Data Mining: Diskriminanzanalyse Hagen Knaf Studiengang Angewandte Mathematik Hochschule RheinMain 26. Januar 2016 Vorwort Das vorliegende Kurzskript enth¨ alt die in der Vorlesung Data Mining dis- kutierten Aspekte der Diskriminanzanalyse, einer Methode zur Untersuchung klassifizierter Daten, die systematisch betrachtet dem mathematischen Ge- biet der multivariaten Statistik zugeh¨ ort. Es empfiehlt sich erg¨ anzend zur Vorlesung entsprechende Kapitel aus B¨ uchern zur multivariaten Statistik zu lesen, um ein vollst¨ andigeres Bild dieser wichtigen Methode zu erhalten. 1 Problemstellung Es sei Ω eine in r ≥ 2 disjunkte, nicht leere Teilmengen Ω i gegliederte, nicht leere Menge: Ω=Ω 1 ∪ ... ∪ Ω r , Ω i ∩ Ω j = ∅ f¨ ur i 6= j. (1) Entsprechend dem in der Vorlesung Data Mining betrachteten Kontext sind die Elemente ω ∈ Ω Objekte, die durch die Auspr¨ agungen x 1 ,...,x m von m ∈ N regul¨ aren Merkmalen M 1 ,...,M m mit den Wertebereichen X 1 ,...,X m beschrieben werden. Mathematisch l¨ asst sich das durch eine Abbildung b :Ω → X 1 × ... × X m (2) 1
Transcript
Data Mining:Diskriminanzanalyse
Hagen KnafStudiengang Angewandte Mathematik
Hochschule RheinMain
26. Januar 2016
Vorwort
Das vorliegende Kurzskript enthalt die in der Vorlesung Data Mining dis-kutierten Aspekte der Diskriminanzanalyse, einer Methode zur Untersuchungklassifizierter Daten, die systematisch betrachtet dem mathematischen Ge-biet der multivariaten Statistik zugehort. Es empfiehlt sich erganzend zurVorlesung entsprechende Kapitel aus Buchern zur multivariaten Statistik zulesen, um ein vollstandigeres Bild dieser wichtigen Methode zu erhalten.
1 Problemstellung
Es sei Ω eine in r ≥ 2 disjunkte, nicht leere Teilmengen Ωi gegliederte, nichtleere Menge:
Ω = Ω1 ∪ . . . ∪ Ωr, Ωi ∩ Ωj = ∅ fur i 6= j. (1)
Entsprechend dem in der Vorlesung Data Mining betrachteten Kontextsind die Elemente ω ∈ Ω Objekte, die durch die Auspragungen x1, . . . , xm vonm ∈ N regularen MerkmalenM1, . . . ,Mm mit den WertebereichenX1, . . . , Xm
beschrieben werden. Mathematisch lasst sich das durch eine Abbildung
b : Ω→ X1 × . . .×Xm (2)
1
darstellen, die jedem Objekt ω seine Auspragungen b(ω) = (x1, . . . , xm) derMerkmale zuordnet. Diese Beschreibungsabbildung ist im allgemeinen wederinjektiv noch surjektiv.
Die Teilmengen Ωi werden in der Diskriminanzanalyse als Klassen be-zeichnet; die Zerlegung (1) ist aquivalent zur Vorgabe einer Labelabbildung
` : Ω→ 1, . . . , r, `(ω) = i⇔ ω ∈ Ωi, (3)
die jedem Objekt sein Klassenlabel zuordnet.Jede Teilmenge Λ ⊆ Ω ist ebenfalls in r disjunkte, moglicherweise aller-
dings leere Teilmengen gegliedert:
Λ = Λ1 ∪ . . . ∪ Λr, Λi := Ωi ∩ Λ. (4)
Im Kontext des Data Mining ist Λ eine zufallig aus der Menge Ω gezogeneendliche Teilmenge. Man nennt Ω dann auch die Population oder Grund-gesamtheit und Λ eine Stichprobe. Die Population wird, was ihren Aufbauangeht, als unbekannt vorausgesetzt; mit Hilfe der bekannten Stichprobe Λwill man Informationen uber Ω gewinnen.
In der Diskriminanzanalyse ist man konkret daran interessiert eine Ab-bildung
ˆ : Ω→ 1, . . . , r (5)
zu ermitteln, die mit der unbekannten Labelabbildung ` moglichst gut uber-einstimmt. Eine solche Abbildung nennt man eine Schatzung von ` eine Klas-sifikationsregel oder einen Klassifikator. Fur ihre Bestimmung steht als In-formationsquelle die Zerlegung (4) der Stichprobe zur Verfugung, sowie dieMerkmalsauspragungen b(ω), ω ∈ Λ.
Auch zur konkreten Berechnung der geschatzten Klassenlabels ˆ(ω) konnennur die Merkmalsauspragungen b(ω) herangezogen werden. Dies hat zur Fol-ge, dass fur zwei Objekte ω, ω′ mit b(ω) = b(ω′) stets ˆ(ω) = ˆ(ω′) gilt. DieLabelabbildung ` selbst muss diese Eigenschaft aber nicht besitzen. DieseTatsache bedeutet, dass der Gute der Schatzung ˆ a priori Schranken gesetztsind, die nicht uberwunden werden konnen.
Um die beschriebene Situation mathematisch zu erfassen fuhrt man ein-deutige Indizes i ∈ I fur die Merkmalsauspragungen b(ω), ω ∈ Λ, ein, dasheißt man wahlt eine bijektive Abbildung
ι : I → Λ, i 7→ ωi
2
zum Beispiel eine Nummerierung der Stichprobenobjekte, und definiert
X := (i, b(ωi)) : i ∈ I ⊆ I ×X1 × . . .×Xm; (6)
siehe auch die Prasentation Was sind Daten?, wo der Index i ∈ I als Be-zeichnermerkmal (Identifier) eingefuhrt wird; er ist kein regulares Merkmal.
Fur die Elemente von X wird die folgende Notation verwendet: Ist(i, x1, . . . , xm) ∈ X, so wird das m-Tupel (x1, . . . , xm) der Auspragungender regularen Merkmale in der Regel mit x bezeichnet, und das Element(i, x1, . . . , xm) selbst mit x(i).
Die Menge X besitzt die der Zerlegung (4) entsprechende Zerlegung
X = C1 ∪ . . . ∪ Cr, Cj := (i, b(ωi) : ωi ∈ Λj. (7)
Beispiel eines diskriminanzanalytischen Problems: Kaufliche Olivenolesind haufig gefalscht, gepanscht oder verschnitten, das heißt der Inhalt einerFlasche Olivenol entspricht nicht den auf dem Flaschenetikett gemachtenAngaben. So kommen die zur Produktion verwendeten Oliven moglicher-weise nicht aus der angegebenen Anbauregion sondern sind Mischungen vonminderwertigen Olivensorten oder das Ol wird mit anderen Pflanzenolen ge-streckt. Eine Kommission der EU beauftragt daher im Jahr 2015 eine Gruppevon Wissenschafltern mit der Entwicklung eines chemischen Schnelltests, deres unter anderem erlaubt, anhand der Ergebnisse einer chemischen Analysedes Ols mit akzeptabler Sicherheit die Herkunftsregion der verwendeten Oli-ven zu bestimmen. In diesem Rahmen ist Ω die Menge aller in den Jahren2010 bis 2015 verkauften Olivenolflaschen – klarerweise ist diese Populationunbekannt, da nicht im Zugriff der Wissenschaftler. Weiter seien i = 1, . . . , aNummern fur die verschiedenen marktrelevanter Anbaugebiete fur Oliven.Dann kann man zu jedem Anbaugebiet i die Klasse Ωi der verkauften Fla-schen mit einem Ol aus Gebiet i betrachten. Zusatzlich kann man verschie-dene Arten des Panschens/Verschneidens von Olivenol betrachten und diesemit den Nummern i = a+ 1, . . . , r versehen. Dann gilt
Ω =r⋃i=1
Ωi.
Als nachsten Schritt legen die Wissenschaftler chemische Substanzen Mj,j = 1, . . . ,m fest, die man zur Herkunftsbestimmung und weiteren Cha-rakterisierung eines Ols nutzen kann. Jeder Flasche ω ∈ Ω ist nun also die
3
chemische Zusammensetzung b(ω) = (x1, . . . , xm) zugeordnet, die aus denAnteilen xi der chemischen Subnstanzen Mi in der Flasche besteht.
Schließlich wird eine Stichprobe Λ ⊂ Ω gezogen, fur deren Elemente ω ∈ Λdie Klassenzugehorigkeit des enthaltenen Ols bekannt ist. Die Erhebung die-ser Stichprobe ist moglicherweise schwierig und kann nur in Zusammenarbeitmit Polizei oder Zoll erfolgen. Anhand der chemischen Zusammensetzungenb(ω), ω ∈ Λ, wird eine Klassifikationsregel ˆ geschatzt.
Kontrolleure konnen diese Regel nun benutzen, um bei verdachtigen Her-stellern zu prufen, ob das abgefullte Ol tatsachlich zu der Beschreibung aufdem Etikett passt: Die chemische Zusammensetzung b(ω) einer Probeflaschewird ermittelt und daraus wird die Klassenzugehorigkeit ˆ(b(ω)) errechnet.Stimmt sie nicht mit den Etikettangaben uberein, wird der Hersteller genauerunter die Lupe genommen.
2 Nachste-Nachbarn-Klassifikation
In diesem Abschnitt wird eine Methode zur Bestimmung einer geschatztenLabelabbildung ˆ beschrieben, die auf der einfachen Idee beruht, dass zweiSamples ω, ω′ ∈ Ω mit ahnlichen Merkmalsauspragungen b(ω) und b(ω′)wahrscheinlich zur gleichen Klasse Ωi gehoren. Um diese Idee mathematischauszuarbeiten, benotigt man zunachst ein Maß fur die Unahnlichkeit vonMerkmalsauspragungen.
Definition 2.1: Es sei Y eine nicht leere Menge. Eine Distanzfunktionoder auch ein Unahnlichkeitsmaß auf Y ist eine Abbildung d : Y × Y → R≥0
mit den Eigenschaften
1. ∀y1, y2 ∈ Y d(y1, y2) = d(y2, y1),
2. ∀y ∈ Y d(y, y) = 0.
Jede Metrik ist also eine Distanzfunktion – das Skript Hilfstechniken,enthalt wichtige Beispiele von Distanzmaßen. Diese kommen nicht nur in derDiskriminanz- sondern auch in der Clusteranalyse zum Einsatz.
Ist eine Distanzfunktion d auf einer Menge Y gegeben, so kann man dienachsten Nachbarn eines Elements y0 ∈ Y definieren:
Definition 2.2: Es sei d eine Distanzfunktion auf Y und y0 ∈ Y . Mansagt die Menge y1, . . . , yk ⊆ Y \y0 besteht aus nachsten Nachbarn (engl.:
4
nearest neighbors) von y0, falls gilt: Besitzt y′ ∈ Y die Eigenschaft d(y0, y′) <
d(y0, yi) fur ein i ∈ 1, . . . , k, so gibt es ein j ∈ 1, . . . , k mit der Eigen-schaft d(y0, y
′) = d(y0, yj).
Man kann nun ein Verfahren zur Bestimmung einer Schatzung ˆ der La-belabbildung ` angeben:
kNN-Diskriminanzanalyse
1. Man wahle eine Distanzfunktion d auf I ×X1 × . . .×Xm, die nur vonden Auspragungen der regularen Merkmalen abhangt.
2. Man wahle ein k ∈ N; aus praktischen Grunden sollte k nicht durchdie Anzahl r der Klassen teilbar sein.
3. Zu einem Sample ω ∈ Ω bestimme man k nachste Nachbarn N ⊆ Xvon b(ω) bezuglich der Distanz d. (Dies ist moglich, da d nur von denAuspragungen abhangt.)
4. Man bestimme die Anzahlen ni := |N ∩ Ci| und definiere
ˆkNN(ω) := j mit nj = max(n1, . . . , nr).
Ist das Maximum nicht eindeutig, so wahlt man j zufallig unter denmoglichen Werten.
Die durch das beschriebene Verfahren gelieferte Abbildung
ˆkNN : Ω→ 1, . . . , r
wird als kNN-Schatzung von ` oder als kNN-Klassifikator bezeichnet.
3 Gute von Klassifikationsregeln I
Bevor man eine geschatzte Labelabbildung ˆanwendet, sollte ihre Gute er-mittelt werden. Gute ist kein mathematisch definierter Begriff; zu ihrerMessung konnen verschiedene Kennzahlen herangezogen werden, von de-nen im vorliegenden Abschnitt einige vorgestellt werden.
Basis jeder Gutebestimmung kann nur der Vergleich von ` und ˆ aufder Stichprobe Λ beziehungsweise X sein, da keine weitere Information zurVerfugung steht.
5
Einen im Hinblick auf die zugeordneten Klassenlabels vollstandigen Ver-gleich liefert die Konfusionsmatrix von ˆ:
Sie zeigt, wie stark die wahren Klassenzugehorigkeiten durch ˆ durcheinan-dergebracht werden. Es gilt: K(ˆ) ist genau dann eine Diagonalmatrix, wennˆ|X = `|X ist.
In der Praxis besonders im Fall r > 2 handlicher sind die klassenweisenTrefferquoten
ti :=nii|Ci|
, i = 1, . . . , r.
Diese kann man durch Bildung eines gewichteten Mittels weiter aggregieren:Man wahlt Gewichte w1, . . . , wr ∈ [0, 1] mit der Eigenschaft
r∑i=1
wi = 1
und definiert die gewichtete totale Trefferquote durch
tw :=r∑i=1
winii, w := (w1, . . . , wr);
sind alle Gewichte wi gleich, so ergibt sich die totale Trefferquote
ttot :=1
|X|
r∑i=1
nii.
Mit Hilfe der Gewichte kann man Situationen behandeln, in denen die kor-rekte Klassifikation in einer der Klassen wichtiger ist als in einer anderen.
Mit Hilfe der oben genannten Kennzahlen soll die Gute der Abbildungˆ : Ω → 1, . . . , r erfasst werden, also etwa die Wahrscheinlichkeit mit derdie Klassenzuordnung ˆ(ω) korrekt erfolgt. Es ist heuristisch betrachtet klar,dass die genannten Kennzahlen hierzu zu optimistische Aussagen machen, dadie bekannten Klassenlabels der Stichprobe Λ in die Erstellung der Schatzungˆ eingeflossen sind, wahrend unbekannt ist wie reprasentativ Λ fur diegesamte Population Ω ist. Im Abschnitt 6 wird diese Problematik adressiert.
Die Gute einer Klassifikationsregel kann auch im Hinblick auf weitere Ei-genschaften untersucht werden. Zu nennen ist hier zum Beispiel die Stabilitat
6
der Klassifikation ˆ(ω) bei kleinen Anderungen von b(ω). Stabilitatsfragendieser Art kann man naturlich nur untersuchen, wenn auf X1 × . . .×Xr einDistanzmaß gegeben ist. Guteuntersuchungen dieser Art werden in diesemSkript nicht behandelt.
4 Probabilistische Formulierung
In den Abschnitten 1 und 3 wird das in der Diskriminanzanalyse addres-sierte Klassifikationsproblem auf einer eher heuristischen Ebene dargestellt.Im Folgenden wird dieses Problem aus wahrscheinlichkeitstheoretischer Sichtformuliert, die erst systematische, quantitative Aussagen ermoglicht.
Zwischen dem Klassenlabel `(ω) und der Beschreibung b(ω) eines Objektsω ∈ Ω muss kein deterministischer Zusammenhang bestehen. Man arbeitetdaher mit Wahrscheinlichkeiten. Im Folgenden sei
X := b(Ω) ⊆ X1 × . . .×Xm
der Raum der moglichen Kombinationen von Merkmalsauspragungen; haufignimmt man hier die Gleichheit an, das heißt die Surjektivitat von b.
Es sei E eine σ-Algebra auf X, mit deren Hilfe man die anwendungsrele-vanten Ereignisse erfassen kann. Im Einzelnen sind das:
• alle Mengen der Form (E1 × . . . × Em) ∩ X, wobei im Fall eines nu-merischen Merkmals Mj die Teilmenge Ej ⊆ Xj ein beliebiges reellesIntervall und andernfalls eine beliebige Teilmenge von Xj sein kann.
Man beachte, dass insbesondere fur jedes x ∈ X die Menge x ein Ereignisist.
Man nimmt nun an, dass die folgenden probabilistischen Informationenvorliegen:
• die Wahrscheinlichkeiten pj, j = 1, . . . , r, dafur bei zufalligem Ziehenaus Ω ein Objekt in der Klasse Ωj zu ziehen. Man nennt diese diea-priori-Wahrscheinlichkeiten.
• die klassenweisen Merkmalsverteilungen P (E|j), E ∈ E , also die Wahr-scheinlichkeit dafur, dass die Merkmalsauspragungen b(ω) eines ω ∈ Ωj
in E liegen.
7
Diese Angaben liefern die Mischverteilung
P (E) =r∑j=1
pjP (E|j) (9)
auf E .
Im Folgenden wird haufig die Notation P (A|B) benutzt, die, wie in derWahrscheinlichkeitsrechnung ublich, die Wahrscheinlichkeit fur das Eintretendes Ereignisses A bei/nach Eintritt des Ereignisses B bezeichnet.
Es sei ˆ : Ω → 1, . . . , r eine Schatzung der wahren Labelabbildung` : Ω→ 1, . . . , r basierend auf den Merkmalsauspragungen b(ω). Zu jedemE ∈ E kann man dann nach dem Satz von Bayes die die fur die Diskriminan-zanalyse zentralen a-posteriori-Wahrscheinlichkeiten
P (ˆ(ω) = j|b(ω) ∈ E) =pjP (E|j)P (E)
(10)
betrachten. Besonders interessant ist das im Fall von E = x und j = `(ω);man erhalt
P (ˆ(ω) = `(ω)|b(ω) = x) =p`(ω)P (x|`(ω))
P (x). (11)
Diese Großen werden als Trefferwahrscheinlichkeiten von ˆ bei x bezeichnet.Entsprechend ist die Fehlklassifikationswahrscheinlichkeit von ˆ bei x
P (ˆ(ω) 6= `(ω)|b(ω) = x) = 1−p`(ω)P (x|`(ω))
P (x).
Man beachte, dass der Wert ˆ(ω) nach Voraussetzung nur von b(ω) abhangt.Die Mengen
Xj := b(ˆ−1(j))
liefern daher eine disjunkte Zerlegung von X. Ab jetzt wird zusatzlich
Xj ∈ E , j = 1, . . . , r
angenommen. Man kann dann die totale Trefferwahrscheinlichkeit von ˆdurch
P (ˆ(ω) = `(ω)) :=r∑j=1
P (Xj)P (`(ω) = j|b(ω) ∈ Xj) (12)
8
und die totale Fehlklassifikationswahrscheinlichkeit von ˆ durch
P (`(ω) 6= ˆ(ω)) := 1− P (`(ω) = ˆ(ω))
definieren.Die Trefferwahrscheinlichkeit von ˆ in der Klasse Ωj ist entsprechend
P (ˆ(ω) = j|j) = P (Xj|j)
undP (ˆ(ω) 6= j|j) =
∑i 6=j
P (Xi|j)
ist die Fehlklassifikationswahrscheinlichkeit von ˆ in der Klasse Ωj.Schließlich ist fur i 6= j noch die Wahrscheinlichkeit
P (ˆ(x) = i|j) = P (Xi|j)
interessant, die man als Verwechslungswahrscheinlichkeit der Klasse Ωj mitder Klasse Ωi bezeichnet.
Ein plausibles Ziel bei der Wahl von ˆ ist die Minimierung der totalenFehlklassifikationswahrscheinlichkeit oder gleichbedeutend die Maximierungder totalen Trefferwahrscheinlichkeit. Dieses Ziel soll nun in zwei Fallen dis-kutiert werden.
Fall 1: Abzahlbare MerkmalswerteDer Menge Xj sei fur jedes Merkmal Mj abzahlbar. Dann ist auch X
selbst abzahlbar. Das Wahrscheinlichkeitsmaß P ist in diesem Fall durch dieFamilie der Werte
(P (x))x∈Xeindeutig festgelegt: Fur jedes Ereignis E ∈ E gilt
P (E) =∑x∈E
P (x),
wobei die rechte Seite eine endliche Summe oder eine konvergente Reihe ist.
9
Fur die totale Trefferwahrscheinlichkeit von ˆ ergibt sich folglich nach(10):
P (ˆ(ω) = `(ω)) =r∑j=1
P (Xj)P (`(ω) = j|b(ω) ∈ Xj)
=r∑j=1
pjP (Xj|j)
=r∑j=1
∑x∈Xj
pjP (x|j)
=r∑j=1
∑x∈Xj
p(x)P (`(ω) = j|b(ω) = x)
Da in der Summe in der letzten Gleichung jedes x ∈ X genau einmal auftrittund p(x) unabhangig von der Zugehorigkeit x ∈ Xj ist, liefert diese letzteGleichung: Die totale Trefferwahrscheinlichkeit wird minimal genau dann,wenn alle Trefferwahrscheinlichkeiten gegeben x maximal werden. Letztereskann man durch die Klassifikationsregel
`B(ω) := k ⇔ P (`(ω) = k|b(ω) = x) = max(P (`(ω) = i|b(ω) = x) : i = 1, . . . , r)(13)
erreichen.Kontinuierliche Merkmalswerte
Der Menge Xk sei fur jedes Merkmal Mk in reelles Intervall. Dann gilt X ⊆Rm. Weiter wird angenommen es gibt Lebesque-integrierbare Funktionen
fi : X→ R, i = 1, . . . , r,
mit der Eigenschaft
P (E|i) =
∫E
fi(x)dx;
eine solche Funktion wird bekanntlich als Wahrscheinlichkeitsverteilung oder-dichte bezeichnet. In diesem Fall ergibt sich
P (ˆ(ω) = `(ω)) =r∑j=1
P (Xj)P (`(ω) = j|b(ω) ∈ Xj)
=r∑j=1
pjP (Xj|j)
=r∑j=1
∫Xjpjfj(x)dx
=r∑j=1
∫Xjp(x)P (`(ω) = j|b(ω) = x)dx.
10
Die Summe der Integrale uber nichtnegative Funktionen in der letzten Glei-chung wird (wieder) maximal, wenn die Xi so definiert werden, dass P (`(ω) =j|b(ω) = x) fur jedes x ∈ X maximal ist. Man erhalt erneut die Klassifikati-onsregel (13).
Definition 4.1: Die durch die Bedingung (13) definierte Klassifikati-onsregel nennt man Bayesklassifikation (der Elemente von X).
Fur sie gilt allgemein, das heißt ohne Voraussetzung an die Merkmals-werte:
Satz 4.2: Die Bayes-Klassifikation `B maximiert die totale Trefferwahr-scheinlichkeit.
Der Beweis wird hier nicht gegeben, folgt aber der obigen Argumentationim Fall abzahlbarer und kontinuierlicher Merkmale, wobei man nach einemMaß integrieren muss.
5 Bayes’sche Diskriminanzanalyse im Fall klas-
senweise normalverteilter Merkmale
Im Folgenden wird angenommen alle regularen Merkmale sind reell,
X1 × . . .×Xm ⊆ Rm,
und ihre Auspragungen x = (x1, . . . , xm) sind klassenweise normalverteilt :
p(x|i) = N(µi,Σi) =1
(2π)m2 det(Σi)
12
e−12
(x−µi)tΣ−1i (x−µi), (14)
wobei µi ∈ Rm der Erwartungswert von x und Σi ∈ Rm×m die Kovarianzma-trix in der Klasse b(Ωi) sind.
Die Bayes-Klassifikation liefert in diesem Fall: Der Datensatz x bzw. daszugehorige Objekt ω wird der Klasse k zugeordnet genau dann, wenn
p(x|k)pk = max(p(x|i)pi : i = 1, . . . , r) (15)
gilt. Da der naturliche Logarithmus eine streng monoton wachsende Funktionist, gilt die Bedingung (15) genau dann, wenn die Bedingung
Im konkreten Fall liegt eine klassifizierte Stichprobe X = C1 ∪ . . .∪Crvor und man berechnet die Schatzer
µi =1
ni
∑x∈Ci
x, ni := |Ci|,
fur die Erwartungswerte µi, sowie die Schatzer
Σi = (1
ni
∑x∈Ci
(xj − µij)(xk − µik))j,k
fur die Kovarianzmatrizen Σi, wobei µij die j-te Komponente von µi ist. DieQuotienten
pi :=nin, n := |X|,
sind Schatzer der a-priori-Wahrscheinlichkeiten. Damit wird die geschatz-te oder empirische Bayes-Klassifikation fur jedes x auf die Bestimmung desMaximums von r reellen Zahlen reduziert, die nach (17) berechnet werdenkonnen, wenn man fur alle unbekannten statistischen Großen die entspre-chenden Schatzer einsetzt.
Fur das Verstandnis einer (empirischen) Klassifikationsregel ist es nutz-lich die Klassengrenzen zu kennen, also diejenigen x ∈ X1 × . . . × Xm
beziehungsweise x ∈ Rm, falls letzteres sinnvoll ist, fur die
p(x|i)pi = p(x|j)pj
gilt. Man beachte, dass ein Datensatz x, der auf einer Klassengrenze liegt,durch die Bayes-Klassifikation moglicherweise nicht eindeutig zugeordnet wer-den kann. Namlich dann nicht, wenn i oder j Indizes sind, bei denen dasMaximum in (15) angenommen wird.
12
Im Fall normalverteilter Merkmale gilt fur alle x ∈ Rm, die auf der Klas-sengrenze zwischen der Klasse i und der Klasse j liegen, die Gleichung
Die linke Seite ist im allgemeinen ein Polynom zweiten Grades in m Varia-blen:
Feststellung 5.1: Bei normalverteilten Merkmalen sind die Klassen
x ∈ Rm : `B(x) = i
der Bayes-Klassifikation durch Stucke von Hyperflachen zweiten Grades be-grenzt, im Fall m = 2 also durch Stucke von Kegelschnitten.
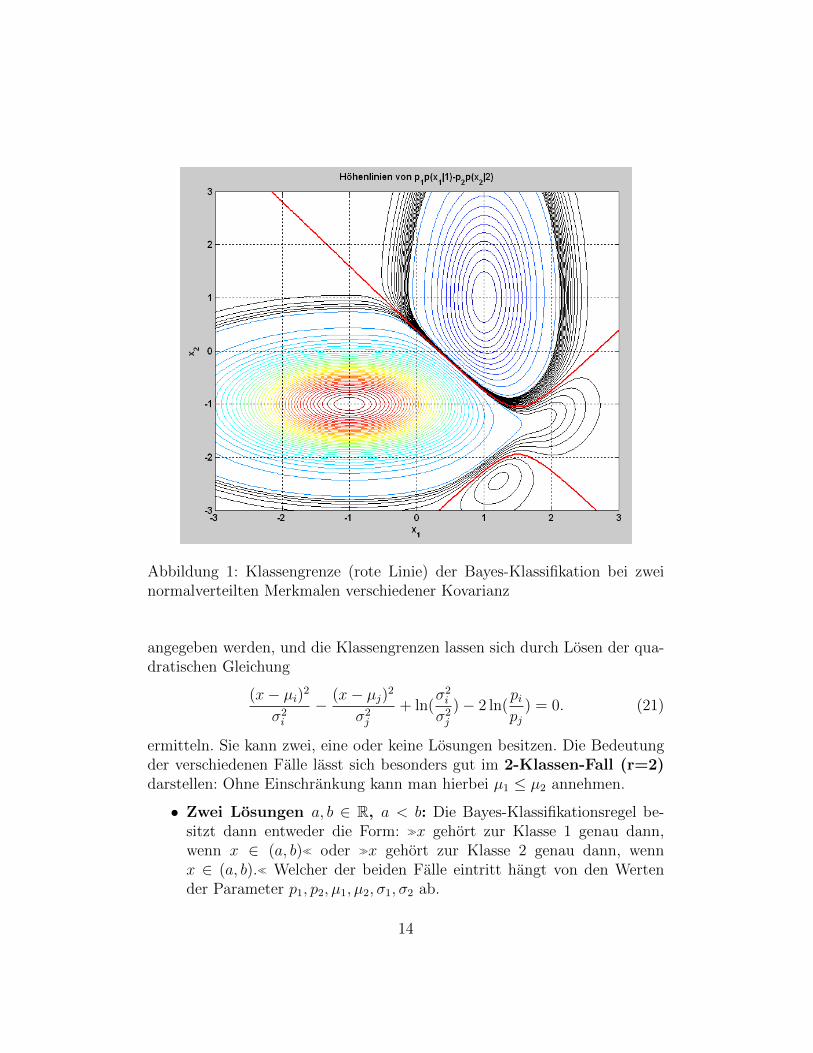
In Abbildung 1 ist die Klassengrenze zwischen zwei Klassen mit p1 = 0.75,p2 = 0.25, µ1 = (−1,−1), µ2 = (1, 1) und
Σ1 =
(1 00 0.3
), Σ2 =
(0.2 00 1.5
)als rote Linie dargestellt – es handelt sich um eine Hyperbel. Die in derAbbildung zu sehenden Konturen sind die der Funktion
g(x) := p1p(x|1)− p2p(x|2);
die 0-Kontur ist also genau die Klassengrenze. Die schwarz gefarbten Kon-turlinien entsprechen Funktionswerten sehr nahe bei 0 und konnten daher inder Darstellung farblich nicht weiter aufgelost werden.
Es werden nun verschiedene Spezialfalle der Bayes-Klassifikation im nor-malverteilten Fall diskutiert:
Fall 1: nur ein Merkmal (m = 1): In diesem Fall gilt Σi = σ2i , wobei σ2
i
die Varianz des Merkmals x in der Klasse b(Ωi) ist. Die Bayes-Klassifikationkann also in der Form
(x−µk)2
σ2k
+ln(σ2k)−2 ln(pk)=min(
(x−µi)2
σ2i
+ln(σ2i )−2 ln(pi):i=1,...,r) (20)
13
Abbildung 1: Klassengrenze (rote Linie) der Bayes-Klassifikation bei zweinormalverteilten Merkmalen verschiedener Kovarianz
angegeben werden, und die Klassengrenzen lassen sich durch Losen der qua-dratischen Gleichung
(x− µi)2
σ2i
− (x− µj)2
σ2j
+ ln(σ2i
σ2j
)− 2 ln(pipj
) = 0. (21)
ermitteln. Sie kann zwei, eine oder keine Losungen besitzen. Die Bedeutungder verschiedenen Falle lasst sich besonders gut im 2-Klassen-Fall (r=2)darstellen: Ohne Einschrankung kann man hierbei µ1 ≤ µ2 annehmen.
• Zwei Losungen a, b ∈ R, a < b: Die Bayes-Klassifikationsregel be-sitzt dann entweder die Form: x gehort zur Klasse 1 genau dann,wenn x ∈ (a, b) oder x gehort zur Klasse 2 genau dann, wennx ∈ (a, b). Welcher der beiden Falle eintritt hangt von den Wertender Parameter p1, p2, µ1, µ2, σ1, σ2 ab.
14
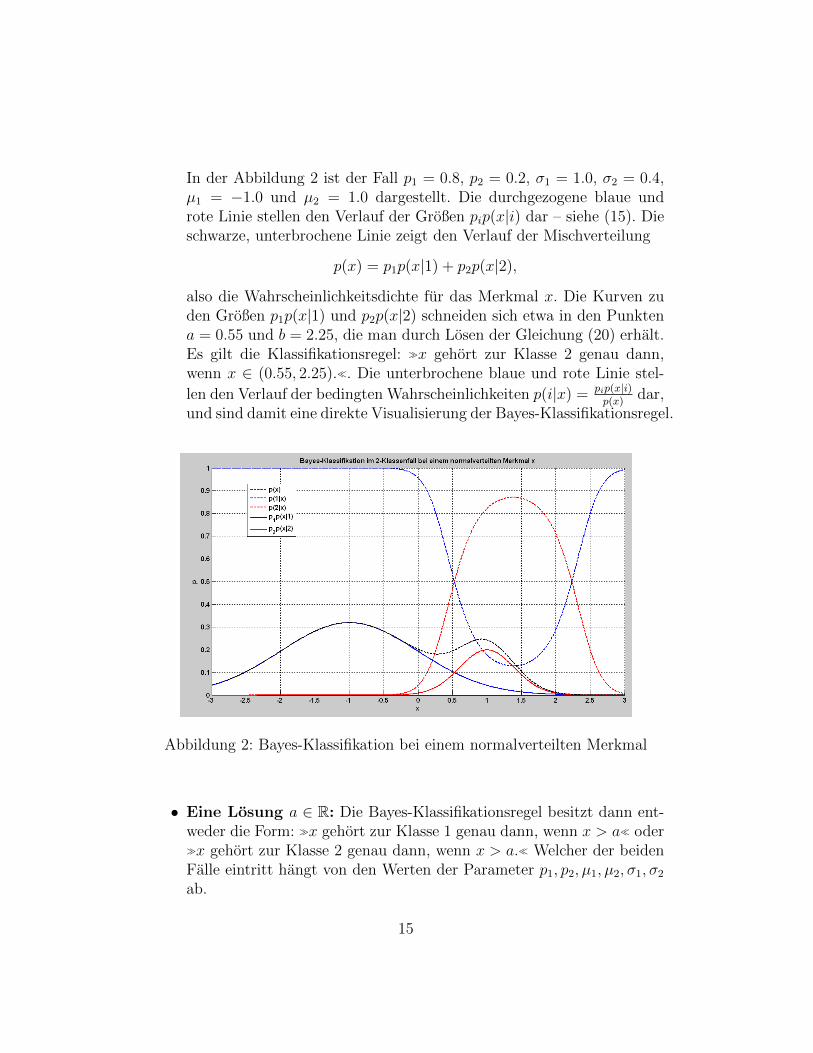
In der Abbildung 2 ist der Fall p1 = 0.8, p2 = 0.2, σ1 = 1.0, σ2 = 0.4,µ1 = −1.0 und µ2 = 1.0 dargestellt. Die durchgezogene blaue undrote Linie stellen den Verlauf der Großen pip(x|i) dar – siehe (15). Dieschwarze, unterbrochene Linie zeigt den Verlauf der Mischverteilung
p(x) = p1p(x|1) + p2p(x|2),
also die Wahrscheinlichkeitsdichte fur das Merkmal x. Die Kurven zuden Großen p1p(x|1) und p2p(x|2) schneiden sich etwa in den Punktena = 0.55 und b = 2.25, die man durch Losen der Gleichung (20) erhalt.Es gilt die Klassifikationsregel: x gehort zur Klasse 2 genau dann,wenn x ∈ (0.55, 2.25).. Die unterbrochene blaue und rote Linie stel-
len den Verlauf der bedingten Wahrscheinlichkeiten p(i|x) = pip(x|i)p(x)
dar,und sind damit eine direkte Visualisierung der Bayes-Klassifikationsregel.
Abbildung 2: Bayes-Klassifikation bei einem normalverteilten Merkmal
• Eine Losung a ∈ R: Die Bayes-Klassifikationsregel besitzt dann ent-weder die Form: x gehort zur Klasse 1 genau dann, wenn x > a oderx gehort zur Klasse 2 genau dann, wenn x > a. Welcher der beidenFalle eintritt hangt von den Werten der Parameter p1, p2, µ1, µ2, σ1, σ2
ab.
15
• Keine Losung: Dieser Fall tritt genau dann ein, wenn entweder stetsp1p(x|1) > p2p(x|2) oder stets p2p(x|2) > p1p(x|1) gilt. Im ersten Fallwerden alle x der Klasse 1 im zweiten Fall werden alle x der Klasse 2zugeordnet.
Die Bayes-Klassifikationsregel ist in diesem Fall wertlos. Er tritt inder Praxis zum Beispiel dann ein, wenn die Zugehorigkeit zu einer vonbeiden Klassen eine sehr kleine a-priori-Wahrscheinlichkeit besitzt, alsoetwa in der medizinischen Diagnose einer seltenen Krankheit.
Fall 2: gleiche Kovarianzmatrizen: Im Fall Σ1 = . . . = Σr = Σ verein-facht sich die Klassifikationsregel (17) zu
Diese letzte Klassifikationsregel besitzt eine interessante Interpretation. Dazumuss man sich einige Fakten aus der linearen Algebra vergegenwartigen.
Satz 5.2: Es sei Σ eine symmetrische, positiv definite Matrix. Dann istdie Abbildung
Rm → R, x 7→√xtΣ−1x
eine Norm auf Rm und daher wird durch
m(x, y) :=√
(x− y)tΣ−1(x− y)
eine Metrik auf Rm definiert; man bezeichnet sie als Mahalanobis-Distanz(zu Σ).
Beweis: Eine Matrix Σ ∈ Rm×m heißt positiv definit, falls fur alle x ∈Rm, x 6= 0, die Ungleichung xtΣx > 0 gilt. Insbesondere ist eine solche Matrixalso invertierbar, womit die Aussage des Satzes sinnvoll wird.
Zu x ∈ Rm, x 6= 0, gibt es ein y ∈ Rm mit x = Σy. Es folgt
xtΣ−1x = (Σy)tΣ−1(Σy) = ytΣtΣ−1Σy = ytΣy > 0,
das heißt auch Σ−1 ist positiv definit.
16
Σ−1 ist auch symmetrisch: Aus ΣΣ−1 = E folgt durch transponieren(Σ−1)tΣ = E, also die Behauptung.
Aus der linearen Algebra ist bekannt, dass jede symmetrische, positivdefinite Matrix A uber die Formel
〈x, y〉 := xtAy
ein Skalarprodukt definiert, und jedes Skalarprodukt liefert uber die Formel
‖x‖ := 〈x, x〉
eine Norm. Damit ist der Satz bewiesen. 2
Die Kovarianzmatrix Σ einer multivariaten Normalverteilung ist nach De-finition symmetrisch und positiv definit. Der eben bewiesene Satz ist alsoanwendbar und besagt, dass die in der Klassifikationsregel (23) auftreten-den Ausdrucke (x−µi)tΣ−1(x−µi) als Mahalanobis-Distanz zwischen x undµi angesehen werden konnen. Diese Klassifikationsregel kann also wie folgtformuliert werden:
Ein Element x ∈ X1×. . .×Xm bzw. das zugehorige Objekt ω wird derjeni-gen Klasse zugeordnet, zu deren Erwartungswert es die kleinste Mahalanobis-Distanz besitzt.
Anmerkungen:
1. Die Mahalanobis-Distanz berucksichtigt die Merkmalskorrelationen beider Distanzbestimmung.
2. Fur die Praxis ist es wichtig sich klar zu machen, das die geschatzteKovarianz Σ moglicherweise nur positiv semi-definit ist. In diesem Falllasst sich eine Schatzung der Mahalanobis-Distanz nicht auf direktemWeg gewinnen. Dieser Fall tritt nur dann ein, wenn die Stichprobe Xin einer Hyperebene des Rm liegt.
woraus sich durch Ausnutzen der Bilinearitat die Formel
2(µj − µi)tΣ−1x+ µtiΣ−1µi − µtjΣ−1µj − 2
ln(pi)
ln(pj)= 0
ergibt. Dies ist die Gleichung einer Hyperebene im Rm. Es wurde bewiesen:
17
Feststellung 5.3: Bei normalverteilten Merkmalen mit gleichen Ko-varianzmatrizen sind die Klassen
x ∈ Rm : `B(x) = i
der Bayes-Klassifikation durch Stucke von Hyperebenen begrenzt, im Fall m =2 also durch Strecken und Halbgeraden.
Abbildung 3: Klassengrenzen der Bayes-Klassifikation bei zwei normalver-teilten Merkmalen gleicher Kovarianz
Fall 3: unkorrelierte Merkmale gleicher Varianz: In diesem Fall besitztdie Kovarianzmatrix die Form
Σ = σ2E.
Daher ist die Mahalanonbis-Distanz bis auf den Faktor σ−2 gleich der eukli-dischen Distanz. Die Resultate aus Fall 2 gelten daher im Fall 3, wobei mandie Mahalanobis-Distanz durch die euklidische Distanz ersetzen kann.
6 Gute von Klassifikationsregeln II
Die im Abschnitt 3 eingefuhrten Trefferquoten einer Schatzung ˆ : Ω →1, . . . , r einer Labelabbildung ` : Ω → 1, . . . , r lassen sich mit Hilfe
18
der Ergebnisse des Abschnitts 4 probabilistisch interpretieren. Im Folgendenwerden die Bezeichnungen dieser beiden Abschnitte verwendet.
Nach dem Gesetz der großen Zahl gilt:
• Die Verhaltnisse |Ci||X| sind Schatzer der a-priori-Wahrscheinlichkeiten pi.
• Die totale Trefferquote ttot ist ein Schatzer der totalen Trefferwahr-scheinlichkeit P (ˆ(ω) = `(ω)).
• Die klassenweisen Trefferquoten ti sind Schatzer von P (Xi|i).
Alle diese Schatzer sind allerdings zu naiv und besitzen daher den folgendenSchwachpunkt: Schatzt man eine Klassifikationsregel ˆ auf der Basis einerklassifizierten Stichprobe X = C1∪ . . .∪Cr, so wird ` in der Regel die Beson-derheiten der Stichprobe X gut widerspiegeln. Die oben genannten Schatzerder Trefferquoten werden also im Allgemeinen zu optimistisch ausfallen, wennman sie mit den wahren Trefferwahrscheinlichkeiten vergleicht. Es stellt sichdie Frage, wie man dieser Schwache in der Praxis entgegenwirkt. Hierfur gibtes mehrere Methoden, von denen zwei im Folgenden beschrieben werden:
Aufteilung in Trainings- und Testmenge (Hold Out): Mit dieserMethode simuliert man die in der Praxis auftretende Situation der Anwen-dung einer geschatzten Klassifikationsregel ˆ auf Daten, die nicht in dieSchatzung eingeflossen sind (neue Daten). Man unterteilt X zufallig inzwei disjunkte Teilmengen Xtrain und Xtest. Die so genannte Trainingsmen-ge Xtrain benutzt man zur Schatzung der Klassifikationsregel; man ermitteltalso ˆ nur auf der Basis der Daten aus Xtrain. Den Vorgang der Schatzungnennt man im Data Mining auch Training (eines Modells der Daten), da-her der Name. Siehe hierzu auch den Artikel [F] und die Bemerkungen imAbschnitt 8.
Hat man ˆ bestimmt, so ermittelt man die im Abschnitt 3 beschriebenenTrefferquoten auf der Testmenge Xtest und erhalt realistischere Schatzerfur die wahren Trefferquoten.
Die Festlegung der Große der Trainings- bzw. Testmenge hangt vom Ge-samtumfang der Stichprobe ab.
Was die Aufteilung von X selbst betrifft, gibt es zwei Alternativen zubedenken:
• Man unterteiltX zufallig ohne auf die Klassenunterteilung vonX Ruck-sicht zu nehmen. Es kann dann passieren, dass in Xtrain oder Xtest eine
19
der Klassen nicht vorkommt, was zumindest fur die Trainingsmengevermieden werden sollte. Dennoch entspricht diese Art der Untertei-lung in vielen Kontexten der Realitat am ehesten, da man auch dortbei vorliegenden neuen Daten nicht weiß, dass alle Klassen vertretensind.
• Man unterteilt X so, dass fur jede Klasse Ci die Anteile |Ci||X| ,|Ci∩Xtrain||Xtrain|
und |Ci∩Xtest||Xtest| etwa gleich sind.
Kreuzvalidierung: Diese Methode ist eine Verallgemeinerung des Hold Out,die gleichzeitig Informationen uber die Gute der der Schatzer der Trefferquo-ten liefert.
Die Stichprobe X wird in k > 2 ungefahr gleich große, disjunkte Teilmen-gen Y1, . . . , Yk geteilt. Wie beim Hold Out gibt es fur die Aufteilung die dortbeschriebenen zwei Moglichkeiten.
Fur jedes j ∈ 1, . . . , k bestimmt man nun eine Schatzung ˆj basierend
auf der Trainingsmenge X \ Yj und schatzt Trefferquoten, zum Beispiel die
totale Trefferquote ttot,j von ˆj basierend auf der Testmenge Yj.
Schließlich bestimmt man eine Schatzung ˆ basierend auf der gesamtenStichprobe X. Dann gilt:
• Der Mittelwert ttot := 1k
k∑j=1
ttot,j ist in der Regel (Heuristik!) ein realis-
tischer Schatzer der Trefferwahrscheinlichkeit von ˆ.
• Die Varianz s2tot := 1
k
k∑j=1
(ttot,j − ttot)2 liefert einen Anhaltspunkt fur
die Gute der Trefferquotenschatzung. Ist die Varianz hoch, so mussman, abhangig von den neu zu klassifizierenden Daten, mit erheblichenAbweichungen der dann beobachteten Trefferquote von ttot rechnen.
7 Lineare Diskriminanzanalyse nach Fisher
In diesem Abschnitt wird am Beispiel von Fisher’s linearer Diskriminanz-analyse gezeigt, wie man die Bayes-Klassifikation verallgemeinern kann. Mangeht dabei vom Fall reeller, regularer Merkmale Mj aus:
X1 × . . .×Xm ⊆ Rm.
20
Ersetzt man die a-posteriori-Wahrscheinlichkeiten in der Bayes-Klassifikationsregel(4.1) durch zunachst beliebige Funktionen
di : X→ R, i = 1, . . . , r,
so erhalt man eine Klassifikationsregel der Art
ˆ(ω) := k ⇔ dk(b(ω)) = max(di(b(ω)) : i = 1, . . . , r). (24)
Man nennt die Funktionen di dann auch Diskriminanzfunktionen. Umeine Diskriminanzanalyse, das heißt eine Schatzung ˆ der Labelabbildung `mittels einer Regel der Form (24) durchzufuhren, legt man zunachst eineKlasse F von Funktionen X → R fest, innerhalb derer man nach geeigne-ten Funktionen di sucht, sowie ferner ein Verfahren zur Bestimmung der di.Letzteres hangt naturgemaß stark von der Klasse F ab. Im Folgenden wirdder einfachste Fall diskutiert:
F = d : Rm → R : d ist affin.
Da affine Funktionen auf einem Vektorraum definiert sind, wurde hier dernaturliche Definitionsbereich X = b(Ω) von Diskriminanzfunktionen aufRm erweitert.
Die folgende Tatsache aus der linearen Algebra wird im Weiteren benutzt:Zu jeder affinen Abbildung d : Rm → R gibt es einen Vektor v ∈ Rm und eina0 ∈ R mit d(x) = 〈v, x〉+a0, wobei 〈·, ·〉 das Standardskalarprodukt des Rm
ist.Es wird ab jetzt weiter angenommen, dass nur zwei Klassen vorliegen:
Ω = Ω1 ∪ Ω2
und daher auchX = X1 ∪X2
fur die Merkmalsauspragungen der vorliegenden Stichprobe Λ = Λ1 ∪ Λ2.Es werden also zwei affine Diskriminanzfunktionen di : Rm → R, i = 1, 2,gesucht, fur die die Klassifikationsregel
ˆ(ω) := 1 ⇔ d1(b(ω)) > d2(b(ω)). (25)
eine gute Schatzung von ` liefert. Die Regel (25) lasst sich vereinfachen, wennman die Funktion
d(x) := d1(x)− d2(x)
21
einfuhrt. Diese ist ebenfalls affin und es gilt:
ˆ(ω) := 1 ⇔ d(b(ω)) > 0. (26)
Man beachte, dass die Klassifikationsgrenze zwischen den beiden Klassen dieHyperebene
H := x ∈ Rm : d(x) = 0 (27)
ist; es liegt also auch eine einfache geometrische Interpretation des betrach-teten Falls vor.
Die Klassifikationsregel (26) andert sich nicht, wenn man d durch dieebenfalls affine Funktion λd, λ ∈ R>0 ersetzt. Man kann also ohne Ein-schrankung der Allgemeinheit annehmen, dass
d(x) = 〈v, x〉+ a0
mit ‖v‖ = 1 gilt. In diesem Fall ist 〈v, x〉v die orthogonale Projektion von xauf die Gerade Rv.
Fisher machte nun folgenden Ansatz zur Bestimmung von v und a0: Wahlev so, dass die projizierten Klassen 〈v,X1〉 und 〈v,X2〉
1. moglichst stark getrennt auf Rv liegen,
2. und moglichst kleine Streuung auf Rv besitzen.
Die Bedingung 1 kann man zum Beispiel durch die Forderung nach Maxi-mierung des Abstandes der Mittelwerte
1
ni
∑x∈Xi
〈v, x〉v = 〈v, xi〉v, xi :=1
ni
∑x∈Xi
x
prazisieren. Dieser Abstand ist:
|〈v, x1〉 − 〈v, x2〉|.
Die Streuung innerhalb der Klassen wird durch die Großen
Si :=∑x∈Xi
‖〈v, x〉 − 〈v, xi〉‖2
22
erfasst, womit die Bedingung 2 durch Minimierung von S1 +S2 erreicht wer-den kann. Um beide Ziele simultan zu verfolgen kann man etwa das Opti-mierungsproblem
max(|〈v, x1〉 − 〈v, x2〉|2
S1 + S2
: v ∈ Rm, ‖v‖ = 1) (28)
losen, was sogar analytisch moglich ist, wie jetzt gezeigt wird.Es gilt zunachst
wobei die Matrix B := (x1 − x2)(x1 − x2)t symmetrisch ist.Es gilt weiter
Si =∑x∈Xi〈v, x− xi〉2
=∑x∈Xi
vt(x− xi)(x− xi)tv
= vt(∑x∈Xi
(x− xi)(x− xi)t)v
= vtWiv,
wobei die Matrix Wi :=∑x∈Xi
(x − xi)(x − xi)t symmetrisch ist. Insgesamt
ergibt sich|〈v, x1〉 − 〈v, x2〉|2
S1 + S2
=vtBv
vtWv=: R(v)
mit der symmetrischen Streuungsmatrix
W := W1 +W2. (29)
Die Funktion R(v) ist eine gebrochen-rationale Funktion in den m Variablenv1, . . . , vm, wobei v = (v1, . . . , vm) gilt, also istR differenzierbar. Eine notwen-dige Bedingung fur das Vorliegen eines Extremums bei v0 = (a1, . . . , am) ∈Rm (siehe (28)) ist daher
R′(v0) = 0;
es sind also die partiellen Ableitungen ∂R∂vk
zu berechnen.
23
Ist C = (cij) ∈ Rm×m eine symmetrische Matrix, so gilt
∂R∂vk
(vtCv) = ∂R∂vk
(m∑i=1
m∑j=1
cijvivj)
=∑i 6=k
cikvivk) +∑j 6=k
ckjvkvj + 2ckkvk
= 2vtck,
wobei ck die k-te Spalte der Matrix C ist, und man die Symmetrie von Cbenutzt. Es folgt
∂R∂vk
= ∂∂vk
( vtBv
vtWv)
= 2vtbk(vtWv)−(vtBv)2vtwk(vtWv)2
also
R′(v) =2(vtWv)vtB − 2(vtBv)vtW
(vtWv)2.
Die Extremwertbedingung lauft also auf die Gleichung
(vtWv)vtB − (vtBv)vtW = 0
hinaus. Wegen vtB = vt(x1 − x2)(x1 − x2)t kann man diese Gleichung durchvt(x1 − x2) teilen, sofern diese Zahl nicht 0 ist. Das ware der Fall, wenn vorthogonal zu x1 − x2 ist. In diesem Fall werden die Punkte x1 und x2 aufdenselben Punkt projiziert, was der Bedingung 1 widerspricht und im ubri-gen das Minimum der Funktion R liefert. In fur die Anwendung relevantenSituationen wird dieser Fall also nicht vorliegen. Es folgt
(vtWv)(x1 − x2)t − (x1 − x2)tvvtW = 0
also
Wv =(vtWv)
vt(x1 − x2)(x1 − x2).
Es wird nun angenommen, dass die Matrix W invertierbar ist. Dann kannman die letzte Gleichung zu
v =(vtWv)
vt(x1 − x2)W−1(x1 − x2)
umformen. Man beachte, dass die so erhaltene Gleichung keine explizite For-
mel fur v ist, da der reelle Faktor (vtWv)vt(x1−x2)
selbst von v abhangt und unbe-kannt ist. Allerdings muss v auch nur bis auf reelle Vielfache λ 6= 0 bestimmt
24
werden, da man dann durch Normieren das gesuchte v erhalt. Aus der letztenGleichung folgt also:
v0 =W−1(x1 − x2)
‖W−1(x1 − x2)‖. (30)
Die Funktion R nimmt bei v0 tatsachlich auch ein Maximum an: Ist namlichW invertierbar, so ist der Nenner von R niemals 0 und R daher auf Rm
definiert.Es bleibt den konstanten Koeffizienten a0 der gesuchten affinen Diskrimi-
nanzfunktion zu berechnen: Die Klassengrenze H (27) soll durch den Mittel-wert 1
2(〈v0, x1〉+ 〈v0, x2〉)v0 der projizierten Mittelwerte der Klassen X1 und
X2 laufen. Es muss also gelten:
d(1
2(〈v0, x1〉+ 〈v0, x2〉)v0) = 〈v0,
1
2(〈v0, x1〉+ 〈v0, x2〉)v0〉+ a0 = 0,
woraus sich die Gleichung
a0 = −〈v0,1
2(x1 + x2)〉 (31)
ergibt. Insgesamt wurde das folgende Ergebnis bewiesen, das in Abbildung4 schematisch auch im Fall einer zweidimensionalen Datenmenge dargestelltist:
Satz 7.1: Es sei X ⊆ Rm eine endliche Menge, die in zwei disjunkte,nichtleere Teilmengen unterteilt ist: X = X1 ∪ X2. Die Streuungsmatrix W(29) sei invertierbar und fur die Mittelwerte der beiden Teilmengen geltex1 6= x2. Dann lost der Vektor v0 (30) das Maximierungsproblem (28) unddie Funktion d(x) := 〈v0, x〉 + a0, a0 wie in Gleichung (31), ist eine affineDiskriminanzfunktion zur Trennung der Klassen X1 und X2.
Praktisch fuhrt man eine lineare Diskriminanzanalyse nach Fisher in fol-genden Schritten durch:
1. Festlegen eines k ∈ N fur die k-fache Kreuzvalidierung; k hangt vonder Große der Datenmenge X ab.
2. Zufallige Aufteilung vonX in k etwa gleich große Teilmengen Y1, . . . , Yk.Hierbei gibt es die Moglichkeit dies so zu tun, dass die Anteile
|Yi ∩X1||Yi|
,|Yi ∩X2||Yi|
25
Abbildung 4: Diskriminanzanalyse nach Fisher
ungefahr gleich den Anteilen
|X1||X|
,|X2||X|
sind. Ob dies eine vernunftige Vorgehensweise ist, hangt vom Anwen-dungskontext ab.
3. Ermitteln der Diskriminanzfunktion di fur die Datenmenge X \ Yi, i =1, . . . , k.
4. Ermitteln der totalen Trefferquote t(i)tot und der klassenweisen Treffer-
quoten t(i)1 , t
(i)2 von di auf der Datenmenge Yi.
5. Bestimmen der Mittelwerte ttot := 1k
k∑i=1
t(i)tot und t
(i)tot := 1
k
k∑i=1
t(i)j , j =
1, 2, sowie der Varianzen
σtot :=1
k
k∑i=1
(t(i)tot − ttot)
2, σj :=1
k
k∑i=1
(t(i)j − tj)2
Naturlich kann statt Kreuzvalidierung auch eine einfache Aufteilung inTrainings- und Testmenge erfolgen.
8 Klassen von Diskriminanzanalyseverfahren
In diesem Skript werden drei verschiedene Diskriminanzanalyseverfahren be-schrieben. Ihre Eigenheiten sind typisch fur die ganz allgemein verwendete
26
Art Data-Mining-Verfahren in Klassen einzuteilen. Im Folgenden werden die-se Eigenschaften deshalb kurz erlautert. Dabei wird der Begriff eines Mo-dells von Daten verwendet. Nach [F] ist ein Modell einer Datenmenge Xjede Beschreibung der Daten X, die uber rein statistische Angaben wie Mit-telwert oder Standardabweichung hinausgehen. In diesem Sinn sind folgendeObjekte Modelle von Daten:
• eine Menge von Assoziationsregeln,
• eine Klassifikationsregel ˆ,
• eine durch Clusteranalyse gewonnene Gruppeneinteilung.
Nichtparametrische Verfahren: ... sind Verfahren, bei deren Durchfuhrungkeine Parameter aus den Daten X geschatzt/ermittelt werden. Wohl aberkann es Parameter geben, die der Anwender vorab wahlen muss, wobei offenbleibt, wie er das tut.
Ein Beispiel ist das in der Vorlesung vorgestellte QT-Cluster-analyseverfahren: Hier muss der Anwender den maximalen Radius der zubestimmenden Cluster, oder alternativ die maximale Elementezahl pro Clus-ter, vorgeben. Diese Parameter konnen vom Verfahren nicht aus den Datenermittelt werden.
Eine weiteres Beispiel ist die kNN-Diskriminanzanalyse: Der Parameterk muss zunachst vom Anwender vorgegeben werden. Wie in der Vorlesunggezeigt, kann aber ein optimales k mittels anderer Verfahren wie der Kreuzva-lidierung aus den Daten geschatzt werden. Allerdings ist die Kreuzvalidierungkein Bestandteil der kNN-Diskriminanzanalyse.
Nichtparametrische Verfahren: ... sind Verfahren, bei deren Durch-fuhrung Parameter aus den Daten geschatzt werden.
Ein Beispiel ist Fisher’s Diskriminanzanalyse, in der die Koeffizienten derDiskriminanzfunktion automatisch aus den Daten X ermittelt werden.
Ein weiteres Beispiel ist die Bayesklassifikation unter Normalverteilungs-hypothese, bei der Erwartungswerte und Kovarianzen aus den Daten zuschatzen sind, sofern diese nicht aus anderer Quelle bekannt sind.
27
Literatur
[F] O. Fayyad, G. Piatetsky-Shapiro, P. Smyth, From Data Mi-ning to Knowledge Discovery in Databases, AI-Magazine Vol.17(3) (1996).
[JWHT] G. James, D. Witten, T. Hastie, R. Tibshirani, An Introduc-tion to Statistical Learning with Applications in R, Springer-Verlag New York 2013.
[Spi] K. Spindler, Hhere Mathematik, Europa Lehrmittel 2010.
[Vap] V.N. Vapnik, The Nature of Statistical Learning Theory,Springer-Verlag New York 2000.