungen
Ein EntscheidungsverfahrenMeist im Computer implementiert. Hier:
T (X) =
{
0, falls X < FN(µ0,σ2
0)(1 − α)
1, falls X ≥ FN(µ0,σ2
0)(1 − α)
Statistik – p. 4/57

Ein Test hat
Namen
Anwendungssituation
Hypothese und Alternative
Voraussetzungen
Ein Entscheidungsverfahren
Statistik – p. 4/57

Das Entscheidungsverfahren
Das Test (also das Entscheidungsverfahren)
T (X) =
{
0, falls S(X) < FP S0
(1 − α)
1, falls S(X) ≥ FP S0
(1 − α)
besteht normalerweise aus:
Einer Funktion S(X), genannt die Teststatistik(hier S(X) = X)
Statistik – p. 5/57

Das Entscheidungsverfahren
Das Test (also das Entscheidungsverfahren)
T (X) =
{
0, falls S(X) < FP S0
(1 − α)
1, falls S(X) ≥ FP S0
(1 − α)
besteht normalerweise aus:
Einer Funktion S(X), genannt die Teststatistik(hier S(X) = X)
und der Verteilung PS0 der Teststatistik unter der
Nullhypothese:(hier PS
0 = N(µ0, σ20))
Statistik – p. 5/57

Das Entscheidungsverfahren
Das Test (also das Entscheidungsverfahren)
T (X) =
{
0, falls S(X) < FP S0
(1 − α)
1, falls S(X) ≥ FP S0
(1 − α)
besteht normalerweise aus:
Einer Funktion S(X), genannt die Teststatistik(hier S(X) = X)
und der Verteilung PS0 der Teststatistik unter der
Nullhypothese:(hier PS
0 = N(µ0, σ20))
Statistik – p. 5/57

Die Berechnung des p-Wertes
Das Entscheidungsverfahren besteht normalerweise aus:
. . . und der resultierenden Entscheidungsregel
T (X) =
{
0, falls S(X) < FP S0
(1 − α)
1, falls S(X) ≥ FP S0
(1 − α)
der p-Wert (kleinstes α-Niveau zu dem abgeleht wird) wirddann wie folgt berechnet:
p = 1 − F−1(S(X))
da dann S(X) = F (1 − p) genau auf der Grenze liegt.
Statistik – p. 6/57

Die Berechnung des p-Wertes
Das Entscheidungsverfahren besteht normalerweise aus:
. . . und der resultierenden Entscheidungsregel
T (X) =
{
0, falls S(X) < FP S0
(1 − α)
1, falls S(X) ≥ FP S0
(1 − α)
der p-Wert (kleinstes α-Niveau zu dem abgeleht wird) wirddann wie folgt berechnet:
p = 1 − F−1(S(X))
da dann S(X) = F (1 − p) genau auf der Grenze liegt.
Statistik – p. 6/57

Die Berechnung des p-Wertes
Das Entscheidungsverfahren besteht normalerweise aus:
. . . und der resultierenden Entscheidungsregel
T (X) =
{
0, falls S(X) < FP S0
(1 − α)
1, falls S(X) ≥ FP S0
(1 − α)
der p-Wert (kleinstes α-Niveau zu dem abgeleht wird) wirddann wie folgt berechnet:
p = 1 − F−1(S(X))
da dann S(X) = F (1 − p) genau auf der Grenze liegt.
Statistik – p. 6/57
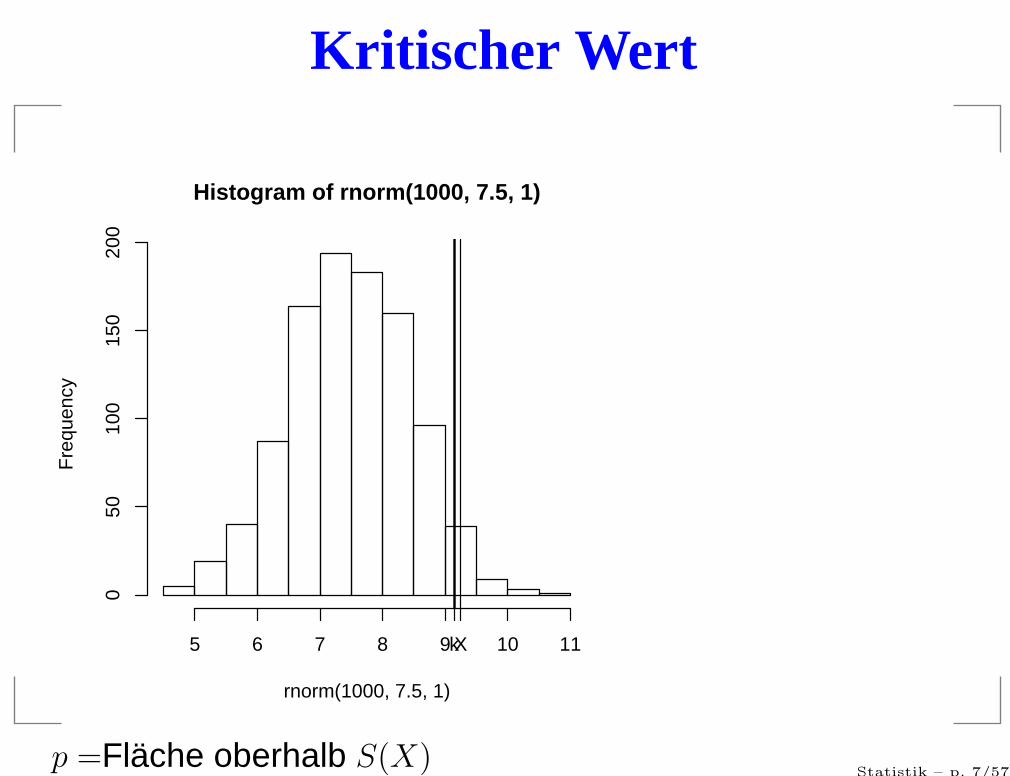
Kritischer Wert
Histogram of rnorm(1000, 7.5, 1)
rnorm(1000, 7.5, 1)
Fre
quen
cy
5 6 7 8 9 10 11
050
100
150
200
kX
p =Fläche oberhalb S(X)Statistik – p. 7/57

Der Test ist im Computer implementiert
EinfacherGauss.test <- function(x,mean=0,var=1) {
parameter <-c(mean=mean,sd=sqrt(var))
statistic <- c(T=x)
structure(list(
data.name=deparse(substitute(x)),
method="Ein Stichproben Gauss-Test",
alternative="greater",
parameter=parameter,
statistic=statistic,
p.value=1-pnorm(statistic,
mean=parameter["mean"],
sd=parameter["sd"])
),
class="htest")
}
Statistik – p. 8/57

Der Test wird im Computer durchgeführt
...
> EinfacherGauss.test(9.46, mean = 7.5, var = 1)
Ein Stichproben Gauss-Test
data: 9.46
T = 9.46, mean = 7.5, sd = 1.0, p-value = 0.025
alternative hypothesis: greater
Jeder im Computer implementierte Test gibt irgendwo einen p-Wert aus. Diesen gilt es zufinden.
Statistik – p. 9/57

Es gibt viele Tests.Wie finde ich den richtigen?
Statistik – p. 10/57

Die Testsituationen
Die Testsituationen werden nach mehrere Kriterienunterteilt:
Anzahl der beteiligten Stichproben
Zu testende Große
Art der Alternative
Art der Voraussetzungen
Anzahl der beteiligten Merkmale
Statistik – p. 11/57

Beteiligte Stichproben
Einzelbeobachtungz.B. ein einzelner Messwert, wie im Beispiel
Statistik – p. 12/57

Beteiligte Stichproben
Einzelbeobachtung
Ein-Stichproben-TestsEs werden Eigenschaften einer Grundgesamtheituntersucht, z.B. wenn das Labor mehrere Messungengemacht hat.
Statistik – p. 12/57

Beteiligte Stichproben
Einzelbeobachtung
Ein-Stichproben-Tests
Zwei-Stichproben-Testswenn zwei Grundgesamtheiten verglichen werdensollen (z.B. behandelte und unbehandelte Flächen).
Statistik – p. 12/57

Beteiligte Stichproben
Einzelbeobachtung
Ein-Stichproben-Tests
Zwei-Stichproben-Tests
Gepaarte Testswenn zwei Messungen am gleichen statistischenIndividuum verglichen werden sollen (z.B. vorher –nachher Vergleiche).Eigentlich: Ein-Stichprobentests mit zwei Merkmalen.
Statistik – p. 12/57

Beteiligte Stichproben
Einzelbeobachtung
Ein-Stichproben-Tests
Zwei-Stichproben-Tests
Gepaarte Tests
Mehr-Stichproben-Tests
Überprüfen, ob mehrere Grundgesamtheiten gleichsind (z.B. nachweisen, dass sich verschiedeneethnische Gruppen in ihrem Sozialverhaltenunterscheiden.)
Statistik – p. 12/57

Zu testende Größe
Mittelwert/Lagez.B. verdienen Männer und Frauen im Schnitt gleichviel, wenn sie als Geologen/Maschinenbauer arbeiten?
Statistik – p. 13/57

Zu testende Größe
Mittelwert/Lage
Varianz/Streuungz.B. Welches von zwei Verfahren mißt genauer?
Statistik – p. 13/57

Zu testende Größe
Mittelwert/Lage
Varianz/Streuung
Verteilungz.B. sind die Daten wirklich normalverteilt?
Statistik – p. 13/57

Zu testende Größe
Mittelwert/Lage
Varianz/Streuung
Verteilung
Unabhangigkeitz.B. bekommen Raucher öfter Krebs? d.h. ist Krebsvom Rauchen abhängig.
Statistik – p. 13/57

Art der Alternative
“Großer”: H0 : µ ≤ 7, 5 vs. H1 : µ > 7, 5
“Kleiner”: H0 : µ ≥ 7, 5 vs. H1 : µ < 7, 5
“Ungleich”: H0 : µ = 7, 5 vs. H1 : µ 6= 7, 5
Die Tests auf größer und kleiner heißen auch einseitigeTests, da von der Hypothese aus die Alternative nur ineiner Richtung liegt. Tests bei denen die Alternative inbeiden Richtungen von der Hypothese liegt heißen auchzweiseitige Tests.
Statistik – p. 14/57

Art der Voraussetzung
Generalvoraussetzung: Unabhängigkeit /repräsentative Stichprobe(n)
Statistik – p. 15/57

Art der Voraussetzung
Generalvoraussetzung: Unabhängigkeit /repräsentative Stichprobe(n)
Normalverteilungsbasierte TestsVoraussetzung: Die Zufallsvariablen sindnormalverteilt.Problem: Falsche Ergebnisse, wenn Ausreißer oderbimodale Verteilungen vorliegen.Betrachtet: Mittelwerte, Varianzen
Statistik – p. 15/57

Art der Voraussetzung
Generalvoraussetzung: Unabhängigkeit /repräsentative Stichprobe(n)
Normalverteilungsbasierte Tests
Nichtparametrische Test/RangtestsVoraussetzung: Die Zufallsvariablen sind stetigverteilt.Problem: Falsche Ergebnisse, wenn zu vieleMesswerte gleich sind.Betrachtet: Ränge, relative Verschiebung, < .Info: Weniger effizient als normalerverteilungsbasierteTests
Statistik – p. 15/57

Art der Voraussetzung
Generalvoraussetzung: Unabhängigkeit /repräsentative Stichprobe(n)
Normalverteilungsbasierte Tests
Nichtparametrische Test/Rangtests
Robuste TestsVoraussetzung: Die Zufallsvariablen sindNormalverteilung, aber es dürfen falscheWerte/Ausreißer vorhanden seinProblem: Verfügbarkeit, Maximaler Anteil der falschenWerte muß angegeben werden.Betrachtet: Mittelwert, Varianz des “Hauptanteils derDaten”Info: Liegen von der Effizienz her zwischen denbeiden anderen.
Statistik – p. 15/57
Sümpfe des multiplen Testens
Rangviertel
Die unwegsamen Ausreißerberge
Die Datenminen
Todeswüste, der nicht erfüllten Voraussetzungen
Steig der
Nich
tparametrik
Gle
tsch
ersp
alt
e der
glei
chen
Mes
swer
te
Nacht der angenommen Hypothesen
Klippe
der
unüber
prü
fbare
n
Vor
auss
etzu
nge
n Klippe der unüberprüfbaren
Voraussetzungen
robuster Weg
Momentenmethoden u.Lineare Modelle
ML-CityBayes-Land
t-DorfModell-Platz
Statistika
Vertrauensbereich
Normalviertel
Vorhersagebereich
Steppe der unwesentlich verletzten Voraussetzungen
Schätzervorstadt
Schlaraffia oder das Land des gelungen statistischen Nachweis Land des offenen Betrugs
BonferroniPassage
BenjaminiPassage
Sequenzielle Passage
Posthoc
Mathe
Schätzung
Daten
Test
Aussichtsturm
Grafingen
Riesige Halde mit nichtrepräsentativen
Daten
Statistik – p. 16/57

Voraussetzungen an die Varianz
Bei Zwei– und Mehrstichproben-Problemen mitNormalverteilungsvoraussetzung ist oft noch dieUnterscheidung nach der Gleichheit der Varianz wichtig.
homoskedastisch: Streuung in allenTeilgrundgesamtheiten gleich.
heteroskedastisch: Streuungen nicht unbedingtgleich.
Statistik – p. 17/57

Anzahl der beteiligten Merkmale
univariat: Es wird nur ein Merkmal betrachtet.
bivariat: Es werden zwei Merkmale betrachet.
multivariat: Es werden mehrere Merkmale betrachtet.
Statistik – p. 18/57

Ein-Stichproben-TestsVerteilungirgendeine Normalverteilung ⇒ Shapiro-Wilk-Testeine bestimmte stetige Verteilung ⇒
(Ein-Stichproben)-KS-Test
Statistik – p. 19/57

Shapiro-Wilk-Test
Shapiro-Wilk-TestSituation:
Test auf Normalverteilung
H0 : X normalverteilt (X ∼ N(µ, σ2))H1 : X nicht normalverteiltVoraussetzungen:
repräsentative Stichprobenicht zu stark gerundet
Bemerkung:d.h. es darf keine “falschen Bindungen” geben
Befehl: shapiro.test(X)
Statistik – p. 20/57

Beispiel
> x <- rexp(20)
> shapiro.test(x)
Shapiro-Wilk normality test
data: x
W = 0.9069, p-value = 0.05563
Statistik – p. 21/57

Kolmogorov-Smirnov-Test
Kolmogorov-Smirnov-TestSituation:
Test auf spezielle Verteilung (stetig)H0 : X hat die Verteilungsfunktion F0: FX ≡ F0
H1 : Die Verteilungsfunktion FX ist ungleich F0
Voraussetzungen:repräsentative Stichprobenicht zu stark gerundet
Bemerkung:d.h. es darf keine “falschen Bindungen” gebenDer Test nimmt zu oft an, wenn die Parameter aus den Daten geschätztwurden.Der Test lehnt zu oft ab, wenn die Parameter aus anderen Datengeschätzt wurden.Eine kleinere Verteilungsfunktion gehört zu größeren Werten.
Befehl: ks.test(X,F0)Statistik – p. 22/57

Ein-Stichproben-TestsLagenormalverteilt, Varianz bekannt ⇒ Gauss-Testnormalverteilt, Varianz unbekannt ⇒ spezieller t-Testnicht normal ⇒ Vorzeichentestdichotom ⇒ Binomial Testdiskret ⇒ . . . spezieller χ2-Test (später)
Statistik – p. 23/57

Gausstest
GausstestSituation:
Test auf Mittelwert bei bekannter VarianzH0 : Erwartungswert µ von X ist µ0: µ = µ0
H1 : Erwartungswert µ von X ist ungleich µ0: µ 6= µ0
Voraussetzungen:repräsentative StichprobeX ist normalverteilt: Xi ∼ N(µ, σ2
0)
σ20 bekannt
Bemerkung:Der Gauss-Test wird sehr selten auf reale Datensätze angewendet, dadie Varianz fast nie bekannt ist. Er ist jedoch der wohl am leichtestentheoretisch zu verstehende Test und daher immer noch überall zufinden.
Befehl: --Statistik – p. 24/57

Einstichproben t-Test
Einstichproben t-TestSituation:
Test auf Mittelwert bei unbekannter VarianzH0 : Erwartungswert µ von X ist µ0: µ = µ0
H1 : Erwartungswert µ von X ist ungleich µ0: µ 6= µ0
Voraussetzungen:repräsentative StichprobeX ist normalverteilt: Xi ∼ N(µ, σ2)
σ2 ist unbekanntBemerkung:
Befehl: t.test(X)
Statistik – p. 25/57

Einstichproben t-Test (einseitig)
Einstichproben t-Test (einseitig)Situation:
Test auf Mittelwert bei unbekannter VarianzH0 : µ ≤ µ0
H1 : µ > µ0
Voraussetzungen:repräsentative StichprobeX ist normalverteilt: Xi ∼ N(µ, σ2)
σ2 ist unbekannt
Bemerkung:Entsprechende einseitige Test gibt es auch fürkleiner und auch für viele andere Tests, wo wirdas nicht im Einzelnen aufführen werden.
Befehl: t.test(X,alternative="greater")
Statistik – p. 26/57

Binomial Test
Binomial TestSituation:
Test auf ErfolgswahrscheinlichkeitH0 : Die Wahrscheinlichkeit p für einen Erfolg ist p0: p = p0
H1 : Die Wahrscheinlichkeit p für einen Erfolg ist nicht p0: p 6= p0
Voraussetzungen:repräsentative StichprobeX ist Binomialverteilt mitErfolgswahrscheinlichkeit p: X ∼ Bi(p, n0)Die Anzahl der Versuche n0 ist bekannt
Bemerkung:
Befehl: binom.test(sum(X),n0*length(X))
Statistik – p. 27/57

Vorzeichentest
VorzeichentestSituation:
Test auf bestimmten MedianH0 : Der Median der Verteilung von X ist m0: FX(0.5) = m0
H1 : Der Median der Verteilung von X ist nicht m0: FX(0.5) 6= m0
Voraussetzungen:repräsentative StichprobeVerteilungsfunktion FX im Median stetig
Bemerkung:
Befehl: binom.test(table(X<m0))
Statistik – p. 28/57

Ein-Stichproben-TestsStreuungnormalverteilt ⇒ χ2-Test (Chi-Quadrat-Test)nicht normal ⇒ . . . problematisch
Statistik – p. 29/57

χ2-Test auf Varianz
χ2-Test auf VarianzSituation:
Test auf gegebenen Varianz beinormalverteilten Daten.
H0 : σ2 = σ20
H1 : σ2 6= σ20 oder σ2 > σ2
0 oder σ2 < σ20
Voraussetzungen:repräsentative StichprobeXi ∼ N(µ, σ2)
Bemerkung:
Befehl: --
Statistik – p. 30/57

Zwei-Stichproben-TestsVerteilungstetig ⇒ zwei Stichproben KS-Testdiskret ⇒ . . . Tafeltests (später)
Statistik – p. 31/57

Zwei Stichproben Kolmogorov-Smirnov-Test
Zwei StichprobenKolmogorov-Smirnov-Test
Situation:Testet die Gleichheit der stetigen Verteilungender Stichproben
H0 : FX ≡ FY
H1 : FX 6≡ FY
Voraussetzungen:repräsentative StichprobenFür X und Y wurde die gleiche Rundungsregelverwendet
Bemerkung:
Befehl: ks.test(X,Y)
Statistik – p. 32/57

Zwei-Stichproben-TestsLagenormalverteilt ⇒ Zwei Stichproben t-testnicht normal aber stetig ⇒ Wilcoxen-Vorzeichen-Rang Test
Statistik – p. 33/57

Zwei-Stichproben-t-Test
Zwei-Stichproben-t-TestSituation:
Vergleich von Mittelwerten zweier Stichprobenbei Normalverteilung und gleicher Varianz
H0 : µX = µY
H1 : µX 6= µY oder µX > µY oder µX < µY
Voraussetzungen:repräsentative StichprobenXi ∼ N(µX , σ2) und Yi ∼ N(µY , σ2)
Bemerkung:Die Normalverteilungsvoraussetzung ist relativ unkritisch, solange keineAusreißer vorliegen und Verteilung ungefähr normal ist. DieNormalverteilungsvoraussetzung kann mit dem Shapiro-Wilk Test unddie Varianzgleichheit mit dem F-Test überprüft werden.
Befehl: t.test(X,Y,var.equal=TRUE)
Statistik – p. 34/57

Welchs t–Test
Welchs t–TestSituation:
Vergleich von Mittelwerten zweier Stichprobenbei Normalverteilung und verschiedenerVarianz
H0 : µX = µY
H1 : µX 6= µY oder µX > µY oder µX < µY
Voraussetzungen:repräsentative StichprobenXi ∼ N(µX , σ2
X) und Yi ∼ N(µY , σ2Y ), i.i.d.
Bemerkung:Die Normalverteilungsvoraussetzung ist relativ unkritisch, solange keineAusreißer vorliegen und Verteilung ungefähr normal ist.
Befehl: t.test(X,Y)
Statistik – p. 35/57

Wilcoxen–Rang–Summen–Test
Wilcoxen–Rang–Summen–TestSituation:
Vergleich der Lage zweier Stichproben mitstetiger Verteilung
H0 : ∀x : FX(x) = FY (x)
H1 : ∃c 6= 0 : ∀x : FX(x) = FY (x − c)
Voraussetzungen:repräsentative Stichprobendie Verteilungen FX und FY sind stetig.
Bemerkung:Dieser Test arbeitet auch für andere Alternativen gut, bei der eineGruppe größere Werte hat.
Befehl: wilcox.test(X,Y)
Statistik – p. 36/57

Zwei-Stichproben-TestsStreuungnormalverteilt ⇒ F-testnicht normal aber stetig ⇒ Fligner Test
Statistik – p. 37/57

F-Test
F-TestSituation:
Test auf Gleichheit der Varianz beiNormalverteilung
H0 : σ2X = σ2
Y
H1 : σ2X 6= σ2
Y oder σ2X > σ2
Y oder σ2X < σ2
Y
Voraussetzungen:repräsentative StichprobenXi ∼ N(µX , σ2
X), Yi ∼ N(µY , σ2Y )
Bemerkung:
Befehl: var.test(X,Y)
Statistik – p. 38/57

Fligner-Test
Für den nichtparametrischen Streuungsvergleich eignetsich auch der Fligner-Test, der als Mehrstichprobentestbesprochen wird.fligner.test(list(X,Y))
Statistik – p. 39/57

Gepaarte-TestsLagenormalverteilt ⇒ gepaarter t-testnicht normal aber stetig ⇒ Wilcoxen-Vorzeichen-Rang Test
Statistik – p. 40/57

gepaarter t-Test
gepaarter t-TestSituation:
Die Werte jeweils zweier aufeinanderfolgenderMessungen am gleichen statistischenIndividuum sollen verglichen werden.
H0 : E[X − Y ] = 0
H1 : E[X − Y ] 6= 0 oderVoraussetzungen:
repräsentative StichprobeXi − Yi ∼ N(µ, σ2)
Bemerkung:Dieses normalverteilungsbasierte Verfahrenhat Probleme mit Ausreißern in der Differenz.
Befehl: t.test(X,Y,paired=TRUE)
Statistik – p. 41/57

Wilcoxen-Vorzeichen-Rang-Test
Wilcoxen-Vorzeichen-Rang-TestSituation:
Testet auf eine mittlere Änderung von 0zwischen beiden Beobachtungen am gleichenIndividuum.
H0 : Die Verteilung von Xi − Yi ist symmetrisch um 0.
H1 : Die Verteilung von Xi − Yi ist symmetrisch um ein c 6= 0
Voraussetzungen:Die Verteilung ist für alle Paare gleich.
Bemerkung:Dieses rangbasierte Verfahren hat Problememit Bindungen in den Differenzen.
Befehl: wilcox.test(X,Y,paired=TRUE)
Statistik – p. 42/57

Tests auf Abhängigkeitstetige Größen⇒ Korrelationstests
Statistik – p. 43/57

Pearson–Korrelationstest
Pearson–KorrelationstestSituation:
Test auf Pearson-Korrelation gleich 0H0 : cor(X,Y ) = 0
H1 : cor(X,Y ) 6= 0
Voraussetzungen:repräsentative StichprobeX,Y gemeinsam normalverteilt
Bemerkung:
Befehl: cov.test(X,Y)
Statistik – p. 44/57

Spearman–Korrelationstest
Spearman–KorrelationstestSituation:
Test auf Spearman-Rang-KorrelationH0 : cor(X,Y ) = 0
H1 : cor(X,Y ) 6= 0 oder cor(X,Y ) > 0 odercor(X,Y ) < 0
Voraussetzungen:repräsentative Stichprobenstetige Verteilung / wenige Bindungen
Bemerkung:
Befehl: cov.test(X,Y,method="spearman")
Statistik – p. 45/57

Tests auf Abhängigkeitdiskrete Größendichotom ⇒ Fishers exakter Testviele ⇒ (spezieller) χ2-Testsonst ⇒ . . . problematisch
Statistik – p. 46/57

χ2-Test auf Unabhängigkeit in Kontingenztafeln
χ2-Test auf Unabhangigkeit in Kontingenztafeln
Situation:Test auf Unabhängigkeit von kategoriellenMerkmalen
H0 : X und Y sind stochastisch unabhängigH1 : X und Y sind stochastisch abhängigVoraussetzungen:
repräsentative Stichprobekategorielle Merkmale
Bemerkung:Der p-Wert des Tests wird nur approximativ berechnet. Die
Approximation ist schlecht, wenn in einzelnen Zellen der Datentafel
unter der Unabhängigkeitsannahme weniger als 3-5 Werte zu erwarten
sind.
Befehl: chisq.test(table(X,Y)) Statistik – p. 47/57

Fishers exakter Test
Fishers exakter TestSituation:
Test auf Unabhängigkeit von 2x2Kontingenztafeln und dichtomer Merkmale
H0 : Die Merkmale sind stochastisch UnabhängigH1 : Die Merkmale sind stochastisch abhängigVoraussetzungen:
repräsentative Stichprobedichotome Merkmale
Bemerkung:Im Gegensatz zum χ2-Test auf Unabhängigkeit wird hier keine
Approximation verwendet. Der Test ist also immer dann vorzuziehen,
wenn er in der Situation anwendbar ist.
Befehl: fisher.test(table(X,Y))
Statistik – p. 48/57

Tests auf AbhängigkeitStetige Größe Abhängig von diskreterGrößedichotom ⇒ Zwei-Stichproben-Testmehrere Kategorien ⇒ Mehr-Stichproben-Test
Statistik – p. 49/57

Mehrstichproben TestsLageNormalverteilt, homoskedastisch ⇒ Varianzanalyseimmerhin stetig ⇒ . . . Kruskal-Wallis-Test
Statistik – p. 50/57

Einfache Varianzanalyse
Einfache VarianzanalyseSituation:
Test auf Gleichheit der Erwartungswertemehrerer normalverteilter Stichproben.
H0 : ∀g, g′ : µg = µg′
H1 : ∃g, g′ : µgi6= µj
Voraussetzungen:repräsentative StichprobenXi ∼ N(µgi
, σ2) wobei gi die Gruppenzugehörigkeit des
Individuums i beschreibt.
Bemerkung:Die Varianzanalyse setzt die Gleichheit derVarianz und Normalverteilung voraus.
Befehl: anova(lm(X∼G))
Statistik – p. 51/57

Kruskal–Wallis–Test
Kruskal–Wallis–TestSituation:
Test auf Gleichheit der Lage mehrerer stetigverteilter Stichproben.
H0 : Alle Gruppen haben die gleiche VerteilungH1 : Die Verteilungen der Gruppen sindgegeneinander verschoben.Voraussetzungen:
repräsentative Stichprobeneigentlich: gleiche nur verschobene Verteilung
Bemerkung:Der Kruskal Wallis Test ist ein RangbasiertesVerfahrung und ist damit potentiell anfälliggegegen zu viele gleiche Messwerte.
Befehl: kruskal.test(X,G)Statistik – p. 52/57

Mehrstichproben TestsStreuungnormalverteilt ⇒ Bartlett–Testimmerhin stetig ⇒ Fligner–Test
Statistik – p. 53/57

Bartlett–Test
Bartlett–TestSituation:
Testet auf gleiche Varianz in mehrereStichproben
H0 : Die Varianzen der Stichproben sind gleichH1 : Die Varianzen der Stichproben sind nicht allegleich.Voraussetzungen:
repräsentative StichprobenXi ∼ N(µGi
, σGi)
Bemerkung:Dieser Test wird oft eingesetzt, um eineVoraussetzung der Varianzanalyse zuüberprüfen.
Befehl: bartlett.test(X,G)Statistik – p. 54/57

Fligner–Test
Fligner–TestSituation:
Testet auf gleiche Streuung in mehrerenStichproben
H0 : Die Streuungen der Stichproben sind gleich.H1 : Die Streuungen der Stichproben sindunterschiedlich.Voraussetzungen:
repräsentative Stichprobenstetige Verteilung
Bemerkung:
Befehl: fligner.test(X,G)
Statistik – p. 55/57
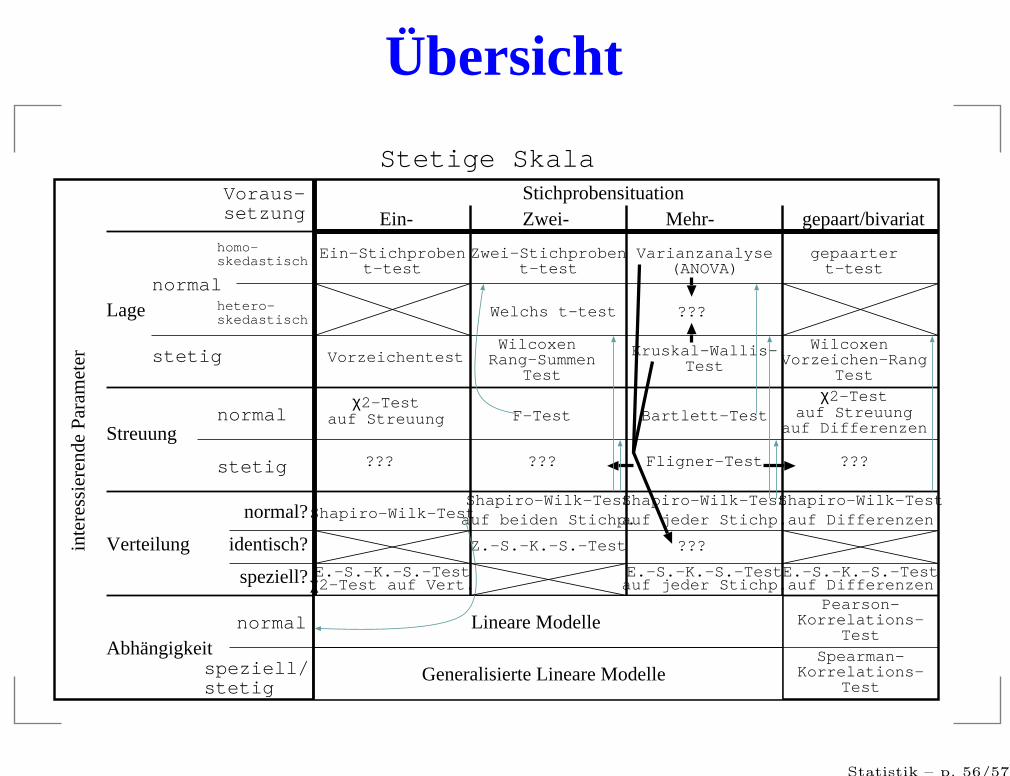
Übersicht
StichprobensituationEin- Zwei- Mehr- gepaart/bivariat
Lage
Streuung
Verteilung
Abhängigkeit
inte
ress
iere
nde
Par
amet
er
Voraus-setzung
normal
stetig
homo-skedastisch
hetero-skedastisch
Stetige Skala
Ein-Stichprobent-test
normal
stetig
Vorzeichentest
Zwei-Stichprobent-test
Welchs t-test
Varianzanalyse(ANOVA)
gepaartert-test
???
Wilcoxen Rang-Summen
Test
Wilcoxen Vorzeichen-Rang
Test
Kruskal-Wallis-Test
χ2-Testauf Streuung
???
F-Test
???
Bartlett-Test
Fligner-Test
χ2-Testauf Streuung
auf Differenzen
???
Shapiro-Wilk-Test
E.-S.-K.-S.-Test
Z.-S.-K.-S.-Test
Shapiro-Wilk-Test
E.-S.-K.-S.-Test
auf Differenzen
auf Differenzen
normal?
speziell?
identisch?
Shapiro-Wilk-Testauf jeder Stichp.
auf jeder Stichp.E.-S.-K.-S.-Test
???
normal
speziell/stetig
Pearson-Korrelations-
TestSpearman-
Korrelations-Test
Lineare Modelle
Generalisierte Lineare Modelle
Shapiro-Wilk-Testauf beiden Stichp.
χ2-Test auf Vert.
Statistik – p. 56/57
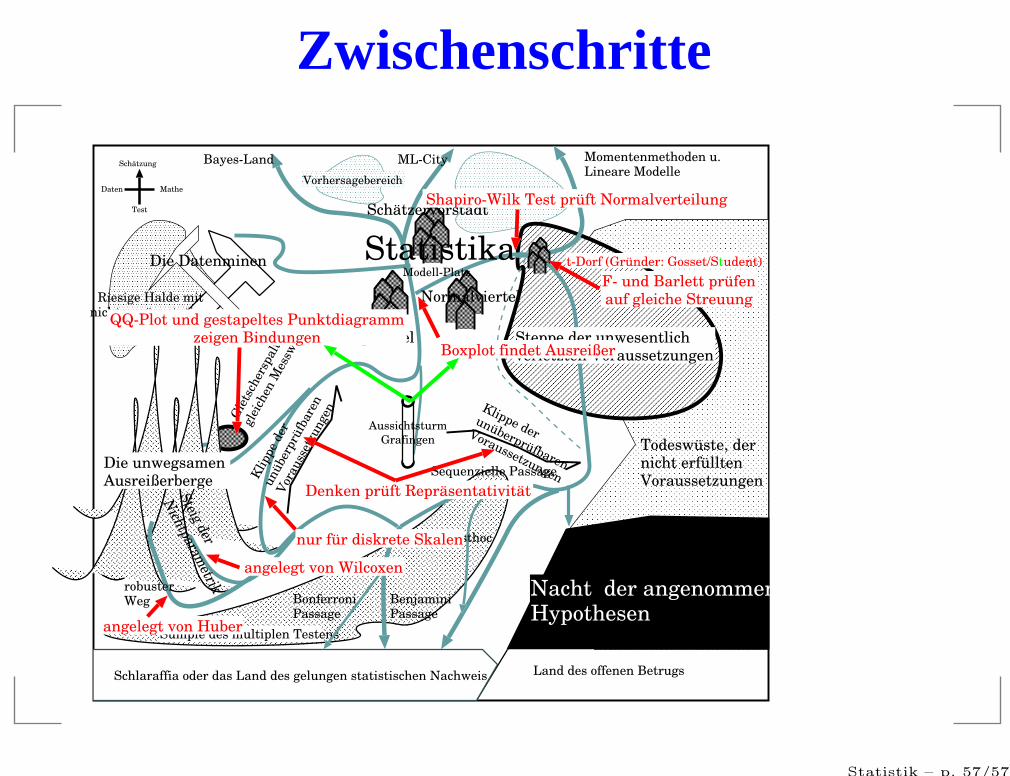
Zwischenschritte
Sümpfe des multiplen Testens
Rangviertel
Die unwegsamen Ausreißerberge
Die Datenminen
Todeswüste, der nicht erfüllten Voraussetzungen
Steig der
Nich
tparametrik
Gle
tsch
ersp
alt
e der
glei
chen
Mes
swer
te
Nacht der angenommen Hypothesen
Klippe
der
unüber
prü
fbare
n
Vor
auss
etzu
nge
n Klippe der unüberprüfbaren
Voraussetzungen
robuster Weg
Momentenmethoden u.Lineare Modelle
ML-CityBayes-Land
t-Dorf (Gründer: Gosset/Student)Modell-Platz
Statistika
Vertrauensbereich
Normalviertel
Vorhersagebereich
Steppe der unwesentlich verletzten Voraussetzungen
Schätzervorstadt
Schlaraffia oder das Land des gelungen statistischen Nachweis Land des offenen Betrugs
BonferroniPassage
BenjaminiPassage
Sequenzielle Passage
Posthoc
Mathe
Schätzung
Daten
Test
Aussichtsturm
Grafingen
Riesige Halde mit nichtrepräsentativen
Daten
Boxplot findet Ausreißer
Shapiro-Wilk Test prüft Normalverteilung
F- und Barlett prüfenauf gleiche Streuung
QQ-Plot und gestapeltes Punktdiagrammzeigen Bindungen
Denken prüft Repräsentativität
angelegt von Wilcoxen
angelegt von Huber
nur für diskrete Skalen
Statistik – p. 57/57

















