67

6 Test von statistischen Hypothesen
Empirische Wissenschaften arbeiten experimentell und stellen aufgrund von Beobach-tungen Hypothesen und Theorien auf. Diese Hypothesen sind vereinfachte Modelle derWirklichkeit. Die Methoden zur Erlangung neuer Erkenntnisse sind induktiv. Man ver-sucht, durch endlich viele Experimente und Beobachtungen auf eine allgemeine Regeloder Aussage zu schlie�en.
Die aufgestellten Hypothesen sind h�au�g sog. statistische Hypothesen. Sie sagenetwas �uber die Verteilung einer Zufallsvariablen voraus. Die Zufallsvariable wird nunim Experiment mehrmals realisiert. Man erh�alt dann eine Stichprobe, aufgrund dererman entscheiden (testen) will, ob man an der aufgestellten Hypothese festh�alt oder sieverwirft.
Grunds�atzlich ist eine statistische Hypothese weder veri�zierbar noch falsi�zierbar. DasErgebnis einer Entscheidung oder eines Tests mu� in Bezug auf die gemachten Beob-achtungen gesehen werden und ist prinzipiell etwas Provisorisches. Verwirft man eineHypothese, so ist dies nicht endg�ultig, d.h. ein Beweis f�ur die Falschheit der Hypothese.Man h�alt vielmehr an der Verwerfung der Hypothese bzw. an der sog. Alternativhy-pothese solange fest, bis evtl. neuere und umfassendere Beobachtungen und Daten zueiner Revision der getro�enen Entscheidung Anla� geben.
Die einzelnen Schritte bei der Erkenntnisbildung eines empirischen Wissenschaftlerssind im wesentlichen:
1. Aufstellen von statistischen Hypothesen aufgrund von Vermutungen, Vorwissenoder auch mit Hilfe explorativer Methoden
2. Gewinnung von empirischen Beobachtungen
3. Durchf�uhrung statistischer Tests
4. Beibehaltung oder Verwerfung der aufgestellten Hypothese
5. evtl. zur�uck zu Punkt 1
Gewinnt man mit Hilfe explorativerMethoden anhand einer Stichprobe eine Hypothese,so darf man die Hypothese nat�urlich nicht an der gleichen Stichprobe, sondern mu� siean einer neuen Stichprobe �uberpr�ufen.

216 6 Test von statistischen Hypothesen
6.1 Grundbegri�e der Testtheorie
Der Statistiker stellt vor Durchf�uhrung eines Versuchs eine statistische Hypothese auf,d.h. er tri�t eine Annahme �uber die Verteilung einer Zufallsvariablen X , z.B. �uber denMittelwert � oder die Standardabweichung � einer normalverteilten Zufallsgr�o�e oderdie Verteilungsfunktion F (x) einer Zufallsvariablen.
Liegt beispielsweise eine Vermutung vor, da� der Mittelwert � der normalverteiltenZufallsvariablen \Ertrag\ einen Wert von �0 hat, dann stellt man die Hypothese � = �0auf. Diese Hypothese hei�t Nullhypothese und wird allgemein so formuliert:
H0 : � = �0 (6.1)
Mit Hilfe einer Stichprobe vom Umfang n will man nun pr�ufen, ob das Ergebnis derStichprobe mit der Nullhypothese H0 im Widerspruch steht. Man f�uhrt also einenstatistischen Test durch und �uberpr�uft, ob die Nullhypothese abgelehnt werden mu�,oder ob eine solche Ablehnung nicht gerechtfertigt ist.
Beispiel:
Das F�ullgewicht einer Abf�ullmaschine sei eine (�; �2)-normalverteilte Zufallsvariable
X . Die Maschine soll Packungen mit einem Nettof�ullgewicht von 1 kg abf�ullen. Der
Abf�ullproze� liefert nicht ausschlie�lich Packungen mit exakt 1 kg F�ullgewicht, denn
die einzelnen F�ullmengen schwanken zuf�allig. Wenn die Maschine jedoch richtig einge-
stellt ist, sollte der Mittelwert � gleich dem geforderten Abf�ullgewicht von 1 kg sein.
Die Nullhypothese lautet in diesem Fall: H0 : � = 1 kg. Die Firma kontrolliert nun
den Abf�ullproze� durch Entnahme von Stichproben. Sie mu� darauf achten, da� der
Stichprobenmittelwert x nicht zu stark von 1 kg abweicht. Ist die Abweichung zu gro�,
d.h. wird die Nullhypothese verworfen, dann mu� die Maschine neu justiert werden.
Der empirische Mittelwert x einer Stichprobe wird selbstverst�andlich kaum mit dem ge-forderten Sollwert �0 �ubereinstimmen. Kleine zuf�allige Schwankungen nach oben oderunten sind aufgrund des zuf�alligen Charakters des Abf�ullprozesses in obigem Beispielzu erwarten. Wann sind aber diese kleinen, unvermeidlichen Abweichungen so gro�, da�man sie nicht mehr durch den Zufall bedingt erkl�aren kann? Man mu� also eine objek-tive Grenze zwischen den kleineren, rein zuf�alligen Abweichungen und den gr�o�eren,oder wie man auch sagt, den signi�kanten Abweichungen ziehen. Dazu ist noch zu
�uberlegen, in welcher Richtung die Abweichungen interessieren: Nach oben, nach untenoder in beiden Richtungen. Man mu� also eine sog. Alternativhypothese aufstellen,die mit H1 abgek�urzt wird.
Ist die Firma aus obigem Beispiel daran interessiert, nicht zuviel in die Packungen zuf�ullen, so lautet die Alternativhypothese:
H1 : � > �0 (6.2)
Kommt es dagegen darauf an, nicht zu wenig abzuf�ullen, so ist die Alternativhypothese:
H1 : � < �0 (6.3)

6.1 Grundbegri�e der Testtheorie 217
Die Alternativhypothesen (6.2) und (6.3) werden auch einseitige Alternativhypo-thesen genannt.
Soll das Abf�ullgewicht schlie�lich nicht zu klein und nicht zu gro� sein, dann lautet diezweiseitige Alternativhypothese:
H1 : � 6= �0 (6.4)
Die Nullhypothese k�onnte im Fall einseitiger Alternativhypothesen auch in analogereinseitiger Form formuliert werden:
H 0
0 : � � �0 gegen H1 : � > �0 bzw.H 0
0 : � � �0 gegen H1 : � < �0(6.5)
Es ist jedoch �ublich, die Nullhypothese in der zweiseitigen Form H0 : � = �0 zu formu-lieren, unabh�angig von der Alternativhypothese. Auf die praktische Durchf�uhrung desTests selbst hat die Formulierung keinen Ein u�. Es treten lediglich kleine Verschie-bungen bzgl. der Sicherheitswahrscheinlichkeit auf.
Wie bekommt man nun aufgrund einer Stichprobe Grenzen, die einen sog. Ableh-nungsbereich und einen sog. Nichtablehnungsbereich festlegen? Beim einseitigenTest H0 : � = �0 mit der Alternative H1 : � > �0 interessiert die kritische Gr�o�e c aufder x-Achse in Bild 6.1.
�0 c
Nichtablehnungsbereich
H0 wird nicht abgelehnt
Ablehnungsbereich
H0 wird abgelehnt
Bild 6.1: Ablehnungs- und Nichtablehnungsbereich beim einseitigen Test
Liegt der Stichprobenmittelwert x links von c, so wird die Nullhypothese H0 nichtabgelehnt, liegt er rechts davon, so wird H0 verworfen. Den Abstand zwischen �0 undc l�a�t man als Spielraum f�ur kleinere zuf�allige Schwankungen von x zu. Die Abweichungvon �0 wird jedoch signi�kant, wenn x in den dick gezeichneten Bereich f�allt.
Beim zweiseitigen Test H0 : � = �0 mit der Alternative H1 : � 6= �0 mu� man zweiGrenzen c1 und c2 bestimmen (Bild 6.2).
�0c1 c2
Ablehnungsbereich
H0 wird abgelehnt
Ablehnungsbereich
H0 wird abgelehnt
Nichtab-
lehnungs-
bereich
Bild 6.2: Ablehnungs- und Nichtablehnungsbereich beim zweiseitigen Test

218 6 Test von statistischen Hypothesen
Bei der praktischen Durchf�uhrung eines Tests berechnet man eine geeigneteTestgr�o�e,in die der zu testende Parameter (z.B. x) eingeht. Diese Testgr�o�e wird mit einementsprechenden Schwellenwert oder einer Testschranke verglichen. Schwellenwertebzw. Testschranken sind Fraktilen oder Grenzen der Verteilung der Testgr�o�e. DerVergleich der Testgr�o�e mit dem Schwellenwert f�uhrt zu einer Entscheidung zwischenAblehnung von H0 oder Nichtablehnung von H0.
Das Prinzip eines statistischen Tests kann auch folgenderma�en erkl�art werden. Manberechnet unter der Annahme der Nullhypothese die Wahrscheinlichkeit daf�ur, da�das festgestellte Ergebnis (z.B. x) oder ein \extremeres\ beobachtet werden kann. DieseWahrscheinlichkeit nennt man �Uberschreitungswahrscheinlichkeit, erreichtes Si-gni�kanzniveau oder auch p-Wert (p-value). Wenn diese Wahrscheinlichkeit \klein\ist, verwirft man H0 und erkl�artH1 f�ur signi�kant. Nach �ublichen Konventionen bedeu-tet \klein\, da� p kleiner als 5%, 1% oder 0:1% ist. Ansonsten wird H0 nicht abgelehnt.Man spricht h�au�g bei 5% Signi�kanzniveau von \signi�kant\, bei 1% Signi�kanzni-veau von \hoch signi�kant\ und bei 0:1% Signi�kanzniveau von \h�ochst signi�kant\.Es sei jedoch darauf hingewiesen, da� ein geringer p-Wert ein kleines Signi�kanzniveaubedeutet.
Bei einem statistischen Test k�onnen zwei Fehlentscheidungen vorkommen.
Ein Fehler 1. Art tritt auf, wenn man die Nullhypothese H0 verwirft, obwohl sierichtig ist. Die Wahrscheinlichkeit, einen solchen Fehler zu begehen, ist das Risiko1. Art und hei�t Irrtumswahrscheinlichkeit oder Signi�kanzniveau � des Tests.Die Gr�o�e 1 � � ist die entsprechende Sicherheitswahrscheinlichkeit. Bei einemeinseitigen Test, z.B. H0 : � = �0 gegen H1 : � > �0 ist die Irrtumswahrscheinlichkeitdurch die Beziehung P (X > c
��� = �0) = � gegeben, wenn c die Grenze zwischenAblehnungs- und Nichtablehnungsbereich ist (vgl. Tab. 6.1 und Bild 6.3).
Ein Fehler 2. Art tritt auf, wenn die Nullhypothese H0 nicht abgelehnt wird, obwohlsie falsch ist. Die Wahrscheinlichkeit daf�ur wird mit � bezeichnet und hei�t Risiko 2.Art. Die Gr�o�e 1�� gibt die Wahrscheinlichkeit an, einen Fehler 2. Art zu vermeidenund hei�t Macht oder G�ute des Tests (vgl. Tab. 6.1 und Bild 6.3).
wahrer (unbekannter) VerteilungsparameterAusfall des Tests H0 richtig (z.B. � = �0) H0 falsch (z.B. � = �1)
richtige Entscheidung Fehlentscheidung 2. ArtNichtablehnung mit der mit der
von H0 Sicherheitswahrscheinlichkeit Wahrscheinlichkeit1� � �
Fehlentscheidung 1. Art richtige EntscheidungAblehnung mit der mit dervon H0 Wahrscheinlichkeit Wahrscheinlichkeit
� 1� �
Tabelle 6.1: M�ogliche Entscheidungen beim Testen eines Parameters

6.1 Grundbegri�e der Testtheorie 219
Die Wahrscheinlichkeiten, einen Fehler 1. oder 2. Art zu begehen, h�angen von derGrenze c ab. Bild 6.3 zeigt, da� man diese Grenze nicht derart festlegen kann, da�beide Fehlerarten gleichzeitig klein werden. W�ahlt man das Risiko 1. Art klein, sokann trotzdem das Risiko 2. Art gro� ausfallen. Dies ist auch der Grund, warum mannicht sagt, \die Hypothese H0 wird angenommen\, sondern vorsichtiger formuliert,\die Hypothese H0 wird nicht abgelehnt\.
�0 �1c
��
Dichte von x,falls H0 zutri�t
Dichte von x,falls H1 zutri�t
Bild 6.3: Veranschaulichung der Fehlentscheidungen beim statistischen Test
Vor der Durchf�uhrung eines Tests legt der Testanwender die h�ochstens tolerierbare Irr-tumswahrscheinlichkeit bzw. das Signi�kanzniveau � fest. Ist die �Uberschreitungswahr-scheinlichkeit p kleiner oder gleich dem vorgegebenen �-Wert, so wird H0 zugunstenvon H1 abgelehnt.
Als Pauschalma�nahme zur Verringerung der Wahrscheinlichkeit � f�ur den Fehler 2.Art bzw. zur Steigerung der G�ute des Tests kann der Versuchsansteller eigentlich nurden Stichprobenumfang n vergr�o�ern. Theoretisch w�urde auch eine Verkleinerung von�2 bzw. s2 die G�ute verbessern. Der Versuchsansteller hat jedoch in der Regel daraufkeinen Ein u�.
Stehen mehrere Testverfahren f�ur eine Fragestellung zur Verf�ugung, so wird man selbst-verst�andlich das Verfahren anwenden, welches bei fester Irrtumswahrscheinlichkeit �und festem Stichprobenumfang n die h�ohere G�ute oder Macht besitzt.
Die Wahl der maximal in Kauf zu nehmenden Irrtumswahrscheinlichkeit �, also demSigni�kanzniveau, geschieht durch den Testansteller willk�urlich. Die Wahl von � =0:05, 0:01 oder 0:001 hat sich eingeb�urgert, ist aber nicht sachlich bzw. objektiv zubegr�unden.
Der Testansteller sollte sich jedoch klarmachen, da� bei festem Stichprobenumfang ndie G�ute des Tests mit abnehmendem � ebenfalls abf�allt (vgl. Bild 6.3) und solltedaher die M�oglichkeiten eines Fehlers 1. bzw. 2. Art gegeneinander abw�agen. Er mu�sich also fragen: Was ist schlimmer? Zu behaupten, die Sorte A ist besser als dieSorte B, obwohl in Wirklichkeit kein Unterschied im Ertrag vorhanden ist, oder einentats�achlich vorhandenen Ertragsunterschied nicht aufzudecken.
Man kann je nach Versuchsfrage verschiedene Strategien bei einem statistischen Testverfolgen. Man spricht von einer sog. Entdecker-Strategie, wenn man H0 verwer-fen will und daher ein gr�o�eres Risiko � und ein kleineres Risiko � akzeptiert. Ein
220 6 Test von statistischen Hypothesen
Versuchsansteller, der als Kritiker gegen die Alternative H1 eingestellt ist, wird sichentsprechend umgekehrt verhalten, d.h. ein kleineres Risiko � und ein gr�o�eres Risiko� akzeptieren.
Von einem sinnvollen Test sollte man nach Neyman und Pearson verlangen, da� dieWahrscheinlichkeit � f�ur einen Fehler 1. Art kleiner ist als die Wahrscheinlichkeit 1��, einen Fehler 2. Art zu vermeiden. Ein solcher Test wird auch unverzerrt (engl.unbiased) genannt. Ein verzerrter Test w�are so konstruiert, da� die Wahrscheinlichkeit,H0 imWahrheitsfall zu verwerfen, mindestens so gro� ist wie die Wahrscheinlichkeit,H0
im Falschheitsfall zu verwerfen. Eine solche Vorschrift w�urde ein Anwender sicherlichals unvern�unftig emp�nden.
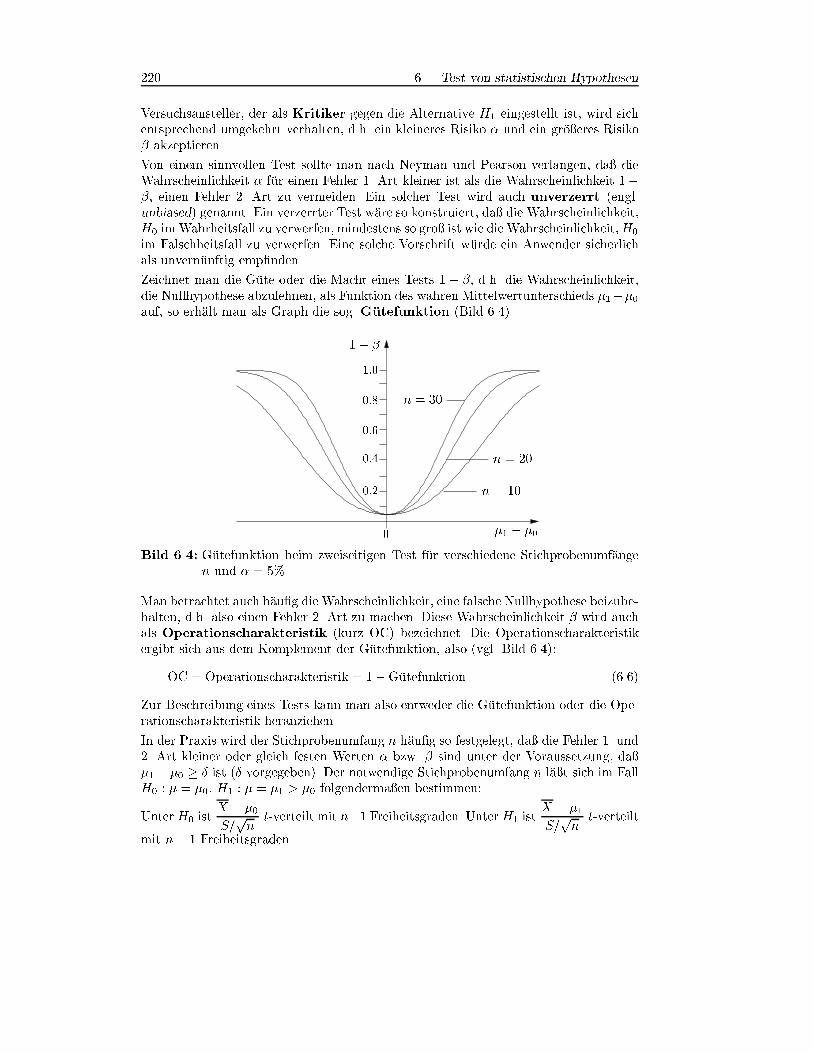
Zeichnet man die G�ute oder die Macht eines Tests 1� �, d.h. die Wahrscheinlichkeit,die Nullhypothese abzulehnen, als Funktion des wahren Mittelwertunterschieds �1��0auf, so erh�alt man als Graph die sog. G�utefunktion (Bild 6.4).
�1 � �00
1� �
0:2
0:4
0:6
0:8
1:0
n = 30
n = 20
n = 10
Bild 6.4: G�utefunktion beim zweiseitigen Test f�ur verschiedene Stichprobenumf�angen und � = 5%
Man betrachtet auch h�au�g die Wahrscheinlichkeit, eine falsche Nullhypothese beizube-halten, d.h. also einen Fehler 2. Art zu machen. Diese Wahrscheinlichkeit � wird auchals Operationscharakteristik (kurz OC) bezeichnet. Die Operationscharakteristikergibt sich aus dem Komplement der G�utefunktion, also (vgl. Bild 6.4):
OC = Operationscharakteristik = 1�G�utefunktion (6.6)
Zur Beschreibung eines Tests kann man also entweder die G�utefunktion oder die Ope-rationscharakteristik heranziehen.
In der Praxis wird der Stichprobenumfang n h�au�g so festgelegt, da� die Fehler 1. und2. Art kleiner oder gleich festen Werten � bzw. � sind unter der Voraussetzung, da��1 ��0 � � ist (� vorgegeben). Der notwendige Stichprobenumfang n l�a�t sich im FallH0 : � = �0, H1 : � = �1 > �0 folgenderma�en bestimmen:
Unter H0 istX � �0
S=pn
t-verteilt mit n�1 Freiheitsgraden. Unter H1 istX � �1
S=pn
t-verteilt
mit n� 1 Freiheitsgraden.

6.1 Grundbegri�e der Testtheorie 221
Dann gilt:
P
�X � �0
S=pn
> tn�1;1��
���H0
�= P
�X > �0 + tn�1;1�� �
Spn
���H0
�= �
P
�X � �1
S=pn
< �tn�1;1�����H1
�= P
�X < �1 � tn�1;1�� �
Spn
���H1
�= �
Es ist �0 + tn�1;1�� �spn= �1 � tn�1;1�� �
spn, denn die beiden Ausdr�ucke stellen die
Testschranke c dar. Somit ist (tn�1;1�� + tn�1;1��) �spn= �1 � �0 = �. Also folgt f�ur
n:
n � s2
�2� (tn�1;1�� + tn�1;1��)
2(6.7)
Die Zahl n kann selbstverst�andlich nicht exakt berechnet werden, weil man n bereitskennen m�u�te, um tn�1;1�� und tn�1;1�� ablesen zu k�onnen. Man kann sich jedochrekursiv an den wahren Wert herantasten. Die Wahl von � h�angt von der Problem-stellung ab, d.h. welche Di�erenzen will man als signi�kant erkennen. Soll z.B. eineneue Sorte bei 10 kg=ha oder erst ab 50 kg=ha Ertragsunterschied als signi�kant besserbetrachtet werden? Diese Frage mu� der Versuchsansteller jeweils aus sachlogischen�Uberlegungen entscheiden. Wird der Test zweiseitig durchgef�uhrt, so folgt analog zu(6.7) die Gleichung:
n � s2
�2� �tn�1;1��=2 + tn�1;1��=2
�2(6.8)
Es gibt einfache Computerprogramme, die die Anzahl n der notwendigen Stichpro-benelemente bei gegebenen Fehlern 1. und 2. Art berechnen oder auch umgekehrt dieFehler 1. und 2. Art ermitteln, wenn der Stichprobenumfang n vorgegeben ist. Einsolches Programm wird in Abschnitt 6.9 vorgestellt.

222 6 Test von statistischen Hypothesen
6.2 Test von Erwartungswerten
Im folgenden Abschnitt werden Tests f�ur Erwartungs- oder Mittelwerte von Normal-verteilungen vorgestellt. Der Erwartungswert ist ein spezieller Parameter, der �uber dieLage oder die Lokation der Verteilung Auskunft gibt. Man spricht daher auch vonLokationstests.
6.2.1 t-Test f�ur den Mittelwert bei unbekanntem �
Der t Test f�ur den Erwartungswert bei unbekannter Streuung � vergleicht aufgrundeiner Stichprobe den Erwartungswert � einer normalverteilten Grundgesamtheit miteinem hypothetischen oder vermuteten Wert �0. Aus der Stichprobe vom Umfang n
berechnet man mit den Stichprobenwerten x1; x2; : : : ; xn, die einer (�; �2)-normalver-
teilten Grundgesamtheit entnommen wurden, die Testgr�o�e t0 nach Gleichung (6.9).Diese Testgr�o�e ist als Realisation einer t-verteilten Zufallsgr�o�e mit � = �0 aufzufas-sen.
t0 =x� �0
s=pn
(6.9)
Der Test der Nullhypothese H0 erfolgt beim vorgew�ahlten Signi�kanzniveau � je nachAlternativhypothese H1:
1. H0 : � = �0 H1 : � < �0 (einseitige Hypothese)
Ist t0 < �tn�1;1��, dann wird die Nullhypothese H0 auf dem Signi�kanzniveau �
abgelehnt. Im anderen Fall besteht kein Grund zur Ablehnung.
2. H0 : � = �0 H1 : � > �0 (einseitige Hypothese)
Ist t0 > tn�1;1��, dann wird die Nullhypothese H0 auf dem Signi�kanzniveau �
abgelehnt, andernfalls erfolgt keine Ablehnung.
3. H0 : � = �0 H1 : � 6= �0 (zweiseitige Hypothese)
Ist jt0j > tn�1;1��=2, dann wird die Nullhypothese H0 beim Signi�kanzniveau �
abgelehnt, ansonsten kann H0 nicht abgelehnt werden.
Das Testschema in Kurzform zeigt Tab. 6.2.
In der Praxis wird man i.a. nicht nur eine dichotome Entscheidung zwischen Ablehnungund Nichtablehnung von H0 auf einem festen Signi�kanzniveau tre�en bzw. protokol-lieren. Vorzuziehen ist in jedem Fall die Angabe des p-Werts. Daran kann der Anwenderdie sachlogische Relevanz eines E�ekts bzw. eines Mittelwertunterschieds selbst beur-teilen.
Freiheitsgrade spielen in der gesamten beurteilenden Statistik eine entscheidendeRolle und tauchen fast immer als wesentliches Indiz f�ur eine Testgr�o�e auf. Der Begri�der Freiheitsgrade in der Statistik lehnt sich an den gleichnamigen Begri� in der Physikan. Allerdings deutet er hier nicht wie in der Mechanik eine unabh�angige Verschiebungeines Massenpunkts an, sondern bedeutet analog eine unabh�angige Bestimmung oderMessung f�ur einen Stichprobenwert. Das statistische Ma� des arithmetischen Mittels x

6.2 Test von Erwartungswerten 223
Voraussetzung: Normalverteilung, � unbekannt
Testgr�o�e: t0 =x� �0
s=pn
H0: � = �0
H1: Ablehnung von H0, wenn
� < �0 t0 < �tn�1;1��� > �0 t0 > tn�1;1�� (Tab. A.4)
� 6= �0 jt0j > tn�1;1��=2
Tabelle 6.2: t-Test f�ur den Erwartungswert bei unbekanntem �
kommt in der Pr�ufgr�o�e t des t-Tests vor. Betrachtet man eine Stichprobe von 5Werten,so gilt: x = (x1+x2+x3+x4+x5)=5. Es gibt unendlich viele M�oglichkeiten f�ur Me�wertex1 bis x5, so da� ein festes x zustande kommt. Die Unabh�angigkeit bzw. die freieAuswahl besteht jedoch nur f�ur 4 Me�werte, der 5. liegt dann aufgrund der Berechnungfest. Darum sagt man in diesem Fall, da� 4 Freiheitsgrade existieren. Allgemein hatman bei n Me�werten und einer statistischen Ma�zahl (z.B. x oder s) entsprechendn�1 Freiheitsgrade. Auch die Standardabweichung s hat n�1 Freiheitsgrade, d.h. beifestem Wert von s und x kann man n� 1 Beobachtungswerte xi beliebig variieren, dern-te liegt dann bereits fest. Darum sagt man schlie�lich, die Testgr�o�e t0, in der x unds vorkommen, hat n� 1 Freiheitsgrade.
Beispiele:
1. Eine Ladenkette fordert von den Erzeugern f�ur Chinakohl ein mittleres Kopfgewicht
von mindestens 1000 g. Es wird eine Stichprobe aus einer Lieferung gezogen und
folgende Kopfgewichte bestimmt:
Kopf 1 2 3 4 5 6 7
Gewicht [g] 920 975 1030 910 955 925 1010
Es soll auf einem Signi�kanzniveau von 0:05 �uberpr�uft werden, ob das mittlere
Kopfgewicht der Forderung entspricht. Der Test erfolgt einseitig, da h�ohere Kopf-
gewichte nat�urlich zugelassen sind. Die Null- und Alternativhypothese lauten also
H0 : � = 1000 g gegen H1 : � < 1000 g.
Der Mittelwert ist x = 960:7 g, die Standardabweichung ist s = 46:5 g.
Die Testgr�o�e lautet t0 =x� �0
s=pn
=960:7� 1000:0
46:5=p7
= �2:236.
Es liegen 7 � 1 = 6 Freiheitsgrade vor. Die t6;0:95-Fraktile kann aus Tab. A.4 im
Anhang bestimmt werden zu t6;0:95 = 1:943. Damit folgt:
�2:236 = t0 < �t6;0:95 = �1:943

224 6 Test von statistischen Hypothesen
Also wirdH0 auf dem Signi�kanzniveau 0:05 zugunsten von H1 abgelehnt (vgl. Tab.
6.2).
Der p-Wert bei Ablehnung der Nullhypothese ist kleiner als 5%. Er liegt etwa in
der Mitte zwischen 0:05 und 0:025, denn t6;0:975 = 2:447 (vgl. Tab. A.4).
2. In M�unchen wurde an einem Sommertag der Ozongehalt der Luft an f�unf verschie-
denen Me�stellen bestimmt:
Me�stelle 1 2 3 4 5
Ozongehalt [�g=m3] 114 128 130 118 123
�Uberschreitet der mittlere Ozongehalt bei einem 5%-Signi�kanzniveau den Grenz-
wert von 120 �g=m3, so mu� eine Warnung der Bev�olkerung erfolgen.
Die Daten werden mit MINITAB ausgewertet. Mit dem set-Befehl werden die Me�-
werte in Spalte 1 eingelesen. Das Kommando ttest 120 c1 f�uhrt den t-Test mit
�0 = 120 �g=m3 f�ur die Werte in Spalte 1 durch. Das Subkommando alternative
1 testet die Alternativhypothese � > �0. Gibt man im Subkommando -1 an, so lau-
tet H1 : � < �0, wird das Subkommando weggelassen, dann erfolgt der zweiseitige
Test, also: H1 : � 6= �0.
MTB > set c1
DATA> 114 128 130 118 123
DATA> end
MTB > ttest 120 c1;
SUBC> alternative 1.
TEST OF MU = 120.000 VS MU G.T. 120.000
N MEAN STDEV SE MEAN T P VALUE
C1 5 122.600 6.693 2.993 0.87 0.22
MINITAB gibt die Hypothesen H0 : MU = 120.000 und H1 : MU G.T. 120.000
(G.T. von engl. greater than) aus. Die Testgr�o�e ist t0 = 0:87. Anstatt ein Signi-
�kanzniveau vorzugeben, berechnen die meisten Statistikprogramme den p-Wert,
der in Computerprogrammen meist mit P VALUE bezeichnet wird. Der p-Wert ist ja
gerade das aufgrund der Daten bzw. der Testgr�o�e erreichte Signi�kanzniveau, also
die Wahrscheinlichkeit, unter Annahme von H0 einen ebenso gro�en oder extreme-
ren Wert der Testgr�o�e zu erhalten. Im vorliegenden Fall k�onnte die Nullhypothese
allenfalls auf einem Signi�kanzniveau von � = 22% abgelehnt werden. Bei � = 5%kann man H0 nicht verwerfen. Mit anderen Worten: Man kann nicht behaupten, da�
der mittlere Ozongehalt signi�kant (auf dem 5%-Niveau) gr�o�er als der Grenzwertvon 120 �g=m3 ist.

6.2 Test von Erwartungswerten 225
3. Eine Maschine zur Abf�ullung von Mehl in Papiert�uten ist auf ein F�ullgewicht von
500 g eingestellt. Es wird vorausgesetzt, da� das Abf�ullgewicht normalverteilt und
die Streuung unbekannt ist. Auf dem 10%-Signi�kanzniveau, d.h. bei maximal 10%Irrtumswahrscheinlichkeit, soll durch eine Stichprobe vom Umfang n = 6 �uberpr�uftwerden, ob das mittlere Gewicht von 500 g eingehalten wird.
Stichprobe 1 2 3 4 5 6
F�ullgewicht [g] 490 496 506 492 502 499
Der zweiseitige Test H0 : � = 500 g gegen H1 : � 6= 500 g erfolgt in MINITAB mit
dem ttest-Befehl ohne Angabe eines Subkommandos.
MTB > name c1 'Gewicht'
MTB > set 'Gewicht'
DATA> 490 496 506 492 502 499
DATA> end
MTB > ttest 500 'Gewicht'
TEST OF MU = 500.000 VS MU N.E. 500.000
N MEAN STDEV SE MEAN T P VALUE
Gewicht 6 497.500 6.058 2.473 -1.01 0.36
Die Pr�ufgr�o�e ist t0 = �1:01 bei 5 Freiheitsgraden. Dies ist der negative Wert der
t5;1�0:36=2 = t5;0:82-Fraktilen, d.h. auf einem Signi�kanzniveau von � � 36% oder
h�oher k�onnte H0 abgelehnt werden, was allerdings unvern�unftig w�are. Bei � = 10%ist eine Ablehnung von H0 jedoch nicht m�oglich.
6.2.2 z-Test f�ur den Mittelwert bei bekanntem �
Falls � bekannt ist, kann der Test des Mittelwerts auf eine normalverteilte Testgr�o�ezur�uckgef�uhrt werden. Man ben�otigt dann die t-Verteilung mit ihren Freiheitsgradennicht. Unter der Annahme der Nullhypothese H0 : � = �0 ist das Stichprobenmittel X(�; �2=n)-normalverteilt. Die Testgr�o�e z0 lautet in diesem Fall:
z0 =x� �0
�=pn
(6.10)
Der Test der Nullhypothese H0 erfolgt beim vorgew�ahlten Signi�kanzniveau � prin-zipiell wie bei unbekannter Varianz. Anstelle der t-Fraktilen sind in diesem Fall dieu-Fraktilen1 bzw. die �-Grenzen der Standardnormalverteilung zu verwenden.
Das Testschema in Kurzform zeigt Tab. 6.3.
Es sei noch angemerkt, da� �2 in den meisten F�allen nicht bekannt ist. Die praktischeBedeutung des z-Tests ist deshalb sehr gering.
1Der Test wird deshalb manchmal auch als u-Test bezeichnet.

226 6 Test von statistischen Hypothesen
Voraussetzung: Normalverteilung, � bekannt
Testgr�o�e: z0 =x� �0
�=pn
H0 : � = �0
H1 : Ablehnung von H0, wenn
� < �0 z0 < �u1��� > �0 z0 > u1�� (Tab. A.2)
� 6= �0 jz0j > u1��=2 = �1��
Tabelle 6.3: z-Test f�ur den Erwartungswert bei bekanntem �
Beispiel:
Ein Voltmeter zur Messung der elektrischen Spannung �uber einem Widerstand hat
laut Herstellerangabe eine Standardabweichung von 0:5 V bei der Spannung 50 V. DasGer�at sollte neu justiert werden, wenn auf 5%-Signi�kanzniveau die mittlere Spannungvon diesem Wert abweicht. Es wird eine Spannung von 50 V angelegt und 10 mal
gemessen.
Messung 1 2 3 4 5 6 7 8 9 10
Spannung [V] 49:8 50:1 48:9 49:4 51:0 48:8 49:3 49:4 49:9 50:0
Die Nullhypothese H0 : �U = 50 V wird gegen die zweiseitige Alternative H1 : �U 6=50 V getestet, da Abweichungen weder nach oben noch nach unten erw�unscht sind. Der
Mittelwert ist U = 49:66 V. Damit lautet die Testgr�o�e:
z0 =U � �U
�U=pn=
49:66 V � 50:00 V
0:5 V=p10
= �2:15
Die 97:5%-Fraktile bzw. 95%-Grenze der Standardnormalverteilung wird in Tab. A.2
im Anhang abgelesen zu u0:975 = �0:95 = 1:96.
Damit folgt: jz0j = 2:15 > 1:96 = u0:975 = �0:95
Die Nullhypothese wird zugunsten der Alternativhypothese abgelehnt. Zum Signi�-
kanzniveau von 5% ist also statistisch gesichert, da� der mittlere Me�wert des Ger�ats
bei einer anliegenden Spannung von 50 V vom Sollwert abweicht.
In MINITAB dient der Befehl ztest ohne Subkommando alternative zur Durchf�uh-
rung des zweiseitigen z-Tests. Einseitige Tests k�onnen mit den Optionen alternative
1 bzw. alternative -1 vorgenommen werden.

6.2 Test von Erwartungswerten 227
MTB > set c1
DATA> 49.8 50.1 48.9 49.4 51.0 48.8 49.3 49.4 49.9 50.0
DATA> end
MTB > ztest 50 0.5 c1
TEST OF MU = 50.000 VS MU N.E. 50.000
THE ASSUMED SIGMA = 0.500
N MEAN STDEV SE MEAN Z P VALUE
C1 10 49.660 0.647 0.158 -2.15 0.032
Der p-Wert ist hier 3:2%. Die Nullhypothese H0 kann also auf Signi�kanzniveaus, die
gr�o�er als 0:032 sind, abgelehnt werden.
6.2.3 Vertrauensintervalle f�ur den Mittelwert
Anstelle des t- und z-Tests kann man auch ein K% = 1 � �-Vertrauensintervall f�urden unbekannten Mittelwert bestimmen und pr�ufen, ob der Sollwert in diesem Intervallliegt. Ist dies nicht der Fall, so kann die Nullhypothese H0 : � = �0 abgelehnt werden.
Die Vertrauensintervalle bei unbekannter Varianz lauten (vgl. Kap. 5.6):
V:I:
��1 < � � x+ tn�1;1�� �
spn
�1��
(einseitig)
V:I:
�x� tn�1;1�� �
spn� � < +1
�1��
(einseitig)
V:I:
�x� tn�1;1��=2 �
spn� � � x+ tn�1;1��=2 �
spn
�1��
(zweiseitig)
(6.11)
Bei bekannter Varianz sind die Vertrauensintervalle (vgl. Kap. 5.2):
V:I:
��1 < � � x+ u1�� �
�pn
�1��
(einseitig)
V:I:
�x� u1�� �
�pn� � < +1
�1��
(einseitig)
V:I:
�x� u1��=2 �
�pn� � � x+ u1��=2 �
�pn
�1��
(zweiseitig)
(6.12)

228 6 Test von statistischen Hypothesen
Beispiel:
Das einseitige nach oben o�ene 95%-Vertrauensintervall f�ur den unbekannten Mittel-
wert des Ozongehalts der Luft im Beispiel auf Seite 224 wird mit dem Mittelwert
x = 122:6 und der Standardabweichung s = 6:7 sowie der Fraktilen t4;0:95 = 2:132 (vgl.Tab. A.4 im Anhang) berechnet:
V:I:
�122:6� 2:132 � 6:7p
5� � <1
�0:95
= V:I: f116:2 � � <1g0:95
Der Grenzwert von 120 �g=m3 ist im einseitigen 95%-Vertrauensintervall des mittlerenOzongehalts der Luft enthalten. Infolgedessen kann die Hypothese, da� der mittlere
Ozongehalt gleich 120 �g=m3 ist, auf 5%-Signi�kanzniveau nicht zugunsten der Alter-
nativhypothese, da� der Ozongehalt gr�o�er als der Grenzwert 120 �g=m3 ist, verworfen
werden. W�urde der Grenzwert allerdings auf 110 �g=m3 reduziert, dann m�u�te eine
Warnung der Bev�olkerung erfolgen, weil man dann die Nullhypothese signi�kant ab-
lehnen k�onnte.
Ein 1 � �-Vertrauensintervall enth�alt alle hypothetischen Werte �0, f�ur die aufgrundeiner vorliegenden Stichprobe die Nullhypothese H0 : � = �0 nicht abgelehnt werdenkann. Umgekehrt ist sofort ersichtlich, f�ur welche Werte von �0 die Nullhypothese aufdem Signi�kanzniveau � abgelehnt werden mu�. Ein Vertrauensintervall liefert alsomehr Information als ein Testergebnis allein.

6.3 Vergleich zweier Erwartungswerte 229
6.3 Vergleich zweier Erwartungswerte
In vielen praktischen Fragestellungen will man zwei verschiedene Dinge miteinandervergleichen, z.B. die Wirksamkeit zweier Medikamente, den Ertrag von zwei Getrei-desorten, die Inhaltssto�e zweier Futtermittel, den Schadsto�aussto� zweier Autotypenusw. Die Frage, ob das eine besser oder schlechter ist als das andere, bzw. ob sich diebeiden unterscheiden, kann auf den t-Test zum Testen des Mittelwerts zur�uckgef�uhrtwerden. Der Test pr�uft die Nullhypothese, da� zwischen zwei Sorten, Medikamenteno.�a. kein Unterschied existiert im Gegensatz zu einer Alternativhypothese, z.B. Sorte 1hat einen h�oheren Ertrag als Sorte 2, oder die beiden Medikamente unterscheiden sichin ihrer Wirksamkeit. Kann man die Nullhypothese nicht ablehnen, so wird man in derRegel die bequemere oder billigere L�osung verwenden. Kann die Nullhypothese abge-lehnt werden, so ist beispielsweise eine Sorte als ertragreicher oder die Wirksamkeitzweier Medikamente als unterschiedlich erkannt worden, selbstverst�andlich mit einergewissen Irrtumswahrscheinlichkeit.
Zur Herleitung eines Tests zum Vergleich zweier Erwartungswerte geht man folgen-derma�en vor: Eine Grundgesamtheit X sei (�x; �
2)- und eine Grundgesamtheit Y(�y ; �
2)-normalverteilt. Die Parameter �X , �Y und � seien unbekannt. Die Streuung�2 soll jedoch in beiden Grundgesamtheiten gleich sein (wie man die Hypothese derHomogenit�at der Varianzen selbst testet, wird in Kapitel 6.4 beschrieben). Auf-grund zweier Stichproben mit den Stichprobenumf�angen nx und ny aus den beidenVerteilungen erh�alt man die Stichprobenmittel x und y und die Standardabweichungensx und sy. Es wird eine neue Zufallsgr�o�e X�Y gebildet, deren gemeinsame Streuungdurch die gepoolte Varianz
s2p =(nx � 1) � s2x + (ny � 1) � s2y
nx + ny � 2(6.13)
gesch�atzt wird. Die Standardabweichung s von X � Y wird gesch�atzt durch:
s = sp �s
1
nx+
1
ny(6.14)
Der Test basiert auf der Testgr�o�e
t0 =x� y
s(6.15)
mit dem Mittelwert �x��y, der bei G�ultigkeit der Nullhypothese H0 : �x = �y wegendes Additionstheorems der Normalverteilung gleich 0 ist. X�Y ist dann t-verteilt mitnx + ny � 2 Freiheitsgraden.

230 6 Test von statistischen Hypothesen
Es sind zwei wichtige F�alle zu unterscheiden:
1. Die beiden Stichproben sind voneinander unabh�angig.
Die Stichprobenumf�ange betragen nx und ny. Diese brauchen nicht gleich gro� zusein.
2. Die beiden Stichproben sind verbunden.
Dann sind die Stichprobenumf�ange automatisch gleich gro�, also nx = ny = n.Jeweils ein Wert xi und yi geh�oren zusammen, weil sie beispielsweise vom selbenVersuchsobjekt (Mensch, Tier, P anze, Parzelle usw.) stammen. Man spricht auchvon einem paarweisen Vergleich oder einem rechts-links-Vergleich.
Beispiele:
1. na Tiere werden mit einer Futtermischung A und nb andere Tiere mit der Futter-
mischung B gef�uttert. Die Gewichtszunahmen der na Tiere sind die Stichproben-
werte a1; a2; : : : ; ana , die Zunahmen der nb anderen Tiere sind die Stichprobenwerte
b1; b2; : : : ; bnb . Da der Versuch an zwei verschiedenen Gruppen von Tieren durch-
gef�uhrt wird, sind die Stichproben unabh�angig.
2. An einer Gruppe von n Personen wird die Wirkung zweier Medikamente getestet.
Die Versuchspersonen erhalten zun�achst das eine Medikament. Nach einiger Zeit
wird das andere Medikament verabreicht und jeweils die Wirksamkeit gemessen.
Diese Messungen sind verbundene Stichproben, da die Versuchspersonen individuell
verschieden auf Medikamente reagieren. In diesem Fall kann man den Ein u� der
Variabilit�at der Individuen, also deren unterschiedliche Reaktion auf Medikamente,
eliminieren. Dies ist der Vorteil des Paarvergleichs. Wird die Gruppe jedoch in zwei
H�alften geteilt, wobei jede H�alfte ausschlie�lich das eine Medikament erh�alt, dann
sind die Stichproben unabh�angig.
Es ist weiterhin zu unterscheiden, ob die Varianzen bekannt oder unbekannt sind undob bei unbekannten Varianzen diese in beiden Stichproben als gleich (homogen) ange-nommen werden oder nicht.
Die Nullhypothese lautet in allen F�allen: H0 : �x = �y. In Worten: Die Mittelwerteder beiden Verteilungen sind gleich. Als Alternative kommt eine der drei M�oglichkeiten�x < �y, �x > �y und �x 6= �y in Frage.
6.3.1 t-Test zum Mittelwertvergleich unabh�angiger Stichproben bei unbe-
kanntem �x = �y
Die Testgr�o�e lautet:
t0 =
snx � ny � (nx + ny � 2)
nx + ny� x� yq
(nx � 1) � s2x + (ny � 1) � s2y(6.16)
F�ur gleiche Stichprobenumf�ange nx = ny = n vereinfacht sich die Testgr�o�e zu:
t0 =pn � x� yq
s2x + s2y
(6.17)

6.3 Vergleich zweier Erwartungswerte 231
Der Test der Nullhypothese H0 : �x = �y erfolgt beim vorgew�ahlten Signi�kanzniveau� nach dem Testschema in Tab. 6.4.
Voraussetzung: Normalverteilung, Unabh�angigkeit, �x = �y unbekannt
Testgr�o�e: t0 =
snx � ny � (nx + ny � 2)
nx + ny� x� yq
(nx � 1) � s2x + (ny � 1) � s2yt0 =
pn � x� yq
s2x + s2y
f�ur nx = ny = n
H0: �x = �y
H1: Ablehnung von H0, wenn:
�x < �y t0 < �tnx+ny�2;1���x > �y t0 > tnx+ny�2;1�� (Tab. A.4)
�x 6= �y jt0j > tnx+ny�2;1��=2
Tabelle 6.4: t-Test zum Mittelwertvergleich unabh�angiger Stichproben bei unbekann-tem �x = �y
6.3.2 t-Test zum Mittelwertvergleich verbundener Stichproben bei unbe-
kanntem �x = �y
Aus den beiden Stichproben xi und yi werden die Di�erenzen di = xi � yi gebildet.Man testet nun die Hypothese, da� die Grundgesamtheit, aus der diese Di�erenzen-Stichprobe stammt, den Mittelwert �d = 0 hat, also:
H0 : �x � �y = 0 bzw. H0 : �d = 0 (6.18)
Die Testgr�o�e t0 berechnet sich mit d =1
n�
nXi=1
di =1
n�
nXi=1
(xi � yi) und
s2d =1
n� 1�
nXi=1
(di � d)2 =1
n� 1�0@ nX
i=1
d2i �1
n�
nXi=1
di
!21A zu:
t0 =d
sd=pn
(6.19)
Die Zahl der Freiheitsgrade ist jetzt nur noch n� 1.
Der Test verl�auft wie beim einfachen t-Test f�ur den Erwartungswert (vgl. Kap. 6.2.1).

232 6 Test von statistischen Hypothesen
Das Testschema in Kurzform zeigt Tab. 6.5.
Voraussetzung: Normalverteilung, Abh�angigkeit, �x = �y unbekannt
Testgr�o�e: t0 =d
sd=pn
H0: �x = �y bzw. �x � �y = �d = 0
H1: Ablehnung von H0, wenn:
�x < �y bzw. �d < 0 t0 < �tn�1;1���x > �y bzw. �d > 0 t0 > tn�1;1�� (Tab. A.4)
�x 6= �y bzw. �d 6= 0 jt0j > tn�1;1��=2
Tabelle 6.5: t-Test zum Mittelwertvergleich verbundener Stichproben bei unbekann-tem �x = �y
6.3.3 t-Test zum Mittelwertvergleich unabh�angiger Stichproben bei unbe-
kannten und verschiedenen �x 6= �y (Welch-Test)
Bisher wurde vorausgesetzt, da� die Standardabweichungen der beiden Grundgesamt-heiten gleich sind. Im Fall unterschiedlicher Streuungen wird die Standardabweichungder Zufallsgr�o�e x� y durch
s =qs2x=nx + s2y=ny (6.20)
gesch�atzt. Die Testgr�o�e ist dann t = (x� y)=s, also:
t0 =x� yq
s2x=nx + s2y=ny
(6.21)
Diese Testgr�o�e ist approximativ t-verteilt. Die Anzahl der Freiheitsgrade ist:
FG =
�s2x=nx + s2y=ny
�2s4x=(n
2x � (nx � 1)) + s4y=(n
2y � (ny � 1))
(6.22)
Falls nx = ny = n gilt:
FG = (n� 1) ��s2x + s2y
�2s4x + s4y
(6.23)
Der Test, der auch unter dem Namen Welch-Test bekannt ist, verl�auft wie beim Ver-gleich zweier Mittelwerte bei gleichen Streuungen, allerdings mit FG Freiheitsgraden.

6.3 Vergleich zweier Erwartungswerte 233
Voraussetzung: Normalvert., Unabh�angigkeit, �x 6= �y unbekannt
Testgr�o�e: t0 =x� yq
s2x=nx + s2y=ny
Freiheitsgrade: FG =
�s2x=nx + s2y=ny
�2s4x=(n
2x � (nx � 1)) + s4y=(n
2y � (ny � 1))
FG = (n� 1) ��s2x + s2y
�2s4x + s4y
f�ur nx = ny = n
H0: �x = �y
H1: Ablehnung von H0, wenn:
�x < �y t0 < �tFG;1���x > �y t0 > tFG;1�� (Tab. A.4)
�x 6= �y jt0j > tFG;1��=2
Tabelle 6.6: t-Test zum Mittelwertvergleich unabh�angiger Stichproben bei unbekann-ten und verschiedenen �x 6= �y
FG ist in der Regel keine ganze Zahl und sollte auf die n�achst niedrigere ganze Zahlabgerundet werden, um auf der sicheren Seite zu bleiben.
Das Testschema in Kurzform zeigt Tab. 6.6.
Der Test zweier Erwartungswerte bei gleichen Streuungen reagiert zwar besser aufMittelwertunterschiede als der Test bei ungleichen Streuungen, allerdings kann eineungerechtfertigte Annahme gleicher Varianzen zu schwerwiegenden Fehlentscheidungenf�uhren. Wenn man sich also nicht sicher ist, ob die Annahme gleicher Streuungenin den beiden Grundgesamtheiten gerechtfertigt ist, sollte der t-Test f�ur verschiedeneStreuungen bevorzugt werden.
6.3.4 z-Test zum Mittelwertvergleich unabh�angiger Stichproben
bei bekanntem �x und �y
Will man zwei Erwartungswerte aus zwei normalverteilten Grundgesamtheiten X undY , deren Standardabweichungen �x und �y bekannt sind, vergleichen, so kann ein Testauf die Di�erenz �x � �y durchgef�uhrt werden, z.B. H0 : �x = �y gegen H1 : �x 6= �y.Aufgrund des Additionssatzes der Normalverteilung ist die Di�erenz X � Y wieder
normalverteilt mit dem Erwartungswert �x � �y und der Streuung�2xnx
+�2y
ny. Deshalb
ist f�ur unabh�angige Stichproben die Testgr�o�e
z0 =x� yq
�2x=nx + �2y=ny
(6.24)

234 6 Test von statistischen Hypothesen
ebenfalls normalverteilt und man kann die Fraktilen u und die Grenzen � der Stan-dardnormalverteilung als Schwellenwerte heranziehen. Das Testschema zeigt Tab. 6.7.
Voraussetzung: Normalverteilung, Unabh�angigkeit, �x = �y bekannt
Testgr�o�e: z0 =x� yq
�2x=nx + �2y=ny
H0: �x = �y
H1: Ablehnung von H0, wenn:
�x < �y z0 < �u1���x > �y z0 > u1�� (Tab. A.2)
�x 6= �y jz0j > u1��=2 = �1��
Tabelle 6.7: z-Test f�ur den Vergleich zweier Erwartungswerte bei bekannten �x und�y f�ur unabh�angige Stichproben
6.3.5 z-Test zum Mittelwertvergleich verbundener Stichproben bei be-
kanntem �x und �y
Auch der Fall, da� die Stichproben verbunden sind, ist auf den Fall �ubertragbar, da�die Varianz �2 bekannt ist. Die entsprechende Varianz �2d der Di�erenz X�Y ist dann:
�2 + �2 = 2�2 (6.25)
Daraus resultiert folgende Testgr�o�e:
z0 =d
� �p2=n
(6.26)
mit d =1
n
nXi=1
(xi � yi).
Das Testschema zeigt Tab. 6.8.

6.3 Vergleich zweier Erwartungswerte 235
Voraussetzung: Normalverteilung, Abh�angigkeit, � = �x = �y bekannt
Testgr�o�e: z0 =d
� �p2=n
H0: �x = �y bzw. �x � �y = �d = 0
H1: Ablehnung von H0, wenn:
�x < �y bzw. �d < 0 z0 < �u1���x > �y bzw. �d > 0 z0 > u1�� (Tab. A.2)
�x 6= �y bzw. �d 6= 0 jz0j > u1��=2 = �1��
Tabelle 6.8: z-Test zum Mittelwertvergleich verbundener Stichproben bei bekanntem�x und �y
Beispiele:
1. In einem Versuch wurden zwei Gruppen von jeweils 8 Schweinen gleicher Rasse
mit Futter von verschiedenem Proteingehalt gem�astet. Es interessiert, ob ein ho-
her Proteingehalt auf einem Signi�kanzniveau von 0:01 h�ohere mittlere t�agliche
Gewichtszunahmen der Tiere verursacht.
Futter mittlere t�agliche Gewichtszunahme [g]
hoher Proteingehalt Hi 715 683 664 659 660 762 720 715
niedriger Proteingehalt Ni 684 655 657 531 638 601 611 651
Die Mittelwerte sind H = 697:3 g und N = 628:5 g. Die unbekannte Standard-
abweichung � wird in beiden Gruppen als gleich angenommen. Die empirischen
Standardabweichungen sind sH = 36:8 g und sN = 47:4 g. Es liegen unabh�angige
Stichproben vor. Die Testgr�o�e t0 berechnet sich dann nach Gleichung (6.16):
t0 =
rnH � nN � (nH + nN � 2)
nH + nN� H �Np
(nH � 1) � s2H + (nN � 1) � s2N=
=
r8 � 8 � (8 + 8� 2)
8 + 8� 697:3� 628:5p
(8� 1) � 36:82 + (8� 1) � 47:42=
=p56 � 68:8p
25207� 3:24
Da der Umfang der beiden Stichproben gleich ist, kann die Berechnung einfacher
nach Gleichung (6.17) erfolgen:
t0 =pn � H �Np
s2H + s2N=p8 � 697:3� 628:5p
36:82 + 47:42= 3:24
Da interessiert, ob das Futter mit dem hohen Proteingehalt h�ohere Gewichtszunah-
me liefert, wird die einseitige Alternativhypothese gew�ahlt:
H0 : �H = �N gegen H1 : �H > �N

236 6 Test von statistischen Hypothesen
Die t-Fraktile bei 99% mit nH + nN � 2 = 14 Freiheitsgraden wird in der Anhang-
stabelle A.4 nachgeschlagen. Es folgt:
t0 = 3:24 > 2:624 = t14;0:99
H0 wird demnach auf dem Signi�kanzniveau � = 1% abgelehnt. Die Alternativhy-
pothese H1, da� das Futtermittel mit dem h�oheren Proteingehalt h�ohere Gewichts-
zunahmen bewirkt, wird angenommen.
MINITAB stellt den Befehl twosample zum Mittelwertvergleich zur Verf�ugung. Oh-
ne Angabe eines K%-Kon�denzniveaus wird ein 95-Vertrauensintervall f�ur die Mit-
telwertsdi�erenz bestimmt. Einseitige Tests k�onnen mit den Optionen alternative
-1 bzw. alternative 1 ausgew�ahlt werden. Ohne Angabe dieses Subkommandos
wird zweiseitig getestet. Zum Test f�ur gleiche Varianzen dient das Subkomman-
do pooled. Ohne Angabe wird von verschiedenen Varianzen ausgegangen und der
Welch-Test durchgef�uhrt.
In der folgenden MINITAB-Session erfolgt nach der Dateneingabe der einseitige t-
Test f�ur ein Kon�denzniveau von 99%, also � = 1%, mit der Alternative H1 : �H >
�N und gepoolten Standardabweichungen.
MTB > name c1 'H' c2 'N'
MTB > set 'H'
DATA> 715 683 664 659 660 762 720 715
DATA> end
MTB > set 'N'
DATA> 684 655 657 531 638 601 611 651
DATA> end
MTB > twosample 99 'H' 'N';
SUBC> alternative 1;
SUBC> pooled.
TWOSAMPLE T FOR H VS N
N MEAN STDEV SE MEAN
H 8 697.3 36.8 13
N 8 628.5 47.4 17
99 PCT CI FOR MU H - MU N: (6, 132)
TTEST MU H = MU N (VS GT): T= 3.24 P=0.0030 DF= 14
POOLED STDEV = 42.5
MINITAB gibt nach den statistischen Ma�zahlen (Mittelwert, Standardabweichung
und Standardfehler des Mittels) das 99%-Vertrauensintervall f�ur die Mittelwerts-
di�erenz aus. Dieses reicht von 6 bis 132. Da die Null nicht in diesem Intervall ent-
halten ist, ist die Nullhypothese der Mittelwertsgleichheit auf 1% Signi�kanzniveau
abzulehnen. Der eigentliche t-Test MU H = MU N (�H = �N ) (VS GT) (engl. versus
greater than) (�H > �N ) liefert die Testgr�o�e T= 3.24, den p-Wert P=0.0030 und
die Freiheitsgrade DF= 14 (engl. degrees of freedom). Der p-Wert ist bekanntlich der

6.3 Vergleich zweier Erwartungswerte 237
Tabellenwert der Verteilung beim 1 � p-Fraktilenwert der Testgr�o�e und den ent-
sprechenden Freiheitsgraden. Im vorliegenden Fall w�urde also in einer Tabelle der
t-Verteilung (vgl. Tab. A.4 im Anhang) bei F (x) = 0:997 der Wert 3:24 abgelesen.Da p = 0:003 < 0:01 = � wird H0 zugunsten von H1 abgelehnt. Anders ausge-
dr�uckt: Man k�onnte H0 bis zu einem Signi�kanzniveau von 0:3% ablehnen k�onnen.
Da MINITAB immer den p-Wert ausgibt, ist es eigentlich egal, welches Kon�denz-
niveau man beim twosample-Kommando angibt. Dies dient lediglich zur Angabe
des Vertrauensintervalls der Mittelwertsdi�erenz. Die letzte Zeile im Output gibt
noch an, mit welcher gepoolten Standardabweichung der Test durchgef�uhrt wurde.
Man sieht, da� beide Standardabweichungen in der gleichen Gr�o�enordnung liegen,
so da� die Voraussetzung gleicher Varianzen vern�unftig erscheint.
2. Austernpilze und Braunkappen sind Holzpilze, die auf Stroh kultiviert werden
k�onnen. Es liegen zwei Stichproben �uber den Frischmasseertrag pro Strohballen
von beiden Pilzarten vor.
Frischmasse [kg/Strohballen]
Austernpilze 4:0 7:6 6:5 5:9 8:6 7:3 5:2 4:8 6:1 6:1Braunkappen 4:7 5:7 5:7 5:0 4:7 4:6 5:5 5:2 5:5 5:5 5:4 5:2
Stichprobe 1 2 3 4 5 6 7 8 9 10 11 12
Es soll getestet werden, ob die mittleren Ertr�age der beiden Pilze unterschiedlich
sind. Die Annahme der homogenen Varianzen ist hier gef�ahrlich, da zwei verschiede-
ne Arten verglichen werden. Es wird deshalb der zweiseitige t-Test f�ur verschiedene
Streuungen (Welch-Test) mit MINITAB durchgef�uhrt. Dazu wird das Kommando
twosample ohne Angabe einer Option verwendet.
MTB > name c1 'Auster' c2 'Braun'
MTB > set 'Auster'
DATA> 4 7.6 6.5 5.9 8.6 7.3 5.2 4.8 6.1 6.1
DATA> end
MTB > set 'Braun'
DATA> 4.7 5.7 5.7 5 4.7 4.6 5.5 5.2 5.5 5.5 5.4 5.2
DATA> end
MTB > twosample c1 c2
TWOSAMPLE T FOR Auster VS Braun
N MEAN STDEV SE MEAN
Auster 10 6.21 1.37 0.43
Braun 12 5.225 0.393 0.11
95 PCT CI FOR MU Auster - MU Braun: (-0.01, 1.98)
TTEST MU Auster = MU Braun (VS NE): T= 2.20 P=0.053 DF= 10
Der p-Wert ist 5:3%. Ein Ertragsunterschied kann demnach auf dem 5%-Signi�-kanzniveau nicht abgesichert werden. Da� die Ablehnung nur knapp verfehlt wurde,
zeigt auch das 95%-Vertrauensintervall f�ur die Mittelwertsdi�erenz, in dem die Null
gerade noch enthalten ist. Der Output zeigt auch, da� die empirische Standardab-
weichung der Austernpilze ca. dreimal so gro� ist wie die der Braunkappen.
238 6 Test von statistischen Hypothesen
F�uhrt man den t-Test mit den gepoolten Varianzen durch, so resultiert folgendes
Testergebnis:
MTB > twosample c1 c2;
SUBC> pooled.
TWOSAMPLE T FOR Auster VS Braun
N MEAN STDEV SE MEAN
Auster 10 6.21 1.37 0.43
Braun 12 5.225 0.393 0.11
95 PCT CI FOR MU Auster - MU Braun: (0.12, 1.85)
TTEST MU Auster = MU Braun (VS NE): T= 2.38 P=0.027 DF= 20
POOLED STDEV = 0.965
Der p-Wert betr�agt nun 2:7%, d.h. die Ertr�age w�aren signi�kant verschieden. Das
Beispiel zeigt also, da� beim Testen mit gepoolten Varianzen Vorsicht geboten ist,
da bei Verletzung der Voraussetzung der Homogenit�at der Varianzen Fehlentschei-
dungen auftreten k�onnen.
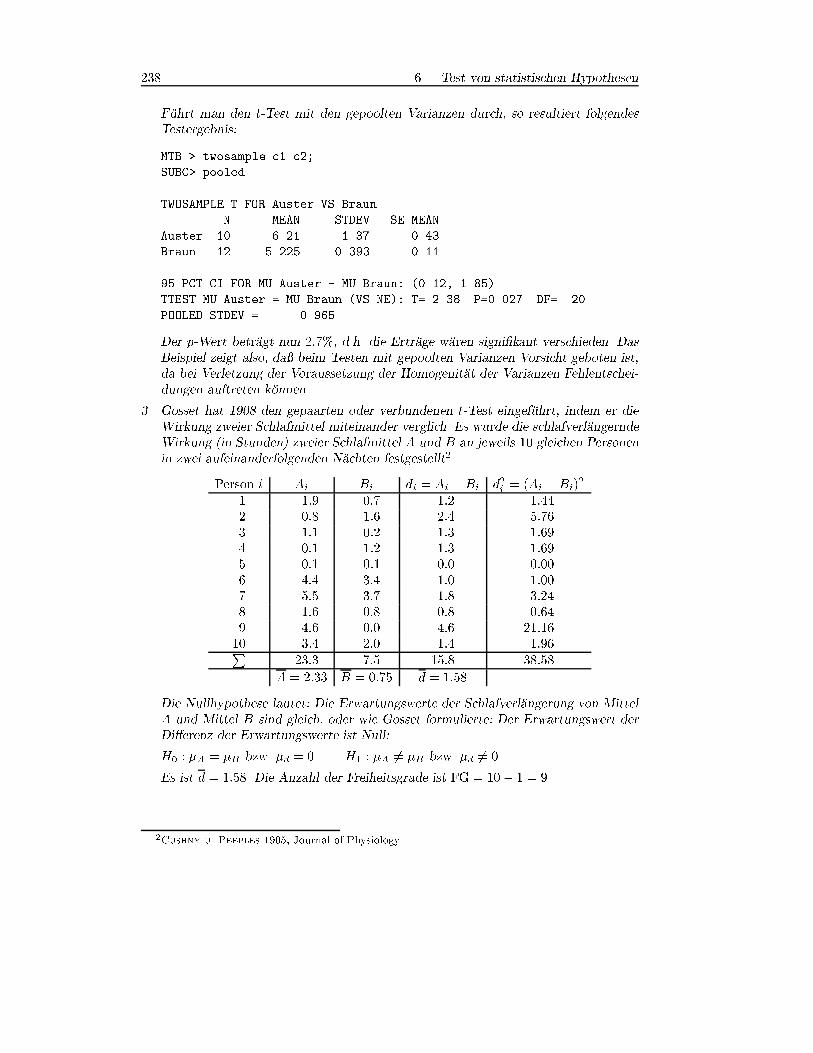
3. Gosset hat 1908 den gepaarten oder verbundenen t-Test eingef�uhrt, indem er die
Wirkung zweier Schlafmittel miteinander verglich. Es wurde die schlafverl�angernde
Wirkung (in Stunden) zweier Schlafmittel A und B an jeweils 10 gleichen Personen
in zwei aufeinanderfolgenden N�achten festgestellt2.
Person i Ai Bi di = Ai �Bi d2i = (Ai �Bi)2
1 1:9 0:7 1:2 1:442 0:8 �1:6 2:4 5:763 1:1 �0:2 1:3 1:694 0:1 �1:2 1:3 1:695 �0:1 �0:1 0:0 0:006 4:4 3:4 1:0 1:007 5:5 3:7 1:8 3:248 1:6 0:8 0:8 0:649 4:6 0:0 4:6 21:1610 3:4 2:0 1:4 1:96P
23:3 7:5 15:8 38:58
A = 2:33 B = 0:75 d = 1:58
Die Nullhypothese lautet: Die Erwartungswerte der Schlafverl�angerung von Mittel
A und Mittel B sind gleich, oder wie Gosset formulierte: Der Erwartungswert der
Di�erenz der Erwartungswerte ist Null:
H0 : �A = �B bzw. �d = 0 H1 : �A 6= �B bzw. �d 6= 0
Es ist d = 1:58. Die Anzahl der Freiheitsgrade ist FG = 10� 1 = 9.
2Cushny u. Peeples 1905, Journal of Physiology.

6.3 Vergleich zweier Erwartungswerte 239
Die Standardabweichung der Di�erenzen ist:
s2d =1
9��38:58� 1
10� 15:82
�= 1:513 ) sd � 1:23
Die Testgr�o�e berechnet sich dann zu:
t0 =d
sd=pn=
1:58 �p10
1:23= 4:06
Wenn � = 0:01 = 1% gefordert wird, dann erh�alt man t9;0:995 = 3:25 aus Tab. A.4im Anhang.
jt0j = 4:06 > 3:25 = t9;0:995
Die Nullhypothese �uber die Gleichheit der beiden Mittel wird auf dem 1%-Signi�-kanzniveau abgelehnt.
Es soll an dieser Stelle noch ausdr�ucklich darauf hingewiesen werden, da� ein Te-
stergebnis kein Beweis f�ur eine Theorie ist. Es kommt sehr stark auf die Formu-
lierung der Hypothesen, die unterstellten Voraussetzungen und auf die Versuchs-
durchf�uhrung an. Das zuerst verabreichte Medikament kann im vorliegenden Fall
noch in der folgenden Nacht wirksam sein und so eine schlafverl�angernde Wirkung
des zweiten Medikaments vort�auschen. Dieser E�ekt ist der sog. carry-over. Es
wird also eine Wirkung in eine folgende Versuchsperiode mit hin�ubergetragen. Es
w�are eventuell sinnvoll, eine Pause zwischen der ersten und zweiten Verabreichung
einzulegen, um einen sog. wash-out zu erreichen. Dies k�onnte allerdings wiederum
zur Folge haben, da� die Versuchspersonen nach dieser Zeitspanne physisch und
psychisch anders reagieren als unmittelbar nach der ersten Nacht.
6.3.6 Unabh�angige oder verbundene Stichproben?
Wenn man die Wahl hat, ein Experiment mit unabh�angigen oder verbundenen Stichpro-ben durchzuf�uhren, emp�ehlt sich eine Versuchsplanung mit verbundenen Stichproben.In diesem Fall bekommt man meist genauere Ergebnisse, weil durch die Di�erenzbil-dung aus den zusammengeh�origen Stichprobenwerten eine kleinere Varianz resultiert(s2d < s2x+s2y). Die Testgr�o�e wird dadurch gr�o�er und �uberschreitet deshalb eher einenSchwellenwert, so da� Unterschiede besser aufgedeckt werden k�onnen. Es gehen aller-dings Freiheitsgrade verloren: Bei zwei unabh�angigen gleich gro�en Stichproben sindes 2n� 2, bei zwei verbundenen Stichproben nur n � 1 Freiheitsgrade. Dadurch wirdder zum Vergleich herangezogene Schwellenwert gr�o�er.

240 6 Test von statistischen Hypothesen
Beispiel:
Es soll gepr�uft werden, ob sich die Benzinqualit�at der Marken Eral und Asso unter-
scheiden. F�ur beide Marken wurde der Verbrauch in l/100 km am gleichen von jeweils
f�unf Autos gemessen.
Typ Eral Asso
Limousine 11:9 12:3Kleinwagen 7:7 7:7Kombi 8:2 8:5Sportwagen 13:4 14:0Mittelklassewagen 8:0 8:3
Die Stichproben sind in diesem Fall nat�urlich verbunden, da der Verbrauch eines Au-
totyps f�ur beide Benzinmarken in der gleichen Gr�o�enordnung liegt.
Die Daten werden diesmal mit dem read-Befehl spaltenweise in MINITAB eingelesen
und anschlie�end zun�achst der t-Test zum Mittelwertvergleich unabh�angiger Stichpro-
ben mit gepoolten Standardabweichungen durchgef�uhrt.
MTB > read c1 c2
DATA> 11.9 12.3
DATA> 7.7 7.7
DATA> 8.2 8.5
DATA> 13.4 14.0
DATA> 8.0 8.3
DATA> end
5 ROWS READ
MTB > name c1 'Eral' c2 'Asso'
MTB > twosample 'Eral' 'Asso';
SUBC> pooled.
TWOSAMPLE T FOR Eral VS Asso
N MEAN STDEV SE MEAN
Eral 5 9.84 2.63 1.2
Asso 5 10.16 2.81 1.3
95 PCT CI FOR MU Eral - MU Asso: (-4.3, 3.6)
TTEST MU Eral = MU Asso (VS NE): T= -0.19 P=0.86 DF= 8
POOLED STDEV = 2.72
Die Hypothese, da� ein Qualit�atsunterschied besteht, k�onnte nur auf Signi�kanzni-
veaus, die gr�o�er als 85:7% sind abgesichert werden. Dies w�urde kein vern�unftiger
Statistiker tun.

6.3 Vergleich zweier Erwartungswerte 241
Der richtige Test f�ur verbundene Stichproben erfolgt mit dem t-Test f�ur den Mittelwert
bei unbekanntem � (Abschnitt 6.2.1), indem man die Di�erenzen der Verbrauchswerte
gegen 0 testet, also: H0 : �d = 0 gegen H1 : �d 6= 0. Dazu werden zun�achst die
Di�erenzen mit dem let-Befehl gebildet und anschlie�end der t-Test durchgef�uhrt.
MTB > name c3 'Diff.'
MTB > let c3=c1-c2
MTB > ttest 0 'Diff.'
TEST OF MU = 0.0000 VS MU N.E. 0.0000
N MEAN STDEV SE MEAN T P VALUE
Diff. 5 -0.3200 0.2168 0.0970 -3.30 0.030
Nun betr�agt der p-Wert gerade noch ca. 3%. Ein Qualit�atsunterschied kann also auf
dem 5%-Niveau signi�kant gesichert werden.
Der krasse Unterschied in den Testergebnissen des Beispiels ist durch die Variabilit�atim Verbrauch der einzelnen Autotypen bedingt. Beim Test f�ur unabh�angige Stichpro-ben wird diese Typenvariabilit�at der jeweiligen Stichprobe angelastet, w�ahrend sie imanderen Fall dem jeweils zusammengeh�origen Wertepaar zugerechnet und deshalb teil-weise eliminiert wird. Es ist auch o�ensichtlich, da� der Verbrauch mit der Marke Assoin allen F�allen h�oher oder gleich war.
6.3.7 Einseitige oder zweiseitige Alternativhypothesen?
Bei einem Mittelwertvergleich will man z.B. einen Unterschied zwischen zwei Metho-den oder Sorten feststellen. �Uber die Richtung eines m�oglichen Unterschieds in derWirkung oder im Ertrag liegen in der Regel jedoch vor der Stichprobenerhebung keineInformationen vor. In diesem h�au�gsten Fall lautet die Alternativhypothese: Die beidenStichprobenmittel entstammen unterschiedlichen Grundgesamtheiten, sie sind also le-diglich verschieden (H1 : �1 6= �2). Ist jedoch aus sachlichen Gr�unden die Richtung deszu erwartenden Unterschieds bekannt oder sind Abweichungen in einer Richtung unin-teressant, dann ist die einseitige Alternativhypothese (H1 : �1 < �2 bzw. H1 : �1 > �2)vorzuziehen. Eine Ablehnung der Nullhypothese und damit eine Annahme der Alterna-tivhypothese ist bei der einseitigen Fragestellung eher m�oglich als bei der zweiseitigen,denn beim einseitigen Test wird die Testgr�o�e mit der (1��)-Fraktilen und beim zwei-seitigen Test mit der (1 � �=2)-Fraktilen verglichen. Die (1 � �=2)-Fraktile ist aberimmer gr�o�er als die (1��)-Fraktile. Der einseitige Test deckt Di�erenzen in den Mit-telwerten fr�uher auf als der zweiseitige. Die Macht des Tests oder die Testst�arke deseinseitigen Tests ist also gr�o�er als beim zweiseitigen Test.
Beispiel:
Auf dem M�unchner Oktoberfest pr�uft ein Stadtbeamter die F�ullmenge der Ma�kr�uge in
einem Bierzelt. Der Wiesenwirt erh�alt eine Verwarnung, wenn der Inhalt auf maximal
5% Signi�kanzniveau kleiner als 0:90 l ist. Der Kontrolleur kauft 10 Ma� Bier, mi�t
den Inhalt und wertet die Daten in MINITAB mit dem t-Test f�ur den Mittelwert bei
unbekanntem � (Abschnitt 6.2.1) aus.

242 6 Test von statistischen Hypothesen
MTB > set c1
DATA> 0.88 0.85 0.91 0.90 0.82 0.86 0.89 0.90 0.89 0.90
DATA> end
MTB > ttest 0.9 c1
TEST OF MU = 0.90000 VS MU N.E. 0.90000
N MEAN STDEV SE MEAN T P VALUE
C1 10 0.88000 0.02828 0.00894 -2.24 0.052
Aufgrund des zweiseitigen t-Tests kann die Alternativhypothese, da� die mittlere Bier-
menge verschieden von 0:9 l ist, auf dem 5%-Niveau nicht angenommen werden.
Interessant ist allerdings ausschlie�lich eine Abweichung nach unten. Es ist also sinn-
voller, folgende Hypothesen aufzustellen:
H0 : � = 0:9 l gegen H1 : � < 0:9 l
In MINITAB erfolgt dieser Test mit dem Subkommando alternative -1.
MTB > ttest 0.9 c1;
SUBC> alternative -1.
TEST OF MU = 0.90000 VS MU L.T. 0.90000
N MEAN STDEV SE MEAN T P VALUE
C1 10 0.88000 0.02828 0.00894 -2.24 0.026
Der p-Wert betr�agt jetzt 2:6%, also die H�alfte von vorher. Die Nullhypothese ist in
diesem Fall auf dem 5%-Niveau abzulehnen. Der Wirt erh�alt eine Verwarnung.
6.3.8 Bekanntes oder unbekanntes �?
Ist die Gr�o�enordnung der Streuung einer Grundgesamtheit (z.B. aus fr�uheren Mes-sungen) bekannt, so wird man diese beim Mittelwertvergleich als bekannt vorausset-zen. Eine Ablehnung der Nullhypothese ist in diesem Fall eher m�oglich, weil dann alsTestschwelle eine Fraktile der Normalverteilung dient. Diese Fraktile ist immer klei-ner als die entsprechende Fraktile der t-Verteilung. Besonders bei kleinen Stichprobe-numf�angen oder wenn extrem hohe bzw. niedrige Werte auftreten ist es m�oglich, da�die gesch�atzte Varianz stark von der tats�achlichen Varianz abweicht. Aus diesem Grundkann es zu krassen Fehlentscheidungen kommen.
Generell ist der z-Test sicherlich sehr selten anzuwenden, da man die Streuung �2 in derRegel nicht oder nicht gen�ugend genau kennt, wenn schon der Mittelwert � unbekanntist.

6.3 Vergleich zweier Erwartungswerte 243
Beispiel:
Es soll der Natriumgehalt (in mg/l) von zwei Mineralw�assern aufgrund folgender Stich-
probe verglichen werden:
Mineralwasser 1 8:17 5:53 7:12 8:01 x1 = 7:21 s1 = 1:21
Mineralwasser 2 9:32 8:24 8:99 9:10 x2 = 8:91 s2 = 0:47
Die Nullhypothese, die mittleren Natriumgehalte sind gleich, wird gegen die Alternativ-
hypothese, die mittleren Natriumgehalte sind verschieden, bei einem Signi�kanzniveau
von � = 1% getestet:
H0 : �1 = �2 H1 : �1 6= �2 � = 0:01
Der t-Test f�ur den Mittelwertvergleich bei unterschiedlichen Streuungen hat als Test-
gr�o�e
t0 =x1 � x2p
s21=n1 + s22=n2=
7:21� 8:91p1:212=4 + 0:472=4
= �2:62
mit
FG =(s21=n+ s22=n)
2
s41=(n2 � (n� 1)) + s42=(n
2 � (n� 1))=
=(1:212=4 + 0:472=4)2
1:214=(16 � 3) + 0:474=(16 � 3) = 3:89:
Die Freiheitsgrade werden auf 3 abgerundet, um auf der sicheren Seite zu bleiben, denn
die Fraktile f�ur 3 Freiheitsgrade ist gr�o�er als die f�ur 4 Freiheitsgrade.
Es ist (vgl. Tab. A.4 im Anhang):
jt0j = 2:62 6> 5:84 = (3)0:99 = t
(3)0:995
Also kann H0 nicht abgelehnt werden.
Allerdings ist der Wert 5:53 der ersten Stichprobe relativ klein im Vergleich zu den
anderen. Au�erdem wei� man aufgrund zahlreicher fr�uherer Untersuchungen, da� der
Natriumgehalt von Mineralw�assern eine Standardabweichung in der Gr�o�enordnung
von � � 0:5 hat. Es kann in diesem Fall der z-Test zum Mittelwertvergleich bei be-
kannten Streuungen herangezogen werden. Die Testgr�o�e lautet:
z0 =x1 � x2p
�2=n1 + �2=n2=
7:21� 8:91p0:52=4 + 0:52=4
= �4:81
Damit folgt (vgl. Tab. A.2 im Anhang):
jz0j = 4:81 > 2:58 = �0:99
Ein Unterschied im mittleren Natriumgehalt kann also auf dem 1%-Niveau statistisch
abgesichert werden.

244 6 Test von statistischen Hypothesen
6.4 Test der Varianz
Im folgenden Abschnitt werden Stichproben aus normalverteilten Grundgesamtheitenbetrachtet. Die Erwartungswerte und Varianzen bzw. Standardabweichungen seien un-bekannt.
6.4.1 �2-Test f�ur die Varianz
Gegeben sei eine (�; �2)-normalverteilte Grundgesamtheit. Anhand einer Stichprobevom Umfang n und der daraus ermittelten empirischen Varianz s2 soll getestet werden,ob die Annahme, da� die Varianz der Grundgesamtheit einen bestimmten Wert �0 hat,aufrechterhalten werden kann oder abzulehnen ist. Die Nullhypothese lautet also:
H0 : �2 = �20 bzw. H0 : � = �0 (6.27)
Die Nullhypothese ist zugunsten der zweiseitigen Alternative H1 : �2 6= �20 auf einem
Signi�kanzniveau von � abzulehnen, wenn der Wert �20 au�erhalb des Vertrauensbe-reichs
V:I:
((n� 1)s2
�2n�1;1��=2
� �2 � (n� 1)s2
�2n�1;�=2
)1��
(6.28)
liegt. Die Fraktilen der �2-Verteilung sind in Tab. A.3 im Anhang tabelliert.
Bei den einseitigen Alternativhypothesen H1 : �2 < �20 und H1 : �2 > �20 sind dieVertrauensintervalle:
V:I:
((n� 1)s2
�2n�1;�� �2 < +1
)1��
V:I:
(�1 < �2 � (n� 1)s2
�2n�1;1��
)1��
(6.29)
Die Testgr�o�e �20 beim entsprechenden Test lautet also:
�20 =(n� 1)s2
�20(6.30)
Der Test der Nullhypothese H0 erfolgt beim vorgew�ahlten Signi�kanzniveau � je nachAlternativhypothese H1 nach dem Schema in Tab. 6.9.

6.4 Test der Varianz 245
Voraussetzung: Normalverteilung
Testgr�o�e: �20 =(n� 1)s2
�20
H0: �2 = �20
H1: Ablehnung von H0, wenn
�2 < �20 �20 < �2n�1;�
�2 > �20 �20 > �2n�1;1�� (Tab. A.3)
�2 6= �20 �20
8>>><>>>:
> �2n�1;1��=2
oder
< �2n�1;�=2
Tabelle 6.9: Test der Hypothese �2 = �20
Beispiel:
Beim Vergleich des Natriumgehalts von zwei Mineralw�assern auf Seite 243 wurde an-
genommen, da� der Gehalt eine Standardabweichung von � = 0:5 �g=l hat. Es soll nungetestet werden, ob diese Annahme aufrecht erhalten werden kann. Es erfolgt der Test:
H0 : � = 0:5 H1 : � 6= 0:5 � = 1%
Die Testgr�o�en f�ur die beiden Mineralw�asser lauten:
�21 =(n1 � 1)s21
�20=
3 � 1:2120:52
= 17:57 und
�22 =(n2 � 1)s22
�20=
3 � 0:4720:52
= 2:65
Die (1� 0:01)=2 = 0:995- und die 0:01=2 = 0:005-Fraktilen m�ussen in der Anhangsta-
belle A.3 bei 3 Freiheitsgraden nachgeschlagen werden:
�23;0:995 = 12:84 und �23;0:005 = 0:07
Es ist �21 = 17:57 > 12:84 = �23;0:995. F�ur Mineralwasser 1 mu� die Hypothese, da�
die Standardabweichung 0:5 �g=l betr�agt, auf dem Signi�kanzniveau von � = 0:01verworfen werden, f�ur Mineralwasser 2 dagegen nicht.
6.4.2 F -Test zum Vergleich zweier Varianzen
Voraussetzung f�ur den Vergleich zweier Erwartungswerte durch den t-Test mit den ge-poolten Varianzen ist die Gleichheit oder Homogenit�at der Varianzen. Aus diesemGrund ist es h�au�g notwendig, zu pr�ufen, ob diese Voraussetzung verletzt wird.
Seien x1; x2; : : : ; xm und y1; y2; : : : ; yn zwei voneinander unabh�angige Stichproben aus
einer (�x; �2x)- bzw. (�y; �
2y)-normalverteilten Grundgesamtheit, so ist die Gr�o�e
S2x=�
2x
S2y=�
2y

246 6 Test von statistischen Hypothesen
eine F -verteilte Zufallsvariable mit m � 1 Z�ahler- und n � 1 Nennerfreiheitsgraden.Fm�1;n�1;K% bzw. Fm�1;n�1;L% seien die F -Fraktilen mit den Prozentwerten K undL sowie den Z�ahlerfreiheitsgraden m � 1 und den Nennerfreiheitsgraden n � 1. Danngilt folgende Wahrscheinlichkeitsaussage:
P
�Fm�1;n�1;L% �
S2x=�
2x
S2y=�
2y
� Fm�1;n�1;K%
�= (K � L)% (6.31)
Das Verh�altnis �x=�y ist unbekannt, w�ahrend sx und sy aufgrund der Stichprobe be-rechnet werden k�onnen. Die Wahrscheinlichkeitsaussage (6.31) wird daher so umfor-muliert, da� ein Vertrauensbereich f�ur �x=�y resultiert:
P
�Fn�1;m�1;L% �
S2x
S2y
� �2x�2y
� Fn�1;m�1;K% �S2x
S2y
�= (K � L)% (6.32)
Mit symmetrischen Grenzen folgt:
P
�Fn�1;m�1;�=2 �
S2x
S2y
� �2x�2y
� Fn�1;m�1;1��=2 �S2x
S2y
�= K% (6.33)
Daraus ergibt sich der entsprechende Vertrauensbereich:
V:I:
�Fn�1;m�1;�=2 �
s2xs2y� �2x
�2y� Fn�1;m�1;1��=2 �
s2xs2y
�1��
(6.34)
Die F -Fraktilen sind den Tabellen A.5 bis A.7 im Anhang zu entnehmen.
Die Pr�ufgr�o�e f�ur das entsprechende Testverfahren lautet also:
F0 =s2xs2y
(6.35)
Der Test der Nullhypothese, also der Varianzhomogenit�at, erfolgt beim vorgew�ahltenSigni�kanzniveau � je nach Alternativhypothese H1 anhand von Tab. 6.10.
Zur Bildung von Fm;n;� bildet man den Kehrwert der 1��-Fraktilen bei vertauschtenZ�ahler- und Nennerfreiheitsgraden:
Fm;n;� =1
Fn;m;1��
(6.36)
Der Vergleich von F0 mit der Fm;n;�=2-Fraktilen braucht nicht durchgef�uhrt zu werden,wenn man zur Berechnung von F0 immer die gr�o�ere durch die kleinere Varianz teilt.

6.4 Test der Varianz 247
Voraussetzung: Normalverteilung
Testgr�o�e: F0 =s2xs2y
H0: �2x = �2y
H1: Ablehnung von H0, wenn
�2x < �2y F0 < Fm�1;n�1;�
�2x > �2y F0 > Fm�1;n�1;1�� (Tab. A.5 { A.7)
�2x 6= �2y F0
8>>><>>>:
> Fm�1;n�1;1��=2
oder
< Fm�1;n�1;�=2
Tabelle 6.10: F -Test zum Vergleich zweier Varianzen
Beispiel:
Im Beispiel mit den Pilzen auf Seite 237 wurde angenommen, da� die Streuungen der
Frischmasseertr�age von Austernpilzen und Braunkappen verschieden sind. Dies soll nun
getestet werden.
H0 : �A = �B H1 : �a 6= �B � = 0:05
F0 =s2As2B
=1:372
0:3932= 12:15
F0 = 12:15 > 3:78 = F9;10;0:975 > F9;11;0:975 (Tab. A.6 im Anhang)
Also ist die Hypothese der Varianzhomogenit�at auf � = 5% abzulehnen.
6.4.3 Pfanzagl- oder Levene-Test zum Vergleich zweier Varianzen
Der F -Test zum Vergleich zweier Varianzen ist nicht sehr robust gegen Abweichun-gen von der Normalverteilung. Falls der Verdacht auf solche Abweichungen besteht,emp�ehlt sich der Pfanzagl-3 oder Levene-Test, der ohne die Annahme der Normal-verteilung auskommt. Man berechnet:
dxi = jxi � xj und dyi = jyi � yj (6.37)
Die Erwartungswerte der dxi und dyi sind proportional zu �x bzw. �y. Die Nullhypo-these H0 : �x = �y kann damit auf eine analoge Nullhypothese �uber die Erwartungs-werte der dxi und dyi zur�uckgef�uhrt werden. Um diese Nullhypothese zu pr�ufen, kannman den t-Mittelwertsvergleich oder einen verteilungsfreien Test wie den Wilcoxon-Rangsummentest (vgl. Band 2) heranziehen.
3Pfanzagl J. 1966: Allgemeine Methodenlehre der Statistik II, G�oschen.

248 6 Test von statistischen Hypothesen
Beispiel:
Zum Vergleich der Varianzen von Austernpilzen und Braunkappen im Beispiel auf
Seite 237 werden zun�achst die Mittelwerte (Kommando mean) in den Konstanten k1
und k2 gespeichert und anschlie�end die absoluten (Funktion abs) Abweichungen der
Me�werte vom Mittelwert berechnet.
MTB > mean c1 k1
MEAN = 6.2100
MTB > mean c2 k2
MEAN = 5.2250
MTB > let c3=abs(c1-k1)
MTB > let c4=abs(c2-k2)
Das twosample-Kommando f�uhrt dann den t-Test durch.
MTB > twosample c3 c4
TWOSAMPLE T FOR C3 VS C4
N MEAN STDEV SE MEAN
C3 10 1.032 0.835 0.26
C4 12 0.325 0.199 0.057
95 PCT CI FOR MU C3 - MU C4: (0.10, 1.319)
TTEST MU C3 = MU C4 (VS NE): T= 2.62 P=0.028 DF= 9
Die Nullhypothese gleicher Varianzen kann bis zu einem Signi�kanzniveau von 2:8%abgelehnt werden.

6.5 Vergleich zweier Bernoulli-Wahrscheinlichkeiten 249
6.5 Vergleich zweier Bernoulli-Wahrscheinlichkeiten
H�au�g wird die Frage gestellt, ob sich die Anteile bestimmter Objekte oder Merkmalein zwei verschiedenen Grundgesamtheiten unterscheiden. Man will z.B. wissen, ob dieBehandlung einer Getreidesorte mit zwei Fungiziden verschiedene Befallsh�au�gkeitenzur Folge hat oder ob die Toxizit�at zweier Umweltschadsto�e unterschiedlich ist. Esexistieren in solchen F�allen also empirische H�au�gkeitswerte h1 und h2, die aufgrundeiner Stichprobe ermittelt wurden. Diese sind Sch�atzwerte f�ur die unbekannten H�au�g-keiten p1 und p2, beispielsweise die Befallsh�au�gkeit mit einem Erreger oder der Anteilgesch�adigter Organismen nach Einwirkung eines Schadsto�s. Es soll dann die Nullhy-pothese, die H�au�gkeiten sind gleich, gegen eine entsprechende Alternativhypothesegetestet werden.
Bei nicht zu geringem Stichprobenumfang ist die relative H�au�gkeit h etwa (p; pq=n)-normalverteilt mit q = 1 � p. Die Di�erenz h1 � h2 zweier Anteile ist dann ebenfallsapproximativ normalverteilt mit dem Erwartungswert p1� p2 und der Standardabwei-chung
pp1q1=n1 + p2q2=n2. Unter Annahme der Nullhypothese H0 : p1 = p2 gilt auch
p1q1 = p2q2 = pq. Man ben�otigt also einen gepoolten Sch�atzwert f�ur p und q aus derAnzahl der beobachteten Daten a1, a2, a1 und a2 (vgl. folgendes Schema).
Ereignis Stichprobe 1 Stichprobe 2 gesamt
A a1 a2 a1 + a2A a1 a2 a1 + a2
gesamt n1 = a1 + a1 n2 = a2 + a2 n = n1 + n2
Es bietet sich daher an, p durch
h =a1 + a2
n(6.38)
zu sch�atzen. Die empirischen H�au�gkeiten sind
h1 =a1
n1und h2 =
a2
n2(6.39)
Die Standardabweichung der Di�erenz �h = h1 � h2 ist:
s�h =
sh � (1� h) �
�1
n1+
1
n2
�(6.40)
Damit erh�alt man die Testgr�o�e:
z0 =h1 � h2
s�h=
h1 � h2sh � (1� h) �
�1
n1+
1
n2
� (6.41)

250 6 Test von statistischen Hypothesen
Voraussetzung: Bernoulli-Experiment, n1, n2 gen�ugend gro�
Testgr�o�e: z0 =h1 � h2p
h � (1� h) � (1=n1 + 1=n2)
mit h1 =a1
n1, h2 =
a2
n2, h =
a1 + a2
n
H0: p1 = p2
H1: Ablehnung von H0, wenn
p1 < p2 z0 < �u1��p1 > p2 z0 > u1�� (Tab. A.2)
p1 6= p2 jz0j > �1�� = u1��=2
Tabelle 6.11: z-Test f�ur den Vergleich zweier Bernoulli-Wahrscheinlichkeiten
Unter Annahme der Nullhypothese ist die Testgr�o�e ungef�ahr standardnormalverteilt.Der Test verl�auft dann nach dem Schema in Tab. 6.11.
Vertrauensintervall f�ur p1 � p2
Da die Gr�o�e(h1 � h2)� (p1 � p2)
s�happroximativ normalverteilt ist, erh�alt man f�ur
das 1� �-Vertrauensintervall:
V:I:fh1 � h2 � �1�� � s�h � p1 � p2 � h1 � h2 + �1�� � s�hg1�� (6.42)
Man beachte, da� in s�h die beiden beobachteten H�au�gkeiten h1 und h2 eingehen,w�ahrend beim Test von H0 : p1 = p2 aufgrund der Annahme von H0 ein gepoolterSch�atzer verwendet wird. Das Vertrauensintervall soll alle Vertrauenswerte p1 � p2einschlie�en, nicht nur den Wert p1 � p2 = 0.

6.5 Vergleich zweier Bernoulli-Wahrscheinlichkeiten 251
Beispiel:
Bei der Toxizit�atspr�ufung zweier chemischer Substanzen wurden Ratten im Labor kon-
taminiert. Die Anzahl der �uberlebenden und verendeten Ratten zeigt folgende Tabelle.
Wirksto�1 2 gesamt
�Uberlebende 48 34 82Tote 81 53 134
gesamt 129 87 216
Die beiden unbekannten �Uberlebenswahrscheinlichkeiten p1 und p2 werden durch die
empirischen H�au�gkeiten h1 =48
129= 0:37 und h2 =
34
87= 0:39 gesch�atzt, der gepoolte
Sch�atzwert f�ur p ist h =48 + 34
216= 0:38. Als Testgr�o�e berechnet man:
z0 =0:37� 0:39s
0:38 � 0:62 ��
1
129+
1
87
� = �0:30
Es gilt: jz0j = 0:30 6> 1:645 = �0:90 = u0:95. Die unterschiedliche Toxizit�at der beiden
Substanzen kann also auf dem 10%-Signi�kanzniveau nicht statistisch gesichert werden.
F�ur das 90%-Vertrauensintervall ben�otigt man s�h:
s�h =
s0:38 � 0:62 �
�1
129+
1
87
�= 0:067
Damit lautet das Vertrauensintervall mit der zweiseitigen 90%-Fraktilen �0:9 = 1:645der Standardnormalverteilung aus Anhangstabelle A.2:
V:I:f�0:02� 1:645 � 0:067 � p1 � p2 � �0:02 + 1:645 � 0:067g0:9 =V:I:f�0:13 � p1 � p2 � 0:09g0:9Ein Toxizit�atsunterschied w�are nur dann abzusichern, wenn der Wert 0 au�erhalb des
Vertrauensintervalls liegen w�urde. Dies ist jedoch nicht der Fall.

252 6 Test von statistischen Hypothesen
6.6 Test der Verteilungsfunktion und Analyse von Kontingenz-
tafeln
Die bisher vorgestellten Tests bezogen sich fast ausnahmslos auf Hypothesen �uber Para-meter von bekannt vorausgesetzten Verteilungen. Die folgenden Chi-Quadrat-Teststesten die Hypothese, da� die Grundgesamtheit eine bestimmte Verteilung besitzt bzw.die Unabh�angigkeit von Merkmalen aufgrund einer gegebenen Kontingenztafel (vgl.Kap. 1.3).
6.6.1 �2-Test f�ur Verteilungsfunktionen
Mit Hilfe einer Stichprobe soll die Hypothese getestet werden, ob eine Grundgesamtheitoder die sie charakterisierende Zufallsvariable X eine bestimmte VerteilungsfunktionF hat. Aus der Stichprobe kann man die empirische Summenh�au�gkeitsfunktion eFberechnen. F und eF werden dann in ihrem ganzen Verlauf miteinander verglichenund die Abweichung bewertet. Wenn man die Wahrscheinlichkeitsverteilung der Ab-weichung unter der Voraussetzung, da� die Hypothese richtig ist, kennt, so ist man inder Lage, einen Test dieser Nullhypothese anzugeben.
Bei der Durchf�uhrung des Tests unterteilt man die x-Achse in r sich nicht �uberlappendeKlassen oder Teilintervalle T1; T2; : : : ; Tr, so da� jedes Teilintervall wenigstens 4 Werteder gegebenen Stichprobe x1; x2; : : : ; xn enth�alt. Sei Bi (i = 1; 2; : : : ; r) die Anzahl derbeobachteten Stichprobenwerte in Ti. Dann berechnet man sich aufgrund der hypo-thetischen Verteilungsfunktion F die Wahrscheinlichkeit pi, da� die Zufallsvariable Xeinen Wert aus dem Intervall Ti annimmt. Wenn die Stichprobe den Umfang n hat,dann sind im Teilintervall Ti theoretisch Ei = n � pi Stichprobenwerte zu erwarten.
Man berechnet nun folgende Testgr�o�e �20:
�20 =
rXi=1
(Bi �Ei)2
Ei
(6.43)
Die Gr�o�e �20, aufgefa�t als Zufallsvariable, ist unter der Voraussetzung, da� die Hy-pothese richtig ist, f�ur n ! 1 �2-verteilt mit r � 1 Freiheitsgraden. Die Nutzanwen-dung dieser Tatsache ist, da� man die Gr�o�e �20 praktisch als �2-verteilt mit r � 1Freiheitsgraden ansehen kann, wenn nur alle Ei � 4 sind (Faustregel). Man legt eineIrrtumswahrscheinlichkeit � fest und sucht den entsprechenden Tabellenwert �2r�1;1��in Anhangstabelle A.3. Ist dann �20 > �2r�1;1��, so wird die Nullhypothese verworfen.
Bisher wurde angenommen, da� die Verteilungsfunktion F vollst�andig bekannt ist.Falls jedoch in der zu testenden Verteilungsfunktion k unbekannte Parameter (z.B.Mittelwert, Varianz usw.) enthalten sind, dann sind diese unbekannten Parameter erstzu sch�atzen. Die Pr�ufgr�o�e �20 nach (6.43) ist in diesem Fall angen�ahert �2-verteilt mitr � k � 1 Freiheitsgraden.
Das Testschema zeigt Tab. 6.12.

6.6 Test der Verteilungsfunktion und Kontingenztafelanalyse 253
Testgr�o�e: �20 =
rXi=1
(Bi �Ei)2
Ei
H0: X � F (x)
H1: Ablehnung von H0, wenn
X 6� F (x) �20 > �2r�s�1;1�� (Tab. A.3)
Tabelle 6.12: �2-Test f�ur Verteilungsfunktionen
Beispiel:
Es soll gepr�uft werden, ob die Milchleistungen der Stichprobe von Tab. 1.8 aus einer
normalverteilten Grundgesamtheit stammen. In Tab. 1.9 sind die absoluten H�au�gkei-
ten der klassi�zierten Stichprobe angef�uhrt. Der Stichprobenumfang ist n = 100, derMittelwert ist x = 5189, die Standardabweichung ist s = 655. Die letzten beiden Werte
werden zun�achst als Parameter der zu testenden Normalverteilung herangezogen. Die
Hypothesen lauten dann:
H0 : X � (5189; 6552)-n.v. H1 : X 6� (5189; 6552)-n.v.
Da in der vorletzten Klasse nur 3 Stichprobenwerte auftreten, ist es zweckm�a�ig, die
letzten beiden Klassen zu einer einzigen Klasse zu vereinigen. Die erwarteten H�au�g-
keiten Ei berechnet man �uber die Wahrscheinlichkeit pi, da� die Milchleistung im
Teilintervall i vorkommt. Zu diesem Zweck ben�otigt man die Verteilungsfunktion F .
Wird wie im vorliegenden Fall die Hypothese der Normalverteilung getestet, so mu�
zun�achst auf die Standardnormalverteilung �(x) transformiert werden. Das gesuchte piergibt sich dann aus der Di�erenz der Funktionswerte der Standardnormalverteilung an
den Klassengrenzen. Die Berechnung der erwarteten H�au�gkeit E1 f�ur die erste Klasse
lautet ausf�uhrlich:
E1 = p1 � n = p1 � 100 = (F (4000)� F (�1)) � 100 ==
��
�4000� 5189
655
�� �(�1)
�� 100 = (�(�1:82)� �(�1)) � 100 =
= (0:034� 0:000) � 100 = 3:4
Die Berechnung der erwarteten H�au�gkeiten f�ur jede Klasse erfolgt zweckm�a�igerweise
in Tabellenform.
Intervallx� 5189
655�
�x� 5189
655
�pi Ei Bi
(Bi �Ei)2
Ei
: : : 4000 : : :�1:82 0:000 : : :0:034 0:034 3:4 5 0:7534000 : : :4400 �1:82 : : :�1:20 0:034 : : :0:115 0:081 8:1 8 0:0014400 : : :4800 �1:20 : : :�0:59 0:115 : : :0:278 0:163 16:3 14 0:3254800 : : :5200 �0:59 : : : 0:02 0:278 : : :0:492 0:214 21:4 22 0:0175200 : : :5600 0:02 : : : 0:63 0:492 : : :0:736 0:244 24:4 20 0:7935600 : : :6000 0:63 : : : 1:24 0:736 : : :0:893 0:157 15:7 24 4:3886000 : : : 1:24 : : : 0:893 : : :1:000 0:107 10:7 7 1:279
1:000 100:0 100 7:556
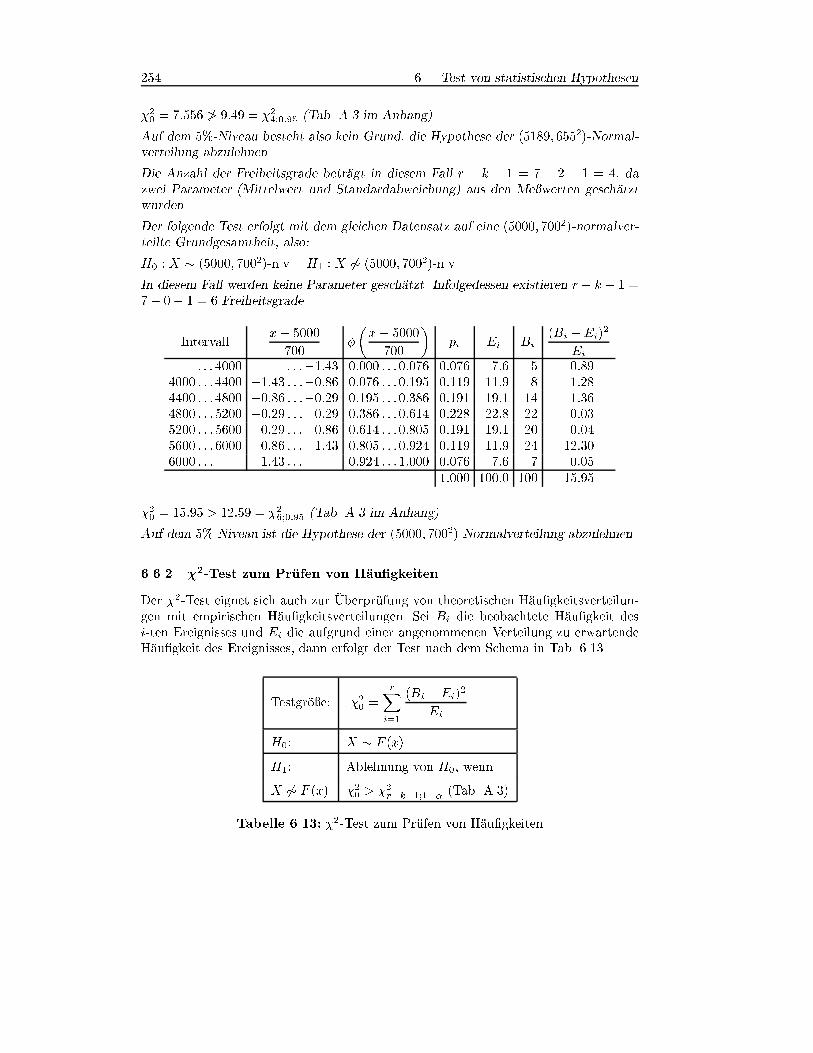
254 6 Test von statistischen Hypothesen
�20 = 7:556 6> 9:49 = �24;0:95 (Tab. A.3 im Anhang)
Auf dem 5%-Niveau besteht also kein Grund, die Hypothese der (5189; 6552)-Normal-verteilung abzulehnen.
Die Anzahl der Freiheitsgrade betr�agt in diesem Fall r � k � 1 = 7 � 2 � 1 = 4, dazwei Parameter (Mittelwert und Standardabweichung) aus den Me�werten gesch�atzt
wurden.
Der folgende Test erfolgt mit dem gleichen Datensatz auf eine (5000; 7002)-normalver-teilte Grundgesamtheit, also:
H0 : X � (5000; 7002)-n.v. H1 : X 6� (5000; 7002)-n.v.
In diesem Fall werden keine Parameter gesch�atzt. Infolgedessen existieren r � k � 1 =7� 0� 1 = 6 Freiheitsgrade.
Intervallx� 5000
700�
�x� 5000
700
�pi Ei Bi
(Bi �Ei)2
Ei
: : : 4000 : : :�1:43 0:000 : : :0:076 0:076 7:6 5 0:894000 : : :4400 �1:43 : : :�0:86 0:076 : : :0:195 0:119 11:9 8 1:284400 : : :4800 �0:86 : : :�0:29 0:195 : : :0:386 0:191 19:1 14 1:364800 : : :5200 �0:29 : : : 0:29 0:386 : : :0:614 0:228 22:8 22 0:035200 : : :5600 0:29 : : : 0:86 0:614 : : :0:805 0:191 19:1 20 0:045600 : : :6000 0:86 : : : 1:43 0:805 : : :0:924 0:119 11:9 24 12:306000 : : : 1:43 : : : 0:924 : : :1:000 0:076 7:6 7 0:05
1:000 100:0 100 15:95
�20 = 15:95 > 12:59 = �26;0:95 (Tab. A.3 im Anhang)
Auf dem 5%-Niveau ist die Hypothese der (5000; 7002)-Normalverteilung abzulehnen.
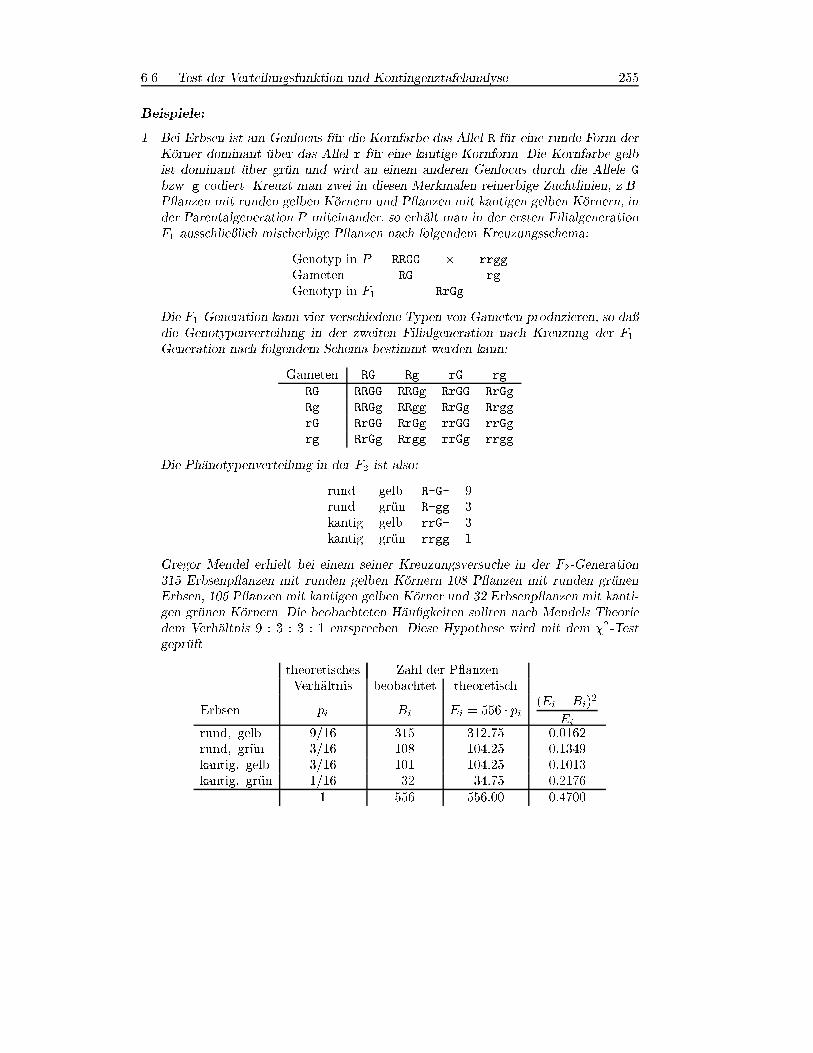
6.6.2 �2-Test zum Pr�ufen von H�au�gkeiten
Der �2-Test eignet sich auch zur �Uberpr�ufung von theoretischen H�au�gkeitsverteilun-gen mit empirischen H�au�gkeitsverteilungen. Sei Bi die beobachtete H�au�gkeit desi-ten Ereignisses und Ei die aufgrund einer angenommenen Verteilung zu erwartendeH�au�gkeit des Ereignisses, dann erfolgt der Test nach dem Schema in Tab. 6.13.
Testgr�o�e: �20 =
rXi=1
(Bi �Ei)2
Ei
H0: X � F (x)
H1: Ablehnung von H0, wenn
X 6� F (x) �20 > �2r�k�1;1�� (Tab. A.3)
Tabelle 6.13: �2-Test zum Pr�ufen von H�au�gkeiten
6.6 Test der Verteilungsfunktion und Kontingenztafelanalyse 255
Beispiele:
1. Bei Erbsen ist am Genlocus f�ur die Kornfarbe das Allel R f�ur eine runde Form der
K�orner dominant �uber das Allel r f�ur eine kantige Kornform. Die Kornfarbe gelb
ist dominant �uber gr�un und wird an einem anderen Genlocus durch die Allele G
bzw. g codiert. Kreuzt man zwei in diesen Merkmalen reinerbige Zuchtlinien, z.B.
P anzen mit runden gelben K�ornern und P anzen mit kantigen gelben K�ornern, in
der Parentalgeneration P miteinander, so erh�alt man in der ersten Filialgeneration
F1 ausschlie�lich mischerbige P anzen nach folgendem Kreuzungsschema:
Genotyp in P RRGG � rrgg
Gameten RG rg
Genotyp in F1 RrGg
Die F1-Generation kann vier verschiedene Typen von Gameten produzieren, so da�
die Genotypenverteilung in der zweiten Filialgeneration nach Kreuzung der F1-
Generation nach folgendem Schema bestimmt werden kann:
Gameten RG Rg rG rg
RG RRGG RRGg RrGG RrGg
Rg RRGg RRgg RrGg Rrgg
rG RrGG RrGg rrGG rrGg
rg RrGg Rrgg rrGg rrgg
Die Ph�anotypenverteilung in der F2 ist also:
rund gelb R-G- 9rund gr�un R-gg 3kantig gelb rrG- 3kantig gr�un rrgg 1
Gregor Mendel erhielt bei einem seiner Kreuzungsversuche in der F2-Generation
315 Erbsenp anzen mit runden gelben K�ornern 108 P anzen mit runden gr�unen
Erbsen, 105 P anzen mit kantigen gelben K�orner und 32 Erbsenp anzen mit kanti-
gen gr�unen K�ornern. Die beobachteten H�au�gkeiten sollten nach Mendels Theorie
dem Verh�altnis 9 : 3 : 3 : 1 entsprechen. Diese Hypothese wird mit dem �2-Test
gepr�uft.
theoretisches Zahl der P anzenVerh�altnis beobachtet theoretisch
Erbsen pi Bi Ei = 556 � pi(Ei �Bi)
2
Ei
rund; gelb 9=16 315 312:75 0:0162rund; gr�un 3=16 108 104:25 0:1349kantig; gelb 3=16 101 104:25 0:1013kantig; gr�un 1=16 32 34:75 0:2176
1 556 556:00 0:4700

256 6 Test von statistischen Hypothesen
Es wird nun mit MINITAB der Wert der Verteilungsfunktion an der Stelle 0:47bei 3 Freiheitsgraden berechnet.
MTB > cdf 0.47;
SUBC> chisquare 3.
0.4700 0.0746
Es besteht wegen des hohen p-Werts von 1�0:0746 = 0:9254 Grund zu der Annah-
me, da� das hypothetische Spaltungsverh�altnis auch zutri�t. Das Gegenteil k�onnte
nicht einmal auf dem 90%-Niveau gesichert werden.
2. Die Gen- oder Allelfrequenz eines Allels ist der relative Anteil des Allels an einem
Genlocus. Bei der Rinderrasse Shorthorn existiert ein dialleler Locus, der f�ur die
Fellfarbe codiert. Der Erbgang ist intermedi�ar. Die folgende Tabelle zeigt die Geno-
und Ph�anotypen sowie deren Anteile an einer Stichprobe von 6000 Herdbuchshor-
thorns4.
Genotyp Ph�anotyp Anteil
RR rot 47.6%RS rotschimmelig 43.8%SS wei� 8.6%
Ist p die Genfrequenz des Allels R und q die Genfrequenz des Allels S, dann gilt:
p + q = 1. Eine Population be�ndet sich im genetischen Gleichgewicht, wenn die
Verteilung der Genotypen (p+ q)2 = p2 RR+ 2pq RS+ q2 SS betr�agt.
Es soll zun�achst auf dem Signi�kanzniveau � = 5% die Nullhypothese gepr�uft
werden, da� sich die Population im genetischen Gleichgewicht mit p = 0:7 und
q = 1� p = 0:3 be�ndet.
pi Ei Bi(Bi �Ei)
2
Ei
RR 0:49 2940 2856 2:40RS 0:42 2520 2628 4:63SS 0:09 540 516 1:07
1:00 6000 6000 8:10
Die Anzahl der Freiheitsgrade betr�agt in diesem Fall 2, da drei Genotypen vorhan-
den sind und kein Parameter gesch�atzt wird.
�20 = 8:10 > �22;0:95 = 5:99 (Tab. A.3 im Anhang)
Damit wird die Nullhypothese auf dem vorgegebenen Signi�kanzniveau von 5%abgelehnt.
Die Allelfrequenzen kann man aus den gegebenen Daten sch�atzen. In den roten
Tieren kommen ausschlie�lich R-Allele vor, in den rotschimmeligen nur zur H�alfte,
in den wei�en gar keine. Die gesch�atzte Genfrequenz bp ist dann:bp = 0:476 + 0:438=2 = 0:695
Damit folgt automatisch f�ur die Frequenz bq des Alternativallels S:bq = 1� 0:695 = 0:305
4aus Pirchner F. 1979: Populationsgenetik in der Tierzucht. Paul Parey Verlag.

6.6 Test der Verteilungsfunktion und Kontingenztafelanalyse 257
pi Ei Bi(Bi �Ei)
2
Ei
RR 0:483 2898 2856 0:61RS 0:424 2544 2628 2:77SS 0:093 558 516 3:16
1:00 6000 6000 6:54
Die Anzahl der Freiheitsgrade betr�agt in diesem Fall 1, da drei Genotypen vorhan-
den sind und die Allelfrequenz von R gesch�atzt wird. Die Frequenz von S wird nicht
gesch�atzt, sondern zu bq = 1� bp berechnet.�20 = 6:54 > �21;0:95 = 3:84
Damit wird die Nullhypothese auf dem vorgegebenen Signi�kanzniveau von 5% auch
hier abgelehnt.
Eine Erkl�arung, da� sich die Population nicht im genetischen Gleichgewicht be�n-
det, ist vermutlich eine Bevorzugung von Rotschimmeln bei der Herdbuchanmel-
dung.
6.6.3 �2-Test zum Pr�ufen auf Unabh�angigkeit
In vielen praktischen Fragestellungen erfolgt eine zweifache Klassi�zierung eines Beob-achtungsmaterials. Beide Merkmale sollten nur nominal sein. Sie sollten also nicht ineine Reihenfolge gebracht werden k�onnen. Kann n�amlich ein Merkmal geordnet wer-den (z.B. stark { mittel { gering), so sollte nach M�oglichkeit der Kruskal-Wallis-Testbevorzugt werden (siehe Band 2).
Das Datenmaterial sei bez�uglich des 1. Merkmals in k Gruppen unterteilt, bez�uglichdes 2. Merkmals in l Gruppen. Man erh�alt dann eine Zweiwegetafel oder zweidi-mensionale Kontingenztafel von folgendem allgemeinen Typ:
2. Merkmal1. Merkmal 1 2 : : : j : : : l
P1 B11 B12 : : : B1j : : : B1l B1:
2 B21 B22 : : : B2j : : : B2l B2:
......
......
......
i Bi1 Bi2 : : : Bij : : : Bil Bi:
......
......
......
k Bk1 Bk2 : : : Bkj : : : Bkl Bk:PB:1 B:2 : : : B:j : : : B:l B:: = n
Der Gesamtumfang der Stichprobe ist n und ist nach den zwei verschiedenen diskretenMerkmalen klassi�ziert. Gepr�uft werden soll die Nullhypothese der Unabh�angigkeit,d.h. das 1. Merkmal beein u�t das 2. Merkmal nicht und umgekehrt. Man kann den Testaber auch als Pr�ufung von H�au�gkeiten interpretieren. Wenn keine Beziehung zwischenden beiden Merkmalen besteht, dann mu� sich theoretisch eine zu den Randh�au�gkeitenproportionale H�au�gkeitsverteilung erwarten lassen.

258 6 Test von statistischen Hypothesen
Bij ist die beobachtete H�au�gkeit in der i-ten Gruppe des 1. Merkmals und in derj-ten Gruppe des 2. Merkmals. Bi: ist die Randh�au�gkeit der i-ten Gruppe, B:j ist dieRandh�au�gkeit der j-ten Gruppe.
Die erwarteten H�au�gkeiten Eij in der i-ten Gruppe des 1. Merkmals und der j-tenGruppe des 2. Merkmals sind dann:
Eij =Bi: �B:j
n(6.44)
Als approximativ �2-verteilte Testgr�o�e dient:
�20 =
kXi=1
lXj=1
(Bij �Eij)2
Eij
(6.45)
Einfacher handzuhaben ist folgende Pr�ufgr�o�e:
�20 = n �0@ kX
i=1
lXj=1
B2ij
Bi: � B:j
� 1
1A (6.46)
Die Anzahl der Freiheitsgrade ist (k � 1) � (l � 1). Die Zahl der Freiheitsgrade gibt dieZahl der Felder einer Zweiwegetafel an, f�ur die man die H�au�gkeiten frei w�ahlen kann,wenn die Randh�au�gkeiten gegeben sind. Die erwarteten H�au�gkeiten sollten � 1 sein.Ansonsten sind mehrere Felder zusammenzufassen, um diese Bedingung zu erf�ullen.
Das Testschema zeigt Tab. 6.14.
Testgr�o�e: �20 =
kXi=1
lXj=1
(Bij �Eij)2
Eij
= n �0@ kX
i=1
lXj=1
B2ij
Bi: � B:j
� 1
1A
H0: Unabh�angigkeit
H1: Ablehnung von H0, wenn
Abh�angigkeit �20 > �2(k�1)(l�1);1�� (Tab. A.3)
Tabelle 6.14: �2-Test zum Pr�ufen auf Unabh�angigkeit

6.6 Test der Verteilungsfunktion und Kontingenztafelanalyse 259
Beispiel:
Bei einer Umfrage unter Mitgliedern von vier verschiedenen Parteien konnten die Pro-
banden mit \ja\, \nein\, oder \wei� nicht\ antworten. Das Ergebnis zeigt folgende
Kontingenztafel:
AntwortPartei ja nein wei� nicht
PA 30 19 16 65B 8 8 39 55C 12 12 24 48D 22 9 11 42P
72 48 90 210
Wenn die Parteimitglieder bez�uglich ihrer Meinungen homogen sind, dann sollten die
theoretischen H�au�gkeiten in den einzelnen Unterklassen proportional zu den einzelnen
Randh�au�gkeiten sein.
Die zu erwartenden H�au�gkeiten f�ur Partei A berechnen sich zu:
EA�ja = E11 =65 � 72210
= 22:29
EA�nein = E12 =65 � 48210
= 14:86
EA�wei� nicht = E13 =65 � 90210
= 27:86
Man erh�alt insgesamt folgende zu erwartenden H�au�gkeiten:
AntwortPartei ja nein wei� nicht
PA 22:29 14:86 27:86 65:01B 18:86 12:67 23:57 55:10C 16:46 10:97 20:57 48:00D 14:40 9:60 18:00 42:00P
72:01 48:10 90:00 210:11
Zu testen ist nun die Nullhypothese: Die Meinung ist unabh�angig von der Parteizu-
geh�origkeit. Man kann die Nullhypothese auch noch anders ausdr�ucken: Zwischen der
beobachteten und der zu erwartenden Verteilung der Grundgesamtheit (d.h. aller Par-
teimitglieder) besteht bei Unabh�angigkeit der Merkmale kein Unterschied.

260 6 Test von statistischen Hypothesen
Die Berechnung der Testgr�o�e nach Gleichung (6.46) ergibt:
�20 = 210 �0@ 4X
i=1
1
Bi:
�3X
j=1
B2ij
B:j
� 1
1A =
= 210 ��1
65��900
72+361
48+256
90
�+
1
55��64
72+64
48+1521
90
�+
+1
48��144
72+144
48+576
90
�+
1
42��484
72+81
48+121
90
�� 1
�=
= 210 ��1
65� (12:5 + 7:5 + 2:8) +
1
55� (0:9 + 1:3 + 16:9)+
+1
48� (2:0 + 3:0 + 6:4) +
1
42� (6:7 + 1:7 + 1:3)� 1
�=
= 210 � (0:35 + 0:35 + 0:24 + 0:23� 1) = 35:7
Die Zahl der Freiheitsgrade betr�agt (4� 1) � (3� 1) = 6
Es ist �20 = 35:7 > 16:81 = �26;0:99 (Tab. A.3 im Anhang). Damit ist eine Abh�angigkeit
der Meinung zur gestellten Frage von der Parteizugeh�origkeit auf dem 1%-Signi�kanz-niveau statistisch gesichert.
MINITAB f�uhrt die Kontingenztafelanalyse zwar nicht automatisch aus, berechnet je-
doch zumindest die �2-Testgr�o�e. In der folgenden Session wird die Kontingenztafel
mit dem read-Befehl eingelesen und anschlie�end das Kommando chisquare f�ur die
Spalten c1 bis c3 eingegeben.
MTB > read c1-c3
DATA> 30 19 16
DATA> 8 8 39
DATA> 12 12 24
DATA> 22 9 11
DATA> end
4 ROWS READ
MTB > chisquare c1-c3

6.6 Test der Verteilungsfunktion und Kontingenztafelanalyse 261
Expected counts are printed below observed counts
C1 C2 C3 Total
1 30 19 16 65
22.29 14.86 27.86
2 8 8 39 55
18.86 12.57 23.57
3 12 12 24 48
16.46 10.97 20.57
4 22 9 11 42
14.40 9.60 18.00
Total 72 48 90 210
ChiSq = 2.670 + 1.155 + 5.047 +
6.251 + 1.662 + 10.099 +
1.207 + 0.096 + 0.571 +
4.011 + 0.038 + 2.722 = 35.530
df = 6
MTB > invcdf 0.99;
SUBC> chisquare 6.
0.9900 16.8119
Der Output enth�alt die erwarteten H�au�gkeiten unter den beobachteten sowie die
Randh�au�gkeiten. Es wird die chi2-Testgr�o�e und die Zahl der Freiheitsgrade aus-
gegeben. Diese kann man dann mit der entsprechenden Fraktile vergleichen, die hier
ebenfalls mit MINITAB berechnet wurde.
Das Testergebnis ist nat�urlich identisch mit dem Ergebnis des per Hand ausgef�uhrten
Tests.
6.6.4 �2-Test bei einer einfachen Zweiwegklassi�kation
Wenn bei beiden Merkmalen jeweils nur zwei Klassen oder zwei Auspr�agungen vor-liegen, kann man ein abgek�urztes Verfahren verwenden. Man erh�alt dann eine sog.2� 2-Tafel oder Vierfeldertafel.
2. Merkmal1. Merkmal 1 2
P1 a b a+ b
2 c d c+ dPa+ c b+ d n
Man berechnet sich aufgrund dieser Tabelle folgende Testgr�o�e �20, die ebenfalls ap-proximativ �2-verteilt ist mit einem Freiheitsgrad.
�20 =n � (a � d� b � c)2
(a+ b) � (c+ d) � (a+ c) � (b+ d)(6.47)

262 6 Test von statistischen Hypothesen
Das Testschema zeigt Tab. 6.15.
Testgr�o�e: �20 =n � (a � d� b � c)2
(a+ b) � (c+ d) � (a+ c) � (b+ d)
H0: Unabh�angigkeit
H1: Ablehnung von H0, wenn
Abh�angigkeit �20 > �21;1�� (Tab. A.3)
Tabelle 6.15: �2-Test zum Pr�ufen einer Vierfeldertafel
Der Test darf jedoch nur angewendet werden, wenn alle erwarteten H�au�gkeiten (diein der Tabelle gar nicht mehr auftauchen und proportional den Randh�au�gkeiten aus-zurechnen sind) gr�o�er als 4 sind und der Gesamtumfang gr�o�er als 50 ist. Selbst wenndiese Bedingungen erf�ullt sind, ist der so durchgef�uhrte Test nicht besonders exakt. Erh�alt das geforderte Signi�kanzniveau � sogar bei einigerma�en gro�en zu erwartendenH�au�gkeiten noch nicht ein, d.h. die Irrtumswahrscheinlichkeit 1. Art, also die Wahr-scheinlichkeit, die Hypothese der Unabh�angigkeit abzulehnen, obwohl sie richtig ist, istin Wirklichkeit etwas gr�o�er als �. Es sollte deshalb nach M�oglichkeit einer exaktenAnalyse der Vierfeldertafel mit dem Test von Fisher oder dem exakten �2-Test stetsder Vorzug gegeben werden (siehe dazu Band 2).
Beispiel:
Es sollen zwei Medikamente A und B auf ihren Behandlungserfolg an insgesamt 200Patienten getestet werden. Die Ergebnisse werden in folgender Vierfeldertafel zusam-
mengefa�t:
Medikament ohne Erfolg mit ErfolgP
A 20 95 115B 5 80 85P
25 175 200
Die Nullhypothese lautet: Der Behandlungserfolg ist unabh�angig vom verwendeten Me-
dikament.
Die Testgr�o�e ist:
�20 =200 � (20 � 80� 5 � 95)2
25 � 175 � 115 � 85 = 5:92
Damit folgt: �20 = 5:92 > 3:84 = �21;0:95 (Tab. A.3 im Anhang). Die Unabh�angig-
keitshypothese wird abgelehnt. Das Medikament A hat also einen vom Medikament B
signi�kant (� = 5%) verschiedenen Behandlungserfolg.

6.6 Test der Verteilungsfunktion und Kontingenztafelanalyse 263
Wenn man die Richtung eines vermuteten Gr�o�enunterschieds kennt, dann kann mansich vor dem Test auch zu einer einseitigen Alternative entscheiden. Ist also bekannt,da� z.B. ein Medikament auf keinen Fall schlechter sein kann als ein Placebo, dann kannder Test H0 : Medikament = Placebo gegen H1 : Medikament > Placebo erfolgen. DieTestst�arke ist hier nat�urlich gr�o�er als im zweiseitigen Fall, d.h. ein vorhandener Un-terschied wird bereits bei geringeren Unterschieden der Stichprobenwerte gesichert. Istjedoch a priori nichts �uber die Wirkung bekannt (z.B. beim Vergleich zweier Medika-mente) dann ist der zweiseitige Test anzuwenden. Die entsprechenden Fraktilen f�ur den�2-Test bei der einseitigen Alternative ergeben sich aus:
peinseitig = 0:5 � pzweiseitig (6.48)
Ein Vergleich der �2-Fraktilen bei einem Freiheitsgrad liefert folgende Tabelle:
Signi�kanzniveauFraktilen 10% 5% 2:5% 1% 0:1%
zweiseitig 2:71 3:84 5:02 6:63 10:83einseitig 1:64 2:71 3:84 7:88 9:55

264 6 Test von statistischen Hypothesen
6.7 Test auf Ausrei�er
Manchmal treten in einer Reihe von Beobachtungen einzelne Werte auf, die extremhoch oder niedrig im Vergleich zu den �ubrigen Werten sind. Solche Werte sind u.U.durch Fehler des Me�ger�ats oder fehlerhaftes Ablesen bzw. Notieren der Me�werteverursacht. Man bezeichnet sie als Ausrei�er, denn es besteht Grund zur Annahme,da� sie aus einer anderen Grundgesamtheit stammen. Ausrei�er werden gew�ohnlichvor einer weiteren statistischen Analyse aus dem Datensatz eliminiert. Wie erkenntman jedoch Ausrei�er? In der explorativen Statistik existieren f�ur ausrei�erverd�achti-ge Werte die Begri�e \au�en\ und \weit au�en\. Um inferenzstatistisch vorzugehen,mu� vorausgesetzt werden, da� die Grundgesamtheit, aus der die Stichprobe stammt,normalverteilt ist.
In erster N�aherung kann man als Faustregel festhalten, da� bei mindestens 10 Beob-achtungswerten ein Wert einen Ausrei�er darstellt, wenn er nicht in das Intervall x�4sf�allt, wobei x und s ohne den fraglichen Ausrei�erwert berechnet werden m�ussen. BeiAnnahme einer Normalverteilung umfa�t der 4�-Bereich [�� 4�; �+ 4�] 99:99% allerWerte. Das Auftreten einer Beobachtung au�erhalb dieses Intervalls ist also mit 0:01%Wahrscheinlichkeit so unwahrscheinlich, da� man vern�unftigerweise annehmen kann, erstammt aus einer anderen Grundgesamtheit.
F�ur Stichproben bis zum Umfang 25 hat Dixon ein Testverfahren vorgeschlagen, dasje nach Stichprobenumfang verschiedene Testgr�o�en emp�ehlt. Zur Herleitung diesesVerfahrens ben�otigt man sog. Ordnungsstatistiken (engl. order statistics), deren Be-handlung den Rahmen dieser Einf�uhrung sprengen w�urde. Unter einer Ordnungsstati-stik versteht man beispielsweise die Verteilung der Spannweite, also der Di�erenz zwi-schen gr�o�ter und kleinster Beobachtung. Um das Verfahren von Dixon zu beschreiben,wird davon ausgegangen, da� die Stichprobenwerte der Gr�o�e nach geordnet vorliegen,also:
x1 � x2 � : : : � xn oder x1 � x2 � : : : � xn
Man bildet nun die absolute Di�erenz des fraglichen Ausrei�ers x1 (also des gr�o�tenoder kleinsten Werts) je nach Stichprobenumfang mit seinen Nachbarwerten x2 oderx3 und bezieht diese Di�erenz auf die Spannweite jx1 � xnj bzw. auf jx1 � xn�1j oderjx1 � xn�2j. Tab. 6.165 zeigt die je nach Stichprobenumfang n zu verwendende Test-gr�o�e. �Uberschreitet der Wert der Testgr�o�e die angegebenen Testschranken, so wirdder fragliche Wert auf dem entsprechenden Signi�kanzniveau als Ausrei�er angesehen.
5Dixon W.J. 1953: Processing data for outliers, Biometrics 9, 74{89.

6.7 Test auf Ausrei�er 265
n � = 0:10 � = 0:05 � = 0:01 Testgr�o�e����x1 � x2
x1 � xn
����3 0:886 0:941 0:9884 0:679 0:765 0:8895 0:557 0:642 0:7806 0:482 0:560 0:6987 0:434 0:477 0:597 ���� x1 � x2
x1 � xn�1
����8 0:497 0:554 0:6839 0:441 0:512 0:63510 0:409 0:477 0:597 ���� x1 � x3
x1 � xn�1
����11 0:517 0:576 0:67912 0:490 0:546 0:64213 0:467 0:521 0:615 ���� x1 � x3
x1 � xn�2
����14 0:492 0:546 0:64115 0:472 0:525 0:61616 0:454 0:507 0:59517 0:438 0:490 0:57718 0:424 0:475 0:56119 0:412 0:462 0:54720 0:401 0:450 0:53521 0:391 0:440 0:52422 0:382 0:430 0:51423 0:374 0:421 0:50524 0:367 0:413 0:49725 0:360 0:406 0:489
Tabelle 6.16: Signi�kanzschranken beim Dixon-Ausrei�ertest
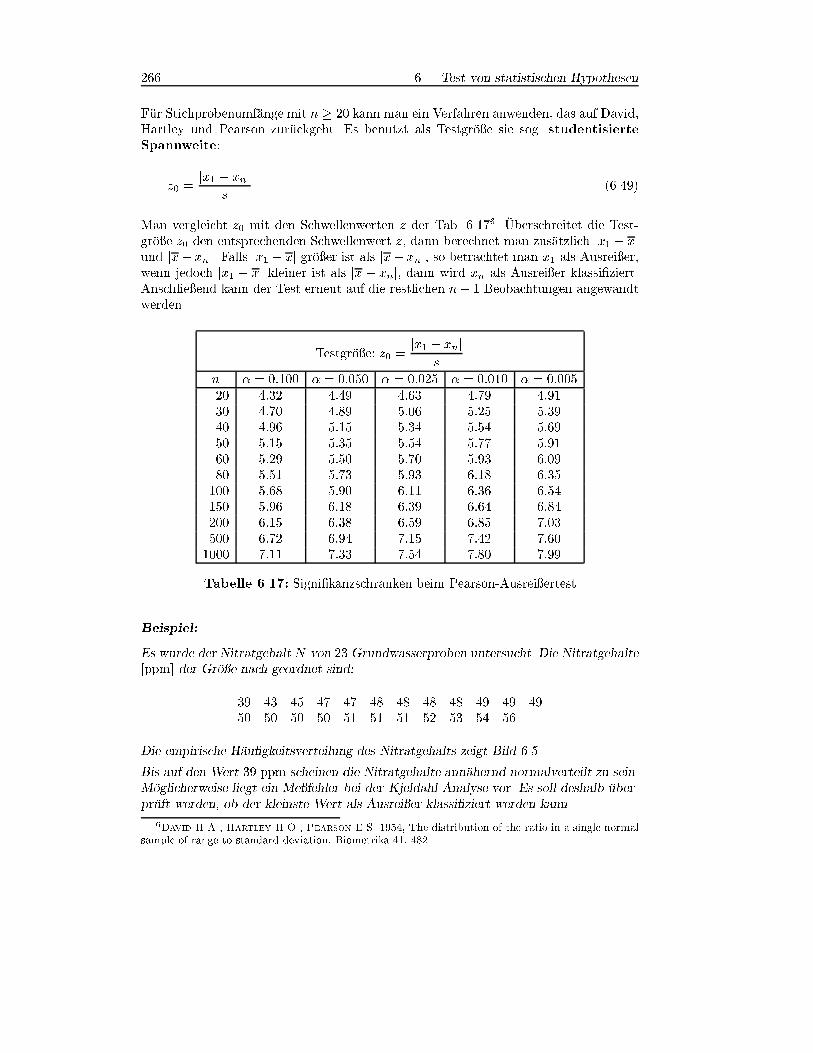
266 6 Test von statistischen Hypothesen
F�ur Stichprobenumf�ange mit n � 20 kann man ein Verfahren anwenden, das auf David,Hartley und Pearson zur�uckgeht. Es benutzt als Testgr�o�e sie sog. studentisierteSpannweite:
z0 =jx1 � xnj
s(6.49)
Man vergleicht z0 mit den Schwellenwerten z der Tab. 6.176. �Uberschreitet die Test-gr�o�e z0 den entsprechenden Schwellenwert z, dann berechnet man zus�atzlich jx1 � xjund jx� xnj. Falls jx1 � xj gr�o�er ist als jx� xnj, so betrachtet man x1 als Ausrei�er,wenn jedoch jx1 � xj kleiner ist als jx � xnj, dann wird xn als Ausrei�er klassi�ziert.Anschlie�end kann der Test erneut auf die restlichen n� 1 Beobachtungen angewandtwerden.
Testgr�o�e: z0 =jx1 � xnj
s
n � = 0:100 � = 0:050 � = 0:025 � = 0:010 � = 0:005
20 4:32 4:49 4:63 4:79 4:9130 4:70 4:89 5:06 5:25 5:3940 4:96 5:15 5:34 5:54 5:6950 5:15 5:35 5:54 5:77 5:9160 5:29 5:50 5:70 5:93 6:0980 5:51 5:73 5:93 6:18 6:35100 5:68 5:90 6:11 6:36 6:54150 5:96 6:18 6:39 6:64 6:84200 6:15 6:38 6:59 6:85 7:03500 6:72 6:94 7:15 7:42 7:601000 7:11 7:33 7:54 7:80 7:99
Tabelle 6.17: Signi�kanzschranken beim Pearson-Ausrei�ertest
Beispiel:
Es wurde der Nitratgehalt N von 23 Grundwasserproben untersucht. Die Nitratgehalte[ppm] der Gr�o�e nach geordnet sind:
39 43 45 47 47 48 48 48 48 49 49 4950 50 50 50 51 51 51 52 53 54 56
Die empirische H�au�gkeitsverteilung des Nitratgehalts zeigt Bild 6.5.
Bis auf den Wert 39 ppm scheinen die Nitratgehalte ann�ahernd normalverteilt zu sein.
M�oglicherweise liegt ein Me�fehler bei der Kjeldahl-Analyse vor. Es soll deshalb �uber-
pr�uft werden, ob der kleinste Wert als Ausrei�er klassi�ziert werden kann.
6David H.A., Hartley H.O., Pearson E.S. 1954, The distribution of the ratio in a single normal
sample of range to standard deviation, Biometrika 41, 482.

6.7 Test auf Ausrei�er 267
56545250484644424038
7
6
5
4
3
2
1
0
Nitratgehalt [ppm]H
äu
figke
it
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAA
56545250484644424038
7
6
5
4
3
2
1
0
Nitratgehalt [ppm]H
äu
figke
it
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAA
Bild 6.5: H�au�gkeitsverteilung des Nitratgehalts im Grundwasser
Mittelwert und Standardabweichung der Stichprobe sind N = 49:0 ppm und sN =3:56 ppm. Mittelwert und Standardabweichung der Stichprobe ohne den Ausrei�erwert
sind N0
= 49:5 ppm und sN 0 = 2:87 ppm.
Das Intervall N0 � 4sN 0 ist [38; 61]. Darin ist der Wert 39 enthalten und gilt demnach
nicht als Ausrei�er.
Der sch�arfere Test nach Dixon hat als Testgr�o�e bei einem Stichprobenumfang von
n = 23 die Testgr�o�e
���� N1 �N3
N1 �N21
���� =����39� 45
39� 53
���� = 0:429. Dieser Wert �uberschreitet die
Signi�kanzschranke 0:421 bei � = 0:05 und n = 23 in Tab. 6.16 und gilt deshalb auf
dem 5%-Signi�kanzniveau als Ausrei�er.
Der Test nach Pearson hat die Testgr�o�e z0 =jN1 �Nnj
sN=j39� 56j3:56
= 4:78. Der
Schwellenwert bei n = 23 und � = 0:05mu� aus Tab. 6.17 durch Interpolation gesch�atzt
werden. Er ergibt sich zu 4:49 + 3 � 4:89� 4:49
10= 4:61. Die Testgr�o�e ist gr�o�er als
dieser Wert, deshalb liegt entweder ein Ausrei�er von 39 ppm oder von 56 ppm vor.
Dies �uberpr�uft man durch den Vergleich von jN1 �N j = 10:04 mit jN �Nnj = 6:96.Die erste Di�erenz ist gr�o�er als die zweite. Der Ausrei�er ist also der Wert 39 ppm.
Die Anwendung des Tests auf die restlichen Stichprobenwerte liefert keinen weiteren
Ausrei�er.

268 6 Test von statistischen Hypothesen
6.8 Test der Normalverteilung
In Abschnitt 6.6.1 wurde bereits der �2-Test f�ur beliebige Verteilungsfunktionen vor-gestellt, mit dem nat�urlich auch die Hypothese der Normalverteilung �uberpr�uft werdenkann.
Ein visueller Test der Normalverteilung ist durch die Auftragung des Histogramms derStichprobenwerte m�oglich. Wenn dieses stark von einer Glockenkurve abweicht, beste-hen Zweifel an der Normalverteilung der Grundgesamtheit. Dies dr�uckt sich auch ineiner o�ensichtlichen Abweichung der Summenh�au�gkeiten im Wahrscheinlichkeitspa-pier (vgl. Kap. 3.1.2) oder im Quantil-Quantil-Plot aus (vgl. Kap. 3.1.5). Aufbauend aufdiesen Darstellungen der Summenh�au�gkeiten oder den Quantils- bzw. Normalwertenals Geraden existiert ein m�achtiger Test, der unter dem Namen Shapiro-Wilk-Test
bekannt ist.
In einem Quantil-Quantil-Plot tr�agt man die der Gr�o�e nach geordneten Stichproben-werte x(i)
7 gegen die entsprechenden Quantilswerte u(i) der Standardnormalverteilung,Normalwerte oder normal scores genannt, auf. Stammt die Stichprobe aus einerNormalverteilung, dann liegen die Werte ann�ahernd auf einer Geraden. Die Berechnungder Quantilswerte verl�auft bei n Werten nach folgenden Regeln. Dem i-ten kleinsten
Wert wird jeweils der Normalwert u(i) = ��1�i� 3=8
n+ 1=4
�zugeordnet. Dabei ist ��1
die Inverse der Standardnormalverteilungsfunktion und n der Stichprobenumfang. DieStandardnormalverteilung kann durch ��1(K%) = 4:91 � (((K%)0:14)� ((1�K%)0:14))approximiert werden. Falls mehrere Werte gleich sind, wird ihnen jeweils derselbe mitt-lere normal score zugeteilt.
Die G�ute der linearen Ann�aherung wird nach Kap. 1.3.2 durch den Korrelationskoe�-zienten gemessen. Es bietet sich daher an, diesen zwischen den Stichprobenwerten undderen normal scores zu berechnen, um die Normalverteilung zu �uberpr�ufen. Wenn dieKorrelation nahe bei 1 ist (negative Korrelationen sind wegen der gr�o�enm�a�igen Ord-nung ausgeschlossen), dann ist eine Normalverteilung nicht von der Hand zu weisen, beiexakter Normalverteilung h�atte man genau eine Gerade im Wahrscheinlichkeitsplot. Jemehr der Graph im Quantil-Quantil-Plot von einer Geraden abweicht, desto gr�o�er istdie Abweichung von der Normalverteilung. Das hei�t, wenn der Korrelationskoe�zientdeutlich kleiner als 1 ist, sind die Residuen nicht normalverteilt. Die Hypothese derNormalverteilung wird verworfen, wenn der berechnete Korrelationkoe�zient r die inAnhangstabelle A.9 aufgef�uhrten kritischen Werte rkrit: unterschreitet.
Beispiele:
1. Die Milchleistungen aus Tab. 1.8 wurden bereits in Bild 3.11 des Beispiels auf Seite
145 als Quantil-Quantil-Plot dargestellt. Eine Berechnung des Korrelationskoe�zi-
enten zwischen den Stichprobenwerten und den normal scores mit MINITAB bringt
folgendes Ergebnis:
MTB >correlation 'Milch' 'Quantil'
Correlation of Milch and Quantil = 0.995
7der geklammerte Index deutet auf die gr�o�enm�a�ige Ordnung hin.

6.8 Test der Normalverteilung 269
Aus Tab. A.9 liest man f�ur n = 100 und � = 10% einen kritischen Wert von
rkrit: = 0:9898 ab. Der berechnete Korrelationskoe�zient von r = 0:995 ist also
gr�o�er als der kritische Wert. Die Hypothese der Normalverteilung kann also auf
10% Signi�kanzniveau nicht abgelehnt werden.
2. InMINITAB existiert auch ein Makro8 normplotmit dem Unterkommando swtest
zur Durchf�uhrung des Shapiro-Wilk-Tests. Mit diesem werden nun die Milchleistun-
gen aus Tab. A.10 im Anhang getestet. Die Dateneingabe ist in Kap. 1.6 beschrie-
ben.
MTB > %normplot 'ML(kg)';
SUBC> swtest.
Bild 6.6 zeigt den Quantil-Quantil-Plot und das Testergebnis. Aufgrund des p-Werts
von 0:0476 kann die Hypothese der Normalverteilung auf � = 5% abgelehnt werden.
Vergleicht man das zweigip ige Histogramm der Milchleistungen in Bild 1.30 mit
dem Quantil-Quantil-Plot in Bild 6.6, so dr�uckt sich der linke Gipfel in einer Ab-
weichung unterhalb der Geraden und der rechte Gipfel in einer Abweichung ober-
halb der Geraden aus. Es ist o�ensichtlich, da� hier nicht von einer normalver-
teilten Grundgesamtheit auszugehen ist. Die Zweigip igkeit resultiert daraus, da�
die Stichprobe aus verschiedenen Rassen mit normalverteilten Milchleisungen aber
unterschiedlichen Mittelwerten besteht (vgl. Kap. 1.6).
p value (approx): 0.0476R: 0.9816W-test for Normality
N of data: 120Std Dev: 722.639Average: 5512.96
7000600050004000
.999
.99
.95
.80
.50
.20
.05
.01
.001
Pro
babi
lity
ML(kg)
Normal Probability Plot
p value (approx): 0.0476R: 0.9816W-test for Normality
N of data: 120Std Dev: 722.639Average: 5512.96
7000600050004000
.999
.99
.95
.80
.50
.20
.05
.01
.001
Pro
babi
lity
ML(kg)
Normal Probability Plot
Bild 6.6: Quantil-Quantil-Plot und Shapiro-Wilk-Test der Milchleistungen aus Tab.A.10
8Ein Makro ist eine Folge von Befehlen, die in einer eigenen Datei abgespeichert sind und bei Aufruf
des Makros abgearbeitet werden. In MINITAB haben Makros die Dateierweiterung .MAC. Ihr Aufruf
erfolgt durch ein vorangestelltes %-Zeichen.

270 6 Test von statistischen Hypothesen
Ein Wahrscheinlichkeitsplot der Normalwerte w�urde �ubrigens exakt eine Gerade erge-ben und die Korrelation w�are genau 1.

6.9 Versuchsplanung und Stichprobenumfang 271
6.9 Versuchsplanung und Stichprobenumfang
Vor der Durchf�uhrung eines Experiments mu� sich der Versuchsansteller die Versuchs-frage und das statistische Ziel �uberlegen. Die Versuchsfrage wird in Form der Nullhy-pothese H0 und der Alternativhypothese H1 formuliert. Formal will man in der Regeldie Nullhypothese ablehnen und die Alternativhypothese annehmen. Dies geschiehtvor allem aus Gr�unden der Interpretation eines statistischen Tests. Die Ablehnung derNullhypothese ist statistisch aussagekr�aftiger als ihre Nichtablehnung. Meistens wirdalso der angestrebte Test als Test auf Unterschied formuliert. Das bedeutet, dieNullhypothese H0 lautet z.B. auf Gleichheit von zwei Methoden oder zwei Mitteln. DieAlternative H1 behauptet, da� sich die beiden Methoden oder Mittel unterscheiden.Grunds�atzlich ist auch ein Test m�oglich, bei dem man die Rollen von H0 und H1 ver-tauscht und einen Test auf Gleichheit oder �Aquivalenz von zwei Methoden durchf�uhrt.Ein solcher Test wird �Aquivalenztest genannt. In diesem Fall wird man die Nullhy-pothese so formulieren: Die beiden Methoden oder Behandlungsmittel unterscheidensich mindestens um einen bestimmten Betrag �. Die entsprechende Alternative H1 istdazu komplement�ar und lautet: Die beiden Methoden oder Behandlungsmittel unter-scheiden sich um weniger als � voneinander, sind also aus sachlogischer Beurteilungdes Problems heraus als �aquivalent oder bio�aquivalent anzusehen.
Beim statistischen Test auf Unterschied, der bisher behandelt wurde, lauten die Tes-thypothesen also:
H0 : �1 = �2 bzw. Behandlungsmittel 1 = Behandlungsmittel 2H1 : �1 6= �2 bzw. Behandlungsmittel 1 6= Behandlungsmittel 2
(6.50)
Der Wert f�ur die Irrtumswahrscheinlichkeit oder das Niveau � wird z.B. auf 5% fest-gelegt. Nichtablehnung von H0 bedeutet nicht, da� H0 mit Wahrscheinlichkeit 1 � �
statistisch gesichert ist. Man kann lediglich festhalten, da� die Stichprobendaten derNullhypothese nicht widersprechen. Ablehnung der Nullhypothese H0 stellt eine ArtUmkehrschlu� dar, n�amlich da� das beobachtete Ergebnis unter der Annahme von H0
so unwahrscheinlich ist, genau mit Wahrscheinlichkeit �, da� H0 falsch sein mu� unddie Alternative H1 angenommen wird. Eine Ablehnung von H0 auf dem Niveau � be-sagt, da�H1 mit einer Irrtumswahrscheinlichkeit von � angenommen wird, und da� mitder Erfolgswahrscheinlichkeit 1 � �, auch Macht oder Power des Tests genannt, eintats�achlich vorhandener Unterschied bei diesem Testverfahren auch entdeckt wird. DerFehler zweiter Art � h�angt dabei von der wahren, unbekannten Di�erenz D = �1 � �2ab.
F�uhrt man einen �Aquivalenztest durch, werden die Testhypothesen folgenderma�enformuliert:
H0 : j�1 � �2j � �H1 : j�1 � �2j < �
(6.51)
� ist eine fest gew�ahlte Grenze. Es soll hier nicht n�aher auf die praktische Durchf�uhrungeines solchen �Aquivalenztests eingegangen, denn man ben�otigt f�ur die Berechnung einer

272 6 Test von statistischen Hypothesen
entsprechenden Testgr�o�e eine nichtzentrale Verteilung, d.h. der Mittelwert der Test-gr�o�e ist ungleich Null. Dies erschwert die numerische Berechnung. Mit entsprechendenComputerprogrammen stellt diese umgekehrte Form des Testens aber prinzipiell keineSchwierigkeit dar. Es wird beispielsweise auf das Programm TESTIMATE der FirmaIDV verwiesen9.
Um z.B. einen statistischen Test auf Unterschied durchzuf�uhren, ist es sinnvoll, eineArt Versuchsplan aufzustellen, in dem neben dem Niveau � festgelegt wird, welcherUnterschied mit welcher Wahrscheinlichkeit bzw. Macht 1 � � entdeckt werden sollund welcher Stichprobenumfang dazu notwendig ist. In der Regel wird man folgender-ma�en vorgehen: Man formuliert zun�achst die Testhypothesen H0 sowie H1 und legtden biologisch oder �okonomisch relevanten Unterschied � bzw. den �Aquiva-
lenzbetrag � fest. Anschlie�end w�ahlt man das Signi�kanzniveau � sowie die Machtdes statistischen Tests 1 � �, mit der eine Di�erenz � nachgewiesen werden soll odermit der eine �Aquivalenz innerhalb der Grenze � bewiesen werden soll. Mit diesenVorgaben erfolgt die Berechnung des dazu notwendigen Stichprobenumfangs n. Beimeinfachen t-Test beispielsweise sind die Gr�o�en Stichprobenumfang n, Fehler 1. und 2.Art � bzw. � sowie der relevante Unterschied � = �1 � �2 und die Varianz �2 bzw.ein Sch�atzwert s2 durch die Beziehungen (6.7) und (6.8) festgelegt, je nachdem, ob essich um eine ein- oder zweiseitige Fragestellung handelt. Im Prinzip kann man darauseine gesuchte Gr�o�e, z.B. den notwendigen Mindeststichprobenumfang n, ausrechnen,wenn man die anderen Gr�o�en festlegt. Die Gleichungen (6.7) und (6.8) kann man zwarnicht explizit nach n au �osen, aber mit einem entsprechenden iterativen Verfahren las-sen sich die L�osungen bestimmen. Es gibt Computerprogramme, z.B. die ProgrammeN10, STPLAN11 oder PLANUNG12, welche etwa den notwendigen Stichprobenumfangf�ur viele Versuchssituationen (Me�daten, Ereignisdaten, verbundene oder unabh�angigeStichproben, Test auf Unterschied oder �Aquivalenztest) ausrechnen.
Nachfolgend werden m�ogliche Versuchsplanungen mit Hilfe des Programms N anhanddreier Beispiele durchgef�uhrt.
9TESTIMATE. IDV Datenanalyse und Versuchsplanung, Gauting 199010N. IDV Datenanalyse und Versuchsplanung, Gauting 198711STPLAN. Fortran-Programm der University of Texas Systems Cancer Center, Houston, Texas
198012PLANUNG. APL-Programm des Deutschen Krebsforschungszentrums, Heidelberg 1985

6.9 Versuchsplanung und Stichprobenumfang 273
Nach dem Aufruf von N und der Eingabe des Versuchsnamens (in diesem Fall Milch-fett), -merkmals, -datums usw. gelangt man in folgendes Men�u:
Hier legt man die Art des Versuchs und die Form der Hypothesen fest. M�oglich istein Versuch mit normalverteilten Me�daten (z.B. Milchfettgehalt, Gewicht) oder bino-mialverteilten Ergebnisdaten, d.h. Bin�ardaten mit zwei Auspr�agungen (z.B. M�unzwurfoder Tre�erergebnis). Man gibt an, ob man eine Gruppe gegen einen festen Wert testenm�ochte oder ob man zwei Gruppen gegeneinander testet, wobei man dann zwischenverbundenem und unverbundenem Test w�ahlen kann. Schlie�lich legt man die Formdes gew�unschten Tests und der Hypothesen, Test auf Unterschied oder �Aquivalenz-test, zweiseitig oder einseitig, fest. Will man z.B. den Milchfettgehalt von K�uhen miteinem einseitigen Test auf Unterschied einer Gruppe (Test) gegen einen festen Wert(Standard) testen und geht au�erdem von normalverteilten Me�daten aus, so stelltman im folgenden Men�u die gew�unschte Parameterkonstellation ein. Der Test soll z.B.gegen einen festen Wert, n�amlich gegen Standard = 3.67 [%] durchgef�uhrt werden.Es soll bei dem Test bereits eine sehr kleine Abweichung (Diff) nach unten um we-nigstens � = 0:02% Milchfettgehalt mit vern�unftiger Erfolgswahrscheinlichkeit 1 � �
und Irrtumswahrscheinlichkeit � erkannt werden, z.B. � = 5% und � = 10%. Mangibt in das Men�u folgende Werte ein: Standard = 3.67 und die praktische relevanteDi�erenz Diff = - 0.02. Der Wert f�ur Test (Test = 3.65) wird daraus automatischberechnet. Ebensogut k�onnte man den Standardwert und den Testwert vorgeben, dannergibt sich die zu erkennende Di�erenz von selbst. Es kommt letztlich nur auf den Wertder Di�erenz Diff an. Das Vorzeichen der Di�erenz gibt die Richtung des einseitigenTests an. Man gibt weiter die Standardabweichung (Sigma) bzw. einen entsprechendenSch�atzer an und w�ahlt das gew�unschte Signi�kanzniveau bzw. den Fehler 1.Art, z.B.� = 0:05, sowie die gew�unschte Macht 1 � � des Tests bzw. den Fehler 2.Art, z.B.� = 0:1. Die Stichprobengr�o�e N wird als Zielgr�o�e festgelegt (Funktionstaste F3). Star-tet man die Berechnungen (F4-Taste), dann erscheint im Feld N nach kurzer Zeit dieStichprobengr�o�e n = 175. Es m�ussen in diesem Beispiel also mindestens 175 Gemelkeuntersucht werden, um auf dem 5%-Niveau mit 90%-iger Erfolgswahrscheinlichkeit eineAbweichung nach unten von mindestens 0:02% Milchfettgehalt zu erkennen.
274 6 Test von statistischen Hypothesen
Mit der Funktionstaste F5 kann man sich die berechneten Ergebnisse etwas detaillierterauf eine Datei (mit F6 auf einen Drucker) ausgeben lassen. Der Ergebnisausdruck istweitgehend selbstbeschreibend. Zus�atzlich zu dem berechneten notwendigen Stichpro-benumfang n wird der kritische Wert f�ur den t-Test und eine Tabelle zur Operations-charakteristik ausgegeben.

6.9 Versuchsplanung und Stichprobenumfang 275
Der kritische Wert besagt: Wenn die Testgr�o�e gr�o�er als �1:654 ist, so kann manschlie�en, da� ein Unterschied von (mindestens) �0:02% Fettgehalt vorhanden ist. DerTestwert weicht also um mindestens 0:02% nach unten vom Standardwert 3:67% ab.Au�erdem wird die sogenannte Operationscharakteristik bzw. die OC-Kurve aus-gegeben. Die OC-Kurve beschreibt den Zusammenhang zwischen der wahren Di�erenzD von Test und Standard und der Wahrscheinlichkeit, diesen Unterschied zu �ubersehen,also dem �-Fehler. OC entspricht diesem Fehler 2. Art �. Aus dem Zusammenhang vonD und � l�a�t sich folgern, da� je gr�o�er die wahre Di�erenz zwischen dem Mittelwertund dem Testwert ist, desto kleiner ist die Wahrscheinlichkeit, diesen Unterschied zu
�ubersehen. Eine Di�erenz von 0:034 und gr�o�er wird praktisch immer, also mit 100%-iger Erfolgswahrscheinlichkeit, aufgedeckt. Umgekehrt ist die Wahrscheinlichkeit, einekleine Di�erenz zu �ubersehen, entsprechend hoch. Gem�a� dem Bildschirmergebnis wirdein Unterschied von 0:02 bzw. �0:02 mit 90%-iger Wahrscheinlichkeit erkannt, d.h.� = 0:1.
Es wird nun davon ausgegangen, da� eine Stichprobengr�o�e von n = 55 vorgegebenist. Um den Fehler 2. Art bei dieser Stichprobengr�o�e zu errechnen, wird das FeldFehler 2.Art als Ziel markiert (F3), die Stichprobengr�o�e N = 55 eingetragen undder Programmablauf neu gestartet (F4).

276 6 Test von statistischen Hypothesen
Es wird ein �-Fehler von 0:507 errechnet. Das bedeutet, da� bei einer Stichproben-gr�o�e von n = 55 die Erfolgswahrscheinlichkeit, eine Di�erenz von �0:02% wirklich zuerkennen, bei nur 49:3% liegt. Der Fehler, eine solche Di�erenz zu �ubersehen, ist alsosehr hoch.
Bemerkungen (siehe auch Handbuch zu N)
� Diff ist nicht die tats�achliche Di�erenz der Mittelwerte, sondern die relevante, d.h.die f�ur den Versuchsansteller relevante Di�erenz �, die mit einer Erfolgswahrschein-lichkeit von mindestens 1�� erkannt werden soll. Die jeweilige Gr�o�e der Abweichungh�angt von sachlogischen und inhaltlichen Kriterien ab, im allgemeinen wird man dieDi�erenz in der Gr�o�enordnung der Standardabweichung w�ahlen. Als Anhaltswertf�ur die relevante Di�erenz dient auch der von Cohen13 vorgeschlagene Bewertungs-ma�stab f�ur die sogenannte standardisierte Di�erenz, das ist der Quotient ausder Di�erenz Diff und der Standardabweichung Sigma:
Diff/Sigma � 0:2: kleiner UnterschiedDiff/Sigma � 0:5: mittlerer UnterschiedDiff/Sigma � 0:8: gro�er Unterschied
� F�ur die Standardabweichung Sigma wird auf einen empirischen Erfahrungswert oderSch�atzwert zur�uckgegri�en. Da er aber in jedem Fall als bekannt vorausgesetzt wird,ist die Berechnung der Standardabweichung als Zielgr�o�e mit dem ProgrammN nichtm�oglich.
� Das Signi�kanzniveau � wird in der Biostatistik meist auf 0:1%, 1%, 5% oder 10%festgesetzt. Es sind jedoch auch beliebige andere, insbesondere gr�o�ere Werte m�og-lich. Der Fehler 2. Art � wird auch vom Versuchsansteller de�niert, wobei � = 0:2schon als vern�unftige Wahl, � = 0:1 jedoch als w�unschenswert gilt. Ein Fehler 2.Art von 10% entspricht einer Macht von 90%. Das bedeutet, bei 10 durchgef�uhrten
13Cohen J. 1977: Statistical Power Analysis for the Behavioral Sciences (Revised Edition). Academic
Press, Inc., London.

6.9 Versuchsplanung und Stichprobenumfang 277
Studien wird bei 9 Studien ein Unterschied bestimmter Gr�o�e auch tats�achlich auf-gedeckt. Stets mu� die Beziehung �+� < 1 erf�ullt sein, wobei � in der Regel kleinerals � gew�ahlt wird. Es gibt verschiedene Faustregeln f�ur die gemeinsame Festlegungvon � und �, auf die anschlie�end noch eingegangen wird.
� Das Programm N macht es m�oglich, bei Vorgabe der anderen Parameter des ge-w�unschten Tests eine beliebige andere Zielgr�o�e zu de�nieren. So kann man z.B.die Stichprobengr�o�e festlegen und (bei sonst gleichen Werten) den Fehler 2. Artberechnen oder beides vorgeben und die relevante Di�erenz ausrechnen lassen usw.
� Bei einem �Aquivalenztest wird Diff (�) durch die vorgegebene Schranke Delta (�)ersetzt. Die Fehlerwahrscheinlichkeiten kehren sich entsprechend um.
Mit Hilfe von N soll untersucht werden, wie gro� das Risiko ist, die Wirkung einesblutdrucksenkenden Mittels zu �ubersehen 14, d.h. eine durchaus relevante Senkung von5 mm Hg gegen�uber der Kontrollgruppe nicht zu erkennen. Dabei stehen pro Gruppe 15Versuchstiere zur Verf�ugung. Die Standardabweichung betr�agt erfahrungsgem�a� � =10 mm Hg. Das Signi�kanzniveau wird auf � = 5% festgesetzt. Da eine Erh�ohung desBlutdrucks ausgeschlossen werden kann, wird einseitig getestet. Die Zielgr�o�e ist derFehler 2. Art. Nach Einsetzen dieser Vorgaben errechnet N ein Risiko von � = 0:621.
Das Ergebnis zeigt, da� die Wahrscheinlichkeit, eine blutdrucksenkende Wirkung vonmindestens 5 mm Hg zu erkennen, nur etwa 38% betr�agt. Das ist i.a. zu wenig, um inder Pharmakologie vorhandene E�ekte aufzudecken. In diesem Fall emp�ehlt sich einesog. �-Adjustierung, d.h. man w�ahlt ein \vern�unftiges\ Risiko 2. Art und adjustiertden Fehler 1. Art entsprechend. Man �andert die Versuchsparameter so ab, da� dieWahrscheinlichkeit, relevante Wirkungen zu �ubersehen, also der Fehler 2. Art, nun aufz.B. vertretbare 10% festgesetzt wird und der Fehler 1. Art zur neuen Zielgr�o�e wird(F3).
14vgl. Beispiel im N-Handbuch S. 66

278 6 Test von statistischen Hypothesen
N errechnet nun eine sehr hohe Irrtumswahrscheinlichkeit � = 0:465. Es bleibt demVersuchsansteller �uberlassen, ob er dieses hohe Risiko akzeptiert. Wenn nicht, bleibtnur die M�oglichkeit, den Stichprobenumfang zu erh�ohen, um bei gleicher Macht eineniedrigere Irrtumswahrscheinlichkeit zu erzielen. Wird etwa ein �-Niveau von 20% ge-fordert, dann m�ussen wenigstens 74 Tiere, 37 je Gruppe bei gleicher Stichprobengr�o�e,untersucht werden, um mit 90%-iger Wahrscheinlichkeit relevante Wirkungen aufzu-decken. Zur Berechnung wurde dazu der Fehler 1. Art auf 0:2 und der Fehler 2. Artauf 0:1 festgesetzt. Zielgr�o�e ist jetzt der Stichprobenumfang der beiden Gruppen. DasVerh�altnis der Stichprobengr�o�en N1/N2 soll 1 sein.
Bemerkungen
� Bei verbundenen Me�reihen ist neben der Standardabweichung Sigma auch der Kor-relationskoe�zient Rho anzugeben. Wie bei der Standardabweichung wird er als be-kannt vorausgesetzt, wobei auf einen empirischen Erfahrungswert oder Sch�atzwertzur�uckgegri�en wird.

6.9 Versuchsplanung und Stichprobenumfang 279
� Bei unterschiedlich gro�en Stichprobenumf�angen kann man entweder beide Gr�o�enN1 und N2 angeben, das Verh�altnis N1/N2 ergibt sich dann von selbst, oder man gibteine Gr�o�e und das Verh�altnis vor, dann ergibt sich der zweite Stichprobenumfangautomatisch. Bei gleichen Stichprobengr�o�en betr�agt das Verh�altnis 1/1.
Als abschlie�endes Beispiel soll der Wurf einer M�unze15 betrachtet werden. Beim M�unz-wurf besteht der Verdacht, da� die M�unze nicht symmetrisch ist. Es stellt sich die Frage,wie oft man die M�unze werfen mu�, um diesen Verdacht zu erh�arten. Die Nullhypo-these eines entsprechenden statistischen Tests lautet: H0 : P = 0:5, die AlternativeH1 : P 6= 0:5. Die M�unze soll als asymmetrisch gelten, wenn die Wahrscheinlichkeit Pf�ur eine Seite, Kopf oder Zahl, um mindestens 10% vom Standardwert 0:5 abweicht,der Testwert ist also 0:45 oder 0:55. Man formuliert einen zweiseitigen Test auf Unter-schied des Standards gegen einen festen Testwert mit binomialverteilten Ereignisdaten.Die Irrtumswahrscheinlichkeit � soll auf 5% festgesetzt werden, d.h. in 95% der F�allesoll eine symmetrische M�unze auch als symmetrisch erkannt werden. Die Abweichungvon 10% vom Standardwert P = 0:5 soll mit einer Wahrscheinlichkeit von 90% erkanntwerden, d.h. der Fehler 2. Art wird auf � = 0:1 festgesetzt. Das Zielfeld ist die Stich-probengr�o�e N. Nach Eintrag aller Parameterwerte und Berechnung des Programmsergibt sich folgendes Bild:
Man mu� die M�unze also mindestens 1055 mal werfen, um mit 90%-iger Erfolgswahr-scheinlichkeit eine Abweichung von 10% vom symmetrischen Standardwert zu erkennen.
Bemerkungen
� Der Fehler 1. Art wurde auf 5% festgelegt und hat sich nach den Berechnungen zu � =0:049 ge�andert. Da es sich um diskrete Ergebnisdaten handelt, ist die Bedingung � =0:05 nicht exakt erf�ullbar. Das Programm N w�ahlt daher den n�achstkleineren Wertf�ur �. Solche Spr�unge k�onnen f�ur binomialverteilte Daten bei �, � oder bei beidenGr�o�en auftreten. Im Ergebnisausdruck hei�t der vom Benutzer eingestellte Fehler1. Art nominelles und der von N berechnete Alpha-Fehler exaktes �-Risiko.
15vgl. Beispiel im N-Handbuch S. 12

280 6 Test von statistischen Hypothesen
� Im obigen Men�u wurde eine Abweichung nach oben von +0:05 (Testwert 0:55)gew�ahlt. Durch die Symmetrie der Binomialverteilung f�uhrt eine Abweichung nachunten von �0:05, also ein Testwert von 0:45, zu v�ollig identischen Ergebnissen.
Der verk�urzte Ergebnisausdruck sieht folgenderma�en aus:
Die angegebene Testentscheidung zeigt die kritischen Tre�erzahlen. Be�ndet sich dieAnzahl von Kopf (bzw. Zahl) bei n = 1055 W�urfen zwischen 496 und 559, dann kanndie Symmetrie der M�unze nicht abgelehnt werden. Unter- oder �uberschreitet die Anzahlvon Kopf (bzw. Zahl) die kritischen Tre�erzahlen, dann kann man mit einer Irrtums-wahrscheinlichkeit von � = 5% bzw. 4:9% und einer Erfolgswahrscheinlichkeit von1 � � = 90% annehmen, da� die M�unze nicht symmetrisch ist. Die OC-Kurve zeigt,da� es praktisch unm�oglich ist, d.h. das Risiko liegt nur bei � = 0:001, eine vergleichs-weise gro�e Di�erenz von 0:08 zu �ubersehen, w�ahrend man eine kleine Abweichung vonz.B. 0:01 doch in etwa 9 von 10 F�allen �ubersieht.

6.9 Versuchsplanung und Stichprobenumfang 281
Festlegung der Risiken � und �
Bei der Versuchsplanung und Vorbereitung eines statistischen Tests spielt neben demStichprobenumfang die Festlegung der beiden Risiken � und � eine wichtige Rolle. Eswurde bisher in der Regel von einem Wert 0:05 bzw. 5% f�ur das Signi�kanzniveau �
ausgegangen. In Abh�angigkeit von der Versuchsfrage und dem Ziel der Untersuchungkann man auch andere Werte f�ur � akzeptieren. Man unterscheidet verschiedene Stra-tegien, je nachdem ob man Pr�ufglieder entdecken m�ochte, die sich unterscheiden odernicht unterscheiden. Es kommt also durchaus darauf an, von welchem Blickwinkel derTest durchgef�uhrt werden soll. Man kann mit einer Kritiker-Strategie oder mit einerEntdecker-Strategie an die Versuchsplanung herangehen (vgl. CADEMO16). Ver-folgt man bei einem Test auf Unterschied eine Entdecker-Strategie f�ur die Alternativ-hypothese (also Unterschied), so akzeptiert man ein gr�o�eres �-Risiko und m�ochte einkleineres �-Risiko eingehen, z.B. � = 25% und � = 5% : : : 10%. Der Versuchsanstellerm�ochte also keine unterschiedlichen Pr�ufglieder �ubersehen und nimmt daf�ur ein h�oheresRisiko in Kauf, irrt�umlich zwei gleiche Pr�ufglieder als unterschiedlich zu erkl�aren. Dieskann durchaus in einer fr�uhen Phase eines Forschungsvorhabens angebracht sein. Ver-folgt man aber eine Entdecker-Strategie f�ur die Nullhypothese, vorausgesetzt Gleichheitwird postuliert, so wird man die Werte f�ur � und � vertauschen, also � = 5% : : : 10%und � = 25% und h�oher. Schl�agt man eine Kritiker-Strategie f�ur die Alternative ein,so m�ochte man bereits vorliegende Forschungsergebnisse �uberpr�ufen und eine sichereAussage tre�en, da� sich die Pr�ufglieder unterscheiden. Man kann die Werte von z.B.� = 5% und � � 25% akzeptieren. Eine Kritiker-Strategie f�ur die Nullhypothese istangebracht, falls man eine sichere Aussage �uber praktisch gleiche Pr�ufglieder tre�enm�ochte. Man kann dann etwa folgende Werte f�ur � und � akzeptieren: � � 25% und� = 5%. Eine neutrale Strategie f�ur beide Hypothesen wird ein Versuchsanstellereinschlagen, wenn er Forschungsergebnisse in einer Art Schiedsrichterfunktion �uber-pr�ufen will. In diesem Fall wird man f�ur � und � in etwa gleich gro�e Werte w�ahlen.Als Anhaltspunkt m�oge gelten: � = � � 25%.
16CADEMO, Dialogsystem zur statistischen Versuchsplanung und Modellwahl. BIORAT GmbH,
Rostock.

















