Page 1
Einführung in SPSS für Windows
Stand: 2005-07-21
SPSS ist eines der bekanntesten Statistikpakete. Es verfügt über eine
besonders leicht zu bedienende Steuerung, die in der vorliegenden Schrift
behandelt wird. Auch die Realisierung beschreibender (tabellarischer und
grafischer) Statistik und einiger der häufigsten Prüfstatistikverfahren wird
dargestellt.
Einleitung
Ziel der vorliegenden Schrift ist es, eine kurze Einführung in die am häufigst benötigten
Aspekte des Umgangs mit der deutschsprachigen Version des Programms SPSS unter
Windows und weitestgehend auch unter Macintosh-Systeme ab OS 9 zu geben.
Ausführliche Anleitungen zur gesamten Funktionalität des Programms finden Sie in der
Originaldokumentation der Firma SPSS, die als zusätzliche CD zu unserer Lizenz
mitgeliefert wird.
Das Programm SPSS für Windows enthält eine Fülle von Möglichkeiten, die in einer
Schrift dieser Größe nicht angesprochen werden können.
Die vorliegende Schrift setzt gute Kenntnisse der Oberfläche von Windows voraus.
Datenbestände für die Übungen und Beispiele
Alle Übungen und Beispiele dieser Schrift benutzen Datenbestände, die Sie entweder auf
CD vom Benutzersekretariat des Leibniz-Rechenzentrums (LRZ) (Raum-Nr. S0502, Tel.
(089) 289-28761) erhalten, oder aber über das Internet holen können:
Unter dem Begriff Datenbestände für die Übungen und Beispiele befinden sich alle in
dieser Einführung angesprochenen Dateien: Klicken Sie mit der rechten Maustaste den
gewünschten Dateinamen an, wählen Sie die Option Verknüpfung speichern unter ... und
speichern Sie die gewählte Übungsdatei lokal ab.
data.dat
data.sav
data.xls
data1.sav
data2.sav
data3.sav
demog.sav
scores.sav
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
1 von 73 08.06.2009 15:59
Page 2
leben.sav
kg1.sav
alcohol.sav
Teil 1: Handhabung der Bedienungsoberfläche
Starten des Programms
SPSS kann durch Doppelklicken (mit der linken Maustaste) auf dem SPSS-Ikon gestartet
werden. Beim Starten des Programms erscheint folgendes Fenster, das verschiedene
Möglichkeiten vor allem bezüglich Zugriff auf Daten anbietet:
Durch Anklicken des Feldes Dieses Dialogfeld nicht mehr anzeigen können Sie das
künftige Erscheinen dieses Fensters permanent unterdrücken.
Der Dateneditor
Unmittelbar nach dem Starten des Programms öffnet sich ein (leeres) Dateneditorfenster.
Die oberste Zeile dieses Fensters beschreibt dessen Funktion (SPSS Daten-Editor) und
enthält den Namen des Fensters: Hier Unbenannt, ein Hinweis darauf, dass das Fenster in
Form einer Datei noch nicht gespeichert wurde:
Die zweite Zeile („Datei...Bearbeiten...Ansicht“ usw.) enthält die Hauptmenüleiste. Diese
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
2 von 73 08.06.2009 15:59
Page 3
erlaubt es, wie bei anderen Windows-Anwendungen auch, verschiedene Funktionen des
Programms zu aktivieren.
Die dritte Zeile enthält den fensterspezifischen Werkzeugkasten, der die schnelle
Aktivierung häufig benötigter Dienste der Hauptmenüleiste im Kontext des Dateneditors
realisieren lässt.
Der „Körper“ des Fensters enthält nummerierte Zeilen und mit der Überschrift var
versehene Spalten. Jede Zeile entspricht einem Fall (Patient, befragte Person, …), jede
Zeile einer Variablen (systolischer Blutdruck, Alter in Jahren, Geschlecht…)
Die leeren Zellen deuten an, dass noch keine Daten zur Verfügung stehen. (Wie SPSS
Daten erhält, sehen wir später.)
Unten links im Datenfenster findet man zwei Reiter:
Diese erlauben es, entweder die eingetragenen Daten — hier noch keine, also das leere
Datenfenster — oder die Variablendefinitionen, die wir später kennen lernen, zu
besichtigen.
Das letzte allgemein gültige Element ist die Informationsszeile, die Sie ganz unten im
aktiven Fenster sehen:
Im Laufe dieser Einleitung lernen Sie weitere Felder dieser Zeile kennen.
Übung
Klicken Sie den Menüpunkt Datei: an! Es erscheint ein Fenster, das Ihnen verschiedene
Möglichkeiten im Bereich der SPSS-Dateiverwaltung anbietet. Wie in Windows üblich,
werden die aktuell benutzbaren Elemente durch eine dunklere Färbung gekennzeichnet:
Ganz unten in diesem Fenster steht Ihnen z.B. die Möglichkeit zur Verfügung, SPSS zu
verlassen (Beenden). Darüber steht eine Liste weiterer Funktionen, die man durch
Anklicken sofort aktivieren kann:
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
3 von 73 08.06.2009 15:59
Page 4
Klicken Sie Öffnen + Daten... an, so erscheint das übliche Windows-Datei-Manager-
Fenster, das Ihnen erlaubt, eine Datei zu öffnen. Dieselbe Funktionalität ist über das
übliche Öffnen-Werkzeug im Werkzeugkasten verfügbar.
Übung
Öffnen Sie die Datei data.sav!
Das Dateneditorfenster enthält die zu untersuchenden Daten und dient zur allgemeinen
Datenverwaltung – Einlesen, Transformieren, Berechnung neuer Variablen und vieles
andere mehr:
Unterhalb des schon besprochenen Werkzeugkastens befindet sich eine zweigeteilte Zeile,
die Information zu dem aktiven Datenfeld gibt: Das Zelleneditorfeld enthält den Wert 57.
Im Feld links davon steht 1:Bogen: Dieser Wert gehört zu dem 1. Fall des Datensatzes und
zur Variablen Bogen. Im Datenteil des Fensters ist das entsprechende Feld markiert
(schwarz umrandet).
Dateneingabe
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
4 von 73 08.06.2009 15:59
Page 5
Unternimmt man eine Studie, so beobachtet man pro Fall (Patient, Schüler usw.)
verschiedene Variablen wie z.B. im obigen Datenfenster Geschlecht, Alter in Jahren,
Englischnote usw. Jeder Fall liefert bestimmte Werte (Daten) zu diesen Variablen: Der
erste Fall in diesem Beispiel lieferte den Fragebogen Nummer 57, besucht den Schultyp 1,
ist 14 Jahre alt, männlich, ist in der 9. Klasse, ... Die beobachteten Werte variieren (daher
die Bezeichnung „Variable“): Zum Beispiel ist der erste Schüler in diesem Datensatz 14
Jahre alt, der zweite ebenfalls, der dritte 10 und so weiter. Die Werte dieser Spalte
variieren, der Begriff „Alter“ bleibt jedoch konstant: Diese gesamte Spalte zur Variablen
Alter enthält ausschließlich die Altersangaben der Kinder.
Es ist von außerordentlicher Wichtigkeit für die gesamte Statistik (insbesondere für die
Prüfstatistik), dass folgende Konventionen eingehalten werden!
· Jede Zeile (Reihe) des Datenfensters enthält Daten zu einem einzigen Fall;
· kein Fall erscheint in mehr als einer Reihe;
· jede Spalte des Datensatzes enthält Werte zu einer einzigen Variablen.
Anmerkung
Es ist selbstverständlich möglich, Datensätze mit mehr als einer Zeile pro Fall in SPSS
einzulesen und zu verwalten. Solche Datensätze müssen jedoch vor der Anwendung
statistischer Prozeduren so umgestaltet werden, dass sämtliche zu analysierenden Variablen
eines jeden Falles in einer einzigen Zeile erscheinen. Das Programm SPSS enthält
Kommandos für dieser Umgestaltung.
Variablendefinition
SPSSbenötigt eine Zuordnung von Daten zu Variablen, die auch zur Kommunikation
zwischen dem Benutzer und dem Programm dient, z.B. um bestimmte Variablen zu
korrelieren oder um Grafiken zu erzeugen. Diese Zuordnung geschieht über die Vergabe
von Variablennamen: Jede Spalte muss mit einem eindeutigen Namen versehen werden.
Oberhalb der Spalten in der Dateiansicht des Daten-Editor-Fensters befindet sich eine
Leiste mit diesen Variablennamen:
Die Variablen in der aktiven Datei heißen also Bogen, Schultyp usw. – insgesamt zehn
Variablen.
Aber auch weitere Informationen zu Ihren Variablen können bzw. müssen definiert
werden. Über den Reiter Variablenansicht (links unten im SPSS Daten-Editor-Fenster)
gelangen Sie zu folgender Darstellung der Variablen, die solche Definitionen ermöglicht:
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
5 von 73 08.06.2009 15:59
Page 6
Dieses Fenster enthält Einzelheiten zu diesen Definitionen:
· Name
Hier können Sie die Namen Ihrer Variablen eingeben. Variablennamen dürfen bis zu 64
Zeichen lang sein, wovon das Erste ein Buchstabe sein muss. Sonst darf das
Unterstreichenzeichen (_) zwar verwendet werden, jedoch lieber nicht als letztes Zeichen
eines Variablennamens. Sonderzeichen (vor allem das Leerzeichen) sollten bzw. müssen
auch vermieden werden. Trotz dieser maximalen Länge von 64 Zeichen, sollte in der Praxis
diese Länge 18 Zeichen nicht überschreiten, denn SPSS hackt einfach rechts ab, falls nicht
genug Platz in der Tabelle oder Diagramm zur Verfügung steht.
!Tipp
Sie machen sich das Leben einfacher, wenn Sie inhaltlich sinnvolle Namen zur Kennung
der Variablen benutzen: Alter ist ein wesentlich besserer Variablenname als etwa x3 oder
Gandalf oder Ähnliches.
· Typ
Klicken Sie im Typ-Feld neben der Variablen Bogen die Option „Numerisch“ und
anschließend auf dem Symbol in diesem nun schwarz umrandeten Feld! Es öffnet
sich folgendes Fenster:
Es befinden sich hier unter anderem die häufigsten Daten Typen Numerisch (das Feld ist
für numerische Werte – Zahlen – vorgesehen, die mathematisch verarbeitet werden
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
6 von 73 08.06.2009 15:59
Page 7
können) und String (das Feld enthält beliebige Zeichen, typischerweise Buchstaben).
String-Variablen haben keine numerische Bedeutung und können natürlich auch nicht
numerisch verarbeitet werden. Die Breite des Feldes (das heißt: Anzahl Stellen insgesamt)
und gegebenenfalls auch davon die Anzahl Dezimalstellen könnten an dieser Stelle gesetzt
oder geändert werden (siehe den folgenden Punkt „Spaltenformat und Dezimalstellen“).
!Tipp
Meiden Sie (zum Beispiel bei Variablen wie Geschlecht) String-Variablen – Variablen
deren Daten, die Zeichen- oder Zeichenfolgen enthalten, wie etwa „m“ und „w“ für die
Ausprägungen einer Variablen Geschlecht; denn die gesamten nicht-parametrischen
Statistiken von SPSS verstehen diese nicht.
· Spaltenformat
Die Breite des Feldes und die Anzahl Dezimalstellen können auch hier gesetzt bzw.geändert werden. Beide Angaben können die Gestaltung der statistischen Ergebnistabellenund -grafiken von SPSS beeinflussen. Hiervon ein kleines Beispiel: Beide der folgendenTabellen enthalten den Mittelwert der Variablen Alter. Die erste Tabelle basiert auf derDefinition „Dezimalstellen = 1“:
Die zweite Tabelle basiert auf der Definition „Dezimalstellen = 2“:
!TippEs ist daher zu empfehlen, bei allen metrischen Variablen, bei denen Sie zum Beispiel
Mittelwerte berechnen möchten, die SPSS Formatierungsvoreinstellung (Feldbreit: 8;
davon Dezimalstellen: 2) unverändert zu akzeptieren. Bei Gruppierungsvariablen wie etwa
Geschlecht könnte man, wie hier, die Anzahl Dezimalstellen auf 0 setzen: Dieser Schritt ist
aber nicht notwendig.
· Variablenlabel
Das Variablenetikett (Variablenlabel) erlaubt die Definition einer längeren Beschreibung
(formal bis zu 256 Zeichen lang), die alle Zeichen der Tastatur enthalten darf
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
7 von 73 08.06.2009 15:59
Page 8
(Sonderzeichen, Groß- und Kleinschreibung u.s.w.): Empfehlenswert ist trotzdem eine
Länge von ca. 18 Zeichen, denn ist ein Etikett zu lang für bestimmte Ausgaben (Tabellen
oder Grafiken), so hackt SPSS das nicht-passende Ende des Etiketts einfach ab.
!Tipp
Diese längeren Variablenlabels erscheinen in fast allen Ausgabetabellen und -grafiken von
SPSS, die Sie mühelos in Ihre Word-Datei importieren können. Nehmen Sie sich die Zeit,
schon bei der Dateneingabe diese Etikette so festzulegen, wie sie in Ihrer Arbeit erscheinen
sollen. Sie sparen sich dadurch viel spätere Mühe.
· Wertelabels
Bei Variablen mit wenigen Ausprägungen empfiehlt es sich, diese einzeln zu etikettieren.
Geschlecht beispielsweise hat gewöhnlich zwei Ausprägungen: männlich und weiblich.
Klicken Sie im Feld Wertelabels der Variablen Geschlecht und dann auf dem
Symbol in diesem nun schwarz umrandeten Feld! Es erscheint folgendes Fenster:
Neben dem Feld Wert geben Sie 0 ein – den Wert, der im Datenfenster die Ausprägung
„männlich“ kennzeichet: Darunter im Feld Wertelabel geben Sie männlich ein! Drücken
des Knopfes Hinzufügen überträgt diese Angabe in das untere Teilfenster. Verfahren Sie
ähnlich mit 1 und weiblich; sodass das Fenster nun so aussieht:
Mit OK werden diese Definitionen übernommen.
· Fehlende Werte
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
8 von 73 08.06.2009 15:59
Page 9
Es kommt oft vor, dass Daten einfach fehlen – der Patient ist entlassen worden; der
Befragte gab keine Antwort; die Frage des Bogens wurde einfach nicht ausgefüllt.
Üblicherweise lässt man die Datenfelder zu solch fehlenden Werten einfach leer. Das Feld
sähe dann so aus:
Manchmal jedoch fehlen Variablen aus unterschiedlichen Gründen, die man getrennt
kodieren und untersuchen möchte. Beispiel: Bei einer Umfrage bei Passanten auf der
Straße zu politischen Ansichten ist eine Verweigerung aus Gewissensgründen (etwa: „Das
geht niemanden was an“) eine ganz andere, als Langeweile (etwa: „Ich will nicht mehr, hab'
was Wichtigeres zu tun“). Will man zwischen unterschiedlich motivierte Lücken im
Datensatz unterschieden, so kann man an dieser Stelle Sonderkodierungen vereinbaren, die
als fehlend gelten, die man jedoch nach Bedarf gezielt untersuchen könnte:
Klicken Sie im Feld Fehlende Werte neben der Variablen IQ und dann auf dem
Symbol um folgendes Fenster zu erhalten:
Die Voreinstellung (das, was SPSS macht, falls Sie keine Angaben machen) ist die, dass
fehlende Werte lediglich durch leere Felder (keine Eingabe) im Eingabefenster
gekennzeichnet sind. Die zweite Möglichkeit (Einzelne fehlende Werte) erlaubt die Angabe
von bis zu drei verschiedenen Kodierungen; die letze die Angabe sowohl von einem
Bereich (vom kleinsten bis zum größten Wert, die als fehlend zu behandeln sind) und
nach Bedarf von einem einzigen, speziellen Wert.
!Tipp
Nehmen Sie als Kodierung für fehlende Werte solche, die auf keinen Fall als normale
Antworten vorkommen können! Bei einer Angabe zum Alter von Schulkindern wäre zum
Beispiel ein Wert wie -999 eine sinnvolle Angabe, die Sie in doppelter Weise vor
Eingabefehlern schützt – das Alter kann weder negativ noch so groß wie 999 werden.
· Spalten
Diese Angabe spezifiert, wie breit die Spalte im Dateneditorfenster sein soll. Sie hat keinen
Einfluss auf die Gestaltung von Tabellen oder Grafiken. Es empfiehlt sich, diese Breite bei
der Voreinstellung zu lassen, damit man den Variablennamen in voller Länge sieht.
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
9 von 73 08.06.2009 15:59
Page 10
(Versuchen Sie aus Spaß, diesen Wert bei einer beliebigen Variablen auf 1 zu setzen und
beobachten Sie die Ergebnisse!)
· Ausrichtung
Auch diese Angabe berührt lediglich das Erscheinungsbild des Dateneditorfensters und
gibt an, ob die Daten links- oder rechtsbündig im Datenfeld angezeigt werden sollten. Auch
hier besteht kein Grund, die SPSS-Voreinstellung (rechtsbündig) zu ändern.
· Messniveau
SPSS unterscheidet drei Messlevels (mehr zu diesem Thema finden Sie in der LRZ-Schrift
SPSS for Windows – Special Topics: Einige Grundbegriffe der Statistik: Siehe Anhang B:
Dokumentation):
1. Nominal: Nominalskalierte Variablen mit einigen, wenigen Ausprägungen (wie zum
Beispiel Geschlecht mit den Ausprägungen 0 für männlich und 1 für weiblich) besitzen
keine numerisch/mathematische Bedeutung: Sie dienen lediglich zur Klassifizierung oder
Gruppierung der Fälle. Solche Variablen dürfen Zeichenketten („m“ und „w“, etwa) oder
aber auch Zahlen beinhalten, aber: Auch wenn zum Beispiel „männlich“ als „1“ und
„weiblich“ als „2“ kodiert wären, besäßen diese Werte trotzdem keine numerische
Bedeutung, sondern fungieren nach wie vor lediglich als Etikett. Man könnte ja die
Etikettierung genau anders herum vornehmen (1 = weiblich, 2 = männlich), oder (99 =
männlich, 999 = weiblich) oder... . Die rein etikettierende Funktion solcher „Zahlen“ (die
im rechnerischen Sinne gar keine Zahlen sind, sondern lediglich beliebige Zeichen) bleibt
unverändert.
2. Ordinal: Die eingetragenen Werte geben bei ordinalen Variablen eine Reihenfolge
an. Kodiere man zum Beispiel Alter in drei Gruppen (jung, mittel, alt), so wüsste man
zwar, dass eine Person der Gruppe „jung“ jünger ist als Personen der beiden anderen
Gruppen, wüsste aber nicht, wie viel jünger. Würde man die Variablen mit „1“ (jung) „2“
(mittel) und „3“ (alt), so wüsste man also, dass zwar Personen der Gruppe 1 jünger sind als
die der Gruppe 2 und Personen beider Gruppen jünger sind als Personen der Gruppe 3:
Man könnte aber nicht behaupten, Personen der Gruppe 2 wären doppelt so alt wie die der
Gruppe 1.
3. Metrisch: Variablen, deren Werte numerische Bedeutung haben. Beispiel: Alter in
Jahren – ein zehnjäriges Kind ist (innerhalb der Messpräzision) doppelt so alt wie ein
fünfjähriges. Der Altersunterschied zwischen einer 16- und einer 18-jährigen Person ist
genauso groß wie der zwischen einer 75- und einer 77-jährigen Person.
!Tipp
Noch einmal (da es so wichtig ist): Es lohnt sich, sich bei der Datendefinition Mühe zu
machen, denn die dort festgelegten Etikette werden auch, soweit möglich, von den
Statistik- und Graphikprozeduren zur Gestaltung der Ausgabe benutzt, sodass diese sofort
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
10 von 73 08.06.2009 15:59
Page 11
ohne weiteres Editieren in druckfertigen Arbeiten übernommen werden kann.
Zugriff auf Dateien
Zu jeder Variablen müssen dem Programm die zu analysierenden Rohdaten bereitgestellt
werden. Hierzu gibt es einige Möglichkeiten:
Eingabe von Rohdaten im SPSS-Daten-Editor-Fenster
Über den Menüpunkt Datei + Neu + Daten öffnen Sie eine neues, leeres Daten-Editor-
Fenster. In diesem Fenster ist ein Datenfeld schwarz umrandet (unmittelbar nach dem
Öffnen eines neuen Fensters ist dies das erste Feld oben links). Tippen Sie als Beispiel nun
die Zahl 017 ein.
Zunächst erscheint diese Eingabe im Zelleneditorfeld oberhalb der Datenfelder: Hier
können Sie Änderungen vornehmen. Mit der Eingabe-Taste wird die Zahl (ohne führende
„0“) in das Datenfeld übertragen, und das Eingabefeld positioniert sich eine Zeile weiter
nach unten. Sie können die Eingabe auch mit der Pfeil-rechts- oder der Tabulator-Taste
quittieren und somit ein Feld weiter rechts weiterpositionieren.
!Tipp
Legen Sie zunächst im Variablensichtfenster sämtliche Variablendefinitionen fest. Erst
dann tragen Sie Ihre Daten ein!
Übung
Anhang A enthält zwei ausgefüllte Beispielfragebögen zu den Variablen Bogen, Schultyp,
Alter, Geschlecht, Klasse, Deutsch, Mathe, Englisch, IQ und Chancen. Öffnen Sie über
Datei + Neu + Daten ein leeres Dateneditorfenster, legen Sie die Variablendefinitionen
fest und tragen Sie die Daten der beiden Bögen ein! Sichern Sie diese Datei (über Datei +
Speichern) unter dem Namen meindat!
Anmerkung:
Die Deutsch-, Englisch- und Mathenoten sind zwar unter dem allgemeinen Begriff „Noten“
hier subsumiert, dieser übergeordnete Begriff ist aber mit keiner eigenen Eingabe
verbunden – und benötigt also keine Spalte für sich. Wir definieren lediglich die
Variablen für die wir einzelne Eingaben haben – hier also Deutsch, Englisch und Mathe.
Öffnen einer schon bestehenden SPSS-Systemdatei
Öffnen Sie einfach die Datei!
Einlesen von Text-Daten
Text-(ASCII-)Daten sind einfach Rohdaten, die zum Beispiel mit einem üblichen
Textverarbeitungsprogramm eingegeben wurden. Datei + Textdaten lesen öffnet ein
Fenster, das die Auswahl einer Text-Datei ermöglicht. Wählen Sie die Datei data.txt aus!
Es öffnet sich der Assistent für Textimport:
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
11 von 73 08.06.2009 15:59
Page 12
Das untere Subfenster (Textdatei:) stellt die einzulesenden Daten dar, wobei die erste Zeile
(wie hier) Variablennamen enthalten darf, die restlichen Zeilen Daten enthalten müssen
(ein eventuell erscheinendes, kleines Quadrat entspricht einem Tabulator in der
ursprünglichen Datei).
Klicken sie nun auf Weiter >! Das Fenster zum zweiten Schritt der Definition öffnet sich.
Im oberen Teil des Fensters wird nach der Art der Formatierung der Daten gefragt. Mit
Trennzeichen bedeutet, dass die Daten zu den Variablen durch bestimmte Zeichen
(Leerzeichen, Kommata,..) getrennt sind:
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
12 von 73 08.06.2009 15:59
Page 13
Feste Breite bedeutet, dass sämtliche Daten zu allen Variablen in bestimmten Spalten
erscheinen.
Der untere Teil des Fensters zeigt die ersten vier Zeilen der einzulesenden Datei an.
Nach Auswahl der passenden Option und anklicken von Weiter > öffnen sich weitere, sich
selbsterklärende Steuerungsfenster zum flexiblen Einlesen von fest- oder freiformatierten
Klartextdatensätze.
Einlesen von „fremden“ Dateiformaten
· Excel-Datenbestände
Das Einlesen von Daten aus Excel-Tabellen oder -Mappen geschieht einfach über die
übliche Funktion Datei öffnen und Auswahl des Dateityps Excel (*.xls):
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
13 von 73 08.06.2009 15:59
Page 14
Markieren Sie nun die gewünschte Datei und klicken Sie auf Öffnen:
Klicken Sie Variablennamen einlesen, um SPSS mitzuteilen, dass die erste (und
ausschließlich die erste!) Zeile der angezeigten Excel-Tabelle SPSS-Variablennamen
enthält: Diese müssen die bekannten SPSS-Namenskonventionen einhalten – maximal 64
Zeichen lang, wovon das erste ein Buchstabe sein muss, die restlichen Buchstaben oder
Ziffern ('_', jedoch nicht als letztes Zeichen; keine Sonderzeichen!) sein dürfen. Handelt es
sich um eine Excel-Mappe, die ja mehrere Tabellen enthalten kann, so erscheint ein leicht
erweitertes Fenster, das Ihnen erlaubt, eine bestimmte Tabelle dieser Mappe zu selektieren
und einzulesen.
Wollen Sie lediglich einen Teil der Tabelle in SPSS einlesen, so definieren Sie im Feld
Bereich diesen gewünschten Teil – zum Beispiel B1:D26, um die zweite, dritte und vierte
Variablen, deren SPSS-Variablennamen und die ersten 25 Datenzeilen der Datei
einzulesen.
· Datenbankzugriffe
SPSS bietet über den Hauptmenüpunkt Datei + Datenbank öffnen... die Möglichkeit an,
Daten aus verschiedenen fremden Quellen wie zum Beispiel Oracle- oder DBase-
Datenbanken zur Verfügung zu stellen und über Datenbankabfragen, bestimmte
Datenmengen im SPSS-Dateneditorfenster zur Verfügung zu stellen. Die SPSS-Manuale
enthalten Einzelheiten dazu.
Gestaltung der Variablenlisten
Typisch für die Steuerung von SPSS-Prozeduren ist ein Steuerungsfenster, die eine Liste
der definierten Variablen beinhaltet:
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
14 von 73 08.06.2009 15:59
Page 15
Die Gestaltung dieser Variablenliste kann über Bearbeiten + Optionen... unter dem Reiter
Allgemein und dort unter Variablenlisten gesteuert werden:
Die obere Hälfte dieses Subfensters steuert die Darstellung als Variablenetikett (Labels
anzeigen) oder aber (wie hier) Variablennamen (Namen anzeigen). Die untere Hälfte
steuert die Reihenfolge der Darstellung: (wie hier) Alphabetisch oder aber in der
Reihenfolge des Erscheinens im Datenfenster (Datei).
Wählen Sie die alphabetische Reihenfolge der Variablennamen (wie oben) aus!
Datenmanipulation
Falls nicht schon getan, öffnen Sie die Datei data.sav!
Es ist manchmal notwendig, bestehende Variablen zu verändern oder aus bestehenden
Variablen neue zu berechnen. Unter dem Menüpunkt Transformieren bietetSPSS hier
einige Möglichkeiten an:
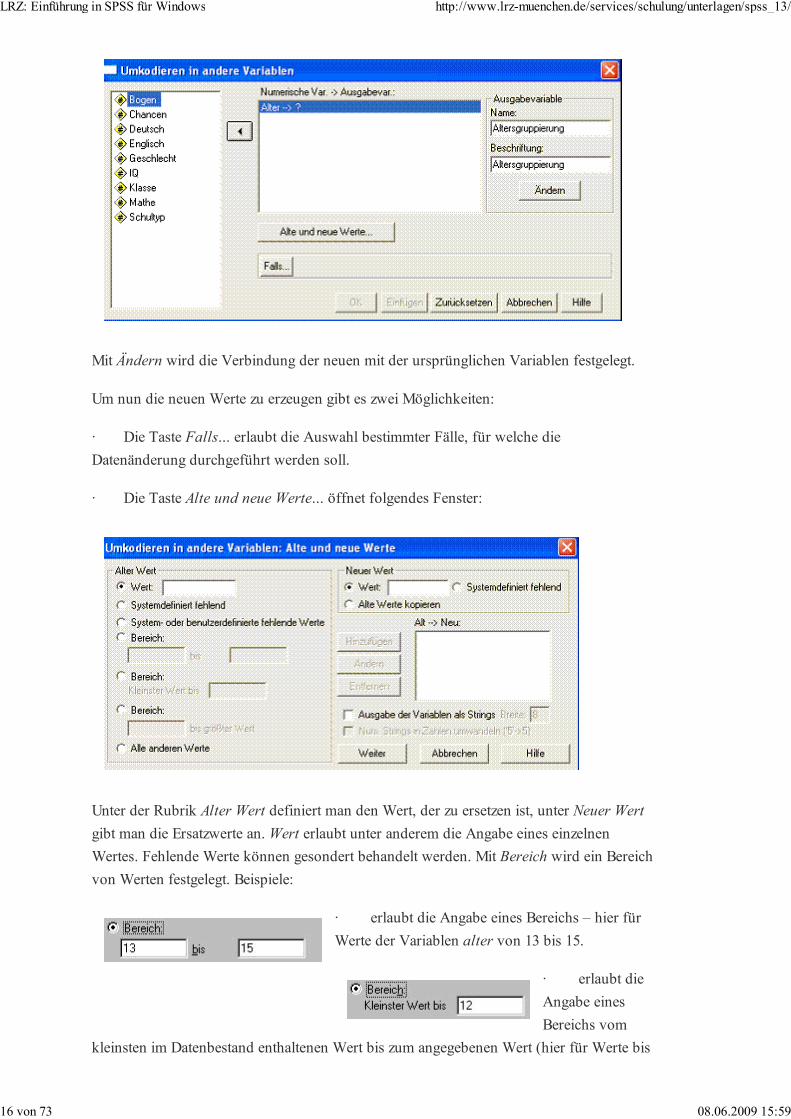
Umkodieren
Umkodieren unterstützt das Verändern der Werte einer schon vorhandenen Variablen (In
dieselben Variablen...) – die alten Werte werden dabei überschrieben (vernichtet) – sowie
das Erzeugen einer neuen Variablen (In andere Variablen...).
!Tipp
Es ist ratsam, eine neue Variable zu kreieren, statt die alte zu vernichten, denn oft braucht
man die alten Werte doch noch.
Übung
Aktivieren Sie Transformieren + Umkodieren + In andere Variablen …! Übertragen Sie
nun die Variable Alter in das Fenster Eingabe Var.: -> Ausgabevar.: - (der Text Eingabe
Var. ändert sich autmatisch in Numerische Var.). Benennen Sie die neu zu kreierende
(Ausgabe) Variablen und sein längeres Etikett wie etwa in folgender Abbildung:
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
15 von 73 08.06.2009 15:59
Page 16
Mit Ändern wird die Verbindung der neuen mit der ursprünglichen Variablen festgelegt.
Um nun die neuen Werte zu erzeugen gibt es zwei Möglichkeiten:
· Die Taste Falls... erlaubt die Auswahl bestimmter Fälle, für welche die
Datenänderung durchgeführt werden soll.
· Die Taste Alte und neue Werte... öffnet folgendes Fenster:
Unter der Rubrik Alter Wert definiert man den Wert, der zu ersetzen ist, unter Neuer Wert
gibt man die Ersatzwerte an. Wert erlaubt unter anderem die Angabe eines einzelnen
Wertes. Fehlende Werte können gesondert behandelt werden. Mit Bereich wird ein Bereich
von Werten festgelegt. Beispiele:
· erlaubt die Angabe eines Bereichs – hier für
Werte der Variablen alter von 13 bis 15.
· erlaubt die
Angabe eines
Bereichs vom
kleinsten im Datenbestand enthaltenen Wert bis zum angegebenen Wert (hier für Werte bis
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
16 von 73 08.06.2009 15:59
Page 17
12 Jahren).
· erlaubt die Angabe eines Bereichs vom angegeben
Wert bis zum größten im Datenbestand enthaltenen Wert
(hier für Werte ab 16).
Unter Neuer Wert können Sie nun die gewünschte neue Kodierung eingeben und mittels
Hinzufügen festlegen.
Übung
Folgende Tabelle verbindet die Werte der ursprünglichen Variablen Alter mit denen der zu
erzeugenden Variablen Altersgruppierung:
Alter Altersgruppierung
bis 14 Jahren 1
14 bis 17 Jahren 2
17 Jahre und älter 3
Führen Sie die Umkodierung durch! Vergessen Sie nicht, von der Variablenansicht des
Datenfensters aus, die Wertelabels entsprechend zu definieren!
Anmerkung: Wie zu erwarten: Gruppe 1 enthält Jugendliche bis 13,999... Jahren; Gruppe 2
von 14 bis 16,999... Jahren; Gruppe 3, 17 Jahre und älter.
Berechnen
Transformieren + Berechnen... öffnet folgendes Fenster:
Im Zielvariablen-Feld wird der Name der zu kreierenden Variablen eingegeben. Das Feld
Numerischer Ausdruck erhält eine Beschreibung, wie diese Zielvariable zu berechnen ist.
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
17 von 73 08.06.2009 15:59
Page 18
Unter Funktionsgruppe wählen Sie Statistisch und im Fenster „Funktionen und
Sondervariablen“ Mean aus (dabei ignorieren Sie diese hässliche Mischung aus Englisch
und Deutsch)! Im Subfenster links davon erscheint eine Erklärung des Angeklickten.
Übung
Berechnen Sie die neue Variable Schnitt, die den Mittelwert pro Schüler der Schulnoten
(Variablen: Deutsch, Englisch, Mathe) enthält. Die Funktion
MEAN(numAusdr,numAusdr,...) aus der Funktionsliste kann hierzu benutzt werden: Diese
kurze Beschreibung der Funktion deutet an, dass die verschiedenen Ausdrücke (hier
einfach: Variablen), deren Mittelwert berechnet werden soll, durch Kommata zu trennen
sind. Benutzen Sie den nach obenhinweisenden, dreieckigen Pfeil, um die Funktion und
die Variablennamen ins Subfenster Numerischer Ausdruck zu übertragen!
Ihr ausgefülltes Steuerfenster sollte nun so aussehen:
Führen Sie (mit OK) den Vorgang durch! Inspizieren Sie das Dateneditorfenster: Die neu
berechnete Variable befindet sich am rechten Ende des Fensters.
!Tipp
Fehlt bei einem bestimmten Fall ein Wert bei einer (oder mehreren) Variablen (hier:
Deutsch, Englisch, Mathe) so erhält die Zielvariable (hier: Schnitt) den Mittelwert der
restlichen, nicht fehlenden Werte. Sollte bei irgendeinem Falle alle drei Werte fehlen, so
wird auch die Zielvariable als fehlend definiert.
Übung
· Definieren Sie passende Ausprägungs-Etiketten für die gerade erzeugte Variable!
Umkodieren in aufeinanderfolgende Zahlen
Mehrere Prozeduren in SPSS erkennen String- (Zeichenketten-)Variablen nicht, sodass
Einträge wie: „j“ für „jung“, „m“ für „mittel“, „a“ für „alt“ in Zahlen umkodiert werden
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
18 von 73 08.06.2009 15:59
Page 19
müssten. Zudem verlangen mehrere Prozeduren eine Kodierung kategorialer Variablen als
aufeinanderfolgenden Zahlen (zum Beispiel: 1, 2, 3, statt 7, 19, 23), anderer laufen
merklich effizienter mit einer solchen Kodierung. Es mag also durchaus Sinn machen ,
Stationen eines Krankenhauses mit den Nummern der Station zu identifizieren, für die
Verarbeitung mit SPSS ist dies jedoch nicht zu empfehlen: Ein Umkodierung ist
angebracht. SPSS bietet ein bequemes Werkzeug hierfür. Über Transformieren …
automatisch umkodieren erhält man das Steuerungsfenster dazu. Übertragen Sie die
Variable Klasse ins Subfenster Variable -> Neuer Name und definieren Sie einen Namen
für die neue Variable. Die restlichen Möglichkeiten des Fensters sind selbsterklärend.
Datensicherung
Der Inhalt des Dateneditorfensters (das heißt natürlich auch: des Datenbestandes) kann
über das Werkzeugkastensymbol oder aber über Datei + Speichern gespeichert
(gesichert) werden. Mit Speichern unter. . . können Sie Ihre Daten auch unter einem
anderen Namen oder zum Beispiel als Excel-Datei speichern.
!Tipp
Falls Sie Ihre Daten ändern, so sichern Sie diese sofort, ohne auf das Ende der
Arbeitssitzung zu warten! So beugen Sie unnötige Datenverluste vor.
Mehr als ein Datensatz?
SPSS erlaubt lediglich ein einziges aktives Datenfenster. Man kann zwar mehrere
SPSS-Sitzungen parallel zueinander starten, das wären aber unabhängige Sitzungen: man
könnte z.B. die Variablen- und Wertelabels aus einer Datei (mittels Kopieren und
Einfügen) in einer zweiten übernehmen, aber die Analyse beider Datensätze ist nur dann
möglich, wenn diese Dateien zusammengefügt werden – d.h.: Daten können nur
zusammen untersucht werden, wenn sie in einem und demselben Datenfenster sind. Wie
fügt man also zwei Datensätze zusammen?
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
19 von 73 08.06.2009 15:59
Page 20
Daten + Dateien zusammenfügen bietet zwei Möglichkeiten an:
Hinzufügen von zusätzlichen Fällen
Über Fälle hinzufügen... teilt man SPSS einfach den Namen der Datei mit, die die Daten
der zusätzlichen Fälle enthält. Diese werden ans untere Ende Ihres Datensatzes hinzugefügt.
Gewöhnlich enthalten beide Dateien Daten zu denselben Variablen. Kommen aber
Variablen in der einen Datei vor, die in der anderen nicht definiert sind, so erzeugt SPSS
automatisch eine Variable, deren Werte im entsprechenden Teil der neuen Datei einfach
fehlen (das heißt: Sie werden als „fehlend“ gespeichert).
Hinzufügen von zusätzlichen Variablen
Um zusätzliche Variablen (über Fälle hinzufügen...) hinzuzufügen muss man etwas
präziser vorgehen: Damit die Dateien korrekt gemischt werden können, müssen beide nach
einer gemeinsamen Variablen sortiert sein.
!Tipp
Alle Datendateien sollten ausnahmslos eine spezielle Variable enthalten, die zur
eindeutigen Identifikation der Fälle dient (Schlüsselvariablen)! Eine solche Variable ist
unter anderem schon bei der Datenkorrektur oder beispielsweise bei der Suche nach
„Ausreißern“ eine große, bei dem Mischen von Dateien eine schier unumgängliche Hilfe.
Bevor Sie den Mischvorgang starten, sortieren Sie beide Dateien aufsteigend nach diesem
gemeinsamen Schlüsselvariablen! Da lediglich eine Datei im Datenfenster zur Verfügung
stehen kann, müssen Sie diese sortieren und schließen, um dann die zweite Datei zu öffnen
und ebenfalls nach dem gemeinsamen Schlüssel zu sortieren. Dies geschieht über Daten +
Fälle sortieren. . .
Übung
Öffnen Sie die Datei demog.sav, die die demographischen Variablen Schultyp, Alter,
Geschlecht, Klasse und die Schlüsselvariablen Bogen enthält. Übertragen Sie letztere ins
Sortieren Nach:-Fenster und sortieren Sie den Datenbestand aufsteigend nach dieser
Schlüsselvariablen! Speichern Sie diese Datei unter dem Namen demog_sortiert.sav und
öffnen Sie die Datei scores.sav, die die Variablen Deutsch, Englisch, Mathe, Chancen und
selbstverständlich auch die Schlüsselvariablen Bogen enthält. Sortieren Sie auch diese
Datei aufsteigend nach der gemeinsamen Schlüsselvariablen und speichern Sie sie unter
dem Namen scores_sortiert.sav!
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
20 von 73 08.06.2009 15:59
Page 21
Nach Daten + Dateien zusammenfügen + Variablen hinzufügen... wählen Sie die Datei
demog.sav aus. Folgendes Fenster öffnet sich:
Das Fenster Ausgeschlossene Variablen listet die Variablen auf, die nicht in der
gemischten Datei erscheinen werden – hier die Variable Bogen aus der Datei demog.sav (+
kennzeichnet Variablen der hinzuzufügenden Datei, * die der aktuellen Arbeitsdatei). Diese
Variable Bogen ist ja schon im Fenster Neue Arbeitsdatei enthalten, das die Variablen der
gemischten Datei anzeigt. Wir können und sollten jedoch diese Variablen als
Schlüsselvariablen zur Verknüpfung beider Dateien benutzen: D.h. Fälle beider Dateien
werden anhand dieser gemeinsamen Variablen verglichen und erst dann zusammengefügt,
falls die Werte der Schlüsselvariablen in beiden Dateien übereinstimmen – ein zusätzlicher
Schutzmechanismus, der für die Abstimmung beider Dateien sorgt. Übertragen Sie nun
Bogen in das Fenster Schlüsselvariablen und führen Sie die Mischung aus!
!Tipp – und eine Warnung!
Da man das Programm SPSS mehrmals starten kann, könnte man es einmal mit dem einen,
einmal mit dem anderen Teildatensatz starten, die Variablen/Fälle im dem einen Teil
markieren, mit Bearbeiten + Kopieren in die Zwischenablage kopieren, zur anderen
Instanz von SPSS wechseln, um dort über Bearbeiten + Einfügen die Daten zuzumischen.
Dieser Vorgang ist zwar schnell und beim Hinzufügen von zusätzlichen Fällen sogar zu
empfehlen: Beim Hinzumischen von zusätzlichen Variablen fehlt jedoch der wichtige
Schutzmechanismus der Schlüsselvariablen.
Auswahl gezielter Untermengen der Fälle
Falls nicht schon getan, öffnen Sie die Datei data.sav!
Untersuchungen anhand einer kategorialen (Gruppierungs-)Variablen
Es ist oft notwendig, eine bestimmte Analyse mit unterschiedlichen Datenmengen zu
wiederholen: Pro Krankenhaus oder -station, Schultyp, Bundesland usw. – d.h. nach den
Ausprägungen einer oder mehrerer kategorialen Variablen.
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
21 von 73 08.06.2009 15:59
Page 22
Daten + Datei aufteilen... öffnet folgendes Fenster:
Per Voreinstellung werden alle Fälle – ohne Gruppierung – untersucht (Alle Fälle
analysieren, keine Gruppen bilden).
Die Auswahl Gruppen vergleichen erzeugt – abhängig von der aufgerufenen Prozedur –
einen Vergleich zwischen den Gruppen, produziert z.B. eine Tabelle mit nach Gruppen
geordneten Einträgen.
Die Auswahl Ausgabe nach Gruppen aufteilen erzeugt z.B. getrennte Tabellen, eine pro
Gruppe.
Die Definition solcher Gruppen geschieht über die Auswahl einer kategorialen
(Gruppierungs-) Variablen (wie etwa Schultyp), die ins Subfenster Gruppen basierend auf
übertragen wird.
!Tipp
Die Informationszeile ganz unten im SPSS Datenfenster zeigt im rechten Feld an, dass
Datei aufteilen aktiviert ist:
Vergessen Sie nicht, diese Funktion wieder zu deaktivieren, sobald der gesamte
Datenbestand wieder untersucht werden soll! Diese Deaktivierung geschieht über das
Fenster Datei aufteilen... und die Auswahl der Option Alle Fälle analysieren, keine
Gruppen bilden: Die Meldung (Datei aufteilen an) in der Informationszeile verschwindet.
Auswahl auch anhand von kontinuierlichen Variablen
SPSS bietet einige Möglichkeiten an, bestimmte Fälle anhand der Werte ihrer Variablen zur
Analyse auszuwählen – zum Beispiel: Alle Patienten der Neurochirurgie, die über 45 Jahre
alt, privat versichert sind und mindestens einmal schon operiert wurden. So lange die
Auswahl in Kraft bleibt, werden nur Daten der selektierten Fälle untersucht, die der
restlichen Fälle ignoriert.
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
22 von 73 08.06.2009 15:59
Page 23
Beispiel
Man möchte die Werte lediglich der Kinder untersuchen, die a) weiblich und b) älter als 13
Jahre sind.
Daten + Fälle auswählen. . . öffnet folgendes Fenster:
Dieses Fenster bietet einige Varianten an, wir besprechen jedoch lediglich die Möglichkeit
Falls Bedingung zutrifft. Aktiviert man diese Option und klickt man auf Falls... so kann
man z.B. Folgendes definieren:
Das „&“ bedeutet, dass beide Bedingungen gleichzeitig erfüllt werden müssen, bevor ein
Fall selektiert wird. Mittels Weiter und OK bewirkt man, dass bis zur Deaktivierung des
Filters, nur Mädchen (Geschlecht = 1) über 13 Jahre (Alter > 13) untersucht werden.
!Tipp
Auch hier zeigt die Informationszeile an, dass ein Filter aktiviert ist:
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
23 von 73 08.06.2009 15:59
Page 24
Zudem sind in der grauen, linken Spalte des Datenfensters in der Datenansicht alle nicht-
ausgewählten Fälle durchstrichen.
Nicht vergessen, auch diesen Filter wieder auszuschalten (mittels Daten + Fälle
auswählen und anklicken von „Alle Fälle“), sobald er nicht mehr benötigt wird.
Steuerung der Statistik-Prozeduren: Überblick
Übung zur Vorbereitung
Starten Sie SPSS und lesen Sie die Datei datal.sav ein!
!Tipp
Ist SPSS schon aktiviert, geht dies wie beschrieben über Datei + Öffnen. Sonst kann es
schneller sein, im Windows Explorer die Datei zu suchen und einfach auf deren Symbol
„doppelzuklicken“. SPSS wird dann automatisch mit dem ausgewählten Datensatz gestartet.
Bei von SPSS schon benutzten Dateien, kann man auch über Datei ... Zuletzt verwendete
Daten diese besonders schnell öffnen.
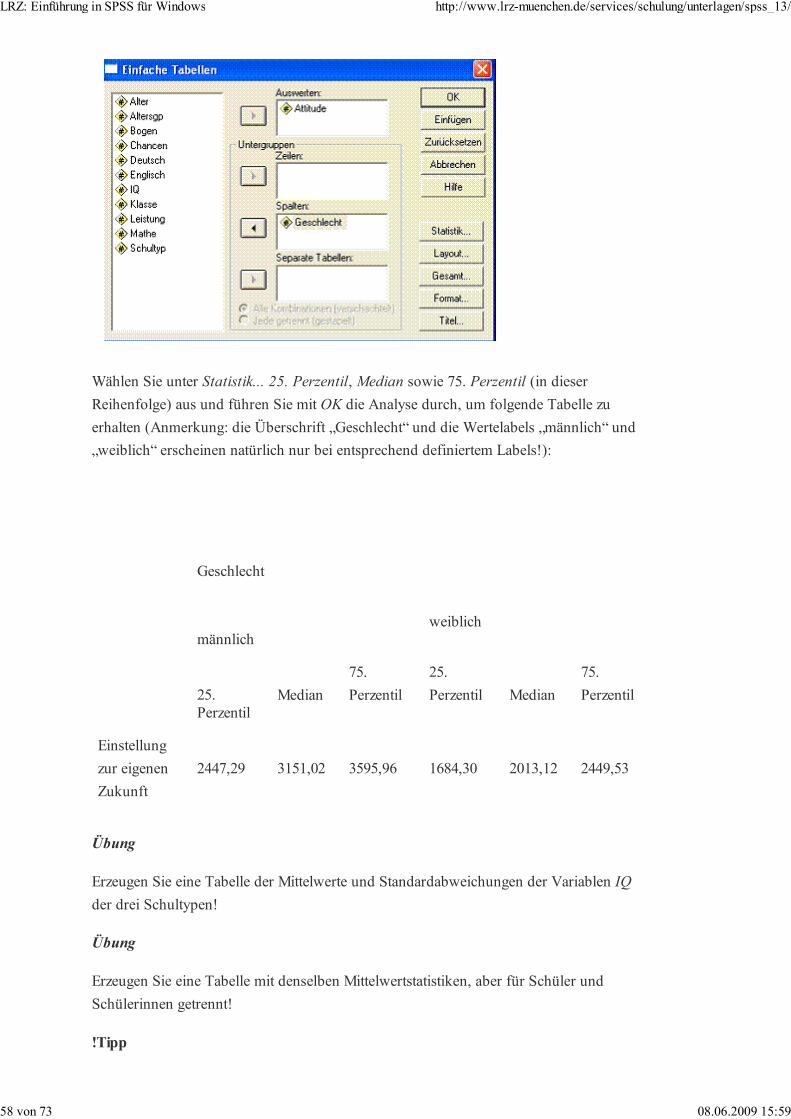
Über den Hauptmenüpunkt Analysieren + Deskriptive Statistiken + Kreuztabellen...
öffnen Sie als Beispiel für die typische SPSS-Prozedursteuerung das Steuerfenster für
Kreuztabellen: Aus der Variablenliste links klicken Sie die Variable Geschlecht an und
übertragen Sie diese durch Anklicken des Dreieck-nach-rechts-Taste in das Zeilen-
Subfenster. Übertragen Sie auf ähnliche Weise die Variable Schultyp in das Subfenster
Spalten:
Dieses Fenster weist einige Eigenschaften aus, die immer wieder bei der Steuerung der
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
24 von 73 08.06.2009 15:59
Page 25
Statistik-Routinen auftreten:
· links erscheint eine Variablenliste;
· rechts davon erscheint ein (oder mehrere) Fenster für die zu analysierende(n)
Variable(n);
· dazwischen sind dreieckige Pfeilknöpfe, die die Übertragung markierter Variablen in
die eine oder andere Richtung ermöglichen.
Getrennt von diesen Variablenauswahldiensten befinden sich prozedurspezifische
Steuerungsmöglichkeiten – in diesem Fall zwei (durch Anklicken) ankreuzbare Schalter
und vier Knöpfe, die weitere Steuerungsfenster öffnen. Einige dieser Möglichkeiten
werden später näher beschrieben.
Das „Anklicken“ in einem Prozedurfenster generiert (zunächst unsichtbare) Steuerbefehle
für SPSS. Ganz rechts sind vier Knöpfe, die das Ausführen dieser Befehle betreffen:
· OK führt die Befehle aus
· Einfügen kopiert die (sonst unsichtbaren) Befehle in Klartext in ein Syntax-Fenster:
Dort können Sie „per Hand“ editiert (erweitert, geändert) werden. Syntax-Fenster werden
später besprochen.
· Zurücksetzen bringt das Fenster in den ursprünglichen Zustand wieder (d.h. alles,
was man definiert hat, wird „vergessen“ und die Voreinstellungen wieder in Kraft gesetzt).
· Abbrechen schließt das Fenster, ohne die Befehle auszuführen.
· Hilfe bietet Unterstützung und lnformationen mittels der Windows-typischen
Hypertext-Schnittstelle an.
Klicken Sie nun auf OK!
Das wissensbasierte Informationssystem von SPSS
Über die rechte Maustaste kann die wissensbasierte Datenbank des Programms konsultiert
werden.
Beispiel:
Über Analysieren + Mittelwerte vergleichen wählen Sie Mittelwerte... aus, um einfache
Statistiken zu Gruppenmittelwerten und -unterschieden zu erhalten. Die Abhängige
Variable soll das IQ, die Unabhängige Variable die Art der Schule sein:
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
25 von 73 08.06.2009 15:59
Page 26
Über Optionen... gelangen Sie nun zu einem Fenster, das eine Fülle von Statistiken
anbietet. Angenommen, Sie möchten wissen, was die Option Anova Tabelle und Eta (im
Kästchen unten links) bedeutet, so klicken Sie mit der rechten Maustaste in dessen
Textfeld, um folgende Erklärung zu erhalten:
Wählen Sie nun Anova Tabelle und eta aus und lassen sie mittels Weiter und OK unter
anderem folgende Tabelle erzeugen:
Zusammenhangsmaße
Eta Eta-Quadrat
Intelligenzquotient
* Art der Schule,725 ,525
Aktivieren Sie durch Doppelklick diese Tabelle, klicken Sie mit der rechten Maustaste auf
der Überschrift Eta-Quadrat, danach auf Direkthilfe. Sie erhalten über das nun
erscheinende Steuerfenster, Auswahl Direkthilfe, detailliertere Auskunft:
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
26 von 73 08.06.2009 15:59
Page 27
Ausgabefenster und der Viewer
Unmittelbar nach dem Starten von SPSS ist lediglich das Daten-Editor-Fenster offen. Falls
kein Ausgabefenster schon geöffnet wurde, so öffnet das Ausführen einer Prozedur
automatisch ein Ausgabefenster, das die Ergebnisse der SPSS-Vorgänge erhält. Nach
Aufruf der Datei-Informationen und der Prozedur Kreuztabelle sähe die Ausgabedatei
(eher: ein Teil davon) so aus:
Alle Meldungen von SPSS, vor allem auch statistische Ausgabe wie Tabellen und
Grafiken, erscheinen in einem solchen Viewer-Fenster. Dieser Viewer ermöglicht sowohl
die schnelle Positionierung innerhalb der unter Umständen umfangreichen Ergebnisse als
auch die flexible Gestaltung dieser Ergebnisse.
Das Viewer-Fenster teilt sich in ein Übersichtstfeld (links) und ein Inhaltsfeld (rechts). Die
Trennlinie zwischen beiden Feldern kann mit Hilfe der linken Maustaste verschoben
werden.
Das Übersichtsfeld ist ein hierarchisch geordnetes Inhaltsverzeichnis, das Ihre
Arbeitssitzung mit SPSS protokolliert. Im Beispiel zeigt es an, dass die Ausgabe zwei
„Absätze“ (eine Kreuztabelle und Ausgabe der Prozedur „Mittelwerte“) enthält. Den Inhalt
beispielsweise des Übersichtsabsatzes Kreuztabellen kann man durch einen Klick auf dem
Minuszeichen links von der Crosstabs-Überschrift verstecken. Das Minus- ändert sich
dann in ein Pluszeichen. Ein erneuter Klick darauf zeigt wiederum den gesamten Inhalt
wieder an.
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
27 von 73 08.06.2009 15:59
Page 28
Dieser Absatz Kreuztabellen enthält vier Elemente: Klicken Sie auf Titel. Der rote Pfeil im
Übersichtsfeld bewegt sich zum Titel und auch im Inhaltsfeld erscheint ein roter Pfeil
neben dem Inhalt des Titels. Der Titel selbst ist mit einem verziehbaren Rahmen versehen.
Im Übersichtsfeld neben Titel ist ein kleines, offenes Buchsymbol: Ein Doppelklick darauf
„schließt“ das Buch; auch der Inhalt im Ausgabefenster wird unsichtbar. (Der Inhalt wird
dadurch nicht gelöscht: Das erreicht man erst mit Markierung des Elements bzw. der
Elemente und Betätigung der Löschtaste der Tastatur.) Ein zweiter Doppelklick öffnet das
Buch: Dessen Inhalt erscheint erneut im Ausgabefenster.
Übung
Über einen Doppelklick im Titelfeld ändern Sie „Kreuztabelle“ in „Crosstabs“. Versuchen
Sie auch, mehrere Zeilen einzutippen. Beenden Sie diese Verarbeitung durch Klicken
irgendwo außerhalb des Feldes.
Mehrere Viewer-Fenster
Für seine Ausgabe benötigt SPSS mindestens ein Viewer-Fenster. Es ist auch möglich,
mehrere solche Fenster zu öffnen. Das Öffnen eines neuen Fensters geschieht über Datei
+ Neu + Ausgabe. Nun muss zwischen
· aktiven und nicht-aktiven
und
· designierten und nicht-designierten Fenstern unterschieden werden:
Ein aktives Viewer-Fenster ist das aktuell angeklickte Fenster, wo sich der Cursor
üblicherweise befindet. Dieses Fenster ist durch eine unterschiedliche Färbung (mit der
Windows-Voreinstellung dunkelblau) der obersten Zeile gekennzeichnet. Klickt man in
einem zweiten Viewer-Fenster, so wird dieses aktiv, alle anderen bleiben/werden
deaktiviert.
Ein designiertes Fenster ist das Viewerfenster, in dem aktuell SPSS seine Ausgabe
(Grafiken, Tabellen, ...) schreibt. Das designierte Fenster wird durch ein rotes
Ausrufezeichen im Informationsbereich (links neben den Prozess-Mitteilungen) angezeigt:
Entsprechend gibt es im Werkzeugkasten eines nicht-designierten Viewerfensters ein rotes
Ausrufezeichen: Anklicken dieses Zeichens macht dessen Fenster zum designierten.
Übung
Öffnen Sie ein neues Viewer-Fenster und machen Sie dieses zum designierten Fenster!
Führen Sie das Kreuztabellen-Beispiel wieder aus!
Werkzeuge im Viewer
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
28 von 73 08.06.2009 15:59
Page 29
Der Viewer bietet einige Werkzeuge zur bequemen Gestaltung Ihrer Ausgabe:
Drei Werkzeuge zum Einfügen von Textelementen erlauben das Einfügen
von einer Absatzüberschrift bzw. von Titelzeilen bzw. von beliebigem Text.
Übung
Fügen Sie eine neue Absatzüberschrift ein!
Zwei Werkzeuge zum Öffnen/Schließen von Absatzinhalten
Expandieren bzw. Kollabieren (Öffnen bzw. Schließen) von Absätzen. Diese
Werkzeuge haben dieselbe Wirkung wie das Anklicken der Plus- bzw. Minus-
Zeichen im Inhaltsübersicht des Viewers.
Werkeuge zum Verändern der Hierarchie:
Schiebt das markierte Element eine Stufe höher bzw. tiefer in der Hierarchie.
Werkzeuge zum Anzeigen und zum Verstecken von Ausgabeteilen:
Den sichtbaren Ausgabeteil unsichtbar bzw. den unsichtbaren sichtbar machen.
Übungen
1. Öffnen Sie die Anmerkungen (per Voreinstellung zunächst nicht sichtbar).
2. Wiederholen Sie den Kreuztabellen-Vorgang (um eine zweite Prozedurausgabe zu
erzeugen).
3. Machen Sie den Inhalt des 1. Kreuztabellen-Absatz unsichtbar! Verschieben Sie den
zweiten Kreuztabellen-Absatz vor den ersten (markieren und anschließend mit gedruckter
Maustaste verschieben)! Fügen Sie einen beliebigen Text unmittelbar nach dem Titel der
ersten Kreuztabelle ein!
4. Löschen Sie die Anmerkungen aus beiden Absätzen!
5. Löschen Sie den gesamten 2. Kreuztabellen-Absatz!
OLAP (OnLine Analytic Processing): Interaktive Datenanalyse
Öffnen Sie falls nötig die Datendatei data1.sav!
Vom Datenfenster aus mittels Analysieren + Berichte + OLAP-Würfel... (OLAP: OnLine
Analytic Processing = interaktive, analytische Verarbeitung) erhält man ein
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
29 von 73 08.06.2009 15:59
Page 30
Steuerungsfenster, das das Erzeugen von interaktiv (um)gestaltbaren Tabellen mit
zusammenfassenden Statistiken ermöglicht:
Übertragen Sie die Variablen Deutsch, Englisch und Mathe (in der Reihenfolge) in das
Fenster Auswertungsvariablen, die Variable Geschlecht in das Fenster
Gruppenvariable(n)! Klicken Sie nun den Statistiken...-Knopf an und aktivieren Sie
lediglich Anzahl der Fälle, Mittelwert sowie Standardabweichung aus (d.h.: entfernen Sie
durch Markieren und Klicken des Dreiecks-nach-links die restlichen Statistiken)! Klicken
Sie Weiter an! Geben Sie über Titel... „Noten und Geschlecht“ als Titel und „LRZ-Kurs“
als Erklärung ein. Über Weiter und OK erhalten Sie folgende Ausgabetabelle:
Noten und Geschlecht
Geschlecht: Insgesamt
N Mittelwert Standardabweichung
Deutschnote 250 6,9920 2,60057
Englischnote 250 6,5800 3,70656
Mathematiknote 250 7,1040 2,54383
LRZ-Kurs
Die Überschrift „Geschlecht Insgesamt“ deutet an, dass die ausgegebenen Statistiken
für die gesamte Stichprobe (also: für beide Geschlechter zusammen) gelten. Solche
so genannte Pivot-Tabellen enthalten jedoch die gesamten angeforderten Informationen.
Aktivieren Sie durch Doppelklick die Tabelle! Sie wird durch eine schraffierte Umrandung
markiert und die Überschrift ergänzt sich um den Knopf . Klicken Sie diesen Knopf, um
die Statistiken für weibliche bzw. männliche Fälle zu inspizieren!
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
30 von 73 08.06.2009 15:59
Page 31
Übung
Aktivieren Sie (falls nötig) mit Doppelklick die Tabelle und wählen Sie die Subtabelle zu
den männlichen Fällen aus! Klicken Sie mit der rechten Maustaste in der Überschrift
Mittelwert und wählen Sie im nun erscheinenden Fenster Auswählen und dort Datenzellen
und Beschriftungen! Anschließend wählen Sie (wieder über die rechte Maustaste)
Diagramm erstellen und Linie!
Sie erhalten folgende graphische Darstellung der markierten Spalte:
(Wie solche Grafiken editiert und weiter gestaltet werden können, lernen wir später.)
Pivot-Tabellen
Tabellen, wie zum Beispiel gerade mit OLAP kreiert, heißen im SPSS-Jargon Pivot-
Tabellen. Diese können auch über andere Prozeduren erzeugt werden und bieten eine sehr
bequeme Möglichkeit, Daten zu untersuchen und deren Darstellung zu gestalten.
Doppelklicken Sie nun diese gerade erzeugte OLAP-Tabelle an. Die Menüleiste ändert sich
in
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
31 von 73 08.06.2009 15:59
Page 32
Wählen Sie unter dem Menüpunkt Pivot die Option Pivot-Leisten aus (unter Umständen
kann diese Option schon ausgewählt sein)! Das nun erscheinende Fenster
ist sowohl eine bildliche Darstellung als auch eine Steuerungsmöglichkeit der Tabelle.
Positionieren Sie den Kursor auf ein Pivot-Symbol , um zu sehen, welchen Teil der
Tabelle dieses symbolisiert. Das Pivot-Symbol der Spalten-Leiste entspricht zum Beispiel
den gewählten Statistiken: Häufigkeit (hier Anzahl genannt), Prozent innerhalb der Zeilen
und Prozent innerhalb der Spalten. Ziehen Sie dieses Symbol aus der Leiste Schicht nach
Zeile ...
...und inspizieren Sie die veränderte Tabelle! Ziehen Sie nun das Symbol für Variablen
(aktuell das linke Quadrat der Zeile) nach Spalte, das für Geschlecht nach Zeile und
beobachten Sie die Veränderung der tabellarischen Darstellung!
Durch Pivoting kann man also auf bequemer Weise Zeilen, Spalten und Schichten
tauschen.
!Tipp
Die Menüpunkte des Pivot-Fensters bieten einige einfache Aktionen automatisch an, unter
anderem:
· Zeilen und Spalten vertauschen
· Schichten in Zeilen verschieben
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
32 von 73 08.06.2009 15:59
Page 33
· Schichten in Spalten verschieben
Dieses einfache Beispiel zeigt lediglich das Prinzip des Arbeitens mit Pivot-Tabellen.
Solche Tabellen können deutlich komplexer sein als die unseres kleinen Beispiels: Die
Steuerung auch komplexerer Tabellen bleibt aber prinzipiell unverändert.
Grafik
(Falls nicht getan: Öffnen Sie die Datei data.sav!)
Grafische Ausgabe kann als „Nebenprodukt“ einiger Prozeduren (wie zum Beispiel, wie
gesehen, OLAP-Würfel) erzeugt werden, wird aber meist über den Menüpunkt Grafiken
kreiert.
Über Analysieren + Deskriptive Statistik + Häufigkeiten öffnen Sie folgendes
Prozedurfenster, über das man beispielsweise ebenfalls Grafiken als Nebenprodukt
erzeugen kann:
Übertragen Sie die Variable Englisch in das Variable(n)-Fenster; schalten Sie
Häufigkeitstabellen anzeigen aus (die darauf erscheinende Warnung können Sie
ignorieren!) und betätigen Sie die Taste Statistik..., um ein Subfenster mit weiteren Steuer-
möglichkeiten zu öffnen. Wählen Sie Mittelwert und Standardabweichung (Std.
Abweichung) aus! Quittieren Sie mit Weiter... Ihre Auswahl! Öffnen Sie nun das
Diagramme...-Subfenster und aktivieren Sie Histogramme und Mit
Normalverteilungskurve:
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
33 von 73 08.06.2009 15:59
Page 34
Quittieren Sie mit Weiter diese Auswahl und führen Sie über OK die Prozedur aus!
Es erscheint die übliche Titelzeile (hier: Häufigkeiten), eine zusammenfassende
Statistiktabelle mit den von Ihnen ausgewählten Statistiken, sowie die gewünschte
Graphik.
Statische Grafik
Über Grafiken + Gallerie erhält man einen Überblick über die verschiedenen von SPSS
unterstützten Grafiktypen.
Weitere Einzelheiten zur Steuerung bestimmter Grafiktypen erhält man durch Anklicken
des entsprechenden Symbols.
An dieser Stelle beschreiben wir die am häufigst anzutreffenden Grafikdarstellungen.
Balkendiagramme
Über Grafiken + Balken erhält man folgendes Steuerfenster:
Die Option Einfach erlaubt die Darstellung von Balken pro Ausprägung einer
Kontrollvariablen. Klicken Sie Definieren an:
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
34 von 73 08.06.2009 15:59
Page 35
Das Feld Kategorienachse erhält den Namen der (Gruppierungs-)Variablen, deren
Ausprägungen zusammengefasst werden sollen (z.B. Schultyp). Per Voreinstellung stellen
die so entstehenden Balken die Anzahl der Fälle pro Ausprägung dar. Die Balken können
aber andere Funktionen der kategorialen Variablen darstellen: Kumulative Anzahl,
Prozent- und kumulative Prozentangaben. Auch mathematische und statistische
Funktionen einer zweiten Variablen können dargestellt werden – zum Beispiel die mittlere
Deutschnote pro Ausprägung der Variablen Schultyp. Diese Möglichkeiten sind über das
Feld Bedeutung der Balken steuerbar.
Über Titel... können Titelzeilen, eine Subtitelzeile sowie Fußnotenzeilen festgelegt werden.
Optionen... bietet einige Möglichkeiten zur Behandlung von fehlenden Werten an, unter
anderem auch, ob fehlende Angaben in Form eines zusätzlichen Balkens dargestellt werden
sollen. Felder anordnen nach erlaubt eine Unterteilung der Darstellung nach den
Ausprägungen einer zusätzlichen kategorialen Variablen.
Übung
Erzeugen Sie ein Balkendiagramm, das die kumulative Prozentanteile der Ausprägungen
der Schultypen darstellt! Übertragen Sie die Variable Geschlecht ins Subfenster Felder
anordnen nach und Zeilen!
Unter Bedeutung der Balken klicken Sie Andere Statistik und übertragen Sie die Variable
Mathe ins Subfenster Variable. Per Voreinstellung wird der Mittelwert berechnet. Unter
Optionen wählen Sie nun Fehlerbalken anzeigen, darunter Standardabweichung und als
Multiplikator tragen Sie die Zahl 1 ein.
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
35 von 73 08.06.2009 15:59
Page 36
Übung
Erzeugen Sie ein Balkendiagramm, das die mittleren (mittels Andere Auswertungsfunktion)
geschätzten Berufschancen (Variable: Chancen) pro Schultyp darstellt!
Wählt man als Bartyp Gruppiert aus, so wird nach einer zweiten kategorialen Variablen
(Gruppen definieren durch) verlangt, deren Ausprägungen die Gruppierung festlegt:
Die Auswirkung dieser zweiten Variablen sieht man am einfachsten anhand eines Beispiels:
Übung
Erzeugen Sie ein gruppiertes Balkendiagramm der mittleren Englischnote pro Schultyp
(Kategorienachse), ergänzt durch die Gruppierungs-Variablen (Gruppen definieren durch)
Geschlecht!
Der Balkentyp Gestapelt ähnelt Gruppiert, die Gruppierungen werden jedoch nicht neben-
sondern übereinander dargestellt:
Übung
Erzeugen Sie ein gestapeltes Balkendiagramm der Häufigkeiten der Ausprägungen der
Variablen Schultyp (an der Kategorienachse, ergänzt durch die Stapel-Variablen (Stapel
definieren durch) Geschlecht!
Gruppen von Fällen (Auswertung über Kategorien einer Variablen), von einzelnen
Variablen (Auswertung über verschiedene Variablen) oder von Einzelfällen (Werte
einzelner Fälle) können über Grafiken + Balken... grafisch zusammengefasst werden.
Linien-, Flächen-, Kreisdiagramme und Boxplots
Die Steuerung von Linien-, Flächen- und Kreisdiagrammen (Linie..., Fläche... und
Kreis...) ähnelt der von Balkendiagrammen sehr und wird deswegen hier nicht näher
beschrieben. Boxplots werden später besprochen.
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
36 von 73 08.06.2009 15:59
Page 37
Streudiagramme
Streudiagramme sind das grafische Pendant zu Korrelationen bzw. Regressionsanalysen.
Sie werden über Grafiken + Streu-/Punkt-Diagramm... erzeugt:
Übung
Generieren Sie ein einfaches Streudiagramm der Variablen IQ (X-Achse) und Chancen
(Y-Achse)!
Aktivieren Sie durch Doppelklick in der Grafik den Diagramm-Editor: Klicken Sie einen
der kleinen Kreise des Diagramms an, um alle zu markieren! Über das Werkzeug
fügen Sie eine lineare Anpassungslinie (die Regressionslinie) hinzu!
Übung
Über Streu-/Punkt-Diagramm erzeugen Sie ein einfaches Punktdiagramm, in dessen Zeilen
die Verteilung nach Schultypen dargestellt wird!
Gestaltung der graphischen Ausgabe
Oft ist das von SPSS gestaltete Diagramm nicht genau die, die man haben will. Um
Diagramme zu editieren, doppelklicke man in der Grafik um den Diagrammeditor zu
starten.
Das Prinzip des grafischen Editierens ist einfach: Anklicken und Ändern. Hier gibt es
mehrere Varianten:
1. einfaches Anklicken und das gewünschte Werkzeug aus dem Werkzeugkasten
benutzen;
oder
2. einfaches Klicken, dann noch einmal Klicken, um z.B. Text zu ändern;
oder
3. Doppelklicken und die darauf erscheinende Fenstersteuerung anwenden;
oder aber
4. einfaches Anklicken mit der rechten Maustaste, um an weitere Werkzeuge zu
gelangen.
Die einzige Möglichkeit, diese flexiblen und umfangreichen Gestaltungsmöglichkeiten
kennenzulernen, ist zu experimentieren. Daher einige Übungen:
Übung:
Erzeugen Sie ein Balkendiagramm der Häufigkeit der Schüler pro Schultyp! Aktivieren sie
durch Doppelklick in dieser Grafik den Diagrammeditor!
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
37 von 73 08.06.2009 15:59
Page 38
Klicken Sie die Beschreibung der Y-Achse („Absolute Werte“) an und ändern Sie (ein
zweites Anklicken ist dazu nötig) diese in „Häufigkeit“! Klicken Sie in einem der Balken,
um alle zu markieren. Klicken Sie anschließend den Balken für die Hochbegabtenschule
und ändern Sie dessen Farbe (Werkzeug in der 2. Reihe)!
Über die rechte Maustaste fügen Sie eine Bezugslinie für die Y-Achse bei 55, eine zweite
bei 35! Färben Sie die Line bei 55 rot! Ändern Sie die Stärke beider Linien zu 3!
Das Ergebnis:
Schließen Sie den Diagrammeditor!
Übung:
Über Grafiken + Balken + Definieren und OK erzeugen Sie das Diagramm erneut!
Aktivieren Sie den Diagramm-Editor, markieren Sie die Balken und über den Menüpunkt
Transofrmieren ändern Sie den Grafik Typ in eine Liniendarstellung! Wählen Sie eine
gestrichelte Linienform mit der Stärke 5 aus!
Profildiagramme
Profildiagramme (siehe Diagramm unten) sind nur mit einigen Tricks zu erzeugen. Drei
Schritte sind notwendig:
1. Aggregieren der Datei so, dass die unabhängige (Gruppierungs-)Variable als
„Break“-Variable, die abhängigen als zu aggregierende Variablen fungieren. Die Funktion
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
38 von 73 08.06.2009 15:59
Page 39
belassen wir bei Mittelwert (Mean).
Dies geschieht über Daten + Aggregieren ... und erzeugt eine neue Datei mit so vielen
Fällen wie Ausprägungen der „Break“-Variablen, jeweils mit den Mittelwerten pro
Ausprägung der aggregierten Variablen.
Mit der Data data.sav und dem Steuerfenster zum Aggregieren wie folgt ausgefüllt
enthält die neue Datei (hier: aggr.sav) zwei Fälle (den Ausprägungen der Variablen
Geschlecht entsprechend) mit den jeweiligen Mittelwerten der Noten:
2. Transponieren (über: Daten + Transponieren) dieser Datei, wobei die
„Namensvariable“ die unabhängige Variablen (hier: Geschlecht) , die „Variablen“ die
abhängigen Variablen (hier: die Noten) sind.
Nun sieht der aggregierte Datendatei so aus:
Über den Reiter „Variablenansicht“ ändern Sie die Variablenlabel-Definitionen, um
Folgendes zuerreichen:
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
39 von 73 08.06.2009 15:59
Page 40
3. Nach der Definition der Variablenlabels erzeuge man mittels Grafiken + Linie ...
und die Auswahl von Mehrfach sowie Auswertung über verschiedene Variablen das
Diagramm: Die CASE_LBL (für das Diagramm in „Noten“ umbenannt) bildet die
Kategorienachse, die restlichen Variablen werden ins Feld Linien entsprechen übertragen.
Als Titel wähle man „Leistungsprofile der Geschlechter“.
Das Ergebnis nach etwas Überarbeiten mit dem Diagrammeditor (versuchen Sie, dies
selber zu realisieren!) ist ein Diagramm der Notenprofile beider Geschlechter:
Identifizierung einzelner Punkte (Fälle) einer Grafik
Übung
Erzeugen Sie ein einfaches Streudiagramm, das den Grad des Zusammenhangs zwischen
der Englischnote (Y-Achse) und dem IQ (X-Achse) darstellt. Aktiveren Sie durch
Doppelklick den Diagrammeditor, klicken Sie dort auf das Symbol und markieren
Sie mit dem daraus entstehenden neuen Cursor einige, beliebige Punkte des Diagramms,
um die Fälle zu identifizieren. Die ausgegebene Zahl ist die aktuelle Reihenfolge des
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
40 von 73 08.06.2009 15:59
Page 41
markierten Falles im Datenfenster (entspricht also der grauen Spalte links neben den
Daten). Klicken Sei erneut, um diese Identifkationszahl wieder verschwinden zu lassen!
Ein zweites Anklicken des Werkzeugs ändert den Cursor in die übliche Pfeil-Variante
zurück.
Zur Identifikation der Fälle kann man bei einigen Grafiktypen eine Variablen zur
Fallbeschriftung angeben, deren Werte beim Anwenden dieses Werkzeugs angezeigt
werden. Erzeugen Sie erneut das Streudiagramm, übertragen Sie jedoch die Variable
Bogen ins Feld „Fallbeschriftung“! Wiederholen Sie obige Editiervorgänge!
Interaktive Grafik
(Falls nicht schon getan, starten Sie SPSS mit dem Datensatz data.sav!)
Gesteuert wird die interaktive Grafik über Grafiken + Interaktiv:
Anhand der Band-(Schleifen-)Grafik werden weitere Aspekte der Steuerung der
interaktiven Grafik vorgestellt: Wählen sie Band...! Es erscheint das zwar
Band-spezifische, aber in seinen Gestaltungsmöglichkeiten für die interaktive Grafik
typische Steuerungsfenster:
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
41 von 73 08.06.2009 15:59
Page 42
Die Reiter (Variablen zuweisen, Bänder, Fehlerbalken, Titel und Optionen) beschreiben
steuerbare Aspekte der Grafik. Allgemein zu allen interaktiven Grafiken ist Variablen
zuweisen:
· links ist die übliche Variablenliste mit drei der Grafik zugrundegelegten
Variablentypen:
1. SPSS-interne Variablen wie Count (Anzahl, Häufigkeit):
2. Kategoriale Variablen mit einigen, wenigen Ausprägungen, üblicherweise ohne
numerische Bedeutung, wie hier Geschlecht:
3. Skalen-Variablen, die eine Quantifizierung implizieren, wie hier IQ:
· rechts oben ein Knopf zur dimensionalen Gestaltung (2D oder 3D) der Graphik:
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
42 von 73 08.06.2009 15:59
Page 43
· Darunter befindet sich eine Darstellung der X-Achse
(waagrechter Pfeil), der Y-Achse (senkrechter Pfeil) und einer möglichen Z-Achse (nach
„hinten“ weisender Pfeil), jeweils mit (hier noch leeren) Felder für die darzustellenden
Variablen:
Per Voreinstellung wird bei der Band-Grafik die Anzahl Fälle in der Y-Richtung pro Wert
der X-Achsenvariablen dargestellt.
Übung
Übertragen Sie (bei der interaktiven Grafik heißt das: Packen und Ziehen) die Variablen
Deutsch in das X-Achsen- (horizontales) Variablenfeld.
Mit OK erzeugen Sie die Grafik. Aktivieren Sie mit einem Doppelklick die interaktive
Steuerung, unter anderem mit folgendem Steuerungsfenster (der so genannten 3-D
Palette):
Mit den Rändelrädern können Sie die Grafik in waag- bzw. senkrechter Richtung, mit dem
Rotationswerkzeug in beiden Richtungen gleichzeitig drehen; mit der Lampe die
Lichtquelle sowohl in der Stärke als auch in der Positionierung ändern. Experimentieren
Sie!
Das interaktive Werkzeugkasten
unterstützt weitere Steuerungsmöglichkeiten:
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
43 von 73 08.06.2009 15:59
Page 44
· bietet die restlichen Steuerungsfelder des Fensters Variablen für Grafik
zuweisen interaktiv an:
So können Sie zum Beispiel statt der Deutschnote eine andere Variablen auf der
waagrechten Achse darstellen; oder weitere Variablen farblich darstellen; oder Variablen
zur Gestaltung der Linientypen bzw. Größe von Symbolen benutzen; oder die
3D-Darstellung in eine 2D-Darstellung mit 3D-Effekt aktivieren.
Übungen:
Ziehen Sie die Variablen Geschlecht in das Feld Farbe: unter Legendenvariablen und
inspizieren Sie das Ergebnis!
Ziehen Sie die Variablen Geschlecht in die Z-Achse (3. Dimension, nach „hinten“
weisend)!
Markieren Sie das Mädchen-darstellende Band und ändern Sie
Farbe und Schraffur !
Ziehen Sie nun das Geschlecht in das Feld Styles: unter Legendenvariablen und
inspizieren Sie das Ergebnis!
Übertragen Sie anschließend die Art der Schule in das Feld Feldvariablen und inspizieren
Sie das Ergebnis!
· erlaubt das Einfügen weiterer Elemente in der Grafik. Klicken Sie das
Werkzeug an und wählen Sie Balken aus!
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
44 von 73 08.06.2009 15:59
Page 45
· bietet über ein Übersichtsbild (den Diagramm-Manager) die Steuerung
verschiedener Elemente der Grafik an:
Durch Markieren des gewünschten Bildaspektes und z.B. Auswahl von Bearbeiten...
können sie weitere Gestaltungsmöglichkeiten realisieren. Experimentieren Sie damit!
!Tipp
Ein Doppelklick auf den gewünschten Grafikteil aktiviert automatisch die Funktion des
Editierens.
· ordnet automatisch Elemente einer Grafik.
· Mit den Pfeilen bzw. können ausgeführte Befehle rückgängig
gemacht bzw. wieder aktiviert werden.
· Mittels kann die 3D-Gestaltung gesteuert werden:
Die 3D-Beleuchtung unterstützt die gleiche Funktionalität
wie die Lampe der 3D-Palette; und letztere kann mittels
des Feldes neben 3D-Palette aktiviert oder deaktivert
werden.
Über das 3D-Symbol kann die Grafik als 2D, 2D mit 3D-Wirkung oder aber mit
einem 3D-Koordinatensystem gestaltet werden.
Am linken Rande des interaktiven Diagrammeditors befinden sich weitere Werkzeuge, um
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
45 von 73 08.06.2009 15:59
Page 46
· zwischen dem Zeiger , Texteingabe bzw. Rotierungswerkzeug
zu schalten.
· einfache Aspekte der Grafik zu gestalten: Farben, Schraffurmuster, Symbole und
Symbolgrößen, Linientypen und -stärke.
Die rechte Maustaste bietet auch viele kontextspezifische Gestaltungsmöglichkeiten an. Vor
allem verlangen einige Prozeduren bestimmte Datentypen: Versucht man zum Beispiel ein
Histogramm von Ordinal-Variablen zu erzeugen, so erscheint die Fehlermeldung
Nach dem Quittieren mit OK kann der Typ der Variablen über die rechte Maustaste
geändert werden.
Man verlässt den interaktiven Diagrammeditor durch Klicken im Ausgabefenster irgendwo
außerhalb des Diagramms.
!Tipp:
Die beste Möglichkeit, die Vielseitigkeit der Grafikfunktionalität kennen zu lernen, ist zu
experimentieren. Also: Spielen Sie!
Übungen:
Versuchen Sie, folgende Grafiken nachzubilden:
1. Balkendiagramm mit veränderter Balkenform und visueller Kennung ausgewählter
Balken:
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
46 von 73 08.06.2009 15:59
Page 47
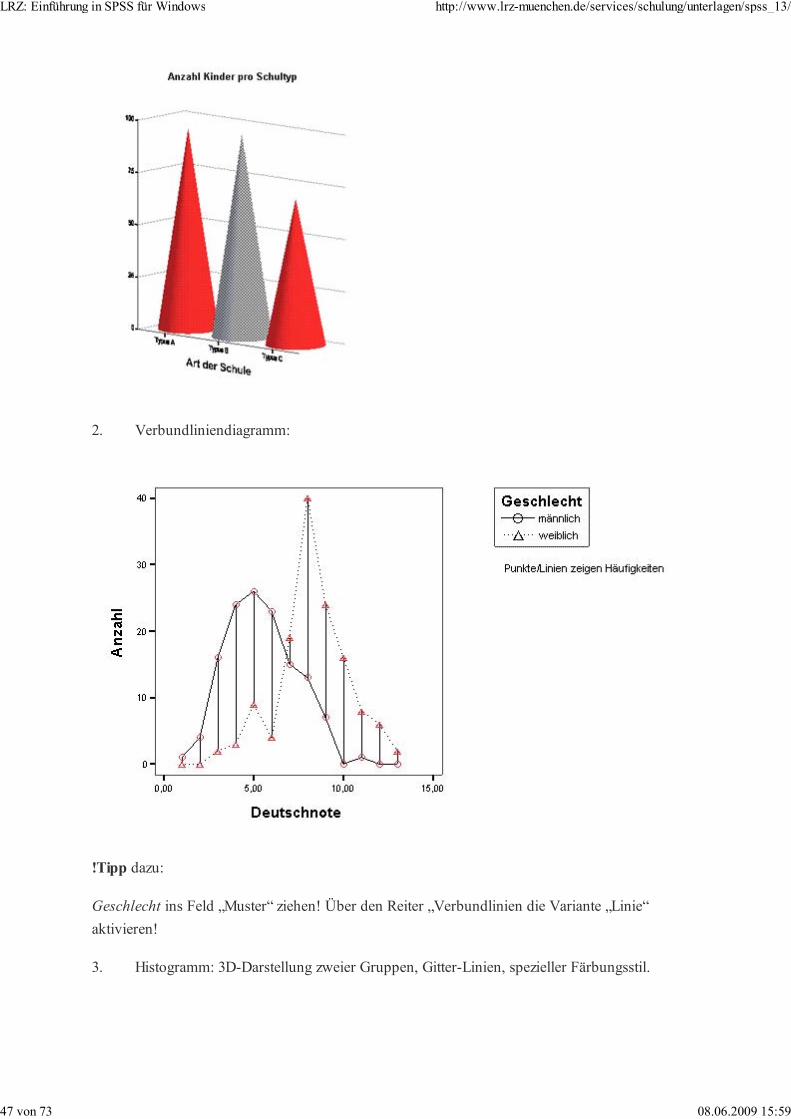
2. Verbundliniendiagramm:
!Tipp dazu:
Geschlecht ins Feld „Muster“ ziehen! Über den Reiter „Verbundlinien die Variante „Linie“
aktivieren!
3. Histogramm: 3D-Darstellung zweier Gruppen, Gitter-Linien, spezieller Färbungsstil.
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
47 von 73 08.06.2009 15:59
Page 48
!Tipp – und ein ganz wichtiger dazu!
Viele dieser dreidimensionalen, buntgefärbten und beleuchteten Grafiken sehen zwar
imposant aus. Man muss sich aber über den Zweck solcher Grafiken Gedanken machen:
Im universitären Bereich geht es nicht darum, zu imponieren, sondern zu informieren –
Daten zusammenzufassen, Ergebnisse schnell und präzis zu vermitteln.
Vergleichen Sie folgende Grafiken:
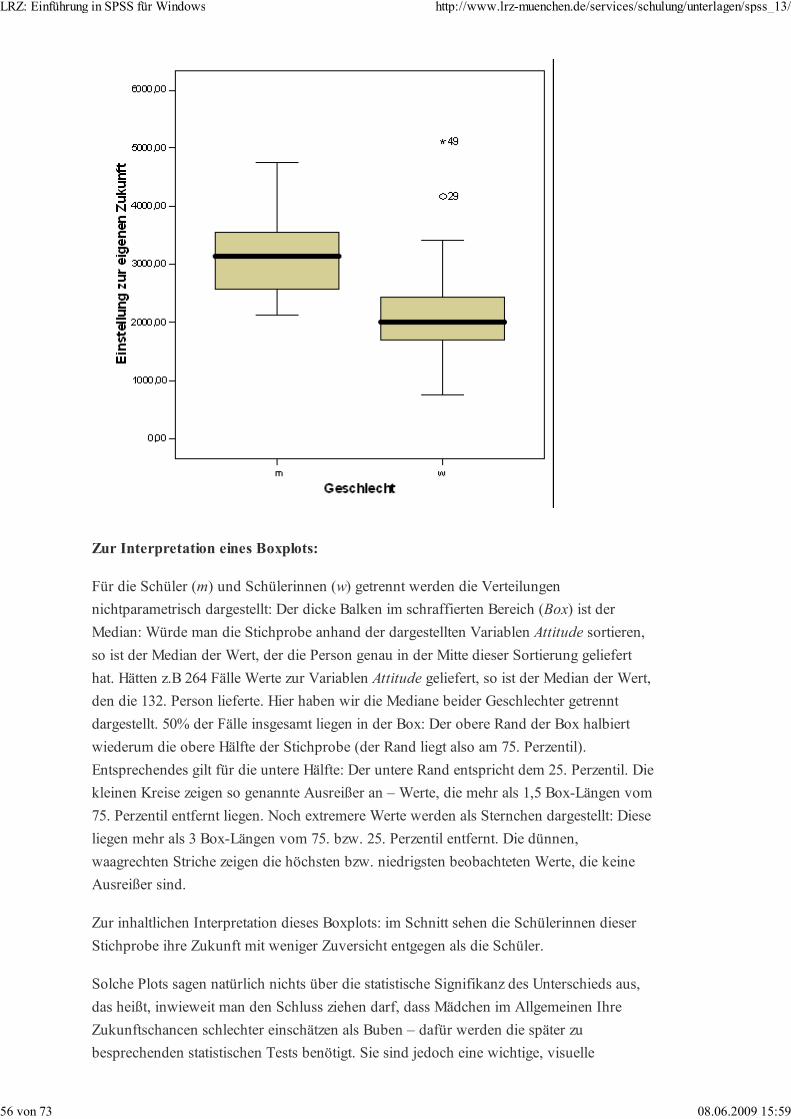
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
48 von 73 08.06.2009 15:59
Page 49
Informativer und vor allem deutlich leichter zu lesen ist die zweite, einfachere Variante, die
somit für wissenschaftliche Berichte besser geeignet ist. Beantworten Sie durch Inspizieren
dieser beiden Grafiken beispielsweise die Frage „Wie viele Kinder haben genau 11 Punkte
bei Ihrer Deutschprüfung erreicht?“.
(In diesem Falle allerdings täuscht die Darstellung als Line eine kontinuierliche Variable
vor. Angenommen, nur ganzzählige Note wären vergeben, so wäre ein Balkendiagramm
vorzuziehen.)
Übung:
Erzeugen Sie entweder mit der konventionellen oder mit der interaktiven Grafik in
Balkendiagramm: Y-Achse ist die Anzahl, X-Achse die Deutschnote.
Syntax-Fenster
SPSS wird durch Kommandos gesteuert. Eine Vielzahl dieser Steuerbefehle wird
automatisch durch Anklicken erzeugt und ausgeführt, ohne dass der Anwender etwas von
den Befehlen im Hintergrund merkt. Man kann solche Befehle aber explizit in einem
speziellen Syntax-Fenster schreiben lassen und dort editieren (ändern, ergänzen, ...). Diese
Syntax-Fenster spielen eine wichtige Rolle in der Handhabung des Programms, denn
mehrere Optionen und sogar ganze Prozeduren können nur über sie gestartet und gesteuert
werden.
Das SPSS Syntax Reference Guide enthält detaillierte Beschreibungen der Befehlssyntax
des Base Systems; Syntax zu den restlichen, fortgeschritteneren Teilen des Programms sind
in den Spezialhandbüchern enthalten (siehe Anhang B: Dokumentation).
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
49 von 73 08.06.2009 15:59
Page 50
Syntax-Fenster haben weitere Vorteile:
zur Protokollierung Ihrer Analysen (zum Beispiel als Anhang in Ihrer Arbeit)
zur exakten Wiederholen von Vorgängen, etwa mit anderen Datensätzen
(sogenanntes „Batch-Processing“)
zum Wiederholen von Vorgängen nach Beseitigung von Datenfehlern. Es ist
erstaunlich, wie oft Datenfehler auch nach vielen Analysen entdeckt werden, und
mehr als lästig, nach der Korrektur, alle Analysen wiederholen zu müssen – es sei
denn, Sie haben diese in Form von Syntaxbefehlen gespeichert.
!Tipp
Viele Statistikprozeduren benötigen wesentlich komplexere Befehle als die dieses
einfachen Beispiels. Gerade in solchen Fällen kann es Zeit sparend sein, beim ersten
Aufruf einer Prozedur die Ausgabe so zu gestalten, wie man sie haben will und die Syntax
dazu zu generieren, um dann bei weiteren Aufrufen (zum Beispiel, um andere Variablen zu
untersuchen), das Syntaxfenster einfach zu editieren und auszuführen.
Und so wird’s gemacht:
Die meisten Fenster unterstützen einen Knopf Einfügen, mit welchem man die durch
Anklicken generierten Befehle in ein Syntax-Fenster schreiben lassen kann.
Wie bei Viewer-Fenstern kann man auch mehrere Syntax-Fenster öffnen. Auch hier gelten
die Begriffe aktiv und designiert; und die Schaltung zwischen den möglichen Zuständen
wird genauso wie bei Viewer-Fenstern realisiert.
Übung
Über Analysieren + Deskriptive Statistiken + Kreuztabellen übertragen Sie Geschlecht ins
Feld „Zeilen“, Schultyp ins Feld „Spalten“.
Betätigen Sie nun Einfügen (statt OK): Es öffnet sich automatisch ein Syntax-Fenster mit
den Befehlen zu Ihrem Kreuztabellen-Aufruf:
Positionieren Sie den Cursor irgendwo innerhalb des Befehls: Klicken Sie nun auf ,
um eine Zusammenfassung der Kreuztabellen-Syntax zu erhalten: Für die genaue
Steuerung braucht man wohl die (umfangreichen und unübersichtlichen) Syntax-
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
50 von 73 08.06.2009 15:59
Page 51
Handbücher — die Befehle sind jedoch oft so verständlich, dass man ohne weitere
Kenntnisse sie sinnvoll ändern kann. So ist es im obigen Beispiel klar, dass eine
Kreuztabelle der Variablen Geschlecht und Schultyp erzeugt wird. Möchte man eine
Kreuztabelle von Geschlecht und Klasse, so könnte man die Syntaxbefehle selbst per Hand
ändern, ohne die Klickerei zu wiederholen – ändern Sie einfach per Hand „Schultyp“ in
„Klasse“.
Ausgeführt werden Befehle im Syntaxfenster durch Markieren der auszuführenden Befehle
und Klicken des Knopfes . Schließen Sie danach dieses Fenster!
Exportieren von SPSS-Ausgabe nach Word
Der bekannte Vorgang Kopieren + Einfügen (Copy + Paste) funktioniert zwischen SPSS
und Word wie bei anderen Programmen auch.
Beim Exportieren von Tabellen allerdings führt dieser Vorgang zu Erzeugen einer
Word-Tabelle, deren Formatierung oft unbefriedigend ist. Wendet man statt Einfügen die
Option Inhalte Einfügen und Grafik, so erscheint die Tabelle in der meist attraktiveren
Form, wie SPSS sie produziert. Das Editieren dieser Tabelle innerhalb von Word ist zwar
nicht mehr leicht möglich, denn Word versteht sie ja als Grafik, aber in den seltenen
Fällen, wo eine eine Veränderung notwendig ist, ist diese sowieso bequem und rapide in
SPSS zu realisieren.
Übungen zu Teil 1
Schließen Sie die SPSS-Sitzung!
Starten Sie SPSS!
Starten Sie SPSS mit der Datei data2.sav!
Inspizieren Sie die Definition der Variablen Geschlecht und stellen Sie sicher, dass
folgende Definitionen gelten:
· Variablenetikett: „Geschlecht“;
· Wertelabels: m = „männlich“, w = „weiblich“;
· Spaltenformat: 8, Dezimalstellen: 2.
Mit der interaktiven Grafik erzeugen Sie eine 2-dimensional Verbundlinie, die die Anzahl
($count) Personen pro Deutschnote für beide Geschlechter getrennt (Geschlecht ins Feld
„Muster“ übertragen) darstellt! Über den Reiter „Verbundlinien“ schalten Sie die Punkte
aus, die Linien ein! Klicken Sie OK!
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
51 von 73 08.06.2009 15:59
Page 52
Im interaktiven Diagramm-Editor entfernen Sie (rechte Maustaste!) die Erläuterung
(„Punkte/Linie zeigen Häufigkeiten“)! Entfernen Sie ebenfalls mit der rechten Maustaste die
senkrechten Verbundlinien!
Ändern Sie bei beiden Achsen über den Reiter „Beschriftungen“ die Zahlendarstellung so,
dass keine Nachkommastellen angezeigt werden! Die X-Achse hat von 0 bis 15 in Schritten
von 5 zu laufen:
Öffnen Sie ein neues, leeres Datenfenster! (Die gerade benutzte Datei data2.sav müssen
Sie nicht sichern!)
Erfinden Sie und geben Sie Daten für vier Patienten einer Klinik für Gewichtskontrolle ein:
Patientennummer (3-stellig, keine Nachkommastellen, Werte größer 25); Geschlecht
(0=männlich, 1 = weiblich); und zwei experimentelle Messungen zwischen 1 und 25
(Variablennamen: id geschl exp_1 exp_2), wobei die 2. Messung größer/gleich die 1. sein
soll.
Sichern Sie diese Daten in der Datei kg2.sav!
Lesen Sie Datei kgl.sav ein, die Daten zu weiteren Patienten der Gewichtskontrollstudie
enthält! Mischen Sie die neuen Fälle aus kg2.sav hinzu!
Berechnen Sie pro Fall die Differenz zwischen den beiden experimentellen Variablen!
Sortieren Sie die Datei absteigend nach dem Wert dieser Differenz!
Bilden Sie ein neue Gruppierungsvariablen (gruppe): Ist die eben berechnete Differenz
kleiner 10, so erhält gruppe den Wert 1, sonst den Wert 2.
Erstellen Sie eine Kreuztabelle gruppe ´ geschl! Aktivieren Sie die durch Doppelklick in
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
52 von 73 08.06.2009 15:59
Page 53
der Tabelle die OLAP-Funktionalität und tauschen Sie die Reihen und Spalten dieser
Tabelle! Ändern Sie die Überschrift in Therapierfolg und Geschlecht!
Erstellen Sie ein Histogramm der berechneten Differenz! Ändern Sie Farbe und Schraffur
der Grafik!
Sichern Sie die gesamte Datei unter dem Namen kg_gesamt.sav!
Beenden Sie die SPSS-Sitzung!
Teil 2: Anwendungsbeispiele
SPSS unterstützt eine sehr breite Palette von statistischen Prozeduren. Dieser Teil des
Kurses befasst sich mit einigen wenigen der häufigeren und einfacheren
Anwendungsgebieten.
Das Ziel hierbei ist ein zweifaches: 1. Das bisher Gelernte zu befestigen und auszubauen; 2.
Grundkenntnisse der Steuerung und der Interpretation einiger Basisstatistikverfahren zu
vermitteln.
Dieser Teil behandelt:
· einfache beschreibende Statistik
· einfache vergleichende (inferentielle oder Prüf-) Statistik
Zur Vorbereitung:
Öffnen Sie die Datei data2.sav!
Beschreibende Statistik
Häufigkeiten und Histogramme
Über Analysieren + Deskriptive Statistiken + Häufigkeiten erhalten Sie folgendes Fenster:
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
53 von 73 08.06.2009 15:59
Page 54
Zur Erinnerung: Typisch für die Steuerung der Statistik- und Grafikprozeduren sind:
· die Liste der Variablen (links) (die ja mittels Bearbeiten + Optionen unter dem Reiter
Allgemein und dort unter Variablenlisten umgestaltet werden kann)
!Tipp
Klicken Sie mit der rechten Maustaste auf einem Variablennamen (nehmen Sie hier
Geschlecht als Beispiel) und anschließend auf Info zu Variable, um ein kurze
Zusammenfassung deren Variablendefinition zu erhalten!
· Das nach rechts weisende Dreieck erlaubt das Übertragen markierter Variablennamen
nach weiteren Fenstern – im aktuellen Falle (Prozedur Häufigkeiten) ein einziges
Variable(n)...-Fenster.
· Die Knöpfe oben rechts haben folgende Funktionen:
OK führt die Befehle aus.
Einfügen schreibt die Befehle in Klartext in ein Syntax-Fenster.
Zurücksetzen bringt das Fenster in den ursprünglichen Zustand wieder (d.h. alles, was
bisher definiert wurde, wird „vergessen“ und die vorherigen Definitionen
wiederhergestellt).
Abbrechen schließt das Fenster, ohne die Befehle auszuführen.
Hilfe Bietet Unterstützung und lnformationen mittels der Windows-typischen
Hypertext-Schnittstelle an.
· Weitere, prozedurspezifische Optionen können durch Auswählen bzw. Knopfdruck
gesteuert werden.
Zur grafischen Darstellung von Häufigkeiten gibt es zwei Möglichkeiten:
1. Kontinuierliche Variablen, bei denen prinzipiell jeder Wert innerhalb eines Bereichs
und der Messpräzision vorkommen kann, werden als Histogramme dargestellt. Beispiele:
Alter in Jahren, Größe in cm.
!Tipp
Hier ist es ratsam, die Option Häufigkeitstabellen anzeigen auszuschalten! (Falls Sie sehen
wollen, warum, lassen Sie sie eingeschaltet!)
2. Diskrete (kategoriale, meist Gruppierungs-)Variablen, die lediglich einige, wenige
Werte (Ausprägungen oder Kategorien) aufweisen, können als Balken(Säulen-) oder
Kreisdiagramme dargestellt werden. Beispiele: Geschlecht, Altersgruppierungen,
Nationalität. Hier hat die Häufigkeitstabelle wieder einen Sinn.
Übung
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
54 von 73 08.06.2009 15:59
Page 55
Erzeugen Sie (mittels Häufigkeiten) ein Histogramm der (kontinuierlichen) Variablen IQ
(vergessen Sie nicht, die Häufigkeitstabelle auszuschalten)! Wählen Sie über den Knopf
Statistik... Mittelwert und Std.-Abweichung (Standardabweichung), über den Knopf
Diagramme... Histogramme sowie Mit Normalverteilungskurve aus!
Einfache beschreibende Statistik und Grafiken
Über Analysieren + Deskriptive Statistiken + noch einmal Deskriptive Statistiken erhält
man eine Tabelle mit ausgewählten Statistiken.
Übung
Aktivieren Sie die Prozedur Deskriptive Statistiken und untersuchen Sie die Variable IQ!
Verteilungsstatistiken und -darstellungen
Über Analysieren + Deskriptive Statistiken + Explorative Datenanalyse... kann man
explorative sowie einige beschreibende Statistiken und Grafiken erzeugen – Boxplots,
beispielsweise.
Übung
Geben Sie mittels Explorative Datenanalyse beschreibende Statistiken zur abhängigen
Variablen Attitude aus! Benutzen Sie die Variable Geschlecht als einzigen Eintrag in der
Faktorenliste, um getrennt pro Geschlecht beschreibende Statistiken auszugeben!
Das Explore-Fenster unmittelbar vor dem Ausführen sieht so aus:
Über den Knopf Diagramme... erzeugen Sie Boxplots: Schalten Sie die Stengel-Blatt-
Darstellung aus!
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
55 von 73 08.06.2009 15:59
Page 56
Zur Interpretation eines Boxplots:
Für die Schüler (m) und Schülerinnen (w) getrennt werden die Verteilungen
nichtparametrisch dargestellt: Der dicke Balken im schraffierten Bereich (Box) ist der
Median: Würde man die Stichprobe anhand der dargestellten Variablen Attitude sortieren,
so ist der Median der Wert, der die Person genau in der Mitte dieser Sortierung geliefert
hat. Hätten z.B 264 Fälle Werte zur Variablen Attitude geliefert, so ist der Median der Wert,
den die 132. Person lieferte. Hier haben wir die Mediane beider Geschlechter getrennt
dargestellt. 50% der Fälle insgesamt liegen in der Box: Der obere Rand der Box halbiert
wiederum die obere Hälfte der Stichprobe (der Rand liegt also am 75. Perzentil).
Entsprechendes gilt für die untere Hälfte: Der untere Rand entspricht dem 25. Perzentil. Die
kleinen Kreise zeigen so genannte Ausreißer an – Werte, die mehr als 1,5 Box-Längen vom
75. Perzentil entfernt liegen. Noch extremere Werte werden als Sternchen dargestellt: Diese
liegen mehr als 3 Box-Längen vom 75. bzw. 25. Perzentil entfernt. Die dünnen,
waagrechten Striche zeigen die höchsten bzw. niedrigsten beobachteten Werte, die keine
Ausreißer sind.
Zur inhaltlichen Interpretation dieses Boxplots: im Schnitt sehen die Schülerinnen dieser
Stichprobe ihre Zukunft mit weniger Zuversicht entgegen als die Schüler.
Solche Plots sagen natürlich nichts über die statistische Signifikanz des Unterschieds aus,
das heißt, inwieweit man den Schluss ziehen darf, dass Mädchen im Allgemeinen Ihre
Zukunftschancen schlechter einschätzen als Buben – dafür werden die später zu
besprechenden statistischen Tests benötigt. Sie sind jedoch eine wichtige, visuelle
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
56 von 73 08.06.2009 15:59
Page 57
Darstellung der Daten.
!Tipp
Es gehören sowohl passende statistische Tests als auch geeignete grafische Darstellungen
gemeinsam in einer Veröffentlichung!
Diese Plots helfen auch bei der zentralen Frage nach dem praktischen Belang vom
Unterschied (formal: nach dem Effek), eine Frage, die nur aus inhaltlichen (zum Beispiel in
diesem Fall didaktischen) Überlegungen entschieden werden kann.
einige Ausreißer (vor allem Fall 49) sind in diesem Boxplot erkennbar: Die Daten dieser
Fälle sollten näher inspiziert werden, denn solche Extremwerte könnten falsch eingetragene
Daten sein (bei diesem aktuellen Datensatz sind sie es nicht).
Man könnte überlegen, ob die angezeigten Ausreißer aus der Analyse ausgeschlossen
werden sollten:
!Tipp
Der Diagrammeditor bietet folgendes Werkzeug an, durch das man individuelle Punkte
identifizieren und auch entfernen kann:
Übung
Aktivieren Sie durch Doppelklick im Bereich der Grafik den Diagrammeditor, und
benutzen Sie dieses Identifikationswerkzeug um die Fall-Identifikation zu inspizieren bzw.
auszuschalten!
!Tipp
Ausreißer können auch über die Sortierfunktion von SPSS identifiziert werden. Sortieren
Sie (im Datenfenster über Daten + Fälle sortieren...) den Datenbestand absteigend nach
der Variablen Attitude: Die Fälle mit extrem hohen Werten sind dann die ersten des
Datenfensters. Fälle mit extrem niedrigen Werten sind am unteren Ende der Daten.
Über Analysieren + Tabellen + Einfache Tabellen... können die relevanten Statistiken
tabellarisch aussgegeben werden. Übertragen Sie die Variablen wie folgt:
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
57 von 73 08.06.2009 15:59
Page 58
Wählen Sie unter Statistik... 25. Perzentil, Median sowie 75. Perzentil (in dieser
Reihenfolge) aus und führen Sie mit OK die Analyse durch, um folgende Tabelle zu
erhalten (Anmerkung: die Überschrift „Geschlecht“ und die Wertelabels „männlich“ und
„weiblich“ erscheinen natürlich nur bei entsprechend definiertem Labels!):
Geschlecht
männlichweiblich
25.Perzentil
Median
75.
Perzentil
25.
Perzentil Median
75.
Perzentil
Einstellung
zur eigenen
Zukunft
2447,29 3151,02 3595,96 1684,30 2013,12 2449,53
Übung
Erzeugen Sie eine Tabelle der Mittelwerte und Standardabweichungen der Variablen IQ
der drei Schultypen!
Übung
Erzeugen Sie eine Tabelle mit denselben Mittelwertstatistiken, aber für Schüler und
Schülerinnen getrennt!
!Tipp
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
58 von 73 08.06.2009 15:59
Page 59
Experimentieren Sie auch mit der komplexeren Tabellenvariante (Analysieren + Tabellen
+ Allgemeine Tabellen...)!
Kreuztabellen: Untersuchung kategorialer Variablen
Öffnen Sie, falls nötig, die Datei data2.sav!
Über Analysieren + Deskriptive Statistiken + Kreuztabellen kann man Kreuztabellen
gestalten.
Übung
Öffnen Sie ein neues Ausgabe-Fenster!
Übung
Erzeugen Sie eine Kreuztabelle: Ausprägungen der Variablen Klasse bilden die Zeilen,
Ausprägungen der Variablen Altersgp bilden die Spalten dieser Tabelle!
Übung
Öffnen Sie erneut das Kreuztabellen-Steuerungsfenster und fügen Sie als Schicht-
Variablen Geschlecht hinzu! Klicken Sie OK, aktivieren Sie die so erzeugte Pivot-Tabelle
(und falls nötig über den Menüpunkt „Pivot“ die Pivot-Leisten-Fenster) und gestalten Sie
diese Tabelle so um, dass die Schichten durch Altersgp, die Zeilen durch Klasse und die
Spalten durch Geschlecht bestimmt werden!
Inspizieren Sie alle Schichten dieser Tabelle!
Prüfstatistik
Die klassischen parametrischen Testverfahren (T-Test, Varianzanalyse, ...) basieren auf
Annahmen der Verteilung der zu untersuchenden (abhängigen) Variablen. In den meisten
Fällen wird die sogenannte „Normalität“ dieser Verteilung angenommen. (Die LRZ-Schrift
SPSS for Windows Special Topics: Einige Grundbegriffe der Statistik enthält Einiges zu
diesem Thema: Siehe Anhang B.)
Korrelation
Falls nötig, öffnen Sie die Datei data.sav!
Die passende Grafik zur Korrelation ist das Streudiagramm – hier anhand der Korrelation
zwischen IQ und der Mathenote: Grafiken + Streu-/Punkt-Diagramm… + Auswahl von
Einfaches Streudiagramm:
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
59 von 73 08.06.2009 15:59
Page 60
(Es ist üblich, die abhängige Variable in der Y-, die unabhängige in X-Achse darzustellen:
in diesem Fall wird die Mathenote als von dem IQ abhängig betrachtet.)
Das Ergebnis:
Jeder Punkt im Diagramm stellt eine oder mehrere Personen dar: deutlich zu sehen ist das
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
60 von 73 08.06.2009 15:59
Page 61
für eine positive Korrelation typische Muster, eine von unten links nach oben rechts
steigende Punktwolke.
Der dazugehörige Korrelationskoeffizienten ist entweder der Pearson’sche Koeffizient r,
der den linearen Zusammenhang zwischen zwei Variablen quantifiziert; oder aber der
Spearman’sche Koeffizient rho, der den monotonen Zusammenhang misst. (Dementgegen,
was in einigen Büchern zu lesen ist, setzt die Berechnung des Pearson’schen Koeffizienten
keine Normalverteilung voraus! Die Normalverteilung wird lediglich für die Berechnung
der Signifikanz dieses Koeffizienten angenommen.). Das Steuerungsfenster erlaubt es
auch, ein- oder zweiseitige Signifikanzen zu berechnen, unterstützt jedoch leider keine
Korrektur für die Signifikanzwerte mehrerer gegenseitig abhängigen Koeffizienten.
Füllen Sie das mittels Analysieren + Korrelation + Bivariat … geöffnete Steuerfenster wie
folgt aus:
um die Ergebnisse zu r und zu rho zu erhalten:
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
61 von 73 08.06.2009 15:59
Page 62
Es ist üblich im Falle vom Pearson’schen Koeffizienten nicht nur den einfachen r sondern
auch r2 als Maß der Effektgröße (Proportion gegenseitig erklärter Varianz) zu berichten. In
Ihrer Arbeit könnte zum Beispiel stehen:
Zum Testen der Hypothese, dass IQ und Mathe einen positiven linearen Zusammenhang
aufweisen wurde der Pearson’sche Koeffizient r herangezogen. Die Hypothese wurde
bestätigt: r = 0,71, p < 0,001; r2 = 0,50 – d.h. 50% der gemeinsamen Varianz wird
durch diesen Koeffizienten erklärt.
Mittelwertvergleiche: T-Test
Der T-Test erlaubt Mittelwertvergleiche entweder:
· anhand von einer Variablen gemessen an zwei zu vergleichenden Gruppen; oder
· innerhalb einer einzigen Gruppe anhand von zwei zu vergleichenden Variablen (d.h.:
jeder Fall liefert beide Variablen).
Öffnen Sie, falls nicht schon getan, die Datei data2.sav!
Gruppenvergleiche mit dem T-Test bei unabhängigen Stichproben
Der T-Test für unabhängige Stichproben testet, ob zwei Gruppen sich im Mittel anhand
von einer Variablen statistisch unterscheiden. Über Analysieren + Mittelwerte vergleichen
+ T-Test bei unabhängigen Stichproben... erhält man folgendes (hier: schon ausgefülltes
Fenster):
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
62 von 73 08.06.2009 15:59
Page 63
(Die zu vergleichenden Ausprägungen „0“ und „1“ der Gruppierungsvariablen Geschlecht
werden über den Knopf Gruppen def. ... festgelegt.) Klicken Sie OK!
Unsere Hypothese: Mädchen haben im Mittel signifikant höhere Noten in Englisch als
Junge.
Das Ergebnis dieses Tests:
Der erste Teil dieser Ausgabe (Gruppentatistiken) enthält beschreibende Statistiken zu den
beiden Gruppen: Hier werden die Geschlechtsgruppen anhand der Englischnote verglichen.
Die Mädchen haben einen rein numerisch höheren Mittelwert als die Jungen. Ob dieser im
statistischen Sinne höher ist, wird in der zweiten Tabelle dargestellt.
Der klassische T-Test beruht auf der Annahme der gleichen Varianzen für beide zu
vergleichenden Gruppen. Die Spalten mit der Überschrift Levene Test der
Varianzgleichheit teilen mit, inwieweit diese Annahme erfüllt ist. Ist dieser F-Test
signifikant (oft wird hier p < 0,1 als Grenzwert genommen), so unterscheiden sich die
Varianzen und man lese die unterste Zeile der Tabelle (Varianzen sind nicht gleich), die
eine Korrektur für die ungleichen Varianzen enthält. Ist er – wie hier – nicht signifikant, so
lese man die Zeile davor (Varianzen sind gleich).
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
63 von 73 08.06.2009 15:59
Page 64
Eine Veröffentlichung zu dieser Studie könnte folgendes berichten:
Im Schnitt ist die Englischnote der Mädchen (Mittelwert: 9,45, Standard Abweichung
2,10) signifikant höher als die der Jungen (Mittelwert 3,38, Standard Abweichung 1,66):
T = -10,992, df = 48, p < 0,001.
In diesem Beispiel testen wir die einseitige Hypothese, dass Mädchen im Schnitt höhere
Englischnoten als Buben erhalten. Das heißt: die Signifikanz ist nur dann relevant—und
darf auch nur dann inspiziert und berichtet werden—wenn der Mittelwert der Mädchen
rein numerisch in der Tat höher ist als der der Buben. Der vom Programm ausgegebene
Signifikanzwert ist aber ein zweiseitiger Wert, der gleichzeitig beide Möglichkeiten testet:
Mädchen besser als Buben und/oder Buben besser als Mädchen. Demnach ist dieser
zweiseitige p-Wert genau das Doppelte vom einseitigen Wert, den wir für unsere Hpothese
benötigen. Die Justierung ist also einfach: Man halbiere den ausgegebenen Wert. Wäre der
zweiseitige Signifikanzwert zum Beispiel p = 0,06, so wäre der einseitige p = 0,03.
Im aktuellen Fall ist dieser von SPSS ausgegeben Wert 0,000, da SPSS per Voreinstellung
lediglich drei Stellen ausgibt. Das heißt, der wahre Wert ist auf jeden Fall kleiner 0,001
(p < 0,001) und auch für den korrigierten, halbierten Wert gilt dies natürlich ebenfalls.
!Tipp:
Enthält die SPSS-Ausgabe – wie in diesem Fall – als Signifikanzwert „0,000“, so berichten
Sie dies als „ p < 0,001“! Sonst nach „ p = “ geben Sie den von SPSS ausgegebenen Wert
an!
Gruppenvergleiche mit dem T-Test für abhängige Stichproben
Der T-Test für gepaarte Stichproben testet, ob zwei Variablen, pro Fall gemessen, sich im
Mittel unterscheiden. Über Analysieren + Mittelwerte vergleichen + T-Test bei gepaarten
Stichproben... aktivieren Sie das Steuerungsfenster und übertragen Sie die Variablen
Mathe und Englisch ins Feld „Gepaarte Variablen“.
Wir testen die Hypothese, dass die Noten in Englisch und in Mathe sich im Mittel
unterscheiden. Das Ergebnis:
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
64 von 73 08.06.2009 15:59
Page 65
Der p-Wert von 0,876 erreicht kein auch nur annähernd signifikantes Level: Statistisch
betrachtet unterscheiden sich die Englisch- und Mathenoten nicht. In Ihrem Bericht
könnten Sie schreiben:
Die Englischnote (Mittelwert: 6,90, Standardabweichung: 3,58) ist zwar numerisch leicht
höher als die Mathematiknote (Mittelwert: 6,80, Standardabweichung: 2,41), diese
Differenz ist jedoch statistisch nicht signifikant (T = 0,157, df= 49, p = 0,876, n.s.).
Mittelwertvergleiche: Einfaktorielle Varianzanalyse (ANOVA)
Der parametrische Test für Mittelwertunterschiede einer Variablen zwischen mehreren
(mehr als zwei) Gruppen (Ausprägungen einer einzigen Klassifikationsvariablen wie zum
Beispiel Schultyp eingeteilt in 1: Realschule, 2: Gymnasium und 3: Hochbegabtenschule) ist
die einfaktorielle Varianzanalyse (ANOVA). Auch dieser Test setzt nicht nur die Normalität
der Variablen sondern auch die Varianzhomogenität (das heißt: Statistisch dürfen die
Varianzen der Gruppen sich nicht unterscheiden) voraus!
Über Analysieren + Mittelwerte vergleichen + Einfaktorielle ANOVA. . . erhält man
folgendes Steuerungs-fenster:
Übung
Testen Sie, ob die drei Schultypen (Faktor = Gruppierungsvariable) sich anhand der
Mathemathiknote (abhängiger Variablen) unterscheiden!
!Tipp
Da der ANOVA-Test die Homogenität der Varianz voraussetzt, müssen Sie dies auch
testen: Über Optionen... schalten Sie den Test ein!
Die Ausgabe bestätigt: Der Levene-Test in der ersten Tabelle zeigt keine signifikante
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
65 von 73 08.06.2009 15:59
Page 66
Abweichung von der Homogenität der Varianzen (auch hier wird einen Grenzwert von 0,1
oft akzeptiert). Wir dürfen also ohne Bedenken die klassische ANOVA-Tabelle (die zweite
Tabelle) interpretieren: Diese bestätigt, dass ein signifikanter Gruppenunterschied besteht:
Berichten könnte man:
Die drei Schultypen unterscheiden sich signifikant: F(2;47)=9,467, p<0,001.
Der klassische ANOVA hört damit auf – meistens will man aber nicht nur testen, ob es
Unterschiede zwischen den Gruppen gibt, sondern auch welche Gruppen sich signifikant
voneinder unterscheiden. Liefert also der klassische Test ein signifikantes Ergebnis, so
wiederhole man die Analyse und schalte dabei über den Knopf Post Hoc. . . einen
nachträglichen Test, der formal dann und nur dann angewendet werden darf, falls der Test,
wie gerade durchgeführt, einen signifikanten Unterschied zwischen allen Gruppen
nachgewiesen hat. In diesem Fall ist dies gegeben, so dass man aus der Testgruppe
Varianz-Gleichheit angenommen (wie vom Levene Test bestätigt) einen passenden Test
für diese paarweisen Vergleiche auswählen kann. Ein häufig angewandter Ansatz zum
Vergleich der Gruppen bei Homogenität der Varianzen ist (wie hier ausgewählt) der von
Bonferroni:
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
66 von 73 08.06.2009 15:59
Page 67
Die Ausgabe dazu:
Diese Tabelle vergleicht alle Ausprägungen der Klassifizierungsvariablen paarweise
miteinander: Schultyp 1 mit Schultypen 2 und 3; Schultyp 2 mit Schultypen 1 und 3 usw.
Die Spalte Signifikanz gibt pro Paar den für multiple gegenseitig abhängige Vergleiche
korrigierten Signifikanzwert aus. Hier unterscheiden sich also die Schultypen 2 und 3
anhand der Mathematiknote nicht, die anderen Paare doch.
Deutet der Levene-Test dagegen auf einen signifikanten Unterschied zwischen den
Gruppenvarianzen, so schalte man einen der Tests aus der Rubrik Keine Varianz-
Gleichheit angenommen ein.
Nichtparametrische Vergleiche
Falls nötig: Öffnen Sie die Datei data2.sav!
Vergleich von zwei Gruppen
Häufig benutzte nichtparametrische Pendants zum T-Test für zwei unabhängige
Stichproben sind der Mann-Whitney-U-Test und der Wilcoxon-W-Test.
Zunächst inspizieren wir die Englischnoten der beiden Geschlechter anhand eines
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
67 von 73 08.06.2009 15:59
Page 68
Boxplots:
Testen wir nun mit dem nicht-parametrischen Mann-Whitney-Test, ob der dargestellte
Unterschied statistische Signifikanz erreicht: Analysieren + Nichtparametrische Tests +
Zwei unabhängige Stichproben...:
Das Ergebnis:
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
68 von 73 08.06.2009 15:59
Page 69
Sowohl Mann-Whitney als auch Wilcoxon bauen ihre Tests auf einen Vergleich der
Rangreihen der Fälle nach der zu untersuchenden Variablen. Die obere Tabelle enthält eine
Zusammenfassung dieser Rangstatistiken: Der mittlere Rang anhand der Englischnote der
Jungen ist in unserem Beispiel 11,19, der der Mädchen 35,86. Überwiegend liegen die
Jungen in den niedrigeren, haben also im Schnitt schlechtere Englischnoten als die
Mädchen. Ob dieses „schlechter“ signifikant ist, wird in der unteren Tabelle berichtet. Der
U-Wert von Mann-Whitney beträgt 4, oder als Z-Werte ausgedrückt einen Wert, der fast
sechs Standardabweichungen vom theoretischen Mittelwert entfernt liegt. Die 2-seitige
Signifikanz (p < .001) bestätigt den Eindruck des Boxplots.
Anmerkung:
Die SPSS-Realisierung der nicht-parametrischen Verfahren zu Gruppenvergleichen
erkennt „String“ (Zeichenketten-)Variablen gar nicht. Hätte man bei Geschlecht zum
Beispiel „m“ und „w“ eingegeben, um zwischen den Geschlechtern zu unterscheiden, so
würde der Variablenname in der Variablenliste nicht einmal erscheinen, und man müsste
die Variable mittels Transformieren + Umkodieren so verändern, dass numerische Werte,
wie etwa „0“ und „1“, die Buchstaben ersetzen. Aus diesem ganz praktischen Grund könnte
man diese Variablen von vonherein so realisieren.
Paarweise Vergleiche von Variablen
Ein häufig anzutreffendes Äquivalent zum paarweisen T-Test ist der Wilcoxon-Test, der
über Analysieren + Nichtparametrische Tests + Zwei verbundene Stichproben... zu
erreichen ist.
Übung
Wiederholen Sie den Vergleich zwischen den Variablen Englisch und Mathe aller Schüler,
jedoch mit dem nichtparametrischen Wilcoxon-Test! Interpretieren Sie die Ergebnisse!
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
69 von 73 08.06.2009 15:59
Page 70
Vergleiche von mehr als zwei Gruppen
Nichtparametrische, einfaktorielle Varianzanalysen (also: Vergleiche von mehr als zwei
Gruppen) können mit dem Kruskal-Wallis-Test realisiert werden: Analysieren +
Nichtparametrische Tests + K unabhängige Stichproben.
Übung
Versuchen Sie, mit Ihrem nun erworbenen Wissen, den Kruskall-Wallis Test anzuwenden,
um die drei Schultypen anhand der Variablen IQ zu vergleichen!
Die SPSS-Ausgabe dazu:
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
70 von 73 08.06.2009 15:59
Page 71
Übungen zu Teil 2
Öffnen sie die Datei alcohol.sav!
Inspizieren Sie die Liste der Variablen (am einfachsten über den Hauptmenüpunkt Extras
+ Variablen...), um ein „Gefühl“ für den Inhalt dieser Datei zu bekommen!
Benutzen Sie grafische Methoden, um die Verteilungen der Variablen stre_v und stre_n zu
untersuchen!
Erzeugen Sie eine Grafik der Verteilungen der Variablen stre_v und stre_n, die
(parametrisch) die Werte der Stadt- und Landbewohner vergleicht! Gestalten Sie diese
Grafik so, dass sie für eine Veröffentlichung benutzt werden könnte! Exportieren Sie diese
Grafik nach Word!
Erzeugen Sie eine Tabelle, die der gerade erzeugten Grafik entspricht (Inhalt: Mittelwert
und Streuung der beiden Variablen, für Stadt- und Landbewohner getrennt)! Exportieren
Sie auch diese Tabelle nach Word!
Berechnen Sie eine neue Variable, die den Unterschied zwischen Stress-Level vor und
Stress-Level nach Alkoholeinnahme enthält!
Unterscheiden sich Stadt- und Landbewohner anhand der Alkoholeinnahme? Anhand des
Stress-Levels vor Alkoholeinnahme? Anhand des Stress-Levels nach Alkoholeinnahme?
Anhand des Stress-Unterschieds vor gegen nach Alkoholeinnahme? Sind diese
Unterschiede statistisch signifikant?
Wiederholen Sie den Geschlechtsvergleich, aber veranlassen Sie, dass SPSS die Tests
getrennt für Stadt und Land durchführt!
Falls Sie signifikante Unterschiede finden, erzeugen Sie passende Grafiken dazu!
Anhang A: Beispielfragebögen
Fragebogen-Nr.: 116 Noten (1 - 15):
Deutsch: 2
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
71 von 73 08.06.2009 15:59
Page 72
Schultyp (1 - 3): 1
Englisch: 6
Mathematik: 2
Alter: 10
IQ: 99
Geschlecht (0=m, 1=w): 0
Chancen: 72
Klasse (5 - 13): 5
Fragebogen-Nr.: 150 Noten (1 - 15):
Deutsch: 1
Schultyp (1 - 3): 1
Englisch: 4
Mathematik: 1
Alter: 10
IQ: 91
Geschlecht (0=m, 1=w): 0
Chancen: 26
Klasse (5 - 13): 5
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
72 von 73 08.06.2009 15:59
Page 73
Anhang B: Dokumentation
Die gesamte Dokumentation zur deutschen bzw. englischen Variante des Programms SPSS
erhalten Sie beim Kauf einer Lizenz als zweite CD zum Programm.
Folgende LRZ-Schriften zum Programm sind sowohl im Internet als auch in gedruckter
Form verfügbar:
Wiseman, M. SPSS für Windows Special Topics: Einige Grundbegriffe der Statistik.
München, 1999: Leibniz-Rechenzentrum der Bayerischen Akademie der Wissenschaften.
Auch im Internet:
http://www.lrz-muenchen.de/services/schulung/unterlagen/grundbegriffe/
Inhalt: Erklärungen und Diskussion zu folgenden Begriffen der Statistik: Skalenniveau;
Normalverteilung (Bedeutung? Wann notwendig? Wie überprüfen?); Signifikanz,
Effektgröße, Power; „Exakte Statistik“ und kleine Stichproben
Wiseman, M. SPSS für Windows Special Topics:Lineare Regression. München, 1999:
Leibniz-Rechenzentrum der Bayerischen Akademie der Wissenschaften. Auch im Internet:
http://www.lrz-muenchen.de/services/schulung/unterlagen/regression/
Inhalt: Detaillierte Diskussion mit Beispielen über die Anwendung und Problematik des
Regressionsmodells
LRZ: Einführung in SPSS für Windows http://www.lrz-muenchen.de/services/schulung/unterlagen/spss_13/
73 von 73 08.06.2009 15:59