140
Algorithmen und Datenstrukturen Dr. Beatrice Amrhein 5. Januar 2016

Algorithmen und Datenstrukturen
Dr. Beatrice Amrhein
5. Januar 2016

ii
Zur umfassenden Ausbildung eines Software-Ingenieurs gehoren grundlegende Kenntnisse der wichtig-sten Datenstrukturen und wie man diese verarbeitet (Algorithmen). Das Kennen von geeigneten Daten-strukturen hilft dem Programmierer, die Informationen richtig zu organisieren und besser strukturierteProgramme zu schreiben.
Lerninhalte
- Abstrakte Datentypen, Spezifikation- Komplexitat von Algorithmen,- Algorithmen-Schemata: Greedy, Iteration, Rekursion- Wichtige Datenstrukturen: Listen, Stacks, Queues, Baume, Heaps- Suchen und Sortieren, Hash-Tabellen- Endliche Automaten, regulare Sprachen, Pattern Matching- Kontextfreie Grammatiken, Parser
Lernziele
Die Studierenden kennen die wichtigsten Datenstrukturen mit ihren Methoden. Sie kennen die klassi-schen Algorithmen und konnen sie anwenden. Ausserdem knnen sie Komplexitatsabschatzungen vonAlgorithmen vornehmen.
Informationen zum Unterricht
Grundlage ist ein Skript, das die wichtigsten Lerninhalte umfasst.
Unterrichtssprache: Deutsch (Fachliteratur zum Teil in Englisch)
Umfang: 12 halbtagige Blocke a 4 Lektionen
Dozentin: Beatrice Amrhein,
Empfohlene Literatur:- Reinhard Schiedermeier Programmieren mit Java, Eine methodische Einfuhrung. Pearson Studi-
um ISBN 3-8273-7116-3.- Robert Sedgewick Algorithms in Java. Addison-Wesley Professional; 2002 ISBN 978-0-2013-
6120-9- M. T. Goodrich & R. Tamassia Algorithm Design: Foundations, Analysis, and Internet Examples.
John Wiley & Sons, Inc.ISBN: 0-471-38365-1.
- Gunter Saake, Kay-Uwe Sattler Algorithmen und Datenstrukturen, Eine Einfuhrung mit Java.dpunkt, 2004. ISBN 3-89864-255-0.

Inhaltsverzeichnis
1 Einfuhrung 1-11.1 Die wichtigsten Ziele dieses Kurses . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-11.2 Einige Begriffe: Datenstrukturen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-21.3 Einige Begriffe: Algorithmen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-91.4 Algorithmen Schema: Iteration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-121.5 Algorithmen Schema: Greedy (die gierige Methode) . . . . . . . . . . . . . . . . . . . . 1-121.6 Algorithmen Schema: Rekursion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-151.7 Ubung 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-20
2 Komplexitat von Algorithmen 2-12.1 Komplexitatstheorie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-12.2 Komplexitatsanalyse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-22.3 Asymptotische Komplexitat . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-52.4 Ubung 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-9
3 Datentypen: Listen, Stacks und Queues 3-13.1 Array Listen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-13.2 Doppelt verkettete Listen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-53.3 Stacks und Queues . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-113.4 Iteratoren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-133.5 Ubung 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-14
4 Datentypen: Baume, Heaps 4-14.1 Baumdurchlaufe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-44.2 Binare Suchbaume . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-84.3 B-Baume . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-104.4 Priority Queues . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-154.5 Ubung 4 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-21
5 Suchen 5-15.1 Grundlagen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5-15.2 Lineare Suche . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5-25.3 Binare Suche . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5-35.4 Hashing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5-55.5 Ubung 5 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5-14
6 Sortieren 6-16.1 Selection Sort . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6-26.2 Insertion Sort . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6-46.3 Divide-and-Conquer Sortieren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6-56.4 Quicksort . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6-6

iv Inhaltsverzeichnis
6.5 Sortieren durch Mischen (Merge Sort) . . . . . . . . . . . . . . . . . . . . . . . . . . . 6-96.6 Ubung 6 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6-12
7 Pattern Matching 7-17.1 Beschreiben von Pattern, Regulare Ausdrucke . . . . . . . . . . . . . . . . . . . . . . 7-17.2 Endliche Automaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7-37.3 Automaten zu regularen Ausdrucken . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7-77.4 Ubung 7 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7-10
8 Top Down Parser 8-18.1 Kontextfreie Grammatik . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8-28.2 Top-Down Parser . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8-78.3 Ubung 8 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8-14
9 Kryptologie 9-19.1 Grundlagen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9-29.2 Einfache Verschlusselungmethoden . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9-39.3 Vernamchiffre, One Time Pad . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9-59.4 Moderne symmetrische Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9-69.5 Asymmetrische Verfahren: Public Key Kryptosysteme . . . . . . . . . . . . . . . . . . . 9-79.6 Ubung 9 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9-12

1 Einfuhrung
1.1 Die wichtigsten Ziele dieses Kurses
Die wichtigsten Ziele des Algorithmen und Datenstrukturen Kurses sind:
• Die Studierenden kennen die wichtigsten Datenstrukturen, konnen damit arbeiten, und kennen derenVor- und Nachteile sowie deren Anwendungsgebiete.
• Die Studierenden erhalten die Grundlagen, um wahrend der Design Phase die richtigen Datenstruk-turen auszuwahlen und dann richtig einzusetzen.
• Die Studierenden kennen die wichtigsten Komplexitatsklassen und deren Einfluss auf das Laufzeit-verhalten eines Systems.
• Die Studierenden kennen die klassischen Algorithmen und konnen diese anwenden. Sie kennenderen Einsatzgebiete (wann soll welcher Algorithmus benutzt werden) und kennen die Komplexitatdieser Algorithmen (in Abhangigkeit der darunterliegenden Datenstrukturen).
• Die Studierenden erhalten einen Uberblick uber verschiedene Vorgehensweisen bei Problemlosun-gen und kennen deren Starken und Schwachen.

1-2 1 Einfuhrung
1.2 Einige Begriffe: Datenstrukturen
Definition: Daten sind Information, welche (maschinen-) lesbar und bearbeitbar sind und in einem Be-deutungskontext stehen. Die Information wird dazu in Zeichen oder Zeichenketten codiert. Die Codierungerfolgt gemass klarer Regeln, der sogenannten Syntax.
Daten sind darum Informationen mit folgenden Eigenschaften:
1. Die Bezeichnung erklart den semantischen Teil (die Bedeutung) des Datenobjekts.
2. Die Wertemenge bestimmt die Syntax (die Form oder Codier-Regel) des Datenobjekts.
3. Der Speicherplatz lokalisiert das Datenobjekts im Speicher und identifiziert dieses eindeutig.
Definition: Ein Datentyp ist eine (endliche) Menge (der Wertebereich des Typs) zusammen mit einerAnzahl Operationen.
Der Wertebereich eines Datentyps bestimmt, was fur Werte ein Objekt dieses Typs annehmen kann. DieElemente des Wertebereichs bezeichnet man auch als Konstanten des Datentyps.
Dazu gehoren die Methoden oder Operatoren, welche auf dem Wertebereich definiert sind und somitauf Objekte dieses Typs angewandt werden konnen.
Beispiel:
Der Wertebereich des Datentyps int besteht aus
Auf diesem Datentyp gibt es die Operationen
Es ist wichtig, dass wir zwischen der (abstrakten) Beschreibung eines Datentyps (Spezifikation) unddessen Implementierung unterscheiden. Wenn wir komplizierte Probleme losen wollen, mussen wir vonden Details abstrahieren konnen. Wir wollen nicht wissen (mussen) wie genau ein Datentyp implementiertist, sondern bloss, wie wir den Datentyp verwenden konnen (welche Dienste er anbietet).

1.2 Einige Begriffe: Datenstrukturen 1-3
Jedes Objekt besitzt einen Datentyp, der bestimmt, welche Werte dieses Objekt annehmen kann und wel-che Operationen auf diesen Werten erlaubt sind. In allen Programmiersprachen gibt es nun Variablen,welche diese Objekte reprasentieren konnen. Es stellt sich nun die Frage, ob auch den Variablen zwin-gend ein Datentyp zugewiesen werden soll. Diese Frage wird in verschiedenen Programmiersprachenunterschiedlich beantwortet.
In untypisierten Sprachen wird den Variablen keinen Datentyp zugeordnet. Das heisst, jede Variablekann Objekte von einem beliebigen Typ reprasentieren. Die Programmiersprachen Smalltalk und Lispsind typische Reprasentanten dieser Philosophie.
In untypisierten Sprachen kann der Compiler keine sogenannten Typentests durchfuhren. Zur Kompi-lationszeit sind alle Operationen auf allen Variablen moglich. Es wird also zur Compilationszeit nichtnachgepruft, ob gewisse Operationen uberhaupt erlaubt sind. Unerlaubte Operationen fuhren zu Lauf-zeitfehlern.
In typisierten Sprachen wird allen Variablen ein Datentyp zugeordnet. Entweder mussen alle Variablendeklariert werden, wie in den Sprachen Pascal, C, C++ oder Eiffel, oder der Datentyp wird aus der No-tation der Variablen klar wie etwa in der Sprache Fortran oder Basic (in Basic sind Variablen, welche mitdem Zeichen % enden, vom Typ Integer).
In einer typisierten Sprache kann schon der Compiler entscheiden, ob die angegebenen Operationentypkorrekt sind oder nicht.
Als atomare Typen bezeichnen wir Datentypen, die in einer Sprache schon vordefiniert sind. Die ato-maren Typen sind die grundlegenden Bausteine des Typsystems einer Programmiersprache. Aus diesenatomaren Typen konnen mit Hilfe von Mengenoperationen (Subtypen, Kartesische Produkte, Listen, ...)weitere Typen abgeleitet werden. Welche atomaren Typen zur Verfugung stehen, hangt von der gewahl-ten Programmiersprache ab.
In allen wichtigen Programmiersprachen existieren die atomaren Typen Integer (ganze Zahlen), Float (re-elle Zahlen, Fliesskomma), Boolean (logische Werte) und Char (Schriftzeichen). Dabei ist zu bemerken,dass diese atomaren Typen naturlich nur eine endliche Teilmenge aus dem Bereich der ganzen, bzw. derreellen Zahlen darstellen konnen.

1-4 1 Einfuhrung
Beispiel: Der strukturierte Typ Array wird aus zwei gegebenen Datentypen, einem Grundtyp und einemIndextyp konstruiert. Der Grundtyp ist ein beliebiger atomarer oder abgeleiteter Datentyp. Der Indextypist normalerweise ein Subtyp (oder Intervall) des Typs int .
Auf Arrays ist immer ein Selektor definiert, welcher es erlaubt, ein einzelnes Element des Arrays zu lesenoder zu schreiben.
Definition: Ein strukturierter Datentyp (eine Klasse) entsteht, wenn wir Elemente von beliebigenTypen zu einer Einheit zusammenfassen. Ein solcher Typ ist formal gesprochen das kartesische Produktvon beliebigen Datentypen.
DT = DT1 ×DT2 ×DT3 × . . .×DTn
Die Datentypen DT1, . . . ,DTn konnen atomare oder auch strukturierte Typen sein.
Dazu gehort ausserdem die Spezifikation der zugehorigen Operationen oder Methoden auf DT .
Beispiel: Wir definieren ein einfaches Interface PushButton als Basis fur einen Button auf einer Be-nutzeroberflache).

1.2 Einige Begriffe: Datenstrukturen 1-5
Abstrakter Datentyp
Der abstrakte Datentyp ist ein wichtiges Konzept in der modernen Informatik: Die Philosophie der ob-jektorientierten Sprachen basiert genau auf dieser Idee. Der abstrakte Datentyp dient dazu, Datentypenunabhangig von deren Implementation zu definieren.
Die Idee des abstrakten Datentyps beruht auf zwei wichtigen Prinzipien: dem Geheimnisprinzip und demPrinzip der Wiederverwendbarkeit.
Geheimnisprinzip: Dem Benutzer eines Datentyps werden nur die auf diesem Datentyp erlaubten Ope-rationen (mit deren Spezifikation) bekanntgegeben. Die Implementation des Datentyps bleibt fur denBenutzer verborgen (abstrakt, Kapselung).
Die Anwendung dieses Prinzips bringt folgende Vorteile:
• Der Anwender kann den Datentyp nur im Sinne der Definition verwenden. Er hat keine Moglichkeit,Eigenschaften einer speziellen Implementation auszunutzen.
• Die Implementation eines Datentyps kann jederzeit verandert werden, ohne dass die Benutzer desDatentyps davon betroffen sind.
• Die Verantwortungen zwischen dem Anwender und dem Implementator des Datentyps sind durchdie Interface-Definitionen klar geregelt. Die Suche nach Fehlern wird dadurch erheblich vereinfacht.
Wiederverwendbarkeit: Ein Datentyp (Modul) soll in verschiedenen Applikationen wiederverwendbarsein, wenn ahnliche Probleme gelost werden mussen.
Die Idee hinter diesem Prinzip ist klar. Es geht darum, die Entwicklungszeit von Systemen zu reduzieren.Das Ziel ist, Softwaresysteme gleich wie Hardwaresysteme zu bauen, das heisst, die einzelnen Kompo-nenten eines Systems werden eingekauft, eventuell parametrisiert und zum Gesamtsystem verbunden.

1-6 1 Einfuhrung
Ein abstrakter Datentyp definiert einen Datentyp nur mit Hilfe des Wertebereichs und der Menge derOperationen auf diesem Bereich. Jede Operation ist definiert durch ihre Spezifikation, also die Input- undOutput-Parameter und die Vor- und Nachbedingungen.
Die Datenstruktur ist dann eine Instanz eines (abstrakten) Datentyps. Sie beinhaltet also die Reprasen-tation der Daten und die Implementation von Prozeduren fur alle definierten Operatoren.
Wir sprechen hierbei auch von der logischen, bzw. der physikalischen Form von Datenelementen. DieDefinition des abstrakten Datentyps ist die logische, deren Implementation die physikalische Form desDatenelements.
Der abstrakte Datentyp spezifiziert einen Typ nicht mit Hilfe einer Implementation, sondern nur als eineListe von Dienstleistungen, die der Datentyp dem Anwender zur Verfugung stellt. Die Dienstleistungennennt man auch Operationen, Methoden oder Funktionen.
Ein abstrakter Datentyp kann viele verschiedene Implementationen oder Darstellungen haben. Der ab-strakte Datentyp gibt darum nicht an, wie die verschiedenen Operationen implementiert oder die Datenreprasentiert sind. Diese Details bleiben vor dem Benutzer verborgen.
Beispiel: Der abstrakte Datentyp Stack wird durch die Menge der angebotenen Dienste definiert: Ein-fugen eines Elements (push ), entfernen eines Elements (pop ), lesen des obersten Elements (peek ) undprufen auf leer (empty ).
Eine solche Beschreibung berucksichtigt also nur, was ein Stack dem Anwender zu bieten hat.
Bei den verschiedenen Methoden muss stehen, was die Methoden tun oder bewirken (Nachbedingung)und was fur Voraussetzungen (Einschrankungen, Vorbedingungen) an die Verwendung der Methodengestellt sind.1
In Java konnte ein Interface fur einen Stack wie folgt aussehen:
1 Optimalerweise steht noch dabei, welchen Aufwand die Methode hat.

1.2 Einige Begriffe: Datenstrukturen 1-7
public interface Stack<E> {/*** Pushes an item onto the top of this stack.* @param item the item to be pushed onto this stack.* @return the item argument.*/
E push(E item);
/*** Removes the object at the top of this stack and returns that* object as the value of this function.* @return The object at the top of this stack (the last* item of the Vector object).* @exception EmptyStackException if this stack is empty.*/E pop();
/*** Looks at the object at the top of this stack without removing* it from the stack.* @return the object at the top of this stack (the last* item of the Vector object).* @exception EmptyStackException if this stack is empty.*/E peek();
/*** Tests if this stack is empty.* @return true if and only if this stack contains no items;*/
boolean empty();}
Bei den Methoden push und empty gibt es keine Vorbedingungen. Die Methoden pop und peek werfeneine Runtime-Exception, wenn der Stack leer ist.

1-8 1 Einfuhrung
Die Spezifikation eines Datentyps muss vollstandig, prazise und eindeutig sein. Weiter wollen wir keineBeschreibung, die auf der konkreten Implementation des Datentyps basiert, obwohl diese die gefordertenKriterien erfullen wurde. Eine Beschreibung, die auf der Implementation basiert, fuhrt zu einer Uberspe-zifikation des Datentyps.
Konkret konnen wir den Datentyp Stack zum Beispiel als Arraystruktur (mit einem Zeiger auf das aktuelleoberste Element head des Stacks) implementieren. Flexibler ist allerdings die Implementation mit Hilfeeiner Listenstruktur..

1.3 Einige Begriffe: Algorithmen 1-9
1.3 Einige Begriffe: Algorithmen
Ein Algorithmus2 beschreibt das Vorgehen oder eine Methode, mit der eine Aufgabe oder ein Problemgelost werden kann, bzw. mit der eine Funktion berechnet werden kann. Ein Algorithmus besteht auseiner Folge von einfachen (Rechen-)Schritten (Anweisungen), welche zur Losung der gestellten Aufgabefuhren. Der Algorithmusgedanke ist keine Besonderheit der Informatik. In fast allen Naturwissenschaftenaber auch im Alltag werden Arbeitsvorgange mit Hilfe von Algorithmen beschrieben.
Jeder Algorithmus muss die folgenden Eigenschaften erfullen:
1. Er muss aus einer Reihe von konkret ausfuhrbaren Schritten bestehen.
2. Er muss in einem endlichen Text beschreibbar sein.
3. Er darf nur endlich viele Schritte benotigen (Termination).
4. Er darf zu jedem Zeitpunkt nur endlich viel Speicherplatz benotigen.
5. Er muss bei der gleichen Eingabe immer das selbe Ergebnis liefern.
6. Nach der Ausfuhrung eines Schrittes ist eindeutig festgelegt, welcher Schritt als nachstes auszufuh-ren ist.
7. Der vom Algorithmus berechnete Ausgabewert muss richtig sein (Korrektheit).
Bemerkung: Die Forderung nach Eindeutigkeit wird etwa in parallelen oder probabilistischen Algorith-men zum Teil fallengelassen. Nach dem Abschluss eines einzelnen Schrittes ist der nachste Schritt nichteindeutig bestimmt, sondern es existiert eine endliche Menge von (moglichen) nachsten Schritten. DieAuswahl des nachsten Schrittes aus der gegebenen Menge ist nichtdeterministisch.
Der Anspruch, dass alle Algorithmen terminieren mussen, bedeutet, dass nicht alle von uns benutztenProgramme Algorithmen sind. Editoren, Shells oder das Betriebssystem sind alles Programme, die nicht(von selber) terminieren.
Wir konnen aber jedes dieser Programme als Sammlung von verschiedenen Algorithmen betrachten,welche in verschiedenen Situationen zur Anwendung kommen.
2 Das Wort Algorithmus stammt vom Persischen Autor Abu Ja’far Mohammed ibn Musa al-Khowarizmı, welcher ungefahr 825 vor Christus einBuch uber arithmetische Regeln schrieb.

1-10 1 Einfuhrung
Algorithmen werden der Einfachheit halber oft in einer Pseudocode Sprache formuliert. Damit erspartman sich alle technischen Probleme, welche die konkrete Umsetzung in eine Programmiersprache mit-bringen konnte.
Beispiel: Grosster gemeinsamer Teiler von m und n: Die kleinere der beiden Zahlen wird so lange vonder grosseren subtrahiert, bis beide Werte gleich sind. Dies ist dann der GgT von m und n.
Gib m aus
Initialisiere m und n
Wiederhole solange m und n nicht gleich sind
Ja Ist m > n ? Nein
Verringere m um n Verringere n um m
Siehe auch [4]: Programmieren in Java, Kapitel 3.
Beispiele von Algorithmen in Java
int proc( int n ){return n/2;
}
bool isPrim( int n ) // return true if n is a prime{return false;
}

1.3 Einige Begriffe: Algorithmen 1-11
Das nachste Beispiel stammt von L. Collatz (1937):
long stepNum( long n ){ // return number of stepslong m = 0;while( n > 1 ){
if( n%2 == 0 ){ n = n/2; }else { n = 3*n + 1; }m++;
}return m;
}

1-12 1 Einfuhrung
1.4 Algorithmen Schema: Iteration
Unter einem Algorithmen-Schema verstehen wir ein Verfahrens-Muster oder eine allgemeine Methode,mit welcher ein Problem gelost werden kann. Nicht jede Methode ist fur jedes Problem gleich gut geeig-net. Umso wichtiger ist es also, die verschiedenen Algorithmen-Schemata zu kennen.
Ein Problem wird durch Iteration gelost, falls der zugehorige Algorithmus einen Loop (while- oder for-Schleife) benutzt. Iteration ist zum Beispiel dann sinnvoll, wenn die Daten in einem Array (oder einerListe) abgelegt sind und wir mit jedem Element des Array die gleichen Schritte durchfuhren mussen3.
Beispiel: Das Addieren zweier Vektoren kann wie folgt implementiert werden:
public DVector sum(DVector v1) throws VectorException {if (v1.size != size)throw new VectorException("Incompatible vector length");
DVector res = new DVector(size);for (int i = 0; i < size; i++)res.value[i] = v1.value[i] + value[i];
return res;}
1.5 Algorithmen Schema: Greedy (die gierige Methode)
Greedy-Verfahren werden vor allem dann erfolgreich eingesetzt, wenn von n moglichen Losungen einesProblems die bezuglich einer Bewertungsfunktion f optimale Losung gesucht wird (Optimierungsproble-me).
Die Greedy-Methode arbeitet in Schritten, ohne mehr als einen Schritt voraus- oder zuruckzublicken. Beijedem Schritt wird aus einer Menge von moglichen Wegen derjenige ausgesucht, der den Bedingungendes Problems genugt und lokal optimal ist.
3 Solche Algorithmen lassen sich oft auch sehr einfach parallelisieren.
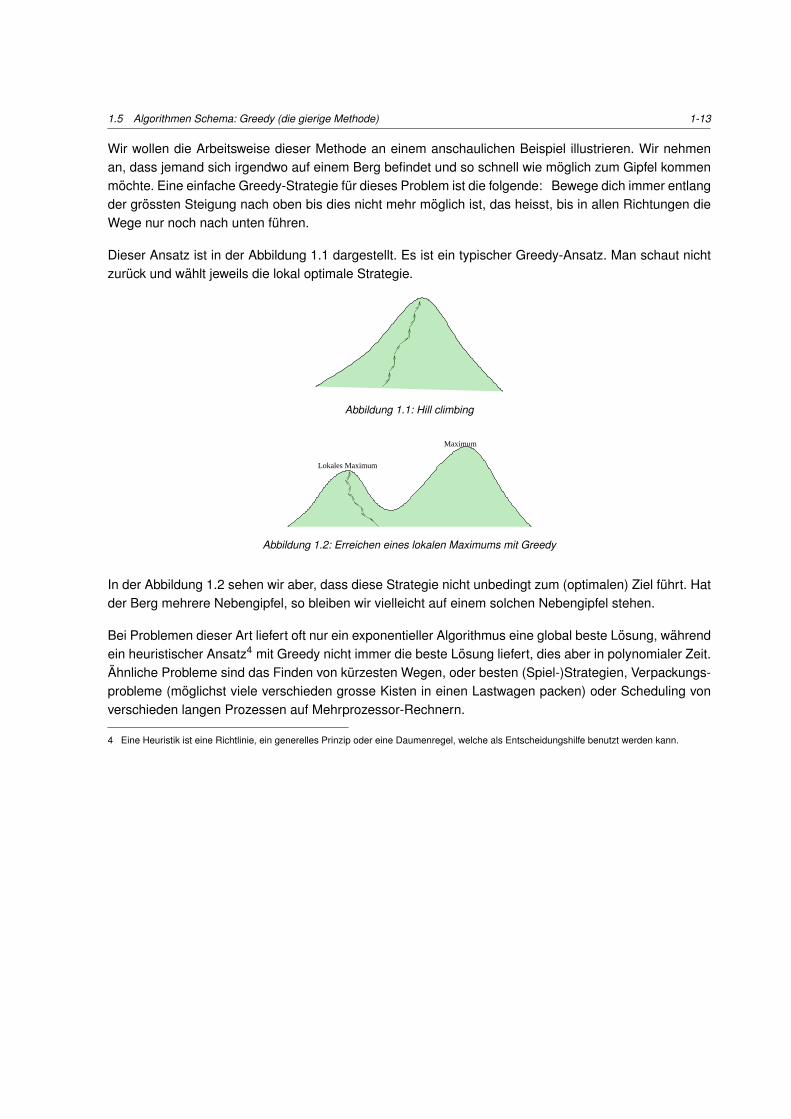
1.5 Algorithmen Schema: Greedy (die gierige Methode) 1-13
Wir wollen die Arbeitsweise dieser Methode an einem anschaulichen Beispiel illustrieren. Wir nehmenan, dass jemand sich irgendwo auf einem Berg befindet und so schnell wie moglich zum Gipfel kommenmochte. Eine einfache Greedy-Strategie fur dieses Problem ist die folgende: Bewege dich immer entlangder grossten Steigung nach oben bis dies nicht mehr moglich ist, das heisst, bis in allen Richtungen dieWege nur noch nach unten fuhren.
Dieser Ansatz ist in der Abbildung 1.1 dargestellt. Es ist ein typischer Greedy-Ansatz. Man schaut nichtzuruck und wahlt jeweils die lokal optimale Strategie.
Abbildung 1.1: Hill climbing
Lokales Maximum
Maximum
Abbildung 1.2: Erreichen eines lokalen Maximums mit Greedy
In der Abbildung 1.2 sehen wir aber, dass diese Strategie nicht unbedingt zum (optimalen) Ziel fuhrt. Hatder Berg mehrere Nebengipfel, so bleiben wir vielleicht auf einem solchen Nebengipfel stehen.
Bei Problemen dieser Art liefert oft nur ein exponentieller Algorithmus eine global beste Losung, wahrendein heuristischer Ansatz4 mit Greedy nicht immer die beste Losung liefert, dies aber in polynomialer Zeit.Ahnliche Probleme sind das Finden von kurzesten Wegen, oder besten (Spiel-)Strategien, Verpackungs-probleme (moglichst viele verschieden grosse Kisten in einen Lastwagen packen) oder Scheduling vonverschieden langen Prozessen auf Mehrprozessor-Rechnern.
4 Eine Heuristik ist eine Richtlinie, ein generelles Prinzip oder eine Daumenregel, welche als Entscheidungshilfe benutzt werden kann.

1-14 1 Einfuhrung
Ein weiteres Problem dieser Art ist das Suchen eines minimalen Pfades in einem allgemeinen Graphen.Um eine optimale Losung zu finden, mussten wir im wesentlichen samtliche Pfade abgehen und derenGewichte aufschreiben. Ein Greedy-Algorithmus lost das Problem viel schneller, indem er jeweils lokalden kurzesten (leichtesten) Pfad wahlt. Allerdings findet man mit dieser Methode nicht unbedingt deninsgesamt kurzesten Pfad.
Es existieren aber auch Probleme, bei denen der Greedy-Ansatz zum optimalen Ergebnis fuhrt. EinGreedy-Algorithmus lost das folgende Problem: Finde ein minimales (maximales) Gerust in einem ge-wichteten Graphen. Dabei wahlt man jeweils die Kante, die das kleinste (grosste) Gewicht hat und keinenZyklus verursacht. Der Algorithmus ist fertig, sobald ein zusammenhangender Teilgraph entstanden ist.
y
x
3
6
8
5
4
7
4
9
6
8
7
8
5
1
5
9
3
3
3
6
8
5
41
x
7
4
9
6
8
7
8
5
5
3
7
7
5

1.6 Algorithmen Schema: Rekursion 1-15
1.6 Algorithmen Schema: Rekursion
Rekursion ist ein fundamentales Konzept der Informatik. Eine Prozedur heisst rekursiv, wenn sie sichdirekt oder indirekt selber aufruft. Dabei mussen wir darauf achten, dass eine Abbruchbedingung existiert,damit die Prozedur in jedem Fall terminiert.
Beispiele: Die rekursive Implementation der Fakultatsfunktion:
long factorial( int n ){if( n <= 1 )return 1;
return n*factorial(--n);}
Der rekursive Aufruf kann auch indirekt erfolgen:
int proc( int a, int b ) int sub( int c ){ {
if( b-a < 5 ) if( c%2 == 0 )return sub( b ); return c*c;
return a * proc(a-1, b/2) return proc(c-2,c+1);} }
Bei einer rekursiven Prozedur sind die folgenden Punkte besonders zu beachten:
• Die Rekursion darf nicht unendlich sein. Es muss also in der Prozedur ein Instruktionszweig existie-ren, der keinen Aufruf der Prozedur enthalt. Diesen Teil der Prozedur nennt man den Rekursions-anfang. Bei indirekter Rekursion (Prozedur A ruft Prozedur B auf und B ruft wieder A auf) ist jeweilsbesondere Vorsicht geboten.
• Es muss sichergestellt sein, dass die Anzahl der hintereinander ausgefuhrten rekursiven Aufrufe(also die Rekursionstiefe) vernunftig bleibt, da sonst zu viel Speicher verwendet wird. Beim rekursivenSortieren von n Elementen sollten zum Beispiel nur O(log(n)) rekursive Aufrufe notig sein.
• Rekursion soll dann angewandt werden, wenn die Formulierung der Losung dadurch klarer undkurzer wird. Auch darf der Aufwand der rekursiven Losung in der Ordnung nicht grosser werden

1-16 1 Einfuhrung
als der Aufwand der iterativen Losung. Insbesondere kann die Rekursion leicht eliminiert werden,wenn die Prozedur nur einen rekursiven Aufruf enthalt und dieser Aufruf die letzte Instruktion derProzedur ist (tail recursion, diese wird von einem optimierenden Compiler normalerweise automa-tisch eliminiert.)
Beispiel Die Fibonacci Funktion ist wie folgt definiert:
fibonacci(0) = 1
fibonacci(1) = 1
fibonacci(n+2) = fibonacci(n+1)+ fibonacci(n)
Diese Definition kann direkt in dieser Form als Rekursion implementiert werden:
Diese Implementierung fuhrt zu einem exponentiellen Aufwand5. Auf jeder Stufe sind zwei rekursive Auf-rufe notig, welche jeweils unabhangig voneinander die gleichen Funktionswerte berechnen. Eine bessereImplementation (ohne Rekursion) benotigt nur linearen Aufwand (vgl. Ubung).
1.6.1 Rekursionselimination
Wie bereits vorher erwahnt, soll Rekursion nur dann verwendet werden, wenn dadurch die Programmeeinfacher lesbar werden und die Komplexitat nicht grosser als die der iterativen Losung ist.
Ist ein Problem durch eine (unnotig aufwandige) Rekursion formuliert, stellt sich die Frage, ob und wiesich die Rekursion allenfalls eliminieren lasst. Prinzipiell kann dies durch folgendes Vorgehen versuchtwerden:
5 Die Prozedur benotigt zum Berechnen von fib(n) in der Grossenordnung von 2·fib(n) rekursive Aufrufe.

1.6 Algorithmen Schema: Rekursion 1-17
Umdrehen der Berechnung (von unten nach oben).
Abspeichern der Zwischenresultate in einen Array, eine Liste oder einen Stack.
Beispiel: Gegeben ist die folgende rekursive Funktion, die wir in eine nichtrekursive Prozedur umschrei-ben wollen:
long rekFunction(int x, int y){
if( x <= 0 || y <= 0 )return 0;
return x + y + rekFunction(x-1, y);}
Etwas komplizierter wird die Rekursionselimination, wenn die Funktion, wie im folgenden Beispiel, vonzwei Parametern abhangt:
long Pascal(int x, int y){
if( x <= 0 || y <= 0 )return 1;
return Pascal(x-1, y) + Pascal(x, y-1);}

1-18 1 Einfuhrung
1.6.2 Divide and Conquer
Die Divide and Conquer Methode (kurz: DAC) zerlegt das zu losende Problem in kleinere Teilprobleme(divide) bis die Losung der einzelnen Teilprobleme (conquer) einfach ist. Anschliessend werden dieTeillosungen zur Gesamtlosung vereinigt (merge)6.
Da das Problem in immer kleinere Teilprobleme zerlegt wird, welche alle auf die gleiche Art gelost werden,ergibt sich normalerweise ein Losungsansatz mit Rekursion.
Ein DAC-Algorithmus hat also folgende allgemeine Form:
void DAC( problem P ) {if( Losung von P sehr einfach ) {
return Losung(P) // conquer}else {
divide( P, Teil1, . . . ,Teiln );return combine( DAC(Teil1),. . .,DAC(Teiln) );
}}
DAC-Algorithmen konnen grob in die beiden folgenden Kategorien unterteilt werden.
• Das Aufteilen in Teilprobleme (divide) ist einfach, dafur ist das Zusammensetzen der Teillosungen(merge) schwierig.
• Das Aufteilen in Teilprobleme (divide) ist schwierig, dafur ist das Zusammensetzen der Teillosungen(merge) einfach.
Wenn sowohl das Aufteilen in Teilprobleme als auch das Zusammensetzen der Teillosungen schwierigist, ist Divide and Conquer vermutlich nicht der richtige Ansatz.
6 Das Divide and Conquer Schema eignet sich vor allem auch zum parallelen oder verteilten Losen von Problemen.

1.6 Algorithmen Schema: Rekursion 1-19
Bekannte Beispiele fur Divide and Conquer sind die Sortieralgorithmen Quicksort und Mergesort.
Quicksort : (Hard Split Easy Join) Die Elemente werden gemass einem Pivotelement in verschiedeneMengen aufgeteilt. Das Einsammeln ist dann trivial.
Mergesort : (Easy Split Hard Join) Die Elemente werden in beliebige (gleichgrosse) Mengen aufgeteilt.Beim Einsammeln der verschiedenen (sortierten) Mengen muss nachsortiert werden.
void Sort( Menge P ) {if( P besteht aus wenigen Elementen ) // zum Beispiel aus weniger als 10{
verwende einfachen (linearen) Sortieralgorithmus und gib sortierte Menge zuruck}else {
divide( P, Teil1, . . . ,Teiln ); // Zerteile P in n Teile// Fuge die sortierten Mengen zusammen (trivial oder durch Nachsortieren).return merge( Sort(Teil1),. . .,Sort(Teiln) );
}}

1-20 1 Einfuhrung
1.7 Ubung 1
1. Nichtdeterministischer Primzahltest Das folgende Verfahren testet, ob ein Kandidat P eine Prim-zahl ist: Wahlen Sie eine genugend grosse Menge beliebiger (zufalliger) Zahlen zi und versuchenSie nacheinander, P durch zi zu teilen. Falls keine der Zahlen zi ein Teiler ist, geben Sie true zuruck,andernfalls false.Formulieren Sie fur das Verfahren einen Algorithmus in Pseudocode (Initialisierung, sequenzelle An-weisungen, if, while, ...)
2. Rekursionselimination: Gegeben ist die folgende Implementation der Fibonacci-Funktion:public long fibonacci( int n ) {
if( n < 2 )return 1;
return fibonacci(n-1) + fibonacci(n-2);}
Finden Sie eine effizientere Implementierung ohne Rekursion fur die Berechnung der Fibonacci-Zah-len.
3. Rekursionselimination:Eliminieren Sie aus den der folgenden Prozedur die Rekursion:
public long procRek(int n) {if(n<=3)return 2;
elsereturn 2*procRek(n-1) + procRek(n-2)/2 - procRek(n-3);
}
4. Rekursion: Zahlen der Knoten eines BaumesImplementieren Sie eine Methode countNodes(), welche mit Hilfe einer Rekursion die Anzahl Knoteneines Baumes berechnet.Die Anzahl Knoten eines Baumes sind rekursiv wie folgt definiert: Wenn ein Baum nur aus einemBlatt (leaf) besteht, dann gilt countNodes(leaf) = 1.Sonst gilt countNodes(node) = 1 + sum(countNodes(c): c the children of node)
Rahmenprogramme finden Sie unter www.sws.bfh.ch/ ∼amrhein/AlgoData/uebung1

2 Komplexitat von Algorithmen
2.1 Komplexitatstheorie
Nicht alle (mathematischen) Probleme (Funktionen) sind algorithmisch losbar (berechenbar). Ausser-dem sind unter den berechenbaren Funktionen viele, deren Berechnung sehr aufwandig und deshalbundurchfuhrbar ist.
In diesem Abschnitt wollen wir nun die prinzipiell berechenbaren Probleme weiter unterteilen: in solche,die mit vernunftigem Aufwand losbar sind und die restlichen.
Durchführbare Algorithmen
Alle Funktionen
Berechenbare Funktionen
Abbildung 2.1: Durchfuhrbare Algorithmen
Fur losbare Probleme ist es wichtig zu wissen, wieviele Betriebsmittel (Ressourcen) fur ihre Losungerforderlich sind. Nur solche Algorithmen, die eine vertretbare Menge an Betriebsmitteln benotigen, sindtatsachlich von praktischem Interesse.

2-2 2 Komplexitat von Algorithmen
Die Komplexitatstheorie stellt die Frage nach dem Gebrauch von Betriebsmitteln und versucht diese zubeantworten. Normalerweise werden fur einen Algorithmus die Betriebsmittel Zeit- und Speicherbedarfuntersucht. Mit Zeitbedarf meint man die Anzahl benotigter Rechenschritte1.
2.2 Komplexitatsanalyse
Mit Hilfe der Komplexitatsanalyse konnen wir die Effizienz verschiedener Algorithmen vergleichen, bzw.versuchen zu entscheiden, ob ein Algorithmus das Problem im Allgemeinen innert nutzlicher Frist lost.
Eine Moglichkeit, die Effizienz verschiedener Algorithmen zu vergleichen ware, alle Algorithmen zu im-plementieren und die benotigte Zeit und den Platzverbrauch zu messen. Allerdings ist dieses Verfahrenhochst ineffektiv. Es muss unnotig viel programmiert werden. Wir konnen auch nicht einschatzen, ob nichtein Algorithmus schlechter programmiert wurde als die anderen oder ob die Testbeispiele eventuell einenAlgorithmus begunstigen2.
Auch mit Hilfe einer Komplexitatsanalyse konnen wir nicht wirklich entscheiden, ob ein Programm schnelllaufen wird. Vielleicht kann ein optimierender Compiler den einen Code besser unterstutzen als den an-deren. Vielleicht sind gewisse Speicherzugriffe ubers Netz notig, die den Code langsam machen. Mogli-cherweise ist der Algorithmus auch einfach schlecht implementiert.
Dennoch kann eine Komplexitatsanalyse einen Hinweis geben, ob ein Algorithmus uberhaupt prinzipi-ell fur unser Problem in Frage kommt. Durch das Zahlen der Anzahl notiger Rechenschritte konnen wirzumindest verschiedene Algorithmen einigermassen fair vergleichen. Ein Rechenschritt besteht dabeiaus einer einfachen Operation, einer Zuweisung oder einem Vergleich (was normalerweise in einer Pro-grammzeile steht).
Algorithmen nehmen Eingabedaten entgegen und fuhren mit diesen eine Verarbeitung durch. Die AnzahlRechenschritte hangt normalerweise von der Lange (Grosse) der Eingabedaten ab.
• Ein Problem kann durch verschiedene Algorithmen mit verschiedener Komplexitat gelost werden. FurProbleme, welche sehr oft gelost werden mussen, ist es von grossem Interesse, einen Algorithmuszu finden, welcher moglichst wenig Betriebsmittel erfordert.
1 Die Komplexitat eines Algorithmus ist naturlich unabhangig von der Geschwindigkeit des verwendeten Computers.
2 Wir mussten fairerweise alle moglichen Eingaben testen, was naturlich nicht machbar ist.

2.2 Komplexitatsanalyse 2-3
• Die Komplexitat eines Algorithmus hangt von der Grosse der Eingabedaten ab. Je grosser die Di-mension n der Matrizen, desto langer wird die Ausfuhrung des Algorithmus dauern. Im Allgemeinenkonnen wir die Komplexitat eines Algorithmus als Funktion der Lange der Eingabedaten angeben.
Als Vereinfachung betrachten wir normalerweise nicht die (exakte) Lange der Eingabe (zum Beispiel inAnzahl Bytes), sondern grossere, fur das Problem naturliche Einheiten. Man spricht dann von der naturli-chen Lange des Problems. Will man nur eine Grossenordnung fur die Komplexitat eines Algorithmusangeben, so zahlt man auch nicht alle Operationen, sondern nur diejenigen, welche fur die Losung desProblems am wichtigsten (zeitintensivsten) sind. In der folgenden Tabelle sind Probleme mit ihrer naturli-chen Lange und ihren wichtigsten Operationen angegeben.
Problem naturliche Einheit Operationen
Algorithmen auf ganzen Zahlen Anzahl Ziffern Operationen in(z.B. Primzahlalgorithmen )Suchalgorithmen Anzahl Elemente VergleicheSortieralgorithmen Anzahl Elemente Vergleiche, VertauschungenAlgorithmen auf reellen Zahlen Lange der Eingabe Operationen in IRMatrix Algorithmen Dimension der Matrix Operationen in IR
Beispiel: Wir berechnen die Komplexitat der folgenden Prozeduren, indem wir die Anzahl Aufrufe vondo something() (abhangig vom Input n) zahlen.
int proc1( int n ) int proc2( int n ){ {int res = 0; int res = 0;for( i = 0; i < n; i++ ) for( i = 0; i < n; i++ )
res = do_something(i); for( j = 0; j < n; j++ )return res; res = do_something(i, j);
} return res;}
Wir verandern die Prozedur etwas und berechnen wiederum die Komplexitat.

2-4 2 Komplexitat von Algorithmen
int proc3( int n ){int res = 0;for( i = 0; i <= n; i++ )
for( j = 0; j <= i; j++ )res = do_something(i, j);
return res;}
Wir zahlen auch hier, wie oft do something() aufgerufen wird.
2.2.1 Best-Case, Average-Case, Worst-Case Analyse
Je nach Input kann die Anzahl benotigter Rechenschritte sehr stark schwanken. Dies geschieht beispiels-weise dann, wenn die Prozedur Fallunterscheidungen (if/else) enthalt.
int proc3( int n ){int res = 1;if( n % 2 == 0 )return res;
for( int i=0; i<n; i++ )res = do_something(res, i);
return res;}

2.3 Asymptotische Komplexitat 2-5
Bei Suchalgorithmen zahlen wir die Anzahl notiger Vergleiche.
public int indexOf( Object elem ) {// lineare Suche, elem != null n = sizefor( int i=0; i < size; i++ ) {
if( elem.equals(elementData[i]) )return i;
}return -1;
}
int procRek( int n ){int res = do_something(n);if( n <= 1 ) return res;if( n % 2 == 0 )
return procRek(n/2);return procRek(n+1);
}
2.3 Asymptotische Komplexitat
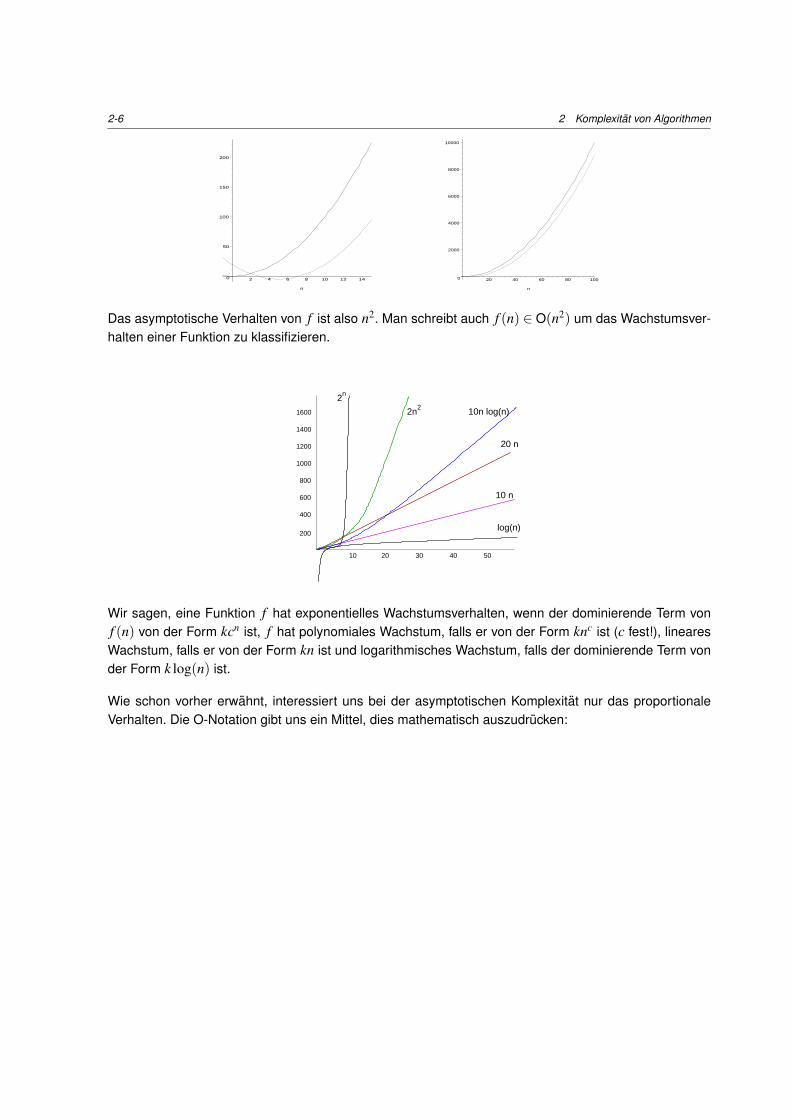
Eine Vereinfachung ergibt sich, wenn man nur das asymptotische Verhalten der Komplexitat einesAlgorithmus betrachtet. Das asymptotische Verhalten eines Polynoms entspricht dessem grossten Term.Konstante Faktoren werden dabei ignoriert.
Beispiel: In der Funktionf (n) = 2n2 −10n+20
fallt fur wachsendes n der Ausdruck 10n+20 gegenuber dem Ausdruck 2n2 immer weniger ins Gewicht.Der dominierende Ausdruck ist in diesem Fall 2n2.
2-6 2 Komplexitat von Algorithmen
0
50
100
150
200
2 4 6 8 10 12 14
n
0
2000
4000
6000
8000
10000
20 40 60 80 100
n
Das asymptotische Verhalten von f ist also n2. Man schreibt auch f (n) ∈ O(n2) um das Wachstumsver-halten einer Funktion zu klassifizieren.
400
200
600
800
1000
1400
1200
1600
10 20 30 40 50
2n
2n2
20 n
10 n
log(n)
10n log(n)
Wir sagen, eine Funktion f hat exponentielles Wachstumsverhalten, wenn der dominierende Term vonf (n) von der Form kcn ist, f hat polynomiales Wachstum, falls er von der Form knc ist (c fest!), linearesWachstum, falls er von der Form kn ist und logarithmisches Wachstum, falls der dominierende Term vonder Form k log(n) ist.
Wie schon vorher erwahnt, interessiert uns bei der asymptotischen Komplexitat nur das proportionaleVerhalten. Die O-Notation gibt uns ein Mittel, dies mathematisch auszudrucken:

2.3 Asymptotische Komplexitat 2-7
Definition: [O-Notation] Eine Funktion f (n) ist aus O(g(n)), falls es Konstanten c und N gibt, so dassfur alle m > N die Beziehung f (m)< cg(m) gilt.
Die Notation sagt genau das aus, was wir vorher schon etwas salopp formuliert hatten: Eine Funktionf (n) gehort zu O(g(n)), falls sie (bis auf eine Konstante) nicht schneller wachst als g(n).
Man sagt auch, f hat das gleiche asymptotische Verhalten wie g.
So gehoren zum Beispiel die Funktionen 300n2 + 2n− 1, 10n+ 12 und 5n3/2 + n alle zu O(n2).Hingegen gehoren die Funktionen 2n oder n3 nicht zu O(n2).
Umgekehrt sagt das Wissen, dass eine Funktion f zu O(g) gehort, nichts uber die Konstanten c undN aus. Diese konnen sehr gross sein, was gleichbedeutend damit ist, dass ein Algorithmus mit dieser(asymptotischen) Komplexitat eventuell erst fur sehr grosse Eingabewerte sinnvoll einsetzbar ist 3.
Nachfolgend sind einige wichtige Regeln (ohne Beweis) angegeben:
• Die Ordnung des Logarithmus ist kleiner als die Ordnung einer linearen Funktion.
log(n) ∈ O(n) n ∈ O(log(n))
• Die Ordnung eines Polynoms ist gleich der Ordnung des Terms mit der hochsten Potenz.
aknk +ak−1nk−1 + . . .+a1n+a0 ∈ O(nk)
• Fur zwei Funktionen f und g gilt:
O( f +g) = max{O( f ),O(g)}
O( f ∗g) = O( f ) ·O(g)
• Die Ordnung der Exponentialfunktion ist grosser als die Ordnung eines beliebigen Polynoms. Fur allec > 1 und k gilt:
cn ∈ O(nk)
3 Der FFT-Algorithmus fur Langzahlarithmetik ist zum Beispiel erst fur Zahlen, die mehrere hundert Stellen lang sind, interessant.

2-8 2 Komplexitat von Algorithmen
Beispiel: Wir berechnen die asymptotische Komplexitat der folgenden Prozeduren.
int proc4( int n ){int res = 0, m = n*n;for( i = m; i > 1; i=i/2 )
res = do_something(res, i);return res;
}
Wir zahlen wieder, wie oft do something() aufgerufen wird:
Eine andere Methode benotigen wir zum Berechnen der Komplexitat im folgenden Beispiel. Der Einfach-heit halber nehmen wir an, n sei eine Zweierpotenz (n = 2k).
int procRec( int n ){int res = 0;if(n <= 1)
return res;for( int i = 0; i < n; i++ )
res = do_something(res, i);return procRec(n/2);}
Wir zahlen wiederum, wie oft do something() aufgerufen wird.

2.4 Ubung 2 2-9
2.4 Ubung 2
1. Komplexiat von einfachen ProzedurenBerechnen Sie die Komplexitat der Prozeduren 1 bis 4. Wie oft wird do something() aufgerufen? Uber-prufen Sie Ihre Losungen, indem Sie die Prozeduren in Java implementieren und einen Zahler einbauen.
void procedure1( int n ){
for(int i=0; i<=n; i++)do something(i,n);
for(int j=n; j>=0; j--)do something(j,n);
}
void procedure3( int n ){
for(int i=0; i<n; i++){int j = 0;while( j < 2*n ){
j++;do something(i,j,n);
}}
}
void procedure2( int n ){for(int i=0; i<n; i++)for(int j=0; j<2*i; j++)do something(i,j,n);
}
void procedure4( int n ){int j=n;while( j > 0 ){j = j/2;do something(i,j,n);
}}

2-10 2 Komplexitat von Algorithmen
2. Komplexitat rekursiver ProzedurenBerechnen Sie die Komplexitat der folgenden rekursiven Prozeduren. Wie oft wird do something() aus-gefuhrt? Wahlen Sie fur n eine Zweierpotenz: n = 2k.
void procRec1( int n ) int procRec2( int n, int res ){ {if( n<=1 ) res = do_something(res, n);return; if( n <= 1 )
return res;do_something(n) res = procRec2(n/2, res);procRec1(n/2); res = procRec2(n/2, res);
} return res;}
3. Komplexitat verschiedener Java Methoden
Bestimmen Sie von den Java Klassen ArrayList und LinkedList die asymptotische Komplexitat der Me-thoden
- public boolean contains(Object o)
- public E get(int index)
- public E set(int index, E element)
- public boolean add(E o)
- public void add(int index, E element)
- public E remove int(index)
- public boolean remove(Object o)
Sie mussen dazu die Algorithmen nicht im Detail verstehen. Es genugt, die Iterationen (auch der benotig-ten Hilfsfunktionen) zu zahlen (wir werden diese Algorithmen in einem spateren Kapitel noch genauerbetrachten).

3 Datentypen: Listen, Stacks und Queues
Listen, Stacks und Queues konnen entweder arraybasiert oder zeigerbasiert implementiert werden. DieImplementierung mit Hilfe von Arrays hat den Vorteil, dass ein wahlfreier Zugriff besteht. Der Nachteilhingegen ist, dass wir schon zu Beginn wissen mussen, wie viele Elemente die Liste maximal enthalt.Viele Kopieraktionen sind notig, wenn der gewahlte Bereich zu klein gewahlt wurde, oder wenn in derMitte einer Liste ein Element eingefugt oder geloscht werden soll.
Eine flexiblere Implementation bietet die Realisation von Listen mit Hilfe von Zeigerstrukturen.
3.1 Array Listen
In einer Array Liste werden die einzelnen Elemente (bzw. die Referenzen auf die Elemente) in einen Array(vom generischen Typ E) abgelegt.
. . . .
size
E[ ] elementDatainitialCapacity
Der Vorteil von Array Listen ist der direkte Zugriff auf das n-te Element. Der Nachteil ist allerdings, dassbei jedem Einfugen oder Loschen von Elementen der Array (in sich) umkopiert werden muss. Ausserdem

3-2 3 Datentypen: Listen, Stacks und Queues
muss der Array in einen neuen, grosseren Array umkopiert werden, sobald die initiale Anzahl Elementeuberschritten wird.
Die ArrayList benutzt also einen Array von (Zeigern auf) Elementen E als Datenspeicher:
public class ArrayList<E> extends AbstractList<E> {
private Object[] elementData;private int size; // The number of elements.
/** Constructs an empty list with the specified initial capacity. */public ArrayList(int initialCapacity) { ... }
/** Returns true if this list contains no elements. */public boolean isEmpty() { ... }
/** Returns the index of the first occurrence of the specified element. */public int indexOf(Object elem) { ... }
/** Returns the element at the specified position in this list. */public E get(int index) { ... }
/** Inserts the element at the specified position in this list.Shifts any subsequent elements to the right. */
public void add(int index, E element) { ... }
/** Removes the element at the specified position in this list.Shifts any subsequent elements to the left. */
public E remove(int index) { ... }
/** Increases the capacity of this ArrayList instance. */public void ensureCapacity(int minCapacity) { ... }
...}

3.1 Array Listen 3-3
Im Konstruktor wird der elementData Array mit Lange initialCapacity initialisiert:
public ArrayList(int initialCapacity) {if (initialCapacity < 0) throw new IllegalArgumentException( ... );elementData = new Object[initialCapacity];
}
Der Zugriff auf ein Element an einer gegebenen Stelle ist direkt und damit sehr schnell.
public E get(int index) {if (index >= size || index < 0) throw new IndexOutOfBoundsException( ... );return (E) elementData[index];
}
Das Einfugen von neuen Elementen in den Array hingegen ist aufwandig, da der hintere Teil des Arrayumkopiert werden muss.
add
. . . .
arrayCopy
public void add(int index, E element) {if (index > size || index < 0) throw new IndexOutOfBoundsException(...)ensureCapacityInternal(size + 1);System.arraycopy(elementData, index, elementData, index + 1,
size - index);elementData[index] = element;size++;
}

3-4 3 Datentypen: Listen, Stacks und Queues
Das Gleiche gilt fur das Loschen von Elementen aus einer ArrayList. Alle Elemente hinter dem geloschtenElement mussen umkopiert werden.
public E remove(int index) {if (index >= size || index < 0) throw new IndexOutOfBoundsException( ... );
E oldValue = elementData(index);int numMoved = size - index - 1;if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData,index, numMoved);
elementData[--size] = null; // Let gc do its workreturn oldValue;
}
Sobald der aktuell angelegte Array voll ist, muss ein neuer Datenspeicher angelegt und der gesamteArray umkopiert werden.
public void ensureCapacity(int minCapacity) {if (minCapacity - elementData.length > 0) // -> grow
int oldCapacity = elementData.length;int newCapacity = oldCapacity + (oldCapacity >> 1);if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;// copy all elements to new (larger) memory areaelementData = Arrays.copyOf(elementData, newCapacity);
}}

3.2 Doppelt verkettete Listen 3-5
3.2 Doppelt verkettete Listen
In einer doppelt verketteten Liste besteht jedes Listenelement aus einem Datenfeld (bzw. einer Referenzauf ein Datenfeld) (element) und zwei Zeigern (next und prev).
Als Listenelemente dient die Klasse Node.
private static class Node<E> {E item;Node<E> next;Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {this.item = element;this.next = next;this.prev = prev;
}}
Die Klasse Node ist eine innere Klasse von List und wird einzig zum Verpacken der Datenelementebentutzt.

3-6 3 Datentypen: Listen, Stacks und Queues
Eine (doppelt) verkettete Liste entsteht dann durch Zusammenfugen einzelner Node Elemente. Beson-dere Node Elemente bezeichnen dabei den Listenanfang und das Ende.
Die Definition einer Liste sieht dann zum Beispiel wie folgt aus:
public class LinkedList<E> {transient Node<E> first;transient Node<E> last;transient int size = 0;
/*** Returns true if this list contains no elements.*/boolean isEmpty(){ ... };
/*** Returns the element at the specified position in this list.* Throws IndexOutOfBoundsException if the index is out of range.*/E get(int index){ ... };
/*** Inserts the element at the specified position in this list.* Throws IndexOutOfBoundsException if the index is out of range.*/void add(int index, E element){ ... };
/*** Removes the element at position index in this list.* Returns the element previously at the specified position.* Throws IndexOutOfBoundsException if the index is out of range.

3.2 Doppelt verkettete Listen 3-7
*/E remove(int index){ ... };
/*** Returns the index of the first occurrence of the specified* element, or -1 if this list does not contain this element.*/int indexOf(Object o){ ... };
. . .}
Wir betrachten hier je eine Implementation fur das Einfugen und fur das Loschen eines Elementes.
Suchen einer bestimmten Stelle
Node<E> node(int index) {if (index < (size >> 1)) {
Node<E> x = first;for (int i = 0; i < index; i++)
x = x.next;return x;
} else {Node<E> x = last;for (int i = size - 1; i > index; i--)
x = x.prev;return x;}
}
3-8 3 Datentypen: Listen, Stacks und Queues
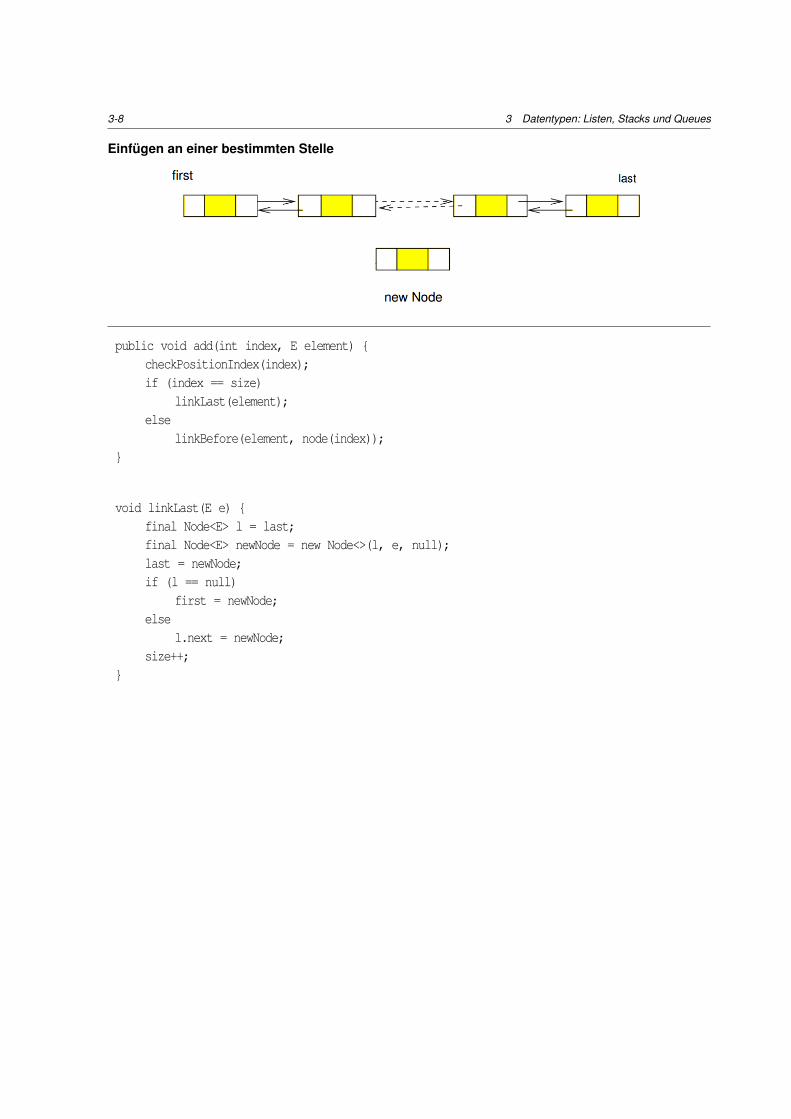
Einfugen an einer bestimmten Stelle
public void add(int index, E element) {checkPositionIndex(index);if (index == size)
linkLast(element);else
linkBefore(element, node(index));}
void linkLast(E e) {final Node<E> l = last;final Node<E> newNode = new Node<>(l, e, null);last = newNode;if (l == null)
first = newNode;else
l.next = newNode;size++;
}

3.2 Doppelt verkettete Listen 3-9
void linkBefore(E e, Node<E> succ) {final Node<E> pred = succ.prev; // assert succ != null;final Node<E> newNode = new Node<>(pred, e, succ);succ.prev = newNode;if (pred == null)
first = newNode;else
pred.next = newNode;size++;
}
void addFirst(E e) { // oder linkFirstfinal Node<E> f = first;final Node<E> newNode = new Node<>(null, e, f);first = newNode;if (f == null)
last = newNode;else
f.prev = newNode;size++;
}
public void add(E e) { // add at the endfinal Node<E> l = last;final Node<E> newNode = new Node<>(l, e, null);last = newNode;if (l == null)
first = newNode;else
l.next = newNode;size++;
}
Am effizientesten ist also das nicht-sortierte Einfugen, das heisst am Ende oder am Anfang.

3-10 3 Datentypen: Listen, Stacks und Queues
Loschen
Beim Loschen von Elementen muss gepruft werden, ob ev. first und/oder last korrigiert werden mussen.
public E remove(int index) {if(index >= 0 && index < size)
return unlink(node(index));else
throw new IndexOutOfBoundsException( ... );}
E unlink(Node<E> x) {final E element = x.item;final Node<E> next = x.next;final Node<E> prev = x.prev;
if (prev == null) {first = next;
} else {prev.next = next; x.prev = null;
}if (next == null) {
last = prev;} else {
next.prev = prev; x.next = null;}x.item = null;size--;return element;
}

3.3 Stacks und Queues 3-11
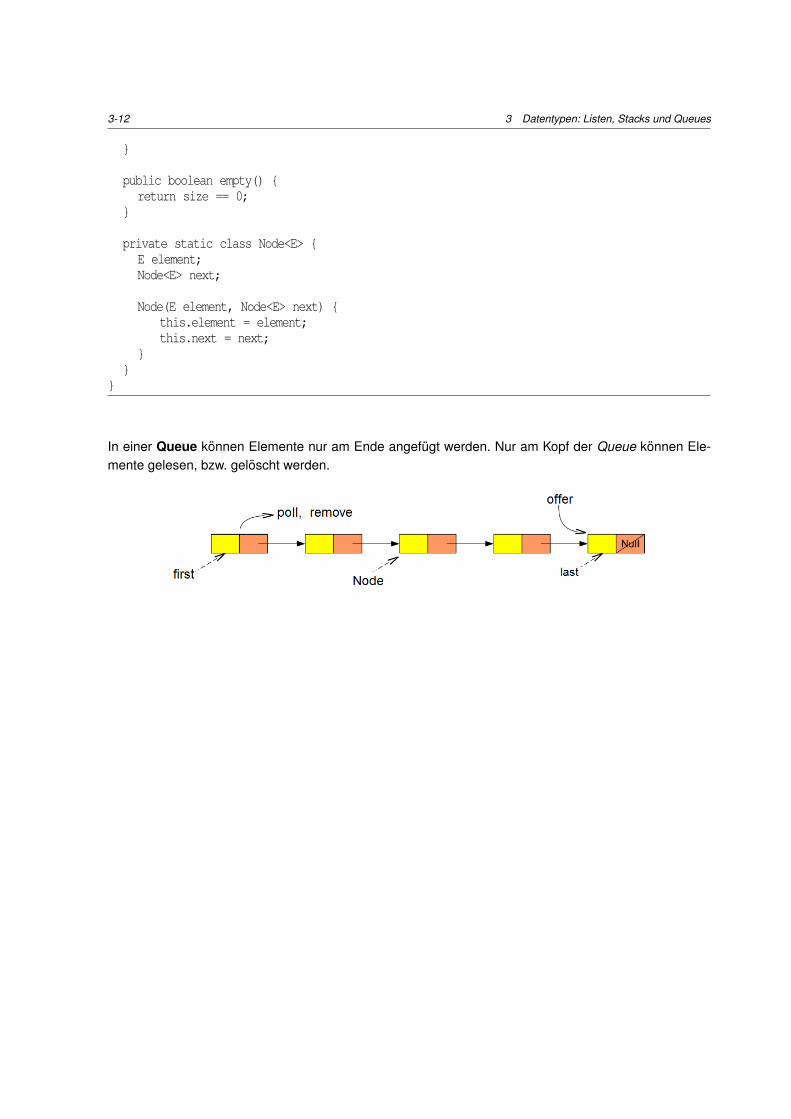
3.3 Stacks und Queues
Ein Interface fur einen Stack hatten wir im Abschnitt 1.2 bereits gesehen. Stacks sind einfache Listen-strukturen, bei denen bloss am Kopf Elemente eingefugt, gelesen, bzw. geloscht werden durfen.
Wir betrachten hier die Implementation eines Stacks mit Hilfe von Zeigerstrukturen.
public class Stack<E> {private Node<E> first;private int size = 0;
public E push(E item) {first = new Node<E>(item, first);size++;return item;
}
public E pop() {if (size==0) throw new EmptyStackException();Node<E> e = first;E result = e.element;first = e.next;e.element = null;e.next = null;size--;return result;
}
public E peek() {if (size==0) throw new EmptyStackException();return first.element;
3-12 3 Datentypen: Listen, Stacks und Queues
}
public boolean empty() {return size == 0;
}
private static class Node<E> {E element;Node<E> next;
Node(E element, Node<E> next) {this.element = element;this.next = next;
}}
}
In einer Queue konnen Elemente nur am Ende angefugt werden. Nur am Kopf der Queue konnen Ele-mente gelesen, bzw. geloscht werden.

3.4 Iteratoren 3-13
3.4 Iteratoren
Auf Listenstrukturen hat man ublicherweise eine Hilfsklasse, welche zum Durchlaufen der Liste dient. Diezwei wichtigsten Methoden von Iterator Klassen sind hasNext zum Prufen, ob das Ende der Liste erreichtist, sowie die Methode next, welche den Inhalt des nachsten Elements zuruckgibt.
public interface Iterator<E> {
/**
* Returns true if the iteration has more elements.
*/
boolean hasNext();
/**
* Returns the next element in the iteration.
* @exception NoSuchElementException iteration has no more elements.
*/
E next();
...
}

3-14 3 Datentypen: Listen, Stacks und Queues
3.5 Ubung 3
Fur die Implementationsaufgabe finden Sie Rahmenprogramme unter
www.sws.bfh.ch/∼amrhein/AlgoData/
1. List IteratorEntwerfen Sie (ausgehend vom Rahmenprogramm) eine Klasse ListItr, welche als Iterator fur die
LinkedList verwendet werden kann.
Implementieren Sie dazu in der MyLinkedList Klasse eine innere Klasse ListItr mit einem Konstruktor
ListItr(int index), welcher ein ListIterator Objekt erzeugt, welches an die Position index zeigt. Imple-
mentieren Sie ausserdem die Methoden Object next(), boolean hasNext(), boolean hasPrevious()
und Object previous().
2. QueueImplementieren Sie eine Queue gemass dem gegebenen Rahmenprogramm.
- Implementieren Sie die Queue zuerst als Liste.
- Als zweites implemtieren Sie die Queue als Array.
In der Array-basierten Queue durfen Sie annehmen, dass die Queue nicht mehr als MAX viele
Elemente enthalten muss. Uberlegen Sie sich eine Implementierung, welche nicht nach jedem
Einfugen oder Loschen den ganzen Array umkopiert.
3. Das Collection InterfaceZeichnen Sie die Klassenhierarchie der (wichtigsten) Collection Klassen.
Zeichnen Sie die Hierarchie der Interfaces List, Queue, Set und SortedSet, sowie der Klassen Array-
List, HashSet, LinkedHashSet, LinkedList, PriorityQueue, Stack, TreeSet, Vector

4 Datentypen: Baume, Heaps
Alle bisher betrachteten Strukturen waren linear in dem Sinn, dass jedes Element hochstens einen Nach-
folger hat. In einem Baum kann jedes Element keinen, einen oder beliebig viele Nachfolger haben. Baume
sind wichtig als Strukturen in der Informatik, da sie auch oft im Alltag auftauchen: zum Darstellen von
Abhangigkeiten oder Strukturen, als Organigramme von Firmen, als Familienstammbaum, aber auch
zum Beschleunigen der Suche.
Definition: Ein Graph ist definiert als ein Paar B = (E,K) bestehend aus je einer endlichen Menge Evon Ecken (Knoten, Punkten) und einer Menge von Kanten. Eine Kante wird dargestellt als Zweiermenge
von Ecken {x,y}, den Endpunkten der Kante.
Ein Baum ist ein Graph mit der zusatzliche Einschrankung, dass es zwischen zwei Ecken nur eine (di-
rekte oder indirekte) Verbindung gibt1.
Wir befassen uns hier zuerst vor allem mit einer besonderen Art von Baumen: den Binarbaumen. Ein
Baum heisst binar, falls jeder Knoten hochstens zwei Nachfolger hat.
1 Ein Baum ist ein zusammenhangender Graph ohne Zyklen.

4-2 4 Datentypen: Baume, Heaps
..
... .
....
..Definition: Ein binarer Baum besteht aus einer Wurzel (Root) und (endlich vielen) weiteren Knoten und
verbindenden Kanten dazwischen. Jeder Knoten hat entweder keine, ein oder zwei Nachfolgerknoten.
Ein Weg in einem Baum ist eine Liste von disjunkten, direkt verbunden Kanten. Ein binarer Baum ist
vollstandig (von der Hohe n), falls alle inneren Knoten zwei Nachfolger haben und die Blatter maximal
Weglange n bis zur Wurzel haben.
Jedem Knoten ist eine Ebene (level) im Baum zugeordnet. Die Ebene eines Knotens ist die Lange des
Pfades von diesem Knoten bis zur Wurzel. Die Hohe (height) eines Baums ist die maximale Ebene, auf
der sich Knoten befinden.
Ein binarer Baum besteht also aus Knoten mit einem (Zeiger auf ein) Datenelement data , einem linken
Nachfolgerknoten left und einem rechten Nachfolgerknoten right .
left right
public class BinaryTreeNode<T> {protected T data;protected BinaryTreeNode<T> leftChild;protected BinaryTreeNode<T> rightChild;

4-3
public BinaryTreeNode(T item){ data=item; }
// tree traversalspublic BinaryTreeNode<T> inOrderFind(T item) { . . . }public BinaryTreeNode<T> postOrderFind(T item) { . . . }public BinaryTreeNode<T> preOrderFind(T item) { . . .}
// getter and setter methods. . .
public class BinaryTree<T> {protected BinaryTreeNode<T> rootTreeNode;
public BinaryTree(BinaryTreeNode<T> root) {this.rootTreeNode = root;
}
// tree traversalspublic BinaryTreeNode<T> inOrderFind(T item) {return rootTreeNode.inOrderFind(item);
}public BinaryTreeNode<T> preOrderFind(T item) { ... }public BinaryTreeNode<T> postOrderFind(T item) { ... }
public BinaryTreeNode<T> postOrderFindStack(T item) { ... }
//getter and setter methods. . .

4-4 4 Datentypen: Baume, Heaps
4.1 Baumdurchlaufe
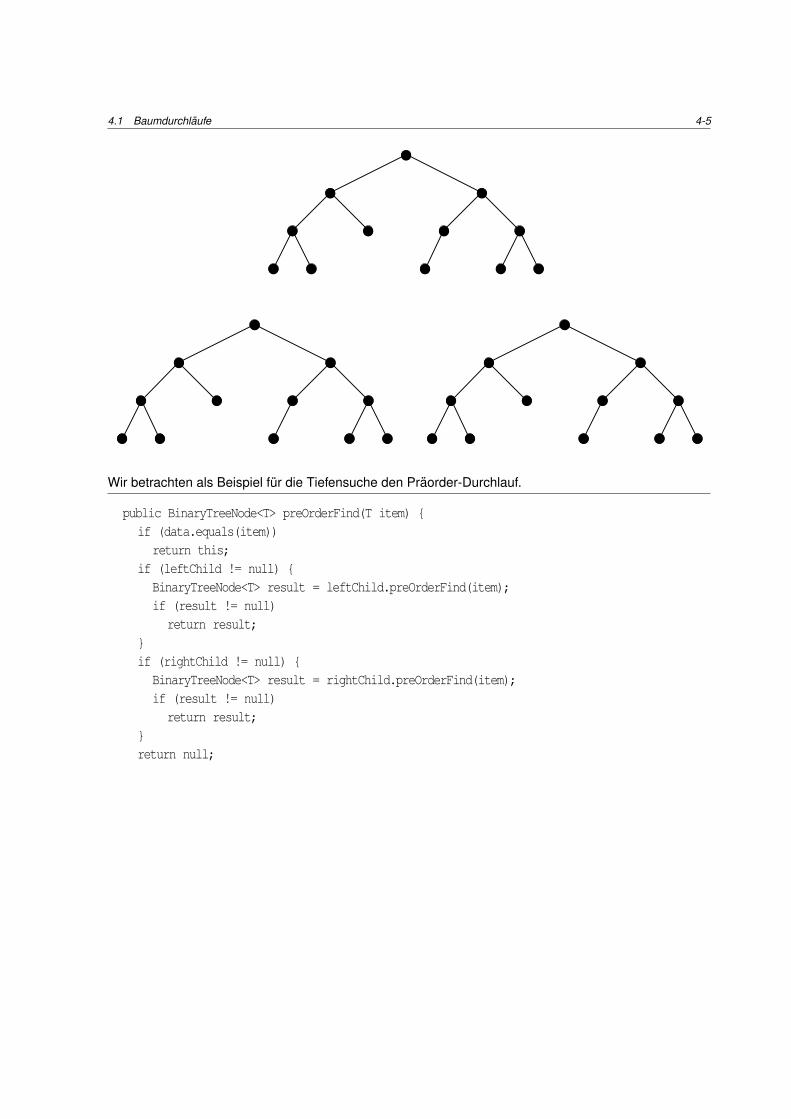
Baume konnen auf verschiedene Arten durchlaufen werden. Die bekanntesten Verfahren sind Tiefensu-
che (depth-first-search, DFS) und Breitensuche (breadth-first-search, BFS). Tiefensuche kann unter-
schieden werden in die drei Typen praorder, postorder und inorder, abhangig von der Reihenfolge der
rekursiven Aufrufe.
4.1.1 Tiefensuche
Praorder
• Betrachte zuerst den Knoten (die Wurzel des Teilbaums),
• durchsuche dann den linken Teilbaum,
• durchsuche zuletzt den rechten Teilbaum.
Inorder
• Durchsuche zuerst den linken Teilbaum,
• betrachte dann den Knoten,
• durchsuche zuletzt den rechten Teilbaum.
Postorder
• Durchsuche zuerst den linken Teilbaum,
• durchsuche dann den rechten Teilbaum,
• betrachte zuletzt den Knoten.
4.1 Baumdurchlaufe 4-5
..
... .
....
..
..
... .
....
...
..
.. ....
...
Wir betrachten als Beispiel fur die Tiefensuche den Praorder-Durchlauf.
public BinaryTreeNode<T> preOrderFind(T item) {if (data.equals(item))return this;
if (leftChild != null) {BinaryTreeNode<T> result = leftChild.preOrderFind(item);if (result != null)return result;
}if (rightChild != null) {BinaryTreeNode<T> result = rightChild.preOrderFind(item);if (result != null)
return result;}return null;

4-6 4 Datentypen: Baume, Heaps
}
4.1.2 Tiefensuche mit Hilfe eines Stacks
Mit Hilfe eines Stacks konnen wir die rekursiven Aufrufe in der praorder Tiefensuche vermeiden. Auf demStack werden die spater zu behandelnden Baumknoten zwischengespeichert.
public BinaryTreeNode<T> preOrderFindStack(T item) {Stack<BinaryTreeNode<T>> stack = new Stack<BinaryTreeNode<T>>();stack.push(this.rootTreeNode);while (!stack.isEmpty()) {BinaryTreeNode<T> tmp = stack.pop();if (tmp.getData().equals(item))return tmp;
if (tmp.getRightChild() != null)stack.push(tmp.getRightChild());
if (tmp.getLeftChild() != null)stack.push(tmp.getLeftChild());
}return null;
}

4.1 Baumdurchlaufe 4-7
4.1.3 Breitensuche mit Hilfe einer Queue
Bei der Breitensuche besucht man jeweils nacheinander die Knoten der gleichen Ebene:
• Starte bei der Wurzel (Ebene 0).
• Bis die Hohe des Baumes erreicht ist, setze den Level um eines hoher und gehe von links nachrechts durch alle Knoten dieser Ebene. .
..
.. ....
...
Bei diesem Verfahren geht man nicht zuerst in die Tiefe, sondern betrachtet von der Wurzel aus zuerstalle Elemente in der naheren Umgebung. Um mittels Breitensuche (levelorder) durch einen Baum zuwandern, mussen wir uns alle Baumknoten einer Ebene merken. Diese Knoten speichern wir in einerQueue ab, so dass wir spater darauf zuruckgreifen konnen.
public BinaryTreeNode<T> levelOrderFind(T item) {QueueImpl<BinaryTreeNode<T>> queue = new QueueImpl<BinaryTreeNode<T>>();queue.add(rootTreeNode);while (!queue.isEmpty()) {BinaryTreeNode<T> tmp = queue.poll();if (tmp.getData().equals(item))return tmp;
if (tmp.getLeftChild() != null)queue.add(tmp.getLeftChild());
if (tmp.getRightChild() != null)queue.add(tmp.getRightChild());
}return null;
}

4-8 4 Datentypen: Baume, Heaps
4.2 Binare Suchbaume
Ein binarer Suchbaum ist ein Baum, welcher folgende zusatzliche Eigenschaft hat:
Alle Werte des linken Nachfolger-Baumes eines Knotens K sind kleiner, alle Werte des rechtenNachfolger-Baumes von K sind grosser als der Wert von K selber.
Der grosse Vorteil von binaren Suchbaumen ist, dass wir sowohl beim Einfugen als auch beim Suchenvon Elementen immer bloss einen der zwei Nachfolger untersuchen mussen. Falls der gesuchte Wertkleiner ist als der Wert des Knotens, suchen wir im linken Teilbaum, anderenfalls im rechten Teilbaumweiter.
Beispiel: Die folgenden zwei Baume entstehen durch Einfugen der Zahlen 37, 43, 53, 11, 23, 5, 17, 67,47 und 41 in einen leeren Baum. Einmal werden die Zahlen von vorne nach hinten eingefugt, das zweiteMal von hinten nach vorne.

4.2 Binare Suchbaume 4-9
public class BinarySearchTreeNode <T extends Comparable<T>> {
public void add(T item) {int compare = data.compareTo(item);if (compare > 0) { // (data > item)?if (leftChild == null)leftChild = new BinarySearchTreeNode<T>(item);
elseleftChild.add(item); // left recursion
} else { // (item >= data)if (rightChild == null)rightChild = new BinarySearchTreeNode<T>(item);
elserightChild.add(item); // right recursion
}}
public BinarySearchTreeNode<T> find(T item) {int compare = data.compareTo(item);if (compare == 0)return this;
if (compare > 0 && leftChild != null) // data > itemreturn leftChild.find(item);
if (compare < 0 && rightChild != null) // data < itemreturn rightChild.find(item);
return null;}
. . .}

4-10 4 Datentypen: Baume, Heaps
4.3 B-Baume
Ein B-Baum ist ein stets vollstandig balancierter und sortierter Baum. Ein Baum ist vollstandig balanciert,wenn alle Aste gleich lang sind. In einem B-Baum darf die Anzahl Kindknoten variieren. Ein 3-4-5 B-Baum ist zum Beispiel ein Baum, in welchem jeder Knoten maximal 4 Datenelemente speichern undjeder Knoten (ausser der Wurzel und den Blattern) minimal 3 und maximal 5 Nachfolger haben darf (derWurzelknoten hat 0-4 Nachfolger, Blatter haben keine Nachfolger).
Durch die flexiblere Anzahl Kindknoten ist das Rebalancing weniger haufig notig.
Ein Knoten eines B-Baumes speichert:
• eine variable Anzahl s von aufsteigend sortierten Daten-Elementen k1, . . . ,ks
• eine Markierung isLeaf, die angibt, ob es sich bei dem Knoten um ein Blatt handelt.
• s+1 Referenzen auf Kindknoten, falls der Knoten kein Blatt ist.
• Jeder Kindknoten ist immer mindestens zur Halfte gefullt.
Die letzte Bedingung lautet formal: es gibt eine Schranke m, so dass m <= s <= 2m gilt. Das heisst,jeder Kindknoten hat mindestens m, aber hochstens 2m Daten-Elemente.
Die Werte von k1, . . . ,ks dienen dabei als Splitter. Die Daten-Elemente der Kindknoten ganz links mussenkleiner sein als k1, diejenigen ganz rechts grosser als ks. Dazwischen mussen die Daten-Elemente desi-ten Kindes grosser als ki und kleiner als ki+1 sein.
Das folgende Bild zeigt einen B-Baum mit m gleich 2. Jeder innere Knoten hat also mindestens 2 undmaximal 5 Nachfolger.

4.3 B-Baume 4-11
Operationen in B-Baumen
Suchen
Die Suche nach einem Datenelement e lauft in folgenden Schritten ab: Beginne bei der Wurzel als aktu-ellen Suchknoten k.
• Suche in k von links her die Position p des ersten Daten-Elementes x, welches grosser oder gleich eist.
• Falls alle Daten-Elemente von k kleiner sind als e, fuhre die Suche im Kindknoten ganz rechts weiter.
• Falls x gleich e ist, ist die Suche zu Ende.
• Anderfalls wird die Suche beim p-ten Kindelement von k weitergefuhrt.
• Falls k ein Blatt ist, kann die Suche abgebrochen werden (fail).
Einfugen
Beim Einfugen muss jeweils beachtet werden, dass nicht mehr als 2m Daten-Elemente in einem Knotenuntergebracht werden konnen.
Zunachst wird das Blatt gesucht, in welches das neue Element eingefugt werden musste. Dabei kanngleich wie beim Suchen vorgegegangen werden, ausser dass wir immer bis zur Blatt-Tiefe weitersuchen(sogar, wenn wir den Wert unterwegs gefunden haben). Falls es in dem gesuchten Blatt einen freienPlatz hat, wird der Wert dort eingefugt.
Einfugen des Werts 31 in den folgenden Baum:

4-12 4 Datentypen: Baume, Heaps
Der Wert 31 sollte in das Blatt (30,34,40,44) eingefugt werden. Dieses ist aber bereits voll, muss alsoaufgeteilt werden. Dies fuhrt dazu, dass der Wert in der Mitte (34) in den Vorganger- Knoten verschobenwird. Da das alte Blatt ganz rechts vom Knoten (20,28) liegt, wird der Wert 34 rechts angefugt (neuer,grosster Wert dieses Knotens). Damit erhalt dieser Knoten neu 3 Werte und 4 Nachfolger.
Dieser Prozess muss eventuell mehrmals (in Richtung Wurzel) wiederholt werden, falls durch das Hoch-schieben des Elements jeweils der Vorganger-Knoten ebenfalls uberlauft.

4.3 B-Baume 4-13
Loschen von Elementen
Beim Loschen eines Elementes muss umgekehrt beachtet werden, dass jeder Knoten nicht weniger alsm Datenelemente enthalten muss.
Falls das geloschte Element in einem Blatt liegt, welches mehr als m Datenelemente hat, kann dasElement einfach geloscht werden. Andernfalls konnen entweder Elemente vom benachbarte Blatt ver-schoben oder (falls zu wenig Elemente vorhanden sind) zwei Blatter verschmolzen werden.
Verschiebung Aus dem linken B-Baum soll das Element 18 geloscht werden. Dies wurde dazu fuhren,dass das linke Blatt zu wenig Datenelemente hat. Darum wird aus dem rechten Nachbarn das kleinsteElement nach oben, und das Splitter-Element des Vorgangers in das linke Blatt verschoben.Analog konnte (falls vorhanden) aus einem linken Nachbarn das grosste Element verschoben werden.
Falls ein Element eines inneren Knotens (z.B. das Element 34) geloscht wird, muss entweder von denlinken Nachfolgern das grosste, oder von den rechten Nachfolgern das kleinste Element nach oben ver-schoben werden, damit weiterhin genugend Elemente (als Splitter) vorhanden sind, und die Ordnungbewahrt wird.

4-14 4 Datentypen: Baume, Heaps
Verschmelzung Aus dem linken B-Baum soll das Element 60 geloscht werden. Dies wurde dazu fuhren,dass das mittlere Blatt zu wenig Datenelemente hat. Weder der rechte noch der linke Nachbar hatgenugend Elemente, um eine Verschiebung durch zu fuhren - es mussen zwei Blatter verschmolzenwerden.
Das linke Blatt erhalt vom mittleren Blatt das Element 55, sowie von der Wurzel das Element 50. DieWurzel muss ebenfalls ein Element abgeben, da nach der Verschmelzung bloss noch 2 Nachfolge-Knotenexistieren. Das rechte Blatt bleibt unverandert.
Mit Hilfe der Verschiebung- und Verschmelzungs-Operation konnen wir nun beliebige Elemente aus ei-nem B-Baum loschen.
Beispiel
Aus dem folgenden Baum loschen wir zuerst das Element 75, danach das Element 85:

4.4 Priority Queues 4-15
4.4 Priority Queues
In vielen Applikationen will man die verschiedenen Elemente in einer bestimmten Reihenfolge (Prioritat)abarbeiten. Allerdings will man das (aufwandige!) Sortieren dieser Elemente nach moglichkeit vermeiden.
Eine der bekanntesten Anwendungen in diesem Umfeld sind Scheduling-Algorithmen mit Prioritaten. AlleProzesse werden gemass ihrer Prioritat in einer Priority Queue gesammelt, so dass immer das Elementmit hochster Prioritat verfugbar ist. Priority Queues haben aber noch weit mehr Anwendungen, zumBeispiel bei Filekomprimierungs- oder bei Graph-Algorithmen.
Eine elegante Moglichkeit der Implementierung einer Priority Queue ist mit Hilfe eines Heaps.
4.4.1 Heaps
Ein Heap ist ein (fast) vollstandiger Baum, in welchem nur in der untersten Ebene von rechts her Blatterfehlen durfen.
15
52
65
56
37 48 45
31 18 6 325

4-16 4 Datentypen: Baume, Heaps
Definition: [Heap] Ein Heap ist ein vollstandiger binarer Baum, dem nur in der untersten Ebene ganzrechts Blatter fehlen durfen mit folgenden Zusatzeigenschaften.
1. Jeder Knoten im Baum besitzt eine Prioritat und eventuell noch weitere Daten.
2. Die Prioritat eines Knotens ist immer grosser als (oder gleich wie) die Prioritat der Nachkommen.Diese Bedingung heisst Heapbedingung.
Aus der Definition kann sofort abgelesen werden, dass die Wurzel des Baumes die hochste Prioritatbesitzt. Weil der Heap im wesentlichen ein vollstandiger binarer Baum ist, lasst er sich einfach als Array2
implementieren. Wir numerieren die Knoten des Baumes von oben nach unten und von links nach rechts.Die so erhaltene Nummerierung ergibt fur jeden Knoten seinen Index im Array.
Die dargestellten Werte im Baum sind naturlich bloss die Prioritaten der Knoten. Die eigentlichen Datenlassen wir der Einfachheit halber weg.
public class Heap<T extends Comparable<T>> {private List<T> heap;
public Heap() { heap = new ArrayList<T>(); }
public T removeMax() { . . . }public void insert(T data) { . . . }
private boolean isLeaf(int position) { . . . }private int parent(int position) { . . . }private int leftChild(int position) { . . . }private int rightChild(int position){ . . . }
2 Dies hat den Nachteil, dass die maximale Anzahl Elemente (size ) beim Erzeugen des Heaps bekannt sein muss.

4.4 Priority Queues 4-17
. . .
15
52
65
56
48 45
31 18 6 325
37
Werden die Knoten auf diese Weise in den Array abgelegt, so gelten fur alle i, 0 ≤ i < length diefolgenden Regeln:
• Der linke Nachfolger des Knotens i befindet sich im Array-ElementFerner gilt: heap[i] heap[ ]
• Der rechte Nachfolger des Knotens i befindet sich im Array ElementFerner gilt: heap[i] heap[ ]
• Der direkte Vorfahre eines Knotens i befindet sich im Array-ElementFerner gilt: heap[i] heap[ ]
Wir sind jetzt in der Lage, die beiden wichtigen Operationen insert und removeMax zu formulieren.
4-18 4 Datentypen: Baume, Heaps
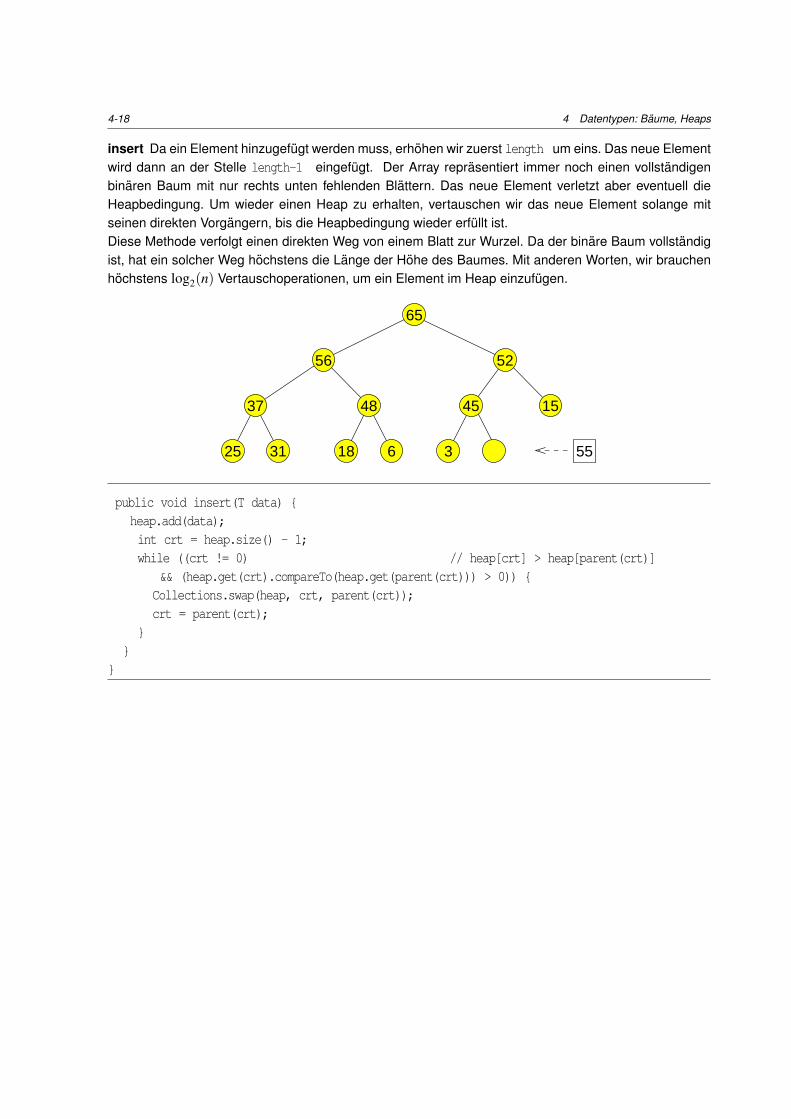
insert Da ein Element hinzugefugt werden muss, erhohen wir zuerst length um eins. Das neue Elementwird dann an der Stelle length-1 eingefugt. Der Array reprasentiert immer noch einen vollstandigenbinaren Baum mit nur rechts unten fehlenden Blattern. Das neue Element verletzt aber eventuell dieHeapbedingung. Um wieder einen Heap zu erhalten, vertauschen wir das neue Element solange mitseinen direkten Vorgangern, bis die Heapbedingung wieder erfullt ist.Diese Methode verfolgt einen direkten Weg von einem Blatt zur Wurzel. Da der binare Baum vollstandigist, hat ein solcher Weg hochstens die Lange der Hohe des Baumes. Mit anderen Worten, wir brauchenhochstens log2(n) Vertauschoperationen, um ein Element im Heap einzufugen.
55
15
52
65
56
48 45
31 18 6 325
37
public void insert(T data) {heap.add(data);int crt = heap.size() - 1;while ((crt != 0) // heap[crt] > heap[parent(crt)]
&& (heap.get(crt).compareTo(heap.get(parent(crt))) > 0)) {Collections.swap(heap, crt, parent(crt));crt = parent(crt);
}}
}
4.4 Priority Queues 4-19
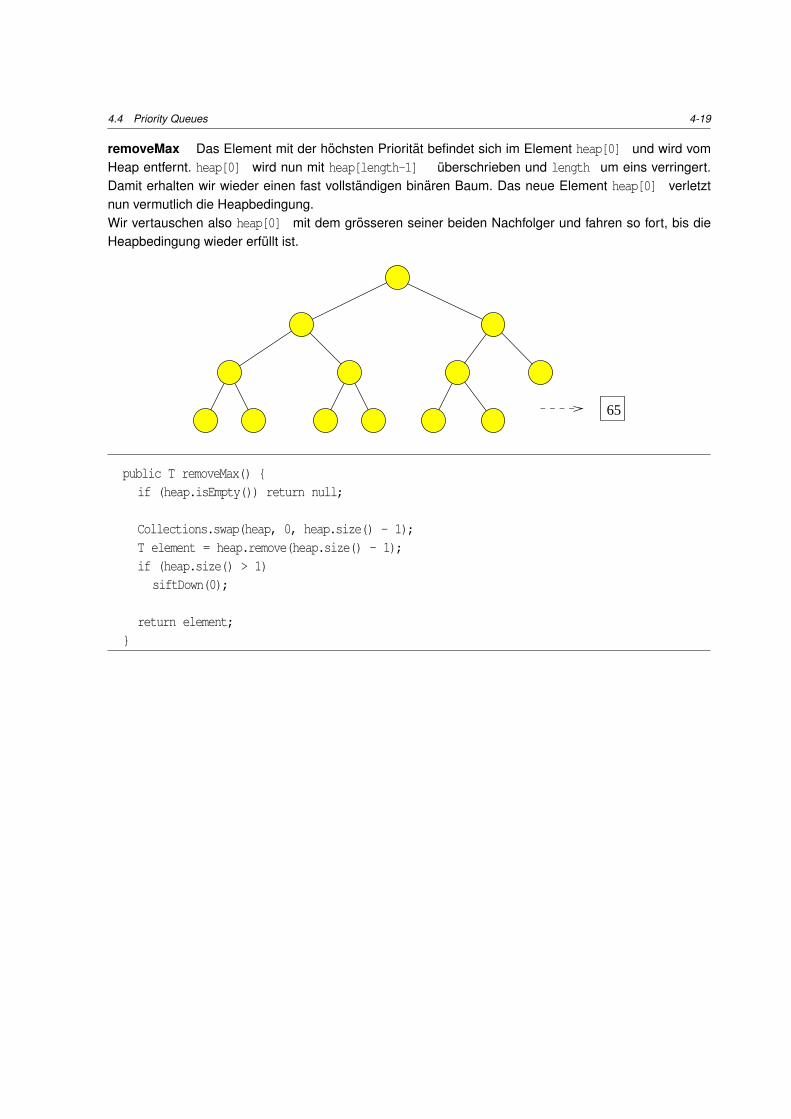
removeMax Das Element mit der hochsten Prioritat befindet sich im Element heap[0] und wird vomHeap entfernt. heap[0] wird nun mit heap[length-1] uberschrieben und length um eins verringert.Damit erhalten wir wieder einen fast vollstandigen binaren Baum. Das neue Element heap[0] verletztnun vermutlich die Heapbedingung.Wir vertauschen also heap[0] mit dem grosseren seiner beiden Nachfolger und fahren so fort, bis dieHeapbedingung wieder erfullt ist.
65
public T removeMax() {if (heap.isEmpty()) return null;
Collections.swap(heap, 0, heap.size() - 1);T element = heap.remove(heap.size() - 1);if (heap.size() > 1)siftDown(0);
return element;}

4-20 4 Datentypen: Baume, Heaps
private void siftDown(int position) {while (!isLeaf(position)) {int j = leftChild(position);if ((j < heap.size() - 1) // heap[j] < heap[j+1]
&& (heap.get(j).compareTo(heap.get(j + 1)) < 0)) {j++;
} // heap[position] >= heap[j]if (heap.get(position).compareTo(heap.get(j)) >= 0) {
return;}Collections.swap(heap, position, j);position = j;
}}
4.5 Ubung 4 4-21
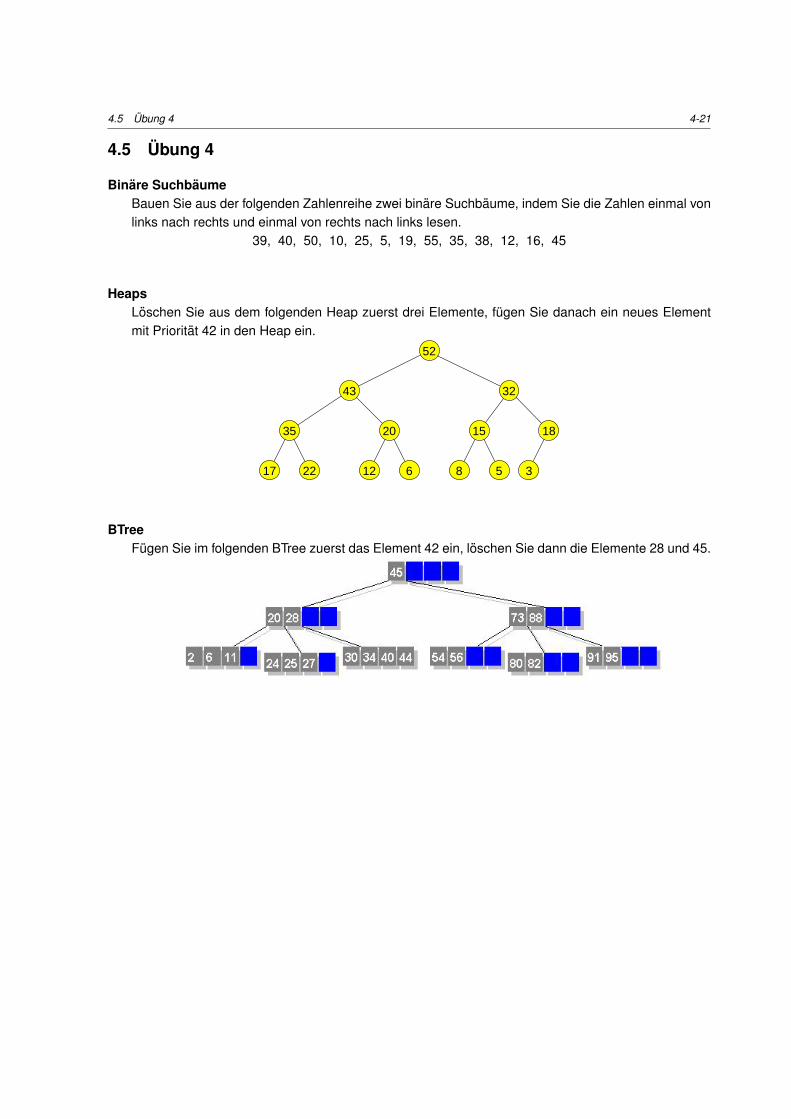
4.5 Ubung 4
Binare SuchbaumeBauen Sie aus der folgenden Zahlenreihe zwei binare Suchbaume, indem Sie die Zahlen einmal vonlinks nach rechts und einmal von rechts nach links lesen.
39, 40, 50, 10, 25, 5, 19, 55, 35, 38, 12, 16, 45
HeapsLoschen Sie aus dem folgenden Heap zuerst drei Elemente, fugen Sie danach ein neues Elementmit Prioritat 42 in den Heap ein.
8
52
43 32
35 20
17 22 12
15
5 3
18
6
BTreeFugen Sie im folgenden BTree zuerst das Element 42 ein, loschen Sie dann die Elemente 28 und 45.

4-22

5 Suchen
5.1 Grundlagen
Suchen ist eine der haufigsten Operationen, die mit dem Computer ausgefuhrt werden. Normalerweisegeht es darum, in einer Menge von Daten die richtigen Informationen zu finden. Wir kennen zum Beispieleinen Namen und suchen die zugehorige Mitgliedernummer. Oder wir geben (mit Hilfe einer EC-Karte)eine Kontonummer ein und das System sucht das dazugehorige Konto. Oder wir kennen eine Telefon-nummer und suchen den dazugehorigen Abonnenten, usw.
Wenn wir im folgenden jeweils Listen von Zahlen durchsuchen, so tun wir das bloss der Einfachheithalber. Die gleichen Algorithmen konnen naturlich fur beliebige Objekte angewandt werden. Ein Ob-jekt kann zum Beispiel eine Klasse Adresse mit den Member-Variablen name, vorname, strasse,wohnort, telefonNummer, kundenNummer sein. Dann verwenden wir eine der Member-Variablenals Suchschlussel, also zum Beispiel Adresse.name .
Da Suchalgorithmen so haufig verwendet werden, lohnt es sich, diese effizient zu implementieren. An-derseits spielt naturlich die Lange der zu durchsuchenden Datenmenge eine entscheidende Rolle: Jegrosser die Datenmenge, desto wichtiger die Effizienz der Suche.
Ausserdem spielt die benutzte Datenstruktur eine entscheidende Rolle. Wir werden hier jeweils anneh-men, dass wir auf alle Elemente der Datenfolge schnellen wahlfreien Zugriff haben (wie z. Bsp. in einerArrayList). Falls dies nicht der Fall ist, sind gewisse Suchalgorithmen sehr viel weniger effizient.

5-2 5 Suchen
Falls kein wahlfreier Zugriff existiert, kann dies mit Hilfe eines Pointer-Arrays simuliert werden, in wel-chem die Adressen der Daten-Objekte gespeichert sind. Die richtige Wahl der benutzten Datenstrukturist entscheidend, ob ein Algorithmus effizient implementiert werden kann oder nicht.
5.2 Lineare Suche
Wie der Name schon sagt, gehen wir bei der linearen Suche linear durch die Suchstruktur und testenjedes Element, bis wir das gesuchte finden oder ans Ende gelangen.
/*** Searches for the first occurence of the given argument.* @param elem an object.* @return the index of the first occurrence of the argument in* this list; returns -1 if the object is not found.*/
public int indexOf(Object elem) {if (elem == null) {for (int i = 0; i < size; i++)if (elementData[i]==null)
return i;} else {for (int i = 0; i < size; i++)if (elem.equals(elementData[i]))
return i;}return -1;
}
Die for -Schleife bricht spatestens dann ab, wenn das letzte Element der Liste gepruft ist.
Komplexitat der linearen Suche
Um die Effizienz der linearan Suche zu bestimmen, bestimmen wir die Anzahl der notigen Vergleiche inAbangigkeit von der Lange n der Folge.

5.3 Binare Suche 5-3
5.3 Binare Suche
Eine Folge, auf die sehr haufig zugegriffen (und nicht so haufig verandert) wird, sollte wenn moglichsortiert gehalten werden1. Dies lasst sich leicht realisieren, indem die neuen Elemente jeweils an derrichtigen Stelle einsortiert werden2.Falls die Daten so dargestellt sind, kann das Suchen auf sehr viel schnellere Art und Weise realisiertwerden, zum Beispiel durch binare Suche. Bei der binaren Suche wird die Folge in zwei Teile
Elem[0] · · · Elem[p-1]︸ ︷︷ ︸ Elem[p+1] · · · Elem[len]︸ ︷︷ ︸geteilt und das Element Elem[p] mit dem zu suchenden Element a verglichen. Falls Elem[p] kleiner alsa ist, suchen wir in der rechten Teilfolge weiter, andernfalls in der linken.
p = (r+l)/2
r = size
l = 0a
Die ersten drei Schritte der binaren Suche
Da die Folge sortiert ist, ist dieses Vorgehen korrekt.
1 Dies setzt naturlich voraus, dass sich die Datenelemente sortieren lassen, also eine Ordnungsrelation < auf den Datenschlusseln existiert.In Java bedeutet dies, die Elemente mussen das Comparable Interface erfullen, d.h. eine compareTo() Methode haben.
2 Im Abschnitt uber Baume sind wir bereits der speziell dafur konzipierten Datenstruktur des binaren Baumes begegnet

5-4 5 Suchen
Wenn wir die Folge jeweils nicht in der Mitte teilen, sondern p = l oder p = r wahlen, erhalten wir dielineare Suche als Spezialfall der binaren Suche.
/*** return index where item is found, or -1*/public int binarySearch( Comparable<T>[ ] a, T x ){int l = 0; int p;int r = a.length - 1;while( l <= r ){p = ( l + r ) / 2;if( a[p].compareTo( x ) < 0 ) // a[p] < x
l = p + 1;else if( a[p].compareTo( x ) > 0 )
r = p - 1; // a[p] > xelse
return p;}return -1
}
Komplexitat der binaren Suche

5.4 Hashing 5-5
5.4 Hashing
Eine Hash-Tabelle ist eine Ubersetzungstabelle, mit der man rasch auf jedes gesuchte Element einerListe zugreifen kann, welche aber trotzdem die Flexibilitat einer zeigerbasierten Liste bietet. Hashtabellenwerden zum Beispiel auch bei Compilern benutzt, um die Liste der Variablen (und ev. deren Typen) zuverwalten.
Ein einfaches Beispiel einer Hash-Tabelle ist ein Array. In einem Array konnen wir auf jedes Elementdirekt zugreifen. Einen Array als Hash-Tabelle zu benutzen ist dann gunstig, wenn wir genugend Platzhaben, um einen Array der Lange Anzahl moglicher Schlussel anzulegen.
Beispiel: Falls alle Mitglieder eines Vereins unterschiedliche Initialen haben, konnen wir dies alsSchlussel fur die Hashtabelle benutzen.
Berta Amman BA 7→ (2,1)Doris Bucher DB 7→ (4,2)Chris Carter CC 7→ (3,3)Friedrich Dunner FD 7→ (6,4)
Mit einem Array der Lange 26×26 konnen wir auf jedes Mitglied direkt zugreifen.
Menge aller Schlüssel
(U,M) (C,F)
(H,A)
Daten(CC)
Daten(BA)
Daten(DB)(B,A)
(D,B)(F,D)
...
...
Benötigte Schlüssel
(H,R)
(D,H)
(W,S)
...
Hash−Tabelle
1 2 3 4123456
(C,C)
Daten(FD)
Der Nachteil hierbei ist, dass wir bei dieser Methode offensichtlich viel Speicherplatz verschwenden. Aus-serdem konnen wir nicht sicher sein, dass nicht eines Tages ein neues Mitglied mit bereits existierendenInitialen in unseren Verein eintreten will. Fur beide Probleme versuchen wir im folgenden Losungen zufinden.

5-6 5 Suchen
5.4.1 Hash-Funktionen
Eine Hash-Funktion ist eine Methode, mit welcher wir mit Hilfe von einfachen arithmetischen Operationendie Speicherstelle eines Elementes aus seinem Schlussel berechnen konnen. Optimalerweise sollte eineHash-Funktion jedem Element einer Menge einen anderen Funktionswert zuordnen (vermeiden von Kol-lisionen). Dies ist leider in der Regel nicht moglich. Allerdings gibt es Hash-Funktionen, welche diesenAnspruch besser, und solche, welcher ihn weniger gut erfullen.
Definition: Eine Hashfunktion sollte mindestens die folgenden Eigenschaften erfullen.
• Der Hashwert eines Objekts muss wahrend der Ausfuhrung der Applikation gleich bleiben.Der Hashwert darf aber bei einer nachsten Ausfuhrung der Applikation anders sein.
• Falls zwei Objekte gleich sind gemass der equals() Methode, muss der Hashwert der beiden Objektegleich sein.
• Zwei verschiedene Objekte konnen den gleichen Hashwert haben.Allerdings wird die Performance von Applikationen verbessert, wenn unterschiedliche Objekte unter-schiedliche Hashwerte haben.
Die folgende Hash-Funktion summiert die ASCII-Werte der Buchstaben eines Strings. Fur das Einfugenin die Hashtabelle muss dieser Wert dann modulo der Lange der Hashtabelle genommen werden.
long Elem_hash(Object key) {String keyString = key.toString();int sum = 0;for (int i = 0; i < keyString.length(); i++)sum = sum + keyString.charAt(i);
return sum;}
Wie wir am folgenden Beispiel sehen, funktioniert diese Methode leider nicht allzu gut. Alle Worter, dieaus den gleichen Buchstaben (in anderer Reihenfolge) bestehen, haben den gleichen Funktionswert.Aber auch sonst verteilt diese Methode verschiedene Worter offensichtlich nicht optimal (erzeugt vieleKollisionen).

5.4 Hashing 5-7
0 2 31 4 5 6 7 8 9 10
Anna Jochen Otto Gabi Tina Kurt
Elem_hash()
AnnaTina Otto
Kurt Gabi
Jochen
Eine oft benutzte, gut streuende Hash-Funktion fur Strings ist die ELF hash -Methode.
long ELFhash(String key) {long h = 0;for (int i = 0; i < key.length(); i++) {h = (h << 4) + (int) key.charAt(i);long g = h & 0xF0000000L; // ANDif (g != 0)h = h ˆ g >>> 24; // XOR, Shift right
h = h & ˜g;}return h;
}
0 2 31 4 5 6 7 8 9 10
Anna Jochen Otto Gabi Tina Kurt
Anna JochenGabiKurt TinaOtto
ELF_hash()

5-8 5 Suchen
Naturlich kann auch die ELF hash -Methode nicht alle Kollisionen vermeiden. Die ELF hash -Methodemit Tabellenlange 11 erhalt zum Beispiel fur “Otto” und “Martin” den gleichen Schlussel.
Die Frage ist darum: wie behandelt man Kollisionen?
5.4.2 Double Hashing
Bei Double Hashing verwenden wir zwei verschiedene Hashfunktionen Hash1 und Hash23. Hash1 dient
dazu, die Hashadresse eines Schlussels in der Tabelle zu suchen. Hash2 dient dazu, bei einer Kollisionin der Tabelle den nachsten freien Platz zu suchen.
0
2
3
4
6
7
8
9
10
11
5
leeres Feld
besetztes Feld
neuer Eintrag
Hash (k)
Hash (k)2
1
Einfugen eines Objekts mit Schlussels k: Zuerst wird die HashadresseHash1(k) mod N
berechnet. Ist dieser Tabellenplatz noch leer, dann wird das Objekt dort eingetragen. Ist der Tabel-lenplatz schon besetzt, so wird nacheinander bei den Adressen
(Hash1(k) + Hash2(k)) mod N,
(Hash1(k) + 2 ·Hash2(k)) mod N,
. . .
3 Im einfachsten Fall wahlen wir Hash2(k) = p fur p gleich 1 oder fur eine Primzahl p, welche die Lange N der Hashtabelle nicht teilt. Dannerhalten wir den sog. Linear Probing Algorithmus. Im Allgemeinen kann Hash2(k) eine beliebige Funktion sein, welche Werte relativ prim zuN liefert.

5.4 Hashing 5-9
gesucht, bis ein freier Platz gefunden wird (N = Lange der Tabelle). An der ersten freien Stelle wirddas Objekt eingetragen.Damit bei der Suche nach einem freien Platz alle Elemente der Tabelle durchsucht werden konnen,muss Hash2(k) fur alle k relativ prim zu N sein (d.h. Hash2(k) und N haben keine gemeinsamenPrimfaktoren). Sobald die Hashtabelle den maximalen Fullstand ubersteigt (z.B. 60%), muss dieHashtabelle vergrossert und ein Rehashing vorgenommen werden (alle Elemente neu zuteilen).
Suchen des Objekts mit Schlussels k: Die HashadresseHash1(k) mod N
wird berechnet. Ist das gesuchte Element mit Schlussel k an dieser Adresse gespeichert, ist dieSuche erfolgreich. Falls nicht, wird der Wert Hash2(k) berechnet und das Element in den Tabellen-platzen
(Hash1(k) + Hash2(k)) mod N,
(Hash1(k) + 2 ·Hash2(k)) mod N,
. . .
gesucht. Die Suche wird durch eine der drei folgenden Bedingungen abgebrochen:• Das Element wird gefunden. Die Suche ist erfolgreich abgeschlossen.
• Ein leerer Tabellenplatz wird gefunden,
• oder wir geraten bei der Suche in einen Zyklus (hypothetischer Fall).In den beiden letzten Fallen ist das gesuchte Element nicht in der Tabelle.
leeres Feld
besetztes Feld
gelöschtes Feld
Hash (k)
Hash (k)1
2

5-10 5 Suchen
Loschen eines Schlussels: Das Loschen von Elementen aus einer Tabelle mit Double Hashing ist et-was heikel. Damit ein in der Tabelle eingetragener Schlussel in jedem Fall wieder gefunden wird,durfen wir die Elemente aus der Tabelle nicht einfach loschen, da wir nicht wissen, ob sie eventuellals Zwischenschritt beim Einfugen von anderen Elementen benutzt wurden.Jeder Tabelleneintrag muss darum ein Flag besitzen, welches angibt, ob ein Eintrag leer, benutztoder geloscht ist. Die oben beschriebene Suche darf dann nur bei einem leeren Element abgebro-chen werden. Beim Loschen eines Schlussels aus der Tabelle muss der Tabellenplatz mit geloschtmarkiert werden.
Als zweite Hashfunktion genugt oft eine sehr einfache Funktion, wie zum Beispiel Hash2(k) = k mod 8 +1. Um sicherzustellen, dass diese Funktionswerte teilerfremd zur Lange der Hashtabelle sind, kann manzum Beispiel als Tabellenlange eine Primzahl wahlen.

5.4 Hashing 5-11
5.4.3 Bucket Hashing
Eine andere Moglichkeit, Kollisionen zu behandeln, ist das Aufteilen des Hash-Arrays in verschiedenebuckets. Eine Hashtabelle der Lange H wird dabei aufgeteilt in H/B Teile (buckets), von der GrosseB. Es wird nur eine Hashfunktion benutzt, Elemente mit gleichem Hashwert (modulo Hashsize) werdenim selben Bucket abgelegt. Die Hashfunktion sollte die Datenelemente moglichst gleichmassig uber dieverschiedenen Buckets verteilen.
Bucket Hashing,Buckets der Lange 4 1
2
3
4
5
6
7
8
. . .
0
Hashtable Overflow
leer
besetzt
gelöscht
Einfugen: Die Hashfunktion ordnet das Element dem entsprechenden Bucket zu. Falls der erste Platzim Bucket bereits besetzt ist, wird das Element im ersten freien Platz des Bucket abgelegt.Falls ein Bucket voll besetzt ist, kommt der Eintrag in einen Uberlauf (overflow bucket) von genugen-der Lange am Ende der Tabelle. Alle Buckets teilen sich den selben Uberlauf-Speicher.Naturlich soll der Uberlauf-Speicher moglichst gar nie verwendet werden. Sobald die Hashtabelleeinen gewissen Fullgrad erreicht hat, muss ein Rehashing erfolgen, so dass die Zugriffe schnellbleiben (die Buckets nicht uberlaufen).
Suchen: Um ein Element zu suchen, muss zuerst mittels der Hashfunktion der Bucket gesucht werden,in welchem das Element liegen sollte. Falls das Element nicht gefunden wurde und im Bucket nochfreie Platze sind, kann die Suche abgebrochen werden. Falls der Bucket aber keine freien Platze mehrhat, muss der Overflow durchsucht werden bis das Element gefunden wurde, oder alle Elemente desOverflow uberpruft sind.
Loschen: Auch beim Bucket Hashing mussen wir beim Loschen vorsichtig sein. Falls der Bucket nochfreie Platze hat, konnen wir den Tabellen-Platz einfach freigeben. Falls nicht, muss der Platz als“geloscht” markiert werden, damit beim Suchen der Elemente auch der Overflow durchsucht wird.

5-12 5 Suchen
Eine Variante des Bucket Hashing ist die folgende: Wir wahlen wiederum eine Bucket-Grosse B. Wirteilen die Hashtabelle aber nicht explizit in Buckets auf, sondern bilden jeweils einen virtuellen Bucketrund um den Hashwert. Dies hat den Vorteil, dass jeder Tabellenplatz als Ausgangsposition fur dasEinfugen benutzt werden kann, was die Anzahl Kollisionen bei gleicher Tabellen-Grosse vermindert.
Bucket Hashing Variante,Buckets der Lange 5
leer
besetzt
gelöscht
neuer Eintrag
Hashtable Overflow
P
P+1
P+2
Einfugen: Die Hashfunktion berechnet den Platz P in der Hashtabelle. Falls dieser Platz bereits besetztist, werden die Elemente rund um P in der Reihenfolge P + 1, P + 2, . . ., P + B − 2, P + B − 1durchsucht, bis ein freier Platz gefunden wurde. Falls kein freier Platz in dieser Umgebung gefundenwird, kommt das Element in den Uberlauf-Speicher.
Suchen: Um ein Element zu suchen, muss zuerst mittels der Hashfunktion der Platz P in der Hashtabellebestimmt werden. Falls das Element an der Stelle P nicht gefunden wird, werden die Elemente rundum P in der selben Reihenfolge wie oben durchsucht.Falls wir das Element finden, oder auf einen leeren Platz stossen, kann die Suche abgebrochenwerden. Andernfalls muss der Overflow durchsucht werden bis das Element gefunden wurde, oderder ganze Overflow durchsucht ist.
Loschen: Das geloschte Feld muss auch in dieser Variante markiert werden, damit wir beim Suchenkeinen Fehler machen.

5.4 Hashing 5-13
5.4.4 Separate Chaining
Die flexibelste Art, um Kollisionen zu beheben, ist mit Hilfe von Separate Chaining. Bei dieser Methodehat in jedes Element der Hashtabelle einen next-Zeiger auf eine verkettete Liste.
Einfugen des Schlussels k: Zuerst wird die Hashadresse Hash(k) berechnet. Dann wird der neueSchlussel am Anfang der verketteten Liste eingefugt.
Suchen des Schlussels k: Die Hashadresse Hash(k) wird berechnet. Dann wird k mit den Schlusselnin der entsprechenden Liste verglichen, bis k entweder gefunden wird oder das Ende der Liste er-reicht ist.
Loschen des Schlussels k: Das Element wird einfach aus der Liste in Hash(k) entfernt.
Hashing mit Separate Chaining

5-14 5 Suchen
5.5 Ubung 5
Linear ProbingFugen Sie mit den Hashfunkionen Hash1(k) = k und Hash2(k) = 1 die Liste der Zahlen
2, 3, 14, 12, 13, 26, 28, 15in eine leere Hashtabelle der Lange 11 ein. Wieviele Vergleiche braucht man, um festzustellen, dassdie Zahl 46 nicht in der Hashtabelle ist?
Double HashingFugen Sie mit den Hashfunkionen Hash1(k) = k und Hash2(k) = k mod 8+1 die Liste der Zahlen
2, 3, 14, 12, 13, 26, 28, 15in eine leere Hashtabelle der Lange 11 ein. Wieviele Vergleiche braucht man, um festzustellen, dassdie Zahl 46 nicht in der Hashtabelle vorkommt?
Bucket HashingFugen Sie mit der Hashfunkion Hash(k) = k die Zahlen 4, 3, 14, 12, 13, 26, 28, 15, 2, 20 in eineleere Hashtabelle der Lange 8 ein mit Bucket Grosse 3 ein.
Overflow:
Java HashtabelleSie finden unter ∼amrhein/AlgoData/uebung5 eine vereinfachte Version der Klasse Hashtable derjava.util Library. Finden Sie heraus, welche der verschiedenen im Skript vorgestellten Variantenin der Java Library benutzt werden.

6 Sortieren
Sortierprogramme werden vorallem fur die die Prasentation von Daten benotigt, wenn die Daten zumBeispiel sortiert nach Zeit, Grosse, letzten Anderungen, Wert, ... dargestellt werden sollen.
Wenn die Mengen nicht allzu gross sind (weniger als 500 Elemente), genugt oft ein einfach zu implemen-tierender, langsamer Suchalgorithmus. Diese haben normalerweise eine Komplexitat von O(n2), wobeider Aufwand bei fast sortierten Mengen geringer sein kann (Bubble Sort). Zum Sortieren von grossenDatenmengen lohnt es sich allerdings, einen O(n log2(n)) Algorithmus zu implementieren.
Noch mehr als bei Suchalgorithmen spielen bei Sortieralgorithmen die Datenstrukturen eine entschei-dende Rolle. Wir nehmen an, dass die zu sortierende Menge entweder eine Arraystruktur (ein Basis-Typ-Array wie float[n] oder eine ArrayList ) oder eine Listenstruktur (wie zum Beispiel LinkedList )ist. Listen erlauben zwar keinen wahlfreien Zugriff, dafur konnen Listenelemente durch Umketten (alsoohne Umkopieren) von einer unsortierten Folge F in eine sortierte Folge S uberfuhrt werden. Arrayserlauben wahlfreien Zugriff. Dafur sind beim Einfugen und Loschen (Umsortieren) von Elementen vieleKopier-Schritte notig.
Speziell ist zu beachten, dass viele Sortier-Algorithmen auf Array-Strukturen zwar sehr schnell aber nichtstabil sind.
Definition: Ein Sortier-Algorithmus heisst stabil, falls Elemente, welche gemass der Vergleichsfunktiongleich sind, ihre Originalreihenfolge behalten.

6-2 6 Sortieren
6.1 Selection Sort
Beim Sortieren durch Auswahlen teilen wir die zu sortierende Menge F (scheinbar) in eine unsortierteTeilmenge U und eine sortierte Menge S. Aus U wird jeweils das kleinste Element gesucht und mit demletzten Element von S vertauscht. Wegen dieser Vertausch-Aktionen ist dieser Algorithmus eher geeignetfur Arraystrukturen. Die Vertauschungen fuhren aber dazu, dass der Algorithmus nicht stabil ist.
public void selectionSort(int l, int r) {int min_pos;
for( int i=l; i<r; i++) {min_pos = findMin(i,r);swap(i, min_pos);
}}
private int findMin(int n, int r) { // find position with minimal Elementint min = n;for( int i = n+1; i<r; i++ )
if( array.get(i).compareTo(array.get(min)) < 0 )min = i;
return min;}
Die Array-Prozedur find min(i) sucht jeweils das kleinste Element aus dem Rest-Array. find minbetrachtet also nur die Elemente mit Positionen j ≥ i im Array (der unsortieren Teilmenge U ). Das neuekleinste Element min (an der Position min pos ) wird mit dem Element an der Position i vertauscht (demletzten der Teilmenge S).
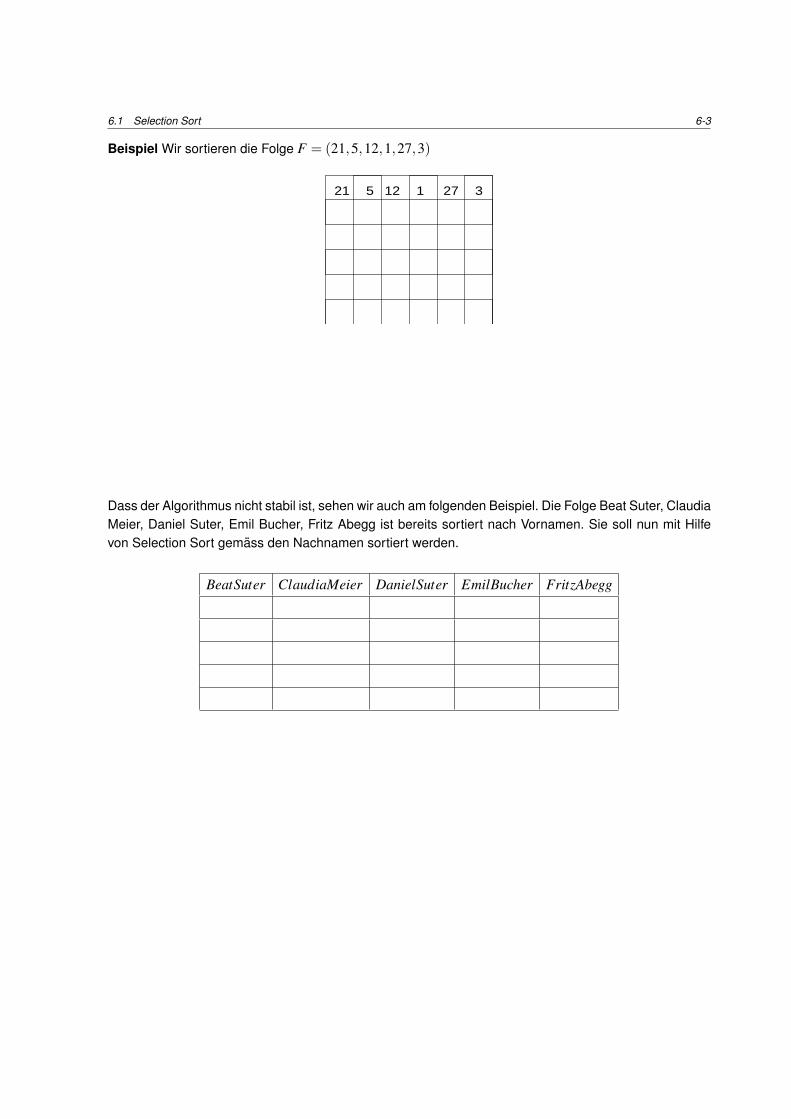
6.1 Selection Sort 6-3
Beispiel Wir sortieren die Folge F = (21,5,12,1,27,3)
1 27 321 5 12
Dass der Algorithmus nicht stabil ist, sehen wir auch am folgenden Beispiel. Die Folge Beat Suter, ClaudiaMeier, Daniel Suter, Emil Bucher, Fritz Abegg ist bereits sortiert nach Vornamen. Sie soll nun mit Hilfevon Selection Sort gemass den Nachnamen sortiert werden.
BeatSuter ClaudiaMeier DanielSuter EmilBucher FritzAbegg

6-4 6 Sortieren
6.2 Insertion Sort
Beim Sortieren durch Einfugen nimmt man jeweils das erste Element aus der unsortierten Folge F undfugt es an der richtigen Stelle in die sortierte Folge S ein. Dieser Algorithmus ist nicht geeignet fur array-basierte Folgen, da in jedem Schritt einige Elemente im Array nach hinten verschoben werden mussten.
Wir betrachten nochmals die Folge vom Beispiel vorher:
1 27 321 5 12
Falls das Element beim Ein-Sortieren jeweils am Ende aller (gemass der Ordnung) gleichen Elementeeingefugt wird, ist dieser Algorithmus stabil.
public void insertSorted(MSEntry<T> o) {MSEntry<T> e = header; // find place for o
while (e.next != null && o.element.compareTo(e.next.element) > 0)e = e.next; // while(o.element < e.next.element)
o.next = e.next; // insert o between e and e.nexte.next = o;if (e == tail)tail = o;
size++;}

6.3 Divide-and-Conquer Sortieren 6-5
public MSList<E> insertSort(MSList<E> list) {MSList<E> newList = new MSList<E>();newList.addFirst(list.removeFirst());while (list.size() > 0)newList.insertSorted(list.removeFirst());
return newList;}
6.3 Divide-and-Conquer Sortieren
Das abstrakte Divide-and-Conquer Prinzip (vgl. Kap. 1.6.2) lautet wie folgt:
1. Teile das Problem (divide)
2. Lose die Teilprobleme (conquer )
3. Kombiniere die Teillosungen (join)
Beim Sortieren gibt es zwei Auspragungen:
Hard split / Easy join: Dabei wird die gesamte Arbeit beim Teilen des Problems verrichtet und dieKombination ist trivial, das heisst, F wird so in Teilfolgen F1 und F2 partitioniert, dass zum Schlussdie sortierten Teilfolgen einfach aneinandergereiht werden konnen: S = S1S2. Dieses Prinzip fuhrtzum Quicksort-Algorithmus.
Easy split / Hard join: Dabei ist die Aufteilung in Teilfolgen F = F1F2 trivial und die Hauptarbeit liegtbeim Zusammensetzen der sortierten Teilfolgen S1 und S2 zu S. Dieses Prinzip fuhrt zum Mergesort-Algorithmus.

6-6 6 Sortieren
6.4 Quicksort
Einer der schnellsten und am meisten benutzten Sortieralgorithmen auf Arrays ist der Quicksort-Algo-rithmus (C.A.R. Hoare, 1960). Seine Hauptvorteile sind, dass er nur wenig zusatzlichen Speicherplatzbraucht, und dass er im Durchschnitt nur O(n log2(n)) Rechenschritte benotigt.Beim Quicksort wird zuerst ein Pivot-Element q ausgewahlt1. Dann wird der zu sortierende Bereich Fso in zwei Teilbereiche Fklein und Fgross partitioniert, dass in Fklein alle Elemente kleiner als q und in Fgross alleElemente grosser gleich q liegen.Danach wird rekursiv Fklein und Fgross sortiert. Am Ende werden die je sortierten Folgen wieder zusammen-gefugt.
Die Prozedur partition sucht jeweils von links ein Element g, welches grosser und von rechts ein Ele-ment k, welches kleiner als der Pivot ist. Diese zwei Elemente g und k werden dann vertauscht. Dies wirdso lange fortgesetzt, bis sich die Suche von links und von rechts zusammen trifft. Zuruckgegeben wirdder Index der Schnittstelle. Anschliessend an partition wird der Pivot an der Schnittstelle eingesetzt(vertauscht mit dem dortigen Element).
Um zu sehen, was beim Quicksort-Algorithmus passiert, betrachten wir das folgende Tracing:
1 q kann beliebig gewahlt werden, optimalerweise ist q aber der Median aller zu sortierenden Werte. Da die Berechnung des Medians viel zuaufwandig ware, wahlt man als Pivot oft einfach das erste Element. Eine bessere Wahl ist das Element an der Stelle length/2 im Array alsPivot; dies fuhrt bei beinahe sortierten Folgen zu einem optimalen Algorithmenverlauf.

6.4 Quicksort 6-7
27489419722839354 39 70 13 36 4 122872 95 100

6-8 6 Sortieren
private int partition( int l, int r, E pivot ){do{ // Move the bounds inward until they meetwhile( array.get(++l).compareTo(pivot) < 0 && l < r );
// Move left bound rightwhile( array.get(--r).compareTo(pivot) > 0 && l < r);
// Move right bound leftif( l < r )
swap( l, r ); // Swap out-of-place values} while(l < r ); // Stop when they cross
if( array.get(r).compareTo(pivot) < 0 )return r+1;
return r; // Return position for pivot}
Quicksort teilt die zu sortierende Menge so lange auf, bis die Teile eine kritische Lange (z.B. 4 oder8) unterschritten haben. Fur kurzere Listen wird der einfachere Selection-Sort Algorithmus benutzt, dadieser fur kurze Listen einen kleineren Overhead hat.
public void quickSort( int i, int j ) {int pivotindex = findPivot(i, j);swap(pivotindex, i); // stick pivot at i
int k = partition(i, j+1, array.get(i));// k is the position for the pivot
swap(k, i); // put pivot in placeif( (k-i) > LIMIT ) // sort left partitionquickSort( i, k-1 );
else // with selection-sortselectionSort( i, k-1 ); // for short lists
if( (j-k) > LIMIT )quickSort( k+1, j ); // sort right partition
elseselectionSort( k+1, j );
}

6.5 Sortieren durch Mischen (Merge Sort) 6-9
Die Komplexitat des Quicksort-Algorithmus ist im besten Fall O(n log2(n). Im schlechtesten Fall (worstcase), wenn das Pivot-Element gerade ein Rand-Element ist, dann wird die Komplexitat O(n2).
Das Finden eines gunstigen Pivot Elements ist zentral fur die Komplexitat des Quicksort Algorithmus. Esgibt verschiedene Verfahren zum Losen diesese Problems wie, wahle als Pivot das erste Element desArrays, wahle das Element in der Mitte des Arrays oder wahle drei zufallige Elemente aus dem Arrayund nimm daraus das mittlere. Eine Garantie fur eine gute Wahl des Pivots liefert aber keines diesesVerfahren. Ausserdem ist der Quicksort Algorithmus nicht stabil.
6.5 Sortieren durch Mischen (Merge Sort)
Der Merge-Sort-Algorithmus ist einer der besten fur Datenmengen, die als Listen dargestellt sind. DieRechenzeit ist in (best case und worst case) O(n log2(n)). Ausserdem wird kein zusatzlicher Speicherbenotigt und der Algorithmus ist stabil.
Beim Merge-Sort wird die Folge F mit Hilfe einer Methode divideList() in zwei (moglichst) gleichgrosse Halften geteilt.
private MSList<E>[] divideList(MSList<E> list) {MSList<E> result[] = (MSList<E>[]) new MSList[2];result[0] = new MSList<E>();int length = list.size();for (int i = 0; i < length / 2; i++)result[0].addFirst(list.removeFirst());
result[1] = list;return result;
}

6-10 6 Sortieren
Die (im rekursiven Aufruf) sortierten Folgen werden dann in einem linearen Durchgang zur sortiertenEndfolge zusammen gefugt (gemischt).
private MSList<E> mergeSort(MSList<E> list) {if (list.size() < LIMIT)return insertSort(list);
// divide list into two sublistsMSList<E>[] parts = divideList(list);MSList<E> leftList = parts[0];MSList<E> rightList = parts[1];
leftList = mergeSort(leftList); // left recursionrightList = mergeSort(rightList); // right recurstion
return merge(leftList, rightList);}
Das Mischen geschieht dadurch, dass jeweils das kleinere Kopfelement der beiden Listen ausgewahlt,herausgelost und als nachstes Element an die neue Liste angefugt wird.
4 7 13 28
8743
3 8 12 15

6.5 Sortieren durch Mischen (Merge Sort) 6-11
private MSList<E> merge(MSList<E> left, MSList<E> right) {MSList<E> newList = new MSList<E>();
while (left.size() > 0 && right.size() > 0) {if (left.getFirst().compareTo(right.getFirst()) < 0)newList.addLast(left.removeFirst());
elsenewList.addLast(right.removeFirst());
}for (int i = left.size(); i > 0; i--)newList.addLast(left.removeFirst());
for (int i = right.size(); i > 0; i--)newList.addLast(right.removeFirst());
return newList;}
Beispiel: Wie Mergesort genau funktioniert, wollen wir anhand dieses Beispiel nachvollziehen.
613 2 3 4 8 2
6 3 4 8 23 2 1
63 2 1 3 4 8 2divi
de
3 4
2 82 3 4 8
1 2 32
2 3
1 6
61 2 3
61 3 42 3 2 8sort
mer
ge

6-12 6 Sortieren
6.6 Ubung 6
InsertSort, SelectionSortErstellen Sie ein Tracing vom InsertSort-, bzw. vom SelectionSort-Algorithmus auf der Eingabe
F = {42,3,24,17,13,5,10}
42 3 24 17 13 5 10 42 3 24 17 13 5 10
Insert Sort Selection Sort
Mergesort, QuicksortErstellen Sie je ein Tracing vom Mergesort-, bzw. vom Quicksort-Algorithmus (einmal mit dem Pivot-Element an der Stelle 1, dann an der Stelle (r+l)/2 , r der rechte, l der Linke Rand des Bereichs)auf der Eingabe
F = {42,3,24,33,13,5,7,25,28,14,46,16,49,15}HeapSort
Uberlegen Sie sich ein Verfahren welches eine gegebene Menge mit Hilfe eines Heaps sortiert.
Welchen Aufwand hat dieses Verfahren im besten / im schlechtesten Fall?
Selbststudium: BucketSort, RadixSortLesen Sie die Unterlagen zum Selbststudium uber die zwei weiteren Suchalgorithmen: Bucket Sortund Radix Sort.Sortieren Sie die obige Menge F mit Hilfe von RadixSort mit 5 Buckets.

6.6 Ubung 6 6-13
42 3 24 13 533 7 25 28 14 46 16 49 15
42 3 24 13 533 7 25 28 14 46 16 49 15
Quick Sort

6-14

7 Pattern Matching
Pattern Matching ist eine Technik, mit welcher ein String aus Text oder Binardaten nach einer Zeichen-folge durchsucht wird. Die gesuchten Zeichenfolgen werden dabei in Form eines Suchmusters (Pattern)angegeben.
Solche Algorithmen werden in der Textverarbeitung (Su-chen nach einem Zeichenstring in einer Datei) aberauch von Suchmaschinen auf dem Web verwendet. DasHauptproblem beim Pattern-Matching ist: Wie kann ent-schieden werden, ob ein Text ein gegebenes Mustererfullt.
7.1 Beschreiben von Pattern, Regulare Ausdrucke
Zunachst brauchen wir eine Sprache, mit welcher wir die Pattern (hier regulare Ausdrucke) beschreibenkonnen (um zu sagen, welche Art von Wortern oder Informationen wir suchen).
Sei E ein Alphabet, d.h. eine endliche Menge von Zeichen. Ein Wort uber E ist eine endliche Folge vonZeichen aus E:
w = e1e2 . . .en, ei ∈ E
Das leere Wort, das aus keinem Zeichen besteht, bezeichnen wir mit λ.Mit E∗ bezeichnen wir die Menge aller Worter uber dem Alphabet E.

7-2 7 Pattern Matching
Beispiel: Fur E = {A,B} ist E∗ =
Die Pattern bauen wir mit Hilfe der folgenden drei Regeln zusammen:
Definition: Ein (einfacher) regularer Ausdruck ist ein Wort (String), welches mit Hilfe der folgenden dreiOperationen zusammengebaut wird:
Konkatenation setzt zwei Worter zusammen. So wird aus den Wortern ’AB’ und ’BC’ das neue Wort’ABBC’.
Auswahl erlaubt uns, zwischen einem der Worter auszuwahlen. Das heisst AB|B ist entweder das Wort’AB’ oder das Wort ’B’. Wir nennen solche Terme auch Or-Ausdrucke.
Iteration repetiert das gegebene Wort beliebig oft (auch 0 mal). A(AB)∗ entspricht also den Wortern ’A’,’AAB’, ’AABAB’, · · ·.
Zu beachten ist in diesem Zusammenhang die Bindungsstarke der drei Operationen: Die Iteration (∗)bindet starker als die Konkatenation. Am schwachsten bindet der Oder-Strich (|).
Beispiele Der Ausdruck (A|BC)∗AB erzeugt die Worter:
Der Ausdruck AB∗C|A(BC)∗ erzeugt die Worter:
Wir beschranken uns hier auf diese wenigen Moglichkeiten zum Erzeugen von Pattern, obwohl es na-turlich noch viele weitere, sehr elegante Operationen gibt: Zum Beispiel mit dem Zeichen ’.’ fur einenbeliebigen Buchstaben konnten lange Or-Ausdrucke viel kurzer dargestellt werden. AB(A|B| · · · |Z)∗Gentspricht dann AB( . )∗G. Allerdings konnen wir damit keine neuen Wortmengen definieren. Darumbegenugen wir uns vorerst mit den obigen Operationen.Um zu entscheiden, ob ein Wort einen regularen Ausdruck erfullt, setzen wir endliche Automaten ein.

7.2 Endliche Automaten 7-3
7.2 Endliche Automaten
Endlichen Automaten begegnen wir im taglichen Leben in Form von Getrankeautomaten, Billetautoma-ten, Bancomaten ... . Allen ist gemeinsam, dass sie ein einfaches endliches Eingabealphabet und eineinfaches endliches Ausgabealphabet haben und jeweils eine endliche Menge von Zustanden annehmenkonnen.
Beispiel Ein Bancomat funktioniert wie folgt: Nachdem die EC-Karte eingeschoben wurde, muss derBenutzer die Geheimzahl (Pincode) eingeben. Falls der Pincode korrekt war, bekommt der Benutzer eineAuswahl prasentiert (Geld abheben, Kontostand abfragen, abbrechen). Je nach Verhalten des Benutzersgibt der Bancomat den gewunschten Geldbetrag aus und/oder gibt die EC-Karte wieder zuruck.
Karte
einschiebenok
Karte ausgeben
Karte ausgeben
Pincodekorrekter
falscher Pincode
Geld
Kontostand
Auswahl
Auswahl
Auswahl Abbruch
Geldbetrag
Geld ausgeben
Error
12
3
4
5
6
Definition: Ein endlicher (deterministischer) Automat besteht aus einer endlichen Menge von Zustan-den, einem Anfangs- (oder Start-) Zustand und einem oder mehreren Endzustanden (oder akzeptieren-den Zustanden).
• Eingabe: Ein Automat wird von aussen bedient, d.h. er wird mit Eingabedaten versorgt. Es gibt alsoeine endliche Menge E von Eingabezeichen, die der Automat lesen kann und die eine gewisse Aktionauslosen. Die Menge E heisst Eingabealphabet.
• Zustand: Ein deterministischer Automat befindet sich stets in einem bestimmten Zustand. Die endli-che Menge Z der moglichen Zustande heisst die Zustandsmenge.

7-4 7 Pattern Matching
• Zustandsubergang: Die Verarbeitung eines einzelnen Eingabezeichens kann durch eine Nachfol-gefunktion, ein Zustandsdiagramm oder durch eine Zustandstafel beschrieben werden. Unter derEinwirkung der Eingabe kann er von einem Zustand in einen andern ubergehen.
• Ausgabe: Im Laufe seiner Arbeit kann der Automat eine Ausgabe produzieren, d.h. er kann Ausgabe-daten ausgeben. Die endliche Menge A der produzierten Ausgabezeichen heisst Ausgabealphabet.
Beispiel: Fur den Bancomat setzen wir
Eingabe: E = {EC-Karte, Pincode (korrekt/falsch), Auswahl (Geld, Kontostand ...), Geld-betrag, Ok }
Zustande: Z = {1 (Startzustand), 2 (warten auf Pincode), 3 (warten auf Auswahl), 4 (Kontostandanzeigen), 5 (warten auf Betrag) }
Ausgabe: A = {EC-Karte, Kontostand, Geld}.
und definieren die Funktionsweise durch die folgende Zustandstafel:
Zustand 1 2 3 4 5 6 (Error)Eingabe
Karte (E)
korrekterPincode (K)
falscherPincode (F)
AuswahlGeld (G)
AuswahlKontostand (S)
AuswahlAbbruch (A)
Geld-betrag (B)
Ok (O)
Mit Hilfe von endlichen Automaten konnen wir entscheiden, ob ein gegebenes Wort einem regularenAusdruck entspricht, also ob ein gefundenes Wort in unser Schema (das vorgegebene Pattern) passt.

7.2 Endliche Automaten 7-5
Beispiel: Worter, welche vom obigen Automaten (Bancomaten) akzeptiert werden, sind:
Worter, welche nicht zum obigen Automaten gehoren (nicht akzeptiert werden) sind:
Ein endlicher Automat heisst deterministisch, falls jede Eingabe des Eingabealphabetes in jedem Zu-stand erlaubt ist und zu einem eindeutigen Nachfolgezustand fuhrt. Ein nichtdeterministischer endlicherAutomat kann fur jeden Zustand und jede Eingabe null, einen oder mehrere Nachfolgezustande haben.Der Automat des vorigen Beispiels ist ein deterministischer endlicher Automat, da alle Eingaben nurin einen eindeutigen Nachfolgezustand fuhren. Nichtdeterministische Automaten konnen aber immer indeterministische Automaten ubergefuhrt werden, indem neue mehrdeutige Zustande eingefuhrt werden.
Beispiele Das folgende ist ein deterministischer, endlicher Automat: in jedem Zustand fuhrt jede Eingabezu einem eindeutigen Nachfolgezustand:
B
B
CB
A
C
0
4
1
32 A
A
C
C
A
B
A
CB A
B
C
0 1 2 3 4
Zustand
Eingabe

7-6 7 Pattern Matching
Das folgende ist ein nichtdeterministischer, endlicher Automat: Manche Eingaben fuhren in gewissenZustanden zu keinem oder zu mehr als einem Nachfolgezustand:
B
B
C
A
C
0
4
1
32B
A
A
C
C
A
A
A
B
C
0 1 2 3 4
Zustand
Eingabe
Ein weiteres Konstrukt in nichtdeterministischen Automaten sind sogenannte leere Ubergange, dasheisst Ubergange ohne gelesenes Zeichen. Solche Ubergange heissen auch epsilon-Ubergange undwerden mit ε bezeichnet.
B
C
A
C
0
4
1
32
A
C
C
A
ε
B
εB
A
B
C
0 1 2 3 4
Zustand
Eingabe

7.3 Automaten zu regularen Ausdrucken 7-7
7.3 Automaten zu regularen Ausdrucken
Wir suchen nun einen zu einem regularen Ausdruck aquivalenten Automaten. Ausgehend vom regularenAusdruck konnen wir mit den folgenden Regeln den entsprechenden nichtdeterministischen endlichenAutomaten herleiten.
Durch das Symbol wird der Startzustand, durch der akzeptierende Zustand des Automatenbezeichnet.
Konkatenation: E1 E2
2
1 :
:
1 2
3 4E
E .
Beispiel:B
A
AA
C
B
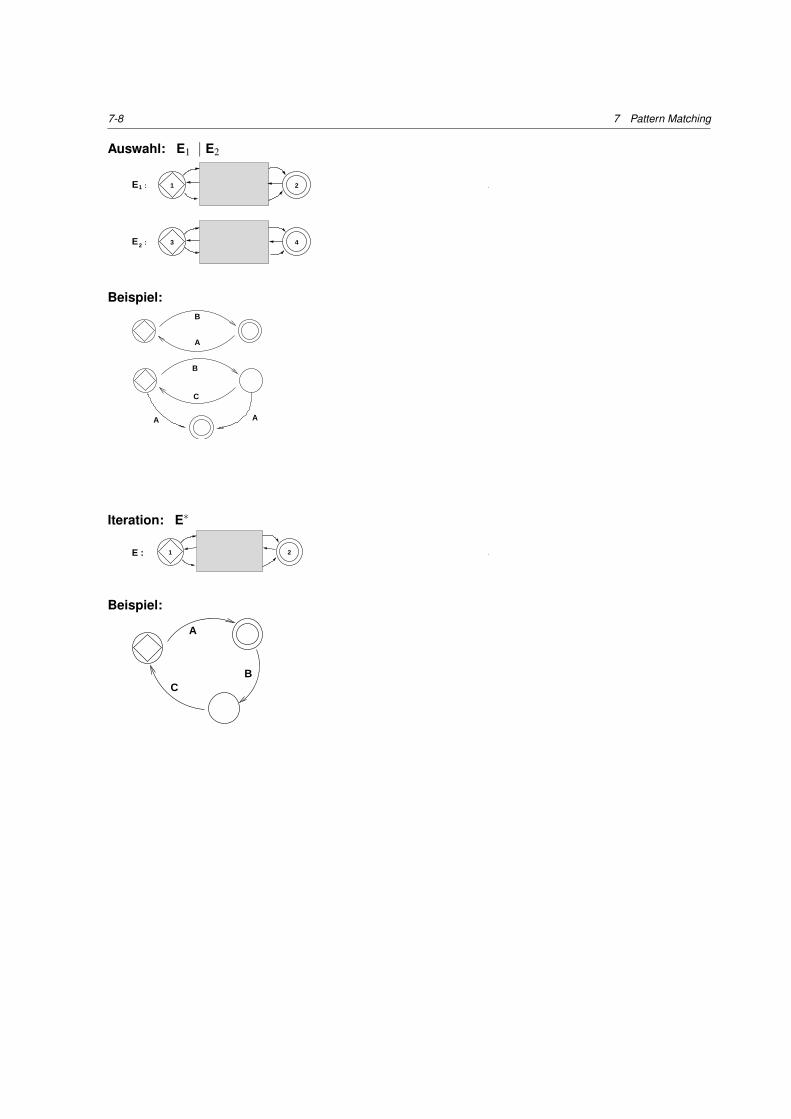
7-8 7 Pattern Matching
Auswahl: E1 | E2
2
1 :
:
1 2
3 4E
E .
Beispiel:B
A
AA
C
B
Iteration: E∗
1 2 .E :
Beispiel:
C
A
B

7.3 Automaten zu regularen Ausdrucken 7-9
Im allgemeinen kann man sehr viel kleinere Automaten konstruieren, welche den gleichen regularenAusdruck beschreiben. Es gibt auch einen Algorithmus, welcher aus einem nichtdeterministischen Auto-maten einen deterministischen Automaten (ohne leere Ubergange) erzeugt. Diesen Algorithmus wollenwir hier aber nicht behandeln.
Beispiel 1: Ein endlicher Automat fur den Ausdruck (AB|C)∗(A|B)
Beispiel 2: Ein Automat fur den regularen Ausdruck (AB|BC)∗(C|BC)

7-10 7 Pattern Matching
7.4 Ubung 7
1. Finden Sie jeweils einen endlichen Automaten und/oder einen regularen Ausdruck, welcher die fol-gende Menge von Wortern uber dem Alphabet {A,B,C} beschreibt:- Alle Worter, welche mit A anfangen und mit C enden.
- Alle Worter, welche eine gerade Anzahl A enthalten und mit C enden.
- Alle Worter, deren Anzahl Buchstaben durch 3 teilbar sind.
- Alle Worter, welche eine gerade Anzahl B und eine gerade Anzahl C enthalten.
2. Erzeugen Sie je einen nichtdeterministischen Automaten fur die regularen Ausdrucke:- (A*BC)*|BB
- ((AB|B)(BA|CB))*
- (BB|CAB*|AB)*Sie mussen dabei die angegebenen Regeln zur Erzeugung des Automaten nicht strikt befolgen – Siekonnen auch versuchen, einen Automaten mit weniger Zustanden zu finden.
3. Erzeugen Sie eine Zustandsubergangs-Tabelle fur den folgenden Automaten.
0
A
1
C2
4
3
B
BA
ε
ε
ε
A
B

7.4 Ubung 7 7-11
4. Lesen Sie die Worter AACBC, ABACA und ACACB mit Hilfe der von Ihnen erzeugten Zustandsuber-gangstabelle, indem Sie Schritt fur Schritt den aktuellen Zustand notieren.
5. Holen Sie sich das Java Programm unter ∼amrhein/AlgoData/uebung7 und beantworten Sie diefolgenden Fragen:- Erklaren Sie die Methoden find , group , start , end , split und replaceAll des java.regex
Package.
- Erganzen Sie das gegebene Programm: Geben Sie vom Input String alle Worter aus, welcheweniger als 5 Buchstaben haben.

7-12 7 Pattern Matching
Die wichtigsten regularen Ausdrucke
Bedeutung
\ Escape, um Instanzen von Zeichen zu finden, welche als Metazeichen benutztwerden (wie Punkt, Klammer, ... )
. Ein beliebiges Zeichen (ausser newline)x Eine Instanz von xˆx Jedes Zeichen ausser x[x] Alle Zeichen in diesem Bereich (z. B. [abuv] die Buchstaben a, b, u oder v, [a-z]
alle Kleinbuchstaben)() runde Klammern dienen fur die Gruppierung| der OR Operator (Auswahl) (a|A)
{x} Der Ausdruck muss genau x mal vorkommen{x,} Der Ausdruck muss mindestens x mal vorkommen{x,y} Der Ausdruck kommt mindestens x mal und hochstens y mal vor
? Abkurzung fur {0,1}* Abkurzung fur {0,}+ Abkurzung fur {1,}ˆ Start einer neuen Zeile$ Ende der Zeile
Beispiele
[a-zA-Z]* Beliebig viele Zeichen aus Buchstaben (z. B. ugHrB).[A-Z0-9]{8} Acht Zeichen aus A bis Z und 0 bis 9, (z. B. RX6Z45UB).[A-Z]([a-z])+ Ein Grossbuchstabe gefolgt von mindestens einem Kleinbuchstaben (z.Bsp Stu).([0-9]-){2}[0-9]} Drei Zahlen, durch Striche getrennt (z. B. 2-1-8).[A-G]{2,} Mindestens zwei Grossbuchstaben aus A bis G (z. B. BGA).[bRxv]{3} Drei Buchstaben aus b, R, x und v (z. B. xxv).

8 Top Down Parser
Hohere Programmiersprachen wie Java oder C++ konnen von einem Prozessor nicht direkt verarbeitetwerden. Die in diesen Sprachen geschriebenen Programme mussen zuerst in eine fur den gewahltenProzessor geeignete Maschinensprache ubersetzt werden. Programme, die diese Aufgabe ubernehmen,nennt man Compiler. Ein Compiler hat im Prinzip zwei Aufgaben zu losen:
1. Erkennen der legalen Programme der gegebenen Sprache. Das heisst, der Compiler muss testen,ob die Syntax des Programms korrekt ist oder nicht. Diese Operation nennt man parsing und dasProgramm, das diese Aufgabe lost, einen Parser.
2. Generieren von Code fur die Zielmaschine.
Auch wenn wir keinen Compiler schreiben wollen, so kommt es doch oft vor, dass wir komplizierte Benut-zereingaben wie zum Beispiel
- Arithmetische Ausdrucke: 2(a−3)+b−21- Polynome: a+3x2 −4x+16- Boole’sche Ausdrucke a⊙ (b⊙ c)⊕b- eine Befehlssprache
- ein Datenubermittlungsprotokoll
- ...
erkennen und verarbeiten mussen.

8-2 8 Top Down Parser
8.1 Kontextfreie Grammatik
Mit Hilfe einer Grammatik beschreiben wir den Aufbau oder die Struktur (-Regeln) einer Sprache. Kon-textfreie Grammatiken1 dienen als Notation zur Spezifikation einer Sprachsyntax.
Beispiel: Ein einfacher deutscher Satz kann zum Beispiel eine der folgenden Strukturen annehmen:S ’ist’ A S ’ist’ A ’und ’ A S ’ist’ A ’oder ’ A
wobei S normalerweise die FormArtikel Nomen
hat und A ersetzt werden kann durch ein Adjektiv wie ’schon’, ’gross’, ’schnell’ oder ’lang’.
Eine kontextfreie Grammatik (bzw. ein Syntaxdiagramm) fur dieses Konstrukt sieht dann etwa wie folgtaus:
Grammatik(EBNF: Extended Backus-Naur Form)
Satz ::= S ’ist’ A
S ::= Artikel Nomen
Artikel ::= ’der’
Artikel ::= ’ein’
. . .
Nomen ::= ’Baum’
Nomen ::= ’Hund’
. . .
A ::= Adjektiv
A ::= Adjektiv ’und’ A
A ::= Adjektiv ’oder’ A
Adjektiv ::= ’schon’
Adjektiv ::= ’gross’
. . .
Syntax-Diagramm
S A
. . . Adjektiv
Adjektiv
oder
und A
Satz
Artikel
A
ein
der
ist
ArtikelS Nomen
1 Es gibt gemass Chomsky-Hierarchie vier Typen von Grammatiken: Typ 3: lineare Grammatik (entpricht endlichem Automat), Typ 2: kontext-freie Grammatik (nur Nichtterminale auf der linken Seite), Typ 1: kontextsensitive Grammatik (nichtverkurzend), Typ 0: allgemeine Grammatik(ohne Einschrankung).

8.1 Kontextfreie Grammatik 8-3
Eine solche Ersetzungs-Regel heisst eine Produktion.
Ein Satz, welcher dieser Grammatik entspricht, ist:
Ein Satz, welcher nicht dieser Grammatik entspricht, ist:
Eine kontextfreie Grammatik beschreibt eine Sprache (Menge von Wortern oder Strings).
Definition: Zu einer kontextfreien Grammatik gehoren vier Komponenten.
1. Eine Menge von Terminalen, d.h. von Symbolen, die am Ende einer Herleitung stehen (hier fettge-druckte Zeichenketten wie ’ist’, ’und’ oder ’oder’).
2. Eine Menge von Nichtterminalen, d.h. von Namen oder Symbolen, die weiter ersetzt werden (hierkursiv gedruckte Zeichenketten).
3. Eine Menge von Produktionen (l ::= r). Jede Produktion besteht aus einem Nichtterminal, das die lin-ke Seite der Produktion bildet, einem Pfeil und einer Folge von Terminalen und/oder Nichtterminalen,die die rechte Seite der Produktion darstellen.
4. Ein ausgezeichnetes Nichtterminal dient als Startsymbol. Das Startsymbol ist immer das Nichttermi-nal auf der linken Seite der ersten Produktion.
Als vereinfachte Schreibweise fassen wir alle rechten Seiten der Produktionen zusammen, welche dasgleiche Nichtterminal als linke Seite haben, wobei die einzelnen Alternativen durch ‘|’ (zu lesen als “oder”)getrennt werden.
Ziffer ::= ’0’Ziffer ::= ’1’
...Ziffer ::= ’9’
kann also auch alsZiffer ::= ’0’ | ’1’ | ’2’ | ’3’ | ’4’ | ’5’ | ’6’ | ’7’ | ’8’ | ’9’
geschrieben werden.

8-4 8 Top Down Parser
Definition: Die Herleitung eines Wortes aus einer Grammatik geschieht wie folgt: Wir beginnen mit demStartsymbol und ersetzen dann jeweils in dem hergeleiteten Wort ein Nichtterminal durch die rechte Seiteeiner Produktion. Dies wird so lange wiederholt, bis im Ausdruck keine Nichtterminale mehr vorkommen.Alle Worter, die aus dem Startsymbol herleitbar sind, bilden zusammen die von der Grammatik definierteSprache.
Beispiel: Die Grammatik G1 besteht aus den Produktionen:
G1 : S ::= ′A′ | ′A′S | b
b ::= ′B′ | ′B′b
G1 erzeugt die folgende Menge von Wortern:
G2 besteht aus den Produktionen:
G2 : S ::= ′A′ | ′B′ | ′A′b | ′B′a
a ::= ′A′ | ′A′b
b ::= ′B′ | ′B′a
G2 erzeugt die Worter:

8.1 Kontextfreie Grammatik 8-5
Beispiel Die Menge der arithmetischen Ausdrucke wird durch die folgende Grammatik erzeugt:
expression ::= term { ′+ ′ term | ′− ′ term }term ::= factor { ′ ∗ ′ factor }
factor ::= ′(′ expression ′)′ | number
number ::= digit {digit }digit ::= ′0′ | ′1′ | ′2′ | ′3′ | ′4′ | ′5′ | ′6′ | ′7′ | ′8′ | ′9′
Geschweifte Klammern bedeuten in der EBNF-Schreibweise null oder beliebig viele Wiederholungen.Eine Expression ist also ein Term oder eine Summe von Termen. Ein Term ist ein Faktor oder ein Produktvon Faktoren. Ein Faktor ist ein Klammer-Ausdruck oder eine Zahl. Eine Zahl besteht aus einer odermehreren Ziffern.
term term
*
factorexpression
+
−
Um zu uberprufen, ob ein Ausdruck ein korrekter arithmetischer Ausdruck ist, beschreiben wir den Her-leitungsprozess mit Hilfe eines Herleitungsbaumes (Parsetree):
Der Parsetree von 12∗4−3∗ (2+14)+21

8-6 8 Top Down Parser
Beispiel: Suchmaschinen erlauben ublicherweise die komplexe Suche nach Mustern wiesoftware ⊕ (schule ⊙ schweiz)
Dafur braucht man eine Sprache, mit welcher der Benutzer diese (boole’schen) Ausdrucke uber Zei-chenfolgen eingeben kann. Die Menge der boole’schen Ausdrucke kann zum Beispiel wie folgt erzeugtwerden:
bexpr ::= bterm [ ′⊕ ′ bexpr ]
bterm ::= bfac [ ′⊙ ′ bterm ]
bfac ::= [ ′− ′ ] ′(′ bexpr ′)′ | [ ′− ′ ] string
string ::= letter { letter }letter ::= ′a′ | ′b′ | . . . | ′z′
Eckige Klammern bezeichnet in der EBNF Schreibweise ein optionales Vorkommen (null oder einmal).
bexprg+� �
-- bterm ............................................................
..........................................................
..............................
..........................
......................bexpr
Wir zeichnen den Parsetree des boole’schen Ausdrucks( a ⊙ b ) ⊙ ac ⊕ abc

8.2 Top-Down Parser 8-7
8.2 Top-Down Parser
Aus einer solchen Grammatik lasst sich nun relativ leicht ein (rekursiver) Top-Down Parser herleiten: Auf-passen mussen wir dabei nur, dass wir keine nichtterminierenden Zyklen einbauen. Vermeiden konnenwir das, indem wir falls notig ein oder zwei Zeichen vorauslesen. Dies kann bei Klammerausdrucken oderOperationszeichen notig sein, bzw. immer dann, wenn es mehrere Moglichkeiten gibt.
8.2.1 Parser fur arithmetische Ausdrucke
Zum Implementieren des Parsers fur arithmetische Ausdrucke schreiben wir eine Klasse Arithmetic-ExpressionParser . Darin definieren wir die Member-Variablen parseString fur den zu parsendenString, position fur die aktuelle Lese-Position und length die Lange des zu parsenden Strings.
public class ArithmeticExpressionParser {private String parseString;private int position;private int length;
public void parse(String aExpr) throws ParseException { . . . }// one method per grammar line. . .
}
Die Methode parse() ruft die Startfunktion expression() auf und testet am Schluss, ob der ganzeString gelesen wurde.
public void parse(String aExpr) throws ParseException {position = 0;parseString = aExpr;length = parseString.length();
expression();if (position < length) throw new ParseException(position, "parse");
}

8-8 8 Top Down Parser
expression() fangt (laut Grammatik) immer mit einem Term an, also rufen wir zuerst die Prozedurterm() auf. Falls ein ’+ ’ oder ein ’- ’ im Ausdruck folgt, haben wir weitere Terme und es ist ein Loopnotig.
private void expression() throws ParseException {term();while (position < length) {if (getNext() == ’+’ || getNext() == ’-’) {
position++;term();
}}
}
getNext() liest das folgende Zeichen (ohne die Position zu verandern).
private char getNext() {return parseString.charAt(position);
}
term() fangt (laut Grammatik) mit einem Faktor an. Falls darauf ein ’* ’ folgt, ist ein rekursiver Aufrufnotig.
private void term() throws ParseException {factor();while (position < length) {if (getNext() == ’*’) {
position++;factor();
}}
}

8.2 Top-Down Parser 8-9
In factor() ist nun eine Abfrage notig, um sicherzustellen, dass jede geoffnete Klammer wieder ge-schlossen wurde. Falls keine Klammer gelesen wurde, muss an dieser Stelle eine oder mehrere Ziffernstehen.
private void factor() throws ParseException {if (position < length && getNext() == ’(’) {
position++;expression();if (position < length && getNext() == ’)’) {
position++;} else {
throw new ParseException(position, "factor, ’)’ expected");}
} else {number();
}}
number() muss mindestens eine Ziffer lesen konnen, andernfalls ist an dieser Stelle im Ausdruck einFehler.
private void number() throws ParseException {int n = position;while (position < length && isNumber(getNext())) {
position++;}if (n == position) {
throw new ParseException(position, "number, digit expected");}
}

8-10 8 Top Down Parser
8.2.2 Parser fur boole’sche Ausdrucke
Als nachstes bauen wir einen Parser fur die von der Grammatik von Seite 8-6 erzeugten boole’schenAusdrucke:
bexpr ::= bterm [ ′⊕ ′ bexpr ]
bterm ::= bfac [ ′⊙ ′ bterm ]
bfac ::= [ ′− ′ ] ′(′ bexpr ′)′ | [ ′− ′ ] string
string ::= letter { letter }letter ::= ′a′ | ′b′ | . . . | ′z′
Da wir auf der normalen Tastatur die Zeichen ′⊙ ′ und ′⊕ ′ nicht haben, schreiben wir im Programmein + fur ′⊕ ′ und ein ∗ fur ′⊙ ′ .
Die Methode parse() konnen wir (fast) aus dem letzten Abschnitt kopieren.

8.2 Top-Down Parser 8-11
public void parse(String aExpr) throws ParseException {position = 0;parseString = aExpr;length = parseString.length();
booleanExpression();if (position < length)throw new ParseException(position, "parse");
}
Ein boole’scher Ausdruck ist entweder ein einfacher Term oder ein OR-Ausdruck (bterm + bexpr)2.
private void booleanExpression( ) throws ParseException {
2 vgl. ∼ amrhein/AlgoData/Parser

8-12 8 Top Down Parser
Ein bterm ist ein AND-Term, also ein bfac oder ein bfac multipliziert mit einem bterm.
private void booleanTerm( ) throws ParseException {
Ein booleanFactor ist ein String, ein negierter String, ein boole’scher Ausdruck oder ein negierter boo-le’scher Ausdruck.
private void booleanFactor( ) throws ParseException {

8.2 Top-Down Parser 8-13
booleanName liest so lange als Buchstaben im Ausdruck erscheinen.
void booleanName() throws ParseException {int n = position;while (position < length && isAlpha(parseString.charAt(position)))position++;
if (n == position)throw new ParseException(position, "booleanVariable: letter expected");
}

8-14 8 Top Down Parser
8.3 Ubung 8
Syntax-Diagramm Gegeben ist das folgende Syntaxdiagramm:
(
F
)
/
*
b
T
-
+
S
T
F a
c
S
S
F T
1. Schreiben Sie es in eine Grammatik um.
2. Welche der folgenden Terme sind durch diese Grammatik erzeugt worden?(a) a*(b-c) (c) a+(a*b)+c (e) (a+b)/(a-b)(b) a/(b*c) (d) a+b+(c*b) (f) ((a*b)/(b*c))
Parser Gegeben sei die folgende Grammatik:r ::= ′L′ ′+′ s | ss ::= ′N ′ | ′N ′ ′(′ t ′)′
t ::= ′M′ ′+′ r | r1. Welche der folgenden Ausdrucke sind von dieser Grammatik erzeugt worden?
(a) L + N(b) N (M + N)
(c) L + N (L + N)
(d) L + N (N + M)
(e) N (L + N (M)))
(f) N (N (L + M))2. Schreiben Sie einen Parser fur diese Grammatik.
Grammatiken
1. Geben Sie eine Grammatik fur die Menge aller Strings uber dem Alphabet { A,B } an, welchehochstens zwei gleiche Buchstaben in Folge haben.
2. Erweitern Sie die Grammatik fur arithmetische Ausdrucke so, dass auch Exponentiation (∧) undDivision (/) als Operationen erlaubt sind.

9 Kryptologie
Mit der zunehmenden Vernetzung, insbesondere seit das Internet immer mehr Verbreitung findet, sindMethoden zum Verschlusseln von Daten immer wichtiger geworden. Kryptologie fand ihren Anfang vor al-lem in militarischen Anwendungen. Seit der Erfindung des elektronischen Geldes findet die Kryptologie1
aber immer mehr Anwendungen im kommerziellen Bereich. Die wichtigsten Stichworte sind hier: Ge-heimhaltung, Authentifizierung(Nachweisen der eigenen Identitat), Integriat (Falschungssicherheit).
Um zu wissen, wie sicher eine Verschlusselungsmethode ist, mussen wir aber auch die andere Seitekennen. Wahrend sich die Kryptographie (Lehre des Verschlusselns) mit den verschiedenen Verschlusse-lungs Methoden beschaftigt, lehrt die Kryptoanalyse, wie man Codes knackt. Nur wenn wir die Methodender Code-Knacker kennen, konnen wir beurteilen, ob eine Verschlusselungsmethode fur unser Ansinnenbrauchbar (d.h. genugend sicher) ist.
Kryptologie = Kryptographie + Kryptoanalyse
In der Regel gilt, je kritischer die Daten sind, desto sicherer muss die Verschlusselung sein, und destoaufwandiger ist das Verschlusselungsverfahren. Je schwieriger namlich ein Code zu knacken ist, destoteurer ist eine Attacke fur den Kryptoanalytiker. Er wird also nur dann eine aufwandige Attacke versuchen,wenn er sich einen entsprechenden Gewinn erhoffen kann. Prinzipiell gilt:
• es gibt keine einfachen Verfahren, die trotzdem einigermassen sicher sind.
• (fast) jeder Code ist knackbar, falls genugend Zeit und genugend verschlusselter Text vorhanden ist.
1 Weitere Informationen zu Kryptographie findet man zum Beispiel unter home.nordwest.net/hgm/krypto .

9-2 9 Kryptologie
9.1 Grundlagen
Ein klassisches Kryptosystem besteht aus einem Sender, einem Empfanger und einer Datenleitung, anwelcher ein Horcher2 zuhort.
EmpfängerSenderKlartext Datenleitung Klartext
Schlüssel
unsichere
sichere ÜbertragungSchlüssel
Horcher
Der Sender verschlusselt eine Meldung (den Klartext) und sendet diesen uber die unsichere Datenlei-tung dem Empfanger. Das Verschlusseln geschiet entweder Zeichenweise (Stromchiffre) oder der Textwird erst in Blocke aufgeteilt und dann werden die Blocke verschlusselt (Blockchiffre). Der Emfpangerentschlusselt dann die Meldung wieder mit der Umkehrfunktion. Der verwendete Schlussel muss vorherauf sicherem Weg (zum Beispiel per Kurier) ubermittelt werden.
Diese Situation ist heute Normalfall nicht (mehr) gewahrleistet. So mochte der Kunde im WWW nicht vor-her per Post mit jedem Anbieter geheime Schlussel austauschen. Trotzdem will er sicher sein, dass keinHorcher das Bankpasswort, die Bestell/Transaktionsdaten oder die Kreditkartennummer erfahrt. Ausser-dem ist das Verwalten von vielen Schlusseln sehr aufwandig (und unsicher).
Das Ziel ist also, ein moglichst effizientes und doch sicheres System zu haben, welches mit moglichstwenig Verwaltungsaufwand auskommt.
2 Als Sender/Empfanger mussen wir davon ausgehen, dass der Horcher weiss, welches Verschlusselungsverfahren angewandt wurde.

9.2 Einfache Verschlusselungmethoden 9-3
9.2 Einfache Verschlusselungmethoden
Eine der einfachsten und altesten Methoden zur Verschlusselung von Texten wird Kaiser Caesar zuge-schrieben. Die Methode heisst darum auch die Caesar Chiffre. Dabei wird jeder Buchstabe des Textesdurch den um k Buchstaben verschobenen Buchstaben ersetzt (Stromchiffre).
Beispiel
Klartext: A B C D E F G H I · · · W X Y Z
Verschlusselt: D E F G H I J K L · · · Z A B C
Der Klartext geheimer Text wird damit zu
Klartext: G E H E I M E R T E X T
Verschlusselt: J H K
Der Schlussel ist k = 3, da alle Buchstaben um drei verschoben werden.
Dieser Code lasst sich sehr leicht knacken, auch wenn wir den Schlussel nicht kennen. Nach hochstens27 Versuchen haben wir den Code entziffert.
Verschlusselt: X Y W J S L E L J M J N R
Klartext:
Eine etwas verbesserte Methode ist, ein Schlusselwort als Additionstabelle zu benutzen (Blockchiffre).Diese Verschlusselungsart ist bekannt als Vigenere Chiffre. Dabei andert sich die Anzahl zu verschie-benden Buchstaben jeweils in einem Zyklus, welcher gleich lang wie das Schlusselwort ist.
Beispiel Wir benutzen das Wort geheim als Schlussel. Die Verschlusselung geschieht dann nach fol-gendem Schema:
Klartext: D I E S E R T E X T I S T · · ·Schlussel G E H E I M G E H E I M
Verschlusselt:
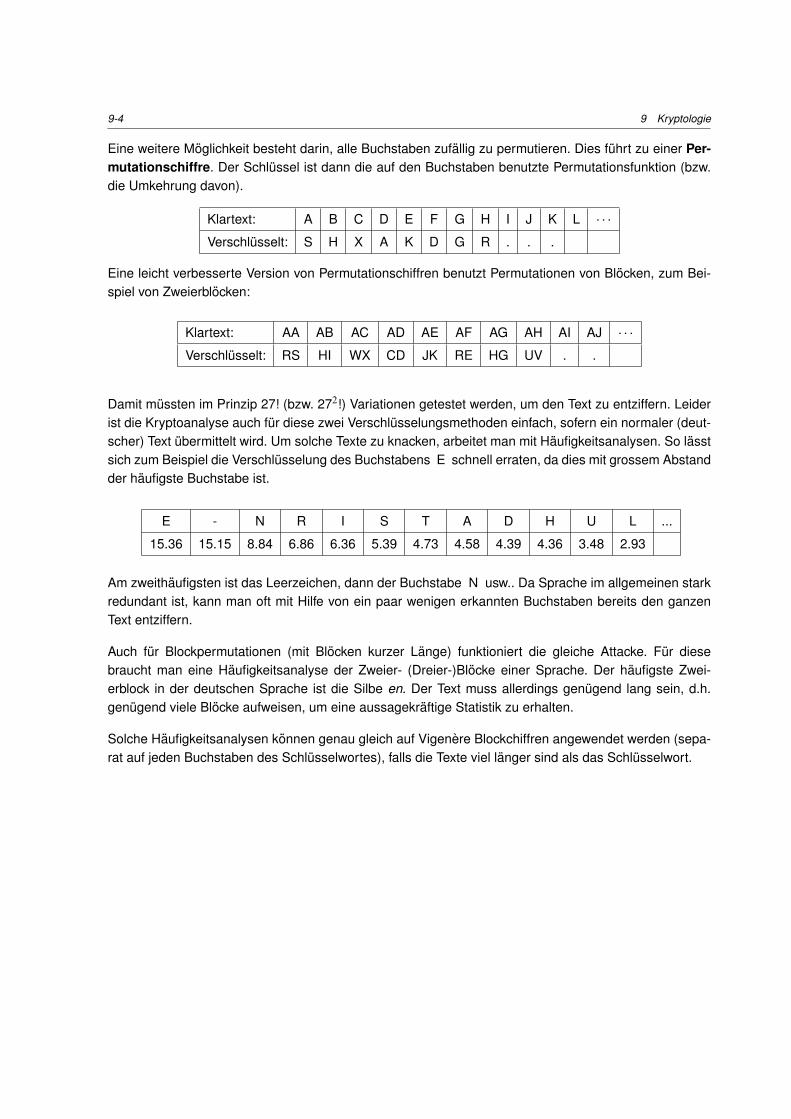
9-4 9 Kryptologie
Eine weitere Moglichkeit besteht darin, alle Buchstaben zufallig zu permutieren. Dies fuhrt zu einer Per-mutationschiffre. Der Schlussel ist dann die auf den Buchstaben benutzte Permutationsfunktion (bzw.die Umkehrung davon).
Klartext: A B C D E F G H I J K L · · ·Verschlusselt: S H X A K D G R . . .
Eine leicht verbesserte Version von Permutationschiffren benutzt Permutationen von Blocken, zum Bei-spiel von Zweierblocken:
Klartext: AA AB AC AD AE AF AG AH AI AJ · · ·Verschlusselt: RS HI WX CD JK RE HG UV . .
Damit mussten im Prinzip 27! (bzw. 272!) Variationen getestet werden, um den Text zu entziffern. Leiderist die Kryptoanalyse auch fur diese zwei Verschlusselungsmethoden einfach, sofern ein normaler (deut-scher) Text ubermittelt wird. Um solche Texte zu knacken, arbeitet man mit Haufigkeitsanalysen. So lasstsich zum Beispiel die Verschlusselung des Buchstabens E schnell erraten, da dies mit grossem Abstandder haufigste Buchstabe ist.
E - N R I S T A D H U L ...
15.36 15.15 8.84 6.86 6.36 5.39 4.73 4.58 4.39 4.36 3.48 2.93
Am zweithaufigsten ist das Leerzeichen, dann der Buchstabe N usw.. Da Sprache im allgemeinen starkredundant ist, kann man oft mit Hilfe von ein paar wenigen erkannten Buchstaben bereits den ganzenText entziffern.
Auch fur Blockpermutationen (mit Blocken kurzer Lange) funktioniert die gleiche Attacke. Fur diesebraucht man eine Haufigkeitsanalyse der Zweier- (Dreier-)Blocke einer Sprache. Der haufigste Zwei-erblock in der deutschen Sprache ist die Silbe en. Der Text muss allerdings genugend lang sein, d.h.genugend viele Blocke aufweisen, um eine aussagekraftige Statistik zu erhalten.
Solche Haufigkeitsanalysen konnen genau gleich auf Vigenere Blockchiffren angewendet werden (sepa-rat auf jeden Buchstaben des Schlusselwortes), falls die Texte viel langer sind als das Schlusselwort.

9.3 Vernamchiffre, One Time Pad 9-5
9.3 Vernamchiffre, One Time Pad
Falls in der Viginere Chiffre das Schlusselwort aus einer zufalligen Buchstabenfolge besteht, die ebensolang ist wie der verschlusselte Text, und falls jeder Schlussel nur einmal verwendet wird, ist das Ver-schlusselungs-Verfahren absolut sicher. Man nennt dieses Verfahren die Vernam-Chiffre oder das OneTime Pad.
Die Vernam-Chiffre ist allerdings sehr umstandlich, da fur jedes zu ubermittelnde Zeichen zuvor ein Zei-chen uber einen sicheren Weg transportiert werden muss. Dennoch wird sie benutzt, wenn absolute,beweisbare Sicherheit notig ist.
Statt einer zufalligen Buchstabenfolge (welche auf einem sicheren Weg ubermittelt werden muss), wirdals Schlussel haufig eine Zufalls-Zahlenreihe benutzt. Diese wird mit Hilfe einer geheimen, vorher aus-gemachten Zufallsfunktion generiert. Solange der Horcher diese Funktion nicht durch Sabotage erfahrt,ist dieses Verfahren sehr effizient und ebenfalls sicher. Oft werden sogar mehrere Zufalls-Funktionenkombiniert oder abwechlungsweise benutzt.
Beispiel: Eine Funktion, welche eine gute “Zufallsfolge” herstellt, ist zum Beispiel die Funktion f (n) =⌊100(sin(n)+1)⌋. Die erzeugte Zahlenreihe ist:
n : 1 2 3 4 5 6 7 8 9 10 11 12 . . .
f (n) : 184 190 114 24 4 72 165 198 141 45 0 46 . . .
f (n) mod 27 : 22 1 6 24 4 18 3 9 6 18 0 19 . . .
Mit Hilfe von solchen Funktionen werden sogennante Verschlusselungs/Entschlusselungs-Maschinen ge-baut, zum Beispiel fur Telefone, die typischerweise die Ubertragung von grossen Datenmengen notigmachen. Beide Gerate erzeugen jeweils die gleiche Zufallsfolge zum (binaren) Ver- bzw. Entschlusselnder geheimen Texte. Die im Telefon eingebauten Schlusselerzeuger sind dann im Prinzip nichts anderesals gute und effiziente Zufallszahlen-Generatoren.

9-6 9 Kryptologie
9.4 Moderne symmetrische Verfahren
Die meisten der heute eingesetzten symmetrischen Verfahren sind Blockchiffren. Dabei wird der Text inBlocke einer gewissen Lange (haufig 8 oder 16 Zeichen, also 64 oder 128 Bits) zerlegt. Auf diese Blockewird dann eine Kombination von verschiedenen einfachen Verschlusselungsverfahren (z.B. modulare Ad-dition, Substitution, Linear-Transformation, Vertauschen von Teilblocken, ...) angewandt.Das folgende Bild zeigt zum Beispiel die Anordnung fur DES.
Normalerweise wird ein geheimer, vorher vereinbarter Schlussel verwendet. Das Entschlusseln geschiehtindem alle Operationen in umgekehrter Reihenfolge (invers) angewandt werden.
Beispiele von Blockhiffren sind: DES (Data Encryption Standard) oder DEA (Data Encryption Algorithm), benutzt einen Schlussel der Lange 56. Triple-DES: Dreimaliges Anwenden von DES mit zwei oderdrei verschiedenen Schlusseln. RC4 Rivest Cipher, 1987 von Ronald L. Rivest, eine Stromchiffre IDEA:arbeitet ahnlich wie DES, CAST, ... SSL (Secure Socket Layer) verwendet RC4, DES oder Triple-DES.S-HTTP (Secure HTTP) verwendet DES, Triple-DES oder IDEA. PGP (Pretty Good Privacy) benutztverschiedene der Verfahren IDEA, Triple-DES, RSA, ...

9.5 Asymmetrische Verfahren: Public Key Kryptosysteme 9-7
9.5 Asymmetrische Verfahren: Public Key Kryptosysteme
Bei kommerziellen Applikationen wie zum Beispiel Telebanking, beim Benutzen von elektronischem Geldoder beim Versenden von (geheimer) Email ist es zu aufwandig, mit jedem Kunden/Partner vorher gehei-me Schlussel auszutauschen. Um genugend Sicherheit zu bieten, mussten lange Schlussel verwendetwerden, welche haufig gewechselt werden. (Die mit den Banken vereinbarten Schlussel/Passworter die-nen beim Telebanking in der Regel in erster Linie zur Authentifikation/Identifikation des Kunden.)
Es gibt aber Verfahren, welche ohne die Verteilung von geheimen Schlusseln auskommen, und die darumPublic Key Kryptosysteme (PKK) genannt werden3. Wie der Name sagt, benutzen PKKs nicht geheime,sondern offentliche Schlussel zum Verschlusseln der Texte.
Verschlüsselung Übermittlung
öffentlicher geheimer
Entschlüsselung
Schlüssel des Empfängers Schlüssel des Empfängers
In PKKs werden fur die Verschlusselung Funktionen benutzt, welche leicht zu berechnen, aber ohnezusatzliches Wissen nicht invertierbar sind. Diese Einwegfunktionen konnen dann offentlich bekanntgegeben werden. Da die Funktionen schwierig zu invertieren sind, ist das Entschlusseln nicht einfachmoglich. Es gilt dann also:
• Jeder kann mit dem offentlichen Schlussel Meldungen codieren.
• Nur wer den geheimen Schlussel kennt, kann die Meldung decodieren.
Definition: Eine bijektive Funktion f : X → Y heisst eine Einwegfunktion falls gilt:
• Die Funktion f ist leicht (mit wenig Rechenaufwand) zu berechnen.
3 Da fur diese Verfahren zwei verschiedene Schlussel zum Ver- bzw. Entschlusseln verwendet werden, spricht man auch von asymmetrischenVerfahren.

9-8 9 Kryptologie
• Die Umkehrfunktion f−1 ist ohne zusatzliche (geheime) Informationen sehr schwierig (mit grossemAufwand) zu berechnen.
Ein einfaches Modell fur eine Einwegfunktion ist ein Telefonbuch, mit welchem sehr schnell zu jedemNamen mit Adresse die Telefonnummer gefunden werden kann. Hingegen ist es sehr aufwandig, mitHilfe eines Telefonbuchs zu einer Telefonnummer den zugehorigen Namen zu finden. Es musste dasganze Buch durchsucht werden.
Das Finden von sicheren Einwegfunktionen ist nicht einfach. Wenn wir den Schlussel kennen, konnen wirin allen bisherigen Verfahren sehr leicht die Umkehrfunktion berechnen. Das Suchen von guten, schnellenund beweisbar sicheren Einwegfunktionen ist ein zentrales Forschungsgebiet der Kryptologie. Heute sindaber schon einige praktisch verwendbare (nicht beweisbar sichere) Einwegfunktionen bekannt.
Die Idee bei einem Public Key Kryptosystem ist, dass jeder Teilnehmer fur sich ein Paar von Schlusselngeneriert: einen offentlichen Schlussel zum Verschlusseln der Meldungen, und einen privaten, gehei-men Schlussel zum Entschlusseln. Der geheime Schlussel darf aus dem offentlichen Schlussel nur mitriesigem Aufwand oder gar nicht berechnet werden konnen.
Der erste Schlussel generiert dann eine Einwegfunktion, welche nur mit Kenntnis des zweiten Schlus-sels (oder nur mit sehr grossem Aufwand) invertiert werden kann.
Um einem Teilnehmer eine Meldung zu verschicken, verschlusseln wir die Meldung mit dessen offentli-chem Schlussel. Nur der Adressat, der den geheimen Schlussel kennt, kann die Einwegfunktion invertie-ren, also die verschlusselte Meldung wieder entschlusseln.
Definition: Fur ein PKK mussen die folgenden Bedingungen erfullt sein:
1. Es gibt genugend viele Paare (V,E) von Verschlusselungs- und Entschlusselungsfunktionen (bzw.von offentlichen und geheimen Schlusseln (v,e)).
2. Fur jede Meldung M gilt E(V (M)) = M.
3. V ist eine Einwegfunktion.
4. V und E sind leicht zu berechnen, wenn man den Schlussel v, bzw. e kennt.

9.5 Asymmetrische Verfahren: Public Key Kryptosysteme 9-9
Das erste PKK ist der Diffie-Hellmann Algorithmus von 1976. Auf einer ahnlichen Idee basiert der um1978 von R. Rivest, A. Shamir und L. Adleman gefundene RSA Algorithmus. Die darauf basierendenVerfahren werden deshalb RSA-Kryptosysteme genannt.
9.5.1 Das RSA Verfahren
Das RSA-Verfahren ist heute das am meisten benutzte PKK. RSA bildet die Grundlage fur SSL (SecureSocket Layer), welche vor allem fur WWW gebraucht werden, fur SET (Secure Electronic Transactions),welche im Zusammenhang mit elektronischem Geld wichtig sind, fur S/Mime, also sichere Email undvieles mehr (z.B. S-HTTP, SSH, ...).
Die Sicherheit des RSA-Verfahren basiert auf dem Problem, eine grosse Zahl in ihre Primfaktoren zuzerlegen und aus dem Problem des diskreten Logarithmus. Das Berechnen von Mvmodm ist relativeinfach. Fur das Berechnen der v-ten Wurzel modulo m ist bisher kein schneller Algorithmus bekannt.
Die beiden Schlussel werden so erzeugt:
• Wahle zwei verschiedene grosse Primzahlen p und q und berechne deren Produkt: m = p∗q. Setzen = (p−1) · (q−1).
• Wahle einen beliebigen Wert e, der kleiner ist als m und teilerfremd zu n. Zu diesem wird dasjenigev berechnet, fur das gilt: e · v = 1+ l ·n (Euklid’scher Algorithmus).
Es gilt dann fur das Verschlusseln: V (M) = Mv mod m fur das Entschlusseln: E(M) = Me mod m.
Übermittlung
öffentlicher geheimer
v eV(M) = M mod m E(M) = M mod m
Schlüssel des Empfängers Schlüssel des Empfängers
Es gilt namlich nach dem Satz von FermatE(V (M)) = (V (M))e mod m = Mve mod m = M(1+ln) modm = M

9-10 9 Kryptologie
9.5.2 Authentifikation mit Hilfe von RSA
Mit Hilfe eines RSA-Kryptosystems konnen wir auch feststellen, ob der Absender einer Meldung tatsach-lich derjenige ist, der er zu sein vorgibt. Durch umgekehrtes Anwenden des RSA-Verfahrens kann derEmpfanger nachprufen, ob die Meldung vom richtigen Sender stammt.Wir wissen bereits, dass E(V (M)) = Mve mod m = M gilt. Die Potenzoperation ist aber kommutativ,so dass auch Mev mod m = M gilt. Wir konnen also die Operationen Verschlusseln/Entschlusseln auchumdrehen.
Verschlüsselung Übermittlung
öffentlichergeheimer, privater
Entschlüsselung
Schlüssel des Senders Schlüssel des Senders
Nur wenn beim Entschlusseln eines Textes mit dem offentlichen Schlussel des Absenders Klartext ent-steht, stammt die Meldung von diesem Absender. Da nur der Absender den zu seinem offentlichenSchlussel passenden geheimen Schlussel kennt, kann nur dieser eine solche Meldung verfassen.
9.5.3 Integritatsprufung: Fingerabdruck, Message Digest
Ein zentrales Problem vor allem von grossen Anbietern (Banken, Online-Verkaufern, ...) ist, den Kundenzu garantieren, dass eine (unverschlusselte) Webseite tatsachlich die richtige Seite ist (und nicht einegefalschte). Dieses Problem kann mit Hilfe einer Hashfunktion und eines PKKs gelost werden.
������������
������������
Verschlüsselung
Übermittlung
Funktion
Hash
HashFunktion
=?
geheimer, privater
Entschlüsselung
öffentlicher
Schlüssel des SendersSchlüssel des Senders

9.5 Asymmetrische Verfahren: Public Key Kryptosysteme 9-11
Falls beim Entschlusseln des Hashcodes mit dem offentlichen Schlussel des Absenders der gleiche Wertherauskmmt, sind wir sicher, dass unterwegs niemand die Meldung verandert hat.
Allerdings funktioniert dies nur, wenn der uns bekannte offentliche Schlussel korrekt ist, uns also keinfalscher Schlussel vorgetauscht wird. Dies garantieren spezielle Firmen und Institutionen, sogenannteTrustcenter wie TC TrustCenter, VeriSign oder Thawte.
9.5.4 Kombinierte (Hybride) Verfahren
Eine kombinierte Methode verbindet die Sicherheit von RSA mit der Schnelligkeit von symmetrischenVerschlusselungsmethoden, wie zum Beispiel DES.
����
������������������
������������������
������������������������������������
������������������
DES
Digital
Envelope
Verschlüsselung
öffentlicher Schlüssel
des Empfängers
DES Schlüssel
Übermittlung
Ein Digital Envelope wird erzeugt, indem der Text durch ein schnelles, weniger sicheres Verfahren ver-schlusselt wird (zum Beispiel mit DES), der DES-Schlussel selber wird mit dem offentlichen RSA-Schlus-sel des Empfangers verschlusselt.
Auf diese Weise konnen die Vorteile beider Systeme kombiniert werden. Es mussen keine geheimenSchlussel auf einem (langsamen) sicheren Weg vorher vereinbart werden. Ausserdem kann fur jedeUbermittlung ein neuer DES-Schlussel verwendet werden. Durch einmaliges Verwenden jedes DES-Schlussels wird die Sicherheit des DES-Verfahrens erheblich verbessert.
Nur der Empfanger kann den DES-Schlussel lesen, da er dazu seinen privaten RSA-Schlussel braucht.Danach kann er mit Hilfe des DES-Schlussels den Text entziffern.

9-12 9 Kryptologie
9.6 Ubung 9
Fragen / Aufgaben zur Kryptologie
Sie finden die Losungen zu den Fragen entweder im Skript oder unter dem Link Einfuhrung in die Kryp-tologieauf der Ubungsseite.
1. Welches sind heute die zentralen Einsatzgebiete der Kryptologie?
2. Was bedeutet Kryptografie?
3. Was bedeutet Kryptoanalyse?
4. Was ist Steganografie?
5. Wie heisst der Uberbegriff fur die Verfahren, bei welcher die Verschlusselung Zeichenweise ablauft?
6. Gewisse Verfahren teilen den Text zuerst in gleich grosse Blocke (zum Beispiel 64 Bit) auf: Welchesist der Uberbegriff fur diese Verfahren?
7. Skizzieren Sie ein symmetrisches Kryptosystem.
8. Verschlusseln Sie mit der Casar Chiffre und dem Schlussel B (k=1) Ihren Namen.
9. Verschlusseln Sie mit der Viginere Chiffre und dem Schlussel BBC Ihren Namen.
10. Welches sind die Vor- und Nachteile des One Time Pad (Vernam Chiffre)?
11. Was waren die Hauptgrunde dafur, dass die Enigma im zweiten Weltkrieg geknackt werden konnte?(Punkte 3, 6 und 7 der Aufzahlung unter http://www.nwn.de/hgm/krypto/ → Enigma)
12. Welche symmetrischen Kryptoverfahren werden heute (noch) verwendet?
13. Skizzieren Sie ein asymmetrisches Kryptosystem.
14. Welches ist der Hauptunterschied zwischen symmetrischen und asymmtetrischen Verfahren?
15. Wer hat das erste PKK erfunden?
16. Worauf basiert die Sicherheit von RSA?
17. Wie lost man mit einem PKK das Authentizitatsproblem?
18. Wie lost man mit einem PKK das Integritatsproblem?
19. Was ist der Vorteil von hybriden Kryptoverfahren?

Literaturverzeichnis
[AHU74] Aho, Hopcroft, and Ullman. The Design and Analysis of Computer Algorithms. Addison Wesley,Reading, Massachusetts, 1974. ISBN 0-201-00029-6.
[AU95] A.V. Aho and J.D. Ullman. Foundations Of Computer Science C Edition. Computer SciencePress An Imprint of W.H. Freeman and Company, New York, 1995. ISBN 0-7167-8284-7.
[Bud94] Timothy A. Budd. Classic Data Structures in C++. Addison-Wesley, Reading, MA, 1994.
[Knu73a] D.E. Knuth. The Art of Computer Programing, volume 3 Sorting and Searching. Addison Wesley,Reading, MA, 1973. ISBN 0-201-03803-X.
[Knu73b] D.E. Knuth. The Art of Computer Programing, volume 1 Fundamental Algorithms. AddisonWesley, Reading, MA, 1973. ISBN 0-201-03809-9.
[Knu81] D.E. Knuth. The Art of Computer Programing, volume 2 Seminumerical algorithms. AddisonWesley, Reading, MA, 1981. ISBN 0-201-03822-6.
[Sed92] Robert Sedgewick. Algorithmen in C++. Addison Wesley, Bonn, 1992. ISBN 3-89319-462-2.
[Sed03] Robert Sedgewick. Algorithmen in Java. Grundlagen, Datenstrukturen, Sortieren, Suchen..Pearson Studium, 2003. ISBN 3-82737-072-8.
[Sha97] Clifford A. Shaffer. A Practical Introduction to Data Structures and Algorithm Analysis. PrenticeHall, London, 1997. ISBN 0-131-90752-2, C++ Version.
[Sha98] Clifford A. Shaffer. A Practical Introduction to Data Structures and Algorithm Analysis: JavaEdition. Prentice Hall, London, 1998. ISBN 0-136-60911-2.
[Wir86] N. Wirth. Algorithmen und Datenstrukturen mit Modula-2. Teubner, Stuttgart, 1986. ISBN0-13-629031-0.
[SaSa04] Gunter Saake, Kay-Uwe Sattler Algorithmen und Datenstrukturen, Eine Einfuhrung mit Java.dpunkt, 2004. ISBN 3-89864-255-0.
[Schied05] Reinhard Schiedermeier Programmieren mit Java, Eine methodische Einfuhrung. PearsonStudium, 2005 ISBN 3-8273-7116-3.

W-2

Index
abstrakter Datentyp, 1-5, 1-6Algorithmus, 1-9
asymptotisches Verhalten, 2-5, 2-7Komplexitat, 2-1O-Notation, 2-7
Allgemeine Strukturen, 1-4Array
Grundtyp, 1-4Indextyp, 1-4Selektor, 1-4
Atomare Typen, 1-3Auswahl, 7-2Automat, 7-3
ε-Ubergang, 7-6Ausgabe, 7-4deterministischer, 7-5Eingabe, 7-3Eingabealphabet, 7-3endlicher, 7-2leerer Ubergang, 7-6nichtdeterministischer, 7-5Zustand, 7-3Zustandsdiagramm, 7-4Zustandstafel, 7-4
B-Baum, 4-10Baume, 4-1
BinNode, 4-2Baumdurchlaufe, 4-4
Breitensuche, 4-7Inorder, 4-4Levelorder, 4-7Postorder, 4-4
Praorder, 4-4Tiefensuche, 4-4, 4-6
Binarbaum, 4-1, 4-2Binare Suchbaume, 4-8
Caesar Chiffre, 9-3Compiler, 8-1
Daten, 1-2Bezeichung, 1-2Semantik, 1-2Syntax, 1-2Wertemenge, 1-2
Datenstruktur, 1-6Datentyp, 1-2
Konstanten, 1-2Methoden, 1-2Operatoren, 1-2Wertebereich, 1-2
Divide and Conquer, 1-18
EBNF, 8-2Einwegfunktion, 9-8Extended Backus-Naur Form, 8-2
Grammatik, 8-2Herleitung, 8-3kontextfreie, 8-2Nichtterminalsymbol, 8-3Produktion, 8-3Terminalsymbol, 8-3
Hashing, 5-5Bucket Hashing, 5-11Double Hashing, 5-8

Kollision, 5-6Linear Probing, 5-8Separate Chaining, 5-13
Heap, 4-15Heapbedingung, 4-16
Iteration, 1-12, 7-2
Klassen, 1-4Komplexitat, 2-1
Best-Case, 2-4Worst-Case, 2-4
Konkatenation, 7-2Kryptoanalyse, 9-1Kryptologie, 9-1
Caesar Chiffre, 9-3Einwegfunktion, 9-8Permutationschiffre, 9-4Public Key Kryptosystem, 9-7, 9-8RSA-Kryptosystem, 9-9Vernam-Chiffre, 9-5Vigenere Chiffre, 9-3
Kryptosystem, 9-2
Liste, 3-1Array Liste, 3-1doppelt verkettet, 3-5Node, 3-5
O-Notation, 2-6
Parser, 8-1Pattern, 7-1
Alphabet, 7-1Wort, 7-1
Pattern Matching, 7-1Permutationschiffre, 9-4Priority Queue, 4-15Priority Queues, 4-15Pseudocode, 1-10Public Key Kryptosystem, 9-7, 9-8
Queue, 3-1, 3-11
Regularer Ausdruck, 7-2Rekursion, 1-15RSA-Kryptosystem, 9-9
Sortieren
Insertion-Sort, 6-4Merge-Sort, 6-9Quick-Sort, 6-6Selection-Sort, 6-2stabiler Algorithmus, 6-1
Spezifikation, 1-8Sprache, 8-3
Herleitung, 8-3Stack, 3-1, 3-11Suchen, 5-1
Binare Suche, 5-3Lineare Suche, 5-2
Top Down Parser, 8-1Trustcenter, 9-11
Vernam-Chiffre, 9-5Verschlusselung, 9-1Vigenere Chiffre, 9-3

















