SS 2018 Prof. Dr. J. Schütze Deskr.1 1 Warum Statistik? Statistik ursprünglich: Erhebung von Daten (Status – Zustand) Beispiele Aufnahme der Wasserstände des Nil: Prognose von Dürre, Hochwasser Volkszählungen, Erfassen von Erntemengen, Steuern … bis zu heutigem statistisches Jahrbuch Statistik weiterentwickelt: Methode zur Entscheidungsfindung bei Unsicherheit unvollständige Information oder nicht kontrollierbare (zufällige) Bedingungen erfordern ‚Rechnen‘ mit Risiken Bezeichnung: Deskriptive (beschreibende) Statistik Datenerfassung, Aufbereitung, Verdichtung, grafische Darstellung Bezeichnung: Induktive (schließende) Statistik Verallgemeinern von Stichprobenergebnissen bei kalkulierbarem Risiko bzw. Sicherheit SS 2018 Prof. Dr. J. Schütze Deskr.1 2 Beispiele Technik Bei der Messung einer bestimmten Größe können nicht alle Einflüsse konstant gehalten werden. Jede Messung führt u. U. zu einem anderen Ergebnis. Aus den verschiedenen Messergebnissen schätzt man die unbekannte Größe. Wie gut bzw. genau ist diese Schätzung? Wie oft sollte man messen? Biologie/Medizin Es soll untersucht werden, ob die Hornhautdicke den Augeninnendruck beeinflusst. Das ist aus Kosten- und Zeitgründen nur an Stichproben möglich. Wie sicher sind die Schlussfolgerungen aus den Messwerten der Stichprobe für die Gesamtpopulation? Quellen zufälliger Einflüsse Technik: Messfehler Biologie/Medizin: Messfehler und biologische Variabilität der Probanden/Patienten SS 2018 Prof. Dr. J. Schütze Deskr.1 3 Warum Biostatistik? How to read a paper Verstehen von Fachliteratur, insbesondere zu experimentellen, klinischen bzw. epidemiologischen Studien Eigene empirische Untersuchungen Praktikumsarbeiten Bachelor-, Masterarbeiten Lernziele Verständnis grundlegender statistischer Schlussweisen Interpretation der Ergebnisse statistischer Verfahren Fähigkeit zur Auswahl geeigneter statistischer Verfahren Churchill Traue keiner Statistik, die Du nicht selbst gefälscht hast. Kompetenzziel Traue keiner Statistik, die Du nicht verstanden hast. SS 2018 Prof. Dr. J. Schütze Deskr.1 4 Überblick Modell Schätzung mit Risikoberechnung Stichprobe Grundgesamtheit Relative Häufigkeit Wahrscheinlichkeit Durchschnitt ... Erwartungswert ... Beschreibende Statistik Schließende Statistik Wahrscheinlichkeitsrechnung
Transcript
SS 2018 Prof. Dr. J. Schütze Deskr.1 1
Warum Statistik?
Statistik ursprünglich: Erhebung von Daten (Status – Zustand)
Beispiele Aufnahme der Wasserstände des Nil: Prognose von Dürre, Hochwasser
Volkszählungen, Erfassen von Erntemengen, Steuern …bis zu heutigem statistisches Jahrbuch
Statistik weiterentwickelt: Methode zur Entscheidungsfindung bei Unsicherheitunvollständige Information oder nicht kontrollierbare (zufällige)Bedingungen erfordern ‚Rechnen‘ mit Risiken
Bezeichnung: Induktive (schließende) StatistikVerallgemeinern von Stichprobenergebnissen bei kalkulierbaremRisiko bzw. Sicherheit
SS 2018 Prof. Dr. J. Schütze Deskr.1 2
Beispiele
TechnikBei der Messung einer bestimmten Größe können nicht alle Einflüsse konstantgehalten werden. Jede Messung führt u. U. zu einem anderen Ergebnis.Aus den verschiedenen Messergebnissen schätzt man die unbekannte Größe.Wie gut bzw. genau ist diese Schätzung? Wie oft sollte man messen?
Biologie/MedizinEs soll untersucht werden, ob die Hornhautdicke den Augeninnendruck beeinflusst. Das ist aus Kosten- und Zeitgründen nur an Stichproben möglich. Wie sicher sind die Schlussfolgerungen aus den Messwerten der Stichprobefür die Gesamtpopulation?
Quellen zufälliger EinflüsseTechnik: MessfehlerBiologie/Medizin: Messfehler und biologische Variabilität der Probanden/Patienten
SS 2018 Prof. Dr. J. Schütze Deskr.1 3
Warum Biostatistik?
How to read a paperVerstehen von Fachliteratur, insbesondere zu experimentellen, klinischen bzw.epidemiologischen Studien
Eigene empirische UntersuchungenPraktikumsarbeitenBachelor-, Masterarbeiten
LernzieleVerständnis grundlegender statistischer SchlussweisenInterpretation der Ergebnisse statistischer VerfahrenFähigkeit zur Auswahl geeigneter statistischer Verfahren
ChurchillTraue keiner Statistik, die Du nichtselbst gefälscht hast.
KompetenzzielTraue keiner Statistik, die Du nichtverstanden hast.
A Beschreibende StatistikHäufigkeitsverteilungen, Kenngrößen, Histogramme, Boxplots Zusammenhangsmaße, Regressionsmodelle
B WahrscheinlichkeitsrechnungWahrscheinlichkeiten, Unabhängigkeit, Wahrscheinlichkeitsverteilungen
C Schließende StatistikSchätzungen, Konfidenzintervalle, ParametertestsParameterfreie Testverfahren
Literatur: Sokal,R, Rohlf, F. Biometry, W.H.Freeman and Company, 2013Timischl, W. Angewandte Statistik für Biologen und Mediziner, Springer 2013Gaus, W., Muche, R. Medizinische Statistik, Schattauer 2014Hilgers, R.-D. u.a. Einführung in die medizinische Statistik, Springer 2007 Hedderich, L., Sachs. L. Angewandte Statistik, Springer 2012 Rudolf, M. u.a. Biostatistik, Pearson Studium 2008Oestreich, M. u.a. Keine Panik vor Statistik, Vieweg+Teubner, 2010
SS 2018 Prof. Dr. J. Schütze Deskr.1 6
Gliederung Teil A
A Beschreibende StatistikZielZusammenfassende, übersichtliche Darstellung beobachteter Daten in Tabellen, Verdichtung durch Kenngrößen bzw. Grafiken; Ausreißerdetektion
3. Mehrdimensionale MerkmaleZweidimensionale HäufigkeitstabellenZusammenhangsmaße bei nominalen MerkmalenZusammenhangsmaße bei ordinalen und metrischen MerkmalenLineare RegressionWeitere Regressionsmodelle
1. Grundbegriffe der beschreibenden Statistik2. Eindimensionale Merkmale
Häufigkeitsverteilungen bei diskreten MerkmalenHistogramm, empirische Verteilungsfunktion, Boxplot bei metrischen DatenStatistische Maßzahlen
SS 2018 Prof. Dr. J. Schütze Deskr.1 7
Grundbegriffe
GrundgesamtheitZielpopulation, alle Elemente, die prinzipiell gemessen, befragt, beobachtetwerden können (von eigentlichem Interesse für die Untersuchung sind)
StichprobeElemente der Grundgesamtheit, die zufällig für die Datenerhebung ausgewählt wurden (um daraus Schlüsse auf die Zielpopulation zu ziehen)
Erhebungseinheit / Merkmalsträgerjedes in die Stichprobe gelangte Element, für das Daten erhoben werden
Bei Daten zur statistischen Auswertung unterscheidet man zwischenSekundärstatistik, wenn man auf bereits vorliegende Erhebungen zurückgreift(z.B. aus Patientenakten)Primärstatistik, wenn die Daten eigens erhoben werden
SS 2018 Prof. Dr. J. Schütze Deskr.1 8
Grundbegriffe
Merkmal / statistische VariableZielgröße der Erhebung / Messung
Mögliche AusprägungenWertebereich der statistischen Variablen 1.1
Der Informationsgehalt der Merkmale hängt von der Skala ab, auf der die Ausprägungen gemessen bzw. beobachtet wurden.Man unterscheidet grob zwischen folgenden Skalenniveaus
qualitativ (kategorial) quantitativ (metrisch)
nominal ordinal diskret stetig
Skalenniveau
SS 2018 Prof. Dr. J. Schütze Deskr.1 9
NominalskalaDaten drücken qualitative Eigenschaft aus (z.B. Blutgruppen, Automarken,…)keine Ordnung oder Skala (nur gleich oder verschieden)Spezialfall: Dichotome Skala, wenn nur 2 Kategorien möglich sind (z.B. Geschlecht)
Skalenniveau von Variablen
OrdinalskalaDaten können in Rangfolge geordnet werden, aber Unterschiede zwischen den Ausprägungen sind qualitativ, nicht genau quantifizierbar (z.B. Krankheitsstadien)
Skalenniveaus bestimmen die Auswahl passender statistischer Verfahren.Statistiksoftware (z.B. SPSS) unterscheidet zwischen nominalen, ordinalen undmetrischen Daten.Der Informationsgehalt nimmt in dieser Reihenfolge zu.
1.2
Metrische Skala Daten sind Messwerte auf diskreter oder kontinuierlicher natürlicher SkalaDiskret: Zähldaten; Kontinuierlich: Messdaten Differenz zwischen Ausprägungen charakterisiert quantitativen Unterschied
SS 2018 Prof. Dr. J. Schütze Deskr.1 10
X wird n - mal gemessen/beobachtet, Stichprobe , n Stichprobenumfangbei k möglichen Ausprägungen sind maximal k der n beobachteten Werte verschieden
Eindimensionale diskrete Merkmale
1,... nx x
1 ,... kx x
Absolute Häufigkeit Anzahl des Auftretens von unter den n Werten der Stichprobe
Relative Häufigkeit ix
( ), 1ih x i k
( ), 1if x i k ( )( ) , 1i
ih xf x i k
n
10 ( ) , ( )
k
i ii
h x n h x n
Eigenschaften
10 ( ) 1, ( ) 1
k
i ii
f x f x
Bei ordinalen Merkmalen definiert man absolute und relative Summenhäufigkeiten
* * * *
: :( ) ( ), ( ) ( )
i k i kk i k ik x x k x x
H x h x F x f x
Datenverdichtung bei diskreten Merkmalen
SS 2018 Prof. Dr. J. Schütze Deskr.1 11
Grafische Darstellung z.B. durch Balkendiagramme absolute Häufigkeiten und prozentuale Summenhäufigkeiten
Einteilung des Intervalls zwischen der kleinsten und der größten Messungin gleichbreite, disjunkte KlassenKlassenanzahl k zwischen 4 und 20, (Faustregel)i.a. Obergrenze jeweils zur Klasse gehörig
k n
, 1iK i k
Stetiges Merkmal X wird n-mal gemessen, Stichprobe dabei sind i.a. alle auftretenden Werte verschieden.
Absolute Klassenhäufigkeit
Relative Häufigkeit ( ), 1if K i k ( )( ) , 1i
ih Kf K i k
n
( ), 1ih K i k 1( ) ,...i n ih K x x K Anzahl der in
Datenverdichtung bei stetigen Merkmalen
SS 2018 Prof. Dr. J. Schütze Deskr.1 13
Eindimensionale stetige Merkmale
Absolute Summenhäufigkeit H(x), Relative Summenhäufigkeit durch sukzessives Aufsummieren der Häufigkeiten über alle Klassen links von bis einschließlich x
alle Kl. links alle Kl. linksbis einschl. bis einschl.
( ) ( ), ( ) ( )i i
x x
H x h K F x f K
( )F x
Eigenschaften der Klassenhäufigkeiten
1( )
k
ii
h K n
1
( ) 1k
ii
f K
Die grafische Darstellung der Klassenhäufigkeiten als Balken über den Intervallender Klassen nennt man Histogramm.
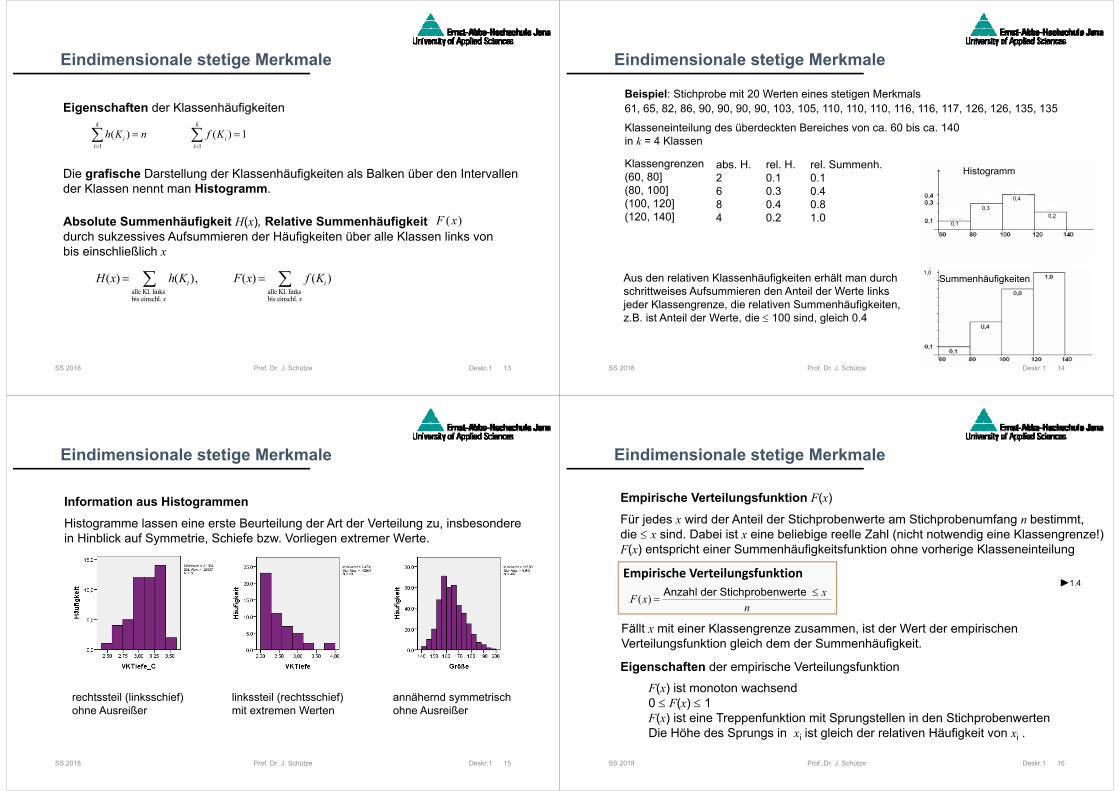
Klasseneinteilung des überdeckten Bereiches von ca. 60 bis ca. 140 in k = 4 Klassen
abs. H. rel. H.2 0.16 0.38 0.44 0.2
rel. Summenh.0.10.40.81.0
Histogramm
0,1
0,3
0,4
0,2
Aus den relativen Klassenhäufigkeiten erhält man durchschrittweises Aufsummieren den Anteil der Werte links jeder Klassengrenze, die relativen Summenhäufigkeiten,z.B. ist Anteil der Werte, die 100 sind, gleich 0.4
Summenhäufigkeiten1,0
SS 2018 Prof. Dr. J. Schütze Deskr.1 15
Eindimensionale stetige Merkmale
Information aus HistogrammenHistogramme lassen eine erste Beurteilung der Art der Verteilung zu, insbesonderein Hinblick auf Symmetrie, Schiefe bzw. Vorliegen extremer Werte.
rechtssteil (linksschief)ohne Ausreißer
linkssteil (rechtsschief)mit extremen Werten
annähernd symmetrischohne Ausreißer
SS 2018 Prof. Dr. J. Schütze Deskr.1 16
Eindimensionale stetige Merkmale
Eigenschaften der empirische VerteilungsfunktionF(x) ist monoton wachsend0 F(x) 1 F(x) ist eine Treppenfunktion mit Sprungstellen in den StichprobenwertenDie Höhe des Sprungs in xi ist gleich der relativen Häufigkeit von xi .
Empirische Verteilungsfunktion F(x)
Für jedes x wird der Anteil der Stichprobenwerte am Stichprobenumfang n bestimmt, die x sind. Dabei ist x eine beliebige reelle Zahl (nicht notwendig eine Klassengrenze!)F(x) entspricht einer Summenhäufigkeitsfunktion ohne vorherige Klasseneinteilung
1.4
Fällt x mit einer Klassengrenze zusammen, ist der Wert der empirischenVerteilungsfunktion gleich dem der Summenhäufigkeit.
Empirische Verteilungsfunktion
( ) Anzahl der Stichprobenwerte xF xn
SS 2018 Prof. Dr. J. Schütze Deskr.1 17
Eindimensionale stetige Merkmale
( ) Anzahl der Stichprobenwerte xF xn
Beispiel: Stichprobe mit n = 20 Werten eines stetigen Merkmals61, 65, 82, 86, 90, 90, 90, 90, 103, 105, 110, 110, 110, 116, 116, 117, 126, 126, 135, 135
x F(x)
x < 61 0
61 x < 65 1/20=0.05
65 x < 82 2/20=0.10
82 x < 86 3/20=0.15
86 x < 90 4/20=0.20
90 x < 103 8/20=0.40
103 x < 105 9/20=0.45
105 x < 110 10/20=0.50
110 x < 116 13/20=0.65
116 x < 117 15/20=0.75
117 x < 126 16/20=0.85
126 x < 135 18/20=0.95
x ≥ 135 1Über Intervallen mit vielen Stichprobenwertenschnelles Wachsen von F(x)
Empirische Verteilungsfunktion
SS 2018 Prof. Dr. J. Schütze Deskr.1 18
Eindimensionale stetige Merkmale
Die empirische Verteilungsfunktion wird durch die Summenhäufigkeitsfunktion genähert,mit geringerer Klassenbreite und zunehmender Klassenanzahl wird die Näherung besser.
Empirische Verteilungsfunktion
Empirische Verteilungsfunktionen eignen sich zum Vergleich von Verteilungen untereinander sowie für Tests auf Vorliegen bestimmter Verteilungstypen (Kolmogorov-Smirnov-Tests).
Summenhäufigkeitsfunktion
SS 2018 Prof. Dr. J. Schütze Deskr.1 19
Eindimensionale stetige Merkmale
Weitere Anwendung von Verteilungsfunktionen: Überlebenskurven
BeispielDauer bis zum Rückfall (Endereignis) bei Raucherentwöhnungsprogrammti (in Monaten): 3, 6, 6, 9, 10, 12, 16, 18, 18, 20
Empirische Verteilungsfunktion Anteil von Ereignissen bis zur Zeit t
ÜberlebensfunktionAnteil ‚Überlebender‘ zur Zeit t
SS 2018 Prof. Dr. J. Schütze Deskr.1 20
Eindimensionale stetige Merkmale
Schätzung der medianen ‚Überlebenszeit‘Zeitpunkt, zu dem die Hälfte der Probanden noch raucherabstinent ist
Mediane Überlebenszeit grafisch: Zeitpunkt, zu der die empirische Verteilungsfunktion gleich 50% ist
3, 6, 6, 9, 10, 12, 16, 18, 18, 20
Aus Daten:Zeitpunkt, den 50% der Werteunterschreiten
Jeder Wert zwischen 10 und 12erfüllt diese Eigenschaft,z.B. t = 11
Probleme entstehen bei zensierten Daten, z.B. wenn Probanden vorzeitig aus der Studie aussteigen oder zu Studienende noch kein ‚Ereignis‘ hattenSpezielles Verfahren: Überlebenszeitanalyse, z.B. Kaplan-Meier-Schätzung
SS 2018 Prof. Dr. J. Schütze Deskr.1 21
Empirische Quantile
ProblemUnterhalb welcher Grenze auf der Messskala liegt ein bestimmter Anteil der (aufsteigend geordneten) Stichprobenwerte, 0 < < 1?
heißt dann empirisches - Quantil.
Zur Berechnung muss man die Stichprobe zunächst ordnen: x(1) ≤… ≤ x(n)
Bei ungeradem n ist der Median genau der mittlere Wert dieser geordneten Reihe.Ist n gerade, stehen 2 Werte in der Mitte, der Median ist ihr Mittelwert.
50% der Stichprobenwerte liegt unterhalb25% der Stichprobenwerte liegt unterhalb75% der Stichprobenwerte liegen unterhalb
Analog verfährt man bei der Berechnung der Quartile.Ist der Stichprobenumfang durch 4 teilbar, liegt das untere Quartil in der Mitte zwischen dem Wert der geordneten Reihe an Position n/4 und n/4 + 1.Für beliebigen Stichprobenumfang braucht man eine Formel zur Berechnung der Quartile bzw. gleich eine Formel für Quantile beliebiger Ordnung .
Spezialfälle
SS 2018 Prof. Dr. J. Schütze Deskr.1 22
Empirische Quantile
InterpretationDas –Quantil teilt den Bereich, den die Stichprobe überdeckt, so in zwei Teile, dass etwa ·100% der Messwerte unterhalb und etwa (1- )·100% oberhalb liegen.
Empirisches α –Quantil für ist die Zahl ( )
( ) ( 1)
, 1 , 11 ( ),2
falls d.h.
falls ganzzahlig
k
k k
x k n k k nx
x x k n
0 1
1.5
Allgemeine Berechnung von Quantilen für beliebiges , 0 < < 1:Bei Stichprobenumfang n entspricht jeder Messwert einem Anteil 1/n, k Werte entsprechen dem Anteil k/n. Auf diesem Raster liegt i.a. nicht exakt.Daher verwendet man eine passende Näherungsformel zur Bestimmung von k.
Basis ist die aufsteigend geordnete Stichprobemin (1) ( 2 ) ( ) max... nx x x x x
SS 2018 Prof. Dr. J. Schütze Deskr.1 23
Empirische Quantile
Median: Mitte zwischen 5. und 6. Wert 0.5 (50 51) / 2 50.5x
Unteres Quartil: = 0.25, somit n = 2.5 nicht ganzzahlig: k = 3 0.25 (3) 49x x
Oberes Quartil: = 0.75, somit n = 7.5 nicht ganzzahlig: k = 8 0.75 (8) 51x x
Quartilsabstand: Differenz zwischen oberem und unterem Quartil
Breite des Bereichs, in dem die mittleren 50% der Werte liegen. .
Boxbreite = Quartilsabstand d = 2 Die Box enthält (etwa) die mittleren 50% der Werte der Stichprobe.
Ausreißerverdächtige Werte werden gesondert gezeichnet (hier Messwert 57).Die Balken kennzeichnen min und max der Werte, die nicht ausreißerverdächtig sind.
Unteres Quartil Median Oberes Quartil
maxmin ausreißerverdächtig
SS 2018 Prof. Dr. J. Schütze Deskr.1 25
Ausreißerdetektion
Im Beispiel: Quartilsabstand = 2, folglichNormalbereich (49 – 1.5·2, 51 + 1.5·2) = (46, 54)Ausreißerverdächtig ist somit hier der Wert 57
Die Balken im Boxplot sind Maximum und Minimum innerhalb des Normalbereichs.
Ausreißerverdächtige Werte : Werte außerhalb des Normalbereichs
Normalbereich wird im Boxplot nicht eingezeichnet!!!
0.25x 0.5x 0.75x
484949
5050
515151 52 57
Normalbereich
u o
SS 2018 Prof. Dr. J. Schütze Deskr.1 26
Empirische Quartile
AnwendungDer Median als Lageparameter schätzt den Zentralwert (Mittelwert),Der Quartilsabstand ist ein Streuungsmaß, der die Breite des Bereichs misst, in dem die mittleren 50% der Stichprobenwerte liegen.Diese Kenngrößen sind robust gegenüber Ausreißern.Daher werden sie bei ausreißerbehafteten Stichproben bzw. schiefen Verteilungengegenüber Durchschnitt und Standardabweichung bevorzugt.
Durchschnitt und Standardabweichung sind die geeigneten Kenngrößenbei normalverteilten Daten. Sie sind auch anwendbar bei anderen metrischen, symmetrischen Verteilungen.Liegen Extremwerte/Ausreißer vor oder ist die Verteilung unsymmetrisch,sind Median und Quartilsabstand die geeigneten Kenngrößen.
Fachhochschule JenaUniversity of Applied Sciences Jena
Fachhochschule JenaUniversity of Applied Sciences Jena
SS 2018 Prof. Dr. J. Schütze Deskr2 2
Mehrdimensionale Merkmale
Werden am gleichen Objekt mehrere Merkmale gemessen, interessiert man sich meistdafür, ob es zwischen ihnen eine Abhängigkeit bzw. einen Zusammenhang gibt.
Beispiel 1 enthält nominale Merkmale, Beispiel 2 metrische Merkmale.Für die Untersuchung der Abhängigkeit muss man das passende Verfahren entsprechenddem Skalenniveau wählen.
Beispiel 1100 zufällig ausgewählten Passanten wurden zum Tempolimit in der Innenstadt befragt. Es waren 70 gegen Tempolimit, 30 dafür. Unter den Gegnern waren 25 Frauen, unter den Befürwortern 20.
Beispiel 2Bei einer Verkehrskontrolle wurde bei straffälliger Höhe der Geschwindigkeitsüberschreitung ( ab 20 km/h) auch das Alter des Fahrers protokolliert.
Fachhochschule JenaUniversity of Applied Sciences Jena
SS 2018 Prof. Dr. J. Schütze Deskr2 3
Abhängigkeit nominaler Merkmale
Zwei diskrete Merkmale X, Y werden am gleichen Objekt gemessen,X mit p verschiedenen möglichen Ausprägungen, Y mit q Ausprägungen.Die Anzahl der Objekte mit der Kombination sei
Kontingenztabelle
( , )i kx y ikn
Y X
y1 y2 ... yq
x1
n11 n12 n1q
x2
n21 n22 n2q
xp
np1 np2 npq
2.1
Fachhochschule JenaUniversity of Applied Sciences Jena
SS 2018 Prof. Dr. J. Schütze Deskr2 4
Empirische RandverteilungenDie Randsummen entsprechen den eindimensionalen Verteilungen.
Aus den Zeilensummen erhält man die Verteilung von X.
Abhängigkeit nominaler Merkmale
YX
y1 y2 ... yq Randverteilung von X (Zeilensummen)
x1 n11 n12 n1q
q
kknn
11.1
x2 n21 n22 n2q
q
kknn
12.2
xp np1 np2 npq
q
kpkp nn
1.
Fachhochschule JenaUniversity of Applied Sciences Jena
SS 2018 Prof. Dr. J. Schütze Deskr2 5
Empirische RandverteilungenDie Randsummen entsprechen den eindimensionalen Verteilungen.
Aus den Spaltensummen erhält man die Verteilung von Y.
Abhängigkeit nominaler Merkmale
YX
y1 y2 ... yq Randverteilung von X (Zeilensummen)
x1 n11 n12 n1q
q
kknn
11.1
x2 n21 n22 n2q
q
kknn
12.2
xp np1 np2 npq
q
kpkp nn
1.
Randverteilung von Y(Spaltensummen)
p
iinn
111.
p
iinn
122.
p
iiqq nn
1.
p
i
q
kiknn
1 1
Fachhochschule JenaUniversity of Applied Sciences Jena
SS 2018 Prof. Dr. J. Schütze Deskr2 6
Empirische Randverteilungen
Verteilung von XAbsolute Häufigkeiten
Relative Häufigkeiten
Verteilung von YAbsolute Häufigkeiten
Relative Häufigkeiten
.1
( )q
i i ikk
n h x n
.1
( )p
k k iki
n h y n
( ) ( ) /i if x h x n
( ) ( ) /k kf y h y n
Abhängigkeit nominaler Merkmale
Fachhochschule JenaUniversity of Applied Sciences Jena
SS 2018 Prof. Dr. J. Schütze Deskr2 7
Aus den eindimensionalen Verteilungen kann man keine Rückschlüsse über einen Zusammenhang zwischen den Merkmalen ziehen.
Abhängigkeit nominaler Merkmale
Bedingte relative Häufigkeiten von X unter Bedingung kY y
.( / ) /i k ik kf X x Y y n n
kY y .( )k kh Y y n
Bedingte relative Häufigkeiten von Y unter Bedingung
.( / ) /k i ik if Y y X x n n iX x
berechnet aus Spalte , normiert mit Spaltensumme iX x .( )i ih X x n
berechnet aus Spalte , normiert mit Spaltensumme
Zusammenhänge untersucht man durch Vergleich der einzelnen Spalten/Zeilen,sie enthalten die bedingten Häufigkeiten nach Kategorien des anderen Merkmals(unter der Bedingung der entsprechenden Ausprägung im Spalten-/Zeilenkopf).
Fachhochschule JenaUniversity of Applied Sciences Jena
SS 2018 Prof. Dr. J. Schütze Deskr2 8
Für einen Zusammenhang zwischen den Merkmalen spricht, dass sich die bedingten Verteilungen von der Randverteilung unterscheiden.Ist der Anteil der Befürworter unter den Frauen dagegen so hoch wie unter den Männern, hat das Geschlecht keinen Einfluss auf die Meinung.
. .
ik im
k m
n nn n
Gleiche Anteile in allen Spalten finden sich dann auch auf dem Rand wieder..
.
ik i
k
n nn n
. .i kik
n nnn
Die Merkmale X, Y sind empirisch unabhängig, falls für alle i, k gilt. .i k
ikn nn
n
Abhängigkeit nominaler Merkmale
Fachhochschule JenaUniversity of Applied Sciences Jena
SS 2018 Prof. Dr. J. Schütze Deskr2 9
Zusammenhangsmaße bei nominalen Merkmalen
Aus den Differenzen zwischen der beobachteten Zellenbesetzung
und der bei Unabhängigkeit erwarteten Zellenbesetzung
erhält man ein Maß für die Stärke des Zusammenhangs.
Dabei quadriert man die Abweichungen, damit sich positive und negative Differenzen nicht kompensieren, und normiert mit den erwarteten Häufigkeiten.
. .ˆ i kik
n nnn
Chi-Quadrat-Maß2
2
1 1
ˆ( )ˆ
p qik ik
i k ik
n nn
ikn
Fachhochschule JenaUniversity of Applied Sciences Jena
SS 2018 Prof. Dr. J. Schütze Deskr2 10
Da die Größe des Chi-Quadrat-Maßes auch von der Dimension der Tabelleund dem Stichprobenumfang abhängt, gibt es daraus abgeleitete Maße, die diese Einflüsse durch Normierung ‚herausrechnen‘.
Zusammenhangsmaße für diskrete Merkmale
Chi-Quadrat-Maß
Kontingenzkoeffizient
Korrigierter Kontingenzkoeffizient
mit d = min(p,q), p Zeilenanzahl, q Spaltenanzahl der Kontingenztabelle
22
1 1
ˆ( )ˆ
p qik ik
i k ik
n nn
2
2Cn
1korrdC C
d
Zusammenhangsmaße bei nominalen Merkmalen
Fachhochschule JenaUniversity of Applied Sciences Jena
SS 2018 Prof. Dr. J. Schütze Deskr2 11
Interpretation
Bei Unabhängigkeit der Merkmale sind die beobachtetet Zellhäufigkeiten gleichden bei Unabhängigkeit zu erwartenden Häufigkeiten, es gilt , damit sind alle Maße Null.ˆik ikn n
Zusammenhangsmaße bei nominalen Merkmalen
Je stärker die Abhängigkeit ist, desto größer ist die Abweichung von Null.
Das Chi-Quadratmaß ist nach oben nicht beschränkt, die abgeleiteten Maße sindauf Werte kleiner als 1 normiert.
Da die abgeleiteten Maße den Stichprobenumfang bzw. die Tabellendimension‚herausrechnen‘, erlauben sie den Vergleich von Abhängigkeiten zwischen Tabellen mit verschiedenen Stichprobenumfängen bzw. verschieden vielen Ausprägungen.
Fachhochschule JenaUniversity of Applied Sciences Jena
Fachhochschule JenaUniversity of Applied Sciences Jena
SS 2018 Prof. Dr. J. Schütze Deskr2 13
Für einen linearen Zusammenhang der Merkmale würde sprechen, dass alle Punkte im ersten und dritten bzw. zweiten und vierten ‚Quadranten‘ liegen, wobei man die Quadranten nach Lage der Mittelwerte der beiden Merkmale unterteilt.
Steigende Tendenz: Fallende Tendenz:
Sind die Punkte über alle Quadranten verteilt, liegt keine lineare Tendenz vor.
, , )( ) 0 oder , somit (i i i i i ix x y y x x y y x x y y , , )( ) 0i i i i i ix x y y x x y y x x y y oder , somit (
Produkte bilden Kernstück für Zusammenhangsmaß( )( )i ix x y y
Zusammenhangsmaße für metrische Merkmale
Korrelationskoeffizient nach Pearson
2 2
( )( )( ) ( )
i i
i i
X X Y YrX X Y Y
1
1Cov( , ) ( )( )1
n
i ii
x y x x y yn
Kovarianz
1. Quadr. 2. Quadr.
3. Quadr.4. Quadr.
x
y
Fachhochschule JenaUniversity of Applied Sciences Jena
SS 2018 Prof. Dr. J. Schütze Deskr2 14
Zusammenhangsmaße für metrische Merkmale
Äquivalente Darstellungen der Pearson-Korrelation
2 2
2 2 2 2
2 2 2 2
( , )Var Var
( )( )( ) ( )
( )( )
( ( ) )( ( ) )
i i
i i
i i
i i
i i i i
i i i i
Cov X YrX Y
X X Y YX X Y Y
X Y nXYX nX Y nY
n X Y X Yn X X n Y Y
EigenschaftenHat die Punktwolke eine steigende Tendenz, ist r > 0.Bei einer fallenden Tendenz ist r < 0.
inX X 2 2 2
2 2
2 2 2 2
( ) ( 2 )
2
2
i i i
i i
i i
X X X X X X
X X X nX
X X nX nX X nX
Basisformeln für Umrechnung
( )( )i i i iX X Y Y X Y nXY
Fachhochschule JenaUniversity of Applied Sciences Jena
SS 2018 Prof. Dr. J. Schütze Deskr2 15
Interpretation der Pearson-Korrelation
Zusammenhangsmaße für metrische Merkmale
Der Korrelationskoeffizient von Pearson misst, wie eng der lineare Zusammenhangzwischen X und Y ist.
Es gilt stets: 1 1r
Bei r = 1 liegen alle Messwertpaare auf einer steigenden Geraden.Bei r = -1 liegen alle Messwertpaare auf einer fallenden Geraden.Bei r = 0 ist keine lineare Tendenz erkennbar.
Klassifizierungkeine Korrelationschwache Korrelationmittlere Korrelationstarke Korrelationperfekte Korrelation, d.h. alle Punkte liegen auf einer Geraden
0.5 0.8r 0.8 1r
1r
0 0.5r 0r
Es gibt statistische Tests, die Abweichungen von 0 auf Signifikanz prüfen.
Fachhochschule JenaUniversity of Applied Sciences Jena
SS 2018 Prof. Dr. J. Schütze Deskr2 16
Beispiel 2 (Fortsetzung)Berechnung des Pearsonschen Korrelationskoeffizienten
Fachhochschule JenaUniversity of Applied Sciences Jena
SS 2018 Prof. Dr. J. Schütze Deskr2 17
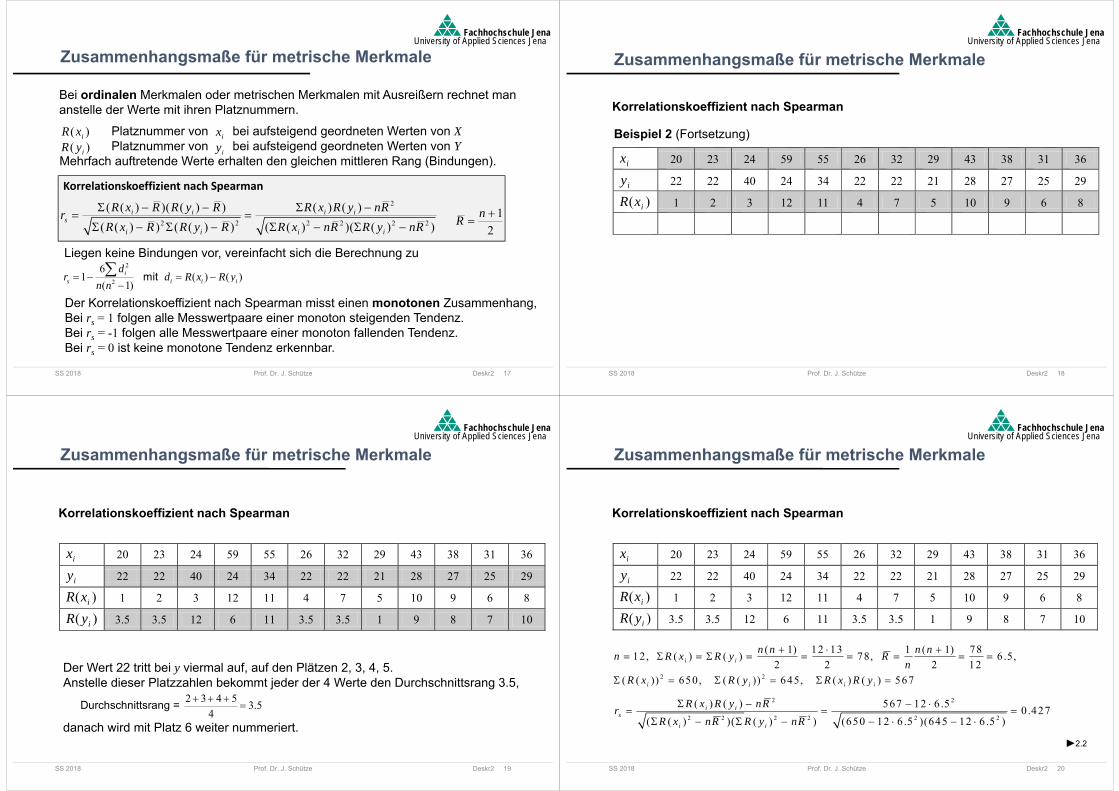
Bei ordinalen Merkmalen oder metrischen Merkmalen mit Ausreißern rechnet mananstelle der Werte mit ihren Platznummern.
Der Korrelationskoeffizient nach Spearman misst einen monotonen Zusammenhang,Bei rs = 1 folgen alle Messwertpaare einer monoton steigenden Tendenz.Bei rs = -1 folgen alle Messwertpaare einer monoton fallenden Tendenz.Bei rs = 0 ist keine monotone Tendenz erkennbar.
Zusammenhangsmaße für metrische Merkmale
Platznummer von bei aufsteigend geordneten Werten von XPlatznummer von bei aufsteigend geordneten Werten von Y
Mehrfach auftretende Werte erhalten den gleichen mittleren Rang (Bindungen).
Fachhochschule JenaUniversity of Applied Sciences Jena
SS 2018 Prof. Dr. J. Schütze Deskr2 21
Nominale Merkmale
Zusammenhangsmaße
Kontingenzkoeffizient2
2Cn
Ordinale Merkmale 2 2
( ( ) )( ( ) )( ) ) ( ( ) )
i is
i i
R x R R y RrR x R R y R
Spearman-Korrelation
Metrische Merkmale2 2
( )( )( ) ( )
i i
i i
X X Y YrX X Y Y
Pearson-Korrelation
Zusammenhangsmaße in Abhängigkeit vom Skalenniveau
Bei Merkmalen mit unterschiedlichem Skalenniveau kann man unter Informationsverlust den Koeffizienten des niedrigeren Niveaus berechnen.Für bestimmte Kombinationen verschiedener Skalen gibt es weitere Koeffizienten, vgl. z.B. Hedderich, Sachs, Statistische Verfahren
Fachhochschule JenaUniversity of Applied Sciences Jena
SS 2018 Prof. Dr. J. Schütze Deskr2 22
Lineare Regression
Bei hoher Pearson-Korrelation stehen die metrischen Merkmale X, Y in engem linearen Zusammenhang, beschrieben durch eine Regressionsgerade.Ansatz: 0 1y a a x
-1
0
1
2
3
-1 1 2 3 4 5x
0 1i iy a a x Residuen = εisind die vertikalen Abweichungender Messpunkte von der GeradenDie Quadratsumme der Residuen wird im Optimalitätskriterium minimiert.
Die Parameter der Regressionsfunktion bestimmt man nach dem Optimalitätskriterium (Methode der kleinsten Quadrate MKQ)
20 1
1min .
n
i ii
y a a x
0 1,a a
Da die Punkte i.a. nicht exakt auf einer Geraden liegen, treten Fehlerterme εi auf0 1i i iy a a x
Fachhochschule JenaUniversity of Applied Sciences Jena
SS 2018 Prof. Dr. J. Schütze Deskr2 23
Lineare Regression
Bestimmung der Parameter der Regressionsfunktion aus Optimalitätskriterium
20 1 0 1
1( , ) ( ) min
n
i ii
f a a y a a x
0 1
20 1
i i
i i i i
y a n a x
x y a x a x
Man berechnet die partiellen Ableitungen von f nach den Parametern und setzt sie gleich Null. Daraus entstehen nach Umformung der Summen dieNormalengleichungen
Als Lösung dieses linearen Gleichungssystems in a0 und a1 erhält man die
Parameterschätzungen des linearen Modells
1 0 122
1i i i ii i
i i
n x y x ya a y a x
nn x x
0 1y a a x
Fachhochschule JenaUniversity of Applied Sciences Jena
SS 2018 Prof. Dr. J. Schütze Deskr2 24
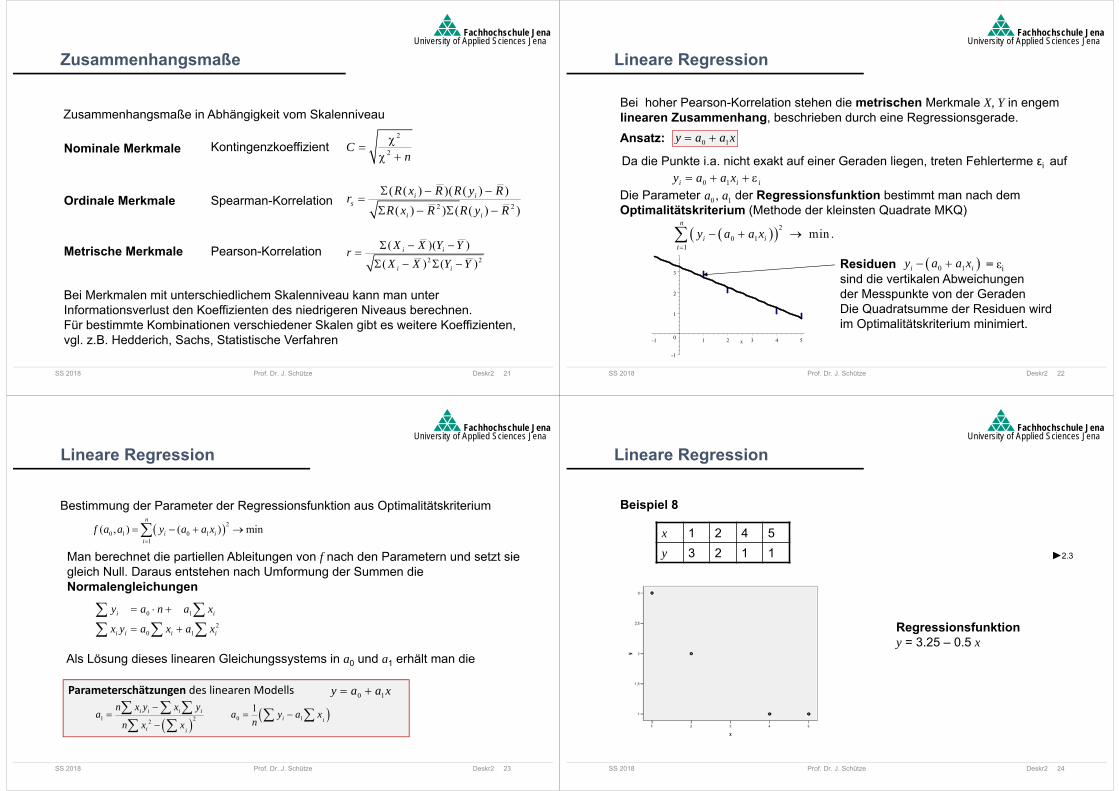
Beispiel 8
Lineare Regression
x 1 2 4 5y 3 2 1 1 2.3
Regressionsfunktiony = 3.25 – 0.5 x
Fachhochschule JenaUniversity of Applied Sciences Jena
SS 2018 Prof. Dr. J. Schütze Deskr2 25
Lineare Regression
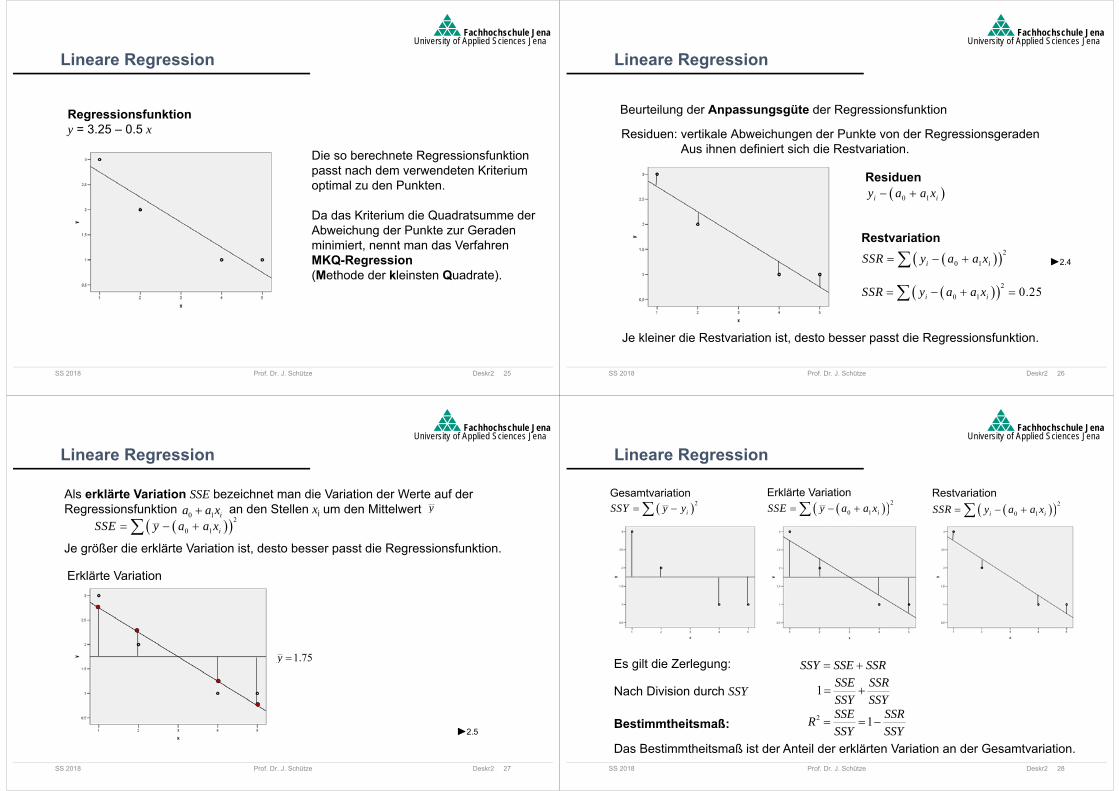
Regressionsfunktiony = 3.25 – 0.5 x
Die so berechnete Regressionsfunktionpasst nach dem verwendeten Kriteriumoptimal zu den Punkten.
Da das Kriterium die Quadratsumme derAbweichung der Punkte zur Geradenminimiert, nennt man das VerfahrenMKQ-Regression(Methode der kleinsten Quadrate).
Fachhochschule JenaUniversity of Applied Sciences Jena
SS 2018 Prof. Dr. J. Schütze Deskr2 26
Beurteilung der Anpassungsgüte der Regressionsfunktion
Lineare Regression
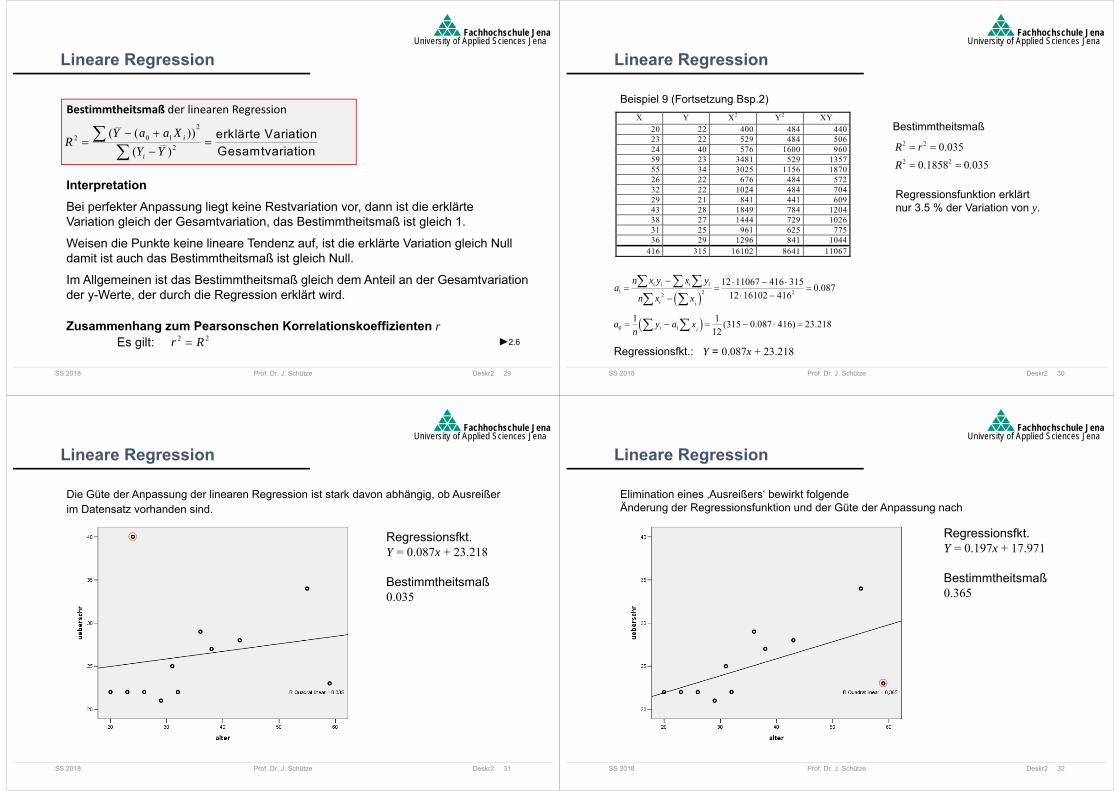
Residuen: vertikale Abweichungen der Punkte von der RegressionsgeradenAus ihnen definiert sich die Restvariation.
20 1i iSSR y a a x
Restvariation
Residuen 0 1i iy a a x
2.4
20 1 0.25i iSSR y a a x
Je kleiner die Restvariation ist, desto besser passt die Regressionsfunktion.
Fachhochschule JenaUniversity of Applied Sciences Jena
SS 2018 Prof. Dr. J. Schütze Deskr2 27
Lineare Regression
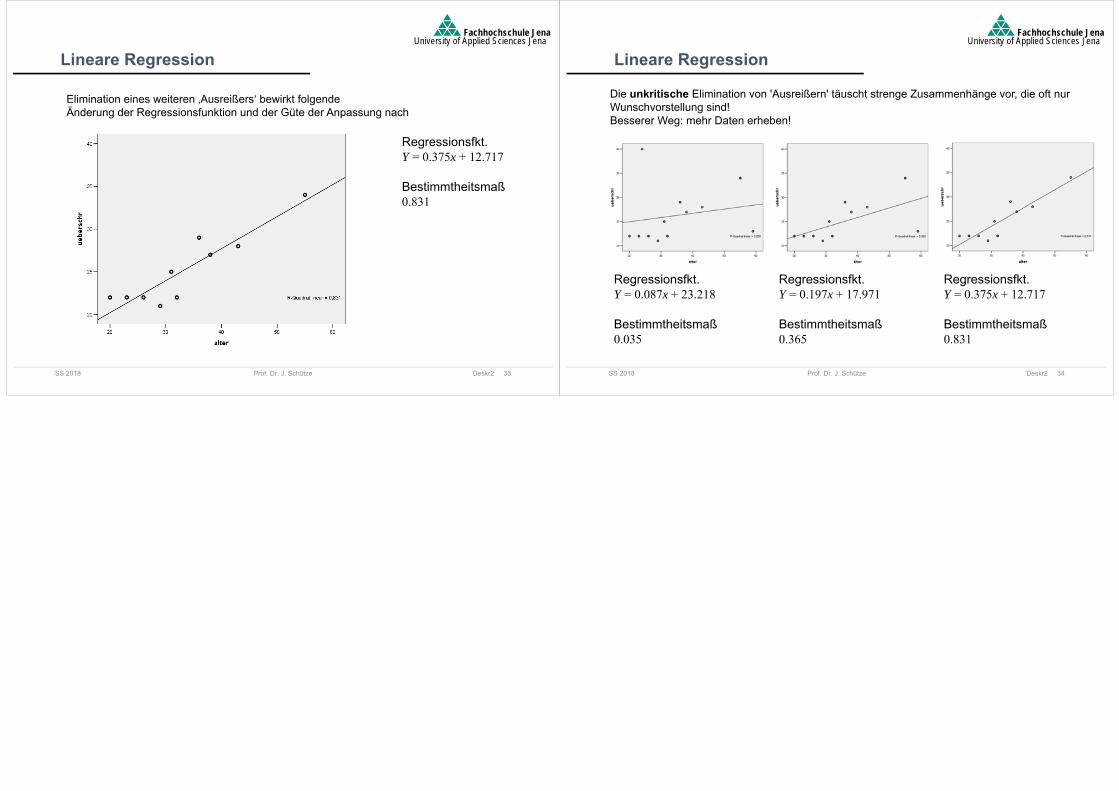
Als erklärte Variation SSE bezeichnet man die Variation der Werte auf der Regressionsfunktion an den Stellen xi um den Mittelwert y
20 1 iSSE y a a x 0 1 ia a x
Erklärte Variation
1.75y
2.5
Je größer die erklärte Variation ist, desto besser passt die Regressionsfunktion.
Fachhochschule JenaUniversity of Applied Sciences Jena
SS 2018 Prof. Dr. J. Schütze Deskr2 28
Lineare Regression
20 1 iSSE y a a x 2
iSSY y y 20 1i iSSR y a a x
Bestimmtheitsmaß:
Das Bestimmtheitsmaß ist der Anteil der erklärten Variation an der Gesamtvariation.
2 1SSE SSRRSSY SSY
SSY SSE SSR Es gilt die Zerlegung:
1 SSE SSRSSY SSY
Nach Division durch SSY
Gesamtvariation Erklärte Variation Restvariation
Fachhochschule JenaUniversity of Applied Sciences Jena
SS 2018 Prof. Dr. J. Schütze Deskr2 29
Lineare Regression
InterpretationBei perfekter Anpassung liegt keine Restvariation vor, dann ist die erklärte Variation gleich der Gesamtvariation, das Bestimmtheitsmaß ist gleich 1.
Weisen die Punkte keine lineare Tendenz auf, ist die erklärte Variation gleich Null damit ist auch das Bestimmtheitsmaß ist gleich Null.
Im Allgemeinen ist das Bestimmtheitsmaß gleich dem Anteil an der Gesamtvariation der y-Werte, der durch die Regression erklärt wird.
Bestimmtheitsmaß der linearen Regression 2
0 122
( ( ))( )
i
i
Y a a XR
Y Y
erklärte VariationGesamtvariation
Zusammenhang zum Pearsonschen Korrelationskoeffizienten r2 2r REs gilt: 2.6
Fachhochschule JenaUniversity of Applied Sciences Jena